
Abstract
Unmeasured confounding is a well-known obstacle in causal inference. In recent years, negative controls have received increasing attention as a important tool to address concerns about the problem. The literature on the topic has expanded rapidly and several authors have advocated the more routine use of negative controls in epidemiological practice. In this article, we review concepts and methodologies based on negative controls for detection and correction of unmeasured confounding bias. We argue that negative controls may lack both specificity and sensitivity to detect unmeasured confounding and that proving the null hypothesis of a null negative control association is impossible. We focus our discussion on the control outcome calibration approach, the difference-in-difference approach, and the double-negative control approach as methods for confounding correction. For each of these methods, we highlight their assumptions and illustrate the potential impact of violations thereof. Given the potentially large impact of assumption violations, it may sometimes be desirable to replace strong conditions for exact identification with weaker, easily verifiable conditions, even when these imply at most partial identification of unmeasured confounding. Future research in this area may broaden the applicability of negative controls and in turn make them better suited for routine use in epidemiological practice. At present, however, the applicability of negative controls should be carefully judged on a case-by-case basis.
Introduction
In epidemiological research on causal effects, there are often concerns that one or more assumptions – such as exchangeability, no measurement error, or assumptions about missing data – are violated. In efforts to lessen these concerns, it has long been suggested that auxiliary variables be used that have a known (e.g. null) causal relation with the exposure or outcome of interest.1–3 Observing an association that contradicts the belief in a causal null might alert the analyst to violations of the assumptions underlying the methods used in the study. Auxiliary variables known to be causally unrelated to the variables of primary interest are called negative controls and have the potential in bias detection as well as partial or complete bias correction in epidemiological research. 4
Applications of negative controls in epidemiological research are diverse. Dusetzina et al. 5 identified 11 studies that used a negative control exposure, negative control outcome, or both in studies on various topics, ranging from peri-operative beta-blocker use and the risk of acute myocardial infarction to proton-pump inhibitors and community-acquired pneumonia risk. Schuemie et al. 6 studied as many as 37 and 67 negative control exposures in two example studies on isoniazid use and acute liver injury and on selective serotonin reuptake inhibitor use and gastrointestinal bleeding, respectively. Increased attention for negative controls is exemplified by mention in, for example, the RECORD-PE reporting guideline for pharmacoepidemiological studies and the STROBE-MR guideline for Mendelian randomisation studies.7,8
In recent years, negative controls have received increasing attention in the epidemiological and statistical literature. The literature on how to leverage negative controls in studies on causal effects has rapidly expanded and several authors have argued that negative controls should be more commonly employed.2,9,4 This article aims to complement these efforts to increase the more routine implementation of negative controls with a discussion about a selection of caveats. Although we zoom in on the limitations of negative control methods, it should be noted that other methods (e.g. instrumental variable methods and conventional adjustment for a minimally sufficient set of covariates) are similarly subject to limitations and need not be universally preferred over negative controls. Focusing on the use of negative controls to address possible violations of the exchangeability assumption, that is, the assumption of no unmeasured confounding, we begin with a brief review of relevant definitions and discuss assumptions for bias detection. We then review methods for bias correction and study their sensitivity to assumption violations.
Negative controls
A negative control outcome (NCO) is a variable that is not causally affected by the exposure of interest
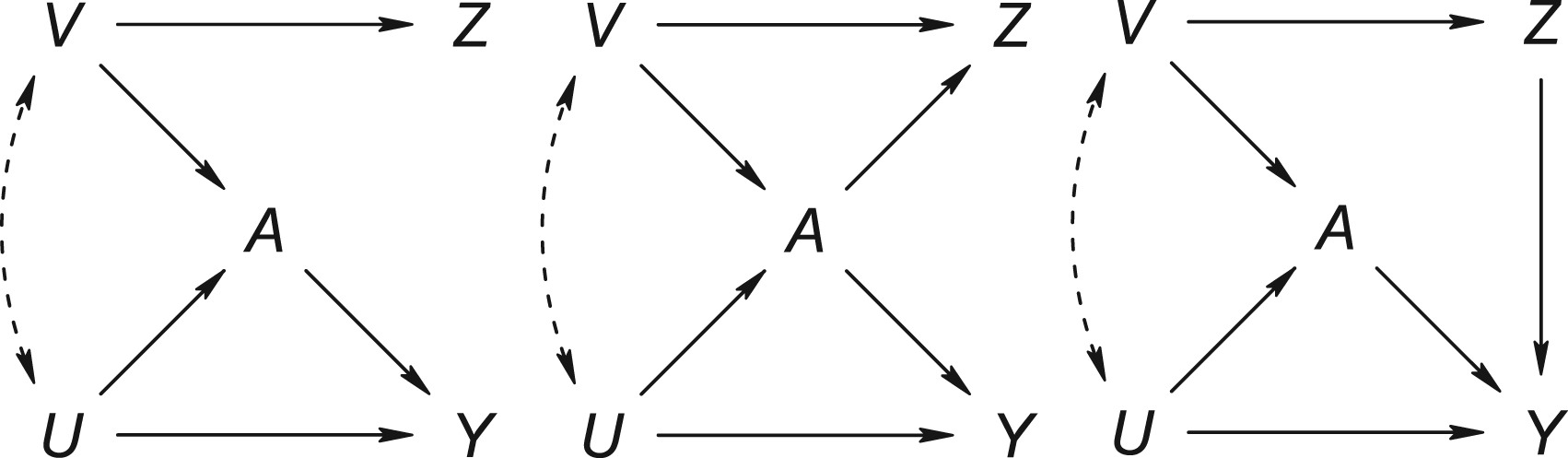
Causal directed acyclic graphs of settings where
Let
Control statement C may refer to the absence of bias of a measure of the association between
Caveats in the use of negative controls to detect unmeasured confounding
There are a number of caveats concerning the use of negative controls for confounding detection. These caveats mainly concern the link between the control statement and exchangeability for the exposure–outcome relation of interest. Unfortunately, the extent to which one confers information about the other need not be evident. 12 A biased negative-control association need not imply unmeasured confounding for the exposure–outcome relation of interest and neither is the converse true generally.
First, while most applications of negative controls assume that confounding is the only source of bias, in reality, it may be one of potentially many sources of bias. A spurious negative control association could have resulted, at least in part, from collider stratification, measurement error, or violations of assumptions about missing data. 9 Even if unmeasured confounding for the negative control association implies unmeasured confounding for the exposure–outcome relation of interest, a biased negative control association need not be a reflection of unmeasured confounding. Conversely, a (near) null finding could be the result of opposing biases, masking the presence of unmeasured confounding. In other words, negative controls are a tool that may lack both specificity and sensitivity with respect to the type(s) of bias they are to detect.
Lipsitch et al.
2
suggested a principle for establishing a link that is based on the extent to which common causes of
With finite samples rather than complete knowledge of the theoretical or population distribution, sampling variability becomes relevant too, making it more important to acknowledge the distinction between absence of evidence and evidence of absence. 13 With finite samples, proving the null hypothesis of a null negative control association is impossible. Even if ‘highly’ powered studies cannot detect bias for the negative control relation, it may be injudicious to assume that the available data are sufficient to adequately control for confounding of the primary relation of interest, because a small degree of bias for the former relation may be associated with a substantial degree of bias for the latter. Sample size and power considerations are often ignored or left at secondary importance. While some papers have considered the power of negative control tests,1,14 it is typically ignored how the negative control association relates to the extent of bias for the exposure–outcome relation of interest, yet high power to detect ‘small departures’ from exposure-NCO or NCE-outcome independence need not imply high power to detect small bias due to unmeasured confounding of the primary relation of interest. What are considered ‘small departures’ should therefore depend on the relationship between bias of the negative control association and the bias of the exposure–outcome relation of interest, or, likewise, depending on the link between the control statement C and the exchangeability condition E (as outlined in Section 2.1). Conversely, even if there is evidence of the contrary to the negative control null hypothesis, the bias due to uncontrolled confounding for the primary exposure–outcome relation may not be meaningful. In any case, it is important to consider the relative size of the biases in the negative control and primary exposure–outcome relations.
Negative control methods for uncontrolled confounding adjustment
The more recent literature on negative controls has considered how and under what conditions negative controls can be leveraged to partially or fully identify target causal quantities rather than merely the presence of bias. Lipsitch et al. 2 give conditions for valid inference about the direction of bias and thus for partial identification of the target causal quantity. These conditions are reviewed in Supplemental Appendix A. In what follows, we review three methods for full identification: the control outcome calibration approach (COCA), the (generalized) difference-in-difference (DiD) approach, and the double-negative control approach. Proofs of identification are given in Supplemental Appendix B for completeness. For each of the methods, we illustrate the potential impact of assumption violations on the identifiability of the targeted quantity. Throughout, departures from identification are termed bias.
Control outcome calibration approach
Identification
It may be tempting to regard the confounded association between the exposure of interest and an NCO as a direct measure of bias for the exposure–outcome effect of interest. However, it cannot generally be assumed that the direction or magnitude of bias is the same for the two relations. As an alternative to the restrictive and probably unrealistic ‘bias equivalence’ assumption, that is, the assumption of equality between the confounded negative control association and the bias due to unmeasured confounding of the exposure–outcome effect of interest, Tchetgen Tchetgen
10
proposed the COCA. The assumption of ‘bias equivalence’ would especially likely be violated if the NCO and primary outcome are measured on different scales and the bias is bounded differently depending on the scale, such as would be the case if the NCO was binary and the primary outcome continuous. The COCA leverages an NCO to adjust for unmeasured confounding without requiring that the NCO and primary outcome
The next result, due to Tchetgen Tchetgen, 10 describes a regression-based approach to implementing the COCA, which – characteristically of the COCA – relies on the assumption that a (set of) counterfactual primary outcome(s) of interest is sufficient to render the NCO conditionally independent of the exposure of interest. Some intuition behind this approach may be obtained upon noting that the counterfactual outcomes may well capture information about baseline covariates and therefore serve as a proxy for unobserved pre-exposure variables that are predictive of the NCO. The reasoning rests on the assumption that the same covariates that explain the lack of exchangeability for the outcome of interest also explain the confounding of the exposure–NCO relation. However, even then it is not evident nor guaranteed that the counterfactual outcome proxy is sufficient to render the NCO and exposure conditionally independent.
A regression-based approach to implementing the COCA under rank preservation
Suppose that the following conditions hold for all levels
Then,
Because counterfactual outcome
Sensitivity analysis for violations of
Suppose the following conditions hold for all levels
Then,
Through the rank preservation assumption, Theorem 1 relies also on the strong assumption that all counterfactual outcomes of an individual are deterministically linked. A prerequisite of this assumption is that the within-person ranks of counterfactuals are the same for all individuals. In the next section, we consider violations of this assumption. However, as Theorem 3 states, in the special case where the outcome and exposure of interest are binary, there should be no concern about violations of this assumption as it can be dropped entirely. 10
COCA for binary primary outcome and exposure
Suppose that the following conditions hold:
Then,
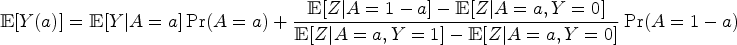
If the assumptions of Theorem 3 are met for
Sensitivity to assumption violations
In this subsection, we consider the sensitivity of the COCA to assumption violations. In particular, we illustrate the potential impact of deviating from rank preservation and of violating the assumption that counterfactual outcome
First, to illustrate the potential impact of deviating from rank preservation, consider the setting where
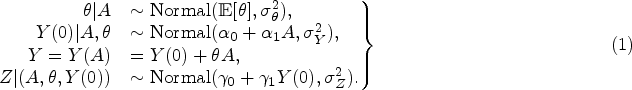
Given a value of the ATE (i.e.
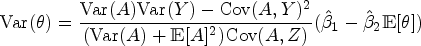

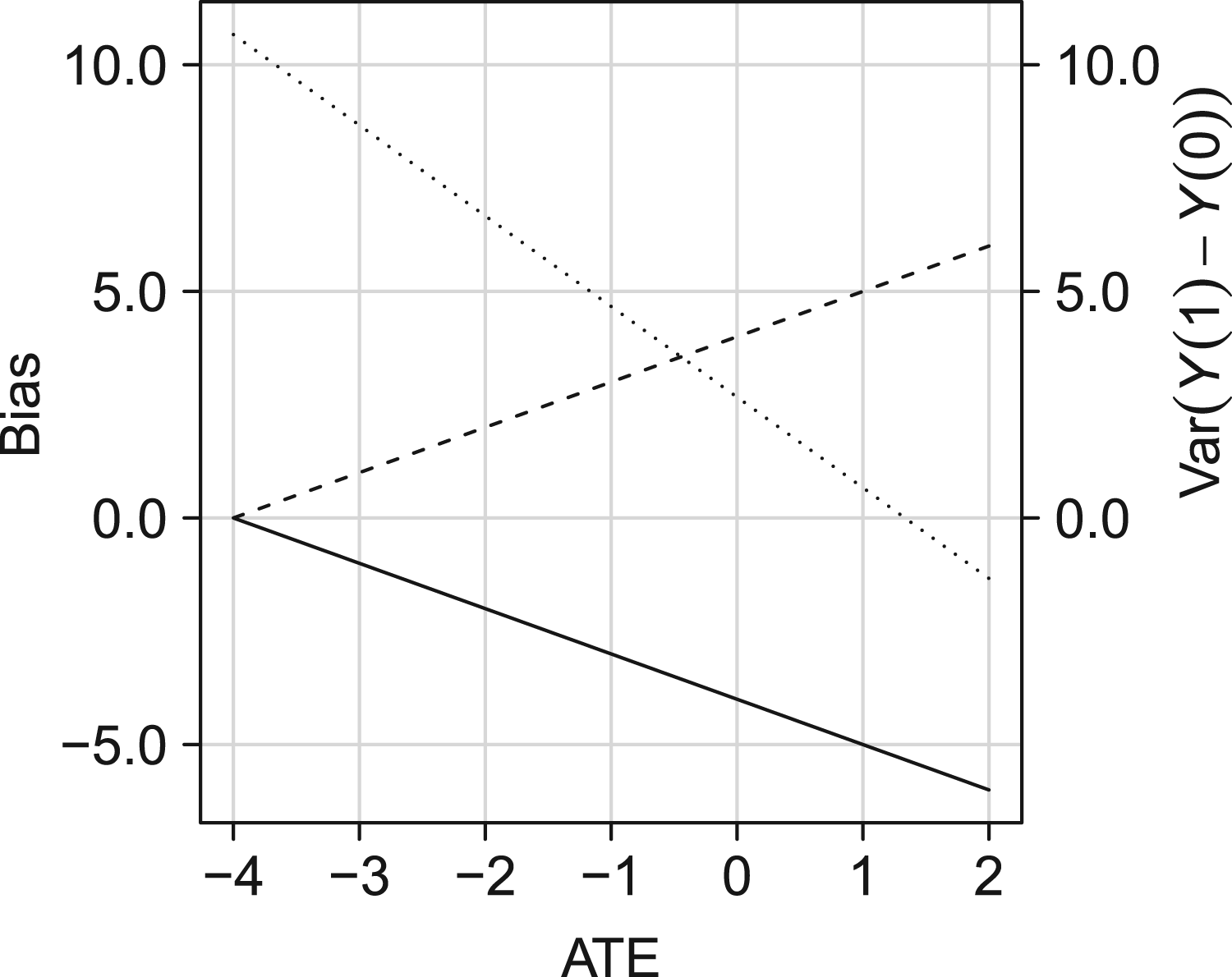
Illustration of the effect of violating the rank preservation assumption on the difference between the quantity identified by the COCA and the ATE (bias of COCA; solid line) and the difference between
In illustrating the sensitivity of the COCA against violations of rank preservation, it was assumed that the other assumptions were maintained. We now turn to the assumption of Exposure–NCO independence given counterfactual outcome
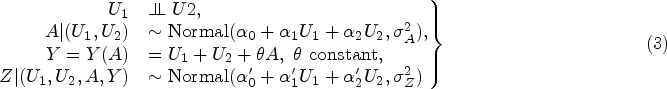
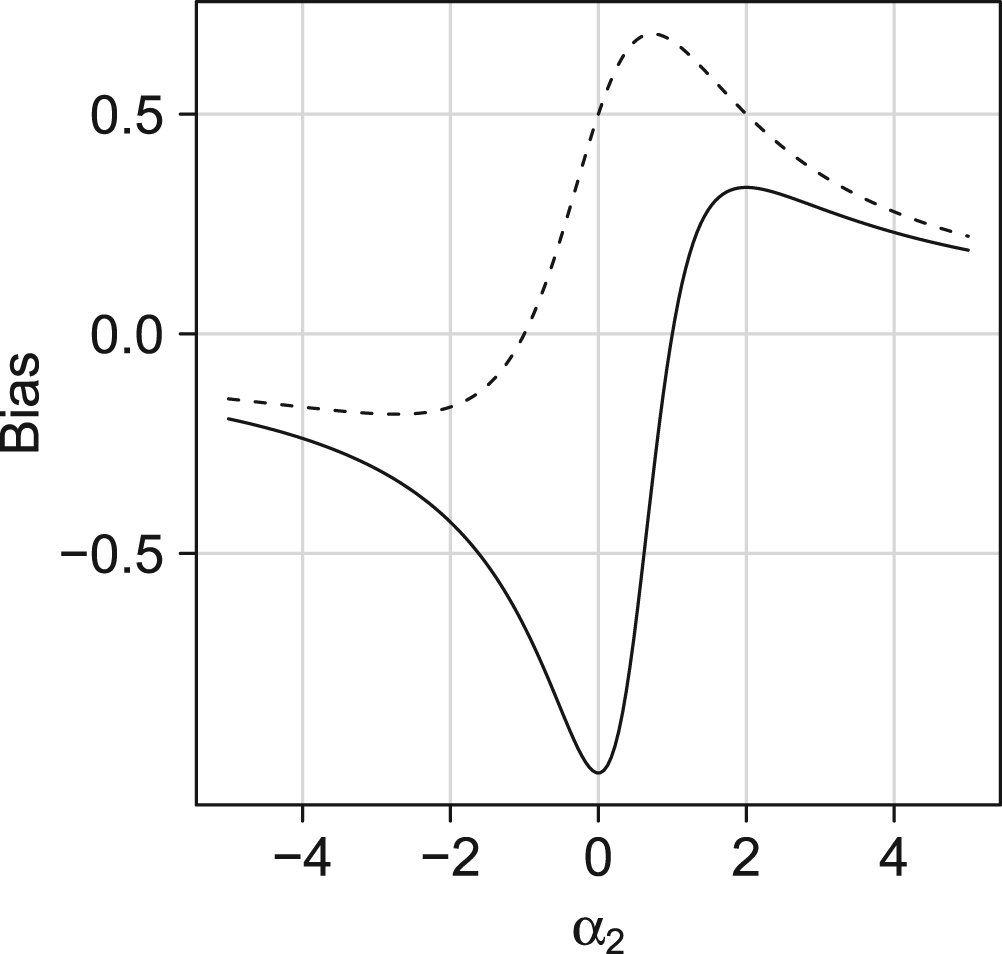
Illustration of the potential impact of violating the assumption that the NCO and exposure of interest are independent given counterfactual outcome
With
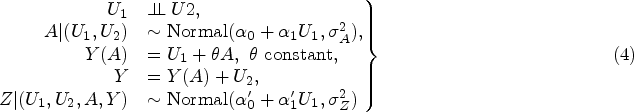
Identification
The DiD approach proposed by Sofer et al.
15
is an alternative approach to the COCA and does not assume rank preservation, nor does it require that the counterfactual outcome
DiD approach for the ATT under additive equi-confounding
Suppose that the following conditions hold for all levels
Then,
Additive equi-confounding is relatively easy to interpret. However, the assumption may be particularly likely to be violated when primary outcome
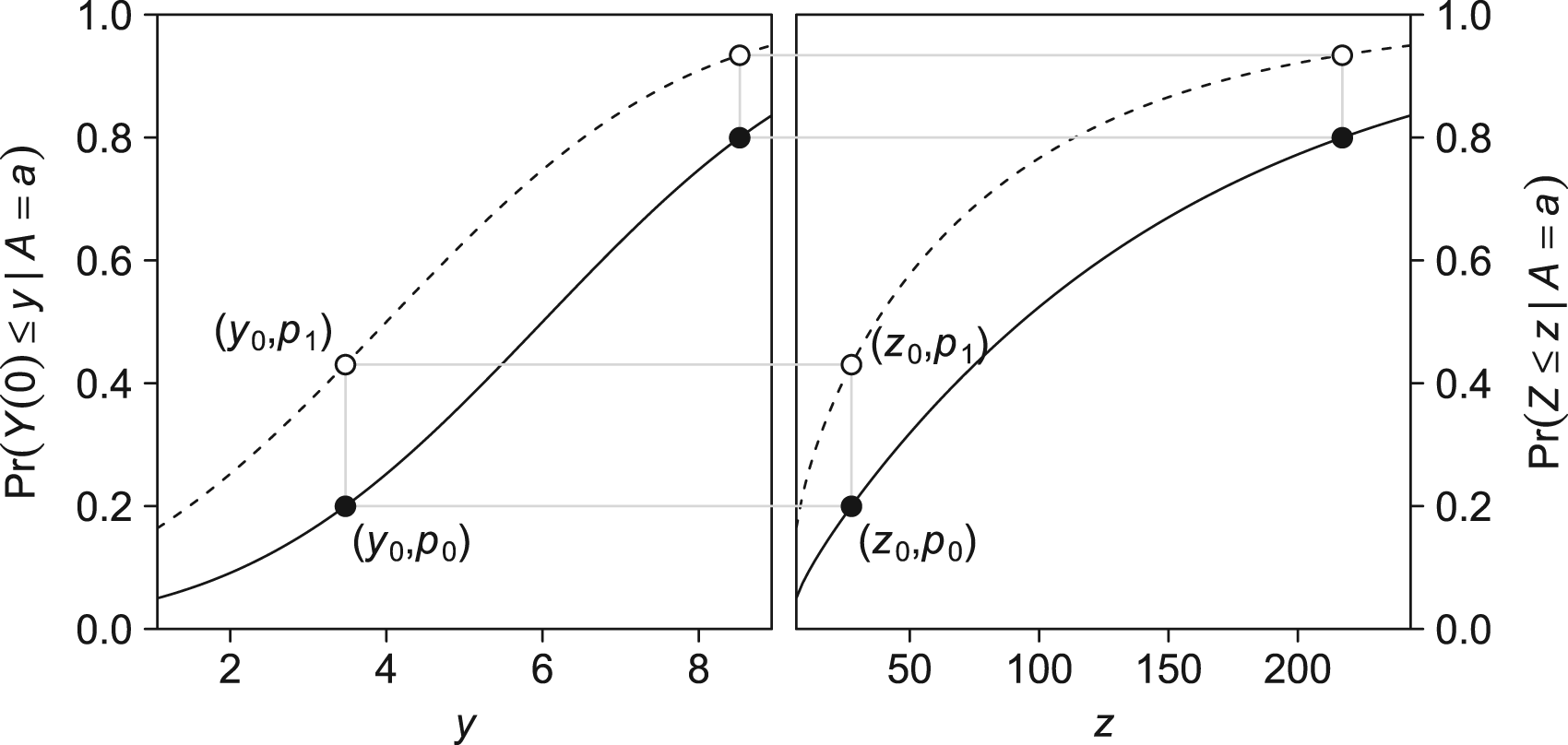
Example of quantile–quantile equi-confounding. Dashed curves represents
Suppose that the following conditions hold for all levels
Then,
Sensitivity to assumption violations
We now give a simple setting where neither additive nor quantile–quantile equi-confounding is guaranteed to hold. The setting is characterized by two common causes
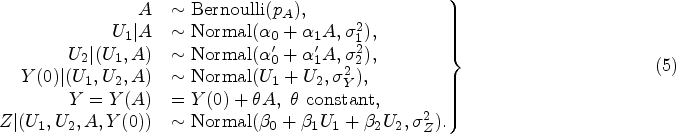
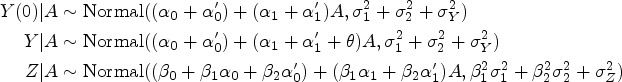
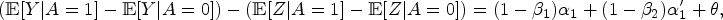
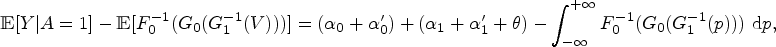
Figure 5 shows, for various parameter specifications, the bias of the (generalized) DiD for the ATT
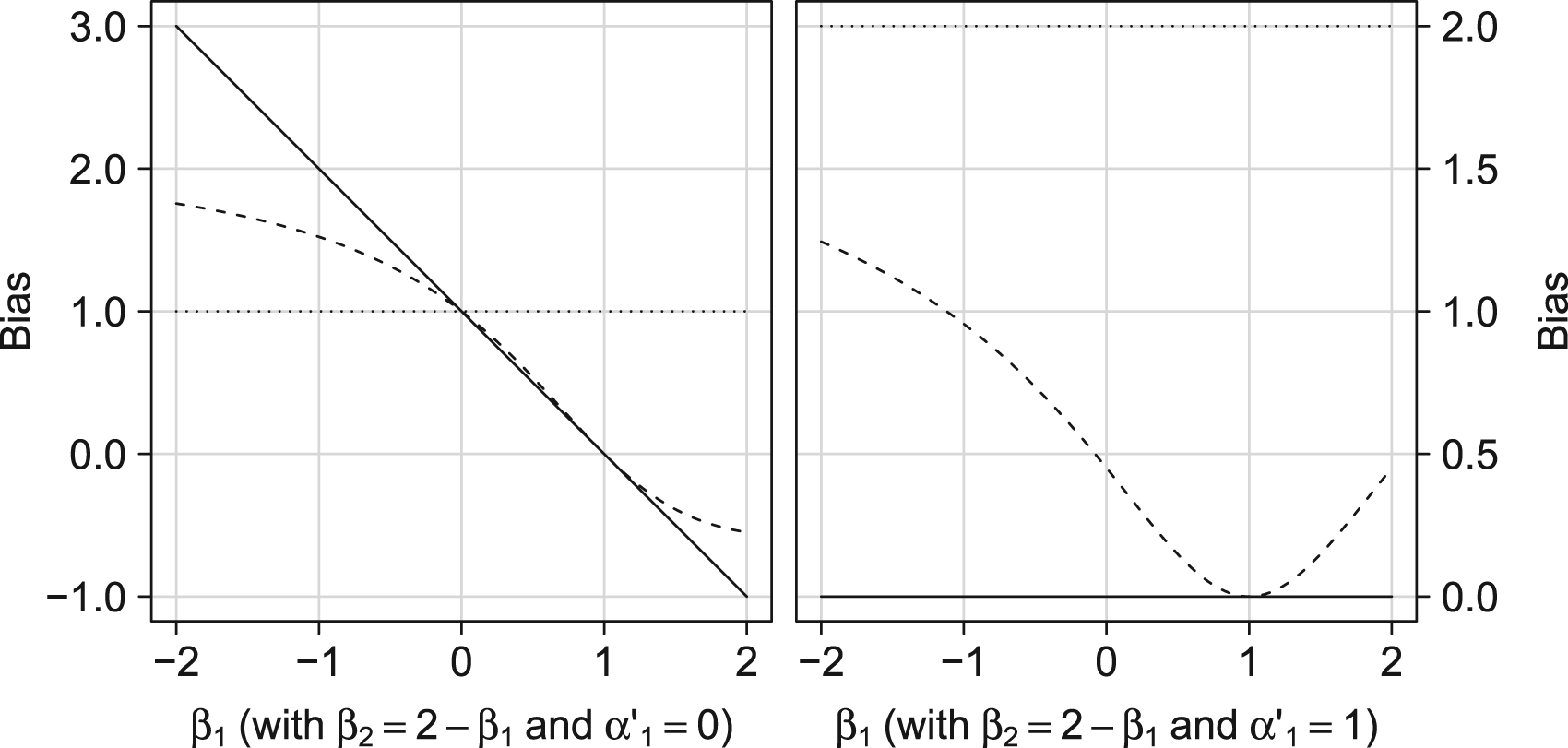
Illustrating of the potential impact of violating additive or quantile–quantile equi-confounding on the bias of the (generalized) difference-in-difference approach. Solid lines represent the difference-in-difference approach; dashed lines the generalized difference-in-difference; dotted lines the bias of a crude analysis,
Identification
Recent developments in the use of negative controls to adjust for unmeasured confounding leverage multiple negative control variables or proxies of unmeasured common causes.16–18,4,19 For example, the next result, due to Miao et al.,
17
gives a set of conditions sufficient to identify the expected marginal counterfactual outcome
The confounding bridge approach
Suppose that for all levels
Let
Figure 6 shows a directed acyclic graph that is consistent with the assumptions of Theorem 6. The proxy variables can be seen to be negative control variables in the sense described by Shi et al.,
4
thus making the confounding bridge approach a (double-)negative control approach. Like the primary exposure-outcome association, the exposure–NCO association is confounded by
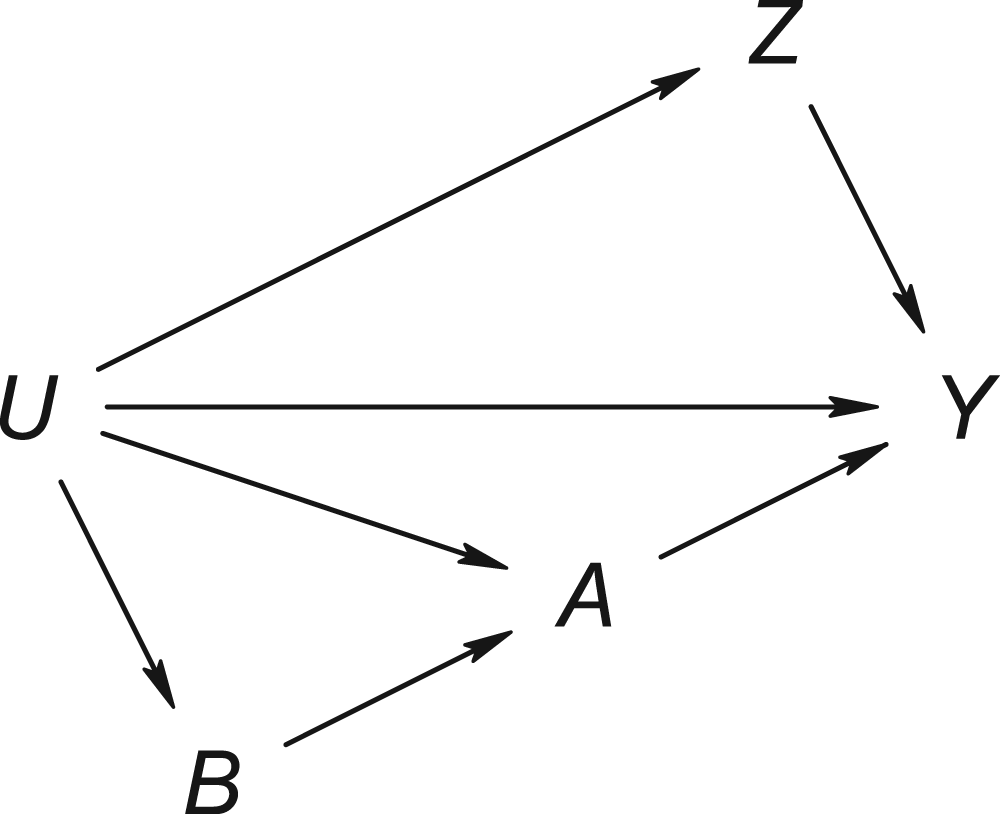
Causal directed acyclic graph with negative control pair satisfying the latent ignorability condition of Theorem 6.
The confounding bridge and completeness assumptions can be difficult to grasp. For categorical variables, however, the assumptions are subsumed under the conditions of the next result, due to Miao et al. 16 and Shi et al. 18
Let
Then,
Here, following Miao et al.,
16
for any categorical variables
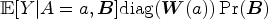
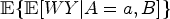
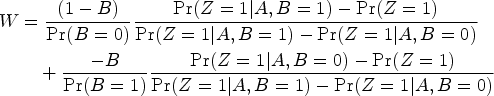
Sensitivity to assumption violations
Theorem 7 can accommodate any number of categories of
In particular, we consider the case where the variables

Figure 7 gives the bias of the proximal g-formula for the ATE
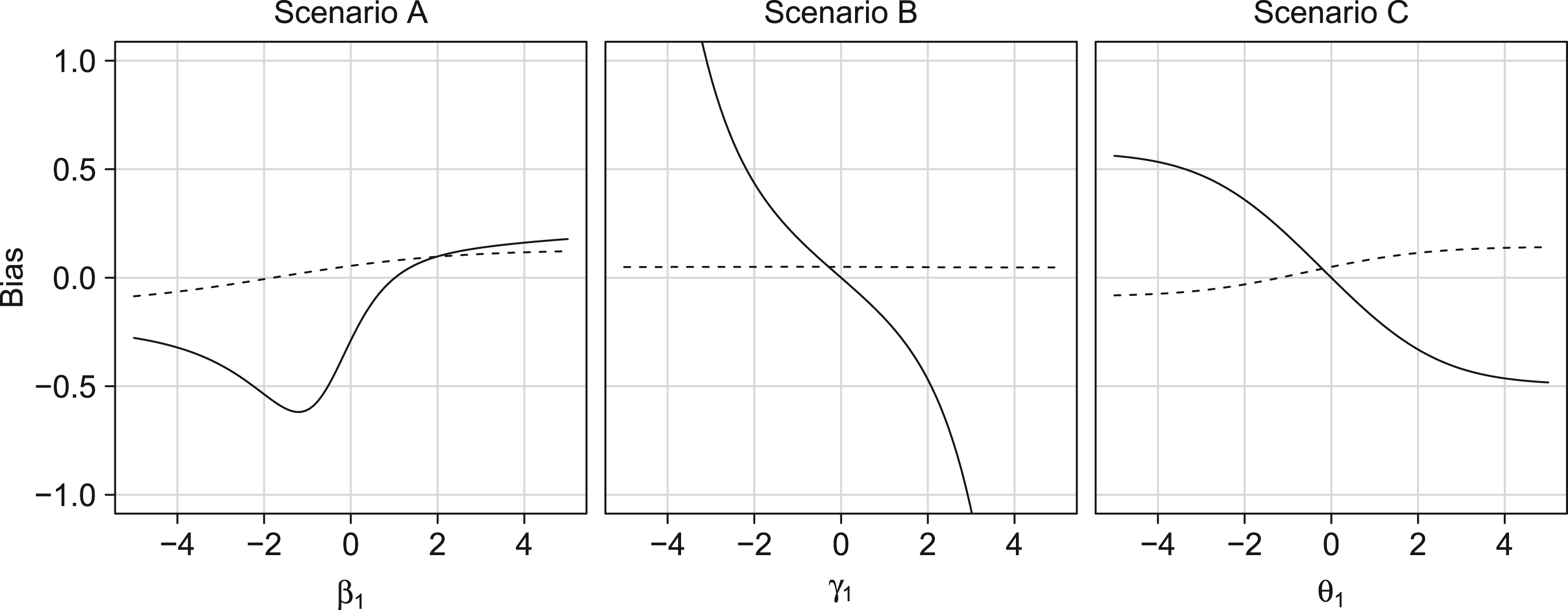
Bias of crude approach (dashed) and proximal g-formula (solid) under violations of the cardinality assumption (scenario A), negative control outcome condition (scenario B), or negative control exposure condition (scenario C).
In an other study, Vlassis et al. 20 found the bias of the crude risk difference to be consistently smaller than that of the proximal g-formula. Our results demonstrate that in some settings, the proximal g-formula results in considerably more bias than what would result from ignoring unmeasured confounding.
Negative controls have gained increasing interest in addressing concerns about the validity of a study. The literature on the topic has tended to consider increasingly ambitious tasks, from confounding detection to full identification of causal effects, typically at the cost of stronger and arguably more complex assumptions. Efforts have been made to introduce negative controls to a broader audience and ensure they are adopted in epidemiological practice. 4 However, little attention has yet been given to the methods’ assumptions and the potential impact of assumption violations. While the assumptions may be tenable enough in some specific cases to justify an application, in other situations substantial violations are possible. We have illustrated that assumption violations, some of which are likely even in very simple settings, may have a considerable impact on the validity of the negative control approach, thereby limiting its utility.
We stress the other methods commonly used to analyse observational data (e.g. covariate adjustment through regression analysis or instrumental variable methods) may also be sensitive to violations of their assumptions. However, a comparison between these methods and methods using negative controls is beyond the scope of this work. Researchers should decide on a case-by-case base of which methods the assumptions appear most plausible and thus which method appears most appropriate. Another aspect that should be considered on a case-by-case base is the magnitude that could arise due to violations of the assumptions underlying negative control methods. The illustrations presented here are based on arbitrary parameter values chosen such that they illustrate the relative bias contributions. However, we do not claim these are necessarily appropriate for a particular study. Considerations about the appropriateness and possible violation of the assumptions of negative control methods are, to a large extent, context-dependent.
Despite the possible abundance of negative controls, their routine use in epidemiological practice may fail to strengthen evidence about exposure–outcome effects unless it can be safely assumed that assumption violations are absent or else if the robustness against these violations is well understood. Given the potential impact of assumption violations, it may sometimes be desirable to replace strong conditions for identification with weaker conditions that are easier to verify, even when these weaker conditions imply at most partial identification. Future research in this area may broaden the applicability of negative controls and in turn make them more suited for routine use in epidemiological practice. When they are used, we advise that researches consider the results of their applications carefully and explicitly in light of the methods’ limitations and assumptions.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231181230 - Supplemental material for Negative controls: Concepts and caveats
Supplemental material, sj-pdf-1-smm-10.1177_09622802231181230 for Negative controls: Concepts and caveats by Bas BL Penning de Vries and Rolf HH Groenwold in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article: RHHG was funded by the Netherlands Organization for Scientific Research (NWO-Vidi project 917.16.430). The content is solely the responsibility of the authors and does not necessarily represent the official views of the funding bodies.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.