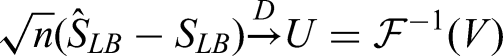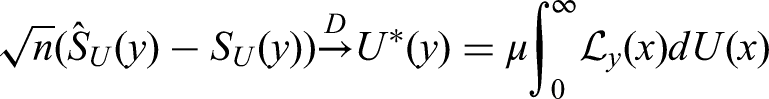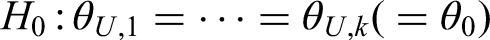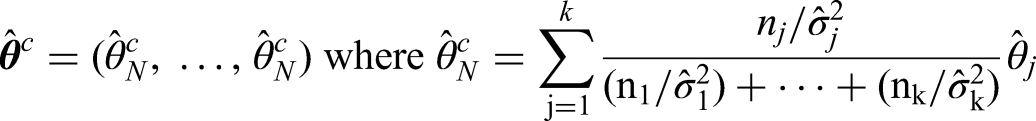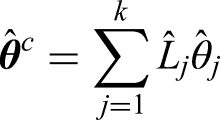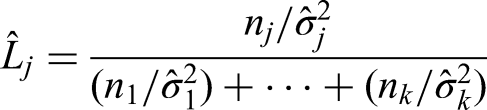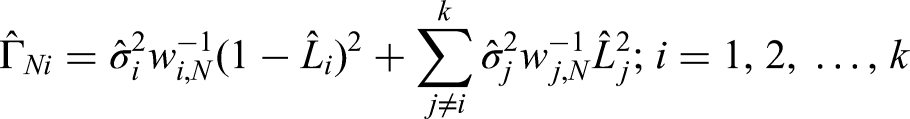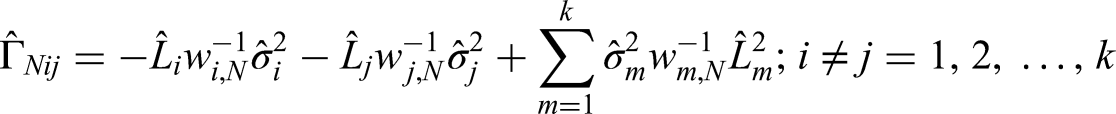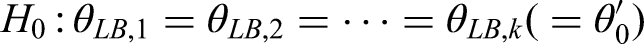The median is a robust summary commonly used for comparison between populations. The existing literature falls short in testing for equality of survival medians when the collected data do not form representative samples from their respective target populations and are subject to right censoring. Such data commonly occur in prevalent cohort studies with follow-up. We consider a particular case where the disease under study is stable, that is, the incidence rate of the disease is stable. It is known that survival data collected on diseased cases, when the disease under study is stable, form a length-biased sample from the target population. We fill the gap for the particular case of length-biased right-censored survival data by proposing a large-sample test using the nonparametric maximum likelihood estimator of the survivor function in the target population. The small sample performance of the proposed test statistic is studied via simulation. We apply the proposed method to test for differences in survival medians of Alzheimer’s disease and dementia groups using the survival data collected as part of the Canadian Study of Health and Aging.
In studies examining a survival time outcome for multiple groups/strata, it is typically of interest to the researcher to compare quantities related to the survival distribution such as the median. For example, Rahbar et al. compared the median waiting times for trauma patients to receive red blood cells using data from the Prospective Observational Multi-Center Major Trauma Transfusion study and, Brookmeyer and Crowley compared the median survival times for subjects receiving four types of cancer treatment using data from a Phase III colorectal cancer clinical trial.1,2 Hypothesis testing procedures based on comparing the median survival times between groups, for a variety of data types, have been well studied in the literature. For right-censored failure time data, Brookmeyer and Crowley proposed a testing procedure for comparing sample medians using the asymptotic properties of the Kaplan–Meier product-limit estimator.1,3 Although their procedure was based on comparing median point estimates, they implicitly assumed that the failure time distributions are members of the same location family. Brookmeyer and Crowley defined a weighted Kaplan–Meier estimate to determine the sample median, however, the non-parametric estimate assumes the group survival distributions are equivalent. Given that members of a location family can be identified by their medians, these authors essentially test the equality of the underlying survival distributions. Rahbar et al. highlight this testing dichotomy by explaining that equality of distributions implies equality of medians whereas the converse statement is not necessarily true.4 Reid validated the bootstrapping procedure of Efron applied to the sample median for right-censored data and discussed the associated confidence interval properties.5,6
Recently, Rahbar et al. proposed a hypothesis testing procedure for comparing population medians using right-censored failure time data which does not require the location family assumption.4 Using the asymptotic distribution of the Kaplan–Meier estimator and an application of the functional delta method, Rahbar et al. derived a quadratic test statistic with an asymptotically chi-squared distribution.7 In this article, we propose an extension to the method of Rahbar et al. for the case in which the failure time data are both length-biased and right-censored using the nonparametric maximum likelihood estimator (NPMLE) of the unbiased survival function.8 We note that when the observed failure times are length-biased, the censoring mechanism is informative yielding an NPMLE which places mass on both the observed failure/censoring times of the prevalent cohort study.8–11 Thus, the unbiased survival function estimator is fully defined over the entire real line establishing the existence of the median point estimate. While other product-limit estimators for left-truncated right-censored failure time data may be applied (see, e.g. Huang and Qin,12 Luo and Tsai,13 and Tsai et al.14), the survival function estimates may not yield a median point estimate when censoring is high. Although there may be instances in which the median point estimate exists when utilizing the bootstrapping procedure of Efron, some bootstrap samples may not yield median estimates requiring them to be discarded.5 In addition to ensuring the existence of the median point estimate, our use of the NPMLE of the unbiased survival function is motivated by its efficiency compared to all other nonparametric estimators.9
In Section 2., we define the notation for prevalent cohort studies with follow-up resulting in length-biased right-censored failure time data and describe how the asymptotic representation of the NPMLE of the unbiased survival function may be utilized to define a statistic for testing differences between multiple population medians. In Section 3., we generate simulated failure time data from prevalent cohort studies with follow-up to assess the performance of the proposed testing procedure and in Section 4., we apply our testing methodology to the Canadian Study of Health and Aging (CSHA) dataset to compare median survival between various dementia/Alzheimer’s disease groups. We provide some extensions and future research directions in Section 5.
Notation and methodology
In a general prevalent cohort study with follow-up, subjects are screened and only diseased cases are followed until failure/censoring for which their respective onset dates are recorded retrospectively.15 Let the fixed constant denote the date at which subjects are tested for the prevalence of the condition/disease under study (prevalence day) and let denote a generic onset time generated from a stationary Poisson point process. Let be the underlying failure random variable with distribution function and mean . A subject is included in the prevalent cohort study if (i.e. they survive past prevalence day) where they are subsequently followed until the end of the study or they are lost to follow-up. Let denote the censoring time measured from with distribution function . Thus, the prevalent cohort consists of the triples made up of the observed truncation times, failure/censoring times and associated indicator functions. When the additional stationarity assumption is made for the underlying onset process of the prevalent cohort data (i.e. the underlying onset dates are drawn from a stationary Poisson point process) the observed failure times are typically referred to as being “length-biased.” For details on testing the validity of the stationary onset process assumption, see the literature.16–19 Let denote the length-biased distribution function for which it may be shown8:
In this setting, it is sufficient to only use the observed failure/censoring times without the observed truncation times in order to make inferences regarding the unbiased survival function. For a set of length-biased right-censored failure time data, Asgharian and Wolfson established uniform consistency and weak convergence for the NPMLE of and showed
where is a Gaussian process.9 Using the relationship between the unbiased and length-biased survival functions given in equation (1), Asgharian et al. established uniform consistency and weak convergence for the NPMLE of the unbiased survival function .8 In particular, they established the following weak convergence result:
where . As the operator acting on the limiting Gaussian process of is a bounded linear operator, it may then be shown that is also a Gaussian process.20
Using similar notation as Rahbar et al., consider the setting in which independent populations are sampled for which the observed samples consist of length-biased failure/censoring times.4 We utilize the subscript , , to differentiate the parameters/estimators between the populations/samples, respectively. For , we define the median as:
for which the sample median estimator, is determined via plugging in the estimator of in equation (2).4 We note that the median estimators for the different groups will always exist as the corresponding unbiased survival function estimators, , under the stationarity assumption, are fully defined over the entire real line. This is a direct result of the informative censoring mechanism which forces non-zero probability mass to fall on the observed censoring times.21 Moreover, as the observed length-biased data are collected from a prevalent cohort study with follow-up through a cross-section at prevalence day, the subjects’ onset dates may occur any time arbitrarily far before prevalence day. This implies that if the follow-up period is short, resulting in a large proportion of the observed failure times being right-censored, the NPMLE of the functions will be unaffected. For details on the NPMLE of without the stationarity assumption, see Tsai et al.14 For group , , it may be shown that the sample median estimator converges to a Gaussian random variable:
We summarize the necessary conditions of this result with a sketch of its proof in Theorem 1 and Corollary 4 in the Appendix. Estimates for , may be obtained by applying the simple bootstrap procedure of Efron to each of the samples by resampling the pairs , , .5
Let be the population medians and let be the sample sizes for each of the samples. Consider the null hypothesis of equal medians for each of the groups:
Following the approach of Rahbar et al., we define the combined median estimator as:
which can be re-expressed as
where
for which .4 Denoting the combined sample size , Rahbar et al. proposed the following quadratic test statistic:
where is a matrix with diagonal entries given by
and off-diagonal entries given by
for which for .4 As remarked by Rahbar et al., the matrix is not necessarily invertible and so the generalized inverse may be utilized instead of expression (4). Using the asymptotic normality of the sample median estimators, , , may be shown to weakly converge to a central distribution with degrees of freedom (see Theorem 2 of Rahbar et al.4). The percentiles of the central distribution may be utilized to test for significance when conducting the equality of medians hypothesis test.
Length-biased/unbiased survival function median comparisons
Although the proposed testing procedure is based on determining differences between the unbiased survival function medians, a question that may be posed is whether the correct conclusion will be reached when testing for equality of the length-biased population medians instead. Using the weak convergence of the length-biased survival function NPMLE , an equivalent form of the test statistic in equation (4) may be formed to test the null hypothesis:
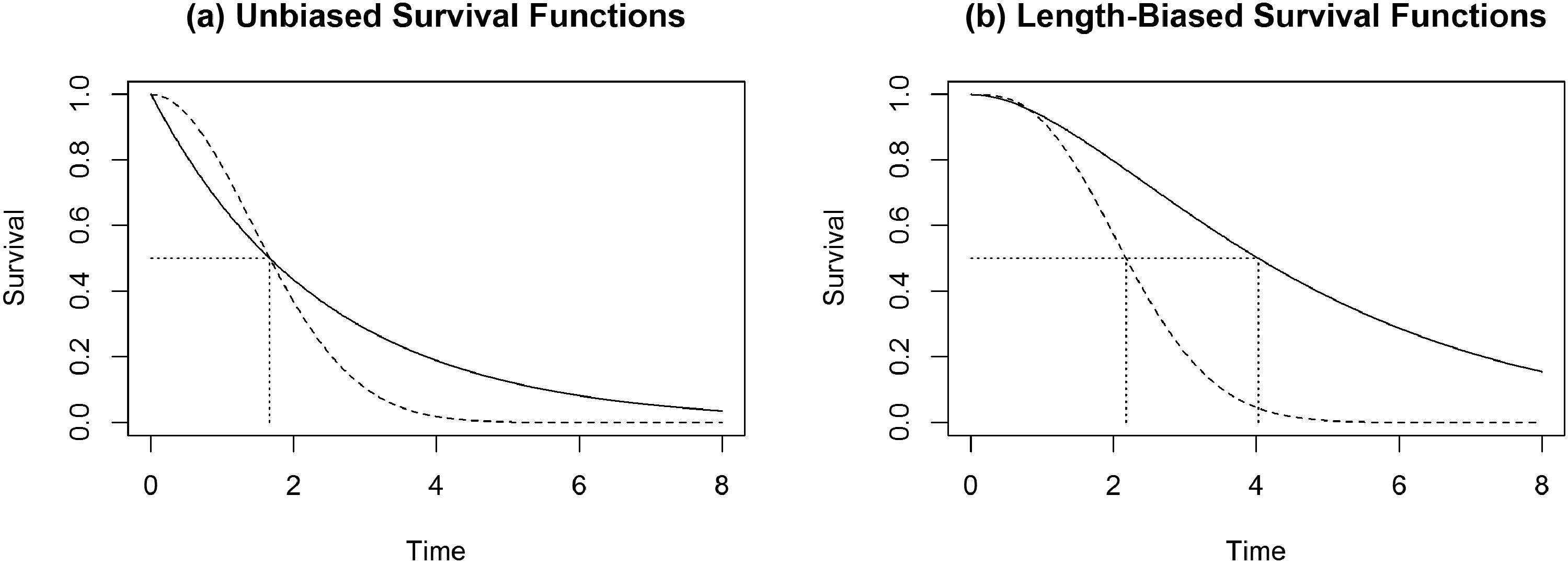
where are the population medians of the length-biased survival functions. For simplicity of exposition, consider the case with in which the medians of two survival distributions are being compared. Addona examined different types of group comparisons between unbiased and length-biased survival curves and found that in the two-sample setting, there exist examples in which , however, (i.e. the ordering of medians is “reversed”).22 In Figure 1, we illustrate a similar phenomenon using Weibull failure time data and show that the unbiased survival curves for two groups can have identical medians whereas the medians of the corresponding length-biased survival curves are clearly different. Therefore, without restriction on the family of underlying failure time distributions, it is not sufficient to test for differences in medians of the length-biased distributions and then subsequently make conclusions regarding the unbiased population medians. For related discussions on testing for equality of survival curves using length-biased failure time and adjusting for time-dependent selection mechanism/covariates, see Ning et al.10 and Huiart and Sylvestre.23
Illustration comparing unbiased and length-biased survival curves for two groups. The two unbiased survival curves were generated from Weibull distributions with (shape, scale) parameters of and yielding equal unbiased medians indicated by the single vertical line in panel (a). The length-biased medians, computed using the length-biased survival functions, are indicated by the two distinct vertical lines in panel (b).
Simulations
To assess the performance of the proposed hypothesis test, we generated samples of length-biased right-censored failure time data from various distributions to control for the values of the unbiased population medians. Specifically, we considered three failure time distributions: uniform distribution with support (median equal to ), the LogNormal distribution with parameters and (median equal to ) and the exponential distribution with rate parameter (median equal to ). To generate a sample of length-biased right-censored failure time data, we sampled an onset time, , from a uniform distribution over where was chosen arbitrarily large such that . We then sampled a failure time and retained both the onset, failure time pair if , otherwise both sampled quantities were discarded. This procedure of accepting/rejecting the sampled (onset, failure time) pairs simulates the effect of left-truncation on the underlying failure time random variables. We censored the forward failure times by drawing an exponentially distributed censoring time, , with rate parameter where we recorded and whether the minimum was a failure/censoring time. The rate parameter was varied to allow for either or censoring.
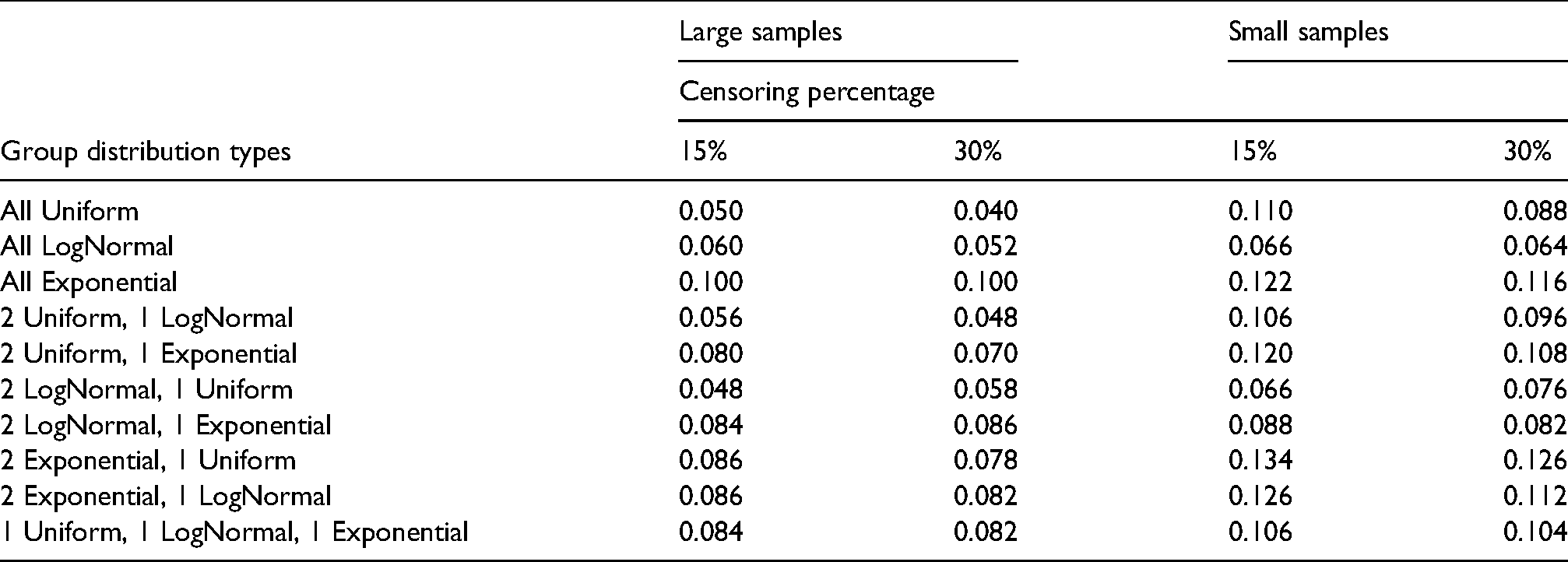
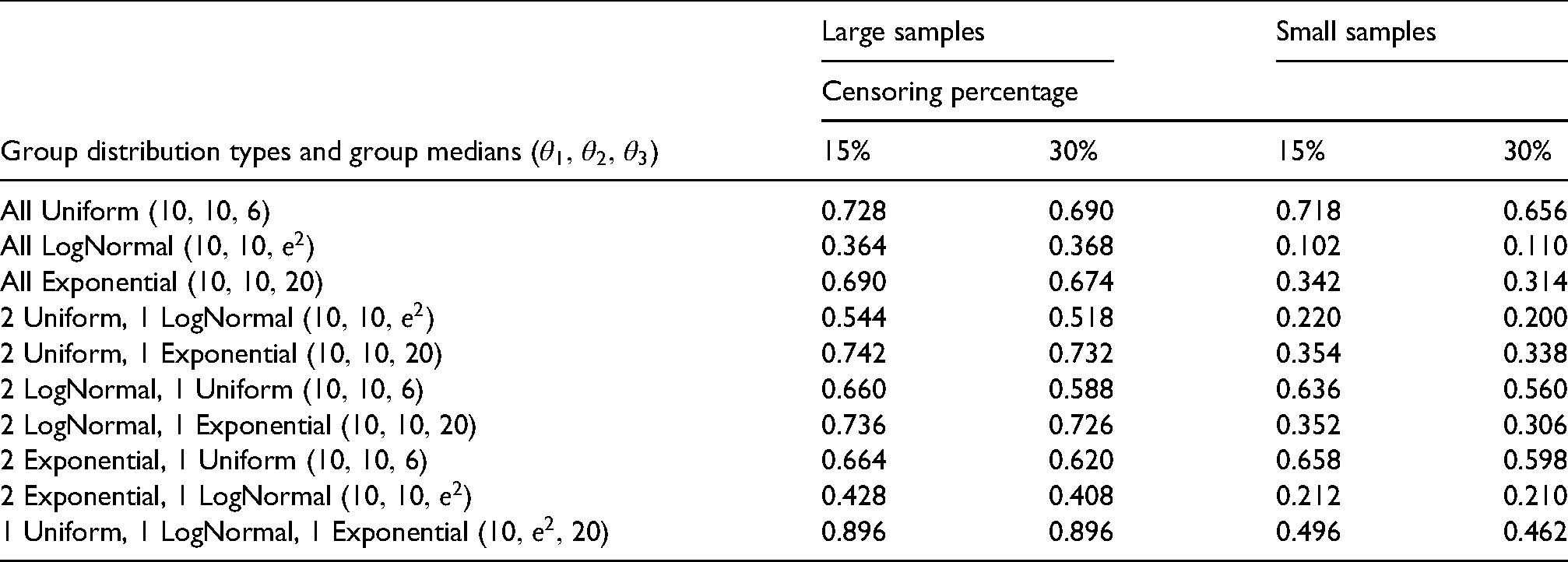
We generated multiple length-biased right-censored failure time data sets and computed the empirical test sizes and empirical powers when the medians of the distributions were equal and different, respectively. We considered the case in which where we allowed the underlying failure time distributions to be equal or different from each other. We set the sample sizes of the three groups equal to , , and , respectively, and performed the same simulations when all three samples were of size . We ran simulation runs and for each run, we estimated the sample median variances using bootstrapped samples. We reported the empirical test sizes in Table 1 and the empirical powers in Table 2. We find that for the majority of cases when the sample sizes are large, the empirical test sizes are similar to the true test significance level of . When the sample sizes of the three groups were small, the empirical sizes increased in most cases. In the cases involving the exponential distribution, we attribute the larger empirical test sizes to the difficulty in drawing a sufficient number of observations arbitrarily close to time . In Table 2, we find that when the sample sizes are large, the empirical powers are in most cases above and when the sample sizes are small, the empirical powers are diminished. This phenomenon is to be expected as with smaller sizes, the variability of the estimators’ increases and it becomes more challenging to detect any differences between the underlying population medians.
Empirical test sizes for simulated length-biased right-censored failure times of three groups drawn from underlying survival distributions with equal medians of . Large sample sizes of three groups: , , . Small sample sizes of three groups: . Simulation runs: 500. Number of bootstrapped samples per run: 1000.
Large samples
Small samples
Censoring percentage
Group distribution types
15%
30%
15%
30%
All Uniform
0.050
0.040
0.110
0.088
All LogNormal
0.060
0.052
0.066
0.064
All Exponential
0.100
0.100
0.122
0.116
2 Uniform, 1 LogNormal
0.056
0.048
0.106
0.096
2 Uniform, 1 Exponential
0.080
0.070
0.120
0.108
2 LogNormal, 1 Uniform
0.048
0.058
0.066
0.076
2 LogNormal, 1 Exponential
0.084
0.086
0.088
0.082
2 Exponential, 1 Uniform
0.086
0.078
0.134
0.126
2 Exponential, 1 LogNormal
0.086
0.082
0.126
0.112
1 Uniform, 1 LogNormal, 1 Exponential
0.084
0.082
0.106
0.104
Empirical powers of a hypothesis test for simulated length-biased right-censored failure times of three groups drawn from underlying survival distributions with varying medians. Large sample sizes of three groups: , , and . Small sample sizes of three groups: . Simulation runs: 500. Number of bootstrapped samples per run: 1000.
Large samples
Small samples
Censoring percentage
Group distribution types and group medians
15%
30%
15%
30%
All Uniform
0.728
0.690
0.718
0.656
All LogNormal
0.364
0.368
0.102
0.110
All Exponential
0.690
0.674
0.342
0.314
2 Uniform, 1 LogNormal
0.544
0.518
0.220
0.200
2 Uniform, 1 Exponential
0.742
0.732
0.354
0.338
2 LogNormal, 1 Uniform
0.660
0.588
0.636
0.560
2 LogNormal, 1 Exponential
0.736
0.726
0.352
0.306
2 Exponential, 1 Uniform
0.664
0.620
0.658
0.598
2 Exponential, 1 LogNormal
0.428
0.408
0.212
0.210
1 Uniform, 1 LogNormal, 1 Exponential
0.896
0.896
0.496
0.462
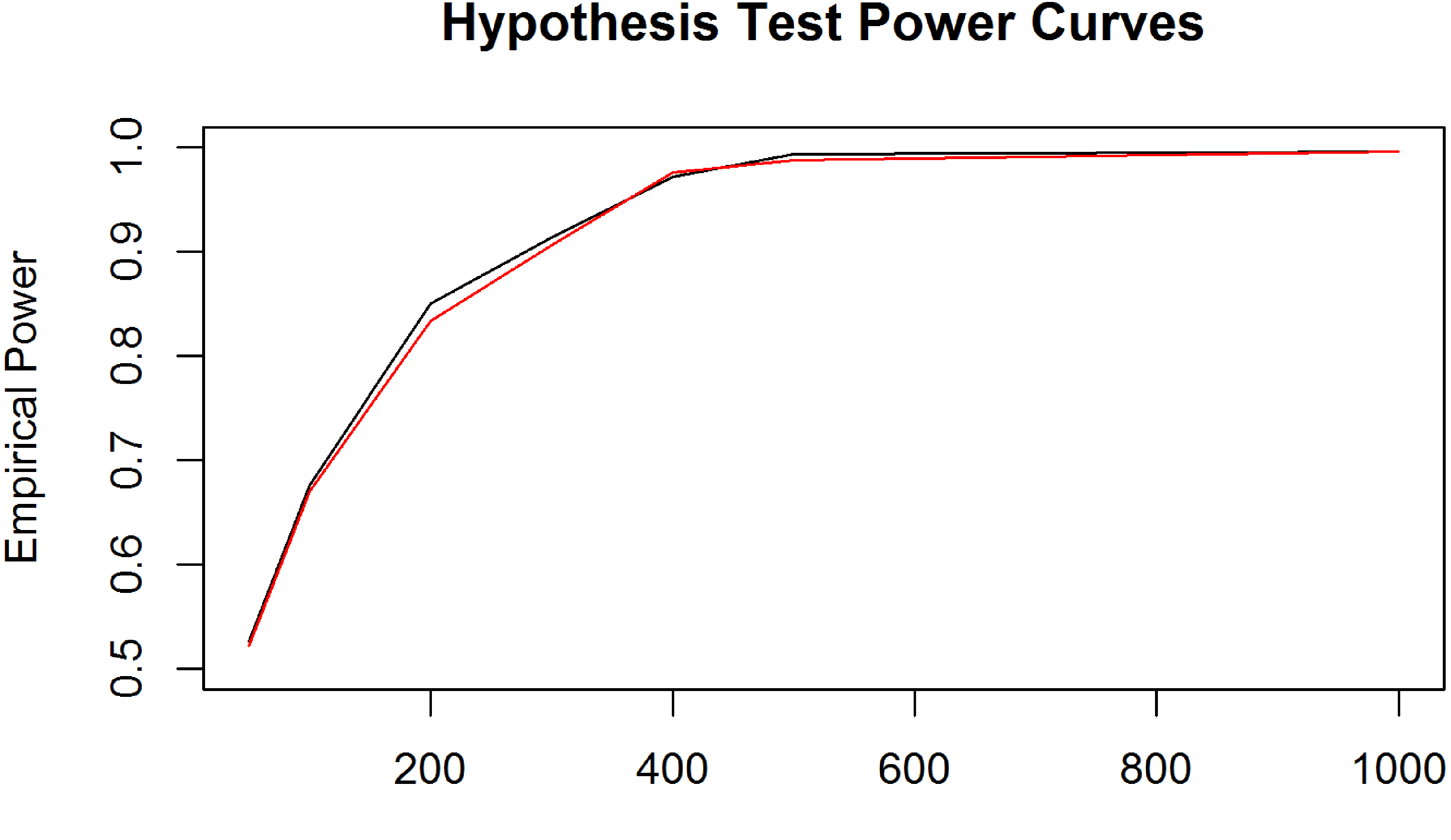
To assess how the power of the hypothesis test varied depending on the group sample sizes, we simulated length-biased right-censored failure time data from three groups with different medians (Uniform: 10, LogNormal: , Exponential: 20). We varied the censoring variable’s rate parameter, , so that either or of the sampled length-biased failure times were right-censored. We computed the empirical powers over simulation runs with bootstrapped samples per run where all three sample sizes were equal to , , , , , , and . The empirical power curves are plotted in Figure 2. Generally, as the sample size of the individual groups’ increases, the power of the test converges to independently of the two different proportions of censoring between the three groups.
Empirical power curves of the median comparison hypothesis test for simulated length-biased right-censored failure data of three groups drawn from Uniform, LogNormal, and Exponential distributions with respective medians of , , and . The empirical powers were computed when the sample sizes of the three groups were equal to , , , , , , and , where the proportion of censoring in the three groups was equal to (black) or (red). Simulation runs: . Number of bootstrapped samples per run: .
Application
The CSHA was a multicenter study of dementia and related geriatric conditions for individuals over the age of 65 in Canada.24 In 1991, in the first stage of the CSHA, approximately 10,000 subjects living in a community or institutional residences were screened for various forms of cognitive impairment. At the second stage of the CSHA in 1996, the subjects who were still alive were screened a second time for cognitive impairment through a clinical evaluation. For the subjects who screened positive at the first stage of the CSHA, their onset dates were obtained through the recollections of their family members and caregivers and the dates of death were recorded for those subjects who died between the first and second stages of the CSHA. Through the screening tests and the clinical evaluations, the prevalent cohort of subjects () consisting of males and females who screened positive at the first stage of the CSHA were classified as having either vascular dementia (), possible Alzheimer’s disease () or probable Alzheimer’s disease (). Subjects’ survival times were (administratively) right-censored if they were still alive at the time of the second stage of the CSHA. Approximately , , and of the subjects screened with vascular dementia, possible Alzheimer’s disease, or probable Alzheimer’s disease, respectively, were right-censored at the second stage of the CSHA.
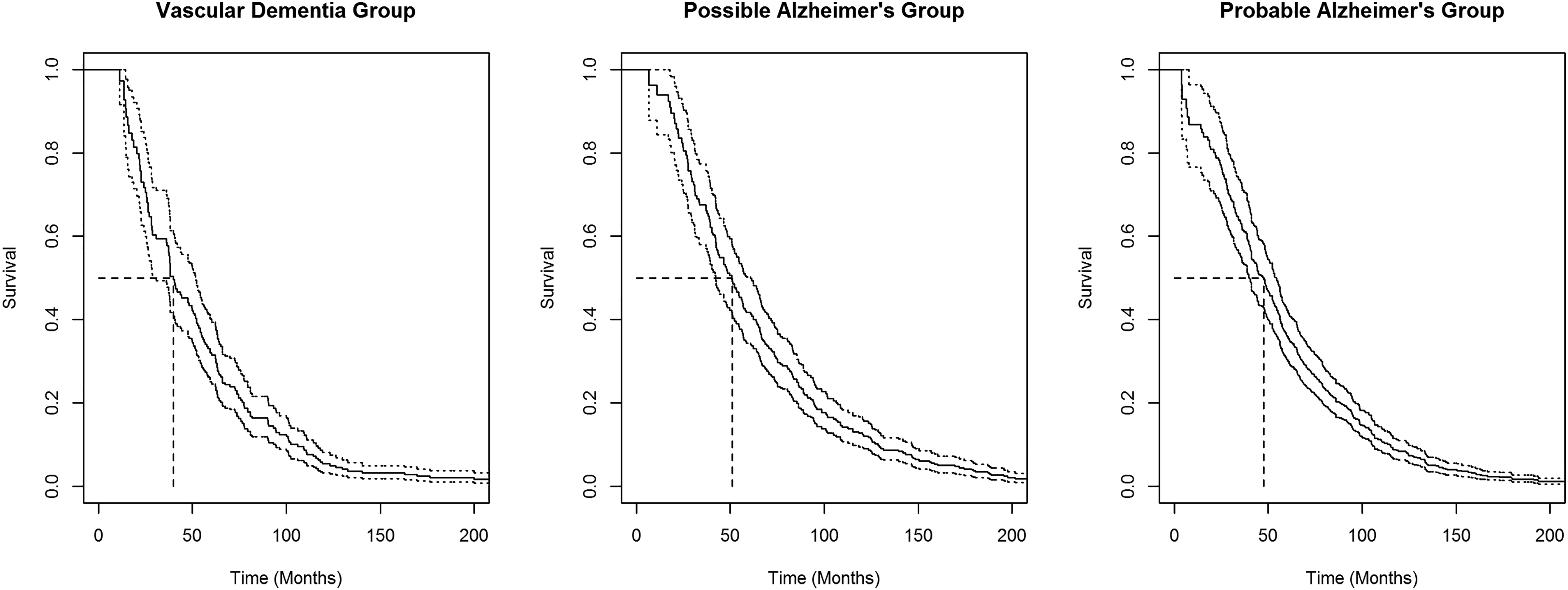
Using the observed failure/censoring times for the three dementia/Alzheimer’s disease groups of the CSHA, we calculated the unbiased survival function estimates and the associated unbiased survival function median estimates (see Figure 3). The medians for vascular dementia, possible Alzheimer’s disease, and probable Alzheimer’s disease groups (in months) were , , and , respectively. For other median estimates and estimates of the hazard ratio for death, stratifying by sex, education level, and age at onset of dementia, see Wolfson et al.24 Using the simple bootstrap, we generated 10,000 bootstrap samples for each group and determined estimates of the sample median variances. Setting the significance level , using the bootstrapped estimates, we calculated the test statistic from equation (4), , and did not reject the null hypothesis that individual dementia/Alzheimer’s disease group medians are equal.
Nonparametric maximum likelihood survival function estimates for vascular dementia, possible Alzheimer’s disease, and probable Alzheimer’s disease groups in the Canadian Study of Health and Aging. Corresponding pointwise 95% confidence intervals are indicated with dotted lines and the median estimates for each group are indicated by dashed lines.
Discussion
The median estimator is a key summary statistic for determining the center of a failure time distribution and can be utilized to compare the failure time distributions of multiple independent groups. Using length-biased right-censored failure time data collected from a prevalent cohort study with follow-up, we proposed an extension to the Rahbar et al. testing procedure using the NPMLE of the unbiased survival function to compare the unbiased medians of groups/populations. We applied our testing procedure to simulated prevalent cohort data sets and to data collected from the CSHA.
Throughout this article, we proposed a testing procedure for comparing the medians of multiple groups/populations using length-biased right-censored failure time; however, a closely related function to the median survival time is the quantile residual lifetime function (qrlt function). The qrlt function satisfies the equality for all and some and determines the conditional quantile when . The median survival time may be regarded as a single point of the qrlt function when and . Recently, Liu et al. utilized the asymptotic properties of the unbiased survival function NPMLE to develop confidence intervals for two test statistics based on the ratio and difference of two qrlt functions.11 It is not immediately clear how to utilize the proposed test statistics in practice when performing a hypothesis test of equality of qltr functions. It remains an open problem how the proposed methodologies may be extended to the sample setting in which multiple population qrlt functions are being compared.
Footnotes
Acknowledgements
The CSHA was supported by the Seniors Independence Research Program, through the National Health Research and Development Program (NHRDP) of Health Canada (Project 6606-3954-MC[S]). The progression of dementia project within the CSHA was supported by Pfizer Canada through the Health Activity Program of the Medical Research Council of Canada and the Pharmaceutical Manufacturers Association of Canada; by the NHRDP (Project 6603-1417-302[R]); by Bayer; and by the British Columbia Health Research Foundation (Projects 38 [93-2] and 34 [96-1]). The authors thank Professor Christina Wolfson for providing access to the data. The authors thank the reviewers for their suggested changes to the manuscript which we believe has led to a greatly improved article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The second author is supported by NSERC RGPIN-2018-05618.
ORCID iD
James Hugh McVittie
Appendix: Theoretical notes
To establish weak convergence of the median estimator, we consider the median residual lifetime function, , where the function must satisfy the relation given by
which in terms of the unbiased survival function is expressed as
Observe the median, , may be regarded as a special instance of , where . The above expression yields the following estimating equation for :
where the plug-in estimator is given by
and the median residual lifetime function estimator, , is defined as the root of equation (6). Using the results of Asgharian and Wolfson,9 some reasonable assumptions on and a weak assumption on the behaviour of for small failure times, we show the estimating equation is consistent and is weakly convergent to a process in, , the space of cadlag functions over , endowed with the uniform topology, the topology induced by the uniform norm. We show that the estimator is also consistent as well as weakly convergent using results from the theory of Z-estimators.20
As remarked above, the median point estimator may be regarded as the median residual lifetime estimator evaluated at , . Using this relation, we state the following weak convergence result for .
References
1.
BrookmeyerRCrowleyJ. A k-sample median test for censored data. J Am Stat Assoc1982; 77: 433–440.
2.
RahbarMChoiSHongC, et al. Nonparametric estimation of median survival times with applications to multi-site or multi-center studies. PLoS ONE2018; 13: e0197295.
3.
KaplanEMeierP. Nonparametric estimation from incomplete observations. J Am Stat Assoc1958; 53: 457–481.
4.
RahbarMChenZJeonS, et al. A nonparametric test for equality of survival medians. Stat Med2012; 31: 844–854.
5.
EfronB. Censored data and the bootstrap. J Am Stat Assoc1981; 76: 312–319.
6.
ReidN. Estimating the median survival time. Biometrika1981; 68: 601–608.
7.
AndersenPBorganØGillR, et al. Statistical models based on counting processes. Springer series in statistics. New York, NY, USA: Springer-Verlag, 1993.
8.
AsgharianMM’LanCWolfsonD. Length-biased sampling with right censoring: An unconditional approach. J Am Stat Assoc2002; 97: 201–209.
9.
AsgharianMWolfsonD. Asymptotic behavior of the unconditional NPMLE of the length-biased survivor function from right censored prevalent cohort data. Ann Stat2005; 33: 2109–2131.
10.
NingJQinJShenY. Nonparametric tests for right-censored data with biased sampling. J R Stat Soc Ser B: Stat Methodol2010; 72: 609–630.
11.
LiuPWangYZhouY. Quantile residual lifetime with right-censored and length-biased data. Ann Inst Stat Math2015; 67: 999–1028.
12.
HuangCYQinJ. Nonparametric estimation for length-biased and right-censored data. Biometrika2011; 98: 177–186.
13.
LuoXTsaiW. Nonparametric estimation for right-censored length-biased data: a pseudo-partial likelihood approach. Biometrika2009; 96: 873–886.
14.
TsaiWYJewellNWangMC. A note on the product-limit estimator under right censoring and left truncation. Biometrika1987; 74: 883–886.
15.
KeidingN. Event history analysis and the cross-section. Stat Med2006; 25: 2343–2364.
16.
AddonaVWolfsonD. A formal test for the stationarity of the incidence rate using data from a prevalent cohort study with follow-up. Lifetime Data Anal2006; 12: 267–284.
17.
AddonaVAthertonJWolfsonD. Testing the assumptions for the analysis of survival data arising from a prevalent cohort study with follow-up. Int J Biostat2012; 8: Article 22.
18.
AsgharianMWolfsonDZhangX. Checking stationarity of the incidence rate using prevalent cohort survival data. Stat Med2006; 25: 1751–1767.
19.
WangMC. Nonparametric estimation from cross-sectional survival data. J Am Stat Assoc1991; 86: 130–143.
20.
van der VaartAWellnerJ. Weak convergence and empirical processes. New York, NY, USA: Springer, 1996.
21.
AsgharianM. Letter to the editor/lettre à la rédaction. Biased sampling with right censoring: a note on Sun, Cui & Tiwari (2002). Can J Stat2003; 31: 349–350.
22.
AddonaV. Group comparisons in the presence of length-biased data. Master’s Thesis, McGill University, 2001.
23.
HuiartLSylvestreMP. Re: Pregnancies, breastfeeding and breast cancer risk in the International BRCA1/2 Carrier Cohort Study (IBCCS). J Natl Cancer Inst2007; 99: 1130–1131.
24.
WolfsonCWolfsonDAsgharianM, et al. A reevaluation of the duration of survival after the onset of dementia. N Engl J Med2001; 344: 1111–1116.
25.
van der VaartA. Asymptotic statistics. Cambridge series in statistical and probabilistic mathematics. Cambridge: Cambridge University Press, 1998. DOI: 10.1017/CBO9780511802256.