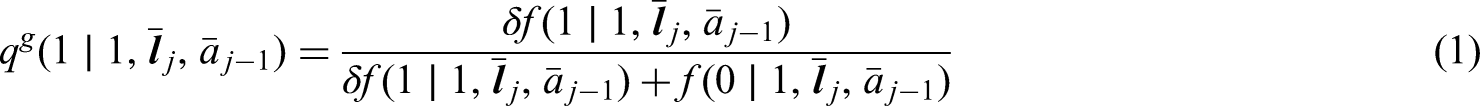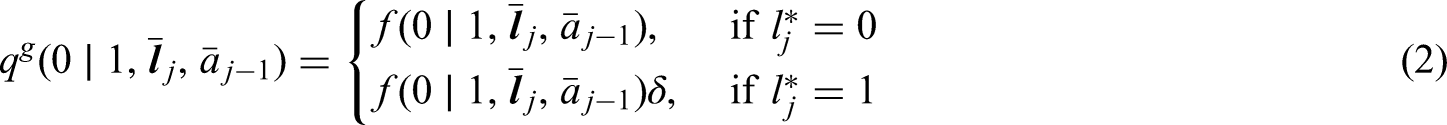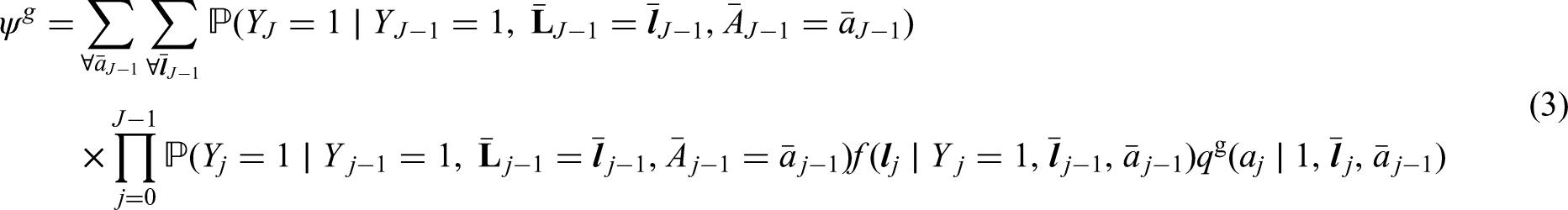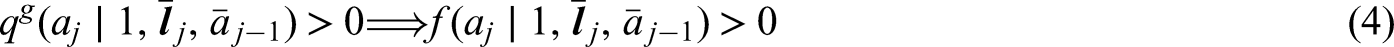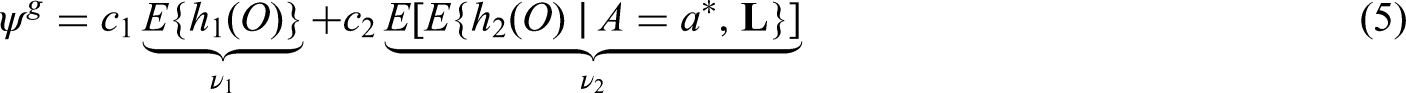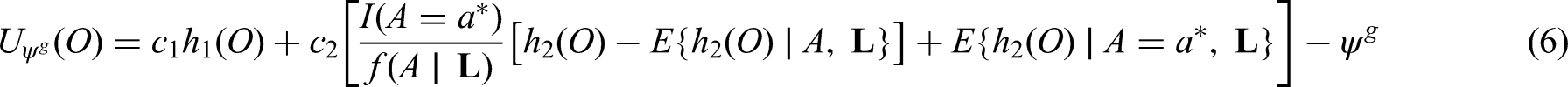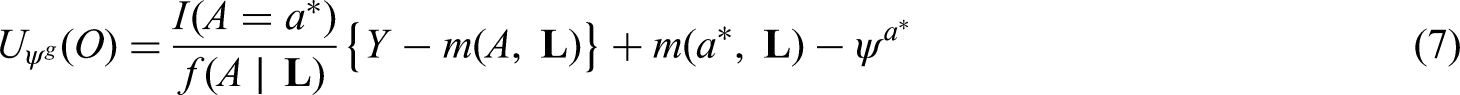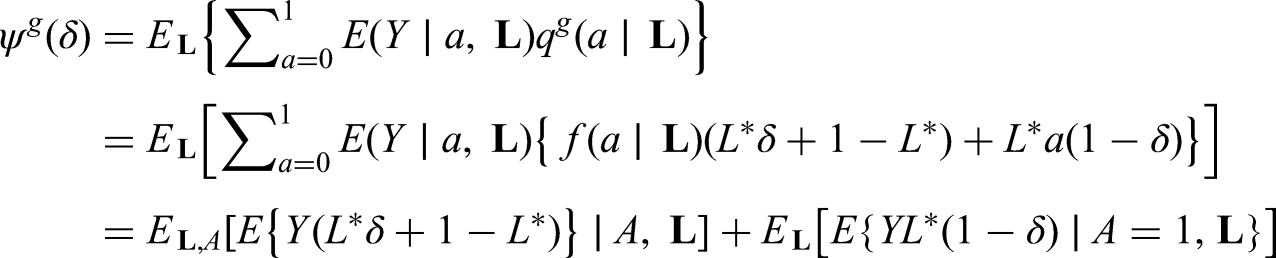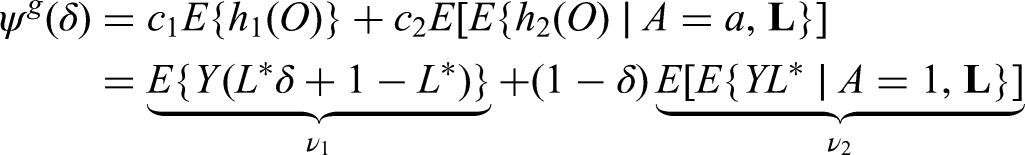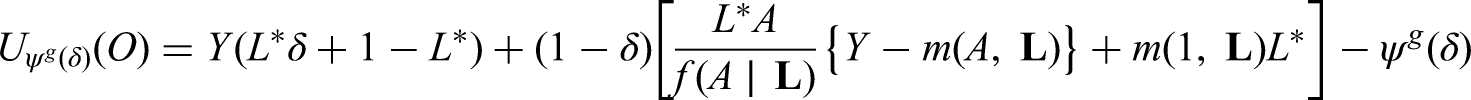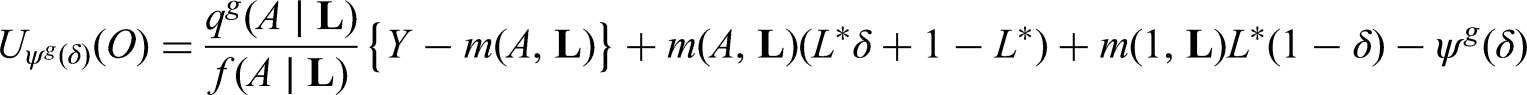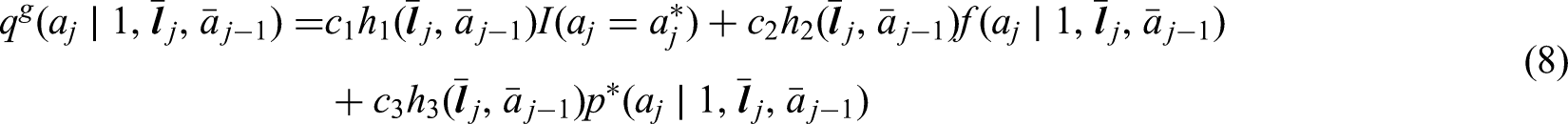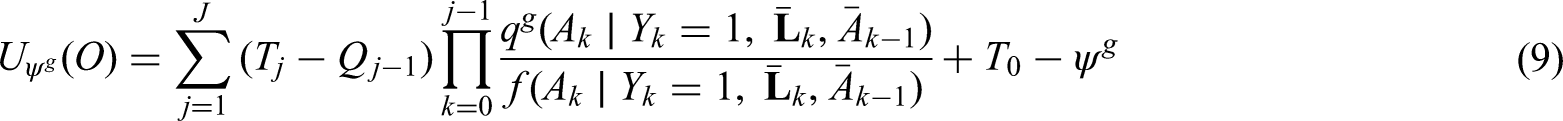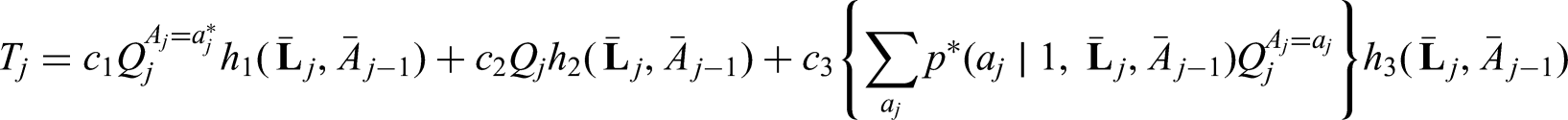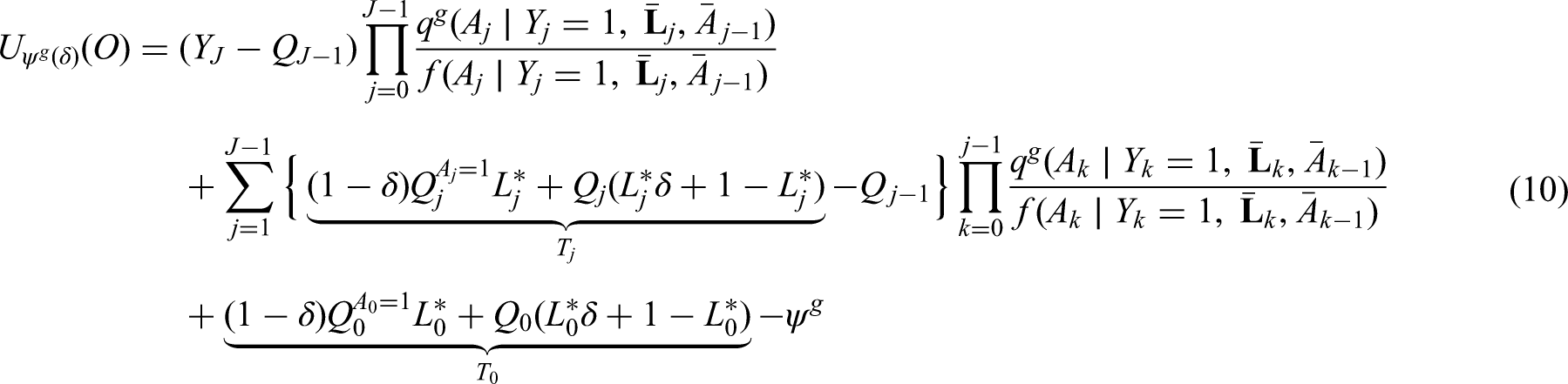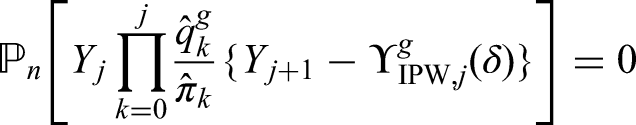The generalized g-formula can be used to estimate the probability of survival under a sustained treatment strategy. When treatment strategies are deterministic, estimators derived from the so-called efficient influence function (EIF) for the g-formula will be doubly robust to model misspecification. In recent years, several practical applications have motivated estimation of the g-formula under non-deterministic treatment strategies where treatment assignment at each time point depends on the observed treatment process. In this case, EIF-based estimators may or may not be doubly robust. In this paper, we provide sufficient conditions to ensure the existence of doubly robust estimators for intervention treatment distributions that depend on the observed treatment process for point treatment interventions and give a class of intervention treatment distributions dependent on the observed treatment process that guarantee model doubly and multiply robust estimators in longitudinal settings. Motivated by an application to pre-exposure prophylaxis (PrEP) initiation studies, we propose a new treatment intervention dependent on the observed treatment process. We show there exist (1) estimators that are doubly and multiply robust to model misspecification and (2) estimators that when used with machine learning algorithms can attain fast convergence rates for our proposed intervention. Finally, we explore the finite sample performance of our estimators via simulation studies.
The goal of many observational analyses is to estimate the causal effect on survival of different time-fixed or time-varying treatment strategies, interventions, or rules in a study population. These causal effects can be formally defined by a contrast (e.g. difference or ratio) in the distributions of counterfactual outcomes had interventions been implemented to ensure those strategies are followed in that population. Robins1 showed that under assumptions that allow complex longitudinal data structures such that measured time-varying confounders may themselves be affected by past treatment, the g-formula indexed by a particular treatment strategy identifies the average counterfactual outcome under that strategy. Therefore, estimators of the g-formula and associated contrasts indexed by different strategies may be used to estimate causal effects.
In practice, the g-formula typically depends on high-dimensional nuisance parameters. In this case, many estimators of the g-formula and associated contrasts have been proposed including the density-based parametric g-formula,1 iterated conditional expectation (ICE) estimators,2,3 inverse probability weighted (IPW) estimators,4,5 and estimators derived from the efficient influence function (EIF).6,7 EIF-based estimators (i.e. estimators constructed to evaluate the EIF from an empirical sample) have several theoretical advantages over the other approaches including they may be -consistent if the nuisance functions are estimated at slower rates through flexible nonparametric or machine learning methods.8–10
EIF-based estimators may also have a model double-robustness property in that when nuisance functions are estimated via parametric models, these estimators may remain consistent and asymptotically normal if models for only one of two (sets of) nuisance functions are correctly specified, not necessarily both. This model double-robustness property always holds for EIF estimators when the g-formula is indexed by a deterministic treatment strategy at most dependent on past treatment and confounders.6,11,12 However, the identification results of Robins1 were not limited to such deterministic strategies but generalized to allow identification of stochastic treatment strategies at most dependent on the measured past. The latter identifying functional or generalized g-formula depends on the intervention treatment distribution, that is, the distribution of treatment under an intervention that ensures the strategy of interest is followed conditional only on the measured past in the observational study. The generalized g-formula coincides with the more familiar g-formula indexed by a deterministic strategy when the intervention treatment distribution is chosen as degenerate conditional on any level of the measured past.
Recently, several practical applications have motivated estimation of the generalized g-formula indexed by intervention treatment distributions that depend on the observed treatment process, that is, the observed treatment distribution conditional on the measured past.13–17 The generalized g-formula indexed by an intervention treatment distribution dependent on the observed treatment process has the particular advantage of relying on relatively weak positivity conditions15,18 even, for example, in observational studies where the propensity score is equal or close to zero for certain measured confounder histories.16 When the (degenerate or non-degenerate) intervention treatment distribution does not depend on the observed treatment process, EIF-derived estimators of the generalized g-formula will be model doubly robust. However, when the intervention treatment distribution does depend on the observed treatment process, such estimators may or may not be doubly robust.14–16,19
In this paper, we exploit particular representations of the generalized g-formula to give sufficient conditions for the existence of doubly robust estimators for point treatment interventions when the chosen intervention treatment distribution depends on the observed treatment process. We also provide a general form of EIFs for a class of intervention treatment distributions that may depend on the observed treatment process in longitudinal settings that guarantee model doubly (and multiply) robust estimators. Motivated by observational studies of the effects of realistic HIV PrEP initiation interventions, we consider a new class of intervention treatment distributions dependent on the observed treatment process that is a variation on the incremental propensity score interventions proposed by Kennedy.16 We show that estimators based on the EIF for our proposed intervention treatment distribution are model doubly/multiply robust, and can attain fast convergence rates even when used in combination with machine learning algorithms, where modeling assumptions are relaxed. We illustrate both EIF-based, as well as simpler singly robust, estimators of the g-formula indexed by this class of intervention treatment distribution in simulated data and in an illustrative data application.
Observed data structure
Consider a longitudinal study with denoting a follow-up time interval (e.g. week and month), where is the end of the follow-up of interest. Assume the following random variables are measured in this study on each of individuals meeting some eligibility criteria at baseline. For each , let denote a vector of time-varying covariates measured at the beginning of time interval , a binary or discrete treatment variable measured during time interval , and an indicator of surviving an event of interest by time interval (e.g. the first diagnosis of bacterial sexually transmitted infection (STI)). For notational simplicity, we will assume throughout that all covariates are discrete in that they have distributions that are absolutely continuous with respect to a counting measure but arguments naturally extend to settings with continuous covariates and Lebesgue measures. By definition, (all individuals are at risk of failure baseline) and by convention we define and . For a random variable , we let denote history through time . We assume the ordering . Without loss of generality, we will assume no individual is lost to follow-up until Section 7.3.
Intervention treatment distribution
Let denote a treatment rule that specifies how a treatment should be assigned at each . Following Richardson and Robins,20 denote and as the natural values of covariates and survival status and the intervention value of treatment at under , respectively. In turn, the distribution of evaluated at some treatment level conditional on the “measured past” under is specified by which we refer to as the intervention treatment distribution at associated with .
When treatment assignment at any time under a selected rule deterministically depends on the measured past, there is only one value given any history for those with . In this case, when and 0 otherwise. Examples include static deterministic rules that assign the same level of treatment to all surviving individuals at all follow-up times and dynamic deterministic rules that assign treatment based on the measured past.
By contrast, when a selected rule assigns treatment stochastically at some (as a random draw from a distribution), at most dependent on the measured past, then there will be multiple values such that we may have when . We focus here on the problem of estimating , the cumulative survival probability by end of follow-up under a choice of , when the intervention treatment distribution associated with has this non-degenerate property of a stochastic rule, in particular, through its dependence on the observed treatment distribution conditional on the measured past as specified by We refer to as the observed treatment process conditional on the measured past. The observed treatment process evaluated at coincides with the so-called propensity score21 at when treatment is binary. In Supplemental Appendix A, we consider several examples of such intervention distributions.
Motivating example and incremental propensity score interventions
Kennedy16 posed incremental propensity score interventions that at each assign a binary treatment according to a strategy based on an intervention treatment distribution defined by a shifted version (on the odds scale) of the propensity score. Specifically, for a particular , treatment is assigned as a random draw from
or equivalently, from . Here we consider a modification of (1) motivated by the PrEP context. Randomized trials have demonstrated that antiretroviral PrEP is highly effective in preventing HIV infection among men who have sex with men (MSM).22–24 Some MSM are motivated to use PrEP not only to reduce HIV risk but also to improve sexual well-being,25,26 including increased intimacy and pleasure facilitated by condomless sex without fear of HIV acquisition.27 Reduced condom use among PrEP users may increase the risk of STIs, making STI screening and treatment an important part of comprehensive PrEP care.28 In our motivating example, we investigated the effect of increases in PrEP uptake on the incidence of bacterial STIs among MSM.
Specifically, for and , a measured marker of risk for HIV acquisition (e.g. receiving a bacterial sexually transmitted infection or STI test at and no prior HIV diagnosis), we consider interventions indexed by the alternative intervention treatment distribution
or after some algebra.
In words, the probability of initiating PrEP conditional on the past under at each will be larger than the observed propensity score at by decreasing its complement by a factor of for those with an indication (). Choosing corresponds to selecting an intervention where individuals with are always treated. Choosing corresponds to an intervention where the intervention treatment distribution coincides with the observed treatment distribution. We will refer to interventions indexed by either (1) or (2) as incremental propensity score interventions, distinguishing them by the classifier odds shift or multiplicative shift, respectively.
Identification by the generalized g-formula
Consider a treatment assignment rule at most dependent on past covariates. Further, let denote the set of all deterministic strategies at most dependent on this past that individuals could be observed to follow under the selected rule , with any element of . In the special case when is initially selected to be a deterministic rule then the only element of is . Otherwise, may contain many elements. Let and denote the natural values of survival status and covariates and the intervention value of treatment at , respectively, under a deterministic though ( and consider the following assumptions:
Exchangeability: .
Consistency: If then and .
Positivity: .
Robins1 showed that given these exchangeability, consistency and positivity conditions hold for all deterministic then had all subjects been assigned treatment according to a random draw from is equivalent to the g-formula:
The function is referred to as the generalized g-formula indexed by the intervention treatment distribution . Note that, under different identifying conditions, the generalized g-formula may identify the outcome mean under a rule that depends on more than the measured past.a,20,18
Generalized positivity
Note the assumption that the positivity condition above holds for all deterministic can be alternatively stated as follows:
for all . The positivity condition (4) generalizes the more familiar definition of positivity often relied on in the literature that there may be treated and untreated individuals within any level of the measured past; that is, the assumption that the propensity score and its complement are positive for all possible measured histories and all . It is straightforward to see that the more general condition (4) reduces to this typical definition of positivity only for the special case of a static deterministic intervention on a binary treatment. By contrast, the more general condition (4) only requires that, for any level of the past possible in the observational study and also plausible under , if an intervention level of treatment can occur under it must also possibly occur in the observational study. Depending on the choice of , this condition may hold when traditional definitions requiring positive propensity scores fail. Intervention treatment distributions that depend on the observed treatment process may help avoid positivity violations by this more general definition and, in some instances, may guarantee that positivity violations cannot occur regardless of the observed treatment process. We discuss this further in the next section.
Similar to arguments given in Kennedy,16 the odds shift (1) has the particular advantage that, by construction, the generalized positivity condition (4) is guaranteed to hold, no matter the nature of the observed treatment process. By contrast, the multiplicative shift (2) only enjoys this guarantee for measured pasts consistent with . However, compared to (1) which is indexed by a shift with no upper bound that quantifies an odds ratio, (2) may be easier to communicate to subject matter collaborators as it constrains the choice of and quantifies a risk ratio. Notably, the performance of weighted estimators of indexed by both (1) and (2) are relatively resilient to so-called “near positivity violations”—such that (4) holds but is still close to zero for some —particularly when is chosen to coincide with relatively small increases in treatment uptake under (see Section 8).
In the PrEP context, the multiplicative shift incremental propensity score interventions are particularly useful because analyses of observational data on the effects of deterministic interventions, such as “always treat” versus “never treat” with PrEP, will result in near or true positivity violations, with propensity scores close to (or equal to) zero for individuals with certain levels of the measured confounders. In conjunction with these challenges, such deterministic treatment effects are not of greatest interest for treatments such as PrEP, where biological benefits are established but population disease burden may be impacted with even small increases in treatment uptake. In the following sections, we will describe efficient estimators for the multiplicative shift incremental propensity score interventions.
Model double robustness when the intervention treatment distribution depends on the observed treatment process
Suppose that the observed data defined in Section 2 follows a law , which is known to belong to , where is the parameter space. The EIF for the causal parameter in a non-parametric model that imposes no restrictions on the law of other than positivity is given by , where is known as the pathwise derivative of the parameter along any parametric submodel of the observed data distribution indexed by , and is the score function of the parametric submodel evaluated at .29,30 In this section, we provide results that aid the intuition on the existence of doubly robust estimators of when the intervention treatment distribution depends on the observed treatment process through understanding properties of the EIF for the parameter .
Point treatment
We begin with the special case of a point treatment where and . In this case, (3) reduces to .
Suppose can be written as a linear combination of the form:
where , , and are constants, and and are known measurable functions of (i.e. they do not depend on ). Then the EIF for is given by
See Supplemental Appendix C for proof. Clearly, under a static deterministic strategy that sets treatment to level for all individuals trivially meets the conditions of Theorem 1 by selecting , , . In this case, the EIF for the g-formula indexed by or equals:
where and .6,31,7 A heuristic justistification for Theorem 1 follows from the fact that the EIF of is simply , and the EIF of can realized by replacing with in Expression (7), as the function does not depend on and therefore its pathwise derivative is zero. Furthermore, it is established that an estimator derived from the influence function (7) (e.g. an estimator solving for ) is model doubly robust in that it remains consistent if estimated under correctly specified parametric models for either one of two (sets of) nuisance functions, specifically or . The following Corollary gives a sufficient condition for the existence of doubly robust estimators of when the intervention treatment distribution depends on the observed treatment process, provided the conditions of Theorem 1 hold.
Suppose the conditions of Theorem 1 hold. If, where is a known measurable function of , then an estimator of derived from an EIF of the form (6) is model doubly robust.
A proof of Corollary 1.1 is given in Supplemental Appendix C. A similar heuristic reasoning for Corollary 1.1 is that the estimator of the EIF of a mean outcome does not rely on any models, and doubly robust estimators exist for because we have simply replaced with in equation (7) which does not depend on . We now consider an application of Theorem 1 and Corollary 1.1 to our multiplicative shift incremental propensity score interventions. Additional examples are provided in Supplemental Appendix C.
Multiplicative shift incremental propensity score interventions for . The intervention treatment distribution is given by .
In this case, for a choice of we have
Selecting , , , , , we have
by Theorem 1 and the EIF for is given by
This can be re-expressed as
which is useful for deriving doubly robust estimators. By Corollary 1.1, the estimators based on the EIF for will be model doubly robust. As Kennedy16 noted, the EIF for indexed by an odds shift (1) is not model doubly robust and, therefore, does not meet the conditions of Corollary 1.1. In fact, it is not hard to see that both IPW estimators and ICE estimators depend explicitly on (1). Thus, the consistency of any estimator that combines IPW and ICE will necessarily always depend on the correct estimation of (1). Thus, intuitively model doubly robust estimators will not exist for the odds shift intervention.
Time-varying treatments
Recently, Molina32 showed that, in time-varying treatment settings, estimators derived from the EIF for a indexed by any intervention treatment distribution that does not depend on the observed treatment process33,6,7 confer more protection against model misspecification than model double robustness. Rather, they showed that these estimators are model multiply robust, which implies model double robustness. The following theorem gives a sufficient condition for the existence of model multiple robust estimators of when the intervention treatment distribution may depend on the observed treatment process and a simple approach to deriving the EIFs for a particular class of such intervention treatment distributions.
Suppose an intervention treatment distribution can be written as the following:
where , , and are constants; , , and are known measurable functions of ; and is a non-degenerate known probability distribution for . Then the EIF for indexed by this intervention treatment distribution is
where and are iteratively defined from such that for , we have and
with . Estimators based on this EIF are model multiply robust in that they are consistent if models for are correctly specified for and the observed treatment models are correctly specified from (for ), where is ∅︀, .
Theorem 2 makes the derivation of the EIF and the corresponding estimators far more straightforward and accessible when intervention distributions are in the form given by (8). In Supplemental Appendix D, we prove that expression (9) is the EIF under a nonparametric model that imposes no restriction on the observed data law for indexed by (8). In Supplemental Appendix E, we prove that estimators based on this EIF are model multiply robust. Note that, by the monotonicity of the survival indicators, we have . This implies that , where . We now apply Theorem 2 to our multiplicative shift incremental propensity score intervention.
Consider the multiplicative shift incremental propensity score interventions from Section 4, recalling the intervention distribution is .
This intervention distribution can be written in the form of equation (8) by selecting , . By Theorem 2, the EIF for this intervention distribution is then given by
It is also straightforward to see that any corresponding to a deterministic static treatment rule meets the conditions of Theorem 2 by selecting , and . In Supplemental Appendix E, we further illustrate the application of Theorem 2 to deterministic dynamic treatment rules, as well as other examples of intervention distributions that depend on the observed treatment process for the time-varying case including representative interventions and dynamic treatment initiation strategies with a grace period. Note that, in these examples and the incremental propensity score intervention example above, Theorem 2 holds by selecting such that need not be specified. More generally, the applicability of Theorem 2 may require specification of . For example, this applies to an alternative grace period strategy where initiation within the grace period is assigned such that there is a uniform probability of initiating at each .4
Note that the EIF given in Diaz et al.19 cover a comprehensive class of interventions that also guarantees estimators with model double robustness, including interventions that depend on the natural value of treatment14,15 also known as modified treatment policies. Following the results of Theorem 2 in Diaz et al.,19 the EIF of the implied modified treatment policy from our proposed intervention necessarily involve randomizer terms,b but their derivation of the corresponding EIF assumes that the distributions of the randomizers are not known, when they certainly will be. Our Theorem 2 provides the EIF for the g-formula indexed by a class of stochastic interventions that may depend on the observed treatment process. It can be shown that nearly all functionals in this class are captured by the g-formula functionals for which Diaz et al.19 provides the EIF. Diaz et al.’s results would capture all of the functionals in this class, including those indexed by our proposed multiplicative incremental propensity score interventions, provided they projected their EIF onto a tangent space corresponding to smaller models whereby the distributions of some conceptualized randomizers are known. We do not take this approach and allow one to derive the EIF directly from a stochastic treatment distribution without requiring one to define an implied modified treatment policy first.c This alternative derivation of the EIF may be more intuitive for treatment distributions that do not depend on the natural value of treatment.
Finally, in Supplemental Appendix C, we use a similar line of reasoning to Theorem 1 and Corollary 1.1 to derive the EIF for and to assess the existence of doubly robust estimators for indexed by an intervention distribution that depends on the observed treatment process when with examples. However, this approach to deriving the EIF is cumbersome for large , providing no simplification over Theorem 2.
In the next section, we consider various estimators of under the multiplicative shift incremental propensity score interventions defined by (2).
Estimators of indexed by multiplicative shift incremental propensity score interventions
EIF-based estimators
Several EIF-based estimators for have been proposed for deterministic treatment interventions including the standard one-step augmented IPW (AIPW) estimator, Bang and Robins (2005)’s estimator,6,34,33 weighted ICE estimator35,12 and targeted maximum likelihood estimator (TMLE).7,36,37Unlike the other estimators, the one-step augmented IPW estimator that solves the empirical EIF does not guarantee sample-boundedness. Weighted ICE and TMLE are variations of Bang and Robins.6 Compared with the one-step AIPW estimator and Bang and Robins,6 weighted ICE can give better performance.2 Unlike Bang and Robins6 and weighted ICE, the one-step AIPW estimator and TMLE can incorporate any machine learning algorithms2 for both sets of nuisance functions. In the absence of machine learning algorithms, weighted ICE and TMLE perform similarly,2 but weighted ICE is easier to implement. In this section, we will consider two estimators: (1) weighted ICE estimator that uses parametric models to estimate the nuisance functions thereby allowing for model multiple robustness and (2) TMLE that also uses sample-splitting and cross-fitting30,38,10 to allow one to incorporate machine learning algorithms to estimate the nuisance functions.
Weighted ICE estimator
Let and let be a working parametric model for with . Denote estimates of with the maximum likelihood estimate (MLE) of computed from the observed data. Subsequently, let be an estimate of as defined in (2) for a choice of , replacing the observed treatment process with the estimate . Let be a working parametric model for defined in Theorem 2. In the following algorithm, each is calculated by replacing in formula (10) with the estimate . The weighted ICE algorithm is specifically implemented as follows:
Algorithm for Weighted ICE.
Compute the MLEs of from the observed data. Set .
Recursively from :
A. Fit a regression model for where the score function for each observation is weighted by in those who survive by time . Here, is a known function of and . More specifically, we solve for in the following estimating equation:
B. Compute from ensuring when .
Estimate
where . Following arguments in Section 6.2, this estimator is model multiply robust. Note that we fit a weighted generalized linear model on by specifying a quasibinomial family with a logit link function (Papke & Wooldridge,39) and weights given by in Step 2A. This type of regression is known as fractional logistic regression.
TMLE with sample-splitting and cross-fitting
This algorithm utilizes sample-splitting and cross-fitting to allow flexible machine learning algorithms for estimating nuisance functions while circumventing Donsker class conditions.40,30 In Supplemental Appendix F, we prove the asymptotic normality of this estimator under the condition that the nuisance functions are estimated consistently at rates faster than when is indexed by the interventions (2).
Suppose that a sample of size is split into disjoint subsets. Let denote the subset of individuals in split and let denote individuals not in split (i.e. ). Moreover, let , and denote estimates of and obtained from machine learning algorithms to individuals in .
Algorithm for TMLE with sample-splitting and cross-fitting.
For each :
A. For individuals in: compute , . Set .
B. Recursively from for individuals in:
Compute by regressing on in those alive at time
Compute from by formula (10), setting if
C. For individuals in, set . Then recursively from :
Solve for in the following set of estimating equations:
Compute from if , otherwise set if
Calculate
Here where is the cardinality of . Note that in Step 1C(a), we fit a weighted generalized linear model on with weights given by and an offset given by among survivors in at time .
Singly robust estimators
We also consider less optimal but computationally simple singly robust estimators of indexed by (2). An IPW estimator can be obtained by the product , where can be interpreted as an estimate of the discrete hazard at under a stochastic strategy where treatment assignment is a draw from (2) given the identifying conditions of Section 5. Each can be obtained by solving for in the following estimating equations:
which can be estimated using weighted generalized linear model on with weights given by . Interestingly, it can also be shown that can be obtained as a special case of the algorithm for weighted ICE above where for all .41 Alternatively, the singly robust ICE estimator, which we will denote , can be obtained as a special case of the algorithm for weighted ICE above where the observational weights are set to 1.
Censoring
Straightforward extensions of the identification arguments in Section 5 in studies with censoring follow by implicitly including in a hypothetical intervention that eliminates censoring throughout follow-up42 with straightforward extensions of the g-formula , properties of its EIF and associated estimation procedures. Briefly, denote as the indicator of censoring by time and adopt the order . Extensions to accommodate censoring for singly robust weighted estimators and the various EIF-based estimators considered, require, in addition to estimating in , also estimating in for with . Further details of modifications to the weighted ICE and TMLE to accommodate censoring are provided in Supplemental Appendix G.
Simulation studies
We conducted two different simulation studies. The first simulation study aims to compare the performance of the weighted ICE, IPW, and ICE estimators when the nuisance functions are estimated through parametric models under various model misspecification scenarios. The second simulation study aims to compare the performance of TMLE with sample-splitting and cross-fitting, IPW and ICE when the nuisance functions are estimated through machine learning algorithms.
Simulation study 1: Using parametric models
In this simulation study, we compare the performance of the weighted ICE estimator with the singly robust estimators (IPW and ICE estimators) for indexed by the intervention distribution (2) which, under identifying conditions discussed in Section 5, equals the cumulative probability of survival at under an intervention that increases the probability of treatment initiation in those with as a function . Recall that this increase is defined such that decreasing values of correspond to an increasing probability of treatment initiation (with coinciding with no treatment intervention).
We simulated 1000 samples of individuals selecting and . We simulated the following variables: , where is the vector of measured confounders. Specifically, we generated and , and . The censoring indicator at each time () was simulated from if and . The outcome at each time () is simulated from if and . The time-varying confounders at time () are simulated from , and if . Treatment at time () is simulated from if . In addition if , and if .
The true cumulative probabilities of survival were calculated by using the true parametric models to generate a Monte Carlo sample of size under all interventions of interest. Our selection of parameters resulted in a scenario where selecting smaller (i.e. interventions with larger increases in the probability of treatment initiation at each ) improves survival.
We considered three estimation scenarios for each choice of and sample size such that (1) all models are correctly specified, (2) only the outcome regression models are correctly specified, and (3) only the treatment (propensity score) and censoring models are correctly specified. The true functional forms of the treatment and censoring models are known under our simulation because treatment and censoring were generated to only depend on past measured variables. Similarly, the functional form of the outcome regression model for is known due to the absence of unmeasured common causes. However, the true functional forms of the outcome regressions for are not known under our simulation. To ensure correctly specified models for , , saturated models were fit, that is, all main terms and interaction terms for . In scenarios with misspecified models, at each time , the misspecified treatment model ignores the censoring process and excludes in the model, and the misspecified outcome regression model excludes any pairwise interactions between the covariates and treatment.
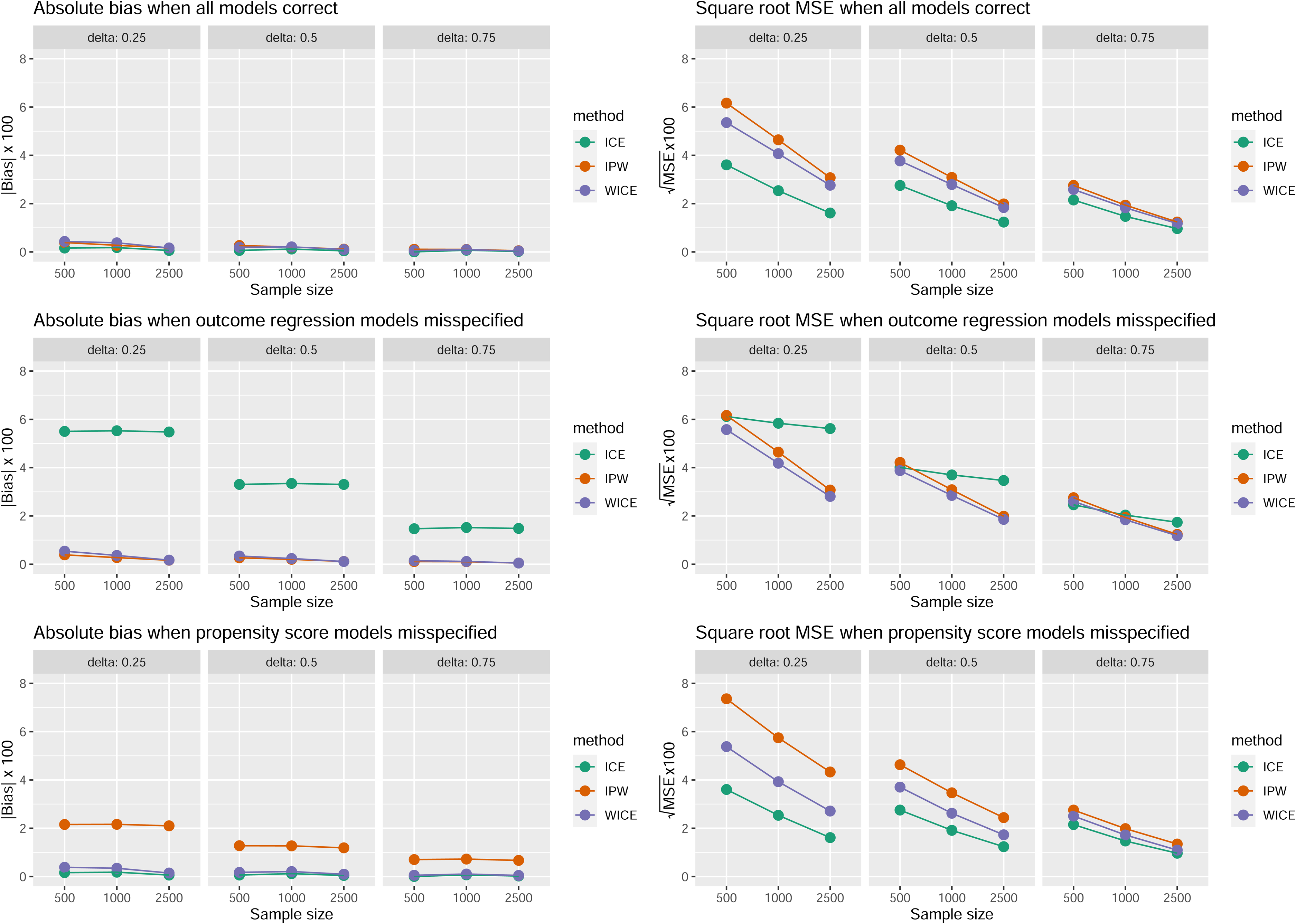
Figure 1 compares performance of the three estimators of indexed by (2) for . Complementary results are given in Tables 3 to 5 in Supplemental Appendix H. As expected, all estimators were nearly unbiased under correctly specified models. Under our model misspecification scenarios, is nearly unbiased, but the IPW estimator is biased when the treatment models are misspecified, and the ICE estimator is biased when the outcome models are misspecified. In addition, under correctly specified models is the most efficient, and is the least efficient estimator. Interestingly, the simulation results show that has smaller mean squared error (MSE) than the IPW estimator in all scenarios.
Results for the simulation study 1.
The simulation results also show that as decreases, the standard error (and MSE) in all three estimators increases. This is due to an increase in the effect of near positivity violations as nears zero. In fact, we would expect all three estimators to have the largest standard errors when , which is equivalent to a strategy that treats all individuals with at all times. In Supplemental Appendix H, we also show model robustness of our weighted ICE estimator in a model misspecification scenario that requires more than model double robustness.
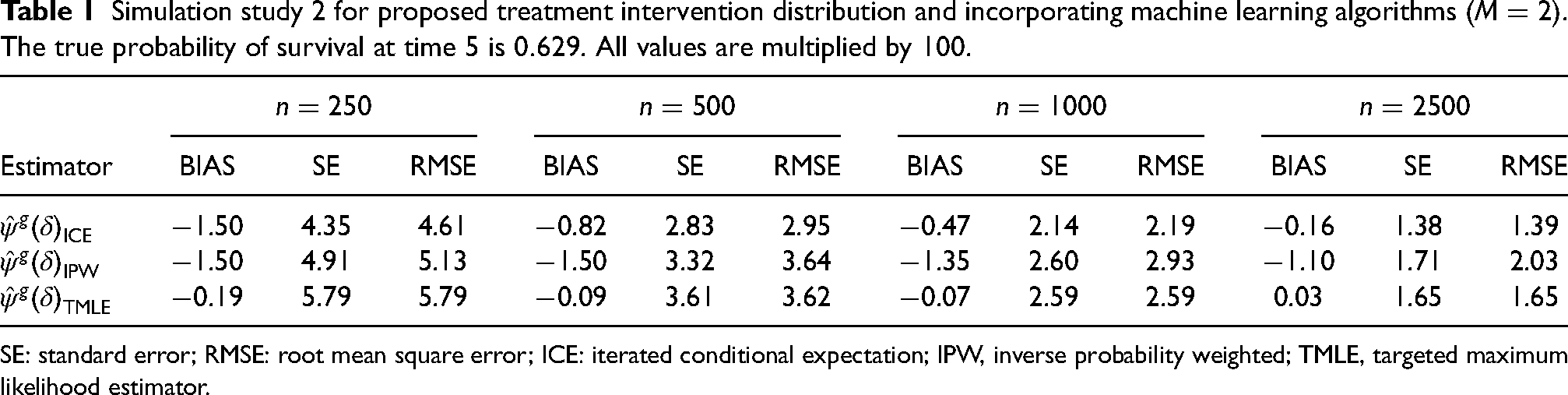
Simulation study 2: Using machine learning methods
In the second simulation, we compare the performance of algorithms that use machine learning to estimate the nuisance functions for indexed by (2) with . Specifically, we compare TMLE with sample-splitting and cross-fitting, IPW and ICE. Given much longer computation times, we limited consideration to one choice of . Unlike Simulation 1, we add model complexity to the data-generating mechanism by considering continuous covariates, which might mimic real-life data more closely. We simulated 1000 hypothetical cohorts of comprising the following variables: , where . In addition, , where and are baseline covariates. In particular, , , and . For , and if . Censoring indicator at each time () is simulated from if and . The outcome at each time () is simulated from if and . Treatment at time () is simulated from if and , and is set to if and .
Nuisance functions were estimated using the Super Learner ensemble, which uses cross-validation to select the best convex combination of predictions from a pool of prediction algorithms.43 The library of potential candidates used here consisted of generalized linear models and their variants (SL.glm, SL.glm.interaction), Bayesian generalized linear models (SL.bayesglm), generalized additive models with smoothing splines (SL.gam), multivariate adaptive regression Splines (SL.earth), neural networks (SL.nnet), and random forest (SL.ranger).
Table 1 compares the performance of the three estimators. The ICE and IPW estimators show bias as they are not expected to converge at rates when machine learning is used for nuisance parameter estimation. TMLE, on the other hand, shows little to no bias in all instances. This agrees with the theory as TMLE allows the nuisance functions to converge at slower nonparametric rates. The results show that even though some of the learners in the Super Learner ensemble (e.g. neural networks and random forest) may not converge at the required rate, other learners in the Super Learner ensemble converged to the truth at sufficiently fast rates. Moreover, the estimated coverage probability of the confidence intervals (CIs) for TMLE based on the asymptotic variance (see Supplemental Appendix F) is very close to the nominal 95%: for , respectively.
Simulation study 2 for proposed treatment intervention distribution and incorporating machine learning algorithms (). The true probability of survival at time 5 is . All values are multiplied by 100.
Estimator
BIAS
SE
RMSE
BIAS
SE
RMSE
BIAS
SE
RMSE
BIAS
SE
RMSE
1.50
4.35
4.61
0.82
2.83
2.95
0.47
2.14
2.19
0.16
1.38
1.39
1.50
4.91
5.13
1.50
3.32
3.64
1.35
2.60
2.93
1.10
1.71
2.03
0.19
5.79
5.79
0.09
3.61
3.62
0.07
2.59
2.59
0.03
1.65
1.65
SE: standard error; RMSE: root mean square error; ICE: iterated conditional expectation; IPW, inverse probability weighted; TMLE, targeted maximum likelihood estimator.
Application
We illustrate the application of the estimators discussed in Section 7 using electronic health record data from the Cambridge Health Alliance—a large community healthcare system in Eastern Massachusetts—to estimate the effects of increasing PrEP uptake on bacterial STI diagnosis by time . In the analysis, baseline covariates included age and calendar year at baseline, race/ethnicity, and time-varying covariates included indicator of any ambulatory encounter, indicator of HIV, indicator of any HIV testing, and indicator of any STI testing. is the indicator of PrEP initiation during time , and is the indicator of not receiving an STI diagnosis by time .
Specifically, we consider multiplicative shift interventions that, beginning at the time of an HIV-negative test, successfully increase the proportion initiating PrEP in each follow-up week only among those receiving an STI test and no prior diagnosis of HIV at time . Thus, is the indicator of receiving an STI test and having no prior diagnosis of HIV at time . An individual with (being tested for STIs and being HIV-free at time ) suggests recent condomless sex and that PrEP would not be used after an HIV diagnosis. No intervention is made for the remainder of the population at time (). Increases in treatment uptake under these interventions are quantified by a specified as defined in (7.), which quantifies the factor by which the probability of treatment non-initiation is decreased (relative to no intervention) at . We consider weeks and, as in simulation study 1, consider representing realistic interventions that result in “low,” “medium,” and “high” success in PrEP uptake relative to no intervention. We use (corresponding to no intervention) as the reference in defining causal effects.
Our analytic dataset was restricted to patients who met all the following inclusion criteria at some point during 2012 to 2017: (1) Cis male with a report of the male gender of sex partner(s); (2) 15 years of age or older; (3) an HIV-negative test; (4) had no PrEP prescription in the 3 months prior to baseline; and (5) had no STI diagnosis in the 12 months prior to baseline. The baseline (week ) for an individual was defined as the first week that all of these inclusion criteria are met. For simplicity, we excluded one individual who met these criteria but died without a bacterial STI diagnosis during the 26-week follow-up period. Our final analytic dataset consisted of individuals. As expected, few initiated PrEP over the follow-up (cumulatively 5.1% over the 26 weeks). The cumulative proportion of those receiving an STI test while being HIV-free over the 26 weeks was 70.7%. Note that no individual was treated as censored in this analysis, requiring additional assumptions that medical care was not sought outside of the Cambridge Health Alliance by any individual included at baseline over the 26-week follow-up.
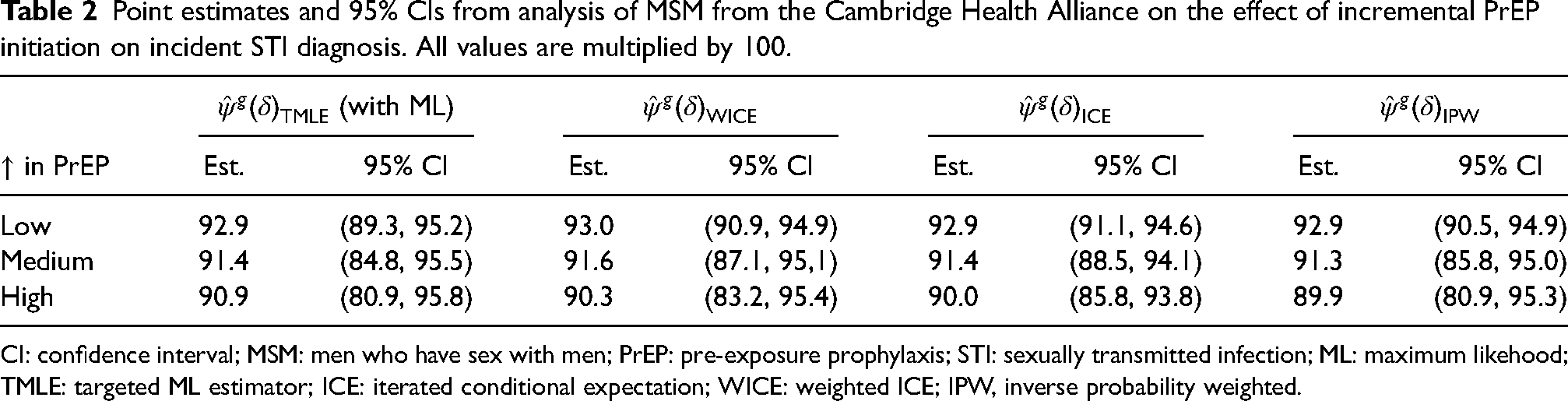
We used the Super Learner ensemble (with the same potential candidates as in the simulation) to estimate all nuisance functions for TMLE with . We compared these results with the IPW, ICE, and weighted ICE estimators described in this paper where the nuisance functions are specified by parametric models. CIs for each of the methods are obtained from 1000 bootstrap samples by taking the 2.5th and 97.5th percentiles of the resulting estimates.
Our estimate of the probability of not receiving an STI diagnosis under no intervention by 26-week follow-up () was 93.7%. Table 2 shows results from the four methods for . In this case, point estimates from all of the methods are similar. The results do not provide sufficient evidence that increasing PrEP uptake increases the risk of STI diagnosis. For instance, compared with no intervention (), the relative survival estimates under low, medium, and high increases in PrEP uptake were 0.99 (), 0.97 () and 0.96 (), respectively, under . The relative survival estimates using other estimators were very similar (see Supplemental Appendix I). We also note that due to an increase in the presence of near positivity violations as nears zero, observational weights calculated under smaller were more variable than larger (see Supplemental Appendix I). We would expect standard errors from all of the estimators to be the largest for .
Point estimates and 95% CIs from analysis of MSM from the Cambridge Health Alliance on the effect of incremental PrEP initiation on incident STI diagnosis. All values are multiplied by 100.
(with ML)
in PrEP
Est.
95% CI
Est.
95% CI
Est.
95% CI
Est.
95% CI
Low
92.9
(89.3, 95.2)
93.0
(90.9, 94.9)
92.9
(91.1, 94.6)
92.9
(90.5, 94.9)
Medium
91.4
(84.8, 95.5)
91.6
(87.1, 95,1)
91.4
(88.5, 94.1)
91.3
(85.8, 95.0)
High
90.9
(80.9, 95.8)
90.3
(83.2, 95.4)
90.0
(85.8, 93.8)
89.9
(80.9, 95.3)
CI: confidence interval; MSM: men who have sex with men; PrEP: pre-exposure prophylaxis; STI: sexually transmitted infection; ML: maximum likehood; TMLE: targeted ML estimator; ICE: iterated conditional expectation; WICE: weighted ICE; IPW, inverse probability weighted.
Discussion
Many methods have been proposed for estimating causal estimands in time-varying treatment settings for survival analysis, and among these methods are estimators that offer protection against model misspecification and can also attain the semiparametric efficiency bound. However, most of these doubly robust estimators have been in the setting of deterministic treatment interventions. In this paper, we provided some sufficient conditions for the existence of doubly robust estimators when a treatment intervention distribution can depend on the observed treatment process for point treatment processes. We also discussed a class of intervention distributions that are always guaranteed to give doubly/multiply robust estimators and gave a general form of the EIFs that are associated with these intervention distributions. Among these intervention distributions is our multiplicative shift incremental propensity score intervention distribution, which aims to increase treatment uptake in a group of individuals who are at high risk of the outcome but have low exposure to treatment. We provided various estimators that can be used for our proposed treatment intervention for both parametric and machine learning algorithms.
We conducted two simulation studies for our proposed multiplicative shift intervention distribution. Our first study shows that even in finite sample settings, the weighted ICE is more robust to model misspecification than IPW and ICE when the nuisance functions are estimated using parametric models. Our second study shows that TMLE with sample-splitting and cross-fitting can outperform singly robust estimators when machine learning algorithms are used. Indeed, the TMLE with sample-splitting and cross-fitting is consistent as long as the nuisance functions are estimated consistently at fast enough rates using machine learning methods, which may not necessarily be . We also illustrated an application of our estimators to a real-world dataset in the PrEP context.
Note that our proposed intervention treatment distribution (2) is guaranteed under a stochastic intervention such that treatment initiation status at time for an individual is a random draw from (2). The identifying conditions reviewed in Section 5 are sufficient to give our effect estimates of this interpretation. A more policy-relevant interpretation might, for example, be an intervention where individuals with are always offered PrEP counseling. In these individuals, the intervention distribution (2) quantifies the hypothesized “success” of such an intervention where in this case really refers to a deterministic strategy relative to the unmeasured treatment “offered PrEP counseling.” Additional assumptions are needed to give our effect estimates of this interpretation following similar arguments to those given in Richardson and Robins20 and Young et al.18
Finally, we note that while machine learning algorithms are more robust to model form misspecification, they are also computationally complex and may be practically infeasible for very large datasets without powerful computing systems. Even though the Super Learner ensemble performed well in the simulation study as it included learners that converged to the truth at fast enough rates, in real-world applications there is no guarantee that such learners exist. When more flexible learners such as neural networks or random forests are required, it is unclear if these machine learning methods will exhibit more or less bias compared with parametric models. Moreover, issues related to data privacy make access to advanced computational resources impossible in many cases. Therefore, estimators that offer model double/multiple robustness are useful in practice as they offer protection against model misspecification and can be easily computed using standard off-the-shelf regression software in R.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802221146311 - Supplemental material for Intervention treatment distributions that depend on the observed treatment process and model double robustness in causal survival analysis
Supplemental material, sj-pdf-1-smm-10.1177_09622802221146311 for Intervention treatment distributions that depend on the observed treatment process and model double robustness in causal survival analysis by Lan Wen, Julia L. Marcus and Jessica G. Young in Statistical Methods in Medical Research
Footnotes
Acknowledgement
The author(s) thank Dr Gerard Coste at Cambridge Health Alliance for assistance with collection of clinical data.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by NIAID grant R21AI143386-01A1.
ORCID iD
Lan Wen
Supplemental material
Supplemental material for this article is available online.
Notes
References
1.
RobinsJM. A new approach to causal inference in mortality studies with a sustained exposure period: Application to control of the healthy worker survivor effect. Math Model1986; 7: 1393–1512.
2.
TranLYiannoutsosCWools-KaloustianK, et al. Double robust efficient estimators of longitudinal treatment effects: Comparative performance in simulations and a case study. Int J Biostat2019; 15.
3.
WenLYoungJGRobinsJM, et al. Parametric g-formula implementations for causal survival analyses. Biometrics2021; 77.
4.
CainLRobinsJMLanoyE, et al. When to start treatment? A systematic approach to the comparison of dynamic regimes using observational data. Int J Biostat2010; 6: 1–24.
5.
NeugebauerRSchmittdielJVan Der LaanM. Targeted learning in real-world comparative effectiveness research with time-varying interventions. Stat Med2014; 33: 2480–2520.
6.
BangHRobinsJ. Doubly robust estimation in missing data and causal inference models. Biometrics2005; 61: 962–973.
7.
Van Der LaanMJRoseS. Targeted learning: Causal inference for observational and experimental data. New York: Springer Science & Business Media, 2011.
8.
RobinsJMLiLTchetgenE, et al. Quadratic semiparametric von mises calculus. Metrika2009; 69: 227–247.
9.
RobinsJMLiLTchetgenE, et al. Asymptotic normality of quadratic estimators. Stoch Process Appl2016; 126: 3733–3759.
10.
ChernozhukovVChetverikovDDemirerM, et al. Double/debiased machine learning for treatment and structural parameters, 2018.
11.
StitelmanOMDeGVVan Der LaanMJ. A general implementation of TMLE for longitudinal data applied to causal inference in survival analysis. Int J Biostat2012; 8: 1–37.
12.
RotnitzkyARobinsJBabinoL. On the multiply robust estimation of the mean of the g-functional. arXiv preprint arXiv:170508582 2017.
13.
TaubmanSLRobinsJMMittlemanMA, et al. Intervening on risk factors for coronary heart disease: An application of the parametric g-formula. Int J Epidemiol2009; 38: 1599–1611.
14.
MuñozIDVan Der LaanM. Population intervention causal effects based on stochastic interventions. Biometrics2012; 68: 541–549.
15.
HaneuseSRotnitzkyA. Estimation of the effect of interventions that modify the received treatment. Stat Med2013; 32: 5260–5277.
16.
KennedyE. Nonparametric causal effects based on incremental propensity score interventions. J Am Stat Assoc2019; 114: 645–656.
17.
YoungJGLoganRRobinsJM, et al. Inverse probability weighted estimation of risk under representative interventions in observational studies. J Am Stat Assoc2019; 114: 938–947.
18.
YoungJGHernánMARobinsJM. Identification, estimation and approximation of risk under interventions that depend on the natural value of treatment using observational data. Epidemiol Method2014; 3: 1–19.
19.
DíazIWilliamsNHoffmanKL, et al. Non-parametric causal effects based on longitudinal modified treatment policies. arXiv preprint arXiv:200601366, 2020.
20.
RichardsonTSRobinsJM. Single world intervention graphs (swigs): A unification of the counterfactual and graphical approaches to causality. Center for the Statistics and the Social Sciences, University of Washington Series Working Paper, 2013; 128.
21.
RosenbaumPRRubinDB. The central role of the propensity score in observational studies for causal effects. Biometrika1983; 70: 41–55.
22.
GrantRMLamaJRAndersonPL, et al. Preexposure chemoprophylaxis for HIV prevention in men who have sex with men. N Engl J Med2010; 363: 2587–2599.
23.
MolinaJCapitantCSpireB, et al. On-demand preexposure prophylaxis in men at high risk for HIV-1 infection. N Engl J Med2015; 373: 2237–2246.
24.
McCormackSDunnDTDesaiM, et al. Pre-exposure prophylaxis to prevent the acquisition of HIV-1 infection (proud): Effectiveness results from the pilot phase of a pragmatic open-label randomised trial. Lancet2016; 387: 53–60.
25.
QuinnKGChristensonESawkinMT, et al. The unanticipated benefits of prep for young black gay, bisexual, and other men who have sex with men. AIDS Behav2020; 24: 1376–1388.
26.
GamarelKEGolubSA. Intimacy motivations and pre-exposure prophylaxis (prep) adoption intentions among HIV-negative men who have sex with men (MSM) in romantic relationships. Ann Behav Med2015; 49: 177–186.
27.
MarcusJLKatzKAKrakowerDS, et al. Risk compensation and clinical decision making—the case of HIV preexposure prophylaxis. N Engl J Med2019; 380: 510.
28.
JennessSMWeissKMGoodreauSM, et al. Incidence of gonorrhea and chlamydia following human immunodeficiency virus preexposure prophylaxis among men who have sex with men: A modeling study. Clin Infect Dis2017; 65: 712–718.
29.
NeweyWK. The asymptotic variance of semiparametric estimators. Econ: J Econ Soc1994; 62: 1349–1382.
30.
Van Der VaartAW. Asymptotic statistics, vol. 3. Cambridge: Cambridge University Press, 2000.
31.
TsiatisA. Semiparametric theory and missing data. 1st ed. New York, NY: Springer, 2006.
32.
MolinaJRotnitzkyASuedM, et al. Multiple robustness in factorized likelihood models. Biometrika2017; 104: 561–581.
33.
RobinsJM. Robust estimation in sequentially ignorable missing data and causal inference models. In: Proceedings of the American statistical association Section on Bayesian Statistical Science (pp. 6–10, Annual meeting of the American Statistical Association). The Association, 2000.
34.
ScharfsteinDRotnitzkyARobinsJ. Adjusting for nonignorable drop-out using semiparametric nonresponse models. J Am Stat Assoc1999; 94: 1096–1120.
35.
RobinsJMSuedMLei-GomezQ, et al. Comment: Performance of double-robust estimators when “inverse probability” weights are highly variable. Stat Sci2007; 22: 544–559.
36.
PetersenMSchwabJGruberS, et al. Targeted maximum likelihood estimation for dynamic and static longitudinal marginal structural working models. J Causal Inference2014; 2: 147–185.
37.
LendleSSchwabJPetersenML, et al. ltmle: An R package implementing targeted minimum loss-based estimation for longitudinal data. J Stat Softw2017; 81: 1–21.
38.
ZhengWVan Der LaanMJ. Asymptotic theory for cross-validated targeted maximum likelihood estimation, 2010.
39.
PapkeLEWooldridgeJM. Panel data methods for fractional response variables with an application to test pass rates. J Econom2008; 145: 121–133.
40.
Van Der VaartAWWellnerJA. Weak convergence. In: Martin Gilchrist (eds) Weak convergence and empirical processes. New York: Springer, 1996, pp. 16–28.
41.
WenLHernánMARobinsJM. Multiply robust estimators of causal effects for survival outcomes. Scand J Stat2022; 49: 1304–1328.
42.
YoungJGCainLERobinsJM, et al. Comparative effectiveness of dynamic treatment regimes: An application of the parametric g-formula. Stat Biosci2011; 3: 119–143.
43.
Van Der laanMJPolleyECHubbardAE. Super learner. Stat Appl Genet Mol Biol2007; 6: 1–21.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.