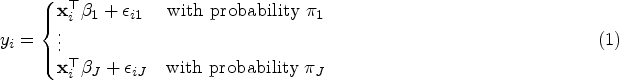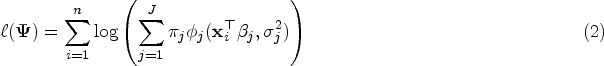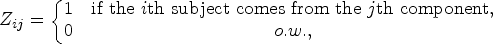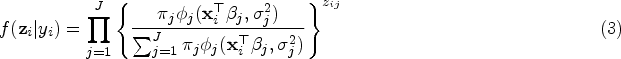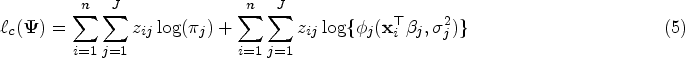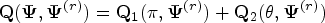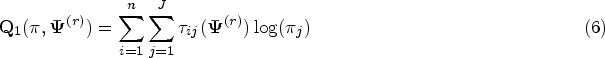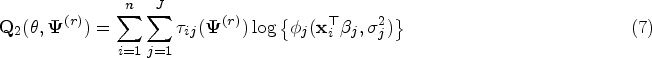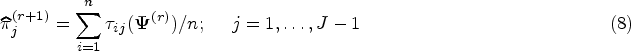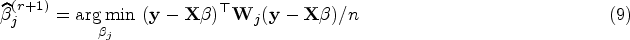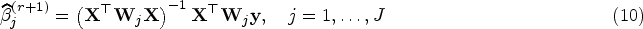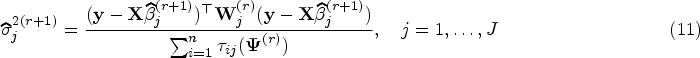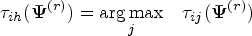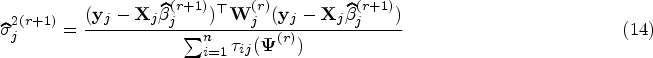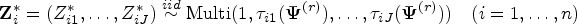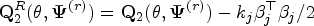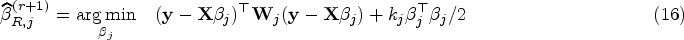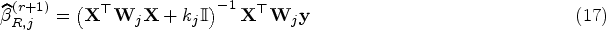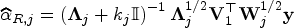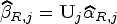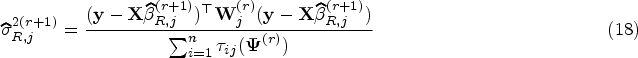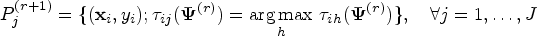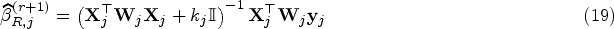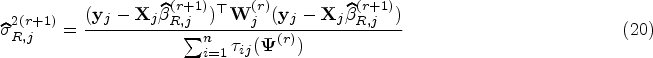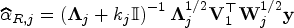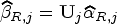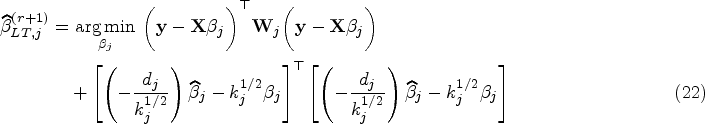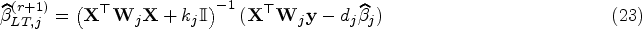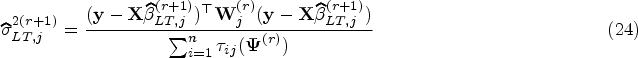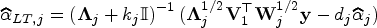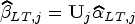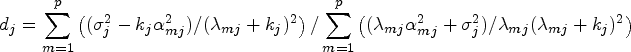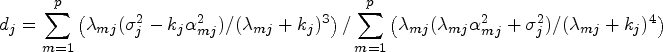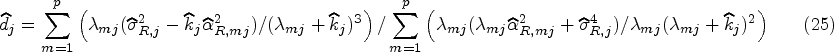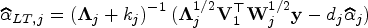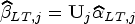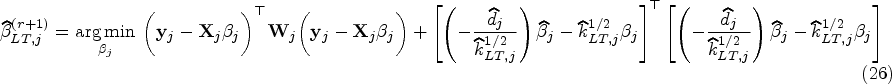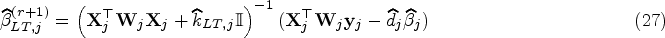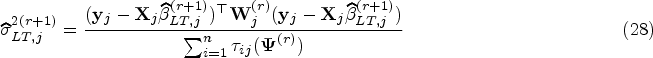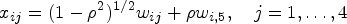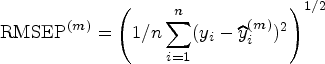The mixture of probabilistic regression models is one of the most common techniques to incorporate the information of covariates into learning of the population heterogeneity. Despite its flexibility, unreliable estimates can occur due to multicollinearity among covariates. In this paper, we develop Liu-type shrinkage methods through an unsupervised learning approach to estimate the model coefficients in the presence of multicollinearity. We evaluate the performance of our proposed methods via classification and stochastic versions of the expectation-maximization algorithm. We show using numerical simulations that the proposed methods outperform their Ridge and maximum likelihood counterparts. Finally, we apply our methods to analyze the bone mineral data of women aged 50 and older.
As a bone metabolic disease, osteoporosis is characterized when the mineral density of bone tissues decreases significantly, leading to various major health problems such as skeletal fragility and osteoporotic fractures. These can occur in different body areas, including the hip, spine, and femur.1,2 Bone mineral density (BMD) is considered one of the most reliable predictors in determining osteoporosis status.3 For example, approximately every 1 out of 3 women and 1 out of 5 men aged 50 and older have osteoporosis and its fractures.4 Osteoporosis typically occurs without any significant symptoms. In South Korea, for example, almost 75% of patients are unaware of their osteoporosis problem.5 BMD score of an individual improves until age 30 and declines as the individual ages. As the aged population is growing, it is essential to study osteoporosis to plan the well-being and life quality of the aged groups of the communities.
BMD values are measured through dual-energy X-ray absorptiometry imaging and require a costly and time-consuming procedure. Unlike BMD scores, clinicians have access to various easily attainable explanatory variables about patients, including BMI, weight, age, and test results from previous years. Linear regression models are well-known statistical tools to investigate the impact of a set of covariates (e.g. patients’ characteristics) on a response variable (e.g. BMD measurement). The least squares (LSs) method is a common method for estimating the regression model coefficients; however, the LS method can lead to extremely unreliable and misleading results in multicollinearity when the covariates are linearly dependent. As a shrinkage method, Ridge regression is a common solution to the multicollinearity problem. A small ridge parameter is not enough to handle the ill-conditioned design matrix when the problem is severe. On the other hand, large values of the ridge parameter render more biases in the estimation. The Liu-type (LT) shrinkage method was proposed in the work of Liu6 to address the multicollinearity and was extended in the work of Duran et al.7 to the semi-parametric regressions. Later on, the Stein-rule LT estimators for elliptical regression models was developed in the work of Arashi et al.8 and properties of rank-based samples was used in the work of Pearce and Hatefi9 to improve the LT shrinkage estimators for linear and logistic regressions.
Finite mixture models (FMMs) are probabilistic model-based tools to analyze heterogeneous populations. The maximum likelihood (ML) method is one of the most popular techniques for estimating the parameters of the FMMs. A part of the popularity comes from the expectation-maximization (EM) algorithm10 that enables computing the ML estimates of the FMMs. The EM algorithm decomposes the ML estimation procedure into E- and M-steps and iteratively estimates the parameters of the FMMs. Stochastic EM (SEM) algorithm11 was developed as a stochastic teacher of the probabilistic EM algorithm for mixture models. Also, Celeux and Govaert12 proposed a classification EM (CEM) algorithm in which a classification step is implemented in the iteration for maximization based on classified data. The mixture of regression models13 incorporates the properties of the FMMs into linear regression models. The ML and EM algorithms to fit a mixture of regression models was investigated in the work of Faria and Soromenho14, Hawkins et al.15, Jones and McLachlan.16 Alternatively, Bayesian estimation techniques have been developed for finite mixture regression models, as outlined in the work of Frühwirth-Schnatter.17 One of the key challenges in FMMs, including mixture regression models, is identifiability. This challenge has been discussed in depth by researchers such as Hennig18, Ho and Nguyen.19 FMMs have found many applications in the core of statistical sciences, such as times series data,20 sampling methods and censored data.21–23 For more details about the theory and applications of the FMMs, see24,25 and references therein.
Despite the flexibility of the mixture of linear regressions, the ML estimates of the mixture coefficients become unreliable in the presense of multicollinearity. Recently, a shrinkage estimation method for the mixture of logistic regressions were proposed in Ghanem et al.26 In this paper, we develop the Ridge and LT shrinkage estimation methods for heterogeneous populations. To do so, we focus on the mixture of linear regression models where each heterogeneous sub-population is treated by multiple regression to investigate the relationship between explanatory and response variables in multicollinearity. The population estimation is designed using an unsupervised statistical learning approach where the observations’ component membership is unknown and estimated iteratively. To estimate the coefficients of the component regressions and mixing proportions, we developed EM, CEM and SEM algorithms to incorporate the Ridge and LT penalized log-likelihood in each iteration of the algorithms. In addition, we proposed the singular value decomposition to translate the LT estimation method of the parameters of the population to iterative canonical regression analysis in each component. From the orthogonal properties of the eigenvalues in the ill-conditioned component design matrices, we find the optimum tuning parameter of the LT estimation method. We used the root mean square errors and root mean square prediction errors using K-fold cross-validation to compare the estimation and prediction performances of the proposed methods.. Through extensive numerical studies, we show that the LT shrinkage method’s classification and SEM algorithms outperform their counterparts and provide more reliable coefficient estimates for component regressions. We finally apply the developed methods to analyze the bone disorder status of women aged 50 and older.
The outline of the paper is as follows: Section 2 develops the shrinkage methods and their EM algorithms. Section 3 evaluates the performance of the methods by simulation studies. The methods are applied for analysis of bone data in Section 4. Section 5 presents summary and concluding remarks.
Statistical methods
Let be the vector of explanatory variables for the th subject in a random sample of size . Let and denote the response vector and the full column rank () design matrix with . The regression model for is one of the most common statistical methods to study the relationship between response variable and the set of the explanatory variables.
The mixture of regression models is a generalization of the regression model when the underlying population comprises of heterogeneous subpopulations. The mixture of regression models is defined by
where represents the coefficients of predictors in the th component regression for and denotes the vector of mixing proportions with and . Also are independent normal random errors from each component of the mixture; that is . Although we assume that the number of components in the mixture model (1) is known throughout the paper, the component memberships of the observations are unknown and should be estimated in an unsupervised approach. Let . Let denote the parameters of the th component. Thus, we represent the vector of all unknown parameters of the mixture (1) with .
From regression model (1), the log-likelihood function of can be written as
where represents the pdf of the univariate normal distribution with mean and variance . We need to maximize (2) in order to obtain the ML estimate of . The gradient of (2) is not tractable with respect to component parameters . We view as incomplete data and apply the EM algorithm of Dempster et al.10 using a complete data to find . For each subject , we introduce latent variables for as
where . From the marginal distribution of latent variables, the conditional distribution of is given by
From the above, it is easily seen that where
Let denote the complete data. Thus, the complete log-likelihood function of is given by
ML estimation method
The EM algorithm is a standard method to find the ML estimates of the mixture model parameters. The EM algorithm employs the latent variables on top of the observed data and decomposes the estimation procedure into an iterative expectation (E) and maximization (M) steps. As an iterative method, EM algorithm begins with an initial value. Let and denote the initial vector and the estimate in the th iteration of the EM algorithm, respectively.
On the th iteration, we require to compute the conditional expectation of (5) in the E-step. The replaces the latent variables by their conditional expectations as
where
and
where is obtained by (4). In the M-step, we maximize with respect to and to update . One can update by maximizing subject to as follows
The maximization of can be reformulated by the weighted least squares (WLS) method as
where is diagonal matrix with diagonal elements for all . One can easily update as the solution to (9) by
From (9) and following,14 we then update as follows
To find , we iteratively alternate the E- and M- steps of the EM algorithm until the stopping criterion becomes negligible.
CEM Algorithm: In the above EM algorithm, we use information from all observations (as membership probabilities) in each iteration to estimate the parameters of the mixture model. Following Celeux and Govaert,12 we shall employ the classification version of EM algorithm (CEM) to estimate . The CEM algorithm incorporates a classification (C) step between E and M steps so that the component parameters of the mixture are updated in M-step using the classified complete data log-likelihood function.
The E-step here is identical to the E-step of the EM algorithm. In C-step, the observations are then assigned to mutually exclusive partitions corresponding to the components of mixture model (1). Let denote the partition in the th iteration. Each subject is assigned to partition when
Note when the maximum weight is not unique, the tie is broken at random. Also the CEM algorithm is stopped and is returned when a partition becomes empty or has only one observation.
In the M-step, we maximize conditional expectation function using . From (6), the mixing proportion is updated by
where is the number of observations allocated to partition . Applying the WLS to each partition , we can update the parameters of the th component () by
where and represent, respectively, design matrix and vector of responses corresponding to . Also is the diagonal weight matrix of size with entries . Finally, we alternate repeatedly the E-, C- and M- steps until .
SEM Algorithm: One can also apply the stochastic version of the EM algorithm11 to fit the mixture of regression models. The SEM algorithm implements a stochastic version of the C-step between E- and M-steps. Although the E- and M-steps are identical to the CEM algorithm, the SEM simulates the component membership of each observation using conditional distribution of the latent variable given incomplete data. On the th iteration, the S-step simulates a random allocation for each observation using one draw out of components as
Then the is classified to partition if . Using the stochastic partitions, we update the mixture parameters from (12), (13) and (14) in M-step. From,11,14 point-wise convergence in the SEM algorithm is not guaranteed. The algorithm resembles a Markov chain where at stationary state fluctuates around the ML estimate. Hence, we alternate the E-, S- and M-steps until either the criterion satisfies or the chain reaches a prespecified maximum number of iterations that is fixed for all the algorithms for fair comparison.
Ridge estimation method
The ML method is a standard tool to estimate ; however, the ML estimates are dramatically influenced by multicollinearity where the covariates are linearly dependent. Ridge method27 is one of the most common methods to encounter with the challenges of the LS method. The ridge estimate for (1) can be obtained as a solution to the penalized log-likelihood function given by
where comes from (2) and is the ridge parameter. In a similar vein to Subsection 2.1, for each observation , we first introduce dimensional latent vector . We then develop an EM algorithm to maximize the complete ridge log-likelihood function and obtain .
The E-step of the ridge EM algorithm is identical to the E-step of Subsection 2.1. In the M-step, the mixing proportion are updated from (8). To update the coefficients of the component regressions, we require to maximize subject to the ridge penalty within each component as
where is from (7) and is the ridge parameter in the th component. Like ML method, one can re-write the maximization of as a WLS subject to the ridge penalty by
where is diagonal matrix with elements obtained from (4). Applying (16), is updated by
Under the assumptions of mixture of regression models (1), suppose and are the eigenvalues and orthonormal eigenvectors of where is diagonal matrix with entries under ridge EM algorithm. Let and . Then the canonical weighted ridge estimator in each component regression is given by
There are various methods available in the literature for the estimation of . Following Hoerl et al.28, Liu6, we estimate the parameter by where and are calculated from (11) and (10), respectively. The E- and M-steps are repeatedly computed until .
Ridge CEM Algorithm: One can also apply the CEM algorithm to find . Similar to the CEM algorithm in Subsection 2.1, we require to accommodate a C-step between E- and M-steps in the ridge EM algorithm. Here the E-step remains the same as before. Similar to the C-step of ML method, we classify the observations to partitions based on the maximum probability of memberships; that is
Based on , we use (12) to update the mixing proportions of the mixture. The ridge parameters are estimated similar to the ridge EM algorithm. We apply (16) to each partition and update the coefficients and variance term of each component regression by
where is design matrix and is vector of responses from observations classified to . is the diagonal weight matrix with entries from (4). Finally, the E-, C-, and M- steps under ridge estimation procedure are alternated until convergence criterion is satisfied.
Ridge SEM Algorithm: Ridge estimation method can be implemented via the SEM algorithm. Like SEM of ML method, the S-step determines stochastically the component membership of observations under ridge method by and updates such that . Based on this stochastic partition of S-step, we update the mixture parameters by (12), (19) and (20).
Under the assumptions of mixture of regression models (1)(with component regression models based on observations and ), suppose and are the eigenvalues and orthonormal eigenvectors of where is a diagonal matrix with entries under the ridge CEM or ridge SEM algorithm. Let and . Then the canonical weighted ridge estimator in each component regression is given by
and
with where are the orthonormal eigenvectors of .
Finally, the E-, S-, and M-steps are iterated until the stopping rule is satisfied or the algorithm reaches a prespecified maximum number of iterations.
LT estimation method
When the design matrix is severely ill-conditioned, adding small values to the diagonal elements by the ridge estimator may be insufficient in addressing the issue. On the other hand, increasing the ridge parameter may result in a more considerable bias in the ridge estimation method. The LT shrinkage method for the multicollinearity in estimating the regression parameters was proposed in Liu.6 Like the ridge method, the LT method optimizes the estimating equation subject to the LT penalty to control the multicollinearity. The LT penalty is given by
where can be any estimator of coefficients and and are two parameters of the LT method. We develop the LT shrinkage method in estimating the unknown parameters of the mixture model (1). We shall find the LT estimate of by maximizing the log-likelihood function (2) subject to the LT penalty.
Similar to Section 2.1, the penalized log-likelihood function based on observed data is not tractable with respect to the component parameters. We develop the LT estimation procedure through an unsupervised approach and use the EM algorithm to estimate . We again require latent vectors to represent the component membership of the th observation . Let denote the complete data. Then EM algorithm under the LT method proceeds as follows.
In th iteration, the E-step remains identical to the E-step of the ML method. The mixing proportions under the LT method are updated by (8). We require to maximize from (7) under the LT penalty within each component to estimate the component parameters. The LT penalized log-likelihood function can be written as a WLS constrained on the LT penalty as
where can be any estimate and is a weight diagonal matrix with elements . From (22), the coefficients and variance terms in each component regression are updated by
Equations (23) and (24) require the estimates of the LT parameters for each component regression. From Liu,6 we can estimate in the th component by where and are the maximum and the minimum eigenvalues of on the the iteration of the EM algorithm.
Under the assumptions of Lemma (1), the canonical LT estimator in the th component regression under EM algorithm is given by
and
where is the canonical estimate of and with are the orthonormal eigenvectors of .
Following Liu6 and Lemma 3, the optimal can be obtained by the next lemma within each component of the mixture of regression models.
Under the assumptions of Lemma 1 and for each , we have
when , then
when , then
minimizes the within each component (1) in the EM algorithm of the LT method.
Although Lemma 4 paves the path in estimating the optimal LT parameter within each component regression, the optimal value still depends on the unknown quantities including , , and for and . From Lemma 4, we propose a practical approach where can be updated in the th iteration of the EM algorithm by
where , is given by Lemma 1 and are eigenvalues of with from (18). The E- and M-steps are alternated until the stopping criterion is satisfied. As the parameters and are updated in each iteration of the EM algorithm, the proposed LT method is henceforth called the iterative LT i.e. Liu_ITE.
Unlike the iterative LT method, one can follow Hoerl et al.28 to estimate the LT parameters based on ridge estimates and . In other words, the mixture parameter and are still iteratively updated in the EM algorithm; however, parameters are estimated only once throughout the EM algorithm using the ridge estimates. Here, we estimate the parameters by . This LT estimation method is henceforth called HKP LT i.e. Liu_HKP.
LT CEM algorithm: Like previous subsections, the CEM algorithm partitions the observations in the C-step and then update the parameters within each partition. In the th iteration of the CEM algorithm, the E-step remains the same as before. The C-step classifies the observations into partition where with are obtained from (4). Using , we update the mixing proportions from (12). We then require to estimate the LT parameters in each iteration of the CEM algorithm. Similar to LT EM algorithm, we propose where and are the maximum and the minimum eigenvalues of .
Under the assumptions of Lemma (1), the canonical LT estimator in the th component regression under the CEM algorithm is given by
and
where is the canonical estimate of and with are the orthonormal eigenvectors of .
From Lemmas 4 and 5 , one can estimate parameter based on partition from (25) where are eigenvalues of and estimate from equation (20). To estimate the regression parameters, we implement a WLS based on the LT penalty as
where and are response vector and design matrix under and can be any estimate for . Also, is a weight diagonal matrix with entries . One can easily find the solution to equation (22) and update the regression parameters by
The E-, C-, and M-steps are repeatedly computed until the convergence criterion is satisfied.
Unlike the iterative LT CEM algorithm, one may estimate the parameters of the mixture model via the HKP LT CEM algorithm where the LT parameters are updated once throughout the algorithm. From Hoerl et al.,28 Liu,6 we propose to estimate and from equation (25) where and come from equations (19) and (20), respectively.
LT SEM algorithm: Similar to the SEM algorithms, the S-step partitions the observations stochastically from for . Once the partition is established, the rest of the LT SEM algorithms are implemented similarly to the LT CEM algorithms.
Simulation studies
In this section, we examine the performance of the ML, Ridge, and LT methods when the underlying population is a mixture of linear regression models with multicollinearity problem. We present two simulations enabling us to study the effect of the sample size, multicollinearity levels, and the number of components of mixture models on the estimation and prediction of the proposed methods.
This paper investigates, for the first time in the literature, the Ridge and LT shrinkage methods for heterogeneous populations using a mixture of regression models. Hence, the main goal of the numerical studies is to compare the estimation performance of the biased shrinkage methods with the commonly used benchmark ML method in the presence of multicollinearity. Although the initial values play an essential role in iterative methods like the EM algorithm, in these simulations as comparative numerical studies, we have matrix of coefficients, mixing proportions and variance terms to deal with the parameters of component regressions each with covariates. For these reasons, in all the numerical studies, we chose the initial values fixed, close to the true values of the parameters and the same for all the EM, CEM, and SEM approaches under ML, Ridge, and LT estimation methods for a fair comparison. Also, we used as the stopping rule for all the estimation methods. We set the maximum number of iterations to be 2000 for all the EM, CEM, and SEM approaches under the ML, Ridge, and LT methods. We used a single start for all the numerical studies. If the EM algorithms, for any reason, did not converge in 2000 iterations, the estimate in the last iteration was treated as the solution in the EM algorithm.
It is well-known that a FMM’s log-likelihood may appear multimodal; hence, the EM algorithm may converge to local maxima. We designed the numerical studies in a comparative way to compare the estimation performance of the proposed shrinkage methods with those of the commonly used ML method. Since the log-likelihood of all the estimation methods is subject to this multimodality, we did not exclude the convergence to the local maxima for all the estimation methods for a fair comparison. Although the algorithms may converge to either local or global maxima, the overall estimation performance of the methods is evaluated. Therefore, the local maxima estimates in simulations indirectly affect the errors of the estimation algorithms.
In the first study, we simulate data from a population corresponding to a mixture of two regression models with four covariates . Following Inan and Erdogan,29 we use to denote the correlation between covariates to simulate the multicollinearity in the mixture model. To do so, we first generate random numbers from the standard normal distribution. The covariates are then generated by
where the correlation matrix of is given by whose diagonal entries are 1 and off-diagonal entries are equal to . Here, we set to simulate the multicollinearity levels in the mixture of regression models. The responses are then generated from mixture model (1) whose true parameters are given by with , , and . We measured the estimation performance of the ML, Ridge, and LT methods by root means square errors (RMSE) in estimating and computed , and , where , , and and denotes teh number of free parameters. We also used the root mean squared errors of prediction (RMSEP) to evaluate the prediction performance of the methods. To do so, we first compute the RMSEP of the th replicate through -fold cross-validation by
where is the predicted response of the th observation in the th replicate.
We computed the estimation and prediction measures for the ML, Ridge, and LT methods as follows. We first generated a sample of size from the underlying mixture of regression models as described above. We selected the starting point of parameters as , , and . We then used the EM, CEM, and SEM algorithms to estimate the parameters of the mixture population via ML, Ridge, and LT methods. We applied the idea of cross-validation to assess the prediction performance of the methods. To this end, we divided the sample into folds of equal sizes. We used folds for training and the remaining fold for prediction. We repeated the procedure for all to compute the . Eventually, we replicated the entire procedures times and computed the median and 95% confidence interval (CI) for the SSE and RMSEP measures. The lower and upper bounds of the CI correspond to 2.5 and 97.5 percentiles of 2000 replications, respectively.
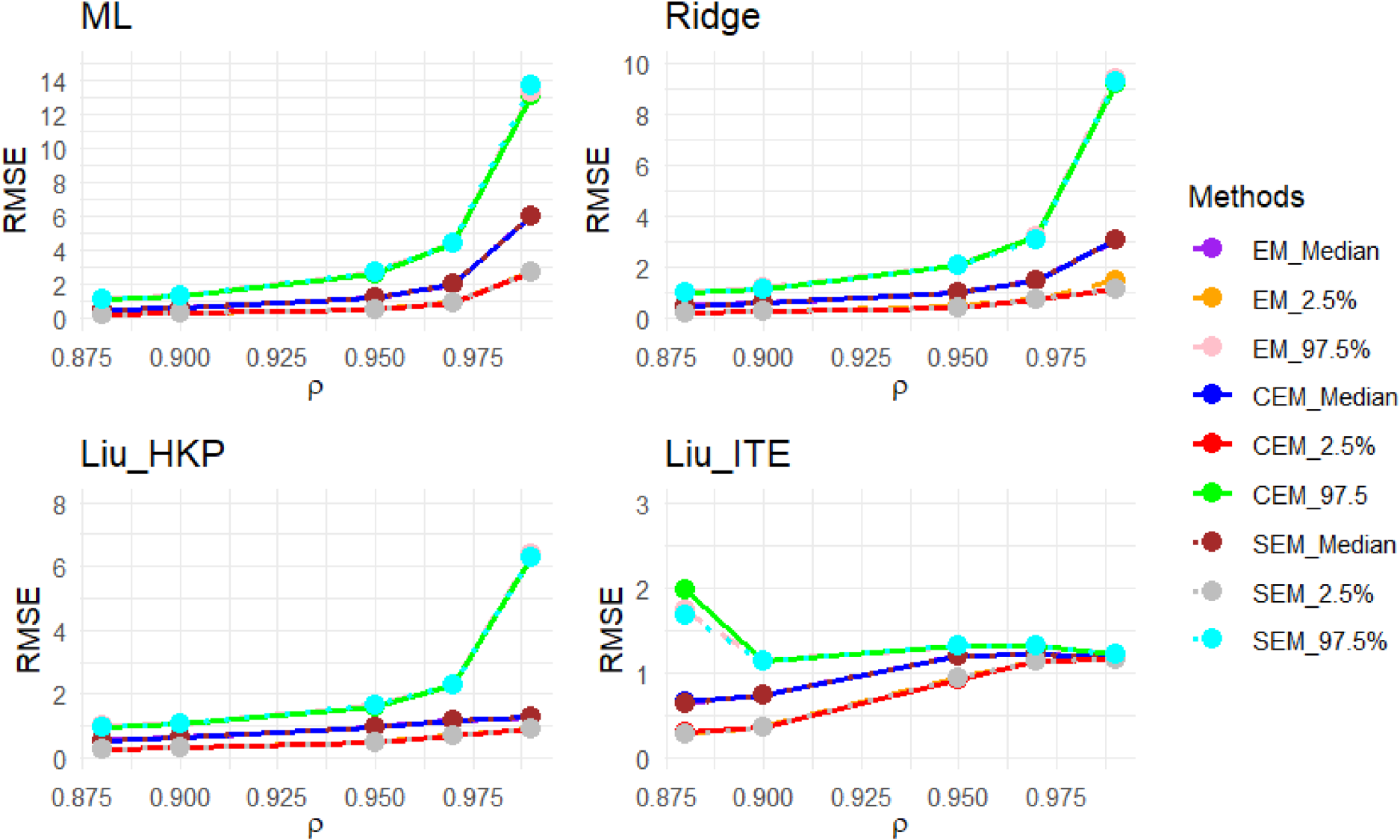
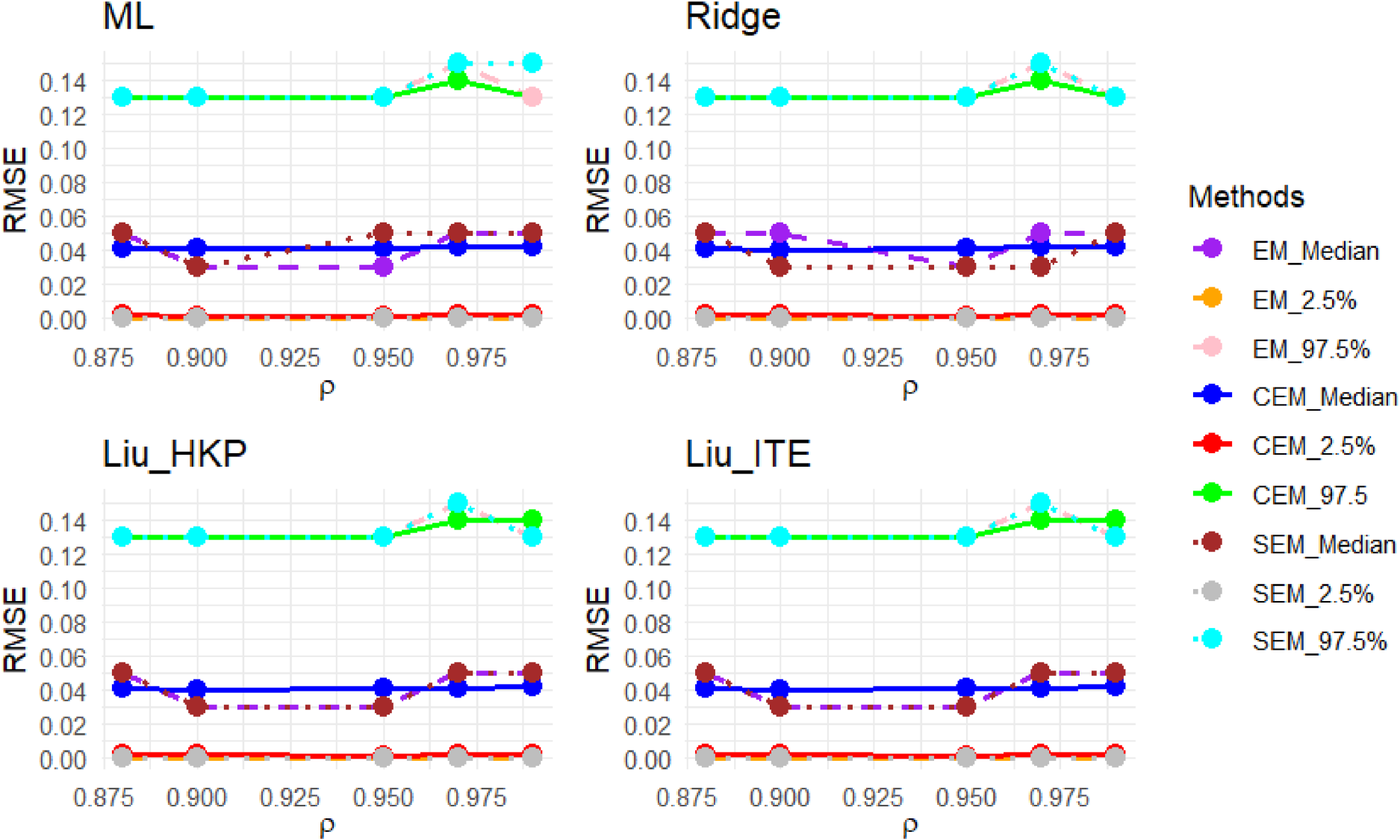
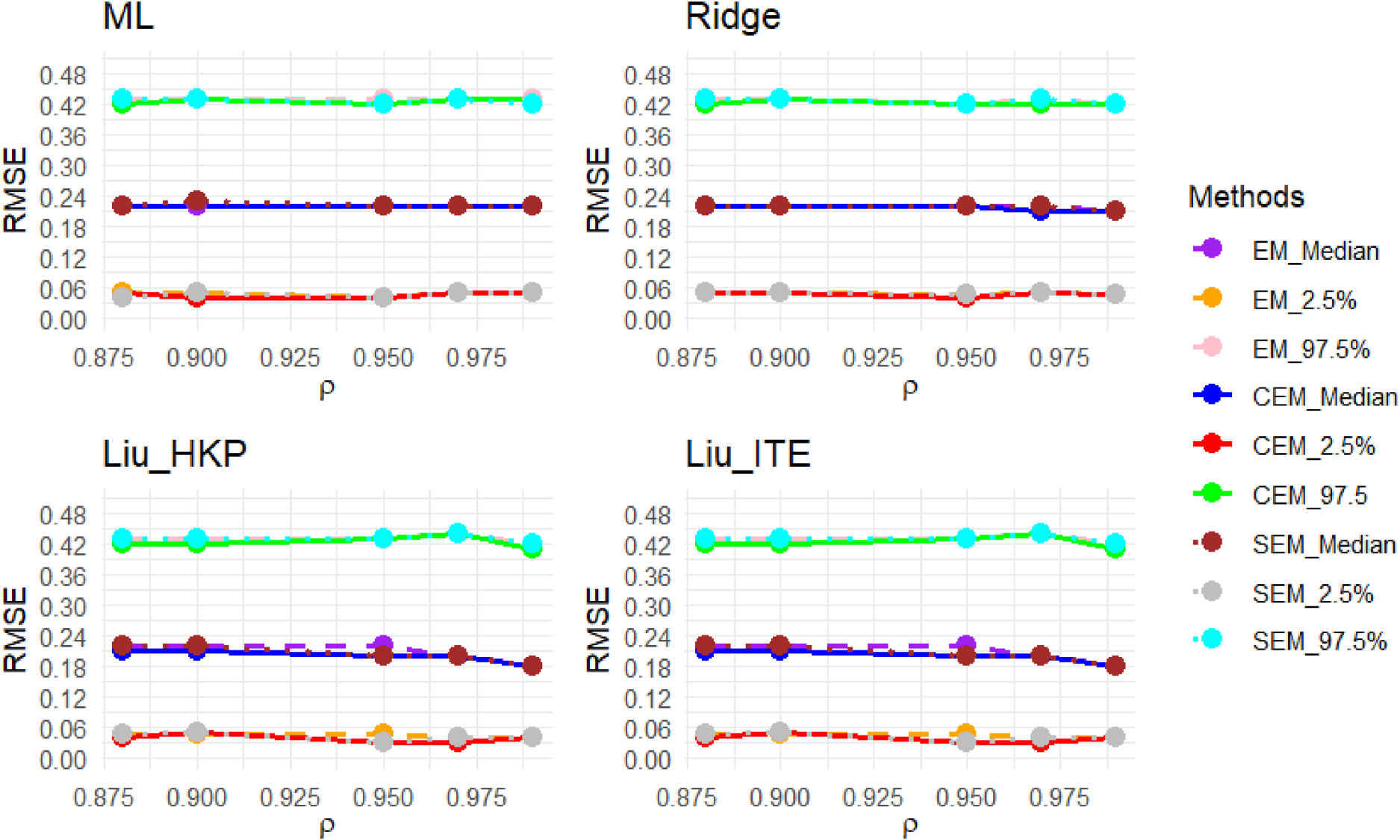
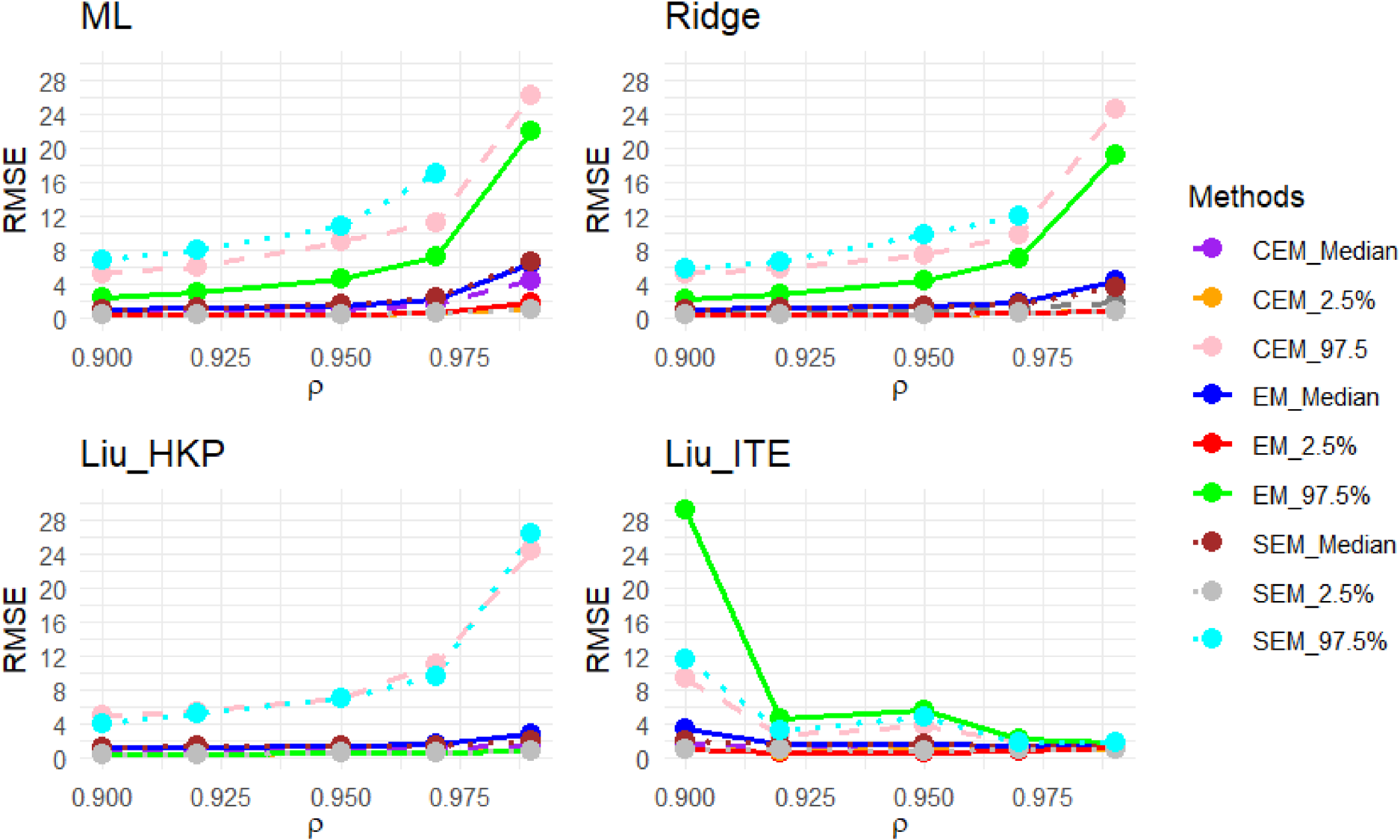
Due to sampling variability, the generated design matrix and response vector change from one replication to another in the simulation. Given this, Figure 55 (in the Appendix) reports the sampling distributions of the covariates and responses for a randomly selected sample with size and . Due to sampling variability, the sample correlation may change slightly from the nominal correlation. Accordingly, for the selected random sample, the sample variance inflation factors (VIFs) are almost around VIF = 45.70 in Figure 55. We show the results of the simulation study in estimating in Figures 1 to 3 and 5 to 28 (in the Appendix). It is observed that the ML methods estimate slightly better the mixing proportion than the ridge and LT methods. This happens because the ridge and LT estimators are biased shrinkage methods where a slight bias is incorporated into the estimation to encounter the multicollinearity problem. We observe that the multicollinearity significantly impacts the ML estimates of the coefficients and results in extremely unreliable estimates for all EM, CEM, and SEM algorithms. Unlike ML estimates, a significant improvement is seen in the performance of the shrinkage methods in estimating the coefficients of the component regressions. The LT methods appear more reliable than their ridge counterparts in the multicollinearity. From a comparison between LT(ITR) and Liu_HKP, we see that Liu_HKP provides more reliable estimates for . Among the Liu_HKP estimators, the CEM algorithm almost always outperforms its EM ad SEM counterparts. Tables 1 and 9 (in the Appendix) show the median and the length of 95% CI of the RMSEP for all the developed methods. The tables clearly show that the prediction performances of all the methods and EM algorithms are almost identical. This finding is consistent with Inan and Erdogan29 that multicollinearity seriously affects the estimation of the methods while prediction levels stay almost the same.
The median, lower, and upper bounds of 95% CIs for of the estimators when the population is a mixture of two regression models with and . RMSE: root means square error; CI: confidence interval.
The median, lower, and upper bounds of 95% CIs for of the estimators when the population is a mixture of two regression models with and . RMSE: root means square error; CI: confidence interval.
The median, lower, and upper bounds of 95% CIs for of the estimators when the population is a mixture of two regression models with and . RMSE: root means square error; CI: confidence interval.
In the second simulation study, we evaluate the performance of the estimators when the underlying mixture model consists of three component regressions with two covariates. We set to simulate the multicollinearity in the mixture. As described earlier, we generated the covariates and responses from the mixture model with parameters , , , and . For example, Figure 56 (in the Appendix) reports the sampling distributions of the covariates and responses for a randomly selected sample with size and . Accordingly, for the selected random sample, the sample VIF is almost around VIF = 10.25. Similar to the settings of the first simulation study, we replicated 2000 times all the estimation and prediction procedures under the EM, CEM, and SEM algorithms and computed the median and 95% CI for the SSEs and RMSEP for sizes . Here again, we set fixed and the same starting points for all the estimation methods. The employed starting points include , , , and . The estimation and prediction results are demonstrated in Figures 4 and 29 to 54 (in the Appendix) and Tables 13 to 21 (in the Appendix), respectively. Here, we also observe that the ML method slightly better estimates the mixing proportions; however, the ML methods result in unreliable estimates for the coefficients of component regressions. It is easy to see that shrinkage estimators do better in estimating the component regression parameters. In addition, the Liu_HKP almost always outperforms other methods and provides a more reliable estimate of the mixture of regression models. Therefore, the Liu_HKP method based on the CEM algorithm is recommended to fit the mixture of linear regression models in multicollinearity.
The median, lower, and upper bounds of 95% CIs for of the estimators when the population is a mixture of three regression models with and .
Although it is well known that the convergence of the SEM (SEM) algorithm (for all the estimation methods) is not guaranteed; the algorithm resembles a Markov chain that fluctuates around the ML estimate.11,14 For this reason, for a fair comparison between all the estimation algorithms, we set the maximum number of iterations to be 2000 for all the EM, CEM, and SEM approaches. If the EM algorithms, for any reason, did not converge in 2000 iterations, the estimate in the last iteration was treated as the solution in the EM algorithm. It is also well known that the log-likelihood of the mixture model may appear multi-model, and the EM algorithm may trap in the local maxima. Although the algorithms in this manuscript may converge to either local or global maxima for all estimation methods, the overall estimation performance of the EM, CEM, and SEM of the ML, Ridge, and LT methods are evaluated in a comparative way using RMSE, which takes into account the squared distance of all the estimates from the true value of the parameters of the mixture model.
To this end, we designed the third simulation study to compare the convergence of the proposed shrinkage estimation algorithms with the commonly used ML counterparts using the same stopping rule. To do so, we used the tolerance levels , while we kept the maximum number of iterations fixed for all methods and the same as 2000. We replicated 2000 times the entire data collection and the estimation in the same way as described above. We then computed the convergence rates of each estimation algorithm by the proportion of times the algorithm converged before reaching the maximum number of iterations. Table 22 (in the Appendix) demonstrates the convergence rates of the different estimation methods and EM algorithms under two different underlying mixtures of regression models with two and three components. From Table 22, we observe that the convergence rates of the Ridge and LT shrinkage methods outperform that of their ML counterpart using EM, CEM, and SEM algorithms in the presence of the multicollinearity. Moreover, this superiority is consistent across both tolerance levels, indicating the robustness of the shrinkage methods in achieving convergence. Additionally, the convergence rates highlight the stability and reliability of the proposed shrinkage estimation algorithms, suggesting their suitability for practical applications in scenarios characterized by multicollinearity.
Bone data analysis
As a bone metabolic disease, osteoporosis occurs when the bone mineral architecture of the body deteriorates. This deterioration results in skeletal fragility and a high risk of osteoporotic fractures in different body areas such as the hip and femur. Osteoporosis and its related diseases significantly impact the patient’s health and survival. For example, one out of every two patients with osteoporotic hip fractures can no longer live independently, and one out of three may die within one year after the medical complication of the broken bone.2,30 The BMD of individuals improves until age 30 and then decreases as individuals age. The BMD score of an individual is compared with a BMD norm to determine the bone disorder status. The BMD norm is computed by the mean BMD scores of healthy adults aged 20–30. The bone status of an individual is diagnosed as osteoporosis when the BMD score is less than SD from the BMD norm of the population.
The BMD scores are obtained via an expensive and time-consuming procedure. Despite this, the researchers have access to various easy-to-measure patients’ characteristics, such as age, weight, BMI, and test results from earlier surveys.31,32 Regression models are among the most common methods to investigate the impact of a set of patients’ characteristics on the BMD responses. The impact of the characteristics may differ at different BMD levels. Hence, the inference on BMD measurements can be handled as a problem of the mixture of linear regression models.
The bone mineral data in this section were obtained from the National Health and Nutritional Examination Survey (NHANES III) administrated by the CDC on more than 33999 American adults between the years 1988–1994. The data set is publicly available on the website of the CDC from (https://wwwn.cdc.gov/nchs/nhanes/nhanes3/Default.aspx). One hundred eighty-two White women aged 50 and older participated in both bone examinations during the survey. Due to the substantial impact of osteoporosis on older women, these 182 women were considered our target population. From the second bone examination, we focused on femur BMD as the response variable. We also used two easily attainable physical characteristics as the explanatory variables of the regression. These physical characteristics include arm and bottom circumferences from the first examination. The association between the two explanatory variables is . Using the ML method based on the information of all individuals in the population, the BIC criterion suggests that a mixture of two regression models is the best fit with parameters , , , and . These parameters were then considered as the true parameters of the mixture population. Figure 57 reports the histograms of the explanatory variables and the responses for the two components. As an unsupervised learning, the true component membership of the observations was obtained as follows. The individuals whose BMD score is less than one standard deviation from the MD norm (the average of the BMD scores from the healthy adults between 20 and 30) were assigned to the first component (osteoporosis) and the others to the second component. We replicated 2000 times the ML, ridge, and LT methods under EM, CEM, and SEM algorithms in estimating the parameters of the bone mineral population based on sample sizes . Similar to Section 3, we selected the fixed and the same starting points for all estimation methods as , , , and . Similar to Section 3, we used as the stopping rule for all the estimation methods with the maximum number of iterations being 2000 for all the EM, CEM, and SEM approaches. We then computed the estimation and prediction measures and MRSEP using 5-fold cross-validation as described in Section 3.
Tables 10 to 12 (in the Appendix) report the median and 95% CI for the above measures in estimating and predicting the bone mineral population. The CI’s lower (L) and upper (U) bounds correspond to 2.5 and 97.5 percentiles, respectively. Although all ML, Ridge, and LT methods almost perform identically in estimating the mixing proportion and component variances, become considerably unreliable. Unlike ML methods, the LT and ridge shrinkage methods could appropriately handle the multicollinearity in estimating the coefficients of component regressions. Comparing the shrinkage methods, we observe that the LT estimators appear more reliable than their ridge counterparts in estimating the parameters of the bone mineral population.
We designed the real data analysis this way for several reasons. First, similar to the simulation studies, we require estimating the parameters of the entire bone data so we can fairly calculate and compare the RMSEs of all the ML, Ridge, and LT methods in estimating the bone mixture population. While the original bone data are co-linear, we applied the benchmark ML method to the entire bone data since the ML method is the only method currently available in the literature in estimating the parameters of the mixture of the regressions. In contrast, we propose the Ridge and LT shrinkage methods as a more reliable alternative to the ML method in estimating the mixture of regression models in the presence of co-linearity. Note that our proposed shrinkage methods outperformed the ML method in estimating the mixture population of the bone data, on average, over 2000 replicates, even in the case where the true parameters of the bone data were estimated by the ML method. Because the simulation studies and the above real data study showed the superiority of the proposed shrinkage methods, we also added a new numerical experiment according to the real-life scenario. In this study, we once applied all the proposed estimation methods to the entire bone data and estimated the parameters of the bone mixture population. Table 23 (in the Appendix) shows the results of this numerical study.
Summary and concluding remarks
In medical and environmental research (e.g. osteoporosis research), linear regression models are used as standard statistical methods to investigate the relationship between a set of covariates with the response variable. When the underlying population is heterogeneous, the impact of the covariates on the response may change in different subpopulations. A mixture of linear regression models can be considered a solution to the problem. The ML method is a common technique to fit a mixture of regression models; however, the ML estimates become unreliable when there is multicollinearity between the covariates. We investigated shrinkage methods, including ridge and LT estimators based on the EM, CEM, and SEM algorithms in estimating the parameters of the mixture of regression models. Through extensive numerical studies, we investigated the estimation performance of the proposed methods on 972 different simulation combinations, accounting for 3 sample sizes, 3 standard deviations, 3 EM algorithms, 3 estimation methods, 2 mixture settings, and 6 multicollinearity levels. We showed that LT estimators outperformed their ridge and ML counterparts through extensive numerical studies. Finally, we applied the developed methods to analyze the bone mineral data of women aged 50 and older. While the methods were only applied to osteoporosis research, the developed methods are generic and can be applied to other medical and environmental studies. The code to implement the simulation studies and real data analysis is accessible through our public GitHub repository (https://github.com/ElsayedGhanem/Mixture-of-Linear-Regression).
While the VIF = 2.91 is not too high in the real data analysis, we selected two physical characteristics: the arm and bottom circumferences mainly because the correlation between these two independent variables is relatively high, 0.81, almost close to the minimum correlation value considered in the simulation studies. Furthermore, these two explanatory variables are easily attainable characteristics of the patients. During the analysis, we only had access to the demographic information of individuals from the first examination, as the mass screening examination. For this reason, we had to use patients’ physical characteristics from the first examination as the explanatory variables. Without loss of generality, the patient’s physical characteristics from the examination can also be used. As another example, according to the high association between different BMD scores from different body tissues, one may consider the different BMD scores as explanatory variables, resulting in more severe multicollinearity in the bone mixture population.
In this paper, we investigated the Ridge and LT shrinkage methods for a mixture of regression models to deal with multicollinearity as one of the most common challenges in regression models. Given these, the proposed estimation methods require extensive iterative algorithms. Consequently, new research is required to investigate the initialization of the iterative algorithms under shrinkage methods and develop reliable and efficient initialization methods33,34 for the shrinkage method for the mixture of regression models. According to the multimodality of the log-likelihood in mixture models, new research is needed to investigate thoroughly this research direction to guarantee the convergence of the EM algorithms to global maxima and possibly from multiple and random starts of the algorithms to use the monotonic properties of the EM algorithms and escape from the local optimums. We only considered the continuous, univariate response variable. It is desirable to develop shrinkage methods for the mixture of regression models with multiple response variables and mixed types of data. In this manuscript, we developed shrinkage methods to address the colinearity challenges in the mixture of regression models using a fully parametric framework. Based on recent advancements in semi-parametric mixture models for linear regression,35 we aim to explore the application of developed shrinkage techniques to mitigate colinearity issues in the semi-parametric mixture of regression models. Last but not least, throughout this manuscript, we did not consider the effects of the sampling weights in all the estimation methods and EM algorithms, even for the commonly used ML method available in the literature. Given the impact of the sampling weights in model misspecification and the estimation biases,36 more research studies are needed in future to assess the impacts of the sampling weights on LT, Ridge, and ML methods under different EM algorithms in estimating the parameters of a mixture of regression models.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241259175 - Supplemental material for Unsupervised Liu-type shrinkage estimators for mixture of regression models
Supplemental material, sj-pdf-1-smm-10.1177_09622802241259175 for Unsupervised Liu-type shrinkage estimators for mixture of regression models by Elsayed Ghanem, Armin Hatefi and Hamid Usefi in Statistical Methods in Medical Research
Footnotes
Acknowledgment
Armin Hatefi and Hamid Usefi acknowledge the research support of the Natural Sciences and Engineering Research Council of Canada (NSERC). The authors would like to thank the two anonymous reviewers whose comments improved the quality and presentation of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Armin Hatefi and Hamid Usefi acknowledge the financial research support received from Natural Sciences and Engineering Research Council of Canada (NSERC).
ORCID iD
Armin Hatefi
Supplemental material
Supplemental material for this article is available online.
References
1.
CummingsSRNevittMCBrownerWS, et al. Risk factors for hip fracture in White women. New Engl J Med1995; 332: 767–774.
2.
NeuburgerJCurrieCWakemanR, et al. The impact of a national clinician-led audit initiative on care and mortality after hip fracture in England: An external evaluation using time trends in non-audit data. Med Care2015; 53: 686.
3.
WHO. Assessment of fracture risk and its application to screening for postmenopausal osteoporosis: Report of a WHO study group [meeting held in rome from 22 to 25 june 1992]. 1994.
4.
LJ MeltonIIIAtkinsonEJO’connorMK, et al. Bone density and fracture risk in men. J Bone Miner Res1998; 13: 1915–1923.
5.
LimH-SKimS-KLeeH-H, et al. Comparison in adherence to osteoporosis guidelines according to bone health status in Korean adult. J Bone Metab2016; 23: 143–148.
6.
LiuK. Using Liu-type estimator to combat collinearity. Commun Stat-Theory Method2003; 32: 1009–1020.
7.
DuranEAHardleWKOsipenkoM. Difference based ridge and Liu type estimators in semiparametric regression models. J Multivar Anal2012; 105: 164–175.
8.
ArashiMKibriaBMGNorouziradM, et al. Improved preliminary test and stein-rule Liu estimators for the ill-conditioned elliptical linear regression model. J Multivar Anal2014; 126: 53–74.
9.
PearceADHatefiA. Multiple observers ranked set samples for shrinkage estimators. arXiv preprint arXiv:2110.07851, 2021.
10.
DempsterAPLairdNMRubinDB. Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc: Ser B (Methodological)1977; 39: 1–22.
11.
CeleuxG. The SEM algorithm: A probabilistic teacher algorithm derived from the EM algorithm for the mixture problem. Comput Stat Quart1985; 2: 73–82.
12.
CeleuxGGovaertG. A classification EM algorithm for clustering and two stochastic versions. Comput Stat Data Anal1992; 14: 315–332.
13.
QuandtRERamseyJB. Estimating mixtures of normal distributions and switching regressions. J Am Stat Assoc1978; 73: 730–738.
14.
FariaSSoromenhoG. Fitting mixtures of linear regressions. J Stat Comput Simul2010; 80: 201–225.
15.
HawkinsDSAllenDMStrombergAJ. Determining the number of components in mixtures of linear models. Comput Stat Data Anal2001; 38: 15–48.
16.
JonesPNMcLachlanGJ. Fitting finite mixture models in a regression context. Aust J Stat1992; 34: 233–240.
17.
Frühwirth-SchnatterS. Finite mixture and Markov switching models. New York: Springer, 2006.
18.
HennigC. Identifiablity of models for clusterwise linear regression. J Classif2000; 17: 273–296.
19.
HoNNguyenX. On strong identifiability and convergence rates of parameter estimation in finite mixtures. Electron J Stat2016; 10: 271–307.
20.
ZhangZLiWKYuenKC. On a mixture GARCH time-series model. J Time Ser Anal2006; 27: 577–597.
21.
HatefiAJozaniMJOzturkO. Mixture model analysis of partially rank-ordered set samples: Age groups of fish from length-frequency data. Scand J Stat2015; 42: 848–871.
22.
HatefiAReidNJozaniMJ, et al. Finite mixture modeling, classification and statistical learning with order statistics. Stat Sin2018; 30: 1–50.
23.
WedelMTer HofstedeFMSteenkampJ-BE. Mixture model analysis of complex samples. J Classif1998; 15: 225–244.
24.
McLachlanGJLeeSXRathnayakeSI. Finite mixture models. Annu Rev Stat Appl2019; 6: 355–378.
25.
PeelDMacLahlanG. Finite mixture models. New York: John & Sons, 2000.
26.
GhanemEHatefiAUsefiH. Liu-type shrinkage estimators for mixture of logistic regressions: An osteoporosis study. Submitted, 2022.
BliucDNguyenNDMilchVE, et al. Mortality risk associated with low-trauma osteoporotic fracture and subsequent fracture in men and women. JAMA2009; 301: 513–521.
31.
FelsonDTZhangYHannanMT, et al. Effects of weight and body mass index on bone mineral density in men and women: The Framingham study. J Bone Miner Res1993; 8: 567–573.
32.
KimSJYangW-GChoE, et al. Relationship between weight, body mass index and bone mineral density of lumbar spine in women. J Bone Metab2012; 19: 95–102.
33.
FurmanWDLindsayBG. Measuring the relative effectiveness of moment estimators as starting values in maximizing likelihoods. Comput Stat Data Anal1994; 17: 493–507.
34.
KarlisDXekalakiE. Choosing initial values for the EM algorithm for finite mixtures. Comput Stat Data Anal2003; 41: 577–590.
35.
MaYWangSXuL, et al. Semiparametric mixture regression with unspecified error distributions. Test2021; 30: 429–444.
36.
PfeffermannD. The role of sampling weights when modeling survey data. Int Stat Rev/Revue Internationale de Statistique1993; 61: 317–337.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.