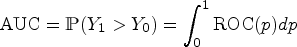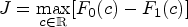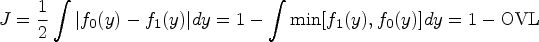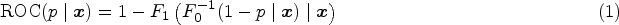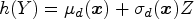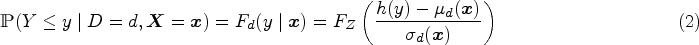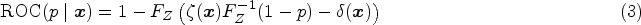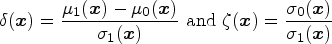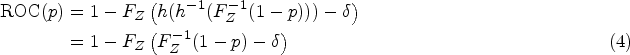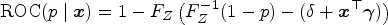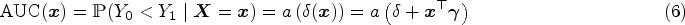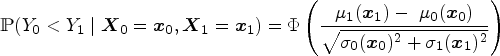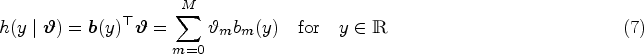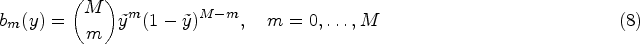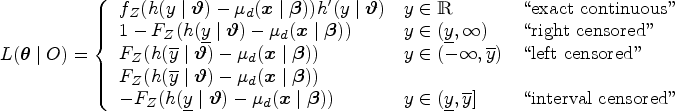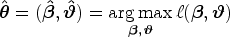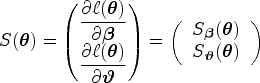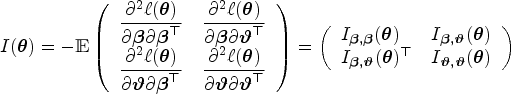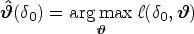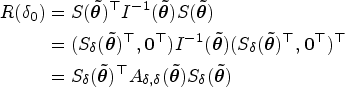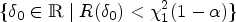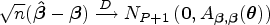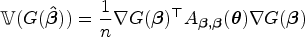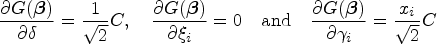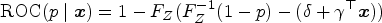Receiver operating characteristic analysis is one of the most popular approaches for evaluating and comparing the accuracy of medical diagnostic tests. Although various methodologies have been developed for estimating receiver operating characteristic curves and their associated summary indices, there is no consensus on a single framework that can provide consistent statistical inference while handling the complexities associated with medical data. Such complexities might include non-normal data, covariates that influence the diagnostic potential of a test, ordinal biomarkers or censored data due to instrument detection limits. We propose a regression model for the transformed test results which exploits the invariance of receiver operating characteristic curves to monotonic transformations and accommodates these features. Simulation studies show that the estimates based on transformation models are unbiased and yield coverage at nominal levels. The methodology is applied to a cross-sectional study of metabolic syndrome where we investigate the covariate-specific performance of weight-to-height ratio as a non-invasive diagnostic test. Software implementations for all the methods described in the article are provided in the tram add-on package to the R system for statistical computing and graphics.
Estimating receiver operating characteristic (ROC) curves for evaluating the performance of medical diagnostic tests has been a main focus of statistical literature over the last decades.1,2 Diagnostic tests screen for the presence or absence of a disease. Characterizing their accuracy is essential to ensure appropriate prevention, treatment and monitoring of diseases. ROC curves are a valuable tool in determining the diagnostic potential of a test and continue to be extensively applied in biomedical studies as new tests or biomarkers are developed in radiology, oncology, genetics, and other related fields. Increasingly more applications can be expected due to advancements in technology and analyzing the resulting data requires a computationally straightforward approach to provide accurate and consistent statistical inference.
Previous research has focused on extending statistical methodology for ROC curve estimation to address issues such as adjustment for covariates,3,4 incorporating censoring due to instrument detection limits5,6 and robustness to model misspecification.7 In addition, a wide variety of parametric and nonparametric methods have been proposed within frequentist and Bayesian paradigms (see Inácio et al.8 for a recent review). However, there is no consensus on an analytic approach that can handle all these issues simultaneously.
An attractive feature of the ROC curve, which has scantly been used for its estimation, is that it remains invariant to monotonic transformations of the test results. Although transformations have been used to bring continuous test results into a form that approximately satisfies the assumptions of a suitable parametric model,4 estimation of a transformation function has been limited to the Box-Cox power transformation family.9,10 For rank-based methods, the transformation function can be left unspecified, but in all cases, a restriction to normality has been previously imposed on the model for the ROC curve.11
In this article, we present a new unifying methodological framework for estimating ROC curves and its associated summary indices by modeling the relationship between the transformed test results and potential covariates. We employ transformation models to jointly estimate the transformation function and regression parameters.12,13 This approach specifies a parametric model for the ROC curve but remains distribution-free because we do not impose any strong assumptions about the transformation function. Using the estimated parameters, we show how to evaluate covariate effects on the discriminatory performance of diagnostic tests. Unlike nonparametric methods which are flexible but difficult to interpret and implement, transformation models excel on both fronts. R implementations of all methods discussed in this article are available, along with a set of supporting examples.
Notation and preliminaries
Let the random variable denote the continuous result of a diagnostic test and let denote the disease status, with if a subject is diseased and 0 if nondiseased. We denote quantities conditional on the disease status using subscripts. For example, and are the test results in the diseased and nondiseased populations with cumulative distribution functions (CDFs) given by and and densities and , respectively. Suppose that the subject is diagnosed as diseased when their test result exceeds a threshold value, . By convention, we assume that larger values of the test result are more indicative of the disease. The probability of truly identifying a diseased and nondiseased subject is defined as sensitivity, , and specificity, , respectively. The set of pairs for all produce the ROC curve. By setting , an equivalent representation of the ROC curve is
Summary indices of the ROC curve quantify the degree of separation between the distributions and . The most widely used index is the area under the ROC curve (AUC) defined by
The AUC represents the probability that the test results of a randomly selected diseased subject exceed the one of a nondiseased subject and is directly related to the Mann–Whitney–Wilcoxon U-statistic (MWW).14 Alternative indices include the Youden index,15, which combines sensitivity and specificity over all possible thresholds to provide the maximum potential effectiveness of a diagnostic test, given by
The Youden index is equivalent to the Smirnov (or the two-sample Kolmogorov-Smirnov) test statistic16 and can be represented as half the distance between the two densities or as the complement of the overlapping coefficient (OVL)17–20:
Additionally, the threshold corresponding to , where sensitivity and specificity are maximized, denoted as , is often used in clinical practice as the optimal classification threshold to screen subjects.
Covariates may impact the level and the accuracy of a diagnostic test. In order to appropriately understand the accuracy of the test in subpopulations, we can use covariate-specific or conditional ROC curves.21 Let denote a vector of covariates that are hypothesized to have an impact on the accuracy of the test. The conditional CDF in the diseased population is given by and analogously given for the nondiseased population. The covariate-specific ROC can be written as
with its counterpart conditional summary indices, and , defined accordingly. The covariate-specific ROC curve can be generated by modeling the conditional distribution of the test results, known as the induced or indirect methodology.3
Overview
The article proceeds as follows. In Section 2, we propose a transformation modeling framework for parameterizing ROC curves from which we derive closed-form expressions for associated AUC and Youden summary indices. We discuss maximum likelihood estimation procedures for our model and corresponding inference. In Section 3, we assess the empirical performance of our methods using simulated data. We apply our approach to a cross-sectional study for detection of metabolic syndrome in Section 4 and conclude the article with a discussion.
Methods
Transformation model
The ROC curve is a composition of distribution functions and thus is invariant to strictly monotonically increasing transformations of . We propose a model for the conditional distribution of the transformed test result given the disease status and covariates. This transformation is obtained from the data and leads to a distribution-free framework to parameterize the covariate-specific ROC curve and its summary indices.
Suppose there exists a strictly monotonically increasing function such that the relationship between the transformed test result and the covariates follows a shift-scale model
where specifies the disease indicator ( for nondiseased and for diseased), a fixed set of covariates, is the shift term, is the scale term, and is a latent random variable with an a priori known absolutely continuous log-concave CDF, . Given that and are fixed, the conditional CDF for is
Equation (2) represents a general class of models called transformation models.22,13 The transformation function uniquely characterizes the distribution of , similar to the density or distribution function. Plugging in this conditional CDF of into equation (1), cancels out and the covariate-specific ROC curve is given by
where
Thus, the ROC curve is completely determined by the shift and scale terms of the model.
The binormal23 and bilogistic24 ROC curves can be obtained by setting to the standard normal distribution function , or the standard logistic distribution function , in equation (3), respectively. Similarly, the proportional hazard25 and reverse proportional hazard alternatives26 for the ROC curve also fall within the purview of our transformation model with specified as (minimum extreme value distribution function) and (maximum extreme value distribution function), respectively.
However, to the best of our knowledge, the only literature where the transformation function is included in the model formulation of the ROC curve is Zou,27 who jointly models the shift term and the parameters of a Box-Cox power transformation function. A key point of this article is that we explicitly estimate jointly with from the observed data and are not restricted to normality imposed by power transformation families. Thus, the methods we propose allow for proper propagation of uncertainty from the estimated transformation function into the estimates of the shift and scale terms of the model.
The ROC curve in equation (3) follows a parametric model depending on , but is distribution-free as by Alonzo and Pepe,28 because no assumptions are made about the transformation and consequently for the distribution of the test results. The approach to model the test results as a function of the disease status and covariates was originally proposed in the latent variable ordinal regression setting by Tosteson and Begg21 and extended by Pepe3 to modeling covariate effects directly on the ROC curve.
Tosteson and Begg21 pointed out that to ensure concavity of the induced ROC curve, the scale term must be omitted, that is, for . The ROC curve is termed proper if it is concave or, equivalently, if the derivative of the ROC curve is a monotonically decreasing function.29 A concave ROC curve is desirable as it yields the maximal sensitivity for a given value of specificity.30 In this sense, as the decision criterion for classifying subjects is optimal when the ROC curve is concave, we focus on the remaining work on the model involving only the shift term. Hence, the effect of covariates on the ROC curve is contained in the difference between the shift terms for diseased and nondiseased subjects, . For a relaxation of this assumption, see Siegfried et al.31 who additionally estimate the scale functions through regression models.
Two-sample case
We first consider the case of two samples without covariates. Let the shift term take the form . The CDF of the test results in the nondiseased population is given by and in the diseased population by . Using Equation (3), the induced ROC curve can be expressed as
The model assumption implies that a monotone function exists to transform both and into the same distribution, separated by a shift parameter, . The induced ROC curve from this model does not assume a particular distribution of the test result, rather, it quantifies the difference between the test result distributions on the scale of a user-defined . In this sense, the difference between the test result distributions is described by . Each choice of leads to a different interpretation of . For example, when is selected to be the standard normal distribution function, is essentially Cohen’s d, the standardized difference in means of the transformed test results comparing the diseased and nondiseased groups, . Similarly, when is the standard logistic distribution function, is the ratio of odds of having a positive test result comparing diseased and nondiseased groups. Closed-form expressions can be derived for summary indices of the ROC curve by solving the appropriate integrals. The expressions of AUC, , the optimal threshold , sensitivity and specificity at are given for some choices of in Table 1.
Closed-form expressions for the area under the receiver operating characteristic curve (AUC), Youden Index (), optimal classification threshold (), sensitivity (), and specificity () at in terms of the shift parameter in the linear transformation model given by .
Index
Conditional ROC curve
The accuracy of a diagnostic test may be influenced by a set of covariates . To evaluate their effect on the ROC curve and its summary indices, we assume a linear transformation model with a shift term that takes the form
where are the coefficient vectors for the covariates and interaction term, respectively. Under this model, the resulting covariate-specific ROC curve is
where the covariate effect on the ROC curve is given by the difference in shift terms between diseased and nondiseased subjects, . Similarly, the covariate-specific AUC is given by
where is the AUC function from the first row of Table 1 for different choices of . The expressions for , , sensitivity and specificity can analogously be adjusted to account for covariates, with replaced by in Table 1. In the case of a single continuous covariate , the interpretation of the interaction coefficient is as follows. For each possible specificity value, a unit increase in results in a -unit increase in the ROC curve (or an increase in the sensitivity) on the scale of . If is positive, an increase in corresponds to an increase in the ROC curve, indicating that a test is better able to discriminate the two populations for larger values of and, vice versa. Note that the ROC curve varies with the covariate contingent upon the presence of an interaction between and . For , the covariate affects the distribution of the test results from the diseased and nondiseased population, but not the ROC curve. That is, for all levels of , the difference between the transformed distributions and is given by and the ROC curve is unchanged. Analogous interpretations hold when we are interested in modeling a set of covariates , which could possibly include categorical covariates.
Standard regression techniques have also been proposed as an alternative to assess the effect of covariates on summary indices rather than deriving the induced ROC curve. For example, Dodd et al.32 model the partial AUC as a regression function of covariates. Our model equivalently results in a regression model for the AUC, where is in the form of a usual linear predictor and is a monotonically increasing inverse link function which defines the scale for the regression coefficients. As will be shown in Section 2.2, an advantage of our approach is that we do not rely on less efficient binary regression techniques and directly estimate the regression parameters of the transformation model using maximum likelihood estimation. In Supplemental Material Section A, we show that our method is additionally related to the probabilistic index model (PIM) of Thas et al.33,34
We can also consider more general and potentially nonlinear formulations of the shift and scale terms in our framework. For the special case of , the AUC from a shift-scale transformation model31 is given by
where and are the corresponding (potentially different) sets of covariates in the nondiseased and diseased populations, respectively. When the scale term depends only on a single set of covariates, , despite varying sets of covariates in the shift terms, all the expressions hold from Table 1 with replaced by . However, such closed-form expressions cannot be derived for other choices of when the scale term depends on the disease indicator or on different sets of covariates. In such cases, AUCs and other summary indices can be derived using numerical techniques on the induced ROC curve.
Estimation
In this section, we propose estimation methods for a transformation model with univariate test results. We provide an explicit parameterization of the transformation function and the shift term. We then maximize the likelihood contributions for a potentially exact continuous, right-, left-, or interval-censored datum to jointly estimate the model parameters. This enables us to fully determine the ROC curve and its summary indices as well as handle test results which are ordinal or impacted by instrument detection limits.
Parameterization
We parameterize the transformation function as
where is a vector of basis functions with coefficients . Polynomials in Bernstein form offer a computationally attractive choice of basis that provides a flexible way of estimating the underlying transformation function. The Bernstein basis polynomial of order is defined on the interval as
where . The restriction for , guarantees the monotonicity of . Observe that the transformation function is linear in the parameters that define it and any nonlinearity of the test results is modeled by the basis functions. If the order is chosen to be sufficiently large, Bernstein polynomials can uniformly approximate any real-valued continuous function on an interval.35
Likelihood
Denote the complete parameter vector as , where are the vector of regression coefficients parameterizing the function from Section 2.1 and are the basis coefficients. We follow the maximum likelihood approach proposed by Hothorn et al.13 to jointly estimate and . The advantages of embedding the model in the likelihood framework are as follows. (i) All forms of random censoring (right, left, and interval) as well as truncation can directly be incorporated into likelihood contributions defined in terms of the distribution function.36 Supplemental Material Section A details how ordinal biomarkers can be accommodated in the proposed modeling framework using interval-censored likelihood contributions. (ii) If the given model is correctly specified, under regularity conditions, the maximum likelihood estimator (MLE) will be asymptotically the most efficient estimator. (iii) The MLE is asymptotically normally distributed and has a sample variance that can be computed from the inverse of the Fisher information matrix. This can be used to generate confidence intervals (CIs) for the estimated parameters. (iv) The MLE is equivariant which implies invariance of the score test (or the Lagrange multiplier test) to reparameterizations.37,38 Specifically, we will show in Section 2.3.1, by inverting the score test, our method produces confidence bands for the ROC curve and appropriate score intervals for its summary indices.
The likelihood contribution of a single observation , where is given by
where is the density function of and is the first derivative of the transformation function with respect to . Given a sample of independent and identically distributed observations for , the log-likelihood is given by , where is the likelihood contribution of observation . The (unconditional) maximum likelihood estimate of is the solution to the optimization problem
subject to the monotonicity constraint for . The resulting ROC curve only depends on which is decoupled from the parameters needed to model the transformation function . The score function is defined as the first derivative of the log-likelihood function with respect to each of the parameters and is given by
We perform constrained optimization using the likelihood and score contributions to determine the maximum likelihood estimates for and (for computational details, see Hothorn39). The asymptotic variance of the MLE can further be estimated by the expected Fisher information matrix which is the variance-covariance matrix of the score function and is defined as
The matrix is partitioned such that the submatrix corresponds to the parameter related to the disease indicator and covariates.
Limit of detection
Instrument precision can affect the evaluation of diagnostic biomarkers. For example, when biomarker levels are at or below the limit of detection (LOD) , the observed value lies in an interval and the resulting measurement is left censored. Often a replacement value is substituted for such measurements. Alternatively, only biomarker values above the LOD are used for the ROC analysis. It has been shown that these approaches lead to biased estimation.40 Various adjustments to ROC curves and its summary indices have been proposed to handle such censored measurements.41,6,42 However, these methods typically do not account for covariates. Our framework naturally accounts for such observations in the likelihood function for left censored test results. Similarly, the right censored likelihood accounts for measurements which are affected by an upper limit of detection. Thus, our method provides a smooth covariate-specific ROC curve for all values of specificity with estimates and inference appropriately incorporating the observed information.
Confidence intervals
In the following section, we present three methods to calculate confidence bands for the ROC curve and CIs for its summary indices. Since these quantities are functions of the regression parameters in the model, to maintain nominal coverage for a CI for , appropriate methods are needed. The methods discussed include inverting the score test, the multivariate delta method and simulation from the asymptotic distribution of the estimate. The methods are ordered by their degree of theoretical justification. We start with score intervals which are invariant to parameter transformations but become computationally expensive when dealing with a large set of parameters. We then discuss estimating the variance using the delta method and conclude with a simple simulation method which is versatile without being computationally demanding.
Score intervals
In the two-sample univariate case where defines the ROC curve, as in equation (5), we can construct score intervals for . Unlike the Wald and other commonly used intervals, score intervals are especially desirable as they are invariant to transformations of the parameters. A score CI for (e.g. the AUC ), provides the same level of coverage as would a score CI for . In turn, under a correctly specified model, a score CI for allows the construction of accurately covered uniform confidence bands for the ROC curve as well as intervals for its summary indices such as the AUC and the Youden index.
We first generate score CIs for by inverting the score test. In this case, the null hypothesis is given by where is a specific value of the parameter of interest. Under , the restricted (conditional) MLE for can be obtained by
or as a solution of the score equations . Note that this estimate is a function of . Letting , the quadratic (Rao) score statistic simplifies to
where denotes the submatrix corresponding to of the inverse Fisher information matrix and is given by the Schur complement . Under , converges asymptotically to a chi-square distribution with 1 degree of freedom, . This result is explained by Rao.43 Inverting the score statistic by enumerating values of allows for the construction of score CIs for defined as
where is the quantile value of the chi-squared distribution with 1 degree of freedom. Equivalently, we can use the square root of the score statistic to construct a score interval using quantiles of the standard normal distribution, . Finally, we apply the function to both the lower and upper limits of the interval to construct score confidence bands for the ROC curve or score CIs for its summary indices.
The score statistic is given by . Testing if there is a significant difference between the nondiseased and diseased populations coincides to the hypothesis test, . This is computationally efficient because only the distribution of needs to be computed. However, computing score CIs for more than one parameter requires updating the restricted MLEs for an enumeration of values. This becomes computationally intractable when enumerating a higher-dimensional grid of parameters.
Delta method
Since the MLE satisfies
then by the multivariate delta method, also follows a normal distribution with
where is the gradient of evaluated at and the inverse Fisher information matrix is given by the Schur complement . For example, when the shift term takes the linear form as in equation (6) and defines the AUC function for , the entries of are given by
where , is the density of the standard normal distribution and indexes the covariates. In general, the gradient can be estimated by calculating such derivatives and evaluating the resulting function at the MLE. Similarly, the variance-covariance matrix of the estimated parameters can be computed by inverting the numerically evaluated Hessian matrix. Thus, a level CI for is given by
Simulated intervals
When the function has complex derivatives, as would be the case for nonlinear shift terms or when calculating optimal thresholds where includes the inverse of the transformation function, constructing CIs using the delta method becomes infeasible. For these cases, we apply a simple simulation-based algorithm which utilizes the asymptotic normality of the MLE to calculate CIs for the ROC curve and its summary indices, which are functions of the parameters of interest. The steps of the algorithm to construct level CIs for can be summarized as follows:
Generate independent samples from the asymptotic multivariate normal distribution of the parameter estimates and denote as .
For each sample , calculate the function of interest .
Construct the CI , where is the empirical quantile function of the sample .
A similar algorithm is presented by Mandel,44 who discuss its asymptotic validity and present several examples that show its empirical coverage adheres to nominal levels with results similar to the delta method.
Empirical evaluation
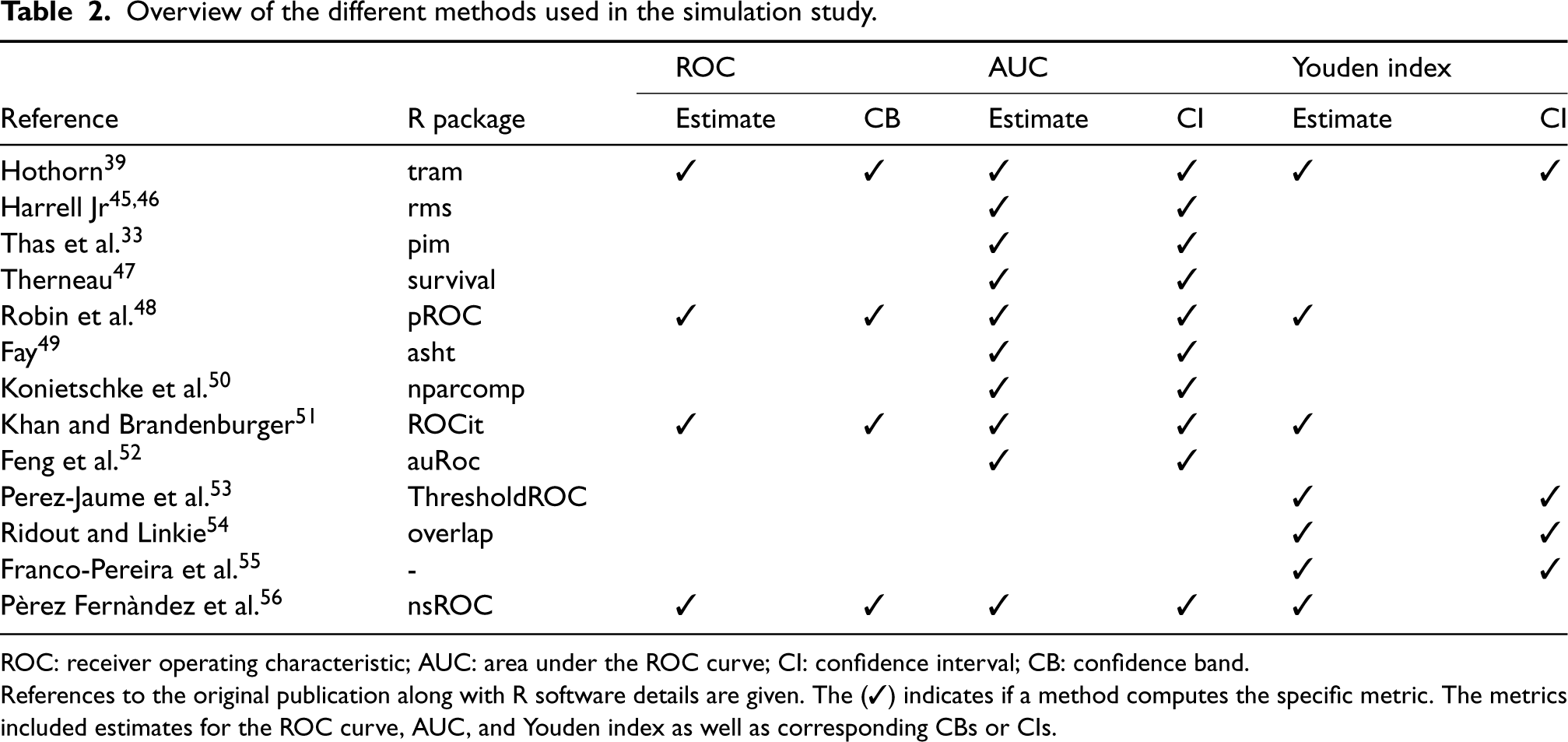
We conducted a simulation study to evaluate the performance of our estimators in the two-sample setting. We chose this setting to be able to compare various estimators commonly used in practice. The software details of all the methods used alongside their respective features and references are summarized in Table 2.
Overview of the different methods used in the simulation study.
ROC: receiver operating characteristic; AUC: area under the ROC curve; CI: confidence interval; CB: confidence band.
References to the original publication along with R software details are given. The () indicates if a method computes the specific metric. The metrics included estimates for the ROC curve, AUC, and Youden index as well as corresponding CBs or CIs.
We considered a data generating process (DGP) such that nondiseased test results followed a standard normal distribution and the diseased test results a distribution with the CDF . To obtain different shapes of the ROC curve, we chose three choices of and varied such that the or that , leading to a variety of configurations. Under this simulation paramaterization, the true ROC curves followed the form of equation (5) and the true summary indices could be calculated as a function of from Table 1.
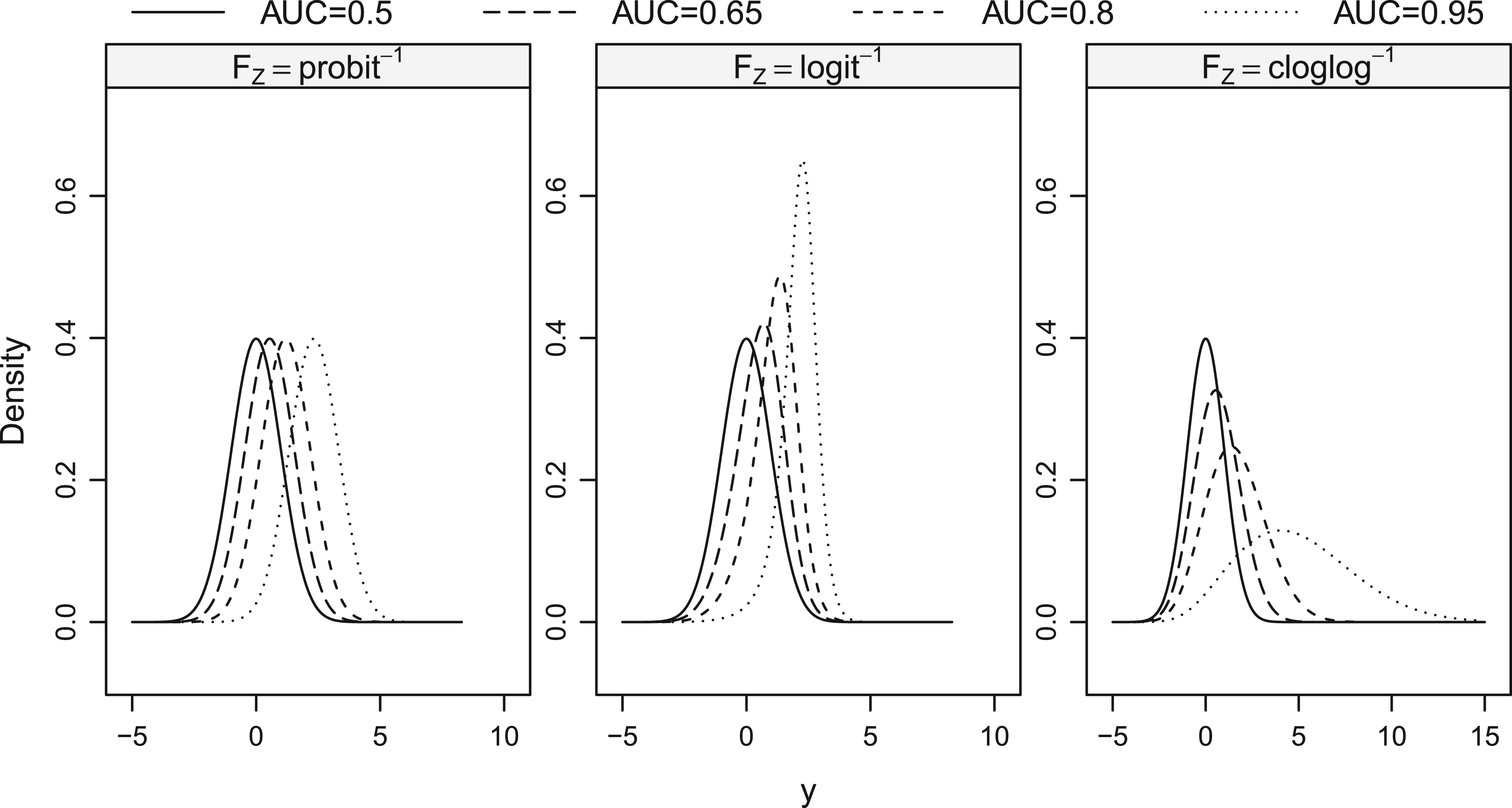
The conventional binormal model corresponded to and induced proper binormal ROC curves. This was the only configuration where the test results for both groups were normally distributed. We included this configuration to ascertain the loss of power associated with our estimators when the standard binormal assumption held. For other choices of with , the resulting distributions of the diseased test results were non-normal, with variances and higher moments differing between the two groups. Specifically, the configuration of led to light tailed distributions for the diseased test results, while led to skewed, heavy-tailed distributions. The corresponding density functions for the data generating model with selected AUC values are given in Figure 1.
Density functions for the model used to generate the data for the simulations. The nondiseased test results followed a standard normal distribution corresponding to an . The diseased test results varied with three choices of : , , and each of which had an AUC of 0.5, 0.65, 0.8, and 0.95. DGP: data generating process; AUC: area under the receiver operating characteristic curve.
For 10,000 replications of each configuration, we generated balanced data sets with sample sizes . The transformation models discussed in Section 2 were fitted to the simulated data sets assuming a parameterization of the transformation function given by a Bernstein basis polynomial of order (see Hothorn39 for a discussion on suitable choices for ). The true data-generating model had a nonlinear transformation function . Our model estimation procedure aimed to approximate this function alongside the shift parameter . The functions implementing transformation models for different choices of are available from the tram add-on package.39 Note that the function is for the data generating process in the simulation study and is distinct from , the inverse link function used in the model. When , the model is correctly specified for the DGP.
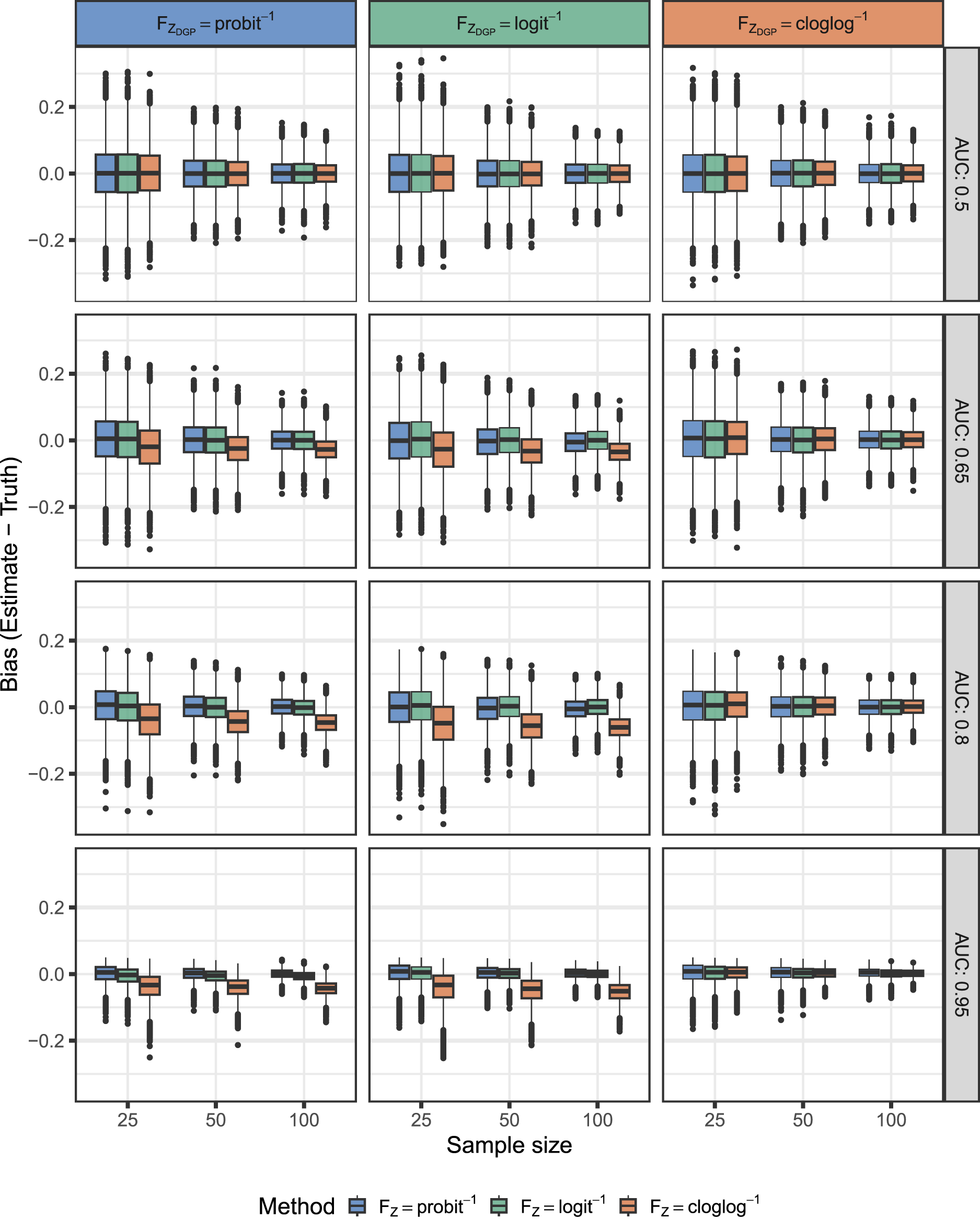
Figure 2 displays the distribution of bias for the AUC estimates using the proposed methods under the various simulation configurations. We found that all three methods had minimal bias for an , where the test results were unable to distinguish between the two groups. The models with yielded approximately unbiased AUC estimates in all cases, even when they were misspecified for the true data generating process. However, estimates based on the proportional hazards model , were biased for data generating processes other than where it was correctly specified.
Distribution of bias from the simulation study for estimation of the AUC. The DGP for nondiseased results was and for diseased results . We varied , , , AUC and sample size. The proposed methods also varied by the same inverse link functions. An alignment of colors in the column (DGP) and the fill of the box plot is indicative that the method is correctly specified for the DGP. DGP: data generating process; AUC: area under the receiver operating characteristic curve.
We compared our approaches to a set of alternative methods (see Table 2) for computing CIs for the AUC and Youden index. We detail the empirical coverage and average width of the CIs for the AUC in Supplemental Figures S1 and S2, respectively. Estimates based on transformation models (R packages tram, orm, pim) yielded coverage close to the nominal level and significantly outperformed the other methods when the model was correctly specified for the true data generating process. All other methods generally performed close to nominal levels for low to medium AUC values (0.5–0.8), but broke down for higher AUC values. In addition, the score CIs from the transformation model with were accurate even when it was misspecified for the true data generating process. However, methods which used gave CIs which were shorter in length (overconfident).
Analogously, Supplemental Figures S3 and S4 detail the coverage and length of the CIs for the Youden index. The methods which were based on the overlap coefficient failed to cover the configuration where because their lower limits were never below 0. Our methods estimated CIs for which naturally accounted for this scenario. The transformation model with provided coverage at nominal levels for all simulation configurations with a relatively small CI width. The approach of Franco-Pereira et al.55 (FP) was also accurate under model misspecification but was more involved. Namely, it consisted of estimating Box-Cox transformation parameters under a binormal framework with bootstrap variance, all carried out on the logit scale and then back-transformed. In a setting with covariates, censoring or with this methodology would be limited.
Supplemental Figures S5 and S6 show the coverage and area of the confidence bands for the ROC curve. All the approaches based on transformation models covered the configuration with accurately. However, the other approaches did not yield coverage close to nominal levels in this configuration with the exception of Martínez-Camblor et al.,57 whose confidence bands had a significantly larger area indicating lower power. For all other configurations, only transformation models which were correctly specified for the true data-generating model provided accurate results.
In addition to the simulations described above, we considered three other scenarios to evaluate the robustness of our proposed methods to model misspecification. The details for each of these scenarios are given in Supplemental Materials Section B. In terms of the AUC, we noticed that our models are generally robust to misspecification, but can break down in certain cases. However, the proportional hazard model with resulted in poor performance under misspecified configurations, indicating that it should be used with caution.
Application
The prevalence of obesity has increased consistently for most countries in the recent decade and this trend is a serious global health concern.58 Obesity contributes directly to increased risk of cardiovascular disease (CVD) and its risk factors, including type 2 diabetes, hypertension, and dyslipidemia.59,60 Metabolic syndrome (MetS) refers to the joint presence of several cardiovascular risk factors and is characterized by insulin resistance.61 The National Cholesterol Education Program Adult Treatment Panel III (NCEP-ATP III) criteria is the most widely used definition for MetS, but it requires laboratory analysis of a blood sample. This has led to the search for non-invasive techniques which allow reliable and early detection of MetS.
Waist-to-height ratio (WHtR) is a well-known anthropometric index used to predict visceral obesity. Visceral obesity is an independent risk factor for development of MetS by means of the increased production of free fatty acids whose presence obstructs insulin activity.62 This suggests that higher values of WHtR, reflecting obesity, and CVD risk factors, are more indicative of incident MetS. Several studies have found that WHtR is highly predictive of MetS.63–65 However, as waist circumference changes with age and gender,66 it is also important to study whether or not the performance of WHtR at diagnosing MetS is impacted by these variables. Evaluation of WHtR as a predictor of MetS after adjusting for covariates is necessary so that more tailored interventions can be initiated to improve outcomes.
We illustrate the use of our methods to data from a cross sectional study designed to validate the use of WHtR and systolic blood pressure (SBP) as markers for early detection of MetS in a working population from the Balearic Islands (Spain). Detailed descriptions of the study methodology and population characteristics are reported in Romero-Saldaña et al.67 Briefly, data on 60 799 workers were collected during their work health periodic assessments between 2012 and 2016. Presence of MetS was determined by the NCEP-ATP III criteria and the sample consisted of 5487 workers with MetS.
Two-sample analysis
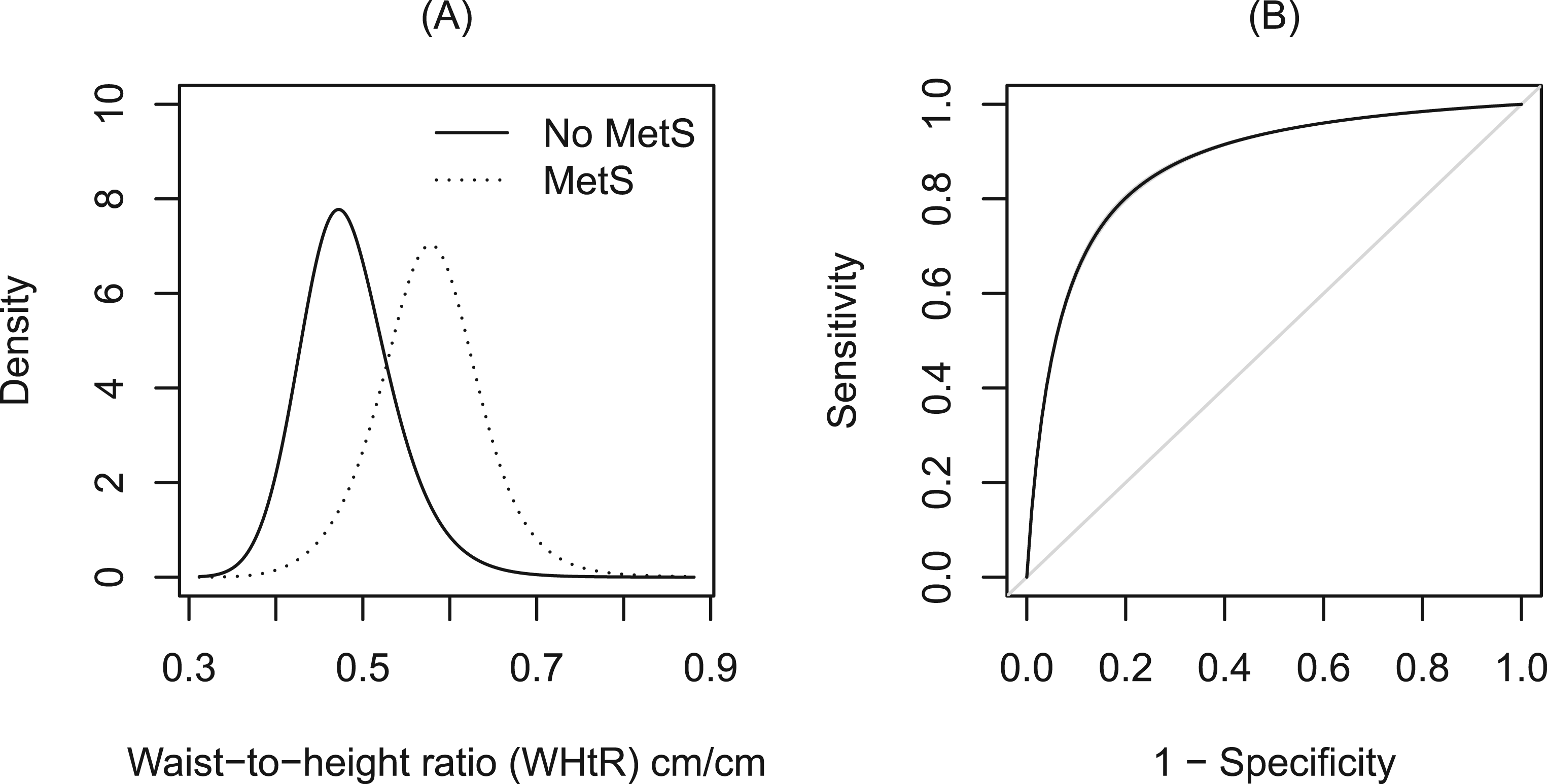
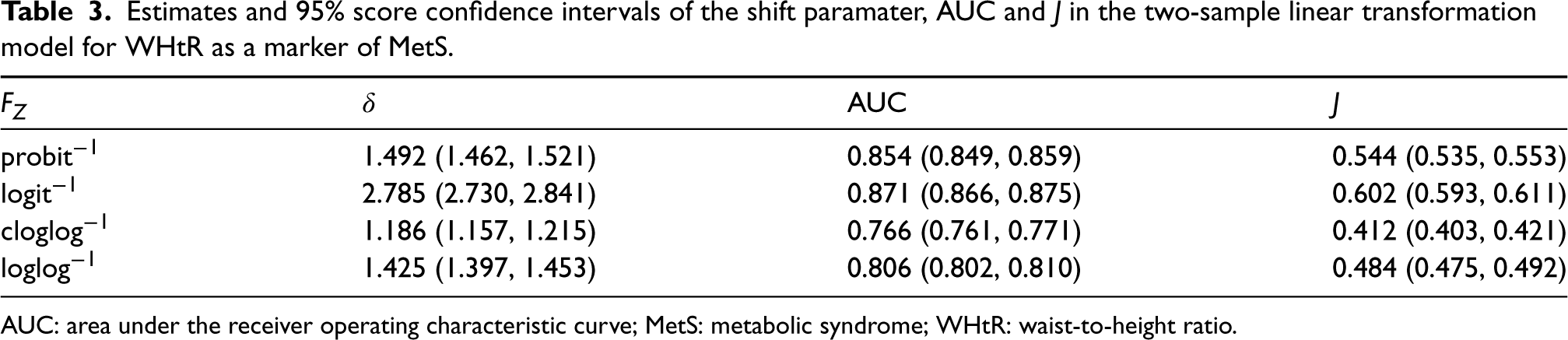
We first examined the unconditional performance of WHtR as a marker to diagnose MetS, denoted and , respectively. We fitted a linear transformation model with corresponding ROC curve of the form in equation (5), where is the shift parameter, for various choices of the inverse link function . Associated inference of the AUC and was calculated using the closed-form expressions from Table 1. The resulting estimates are presented in Table 3. The AUCs were consistently bounded away from indicating a good capacity of WHtR to discriminate between workers with and without MetS. This can also be seen from the estimated ROC curve plotted in Figure 3 which lies well above the diagonal line as well as the modeled densities which have a small degree of overlap. The CIs and uniform confidence bands were quite small due to the large sample size.
Estimates from the linear transformation model with a single shift parameter, , where is chosen to be a standard logistic distribution. (A) Density functions of WHtR for the workers who were diagnosed with MetS (dotted line) and those who were not (solid line). (B) ROC curve for WHtR as a marker of MetS with 95% uniform score confidence bands are represented by gray shaded areas. MetS: metabolic syndrome; WHtR: waist-to-height ratio.
Estimates and 95% score confidence intervals of the shift paramater, AUC and in the two-sample linear transformation model for WHtR as a marker of MetS.
AUC
1.492 (1.462, 1.521)
0.854 (0.849, 0.859)
0.544 (0.535, 0.553)
2.785 (2.730, 2.841)
0.871 (0.866, 0.875)
0.602 (0.593, 0.611)
1.186 (1.157, 1.215)
0.766 (0.761, 0.771)
0.412 (0.403, 0.421)
1.425 (1.397, 1.453)
0.806 (0.802, 0.810)
0.484 (0.475, 0.492)
AUC: area under the receiver operating characteristic curve; MetS: metabolic syndrome; WHtR: waist-to-height ratio.
Conditional ROC analysis
Next, we investigated if the discriminatory ability of WHtR in separating workers with and without MetS varies with covariates. We considered a transformation model that included the main effects of covariates plus interaction terms with the disease indicator, which leads to the ROC curve given by
where the covariates included age, gender, and tobacco consumption. The choice of was made using repeated holdout validation. We describe this model selection procedure in Supplemental Material Section C and show the results for different model choices and parameterizations.
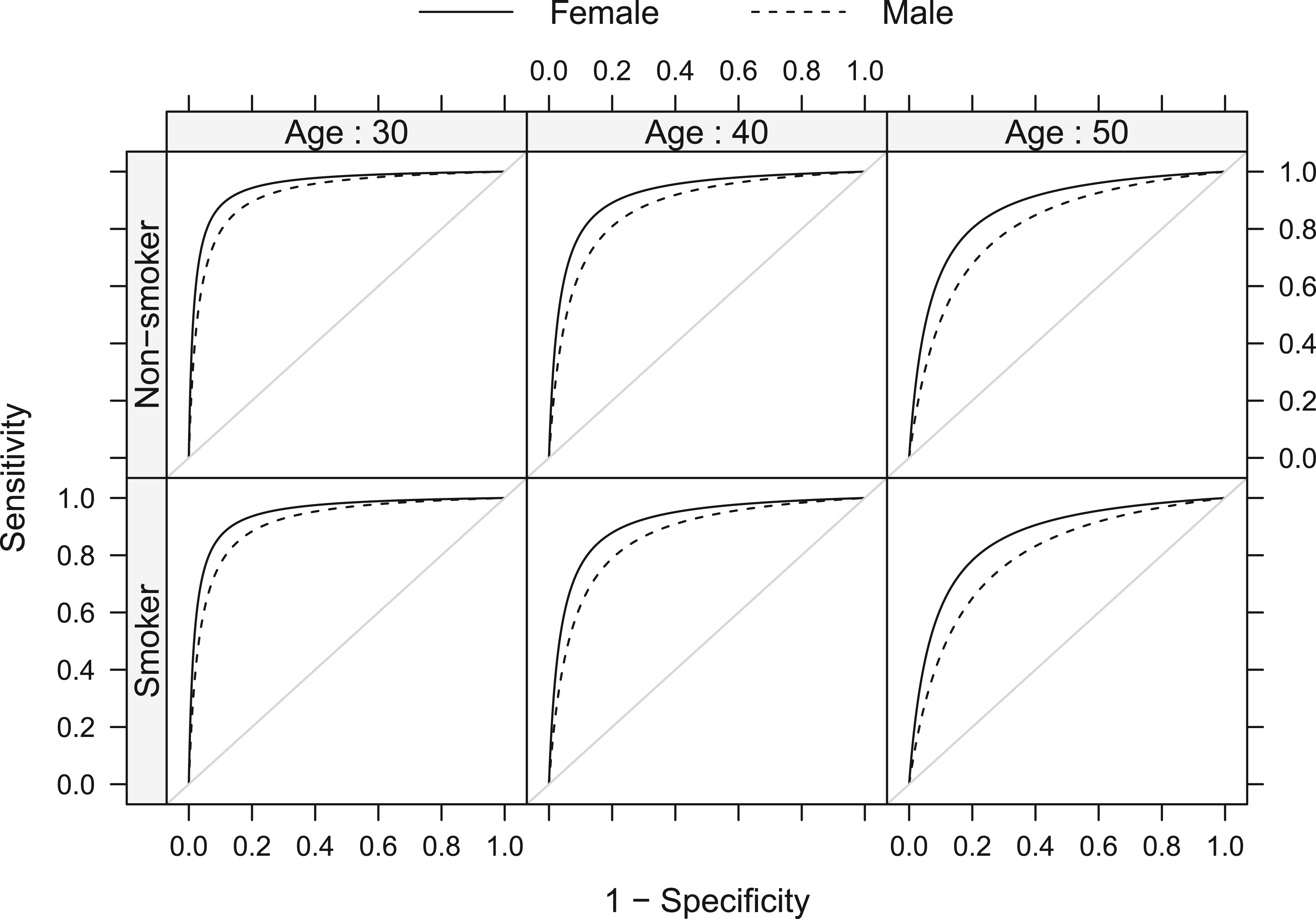
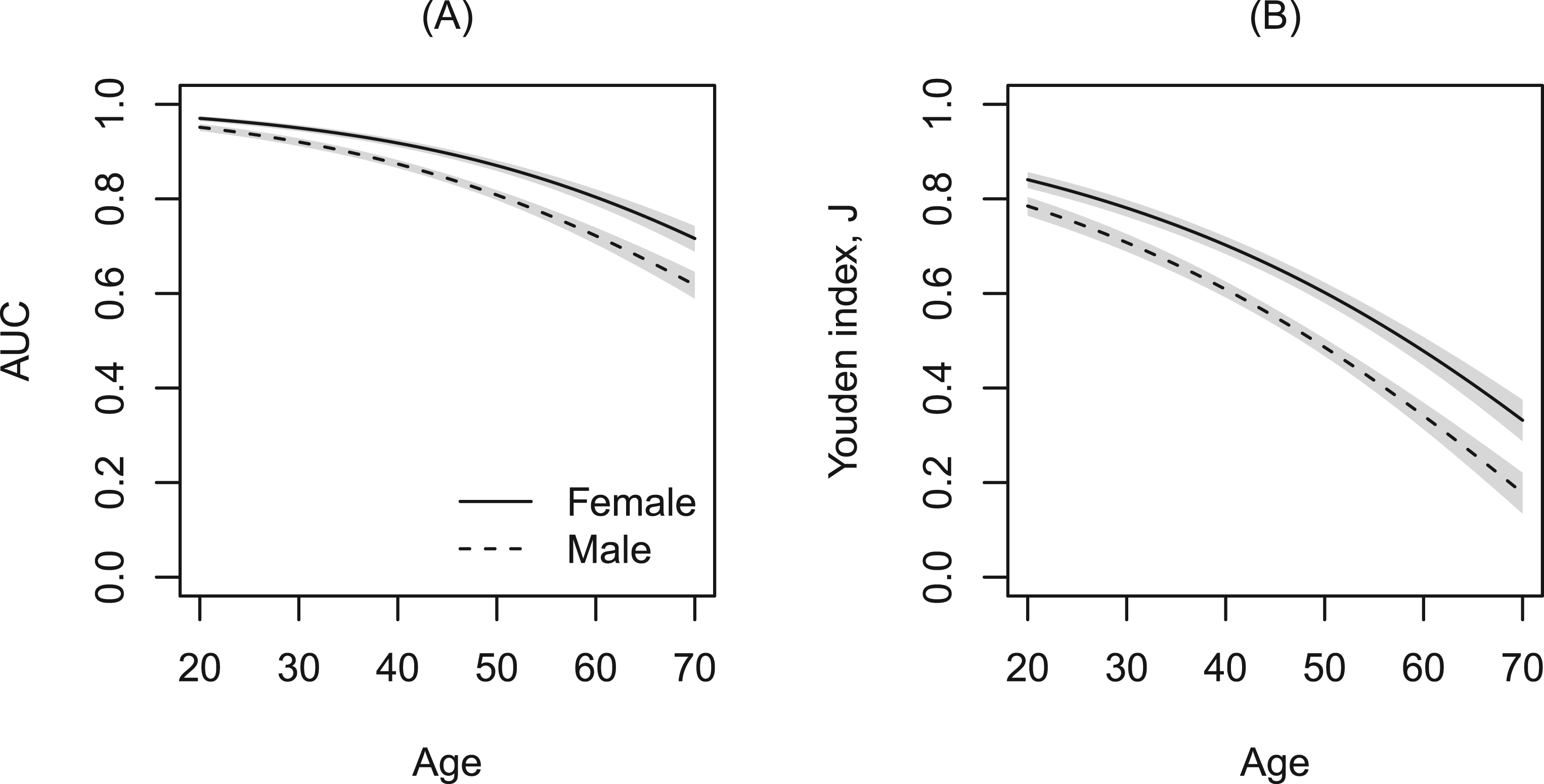
Figure 4 displays the covariate-specific ROC curves fitted to these data. The performance of WHtR appeared to be better for females compared to males and decreased with age. The effect of smoking, although significant in the model, does not seem to substantially alter the ROC curves given the other covariates are kept fixed. To inspect the covariate effect further, we calculated the age- and gender-specific AUCs and Youden indices from the model. Figure 5 clearly shows that the discriminatory capabilities of WHtR in distinguishing workers with MetS is consistently better for females and decreases with age.
Estimated covariate-specific ROC curves for WHtR as a marker of MetS for female (solid line) and male workers (dashed line). Vertical panels represent a specific age (30, 40, 50) and horizontal panels smoking status. ROC: receiver operating characteristic; MetS: metabolic syndrome; WHtR: waist-to-height ratio.
Age-based AUC and Youden indices where WHtR is used as a marker to detect MetS for non-smoking female (solid line) and male (dashed line) workers. 95% Wald pointwise confidence bands are represented by gray shaded areas. AUC: area under the receiver operating characteristic curve; MetS: metabolic syndrome; WHtR: waist-to-height ratio.
Discussion
This article presents a new modeling framework for ROC analysis that can be used to characterize the accuracy of medical diagnostic tests. Our model is based on estimating an unknown transformation function for the test results and yields a distribution-free yet model-based estimator for the ROC curve. Covariates that influence the diagnostic accuracy of tests can naturally be accommodated as regression parameters into the model and covariate-specific summary indices such as the AUC and Youden index are easily computed using closed-form expressions.
Our proposed approach has several features which distinguish it from contemporary methods of ROC analysis. Firstly, we employ maximum likelihood to jointly estimate all parameters defining the transformation function and regression coefficients. This implies the variation in the estimated transformation parameters is accounted for and appropriately propagated to inference for the ROC curve. In turn, asymptotic efficiency is guaranteed for our estimators and we avoid reliance on resampling procedures for the construction of CIs. Secondly, transformation models focus on estimating the conditional distribution function whose evaluation directly provides the likelihood contributions for interval, right-, and left-censored data that commonly arises due to instrument detection limits. Thirdly, no strong assumptions are made regarding the transformation function which results in a highly flexible model that retains interpretability of the regression coefficients. Lastly, software implementations for all the methods described in this article are available in the tram R add-on package (see Supplemental Material for example code), thus enabling a unified framework for ROC analysis.
In our simulation study, interestingly, we found that a model with provided accurate results even when it was misspecified for the true data generating process. This model also behaves very similarly to the semiparametric cumulative probability model,68 both of which estimate a log-odds ratio . The equivalence of the transformation model’s odds ratio to the MWW test statistic has been well studied.69 The MWW statistic has a bounded influence function and is robust to contaminations of the specified model.70 Due to their equivalence, we hypothesize that the transformation model with is also endowed with the same robustness properties as the MWW and thus can be chosen when no a priori model is known.
One aspect that warrants further investigation is model selection, specifically with regards to the choice of . One strategy would be to define tailored to a specific interpretation of the parameters , , and , for example, as log-odds ratios with or for hazard ratios.34 A second option is to use some form of cross validation in combination with model assessment via the probability integral transform (PIT) (as discussed in Supplemental Materials Section C). Third, and in analogy to single index models, one could introduce parameters to such that the shape of the inverse link function is estimated along with all other model parameters (McLain and Ghosh71 discuss a family of link functions including the complementary log-log and logit). Finally, we could completely relax the assumption that the difference between the diseased and nondiseased distributions is described by a shift-term. In this case, separate transformation functions would be allowed in each of the two groups. Namely, consider a stratified model where the nondiseased results follow a distribution with the CDF and the diseased with the CDF . Defining a new transformation function , the smooth ROC curve with no shift assumptions is given by . This model has more flexibility but sacrifices the properness property desirable for the ROC curves. Furthermore, care has to be taken in defining the correct likelihood contributions for accurate inference of this model as uncertainty enters from both transformation functions.
In future work, we plan to pursue various extensions of transformation models for ROC analysis to consider (1) penalty terms for high-dimensional covariates,72 (2) mixed effects for clustered observations,73 and (3) covariate-dependent transformation functions through forest-based machine learning methods.74
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231176030 - Supplemental material for Estimating transformationsfor evaluating diagnostic testswith covariate adjustment
Supplemental material, sj-pdf-1-smm-10.1177_09622802231176030 for Estimating transformationsfor evaluating diagnostic testswith covariate adjustment by Ainesh Sewak and Torsten Hothorn in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Swiss National Science Foundation, grant number 200021_184603.
ORCID iD
Torsten Hothorn
Supplemental material
Supplemental materials for this article are available online.
References
1.
PepeMS. The Statistical Evaluation of Medical Tests for Classification and Prediction. Oxford, UK: Oxford University Press, 2003.
2.
ZouKHLiuABandosAI, et al. Statistical Evaluation of Diagnostic Performance: Topics in ROC Analysis. Boca Raton, FL, USA: CRC Press, 2011.
3.
PepeMS. A regression modelling framework for receiver operating characteristic curves in medical diagnostic testing. Biometrika1997; 84: 595–608.
4.
FaraggiD. Adjusting receiver operating characteristic curves and related indices for covariates. J R Stat Soc: Ser D (The Statistician)2003; 52: 179–192.
5.
PerkinsNJSchistermanEFVexlerA. Receiver operating characteristic curve inference from a sample with a limit of detection. Am J Epidemiol2007; 165: 325–333.
6.
BantisLEYanQTsimikasJV, et al. Estimation of smooth ROC curves for biomarkers with limits of detection. Stat Med2017; 36: 3830–3843.
7.
InácioVLourençoVMde CarvalhoM, et al. Robust and flexible inference for the covariate-specific receiver operating characteristic curve. Stat Med2021; 40: 5779–5795.
8.
InácioVRodríguez-ÁlvarezMXGayoso-DizP. Statistical evaluation of medical tests. Annu Rev Stat Appl2021; 8: 41–67.
9.
ZouKHTempanyCMFieldingJR, et al. Original smooth receiver operating characteristic curve estimation from continuous data: statistical methods for analyzing the predictive value of spiral CT of ureteral stones. Acad Radiol1998; 5: 680–687.
10.
ZouKHHallW. Two transformation models for estimating an ROC curve derived from continuous data. J Appl Stat2000; 27: 621–631.
11.
ZouKHHallWJShapiroDE. Smooth non-parametric receiver operating characteristic (ROC) curves for continuous diagnostic tests. Stat Med1997; 16: 2143–2156.
12.
HothornTKneibTBühlmannP. Conditional transformation models. J R Stat Soc: Ser B (Statistical Methodology)2014; 76: 3–27.
13.
HothornTMöstLBühlmannP. Most likely transformations. Scand J Stat2018; 45: 110–134.
14.
BamberD. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. J Math Psychol1975; 12: 387–415.
15.
YoudenWJ. Index for rating diagnostic tests. Cancer1950; 3: 32–35.
16.
KomabaAJohnoHNakamotoK. A novel statistical approach for two-sample testing based on the overlap coefficient, 2022. https://arxiv.org/abs/2206.03166. arXiv:2206.03166 [math.ST].
17.
WeitzmanMS. Measures of Overlap of Income Distributions of White and Negro Families in the United States. 3. Washington, DC: US Bureau of the Census, 1970. Washington, D.C.
18.
FellerW. An Introduction to Probability Theory and Its Applications. New York, NY, USA: Wiley, 1991.
19.
SchmidFSchmidtA. Nonparametric estimation of the coefficient of overlapping—theory and empirical application. Comput Stat Data Anal2006; 50: 1583–1596.
20.
Martínez-CamblorP. About the use of the overlap coefficient in the binary classification context. Commun Stat-Theor Method2022; 1–11.
21.
TostesonANABeggCB. A general regression methodology for ROC curve estimation. Med Decis Making1988; 8: 204–215.
22.
BickelPJDoksumKA. An analysis of transformations revisited. J Am Stat Assoc1981; 76: 296–311.
23.
DorfmanDDAlf JrE. Maximum-likelihood estimation of parameters of signal-detection theory and determination of confidence intervals-rating-method data. J Math Psychol1969; 6: 487–496.
24.
OgilvieJCCreelmanCD. Maximum-likelihood estimation of receiver operating characteristic curve parameters. J Math Psychol1968; 5: 377–391.
25.
GönenMHellerG. Lehmann family of ROC curves. Med Decis Making2010; 30: 509–517.
26.
KhanRA. Resilience family of receiver operating characteristic curves. IEEE Trans Reliab 2022. DOI: 10.1109/TR.2022.3194710.
27.
ZouKH. Analysis of Some Transformation Models for the Two-sample Problem With Special Reference to Receiver Operating Characteristic Curves. PhD thesis, University of Rochester, 1997.
PanXMetzCE. The “proper” binormal model: parametric receiver operating characteristic curve estimation with degenerate data. Acad Radiol1997; 4: 380–389.
30.
McIntoshMWPepeMS. Combining several screening tests: optimality of the risk score. Biometrics2002; 58: 657–664.
31.
SiegfriedSKookLHothornT. Distribution-free location-scale regression. Am Stat 2022. DOI: 10.1080/00031305.2023.2203177.
32.
DoddLEPepeMS. Partial AUC estimation and regression. Biometrics2003; 59: 614–623.
33.
ThasONeveJDClementL, et al. Probabilistic index models. J R Stat Soc: Ser B (Statistical Methodology)2012; 74: 623–671.
34.
De NeveJThasOGerdsTA. Semiparametric linear transformation models: effect measures, estimators, and applications. Stat Med2019; 38: 1484–1501.
35.
FaroukiRT. The bernstein polynomial basis: a centennial retrospective. Comput Aided Geom Des2012; 29: 379–419.
36.
LindseyJK. Parametric Statistical Inference. Oxford, UK: Oxford University Press, 1996.
37.
RaoCR. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. In Mathematical Proceedings of the Cambridge Philosophical Society, volume 44. Cambridge, UK: Cambridge University Press, 1948. pp. 50–57.
HothornT. Most likely transformations: the mlt package. J Stat Softw2020; 92: 1–68.
40.
LynnHS. Maximum likelihood inference for left-censored HIV RNA data. Stat Med2001; 20: 33–45.
41.
MumfordSLSchistermanEFVexlerA, et al. Pooling biospecimens and limits of detection: effects on ROC curve analysis. Biostatistics2006; 7: 585–598.
42.
XiongCLuoJAgboolaF, et al. A family of estimators to diagnostic accuracy when candidate tests are subject to detection limits—application to diagnosing early stage Alzheimer’s disease. Stat Methods Med Res2022; 31: 882–898.
43.
RaoCR. Score test: historical review and recent developments. In Advances in Ranking and Selection, Multiple Comparisons, and Reliability. Boston, MA, USA: Birkhäuser, 2005; pp. 8–20.
44.
MandelM. Simulation-based confidence intervals for functions with complicated derivatives. Am Stat2013; 67: 76–81.
45.
Harrell JrFE. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis. 608. New York: Springer, 2001.
KonietschkeFPlaczekMSchaarschmidtF, et al. nparcomp: an R software package for nonparametric multiple comparisons and simultaneous confidence intervals. J Stat Softw2015; 64: 1–17. DOI: http://www.jstatsoft.org/v64/i09/.
51.
KhanMRABrandenburgerT. ROCit: Performance Assessment of Binary Classifier with Visualization, 2020. https://CRAN.R-project.org/package=ROCit. R package version 2.1.1.
Perez-JaumeSSkaltsaKPallarèsN, et al. ThresholdROC: optimum threshold estimation tools for continuous diagnostic tests in R. J Stat Softw2017; 82: 1–21.
54.
RidoutMLinkieM. Estimating overlap of daily activity patterns from camera trap data. J Agric Biol Environ Stat2009; 14: 322–337.
55.
Franco-PereiraAMNakasCTReiserB, et al. Inference on the overlap coefficient: the binormal approach and alternatives. Stat Methods Med Res2021; 30: 2672–2684.
56.
Pérez FernándezSMartínez CamblorPFilzmoserP, et al. nsROC: an R package for non-standard ROC curve analysis. R J2018; 10: 55–77.
57.
Martínez-CamblorPPérez-FernándezSCorralN. Efficient nonparametric confidence bands for receiver operating-characteristic curves. Stat Methods Med Res2018; 27: 1892–1908.
58.
Abarca-GómezLAbdeenZAHamidZA, et al. Worldwide trends in body-mass index, underweight, overweight, and obesity from 1975 to 2016: a pooled analysis of 2416 population-based measurement studies in 128.9 million children, adolescents, and adults. Lancet2017; 390: 2627–2642.
59.
ZalesinKCFranklinBAMillerWM, et al. Impact of obesity on cardiovascular disease. Endocrinol Metab Clin North Am2008; 37: 663–684.
EckelRHAlbertiKGMMGrundySM, et al. The metabolic syndrome. Lancet2010; 375: 181–183.
62.
BoselloOZamboniM. Visceral obesity and metabolic syndrome. Obes Rev2000; 1: 47–56.
63.
ShaoJYuLShenX, et al. Waist-to-height ratio, an optimal predictor for obesity and metabolic syndrome in Chinese adults. J Nutr Health Aging2010; 14: 782–785.
64.
Romero-SaldañaMFuentes-JiménezFJVaquero-AbellánM, et al. New non-invasive method for early detection of metabolic syndrome in the working population. Eur J Cardiovasc Nurs2016; 15: 549–558.
65.
SuligaECieslaEGłuszek-OsuchM, et al. The usefulness of anthropometric indices to identify the risk of metabolic syndrome. Nutrients2019; 11: 2598.
66.
StevensJKatzEGHuxleyRR. Associations between gender, age and waist circumference. Eur J Clin Nutr2010; 64: 6–15.
67.
Romero-SaldañaMTaulerPVaquero-AbellánM, et al. Validation of a non-invasive method for the early detection of metabolic syndrome: a diagnostic accuracy test in a working population. BMJ Open2018; 8: e020476.
68.
TianYHothornTLiC, et al. An empirical comparison of two novel transformation models. Stat Med2020; 39: 562–576.
69.
WangYTianL. The equivalence between Mann-Whitney Wilcoxon test and score test based on the proportional odds model for ordinal responses. In 4th International Conference on Industrial Economics System and Industrial Security Engineering (IEIS). Kyoto, Japan: IEEE, pp. 1–5.
70.
HampelFR. The influence curve and its role in robust estimation. J Am Stat Assoc1974; 69: 383–393.
71.
McLainACGhoshSK. Efficient sieve maximum likelihood estimation of time-transformation models. J Stat Theory Pract2013; 7: 285–303.
72.
KookLHothornT. Regularized transformation models: the tramnet package. R J2021; 13: 581–594.
73.
TamásiBHothornT. tramME: mixed-effects transformation models using template model builder. R J2021; 13: 581–594.
74.
HothornTZeileisA. Predictive distribution modeling using transformation forests. J Comput Graph Stat2021; 30: 1181–1196.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.