
Abstract
Motivated by measurement errors in radiographic diagnosis of osteoarthritis, we propose a Bayesian approach to identify latent classes in a model with continuous response subject to a monotonic, that is, non-decreasing or non-increasing, process with measurement error. A latent class linear mixed model has been introduced to consider measurement error while the monotonic process is accounted for via truncated normal distributions. The main purpose is to classify the response trajectories through the latent classes to better describe the disease progression within homogeneous subpopulations.
Keywords
Introduction
Osteoarthritis (OA) is a chronic debilitating joint disease with no cure and a global prevalence of
Given the increasing number of patients and rising costs, it is paramount to differentiate groups of patients according to their disease performance over time. In statistical terms, this differentiation can be achieved by identifying trajectory groups (or classes) according to their longitudinal trends. Latent class linear mixed models (LCLMMs)3,4 provide a useful statistical approach to identify such classes by defining subpopulations that could in turn be linked to differences in other individual characteristics. Identifying subpopulations with distinct disease trajectories will aid in determining a more strategical use of resources for OA management. For instance, patients classified with a ‘stable non-deteriorating’ trajectory could be minimally treated or maintenance approaches can be sought whereas patients with a ‘rapid-progressing’ trajectory could be targeted for novel interventions or followed up more regularly.
The LCLMM combines attributes of the linear mixed model (LMM) with a categorical latent variable, that is, a latent class, which allows splitting a heterogeneous population with different trajectories over time into subpopulations with more homogeneous observations. Briefly, the LMM explains dependency or correlation among repeated outcomes of individuals, for example, individual trajectories over time for longitudinal data, by incorporating in the formulation a set of covariates to determine their possible fixed and random effects. In LMMs, the fixed effects account for the overall impact of specified covariates whereas the random effects account for variation within and between groups. 5 At the same time, different classes of latent trajectories aim to capture heterogeneity in a population with different growth curves shapes. LCLMM combines the underlying subpopulations through the use of a finite mixture.
OA is most commonly presented in the knee joints and radiography, that is, x-rays, is typically used to diagnose structural changes. Kellgren and Lawrence 6 introduced a radiographic grading system which became widely used to assess the severity of knee OA, disease. The Kellgren–Lawrence (KL) score is a discrete grade ranging from 0 to 4, which indicates increasing OA severity. The KL grading scales result from a classification system involving four radiographic features: joint space width, osteophyte formation, presence of sclerotic walls and bone deformity. Of these features, joint space width (JSW) and its narrowing over time is likely to capture disease progression with greater granularity compared to the other features denoting the presence/absence of a given characteristic. 7
However, errors in accurately measuring JSW can be introduced in the diagnostic process due to the grader, machine, or image angle. Thus, modelling approaches aiming to describe the disease trajectories based on JSW should consider these measurement errors into account as these may raise different problems. For example, Carroll et al. 8 mentioned that measurement error can cause bias in parameter estimation, lead to a loss of power for detecting relationships among variables; and mask data features. Therefore, the measurement error problem could be tackled using models with a general common structure, or ‘ingredients of a measurement error problem’ 9 : a model for the true value (a statistical model); a measurement error model (a specification of the relationship between the true and observed values); and extra data (information or assumptions needed to correct for measurement error, e.g. constraints or informative prior distributions for the measurement error parameters). To address this challenge for modelling JSW, we extend here the use of monotonic constraints (as the ‘extra data’ ingredient), which have been previously used for hidden Markov models,10,11 in the context of LCLMM for data arising from a heterogeneous population subject to measurement errors.
To be specific, we propose a Bayesian approach to identify latent classes based on the trajectories of longitudinal continuous response data subject to monotonicity and measurement error. The novelty of the LCLMM proposal is twofold as it (1) preserves monotonic patterns and (2) addresses measurement errors in the continuous responses. The main purpose of incorporating these features is to aid the latent class identification that best describe different progression trends between subpopulations.
The remaining of this article is organized as follows. The motivating data is introduced in Section 2. The proposed approach is presented in Section 3, which introduces a LCLMM subject to a monotonic constraint and measurement error. Bayesian analysis is explored in Section 4. Analysis results for a simulation study and motivating data are presented in Section 5. Discussion and concluding remarks can be found in Section 6.
Motivating data
The Osteoarthritis Initiative OA initiative (OAI) is a cohort study which started in 2002 across multiple centers in the United States with the objective of pinpointing risk factors and biomarkers for knee OA. A total of 4796 participants were recruited into one of three subcohorts: progression, incidence, and control according to distinct inclusion criteria and followed up for almost 10 years.
12
Briefly, the progression subcohort (
As previously mentioned, our main interest lies in identifying trajectory groups based on the reported medial minimum JSW (MCMJSW) measured in millimeters, which is subject to measurement error and follows a non-increasing process due to the chronic and progressive nature of OA. Here, we focus on a subset of participants in the progression subcohort with complete information across visit times (
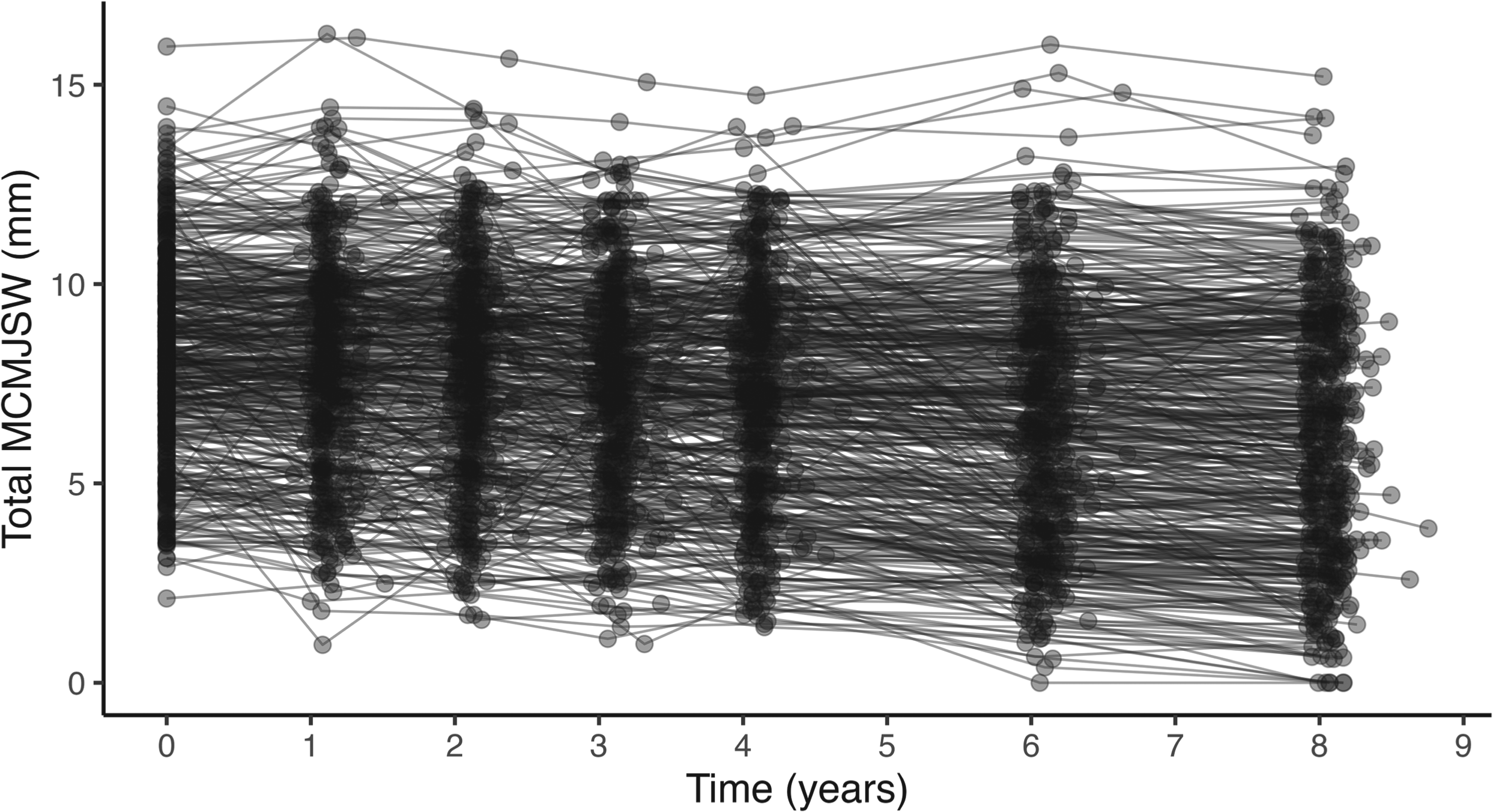
Spaghetti plots for the subjects’ trajectories (
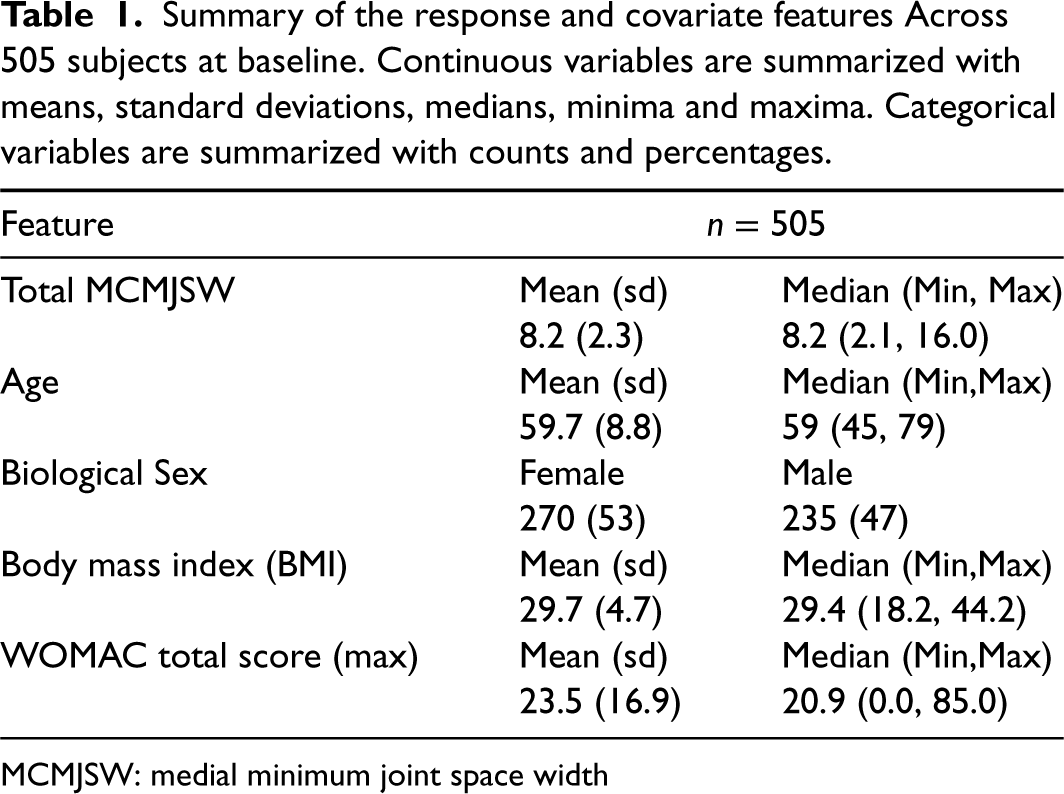
Summary of the response and covariate features Across 505 subjects at baseline. Continuous variables are summarized with means, standard deviations, medians, minima and maxima. Categorical variables are summarized with counts and percentages.
MCMJSW: medial minimum joint space width
The aim of the proposed approach is to identify latent classes that characterize the response trajectories. We consider a continuous latent monotonic non-increasing time-dependent process, which underlies an observed continuous response subject to measurement errors. The description of the approach is given in the following subsections.
Latent class linear mixed models
A LCLMM is a mixture of
For 
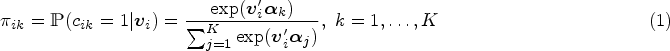
Suppose that the response score is obtained for the
Let 
Assume that the response scores follow a monotonically non-increasing continuous process, that is,
The response variable 
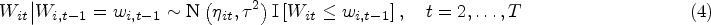
Let 
The proposed full model is a LCLMM comprised by equations (1) to (5) in Section 3. The prior and posterior distributions, as well as the needed constraints are described in the following subsections.
Prior elicitation
Some components of the prior distribution have been chosen to be conditionally conjugate distributions. In general, normal prior distributions are used for the regression coefficients in the linear predictor,
On the other hand, in order to ensure the identifiability of the parameters in the covariance matrix of the random effects’ regression coefficients,
Similarly, normal prior distributions are used for the regression coefficients in the logistic model in each latent class, that is,
In finite mixture models, informative prior distributions should be considered to ensure that observations are assigned to each mixture component. Following a previously proposed hierarchical prior distribution,
16
we set the variance of the latent variable to follow an inverse Gamma distribution, or equivalently
Nonidentifiability problems and label switching
In a finite mixture model, there are three types of nonidentifiability problems that could arise 17 : (i) invariance of the likelihood under the relabelling of the components, a phenomenon called label switching; (ii) potential overfitting introduced when either one component is empty or two components are equal, which means that there are more components defined than actually needed; and (iii) another generic property, for example, when different parameters describe the same density. Under a Bayesian framework, the posterior distribution of finite mixture and hidden Markov models will inherit the likelihood invariance, affecting inference. It is worth noting that label switching in a well-separated arrangement of data might not occur, however for the problem at hand this setting is unlikely. Furthermore prediction could be masked amidst the self-supervised learning task of the chosen model as previously described. 18
Although identifiability may be achieved by imposing artificial constraints on the parameter space, several authors have pointed out that this approach seldom provides a satisfactory solution. Furthermore, label switching is a prerequisite for Markov chain Monte Carlo (MCMC) convergence as earlier work summarizes. 19 In order to deal with the label switching problem there are several relabelling proposals which often involve a post-process of the simulation output. Some use cluster like tools 20 based on a modal region, ideally chosen before the label switching occurs. Stephens 21 proposed a decision theoretic approach which involves an optimization criterion that could depend on the starting point. Frühwirth-Schnatter 22 used permutation samplers that in turn could be used to find suitable identifiability constraints. Papastamoulis and Iliopoulus 23 proposed the equivalent classes representatives (ECR) method, which finds a permutation that minimizes the simple matching distance (SMD) between a true allocation and the permutations. Therefore one must chose a pivot as the true allocations to compare others with making the process pivot-dependent. Rodríguez and Walker 19 used the fact that observations that are often allocated together must remain similar, hence they used the observed data to inform the loss function within an ECR method. They obtain an initial pivot estimate using one modal region of the posterior distribution to calculate the mean and standard deviation of the allocated data, relaxing pivot dependence. Therefore, performance of each of the aforementioned algorithms will be affected in some cases by the initial point or pivot used in the optimization process or would lead to heavy computational burden. Hence, to select one that performs well requires a careful analysis of the particular problem.
We use R package label.switching, which includes eight relabelling methods.
24
These algorithms are used as a post process to relabel the latent classes in the fitted model. Some of these algorithms will require the allocation conditional probability for observation 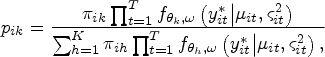
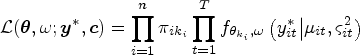
To ameliorate the identifiability issues we propose the following strategy. We have two types of variances associated to the linear predictor in the latent process, the covariance matrix for the random effects
Note that by applying the first step of the proposed post-process, that is, omitting the random effects, we reduce the variability of the model by considering a marginal model for longitudinal data. We focus on this population-level approximation, instead of an individual-level model, to identify the latent classes employing the average estimates of the sub-populations. The second step consists of obtaining the unswitched latent class membership using a relabelling post-process. Finally, the proposed model is estimated by incorporating some constraints needed to identify parameters, see details in the Supplemental Material (Section S3).
Exploring posterior distributions
The likelihood function for the post-process, that is, after label switching has been addressed, given the label of latent classes can be defined by using conditional independence assumptions, considering the observed variables 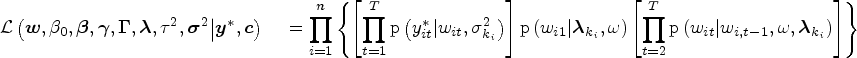
The joint posterior distribution of the latent variables 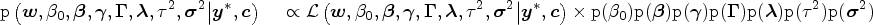
In this section, we evaluate the performance of the proposed model using simulated data where there are latent classes with both non-increasing monotonic trajectories and measurement errors in the response variable. The utility is also demonstrated by fitting the model on the motivating data. Details are described below. The proposed model was fitted using JAGS 4.3.0 and its R package interface rjags v4-12.
Simulation example
Data generation
Performing a full-scale simulation study is difficult because of all the possible parameters and variations that data may have, and therefore it would become computationally and time demanding. In this section, we have done an experimental simulation considering a feasible number of scenarios varying key study design parameters (namely
A sample of
To compute the linear predictor (2), the fixed effects variables
The latent variables
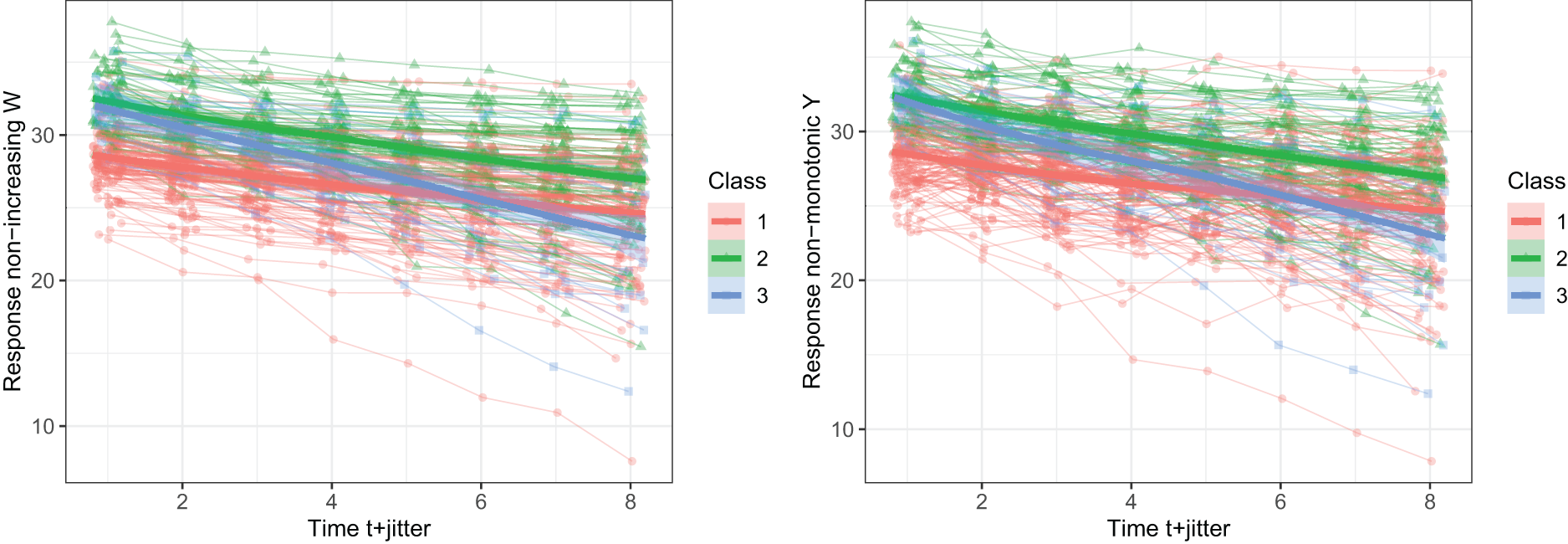
Simulated profiles of response variables for a dataset with
Finally, to simulate the response variable subject to measurement error
Parameter and covariate values are fixed for all replicated data sets, and therefore, all replicates have the same linear predictor. What varies in each simulated sample is the latent variable subject to the monotonic constraint, which in turn also changes the observed response variable subject to measurement error.
As described above, we simulated 100 data sets to show the empirical properties of the proposed model, models without and with monotonic constraint have been fitted varying the number of estimated classes,
A total of 30,000 iterations were performed with 15,000 burn-in iterations and a thinning factor of 15, generating four chains by using the MCMC sampling algorithm. The potential scale reduction statistic (
Given our data simulation strategy, when
In general, the number of latent classes is unknown, as such it can be fixed according to prior information (if available), or it can be selected based on information criteria for model assessment, like the ones described by Gelman et al. 29 We have used the R package loo, 30 which uses leave-one-out cross-validation (LOO) and the widely applicable information criterion (Watanabe-Akaike information criterion, WAIC) methods to compute the expected log pointwise predictive density (ELPD).
The information criteria based on WAIC and LOO (equal to
Simulation: Average number (SD) of the criteria using
latent classes for 100 data sets across different values of
and
. WAIC and LOO values for LCLMM (without monotonic constraint) and the proposed model (with monotonic constraint).
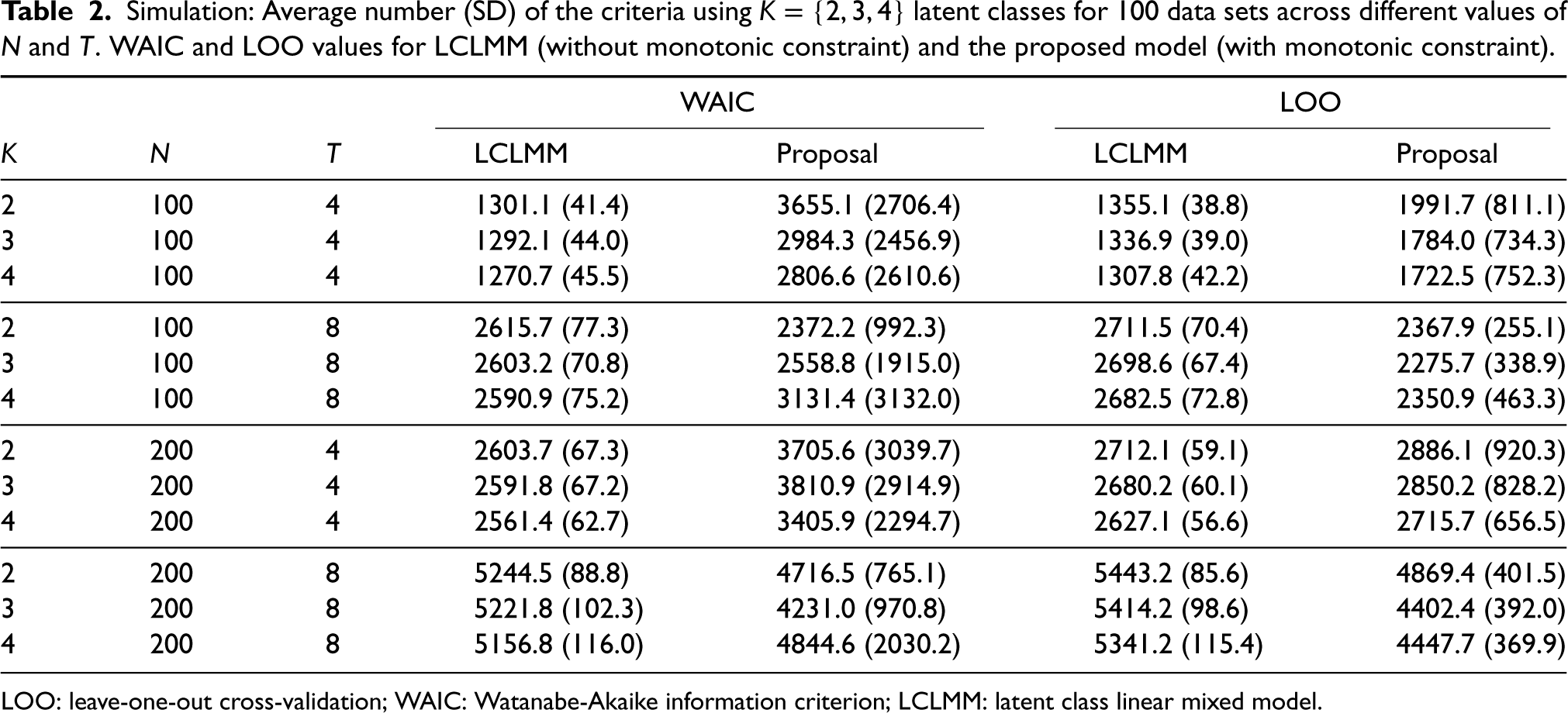
Simulation: Average number (SD) of the criteria using
LOO: leave-one-out cross-validation; WAIC: Watanabe-Akaike information criterion; LCLMM: latent class linear mixed model.
To further illustrate the findings, we summarize the results by comparing the true classes with those estimated from the model when
Table 3 shows the confusion matrix comparing the number of true against estimated classes, for different values of
Simulation: average number (SD) of cases for true class and estimated class (
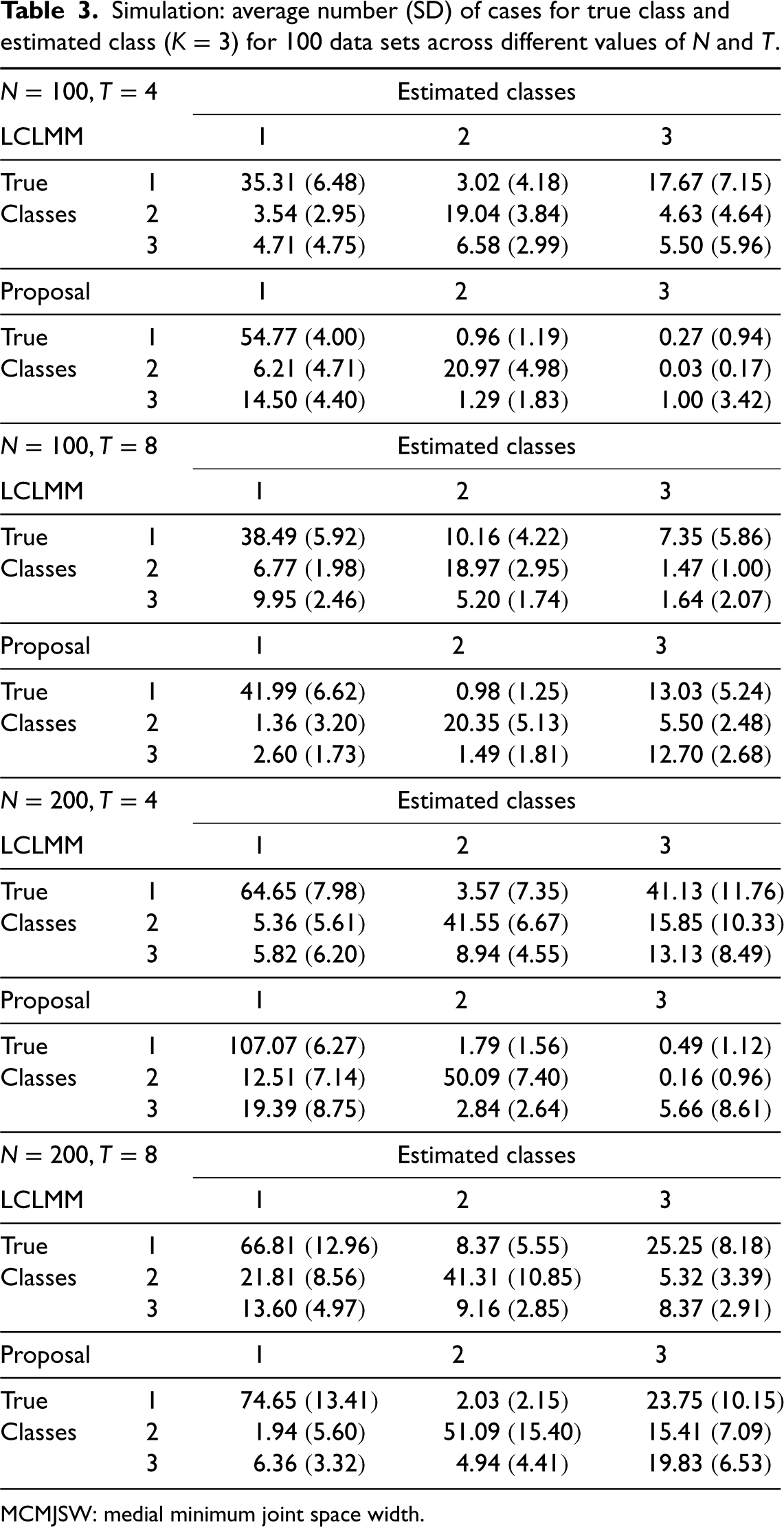
MCMJSW: medial minimum joint space width.
Table 4 shows the mean estimates and standard deviations of the estimated parameters, as well as the MAE comparing the true values with the estimates, for the case
Simulation: average (SD) and percentiles (2.5%,97.5%) of the median posterior estimates and MAE for 100 data sets with
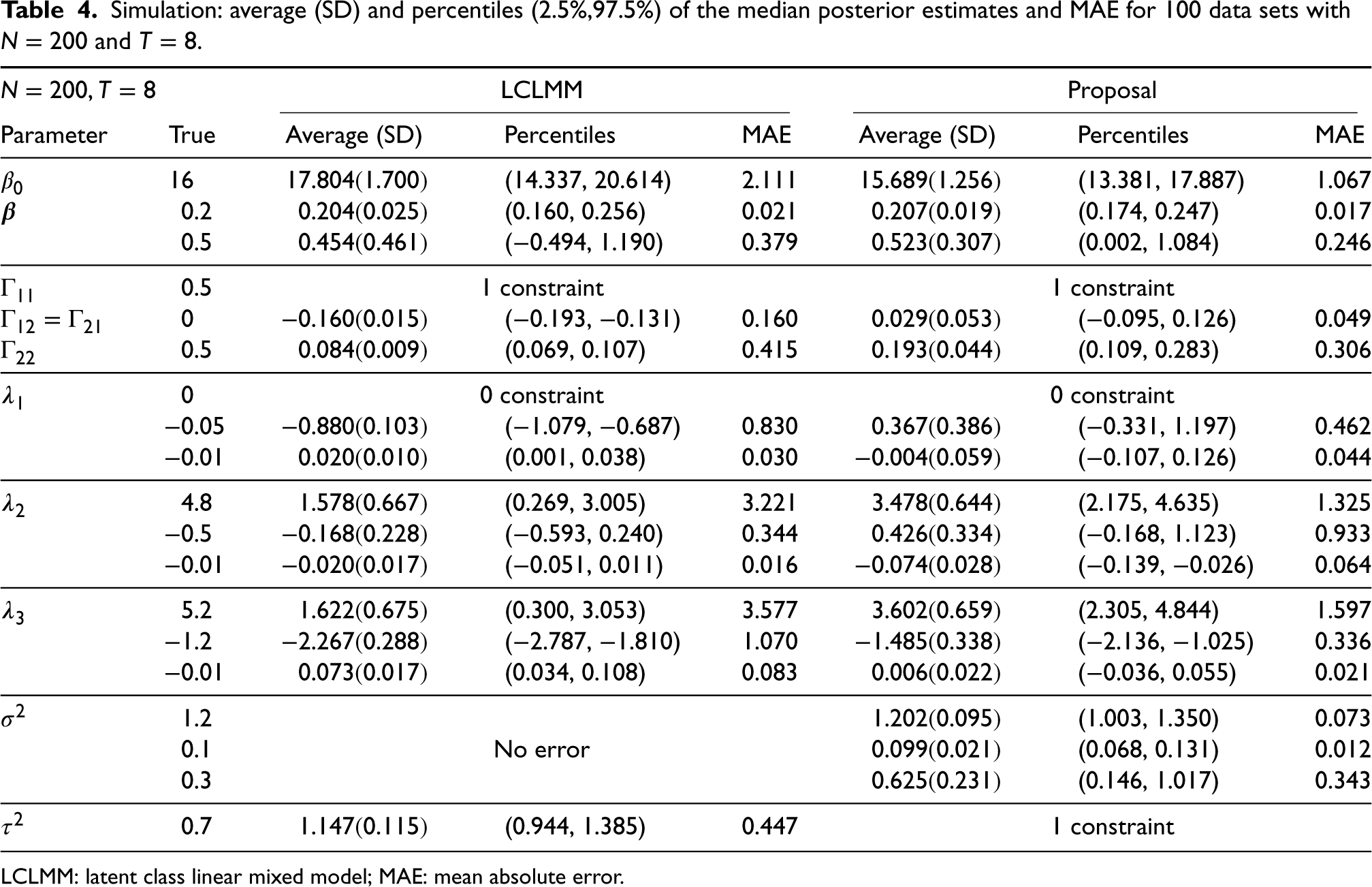
LCLMM: latent class linear mixed model; MAE: mean absolute error.
This section addresses the analysis of the motivating data, we fit the two the models outlined before, that is, the LCLMM without monotonic constraint and the proposed model including the constraint, to the OAI. Potential label switching was addressed as before using R package label.switching. After evaluating the available methods, we focus on the results from the first iterative version of equivalence classes representatives (ECR-1) algorithm, which uses the simulated allocation variables and is initialized by a pivot selected at random, as it has shown in this case to be less dependent on starting quantities as opposed to other approaches.23,19
Age, biological sex, BMI and WOMAC total score were deemed as overall fixed effects (
The identified classes for both models across each value of
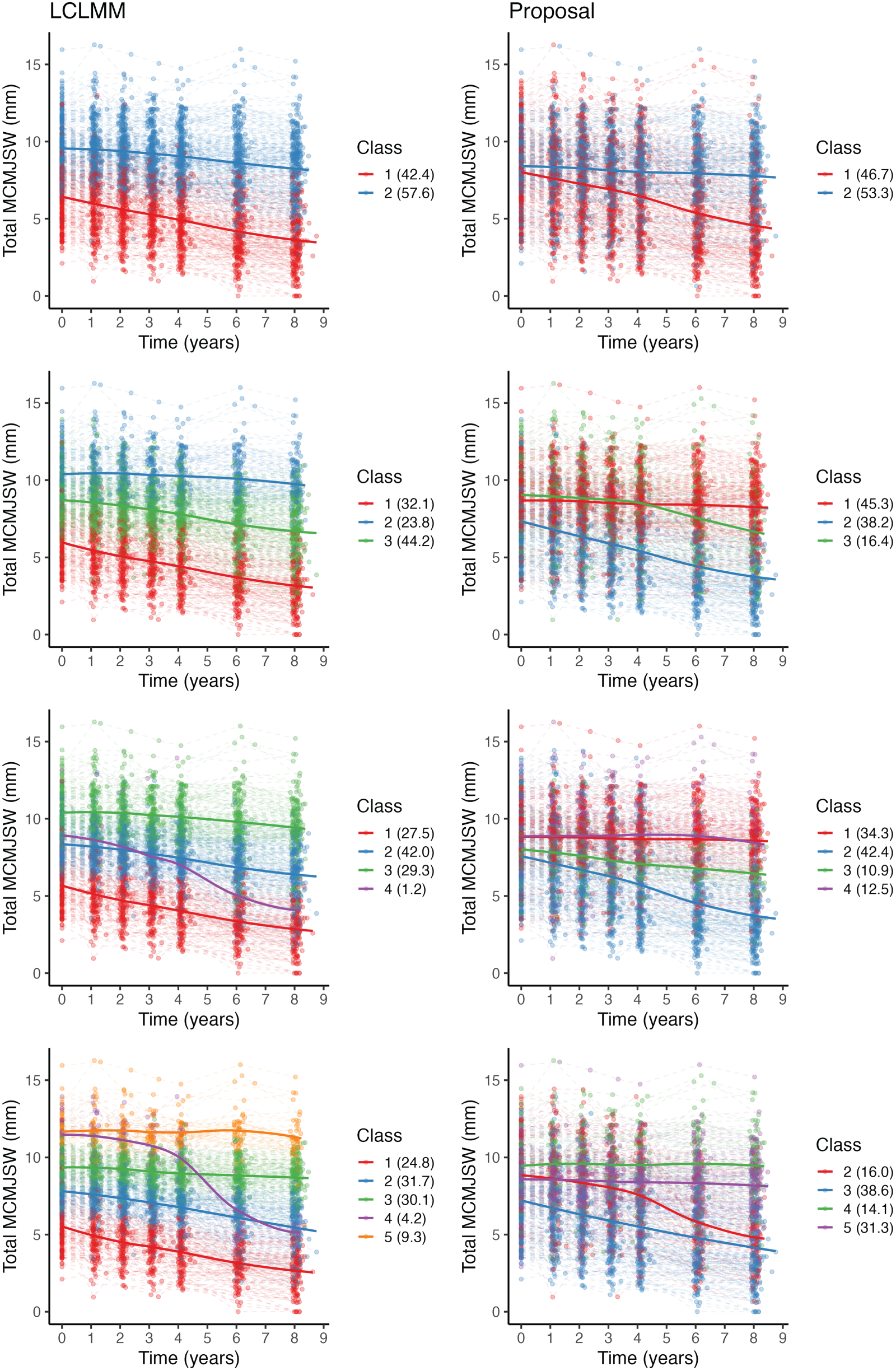
Spaghetti plots for the subjects’ trajectories (
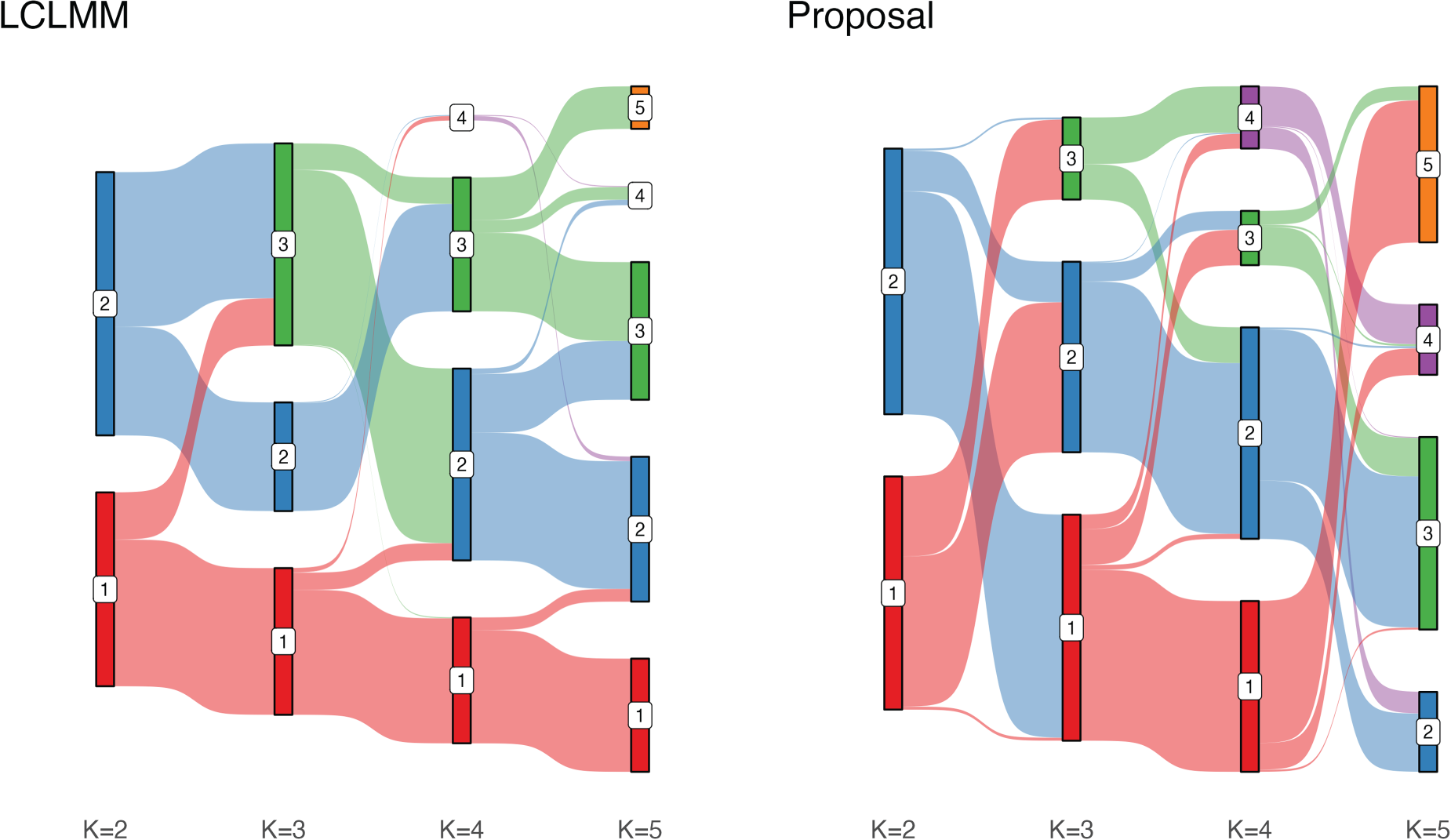
Sankey diagrams representing the classes splitting across values of
To further ascertain the most adequate number of classes, the WAIC, and LOO criteria were computed for each model using the loo package in R (Table 5). In theory, a model with the smallest information criterion value should be selected. Nonetheless, in practice, other factors such as parsimony and/or interpretability could also be factored in. Consequently, in the strict sense, among the evaluated number of classes
WAIC and LOO values for LCLMM (without monotonic constraint) and proposed (with monotonic constraint) models when the number of classes (
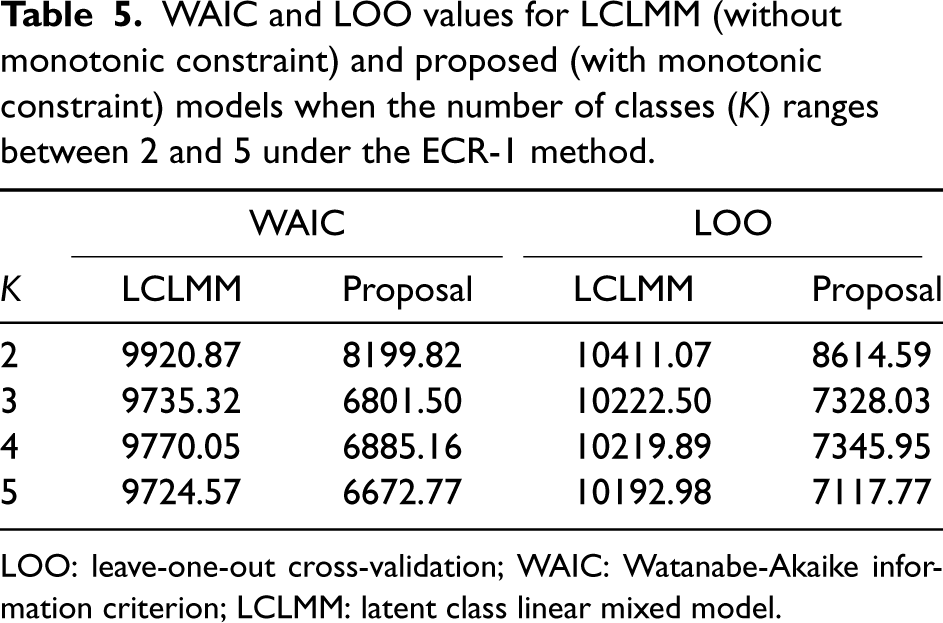
LOO: leave-one-out cross-validation; WAIC: Watanabe-Akaike information criterion; LCLMM: latent class linear mixed model.
Therefore, we can identify three distinct trajectory classes under the proposed model: (1) a stable disease, (2) an initially stable disease with a sudden drop midway and (3) a rapidly deteriorating disease. The parameter estimates for this model are displayed in Table 6. Based on the 95% credible intervals, all fixed effects in the proposed model excepting BMI display non-null effects, which contrasts with the LCLMM where all factors display non-null effects. However, all mean values are comparable between models. Meanwhile, the variance components for the random effects showcase that the random intercept and slope are roughly uncorrelated in both models. The main discrepancy between the models lies in the class-specific fixed effects as the LCLMM exhibits null effects across all class 1 terms (
Mean, standard deviation (SD) and 95% credible interval (CI) from the MCMC posterior samples for LCLMM (without monotonic constraint) and proposed (with monotonic constraint) when
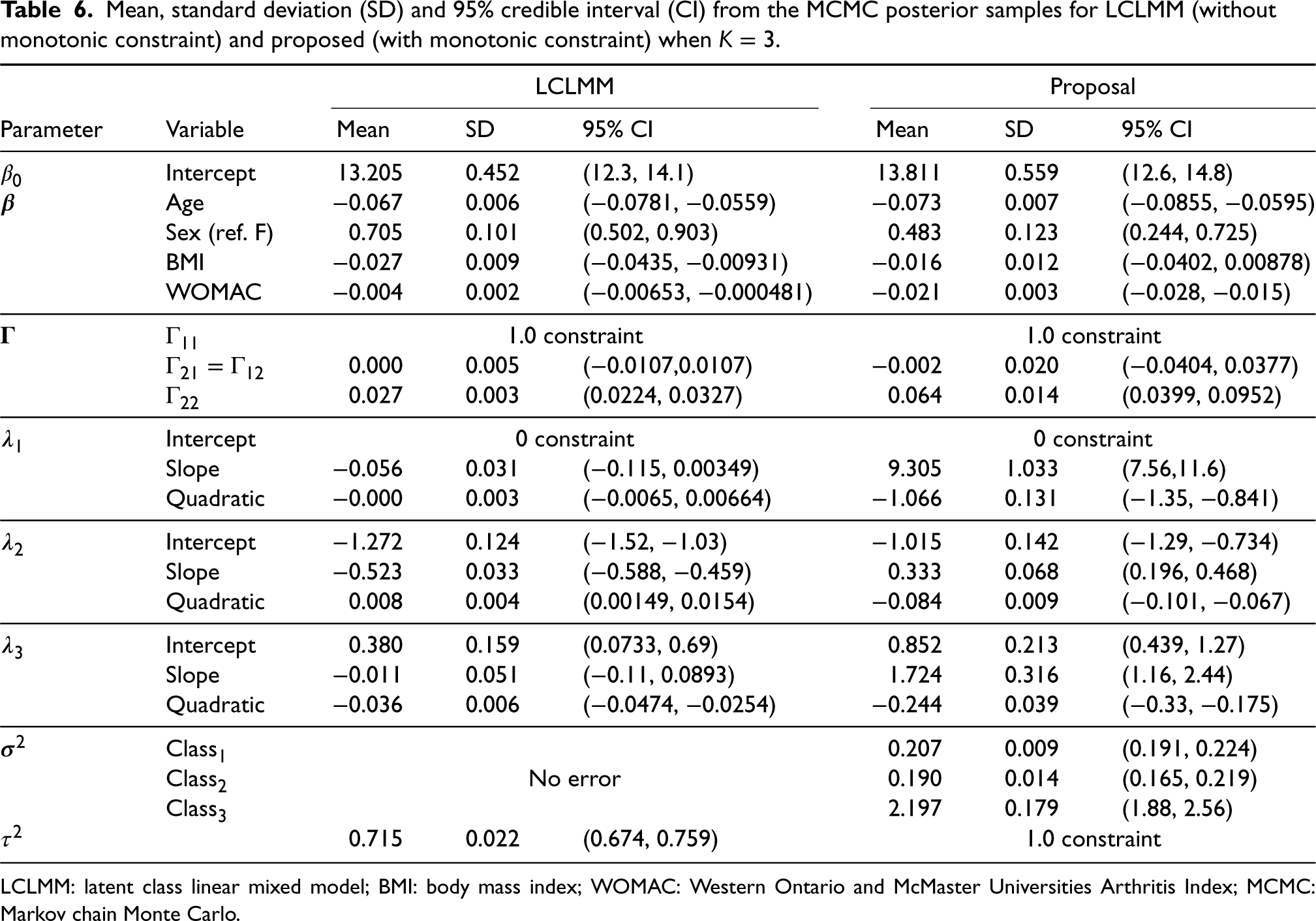
LCLMM: latent class linear mixed model; BMI: body mass index; WOMAC: Western Ontario and McMaster Universities Arthritis Index; MCMC: Markov chain Monte Carlo.
The proposed novel latent class linear mixed model accommodates both measurement error and monotonicity in a continuous process, which are challenging aspects in model-based clustering. In the motivating data, measurement error can be introduced due to variations in diagnostician, x-ray machine or knee positioning. Of note, the proposed model is not appropriate in all situations as JSW possesses a special characteristic that makes the truncation approach to tackle monotonicity adequate. In particular, JSW has a natural boundary at zero, that is, a negative JSW is physically impossible. Moreover, due to the chronic nature of OA, it is believed that the knee joint damage reflected by its spacing is irreversible (and thus follows a monotonic behaviour). Nonetheless, such a constraint can be used whenever there is a good rationale for sustained increasing/decreasing values in disease outcomes, which may occur in other chronicconditions.
We have shown in simulations that in the presence of an underlying monotonic process, the estimated parameters of the proposed model can be accurately recovered. Additionally, we note that increasing the sample size and number of timepoints improves the model selection when using WAIC and LOO. Moreover, the proposed Bayesian approach has appealing features regarding the uncertainty associated with the class probabilities, which can aid in assigning a particular subject into a potential treatment/intervention. For instance, low uncertainty in class may establish a plan of action whereas larger uncertainty may refrain practitioners from proposing a more definite intervention (or lack thereof) and suggest closer monitoring instead. Lastly, from the motivating data, it becomes apparent that introducing a monotonic constraint aids in identifying the number of classes in the model. Indeed, such constraint incorporates additional information on the response behaviour that ultimately support model evaluation.
Despite the aforementioned advantages, there are remaining challenges to be addressed. First, latent class models usually suffer from label switching due to the likelihood being maximized whether the classes were properly labelled or not. We were able to obtain a stable result after label switching, which is achieved through a post-processing of the class labels. We decided to use this post-process given that strategies that only introduced parameter constraints led to unsatisfactory chain mixing and lack of convergence. However, it is worth noting that ‘generic identifiability’ issues may remain due to the nature of mixture modelling as previously reviewed.
31
Even though we focused on the ECR-1 algorithm in this work, discerning the most adequate label switching algorithm in more general settings introducing monotonic constraints deserves further investigation. Lastly, the computational time of model remains high especially for increasing number of classes (
The proposed model can be extended in several directions. First, as noted by one of the reviewers, the variance of latent variables
In the motivating data, we focused on a subset of subjects with complete information. However, missing data commonly occur in longitudinal studies. In principle, the proposed LCLMM is robust to missing (completely) at random mechanisms. However, different considerations must be made under missing not at random (MNAR) mechanisms, which may influence the class probabilities.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231225963 - Supplemental material for A latent class linear mixed model for monotonic continuous processes measured with error
Supplemental material, sj-pdf-1-smm-10.1177_09622802231225963 for A latent class linear mixed model for monotonic continuous processes measured with error by Osvaldo Espin-Garcia, Lizbeth Naranjo and Ruth Fuentes-García in Statistical Methods in Medical Research
Footnotes
Acknowledgements
Data and/or research tools used in the preparation of this manuscript were obtained and analyzed from the controlled access datasets distributed from the Osteoarthritis Initiative (OAI), a data repository housed within the NIMH Data Archive (NDA). OAI is a collaborative informatics system created by the National Institute of Mental Health and the National Institute of Arthritis, Musculoskeletal and Skin Diseases (NIAMS) to provide a worldwide resource to quicken the pace of biomarker identification, scientific investigation and OA drug development. This research was enabled in part by support provided by the SciNet and SHARCNET HPC Consortia and the Digital Research Alliance of Canada (![]() ). Computations were performed on the Niagara and Graham supercomputers. SciNet is funded by Innovation, Science and Economic Development Canada; the Digital Research Alliance of Canada; the Ontario Research Fund: Research Excellence; and the University of Toronto. The authors thank the two anonymous reviewers for their comments and suggestions that helped enriching this work.
). Computations were performed on the Niagara and Graham supercomputers. SciNet is funded by Innovation, Science and Economic Development Canada; the Digital Research Alliance of Canada; the Ontario Research Fund: Research Excellence; and the University of Toronto. The authors thank the two anonymous reviewers for their comments and suggestions that helped enriching this work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Lizbeth Naranjo and Ruth Fuentes-García have been supported by UNAM-DGAPA-PAPIIT, Mexico (Project IN100823). Lizbeth Naranjo has been supported by UNAM-DGAPA-PASPA scholarship.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.