
Abstract
Multivariate disease mapping is important for public health research, as it provides insights into spatial patterns of health outcomes. Geostatistical methods that are widely used for mapping spatially correlated health data encounter challenges when dealing with spatial count data. These include heterogeneity, zero-inflated distributions and unreliable estimation, and lead to difficulties when estimating spatial dependence and poor predictions. Variability in population sizes further complicates risk estimation from the counts. This study introduces multivariate Poisson cokriging for predicting and filtering out disease risk. Pairwise correlations between the target variable and multiple ancillary variables are included. By means of a simulation experiment and an application to human immunodeficiency virus incidence and sexually transmitted diseases data in Pennsylvania, we demonstrate accurate disease risk estimation that captures fine-scale variation. This method is compared with ordinary Poisson kriging in prediction and smoothing. Results of the simulation study show a reduction in the mean square prediction error when utilizing auxiliary correlated variables, with mean square prediction error values decreasing by up to 50%. This gain is further evident in the real data analysis, where Poisson cokriging yields a 74% drop in mean square prediction error relative to Poisson kriging, underscoring the value of incorporating secondary information. The findings of this work stress on the potential of Poisson cokriging in disease mapping and surveillance, offering richer risk predictions, better representation of spatial interdependencies, and identification of high-risk and low-risk areas.
Introduction
Multivariate disease mapping plays a vital role in public health research by providing valuable insights into the spatial distribution and patterns of health outcomes and putative risk factors. It aims to identify shared risk factors, establish relationships between diseases and implement integrated disease surveillance systems. Geostatistical methods are valuable for analyzing spatially dependent health data, enabling the modeling and predicting of disease rates across geographical regions. 1 Nonetheless, when dealing with spatial counts, such as the number of disease cases, several challenges arise within the geostatistics framework.
Traditional geostatistical methods, such as kriging, struggle to accurately model disease count data due to the heterogeneous nature of the observed cases and the frequent presence of low count distributions. It often yields improper estimation of the spatial dependence, over smoothed risk predictions and poor prediction uncertainty.2–5 Disease risk estimation procedures, which require the division of observed cases between the population sizes, further aggravate these issues. The resulting raw risk distributions are heavy-tailed, highly asymmetric and unreliable given the inherent spatial variability of population sizes.
To face these challenges, the geostatistical literature offers a range of methods for modeling disease count data. Binomial cokriging 6 and beta-binomial kriging 7 were developed to handle disease proportions derived from disease counts. Such proportions typically result in loss of information and biased inference. 8 In disease mapping analyses, counts are generally preferred due to their ability to handle small counts and facilitate detailed spatial analysis. Poisson kriging, introduced by Monestiez et al. 2 and extended and applied to disease count data,3,4,9–11 has stood as a prominent geostatistical method for analyzing disease count data. Poisson kriging allows inferring the underlying disease risk while accounting for the non-stationarity of the observed disease counts induced by the population size variability. Payares-Garcia et al. 5 extended this methodology to operate in a bivariate context, addressing challenges posed by sparse observations and allowing for the estimation of disease risk at locations with absent or inaccessible data but with information available on a closely related disease. The model enhanced risk prediction precision, captured diseases’ geographical cross-correlation and produced smoothed risk maps accurately mirroring the underlying disease risk. Restricting the analysis to bivariate disease interactions, however, fails to fully exploit the potential of cokriging and to meet the increasing need for multivariate disease mapping.
Outside the multivariate geostatistics domain, Bayesian hierarchical models are useful for multivariate mapping of disease counts. Their widespread adoption remains, however, constrained due to limited user-friendly software implementations and substantial computational costs of Markov chain Monte Carlo and integrated nested Laplace approximation estimation, particularly when the number of diseases increases.12,13 The primary modeling strategies of shared component models 14 and multivariate spatial distributions, such as the multivariate conditional autoregressive,15–17 coregionalization,18,19 model-based geostatistics, 1 and computationally efficient M-models frameworks, 20 are hard to scale to large spatial datasets, with inference becoming prohibitive at times. The selection of an appropriate prior distribution poses as well practical challenges to non-experts in the domain.4,9 While valuable, multivariate disease mapping outside of geostatistics often grapples with computational, interpretability and scalability obstacles. Cokriging integrates multivariate dependence and ancillary information using accessible, interpretable, and rapid estimation procedures. Likewise the ability of cokriging to predict at unobserved locations, makes it an advantageous tool against its counterparts for multivariate mapping.
In this study, we present a generalization of Poisson cokriging for the prediction and smoothing of multivariate disease spatial counts. It capitalizes on the pair-wise correlation between a target variable and multiple ancillary variables in the form of disease counts. Building upon the model proposed by Payares-Garcia et al., 5 we adopt a pair-wise covariance model, as a specific instance of the multivariate Poisson distribution as outlined by Mahamunulu. 21 The proposed methodology for multivariate disease mapping has critical implications for public health planning and interventions. By enabling precise identification of geographical disease clusters and at-risk populations, this method supports policymakers in strategic resource allocation and targeted prevention programming.
The article is organized as follows. First, we provide a detailed exposition of the mathematical foundations of Poisson cokriging and elucidate the theoretical principles that underpin its development. Then, we illustrate our model’s prediction and smoothing capabilities by means of a comprehensive simulation analysis and a real data application to human immunodeficiency virus (HIV) incidence and sexually transmited diseases (STDs) data in Pennsylvania. The results and implications of our research are synthesized and discussed in the final section, providing a comprehensive summary of our findings.
Statistical modeling
Model
Let (
The vector of disease counts (

In disease mapping, the parameter

The total set of risk variables
Following Monestiez et al.,
2
Goovaerts,
4
and Payares-Garcia et al.,
5
the conditional mean and variance of variable
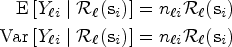
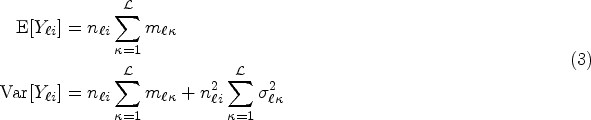
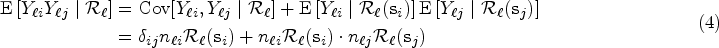
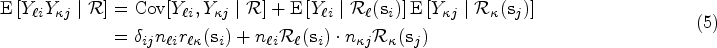
The covariance terms in (4) and (5) can be expressed in matrix form as follows:
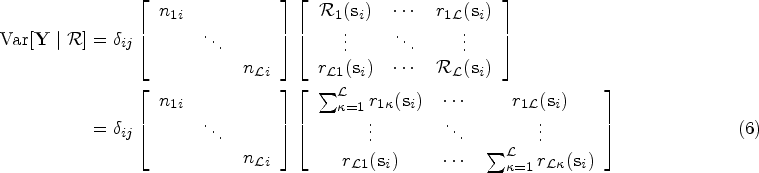
Kriging of the total risk


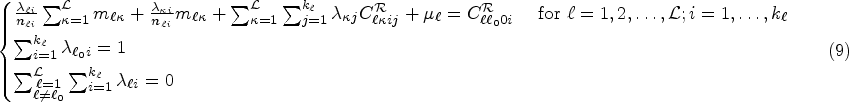
Note that the terms

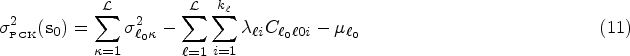
In our analysis, we adopt a generalized formulation of the empirical semivariogram estimators
Let
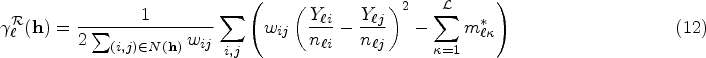
Similarly, the cross-semivariogram is defined as
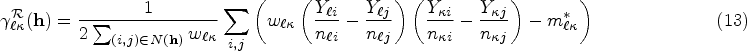
In (12) and (13), the inclusion of weights
Let
In contrast, smoothing is achieved when the sample risk
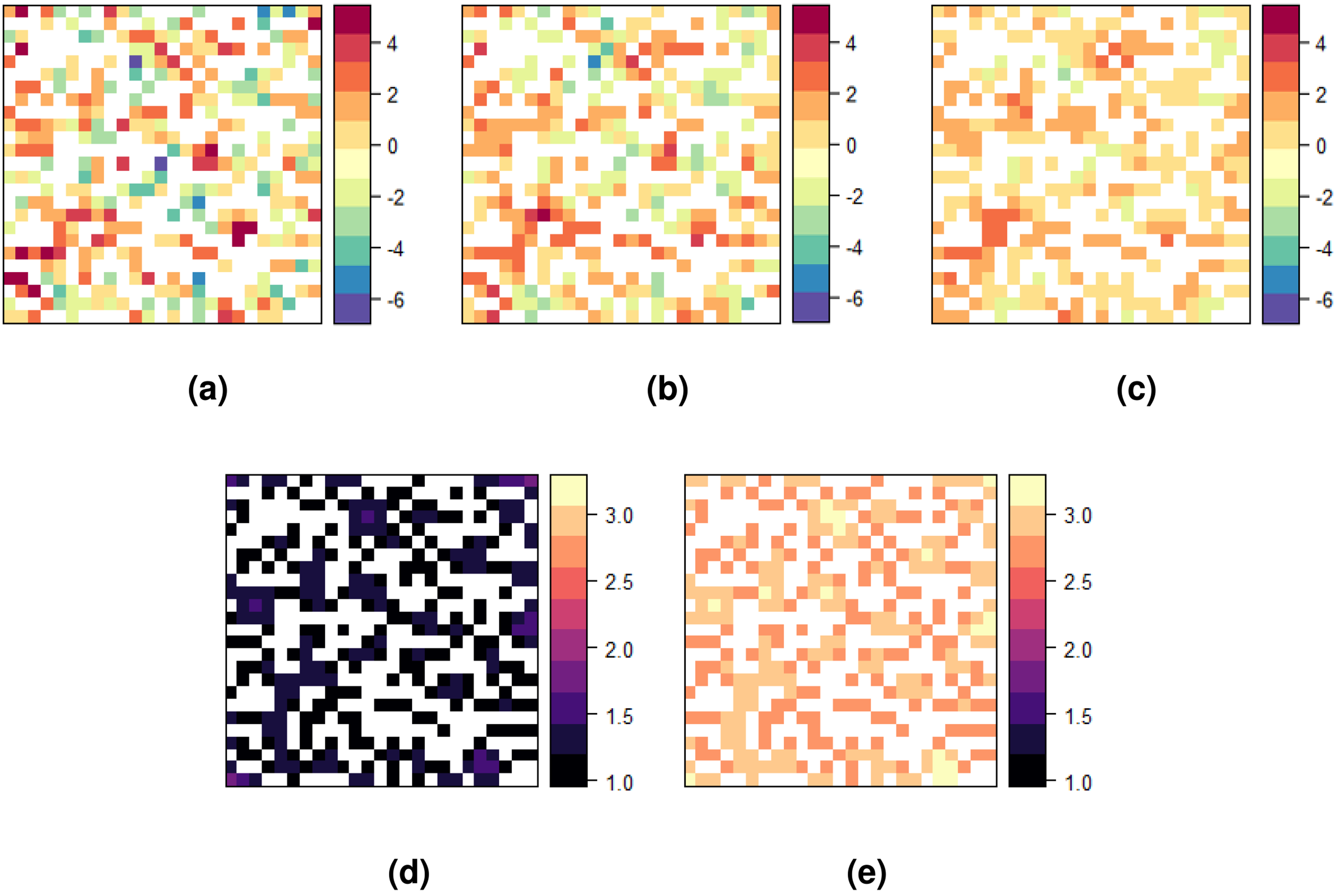
The performance for both the prediction and smoothing processes can be assessed using the average error (AE), the mean squared prediction error (MSPE), and the Pearson’s correlation (
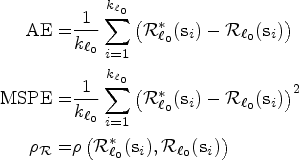
Note that the assessment of the predicted and smoothed risk values is carried out jointly, as predicted values inherently lack ground truth data for independent validation. The AE, MSPE, and
Simulation studies
Simulation design
We conducted a simulation study involving 1000 datasets and three distinct diseases (
The dependence between the sample counts was modeled using Poisson correlation, as discussed by Kawamura.
24
Specifically, we set the Poisson correlations to
To create a realistic scenario where the target variable
Training sampling locations for the total risk of the diseases
Spatial structure
The theoretical semivariograms and cross-semivariograms for the three processes were estimated using the estimators described in (12) and (13). Subsequently, an isotropic nested variogram comprising an exponential and a spherical covariance function was fitted using weighted least-squares for each dataset.
Figure 2 displays the summaries of the fitted semivariograms, accompanied by their respective error bandwidths. Notably, the averaged estimated theoretical semivariograms closely align with the underlying covariance structure, indicating unbiassedness across distances. This outcome can be attributed to the introduction of bias terms (10) in the estimators of the population-weighted semivariograms.
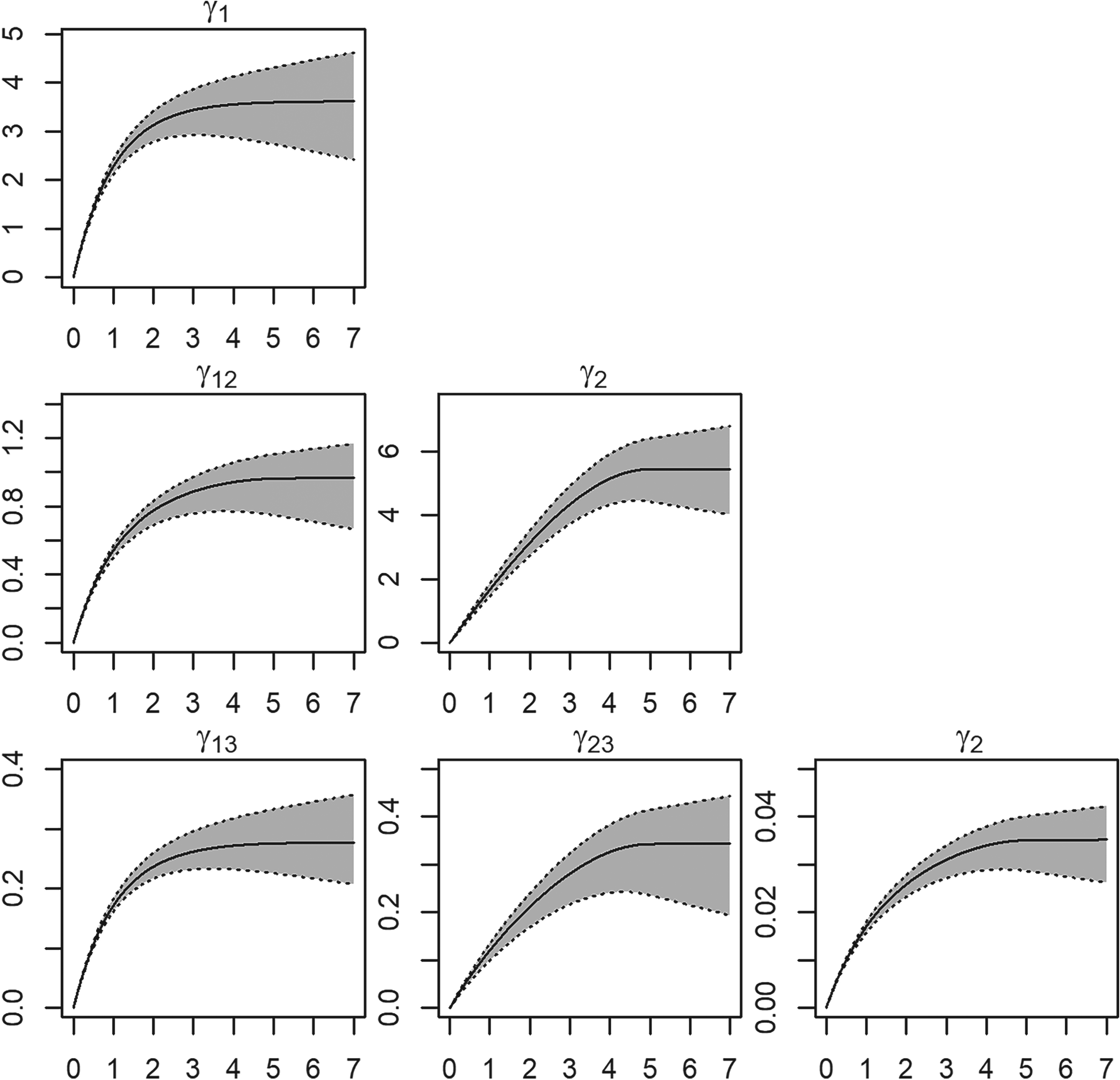
Semivariogram and cross-semivariogram estimation summaries for the 1000 simulated datasets. Average semivariograms estimate (solid line) and “error bandwidths” (gray polygon) with one standard deviation of the semivariogram estimates; the dotted lines represent the lowest and highest deviations from the average estimates.
The sampling variability exhibits both positive and negative fluctuations concerning the true covariance function, with increased variability observed at larger distances. However, at a zero lag distance (
Poisson cokriging is both a predictive method for estimating the total risk
We conducted predictions of the total risk
We compared our results with Poisson kriging using the AE, MSPE, the coverage probability of prediction intervals (95% confidence), and
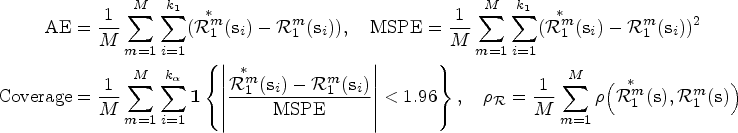
Prediction
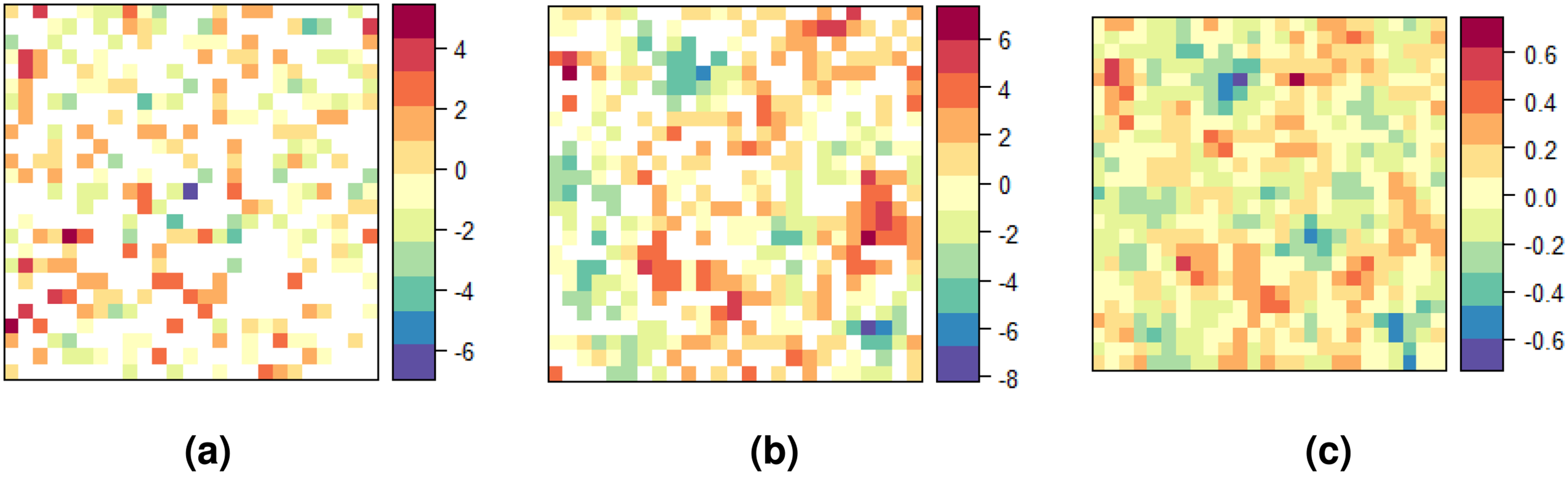
Figure 3 presents the averaged predicted risks at unsampled locations, along with their corresponding variance of the prediction error, for both Poisson cokriging (PCK) and Poisson kriging (PK), in comparison to the underlying risk. The predictions generated by Poisson cokriging (Figure 3(b)) successfully capture both the intensity and spatial patterns of the true risk, while simultaneously attenuating the influence of highly variable risk areas. This result can be attributed to the inclusion of the population sizes in our method, particularly in regions where populations exhibit spatial heterogeneity. Consequently, the resulting predictions display a smoothed pattern that closely resembles the underlying risk distribution, and thus facilitate the visual identification of high and low-risk areas.
Maps of (a) true total risk log
Poisson kriging (Figure 3(c)) yields over-smoothed predictions in which the risk levels are highly softened. This is particularly evident in the loss of extremely high and low risk values. Its variance map reveals that Poisson kriging exhibits approximately twice the variability compared to PCK. In both models, the confidence of the predictions diminishes as the spatial variability between the risk levels of neighboring cells increases.
The evaluation metrics (Table 1) highlight the superior prediction performance of Poisson cokriging. Specifically, AE, MSPE, and
Smoothing
Figure 4 illustrates the averaged smoothed risks across the entire study area, accompanied by the variance of the prediction error. It presents a comparison between the univariate and multivariate versions of Poisson kriging, similar to Figure 3.
Summary assessment metrics to constrain Poisson cokriging and Poisson kriging as predictors for the 1000 simulated datasets.
AE: average error; MSPE: mean squared prediction error;
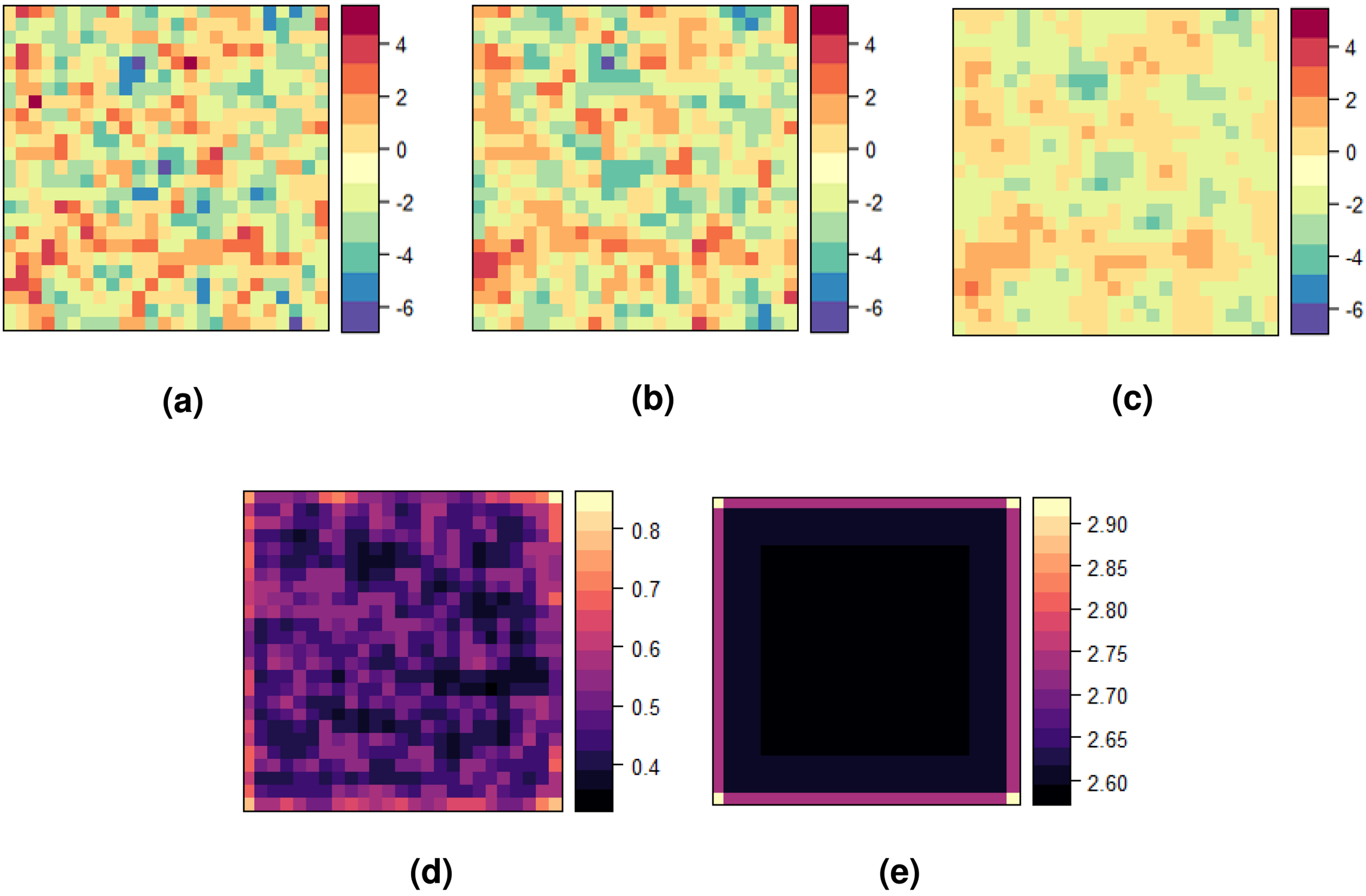
Maps of (a) the observed total risk log
The smoothed map produced by Poisson cokriging (Figure 4(b)) provides a denoised representation of the observed sample counts (
Table 2 summarizes the assessment metrics for Poisson cokriging and Poisson kriging as smoothers based on the 1000 simulated datasets. For Poisson cokriging, the average error is close to zero, indicating a low bias in the risk estimation. The MSPE value equals 1.530, suggesting a relatively low prediction error. Furthermore, the
Summary assessment metrics to constrain Poisson cokriging and Poisson kriging as smoothers for the 1000 simulated datasets.
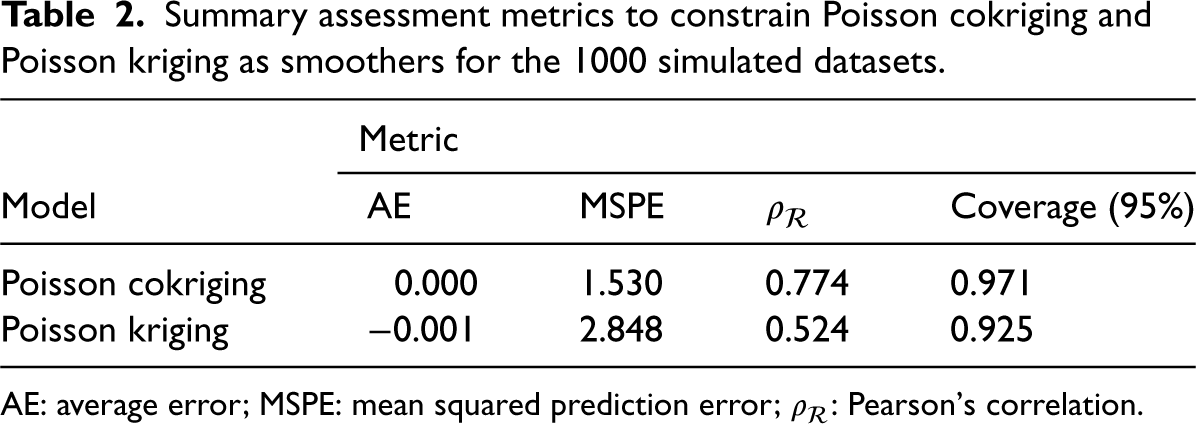
AE: average error; MSPE: mean squared prediction error;
Evaluating the computational efficiency of a modeling approach is crucial, especially in scenarios where real-time performance or the analysis of large datasets is required. In this simulation study, we assessed the computational time of the Poisson cokriging method for both prediction and smoothing processes.
Table 3 presents the average run time estimates in seconds (s) for the 1000 simulated datasets. The smoothing process (0.031 s/sample), naturally, is more computationally intensive than the prediction process (0.072 s/sample). This result is expected due to the iterative removal of observed data points, covariance matrix re-calculation and risk estimation involved in smoothing the disease rates. Nonetheless, the running times, even for the smoothing process, remain reasonably short, with standard deviations of < 2 s.
Average run time estimates of Poisson cokriging for the 1000 simulated datasets.
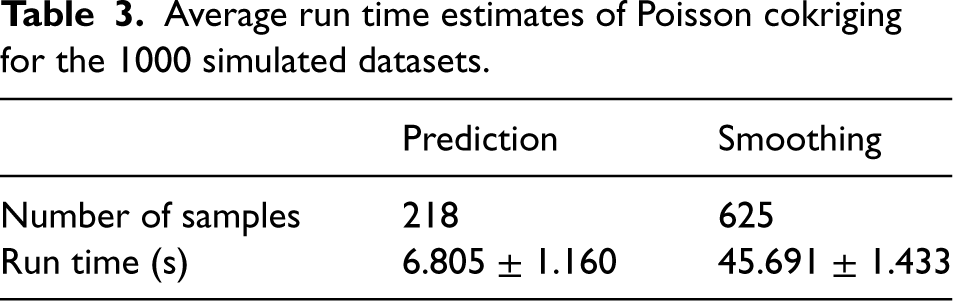
Average run time estimates of Poisson cokriging for the 1000 simulated datasets.
While the computational cost of spatial modeling techniques can be influenced by various factors, such as the number of samples, the complexity of the spatial dependence structure, and the available computational resources (e.g. CPU, RAM, and parallelization capabilities), our results demonstrate that Poisson cokriging exhibits efficient performance in both prediction and smoothing with a moderate sample size of 625 observations. Since disease risk estimation is typically performed for geographical units, and large datasets are relatively rare at the areal level, these computational time estimates for Poisson cokriging are promising and suggest its suitability for practical applications in the field of disease risk assessment.
In the United States (U.S.), the prevalence of these STDs remains a concern. According to data from the Centers for Disease Control and Prevention (CDC), rates of HIV, gonorrhea, and chlamydia disproportionately affect marginalized groups such as racial/ethnic minorities, gay, and bisexual men, youth, and lower income populations. 25 While southern states present the highest rates overall, Pennsylvania remains above national averages, with over 1000 new HIV diagnoses in 2019 in cities like Philadelphia and Pittsburgh. Stigma and insufficient screening persist in enabling these syndemics, though data suppression further obscures the true burden. To protect privacy, HIV/STD data with low-counts or vulnerable groups is often restricted, limiting statistical reliability. 26 While ethically justified, this constrains public health capacity.
Leveraging data on correlated STDs like gonorrhea and chlamydia could help estimate geographic HIV burden where direct data is limited or missing. As these STDs are highly correlated, their incidence provides information about unobserved HIV risk and improves representation beyond what constrained surveillance data can directly capture.5,9 Research shows that in the context of HIV, gonorrhea, and chlamydia is important. Co-infection with gonorrhea or chlamydia can increase HIV susceptibility 2–5 fold during exposure due to genital inflammation and higher viral load in genital secretions,27,28 and geographic research reveals substantial overlaps between populations affected by HIV and these other STDs.29–31 Those with the highest HIV rates often have high gonorrhea and chlamydia burdens as well, concentrated in marginalized groups facing healthcare access barriers, stigma, poverty, and heightened behavioral risks like multiple partners or commercial sex work.32,33 These social and structural vulnerabilities create geographic hotspots where HIV, gonorrhea, and chlamydia are syndemic.
To analyze HIV incidence in Pennsylvania, we used 2021 data on HIV, chlamydia, and gonorrhea incidence and HIV prevalence from the 66 counties of Pennsylvania (excluding Philadelphia county). We include the HIV prevalence data as an auxiliary variable as it shares similar pattern with the HIV incidence data. The data came from the STD Surveillance System managed by the CDC. While the cases and population data were aggregated at the state-level, some state-level data were suppressed or undisclosed, particularly for HIV.
To address the data absence and unreliability, we will use the method described above. The high degree of overlap between gonorrhea, chlamydia, and HIV makes them suitable for synergistic modeling. Poisson cokriging incorporates the auxiliary gonorrhea and chlamydia data to estimate HIV prevalence in unmeasured locations. Also, it filters noise in the observed data, producing improved representations of Pennsylvania’s underlying HIV risk surface compared to using the sparse surveillance data alone. Applying Poisson cokriging facilitates more accurate HIV burden estimates and helps to fully characterize Pennsylvania’s epidemic given constraints around existing public health data.
Preliminary analysis showed that Philadelphia’s STDs data exhibited high variance and did not correlate—spatially—well with other counties, so it was excluded to reduce noise and improve signal detection.
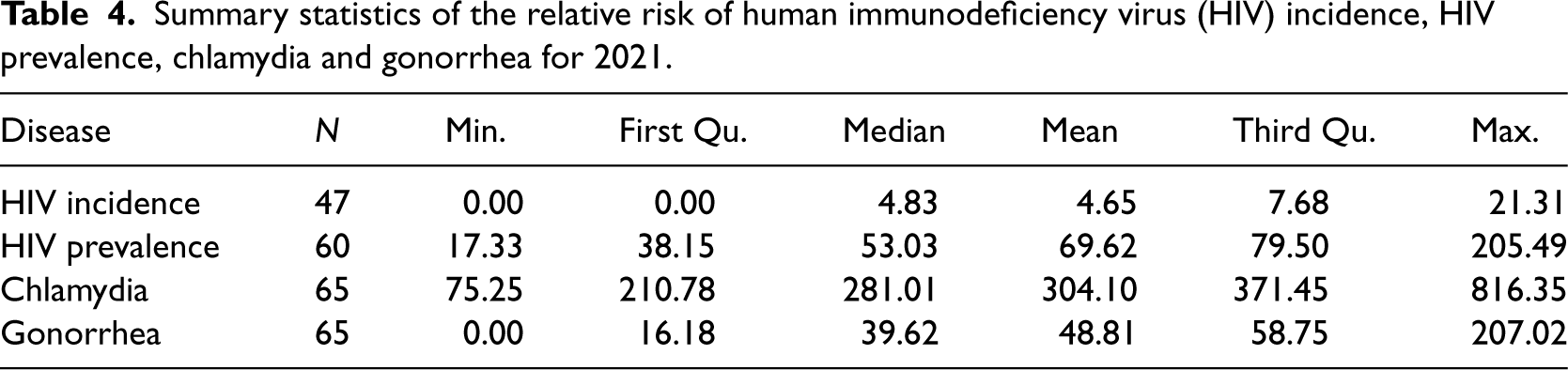
Table 4 and Figure 5 show summary statistics and spatial distribution of STDs risk across counties. HIV incidence risk ranged from 0 to 21.3 per 100,000 inhabitants, though this interval is unreliable given 30% suppressed data. HIV prevalence oscillated between 1.33 and 233 in 2021. Chlamydia and gonorrhea risk ranged from 1 to 816.30 and 0 to 207.00, respectively. Spatial distribution was similar for southeastern and northwestern counties, while central county risk differed across diseases.
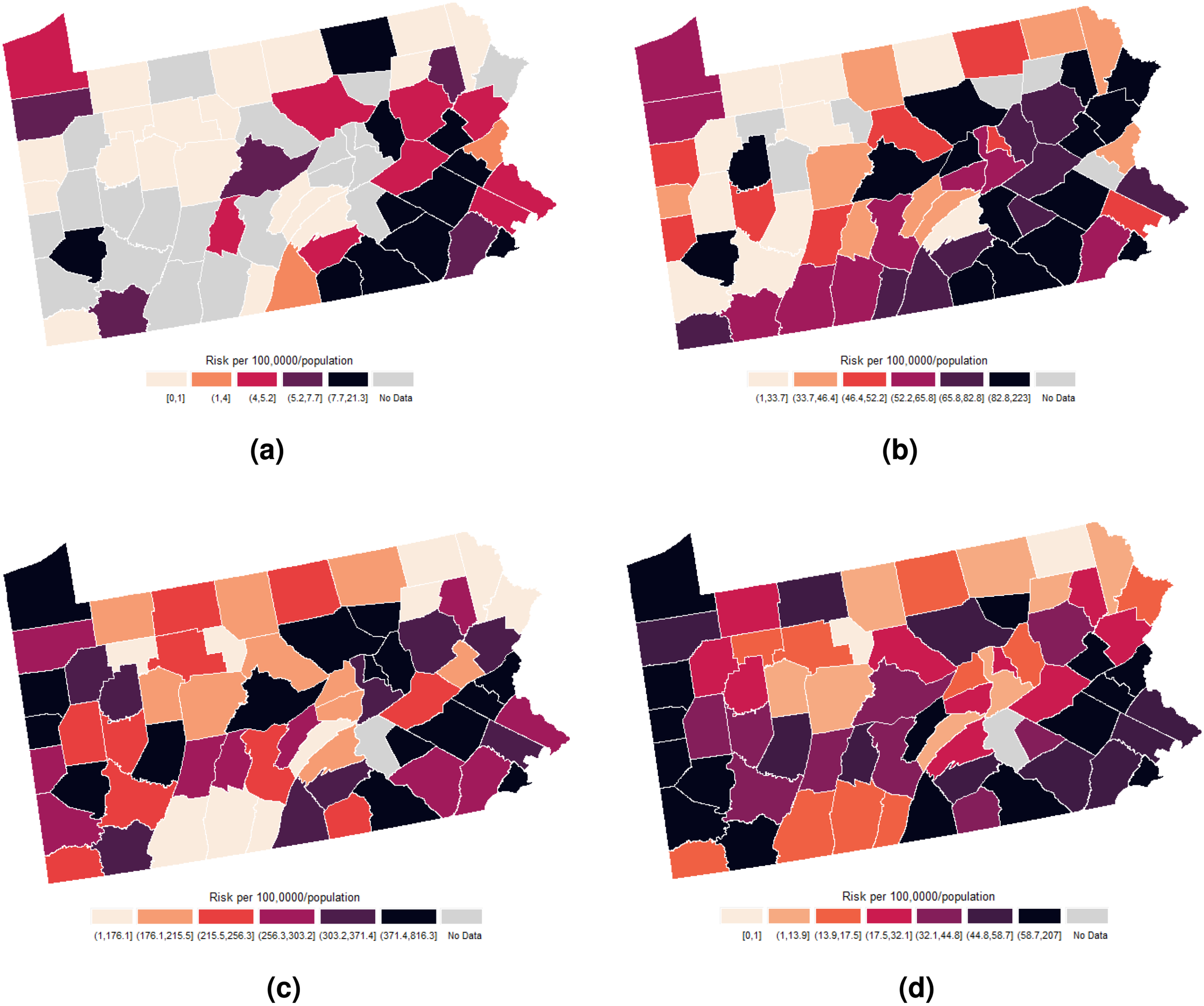
Spatial distribution of the sample risks of human immunodeficiency virus (HIV) incidence, HIV prevalence, chlamydia, and gonorrhea for Pennsylvania in 2021. (a) HIV incidence; (b) HIV prevalence; (c) chlamydia incidence; and (d) gonorrhea incidence.
Summary statistics of the relative risk of human immunodeficiency virus (HIV) incidence, HIV prevalence, chlamydia and gonorrhea for 2021.
We computed the empirical semivariogram and cross-semivariogram defined by (12) and (13) under the assumption of isotropy. Rather than using the geographical centroids of each county, we calculated the semivariograms using population-weighted centroids. This provided a more reliable representation of the proximity structure within Pennsylvania counties. Population census data at the census tract level 34 were leveraged to determine the weighted centroids.
Figure 6 shows the estimated semivariograms and their fitted theoretical models. We fitted a stable model with zero nugget effect by least squares. While the semivariogram plots suggest a potential nugget effect, the lack of semivariance estimates for county pairs at short distances (
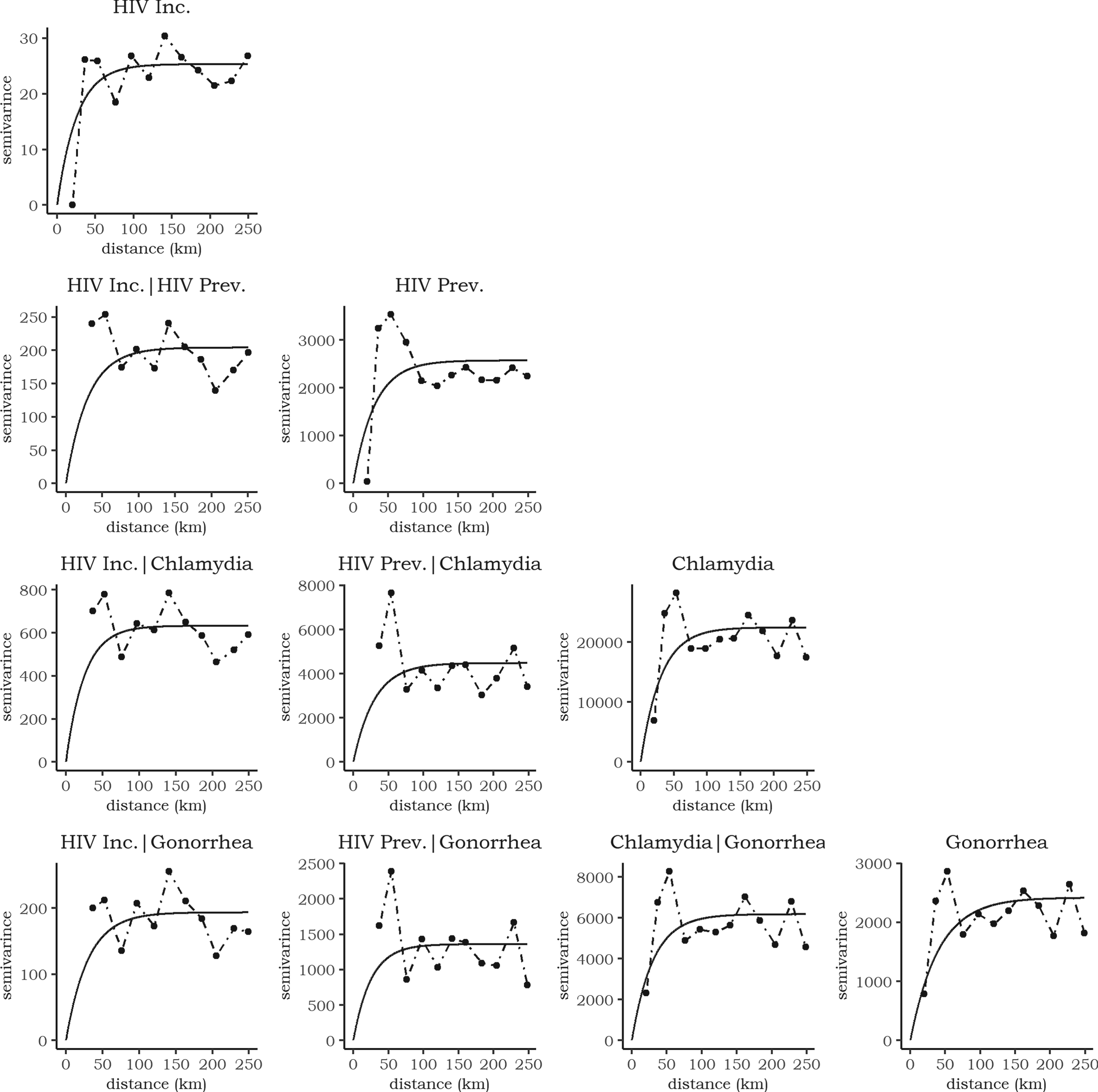
Empirical (points) and fitted (black line) semivariogram and cross-semivariogram for the four sexually transmitted diseases (STDs). The dashed lines connect the empirial estimates.
High semivariance values at the second and third lags resulted from two factors: the limited observations at these distances and the high STD risk in Pittsburgh. Subsequent semivariance values stabilized as the number of observations increased. Most point estimates were biased due to data overdispersion, but the semivariogram and cross-semivariogram fits were satisfactory. The HIV incidence semivariograms showed the lowest variability, indicating shared spatial processes with other STDs. Chlamydia risk displayed high spatial variability, with notable differences compared to other diseases.
The sills ranged from 25.5 to 22440.5, with HIV incidence having the smallest and chlamydia the highest sill. The effective ranges were 25.8–66.6 km, suggesting that spatial correlations were local, occurring between counties and their immediate neighbors. The smoothness parameters of the stable model ranged from 1.2 to 1.7, meaning the semivariograms were close to exponential (smoothnes of 1) or Gaussian (smoothness of 2) models.
We performed prediction and smoothing to estimate HIV incidence risk. For counties with suppressed data, we predicted risk values. By predicting values for counties with missing information, we can conduct a comprehensive analysis across the entire state of Pennsylvania. This ensures that no geographic regions are excluded, which could lead to an incomplete understanding of the spatial patterns and drivers of the HIV incidence. For counties with available data, we smoothed the risk values. Smoothed risk values account for the spatial dependence structure and reduce the impact of local noise and outliers in the data. HIV prevalence, chlamydia, and gonorrhea risks were used as auxiliary variables to improve the cokriging estimates.
Figure 7(a) shows the smoothed map of estimated HIV incidence risk after integrating the predicted and filtered values. The map reveals spatial clustering of high HIV incidence rates in Pennsylvania’s densely populated southeastern and northwestern counties. The top four counties—Allegheny, Delaware, Montgomery, and Chester—account for 46% of the state’s population and 58.7% of diagnosed infections, besides Philadelphia. Urbanization appears to be a key driver, as these counties encompass major metropolitan hubs like Pittsburgh. Proximity to cities has been associated with higher HIV transmission, potentially due to factors like poverty, drug use, and stigma facing marginalized groups. 25
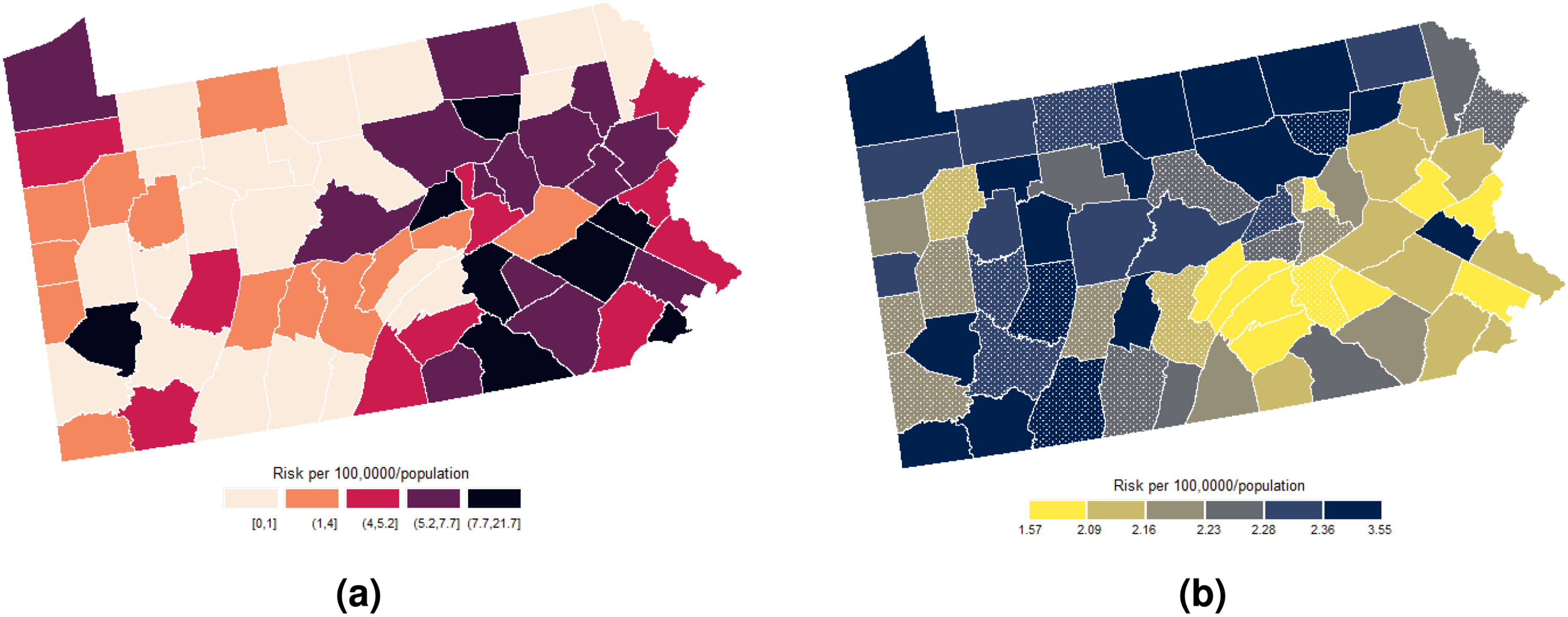
(a) Spatial distribution of the predicted and smoothed risks of human immunodeficiency virus (HIV) incidence and (b) its corresponding prediction error variance. The dotted polygons represent the prediction counties. (a) prediction and (b) variance.
Beyond urbanization, limited healthcare access also correlates with increased incidence. Counties such as Lehigh, Cambria, Jefferson, and Fayette with the high HIV rates have disproportionately high rates of uninsured individuals, constraining prevention and treatment. 35 Systemic disparities also manifest geographically—counties like Bucks, Delaware, and Erie with large African American populations face higher incidence stemming from social stigmas and inequalities. 36
High pre-exposure prophylaxis prescription rates across counties intended to prevent HIV transmission correspond to spikes in incidence, suggesting risk compensation behaviors may be occurring. 37 Furthermore, overlapping high rates of fatal and nonfatal overdoses indicate links between injection drug use and transmission. 25
In contrast, lower incidence clusters in rural counties across southeastern and southcentral Pennsylvania like Huntingdon, Juniata, Mifflin, and Fulton counties. These regions tend to have lower population densities, higher insurance coverage, and less presence of marginalized groups. Clusters of high incidence in specific counties, however, highlight the need for targeted prevention efforts and resources to mitigate disparities. Further research on sociogeographic drivers is as well warranted.
Figure 7(b) displays the cokriging variance map. The cokriging variance map serves as an uncertainty map, quantifying the prediction error variance as measures of spatial uncertainty. The cokriging variance can be used as the corresponding prediction/smoothing variance as it reflects the uncertainties in the estimated risk surface, considering the spatial dependence structure and the relationships with auxiliary variables.
Overall, variances tend to be lower in counties with smoothed risk estimates as compared to those with predicted estimates. Counties with few immediate neighbors, such as those along state boundaries such as Erie, Potter, Tioga, and Bradford, exhibit higher variances. This reflects the spatial influence structure defined by between-county semivariances. Since Poisson cokriging modulates population size effects, variances tend to be inversely proportional to county populations—densely populated counties have smaller variances. Uncertainty also appears problematic in “low-count neighborhoods,” that is, counties surrounded by areas with very low or zero observed HIV risk, such as Brandford, Fayette, and Forest.
The spatial configuration of counties and the sampling pattern govern variance through the modeled dependence structure. Less inter-county dependence and fewer observations produce greater prediction uncertainty. Variance stabilization occurs in more densely sampled areas and for counties nearer to neighbors with data (such as the southeastern counties), as more information is shared through spatial smoothing.
The map in Figure 7(b) thus reveals the geography of reliability, highlighting counties requiring additional sampling, complementary data, or closer inspection while conveying spatially structured confidence in the estimated HIV incidence risk surface. In this sense, the HIV incidence risk estimates for southeastern counties like Bucks, Montgomery, Delaware, and Northampton have higher reliability. Direct application of preventive and control public health measures is therefore suggested. Conversely, counties in the northeastern region such as Potter, Tioga, Bradford, and Sullivan demand further examination before implementing policies, given their greater uncertainty.
The variance map, in the context of the HIV epidemics in Pennsylvania, provides a crucial spatial context for informed decision-making and efficient resource allocation for the local public health practice. It indicates where available HIV estimates per each county may be directly usable versus counties that would benefit from additional sampling or validation. It can also guide future data collection strategies and resource allocation for surveillance and reporting in areas with greater uncertainty.
To quantitatively evaluate and compare the predictive performance of the Poisson cokriging and kriging models fitted to the Pennsylvania HIV incidence data, we used the assessment metrics described in Section 3.2.2 except the coverage probability for
The assessment metrics for Poisson cokriging (bivariate, trivariate, and quadvariate) and Poisson kriging are presented in Table 5. Univariate Poisson kriging, which disregards auxiliary information, exhibits the poorest outcomes across all metrics with a MSPE value equal to 25.48, a correlation coefficient of 0.37 between observed and smoothed values, and high kriging variance of 22.76. Incorporating additional correlated covariates through multivariate Poisson cokriging markedly improves predictive accuracy and uncertainty quantification. The predictive accuracy reflects the similarity between the estimated values and the true values considering the inherent uncertainties arising from the modeling process and the noise present in the observed data, while the uncertainty quantification provides an assessment of the reliability of the predictions.
Summary assessment metrics to constrain Poisson cokriging (bivariate, trivariate, and quadvariate) and Poisson kriging on the STDs data.

Summary assessment metrics to constrain Poisson cokriging (bivariate, trivariate, and quadvariate) and Poisson kriging on the STDs data.
STDs: sexually transmitted diseases; AE: average error; MSPE: mean squared prediction error;
The bivariate model, leveraging both HIV incidence and HIV prevalence variables, reduces the MSPE by over 60% and increases correlation to 0.56. The trivariate approach further decreases the MSPE to 7.66 and improves correlation to 0.77 by also incorporating the chlamydia data. Finally, the quadvariate cokriging model, which additionally uses gonorrhea incidence, provides optimal performance as evidenced by the lowest MSPE and average error alongside the highest correlation.
Table 6 presents the running time estimates in seconds for the four Poisson cokriging cases, where we predicted and smoothed the HIV risk for the 66 counties of the study case. As more diseases are incorporated into the analysis, the running time increases for both prediction and smoothing processes. However, the incremental increase in running time is relatively small when adding additional diseases. For instance, despite the added complexity, the running time for quadvariate prediction (0.458 s) is only marginally higher than the bivariate case (0.200 s).
Run time estimates in seconds (s) of Poisson cokriging (univariate, gbivariate, trivariate, and quadvariate) on the sexually transmitted diseases (STDs) data.
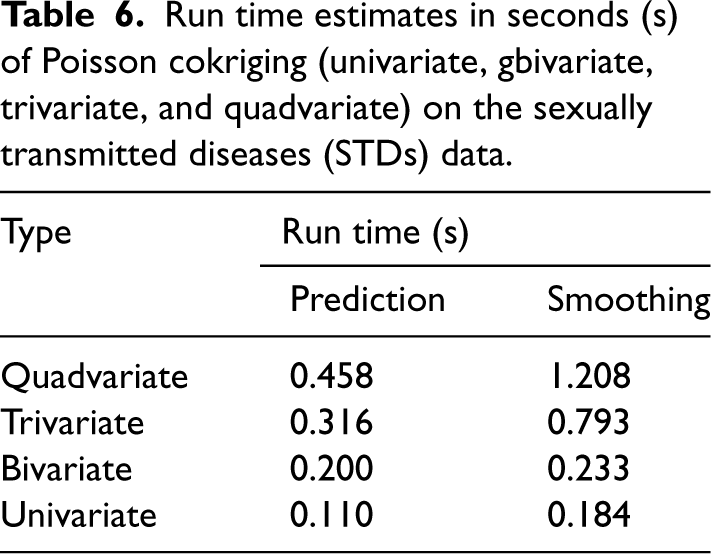
The smoothing process generally has a larger computational burden than the prediction process. Nevertheless, even in the computationally more demanding quadvariate case, the smoothing time cost (1.208 s) remains reasonably low.
Althought the running time raises when introducing more diseases into the modeling framework, prediction accuracy also improves (Table 5). This trade-off between computational cost and data richness must respond to the specific needs of the analysis. For time-critical applications requiring rapid predictions, lower-order models, such as the univariate or bivariate cases, may be preferred due to their shorter computational times. Conversely, in scenarios where maximizing prediction accuracy is the primary objective, the quadvariate model may be the most suitable choice, despite its slightly longer running time.
In this article, we addressed the challenges associated with multivariate geostatistical modeling of disease count data and introduced a generalized version of Poisson cokriging, presented by Payares-Garcia et al. 5 for the prediction and smoothing of spatial disease counts. Our method builds upon pair-wise correlations between a target variable and other ancillary variables exemplified as spatial counts, enabling the modeling of complex spatial dependencies and the incorporation of auxiliary information.
By means of a simulation analysis, we demonstrated the effectiveness of Poisson cokriging in accurately estimating disease risk and producing smoothed risk maps that capture fine-scale variations in disease occurrence. Compared to Poisson kriging, it showed superior prediction performance, with smaller MSPE values and higher
Poisson cokriging proved to be a valuable spatial modeling tool for estimating and mapping disease risk in practical settings. By incorporating auxiliary information from correlated variables like chlamydia and gonorrhea incidence, the multivariate approach borrowed strength and improved characterization of the complex incidence patterns of HIV incidence risk across Pennsylvania counties. The Poisson cokriging model integrating four STDs variables achieved the best prediction error and correlation between observed and predicted HIV incidence. Cross-validation confirmed the superiority of cokriging over univariate Poisson kriging, with accuracy gains of over 50% for multiple metrics. The enhanced predictions quantify and visualize local HIV hotspots, while the uncertainty estimates delineate regions requiring additional sampling and screening. Overall, Poisson cokriging leveraged spatial multivariate dependence to generate reliable, high-resolution HIV incidence risk estimates from sparse, incomplete public health surveillance data. The methodology could be easily applied to prediction and mapping of disease rates in other settings.
Our findings underscore the potential of Poisson cokriging for disease mapping and surveillance. By leveraging the multivariate nature of disease counts and incorporating auxiliary information, it offers meaningful and richer risk predictions, a better depiction of spatial interdependencies, and enhanced identification of high-risk and low-risk areas. Moreover, it holds promise in elucidating the existence of shared risk factors and uncovering unknown associations between diseases. Likewise, integrating uncertainty visualization with disease mapping enables making data-driven decisions tuned to local reliability. This allows public health officials to target efforts where impact can be maximized based on the spatial structure of confidence in the model outputs. These advantages make Poisson cokriging a promising method for public health research and decision-making, supporting the development of targeted interventions and resource allocation strategies. Whilst multivariate Poisson cokriging is developed to deal with epidemiological data, given its nature, it can be extended to other domains such as economy, biology, and ecology, in which dependence between count variables is also spatially located.
Poisson cokriging still requires further enhancements to realize its full potential in multivariate disease mapping applications. Currently, it exclusively accommodates positive spatial correlations among disease counts. A future extension of our method will incorporate negative spatial correlations as well. This phenomenon has been documented by Li et al., 38 Yii et al., 39 and Sayar et al. 40 Another avenue for advancement lies in the inclusion of non-count auxiliary variables. Introducing ancillary data in the form of risk factors will not only enrich the prediction process but also downscale the risk when high-resolution data are available. Further research could explore integrating socioeconomic and demographic covariates to potentially improve representations of the complex multivariate processes driving disease transmission. Incorporating space-time observations might as well advance Poisson cokriging understanding of the spatial-temporal character of diseases. This extension might offer further insights into disease incidence, prevalence, and distribution, which are crucial in detecting emerging outbreaks, assessing the effectiveness of interventions, and monitoring disease control measures. 41 Another step is appropriately accounting for the variable support, as Goovaerts 9 suggested. The implementation of multivariate Poisson cokriging up to four variables in the form of R code can be found at https://github.com/DavidPayares/Poisson-cokriging-multivariate.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.