
Abstract
Many randomized trials have used overall survival as the primary endpoint for establishing non-inferiority of one treatment compared to another. However, if a treatment is non-inferior to another treatment in terms of overall survival, clinicians may be interested in further exploring which treatment results in better health utility scores for patients. Examining health utility in a secondary analysis is feasible, however, since health utility is not the primary endpoint, it is usually not considered in the sample size calculation, hence the power to detect a difference of health utility is not guaranteed. Furthermore, often the premise of non-inferiority trials is to test the assumption that an intervention provides superior quality of life or toxicity profile without compromising survival when compared to the existing standard. Based on this consideration, it may be beneficial to consider both survival and utility when designing a trial. There have been methods that can combine survival and quality of life into a single measure, but they either have strong restrictions or lack theoretical frameworks. In this manuscript, we propose a method called health utility adjusted survival, which can combine survival outcome and longitudinal utility measures for treatment comparison. We propose an innovative statistical framework as well as procedures to conduct power analysis and sample size calculation. By comprehensive simulation studies involving summary statistics from the PET-NECK trial, we demonstrate that our new approach can achieve superior power performance using relatively small sample sizes, and our composite endpoint can be considered as an alternative to overall survival in future clinical trial design and analysis where both survival and health utility are of interest.
Keywords
Statement of significance
We propose a composite endpoint that can be considered as an alternative to overall survival in future clinical trial design and analysis where both survival and health utility are of interest. It may achieve higher power to demonstrate the benefit of a treatment while requiring a smaller sample size.
Introduction
In many clinical studies, overall survival (OS) is used as the primary endpoint to assess the efficacy of treatments. Superiority trials are used to test whether a new treatment is better than a standard or control treatment, while non-inferiority trials are used to test whether the new treatment is not unacceptably worse than control. Non-inferiority trials are especially important in circumstances where the new treatment may have other benefits (e.g., lower costs, fewer side effects, improved quality of life, or is easier to implement) compared to control, and people are only interested in showing the new treatment is not worse than control in terms of OS. When non-inferiority has been established, clinicians may be interested in further examining whether the new treatment can benefit patients more in terms of health utility.
1
Health utility is a construct, usually ranging from 0 to 1 (although theoretically can also have negative values), that quantifies the preference for a given health state experienced by a patient at a certain time point. A higher value means a healthier state, while death usually corresponds to 0. Using health utility scores at different time points during the treatment and post-treatment, statistical analysis may be performed to compare different treatment groups’ utility scores.2–4 However, given that the study design is usually based on the primary endpoint of OS without considering health utility, whether there will be enough power for health utility analysis is uncertain. Also, conducting tests for OS and health utility separately may not be the most efficient, because it involves multiple testing adjustment and can lose statistical power. Hence, it may be beneficial to consider using a composite endpoint that combines survival and utility, which may lead to increased statistical power and smaller required sample sizes. There are some commonly used approaches that do not require multiplicity adjustment, but literature has shown their own issues. For example, in hierarchical testing, if survival is placed above utility in the hierarchy, then if there is no significant difference in survival, the procedure will skip the health utility assessment, even if utility may have a very small p-value (e.g.,
Creation of a composite endpoint of survival and utility, can aid in clinical interpretation of non-inferiority trials where non-inferiority of survival is not the only acceptable outcome. For example, a new therapeutic intervention may be purported as offering improvements in quality of life or toxicity. However, clinicians may not be willing to sacrifice disease control to provide these other benefits. In this case, testing this new intervention in phase 3 non-inferiority trial where OS is the primary outcome and quality of life or toxicity is a secondary outcome may establish the intervention as non-inferior from a survival perspective and then falsely identify the new intervention as a standard of care without appropriate consideration of the quality of life and toxicity. On the other hand, one may consider a situation where a patients’ preference for improved quality of life (or utility) may outweigh their desire to have non-inferior survival. In this instance, demonstration of superiority of utility may not be enough if it is associated with a significant loss of survival and the two outcomes cannot be interpreted in isolation. In this instance, a combination of both survival and utility endpoints may be needed to declare a new intervention superior.
Some methods that can combine survival and utility have been proposed and used to analyze clinical trial data, and the most commonly used method is called quality-adjusted time without symptoms of disease or toxicity (Q-TWiST).7–14 Though Q-TWiST has not been commonly seen as a primary endpoint for designing new studies, researchers have derived its statistical properties as well as formulas for sample size calculations. 10 That being said, one major issue about Q-TWiST is that it divides each patient's status into three states (toxicity, time without symptoms and toxicity, and relapse) and uses pre-selected weights for different states. In many scenarios, with utility scores measured as continuous variables at different time points throughout the trials, it may be much more desirable to analyze them in their original scales rather than forcing to have three categories, which may likely result in loss of information and decreased statistical power.
Quality-adjusted life years (QALY), of which Q-TWiST can be considered as a special case, is the most intuitive way to combine survival with utility when comparing different treatments.7,15–19 It has also been used in the field of cost-utility analysis, where similar methods have been proposed and compared.20–23 Quality-adjusted progression-free survival, a similar concept with a slightly different focus, has also been used to assess the benefits of different treatments in randomized trials.24–26 However, such measures have rarely been considered as a primary endpoint for designing new trials, and we are not aware of any detailly developed statistical framework or comprehensive simulation studies that demonstrate the advantages and feasibility of a quality-adjusted survival endpoint compared to the traditional survival endpoint.
With these limitations and considerations, we propose an innovative composite endpoint for combining longitudinal health utility and survival, called health utility adjusted survival (HUS), with a detailed statistical testing framework as well as procedures to perform power analysis and sample size calculations. By assigning weights to health utility and survival, HUS can be modified to suit different scenarios with increased power.
This new endpoint may help better interpret the findings in clinical trials. Often non-inferiority trials are plagued with uncertainty of the efficacy of a new intervention that is statistically deemed non-inferior based mainly on survival estimates but that has not been clearly shown to be more effective from a toxicity reduction or quality of life improvement perspective. In Table 1, we provide several scenarios of how the new composite endpoint of HUS may improve interpretation of clinical trial findings if this composite endpoint is used in place of standard primary endpoints. For example, one may consider three scenarios in which a new treatment is deemed non-inferior based on a primary outcome of survival in a typical non-inferiority design where different utility scores may produce drastically different trial conclusions if a composite HUS endpoint were used. If a new intervention had lower utility than the comparator, a non-inferior trial would declare the new intervention non-inferior, when in fact, a HUS endpoint would appropriately declare the new intervention inferior. In addition, as we will show in the simulations, sufficient power may be achieved with smaller sample sizes to make statistical inferences than non-inferiority trials based on a non-inferiority margin of survival. This feature may improve the efficiency of trial conduct and arriving at meaningful conclusions with smaller samples.
Interpretations for different scenarios of survival and utility.
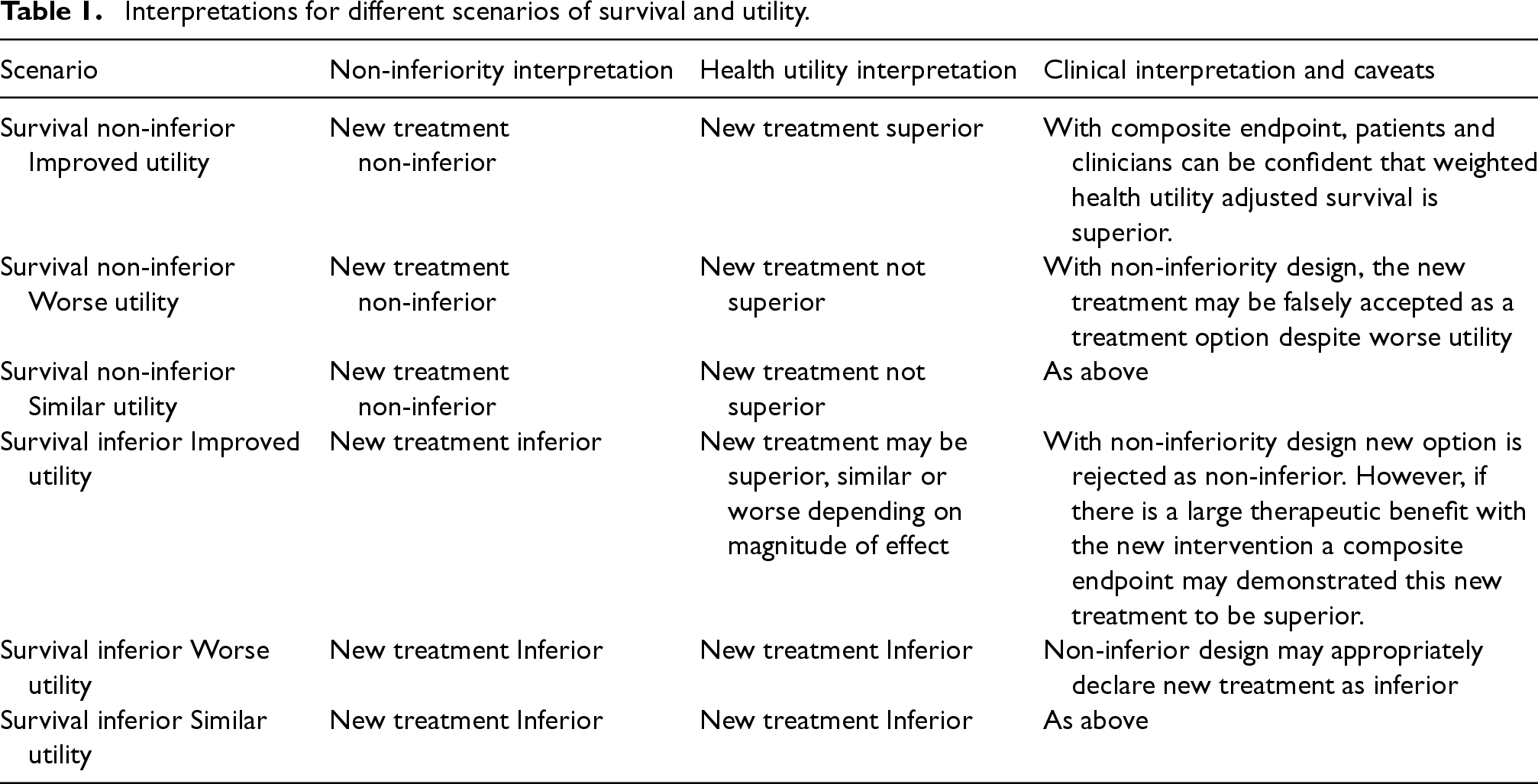
Interpretations for different scenarios of survival and utility.
This manuscript is structured as follows. In section 2, we present the methodology of the HUS endpoint, including its construction, sample size calculation, and power analysis. In section 3, we use comprehensive simulation studies with various settings, including scenarios incorporating parameter estimates based on the PET-NECK trial 1 to demonstrate the power advantage of HUS when analyzing study data and its potential to reduce required sample sizes when designing new trials. At last, we provide a discussion on the advantages, limitations and future directions for HUS in section 4.
Health utility adjusted survival
In this section, we describe the basic framework of HUS. In many clinical studies, OS is chosen as the primary endpoint, which determines the sample size, while health utility scores are usually analyzed in the secondary analyses. To construct a composite endpoint combining survival and health utility, we can take the product of the survival curve and the utility curve, as illustrated in Figure 1.
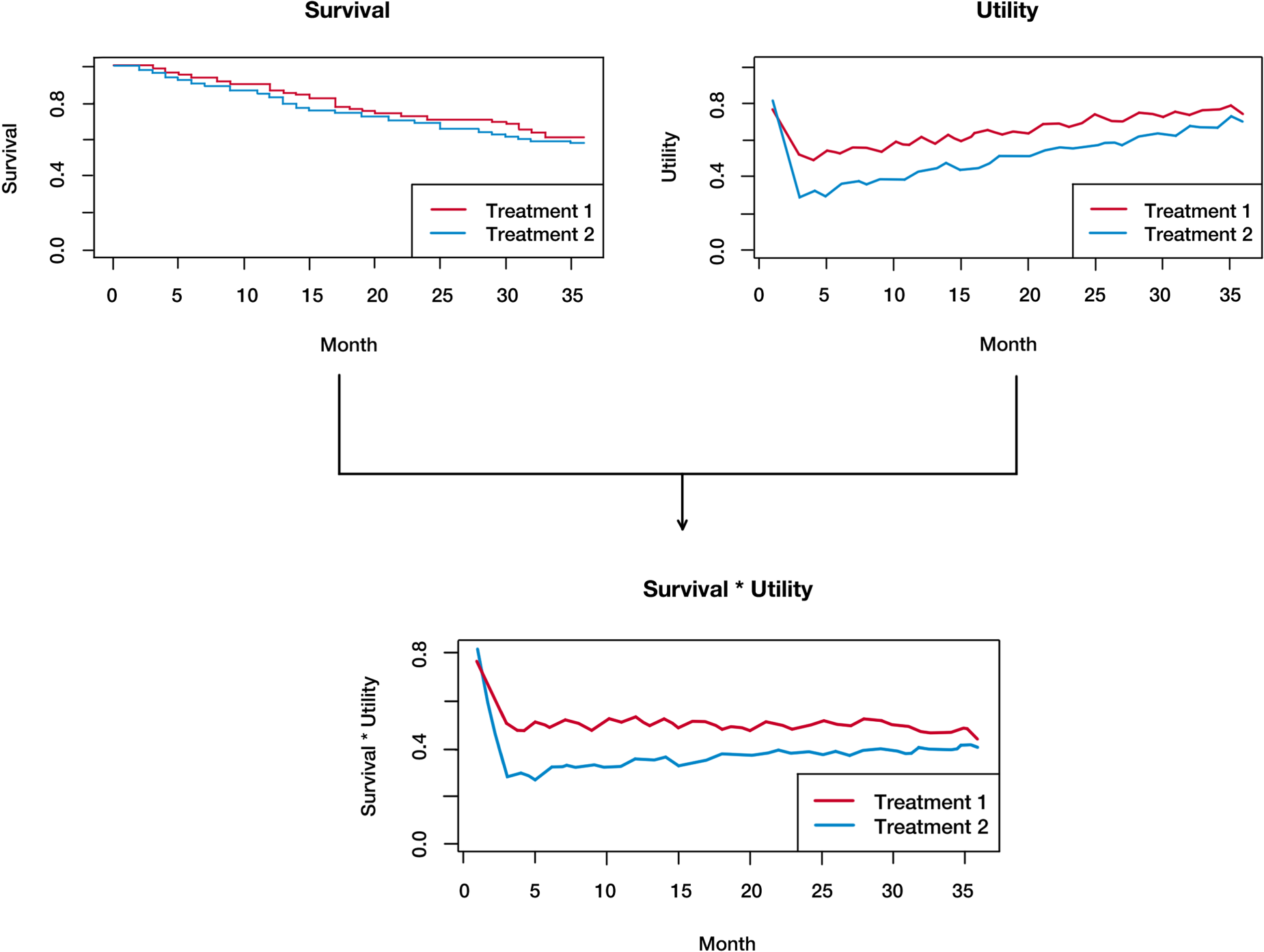
Basic framework of health utility adjusted survival (HUS), using the product of survival and health utility.
Suppose the total length of the study follow-up time is T, and we are interested in comparing survival and health utility between treatment groups 1 and 2. We define a Q-statistic to represent the HUS of each treatment group as


We can also assign weights to the survival and utility separately by defining


If
To examine the difference in HUS between the two treatment groups, we can define the test statistic as

To perform a one-sided test on whether group 1 has better HUS than group 2, we can either use the bootstrap method to obtain the confidence interval of For iteration b ( Calculate the After obtaining
The permutation procedure can be described as follows:
For iteration b ( Calculate the After obtaining
Note that the distribution generated by bootstrap is under the alternative hypothesis, whereas the distribution generated by permutation is under the null hypothesis, which is why the former is compared with 0, while the latter is compared with the observed test statistic. Based on our experience, both bootstrap and permutation methods can control type I errors, but bootstrap tends to have slightly higher power than permutation. Hence, we focus on the bootstrap method by default. Some simulation results comparing bootstrap and permutation can be found in the supplementary materials (Table S4, Figure S1). Besides, as hinted by Glasziou et al.,
15
Jackknife resampling can also be used to obtain the distribution of
If we assume the survival time follows a piecewise exponential distribution, we can derive a Monte Carlo approach to calculate the variance of the test statistic, which can be used for power analysis and sample size calculation. 30 A similar idea was used by Royston and Parmar 31 to calculate the variance for restricted mean survival time.32–34
We consider a simple case with three key time points: 0 (baseline), C (end of surgery), and T (end of study). Focusing on one treatment group, suppose the survival time is piecewise exponential, with piecewise constant hazards 

Denote 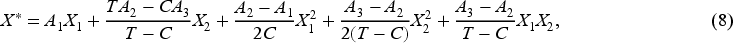

Note that when two treatment groups are compared, they should have their own variance balance factors, which we denote as 


For the one-sided test, we can reject the null hypothesis if
In any scenario with prespecified parameters, given different sample size, we can calculate the corresponding power of HUS using simulations. Then we can obtain a table showing different power under different sample sizes, which can be used to determine the sample size needed to achieve specific power (e.g., 80%) for a new trial. Detailed examples are provided in section 3.1.
If we assume that the special case described in section 2.3 is true, then we only need to run one simulation given a fixed sample size (e.g., 200 subjects per treatment group), which can give us estimates of 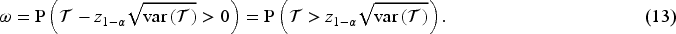
Assume 
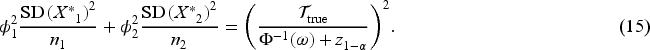
If we assume 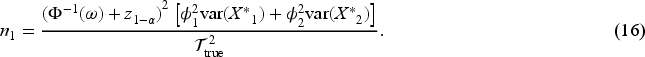
Note that it is difficult to calculate Calculate Simulate samples to estimate For each new sample size combination Calculate
On the other side, we can use the following procedure to calculate the sample size required to achieve specific power:
Calculate Simulate samples to estimate Calculate
In clinical studies, utility scores may not be available at each time point for all subjects, while the current framework of HUS requires complete utility profiles to calculate the test statistic. The most intuitive way is to impute the utility scores. We use linear functions to fill in the utility scores using the available data. If a subject's utility score is only available at one-time point, then we use that score as the imputed utility at all other time points. This approach may seem simple, but it can be quite effective. Another method we consider is to impute the group average at each key time point (i.e., each time point at which at least one subject has their utility score recorded), and then use linear functions to fill in the other missing scores. This approach can be regarded as a combination of the cross-mean and linear interpolation methods. 35 While imputing the group average, we can also add some variation using a normal distribution with mean zero and its standard deviation equal to the standard deviation of the recorded scores at that time point. In this way, the imputed values may be closer to the true values, which may lead to an increase of statistical power. It is also worth noting that many other methods are available for imputing longitudinal data, and a very recent study has compared the effects of different imputation methods and shown that most of them are similar in various scenarios, whereas trajectory mean single imputation has the best overall performance. 35 Hence, we consider trajectory mean imputation as a third method. A comparison of the three methods using simulation results is provided in the supplementary materials (Table S1), which shows that method 1 has much worse performance when the missing rate is higher, while methods 2 and 3 are not affected as much. For convenience, we use method 2 by default.
Results
Simulations with simplified settings
Power comparison
We conduct simulations in various scenarios to assess the performances of HUS. Suppose we are designing a randomized clinical trial with two treatment arms. The total length of study is 36 months (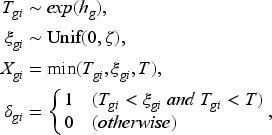
To simulate the health utility score, we first define base utility functions for the two groups. The base utility at time t for group g can be written as
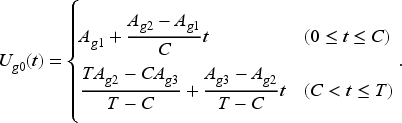
This definition means the average utility for group g starts from
In practice, we do not expect health utility scores to be collected at each time point. Furthermore, some of the scores scheduled to be collected may be missing. For our main simulation study, we assume that the health utility scores are only collected at
In this section, we focus on the situation where the two treatment groups do not have a difference in OS, which is the situation that motivated our HUS framework. Other situations (e.g., the two treatment groups differ in both OS and health utility) are explored in section 3.2 and the supplementary materials (Tables S6-S9). Table 2 shows a summary of our major scenarios. In each scenario, we compare the theoretical rejection rate using our results from section 2.4 and the empirical rejection rates of HUS using bootstrap with
Simulation settings with different scenario.
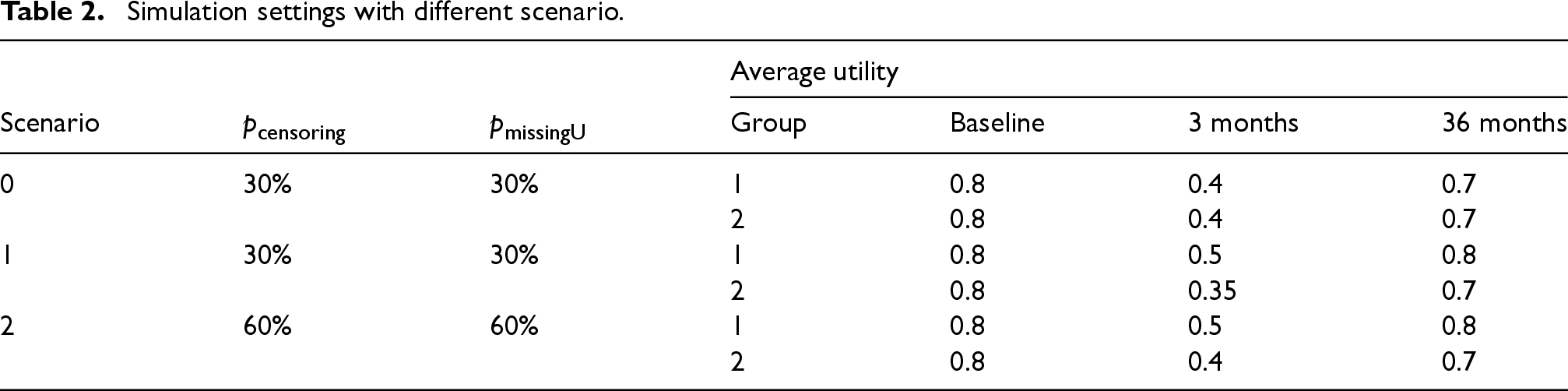
Simulation settings with different scenario.
In scenario 0, we examine the rejection rates of different methods when the two treatment groups have the same OS and health utility. As shown in Table 3, all of the superiority tests are able to control type I errors at 0.05. The rejection rates of the non-inferiority tests are power instead of type I errors, since the alternative is true (treatment 1 is not inferior to treatment 2). This is why they may be higher than 0.05.
Rejection rates of different methods in scenario 0 based on 1000 replications.
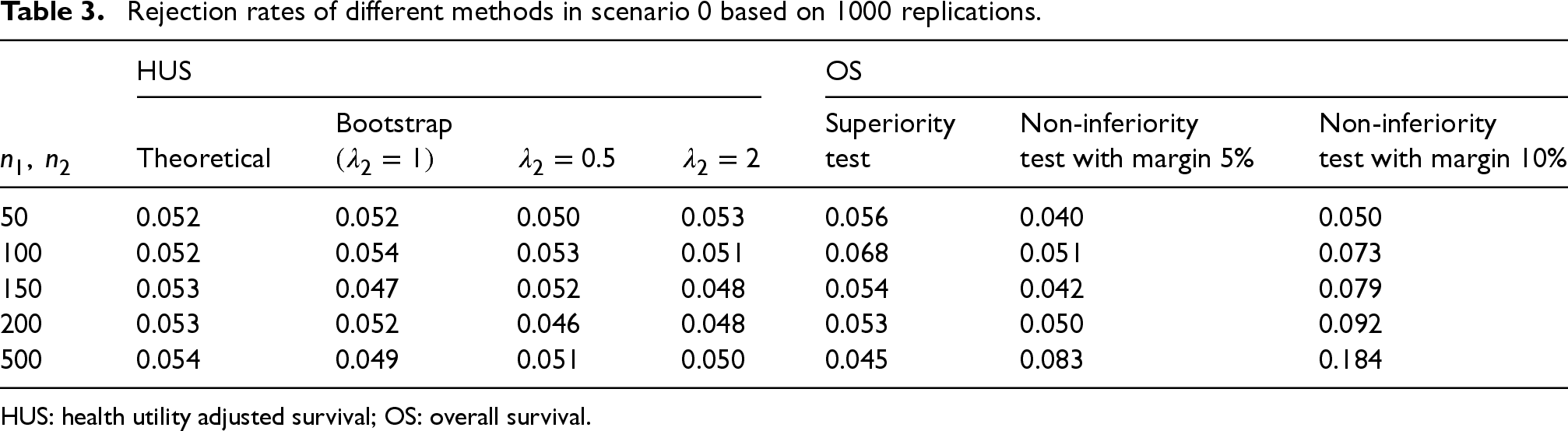
HUS: health utility adjusted survival; OS: overall survival.
In scenario 1, we compare the power of different methods when treatment group 1 has better health utility than treatment group 2. For the theoretical power analysis, firstly, we run one simulation with
As shown in Table 4, the bootstrap method with
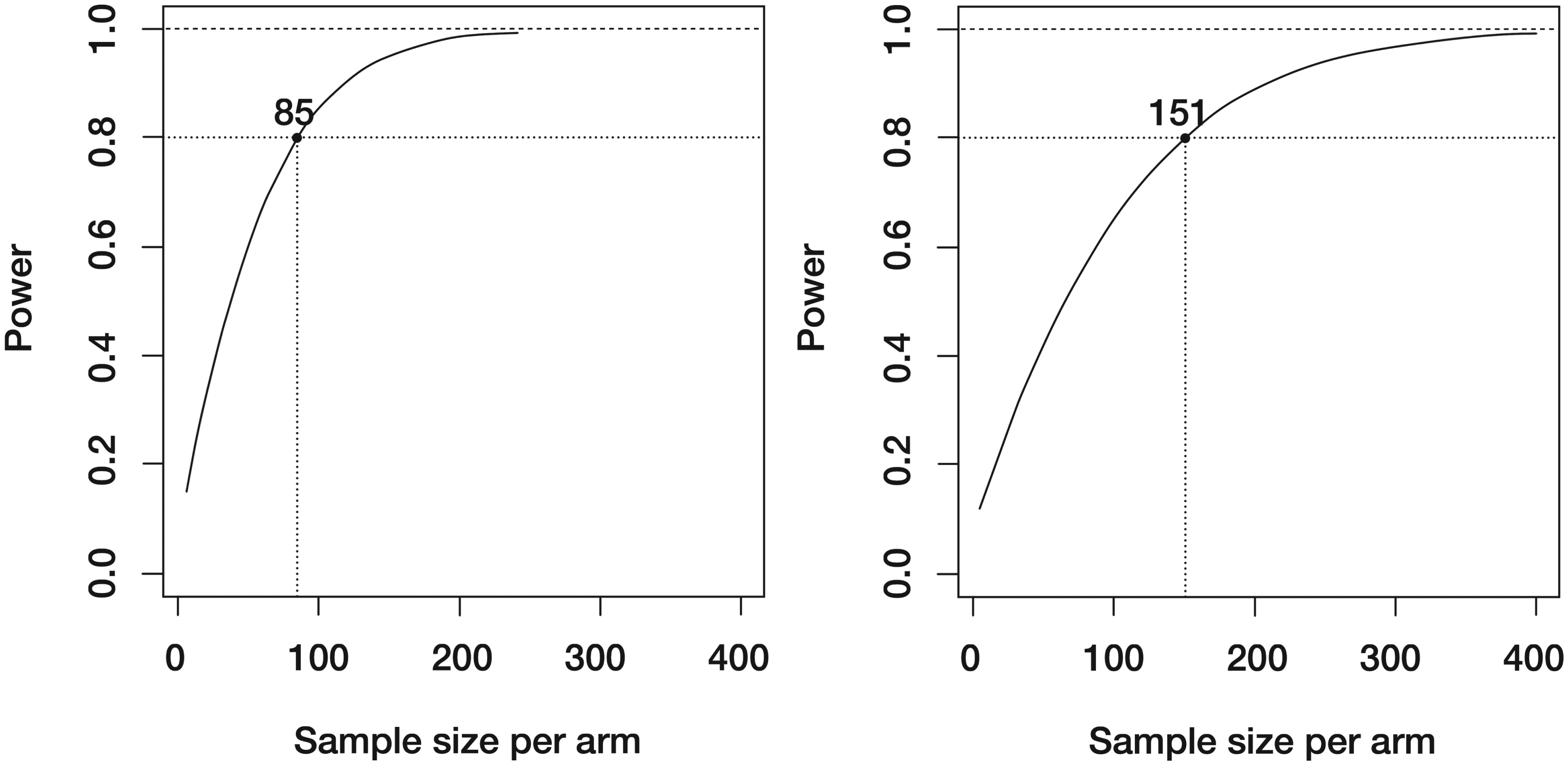
Power curves based on theoretical calculations. Left- scenario 1; right- scenario 2.
Power comparison of different methods in scenarios 1 and 2 based on 200 replications.
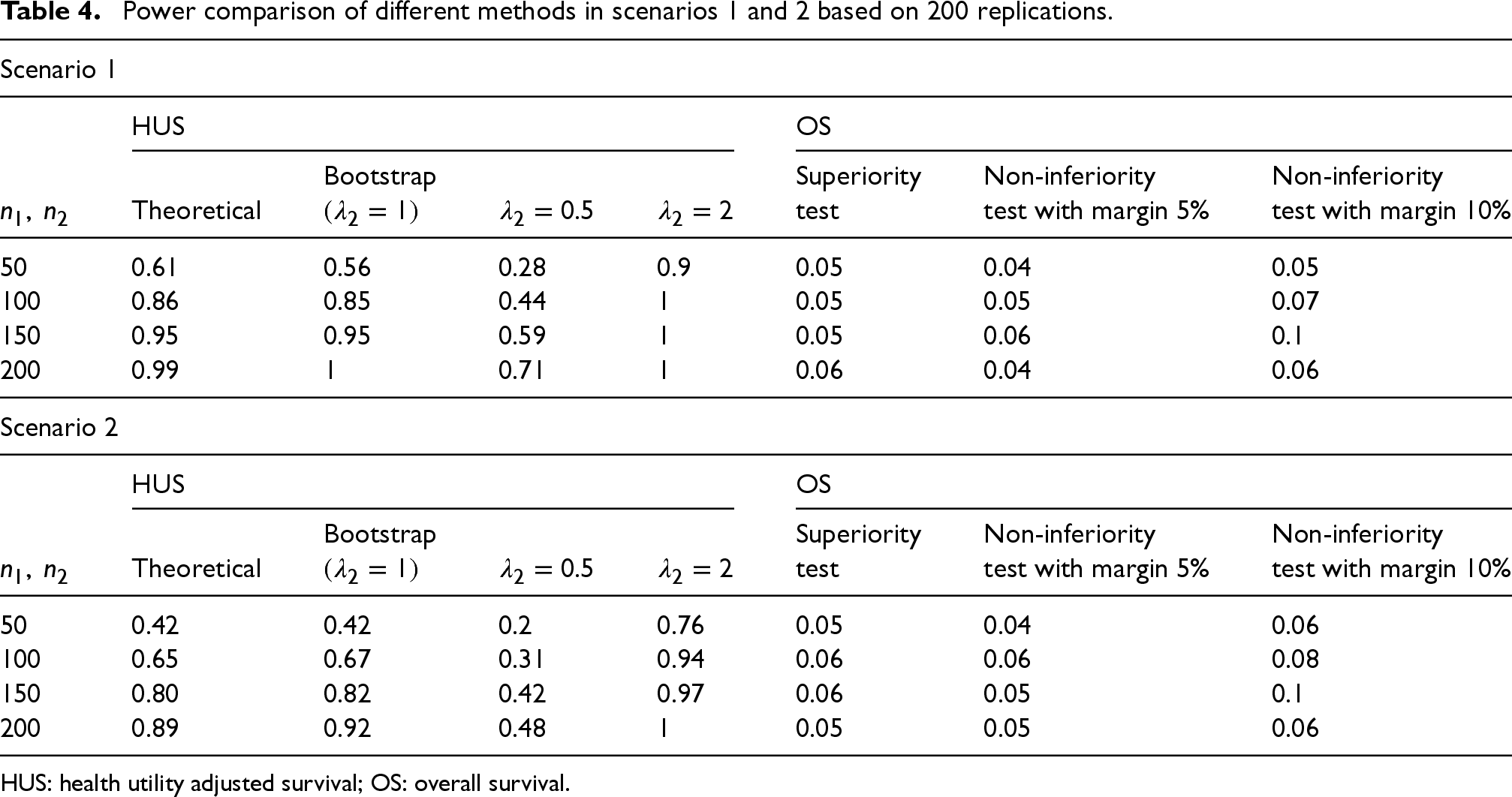
HUS: health utility adjusted survival; OS: overall survival.
In scenario 2, we increase the censoring rate to 60% and missing rates to 60%, and reduce the difference between the two group's health utility scores. As shown in Table 4 and Figure 2, results are very similar to those in scenario 1. Again, HUS is able to obtain decent power with relatively small sample sizes while the superiority and non-inferiority tests struggle to find enough evidence to show treatment 1's benefit compared to treatment 2. If we design a trial based on HUS with the assumptions in scenario 2, we only need to have 151 patients in each treatment group.
We would like to point out that even though choosing a larger
In this subsection, we use our developed sample size calculation formulas to calculate sample sizes needed for the composite endpoint, and the standard formulas to calculate sample sizes needed for the basic survival endpoint (implemented in PASS 2023, v23.0.2 with the one-sided log-rank test), to further demonstrate the advantage of HUS. Following scenario 1 from 3.1.1, where treatment 1 has better utility than treatment 2, we consider four different cases. In the first case, there is no survival difference, which is consistent with the focus of this manuscript, and the endpoint OS does not have power. In the second case, we assume that treatment 1 has better survival than treatment 2, while in the third case, we assume that treatment 2 has better survival. In the last case, we assume treatment 1 has better survival, but there is no difference in utility, and the utility function is the same as that in scenario 0. As shown in Table 5, with scenario 1's utility functions, when
Sample size calculation under a significance level of 0.05. When there is a utility difference, utility functions from scenario 1 are used. When there is no utility difference, utility functions from scenario 0 are used.
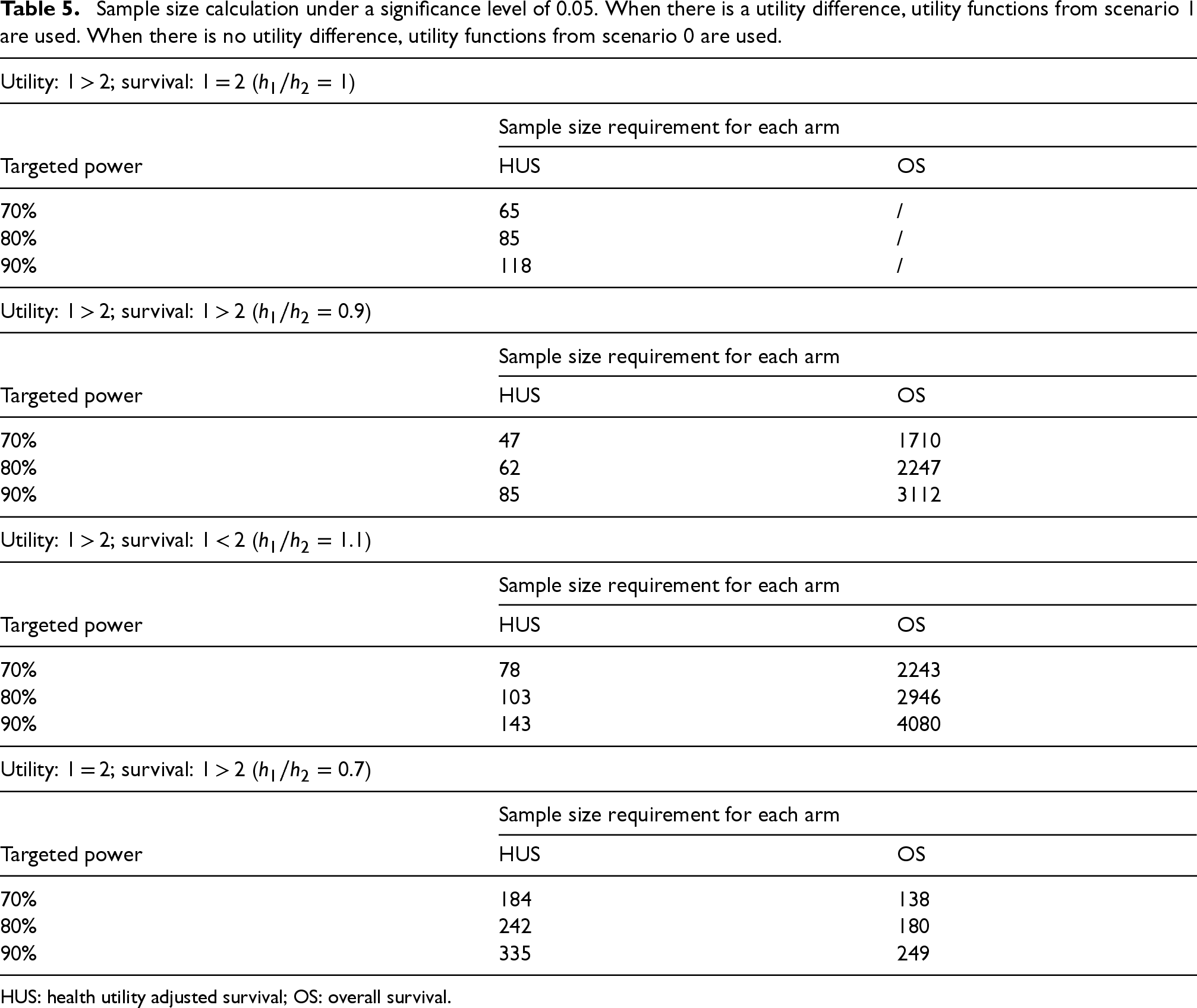
Sample size calculation under a significance level of 0.05. When there is a utility difference, utility functions from scenario 1 are used. When there is no utility difference, utility functions from scenario 0 are used.
HUS: health utility adjusted survival; OS: overall survival.
To demonstrate the benefit of HUS in a more practical scenario, we conduct additional simulations with average utility scores and the hazard ratio mimicking the summary data provided in a real randomized trial PET-NECK.
1
PET-NECK is a randomized phase III non-inferiority trial that compares positron emission tomography-computerized tomography (PET-CT)-guided watch-and-wait policy with planned neck dissection (planned ND) for head and neck cancer patients. The two-year OS rates of the two treatment groups (PET-CT and planned ND) with 282 subjects per arm, are 84.9% and 81.5%, respectively, which leads to a hazard ratio of 0.80. We conducted simulations utilizing the parameter setting to emulate the survival times in PET-NECK. Figure 3 shows the average utility scores at different time points in the study, with the maximum time being 24 months. Hence, in this scenario, we set
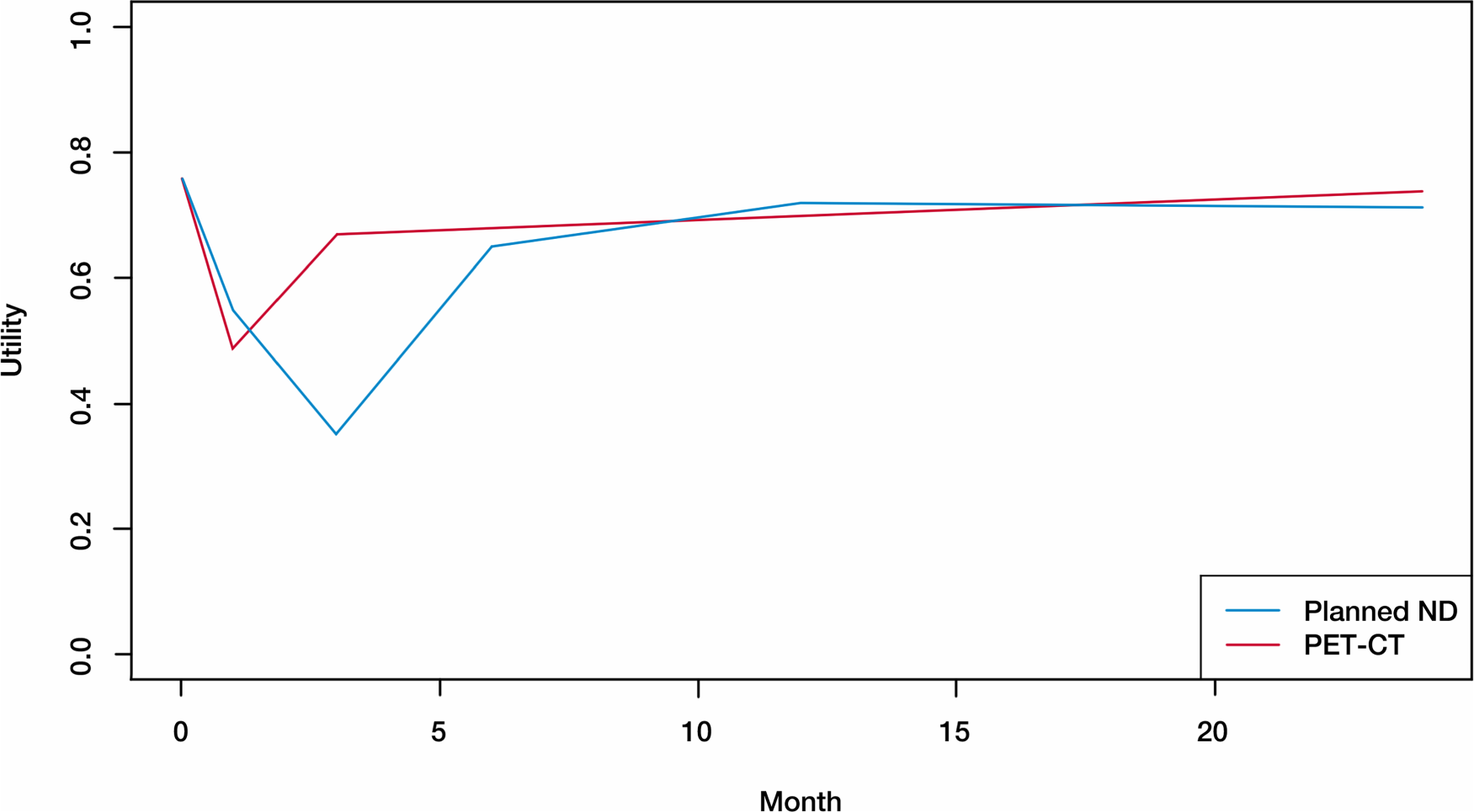
Average utility scores based on real summary data.
As shown in Table 6, with the two groups differing in both OS and health utility, the superiority test based on HUS still has much higher power than the superiority and non-inferiority tests based on OS. We would only need 200 subjects per arm to achieve 80% power of showing PET-CT has better HUS than planned ND, which is fewer than the subjects in the original study which were based on OS comparison. In terms of weighting,
Power comparison for simulations using real data estimates.
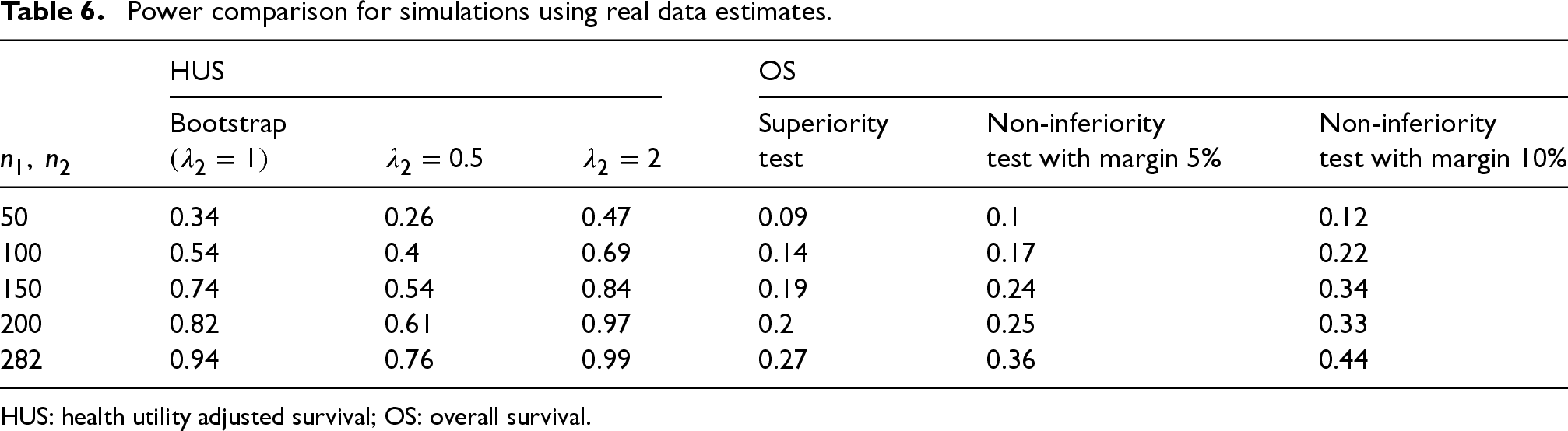
HUS: health utility adjusted survival; OS: overall survival.
We have presented a methodological framework to compare two treatment groups using HUS as a composite endpoint combining survival and health utility. As demonstrated by our comprehensive simulation studies, when there is a difference in health utility, HUS has a significant power advantage over the statistical tests based on OS endpoint, meaning that using HUS as an endpoint for new trials may require much smaller sample sizes to achieve decent power. We have also demonstrated two different procedures (theoretical and empirical approaches) to conduct power analysis and sample size calculation with specified parameters. When the model assumptions are met, the two procedures yield similar results.
There are several different options when applying HUS. We recommend using bootstrap given its popularity as well as its convenience of constructing confidence intervals for the test statistic, though permutation may be theoretically more appropriate for testing the null hypothesis, since it can obtain the null distribution of the test statistic.
In practice, the choice of weights of HUS is important. The main purpose of this paper is to provide the methodology framework of the model, currently, by default, we use equal weights, which gives an equal balance to survival and health utility. There are a few recommendations for future clinical study design. First, clinicians’ input should be considered. For example, for the new treatment evaluation, physicians may have more interests in the survival difference or the utility difference. Besides that, if preliminary clinical data are available from pilot studies, researchers can estimate the weights from such data. In addition, for studies that there is not enough prior information about the new treatment effects, or the clinicians have no obvious input, we would suggest the study design considering the default equal weights. In the data analysis stage, if non-equal weights are chosen, we recommend conducting sensitivity analyses by assigning several weight schemes (up weight or down weight) on survival to assess the robustness of the model performance. Another possible way to combine different weighting options without having to choose one is to apply an idea similar to the aSPU test.36,37
Note that the theoretical properties we have presented are based on assumptions by analogy with the assumptions used by Royston and Parmar, 31 though we have shown the validity of our theoretical results in our simulations. Similar to the approximate distribution of the difference between weighted mean survivals derived by Shen and Fleming, 38 we are exploring the asymptotic property of the HUS test statistics, especially for the complicated weighted HUS models, which may improve computational efficiency. We would also like to point out that the linear imputation method we use to fill in the utility scores may be problematic in some cases, especially if the scores are only recorded at a few time points and the missing rate is high. We may consider other imputation methods or modifying the definition of HUS so that it does not require complete utility score profiles as input.39,40 Besides that, given the possible drawbacks brought by KM estimates, sometimes it may be beneficial to apply other models, including the flexible parametric model for survival analysis. 41
Another possible direction worth exploring is to take different functions of the utility score into consideration. One special case is that in many clinical studies, multiple measures of health status are recorded. There are various ways to combine different measures into a single utility score.42–44 Extending HUS to be able to handle any function of utility may potentially increase power and help us gain insight on how the utility is different in different treatment groups. Furthermore, considering utility may have different importance at different time points, we may assign different weights across time. For example, having a better utility score at the later stage of the study, which means the patients have recovered better, may be more important than having a better utility score at the end of surgery. In such case, we can consider giving higher weights to later time points, and the resulted HUS may provide a clearer picture of which treatment is more beneficial for recovery.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802251338409 - Supplemental material for Health utility adjusted survival: A composite endpoint for clinical trial designs
Supplemental material, sj-pdf-1-smm-10.1177_09622802251338409 for Health utility adjusted survival: A composite endpoint for clinical trial designs by Yangqing Deng, John de Almeida andWei Xu in Medical Research
Footnotes
Acknowledgments
The authors would like to acknowledge the contributions of Dr Hisham Mehanna (Institute of Head and Neck Studies and Education, University of Birmingham) and Dr Sue Yom (Department of Radiation Oncology, University of California) for clinical insights and discussion.
Data availability
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Alan Brown Chair in Molecular Genomics, the Lusi Wong Family Fund, and the Posluns Family Fund, all through the Princess Margaret Cancer Foundation.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.