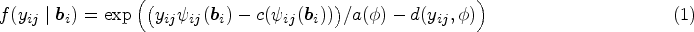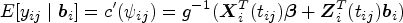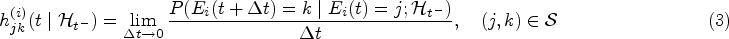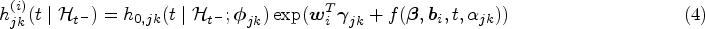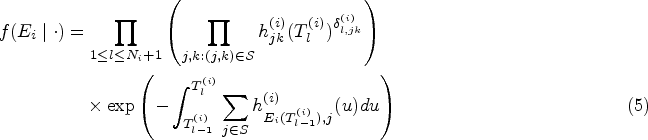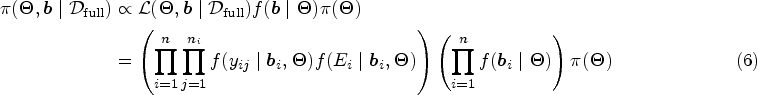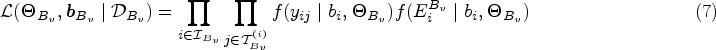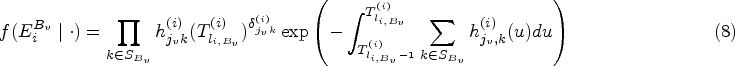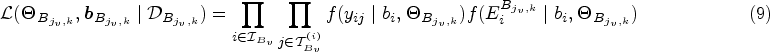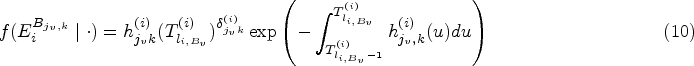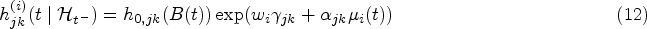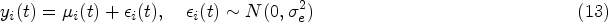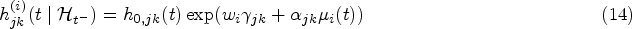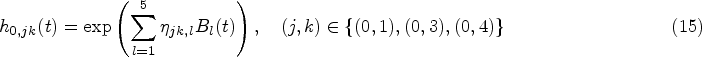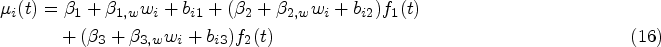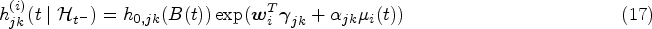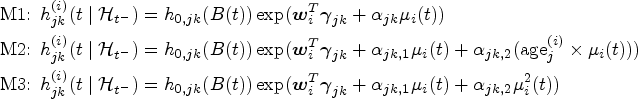Multistate models provide a useful framework for modelling complex event history data in clinical settings and have recently been extended to the joint modelling framework to appropriately handle endogenous longitudinal covariates, such as repeatedly measured biomarkers, which are informative about health status and disease progression. However, the practical application of such joint models faces considerable computational challenges. Motivated by a longitudinal multimorbidity analysis of large-scale UK health records, we introduce novel Bayesian inference approaches for these models that are capable of handling complex multistate processes and large datasets with straightforward implementation. These approaches decompose the original estimation task into smaller inference blocks, leveraging parallel computing and facilitating flexible model specification and comparison. Using extensive simulation studies, we show that the proposed approaches achieve satisfactory estimation accuracy, with notable gains in computational efficiency compared to the standard Bayesian estimation strategy. We illustrate our approaches by analysing the coevolution of routinely measured systolic blood pressure and the progression of three important chronic conditions, using a large dataset from the Clinical Practice Research Datalink Aurum database. Our analysis reveals distinct and previously lesser-known association structures between systolic blood pressure and different disease transitions.
Joint models (JMs) for longitudinal and time-to-event data have gained increasing interest in clinical and biomedical research.1 These models are instrumental in uncovering relationships between biomarkers and key health events, such as disease progression or death. Moreover, they facilitate principled, individualized predictions of these outcomes’ trajectories. Theoretical and empirical evidence shows that analysing both types of outcomes jointly leads to more accurate and efficient inference for each outcome process than analysing them separately.2,3
The basic formulation of JM involves a single time-to-event outcome. However, in some application contexts, more complicated event processes may arise. For instance, a subject of interest may experience a succession of intermediate events, each representing a disease/health status. Multistate models (MSMs) extend the traditional survival model to encompass more states, providing a useful probabilistic framework for modelling complex longitudinal event history data.4 Well-known models such as competing risks and illness-death models are special cases of MSM. MSMs have recently been extended into joint longitudinal and MSMs to allow for handling endogenous longitudinal covariates. Examples of applications of such JMs can be found by, for example, Dantan et al.5 for jointly studying cognitive decline, risks of dementia and death, Ferrer et al.6 for analysing the progression of prostate cancer, and Dessie et al.7 for predicting the clinical progression of HIV infection. Inference for such JMs has conventionally been based on the maximum likelihood estimation theory. More recently, Furgal8 explored a Bayesian estimation framework. However, we recognise that existing estimation methods face significant computational challenges with large sample sizes and when the longitudinal and/or the multistate processes become complex.9,10 For the frequentist approach, the main difficulty with inference arises from the numerical approximation of the integral over the random effects, which is required in computing the likelihood function. In the Bayesian approach, posterior inference is typically based on Markov chain Monte Carlo (MCMC) sampling methods, which can be computationally expensive and sometimes face difficulties with mixing and convergence. Therefore, the application of such joint longitudinal and MSMs is currently limited to relatively small sample sizes and/or simple longitudinal and multistate structures due to computational limitations.
In this article, we introduce novel Bayesian estimation approaches for joint longitudinal and MSMs for efficiently and flexibly handling complex event processes and large data sets while allowing for straightforward implementation. Instead of sampling from the joint posterior distribution of model parameters based on the entire longitudinal and multistate data, as the standard approach would do, we propose two blockwise approaches that decompose the original estimation task into smaller inference blocks. In this way, parameters associated with each block are estimated in a parallel and adaptive manner, utilizing only the longitudinal and time-to-event data pertinent to that particular block. More specifically, the first approach employs competing risk decompositions of the multistate process, estimating a joint longitudinal and competing risk model for each competing risk block. When the focus of inference and prediction lies in the multistate process, we propose a more computationally efficient blockwise inference strategy by working with each transition in the MSM individually, estimating a joint longitudinal and survival model for each transition. With blockwise approaches, model selection can be conveniently and efficiently performed in a block-specific manner using techniques such as Bayesian leave-one-out cross-validation.11 This facilitates the flexible specification of different models for different blocks/transitions (e.g. the association structure between the longitudinal and the multistate processes), which is a challenging task with the standard approach. Our extensive simulation studies demonstrated that the proposed approaches provide satisfactory estimation accuracy and notable efficiency gains compared to standard estimation strategy. In addition, blockwise approaches can provide more robust inference for the association and other multistate parameters in cases of model misspecification within the longitudinal process.
Multimorbidity, referred to as the co-existence of two or more long-term conditions in a single patient, is becoming increasingly prevalent and poses significant challenges to patients and public health.12 While previous studies have largely focused on cross-sectional patterns of multimorbidity, there is an important need to better analyse and understand the longitudinal accumulation of diseases for improved management and treatment.13 MSMs provide a useful framework and have been recently employed to study longitudinal patterns of multimorbidity;14,15 however, to our knowledge, no previous work has examined the association between longitudinal biomarkers and multimorbidity progression within a joint modelling framework. Motivated by and building on the recent study by Chen et al.,16 we analysed the coevolution of routinely measured systolic blood pressure (SBP) and the progression of three important chronic conditions: type-2 diabetes (T2D), mental health conditions (MH), and cardiovascular diseases (CVDs). Our analysis dataset was derived from a large electronic health records (EHRs) database in England, the Clinical Practice Research Datalink (CPRD) Aurum, which contains longitudinal routinely-collected primary care EHRs from 19 million participants across the 738 English general practices that use EMIS Web software.17 Notably, our proposed approaches enable us to utilize a much larger volume of patient data during inference compared to the standard inference approach. This facilitates the identification of differing association patterns between SBP and different disease transitions with enhanced statistical evidence.
The rest of the article is structured as follows. Section 2 introduces the basic Bayesian joint longitudinal and MSM and the corresponding estimation method. In Section 3, we present the proposed blockwise inference approaches, and their performance is evaluated through a simulation study in Section 4. In Section 5, we illustrate the application of the proposed approaches in a longitudinal multimorbidity analysis of large UK health records. Finally, Section 6 provides a discussion and possible directions for further work.
The Bayesian joint longitudinal and MSM
We consider a joint model consisting of longitudinal and multistate submodels, linked through shared parameters.
Longitudinal submodel
Let be the value of the longitudinal process of subject measured at time , and let be the observed -dimensional longitudinal response vector for the subject, where , . Typically, the longitudinal responses are modelled under a generalized linear mixed modelling (GLMM) framework. Conditional on the -dimensional random effects vector , assumed to be independently distributed according to a normal distribution , the responses are assumed to be independent and belong to a member of the exponential family with density
where and denote the natural and dispersion parameters in the exponential family, respectively, and , and are known functions specifying the member of the exponential family. The conditional mean of given the random effects is linked to the linear predictors via
where denotes a known monotonic link function, is a -dimensional fixed effects vector, and and denote the possibly time-dependent design vectors for the fixed and random effects, respectively. In this article, motivated by our case study, we focus on continuous longitudinal responses, in which case the GLMM reduces to a standard Gaussian linear mixed model (LMM)
where and is the error variance. The collection of parameters associated with the longitudinal submodel is denoted by .
Multistate submodel
Let be a continuous-time multistate process for subject with a common state space , where denotes the state that subject occupies at time . Let . The evolution of the process can be fully characterized by the transition intensities
which represents the instantaneous risk of transiting from state to state at time given the history up to time , . In this article, motivated by our real data application, we focus on unidirectional MSMs, that is, transitions between states can only occur in one direction. The regression models for the transition intensities are commonly specified in the form
with representing a baseline intensity function parameterized by and be the -dimensional vector of exogenous risk factors associated with the coefficient vector . The collection of parameters associated with the transition in the multistate submodel is denoted by . Depending on the application context, it is common to impose either a Markov (i.e. ) or a semi-Markov assumption (i.e. , where is the time since entry into the current state ) on the transition intensities to simplify the dependence structure on the history of the process.18 The function , parametrized by , describes the association between the longitudinal marker’s dynamics and the multistate process. Some common choices of are (current value association), (current slope association) or (shared random effects). In particular, quantifies the strength of the association between the two processes.
To formally define the model likelihood, we assume that each subject is followed up continuously for some period of time, subject to a right censoring time , and let be the observed multistate process for subject . Let be the sequence of observed transition times such that ; is the total number of observed transitions ( if the subject is censored without having a transition), and let and . We additionally define the transition indicator variables such that if the transition occurs at event time and otherwise. With the notation and assumptions above, the likelihood contribution of the multistate process for subject can be expressed as follows:
where the intensity functions are given by (4) (for brevity, here and in what follows we omit the conditioned history and parameter set) and we adopt the convention that is taken to be one. A rigorous derivation of the likelihood can be made based on the counting process theory, see Cook and Lawless4 for details. Note that in general integrals in (5) cannot be computed analytically and numerical approximation is required. In our implementation, we used the Gaussian-Legendre quadrature method (with 15 quadrature points).
Bayesian inference for the joint longitudinal and MSM
Assuming that the longitudinal and multistate processes are conditionally independent given the random effects, as adopted in earlier literature,6 the posterior distribution of the model parameters and random effects can be factorised as follows:
where is the full model parameter vector with , and represents the full dataset. The conditional densities in (6) are given in (1) and (5). To complete the Bayesian formulation, the joint prior distribution for all the model parameters, , needs to be specified. In practice, independent and weakly informative prior distributions are commonly used for parameters in JMs.19,20 The posterior defined in (6) is not analytically tractable. MCMC methods can be employed for inference purposes.
Blockwise parallel inference
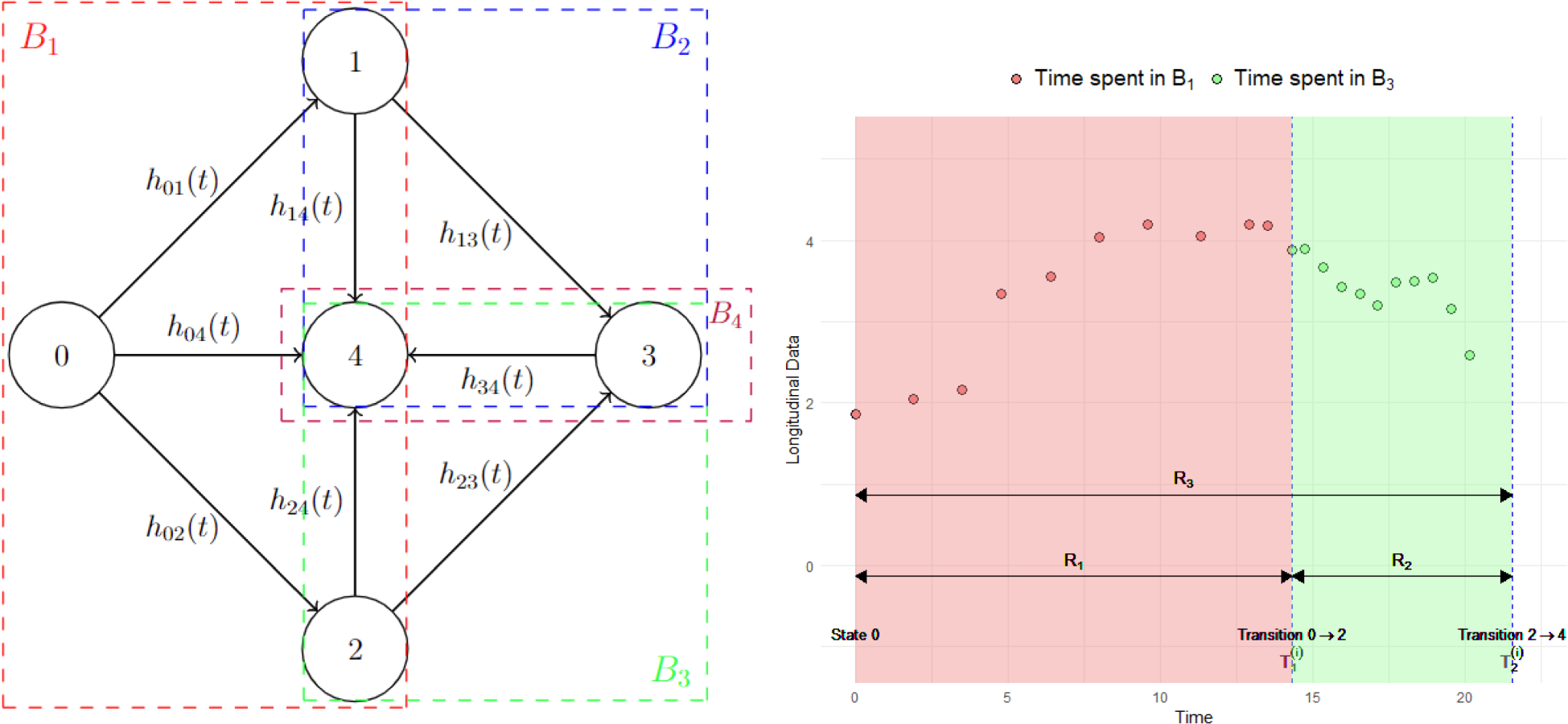
In this section, we describe the proposed intuitive blockwise inference approaches to alleviate the computational challenges of fitting the joint longitudinal and MSM (JM-MSM) described in Section 2. To help illustrate the idea, we employ an example throughout as shown in Figure 1. A high-level comparison of the standard and proposed inference approaches is provided in Table 1, whereas a more detailed comparison of the asymptotic and finite sample behaviours of these approaches is provided in Supplemental Section A.
Illustration of the blockwise inference approach. Left panel: multistate progressive scheme with its transition blocks. A total of eight different transitions are allowed: , , , , , , and with corresponding transition intensities , , , , , , and . For the JM-CR approach there are four blocks: , , and , as indicated by coloured dashed boxes. The JM-ST approach has eight blocks, corresponding to each permitted transition. Right panel: hypothetical longitudinal profile of a marker over time for an imaginary subject experiencing transition at and transition at . The data collected during the time spent in (indicated by ) and (indicated by ) are indicated with red and green shades, respectively. The entire follow-up period for this subject is indicated by . JM-CR: joint longitudinal and competing risk; JM-ST: joint longitudinal and single transition.
Comparing the standard (JM-MSM) and blockwise approaches (JM-CR and JM-ST) in terms of data used in the posterior computation, with notations defined as in Sections 2 and 3. represents a generic competing risk block, and denotes a generic transition within the block. and , respectively, indicate the index sets of subjects entering and the longitudinal data points used for inference in for subject . and are subsets of the full dataset, .
Individual-level data
Approach
Time-to-event data
Longitudinal data
Subjects involved
Dataset
JM-MSM
Multistate data
All data
All subjects
JM-CR
Competing risk data
Block-specific subset
Block-specific subset
JM-ST
Survival data
Block-specific subset
Block-specific subset
JM-MSM: joint longitudinal and multistate model; JM-CR: joint longitudinal and competing risk; JM-ST: joint longitudinal and single transition.
The joint longitudinal and competing risks (JM-CRs) approach
Our first proposal involves breaking down the multistate process into separate connected blocks of competing risk processes. This decomposition is unique and we utilize this to fit a JM-CR model to each block independently, using only the longitudinal and time-to-event data that are associated with the block. In the example shown in Figure 1, the multistate process can be decomposed into four competing risk blocks, , , and . Consider a generic competing risk block . Let denote the index set of subjects who entered the initial state in and were at risk for transitions in . Let denote the index set for time point such that represents the longitudinal data linked to block for subject (see Section 3.3 for more details on the construction of this index set), be the observed competing risk process associated with , and be the set of the indices of the terminal state in . Then we define the likelihood function for the JM-CR approach for as
where and are vectors of the associated model parameters and random effects, denotes the total conditioning data for inference in block and
where denotes the initial state index in , is the transition indicator variable defined analogously as before indicating if the individual makes a transition from and such that denotes the observed transition time within or the right censoring time. Posterior inference under JM-CR is performed by sampling from independently for each block instead of sampling from jointly at once (see also Table 1).
The joint longitudinal and single transition (JM-ST) approach
The JM-ST approach treats each allowed transition as a block, denoted by , and estimates a joint longitudinal and survival model independently for each such block. Consider a generic competing risk block and let denote the observed survival process for subject considering the transition , (i.e. subjects who transition to a competing state or are censored are both treated as censored). We define the working likelihood function of the JM-ST approach for as
where and are vectors of the transition-specific model parameters and random effects, respectively. denotes the data for inference in . The index sets and are defined as in the JM-CR approach, and is given by
which corresponds to a standard survival likelihood, with defined as in (8). Therefore, when using the JM-ST approach to estimate each transition, , the same subset of subjects () is used as in the JM-CR approach for estimating block , and the same set of longitudinal data is used if the same index set is adopted (see Table 1). Posterior inference under JM-ST is performed by sampling from independently for each transition. Note that the JM-ST approach is applicable when the focus of inference or prediction is on the multistate process. Unlike the JM-MSM or JM-CR approaches, it does not allow estimating individual-specific trajectories for the longitudinal marker as subjects are reused to estimate transitions within a competing risk block, resulting in multiple sets of longitudinal parameter and random effect estimates per subject.
Incorporating longitudinal data in model blocks
When applying the JM-CR or JM-ST approach to perform inference in a specific block, we need to specify the index set , which determines the amount of longitudinal data used for estimating the longitudinal trajectories. In principle, assuming that the longitudinal submodel is correctly specified, we could achieve increasingly accurate inference as the cardinality of increases (see also the discussion in Supplemental Section A). However, in practice, the correct specification assumption may not hold, so there is a bias-variance trade-off between the amount of data used and potential misspecification bias. In this article, we consider two natural proposals. The first is to always use all available historical data collected since the start of the follow-up. In the example shown in Figure 1, this corresponds to using both the red and green shaded data (data collected during ) when using JM-CR for or JM-ST for transitions and . This strategy could be particularly useful if most subjects have little or no longitudinal data within the block, as it allows borrowing information from historical data. The second strategy is to use only the concurrent data collected during the time subjects spent in the given block (if no data are available within the block for a subject, historical data will be used). Referring again to the example in Figure 1, this means that only the green shaded data (data collected during ) would be used for inference in when applying JM-CR, or for transitions and when using JM-ST. In our experience, the latter often works well with a moderate amount of longitudinal data as it allows a more adaptive modelling of the marker’s trajectory. A more formal comparison between these two options can be conducted within the Bayesian inferential framework using the criterion described in Section 3.4.
Model comparison
To compare candidate models for the same data, we consider a Bayesian leave-one-out cross-validation (LOO-CV) score as suggested by Vehtari et al.11 for approximating the predictive accuracy of a fitted Bayesian model. The LOO-CV score is defined as follows:
where denotes the th observation, and represents the dataset excluding the th observation. Note that , where is a vector of model parameters, measures how well the model would predict the th observation based on the model estimated using the data without including that observation. The LOO-CV can be effectively estimated based on existing simulated MCMC samples using a Pareto smoothed importance sampling approach proposed by Vehtari et al.,11 which is implemented in the R package loo,21 avoiding the need to refit the model times. In this joint modelling context, it is natural for the th observation to include both longitudinal and time-to-event data; that is, for JM-CR, or for JM-ST. Model selection can be performed in a blockwise manner when implementing the JM-CR or JM-ST approach. For instance, with JM-ST, for each transition, different candidate models are fitted and a model can be selected based on the LOO-CV computed for the data associated with that transition.
Simulation study
To thoroughly evaluate the accuracy and computational efficiency of our proposed blockwise approaches for inference in Bayesian joint longitudinal and MSMs, we conducted simulation studies under both realistic and hypothetical scenarios. For each of the JM-CR and JM-ST approaches, we explored two different configurations as outlined in Section 3.3: one using solely concurrent longitudinal data (JM-CR-C and JM-ST-C) and another utilizing all available historical longitudinal data (JM-CR-H and JM-ST-H) for inference in a given block. The benchmark comparator is the standard JM-MSM approach described in Section 2. For all approaches, the same set of weakly informative priors was used, and posterior sampling was conducted using Rstan22 with the no-U-turn sampler (NUTS),23 a state-of-the-art MCMC algorithm.
Simulation models
Here we briefly describe the settings for the two main simulation models, which are motivated by two different real data applications.
Model 1
Model 1 is derived from our case study in Section 5 for analysing longitudinal multimorbidity progression. The multistate process is shown in Figure 1. We assume clock-reset semi-Markov transition dynamics with the transition intensities specified as follows:
where , is the Weibull hazard function specified by the shape parameter and scale parameter , and is a baseline covariate for subject and is the unobserved longitudinal trajectory for subject at time . For the longitudinal process, we consider a basic LMM with a random intercept and slope:
with and .
Model 2
Model 2 is derived from Ferrer et al.,6 where the authors use the model to analyse the progression of prostate cancer. The associated multistate transition diagram extends that in Figure 1 by adding two additional transitions and (see Figure 3 by Ferrer et al.6). For this model, we can identify four blocks for the JM-CR approach and 10 blocks for the JM-ST approach. The regression models for the transition intensities are specified with the Markov assumption and a clock forward time scale as
where . The baseline intensity functions are modelled using cubic B-splines as
where the are pre-specified cubic B-spline basis functions and are the associated spline coefficients. Baseline intensities for other transitions are proportional to these transitions via re-scaling. The longitudinal data are generated from a LMM exhibiting a non-linear trend, with
where , , and the s are fixed effect parameters.
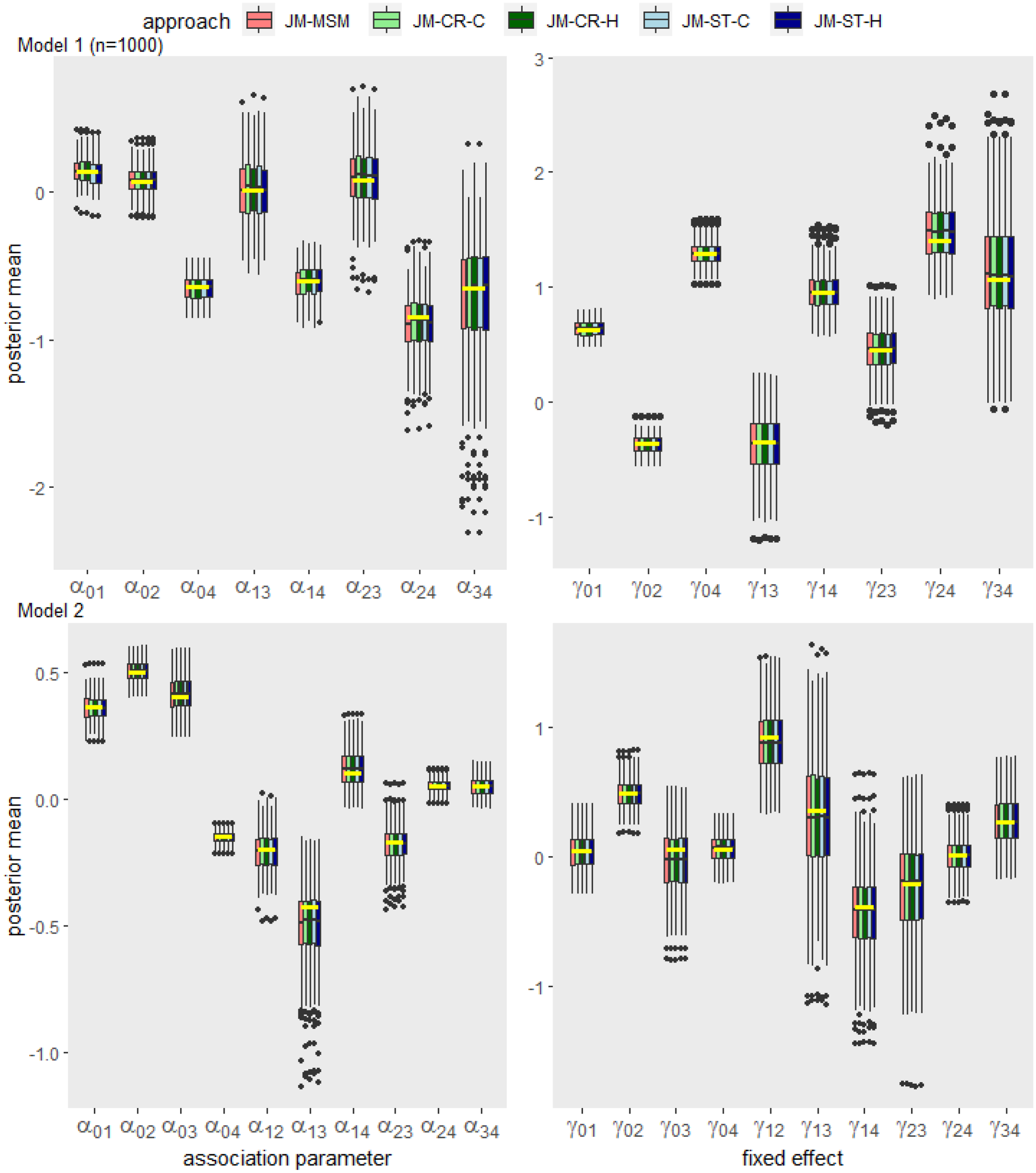
Box plot summary of the posterior means of the association and fixed effect parameters obtained by each approach across 200 data replications for Model 1 (; upper panel) and Model 2 (; lower panel). The true values for each parameter are indicated by yellow horizontal bars.
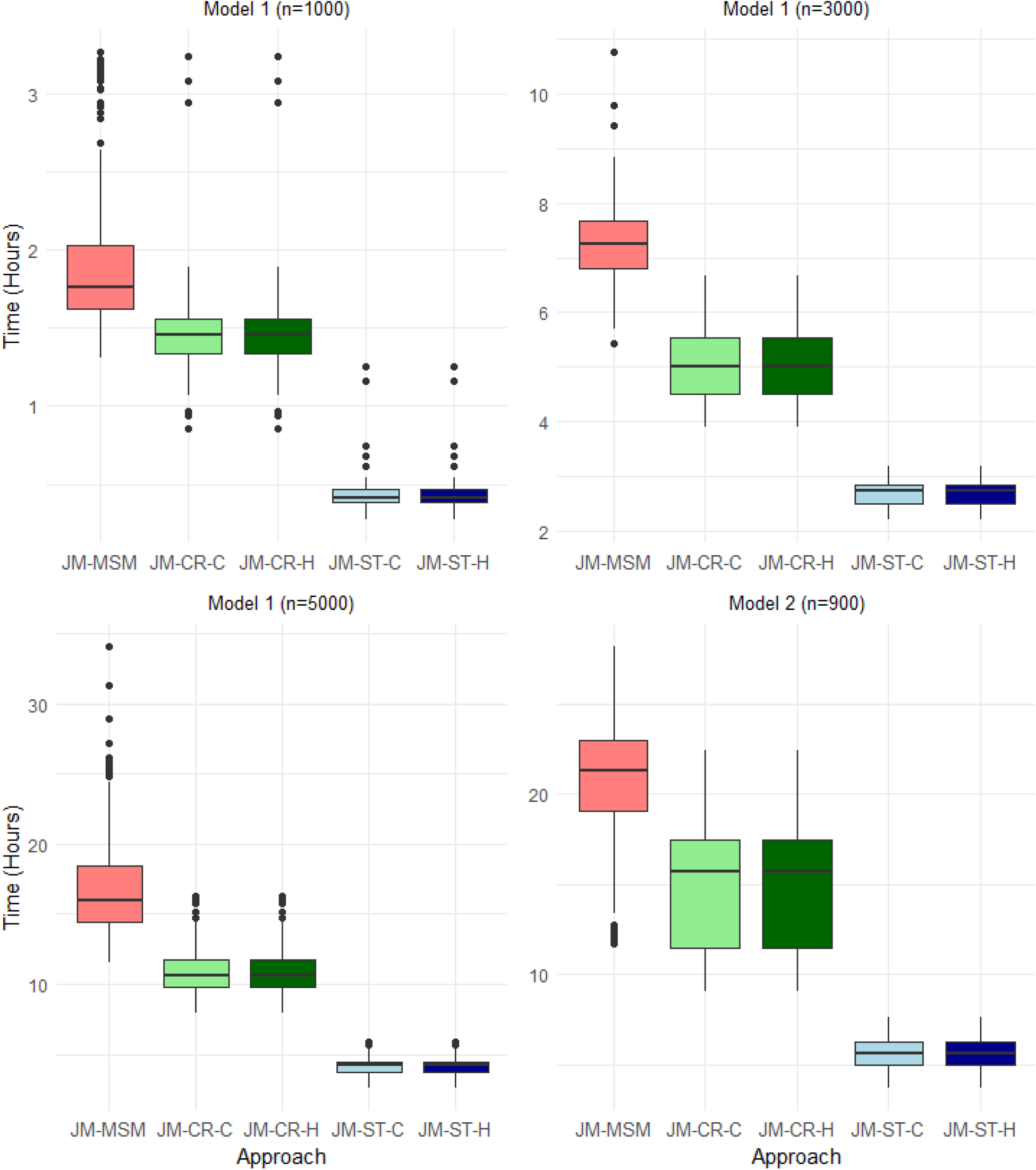
Box plot summary of the total computation times required to obtain 1000 convergent Markov chain Monte Carlo (MCMC) samples, including the time spent in the burn-in period, for each approach across 200 replications of the data for Models 1 (upper left, upper right and lower left panels) and 2 (lower right panel). For all cases and approaches, parameters were initialized at zero on the transformed unconstrained space in Rstan.
Data generation and prior settings
We use the following parameter settings to simulate data from the simulation models. For Model 1, is considered as an artificial ‘age’ covariate, generated from a mixture of uniform distributions defined over the intervals , and with weights , and , respectively. The variable is then normalized to have a mean of 0 and a standard deviation of 1. For each subject, we generate a random right censoring time from a uniform distribution, . To generate the visiting time points , we set an equidistant sampling interval of before the first transition, and decrease it to and after the first and second transitions, respectively. To set the transition-specific parameters in the multistate submodel (i.e. , , and ), we fit a separate JM for each transition using the JM-ST-C approach based on a random subset of subjects’ data from the CPRD dataset. Parameters in the longitudinal submodel are obtained by fitting a LMM (as specified in (13)) on the standardised log-transformed SBP based on subjects in the CPRD dataset who has had a diagnosis of T2D. For Model 2, we set , and the visiting time points are generated with an equidistant gap of . All other model parameters are based on the setting by Ferrer et al.,6 and we refer to their paper for details.
Given the parameter values, a joint longitudinal and multistate process can be simulated according to the generative process of the model. Firstly, subject-specific random effects are simulated independently from their prior distribution , and for each subject , we generate a right censoring time point (either randomly or deterministically). Conditional on the , we simulate the multistate process for using the scheme as described by, for example, Crowther et al.24 Then, the longitudinal trajectory is simulated by first generating the measurement time points during the follow-up period up to reaching the terminal absorbing state. Subsequently, the data are generated according to the specified longitudinal submodel.
In our implementation, we used the following set of weakly informative and independent prior distributions for all approaches and simulation scenarios: ; ; ; and ; where denotes a half-Cauchy distribution with location parameter and scale parameter and denotes an inverse Gamma distribution with shape parameter and scale parameter . For the covariance matrix of the random effects, we followed Stan’s recommendation to decompose it into a vector of standard deviations and a correlation matrix. Each standard deviation was assigned a prior, and the correlation matrix was assigned a prior.25 In our experiments, the results were insensitive to the choice of these priors.
Results
For Model 1, we examined three different sample sizes: , and ; and for Model 2, we fixed , considering the constraints of available computational resources. In each case, we generated independent replications of the dataset. For the JM-CR and JM-ST approaches, parameters within each block were sampled from the respective posteriors in parallel, and the computation time was determined by taking the maximum computing time across all blocks. Posterior summaries were derived based on samples generated by NUTS, using default control parameters. A suitable burn-in period, , was determined based on preliminary runs and convergence was assessed based on the trace plots and the scale reduction statistic . For Model 1, we set for and for larger sample sizes and for Model 2 we set . All computations were performed on the Cambridge Service for Data Driven Discovery (CSD3) High-Performance Computing (HPC) system using the Ice Lake CPUs.
Figure 2 summarizes the estimated posterior means of the association and fixed effect parameters obtained by each approach across 200 data replications for Model 1 () and Model 2. For both models, the distributions of the point estimates obtained from the JM-CR and JM-ST approaches align with those from the JM-MSM approach, which is based on the ground truth model that generated the simulation data. Supplemental Figures 1 to 4 show additional estimation results for Model 1, including cases with larger sample sizes. As the sample size increases, the estimation accuracy of all five approaches improves, and variability of the estimates from all approaches decreases at a similar rate. Supplemental Tables 1 to 5 show the coverage probability (the proportion of times that the credible interval contains the true value of the parameter in repeated simulations) of the estimated credible intervals for the association and other MSM parameters obtained by each approach across the 200 data replications for Models 1 and 2. In all scenarios, all approaches yielded similar coverage probabilities with slight variations around the theoretical value of .
Figure 3 shows the comparison of the total computation times, including the burn-in period, required by the five approaches to obtain 1000 convergent MCMC samples for Models 1 and 2. As expected, the JM-ST approach is the most efficient in all scenarios, while the JM-MSM approach requires the longest computation time. For the blockwise approaches, the two sub-versions (JM-CR-C/JM-ST-C and JM-CR-H/JM-ST-H) have almost the same computational costs. Additional experiments suggest that the initialization strategy of the sampler and the sample size (not shown here) appear to have a more substantial impact on the convergence of the JM-MSM approach compared to the blockwise approaches. With random or overdispersed initialization, or with increasing sample sizes, JM-MSM typically requires a longer burn-in period to reach convergence, whereas JM-ST is the least affected.
We performed additional simulations building on Model 1 to examine the performance of the blockwise approaches in the presence of misspecified longitudinal trajectory or multistate transition dynamics, and the details are provided in Supplemental Section B. In brief, the blockwise approaches can offer greater robustness in the former scenario (see Supplemental Figure 5) and do not exhibit greater estimation bias than the JM-MSM approach in the latter scenario (see Supplemental Figure 6).
Application to the CPRD data
Here we illustrate the use of the proposed approaches by analysing the association between routinely measured SBP and the progression of multimorbidity defined as the combinations of T2D, MH and CVD. We used the CPRD Aurum cohort considered by Chen et al.,16 which comprises electronic primary care records from 13.48 million participants in England. The data span from 2005 to 2020, with a median follow-up of 4.71 years (IQR: 1.78–11.28). In this analysis, we focused on subjects with an initial T2D diagnosis (among the three conditions) and had at least one SBP measurement recorded during their follow-up period (any SBP measurements taken within 3 months before death were removed to reduce the potential confounding effects of the near-death period on the SBP). We modelled the standardized log-transformed SBP using a LMM, incorporating a random intercept and slope as in equation (13). The disease progression was modelled using the multistate process depicted in Figure 1, where state 0 represents the T2D diagnosis at baseline, states 1, 2 and 3 represent disease combinations T2D+CVD, T2D+MH and T2D+CVD+MH, respectively. The terminal absorbing state, state 4, denotes the death state. The transition intensities, assuming a clock-reset timescale and a current value association structure between SBP and disease transition rate, are specified as follows:
where for modelling flexibility, we follow Ferrer et al.6 to specify baseline intensities using cubic B-splines as , with being the -th basis function defined with boundary knots at 0 and 16 and one internal knot placed at the median of the associated observed transition times. For the baseline risk factors , motivated by the analysis by Chen et al.,16 we considered four important sociodemographic characteristics associated with multimorbidity progression: ethnicity groups (White, South Asian, Black, Mixed, and Others), social and material deprivation (approximated using the English Index of Multiple Deprivation (IMD)), age at entry to the current state (in decades), and sex (1: male; 0: female). Results by Chen et al.16 suggest a significant imbalance among the non-White groups, who generally have a hazard ratio of < 1 compared to Whites for the transitions in our model. We, therefore, treat ethnicity as a binary variable, where ‘0’ represents the reference White group, and ‘1’ represents all other non-White groups. For deprivation, the raw IMD ranges from 1 (least deprived) to 10 (most deprived). In our model, we treated it as a continuous variable, given its ordered nature and for modelling simplicity. For further details on the data extraction, disease and variable definitions, and codelists, we refer to Chen et al.16
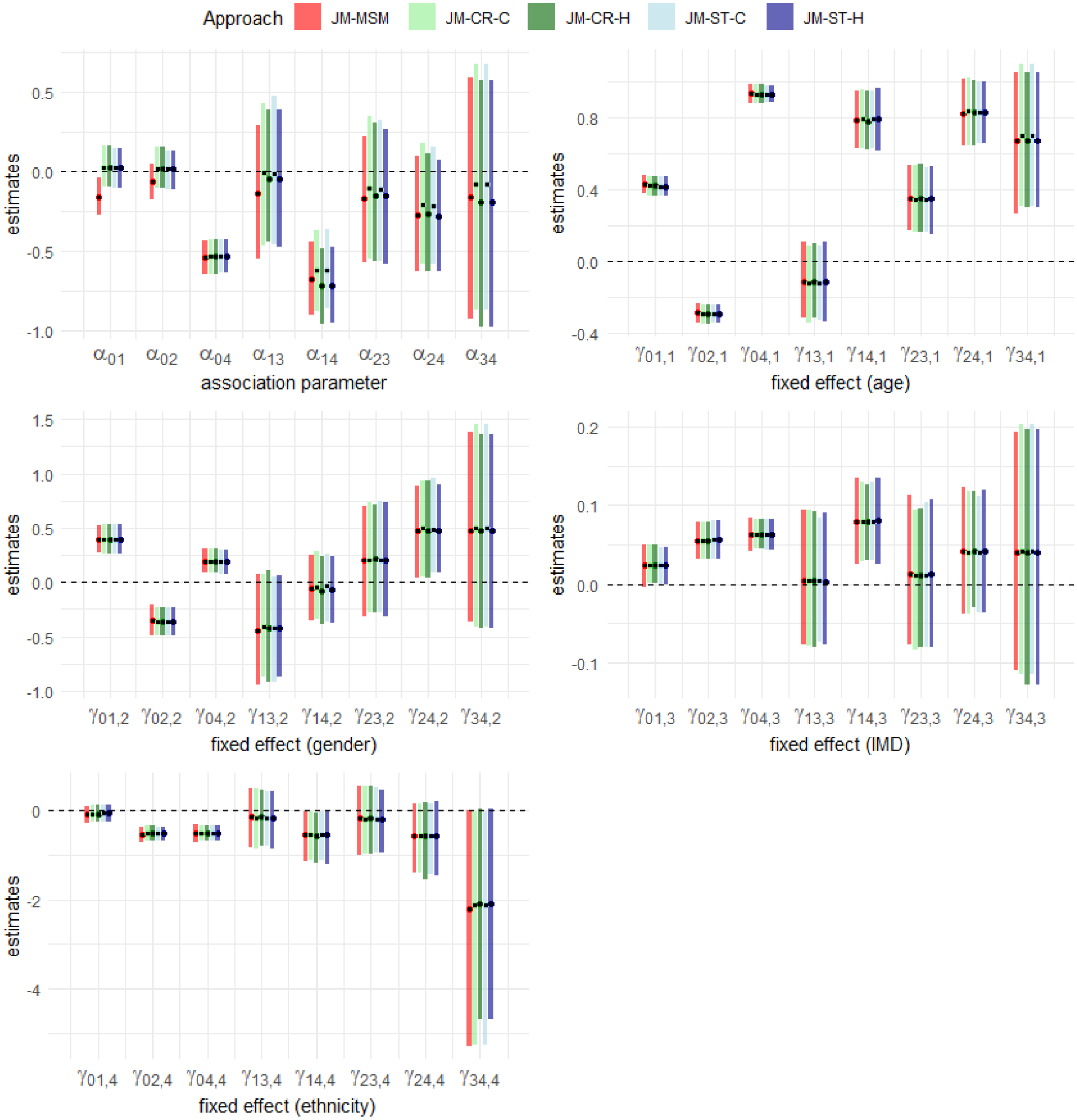
First, we compared the estimation results from the five approaches – JM-MSM, JM-CR-H, JM-CR-C, JM-ST-H and JM-ST-C, as considered in the simulation study. When implementing the blockwise approaches (JM-CR-C and JM-ST-C), historical SBP data were used for inference if a subject lacked an SBP reading associated with the block (see Section 3.3). For this comparison, we used a randomly selected subset of the cohort, consisting of subjects after processing. This sample size is about the largest manageable size for JM-MSM under the computational constraints of the HPC. For all approaches, we used the following set of weakly informative priors: ; ; and ; where and represent the variances of the random effects, is the correlation between the two random effects, and denotes a Beta distribution with shape parameters and . Posterior inference was based on 1000 NUTS samples after a burn-in period of for JM-MSM and for JM-CR and JM-ST approaches, selected based on pilot runs and convergence diagnostics. Using the previously specified computing resources, the entire sampling process took approximately , and hours for JM-MSM, JM-CR-C/JM-CR-H and JM-ST-C/JM-ST-H, respectively. As expected, JM-MSM was the most computationally demanding approach, followed by JM-CR, with JM-ST being the most computationally efficient. For this dataset, JM-CR provided a limited computational efficiency gain over JM-MSM, as a significant proportion of subjects were censored within block 1, and this estimation dominated the computing time. Figure 4 displays the posterior means and the associated credible intervals for both the association and fixed effect parameters in the multistate submodel, obtained by each of the five approaches. For the fixed effect parameters, the results are closely aligned across the approaches and are consistent with the findings reported by Chen et al.16 For the association parameter, we observe minor discrepancies among the approaches in some transitions. This could be attributed to differences in the amount of longitudinal data used for inference (see Section 3.3). Using the JM-ST approach, we then compared the two data inclusion strategies, JM-ST-C and JM-ST-H, for each transition using the LOO-CV as described in Section 3.4. We consistently found a preference for JM-ST-C over JM-ST-H across all relevant transitions: , , , and . This result aligns with our impression that JM-ST-C offers a more flexible modelling of the longitudinal trajectory, which can be particularly relevant in complex multistate settings.
Estimation results for the association parameter () and fixed effects for age (in decades) at entry into the current state (), gender (), IMD () and ethnicity (). The results were obtained using the JM-MSM, JM-CR-C, JM-CR-H, JM-ST-C and JM-ST-H approaches, applied to a subset of the CPRD Aurum data with a sample size of . The black dot represents the posterior mean and the superimposed rectangular bar represents the corresponding credible interval. For each parameter, the results from left to right correspond to the JM-MSM, JM-CR-C, JM-CR-H, JM-ST-C and JM-ST-H approaches, respectively. IMD: Index of Multiple Deprivation; CPRD: Clinical Practice Research Datalink; JM-MSM: joint longitudinal and multistate model; JM-CR-C: joint longitudinal and competing risk model (concurrent longitudinal data); JM-ST-C: joint longitudinal and survival model (concurrent longitudinal data); JM-CR-H: joint longitudinal and competing risk model (all historical longitudinal data); JM-ST-H: joint longitudinal and survival model (all historical longitudinal data).
Motivated by the comparison results above, we continued the analysis using the JM-ST-C approach to examine the association patterns between SBP and disease transitions with more patients’ data, noting that in Figure 4, estimation results for later stage transitions exhibit high uncertainty due to a lack of data. With the JM-ST approach, we were able to utilise all available data in our cohort for estimating transitions , , , and , with a total of subjects’ data being used for model fitting (see Supplemental Table 6 for the number of patients’ data used in estimating each transition). For each transition, we further explored three different candidate association structures. Model 1 (M1) includes only the current underlying value of the longitudinal marker SBP. Model 2 (M2) includes the current value of SBP and an interaction effect between age and SBP. Model 3 (M3) extends M1 by adding a quadratic association term, thus allowing for a non-linear relationship between the current value of SBP and the rate of transition. The transition intensities under M1, M2 and M3 are, therefore, given by
where denotes the age (in decades) of subject when entering the current state . Under each model, we implemented the JM-CR-C approach where inference was based on the 1000 NUTS samples following a burn-in of 500 samples (convergence diagnostics based the on trace plots and scale reduction statistic suggest that this is sufficient). We compared M1, M2 and M3 for each transition using the LOO-CV as described in Section 3.4. Supplemental Table 7 shows the posterior summaries of the association parameter(s) obtained under each model, with the favoured model for each transition highlighted in blue shade. It is noteworthy that different association structures were suggested for different types of disease transitions, and for many transitions, the association is significant (as indicated by the fact that the associated credible interval(s) for the association parameter(s) exclude zero). In particular, we observed that a quadratic association pattern is suggested for several transitions, including most of those leading to death. The coefficient of the quadratic effect, , maintains a positive value across these transitions, indicating that both lower or higher SBP values are linked with an increased rate of disease progression or mortality. The precise quadratic relationship (controlled by both and ) varies depending on the subject’s comorbidity status prior to the transition. While it is well established that high SBP is a risk factor for mortality, our finding of an elevated risk at lower SBP levels for multimorbidity progression and mortality is less commonly recognized, and echoes well with recent findings based on Cox regression analysis.26,27 Furthermore, the association pattern of SBP level on the rate of transitioning into CVD ( and ) or MH ( and ) is found to be influenced by the underlying comorbidity status. For instance, for transitions into CVD, a quadratic association with SBP is identified when T2D is the only existing condition. However, when MH is present as an additional existing comorbidity, an interaction effect between SBP and age is suggested. Our results highlight the complexity of the relationship between a health marker like SBP and the temporal trajectory of multimorbidity.
Discussion
In this article, we introduce novel yet intuitive blockwise approaches for Bayesian inference in joint longitudinal and MSMs, where the blocks are uniquely determined based on either a competing risks process (JM-CR) or a single transition (JM-ST). Compared to the standard inference approach (JM-MSM), which is based on the posterior distribution of all model parameters conditioned on the full dataset, our proposed blockwise approaches offer enhanced computational efficiency without compromising estimation accuracy. JM-CR enables the inference of both multistate and subject-specific longitudinal parameters. When the interest of inference lies solely in the state transition rates and their associations with the longitudinal process, JM-ST stands out as being the most computationally efficient. For both blockwise approaches, we compared two different strategies for incorporating longitudinal data when performing inference in a block. We found that using only concurrent longitudinal data within the block, when applicable, can be a reasonable choice as it offers more robust inference in the presence of longitudinal model misspecification compared to its counterpart. The practical feasibility and scalability of the blockwise approaches are demonstrated through an application to the CPRD data, where the interest lies in analysing concurrent evolution of SBP and the progression of comorbidities arising from T2D, CVD and MH. Using the JM-ST approach, we were able to utilize data from more patients for inference and efficiently explore different model configurations. Our analysis revealed distinct and previously lesser-known association structures between SBP levels and different disease accumulation trajectories.
The proposed approaches can accommodate broader modelling scenarios than those demonstrated in this article. For instance, multivariate longitudinal processes can be handled using a multivariate GLMM framework,28 and nonlinear mixed-effect models can be employed to model the trajectory of specific markers.29 More general unidirectional non-Markov multistate processes can also be handled using the same decomposition strategy as considered in Section 3. We anticipate that the computational advantages of using these blockwise approaches will be even more prominent in more complex modelling scenarios. The recent two-stage approach proposed by Alvares and Leiva-Yamaguchi30 for JM estimation can also be employed alongside our blockwise approaches to further accelerate the inference in each block. Furthermore, although this article primarily focuses on inference in the multistate process, both JM-CR and JM-ST can be employed to obtain dynamically updated, subject-specific predictions of the risk of transitioning to the next state. This can be achieved either by following the framework described by Ferrer et al.31 (if using JM-CR) or by employing a simulation-based approach as described by Crowther and Lambert24 (if using JM-ST).
There are several avenues that require future research. In scenarios, where reversible transitions are allowed (i.e. a state can be visited more than once), a subject may have multiple episodes of longitudinal and time-to-event data associated with a specific block. In such cases, additional assumptions need to be introduced to make the blockwise approaches applicable, and their performance in such settings needs to be investigated. In addition, we have focused on scenarios where the multistate process is continuously observed, that is, the exact time of transition is known. However, in some application contexts, these transition times may be subject to interval censoring. This would bring additional computational challenges due to the intractability of the likelihood function for the resulting multistate data.32 It would be of interest to explore efficient estimation strategies in these settings.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241281959 - Supplemental material for Bayesian blockwise inference for joint models of longitudinal and multistate data with application to longitudinal multimorbidity analysis
Supplemental material, sj-pdf-1-smm-10.1177_09622802241281959 for Bayesian blockwise inference for joint models of longitudinal and multistate data with application to longitudinal multimorbidity analysis by Sida Chen, Danilo Alvares, Christopher Jackson, Tom Marshall, Krish Nirantharakumar, Sylvia Richardson, Catherine L Saunders and Jessica K Barrett in Statistical Methods in Medical Research
Footnotes
Acknowledgements
This work used data from the Clinical Practice Research Datalink (CPRD) for ISAC protocol 19_265. The data were provided by patients and collected by the NHS as part of their care and support.
For the purpose of open access, the author has applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising from this submission.
Data availability
The data were provided under license by the Clinical Practice Research Datalink (CPRD), and so are not publicly available. Access to CPRD data is subject to protocol approval via CPRD’s Research Data Governance (RDG) Process. The code used for the simulation and real data analysis is made available at .
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work is part of the Bringing Innovative Research Methods to Clustering Analysis of Multimorbidity (BIRM-CAM) project funded by the UKRI. SC was funded by the MRC/NIHR grant MR/S027602/1 (BIRM-CAM). CJ was funded by the Medical Research Council programme MRC_MC_UU_00002/11. TM was supported by the National Institute for Health Research Collaboration Applied Research Collaboration West Midlands (NIHR ARC WM). KN and TM are part-funded through the National Institute for Health and Care Research (NIHR, Artificial Intelligence for Multiple Long-Term Conditions (AIM), OPTIMising therapies, disease trajectories, and AI assisted clinical management for patients Living with complex multimorbidity (OPTIMAL study), NIHR202632). This work is independent research funded by and the views expressed in this publication are those of the author(s) and not necessarily those of the NHS, the National Institute for Health and Care Research or The Department of Health and Social Care. SR was funded by MRC unit programme MC_UU_00002/10. DA and JB were funded by MRC unit programme MC_UU_00002/5.
ORCID iDs
Sida Chen
Danilo Alvares
Christopher Jackson
Jessica K Barrett
Supplemental material
Supplemental materials for this article are available online.
References
1.
RizopoulosD. Joint models for longitudinal and time-to-event data: with applications in R. London: Chapman & Hall/CRC, 2012.
2.
VerbekeGDavidianM. Joint models for longitudinal data: introduction and overview. In: Fitzmaurice G, Davidian M, Verbeke G and Molenberghs G (eds) Longitudinal data analysis. Handbooks of Modern Statistical Methods, chap. 13. New York: Chapman & Hall/CRC, 2009.
3.
IbrahimJGChuHChenLM. Basic concepts and methods for joint models of longitudinal and survival data. J Clin Oncol2010; 28: 2796–2801.
4.
CookRJLawlessJF. Multistate models for the analysis of life history data. Boca Raton, FL: Chapman & Hall/CRC, 2018.
5.
DantanEJolyPDartiguesJFet al. Joint model with latent state for longitudinal and multistate data. Biostatistics2011; 12: 723–736.
6.
FerrerLRondeauVDignamJet al. Joint modelling of longitudinal and multi-state processes: application to clinical progressions in prostate cancer. Stat Med2016; 35: 3933–3948.
7.
DessieZGZewotirTMwambiHet al. Modelling of viral load dynamics and CD4 cell count progression in an antiretroviral naive cohort: using a joint linear mixed and multistate Markov model. BMC Infect Dis2020; 20: 1–14.
8.
FurgalA. Bayesian models for joint longitudinal and multi-state survival data. PhD Thesis, University of Michigan, 2021.
9.
HickeyGLPhilipsonPJorgensenAet al. Joint modelling of time-to-event and multivariate longitudinal outcomes: recent developments and issues. BMC Med Res Methodol2016; 16: 1–15.
10.
HickeyGLPhilipsonPJorgensenAet al. Joint models of longitudinal and time-to-event data with more than one event time outcome: a review. Int J Biostat2018; 14: 1–19.
11.
VehtariAGelmanAGabryJ. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat Comput2017; 27: 1413–1432.
12.
WallaceESalisburyCGuthrieBet al. Managing patients with multimorbidity in primary care. BMJ2015; 350: 1–6.
13.
CezardGMcHaleCTSullivanFet al. Studying trajectories of multimorbidity: a systematic scoping review of longitudinal approaches and evidence. BMJ Open2021; 11: 1–19.
14.
Singh-ManouxAFayosseASabiaSet al. Clinical, socioeconomic, and behavioural factors at age 50 years and risk of cardiometabolic multimorbidity and mortality: a cohort study. PLoS Med2018; 15: 1–16.
15.
FreislingHViallonVLennonHet al. Lifestyle factors and risk of multimorbidity of cancer and cardiometabolic diseases: a multinational cohort study. BMC Med2020; 18: 1–11.
16.
ChenSMarshallTJacksonCet al. Sociodemographic characteristics and longitudinal progression of multimorbidity: a multistate modelling analysis of a large primary care records dataset in England. PLoS Med2023; 20: e1004310.
17.
WolfADedmanDCampbellJet al. Data resource profile: clinical practice research datalink (CPRD) aurum. Int J Epidemiol2019; 48: 1740–1740g.
18.
PutterHFioccoMGeskusRB. Tutorial in biostatistics: competing risks and multi-state models. Stat Med2007; 26: 2389–2430.
19.
PapageorgiouGMauffKTomerAet al. An overview of joint modeling of time-to-event and longitudinal outcomes. Annu Rev Stat Appl2019; 6: 223–240.
20.
AlvaresDRubioFJ. A tractable Bayesian joint model for longitudinal and survival data. Stat Med2021; 40: 4213–4229.
21.
VehtariAGabryJMagnussonMet al. loo: efficient leave-one-out cross-validation and WAIC for Bayesian models. R package version 2.5.0. https://mc-stan.org/loo/. 2022.
22.
Stan Development Team. RStan: the R interface to Stan. R package version 2.21.3. https://mc-stan.org/. 2022.
23.
HoffmanMDGelmanA. The no-U-turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. J Mach Learn Res2014; 15: 1593–1623.
24.
CrowtherMJLambertPC. Parametric multistate survival models: flexible modelling allowing transition-specific distributions with application to estimating clinically useful measures of effect differences. Stat Med2017; 36: 4719–4742.
25.
LewandowskiDKurowickaDJoeH. Generating random correlation matrices based on vines and extended onion method. J Multivar Anal2009; 100: 1989–2001.
26.
VamosEPHarrisMMillettCet al. Association of systolic and diastolic blood pressure and all cause mortality in people with newly diagnosed type 2 diabetes: retrospective cohort study. BMJ2012; 345: 1–10.
27.
MasoliJAHDelgadoJPillingLet al. Blood pressure in frail older adults: associations with cardiovascular outcomes and all-cause mortality. Age Ageing2020; 49: 807–813.
28.
MauffKSteyerbergEKardysIet al. Joint models with multiple longitudinal outcomes and a time-to-event outcome: a corrected two-stage approach. Stat Comput2020; 30: 999–1014.
29.
AlvaresDMercierF. Bridging the gap between two-stage and joint models: the case of tumor growth inhibition and overall survival models. Stat Med2024; 43: 3280–3293.
30.
AlvaresDLeiva-YamaguchiV. A two-stage approach for Bayesian joint models: reducing complexity while maintaining accuracy. Stat Comput2023; 33: 1–11.
31.
FerrerLPutterHProust-LimaC. Individual dynamic predictions using landmarking and joint modelling: validation of estimators and robustness assessment. Stat Methods Med Res2019; 28: 3649–3666.
32.
LovblomLE. Joint multistate models for correlated disease processes: extending approaches for interval-censoring, mixed observation schemes, and multiple longitudinal outcomes. PhD Thesis, University of Toronto (Canada), 2023.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.