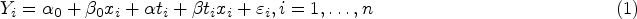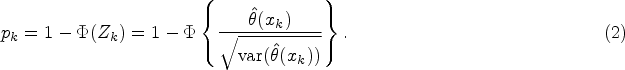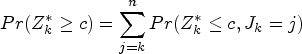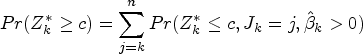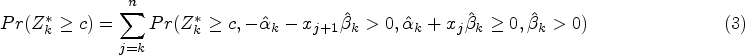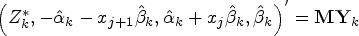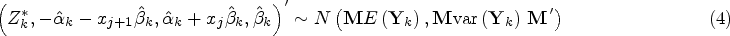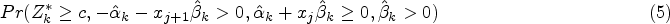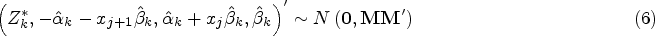There is a growing interest in clinical trials that investigate how patients may respond differently to an experimental treatment depending on the basis of some biomarker measured on a continuous scale, and in particular to identify some threshold value for the biomarker above which a positive treatment effect can be considered to have been demonstrated. This can be statistically challenging when the same data are used both to select the threshold and to test the treatment effect in the subpopulation that it defines. This paper describes a hierarchical testing framework to give familywise type I error rate control in this setting and proposes two specific tests that can be used within this framework. One, a simple test based on the estimated value from a linear regression model with treatment by biomarker interaction, is powerful but can lead to type I error rate inflation if the assumptions of the linear model are not met. The other is more robust to these assumptions, but can be slightly less powerful when the assumptions hold.
Recent advances in the understanding of the heterogeneity of patients and disease types have led to an increasing desire to understand how patients may respond differently to a particular treatment. This in turn has led to development of a number of novel clinical trial approaches that attempt to identify a subgroup of patients that may benefit from an experimental therapy.1,2
One particular approach is the adaptive enrichment design.3,4 This is a two-stage design. In the first stage, patients are recruited from the whole population. Data from these patients are then used to select some subgroup of the population, which may be the whole population, in which a positive treatment effect is anticipated, with patients recruited from this subpopulation in the second stage. One such trial is described by Ho et al.5 At the end of the trial, the question of interest is whether the treatment can be shown to be effective in the subpopulation selected.
If this is a confirmatory, phase III, randomised controlled trial, as highlighted, for example, by Simon,6 the final analysis of the trial is challenging. It is often considered desirable to conduct a hypothesis test of the treatment effect in the selected subgroup, but if the final analysis uses data from both stages the fact that stage 1 data are used both to select the subpopulation to be included in the second stage and to assess the effectiveness of the treatment in that subpopulation can lead to inflation of the type I error rate. In order to control the type I error rate it has been suggested that only the data from the second stage might be used in the final analysis7 or that data from all patients in the first stage are combined with those in the second stage irrespective of whether or not they are in the selected subpopulation,4but such approaches are generally inefficient.8
While there has been some work on methods that enable use of the first stage data in the final analysis and control the type I error rate, these have predominantly been in the case in which the subpopulation is defined on the basis of a single binary biomarker so that in the second stage recruitment is either from the whole population or restricted to a predefined subgroup including only biomarker positive patients.9–13
There has been more limited work on the setting in which the biomarker is continuous. In this case, while some authors assume that this continuous biomarker divides the patients into two distinct groups with different levels of treatment effect,14, it is more common to assume that the biomarker has a monotonic effect on the treatment effect, often with the direction of this assumed, so that, for example, the treatment effect is assumed to be non-decreasing with increasing biomarker values. Selection of the subpopulation thus corresponds to identification of a threshold level for the biomarker so that the subgroup is comprised of all patients with biomarker levels above this threshold. Lin et al.8 consider this problem in the setting of a single-arm trial, and propose selection of the subgroup that maximises the standardised average subpopulation effect relative to a specified value, which may be a historical treatment effect. Stallard15 considers the setting of a two-arm study with the subgroup selected to maximise one of the measures including the test statistic comparing the treatment groups in the selected subgroup and the estimated treatment difference in the subgroup. Selection based on maximisation of a test statistic such as the estimated treatment difference can, however, lead to selection of small subgroups when the treatment effect is increasing with the biomarker.
Frieri et al.16 extend the setting of Lin et al.8 to that of a comparative trial, with patients randomised to receive either an experimental treatment or a standard treatment considered as a control. Like Lin et al.,8 they assume that the biomarker and the response follow a bivariate normal distribution, so that the expected response is linearly related to the biomarker level, and propose selection of the subpopulation of patients with biomarker levels such that the expected response on the experimental treatment exceeds that on the control treatment by some specified amount. Frieri et al., like Wang et al.,17 who consider time to event data, and Baldi Antognini et al.,18who consider design issues, focus primarily on estimation of a threshold level for the continuous biomarker above which the treatment effect is positive. The final analysis they propose is, however, based only on the stage 2 patients from the selected subgroup, so does not need to take account of the data-dependent treatment selection but does not use all available data. The focus of the current paper is more on hypothesis testing when data from both stages are used, the aim being to identify a subpopulation in which the null hypothesis that the treatment is ineffective can be rejected whilst allowing for the multiple testing that arises from the same data being used to both identify the subpopulation and conduct the test.
Setting and notation
Since, as outlined above, the statistical challenges arise from the use of the same data for both subgroup selection and hypothesis testing within the selected subgroup, we will focus specifically on the analysis of data from stage one. Data from stage two can be added, for example, via a combination test,19 as described in more detail in the Discussion section below. We thus consider a single-stage study in which a continuous biomarker is used to identify a subpopulation with the treatment effect tested in that subpopulation. Like Lin et al.8 and Frieri et al.,16 we will specifically consider the setting of a continuous response that can be assumed to be normally distributed, though we will make no similar assumption about the distribution of the biomarker.
In detail, suppose patients are assigned to two groups, with indicating group membership for patient , , with for patients receiving a control treatment and for patients receiving an experimental treatment. Let and denote the numbers of patients in treatment groups 1 and 0, respectively. Treatment allocation is typically assigned at random or using a randomly permuted blocks design to ensure that .
Let denote the biomarker value for patient , . We will condition these values, considering them fixed. Without loss of generality, assume .
Let denote the response for patient , with denoting the observed value of , , and normally distributed and related to and via a linear regression model with main effects and interaction. That is
with independent for some unknown .
We will assume that larger values of are more desirable, and will further assume that it is known, or can be assumed a priori, that ; that is, if the biomarker has a predictive effect then it is in the direction such that treatment effects are larger for larger biomarker values.
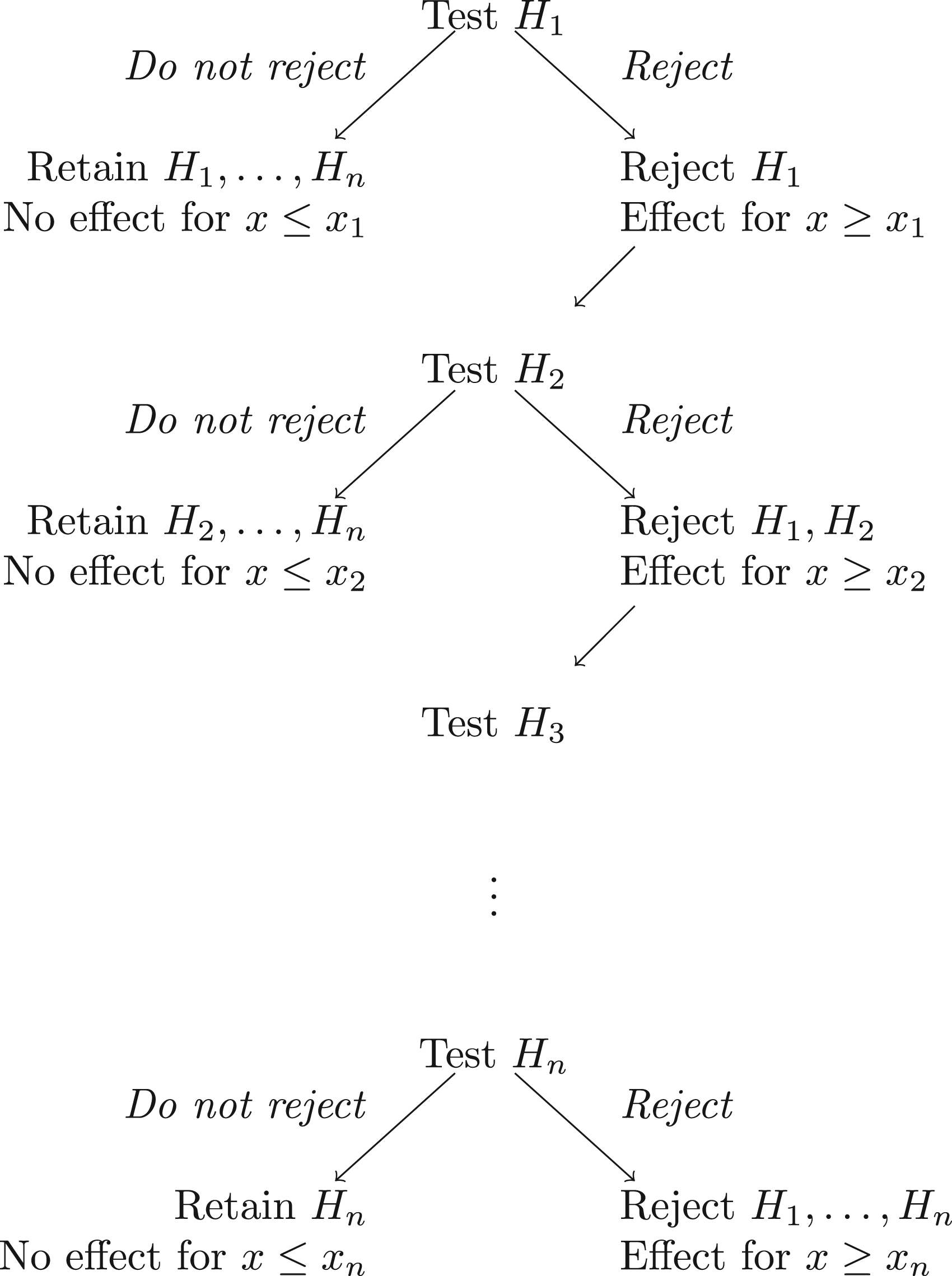
Closed testing procedure for strong familywise error rate control
Let denote the treatment effect at biomarker level , so that, from equation (1), we have , and write for . We wish to test the family of null hypotheses for . Note that, since , the assumption means that . Hence and implies for all . Conversely, if we reject and conclude , this implies we may conclude that for all . Rejecting thus leads to the conclusion that the treatment is effective for patients with biomarker level or larger.
Since , the set is closed under intersection. Applying the closed testing procedure,20 for given , the familywise error rate (FWER) is controlled in the strong sense by a procedure under which can be rejected if all intersection hypotheses that are subsets of can be rejected at the nominal level. In this case, this corresponds to the rejection of .
The FWER is thus strongly controlled by the hierarchical testing procedure illustrated in Figure 1, in which we test each at the nominal level, starting with . If is not rejected at the nominal level, we do not reject any of and conduct no further tests. If is rejected at the nominal level, we reject , concluding that for all , and proceed to step .
The hierarchical testing procedure for the family of hypotheses .
A simple regression-based test of
In order to apply the hierarchical testing procedure just described, a test of is required. As noted above, implies and hence for all , thus in particular for . A test of can thus be based on data . Although this test is not based on the entire data set, and so may lack power for larger , omitting data means that rejection of , and a conclusion that the treatment is effective at biomarker level , cannot arise due to observed data indicating a large treatment effect at higher biomarker levels.
In order to test based on the data we can fit the linear model given by (1) to the data , noting that this requires for parameter estimates to be identifiable. Fitting the model provides estimates of the treatment and treatment by biomarker interaction effects, and , together with their estimated variances and covariance. The estimated treatment effect at a biomarker value is then with expected value and variance where estimates and their variances can be obtained using standard software, for example, using the lm and vcov commands in R,21or via expressions in, for example, Madsen and Thyregod.22. Since , we can test using , which under has an asymptotic distribution that is stochastically no larger than a -distributed random variable.
If , so that the data support a treatment effect that increases with , a (one-sided) -value for the test can thus be obtained as
If , indicating a treatment effect that decreases with , we do not wish to conclude that for all , so set .
Similarly, for , when it is impossible to fit the linear model (1) to the data , we set and fail to reject . In practice, this is unlikely to be of concern when is of reasonable size as it is not desirable to conclude that the treatment is effective for a very small subset of the population.
A more robust test of
As the estimate on which the -value given by (2) is based is taken directly from the linear model (1), it might be anticipated that the test based on this -value would be sensitive to departure from the linearity assumed, and it is shown below that this can be the case, particularly when the true treatment effect is increasing and concave. An alternative, more robust, test of is thus also proposed.
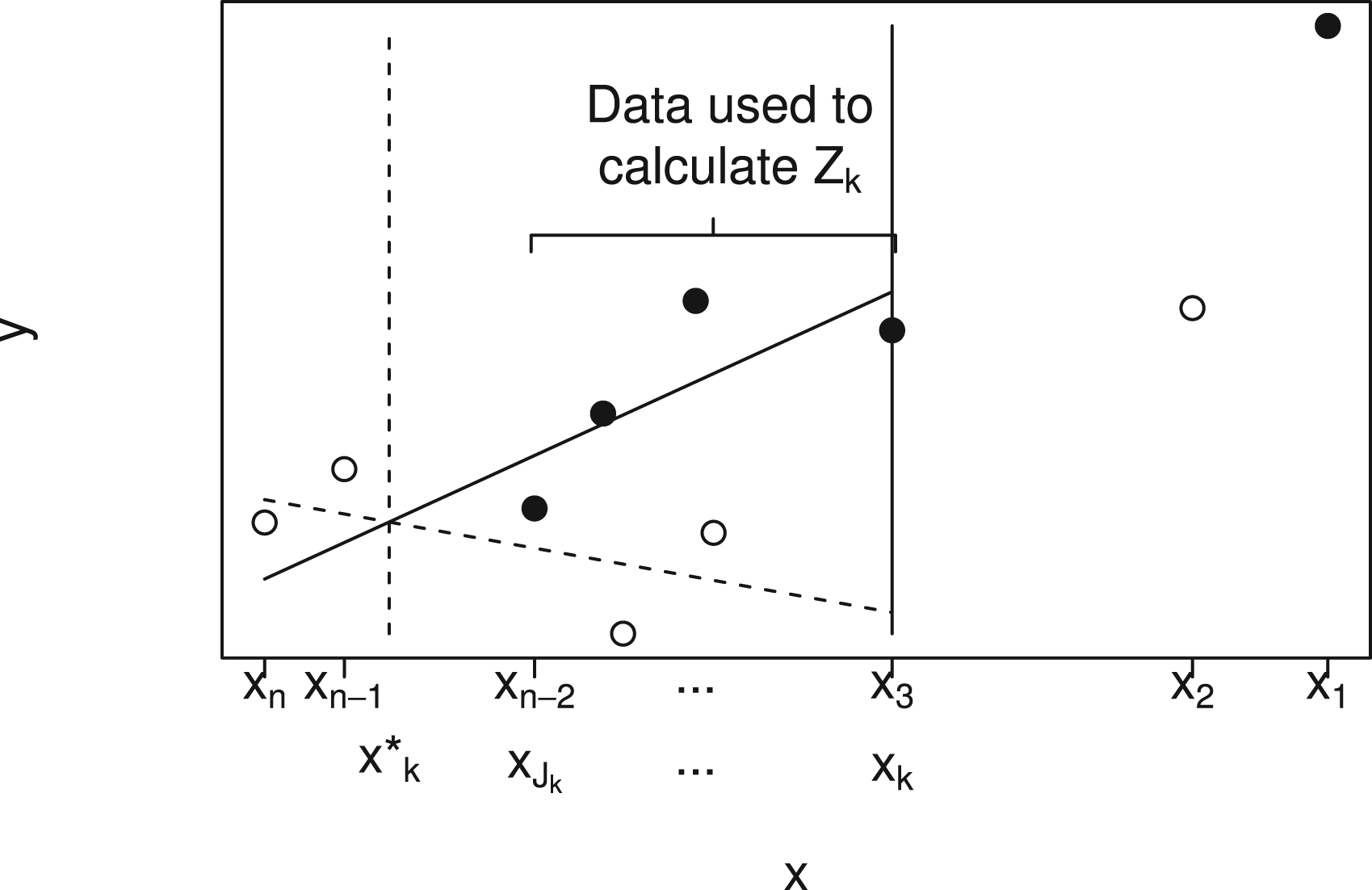
As in the simpler test above, the test of is based on data , that is, data with . With this procedure, we first identify a value such that a positive treatment effect is anticipated for , then use data with to test for a treatment effect after adjusting for to test the hypothesis .
The procedure is illustrated by Figure 2, which shows a plot of against for a particular data set. Solid points indicate and hollow points . In order to test , data , are used. This is illustrated in the figure for , so that data given by points to the right of the solid vertical line at are not used.
Plot showing plotted against for a single small data set using solid points for and hollow points for to illustrate notation and data used to test (here with ). A linear model with treatment by biomarker interaction is fitted to data for patients and the value of at which the lines cross is denoted by . The value is then the largest with . Data for patients are used to calculate the test statistic, which will be denoted .
We first fit the linear model (1), with main effects and interaction, to the data , again requiring that , to obtain estimates , with estimated treatment effect at a biomarker value given by . If , so that the data support a treatment effect that increases with , the estimated treatment effect, is positive for all where .
The fitted lines from model (1) are shown in Figure 2 by the dashed line (group 0) and solid line (group 1). The point at which these lines cross is , shown by the vertical dashed line. Given , we define , with if is empty, so that is the smallest at least as large as .
If and , the treatment effect in the range adjusted for can be estimated by fitting a linear model with main effects of treatment and biomarker but no interaction to data assuming . A test statistic, , for can then be obtained as the test for a treatment effect adjusted for from this model. The data used to obtain fit lie between the vertical dashed and solid lines in Figure 2. If or , the data do not indicate that there are any with and we set .
In order to obtain a -value, , for the test of , the observed value of the test statistic can be compared to its null distribution. This distribution is derived in the following subsection.
Null distribution of , the test statistic for a treatment effect in the selected subgroup
In order to base a test of , we require its null distribution.
We start by giving a derivation of the distribution of under the simple null hypothesis .
As described above and illustrated in Figure 2, let and . We wish to obtain the distribution of , that is, specifically to obtain
We have
which, since if , means that
Now, for , we must have , that is, If , that is, and so that
Since and are all linear combinations of coefficients from a linear model involving data from patients , we have
for some matrix , with , so that
(see Appendix 1 in the Supplemental material for details).
If were known, the probability
could thus be given by a multivariate normal tail area.
Since the terms on the left-hand side, all come from linear models adjusting for the biomarker levels, they do not depend on or , so these may be set to 0 in the distribution (4). Hence under the null hypothesis , we can take , the zero vector, so that the four elements of the vector on the left-hand side of equation (4) all have mean 0.
Thus, the value of is invariant to scaling of , since it is divided by . Scaling of will lead to scaling of , and , but since in the probability given in equation (5) these are compared with their mean values 0, the probability will remain unchanged. We may thus scale each to have unit variance so that equation (4) becomes
Denoting by the complementary distribution function giving the probability when has a multivariate normal distribution with mean and variance–covariance matrix , the probability given by equation (5) is equal to This then enables calculation of given by equation (3) as required.
In practice, since is unknown, the estimated value from the linear regression (1) could be used. This estimate could be obtained separately for each using data . However, since the estimate may be poorly estimated when the sample size used to fit the models is small, as will be the case when testing for large or when is close to , an alternative is to use an estimate of obtained from fitting the model (1) to the whole data set when calculating and the corresponding -value. This will provide a more precise estimate if (1) holds with for all .
The -value given by (3) was based on the distribution of under the simple null hypothesis . Supplemental Appendix 2 shows that this distribution is stochastically larger than that under any such that and , and hence , that is, , for all , so that a test based on the -value obtained is thus conservative under any other null scenario.
The test statistic is obtained by using the data in the range to test for a treatment effect adjusting for . Alternative tests could fit a model to these data with a treatment effect but without adjusting for , or adjusting for both and an interaction between and treatment, could also be used, with the distribution of the test statistic obtained in a similar way to that of .
Simulation study
Comparison of operating characteristics
A simulation study was conducted to assess the properties of the testing procedures described above.
Taking , for each of 10,000 simulated data sets, values were sampled at random without replacement from the set with 40 elements equal to 0 and 40 elements equal to 1 so that and values were simulated from a normal distribution with mean 0 and variance 1 and ordered such that . Values were then simulated from the model
with and taken to be 0, 0.5, and 1 to illustrate a range of treatment by biomarker interaction effects. As the models used adjust for the biomarker, the results of the hypothesis tests are invariant to and and these were arbitrarily set to zero. Hypotheses were tested at FWER 0.025 using the tests based on and as described above.
For , a type I error corresponds to rejection of any while for , since so that if and only if , a type I error corresponds to rejection of any with . The number of simulations leading to a type I error was recorded. For , the number of simulations leading to rejection of for each was also recorded as a measure of power. Note that the hierarchical testing procedure used, as illustrated in Figure 1, means that this number is increasing in (and decreasing in ).
In order to provide a comparison with the approaches described above, the data were also used to test using an approach based on that described by Stallard.15 In this approach, a nominal test of was conducted by fitting the linear model to test for a treatment effect adjusted for a biomarker effect to data sets for and taking the test statistic to be the largest observed from the test statistics obtained. A -value for the test based on this maximum can be obtained as described by Stallard15 and the hierarchical testing procedure applied as above.
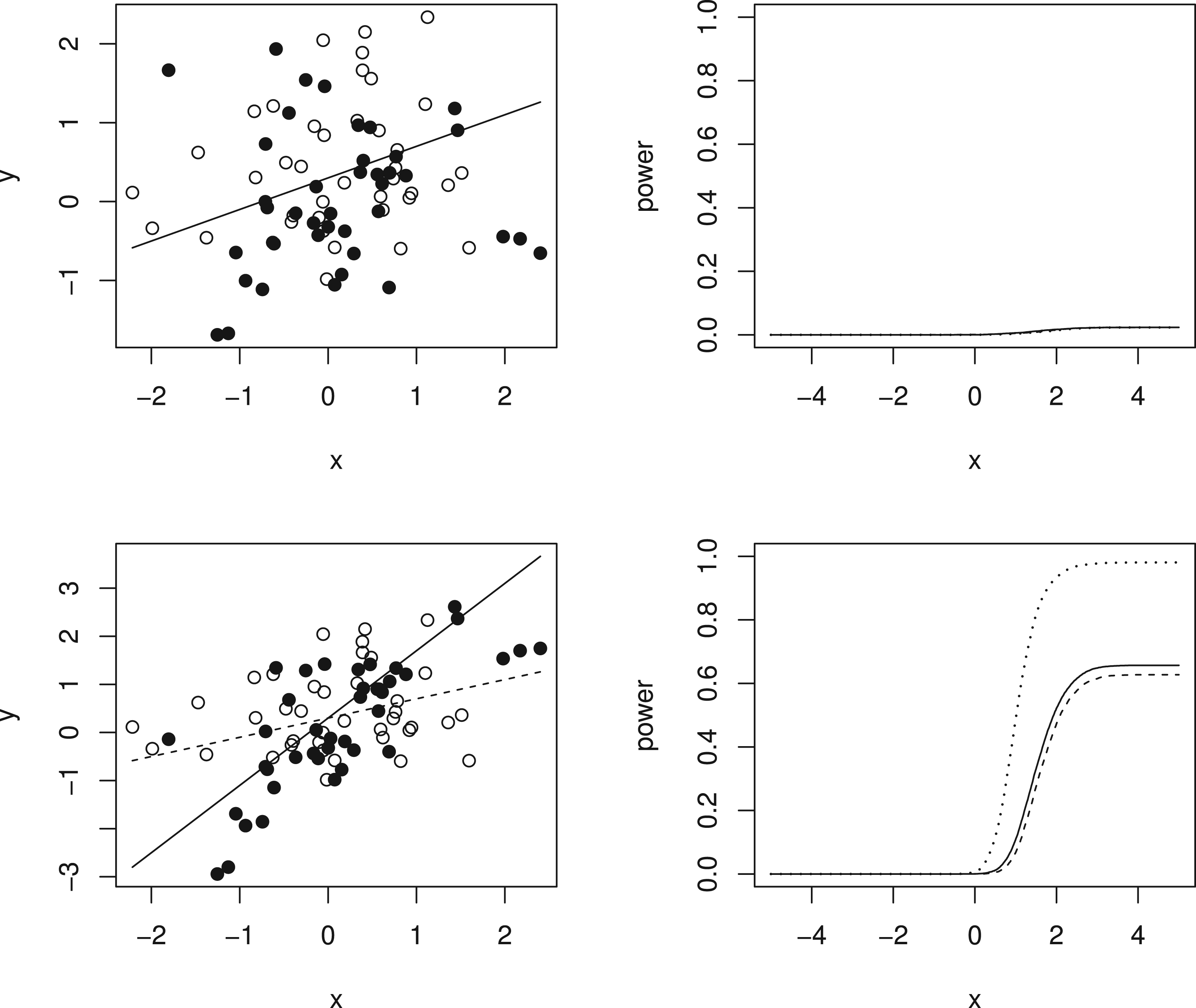
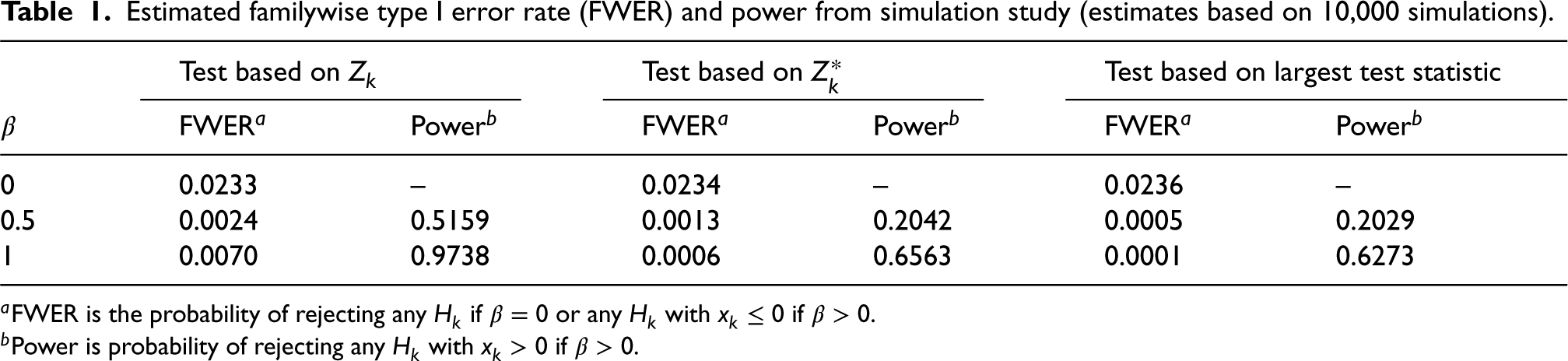
Simulation results are given in Figure 3 and Table 1. The left-hand panels of Figure 3 show the expected values under the simulation models for (dotted line) and (solid line) for equal to 0 in the top row, so that the dashed and solid lines coincide, and to 1 in the second row, together with one simulated data set in each case with hollow points for and solid points for given as for illustration of the variability of the data around the expected values. The right-hand panel shows, for the same values of , the estimated probability of rejecting plotted against for using the tests described above based on and and using the test proposed by Stallard.15. This probability corresponds to the type I error rate in the upper plot, and to the type I error for and the power for in the lower plot. The overall type I error and power for for in each case are given in Table 1.
Simulation models and example data sets and simulation results for (upper panels) and (lower panels). Left-hand panels show simulation models and one simulated data set for (dashed line gives expected values and hollow points give simulated values) and (solid line gives expected values and solid points give simulated values). Right-hand panels show simulated probability from 10,000 simulations per scenario of rejecting plotted against for tests as in Stallard15 (dashed line) and using (dotted line) and (solid line). Probabilities are type I error rates for and for when and powers for and .
Estimated familywise type I error rate (FWER) and power from simulation study (estimates based on 10,000 simulations).
Test based on
Test based on
Test based on largest test statistic
FWERa
Powerb
FWERa
Powerb
FWERa
Powerb
0
0.0233
–
0.0234
–
0.0236
–
0.5
0.0024
0.5159
0.0013
0.2042
0.0005
0.2029
1
0.0070
0.9738
0.0006
0.6563
0.0001
0.6273
aFWER is the probability of rejecting any if or any with if .
bPower is probability of rejecting any with if .
It can be seen that all of the proposed procedures control the familywise type I error rate at the 0.025 level as required. For the FWER is close to the nominal level. For larger , the type I error rate reported is the probability of rejecting any with . Since in this case the treatment effect decreases with , for small values we can have well below 0, leading to conservatism in the test.
It is also evident that the test using is more powerful than that using , and that this is slightly more powerful than the test proposed by Stallard15 that chooses the value of that gives the largest test statistic.
The probability of rejecting for specified shown in the lower right-hand plot shows the power to detect a treatment effect at different biomarker levels, . As the hierarchical testing procedure ensures that rejection of leads to rejection of for all , this power increases with , reducing towards the type I error rate as approaches zero from above, for any testing method. This seems reasonable for the model considered, for which the treatment effect is reducing towards zero at . Since in the simulations the values are simulated from a distribution, many of the values are close to 0, so that even for many true treatment effect values, , are small. The power to reject is thus low for many , leading to low true discovery rates, which, for are, respectively, estimated from the simulations to be 35%, 13% and 10% for the methods using , and the approach of Stallard.
Robustness to departures from the linear model
Both of the tests for described above are based on the linear model (1). If the assumed model is incorrect, neither of the test statistics nor will follow the distributions obtained and the test may be inaccurate.
In order to assess the robustness of the methods to departures from (1) a number of simulations were conducted with data simulated from other models. In order to assess potential type I error rate inflation, simulations were conducted under null scenarios in which for all .
Writing for , the first sets of simulations were conducted with data simulated from models with for all but with not linearly related to , that is, with the biomarker having no predictive effect but a non-linear prognostic effect. Additional sets of simulations were conducted with constant and non-linearly increasing in but with simulated values of restricted to ensure that for all simulated values. These models correspond to the biomarker having no prognostic effect but a non-linear predictive effect such that the treatment is not effective for any patients. The first two sets of simulation models thus all correspond to null models in which there is no positive treatment effect at any biomarker level. A third set of simulations were conducted with constant and non-linearly increasing in but with for and for .
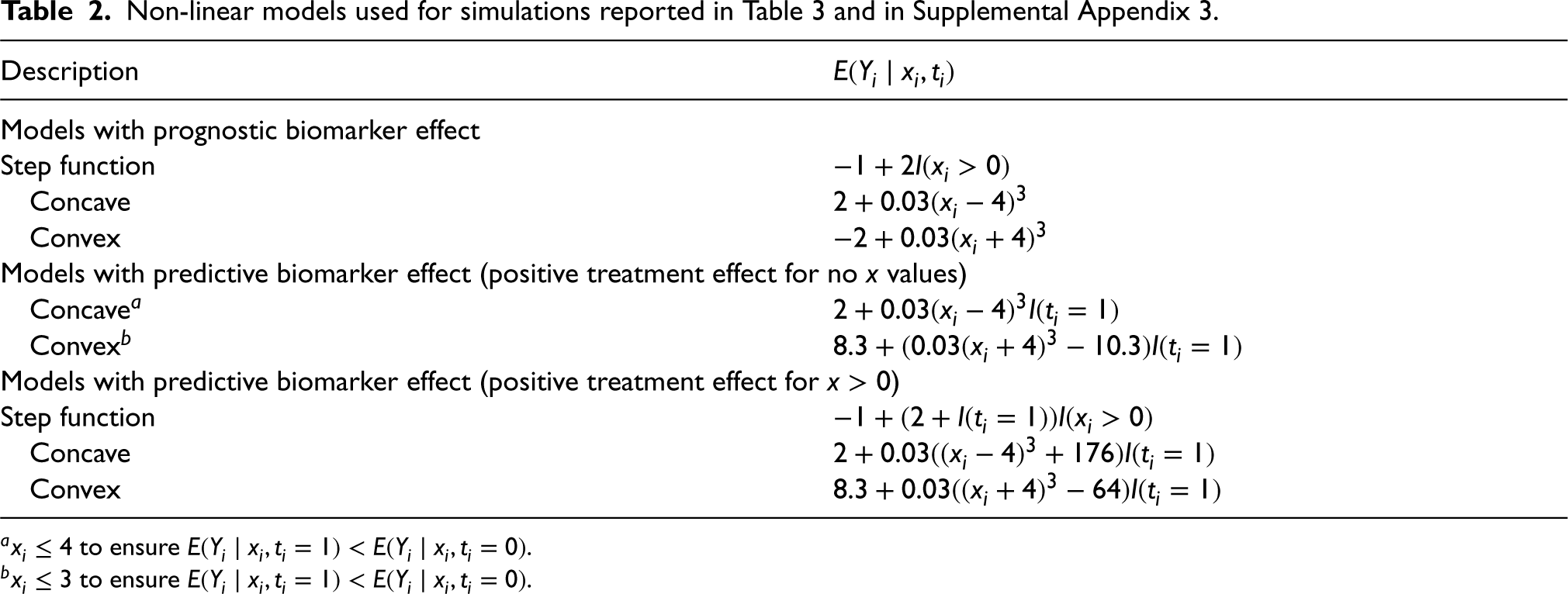
The simulation models are given in Table 2, and are also illustrated, along with one example simulated data set in each case, in the left-hand panels of Figures A1 to A3 given in Appendix 3 in the Supplemental material, which are analogous to Figure 3 above. In each case, data were simulated with , and normal with variance 1 and mean related to according to the expression given in the table.
Non-linear models used for simulations reported in Table 3 and in Supplemental Appendix 3.
Description
Models with prognostic biomarker effect
Step function
Concave
Convex
Models with predictive biomarker effect (positive treatment effect for no values)
Concavea
Convexb
Models with predictive biomarker effect (positive treatment effect for )
Step function
Concave
Convex
a to ensure .
b to ensure .
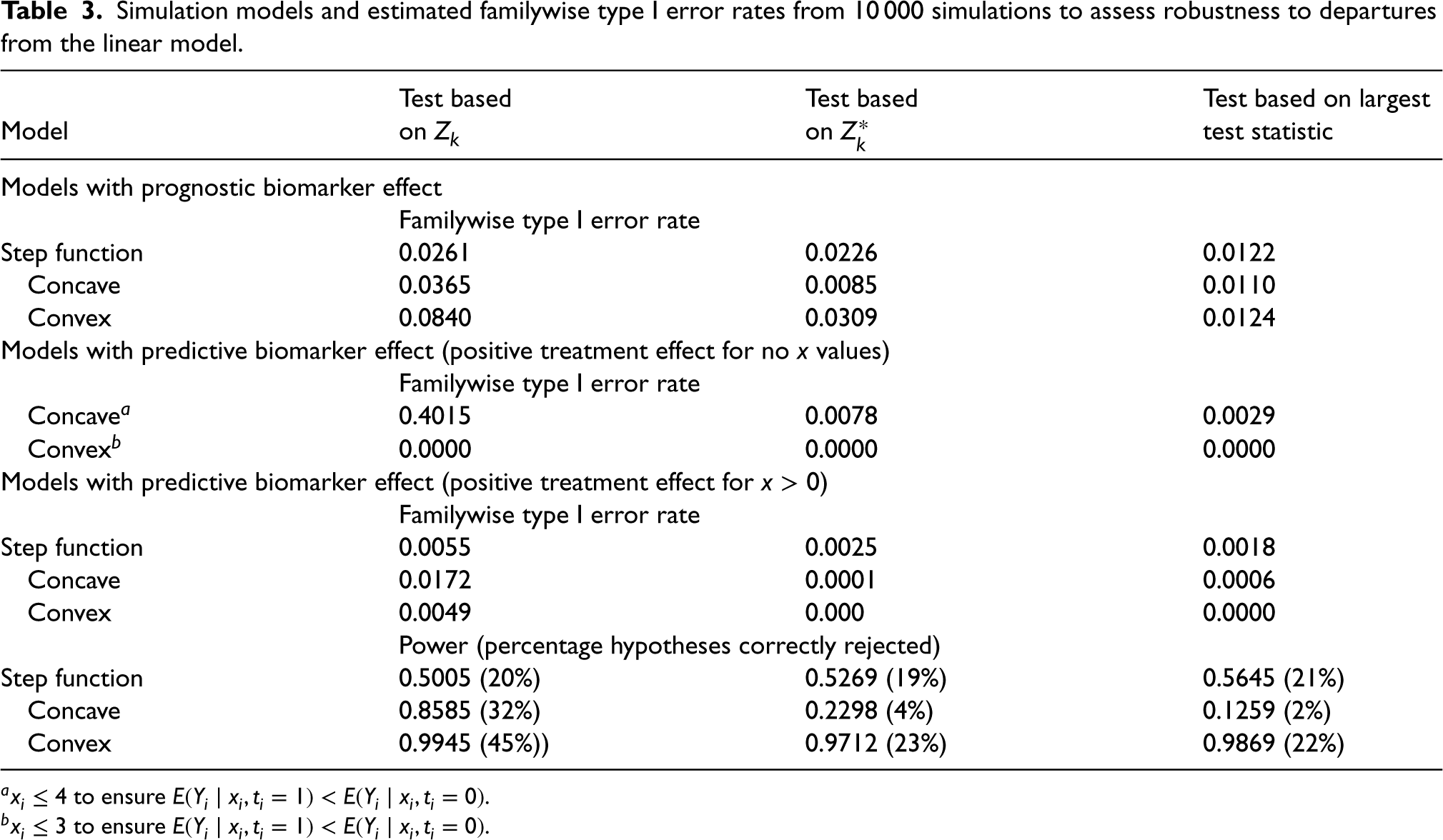
Estimated type I error rates based on 10,000 simulations under each model are given in Table 3 and are also given in Figures A1 to A3 in Appendix 3 in the Supplemental material. It can be seen that there is a slight increase in the type I error rate above the nominal level for tests based on and when there is a convex prognostic effect of and for the test based on when there is a concave prognostic effect. Particularly notable, however, is the very large increase in the type I error for the test based on when there is a concave predictive effect of . The tests proposed by Stallard15 that do not use a linear model control the type I error rate in all cases, but are again conservative, unsurprisingly particularly when for some values of .
Simulation models and estimated familywise type I error rates from 10 000 simulations to assess robustness to departures from the linear model.
Test based
Test based
Test based on largest
Model
on
on
test statistic
Models with prognostic biomarker effect
Familywise type I error rate
Step function
0.0261
0.0226
0.0122
Concave
0.0365
0.0085
0.0110
Convex
0.0840
0.0309
0.0124
Models with predictive biomarker effect (positive treatment effect for no values)
Familywise type I error rate
Concavea
0.4015
0.0078
0.0029
Convexb
0.0000
0.0000
0.0000
Models with predictive biomarker effect (positive treatment effect for )
Familywise type I error rate
Step function
0.0055
0.0025
0.0018
Concave
0.0172
0.0001
0.0006
Convex
0.0049
0.000
0.0000
Power (percentage hypotheses correctly rejected)
Step function
0.5005 (20%)
0.5269 (19%)
0.5645 (21%)
Concave
0.8585 (32%)
0.2298 (4%)
0.1259 (2%)
Convex
0.9945 (45%))
0.9712 (23%)
0.9869 (22%)
a to ensure .
b to ensure .
For models with a positive treatment effect for some values, estimated power, again based on 10,000 simulations under each model, is also given in Table 3 together with estimated true rejection rates. It can be seen that the power of all methods depends on the true model for the data. In particular, the estimated power is largest for the convex model for which the true treatment effect, , is large for larger , and smallest for the concave model for which is relatively small for all , and particularly for smaller positive . The test based on has the highest power, consistent with the increased type I error rate, though, for the step function model, all three methods have similar power.
Example: Analysis of data from an Alzheimer’s disease study
Schnell et al.23 report an analysis of data from a trial of an experimental therapy for Alzheimer’s disease. They compare patients receiving low-dose treatment with those receiving a placebo in terms of their change in cognitive impairment, with positive values indicating an improvement, that is, a reduction in cognitive impairment, identifying a positive treatment by age interaction indicating that the treatment is more effective for older patients.
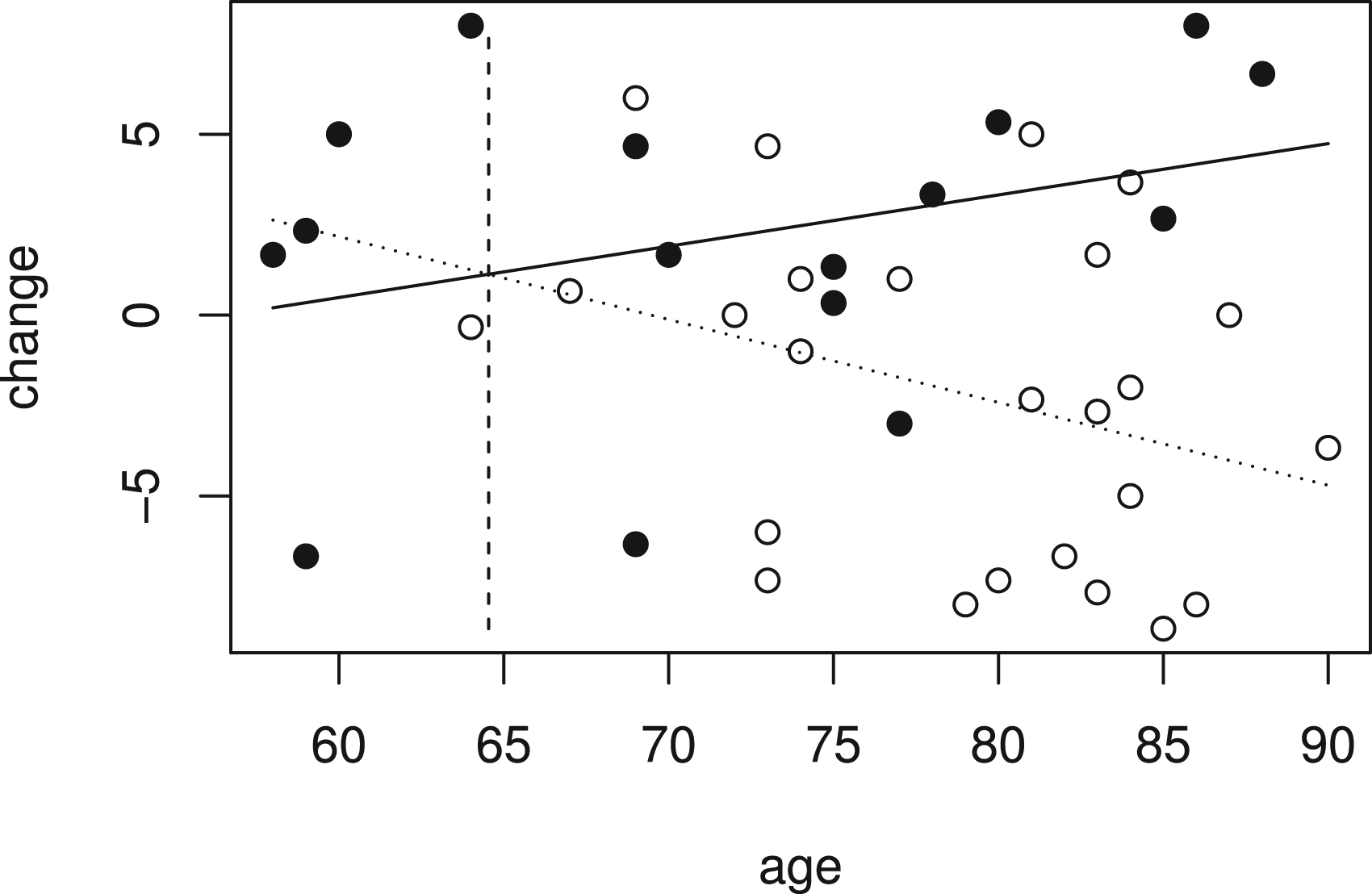
The data from 41 patients, with 16 receiving low-dose treatment and 25 receiving placebo, are available from Schnell et al.23 and are shown in Figure 4, where the outcome is plotted against age with placebo patients represented by a hollow circle and low-dose patients by a solid circle.
Improvement in cognitive impairment and age for patients in low dose (solid points) and placebo groups (hollow points) in Alzheimer’s disease study.
Figure 4 also shows fitted values for the linear model given by (1) that includes terms for treatment, age and a treatment by age interaction fitted to the whole data set. This can be used to test the null hypothesis . From the linear model, the estimate is equal to 0.371, so is greater than zero, indicating that the treatment effect is increasing with age, and the estimated treatment effect at the largest observed age, , is 9.44 with standard error 2.86, so that , corresponding to a -value of 0.0005. Fitted treatment effects are positive for patients of age and above. The value of is shown by the vertical dashed line in Figure 4. Using data from patients with to construct gives . A -value can be found as described above, and in this case is equal to 0.0036.
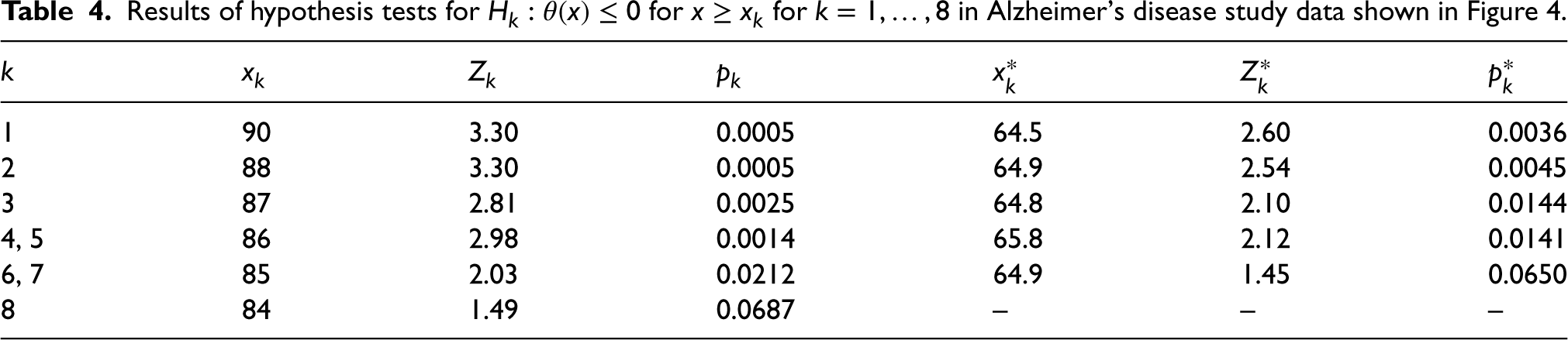
In order to control the FWER for testing of hypotheses , the hierarchical procedure described above and illustrated in Figure 1 is applied. Results of tests for hypotheses based on and are given in Table 4. In this data set, and , so that the hypotheses and and the hypotheses and are identical and are tested using the same data and respectively. The results for the tests of each of these pairs of hypotheses are thus given in the same line in Table 4.
Results of hypothesis tests for for in Alzheimer’s disease study data shown in Figure 4.
1
90
3.30
0.0005
64.5
2.60
0.0036
2
88
3.30
0.0005
64.9
2.54
0.0045
3
87
2.81
0.0025
64.8
2.10
0.0144
4, 5
86
2.98
0.0014
65.8
2.12
0.0141
6, 7
85
2.03
0.0212
64.9
1.45
0.0650
8
84
1.49
0.0687
–
–
–
Using the test based on , the hierarchical procedure leads to rejection of hypotheses at the one-sided 0.025 level, and to retention of hypotheses without any further testing, since the -value for the test of is 0.0687, and thus exceeds 0.025. As , we can conclude that there is a significant effect of treatment for patients aged 85 and above.
For the test based on hypotheses are rejected at the one-sided 0.025 level with retained as exceeds 0.02. In this case, it would be concluded that there is a significant treatment effect for patients aged and above.
It is worth noting that the smallest for which is rejected, in this case, or , are considerably larger than , the estimated value above which the treatment effect is positive, which in this case is equal to 64.5 as noted above. This reflects the fact that the subgroup for which there is evidence of benefit is smaller than that for which there is an indication of benefit.23 While this is a particular feature of a setting such as this when the sample size is low, in general, since we desire to have a low probability of rejecting for with , the power will be low for values of just above this even for larger sample sizes. This is analogous to the setting in a simple comparison of groups where the treatment effect estimate may be positive but not statistically significantly larger than 0.
Discussion
This paper has presented an approach for hypothesis testing to compare two groups in a subpopulation selected on the basis of some continuous biomarker when the same data are used for the selection and the hypothesis test. Although motivated by the setting of a clinical trial with a predictive biomarker, the method could be applied in other settings in which a subgroup of a data set is selected.
In the biomarker setting, as described in the Introduction, a popular approach is to use an adaptive enrichment design in which recruitment is restricted to the selected subpopulation in the second stage of a two-stage trial. The method proposed could be used in such a setting by using a combination test to combine evidence from both stages for tests of each hypothesis within the hierarchical testing framework described. Stage two patients could either be recruited from a subpopulation defined to be patients with any biomarker level with a positive estimated effect based on the analysis of the stage one data or from the subpopulation with biomarker values corresponding to a sufficiently small -value based on the stage one data.
Like the approaches of Lin et al.8 and Frieri et al.,16 the proposed method is based on a model in which a continuous response is related to the biomarker values via a normal linear model. Unlike these authors, however, we do not assume bivariate normality for the biomarker and response values. Rather, we condition the biomarker values, so that the methods make no assumption about their distribution in the population. The method could thus also be used in settings where biomarker levels are chosen by design or sampled from a restricted range within the population. In the simulations and example presented above, the values at which the null hypotheses are tested are the observed biomarker levels for the patients in the study, with these patients sampled at random from the population under investigation. An alternative approach might be to either stratify sampling or to use test hypotheses at biomarker levels that do not correspond to all observed values, for example corresponding to certain quantiles of the anticipated or empirical distribution of biomarker levels observed. Such an approach could also ensure that the number of patients with data used for tests of for larger was not too small.
In contrast to Frieri et al. and Baldi Antognini et al.18 our focus is not primarily on estimation of the biomarker level above which the experimental treatment is more effective than the control, but on identification of a subpopulation in which a positive treatment effect can be demonstrated. It should also be noted that we do not take as our parameter of interest the average treatment effect in the identified subpopulation. If the treatment effect depends on a continuous biomarker, a group selected with a positive average treatment effect will include patients with biomarker levels such that the expected treatment effect is negative. Our test based on , the smallest treatment effect in the selected group, will avoid this.
The methods proposed are based on the assumption that response and biomarker values are linearly related, with the usual assumptions of a normal linear regression model holding. This is a common assumption in this setting and may often be reasonable, but should be checked using the data. The second method presented, based on the test statistic , appears to be more robust, as indicated in the simulation study presented, but can still lead to type I error rate inflation. The alternative method proposed by Stallard15 does not rely on linear model assumptions for control of the family wise type I error rate. This could thus be a more appropriate method to use if it was considered that the assumption of a linear relationship between response and biomarkers might not hold. The simulation studies reported above indicate, however, that the gain in robustness of the method of Stallard15 comes at a cost of a loss in power relative to the approach proposed above. In practice, it is recommended that simulation studies are used to assess both the type I error rate and the power of the approach selected for a range of possible scenarios and sample sizes to ensure that the method is sufficiently robust and the study appropriately powered.
Other tests, including those not based on a linear model or including higher order polynomial terms to allow for a non-linear biomarker effect, could also be used within the hierarchical testing framework described and might have attractive properties in terms of type I error rate control and power. Simulation studies could also be used to assess the power of alternative testing methods under a range of treatment effect scenarios considered to be likely. An assumption that the treatment effect is increasing in the biomarker is required, though this may well be considered reasonable in many contexts where a predictive biomarker effect is hypothesised.
It is also assumed that the biomarker levels are measured without error. In some settings, error in these measurements might be considered sufficiently small that it can be ignored and conventional linear regression models, as proposed above, can be used. If this is not considered reasonable, alternative error-in-variables methods could be used to replace the tests proposed above to allow for the uncertainty in the true biomarker levels,24 though this would still assume that the subsets used in the hierarchical testing approach are correct.
The methods proposed have been developed and applied with a continuous, normally distributed response. The hierarchical testing framework could be used with other settings such as those with binary or time-to-event responses given suitable tests of the individual hypotheses . Extensions of the first method proposed might be possible based on estimated treatment effects from a logistic or Cox regression model, but a derivation of the distribution of the test statistic using an extension of the second method might be more challenging.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241277764 - Supplemental material for Testing for a treatment effect in a selected subgroup
Supplemental material, sj-pdf-1-smm-10.1177_09622802241277764 for Testing for a treatment effect in a selected subgroup by Nigel Stallard in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The author is grateful to Dr Peter Kimani and three anonymous referees for their helpful comments that have led to improvements in the manuscript. For the purpose of open access, the author has applied a Creative Commons Attribution (CC-BY) licence to any author accepted manuscript version arising from this submission.
Data availability statement
Data sharing is not applicable to this article as no new data were created or analysed in this study.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Medical Research Council (grant numbers MR/V038419/1, MR/W021013/1).
ORCID iD
Nigel Stallard
Supplemental material
Supplemental material for this article is available online.
References
1.
AntoniouMJorgensenALKolamunnage-DonaR. Biomarker-guided adaptive trial designs in phase II and phase III: A methodological review. PLoS ONE2016; 11: e0149803.
2.
LinJBunnVLiuR. Practical considerations for subgroups quantification, selection and adaptive enrichment in confirmatory trials. Stat Biopharm Res2019; 11: 407–418.
SimonNSimonR. Adaptive enrichment designs for clinical trials. Biostatistics2013; 14: 613–625.
5.
HoTWPearlmanELewisD, et al. Efficacy and tolerability of rizatriptan in pediatric migraineurs: Results from a randomized, double-blind, placebo-controlled trial using a novel adaptive enrichment design. Cephalagia2012; 32: 750–765.
RenfroLCoughlinCGrotheyA, et al. Adaptive randomized phase ii design for biomarker threshold selection and independent evaluation. Chin Clin Oncol2014; 3: 3.
8.
LinZFlournoyNRosenbergerWF. Inference for a two-stage enrichment design. Ann Stat2021; 49: 2697–2720.
9.
WangSJO’NeillRTHungHMJ. Approaches to evaluation of treatment effect in randomized clinical trials with genomic subset. Pharm Stat2007; 6: 227–244.
10.
SpiessensBDeboisM. Adjusted significance levels for subgroup analyses in clinical trials. Contemp Clin Trials2010; 31: 647–656.
11.
FriedeTParsonsNStallardN. A conditional error function approach for subgroup selection in adaptive clinical trials. Stat Med2012; 31: 4309–4320. DOI: 10.1002/sim.5541.
12.
StallardNHamborgTParsonsN, et al. Adaptive designs for confirmatory clinical trials with subgroup selection. J Biopharm Stat2014; 24: 168–187.
13.
RosenblumMLuberBThompsonR, et al. Group sequential designs with prospectively planned rules for subpopulation enrichment. Stat Med2016; 35: 3776–3791.
14.
DioaGDongJDonglinZ, et al. Biomarker threshold adaptive designs for survival endpoints. J Biopharm Stat2018; 28: 1038–1054.
15.
StallardN. Adaptive enrichment designs with a continuous biomarker. Biometrics2023; 79: 9–19.
16.
FrieriRRosenbergerWFlournoyN, et al. Design considerations for two-stage enrichment clinical trials. Biometrics2023; 79: 2565–2576.
17.
WangTWangXGeorgeS, et al. Design and analysis of biomarker-integrated clinical trials with adaptive threshold detection and flexible patient enrichment. J Biopharm Stat2020; 30: 1060–1076.
18.
Baldi AntogniniAFrieriRRosenbergerW, et al. Optimal design for inference on the threshold of a biomarker. Stat Methods Med Res2024; 33: 321–343.
19.
BrannathWPoschMBauerP. Recursive combination tests. J Am Stat Assoc2002; 97: 236–244.
20.
MarkusRPertizEGabrielKR. On closed testing procedures with special reference to ordered analysis of variance. Biometrika1976; 63: 655–660.
21.
R Core Team. R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing, 2021.
22.
MadsenHThyregodP. Introduction to general and generalized linear models. Boca Raton: CRC Press, 2010.
23.
SchnellPTangQOffenW, et al. A Bayesian credible subgroups approach to identifying patient subgroups with positive treatment effects. Biometrics2016; 72: 1026–1036.
24.
FullerW. Measurement error models. New York: John Wiley and Sons, 1987.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.