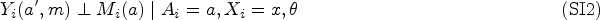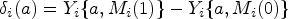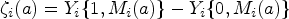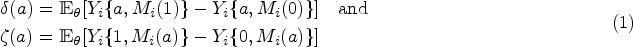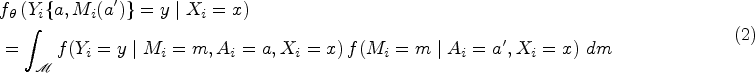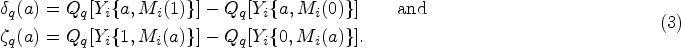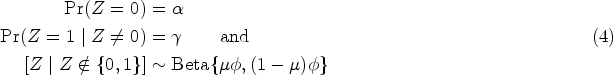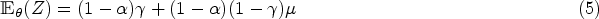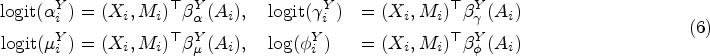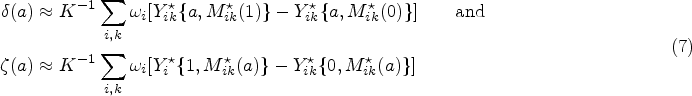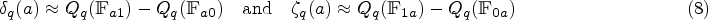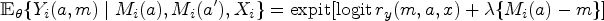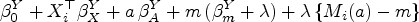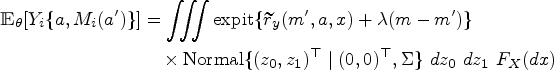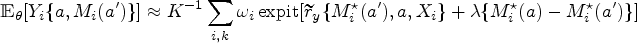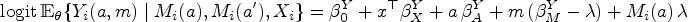The goal of causal mediation analysis, often described within the potential outcomes framework, is to decompose the effect of an exposure on an outcome of interest along different causal pathways. Using the assumption of sequential ignorability to attain non-parametric identification, Imai et al. (2010) proposed a flexible approach to measuring mediation effects, focusing on parametric and semiparametric normal/Bernoulli models for the outcome and mediator. Less attention has been paid to the case where the outcome and/or mediator model are mixed-scale, ordinal, or otherwise fall outside the normal/Bernoulli setting. We develop a simple, but flexible, parametric modeling framework to accommodate the common situation where the responses are mixed continuous and binary, and, apply it to a zero-one inflated beta model for the outcome and mediator. Applying our proposed methods to the publicly-available JOBS II dataset, we (i) argue for the need for non-normal models, (ii) show how to estimate both average and quantile mediation effects for boundary-censored data, and (iii) show how to conduct a meaningful sensitivity analysis by introducing unidentified, scientifically meaningful, sensitivity parameters.
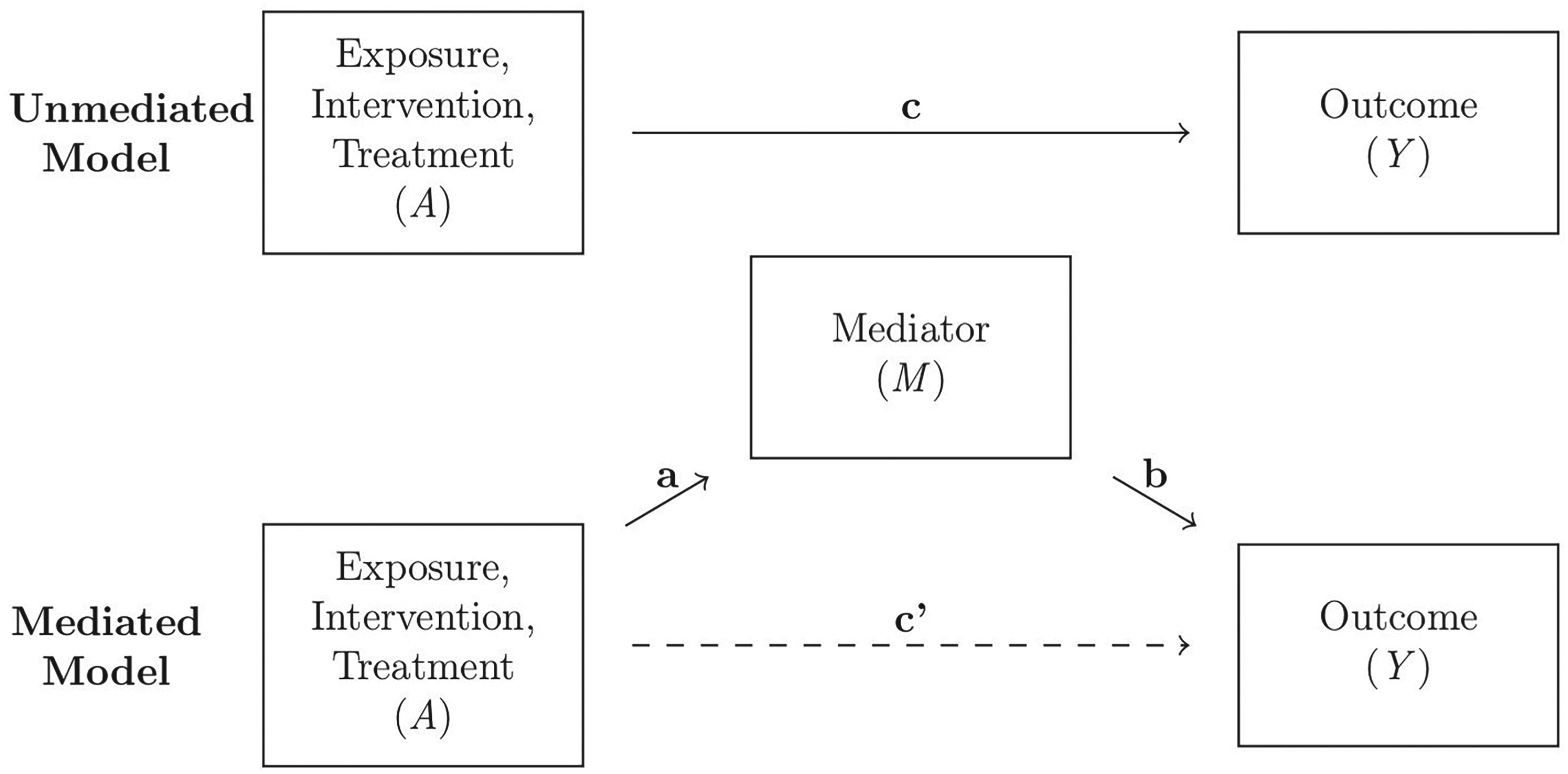
Mediation analysis is conducted across many scientific fields to understand the underlying mechanisms behind cause and effect relationships; examples include epidemiology, economics, and social science. Causal mediation analysis, often couched in the potential outcomes framework,1,2 decomposes the effect of an exposure on the outcome along different causal pathways. A schematic depiction of a standard single-mediator model is given in Figure 1. In this diagram, denotes the exposure for the observational unit, denotes the outcome, and denotes a mediator which may be on the causal pathway from the exposure to the outcome. When the mediator is accounted for in the relationship between and , we measure a direct effect, while when the mediator is ignored we measure the total effect. The indirect effect of the exposure through its effect on the mediator uses pathways and to affect the outcome.
Schematic depiction of a causal structure with a single variable mediating the effect of the treatment on the outcome . Top: the causal structure ignoring the existence of the mediator. Bottom: the causal structure with the mediator included.
While most works on mediation analysis have focused on the case where the mediator and outcome are continuous/normal or Bernoulli distributed, in our experience, it is common that one (or both) of the mediator or outcome will have a mixed-scale support. In this article, we focus on the case where the mediator and outcome are mixed continuous and discrete random variables; in particular, we assume that they have a continuous distribution on with mass at the boundary points and . We argue that, particularly when taking a parametric Bayesian approach to estimation, it is important to adequately model the data, both for the purpose of reducing bias and to adequately account for uncertainty in effect estimation. To meet this challenge, we develop a general framework for performing causal mediation analysis with mixed-scale data. In principle, this framework can be used regardless of the model for the observed data, and we use a zero-one inflated beta regression model to illustrate.
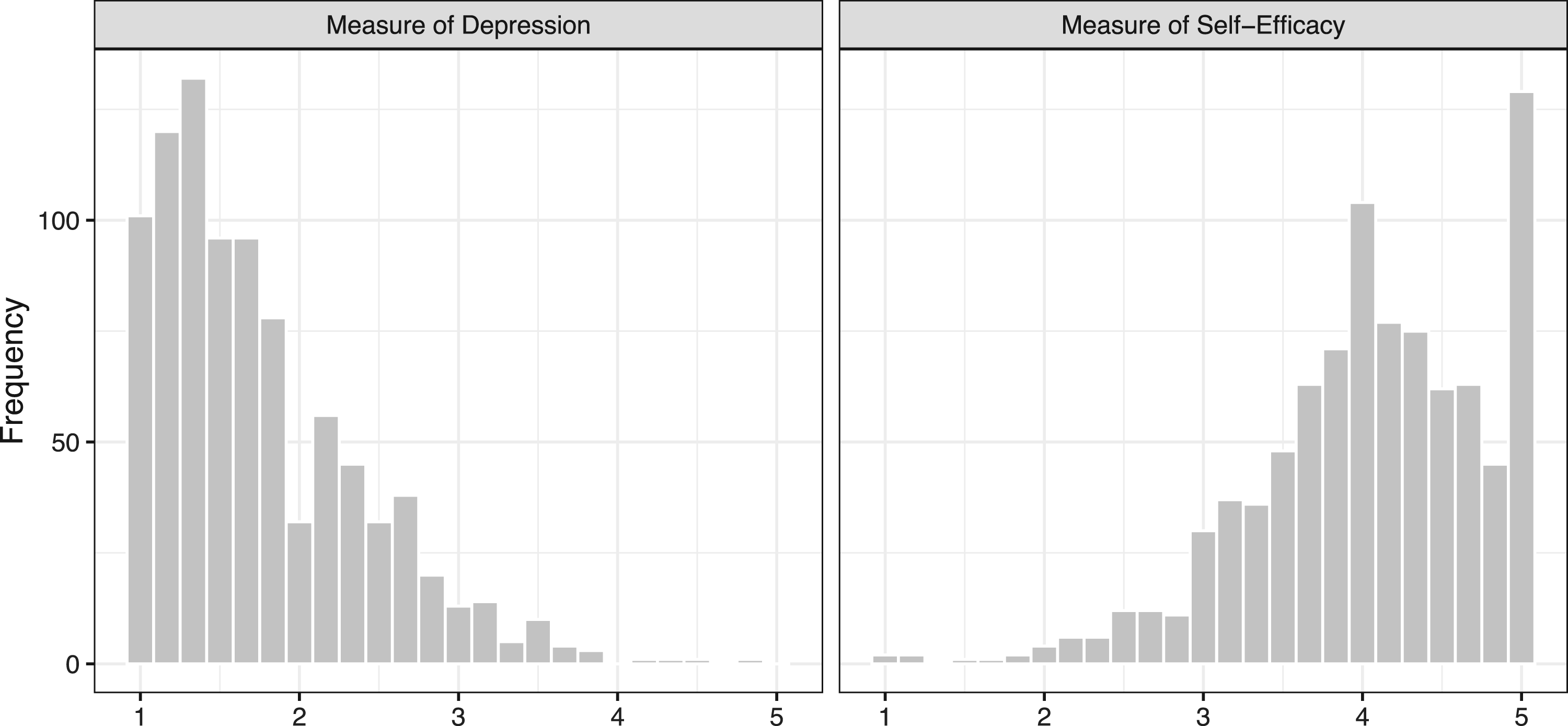
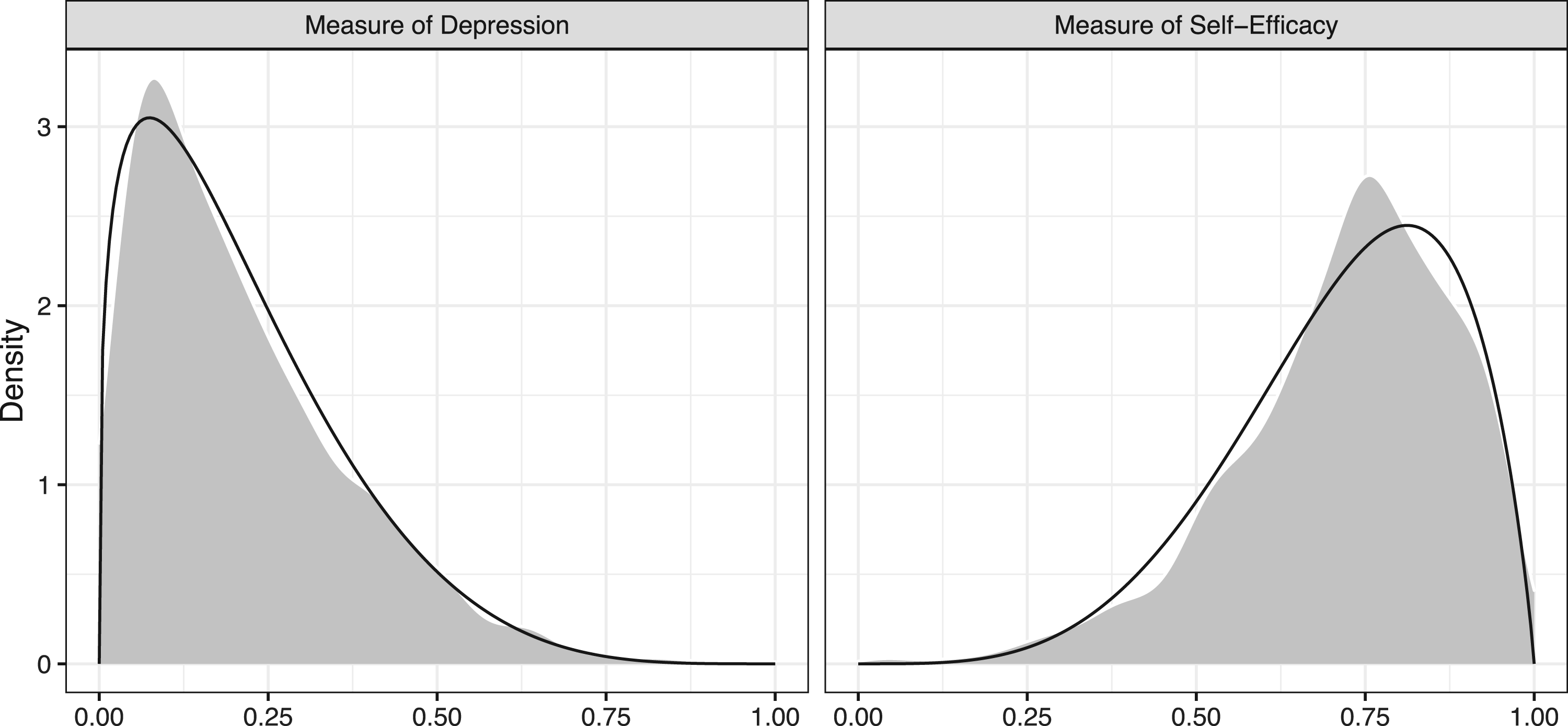
For the sake of reproducibility, we focus on the JOBS II study of Vinokur et al.,3 for which a subset of data is available in the mediation package in R. A description of this dataset is given in Section 2.1. Imai et al.1 present several analyses of this dataset, essentially operating under the assumption that the mediator (a measure of self-efficacy in finding a job) and the outcome (a measure of depression) are normally distributed. As shown in Figure 2, however, it is apparent that neither the outcome nor the mediator is well-described by a normal distribution; both exhibit skewness and there is a substantial mass at the boundary values of for depression and for self-efficacy.
Empirical distribution of (left) measured depression level (right) measured job-search self-efficacy at the end of study.
An additional challenge with mixed-scale models is assessing the sensitivity of inferences to untestable assumptions. As with most estimands in causal inference, it is well-known that the causal mediation effects are not identified on the basis of the observed data distribution alone, and can only be consistently estimated under additional (unfalsifiable) assumptions. A useful benchmark assumption is sequential ignorability (SI, Imai et al.1), which essentially rules out the existence of unmeasured confounders. We found performing sensitivity analysis in the mixed-scale setting to be challenging, as to the best of our knowledge none of the existing proposals for sensitivity analysis can be applied directly. For example, the approaches proposed by Imai et al.1 are justified by a linear structural equation model (LSEM, Baron and Kenny4), which is not applicable in this setting. Similarly, the limited work with non-continuous or categorical data5,6 also does not apply directly to the mixed-scale setting. We develop a pair of widely-applicable sensitivity analysis strategies that accomplish the two goals of (i) assessing the extent to which our conclusions are driven by unmeasured confounding and (ii) neither imposing any additional restrictions on, nor adding information about, the distribution of the observed data. Our second goal is part of a recent trend in causal inference and missing data research of proposing sensitivity analyses that clearly and unambiguously separate the (parametric) assumptions used to model the observed data from the assumptions used to identify the causal effects of interest.8,9,7,10
Review of existing methods
The traditional approach to mediation analysis uses structural equation modeling (SEM) to quantify mediation; linear structural equation models (LSEMs) are particularly popular.11 However, LSEMs do not generalize easily to non-linear systems.12 Additionally, Imai et al.1 make the point that the identification assumptions used in LSEMs are inexorably tied to the choice of parametric model, stating: “[because] the key identification assumption is stated in the context of a particular model, [it is] difficult to separate the limitations of research design from those of the specified statistical model.” Motivated by this argument, Imai et al.1 proposed a more general approach to mediation analysis using a potential outcomes framework, introduced the nonparametric assumption of sequential ignorability to identify the effects, and showed that the single mediator LSEM is a special case of the potential outcomes framework that is valid as long as the linearity assumption holds.
There is a rich literature addressing the causal mediation problem from the semiparametric perspective. An emphasis in this literature is the development of methods that are both statistically efficient and multiply robust in the sense that they produce consistent estimates even if one of several models required for estimation are misspecified.13,14 An advantage of these approaches is that one can easily use them with modern machine learning methods via cross-fitting.15 To the best of our knowledge, however, these methods have not been developed in the context of mixed-scale data. Bayesian nonparametric and semiparametric models based on infinite mixture models have also been proposed,16 although not for mixed-scale data.
A variety of models have also extended beyond continuous/binary models for the mediator and outcome. These include models for the zero-inflated count, survival, and ordinal data, as well as quantile regression models.6,17,18,1
Contributions
We make the following contributions in this article. First, we describe how to implement the -formula for computing both mean and quantile causal effects for generic mixed-scale models under the sequential ignorability assumption. Second, we illustrate these concepts using a zero-one inflated beta regression model and argue for its appropriateness on the benchmark JOBS II dataset. Third, we show how to conduct a principled sensitivity analysis to check the sensitivity of our conclusions to the untestable sequential ignorability assumption; the sensitivity parameters we introduce are designed to be unidentified, so that varying them does not affect the distribution of the observed data. We show how to introduce sensitivity parameters that are shifts of the mean on either a linear or logit scale; both of these approaches are very easy to incorporate into our models by post-processing the model fit. These mean-shift assumptions are weaker than the usual sequential ignorability assumption in that they only identify the mean of the potential outcomes rather than their whole distribution, but include the results of sequential ignorability as a special case.
We also present a flexible zero-one inflated beta (ZOIB) model19 for mediation analysis with boundary-censored data and show how to perform inference with this model. The ZOIB models we use here are conceptually related to other zero-inflated models, such as the zero-inflated Poisson (ZIP), zero-inflated negative binomial (ZINB), zero-inflated gamma (ZIG), and zero-inflated log-normal (ZILN). See Zuur et al.20 for a review of zero-inflated models for count data and Liu et al.21 for semicontinuous zero-inflated models. Like the ZIG and ZILN (and unlike the ZIP and ZINB) models, the ZOIB model is semicontinuous, as the boundary points 0 and 1 occur with probability 0 in a standard beta regression model. These models are cast as a covariate-dependent mixture model, with the ZOIB being a mixture of a beta distribution and a Bernoulli distribution (where the parameters of the beta and Bernoulli distributions themselves are also covariate dependent).
A Bayesian implementation of this model is given at www.github.com/theodds/ZOIBMediation. Our model is implemented in Stan, with both the average and quantile causal mediation effects computed using a Monte Carlo implementation of the -formula. The Bayesian framework provides a straightforward approach to incorporating uncertainty in the sensitivity parameters through the use of informative priors, which can be elicited from subject-matter experts.22 In principle, however, one could also apply Frequentist inference using the nonparametric bootstrap.23
Outline
In Section 2 we review the potential outcomes framework for mediation analysis and argue for the use of mixed-scale models on the JOBS II dataset. In Sections 3 and 4 we present our framework for causal mediation analysis, show how to compute the mean and quantile mediation effects, and develop our zero-one inflated beta regression model. In Section 5, we present two alternative assumptions to sequential ignorability which allow for a sensitivity analysis, and show that these assumptions identify the average causal mediation effects. In Section 6, we illustrate our methodology on synthetic data and real data. We conclude in Section 7 with a discussion. Proofs are in the Appendix. Some additional algorithms, additional sensitivity analyses, and Markov chain Monte Carlo diagnostics are given in the Supplemental Material.
Notation and definitions of causal effects
JOBS II dataset
For the sake of reproducibility, we motivate concepts and illustrate our methods on a subset of the JOBS II dataset3 which is available publicly in the mediation package in R. The JOBS II data was used to evaluate the potential benefits of participation in a job-search skills seminar in southeastern Michigan. Subjects were recently unemployed adults during 1991–1993. Participants were pre-screened and classified according to their risk of depression and anxiety. High-risk participants, along with a random sample of low-risk participants, were invited to participate in the study. Prior to the seminar, questionnaires were sent out to the respondents. The questionnaires covered a range of topics about the respondent, including their loss of employment, the quality of work-life at their previous job, their health problems, and their history of substance abuse. The primary baseline covariates, which we denote as , include measures of depression at baseline, education, income, race, marital status, age, sex, previous occupation, and level of economic hardship. The participants were randomly assigned to treatment and control groups. The treatment group, was assigned to attend a seminar that taught participants job search skills and coping strategies for dealing with setbacks in the job hunt. The control group, , received a booklet of job search tips. Prior to measuring the outcome, but post-intervention, researchers measured an underlying mechanism in the relationship between the intervention and outcome. This mediator was a continuous measure of job search self-efficacy, . In this study, two outcomes were measured: a continuous measure of depression using the Hopkins Symptom Checklist24 and a binary variable for employment at the follow-up time. We will focus on the continuous measure of depression, .
Even for a benchmark dataset like the JOBS II data, which has been analyzed using LSEMs,1 there is overwhelming evidence that neither the outcome nor the mediator are normally distributed. The observed values of the outcome and mediator, which are supported on and highly skewed, are displayed in Figure 2, and it is apparent from the figure that the assumption of (say) a normally distributed error is untenable.
The potential outcomes framework
Using the potential outcomes framework, the causal effect of the job training program can be defined as the difference between two potential outcomes. One potential outcome is realized if the subject participates in the training program and the other is realized if the subject does not.
Associated with the outcome and the mediator are potential outcomes that would have been observed had the treatment assignment has been different. A potential outcome is defined as the outcome which would have been observed under an exposure a participant did not actually receive. We let denote the value of the mediator had the treatment has been assigned to the value ; in terms of the JOBS II study, this is the self-efficacy which would have been realized had the treatment for individual had been fixed at either receiving the treatment () or not (). Similarly, we let denote the value of the outcome that would have been realized had the treatment for individual been fixed at and the mediator fixed at ; in terms of the JOBS II study, this is the depression level which would have been observed at a given level of self-efficacy under the two treatments.
We link the potential outcomes to the observed data through the consistency assumption that and . The primary challenge in estimation of the mediation effects, that is, the effects of changes of and on , lies in the fact that we cannot observe the counterfactual outcomes , as this would require observing what would have happened under both and .
Throughout, we assume that the distribution of the potential outcomes, the mediator, and the exposure is distributed according to a distribution in some parametric family . Abusing notation, we use as the conditional and marginal density/mass functions as needed, with its meaning inferred from context; for example, denotes the probability of given .
Sequential ignorability
As a starting point for identifying the causal effects of interest we will use the sequential ignorability assumption of Imai et al.1 For subject , let be the support of the distribution of and let be the support of . The SI assumption imposes the following restrictions on the model parameterized by an unknown :
for all and , where the expression means that is conditionally independent of given . Additionally, we require the overlap condition (SI3) that and , for all . In words, SI1 states that, given the observed confounders, the treatment assignment is independent of the potential outcomes and ; this will hold whenever the treatment assignment is randomized. On the other hand, SI2 states that the assignment of the mediator does not affect the outcome, given the observed treatment and pre-treatment covariates. Of the two assumptions, SI2 is generally the more problematic; for example, in the JOBS II study, the job-search self-efficacy is not randomized by study design, so that SI2 makes the unfalsifiable assertion that all common causes of and have been measured.
Causal mediation effects
We define the following causal mediation effects26,25 using the JOBS II study for context. The natural indirect effect (NIE), also called the causal mediation effect, is defined for as
For example, in the JOBS II study, is the effect of increasing/decreasing a subject’s self-efficacy from their baseline level to the level we would have observed had they attended the seminar, holding fixed that the subject did not attend the seminar. The natural direct effect (NDE) is defined for as
For example, in the JOBS II study, is the difference between the two potential depression levels for subject according to whether they participated in the job training seminar or not, under the assumption that their job search self-efficacy is held constant at the level which would have been observed if they had attended theseminar.
Because we cannot observe when , we cannot directly observe either or . Nevertheless, under sequential ignorability we can estimate the average mediation effects
The mediation effects and decompose the average total effect in the sense that . The total effect is analogous to the usual average causal treatment effect (ATE) of the treatment assignment.
Under sequential ignorability, Imai et al.1 showed that the distribution of the potential outcomes for any is nonparametrically identified as
for all . The marginal distribution of is then so that it (along with the average direct and indirect effects) is also identified. While there usually will not be a simple analytical expression for (2), it is nevertheless easy to approximate (2) using Monte Carlo integration; this approach was popularized by Robins27 as a tool to implement the -formula in causal inference.
While the average causal mediation effects are the most commonly studied, one may also be interested in causal effects on other aspects of the distribution of the outcome. Let denote the quantile of a random variable . Then the quantile mediation effects at the quantile are
Because (2) fully identifies the distribution of , the quantile mediation effects are also identified under SI. We note that, rather than the difference in the quantiles, one might be tempted to define (and similarly for ), which represents the causal mediation effect as a quantile of the differences. There are two issues which arise from doing this. First, SI is not sufficient to identify , as SI does not identify the joint distribution of the potential outcomes. Second, we lose the decomposition property so that the mediation effects no longer serve as a decomposition of the total effect. The terms and as defined in (3) do have a compelling causal interpretation: rather than representing a causal effect on the individual level, they capture the causal effect on the quantiles from shifting the entire population from untreated to treated.
Observed data models for zero-one inflated data
Estimating the causal mediation effects under SI requires only that we estimate the distribution of the observed data. Without loss of generality, we assume that and can be rescaled to lie in the interval ; for the JOBS II dataset, this can be done with the transformations and , as the measures of depression and self-efficacy were measured on a scale from 1 to 5.
A flexible distribution for zero-one inflated data on is the zero-one inflated beta (ZOIB) distribution, which we denote by . If then is a mixed discrete-continuous random variable such that
The parameterization of the beta distribution in (4) is chosen so that is the mean of the beta distribution, that is, . The mean of the distribution is given by
Figure 3 shows that the beta distribution is effective at modeling the shape of the data for the continuous part of the JOBS II data, while the parameters and allow for an increased chance of observing the boundary values and .
Kernel density estimate (gray) and fitted beta distribution (solid black) of the distribution of and conditional on and .
Our ZOIB model assumes that and . We model the parameters of these ZOIB distributions with generalized linear models of the form
The dependence of the ’s on is included to allow for heterogeneous effects of the covariates and mediator; the homogeneous model is included as a special case where only the intercept varies with . Similar models are specified for . As a default, all of the regression coefficients are given flat priors, where is taken to be large after centering and scaling the covariates (except for the intercept) to have mean and standard deviation .
To estimate the mediation effects we also require a model for the distribution of the covariates. As a default, we assume that is discretely supported on the observed values of the ’s, that is, where are the observed values of the covariates. We then specify an improper Bayesian bootstrap28 prior for , that is, . After observing the data, the posterior distribution of is , and can be sampled exactly. Specifying a Bayesian bootstrap prior for avoids the notoriously difficult task of estimating via density estimation, and has been shown in other settings to result in improved theoretical properties of Bayesian causal inference methods.29
Posterior computation and inference
We divide inference into two steps:
Draw a set of approximate samples from the posterior distribution of .
For each , compute , and , yielding approximate samples from the posterior distribution for these mediation effects.
For the first step, we use the probabilistic programming language Stan, which implements an adaptive version of Hamiltonian Monte Carlo (HMC) to sample ’s.30 The sole exception to this sampling scheme is that we sample directly from the posterior distribution.
Average mediation effects
Due to the nonlinearities of the ZOIB model, the mediation effects and are not available in closed form and must be approximated. To compute the mediation effects, we use a Monte Carlo implementation of the -formula. The idea is to note that, because (2) identifies the distribution of for all , we can simulate new realizations for from the model, in which case
are unbiased estimators of and . The approximations in (7) are less efficient than using the true values and because they contain Monte Carlo error, but are conservative in the sense that using them results in valid inference. The approximations can be improved by using various tricks to eliminate the Monte Carlo error. One improvement is to notice that we can decrease the variance of (7) by replacing with the conditional expectation ; for the ZOIB model, this is given by where and are given by (6) with evaluated at and evaluated at .
The Monte Carlo integration strategy is summarized in Algorithm 1, and it applies to any model. In Algorithm 2, we give the special case of our ZOIB regression models. In these algorithms, denotes the generalized inverse of the cumulative distribution function of .
Quantile mediation effects
Equation (2) can also be used to form a Monte Carlo estimate of the quantile mediation effects, although the implementation is somewhat more subtle. If we have a sample of ’s from the marginal density then we can approximate its quantile as , where is the empirical distribution of the ’s and is the quantile of . We can then calculate (3) using the approximation
Note that for this to be valid we must sample the covariates ’s used to generate and according to , rather than averaging over as in (7). This results in higher Monte Carlo error in (8) than in (7).
Reducing Monte Carlo error in (8) can also be done, although it requires different strategies; for example, it is no longer valid to replace with its mean. One may take very large, but this can substantially increase computation time. Another trick is to construct the joint distribution of in a way which makes the potential outcomes highly correlated. Interestingly, because (3) depends only on the marginal distributions of the potential outcomes, it is invariant to our choice of joint distribution; hence, this does not actually imply any additional restrictions on the model. To ensure a strong dependence between the ’s, we simulate and to be comonotone,31 that is, we simulate and apply the probability integral transform to get and (note that the same and are used for different values of and ). This, combined with taking to be modestly large (say, ) is sufficient to effectively eliminate the Monte Carlo error.
Our general algorithm for approximating the quantile mediation effects is given in Algorithm 3, with the extension to the specific setting of the ZOIB model being derived in the same way Algorithm 2 was derived from Algorithm 1.
Assessing the Monte Carlo error
Linero23 introduced a method for computing and (in the case where the effects are approximately normal) correcting for the Monte Carlo error in the types of estimators we have proposed; code for implementing this is available at www.github.com/theodds/AGC. This approach requires and, in all cases we have considered, the Monte Carlo error is negligible for . Linero23 also shows that naive estimators that are not designed to eliminate Monte Carlo error can be very inefficient unless is taken rather large (say, ).
Sensitivity analysis
Because SI is an untestable assumption, it is essential to assess the extent to which the conclusions of an SI-based analysis are sensitive to the existence of unmeasured confounders, that is, SI2. Accordingly, we now present a framework for performing sensitivity analysis using the mixed-scale models we have developed. Without loss of generality, we assume that the data has been scaled so that both and take values in . As a guiding principle, we require that any sensitivity parameters be pure in the sense that varying them does not alter the fit of the model to the data. This allows us to independently assess (i) goodness-of-fit for the observed data model and (ii) the impact of SI2 failing.
Sensitivity on the logit scale
We propose an approach to sensitivity analysis that allows for dependence between and even after accounting for and . We replace assumption SI2 with the following two assumptions:
Conditional on , the potential outcomes and are jointly distributed according to a Gaussian copula with correlation . More precisely, we have where denotes the generalized inverse cdf of given and , and , is jointly standard normal with correlation .
Conditional on , , and , the mean of is given by
where .
SI2B has been chosen specifically so that it reproduces the inferences under SI2 when while leaving the sensitivity parameters and unidentified so that they can be varied freely without changing the fit of the model to the data. The most closely related sensitivity analysis framework which we are aware of is the “hybrid” approach of Albert and Wang,5 although this approach differs importantly in that the hybrid approach replaces the term with a term of the form , which is similarly designed to drop out of the distribution of the observed data.
To motivate the choice of SI2B (in particular, the term ), we note that a natural way to induce correlation between the potential mediators and outcomes is to add an additional linear term to the regression model; that is, if we (for the sake of simplicity) replace our ZOIB model with a logistic regression model for the mean, we could incorporate into the linear predictor as , with the term capturing any association due to unmeasured confounding between and . The issue with using this expression directly is that is confounded with ; adding and subtracting , however, gives
Because , the term disappears from the distribution of the observed data; consequently, only the term is identified. Our decision to write our assumption as in SI2B (with subtracted off explicitly) only has the effect of reparameterizing the above model in terms of the identified parameter . While this argument only holds exactly for the logistic regression mean model, the intuition is the same for generic models: subtracting allows us to parameterize the distribution of the observed data with identifiable parameters.
The following proposition establishes that is identified for all so that the average causal mediation effects are also identified. A proof is given in Appendix 7.
Suppose that SI1, SI2A, SI2B, and SI3 hold. Then we have
where , , and we define and in the integral.
As in Section 4, there is no analytical expression for , and hence we must resort to Monte Carlo integration. Fortunately, by noting that the approximation
is unbiased, it is straight-forward to modify Algorithm 1 to compute under this assumption as well. A procedure for computing the mediation effects under SI2A and SI2B is given in Algorithm S.1 of the Supplemental Material.
As there is no information in the data about the sensitivity parameters and , it is essential that we are able to elicit plausible ranges for their values. To gain better intuition about the role of , suppose that we had instead posited the logistic regression model . In this case, we can rewrite
In words, (which produces the same inferences as SI2) attributes the entirety of the association between and to a causal effect from shifting the value of in the potential outcome . When this association is instead parsed into an effect of size for shifting in and a residual association of size between and , above-and-beyond the causal effect of shifting due to unmeasured confounding. In the absence of subject-matter expertize about the likely values of , one can use weak prior knowledge about the magnitude of the mediation effect to narrow down the range of plausible values. In the JOBS II study, we do this by constructing a pilot estimate of of the form . In most cases, we feel that it is reasonable to assume that the effect of unmeasured confounding will not dominate the causal effect associated to , so that is a conservative collection of plausible values of .
The parameter measures dependence in the mediator process . Since and is typically believed to be positive, we recommend repeating the sensitivity analysis for a small number of ’s in . For the JOBS II data, we consider , with the results for given in the Supplemental Material.
The use of copulas in SI2A bears a passing resemblance to our use of comonotone random variables to reduce Monte Carlo error in Section 4. In this case, however, the choice of does impact the model, and so we can no longer reduce the Monte Carlo error by making and comonotone.
In the Supplemental Material, we provide a scheme for performing sensitivity analysis on a linear, rather than logit, scale. The linear scale sensitivity analysis has the advantage of not requiring the specification of .
Illustrations
Application to JOBS II
We apply our methodology to the JOBS II dataset using SI as a benchmark. As potential confounders we include numeric variables measuring economic hardship (econ_hard), baseline depression (depress1), and age (age), as well as the categorical variables measuring (sex), race (nonwhite), income bracket (income), occupation (occp), marital status (marital), and education level (educ).
We posit generalized linear models for each component of the ZOIB models with a homogeneous effect for the treatment and mediator. That is, we use linear predictors of the form for the mediator and linear predictors of the form for the outcome (with separate coefficients for each model component). Note that the homogeneity assumption implies neither that nor that due to the nonlinearity of the link functions in (6).
The observed data models for and are fit using Markov chain Monte Carlo (MCMC) in Stan, with a total of samples collected over four parallel chains and samples discarded to burn-in. There is no evidence of failure of the chains to mix: all traceplots indicate rapid mixing (see Figures S.4 and S.5 in the Supplemental Material), all values of the Gelman-Rubin diagnostic32 are effectively (minimum of 0.9991, maximum of 1.003), and the minimal effective sample size across all of the monitored parameters is 1807.
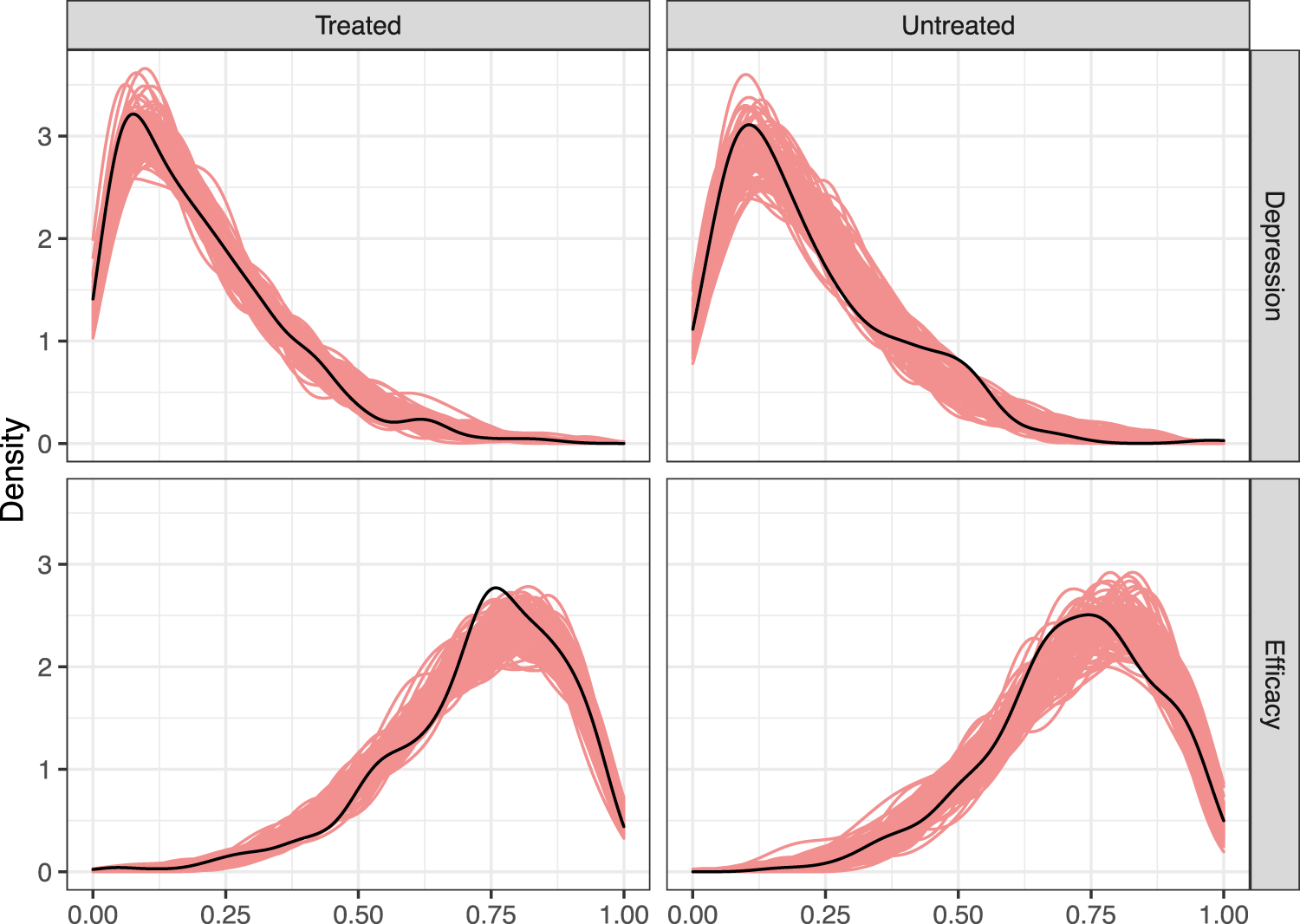
We now perform posterior predictive checks to compare the observed data and to replicate datasets simulated from the fitted model. The goal of these checks is to assess how well the fitted model aligns with the observed data. In Figure 4, we check the fit of the beta distribution to the continuous part of the observed mediator/outcome distributions by comparing a kernel density estimate of the observed-data distribution of and to 100 replicated datasets sampled from the posterior predictive distribution; the top row shows density estimates for the depression level under each treatment level for the continuous part of the data, while the bottom row shows the same for job-search self-efficacy. The posterior predictive distribution produces datasets that closely match the observed data, suggesting that the beta model for the continuous part of the data is adequate.
Kernel density estimates of the non-boundary proportion of the original data (black) and 100 replicated datasets (red).
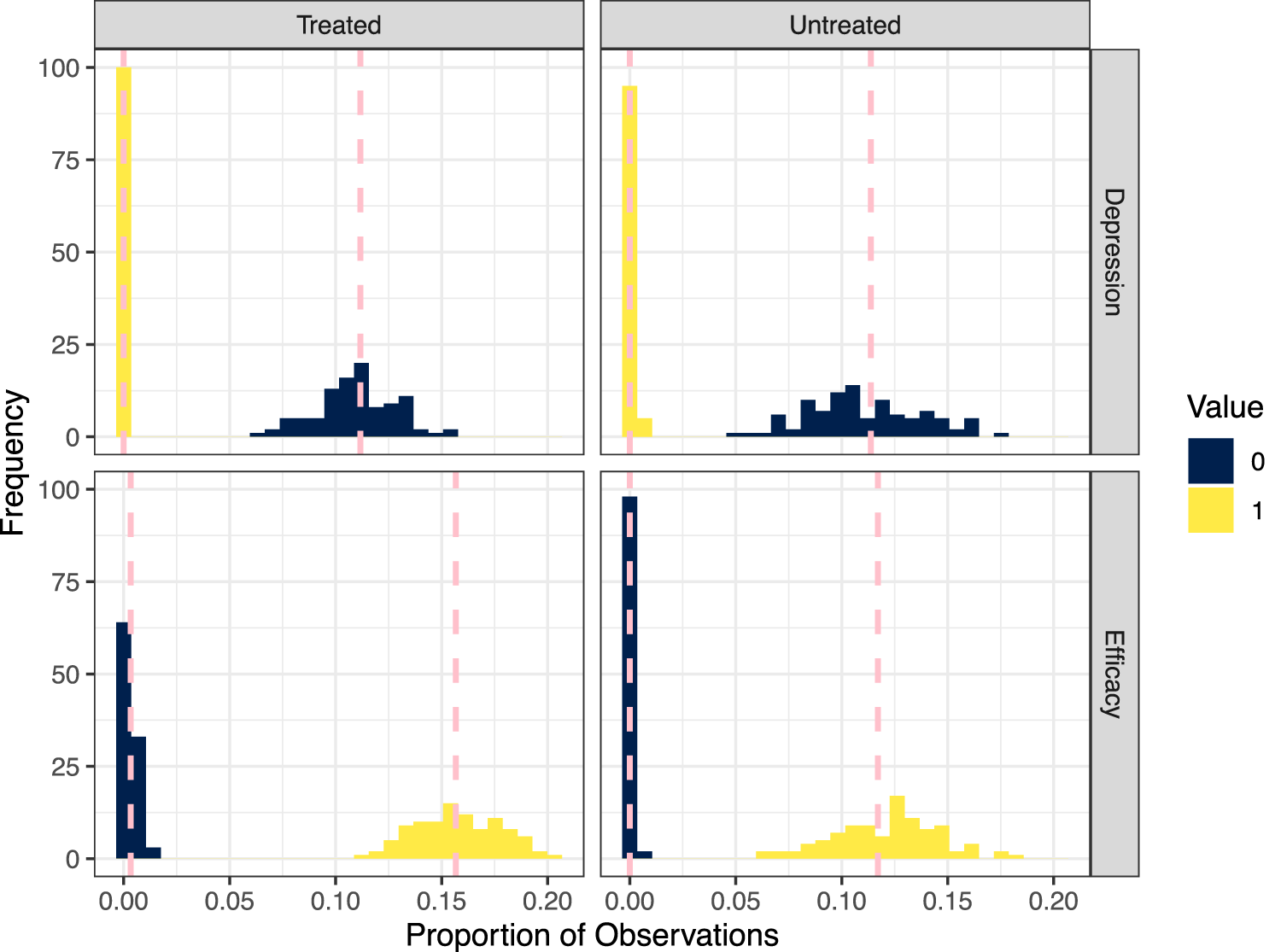
In Figure 5, we check the fit of the logistic regression models to the boundary points and by comparing the observed proportion of s and s for the outcome and mediator to what is observed in replicated datasets. Again, there is close agreement between the model and simulated data.
Histograms of the proportions of individuals taking the boundary values (in dark blue) and (in light yellow) across 100 replicated datasets for the outcome (depression, first row) and mediator (efficacy, second row), separately for the treated and untreated groups. The proportions of the observed data taking boundary values are given by the pink vertical dashed lines.
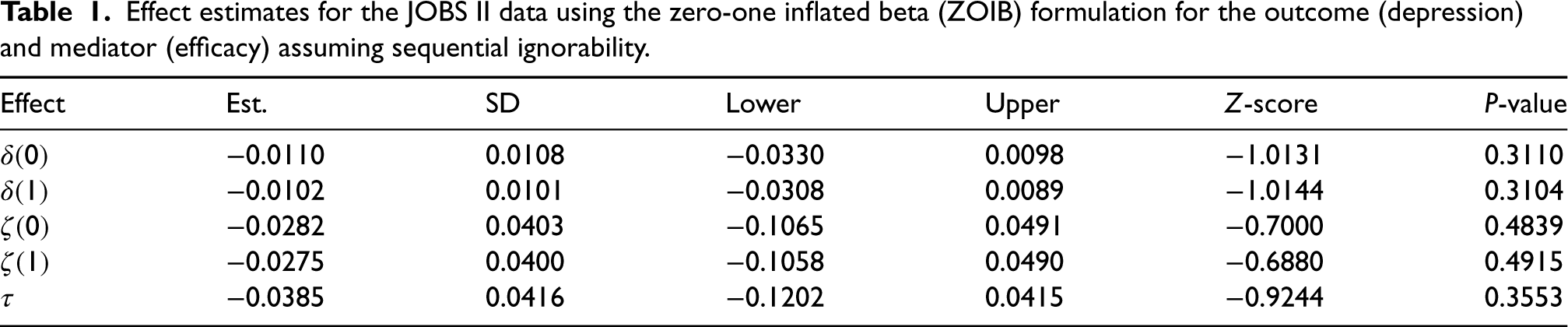
Since the outcomes in the analysis were scaled by the transformation , the causal estimates can be brought back to their original scale by multiplying the estimates by 4. The results for the average causal mediation effects on the original scale are given in Table 1.
Effect estimates for the JOBS II data using the zero-one inflated beta (ZOIB) formulation for the outcome (depression) and mediator (efficacy) assuming sequential ignorability.
Effect
Est.
SD
Lower
Upper
-score
-value
−0.0110
0.0108
−0.0330
0.0098
−1.0131
0.3110
−0.0102
0.0101
−0.0308
0.0089
−1.0144
0.3104
−0.0282
0.0403
−0.1065
0.0491
−0.7000
0.4839
−0.0275
0.0400
−0.1058
0.0490
−0.6880
0.4915
−0.0385
0.0416
−0.1202
0.0415
−0.9244
0.3553
Although the average causal mediation effect estimates are small (less than a tenth of a point for all effects) and not statistically significant, all treatment effect estimates are negative, which would imply that participation in the job training seminar decreased the depression of subjects both directly through their participation in the seminar and indirectly through the effect of the training seminar on the self-efficacy of participants in finding a job. Of particular interest for us is the decomposition , which captures (i) the benefit of increasing self-efficacy generally for those who do not receive treatment and (ii) the additional benefit of the seminar above and beyond its effect on increasing a subject’s self-efficacy. However, there is little evidence for either a direct or indirect effect of the treatment on the outcome; in particular, the signs of the mediation effects are uncertain. Similar results are obtained for the quantile mediation effects.
Sensitivity analysis
While there is no evidence for either a direct or indirect treatment effect under SI, we may be concerned that the effects are being masked by unobserved confounding. We now apply the sensitivity analysis techniques introduced in Section 5 to assess the impact of unmeasured confounding.
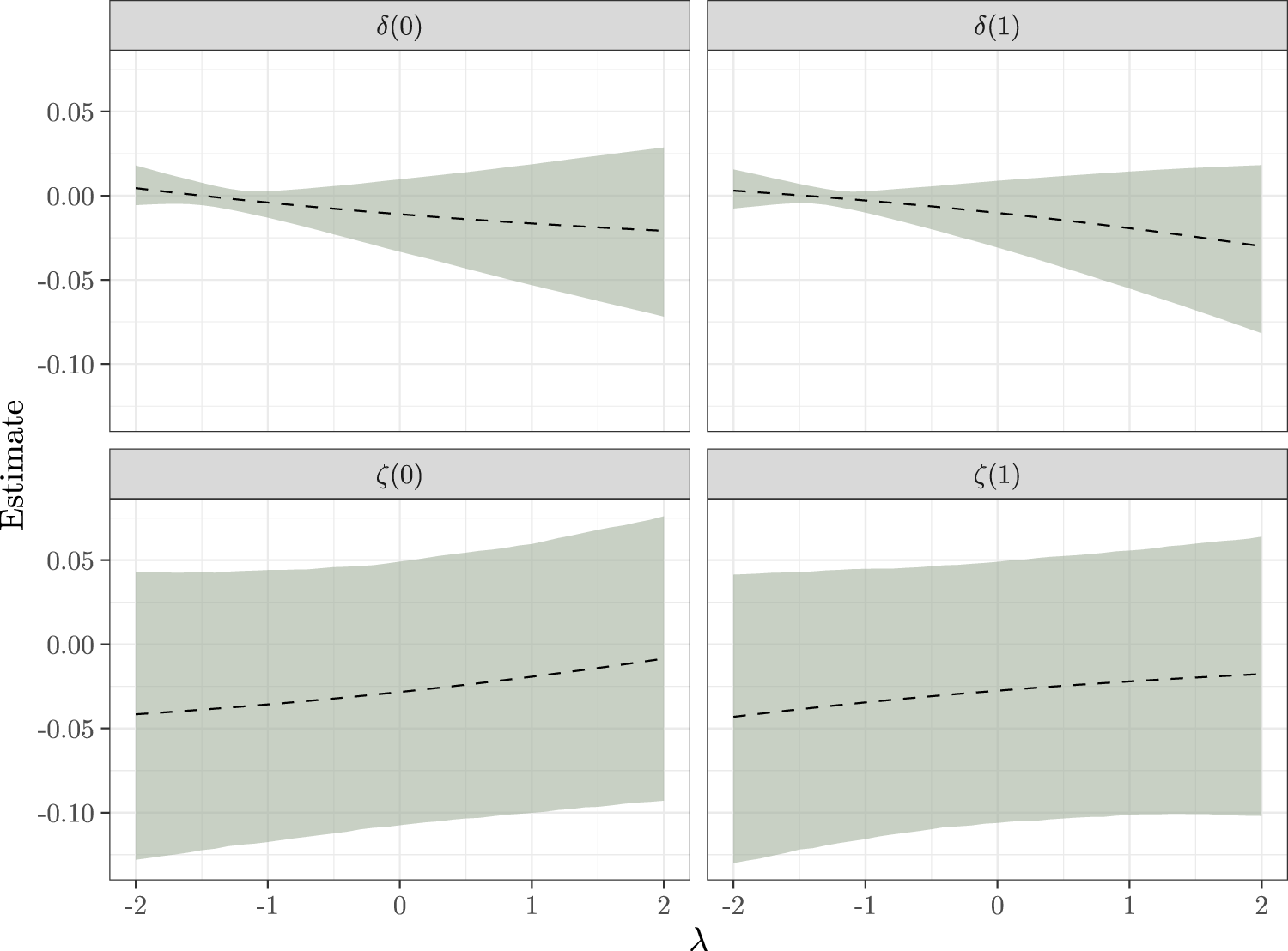
Setting , Figure 6 shows how inferences about the mediation effects change as is varied across a range of plausible values. To calibrate , we fit a linear model to the conditional mean using quasi-likelihood and then considered values of no more than twice as large in magnitude than the estimated effect of in this model; this corresponds to the belief that most of the association of with should be attributable to a causal effect of the mediator rather than confounding between the outcome and mediator processes.
Sensitivity of inferences about and to changes in the sensitivity parameter under assumptions SI2A and SI2B. The dashed line is the posterior mean, and the bands delimit a pointwise 95% credible interval.
From Figure 6, inferences for the direct effects are robust to unmeasured confounding between and , while inferences for the indirect effects are less robust. When is negative, there is less uncertainty in , although the estimates are also pulled towards zero. For larger values of , the estimates of are larger (in magnitude), but also more uncertain. The substantive conclusion remains the same: there is little evidence regarding the sign of either the direct or indirect effects.
We provide a more in-depth sensitivity analysis in the Supplemental Material. In particular, we consider both varying and a linear variant of assumption SI2B. While the substantive conclusions don’t change from varying , we do see that interacts strongly with , with the trends for being markedly nonlinear.
Simulation example
We evaluate Algorithm 2 under a variety of different data generating mechanisms based on the JOBS II data. To devise relevant simulation settings, we first fit our model to the JOBS II data and then modified the estimated coefficients of the fitted beta-regression model. We consider homogeneous effects for both the mediator and outcome, and write and for the estimated coefficient for the effect of on and , respectively. The following features of the data generating mechanism were varied.
We consider , which is equal to the size of the JOBS II dataset and twice the size of the JOBS II dataset.
We consider ; the first setting corresponds to no indirect effect of treatment, the second to a realistic indirect effect of the treatment, and the last to a very large indirect effect on the treatment.
We consider , the choices of which are analogous to the ones for the treatment effect on the mediator.
We consider five data generating mechanisms: (1) no mediation, where ; (2) complete mediation, where ; (3) strong no mediation, where ; (4) strong complete mediation, where ; and (5) no modifications, where . For each scenario, we used simulated 200 datasets to compute the bias of the effect estimates, the root-mean-squared error (RMSE), coverage of nominal 95% credible intervals, and the average length of a nominal 95% interval.
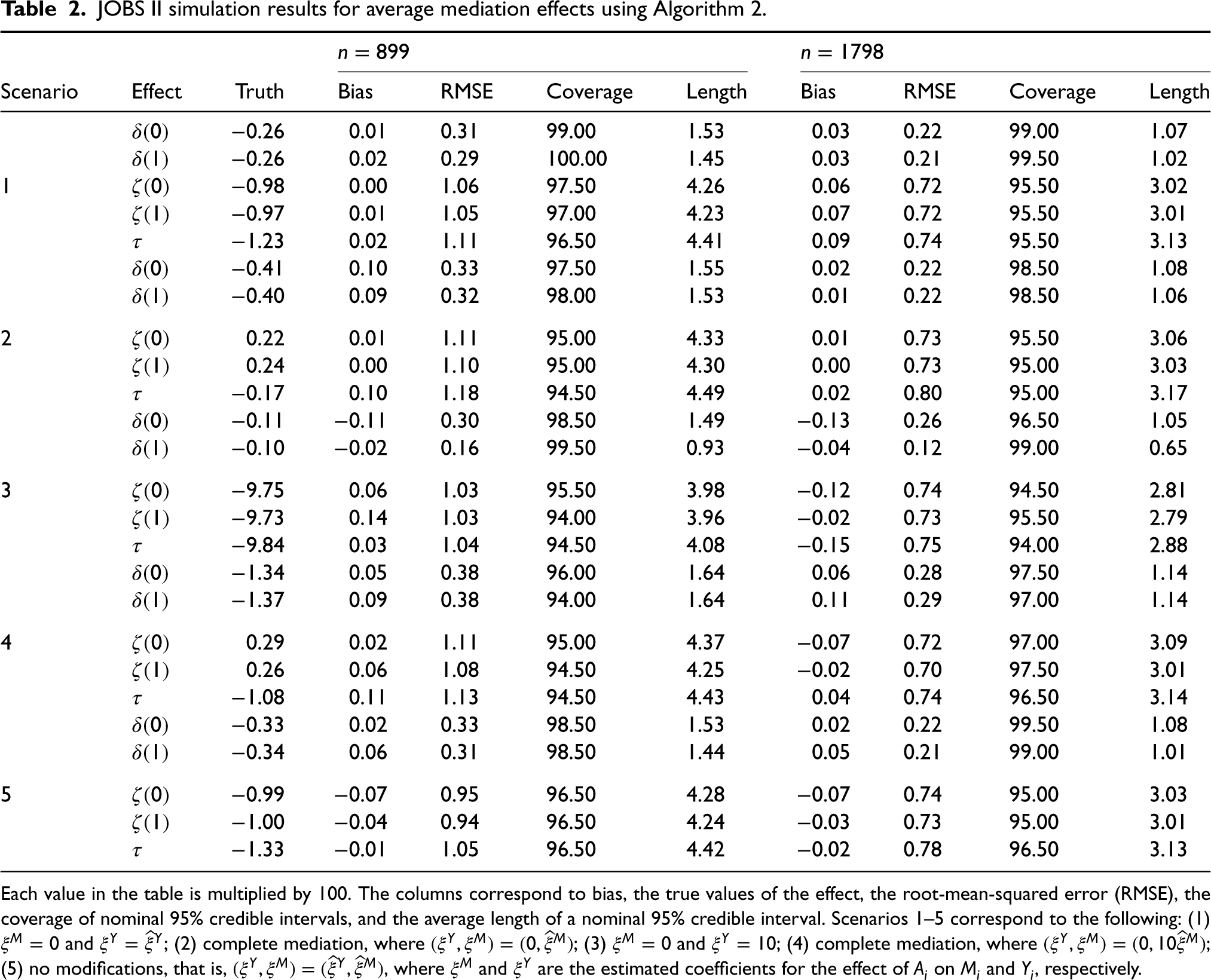
Table 2 summarizes the results for each scenario. For readability, all entries of the table are multiplied by . Prior to the simulation experiment, we computed the true direct, indirect, and total effects using Monte Carlo integration with samples (101 times the size of the original data). For each simulated dataset, we collected a total of 2000 samples across eight parallel chains, with 250 burn-in samples per chain. Our method performs well in terms of bias for both sample sizes and, as expected, we observe lower RMSEs for the larger sample size. The 95% credible intervals are slightly conservative, particularly for the indirect effect; across all scenarios and effects, the smallest coverage probability was 94%. Ultimately, the results show that our approach to computing the mediation effects, while tending to be conservative, appears to work well.
JOBS II simulation results for average mediation effects using Algorithm 2.
Scenario
Effect
Truth
Bias
RMSE
Coverage
Length
Bias
RMSE
Coverage
Length
−0.26
0.01
0.31
99.00
1.53
0.03
0.22
99.00
1.07
−0.26
0.02
0.29
100.00
1.45
0.03
0.21
99.50
1.02
1
−0.98
0.00
1.06
97.50
4.26
0.06
0.72
95.50
3.02
−0.97
0.01
1.05
97.00
4.23
0.07
0.72
95.50
3.01
−1.23
0.02
1.11
96.50
4.41
0.09
0.74
95.50
3.13
−0.41
0.10
0.33
97.50
1.55
0.02
0.22
98.50
1.08
−0.40
0.09
0.32
98.00
1.53
0.01
0.22
98.50
1.06
2
0.22
0.01
1.11
95.00
4.33
0.01
0.73
95.50
3.06
0.24
0.00
1.10
95.00
4.30
0.00
0.73
95.00
3.03
−0.17
0.10
1.18
94.50
4.49
0.02
0.80
95.00
3.17
−0.11
−0.11
0.30
98.50
1.49
−0.13
0.26
96.50
1.05
−0.10
−0.02
0.16
99.50
0.93
−0.04
0.12
99.00
0.65
3
−9.75
0.06
1.03
95.50
3.98
−0.12
0.74
94.50
2.81
−9.73
0.14
1.03
94.00
3.96
−0.02
0.73
95.50
2.79
−9.84
0.03
1.04
94.50
4.08
−0.15
0.75
94.00
2.88
−1.34
0.05
0.38
96.00
1.64
0.06
0.28
97.50
1.14
−1.37
0.09
0.38
94.00
1.64
0.11
0.29
97.00
1.14
4
0.29
0.02
1.11
95.00
4.37
−0.07
0.72
97.00
3.09
0.26
0.06
1.08
94.50
4.25
−0.02
0.70
97.50
3.01
−1.08
0.11
1.13
94.50
4.43
0.04
0.74
96.50
3.14
−0.33
0.02
0.33
98.50
1.53
0.02
0.22
99.50
1.08
−0.34
0.06
0.31
98.50
1.44
0.05
0.21
99.00
1.01
5
−0.99
−0.07
0.95
96.50
4.28
−0.07
0.74
95.00
3.03
−1.00
−0.04
0.94
96.50
4.24
−0.03
0.73
95.00
3.01
−1.33
−0.01
1.05
96.50
4.42
−0.02
0.78
96.50
3.13
Each value in the table is multiplied by 100. The columns correspond to bias, the true values of the effect, the root-mean-squared error (RMSE), the coverage of nominal 95% credible intervals, and the average length of a nominal 95% credible interval. Scenarios 1–5 correspond to the following: (1) and ; (2) complete mediation, where ; (3) and ; (4) complete mediation, where ; (5) no modifications, that is, , where and are the estimated coefficients for the effect of on and , respectively.
Robustness to model misspecification
We now consider two simulation experiments designed to answer the following questions: (i) is the ZOIB model robust to model misspecification when the data is semi-continuous but the continuous part is not a beta regression? and (ii) does the commonly-used linear structural equation modeling (LSEM) framework perform well with semi-continuous data despite assuming that the underlying distribution is continuous?
To assess the robustness of the ZOIB model to model misspecification, we generate data under a censored regression model, where latent variables and are modeled using normal linear models such that we observe (say) if and if . We generated plausible linear models by fitting unconstrained linear models to the JOBS II data.
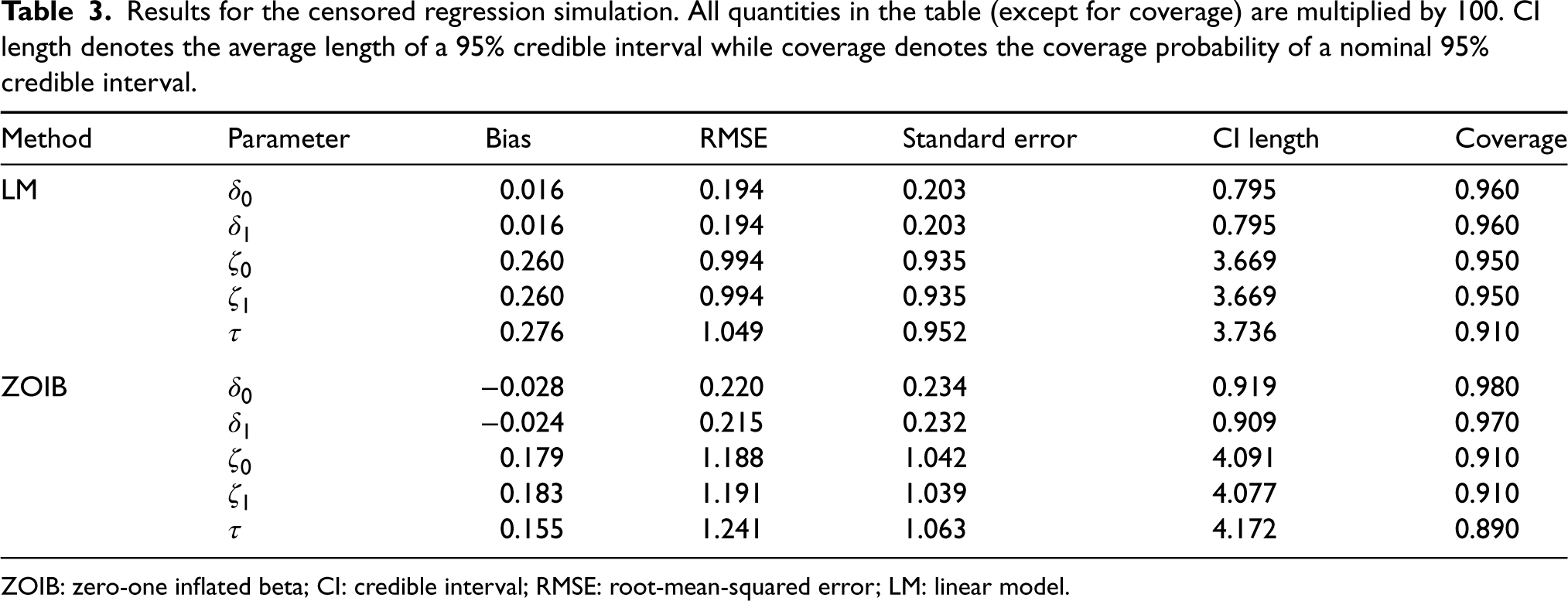
Results for the censored regression simulation are given in Table 3, with the estimands being the median causal mediation effects. For comparison, results for fitting an unconstrained LSEM are also given. Both LSEM and the ZOIB models have performance that does not reach the nominal coverage level, with the ZOIB performing slightly worse overall in terms of RMSE, interval length, and coverage and slightly better in terms of bias. Interestingly, LSEM seems to perform well when the ground-truth is the censored linear model despite the fact that it does not respect the semicontinuous nature of the data; considering that LSEM is correctly specified except for the fact that it does not capture the boundary behavior correctly, this is not entirely unexpected.
Results for the censored regression simulation. All quantities in the table (except for coverage) are multiplied by . CI length denotes the average length of a 95% credible interval while coverage denotes the coverage probability of a nominal 95% credible interval.
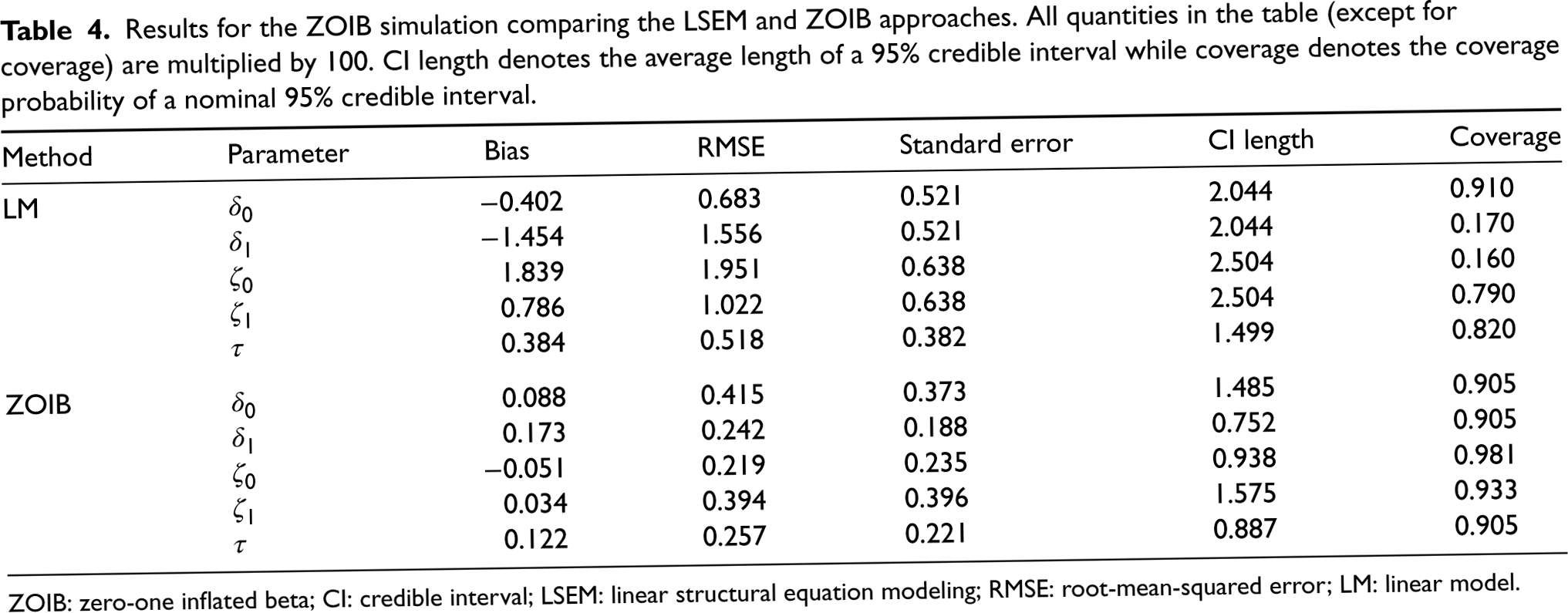
While LSEM performs reasonably well when the underlying data-generating process is a censored linear regression, our next simulation shows that the LSEM can perform poorly when the underlying data-generating process is a ZOIB model. This simulation setting is also based on the JOBS II data, but with stronger treatment effects in the beta part of the regression ( and ) and with a constant precision. Results are given in Table 4. For this setting, we find that the LSEM is heavily biased and inefficient, with coverage probabilities as low as 16%. The ZOIB model, while not perfect, is more efficient, less biased, and is much closer to the nominal coveragelevels.
Results for the ZOIB simulation comparing the LSEM and ZOIB approaches. All quantities in the table (except for coverage) are multiplied by . CI length denotes the average length of a 95% credible interval while coverage denotes the coverage probability of a nominal 95% credible interval.
Method
Parameter
Bias
RMSE
Standard error
CI length
Coverage
LM
−0.402
0.683
0.521
2.044
0.910
−1.454
1.556
0.521
2.044
0.170
1.839
1.951
0.638
2.504
0.160
0.786
1.022
0.638
2.504
0.790
0.384
0.518
0.382
1.499
0.820
ZOIB
0.088
0.415
0.373
1.485
0.905
0.173
0.242
0.188
0.752
0.905
-0.051
0.219
0.235
0.938
0.981
0.034
0.394
0.396
1.575
0.933
0.122
0.257
0.221
0.887
0.905
ZOIB: zero-one inflated beta; CI: credible interval; LSEM: linear structural equation modeling; RMSE: root-mean-squared error; LM: linear model.
Summarizing, this simulation study shows that the ZOIB model performs reasonably well when the data-generating process is either a censored linear regression or ZOIB, while we found that LSEM performed well only when the data-generating process was a censored linear regression.
Discussion
In many practical situations, either the mediator or outcome (or both) will have a mixed-scale distribution, necessitating the use of models beyond the usual linear and generalized linear models. We proposed a zero-one inflated beta distribution after scaling the data to lie in . This family of distributions includes many distributional shapes.
The framework proposed here is flexible enough for users to adapt Algorithm 1 and Algorithm 3 to fit essentially arbitrary zero-one inflated models; for example, it is straight-forward to adapt this approach to handle censored regression models.33 It is also straight-forward to extend our approach to a Bayesian nonparametric setting using Dirichlet process mixture models16 and nonparametric Bayesian additive regression tree models.34
Just as important as the model we have proposed is our description of how to perform a sensitivity analysis with this type of data. The framework for sensitivity analysis we presented is simple, interpretable, and also extends easily to other model specifications such as the censored linear regression model.
While we have taken a Bayesian approach in this paper, there is nothing in principle which stops us from applying our approach in the Frequentist framework. Taking a Frequentist approach using the bootstrap helps ensure that the estimated standard errors of the parameters remain honest even when the model is misspecified; on the other hand, the estimands may no longer correspond to the de-jure causal effects of interest resulting in a tradeoff that is not worthwhile. Bayesian approaches are also well-suited to settings with hierarchical structures, where software tools such as Stan make it very easy to consider many different models, and also allows for researchers to incorporate subject-matter expertize via the prior distribution. A potential downside is that, depending on the number of parameters, the Bayesian approach may result in high computational costs. As shown by Linero,23 the -computation framework we used here can be used with the nonparametric bootstrap as well; hence, we could have performed maximum likelihood estimation and used the bootstrap to perform uncertainty quantification rather than using Bayesian inference.
In this work, we assumed that all relevant causal effects are defined with respect to the population that the covariates were sampled from. However, it can easily be modified to accommodate a stratified sample from a target population . For example, in Algorithm 3, given a population defined by we simply replace sampling from (which is sampled from the Bayesian bootstrap) with sampling from . In the case of stratified sampling on a binary covariate , with known, we might model the distribution of and with independent Bayesian bootstraps and and then sample .
sj-pdf-1-smm-10.1177_09622802231173491 - Supplemental material for Causal mediation and sensitivity analysis for mixed-scale data
Supplemental material, sj-pdf-1-smm-10.1177_09622802231173491 for Causal mediation and sensitivity analysis for mixed-scale data by Lexi Rene, Antonio R Linero and Elizabeth Slate in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This material is based upon work supported by the National Science Foundation under Grant No. DMS-2144933 and the National Institute of Health under Grant Nos. NIH/NICHD-R01HD093055, NIH/NIMH-R01MH121364, and NIH/NIMH-R01MH121627.
ORCID iD
Antonio R Linero
Supplemental material
Supplemental material for this article is available online.
Appendix. Proof of Proposition 1
By iterated expectation and SI2B, we have
By SI2A, we have that and , where is jointly standard normal with correlation matrix . Therefore
where and , completing the proof.
References
1.
ImaiKKeeleLTingleyD. A general approach to causal mediation analysis. Psychol Methods2010; 15: 309.
2.
RubinDB. Direct and indirect causal effects via potential outcomes. Scand J Stat2004; 31: 161–170.
3.
VinokurADPriceRHSchulY. Impact of the JOBS intervention on unemployed workers varying in risk for depression. Am J Community Psychol1995; 23: 39–74.
4.
BaronRMKennyDA. The moderator–mediator variable distinction in social psychological research: conceptual, strategic, and statistical considerations. J Pers Soc Psychol1986; 51: 1173.
Tchetgen TchetgenEJShpitserI. Semiparametric theory for causal mediation analysis: efficiency bounds, multiple robustness, and sensitivity analysis. Ann Stat2012; 40: 1816.
14.
ZhengWvan der LaanMJ. Targeted maximum likelihood estimation of natural direct effects. Int J Biostat2012; 8. 10.2202/1557-4679.1361
15.
FarbmacherHHuberMLafférsL, et al. Causal mediation analysis with double machine learning. Econom J2022; 25: 277–300.
16.
KimCDanielsMJMarcusBH, et al. A framework for Bayesian nonparametric inference for causal effects of mediation. Biometrics2017; 73: 401–409.
17.
ChengJChengNFGuoZ, et al. Mediation analysis for count and zero-inflated count data. Stat Methods Med Res2018; 27: 2756–2774.
18.
VanderWeeleTJ. Causal mediation analysis with survival data. Epidemiology2011; 22: 582.
19.
OspinaRFerrariSLP. A general class of zero-or-one inflated beta regression models. Comput Stat Data Anal2012; 56: 1609–1623.
20.
ZuurAFIenoENWalkerNJ, et al. Zero-truncated and zero-inflated models for count data. In Mixed effects models and extensions in ecology with R, Springer, 2009, pP.261–293.
21.
LiuLShihY-CTStrawdermanRL, et al. Statistical analysis of zero-inflated nonnegative continuous data: a review. Stat Sci2019; 34: 253–279.
22.
HoganJWDanielsMJHuL. A Bayesian perspective on assessing sensitivity to assumptions about unobserved data. In: Molenberghs G, Fitzmaurice G, Kenward MG, Tsiatis A, and Verbeke G, (eds), Handbook of Missing Data Methodology. CRC Press, 2014.
DerogatisLRLipmanRSRickelsK, et al. The Hopkins symptom checklist (HSCL): a self-report symptom inventory. Behav Sci1974; 19: 1–15.
25.
PearlJ. Direct and indirect effects. In: Breese J and Koller D (eds), Proceedings of the 17th Conference on Uncertainty in Artificial Intelligence, San Fancisco, CA. Morgan Kaufmann, 2001, pp. 411–420.
26.
RobinsJMGreenlandS. Identifiability and exchangeability for direct and indirect effects. Epidemiology1992; 3: 143–155.
27.
RobinsJ. A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survival effect. Math Model1986; 7: 1393–1512.
28.
RubinDB. The Bayesian bootstrap. Ann Stat1981; 9: 130–134.
29.
RayKvan der VaartA. Semiparametric Bayesian causal inference. Ann Stat2020; 48: 2999–3020.
30.
CarpenterBGelmanAHoffmanM, et al. Stan: a probabilistic programming language. J Stat Softw2016; 20: 1–37.
31.
DeelstraGDhaeneJVanmaeleM. An overview of comonotonicity and its applications in finance and insurance. In: Di Nunno G and ksendal B (eds), Advanced Mathematical Methods for Finance. Berlin, Heidelberg: Springer, 2011, pp. 155–179. 10.1007/978-3-642-18412-3_6
32.
GelmanARubinDB. Inference from iterative simulation using multiple sequences. Stat Sci1992; 7: 457–472.
33.
McDonaldJFMoffittRA. The uses of tobit analysis. Rev Econ Stat1980; 62: 318–321.
34.
LiYLineroARMurrayJ. Adaptive conditional distribution estimation with Bayesian decision tree ensembles. J Am Stat Assoc2022. 10.1080/01621459.2022.2037431
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.