
Abstract
Standard survival models such as the proportional hazards model contain a single regression component, corresponding to the scale of the hazard. In contrast, we consider the so-called “multi-parameter regression” approach whereby covariates enter the model through multiple distributional parameters simultaneously, for example, scale and shape parameters. This approach has previously been shown to achieve flexibility with relatively low model complexity. However, beyond a stepwise type selection method, variable selection methods are underdeveloped in the multi-parameter regression survival modeling setting. Therefore, we propose penalized multi-parameter regression estimation procedures using the following penalties: least absolute shrinkage and selection operator, smoothly clipped absolute deviation, and adaptive least absolute shrinkage and selection operator. We compare these procedures using extensive simulation studies and an application to data from an observational lung cancer study; the Weibull multi-parameter regression model is used throughout as a running example.
Keywords
Introduction
The most popular regression model for censored survival data is Cox’s proportional hazards (PH) model,
1
with a hazard function given by
Rather than treating the hazard shape as a nuisance, we make use of a fully parametric hazard function characterized by multiple distributional parameters. In the two-parameter case that we focus on in this article, the hazard has the form
As a motivating example, Figure 1 displays data from a lung cancer study used in Burke and MacKenzie, 4 where it is clear that the MPR model has the flexibility to adapt to the different distributional shapes evident across the treatment groups (see Section 5 for a multi-factor analysis of this dataset). Indeed, Burke and MacKenzie 4 explored the general use of MPR models in the survival context, demonstrating the usefulness of jointly modeling the scale and shape of the Weibull distribution. Earlier examples of MPR models in survival analysis include a location-dispersion extension of the Weibull accelerated failure time (AFT) model, 9 and first-hitting-time models with covariate-dependent drift and initial-state parameters.10,11 More recently, MPR survival models have been developed further through the incorporation of frailty effects in interval-censored data, 12 the use of the adapted power generalized Weibull model, 13 which is more general than the Weibull and has also been extended to handle bivariate data, 14 and a semi-parametric extension of the AFT model. 15
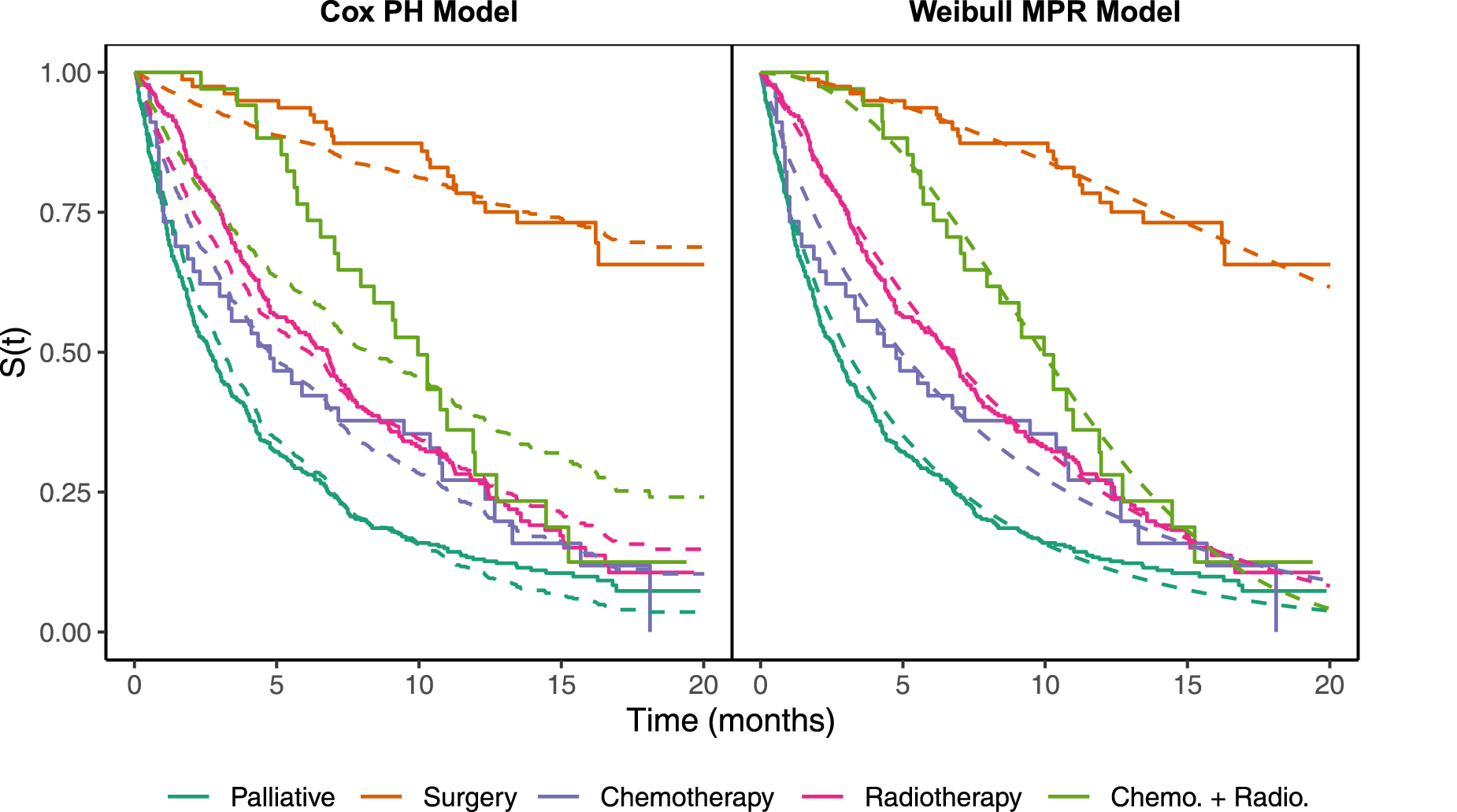
Kaplan–Meier curves (solid) for different treatment groups with model-based curves overlaid (dashed) for the Cox PH model (left) and Weibull MPR model (right). PH: proportional hazards; MPR: multi-parameter regression.
Regardless of the modeling approach taken (MPR or otherwise), a commonly encountered challenge in statistical applications is the selection of a subset of explanatory variables of interest,16,17 that is, the elimination of unimportant variables to yield simpler, more explainable models. However, the literature in this area is somewhat lacking for MPR survival models beyond a stepwise procedure developed by Burke and MacKenzie.
4
Due to the inherent discreteness of stepwise procedures (i.e., covariates are either “in” or “out”), they may be unstable in terms of the selected model.
18
Furthermore, they can be computationally demanding since, with
To the best of our knowledge, the use of the aforementioned penalized procedures for MPR survival models is lacking. Given that classical statistical models contain only one regression component, it is not unexpected that the penalized estimation literature is focused around this setting. 22 An exception is the work of Groll et al. 23 who develop LASSO-type penalization for generalized additive models for location, scale and shape (GAMLSS) albeit not in a survival context. Therefore, the aim of this article is to develop such procedures for MPR survival models. More specifically, we use the Weibull MPR model as an example, develop gradient-based estimation procedures for LASSO, SCAD, and ALASSO by using a smooth approximation to the absolute value function,24–26 and investigate the need for a separate tuning parameter for each regression component. Tuning parameter selection is carried out using a Bayesian information criterion (BIC) function, where, due to the intensivity of grid search when there are multiple regression components (as noted in the GAMLSS context 23 ), we make use of a differential evolution “global” optimization procedure27,28 to explore the tuning parameter space.
The remainder of this article is organized as follows. In Section 2, we present the Weibull MPR model, the penalty functions, and the penalized likelihood estimation procedure. Section 3 describes the model estimation and inference procedure along with the algorithm for selecting tuning parameters. Simulation studies are provided in Section 4 where we evaluate the performance of the proposed methods, and these methods are then applied to data from an observational study of patients with lung cancer in Section 5. We conclude with some final remarks in Section 6.
Weibull MPR model
Although the variable selection methods we consider in this article can be applied to any parametric MPR model, it is helpful to focus on a specific example. We, therefore, consider the Weibull MPR model since the Weibull distribution is one of the most popular parametric survival distributions. In this case, the hazard function for survival time
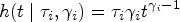

Without the loss of generality, we consider the ratio of hazards under this model for individuals
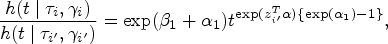
Parameter estimation within the unpenalized MPR model can be carried out in a standard fashion using maximum likelihood. First, let
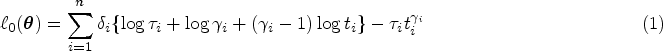
Penalized MPR estimation can be developed on the basis of maximizing a penalized log-likelihood given by
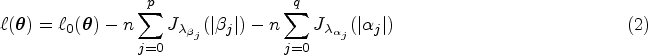
Although we have defined single penalty,
single adaptive penalty,
separate non-adaptive penalties,
separate adaptive penalties,
(i) and (ii) are standard approaches where a single penalty,
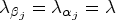
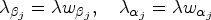


For the purpose of this article, we consider the most commonly used penalties, namely the LASSO,
19
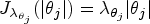
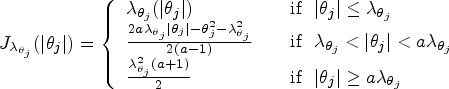
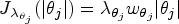
Model fitting
We define

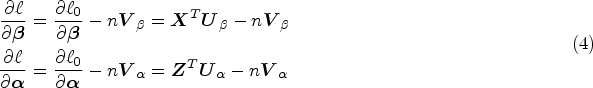
Note however, the presence of the absolute value function renders the penalty functions non-differentiable at zero. Various algorithms have been developed to overcome this issue including quadratic programing,
19
least-angle regression (LARS),
34
co-ordinate descent,
35
and the local quadratic approximation.
20
In this article, we take a similar approach to that of Hunter and Li,
24
Oelker and Tutz,
25
and Lloyd-Jones et al.,
26
and use an extension of the absolute value function given by
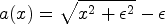
We denote by The BIC function evaluated at different tuning parameter values for the Weibull MPR model with the one tuning parameter LASSO penalty for the lung cancer data analysed in Section 5. The equivalent plot for the two tuning parameter LASSO penalties can be found in the Supplemental Material. BIC: Bayesian information criterion; MPR: multi-parameter regression;LASSO: least absolute shrinkage and selection operator.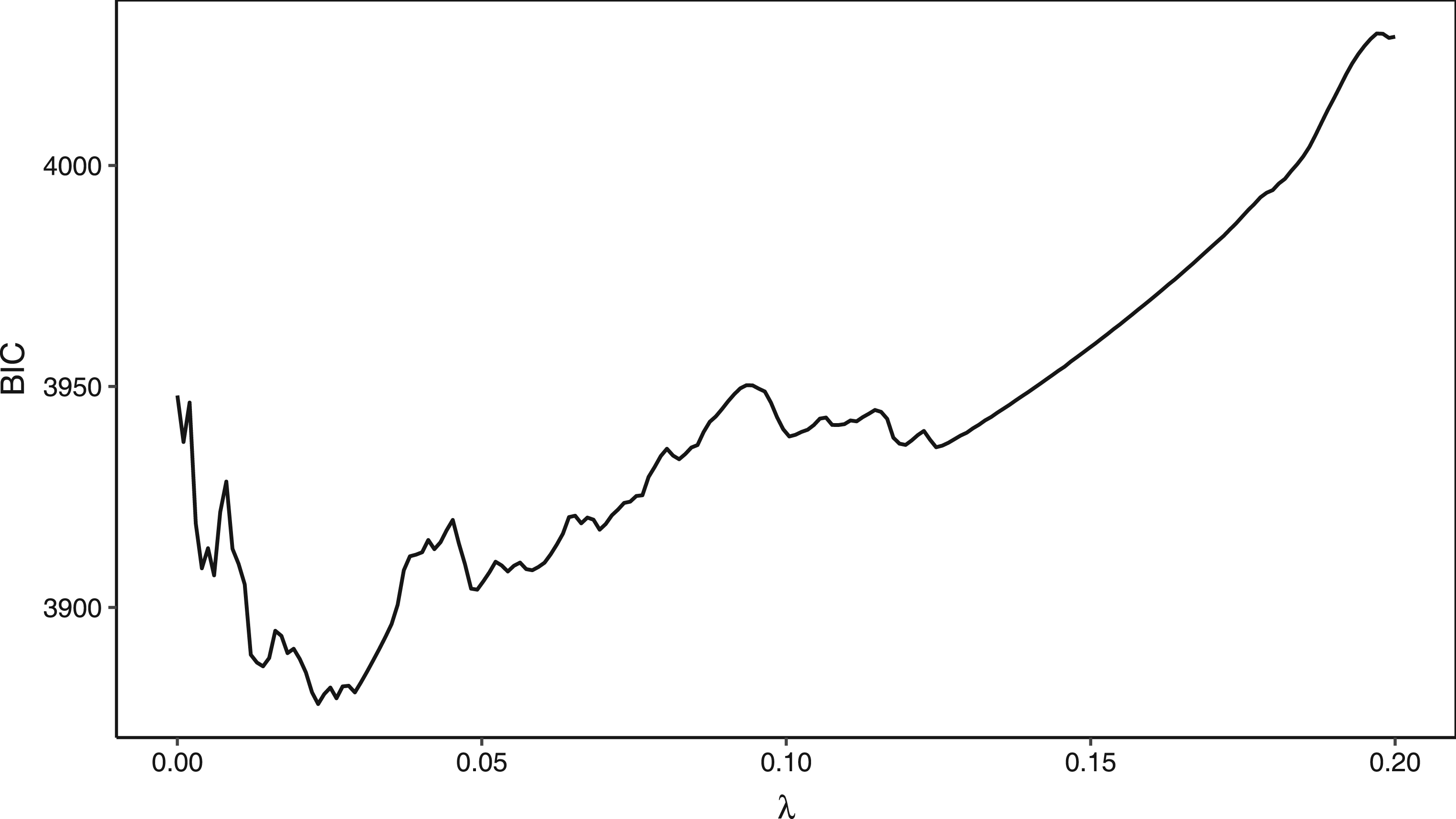
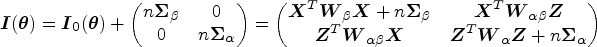
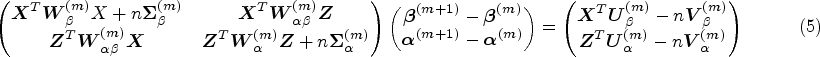

The selection of the optimal tuning parameter(s) is typically done through the use of data-driven criteria such as generalized cross-validation (GCV), Akaike information criterion (AIC), or BIC. GCV and the AIC are known to be less efficient and selection inconsistent as model selection criteria.39–41 Wang et al.
42
provided a formal proof that the shrinkage or tuning parameter selected using GCV may not be able to identify the true model consistently for the SCAD estimator in linear models and partially linear models. Instead, they suggest using the BIC and prove its model selection consistency property. A similar conclusion has been reached by Wang and Leng
43
for the ALASSO. Hence, due to its widely reported superior empirical performance in variable selection, we use a BIC-type criterion to determine the values of the tuning parameter(s), where


The simplest method to solve this optimization problem is grid search. While it is straightforward to implement, grid search is known to suffer from the curse of dimensionality, that is, the number of grid points grows exponentially with the dimension. Furthermore, if the grid is too coarse, the minimum may be overlooked. This is especially true in the case of a multi-modal function, such as the BIC objective function as shown in Figure 2. This multi-modality arises in the BIC due to the tradeoff between complexity (
The degrees of freedom, likelihood function, and BIC value evaluated at different tuning parameter values for the model with the LASSO penalty (one tuning parameter case) for the lung cancer dataset analysed in Section 5.
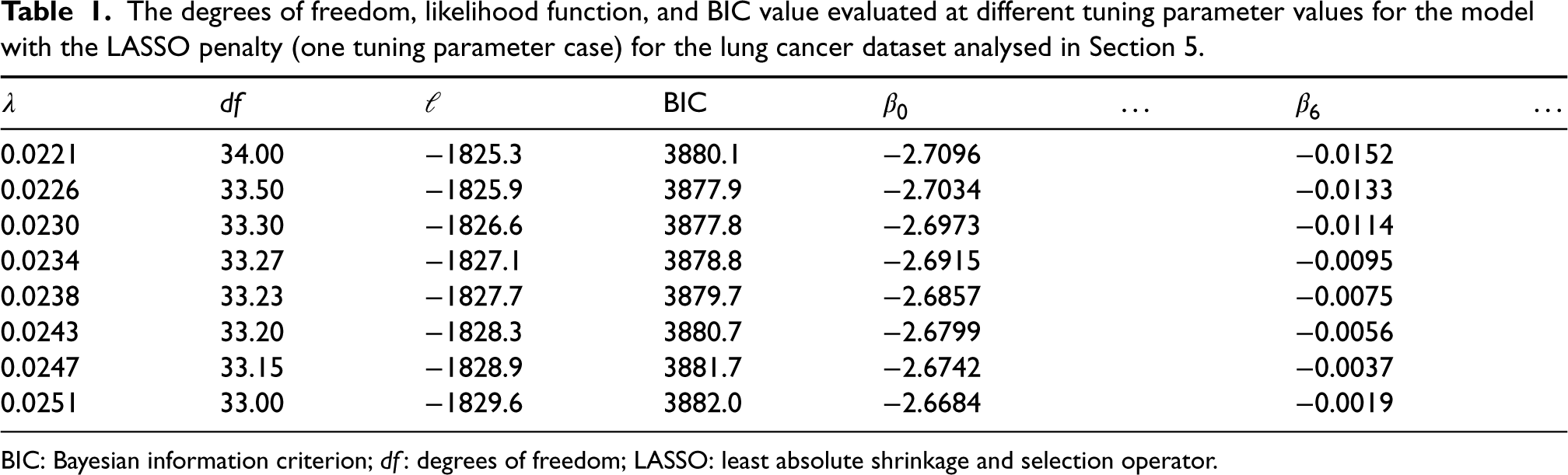
BIC: Bayesian information criterion; df: degrees of freedom; LASSO: least absolute shrinkage and selection operator.
Although the BIC’s consistency property has led to its extensive use in tuning-parameter selection, we suggest that such a multi-modal function would be better optimized by a “global” optimizer (rather than grid search as is typically used in the literature). In an empirical comparison of a wide variety of (stochastic and deterministic) algorithms for continuous global optimization, Mullen
28
found
The variable selection algorithm described above is summarized in the following points:
Initialization. Set
Optimization.
Outer. Minimize Inner. For a given value of Output. The estimates
Setup
The performance of the proposed variable selection methods is evaluated through simulation studies. The failure time is simulated from a Weibull MPR model with
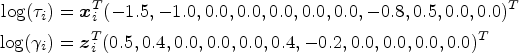
Simulation results
The variable selection and estimation procedures described in Sections 2 and 3 are applied to the simulated data and the results are summarized and discussed here. A number of metrics are used to evaluate the performance of the variable selection procedures, namely the average number of true zero coefficients correctly set to zero (C), the average number of true non-zero coefficients incorrectly set to zero (IC), and the probability of choosing the true model (PT); for the oracle model, C = 7 and IC = 0. As a measure of prediction accuracy, we also consider the mean squared error (MSE), given by
Selection results: Variable selection metrics averaged over 1000 simulation replicates.
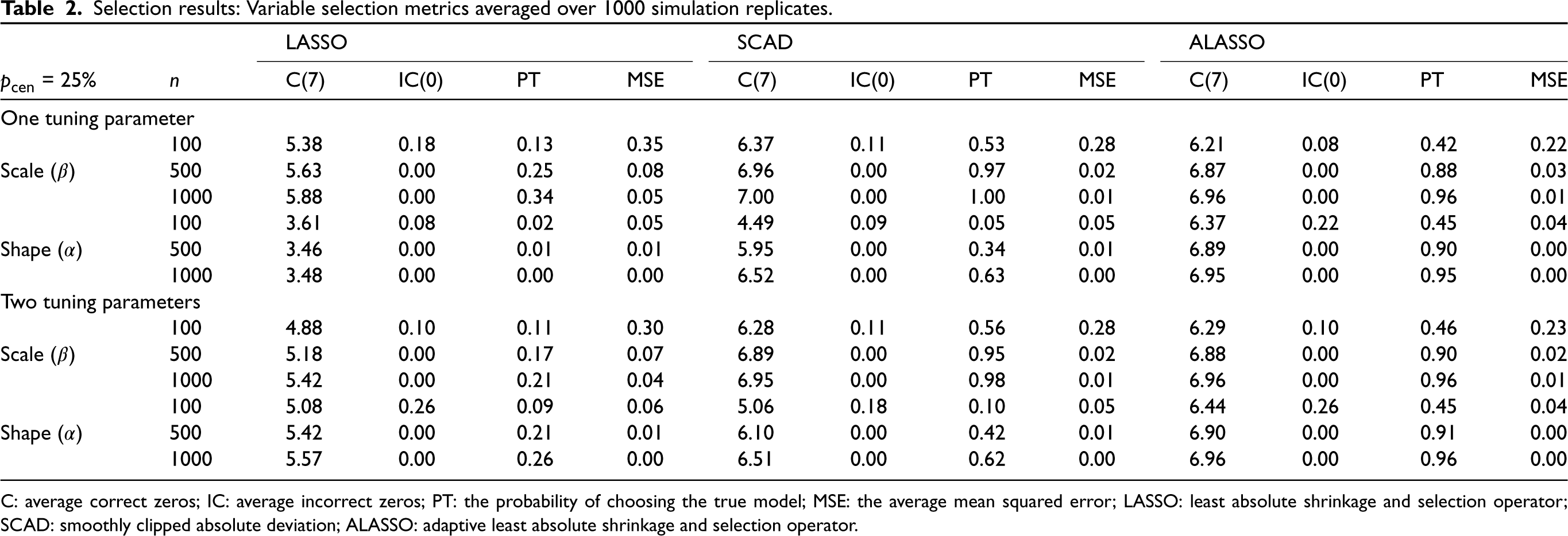
Selection results: Variable selection metrics averaged over 1000 simulation replicates.
C: average correct zeros; IC: average incorrect zeros; PT: the probability of choosing the true model; MSE: the average mean squared error; LASSO: least absolute shrinkage and selection operator;SCAD: smoothly clipped absolute deviation; ALASSO: adaptive least absolute shrinkage and selection operator.
As the sample size increases, we see an improvement across all four metrics, for both the shape and the scale parameters and across all penalties. However, it is evident that the LASSO penalty does not set enough covariates equal to zero (i.e., it selects an overly complex model). While the LASSO with one tuning parameter outperforms the LASSO with two tuning parameters in the scale component, it has very poor performance in the shape component (and we can also confirm that the BIC values are much higher). In any case, the LASSO over-selects irrespective of whether it has one or two tuning parameters, leading to quite low PT values. SCAD performs better than the LASSO, but still over-selects somewhat in the shape component. The best overall performance comes from the ALASSO penalty, which, for the largest sample size, selects the true scale and shape covariates more than 90% of the time. Interestingly, the ALASSO performs well even with a single tuning parameter (but it does improve with two tuning parameters). In terms of the computation time, SCAD has been found to be slower than the LASSO and ALASSO penalties. Furthermore, the computation times for the cases with two tuning parameters are two to three times longer than those with one tuning parameter.
Figure 3 provides the boxplots of the C and MSE performance metrics over simulation replicates to account for variability in the results (for the penalties with two tuning parameters). Moreover, we additionally include the results for the full unpenalized and true oracle models, respectively, to act as worst-case and best-case benchmarks. It is clear that the C metric tends to be lower in the LASSO than SCAD and the ALASSO. The latter two are comparable in the scale component but the ALASSO outperforms SCAD in the shape, achieving the oracle value of C
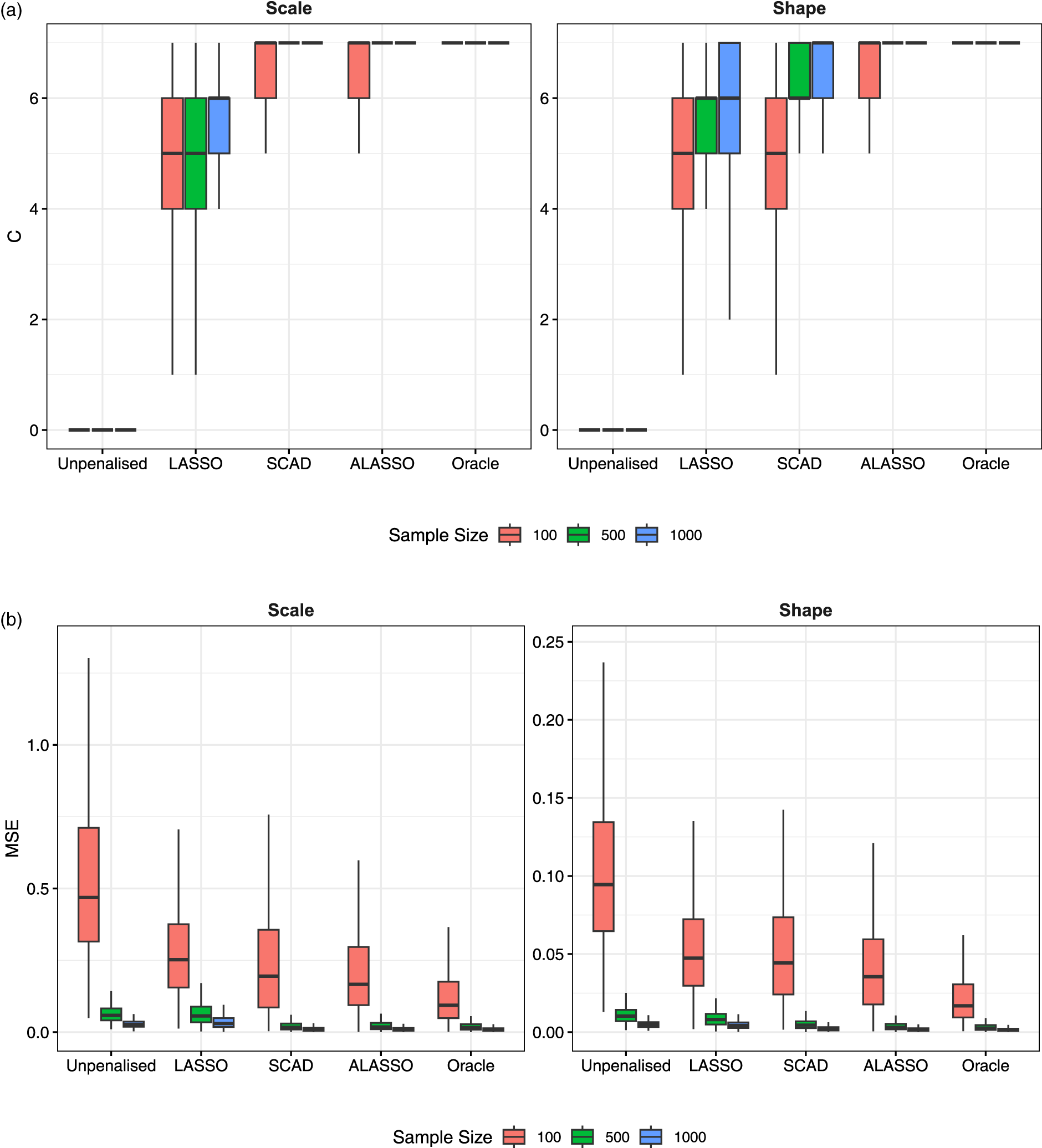
(a) True zero coefficients correctly set to zero (C) and (b) mean squared error (MSE) by model, distributional parameter and sample size across 1000 replicates for the models with two tuning parameters.
In addition to variable selection performance, we also consider parameter inference in terms of estimation bias, accuracy of the estimated standard error (SEE) computed using the sandwich formula, (6) compared to the true standard error (SE) compuated as the standard deviation over simulation replicates, and the empirical coverage probability (CP) of a nominal 95% confidence interval. The results for the ALASSO penalty (for the 25% censoring level) are presented in Table 3. Overall, we can see that the estimation bias and SEs reduce with the sample size and the CP values get closer to the nominal 95% level. However, at
Inferential results: estimates, standard errors, and confidence intervals.
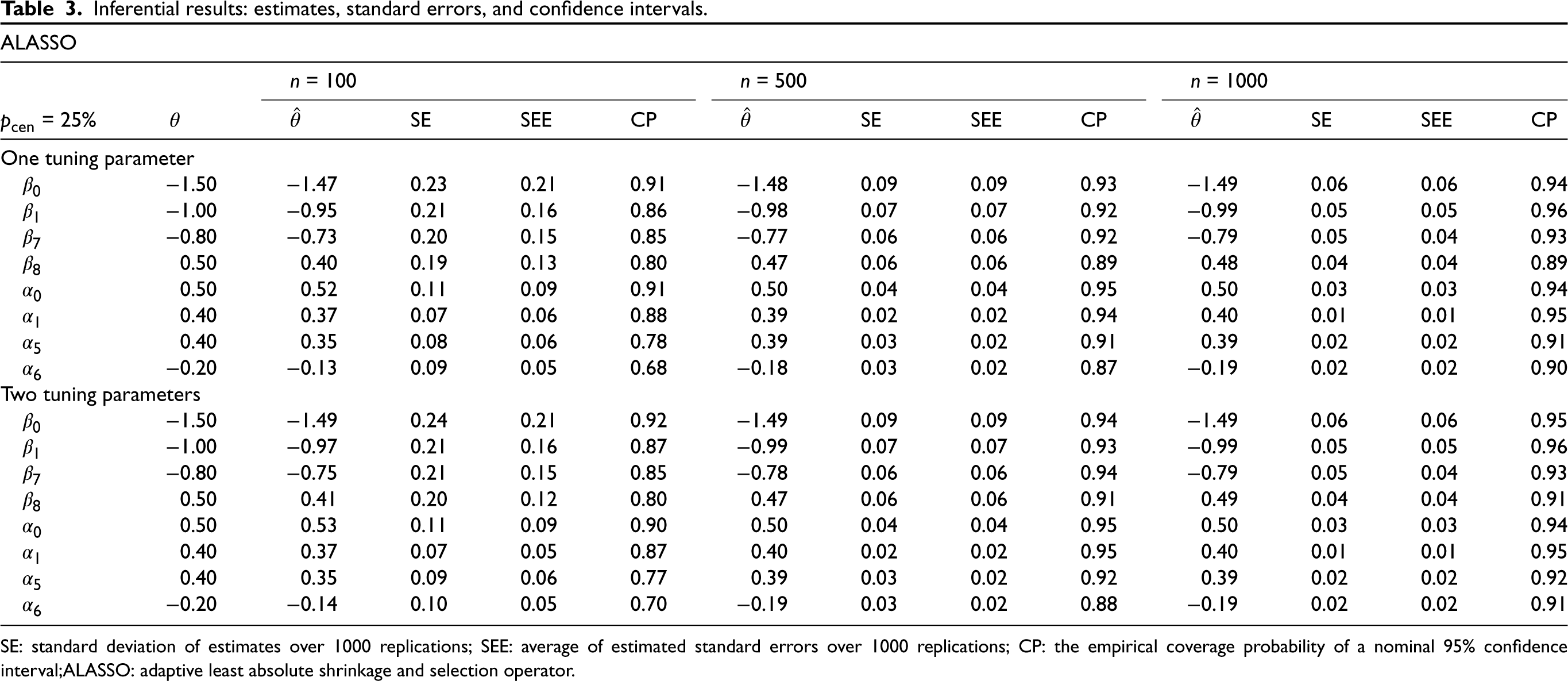
SE: standard deviation of estimates over 1000 replications; SEE: average of estimated standard errors over 1000 replications; CP: the empirical coverage probability of a nominal 95% confidence interval;ALASSO: adaptive least absolute shrinkage and selection operator.
Figure 4 displays the boxplots of estimates of
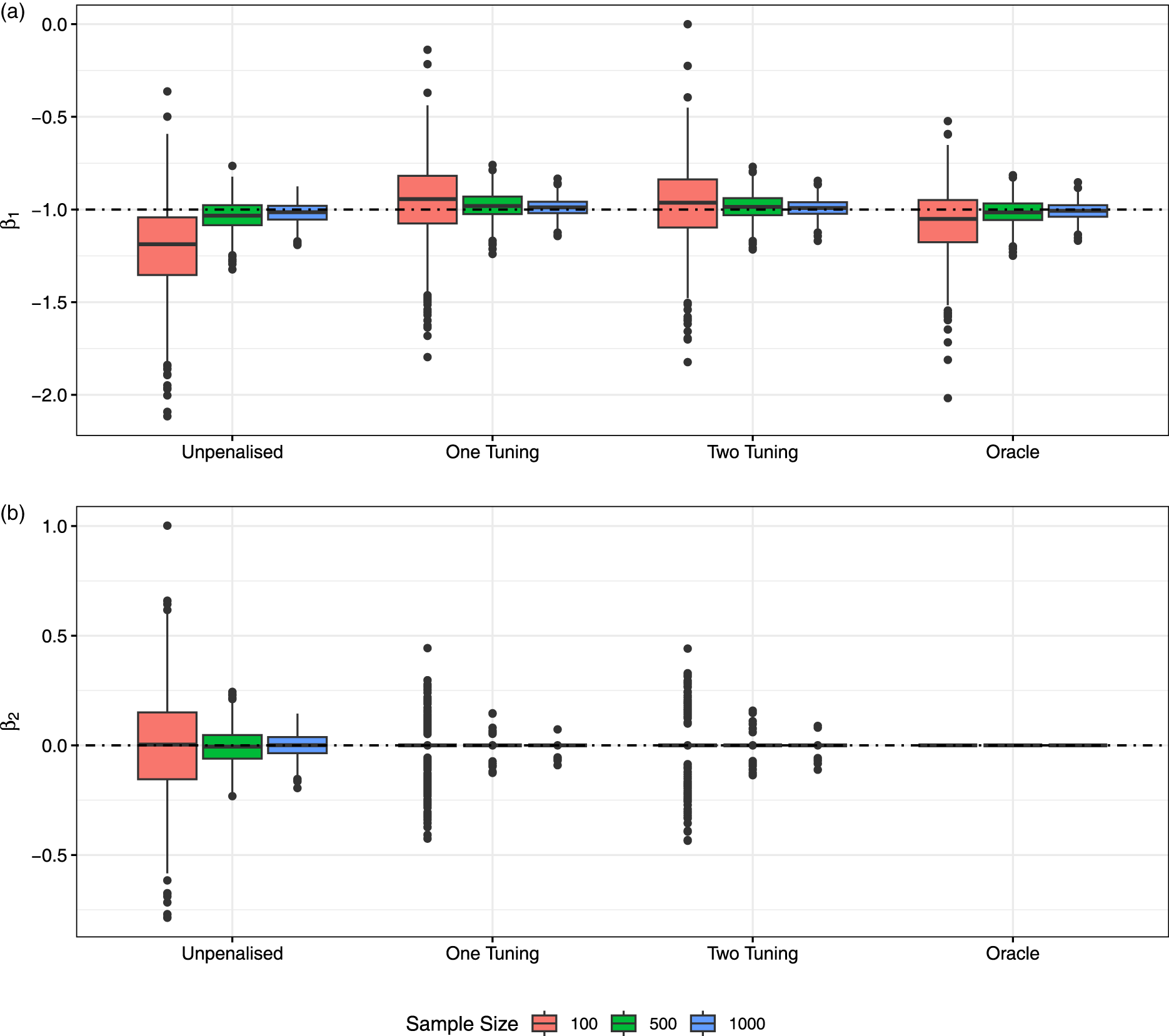
Coefficient estimates from the models with adaptive least absolute shrinkage and selection operator (ALASSO) penalties by sample size and across the 1000 replicates: (a)
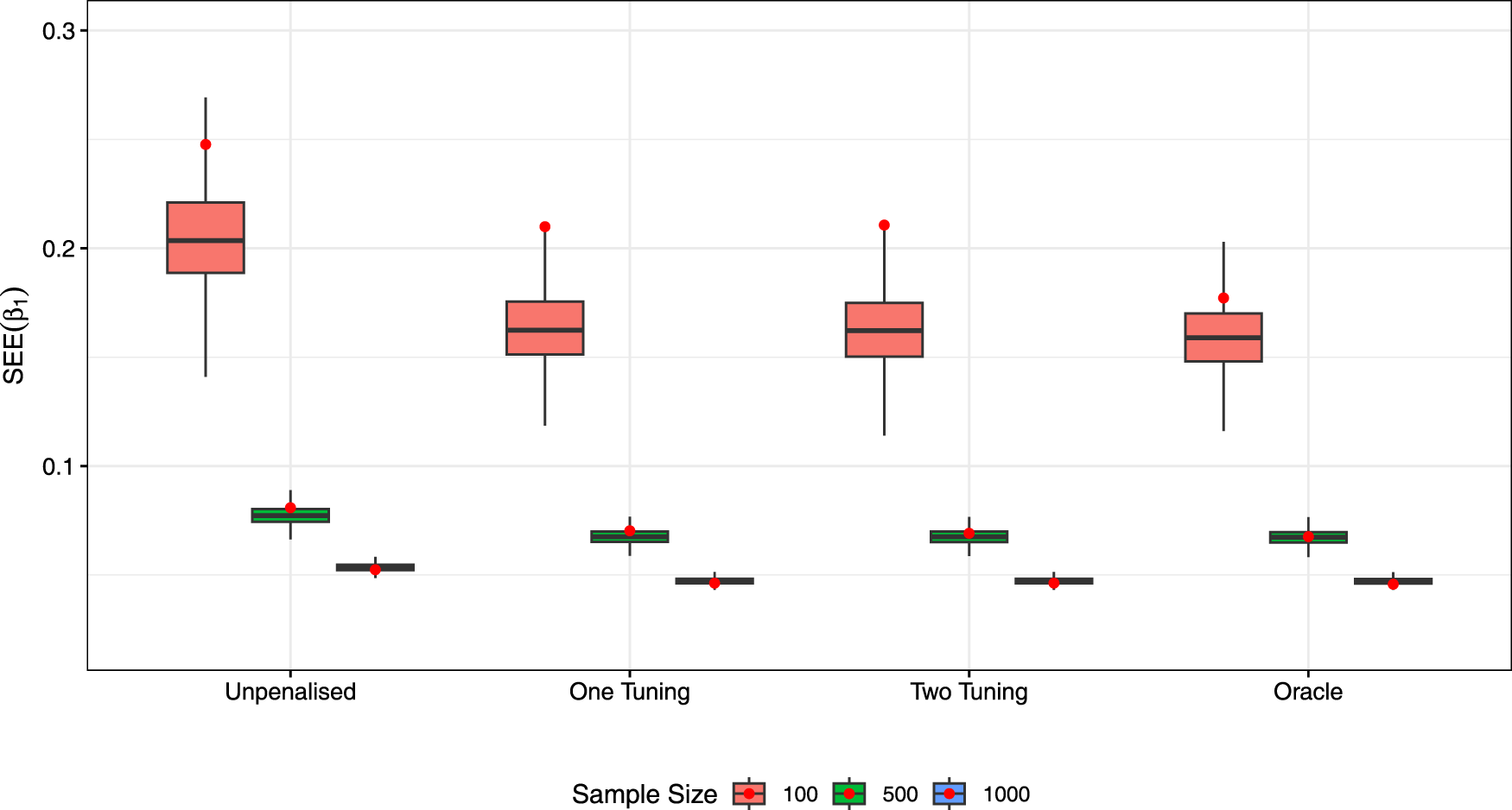
Boxplots of SEEs for
We have also tested all approaches at the higher censoring proportion of 50% (see Supplemental Material), where performance decreases across all metrics (e.g., reduced selection performance, increased bias, and variability), especially at smaller sample sizes. However, at
Here we consider data from an observational lung cancer study which was collected by Wilkinson
49
(see also Burke and MacKenzie
4
). This study includes all individuals, of all ages, diagnosed with lung cancer in Northern Ireland during the one-year period 1 October 1991 to 30 September 1992. Only cases of primary lung cancer were included. The date of diagnosis was taken to be the time origin for an individual and the end point was the earlier of the occurrence of death or the study end date, which was on 30 May 1993. Individuals who were still alive on the study end date were taken to have censored survival times. Individuals who died from another cause or who dropped out of the study were also censored. The final dataset included 855 patients, of which there were 673 deaths and 182 censored times. Besides the survival time and the censoring indicator, a number of other variables were recorded for each of the patients enrolled in the study (reference categories are listed first): age group (< 40-, 50-, 60-, 70-, and > 80), sex (female and male), treatment group (palliative, surgery, chemotherapy, radiotherapy, chemotherapy, and radiotherapy), WHO status (normal activity, light work, unable to work,
Adequacy of Weibull
Before considering covariates and variable selection, we first carry out an initial check that a baseline Weibull distribution is appropriate for the lung cancer data. The cumulative hazard function for the Weibull model is given by
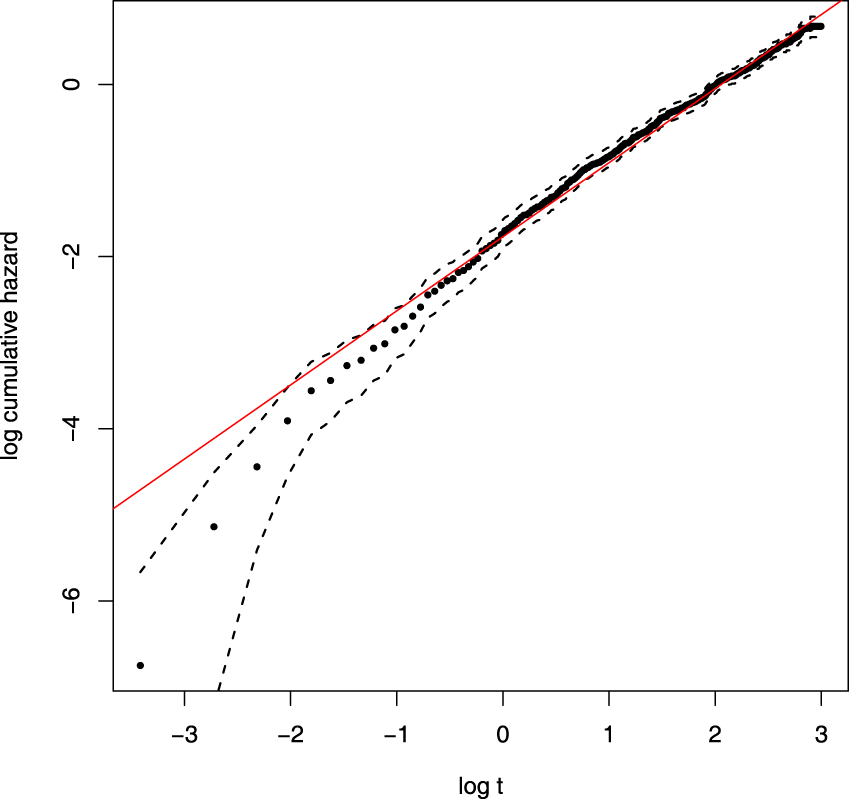
Weibull model check. Here
The variable selection results for the different penalties are summarized in Table 4. In line with the results of the simulation study, the LASSO penalty selects the most complex model and the ALASSO penalty selects the least complex. Both ALASSO penalties (one and two tuning parameter cases) are in agreement on the non-importance of sex and smoking status, and although age group is selected in the scale in the case with one tuning parameter, it is not significant. Interestingly, the two tuning parameter ALASSO selects the same set of covariates as identified by Burke and MacKenzie 4 using a BIC stepwise procedure (albeit they additionally selected treatment in the shape). We also see that, in the two tuning parameters cases, the scale tuning parameter is smaller than that of the one tuning parameter case, while the shape tuning parameter is larger. This suggests that the single penalty over-penalizes the scale coefficients and under-penalizes the shape; this is also evident from the scale and shape degrees of freedom. Interestingly, the one tuning parameter ALASSO converges in less than half the time of the two tuning parameter ALASSO, and achieves similar results. We expect this based on our simulation studies, and also expect the results of the two tuning parameter case to be marginally better (albeit it takes longer to converge).
Summary of penalized models (lung cancer data).
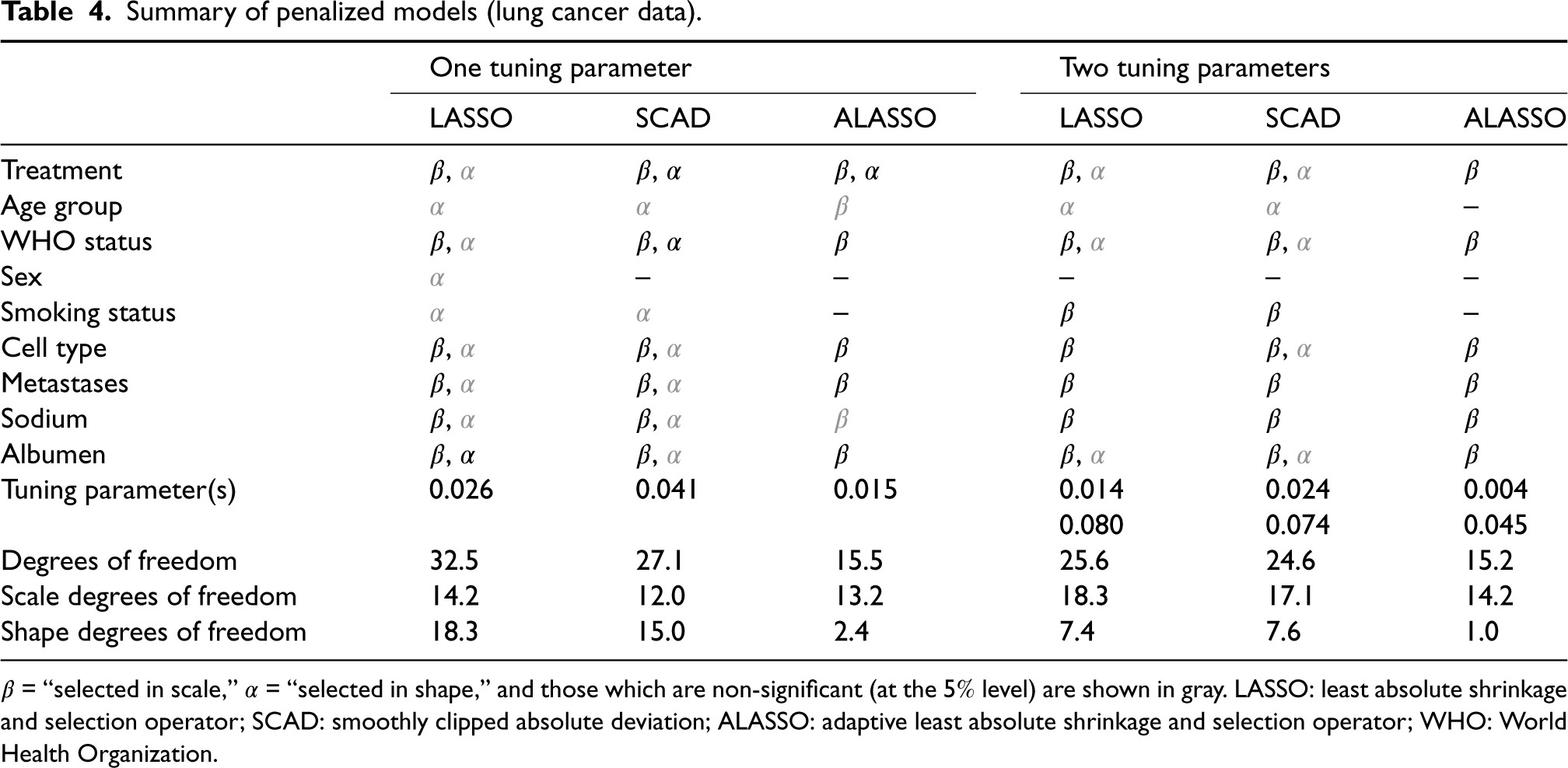
Summary of penalized models (lung cancer data).
Table 5 displays the estimated coefficients for both ALASSO penalties along with the unpenalized coefficients (we focus on the ALASSO due to its superior performance in our simulation studies, but similar tables for LASSO and SCAD can be found in the Supplemental Material). Note that the scale coefficients characterize the overall scale of the hazard (a positive value indicates an increase relative to the reference category), while the shape coefficients characterize its time evolution (a positive value indicates a hazard which increases over time relative to the reference category). We clearly see the similarity of the coefficient values for both the one and two tuning parameter ALASSO penalties, and, furthermore, that the selected variables are broadly in line with those which are statistically significant in the unpenalized model. Focusing on the results of the two tuning parameter case we find that all treatments (apart from chemotherapy) have a negative scale coefficient suggesting that treatment reduces hazard (relative to palliative care); however, worse WHO status, small cancer cell type, presence of metasteses, and reduced sodium and albumen levels increase the hazard; lastly, sex, age group, and smoking status have no significant effect on the hazard. Since no variable appears in the shape component (i.e. all shape coefficients are set to zero), the selected model is a PH model, and exponentiating the scale coefficients yields the hazard ratios, for example, the surgery hazard ratio is
Coefficients estimates and standard errors for the ALASSO penalties (lung cancer data).
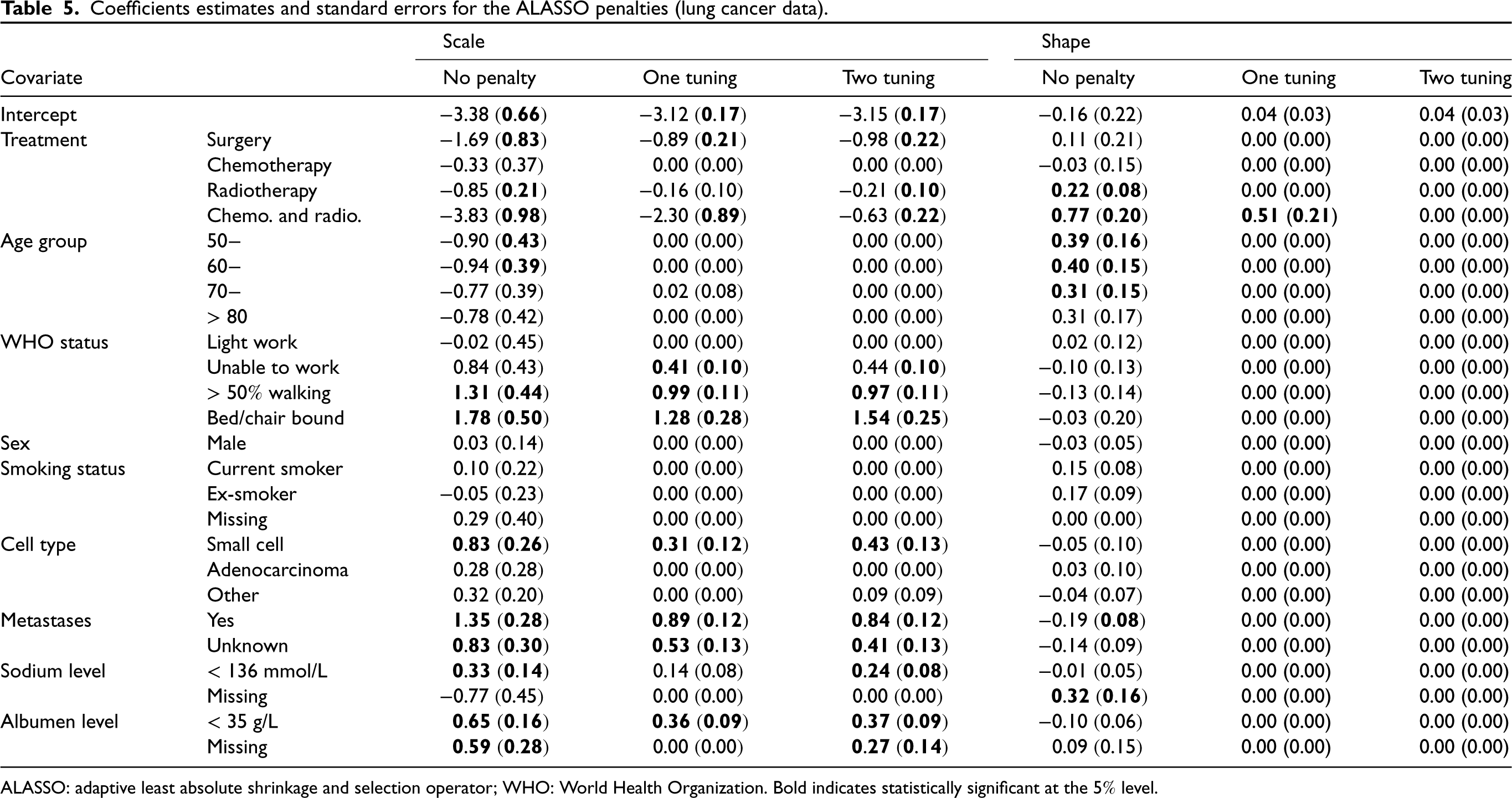
ALASSO: adaptive least absolute shrinkage and selection operator; WHO: World Health Organization. Bold indicates statistically significant at the
The MPR approach results in flexible models which extend standard models, but the presence of multiple regression components means that variable selection is necessarily more challenging than in standard settings where there is only a single regression component. In this article, we have proposed a penalized variable selection procedure for the simultaneous selection of variables in the scale and shape parameters of a Weibull MPR model in the survival analysis setting. The favorable performance of these methods was examined using simulation studies, and an analysis of lung cancer data was presented. While we have considered the Weibull model example in this article, the proposed variable selection procedures can be applied straightforwardly to other MPR survival models by adapting the likelihood function.
Given that we model different distributional parameters (a scale and a shape parameter), there is no reason to assume that variable selection can be achieved with a single penalty applied to both regression components; hence, we also investigated the need for a separate tuning parameter for each regression component. We have found that the ALASSO performs very well in terms of identifying the true subset of covariates and coverage of calculated confidence intervals. This is true even with a single tuning parameter, however the results are improved when there are two tuning parameters (albeit this is more computationally intensive). On the other hand, SCAD does not perform well in the MPR setting, selecting an overly complex model and with poor confidence interval coverage for shape parameters.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231203322 - Supplemental material for Penalized variable selection in multi-parameter regression survival modeling
Supplemental material, sj-pdf-1-smm-10.1177_09622802231203322 for Penalized variable selection in multi-parameter regression survival modeling by Fatima-Zahra Jaouimaa, Il Do Ha and Kevin Burke in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first author was funded by the Irish Research Council. The second author was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. NRF2020R1F1A1A01056987). The third author was supported by the Confirm Smart Manufacturing Centre (![]() ) funded by Science Foundation Ireland (Grant Number: 16/RC/3918).
) funded by Science Foundation Ireland (Grant Number: 16/RC/3918).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.