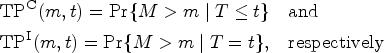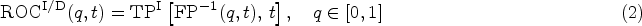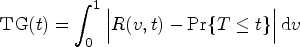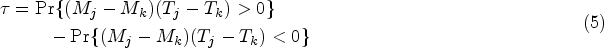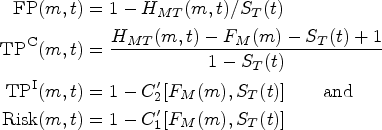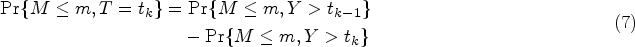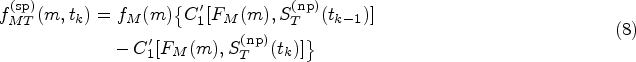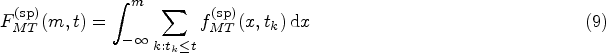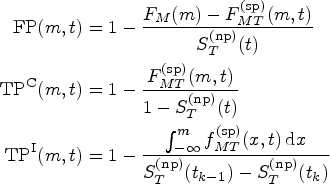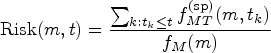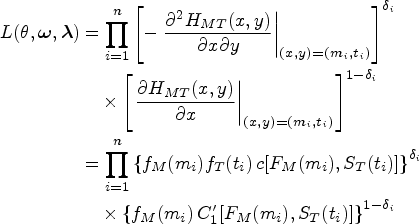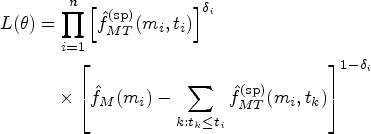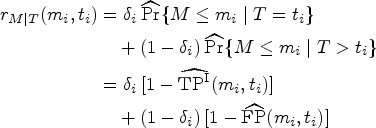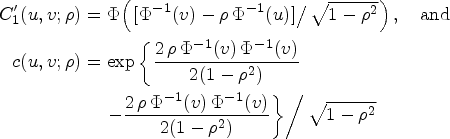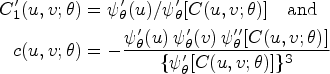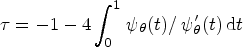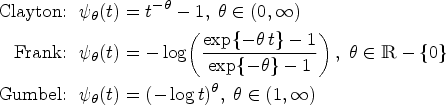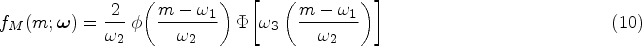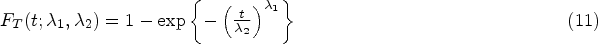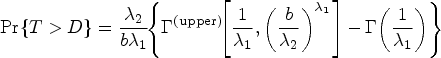The discriminative and predictive power of a continuous-valued marker for survival outcomes can be summarized using the receiver operating characteristic and predictiveness curves, respectively. In this paper, fully parametric and semi-parametric copula-based constructions of the joint model of the marker and the survival time are developed for characterizing, plotting, and analyzing both curves along with other underlying performance measures. The formulations require a copula function, a parametric specification for the margin of the marker, and either a parametric distribution or a non-parametric estimator for the margin of the time to event, to respectively characterize the fully parametric and semi-parametric joint models. Estimation is carried out using maximum likelihood and a two-stage procedure for the parametric and semi-parametric models, respectively. Resampling-based methods are used for computing standard errors and confidence bounds for the various parameters, curves, and associated measures. Graphical inspection of residuals from each conditional distribution is employed as a guide for choosing a copula from a set of candidates. The performance of the estimators of various classification and predictiveness measures is assessed in simulation studies, assuming different copula and censoring scenarios. The methods are illustrated with the analysis of two markers using the familiar primary biliary cirrhosis data set.
Marker development is a major research topic for supporting medical decision-making in the prognosis and timely treatment of progressive diseases. Consequently, the development and estimation of marker performance and decision-analytic measures are crucial topics in medical research. Important aspects of measurement include discrimination and prediction, which can be quantified by the receiver operating characteristic (ROC) and the predictiveness curves, respectively. For time-to-event data, both curves can be obtained when considering the status of a survival outcome at a certain time of the follow-up study, in order to both assess the performance of the marker and identify subjects that are at high risk of experiencing the outcome.
Previously proposed methodologies for studying time-varying performance measures have mainly addressed the estimation of a specific type of ROC curve only by employing non-parametric and semi-parametric (SP) techniques1; also, the estimation of the time-varying area under the ROC curve, which is a measure that describes the discriminatory value of the marker, has been an ongoing research focus, with existing smoothing methods proving to be cumbersome when it comes to implementation.2 Furthermore, the estimates of the ROC curve and its summaries when employing kernel smoothing methods are not transformation invariant; that is, monotone transformations to either the marker or the survival time, or both, may lead to different estimates for the ROC curve and its summaries.3 This is exacerbated by the fact that there is no methodology that brings both curves and their summaries together under a common framework, with a partial estimation of the predictiveness curve being the best scenario when a parametric ROC model is provided.4
Since employing different techniques to separately estimate measures from each curve may potentially result in misleading inferences, the correct representation of the joint model of the continuous-valued marker and the survival time should both enable the characterization of both curves and lead to coherent estimates. In this paper, two copula-based approaches are proposed to characterize such joint model. The first model is an extension of the model for cross-sectional data in Escarela et al.,5 which is conveniently constructed by customizing and linking with a copula a parametric marginal continuous cumulative distribution function (CDF) for and a parametric marginal survival distribution function for , leading to a fully parametric (FP) formulation. Such construction is appealing since the copula that characterizes the joint behavior of monotone increasing transforms of and is exactly the same copula as for the original pair ; that is, the unique copula associated with is invariant under monotone increasing transformations of the margins,6 which clearly benefits both the modeling and the inference process.
The second model represents the joint density function of the marker and the survival time by applying a latent variable transformation to the margin of the survival time in the aforementioned parametric copula model, in such a way that the transformed model allows for the marginal survival distribution of the time to event to be specified as discrete, resulting in a SP specification that is particularly useful when the parametric margin of does not appear to be adequate, or when the survival data are either discrete or subject to interval-censoring. Expressions of the ROC and predictiveness curves along with their summaries are then obtained in terms of the resulting joint models. Residual-based diagnostics are proposed to criticize the fit of the two joint models and, thus, to help in the choice of a copula. Simulation studies are carried out to assess the performance of the procedures under different copula and censoring scenarios. As an illustration, the performance of two markers for survival outcomes of the Mayo Clinic Primary Biliary Cholangitis (PBC) follow-up is studied.
Methods
Background: Marker performance measures
Define the dynamic false positive rate at cut-point and time as , and define the cumulative true positive and incident true positive rates at cut-point and time as
Two main definitions of the ROC curve have been proposed for measuring the time-dependent discriminating ability of the marker. The Cumulative/Dynamic ROC curve at time , , is defined as the plot of , where is the real line; that is
where , for . The Incident/Dynamic ROC curve at time , , is defined as the plot of ; that is
Common measures of marker discrimination effectiveness at a specific time are the areas under the ROC curve and ; here, is equal to the probability that the marker will assign a higher value to a randomly chosen subject who has died by time than to a randomly chosen subject who is still alive by time , whereas is the probability that the marker will assign a higher value to a randomly chosen subject who dies at time than to a randomly chosen subject who is still alive by time . is useful in a setting where discrimination accuracy of short-term survival has to be assessed, and is a summary that indicates time-varying performance with no need to select a specific time-frame.1
The risk function at time is defined as . If is monotonous increasing in at time , the time-dependent predictiveness curve is defined as
where is the quantile function corresponding to the marginal CDF of , denoted here by . The predictiveness function in equation (3) is the plot of . For a fixed time , displays the distribution of the predicted risk of the event occurring within time , and its inverse is the CDF of the risk function; that is, , for . In clinical decision-making, pre-specified percentiles of are used as thresholds for clustering subjects who share similar risks; for instance, if is the percentile for the high-risk group according to a prespecified criterion, then is the proportion of the population deemed to be at high risk. A summary measure of time-dependent risk prediction is the total gain, which is defined as
High values of total gain are obtained when the predictiveness curve is steep, which is a consequence of a useful predictive marker, reaching a maximum at time equal to .7 An alternative summary quantification of predictiveness is the time-varying standardized total gain, which is defined as , and provides a time-dependent measure that allows for comparisons across different studies.
A global measure of marker usefulness can be established using a measure of concordance between the marker and the outcome such as the C-index, whose definition for survival outcomes is given by the probability that an individual who died at an earlier time than another individual’s has a larger value of the marker; that is8:
Extending the results in Liu et al.,9 it can be shown that the C-index can be expressed in terms of a linear combination of Kendall’s tau; namely, , where is Kendall’s tau, defined by
with and being independent copies of . Markers whose association with the time to event lies between that of countermonotonicity, where and , and that of independence, where and , are expected to exhibit useful discriminative and predictive properties.
Copula modeling
A strategy for constructing a joint model for the continuous random vector is provided by the copula function, which is defined as a bivariate distribution function whose margins are uniform on . In the usual setting, given continuous CDF’s and of and , respectively, Sklar’s theorem indicates that there is a unique copula such that the joint CDF of can be defined as . Since some popular copulas mainly represent dependence structures whose association, as measured by Kendall’s tau, mainly cover the positive range for , this study instead adopts the following joint representation:
The formulation in equation (6) is known as the semi-survival copula and the association between and is the negative of that obtained when enters the model as in the joint CDF of ,10, thus allowing popular copula families, whose association range mainly cover the interval (0,1), to model useful discriminative and predictive markers.
Define , for . It can be shown that
Also, in the semi-survival copula setting given by equation (6), it can be shown that the corresponding Kendall’s tau can be expressed in terms of the underlying copula as Nelsen11, which is free of marginal effects.
When follows a non-parametric distribution in the form of a step-wise function, with jumps at times , it is possible to adopt the latent variable strategy described in de Leon and Wu12 in order to construct the joint model for . Assume that the random couple is continuous, with taking values in the positive reals, and let , where if and otherwise, and , then
The joint density function of is obtained by differentiating equation (7) with respect to , and can be written in terms of the copula representation in equation (6) as follows:
for and ; here, and is an ordinal discrete survival distribution, with for . The corresponding joint CDF, defined as , can be computed as:
It follows that
for , and
Inference
Estimation
Consider the pair of marker and survival time , and let denote an independent right-censoring time for independent subjects . Let be the observed value of , and let be the observed survival time of and let be the corresponding censoring status , where is an indicator function. For the FP model in equation (6), the observed likelihood function is given by
where is the dependence parameter of the copula function, and are the vector of parameters of and , respectively, , and . In this study, the function nlm of the R language was employed to find the optimum of , and the corresponding Hessian. Standard errors (SEs) for the parameters can be computed as the squared root of the diagonal entries in the inverse of the observed information matrix.
For the SP model in equation (8), a two-stage estimation procedure was adopted. The first stage involves the estimation of both margins and under the independence working assumption; here, maximum likelihood is used to estimate , and the Kaplan–Meier estimator is used for . The second stage involves maximum likelihood of the dependence parameter with the margins held fixed from the first stage; that is, by maximizing the following likelihood function:
where and are the estimators of and , respectively.
SE’s and confidence intervals (CI’s) for the various parameters and quantities can be obtained by extending the conditional bootstrap for univariate censored data in Karrison13. The resulting procedure is in fact a specialization of the non-parametric bootstrap for a copula model with censoring presented in Lawless and Yilmaz14, and is described as follows:
First, obtain the estimates of and , and of either or depending on the model specification. These are then employed to characterize the populations from which the pairs of marker and survival time are sampled.
Generate random pairs from the fitted copula model , and then obtain and , for .
Simulate censoring times from an estimated censoring distribution, which can be obtained from the Kaplan–Meier estimate of , and then let and .
Obtain the estimates , , for the bootstrap dataset .
Compute the statistic of interest .
Repeat steps 2–5 number of times.
With the sequence of bootstrap estimates , the corresponding standard deviation is estimated by computing the standard deviation of the estimates. Also, a for can be estimated using the pivotal method,15 which is computed as , where is the point estimator of from the observed dataset, and is the empirical quantile function corresponding to the CDF of the bootstrap estimates . In this study, the R package was employed to obtain from each copula family described below. In the illustration below, the implementation of the bootstrap procedure did not appear to be computationally demanding.
A strategy for copula selection from a given set can be performed using model diagnostics for each conditional distribution of each copula model, as both conditional distributions uniquely determine the joint model. Model criticism for the conditional distribution of given can be borrowed from the survival analysis literature because the marker is assumed to be always observed. Let be the estimated conditional cumulative hazard at time given that , with being the estimate of and computed as the estimate of . If denotes the Kaplan–Meier for and the conditional distribution of given is correct, then the plot of vs for , should roughly yield a straight line with slope .
Residuals for assessing the distribution of given can be obtained by modifying Dunn and Smyth’s16 normalized quantile residuals for a univariate continuous CDF . If denotes the observed random sample, such quantile residuals are defined as , where denotes the fitted distribution function of for the -th subject. If is correct, the residuals are independent and exactly normal, and thus usual graphic inspections, such as the quantile-quantile plot, can be employed for the assessment; in the current conditional context, however, such residuals must be defined according to the censoring status as either the estimate of the conditional CDF of given that has been observed, or the conditional CDF of given that exceeds the censoring time; that is,
Families of copulas and margins
This study employed the four most commonly applied copula families, including the Gaussian which is defined as , where is the joint CDF of the bivariate Gaussian distribution with the vector of means equal to , and the covariance matrix equal to a non-singular matrix with in each diagonal entry and the dependence parameter in each off-diagonal entry, , and is the inverse of the standard normal CDF . The corresponding conditional copula and the copula density functions are17
respectively; also, it can be verified18 that Kendall’s tau for is given by , implying that the range of useful markers corresponds to . In the estimation, this study adopted an arctanh-link (Fisher’s transformation) for , so that takes values in .
Three popular copulas belonging to the Archimedean class were also employed in this study. The Archimedean class considered here is represented as , where is a convex decreasing generating function with parameter that satisfy and . It can be shown that the conditional copula and the copula density functions can be written in terms of the generating function and its derivatives as19:
respectively, and that Kendall’s tau for is given by20:
This study adopted the following Archimedean copulas, which are characterized by their generating functions:
In the estimation procedures described above, the dependence parameter of the Clayton and Gumbel copulas were parameterized as and , respectively, so that the parameter space is bounded accordingly while the parameter takes values in the real line.
Since biomarkers are often skewed,21 this study adopted the skewed-normal distribution for the marginal distribution of , whose probability density function (PDF) is characterized by22:
where , , with , and being the location, scale and shape parameters, respectively, and denotes the standard normal PDF. For the parametric model, it was assumed that the marginal distribution of the survival time is Weibull, with the corresponding CDF given by:
where , and and are the shape and scale parameters, respectively. In the estimation process, this study employed a log-link for the parameters whose parameter-space is .
Simulation studies
To evaluate and investigate the performance of the approaches developed here, datasets under the Frank and Gumbel copula models with an assumed association corresponding to , and two censoring scenarios were generated and then fitted using the FP and SP models. was taken as the skewed-normal distribution characterized in equation (10), with , and , and was taken as the Weibull represented in equation (11), with and . The censoring times were generated from a uniform distribution over , where was determined according to a predetermined proportion of censored times . Under the assumed families of distributions for and , it can be shown that if and are independent
where is the upper incomplete gamma function and is the gamma function; thus, for the and of censored times considered in the simulations below, and , respectively.
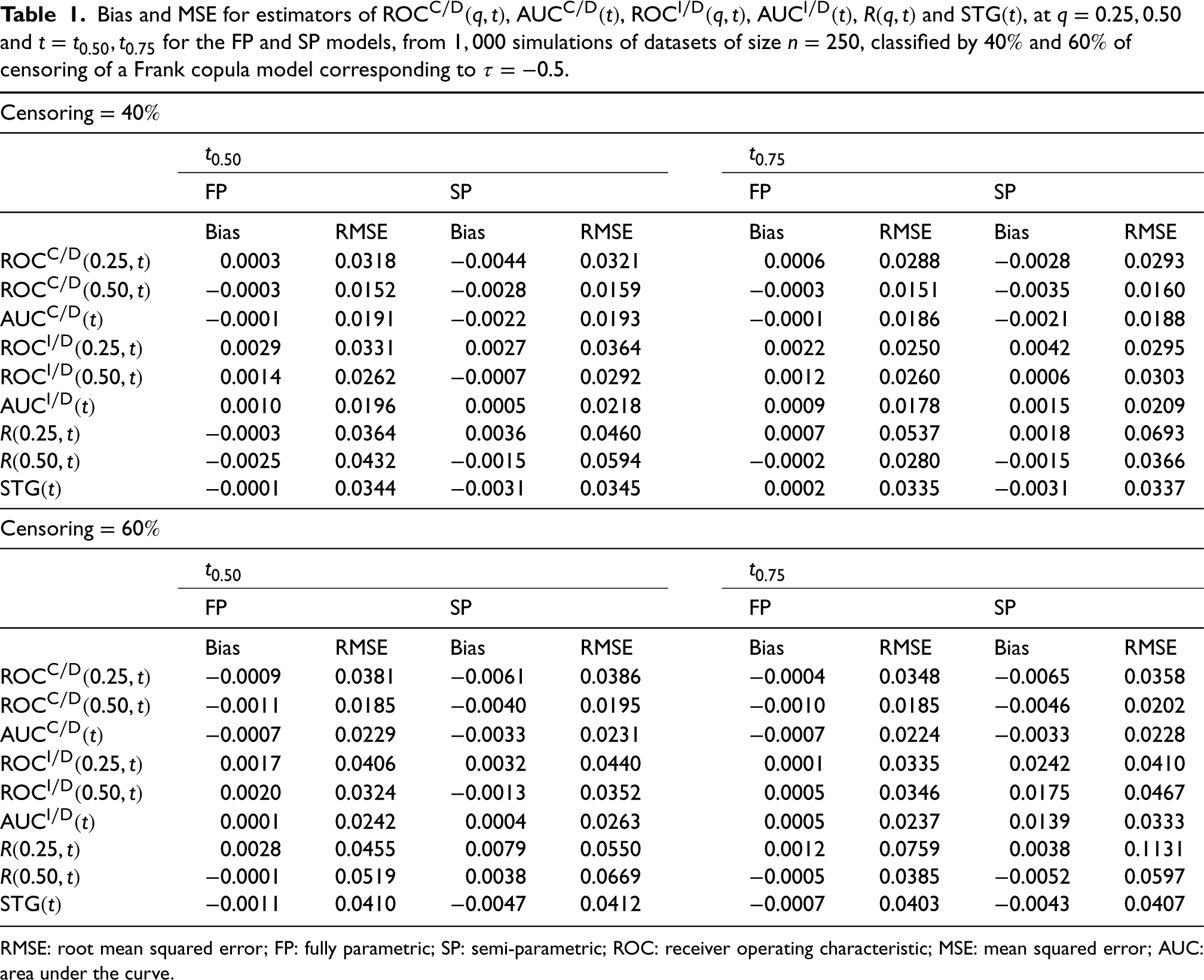
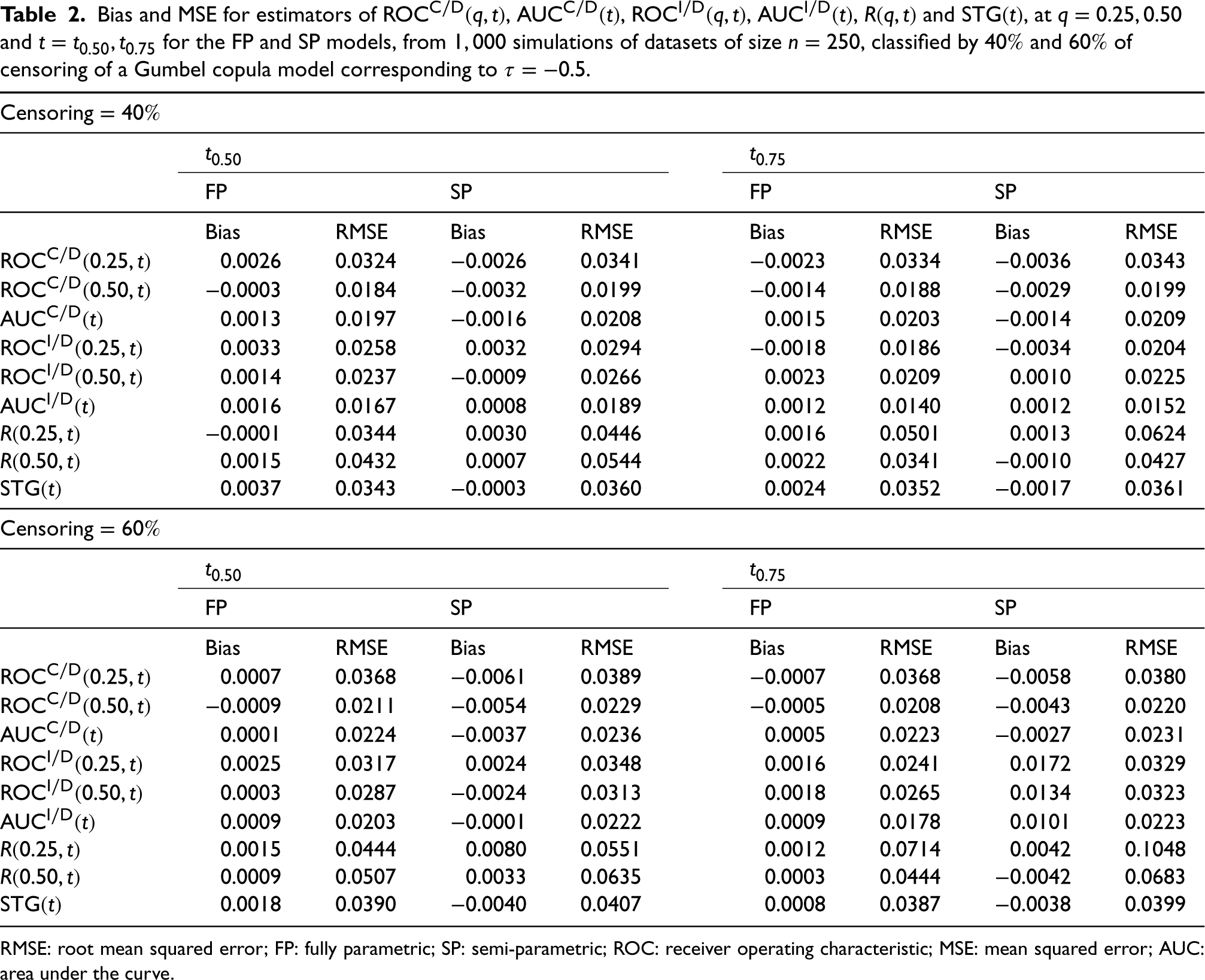
In this study, 1000 datasets of independent vectors from the Gumbel copula with uniform margins on were generated. The marker and actual survival time were computed as and , respectively. For each dataset, censoring times from a uniform distribution over were generated, and the survival time and the corresponding censoring indicator were computed as and , respectively. The FP and SP models were then fitted to the resulting dataset, given by ; here, the parametric families were correctly specified in the corresponding components to construct both models. Results of bias and root mean squared error (RMSE) of the estimators from the FP and SP models for , , , , and , for , and at the median and third quartile of , classified by and of censored times, for the Frank and Gumbel copula models are shown, respectively, in Tables (1) and (2).
Bias and MSE for estimators of , , , , and , at and for the FP and SP models, from simulations of datasets of size , classified by and of censoring of a Frank copula model corresponding to .
FP
SP
FP
SP
Bias
RMSE
Bias
RMSE
Bias
RMSE
Bias
RMSE
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
FP
SP
FP
SP
Bias
RMSE
Bias
RMSE
Bias
RMSE
Bias
RMSE
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
RMSE: root mean squared error; FP: fully parametric; SP: semi-parametric; ROC: receiver operating characteristic; MSE: mean squared error; AUC: area under the curve.
Bias and MSE for estimators of , , , , and , at and for the FP and SP models, from simulations of datasets of size , classified by and of censoring of a Gumbel copula model corresponding to .
FP
SP
FP
SP
Bias
RMSE
Bias
RMSE
Bias
RMSE
Bias
RMSE
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
FP
SP
FP
SP
Bias
RMSE
Bias
RMSE
Bias
RMSE
Bias
RMSE
−
−
−
−
−
−
−
−
−
−
−
−
−
−
RMSE: root mean squared error; FP: fully parametric; SP: semi-parametric; ROC: receiver operating characteristic; MSE: mean squared error; AUC: area under the curve.
Both Tables show similar results, with the FP model tending to exhibit smaller biases and RMSE’s than the estimators of the SP model, more notably when censoring is . Discrepancies between the two estimators do not appear to be relevant for all scenarios, and there are no noticeable differences or trends when varying and . In general, all estimators perform well, showing relatively small biases and RMSE’s.
Illustration: Application to the PBC dataset
The methods presented in this study are illustrated using data from the Mayo Clinic trial in PBC conducted between 1974 and 1984, which is available in the survival package of the R program. PBC is an autoimmune disease in which the bile ducts in the liver are slowly destroyed, leading to irreversible scarring of liver tissue (cirrhosis), and eventually liver decompensation and, consequently, premature death.23 Patients with PBC who are at high risk of death can potentially benefit from a liver transplant, the only curative treatment for PBC24; therefore, identifying such high-risk group with a marker is crucial for medical decision making.
The dataset considered here consisted of a cohort of 312 patients with PBC. There were 125 (40%) deaths and 19 liver transplant recipients during the follow-up. The main goal of the study was to assess the time-varying discriminative and predictive power of a marker in mortality outcomes after registration, and thus the time to transplantation was taken as a censored time. Similar to the illustration in Bansal and Heagerty,25 this study analyzed the performance of the following two markers, which were computed as the linear predictor obtained from the usual Cox regression model: (a) 4-cov, from the model that includes orthogonal polynomials of degree 1 of albumin and age, natural logarithm of prothobin time and edema status (two levels: Edema despite diuretic therapy and otherwise); and (b) mayo, from adding the natural logarithm of bilirubin to the set of covariates in 4-cov, thus emulating the Mayo marker.26
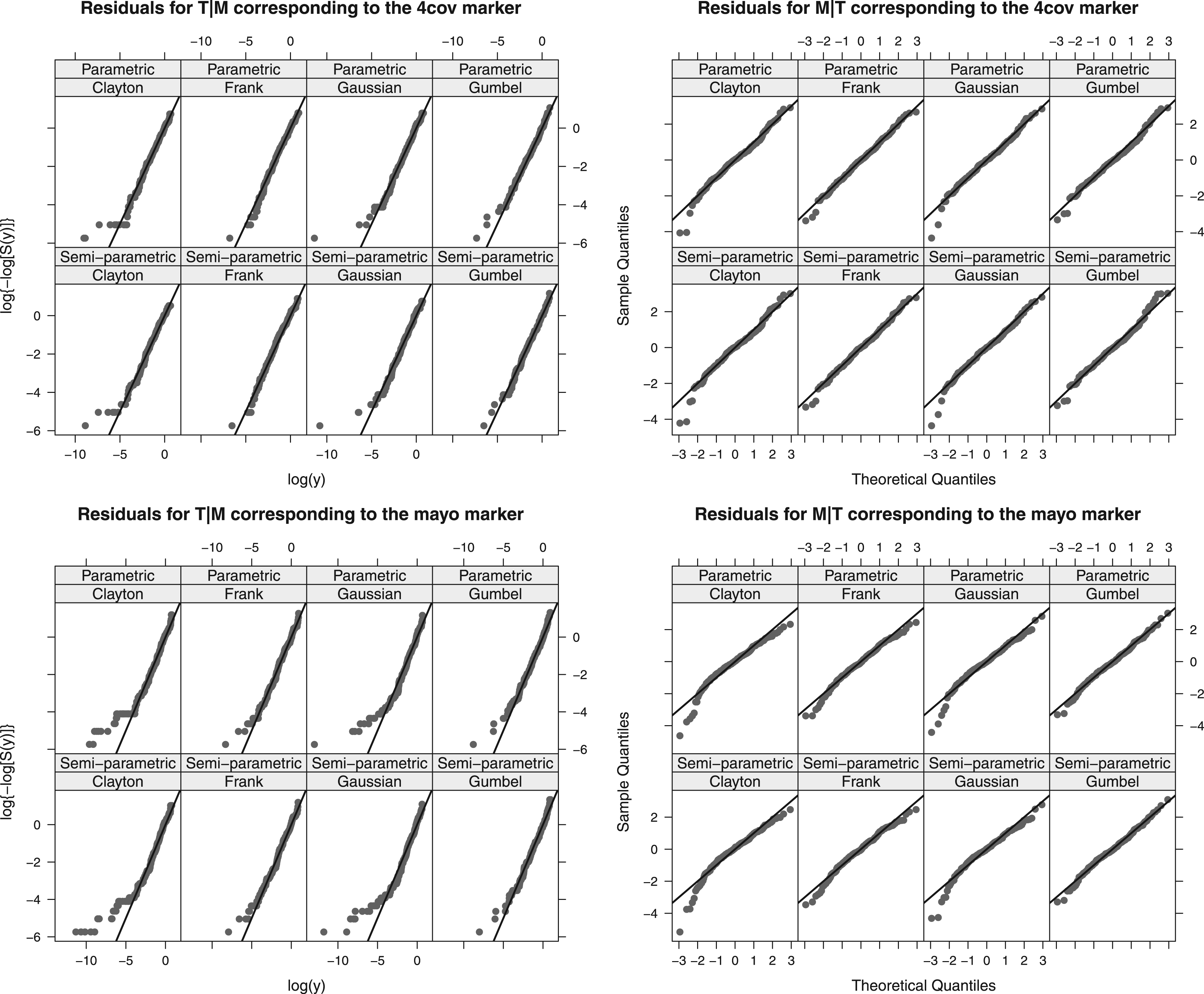
Figure 1 displays conditional residual plots for given and given of FP and SP models constructed with the Clayton, Frank, Gaussian and Gumbel copulas. The Clayton and Gaussian copulas yield the worst fits, whereas the Frank and Gumbel copulas appear to give reasonable fits to the 4-cov and mayo markers, respectively. The plots show negligible discrepancies when comparing the residuals of the FP and SP models for each copula and marker. Accordingly, this study adopted the Frank and Gumbel copulas for the 4-cov and mayo markers, respectively, in both the FP and SP models.
Conditional residual plots from the fully parametric and semi-parametric model fits to the markers 4-cov and mayo using the Clayton, Frank, Gaussian and Gumbel copulas.
For the FP Frank copula model of 4-cov, it was found that the parameter of the Weibull distribution was non-significant (), and then it was set to in order to obtain the best-fitting model; that is, an exponential distribution was used for the margin of . The maximum likelihood estimators (MLE’s) of the resulting model were: (SE ), (SE ), (SE ), (SE ) and (SE ); here, the corresponding Kendall’s tau was estimated as , with its 95% bootstrap CI computed as . The two-stage estimates of the SP Frank copula model for 4-cov were: (SE ), (SE ), (SE ) and (SE ), with and its 95% bootstrap CI computed as .
For the FP Gumbel model of mayo, the parameter that is linked to the dependence parameter as turned out not to be significant (), and then it was set to , and therefore was set to , which corresponds to . The resulting parsimonious model yielded the following MLE’s: (SE ), (SE ), (SE ), (SE ) and (SE ). The two-stage estimation for the SP Gumbel copula model of mayo yielded , with the corresponding 95% bootstrap CI computed as ; consequently, was set to as well, obtaining then the following estimates: (SE ), (SE ) and (SE ).
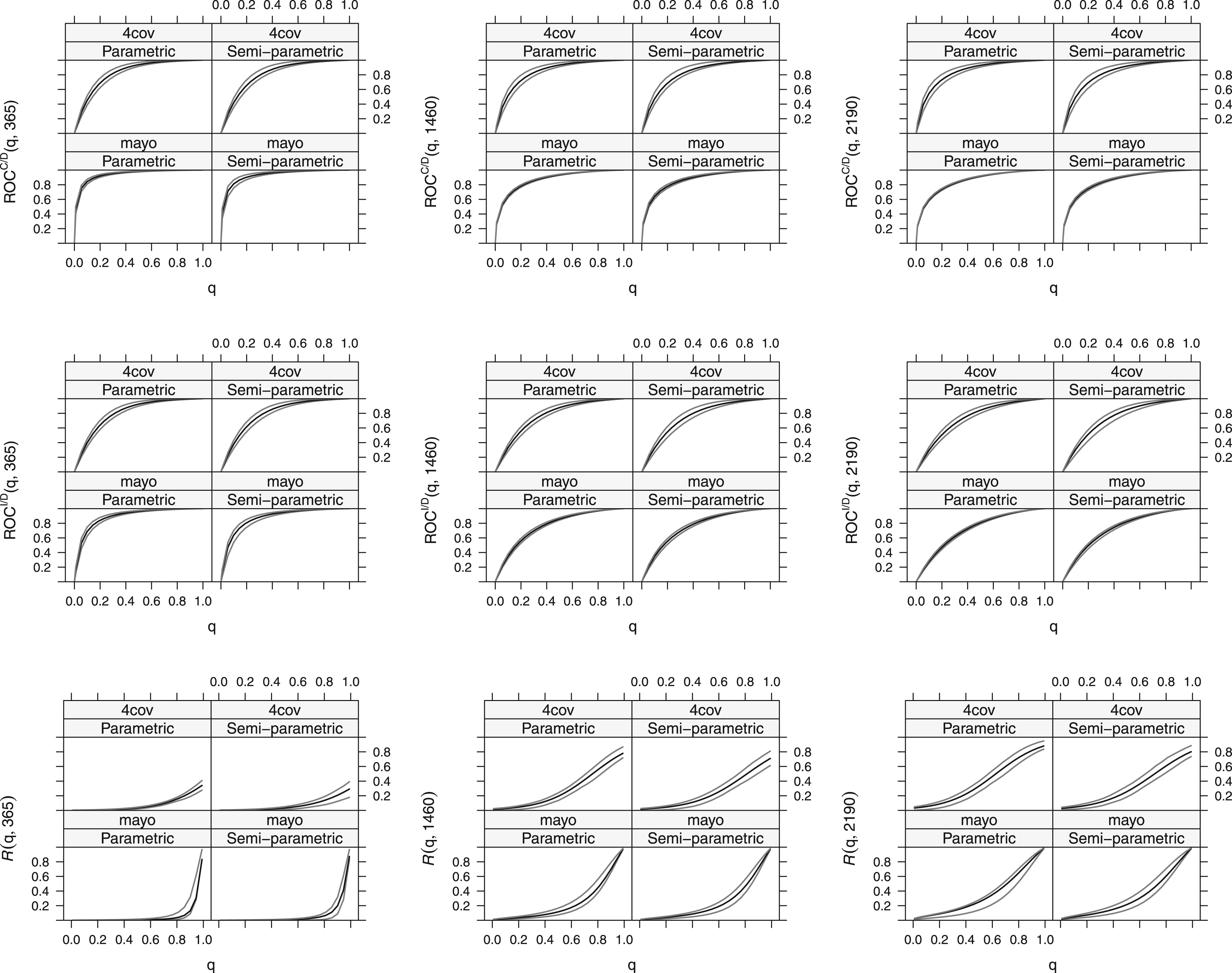
Figure 2 shows estimates and 95% confidence bounds of , and for both markers at year 1, 4 and 6 from both the FP and SP copula models; here, the confidence bounds were constructed by joining pointwise CIs for each curve at various cut points of the marker quantile . It is clear that both models yield very similar fitted curves, with the confidence bounds being slightly wider for the SP model. All ROC curves indicate that both markers provide useful discriminating power for either outcome; in addition, the shapes of the confidence bounds of the ROC curves suggest that the corresponding population curves are at least approximately convex, which is a crucial feature for rational decision making,27 that implies that larger values of the marker are associated with a higher likelihood of outcome presence (e.g. Lloyd28). When it comes to comparing the discriminatory power of the two markers, mayo outperforms 4-cov since the corresponding ROC curves show estimates closer to the point , particularly for years 1 and 4; also, the three predictiveness curves of mayo appear to be steeper and closer to the point , allowing for better election of marker thresholds, which indicates that mayo provides higher predictive accuracy.
Parametric and semi-parametric estimates, along with 95% confidence bounds, of receiver operating characteristic (ROC), and for markers 4-cov and mayo at times , and (days after registration).
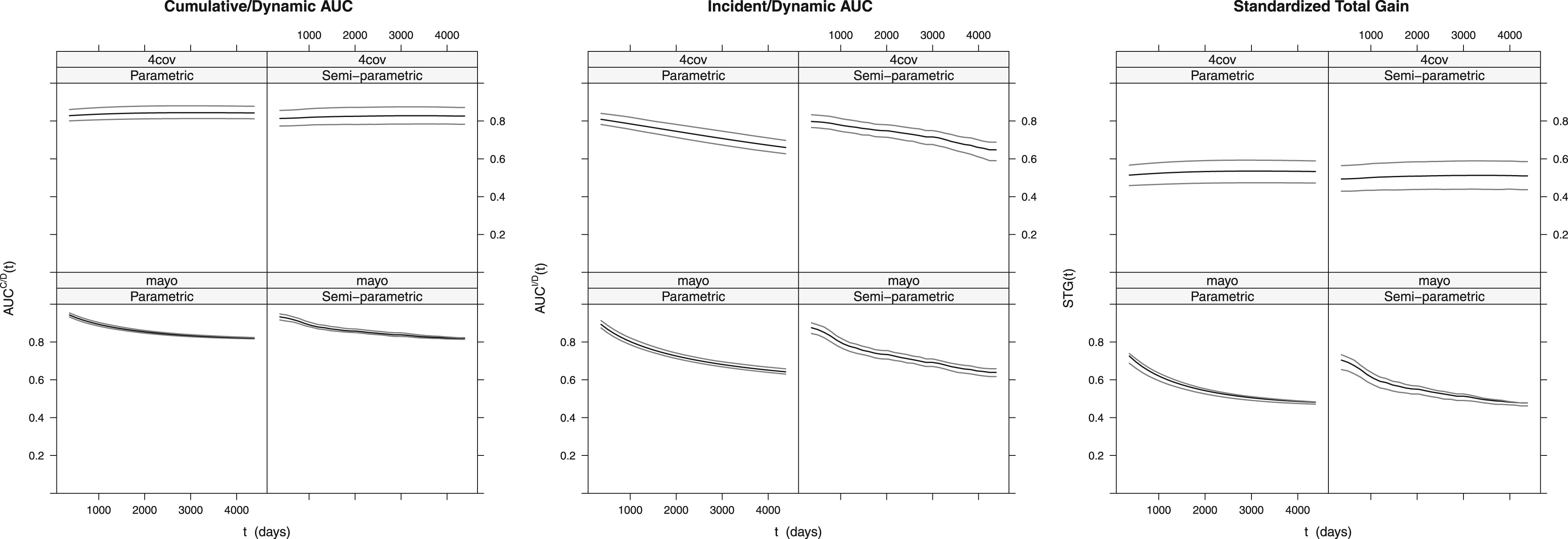
Figure 3 depicts estimates and 95% confidence bounds of , and , for greater than one year, for 4-cov and mayo from the parametric and SP models; here, the confidence bounds were drawn by joining the pointwise CIs for each measure at different time points. The estimated functions appear somehow similar for both models, with the SP approach estimating wider confidence bounds, particulary for 4-cov. The cumulative/dynamic plots indicate that 4-cov keeps a fairly constant discriminatory rate for the status of the event occurring within time at around 0.8, and that the corresponding discriminatory rate of mayo decreases steadily with time to . The cumulative/dynamic plots show that the rate for discriminating the status of the event instantaneously occurring at time decreases steadily with time to 0.6 using either marker, with both markers yielding estimates of the AUC that exceed in the first 2000 days of the follow-up. More marked differences between both markers can be noticed in the plots of , where the estimate for 4-cov appears fairly constant over time at around 0.5, whereas the estimate for mayo decreases steadily from around 0.7 to around 0.5, which supports the predictiveness superiority of mayo.
Parametric and semi-parametric estimates, along with 95% confidence bounds, for area under the curve (AUC), and corresponding to markers 4-cov and mayo.
Discussion
In this paper, two new copula-based approaches to the representation of the joint model of marker and time to event were proposed, leading to parametric and SP characterizations of marker classification and predictivenes performance measures for survival outcomes. While the parametric representation of the model allows for the independent customization of each margin, such tailored specification is only required for the margin of the marker in the SP formulation, with the margin of the survival time being provided by a non-parametric estimator. In both models, the copula function encodes the dependence structure between the two random variables.
Maximum likelihood and a two-stage procedure were employed to obtain estimates in the parametric and SP specifications, respectively, and bootstrapping was performed for both approaches to obtain SEs and CIs. A strategy for choosing a copula from a set of candidates was based on assessing diagnostics plots for each conditional distribution. Simulation studies, which considered bias and RMSE for the assessment of the point estimators corresponding to classification and predictiveness measures, showed that both approaches performed well under different dependence and censoring scenarios.
The analysis of two markers from the PBC Mayo Clinic data illustrated the modeling process of the proposed methods, with both approaches producing similar results. This is the first study that displays ROC and predictiveness curves under the same framework. Meticulous investigation of the copula choice was necessary, and residuals plots for the conditional distributions offered a useful tool for the identification of the copula class with best fit for each marker. Unlike previous studies, where the methodologies were focused on point estimators mainly, the displays of the time-varying curves are by no means erratic (see e.g. Bansal and Heagerty,1 Kamarudin et al.,29 and Viallon and Latouche30); in addition, the curves estimated here and their summaries showed CIs that are relatively narrow. Therefore, the methods developed in this paper provided an enhancement in the understanding of the classification and predictiveness characteristics of each marker.
The quantities that are used to compute a marker are registered at the beginning of the follow-up and tend to be fully observed, with the resulting observations being relatively easy to model parametrically by employing valid transformations, similar to the modeling of the usual parametric ROC analysis (e.g. Hanley31). Linking a FP model for the marker with a non-parametric survival distribution for the time to event via the copula, in order to obtain the SP joint model, represents a convenient extension of the parametric joint model when univariate parametric models fail to give satisfactory fits to the survival margin, or when the survival time is subject to sampling schemes that lead to complex incomplete data structures such as interval censoring, which are difficult to model parametrically in the bivariate setting.
Although the copula-based methods do not lead to closed-form estimates of marker performance measures, they are appealing alternatives since the estimation procedures are for all measures within the same framework, and they consider all marker values and all failure and censoring times, with no information appearing to be lost. Previously proposed methods for estimating only, for instance, have mainly been based on smoothing techniques, and have proved to be highly influenced by data corresponding to earlier time points than , which can be considered a drawback since the focus is on assessing the prospective performance of a marker, not the retrospective.2
While the copula-based methods presented in this study represent a convenient way to model the dependence between the marker and the survival time, they were formulated using four copula families only. Various bivariate models have been defined in terms of finite mixtures of copulas, leading to rich classes of joint models that can be employed to study complex dependencies32,33; however, with the adoption of such mixture models, new problems arise, including the customization of the margins in each component, which might not be easy to address, particularly because the survival time is subject to various types of censoring.
In the cross-sectional data context, there has been interest in comparing ROC curves corresponding to two correlated markers. The three main comparison scenarios include34: (a) Testing whether the two ROC curves are equal for all marker quantiles , (b) Testing whether the two AUC’s are equal, and (c) Testing whether the two ROC curves are equal at a particular marker quantile. In the survival outcome setting, Zhang and Shao35 developed vine copula-based algorithms to generate multivariate data for correlated markers, focusing mainly on the simulation for given concordance indexes. It is fair to say that extensions of the characterizations presented in this paper can be used in the three-dimensional framework by using vine copulas, to then elaborate the corresponding hypothesis tests for the various comparison scenarios. This, of course, warrants further research.
Footnotes
Software availability
R functions and codes for this manuscript can be accessed through the following GitHub link respecting the corresponding copyrights:
.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article: This research was supported in part with individual career development grants from CONACYT, Mexico, through Sistema Nacional de Investigadores.
ORCID iD
Gabriel Escarela
Appendix
Proofs for the continuous-valued time forms of , , and in the “Methods” Section.
Clearly
Since
and employing the following survival copula given in Nelsen11
where , then
and thus
Also,
here, is the PDF of . The Risk function can be obtained using equation (12) as follows:
here, is the PDF of .
References
1.
BansalAHeagertyPJ. A tutorial on evaluating the time-varying discrimination accuracy of survival models used in dynamic decision making. Med Decis Making2018; 38: 904–916.
2.
van GelovenNHeYZwindermanAH, et al. Estimation of incident dynamic AUC in practice. Comput Stat Data Anal2021; 154: 1–15.
3.
TangLDuPWuC. Compare diagnostic tests using transformation-invariant smoothed ROC curves. Stat Plan Infer2010; 140: 3540–3551.
4.
HuangYPepeMS. A parametric ROC model-based approach for evaluating the predictiveness of continuous markers in case-control studies. Biometrics2009; 65: 1133–1144.
5.
EscarelaGRodríguezCENúñez-AntonioG. Copula modeling of receiver operating characteristic and predictiveness curves. Stat Med2020; 39: 4252–4266.
6.
GenestCFavreA-C. Everything you always wanted to know about copula modeling but were afraid to ask. J Hydrol Eng2007; 12: 347–368.
7.
BuraEGastwirthJL. The binary regression quantile plot: assessing the importance of predictors in binary regression. Biom J2001; 4: 5–21.
8.
HeagertyPJZhengY. Survival model predictive accuracy and ROC curves. Biometrics2005; 61: 92–105.
9.
LiuXNingJChengY, et al. A flexible and robust method for assessing conditional association and conditional concordance. Stat Med2019; 38: 3656–3668.
10.
ChaiebLLRivestLPAbdousB. Estimating survival under a dependent truncation. Biometrika2006; 93: 655–669.
11.
NelsenRB. An introduction to copulas. New York: Springer-Verlag, 2006.
12.
de LeonARWuB. Copula-based regression models for a bivariate mixed discrete and continuous outcome. Stat Med2011; 30: 175–185.
13.
KarrisonT. Bootstrapping censored data with covariates. J Stat Comput Simul1990; 36: 195–207.
14.
LawlessJFYilmazYE. Semiparametric estimation in copula models for bivariate sequential survival times. Biom J2011; 53: 779–796.
15.
DavisonACHinkleyDV. Bootstrap methods and their application. Cambridge: Cambridge University Press, 1997.
GenestCMacKayJ. The joy of copulas: Bivariate distributions with uniform marginals. Am Stat1986; 40: 280–283.
21.
van DomelenDRMitchellEMPerkinsNJ, et al. Gamma models for estimating the odds ratio for a skewed biomarker measured in pools and subject to errors. Biostatistics2019; 22: 250–265.
22.
AzzaliniA. A class of distributions which includes the normal ones. Scand J Stat1985; 12: 171–178.
23.
LammersWJKowdleyKVvan BuurenHR. Predicting outcome in primary biliary cirrhosis. Ann Hepatol2014; 13: 316–326.
24.
Liermann GarciaRFEvangelista GarciaCMcMasterP, et al. Transplantation for primary biliary cirrhosis: retrospective analysis of 400 patients ina single center. Hepatology2001; 33: 22–27.
25.
BansalAHeagertyPJ. A comparison of landmark methods and time-dependent ROC methods to evaluate the time-varying performance of prognostic markers for survival outcomes. Diagn Prognostic Res2019; 3. Article number: 14.
26.
DicksonERGrambschPMFlemingTR, et al. Prognosis in primary biliary cirrhosis: model for decision making. Hepatology1989; 10: 1–7.
27.
EganJP. Signal detection theory and ROC analysis. New York: Academic Press, 1975.
28.
LloydCJ. Estimation of a ROC curve. Stat Probab Lett2002; 59: 99–111.
29.
KamarudinANCoxTKolamunnage-DonaR. Time-dependent ROC curve analysis in medical research: current methods and applications. BMC Med Res Methodol2017; 17, Article number: 53.
30.
ViallonVLatoucheA. Discrimination measures for survival outcomes: connection between the AUC and the predictiveness curve. Biom J2011; 53: 217–236.
31.
HanleyJA. The use of the ’binormal’ model for parametric ROC analysis of quantitative diagnostic tests. Stat Med1996; 15: 1575–1585.
32.
ArakelianVKarlisD. Clustering dependencies via mixtures of copulas. Commun Stat – Simul Comput2021; 43: 1644–1661.
33.
ZhuangHDiaoLGraceYY. A bayesian nonparametric mixture model for grouping dependence structures and selecting copula functions. Economet Stat2022; 39: 172–189.
34.
BantisLEFengZ. Comparison of two correlated ROC curves at a given specificity or sensitivity level. Stat Med2016; 35: 4352–4367.
35.
ZhangYShaoY. A numerical strategy to evaluate performance of predictive scores via a copula-based approach. Stat Med2020; 39: 2671–2684.