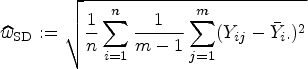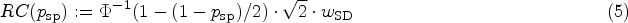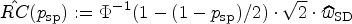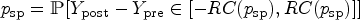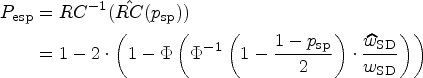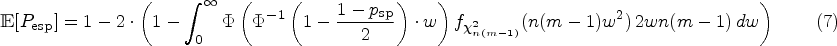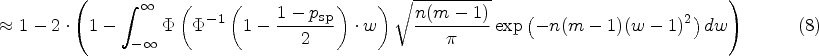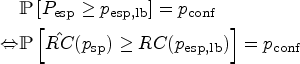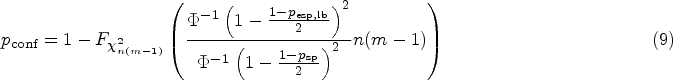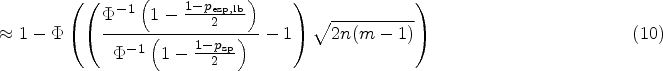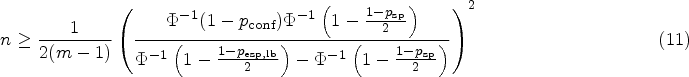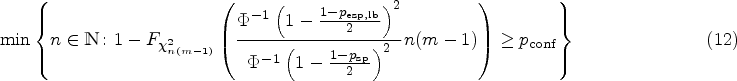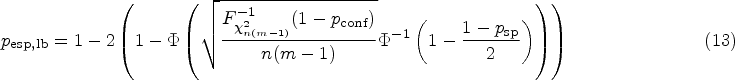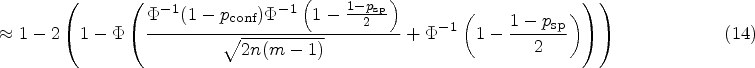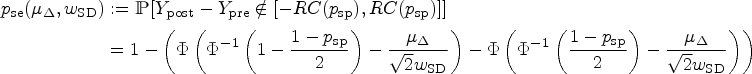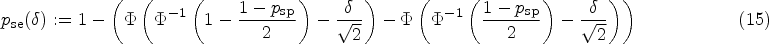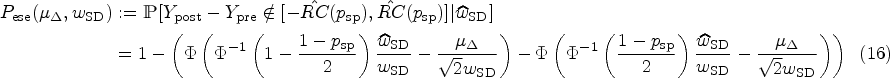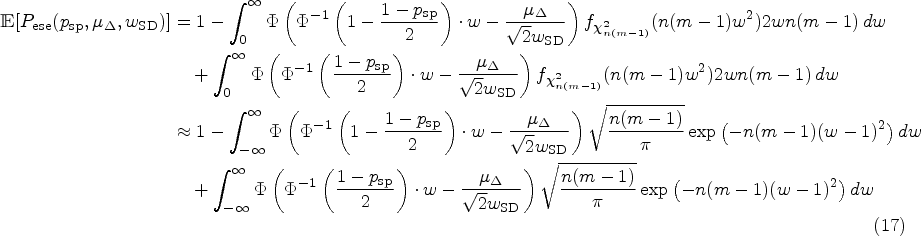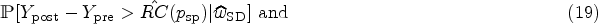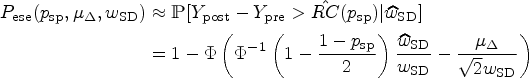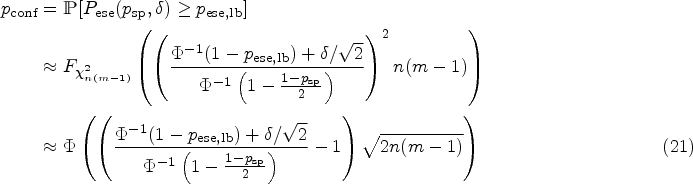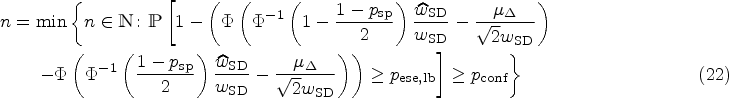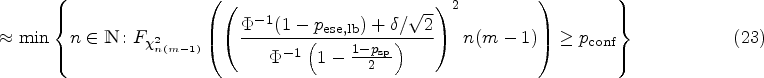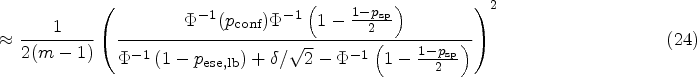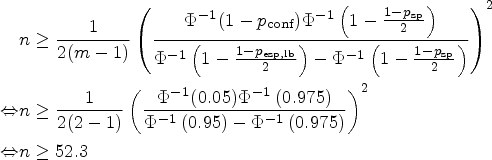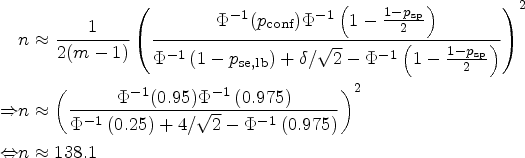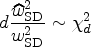There is an increasing number of potential quantitative biomarkers that could allow for early assessment of treatment response or disease progression. However, measurements of such biomarkers are subject to random variability. Hence, differences of a biomarker in longitudinal measurements do not necessarily represent real change but might be caused by this random measurement variability. Before utilizing a quantitative biomarker in longitudinal studies, it is therefore essential to assess the measurement repeatability. Measurement repeatability obtained from test–retest studies can be quantified by the repeatability coefficient, which is then used in the subsequent longitudinal study to determine if a measured difference represents real change or is within the range of expected random measurement variability. The quality of the point estimate of the repeatability coefficient, therefore, directly governs the assessment quality of the longitudinal study. Repeatability coefficient estimation accuracy depends on the case number in the test–retest study, but despite its pivotal role, no comprehensive framework for sample size calculation of test–retest studies exists. To address this issue, we have established such a framework, which allows for flexible sample size calculation of test–retest studies, based upon newly introduced criteria concerning assessment quality in the longitudinal study. This also permits retrospective assessment of prior test–retest studies.
A biomarker is a characteristic objectively measured and evaluated as an indicator of normal biological processes, pathogenic processes, or response to a therapeutic intervention.1 Biomarkers used as indicators of response to a therapeutic intervention, or disease progression, are called treatment response biomarkers. One prime, established treatment response biomarker is lesion size change in cross-sectional imaging. For clinical trials concerning solid tumors, the measurement of lesion size is formalized in the so-called response evaluation criteria in solid tumors (RECIST),2 that categorize treatment response. With the rapid advancement in medical sciences, there is an increasing number of new potential treatment response biomarkers that could possibly allow for early and objective assessment of treatment response or disease progression in clinical trials and clinical practice.3
However, using a biomarker in practice requires some basic research into the reliability of its measurement. In addition to a fixed systematic measurement error (bias), which can be investigated by comparing measurements with a known target value (e.g. phantom studies), it is important to take into account that measurements of quantitative biomarkers are subject to random variability. Hence, changes in a biomarker in longitudinal measurements made under the same conditions do not necessarily represent real change but might be caused by exactly this random measurement variability. Before testing or even utilizing a quantitative biomarker in longitudinal studies, it is therefore of principal importance to assess the measurement repeatability.4
The repeatability of measurement is determined by test–retest studies, which then are also referred to as repeatability studies. In such studies, replicate measurements are made on a sample of subjects under conditions that are as constant as possible.5 Measurement repeatability can be quantified by the within-subject standard deviation (). Using , the repeatability coefficient () can be calculated.4,6,7 is then used in the longitudinal study to determine if a difference in the biomarker represents presumed real change or is within the range of random measurement variability. It is defined in such a way that a desired specificity to detect changes—usually 95%—is targeted.
The and the , as determined by the test–retest study, are point estimates, and hence suffer from random error. As we will show, the targeted specificity is therefore generally not achieved in practice. Following standard statistical results, the more subjects and the more repeated measurements are included in the test–retest study, the more reliable the estimates of and will be. Accordingly, the probability of a relevant deviation of the actually achieved value from the targeted specificity will decrease. The quality of assessments in the longitudinal study and consequently the validity of its results is directly governed by the precision of the estimates of and .
Of course, exact knowledge of measurement repeatability is not only crucial for biomarkers. For example, excellent measurement repeatability of scales and other laboratory instruments is mandatory. The reliability of a scale can be checked using weights with a known mass and it is possible to perform many repeated measurements. In contrast, many biomarkers are measured in-vivo, rendering attainment of large sample sizes difficult. Also, it might be necessary from an ethical point of view to keep sample sizes as low as possible, since the measurement in question might be inconvenient, invasive, or even harmful for the patient or the healthy test person. For example, a biomarker might be derived from computed tomography, which involves ionizing radiation. Yet, if the sample size in the test–retest study is small, there is a high chance of obtaining suboptimal estimates of with associated detrimental effects on sensitivity and specificity in the longitudinal study.
Related to but different from repeatability is reproducibility. While repeatability represents the measurement precision under constant conditions, that is, same measurement procedure, same operators, same measuring system, etc., reproducibility is, in contrast, measurement precision under differing conditions as various operators, measuring systems, etc.8 In the following, we will focus solely on repeatability.
Statistical literature concerning requirements for test–retest studies is scarce. One notable study investigating sample size requirements is by Obuchowski and Bullen.6 Their work includes a critical examination of several statistical issues that arise in the use of quantitative imaging biomarkers in clinical applications. The technical performance of these markers is investigated by multiple simulation studies. The repeatability and reproducibility of measurements as well as their bias are analysed. In addition to the standard models, heteroscedasticity and non-linear relationships are also considered. One aspect of their work concerns the relation between the sample size in the test–retest study and the difference between a fixed targeted specificity of 95% and the expected value of the specificity actually achieved in a following longitudinal study. In order to limit this difference to 1 percentage point, the authors give a blanket recommendation for the sample size of test–retest studies with two repeated measurements based on their results from a fixed set of simulation parameters.
Our goal is to expand upon the results of Obuchowski and Bullen6 for the particular problem of specificity. First, we want to introduce new quality criteria for the planning of test–retest studies. For this purpose, random variables are introduced to distinguish between the targeted specificity and the specificity actually achieved in a subsequent longitudinal assessment that is based upon the results of a test–retest study. Furthermore, we will expand the considerations to include sensitivity, which has not been investigated in the literature so far. Finally, we aim to provide analytical solutions. In contrast to simulation studies, this allows for flexible calculation of sample size requirements without restrictions to fixed parameters and also the retrospective assessment of test–retest studies, as we will show. In doing so, we establish a comprehensive framework in which the notions introduced above are precisely defined.
In what follows, we will introduce the model used for our framework and study the aspects of specificity and sensitivity in separate sections. Afterwards, we demonstrate the application of our concepts in a practical example and discuss our results.
Definitions
One possible approach to distinguish true change from random variation in the longitudinal study is to estimate measurement variability in a test–retest study. For this purpose, patients are measured times within a short period of time, in which their true value presumably does not change. For our considerations we assume independent subjects, for example, measurement of one target per patient. In addition, independent replicate measurements are necessary, that is measurements on a subject need to be made independent of the knowledge of its previous value(s).9 Consequently, we establish the following model for the -th measurement of the -th patient of the test–retest study:
where is the true value for the -th patient and is the random error. For our following considerations, it is irrelevant whether the values stem from a fixed effects or a random effects model. We assume the random errors to be independent and normally distributed with mean and variance .6 In particular, it follows that for any and . This model is appropriate when true replicates are studied and a learning effect can be ruled out. As we are only addressing measurement repeatability, a fixed bias does not need to be considered since it cancels out. We also assume that measurement error is independent from the magnitude of . From this data, we can estimate the within-patient standard deviation 7 by
where denotes the mean value of the measurements of patient . In this formula, the patient-specific means directly cancel each other out. Following Cochran’s theorem,10 the distribution of this entity can be derived from
A two-sided confidence interval for at level is given by
where denotes the -quantile of the -distribution with degrees of freedom.
For any fixed , a central limit theorem can be applied to for . A subsequent application of the delta method11 using the square root function yields the convergence
for any fixed , where is a standard normally distributed random variable. Furthermore, this convergence also holds for any fixed when goes to infinity. This is a consequence of two subsequent applications of the delta method11 and the commutativity of addition and convergence in distribution for independent random variables.
If the number of repeated measurements differs between subjects, that is, the -th subject is measured times, the value needs to be replaced by in all formulas. For the sake of simplicity, we restrict ourselves to the case of an equal number of repetitions per subject.
In order to assess changes in the measurements of a single patient in the subsequent longitudinal study, the is computed.7 It indicates the range in which two repeated measurements are expected to fall with a certain probability. In what follows, we restrict ourselves to the assessment of changes in both directions. We want to keep our decision rules flexible, that is, we establish a target specificity which shall be reached for patients with no change in their true biomarker value. Hence is a function of and is given by
In most literature, the is only considered for a fixed targeted specificity of 95%, that is, .4,12
In practice, is unknown and hence replaced by its consistent estimator to obtain the estimated RC
A confidence interval for the at level is given by multiplying the limits of the corresponding confidence interval for in (3) with .
The point estimate can be applied as cutpoint in a longitudinal study to determine whether there has been change between two consecutive measurements and . Here, we also assume, that the measured values have independent errors, but the true levels and might actually be different, that is, we have and with and being independent and normally distributed with mean and variance .
In case the true values have not changed, that is, , the difference is normally distributed with mean and variance . Hence, following the definition of from (5), we obtain in this case
The rule to decide whether there is a change in a patient with the two measured values and should thus be whether their difference lies outside or inside the interval . As the bounds are unknown in practice, this decision rule is replaced by the decision rule based on the estimated interval . Consequently, the targeted specificity will never be exactly met. This applies analogously to considerations for the sensitivity of this procedure.
Effective specificity as a criterion for sample size estimation
Our goal is to quantify the uncertainty introduced by the replacement of by its estimator . As mentioned, the targeted specificity () is not met in practice. To assess this problem, we introduce the effective specificity which is the specificity actually achieved if a realisation of the estimate is plugged in. Hence, is a random quantity as it depends on the value of . We use a capital letter to emphasize that it is indeed a random variable. It can be implicitly defined via
Although this quantity is unknown in practice, we can nevertheless analyse its distribution. Firstly, we can compute the expected value and the bias, that is, the difference . This is also the quantity targeted by Obuchowski and Bullen.6 Their quality criterion requires to be at most 0.01, that is, they want the mean effective specificity to differ by no more than 1 percentage point from the target specificity, which they set to 95%. But what is even more important, from our point of view, is that we can compute quantiles of the distribution of which will enable us to establish quality guarantees on the effective specificity of the longitudinal studies based on the design parameters and of the test–retest study.
The function can be inverted as it is a continuous, monotonically increasing function on . The expectation of this random quantity can be computed exactly using (2) or approximately using the central limit theorem (4), according to which the distribution of can be approximated with a normal distribution with expectation and variance . Hence, we get
where denotes the probability density function (PDF) of a -distributed random variable with degrees of freedom. By numerical evaluation of the terms in (7) and (8), the bias can be computed.
Quantiles of the distribution of
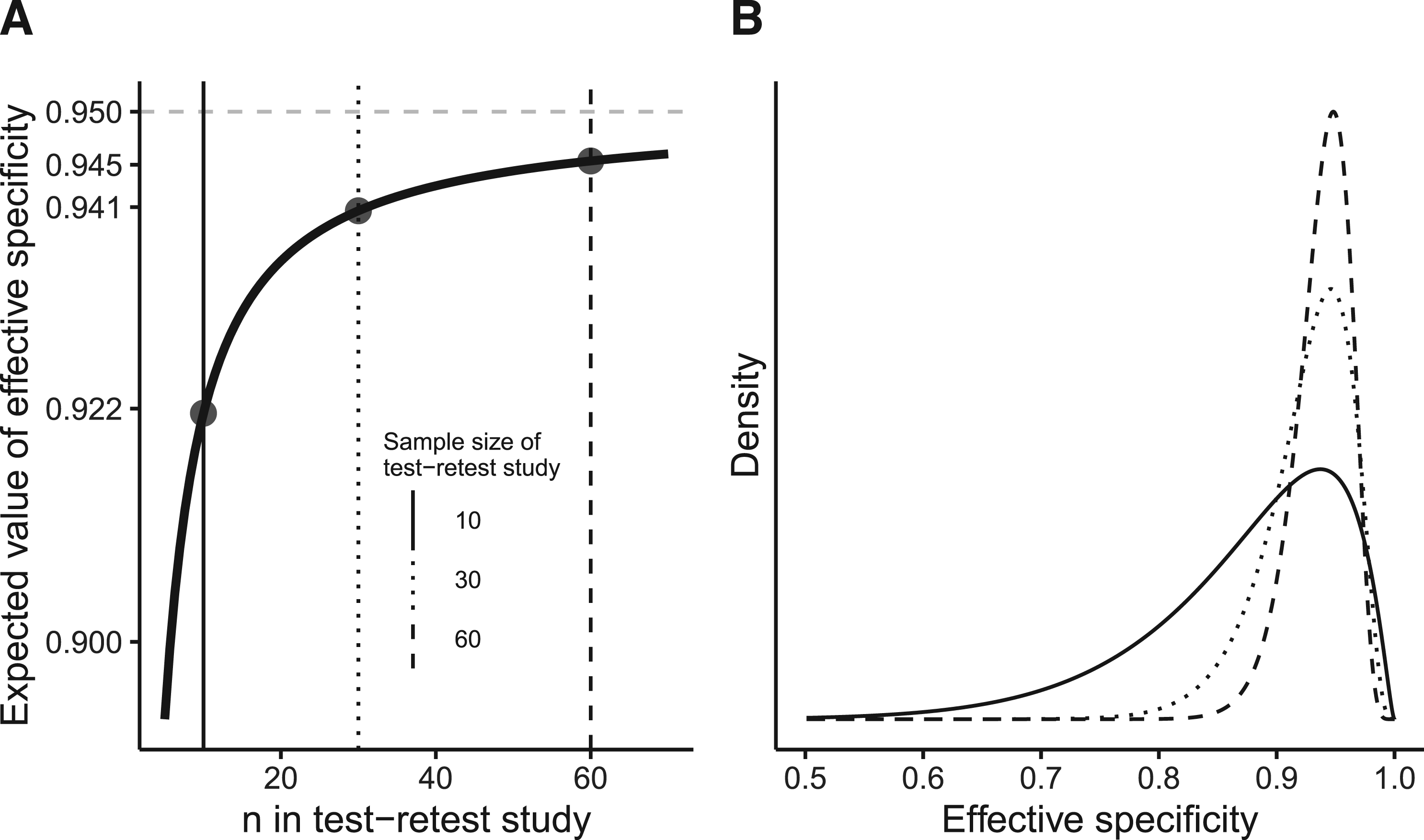
We need to be aware that even if is close to , that is, the bias is low, the probability for a substantial deviation of the actually realized specificity from the targeted specificity might be large (Figure 1).
(A) Expected value of the effective specificity () as a function of in the test–retest study for a target specificity of 95% and . Already for a small case number of 10 (solid vertical line), the expected value is comparably high. For a case number of 30 (dotted vertical line), the bias () is below 1 percentage point and does not change substantially with an increase of the case number to 60 (dashed vertical line). (B) However, while is already relatively high for a case number of 10, the tails of the corresponding PDF (solid line) are prominent, resulting in a high chance of obtaining a low in practice. The dotted and dashed lines represent the PDF of the effective specificity for and , respectively.
Therefore, we want to know with which confidence we can say that the effective specificity is larger than some lower bound . This is expressed by the formula
We want to introduce a new quality criterion based on this concept.
The quantity is a function of and of course also depends on , and . For notational convenience, however, we omit those arguments. After some calculations, one obtains
where denotes the cumulative distribution function of a -distributed random variable with degrees of freedom. These formulas can now be used in different ways. In the above form, one can determine the confidence with which the effective specificity exceeds a fixed bound with given design parameters and of the test–retest study. Analogous considerations can be made for upper bounds by computing the probability of the complementary event. The Supplemental Material contains a simulation study that confirms this key calculation.
In the planning stage of the test–retest study, it could be beneficial to choose the sample size in such a way that a desired lower bound is achieved with a prespecified confidence . To this end, the asymptotic formula (10) can be solved explicitly for :
The exact formula (9) cannot be explicitly solved for . However, one can numerically solve
In our application example, we will apply these formulas in the planning stage of a hypothetical test–retest study.
The need for a number of measurements to ensure compliance with the quality criteria proposed here cannot only be formulated based on the number of cases for an arbitrary fixed . Although this is common practice, the formulas given here show that the product is decisive. Hence, if the number of replicated measurements can also be chosen freely, the total number of measurements can be reduced by increasing . In this sense, setting and is the most efficient configuration. However, such a design of a test–retest study might be regarded inadvisable for several reasons as laid down in the discussion.
If one wants to identify the worst possible cases for given and , one could compute the lower bound of the effective specificity which is reached with confidence :
Accordingly, in of all cases, the effective specificity will be even lower than the obtained .
From our point of view, the probability of exceeding a lower bound is a valid criterion for evaluating the quality of assessment in a longitudinal study. Different from the expected value of which has been previously proposed as a quality criterion,6 our criterion considers the tails of the distribution of . This allows to bound the probability of strongly deviating from the desired specificity.
Consideration of effective sensitivity
Concerning the sensitivity, that is, the ability to detect real change between two measurements of one patient in the longitudinal study, we can make similar considerations. Before coming back to the problem of the uncertainty caused from the estimation of , we first assume, that and hence also is known. Of course, the sensitivity strongly depends on the difference between and . Also, such differences are more difficult to detect if is large and a large target specificity is chosen. To be more precise, the sensitivity to detect a difference can be written as a function of , and the chosen specificity . If the intercepts and are considered random, all the following probability statements are conditional on . Then, this relationship is given by
In this form, the function can also be seen as a function of the effect size , that is,
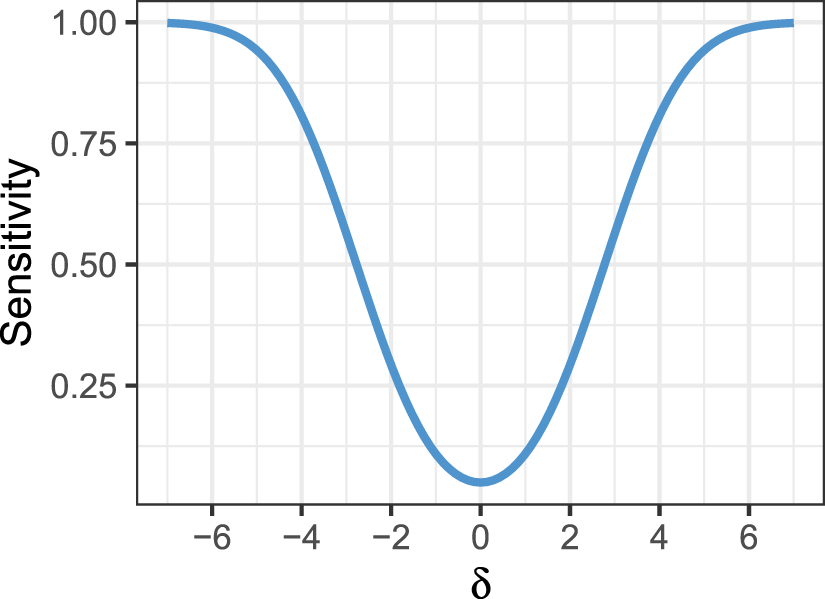
This dependence of the sensitivity on the effect size is visualized in Figure 2.
Sensitivity as a function of effect size for =0.95. Note that we assume to be known here.
As is unknown and needs to be estimated by which will then be plugged in to compute , the sensitivity computed in (15) will not be reached. Analogously to our considerations for the specificity, we introduce the effective sensitivity which is the sensitivity that is actually achieved if a realization of the estimate is plugged in. Of course, it is also a random variable and does depend again on , and . It can be defined by the equation
With this expression and the exact distribution of given as in (2) resp. the approximation of the distribution of by a normal distribution from (4) we can now quantify the bias caused by the replacement of by and compute quantiles of the distribution of which will enable us to also give quality guarantees on the effective sensitivity. Unlike our considerations for the specificity, these values will also depend from the actual and the difference of the longitudinal study and hence will be regarded as functions thereof.
Expected value and bias
To compute the bias in dependence from , , and , we can take the expectation of the right hand side of (16) and use the exact distribution (2) and the central limit theorem (4) to obtain the result
Please note that this can essentially be seen as a function of . Following (16), the bias of the effective sensitivity can be considered a function of for any given , i.e. .
Quantiles of the distribution of
For the most accurate examination of the distribution of , we would need to consider both events
However, this leads to expressions that are difficult to handle analytically. Actually, the two probabilities
sum up to the effective sensitivity. However, in the presence of an effect, one of them will be much larger than the other. In the case , the probability in (19) is larger than that from (20) which is bounded from above by 0.025 and quickly converges to 0 as increases. To enable the derivation of analytical formulas, we will therefore restrict ourselves to the consideration of and the event (18). It is nevertheless possible to circumvent this simplification by numerical inversion of the relationship given in (16). But here, we will approximate
In analogy to the previous section, we can provide confidence levels which indicate the probability that the effective sensitivity for some effect exceeds the lower bound :
Of course, such considerations only make sense if for the chosen effect size . As above, analogous considerations can be made for upper bounds by computing the probability of the complementary event.
While (21) allows to compute the confidence of reaching a certain lower bound of the sensitivity for an effect , this formula may also be transformed to be used in the planning stage of the test–retest study. If one wants to achieve a fixed confidence with which the effective sensitivity for an effect size exceeds some lower bound, one can use the exact results from above or the approximations made thereafter to determine the sample size of the test–retest study in which each patient is measured times. It shall be chosen such that
Analogous to the preceding section, we can use these results in the planning stage of a test–retest study, as we will demonstrate in the following application example. Even if a study is planned based on considerations of the specificity, the formulas allow to assess the distribution of the effective sensitivity for any given effect size of interest.
Calculations for follow analogously to the considerations for .
Application example
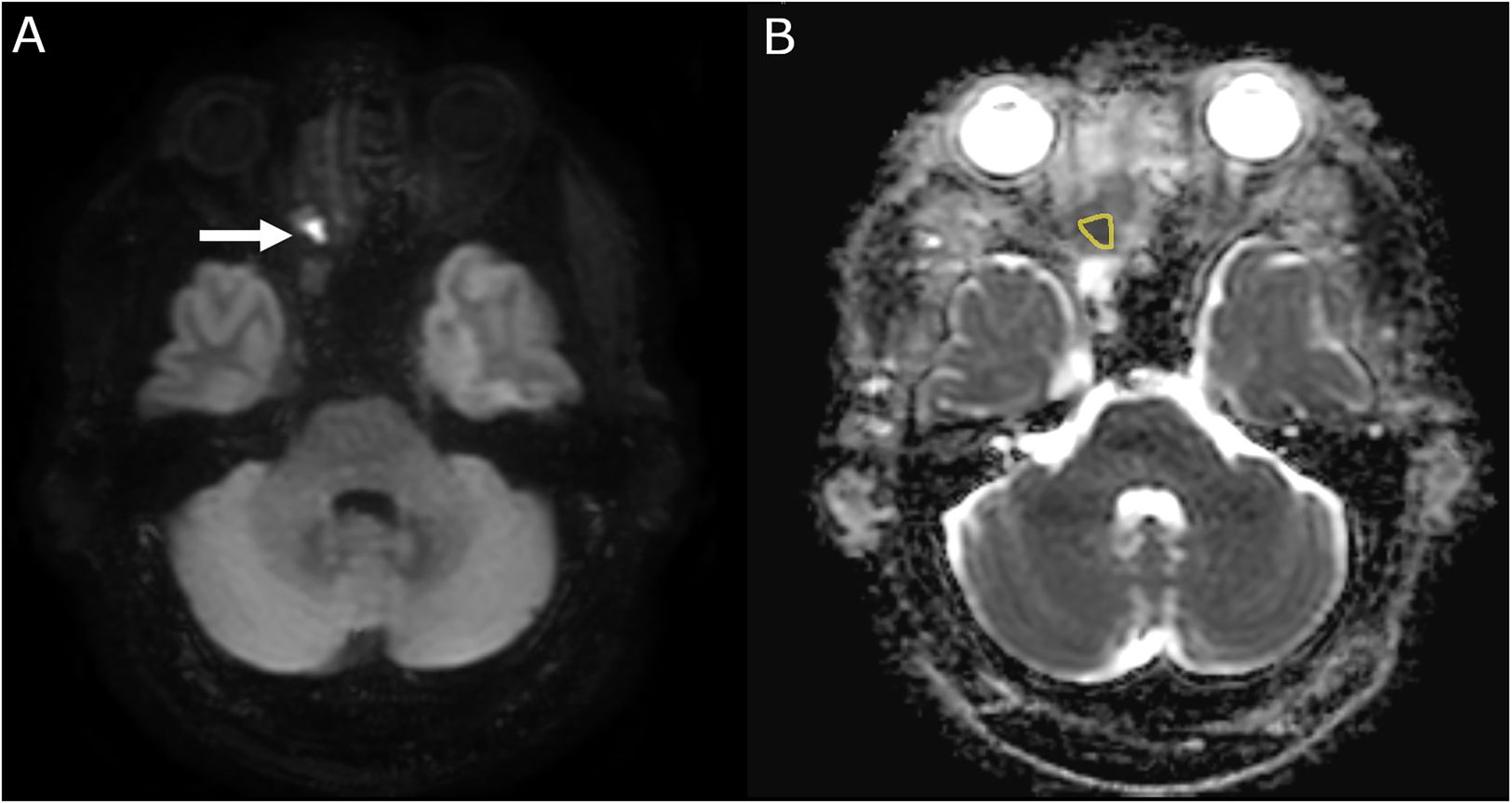
To illustrate our considerations, we will discuss a hypothetical application for early treatment response assessment in recurrent or metastatic nasopharyngeal carcinoma. While some patients with recurrent nasopharyngeal carcinoma show response or stable disease after systemic treatment, many patients will have progressive disease, which is invariably lethal.13,14 Nevertheless, futile treatments should be avoided due to associated toxicity.13,15 To suspend futile treatment as soon as possible an imaging biomarker is desirable which accurately classifies treatment response earlier than change in morphologic lesion size, the current standard. A promising biomarker in this context is diffusion weighted magnetic resonance imaging (DWI).16 DWI depends on the differences in the movement of water molecules based on Brownian motion, which can be quantified by the apparent diffusion coefficient (ADC). An exemplary measurement of ADC is shown in Figure 3. Change in ADC has shown promise as an early treatment response marker in various tumors, including nasopharyngeal carcinoma.16–19
Example case of a tumor in the right nose showing restricted diffusion (A) with a mean apparent diffusion coefficient (ADC) of mm2/s. (B) Region of interest outlined in yellow.
Prospective planning of test–retest studies
As laid out above, before conducting a longitudinal study in which a biomarker is applied to assess treatment response, a test–retest study should be conducted to assess repeatability. In our example, we will set to 95% and , as these are the usual values in the literature. We imagine the researcher would want to obtain a specificity of at least 90% () with 95% certainty () in the longitudinal study. What sample size () is necessary in the test–retest study? This question can be answered using the asymptotic formula (11):
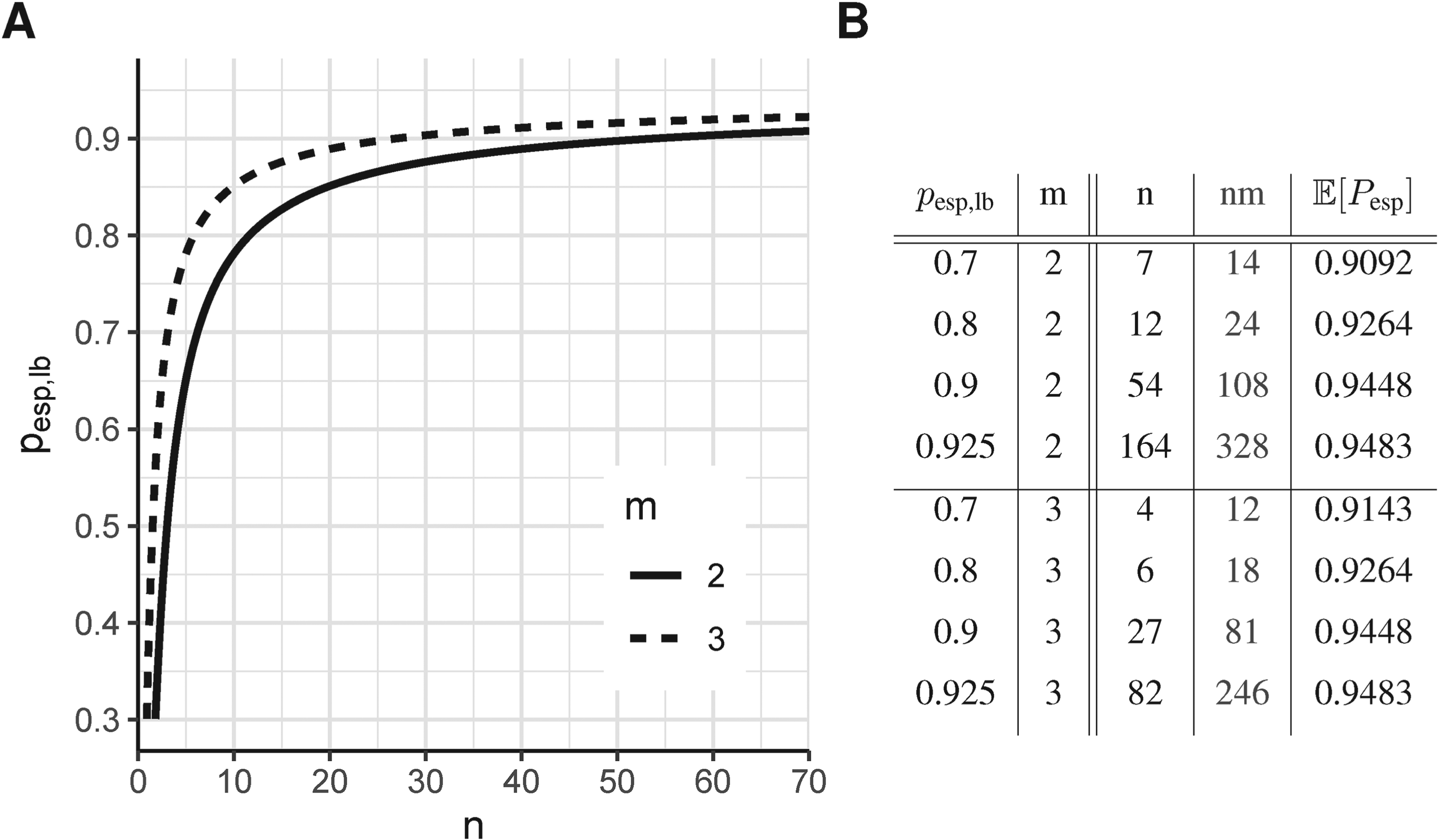
This can also be concluded from Figure 4(A). Numerical solution of the exact formula (12) yields a sample size of 54. Resulting sample sizes for other values of can be taken from Figure 4(B). The resulting scenario in terms of the distribution of the relative error in the estimation of and its effect on is displayed in Figure 5(A). As already noted in Section 3.2, it can be seen in Figure 4(B) that the overall number of measurements can be reduced by increasing . Here, for , a total number of measurements is necessary, while for , are required. Taking this to the extreme, measurements of only one patient would yield the same result in terms of the distribution of , although this may not be advisable.
(A) Lower bound of effective specificity reached with confidence of 95% as a function of sample size () and number of repeated measurements () of the test–retest study. (B) Sample size resulting from (12) for different values of the desired lower bound that shall be exceeded with a fixed confidence of 95%.
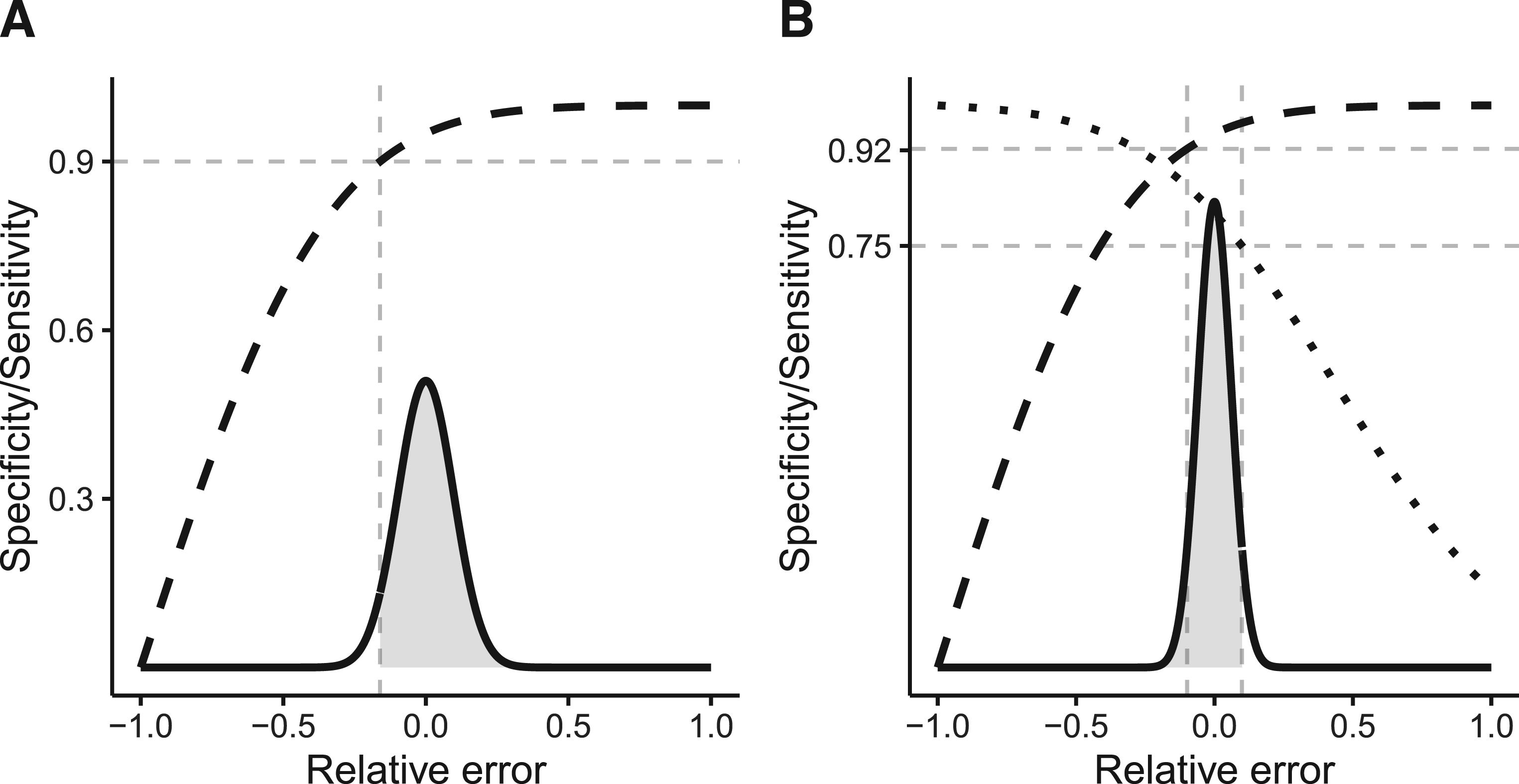
Visualization of the application example. The x-axis denotes the relative error between and . The solid black line represents the asymptotic probability density function (PDF) of the relative error. The dashed line shows the effective specificity. Analogously, the dotted line shows the effective sensitivity for an underlying effect size of . (A) For and : The area shaded in light gray represents 95% of the area under the normal curve. That is, there is a 95% chance of obtaining a from the test–retest study that will result in an effective specificity of >90%. (B) For and : The area shaded in light gray represents 95% of the area under the normal curve. That is, there is a 95% chance of obtaining a from the test–retest study that will result in a specificity of >75%. In this case, an effective specificity of 92.27% will be reached with a certainty of 95%.
Analogous considerations can be made for the effective sensitivity. We consider the sensitivity for an underlying true effect size of in a study with and . According to formula (15), a sensitivity of 80.74% was achieved if was a known quantity. However, this will not be met in practice. What is the minimum sample size () of the test–retest study such that we can be 95% () sure to achieve at least a sensitivity of 75% () for that effect size? This question can be answered using the approximate formula (24).
Accordingly, a sample size of 139 patients in the test–retest study would be recommended to achieve the set targets. Using the exact formula (13) or the asymptotic formula (14), an effective specificity of at least 92.25% resp. 92.27% is reached with a certainty of 95%, in this scenario. This is also depicted by Figure 5(B).
Retrospective assessment of test–retest studies
Conducting a test–retest study prior to a longitudinal study may not always be necessary. The used in the longitudinal study might be adopted from already published test–retest studies. If one intends to use the point estimate of the obtained in a previous study, it is advisable to retrospectively assess the resulting distribution of the effective specificity and sensitivity. This allows to evaluate the impact of the sample size of the used test–retest study on quality criteria of the longitudinal study, especially the probability of exceeding a given .
Common sample sizes in test–retest studies are around 10 and 20.20–25 If the point estimator of resulting from a test–retest study with a sample size of 10 and two repeated measurements is used, the distribution of the effective specificity will have prominent tails as illustrated in Figure 1. According to (13), for sample sizes of 10 and 20, the lower bounds of the effective specificity obtained with 95% confidence are 0.7814 and 0.8512, respectively (Figure 4). This might be insufficient. Note that for the recommendation by Obuchowski and Bullen6 of a sample size of 35 for test–retest studies with the probability of achieving an effective specificity below 94% is 39.74%.
Such considerations are also possible for the effective sensitivity.
Discussion
We have established a comprehensive framework for planning of test–retest studies concerning repeatability. It enables flexible calculation of sample size requirements and retrospective assessment of such studies with regard to different quality criteria.
To better discuss planning of test–retest studies we have introduced the notions of effective specificity () and effective sensitivity (), allowing for clearer differentiation of the targeted specificity and sensitivity from the values actually achieved in the longitudinal study. Both and are random quantities and their actual values are unknown in practical application. However, we can determine their distribution and thus can compute different characteristics which properly reflect the uncertainty caused by the estimation process.
Expanding on the work of Obuchowski and Bullen,6 we have introduced a new quality criterion for sample size calculation of test–retest studies. In their work, Obuchowski and Bullen6 demand that the mean effective specificity () deviates at most by 0.01 from the fixed targeted specificity () of 0.95. However, using the mean effective specificity as sole quality criterion has limitations, since the whole distribution of the effective specificity is not properly taken into account. As illustrated in Figure 1, there is a high probability that the actually achieved effective specificity deviates strongly from its target even if the mean effective specificity may be close to the targeted specificity. Therefore, we propose a quality criterion for sample size calculations based on the probability that the effective specificity exceeds a chosen lower bound, taking into account the tails of the distribution of .
Typically, the number of repeated measurements per patient is set to . Nevertheless, efficiency gains in the total number of measurements of the test–retest study can be attained by increasing , as the distribution of only depends from the product . However, caution is advised here as a very small number of subjects with a large number of repeated measurements may come with some disadvantages. From an ethical point of view, it can be unjustified to subject a patient to a high number of potentially harmful examinations. But also from a statistical point of view this can be unfavorable. Assumptions of the underlying model, such as homoskedasticity, cannot be investigated properly in such a trial and habituation effects after a large number of measurements could bias the estimate of .
In contrast to previous works, we expand our consideration also to issues of sensitivity. Here, of course, it must also be taken into account that the sensitivity depends on the underlying effect size. Nevertheless, we can determine the distribution of the effective sensitivity for any effect size and provide analogous sample size formulas as for the specificity.
Finally, our study is the first to provide analytical rather than simulation results. This provides greater flexibility as the targeted specificity and number of repeated measurements may be chosen freely. Hence, it allows the readers to avoid conducting time-consuming simulation studies themselves. While our formulas enable flexible calculations for all scenarios, for convenience of the reader we also provide a table with sample sizes for some exemplary scenarios in Figure 4(B). Sample sizes resulting from other choices of the parameters , , , and can be found in Supplemental Tables S1 to S4.
A larger sample size than often found in the literature for test–retest studies is required if a high quality of the estimate is desired according to the choices of , , and . From a purely statistical perspective, multiple estimates of the within-patient standard deviation can be combined (e.g. from different studies) in a meta-analytic way to meet this increased sample size requirement by defining
The properties of this aggregated estimate can be investigated using all the tools introduced in our work as
However, for this combination to be sensible, it must be ensured that all of these estimators estimate the same quantity.
Our study has some limitations. The field of application is restricted to test–retest studies in which true replicates of measurements are possible, for example, in quantitative imaging markers. Our considerations are not valid if the measurement process itself results in a change of the measurand (learning/practice effect) as has been described for some psychological assessments.26,27
Our standard model (1) assumes independent and identically normally distributed errors. It is, therefore, advisable to examine whether there is a relationship between the within-subject variation and the level of the measured value before applying our approach.28 If the variability of the measurement error increases with the magnitude of the measured value, a log transformation might resolve the issue.29,30,28 Beyond that, non-normally distributed error terms are not covered so far. We also have not specifically considered the scenario of clustered data, for example, measuring multiple lesions per subject. However, if a hierarchical model structure with independent errors can be assumed, this does not pose a restriction to application of our approach.
It should be noted that exact solutions based on the -distribution for all our considerations are available. In some cases, when an analytic solution is not possible, these exact solutions require the application of numerical methods. In order to give completely analytic solutions, some of our formulas rely on asymptotic results and approximations. The differences between exact and approximate results are most severe for small sample sizes and small effect sizes. Applying both exact and approximate formulas in our application example, it can be seen that these differences are negligible in practically relevant scenarios. However, we recommend using the exact calculations for a final planning of a test-retest study. Implementations of exact and approximate solutions can be found in our Supplemental R Code.31
So far, our considerations are limited to repeatability, that is, assuming same measurement conditions for the repeated measurements. However, for real world application of biomarkers, consideration of reproducibility is also important since longitudinal measurements are often performed under different measuring conditions, for example, varying readers or scanners. Therefore, our model should be enhanced to include aspects of reproducibility such as a fixed bias as, for example, in some models considered by Obuchowski and Bullen6 or multiple variance components that take into account different sources of variability in such settings. Nevertheless, since repeatability limits reproducibility, a good knowledge of the former is useful in order to interpret reproducibility studies properly.9
Test–retest studies of repeatability should be well planned to guarantee for a sufficient quality of dependent longitudinal studies. Our framework allows the derivation of analytical solutions for quality criteria that can be used to assess implications of the test–retest study design on subsequent longitudinal studies.
Supplemental Material
sj-r-1-smm-10.1177_09622802241227959 - Supplemental material for A statistical framework for planning and analysing test–retest studies of repeatability
Supplemental material, sj-r-1-smm-10.1177_09622802241227959 for A statistical framework for planning and analysing test–retest studies of repeatability by Moritz Fabian Danzer, Maria Eveslage, Dennis Görlich and Benjamin Noto in Statistical Methods in Medical Research
Supplemental Material
sj-pdf-2-smm-10.1177_09622802241227959 - Supplemental material for A statistical framework for planning and analysing test–retest studies of repeatability
Supplemental material, sj-pdf-2-smm-10.1177_09622802241227959 for A statistical framework for planning and analysing test–retest studies of repeatability by Moritz Fabian Danzer, Maria Eveslage, Dennis Görlich and Benjamin Noto in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Benjamin Noto was funded as a clinician scientist by the Medical Faculty, University of Münster, Germany. There was no dedicated funding for this study.
ORCID iDs
Moritz Fabian Danzer
Maria Eveslage
Supplemental material
Supplemental material for this article is available online. Implementations of exact and approximate formulas can be found in the Supplemental R Code. The Supplemental Material contains sample size tables based on formula (12) generated using our R code, the results of a simulation study to confirm our calculations and the derivation of formulas (9) and ().
References
1.
Biomarkers Definitions Working Group. Biomarkers and surrogate endpoints: preferred definitions and conceptual framework. Clin Pharm Therap2001; 69: 89–95.
2.
EisenhauerEATherassePBogaertsJet al. New response evaluation criteria in solid tumours: revised RECIST guideline (Version 1.1). Eur J Cancer2009; 45: 228–247.
3.
KoCCYehLRKuoYTet al. Imaging biomarkers for evaluating tumor response: RECIST and beyond. Biomark Res2021; 9: 52.
4.
Shukla-DaveAObuchowskiNAChenevertTLet al. Quantitative imaging biomarkers alliance (QIBA) recommendations for improved precision of DWI and DCE-MRI derived biomarkers in multicenter oncology trials. J Magn Reson Imaging2019; 49: e101–e121.
5.
BarnhartHXHaberMJLinLI. An overview on assessing agreement with continuous measurements. J Biopharm Stat2007; 17: 529–569.
6.
ObuchowskiNABullenJ. Quantitative imaging biomarkers: effect of sample size and bias on confidence interval coverage. Stat Methods Med Res2018; 27: 3139–3150.
7.
BlandJMAltmanDG. Education and debate–statistical notes: measurement error. Br Med J1996; 313: 744.
8.
KesslerLGBarnhartHXBucklerAJet al. The emerging science of quantitative imaging biomarkers terminology and definitions for scientific studies and regulatory submissions. Stat Methods Med Res2015; 24: 9–26.
9.
BlandJMAltmanDG. Measuring agreement in method comparison studies. Stat Methods Med Res1999; 8: 135–160.
10.
CochranWG. The distribution of quadratic forms in a normal system, with applications to the analysis of covariance. Math Proce Camb Philos Soc1934; 30: 178–191.
11.
van der VaartAW. Asymptotic Statistics. 1st ed.Cambridge: Cambridge University Press, 1998, pp.26-27.
12.
RaunigDLMcShaneLMPennelloGet al. Quantitative imaging biomarkers: a review of statistical methods for technical performance assessment. Stat Methods Med Res2015; 24: 27–67.
13.
GlazarDJJohnsonMFarinhasJet al. Early response dynamics predict treatment failure in patients with recurrent and/or metastatic head and neck squamous cell carcinoma treated with cetuximab and nivolumab. Oral Oncol2022; 127: 105787.
14.
MaBBLimWTGohBCet al. Antitumor activity of nivolumab in recurrent and metastatic nasopharyngeal carcinoma: an international, multicenter study of the mayo clinic phase 2 consortium (nci-9742). J Clin Oncol2018; 36: 1412.
15.
ChanATHsuMMGohBCet al. Multicenter, phase II study of cetuximab in combination with carboplatin in patients with recurrent or metastatic nasopharyngeal carcinoma. J Clin Oncol2005; 23: 3568–3576.
16.
LeeMKChoiYJungSL. Diffusion-weighted MRI for predicting treatment response in patients with nasopharyngeal carcinoma: a systematic review and meta-analysis. Sci Rep2021; 11: 1–11.
17.
TorkianPMansooriBHillengassJet al. Diffusion-weighted imaging (DWI) in diagnosis, staging, and treatment response assessment of multiple myeloma: a systematic review and meta-analysis. Skelet Radiol2023; 52: 565–583.
18.
WinfieldJMMiahABStraussDet al. Utility of multi-parametric quantitative magnetic resonance imaging for characterization and radiotherapy response assessment in soft-tissue sarcomas and correlation with histopathology. Front Oncol2019; 9: 280.
19.
WinfieldJMWakefieldJCDollingDet al. Diffusion-weighted MRI in advanced epithelial ovarian cancer: apparent diffusion coefficient as a response marker. Radiology2019; 293: 374–383.
20.
BarrettTLawrenceEMPriestANet al. Repeatability of diffusion-weighted MRI of the prostate using whole lesion ADC values, skew and histogram analysis. Eur J Radiol2019; 110: 22–29.
21.
GiannottiEWaughSPribaLet al. Assessment and quantification of sources of variability in breast apparent diffusion coefficient (ADC) measurements at diffusion weighted imaging. Eur J Radiol2015; 84: 1729–1736.
22.
MiquelMScottAMacdougallNet al. In vitro and in vivo repeatability of abdominal diffusion-weighted MRI. Brit J Radiol2012; 85: 1507–1512.
23.
JeromeNPVidićIEgnellLet al. Understanding diffusion-weighted MRI analysis: repeatability and performance of diffusion models in a benign breast lesion cohort. NMR Biomed2021; 34: e4508.
24.
BarwickTOrtonMKohDMet al. Repeatability and reproducibility of apparent diffusion coefficient and fat fraction measurement of focal myeloma lesions on whole body magnetic resonance imaging. Brit J Radiol2021; 94: 20200682.
25.
MichouxNFCerankaJWVandemeulebrouckeJet al. Repeatability and reproducibility of ADC measurements: a prospective multicenter whole-body-MRI study. Eur Radiol2021; 31: 4514–4527.
26.
Hinton-BayreAD. Specificity of reliable change models and review of the within-subjects standard deviation as an error term. Arch Clin Neuropsychol2011; 26: 67–75.
27.
MaassenGH. The two errors of using the within-subject standard deviation (WSD) as the standard error of a reliable change index. Arch Clin Neuropsychol2010; 25: 451–456.
AltmanDGBlandJM. Measurement in medicine: the analysis of method comparison studies. J R Stat Soc Series B1983; 32: 307–317.
30.
BlandJMAltmanDG. Statistics notes: measurement error proportional to the mean. Br Med J1996; 313: 106.
31.
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2022. https://www.R-project.org/.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.