
Abstract
The sequential treatment decisions made by physicians to treat chronic diseases are formalized in the statistical literature as dynamic treatment regimes. To date, methods for dynamic treatment regimes have been developed under the assumption that observation times, that is, treatment and outcome monitoring times, are determined by study investigators. That assumption is often not satisfied in electronic health records data in which the outcome, the observation times, and the treatment mechanism are associated with patients’ characteristics. The treatment and observation processes can lead to spurious associations between the treatment of interest and the outcome to be optimized under the dynamic treatment regime if not adequately considered in the analysis. We address these associations by incorporating two inverse weights that are functions of a patient’s covariates into dynamic weighted ordinary least squares to develop optimal single stage dynamic treatment regimes, known as individualized treatment rules. We show empirically that our methodology yields consistent, multiply robust estimators. In a cohort of new users of antidepressant drugs from the United Kingdom’s Clinical Practice Research Datalink, the proposed method is used to develop an optimal treatment rule that chooses between two antidepressants to optimize a utility function related to the change in body mass index.
Keywords
Introduction
In recent years, significant effort has been put towards developing statistical methods that can leverage observational data to make valid causal inference about treatment (or exposure) effects (see e.g. Bang and Robins, 1 Stuart 2 , Moodie et al., 3 and Schuler and Rose. 4 ) Much of the literature on causal inference has focused on assessing marginal effects of treatments in the whole population, that is, how the outcomes in the study population would differ, on average, had we given everyone one treatment versus another. Though such marginal effects are often interesting from a policy standpoint, they are not always the most relevant in clinical practice, where patients hope to receive a treatment that is tailored to their unique characteristics. Individualized treatments (often falling under the umbrella term of precision medicine 5 ) may be especially interesting in settings where it is known that the treatment effect for some individuals differs considerably from the marginal effect. In this work, we focus on the estimation of dynamic treatment regimes (DTRs), which formalize individualized, possibly sequential, treatment decisions taken as functions of patient’s characteristics. We limit the DTRs under consideration to those that optimize an expected outcome, the so-called ‘optimal’ DTRs.
Three common methods for developing optimal DTRs are g-estimation, 6 Q-learning (see Laber et al. 7 for a review), and dynamic weighted ordinary least squares (dWOLS). 8 These methods are implemented in standard software (see e.g. Wallace et al.,9,10 Simoneau et al., 11 Tsiatis et al., 12 Linn et al., 13 and McGrath et al. 14 ). The latter method, dWOLS, optimizes the expected outcome by estimating treatment effects within strata of patients’ characteristics; these effects are sometimes termed effect modifications by patients’ characteristics. The dWOLS method provides intuitive estimators for optimal DTRs while combining the advantages of Q-learning and propensity-score based weighting.15,16 It also achieves similar properties to the estimators derived from g-estimation but under a more familiar framework. In particular, under conditions stated in Section 2, the estimators derived using dWOLS are doubly robust in the sense that they are consistent if either the treatment model or the outcome model is correctly specified.
Electronic health records (EHRs) data are often used to develop DTRs.11,17,18 These data are recorded irregularly across all patients, with the observation of patients’ outcome and treatment likely depending on their unique characteristics (such as symptoms, comorbidites, age, sex, etc.). That is, observation indicators, which represent whether or not a patient was observed at a given time, are associated with covariates that could be associated with the longitudinal outcome. In such situations, conditioning on observed data without making any adjustments for the treatment and observation processes may lead to DTRs with spurious associations caused by collider-stratification bias. 19 The observational nature of studies that are based on EHR data also means that patients were not randomized to treatment but prescribed treatment based on their individual characteristics (a feature that is commonly called confounding when the same covariates affect the longitudinal outcome). Given the spurious associations mentioned above, using EHR data to assess treatment effects (or treatment effect modifications) must be done carefully. Drawing a causal diagram that represents the assumed data generating mechanism can help in determining whether these associations are problematic. 20
Though the statistical literature has extensively discussed confounding in the context of developing optimal DTRs, it has paid little attention to covariate-driven observation times. Robins et al. 21 discussed the identification of causal effects when jointly modeling DTRs and monitoring (observation) schedules as well as some issues related to the extrapolation of optimal treatment and testing strategies. They introduced a no direct effect assumption for observation, which requires that observation decisions have no effect on patient characteristics (including outcomes) after conditioning on the treatment decision. Neugebauer et al. 22 extended their work to settings with survival outcomes and differentiated five classes of counterfactual variables that may be of interest in such context. Kreif et al. 23 tackled another important issue related to the varying observation schedules in EHR data and the development of DTRs by proposing a way to analyze irregularly measured time-varying confounders. 23 Bayesian approaches have been proposed to estimate optimal two-stage strategies in settings with interval censoring 24 and to estimate causal effects via g-computation under irregular observation schedules. 25 Most recently, Yang 26 proposed a methodology to estimate the parameters of a continuous structural nested mean model when data are irregularly observed and the observation schedule may confound the treatment effects. Yang built on the work of Lok, 27 who had proposed estimating equations for the same parameters. An important development of Yang is the use of semiparametric theory of influence functions to construct an efficient estimator for continuous-time structural nested mean models. The method does not model explicitly the observation times and relies on a no unmeasured confounding assumption based on a martingale condition, which does not allow for mediators of the treatment–outcome relationship to drive observation times.
While few methods have been proposed in the literature on DTRs that simultaneously account for covariate-driven mechanisms for treatment and observation times, the issues mentioned above have been covered in the literature on the estimation of the marginal effect of covariates (e.g. treatment) on a longitudinal outcome (see, e.g. Goldstein et al. 28 who demonstrated the strength of bias due to the association of a risk factor with the outcome and the observation processes, and McCulloch et al. 29 who also discussed the estimation of such marginal parameters when the corresponding covariates are associated with random effects). To account for the observation process, authors have proposed the use of inverse intensity of visit (IIV) weights,30–32 random or latent effects,33–35 or fully parametric inference by specifying the full joint likelihood of the outcome and observation processes. 36 Within the causal inference framework, the bias due to the spurious associations mentioned above in the estimation of the marginal effect of a binary treatment on a longitudinal outcome using EHR data was demonstrated in Coulombe et al. 37 In that work, two semiparametric estimators were proposed for the causal marginal effect of a binary treatment on a continuous longitudinal outcome that accounted for the covariate-driven treatment and observation mechanisms. 37 Here, we extend one of these estimators to the case of DTRs.
In this work, we focus on a single-stage rule, known as an individualized treatment rule (ITR), which is a special case of a DTR. We consider repeated measurements of the treatment and outcome of each individual. Patients can, therefore, contribute multiple measurements in the estimation of the ITR, which we term a repeated measures ITR. The more general case of DTRs comprising multiple sequential rules corresponding to multiple treatment decisions is a topic of future work. We show here that by extending one of the estimators proposed by Coulombe et al. 37 to an ITR setting, we can consistently estimate the conditional effect of treatment within strata of patients’ variables rather than a single marginal effect. For that, we use dWOLS and a new weighting mechanism that incorporates independently the informative observation times and the treatment process under assumptions that are commonly postulated in the causal inference literature. To our knowledge, we propose the first estimator for optimal repeated measures ITR for binary treatment and continuous longitudinal outcome that applies to data subject to covariate-driven observation and treatment processes.
This article is divided as follows. We introduce the proposed methodology and the required assumptions in Section 2. We test the method through extensive simulation studies, the details and results of which we describe in Section 3. In Section 4, we apply the methodology to develop a repeated measures ITR that chooses between two commonly prescribed antidepressants, citalopram and fluoxetine, to maximize a utility function related to changes in body mass index (BMI). The optimal treatment rule is estimated using a cohort of patients with depression taken from the United Kingdom’s (UK) Clinical Practice Research Datalink (CPRD). 38 Finally, a discussion follows in Section 5.
Methods
Notation
We suppose that we have a random sample of
Assume that a larger
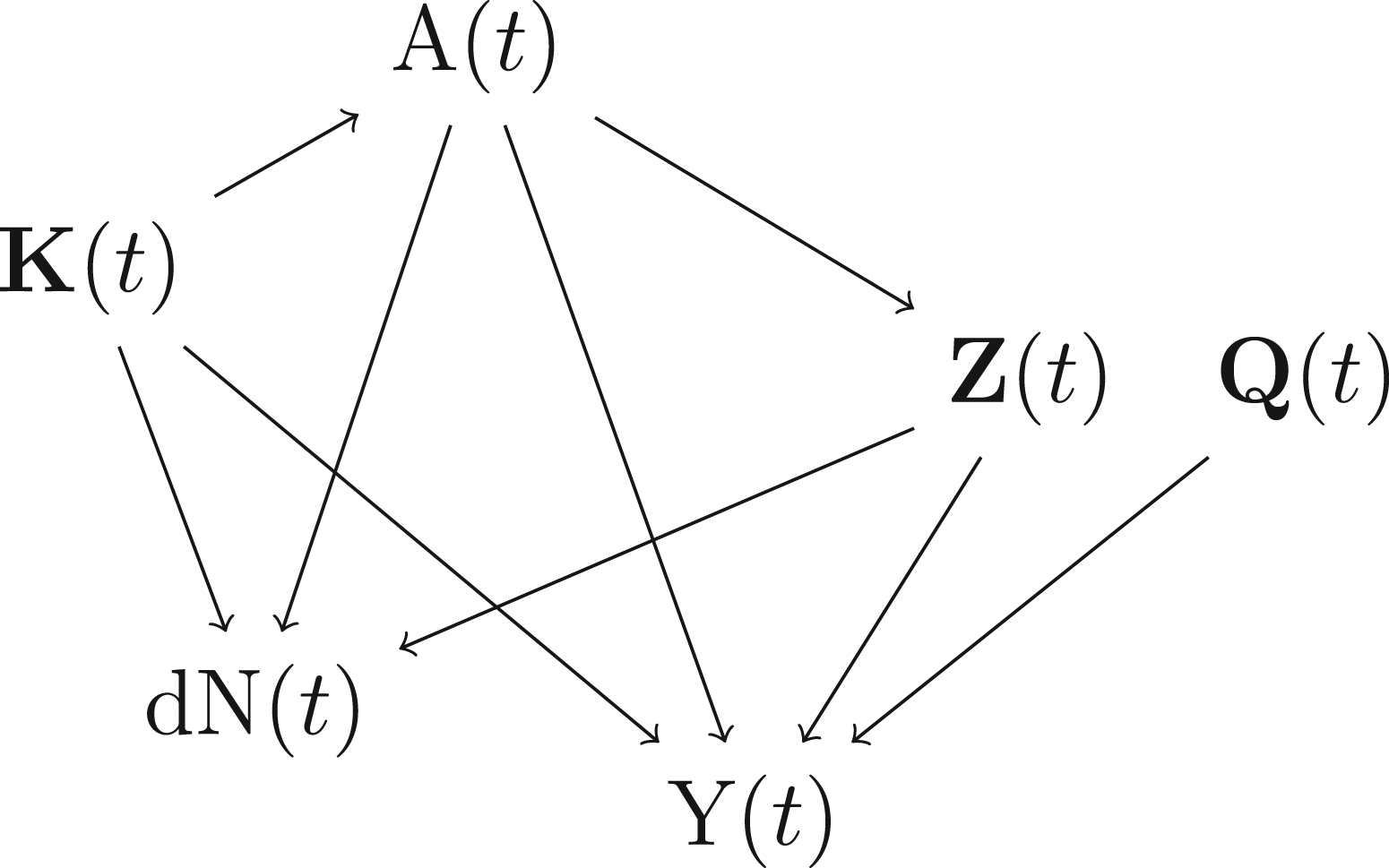
Data generating mechanism considered in our simulation studies (the causal diagram is presented only for time
We present in Supplemental Material A a summary of the notation introduced in the whole Methods Section and the abbreviations used in this manuscript (Supplemental Table 1) along with the potential overlaps between the sets of covariates
Some assumptions on the acuteness of the treatment effect are required for using repeated measures of ITR. Omitting the patient index for ease of notation, we broadly assume that
We use the potential outcome framework39,40 and introduce two potential outcomes for inference, denoted by
For simplicity, denote by
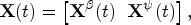
As in Coulombe et al.,
37
we make the following assumptions (P1) to (P3):
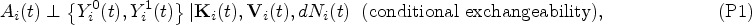
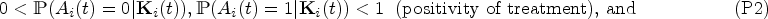
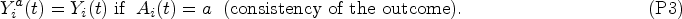
To account for the observation process, we assume that observation at time
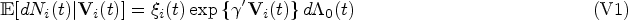
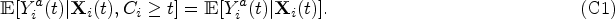

The interactions between the treatment and tailoring variables and their effects on the mean outcome can inform the best treatment decision to maximize an expected outcome
The following outcome mean model is further postulated, conditional on the risk factors and tailoring variables
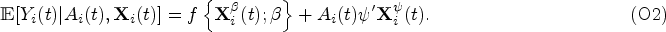
To estimate an optimal ITR under our postulated assumptions, it suffices to estimate the coefficients
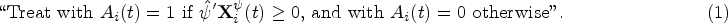
If one or both of the treatment model and the outcome model are correctly specified, the blip function is correctly specified, and we use an inverse probability weight that meets the balancing condition introduced in Wallace and Moodie, 8 the dWOLS method leads to consistent estimators. The estimator is, therefore, called doubly robust. Note, a correct specification for one of the treatment or treatment-free models requires that (i) the correct set of confounders be included in that model and (ii) the confounders be incorporated as predictors in the model using the appropriate functional form (e.g. a variable that is deemed to affect quadratically the outcome must be included as a quadratic term in the outcome mean model). As mentioned in their introductory paper, 8 the well known inverse probability of treatment (IPT) weights15,16 meet the balancing condition.
Wallace and Moodie
8
assumed that the observation times were not driven by covariates. In the current work, the data generating mechanism assumed for each time
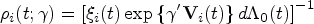

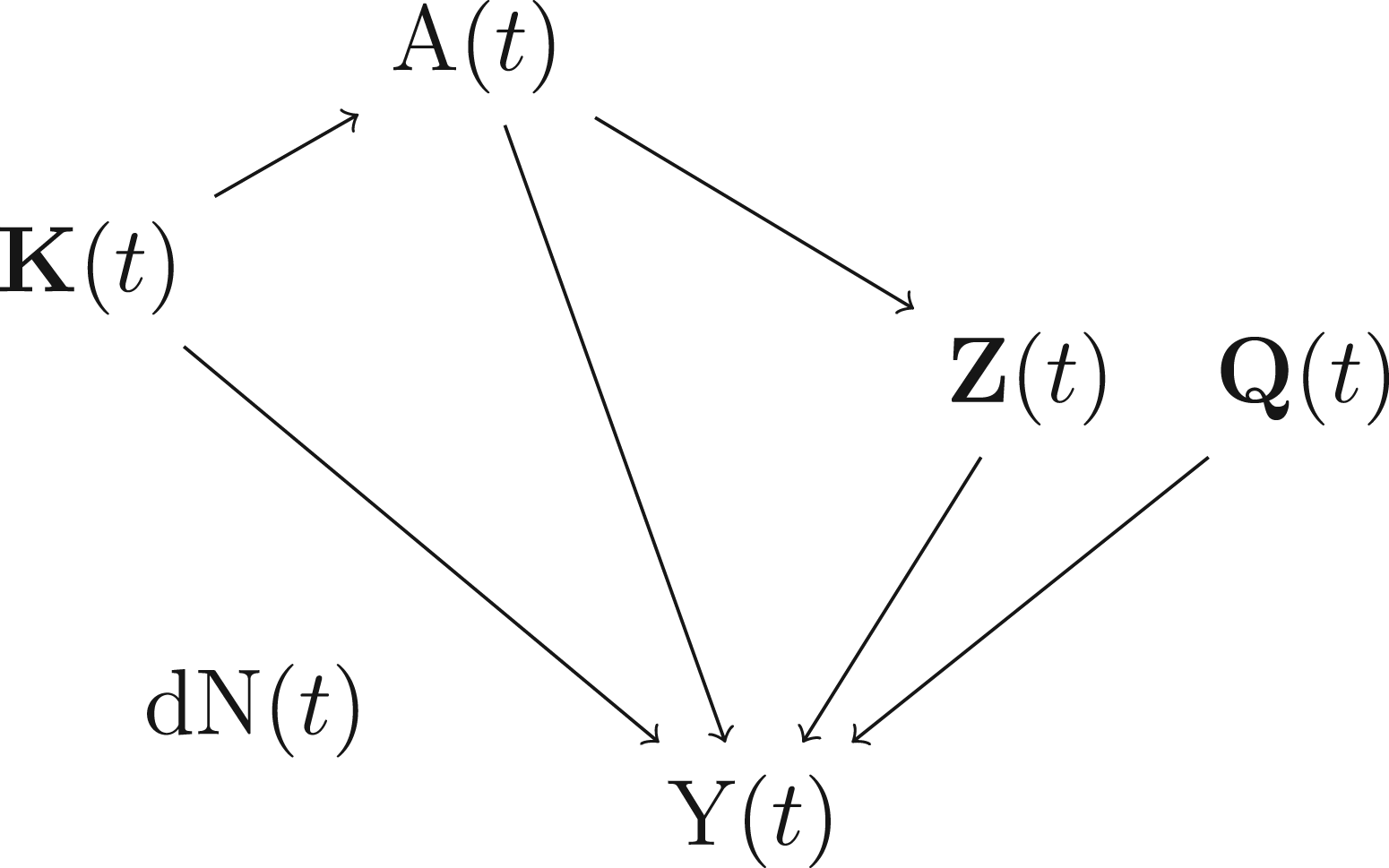
Data generating mechanism after re-weighting data by the correctly specified IIV weight. Additional reweighting by IPT weights further removes the arrow from
We fit the propensity score
47
using a logistic regression model and use the resulting IPT weight as our balancing weight in the dWOLS. In the logistic regression model, we include all potential confounders as predictors of the treatment
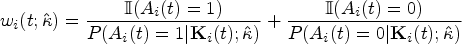
A weighted least squares (dWOLS in a one-stage treatment setting) that incorporates both weights is then fit to the data to estimate the blip function in (O2). The proposed methodology corresponds to solving the following estimating equation for the coefficients of the mean outcome model in (O2) :
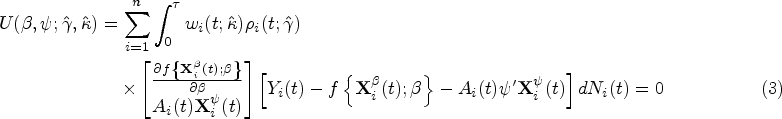
The asymptotic variance of the estimators
We conducted several simulation studies, with different strengths of dependance of the observation times on covariates, to assess the performance of our estimators
Data generating mechanism at time
Our simulation studies were similar to those of Coulombe et al.
37
except that new tailoring variables were simulated and interaction terms were added to the outcome mean model. We tested sample sizes of either 250 or 500 patients and conducted 1000 simulations for each sample size. A sensitivity analysis was also conducted in which the sample size was increased to 50,000 for a few of the studied scenarios. In the description that follows, we removed the patient index for ease of notation. First, three baseline confounders
As discussed earlier, a challenge in the estimation of the optimal ITR is that the outcome is observed irregularly, and its observation depends on patients’ covariates. To reproduce this behavior, the quantities above were first simulated in continuous time, with time discretized over a grid of 0.01 units, from 0 to
Simulation study results (
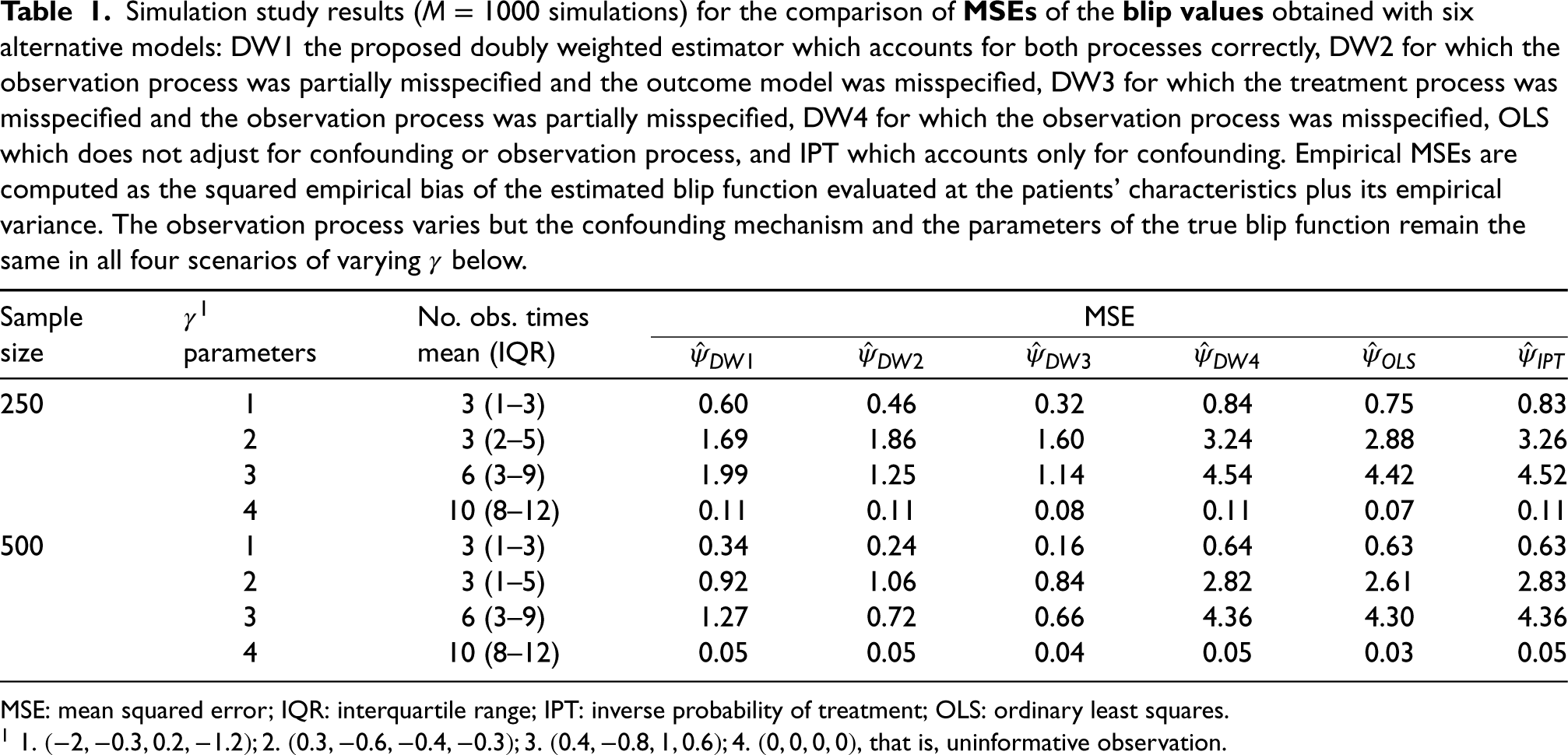
MSE: mean squared error; IQR: interquartile range; IPT: inverse probability of treatment; OLS: ordinary least squares.
In our simulation setting, the true value of the blip function (or “gold standard”) at time
The results of the comparison of MSE of the blip values across all six estimators for
We observe similar patterns of results when comparing the treatment decisions from each estimator. Some scenarios for the parameters
In scenarios 2 and 3 for the
The results above on the MSE and empirical bias of the blip values and error rates on the treatment decisions also agree with the results on the absolute bias of each blip coefficient found in Supplemental Table 5 (Supplemental Material C). In general, the bias in the estimation of the intercept coefficient of the blip function is small for the three preferred estimators
The performance as measured by the value function is also consistent with the other results above, showing a more important difference across the estimators under scenarios 2 and 3 for the observation process (Supplemental Table 6 in Supplemental Material C). The results for scenarios 2 and 3 convey the differences in optimal treatment decisions found across the correctly specified and the other estimators. Again, the results for the average outcome are similar across the three estimators
In most results, we find that the estimator
The results in this section and in Supplemental Material C demonstrate empirically that
Illustration with the CPRD
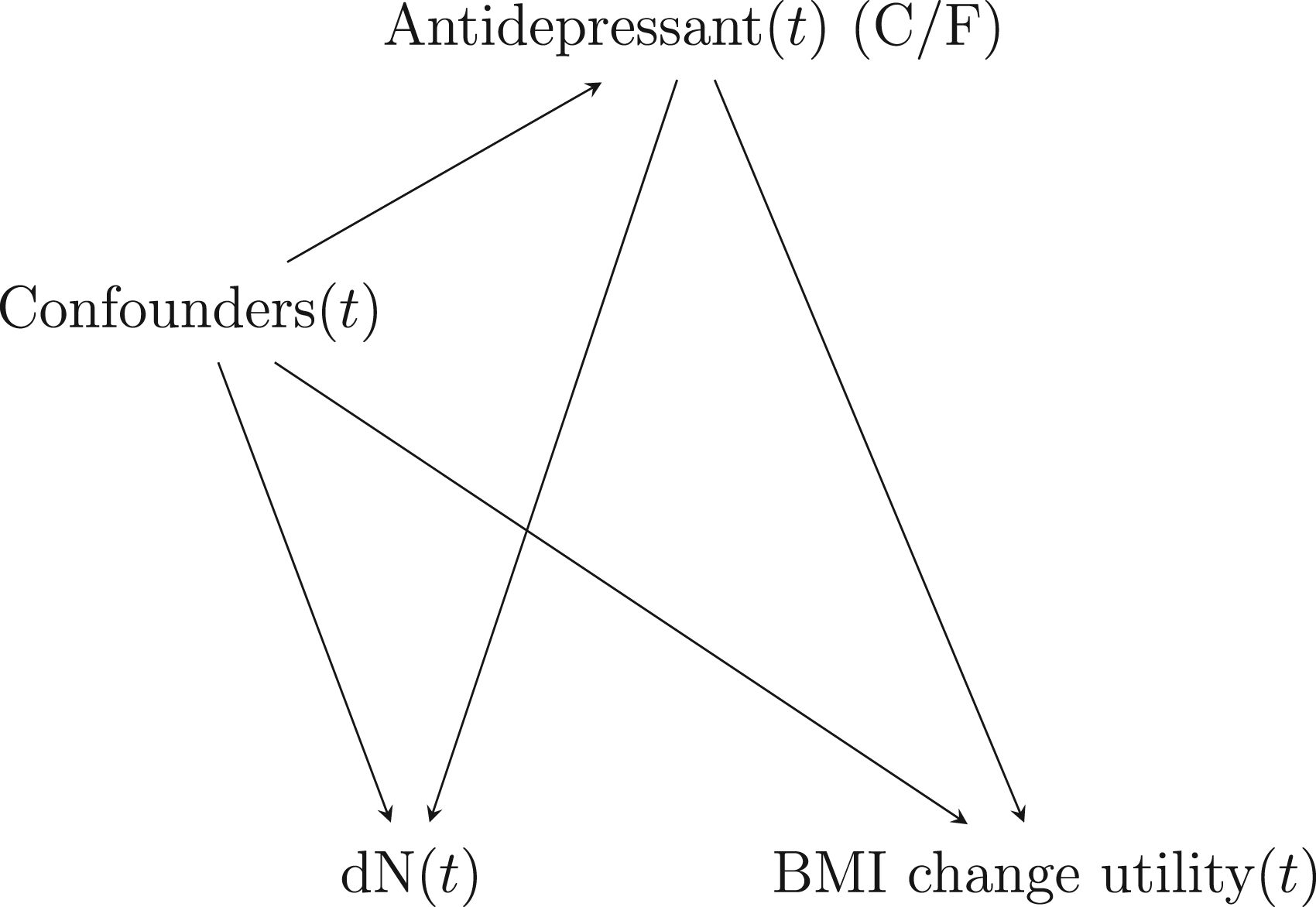
We applied the proposed methodology for the estimation of a repeated measures ITR to data from the UK’s CPRD. Our aim was to develop an optimal ITR that chooses between two commonly prescribed antidepressant drugs, citalopram and fluoxetine, to optimize a BMI utility function. The BMI utility function was repeatedly and irregularly measured in time. We assumed that confounding and covariate-driven observation times were potential concerns and could cause bias in the estimation of the ITR. The causal diagram we assumed at each time is depicted in Figure 3. The causal diagram encapsulates the general assumptions we make about the variables affecting the treatment, the visit, or the outcome models, but whether some of these variables come before or after the treatment is, in some cases, unclear (especially since some of these will be adjusted as time-varying variables in the visit model). Thus, the unblocked paths due to the visit process could be due to confounders linking the treatment and the visit indicator to the outcome, or to mediators of the treatment-outcome relationship linking the treatment and the visit indicator to the outcome. These precise assumptions are left unspecified and we aim, with our approach, to merely remove or block any path going into the treatment, the visit, and the outcome, separately, via the propensity score, the proportional rate model for the visit, and the treatment-free model for the outcome, respectively. Furthermore, given that our proposed method cannot accommodate settings in which the outcome itself affects its observation process, we did not draw an arrow from BMI to the indicator
Data source
CPRD is one of the largest primary care databases of anonymized health records and comes from a network of more than 700 general practictioner practices in the UK. The data contain demographics, lifestyle factors, prescription drugs, medical diagnoses, and referrals to specialists and hospitals for more than 13 million patients. Information on prescription drugs comes from written prescriptions (as opposed to filled medications). The data we used were linked with the Hospital Episode Statistics, which contains information on hospital diagnoses, and the Office for National Statistics mortality database, which provides details on dates and causes of death. The study protocol was approved by the Independent Scientific Advisory Committee of the United Kingdom Clinical Practice Research Datalink (CPRD) (protocol number 19_017R) and the Research Ethics Committee of the Jewish General Hospital (Montréal, Québec, Canada).
We defined a cohort of new users of citalopram or fluoxetine with a recent diagnosis of depression. That cohort was previously defined and described 17 and a flow chart for the cohort creation is shown in Supplemental Material F. Briefly, patient follow-up started at the time of initiation of either citalopram or fluoxetine, and follow-up was stopped (censored) when a patient discontinued their treatment, switched to another antidepressant drug, became pregnant, died, reached the end of registration with the practice, or the end of the study period (December 2017), whichever occurred first. Although we censored patients’ follow-up time when they discontinued or switched treatment, we were interested in a repeated measures ITR, in which treatment decisions are taken not only at cohort entry, but also at anytime during follow-up when a treatment decision must be made to reduce the potential weight change. We defined the end of a prescription as the prescription date plus its duration in days and considered that treatment discontinuation occurred whenever 30 days had passed since the end of the last prescription for the corresponding drug without any new prescription for that drug being issued. Note, we did not consider informative censoring in this work but it is possible that, for instance, censoring at treatment discontinuation could be informative. In such case, inverse probability of censoring weights could be used to account for informative censoring.52,53 We only kept in the study cohort patients who had at least one BMI measurement before or at cohort entry and used the most recent BMI measurement to define their baseline BMI. Then, any BMI measurement recorded during patient follow-up was kept as an outcome for analysis (i.e. an outcome for which we aim to optimize the expectation under the ITR). If a BMI value was smaller than 15 or larger than 50, it was replaced by a missing value and not used in the analysis.
Outcome definition
For the repeated outcome, we defined a continuous utility function that conveyed the negative impacts of weight gain or weight loss while being treated with antidepressant drugs. That outcome was defined every time when BMI was measured as
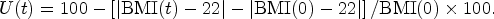
Briefly, that function varies according to the baseline BMI of a patient and, for any baseline BMI value, it is maximized around the normal BMI range (18.5–24.9) for a BMI measurement taken at time
Confounder, tailoring variables, and predictors of observation
We defined the potential confounders of the relationship between the prescribed antidepressant and the utility function at baseline (cohort entry) and included the continuous-valued age, sex, continuous-valued BMI at baseline, current smoking status (smoker or non-smoker), alcohol abuse, calendar year of cohort entry (1998–2005, 2006–2011, 2012–2017), psychiatric disease history (which included autism spectrum disorder, obsessive-compulsive disorder, bipolar disorder, and schizophrenia), anxiety, or generalized anxiety disorder (further referred to as anxiety), antipsychotics use, any other psychotropic medication use (benzodiazepine drugs, anxiolytics, barbiturates, and hypnotics), lipid-lowering drugs, the number of psychiatric admissions, or hospitalizations for self-harm in the 6 months prior to cohort entry and the Index of Multiple Deprivation 54 as a proxy for the socioeconomic status. For the tailoring variables used to construct the optimal repeated measures ITR, similar to previous work 17 , we included in the models the interaction terms between the treatment and age, sex, smoking status, a composite indicator of psychiatric disease history (a diagnosis for either autism spectrum disorder, obsessive-compulsive disorder, bipolar disorder, or schizophrenia), a diagnosis for anxiety, and the number of psychiatric admissions or hospitalizations for self-harm in the previous 6 months. Note, we could also have defined time-varying confounders and tailoring variables, which our methodology allows for, but we used simpler definitions for our illustration. Comorbidities were defined using any diagnostic codes recorded by cohort entry, and medication use, using any prescriptions in the year prior to cohort entry.
In the observation intensity model for the outcome, we included the same set of covariates as confounders but these were defined in a time-varying manner, except for BMI at baseline. Our rationale for this is that we wish to capture any effect of these variables on the observation intensity, and time-varying variables may, therefore, provide more sensitivity to any such effect. For those time-varying covariates, we used different definitions. We considered a patient exposed to a medication for the duration of the corresponding prescription (medication considered were the lipid-lowering drugs, antipsychotics, and other psychotropic drugs). Then, after any first diagnosis for a chronic disease (including alcohol abuse, anxiety, and other psychiatric diseases), a patient was considered to have the condition for the remainder of the follow-up. The smoking status was updated at any time a new code related to smoking was recorded during follow-up (this included codes for smoking status and smoking cessation therapy). At any other time, it was defined using the most recent code for smoking.
As with the rest of the manuscript, we assumed in the illustration that the treatment was known (observed) at all times, which is realistic given that we had access to any prescriptions given by general practitioners. We also assumed that covariates in the two nuisance models (observation and treatment models) were always measurable. However, the smoking status at baseline and the Index of Multiple Deprivation were missing for some individuals. We assumed that individuals with no smoking status recorded (at anytime before cohort entry) were non-smokers, and we removed from the study the few individuals (< 1%) with a missing Index of Multiple Deprivation. For all other covariates (confounders, tailoring variables or time-dependent features in the observation intensity model), we assumed that any existing condition was recorded in the database and that any drug prescribed was also recorded and available for defining the medication variables (and therefore, had no missing values).
In the final outcome model, the design matrix incorporated the potential confounders, the treatment (citalopram or fluoxetine), and the interaction terms corresponding to all tailoring variables. The model, which predicted the utility function defined above, also incorporated both the IPT weight as a function of the propensity score and the IIV weight computed using the Andersen and Gill model. All predictors were included as linear terms in both nuisance models. Only the times when the utility function was available (i.e. when BMI was available) were included in the analysis and accounted for in the model fit. Those times corresponded to the repeated measures in the repeated measures ITR. It is likely that the value of
Results
After applying the exclusion criteria, the final cohort comprised 109,756 citalopram initiators and 85,606 fluoxetine initiators with a baseline BMI measurement who contributed to the treatment and the monitoring models. Of those, a total of 31,120 patients (60% citalopram initiators) had at least one follow-up BMI measure and contributed to the outcome model. A total of 47,938 records for BMI during follow-up were used for estimating the repeated measured ITR (60% of which were measured in citalopram initiators). Both the patients initiating citalopram and those initiating fluoxetine had an average of 1.6 BMI measures during follow-up. We present a comparison of patients’ covariates at cohort entry, stratified by the study antidepressant, for both the cohort of 195,362 patients with a baseline BMI and for the cohort of 31,120 patients who contributed to the outcome model fit in Supplemental Table 8 (Supplemental Material G). Some differences were found across the two groups, especially for the distribution of calendar year at cohort entry and the proportion of patients diagnosed with anxiety. These variables may act as confounders for the relationship between the antidepressants and the weight utility function. In the bottom of Supplemental Table 8, we also present for the latter cohort the time to a first BMI measurement during follow-up and the mean of that first BMI value.
The estimated rate ratios obtained from the observation model are presented in Supplemental Table 9 (Supplemental Material G) along with their 95% bootstrap CIs. A few variables were found to be associated with the observation intensity. Prescription for citalopram, male sex, and later calendar year of cohort entry were statistically significantly associated with lower chances for the weight to be recorded. On the other hand, a higher Index of Multiple Deprivation quintile, being an ever smoker, or the use of antipsychotics, other psychotropic drugs, or lipid-lowering drugs, were all statistically significantly associated with it being more likely for the outcome to be recorded.
When taking the average of all the observed BMI records, we found a crude mean utility function of 99.1 (SD 8.2) in patients who initiated citalopram and of 99.3 (SD 8.1) in those who initiated fluoxetine. The minimum utility value across the cohort was 50.3. and the maximum utility was 144.2. We present in Supplemental Table 10 (Supplemental Material G) the fitted coefficients for the tailoring variables in the mean outcome model, along with the corresponding 95% bootstrap CIs. The fitted optimal ITR under our proposed methodology is given by:
Treat with citalopram if
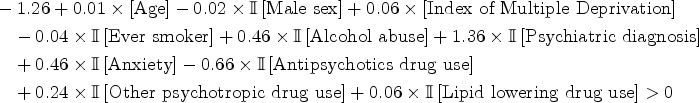
With all four estimators, we have found that the interaction term between age and the treatment was statistically significant at the 0.05 level (Supplemental Table 10). It is a signal that patients’ age may generally be useful in tailoring the antidepressant drug, after accounting for the covariate-driven treatment and observation processes. To generalize these results, however, the study should be reproduced in other (possibly larger) study cohorts.
Comparison of the fitted outcome (i.e. a BMI-related utility function) under each estimated optimal ITR and compared to the actual treatment received, comparison for each of the four estimators: OLS which does not adjust for confounding or observation process, IPT which accounts only for confounding, IIV which accounts only for the observation process, and the proposed doubly weighted estimator which accounts for both processes, CPRD, UK, 1998–2017,
31,120 individuals.
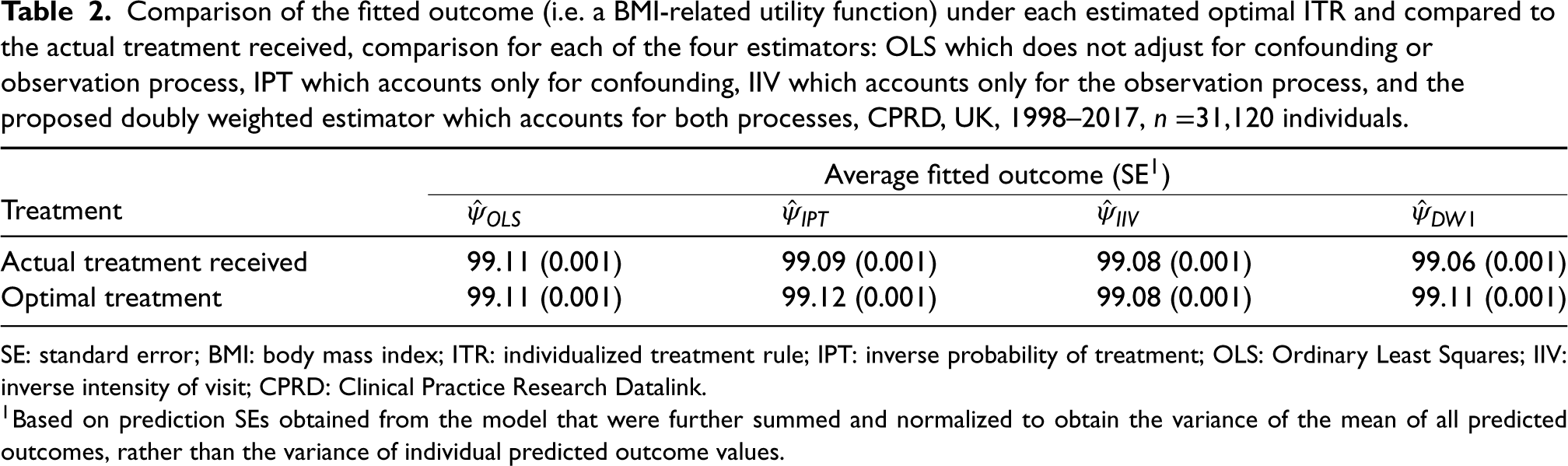
Comparison of the fitted outcome (i.e. a BMI-related utility function) under each estimated optimal ITR and compared to the actual treatment received, comparison for each of the four estimators: OLS which does not adjust for confounding or observation process, IPT which accounts only for confounding, IIV which accounts only for the observation process, and the proposed doubly weighted estimator which accounts for both processes, CPRD, UK, 1998–2017,
SE: standard error; BMI: body mass index; ITR: individualized treatment rule; IPT: inverse probability of treatment; OLS: Ordinary Least Squares; IIV: inverse intensity of visit; CPRD: Clinical Practice Research Datalink.
In observational studies using longitudinal data extracted from EHR, patients are often observed at irregular times that may depend on their own characteristics. When these same characteristics are associated with the treatment and/or the outcome, causal inference on treatment effects can be affected. In developing optimal ITRs that rely directly on those treatment effects, it is important to determine how observation times can impact the inference. Drawing causal diagrams56,57 can help in finding potential biasing paths between the treatment and the outcome that should be blocked via, for example, IPT weighting or IIV weighting.
In this work, we proposed a novel methodology to account for covariate-driven treatment and observation mechanisms simultaneously in the estimation of optimal repeated measured ITRs. In extensive simulation studies, we demonstrated the consistency of the methodology. The proposed method is a straightforward extension of previous work, 37 and the same asymptotic theory can be used to develop the asymptotic variance of our proposed estimators. Our method is easy to implement and more easily understood than methods such as g-estimation. We applied the method to data from the UK’s CPRD and proposed an optimal ITR for choosing between citalopram and fluoxetine (two commonly prescribed antidepressants) to treat depression while reducing BMI changes that could be detrimental for one’s health.
The proposed methodology relies on assumptions that must be met for consistent estimation of an ITR. We now discuss these in the context of the CPRD application, starting with the causal assumptions. Our propensity score model must contain all potential confounders and it should be specified correctly as a function of the confounders (correct functional formats). In the CPRD application, depression severity is one potential confounder that was not measured. We have used the number of psychiatric hospitalizations as a proxy for severity and think it is unlikely that our application would be highly affected by unmeasured confounding. We do not expect important differences at baseline across the two treatment groups because the two study drugs are prescribed rather interchangeably. We also have assumed treatment and observation positivity, which can be unrealistic in certain settings with EHR. In the CPRD application, because both drugs are prescribed interchangeably, it is unlikely that treatment positivity is violated. However, coarsening of the data in time may be used to circumvent non-positivity issues. The work of Robins et al. 21 (Section 6) and Neugebauer et al. 22 also allowed causal inference under a weaker positivity assumption for the monitoring and could possibly be extended to our setting. Moreover, given that our work focuses on one-stage ITRs (as opposed to multiple stages DTRs), the positivity assumption for treatment is weaker (i.e. easier to meet) than the one typically made when building multiple decisions rules where long sequences of treatment must have a non-zero chance of occurring. In this work, we did not consider a sequence of treatments but rather the cross-sectional impact of a binary treatment and we allowed each patient to contribute multiple measurements, one for each outcome observed. Regarding observation positivity, some segments of person-time might have been included over which patients had no chance of having their weight observed, which could affect our observation model. We suspect that the effect of violating observation positivity would be relatively modest in this study (and not differential across the two treatment groups). The third causal assumption, outcome consistency, encompasses that the treatment definition be clear and that there be no interaction between individuals (no spillover in treatment effects). In our setting, the latter assumption is realistic as the antidepressant drug taken by one patient is unlikely to affect another patient’s weight, and the CPRD data are collected over a large geographic area (such that patients are unlikely to interact with most other patients in the study cohort). The treatment definition is also clear and simple in our application to the CPRD, such that it is unlikely that there are treatment variations that might affect the consistency of the potential outcome. We also have assumed that covariates in the observation intensity model were always measured (in continuous time). Given that we used electronic health records from the CPRD, we had all the information on the treatments prescribed by general practitioners to patients, however, we could not verify whether these drugs were dispensed or used and covariates in the observation model may be misclassified (i.e. the covariates might have been measured with error). We have assumed that all other predictors in the observation model were always measured however we suspect that variables like smoking status, alcohol abuse, or anxiety were measured informatively, which could affect our inference in a way that is hard to assess. Finally, since our method uses repeated measures of the outcome, it requires the standard assumptions for one-stage repeated measures ITRs, that is, treatment effects should be acute and there should be no antagonistic or synergistic effect due to previous treatments affecting the current one. 43 Although measurements of the outcome were taken far apart in time in our illustration using CPRD data, we cannot exclude the possibility of a cumulative effect of the initiating medication on the BMI outcomes.
In future work, we aim to extend the proposed methodology to the more complex setting of the more traditional, multiple stage DTRs using dWOLS. In that setting, dWOLS has great advantages as it can incorporate weights that are cumulated over time (similarly to marginal structural models). As such, it is a method of choice for treating complex covariate-driven observation processes (such as those that depend on an endogenous covariate process 20 ) and time-dependent confounding, in which there can be a biasing feedback between the covariates and the processes.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231158733 - Supplemental material for Estimating individualized treatment rules in longitudinal studies with covariate-driven observation times
Supplemental material, sj-pdf-1-smm-10.1177_09622802231158733 for Estimating individualized treatment rules in longitudinal studies with covariate-driven observation times by Janie Coulombe, Erica EM Moodie, Susan M Shortreed and Christel Renoux in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors would like to thank Dr. Shannon Holloway for reading the manuscript and providing significant help with editing. The authors are also indebted to two anonymous reviewers, the comments of whom greatly improved this manuscript.
This research was enabled in part by support provided by Compute Canada (![]() ). Computations were performed on the Niagara supercomputer at the SciNet HPC Consortium. SciNet is funded by the Canada Foundation for Innovation; the Government of Ontario; Ontario Research Fund – Research Excellence; and the University of Toronto.
). Computations were performed on the Niagara supercomputer at the SciNet HPC Consortium. SciNet is funded by the Canada Foundation for Innovation; the Government of Ontario; Ontario Research Fund – Research Excellence; and the University of Toronto.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Dr. Shortreed has worked on grants awarded to Kaiser Permanente Washington Health Research Institute (KPWHRI) by Bristol Meyers Squibb and by Pfizer. She was also a co-Investigator on grants awarded to KPWHRI from Syneos Health, who represented a consortium of pharmaceutical companies carrying out FDA-mandated studies regarding the safety of extended-release opioids. Authors JC, EEMM and CR have no conflict of interest to declare. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Part of the research was funded by an Innovative Ideas Award from Healthy Brains for Healthy Lives [HBHL 1c-II-11]. Dr. Coulombe and Dr. Shortreed are supported by the National Institute of Mental Health of the National Institutes of Health [R01 MH114873]. Dr. Moodie holds a Canada Research Chair (Tier 1) in Statistical Methods for Precision Medicine. Dr. Moodie further acknowledges support from a Discovery Grant from the Natural Sciences and Engineering Research Council (NSERC) and a chercheur de mérite career award from the Fonds de recherche du Quèbec–Santè. Dr. Renoux is supported by a chercheur-boursier salary award from the Fonds de recherche du Québec-Santé.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.