
Abstract
Response-adaptive randomization allows the probabilities of allocating patients to treatments in a clinical trial to change based on the previously observed response data, in order to achieve different experimental goals. One concern over the use of such designs in practice, particularly from a regulatory viewpoint, is controlling the type I error rate. To address this, Robertson and Wason (Biometrics, 2019) proposed methodology that guarantees familywise error rate control for a large class of response-adaptive designs by re-weighting the usual
Introduction
Randomized clinical trials are often designed in such a way that a decision about treatment efficacy is reached as quickly as possible and with a minimum number of patients exposed to inferior treatment options. Response-adaptive randomization (RAR) can help achieve such goals by an allocation process that makes randomization of a newly recruited patient dependent on responses to treatment from previous study participants. This can offer advantages in terms of the benefit for patients recruited into the study, increasing the willingness of patients to participate in the study, or the study’s power to detect treatment effects. Many different classes of RAR procedures have been proposed for various trial contexts, and a recent review of methodological and practical issues around the use of RAR in clinical trials can be found by Robertson et al. 1 However, one major concern is about the potential for type I error rate inflation arising from such studies. This is particularly the case from a regulatory viewpoint, where control of the type I error rate is required for confirmatory studies.2,3
Robertson and Wason
4
proposed a methodology that guarantees a type I error rate control for normally distributed outcomes by reweighting the usual
In this article, we present an improvement of their proposal based on the CIV principle. It is simpler in that it requires only modifying the final test statistic so that it has a known variance, and not a known mean. This restricts the method to trials where the patients are allocated to the experimental arms in blocks (i.e. groups) using RAR while the allocation to the control arm is fixed. On the other hand, by construction, the method guarantees that there will never be negative weights for the contribution of each block of data to the adjusted test statistic, and the modified method can also provide a substantial power advantage in practice.
The outline of the rest of the article is as follows. In Section 2, we describe the proposed testing procedure and its connection with existing approaches. A simulation study is presented in Section 3 to compare the testing strategies, and a case study is given in Section 4. We conclude with a discussion in Section 5.
Proposed testing procedure
Consider a trial with
For simplicity, we consider testing each elementary null hypothesis
The standard
In order to tackle this issue, like in Robertson and Wason
4
we introduce a hypothetical ‘auxiliary design,’ which can be thought of as one of the allowed randomization lists, chosen before the beginning of the trial. Unless there are reasons to choose otherwise, a default option would be to use fixed (equal) randomization to reflect the uncertainty before the trial begins over which of the treatment options will be superior. Since the allocations to the treatments are all fixed in advance in the auxiliary design, the standard
For the auxiliary design, let
In this setup, the actual trial design (i.e. the realized allocations of patients to treatments using RAR) can be viewed as a series of data-dependent modifications of the auxiliary design, where we account for these modifications using the CIV principle. Robertson and Wason
4
proposed a modified test statistic
We now describe a simplification of the handling of the control group in this setup. The basic idea of the modified proposal is to only match the variances of the test statistics under the auxiliary and actual trial designs, and not matching the means. Due to this, the CIV principle may no longer be used as a justification for the algorithm, but a minor modification of it still applies.
Let
The following formulae define the resulting summary statistics and their (conditional) distributions:
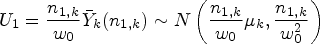
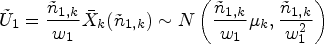
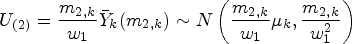
We now form the overall test statistics for blocks
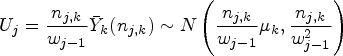
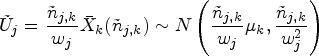
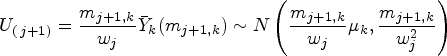
We form the overall test statistics for blocks
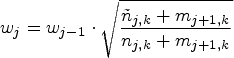
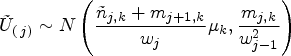
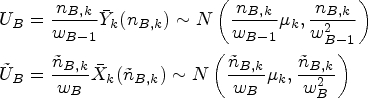
Since we did not modify the randomization to the control treatment, we have a consistent estimate of
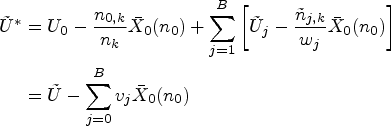
If
Regarding the estimation of
If there is a sequence
Note that a test of
Connection with existing approaches
There is a close connection between the proposal of Robertson and Wason
4
(and hence our modified proposal) and more traditional adaptive designs. Assume that we want to test the one-sample hypothesis
At the next stage (stage 2), we pick a new sample size
Application within a closed test procedure
The approach described above for controlling the type I error rate for a single hypothesis All observations of the experimental treatment arms in Assume that the approach from Section 2 is used on all experimental treatment arms separately, leading to test statistics
In contrast, a ‘Dunnett-like’ closed test (see Magirr et al.
8
) is not straightforward. The marginal null distribution
Simulation studies
To investigate the operating characteristics of the suggested design, we use the set-up of a trial with
Bayesian adaptive randomization
We compare the methods under a Bayesian adaptive randomization (BAR) scheme. Following Robertson and Wason,
4
we use a block-randomized BAR scheme by Wason et al.
9
The randomization probabilities
Error inflator scheme
To assess the FWER and power in a situation where type I control is known to be violated, we also investigate the allocation scheme presented in Section 2.3 of Robertson and Wason,
4
adapted to block randomization. This rule keeps on allocating patients to treatment 1 (apart from one patient per block to each of the other experimental treatments) as long as the mean response of treatment 1 remains below a fixed threshold of 0.5. As soon as the fixed threshold is crossed, all subsequent patients not randomized to control are allocated with equal probability to the other experimental treatments (except for one patient per block on treatment
Examples of weights
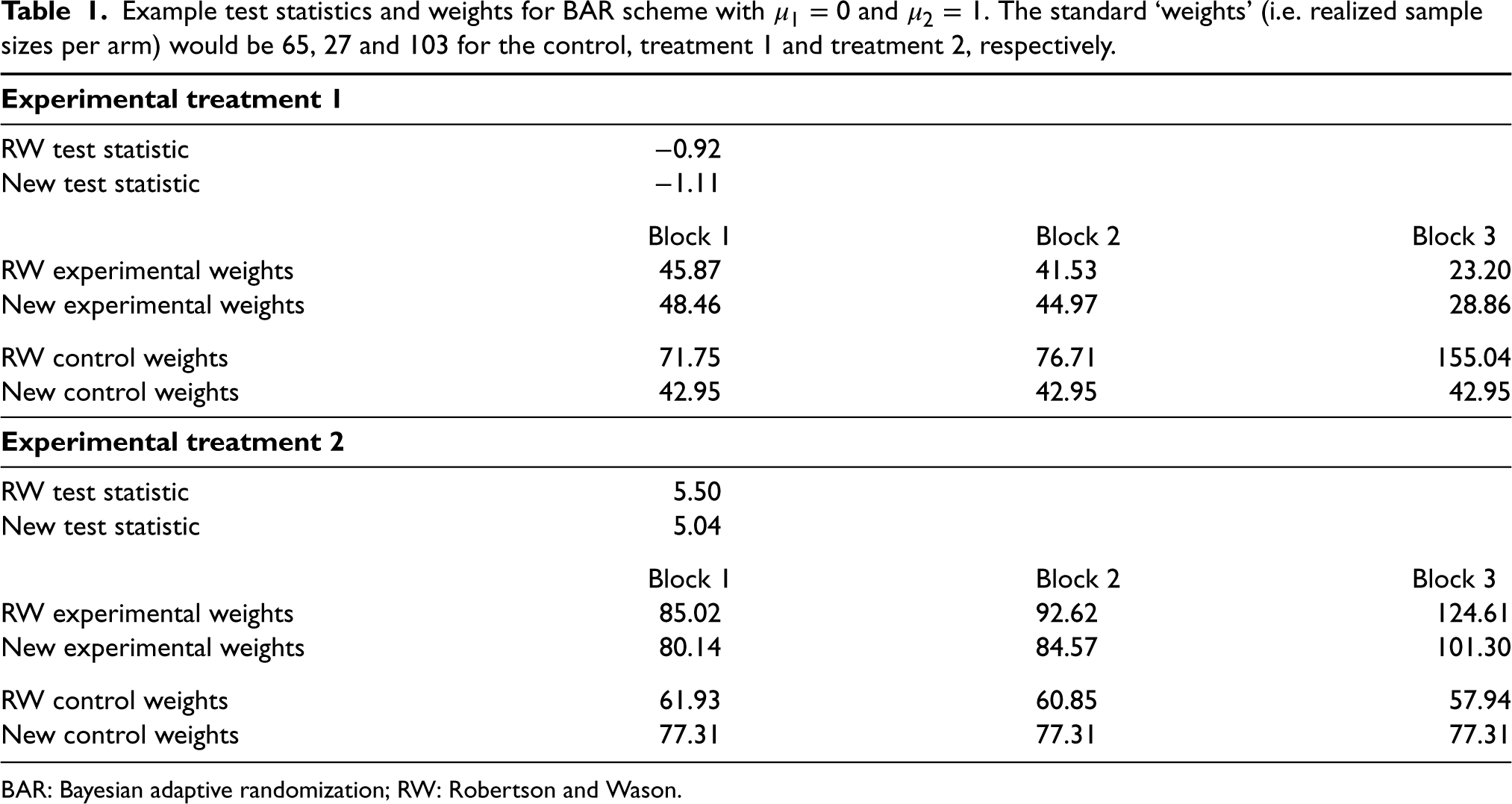
Tables 1 and 2 show the weights from two simulations under BAR and the error inflator scheme, respectively. Throughout, we set
Example test statistics and weights for BAR scheme with
and
. The standard ‘weights’ (i.e. realized sample sizes per arm) would be 65, 27 and 103 for the control, treatment 1 and treatment 2, respectively.
Example test statistics and weights for BAR scheme with
BAR: Bayesian adaptive randomization; RW: Robertson and Wason.
Example test statistics and weights for the error inflator scheme with
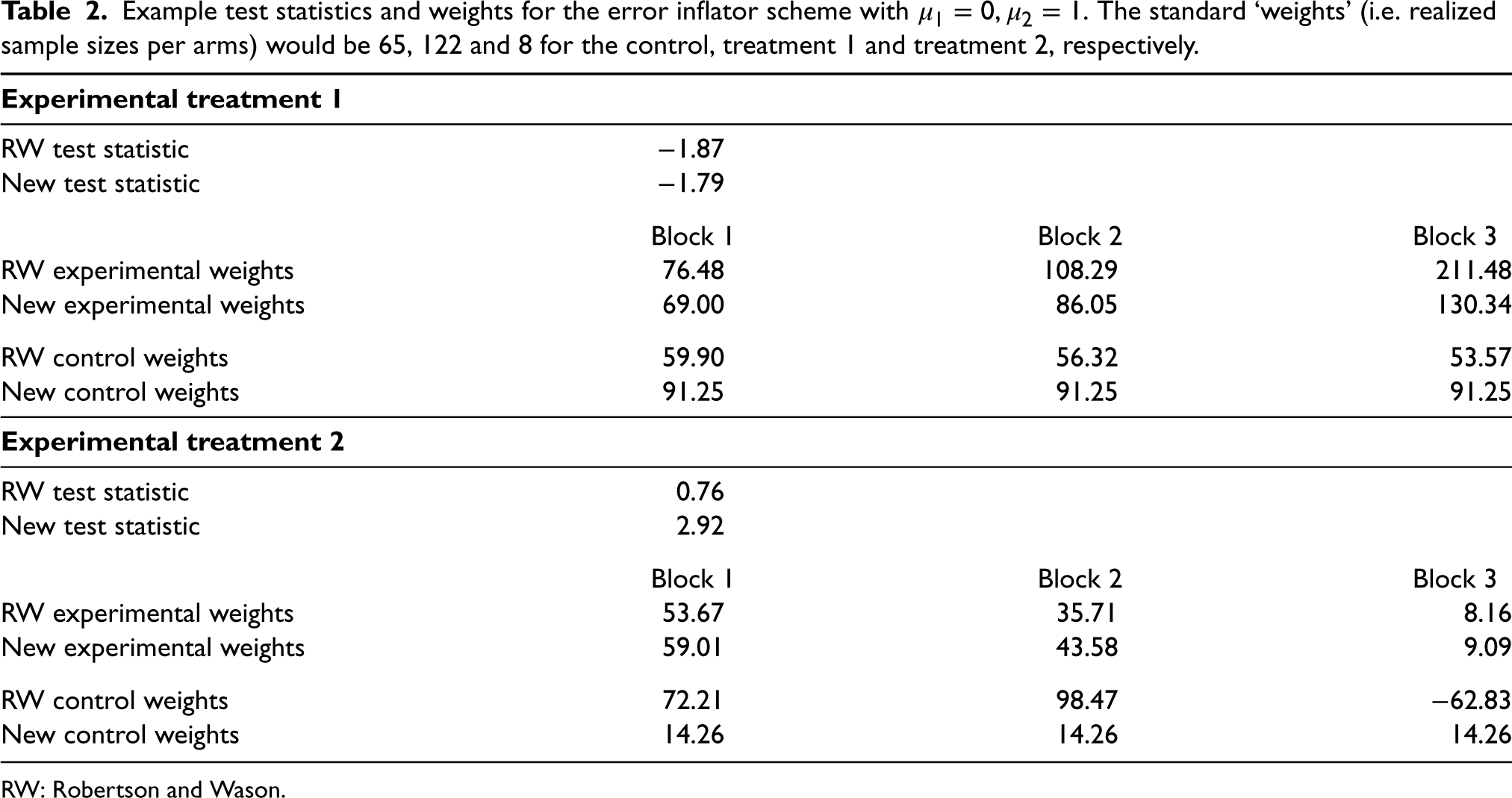
RW: Robertson and Wason.
In both examples, the weights can be very different for the two methods and also differ from both the observed sample sizes and the sample sizes in the auxiliary design. Both weight calculations up-weight the treatment arm with fewer allocations, while the RW weights tend to be more variable overall. The weight calculation from Robertson and Wason also produces negative weights for the control group for the error inflator scheme – something that is not possible with the calculation from Section 2. Note that the statements refer to a single simulation run. For the error inflator scheme, this is a case where treatment 2 crossed the threshold after block 0. Observed sample sizes and weights are very different for other simulation runs where this does not happen.
To investigate the performance of the various approaches, we conducted simulations for both the BAR and the error inflation scheme. As a standard comparison, we also provide simulation results for fixed (equal) randomization in the Supplemental material. The weighing approach from Robertson and Wason,
4
the proposal from Section 2 and the naive approach (treating observed sample sizes as if they had been fixed in advance) were used. In all these approaches, the closed test procedure and the Bonferroni-Holm procedure are applied to adjust for the multiplicity arising from the testing of experimental treatments against a common control. In Tables 3 and 4, disjunctive power is the probability to reject at least one false null hypothesis (if there is one) and error is the FWER. Nominal test levels are assumed to be
Familywise error rate and disjunctive power for BAR using block randomization with a fixed control allocation. There were
simulated trials for each set of parameter values.
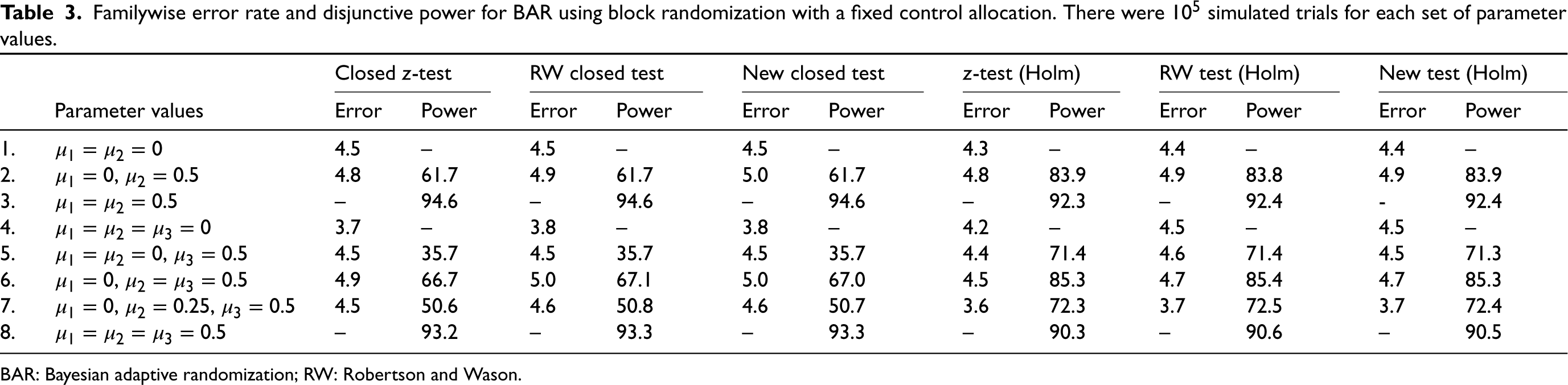
Familywise error rate and disjunctive power for BAR using block randomization with a fixed control allocation. There were
BAR: Bayesian adaptive randomization; RW: Robertson and Wason.
Familywise error rate and disjunctive power for the error inflator scheme using block randomization with a fixed control allocation. There were
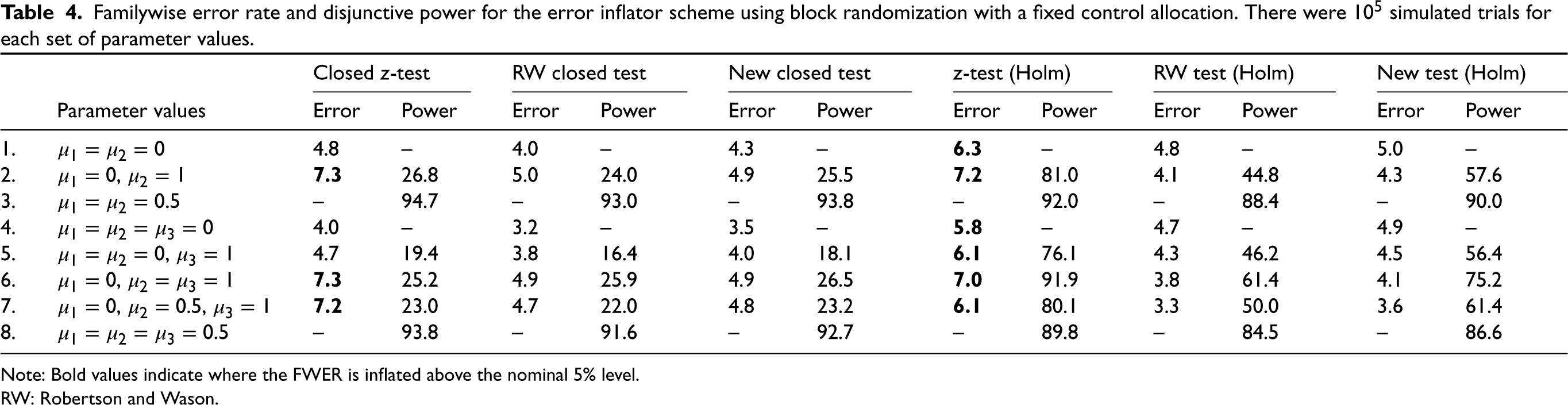
Note: Bold values indicate where the FWER is inflated above the nominal 5% level.
RW: Robertson and Wason.
Table 3 shows the results for the BAR scheme. As is well known, the closed test procedure has a slight power advantage if the treatments are equally effective, but is inferior when one of the treatments is effective, but the other(s) is not. FWER inflation did not occur in the simulations, even if the naive approach is used. The naive, the RW and the proposed approach lead to practically identical type I errors and power here. Although our new method does not perform better in terms of power, we consider it reassuring that it does not lose any power compared to the standard analysis either. Hence, in this specific case, there is no ‘price to pay’ for the guarantee of type I error control.
The results for the error inflator scheme are shown in Table 4. We see that the error inflator scheme indeed does not control the FWER. The inflation remains modest with a FWER not exceeding
In this section, we revisit the case study used in Robertson and Wason 4 of a phase II placebo-controlled trial in primary hypercholesterolemia to compare the effects of using the SAR236553 antibody with high-dose or low-dose atorvastatin, as compared with high-dose atorvastatin alone (Roth et al. 10 ). The primary outcome was the least-squares mean percent reduction from baseline of low-density lipoprotein cholesterol. Patients were randomly assigned, in a 1:1:1 ratio, to receive 80 mg of atorvastatin plus placebo, 10 mg of atorvastatin plus SAR236553 or 80 mg of atorvastatin plus SAR236553. For convenience, we label these interventions as the ‘control’, ‘low dose’ and ‘high dose’, respectively.
We use the observed values from the trial and assume that the distribution of the primary outcome variable is distributed according to
Table 5 gives the results for a simulated trial with standard weights (i.e. realized sample sizes) 31 for the control, 27 for the low dose and 34 for the high dose. For the experimental doses, the realized breakdown per block (excluding the burn-in period) was
Test statistics,
-values and weights for a simulated block randomized trial using a BAR scheme. L = Low dose, H = High dose, C = Control. The standard weights (i.e. realized sample sizes) are 31 for the control, 27 for the low dose and 34 for the high dose.
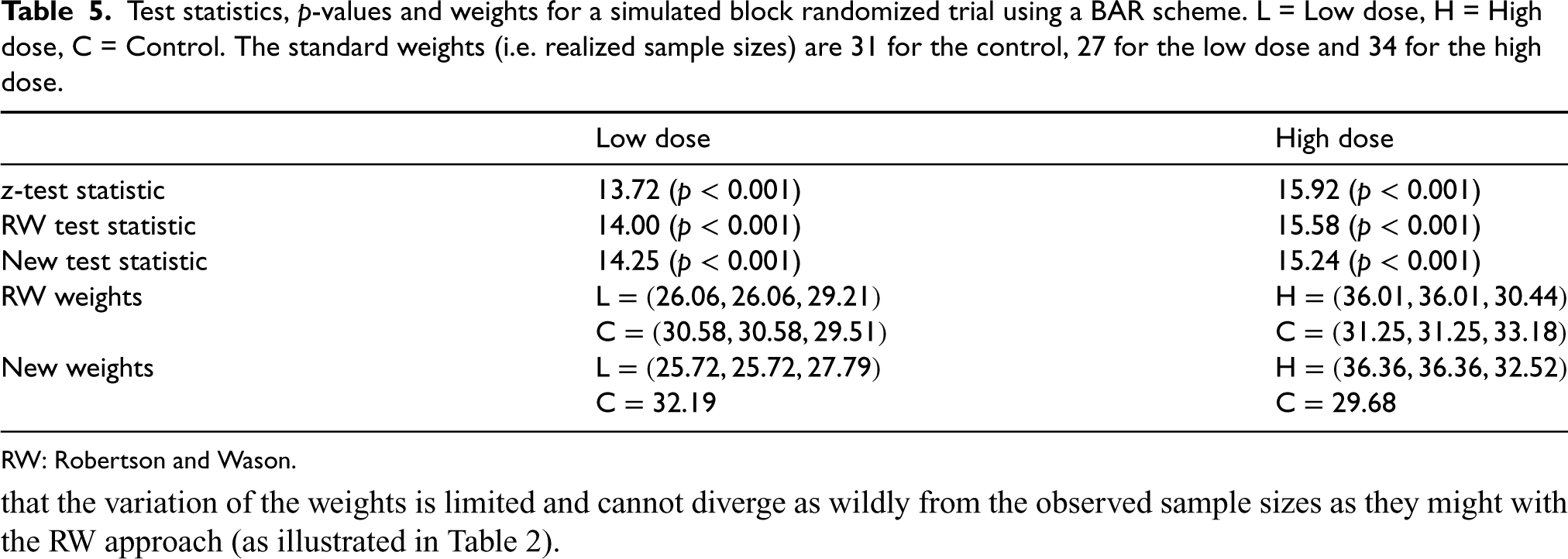
Test statistics,
RW: Robertson and Wason.
In this article, we have proposed an improved testing strategy based on the one by Robertson and Wason, 4 which guarantees FWER control in the context of block-randomized response-adaptive trials with a fixed control allocation. Our proposal is simpler but is more restrictive as it is not applicable to fully sequential RAR or having an adaptive control allocation. However, our proposal guarantees that the weights are non-negative, and there can be substantial power gains in some settings.
As noted by Robertson and Wason, 4 since the proposed testing procedure is based on the CIV principle, it has the additional important flexibility of being valid when the allocation is changed due to external information. Our proposal is also designed for normally distributed outcomes, although it can apply to other types of outcomes asymptotically. However, a natural extension of this work would be to work directly with binary endpoints (for example) and potentially apply the CIV principle to this setting.
The use of the CIV principle to ‘reweight’ the test statistics raises interesting questions around the design of optimal response-adaptive trials (i.e. the formulation of RAR procedures that optimize certain criteria). For example, some RAR procedures incorporate a formal power constraint, but this is based on standard test statistics. If an alternative testing strategy such as our proposed one is used, then there is a mismatch between the optimality criterion and the subsequent analysis of the trial.
More generally, it is important to remember that there can be trade-offs between the different objectives in a trial. For example, we have seen that insisting on the use of RAR methods which guarantee FWER control can lead to a substantial loss in power. As another example, more ‘extreme’ RAR procedures (i.e. those that skew the randomization probabilities close to 0 or 1) that perform well in terms of patient benefit metrics may conversely have low power and mean that analysis methods developed for a completely random sample are no longer appropriate. Hence the question of whether to use RAR as opposed to a fixed randomisation scheme is not a simple one, and crucially depends on the trial context and goals.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231167437 - Supplemental material for Familywise error rate control for block response-adaptive randomization
Supplemental material, sj-pdf-1-smm-10.1177_09622802231167437 for Familywise error rate control for block response-adaptive randomization by Ekkehard Glimm and David S Robertson in Statistical Methods in Medical Research
Footnotes
Data availability
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: DSR was funded by the UK Medical Research Council (MC_UU_00002/14) and the Biometrika Trust. This research was supported by the NIHR Cambridge Biomedical Research Centre (BRC1215-20014). The views expressed in this publication are those of the authors and not necessarily those of the NHS, the National Institute for Health Research or the Department of Health and Social Care (DHSC). For the purpose of open access, the author has applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising.
Supplemental material
Supplemental material for this article is available online. Web Appendices and tables are available with this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.