
Abstract
Most of the studies for longitudinal quantile regression are based on the correct specification. Nevertheless, one specific model can hardly perform precisely under different conditions and assessing which conditions are (approximately) satisfied to determine the optimal one is rather difficult. In the case of the mixed effect model, the misspecification of the fixed effect part will cause a lack of predicting accuracy of random effects, and affect the efficiency of the cumulative function estimator. On the other hand, limited research has focused on incorporating multiple candidate procedures in longitudinal data analysis, which is of current emergency. This paper proposes an exponential aggregation weighting algorithm for longitudinal quantile regression. Based on the secondary smoothing loss function, we establish oracle inequalities for aggregated estimator. The proposed method is applied to evaluate the cumulative
Keywords
Introduction
Quantile regression (Koenker and Bassett
1
) is an increasingly prevalent tool. It provides a constructive strategy for examining the effect of covariates on the entire response distribution and offers a more flexible, robust approach for data analysis. In longitudinal studies, the conditional

One of the significances for longitudinal quantile regression is dealing with censoring. Galvao et al.
6
proposed a three-step estimator in the sense of panel quantile regression with fixed individual effects and left censoring. Harding and Lamarche
7
developed a penalized estimation with a parametric or nonparametric mechanism to reduce attrition bias in Big Data, which is applicable to censored data as well. Recently, Liu et al.
8
discussed the estimation of the cumulative
In practice, identifying an extremely correct model is rather difficult for the data at hand. Traditional model selection is commonly used to search for the most approximate one. Machado 14 proposed a robust selection criterion for general M-estimators which is applicable to quantile regression, and Koenker 15 suggested the traditional Akaike information criterion. The shortcoming of the above methods is frequently ignoring the level of uncertainty associated with the choice of the model while reporting precision estimates. One approach to incorporating such uncertainty is model averaging, which combines competing specifications via propensity weights. Since the pioneering contribution of Hjort and Claeskens, 16 the number of works on the topic has proliferated in the past few years. For instance, Hansen 17 proposed the Mallows’ criterion for selecting weights of least squares regressive models; Lu and Su 18 used a jackknife model averaging strategy to sort weights in general quantile regression; and Wang et al. 19 generalized the method with high-dimensional covariates, etc.
It is noted that the aforementioned thoughts are based on the weights via vested information criterion, and emphasize the parametric model assumption. To make the comparison with complex nonparametric forms, Yang
20
proposed an adaptive estimation for least squares regression by model mixing. Recently, Shan and Yang,
21
Gu and Zou
22
imposed the method to contribute the aggregation algorithm for quantile regression and expectile regression, respectively. The estimators are theoretically shown to approach the best candidate. However, few literary works considered the aggregation for longitudinal quantile regression, especially in view of
In an effort to acquire the asymptotic properties of aggregated estimator, we establish the oracle inequalities under particular risk measures. Since the risk bound under the squared error loss can be hardly derived in quantile regression, (Gu and Zou
22
), we propose a novel smoothing scheme for the quantile check loss function, which supplies the strong convexity and the
The rest of the paper is organized as follows. In Section 2.1 we introduce the EAW algorithm for (1). We propose a secondary smoothing approximation to check the loss function and employ it during the weighting algorithm. We apply EAW algorithm to additive mixed effect model and propose an estimator for
In this section, we establish several aggregated estimators for longitudinal quantile regression. We firstly propose the EAW algorithm in the sense of model (1), and apply it to evaluate the cumulative
EAW algorithm
Suppose there is a sample of
Gu and Zou
22
proposed the aggregated regression for the asymmetric squared loss. Note that for quantile regression the loss function is

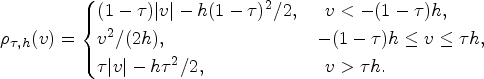
There are two smoothing coefficients in the secondary smoothing loss function (2). Figure 1 plots the curves of
The curves comparing with the proposed secondary smoothing loss function and the original check loss function. Different dotted lines represent the secondary smoothing loss under different values of
In what follows, we propose EAW algorithm for longitudinal quantile regression. The algorithm is based on the multiple splits for the observed dataset, which is typically considered in machine learning, and utilizes the secondary smoothing loss during the weighting process.
( For each procedure Given a sequence Repeat steps 1-3 by
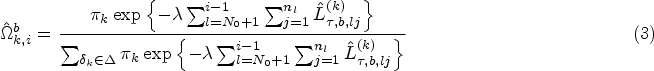
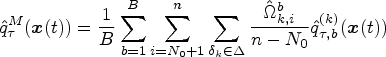
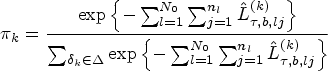
In this subsection, we evaluate
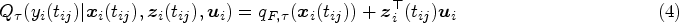
Note that
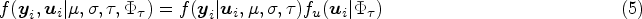
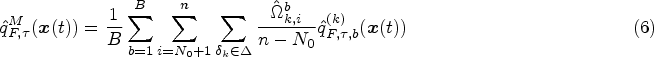
For the
Let
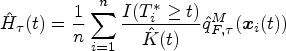
The
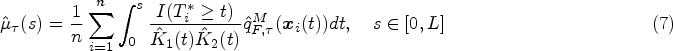
Let
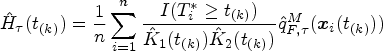
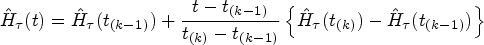
Predicting random effects for LQMM is an ongoing research issue. Geraci and Bottai
26
proposed a best linear prediction (BLP) of
As we mentioned previously, candidate predictors can be generated with a full-data set as long as we ignore the sequential updating mechanism. It is suitable since the predictor may be lack of efficiency if we only use a fraction of the samples to predict all random effects. Let
In this section, we build the asymptotic properties of proposed estimators. The outperformance of EAW estimator is critiqued by the oracle inequalities to show that the risks are automatically close to those of the best candidate. By the secondary smoothing loss function (2), we derive a homologous risk bound under quadratic losses. On the other hand, the consistency of the proposed
Oracle inequalities
We illustrate the theoretical properties of EAW estimator of equation (1). The intended adaptivity of the estimator is emerged via oracle inequalities, which provide statistical risk bounds in the sense of original check loss and squared error loss, respectively. For longitudinal data, risk bounds depend on the formulation of data collection as well. Define the counting process of time points for observations on the
Let Under conditions
Condition (A.1) and the upper-boundedness of the sub-exponential norm are fairly common in the related work of aggregations. The constraints are mild to be satisfied only if
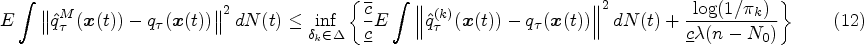
In this subsection, we anchor our investigation to demonstrate the consistency of estimators in Section 2.2. Let
Conditional on For any For Given a positive constant There exists a constant There exits some Suppose that Conditions
Aforementioned assumptions are widely considered in Zeng and Cai,
29
Deng,
27
and Liu et al.,
8
which are essential to longitudinal time-to-event data with censoring mechanism. Condition (B.3) is typically recommended to respond the misspecification of
It is worthily shown that the same construction of Theorem 2 will be derived in terms of
Simulation
In this section, we report the performance of EAW estimators proposed in previous sections by Monte Carlo simulation studies for longitudinal quantile regression. We firstly design an experiment for equation (1), then fit
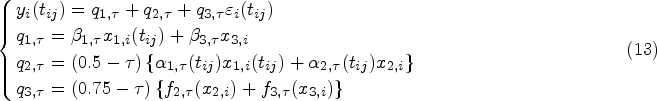
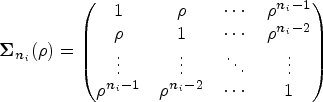
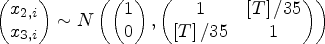
According to the above specification, the LQR:
Vary-Coefficient LQR (VCLQR):
Nonprametric additive quantile regression (NAQR):
We use the LQR for estimating LQR, and B-spline estimations for VCLQR and NAQR. We take the size of subjects as
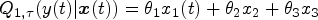
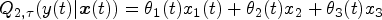
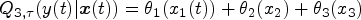
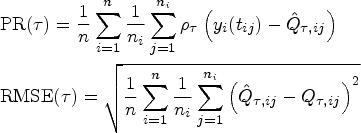
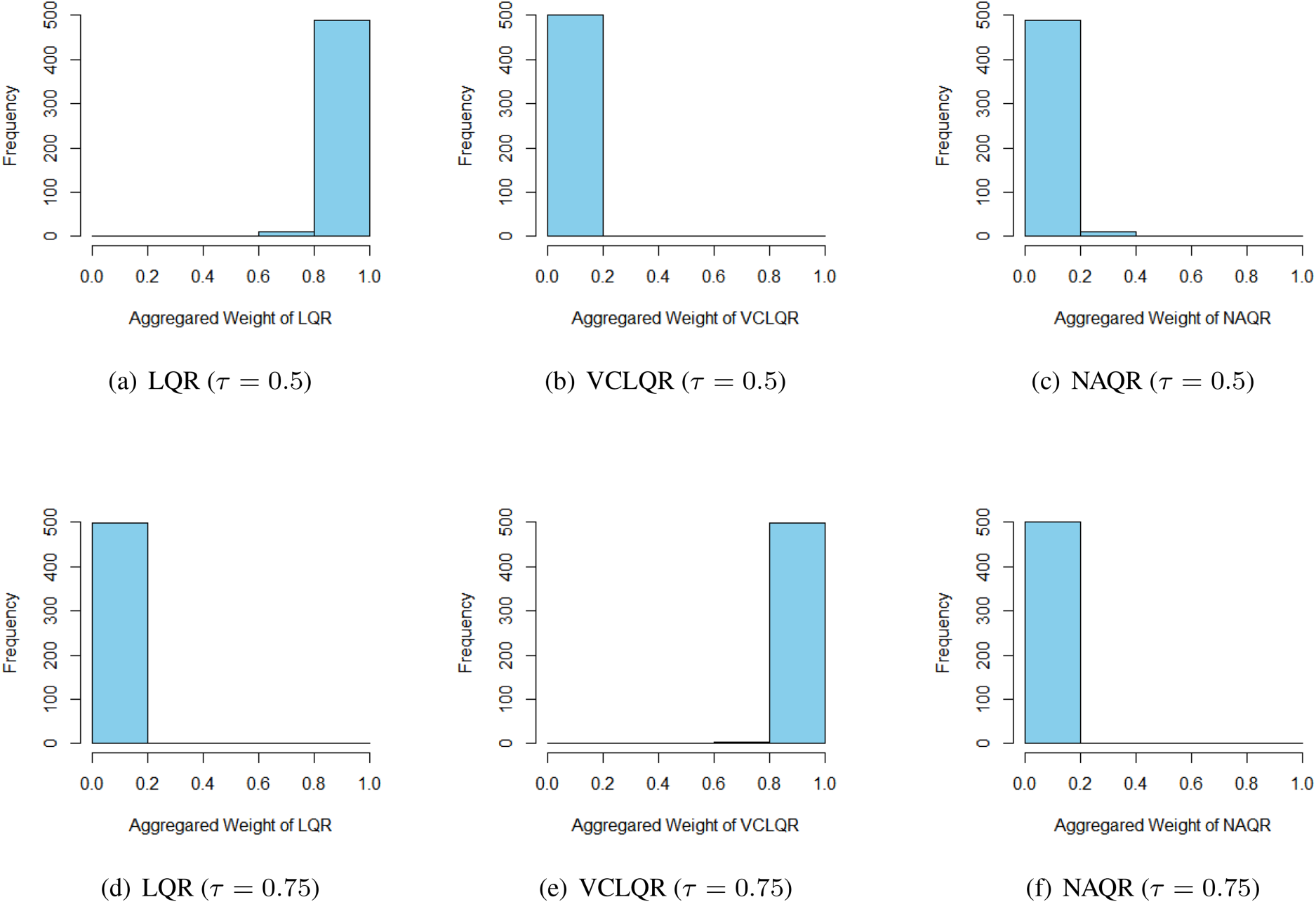
Histograms of exponential aggregation weights of candidate procedures for either
To demonstrate the rationality of the methodology in Section 2.2, we conduct the following simulation.
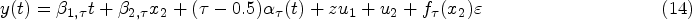
PRs, RMSEs, and related SEs (in parentheses) for kinds of estimations of Experiment 1, with the correlation coefficient
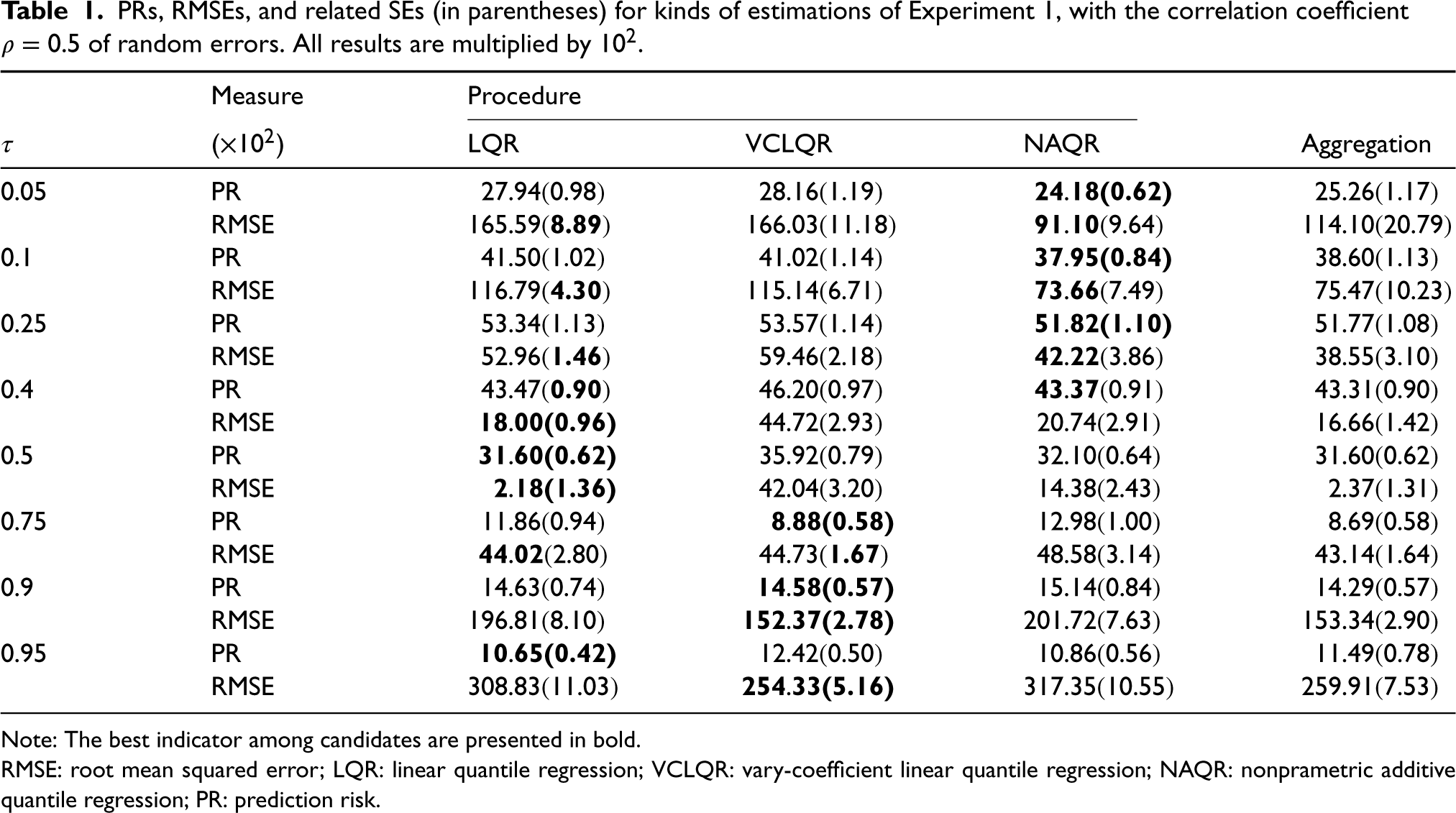
Note: The best indicator among candidates are presented in bold.
RMSE: root mean squared error; LQR: linear quantile regression; VCLQR: vary-coefficient linear quantile regression; NAQR: nonprametric additive quantile regression; PR: prediction risk.
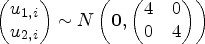
To specify different observed times of an unbalanced design, we utilize the following hazard function to generate the survival time 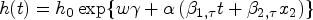
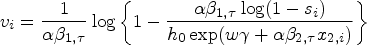
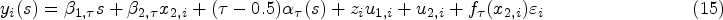
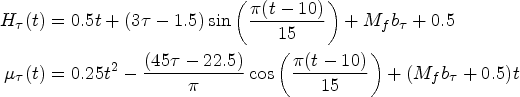
We implement the aforementioned experiment with sample size 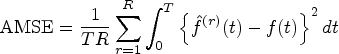
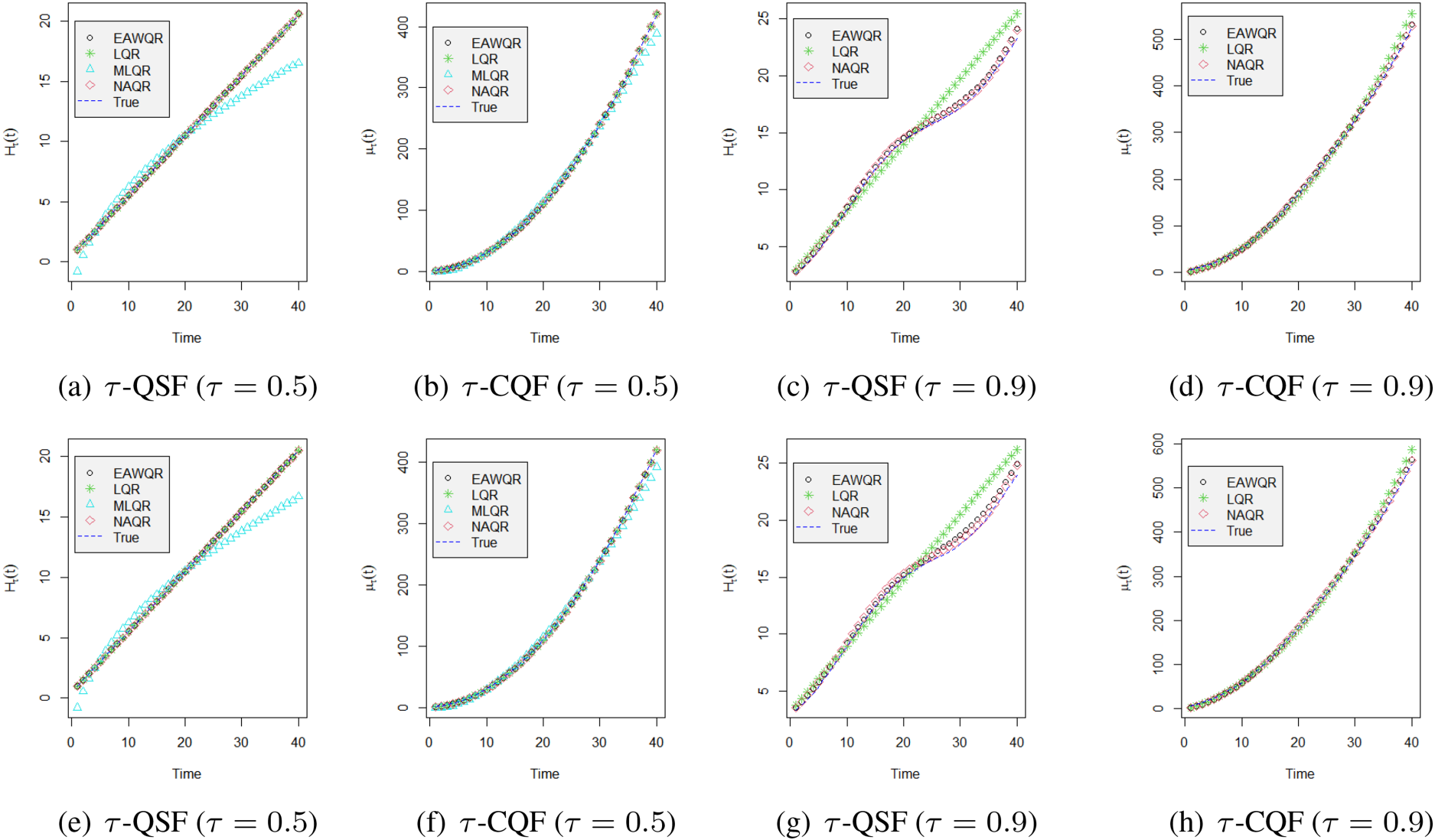
Fitted values versus the true curve of
Fitting the fixed effect of Experiment 2, estimating
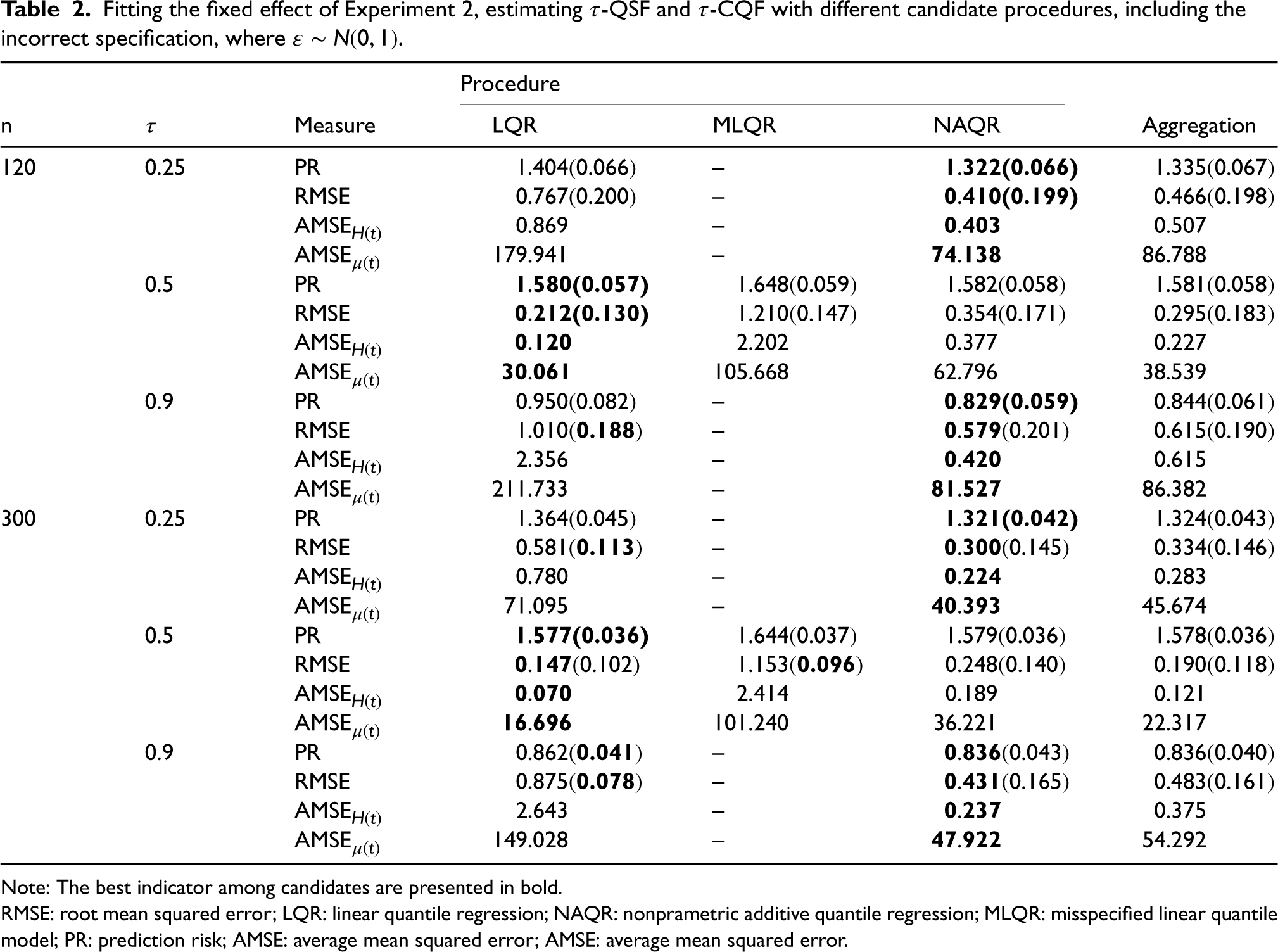
Note: The best indicator among candidates are presented in bold.
RMSE: root mean squared error; LQR: linear quantile regression; NAQR: nonprametric additive quantile regression; MLQR: misspecified linear quantile model; PR: prediction risk; AMSE: average mean squared error; AMSE: average mean squared error.
Fitting the fixed effect of Experiment 2, estimating
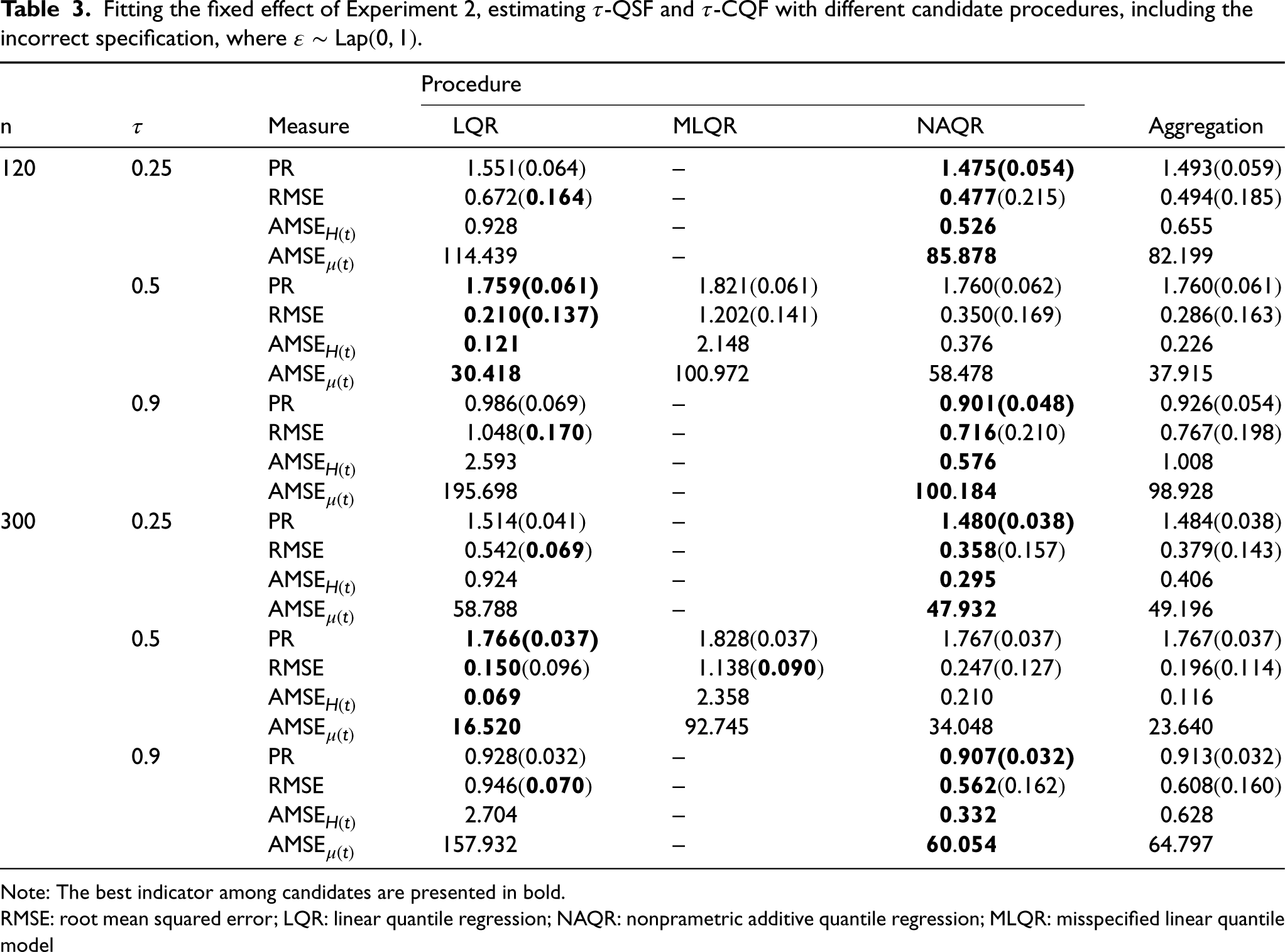
Note: The best indicator among candidates are presented in bold.
RMSE: root mean squared error; LQR: linear quantile regression; NAQR: nonprametric additive quantile regression; MLQR: misspecified linear quantile model
To check the efficiency of (10), we design a series of simulations for the similar mixed effect model in Experiment 2 but with different distributions of
Taking normal error as an example, the simulation is carried out in view of
MSEs of BLP
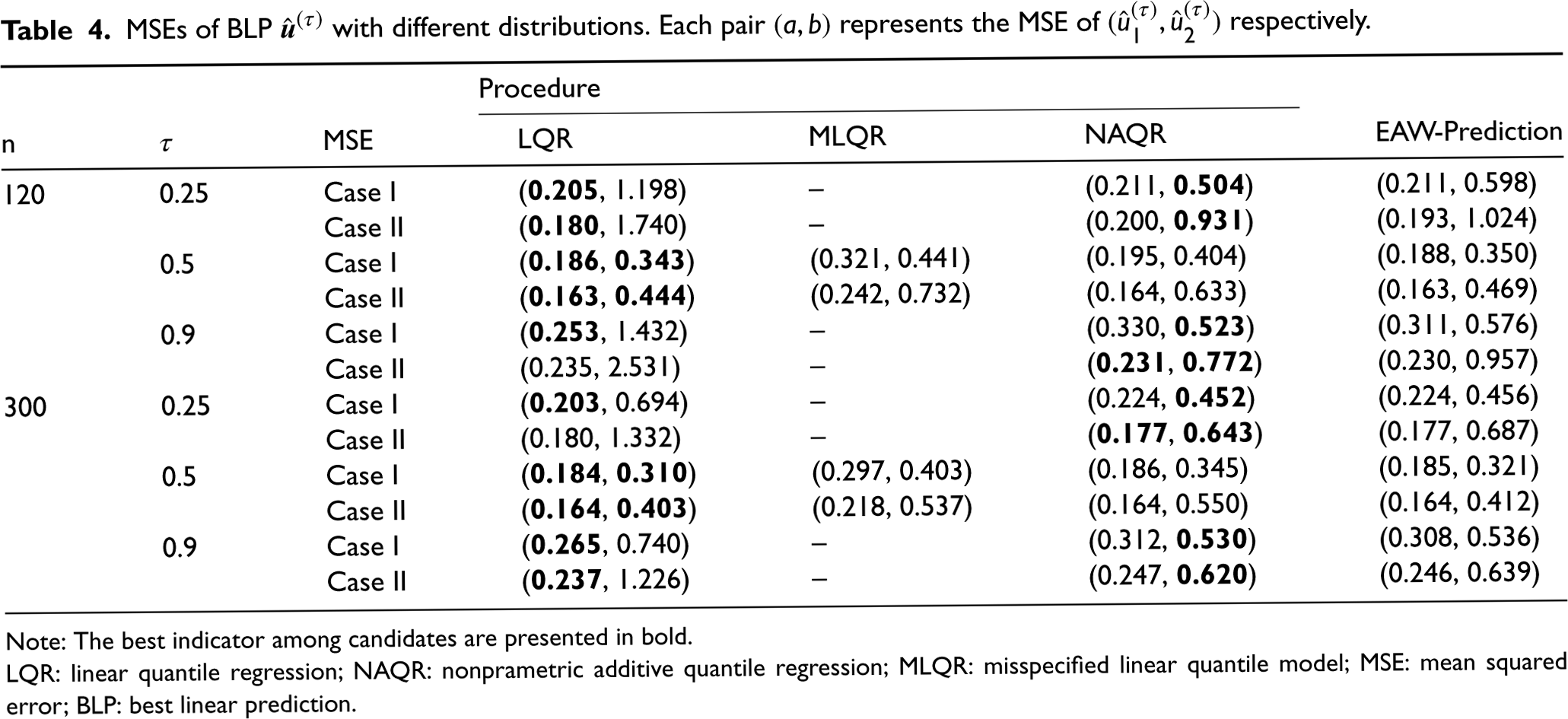
Note: The best indicator among candidates are presented in bold.
LQR: linear quantile regression; NAQR: nonprametric additive quantile regression; MLQR: misspecified linear quantile model; MSE: mean squared error; BLP: best linear prediction.
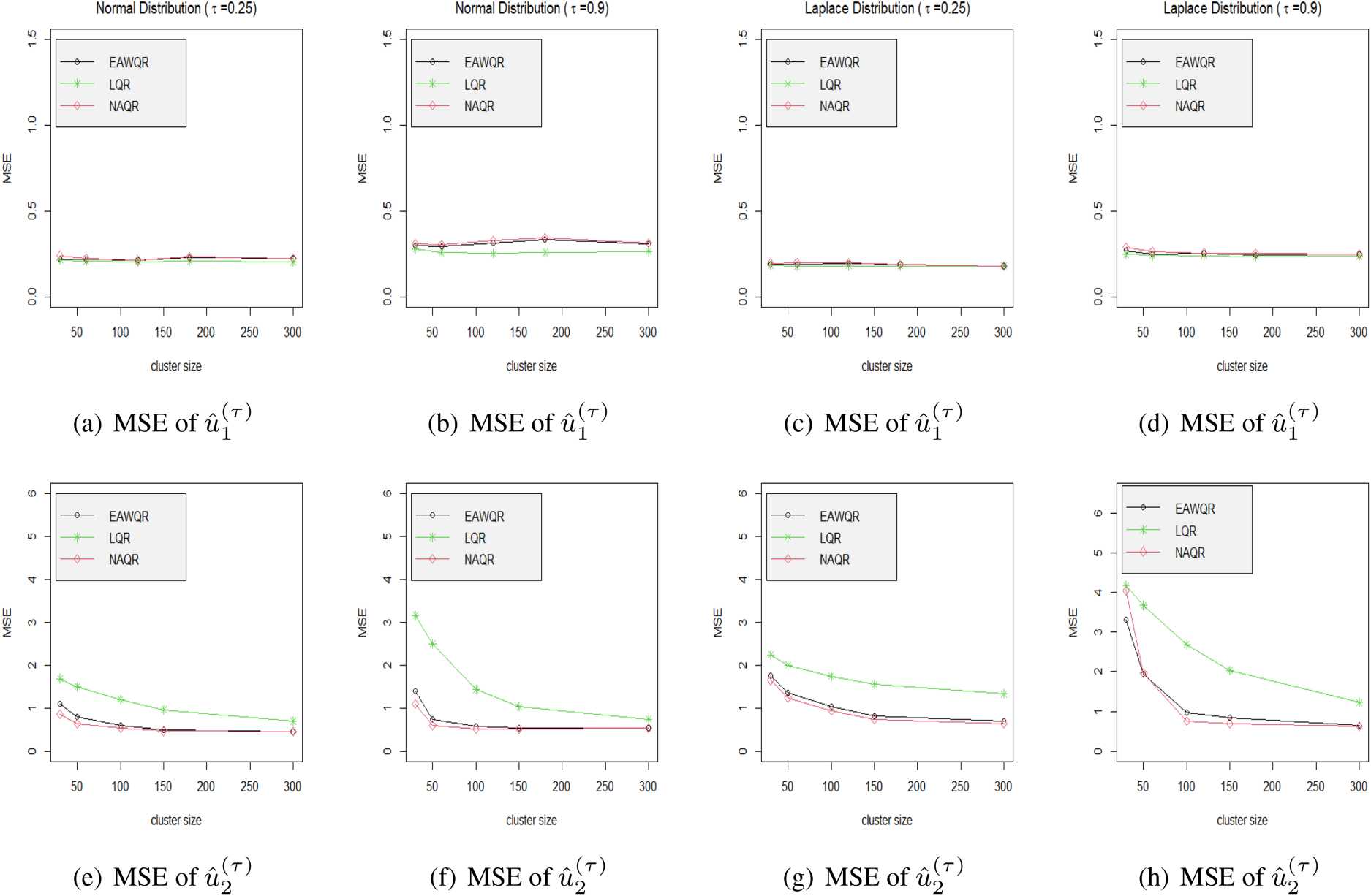
Mean squared errors of predicted random effects under different model specifications in Experiment 2. Different columns contain different distributions via the probability level be either 0.25 or 0.9.
To illustrate the practical superiority of the EAW estimation, we apply the methodology to analyze the MADIT data. The dataset has been studies by Deng 27 and Liu et al. 8 Note that most of the statistical modeling and estimating are based on the particular specification, and have not explicated the outperformance of the fitted model or estimating methodologies. We will demonstrate the rationality and the advantage of our method.
The MADIT was designed to evaluate the effectiveness of an implantable cardiac defibrillator (ICD) in preventing sudden death in high-risk patients. In the collected database, a total of 181 patients from 36 centers in the United States were recruited to be fully sequential and randomly observed. Of which 89 patients were assigned to the ICD group and others were assigned to the conventional therapy group, and all of the observations were censored in large degree. Concretely, the data set consists of patient ID code, Treatment code (1 for ICD and 0 for conventional), observed survival time in days, death indicator (1 for death and 0 for censored), cost type, and daily cost from the start to the completion of the trial. Following types of cost were present in the experiment: Type 1 is for hospitalization and emergency department visits; Type 2 is for outpatient tests and procedures; Type 3 is for physician/specialist visits; Type 4 is for community services; Type 5 is for medical supplies, and Type 6 is for medications.
It is widely accepted that the medical costs are not affected by Treatment Types as they often appear in the survival part to influence the risk rate of a subject, thus we will not consider it in the outcome model. On the other hand, patients may have more than one cost types simultaneously even at the same time point, seven significant covariates 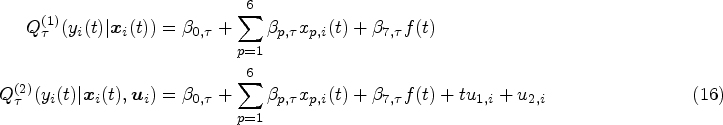
We implement EAW estimator among
Fitting residuals, 5-year and total period estimated cumulative quantile costs for complete MADIT dataset with different specifications of
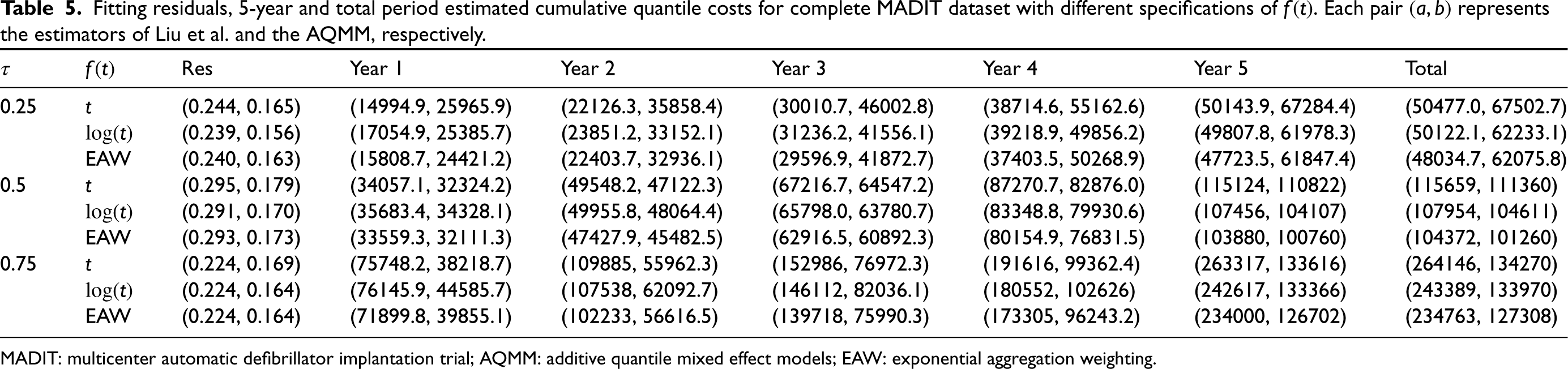
MADIT: multicenter automatic defibrillator implantation trial; AQMM: additive quantile mixed effect models; EAW: exponential aggregation weighting.
In order to inspect the efficiency of different models we randomly split 120 of the 181 subjects from the data set to train the specified models, and use the remaining 61 subjects to the out-of-sample test. The prediction test prediction risk (PT-PR) and the prediction test MSE (PT-RMSE) of the estimated 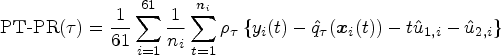
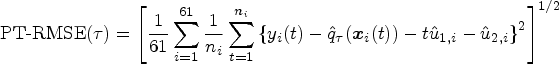
PT-PRs, PT-RMSEs (in parentheses) and aggregated weights (the second row of each group) for MADIT data: linear quantile models constructed in Liu et al., AQMM, and EAW-estimation.
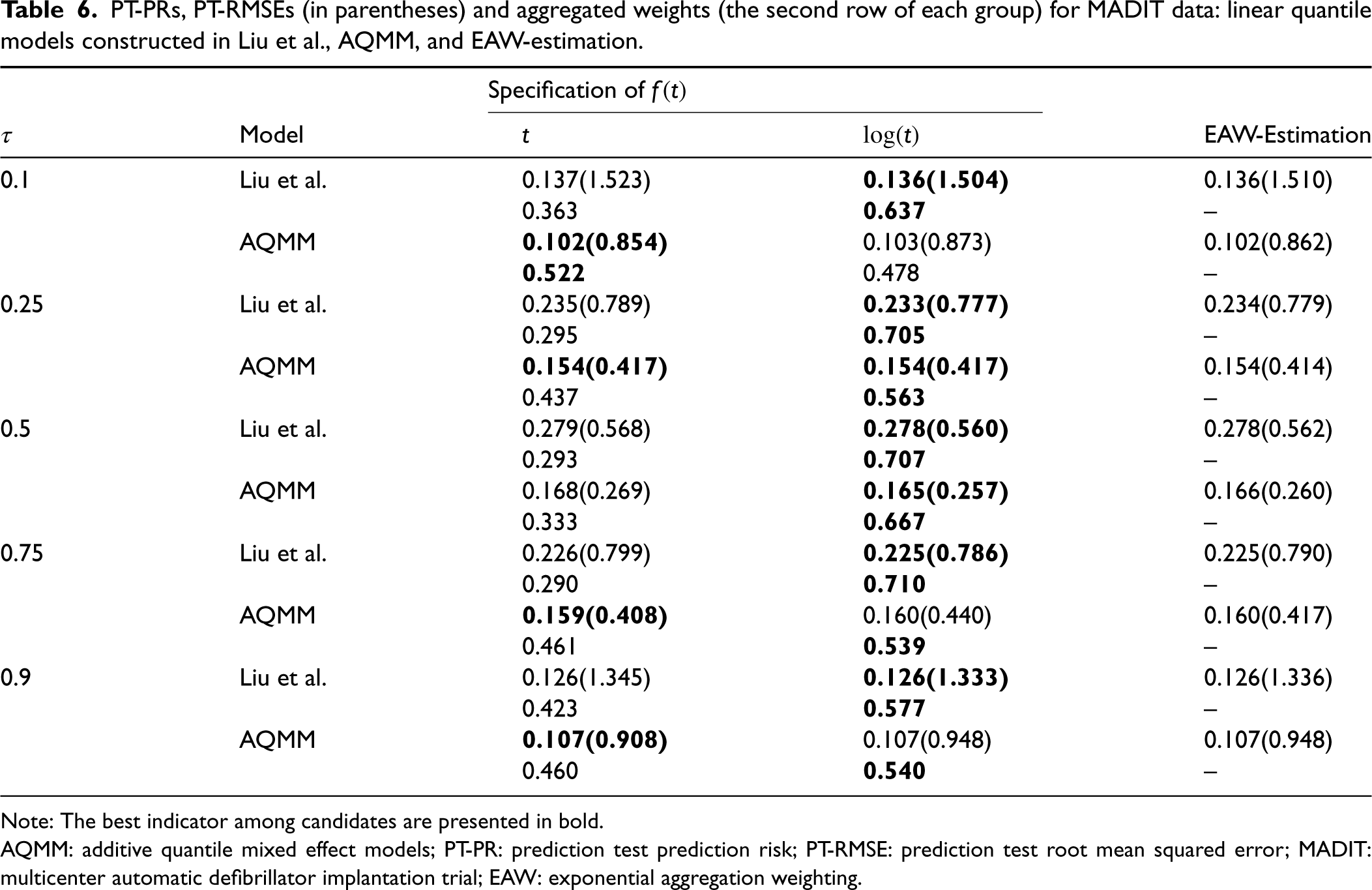
Note: The best indicator among candidates are presented in bold.
AQMM: additive quantile mixed effect models; PT-PR: prediction test prediction risk; PT-RMSE: prediction test root mean squared error; MADIT: multicenter automatic defibrillator implantation trial; EAW: exponential aggregation weighting.
This paper investigates the adaptive estimation for longitudinal quantile regression via EAW algorithm. Under time-dependent covariates and right-censored history process, EAW estimator and IPCW method are combined to derive
It is worthy to point out that the secondary smoothing loss has some good theoretical properties: It supplies the differentiability at origin, guarantees the convexity and strong smoothness as well. On the other hand, the quadratic smooth pattern provides the analogous strong convexity as that of squared-type losses, which is essential for the risk bound under squared error loss, and simplifies the verification of the consistency of cumulative quantile function estimator. However, in practice, smoothing parameters should not be valued too large to affect the aggregated result, searching a convenient recommendation for
The idea of aggregation is not difficult to be extended into fixed effect models: when the individual effect is specified, candidates of
Supplemental Material
sj-zip-1-smm-10.1177_09622802231164730 - Supplemental material for Adaptive aggregation for longitudinal quantile regression based on censored history process
Supplemental material, sj-zip-1-smm-10.1177_09622802231164730 for Adaptive aggregation for longitudinal quantile regression based on censored history process by Wei Xiong, Dianliang Deng, Dehui Wang and Wanying Zhang in Statistical Methods in Medical Research
Footnotes
Acknowledgments
The authors thank the Editor, Associate Editor, and Referees for their insightful comments. They thank all who helped them in writing this LATEX sample file.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by National Natural Science Foundation of China (No. 12271231, 12001229, 11901053), China Scholarship Council and Natural Sciences and Engineering Research Council of Canada (NSERC).
Supplemental material
Supplementary material for this article is available online.
Appendix
In Appendix, we give the proof of theoretical results in main sections. As we considered the secondary approximation of
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.