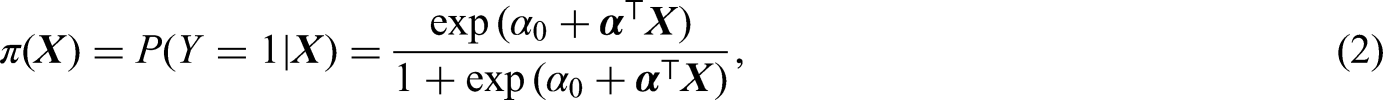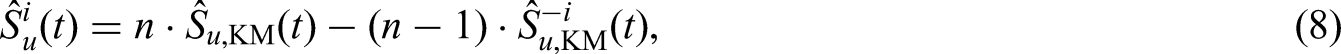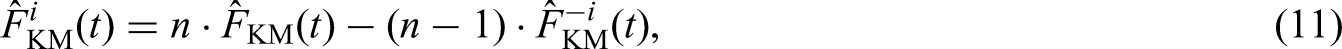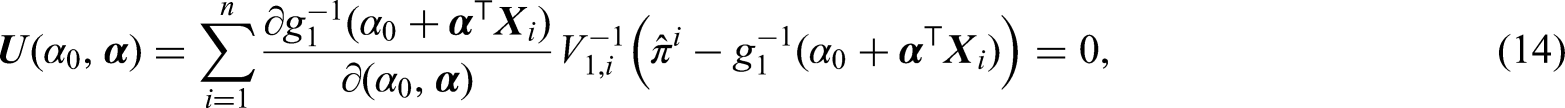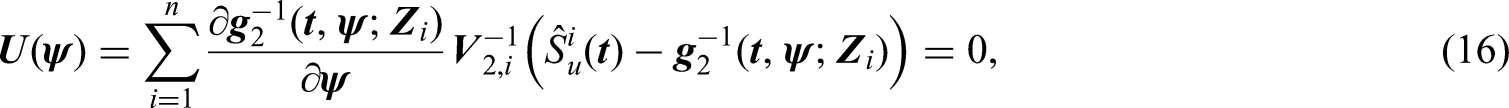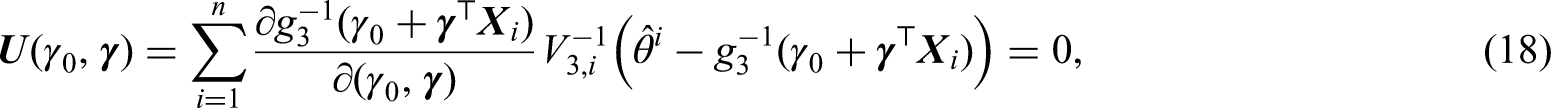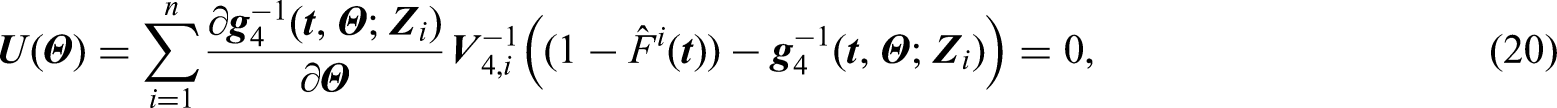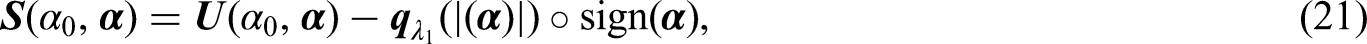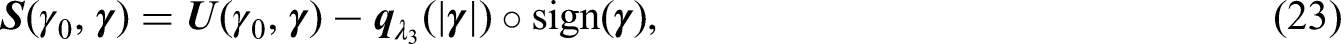In biomedical studies, survival data with a cure fraction (the proportion of subjects cured of disease) are commonly encountered. The mixture cure and bounded cumulative hazard models are two main types of cure fraction models when analyzing survival data with long-term survivors. In this article, in the framework of the Cox proportional hazards mixture cure model and bounded cumulative hazard model, we propose several estimators utilizing pseudo-observations to assess the effects of covariates on the cure rate and the risk of having the event of interest for survival data with a cure fraction. A variable selection procedure is also presented based on the pseudo-observations using penalized generalized estimating equations for proportional hazards mixture cure and bounded cumulative hazard models. Extensive simulation studies are conducted to examine the proposed methods. The proposed technique is demonstrated through applications to a melanoma study and a dental data set with high-dimensional covariates.
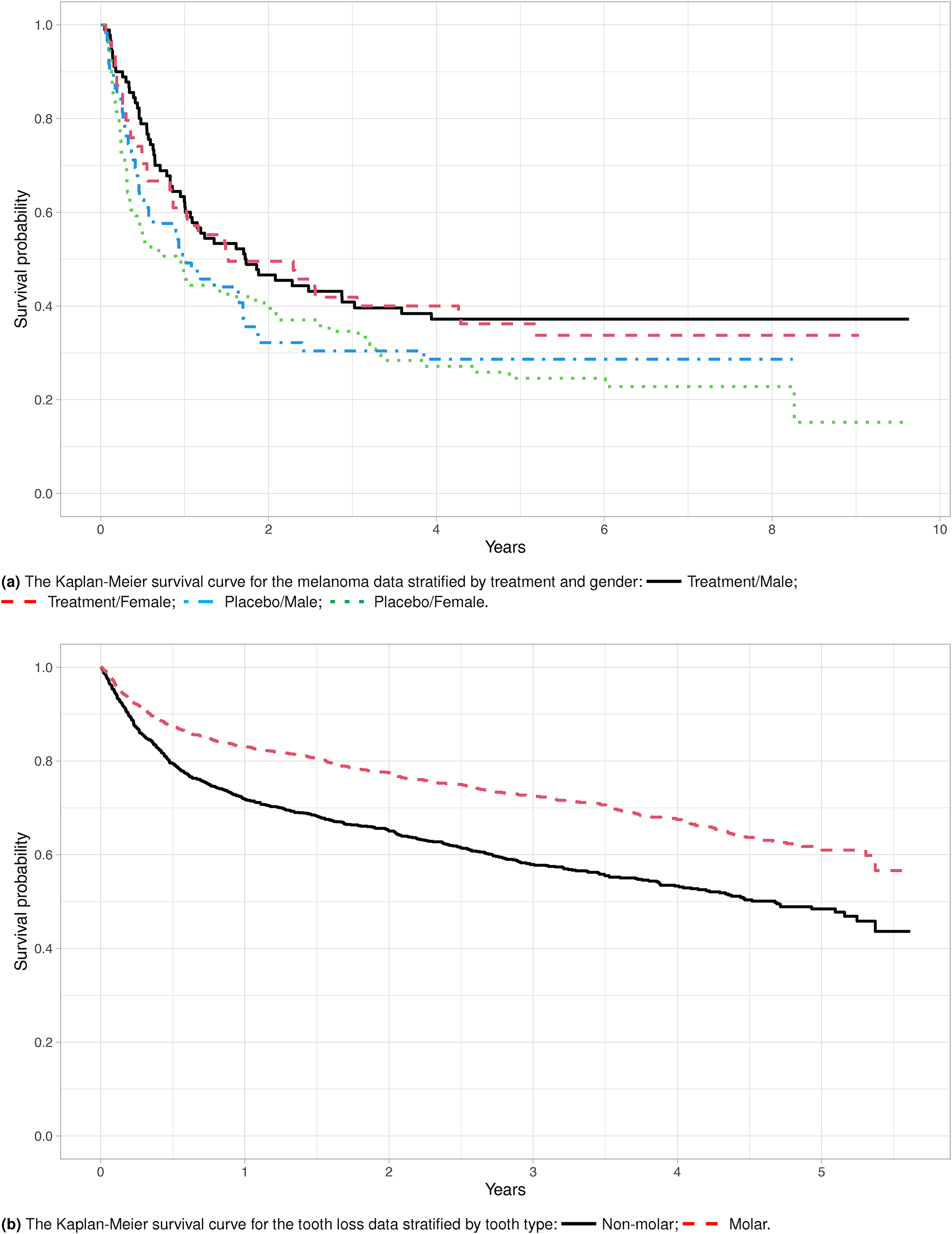
In the time-to-event analyzes, it is usually assumed that all subjects will eventually experience the event of interest if the follow-up period is sufficiently long. However, in many research fields, including biomedical, genetic, and social studies, some subjects may never experience the event of interest in their lifetime. These subjects are referred to as the cured or nonsusceptible subjects. For example, in a melanoma progression study,1 the cured patients never experience a melanoma relapse after the initial treatment. On the other hand, in a dental study,2 the cured subjects are the teeth that underwent proper periodontal treatments and can last a lifetime. In general, it is difficult to identify the cured subjects, but their presence is signaled by a leveling of the Kaplan-Meier (KM) survival curve at the end of the follow-up, for example, Figure 1(a). Standard models do not account for the cure fraction and could lead to biased estimates of the survival of susceptible subjects.3 Even if the cure fraction is accounted for, the dental study posts additional challenges on high-dimensionality. More than 50 predictors relevant to decision making in periodontal treatments are potential risk factors affecting the teeth’ survival. Motivated to tackle these emerging and challenging scientific questions, we propose a new estimating procedure using a pseudo-observations approach for the statistical inference on the parameters of interest and extend the proposed methods to regularized regression.
The Kaplan-Meier survival curves for the melanoma data and the tooth loss data to access potential cure fraction.
Two types of cure models have been popular in the literature, with most emphasis on the mixture cure (MC) model.4 The MC model assumes that the population consists of two types of patients, a cured group in which the patients are not at risk of experiencing the event and a susceptible group in which they eventually experience the event. The MC model consists of two components, incidence and latency. The former indicates whether the subject is susceptible, and the latter represents the time to the event when the patient is in the susceptible group. For the incidence component, a logistic regression model is often used to describe the covariate effects on the cure fraction. In contrast, parametric and semiparametric models have been proposed for the latency component to describe the underlying failure time distribution of susceptible subjects. Among those, Weibull model,4 generalized model,5 Cox proportional hazards (PH) model,6 and accelerated failure time model7 have been studied.
The second type of cure model is the bounded cumulative hazard (BCH) model, also known as the promotion time cure model, which models the survival times through an improper survival function, e.g Tsodikov8 The idea was first introduced by Yakovlev et al.9 in biological considerations, in which cancer recurrence is promoted by the number of carcinogenic cells and disease progression. Thus, the parameters specified in the BCH model bear exact biological meaning. Treating the carcinogenic cell counts as latent and nuisance, the BCH model is suitable for any survival data types as long as it is reasonable to assume the data have a cure fraction.10 Incorporating covariates into the BCH model modifies the cure fraction and introduces a long-term covariate effect on the survival. The BCH model has a PH structure through the long-term effect parameter. Tsodikov et al.11 further incorporated covariates to the baseline survival function through another PH structure, introducing a short-term covariate effect on survival. The two-component BCH model of Tsodikov et al.11 is termed the PHPH model. The MC model and the PHPH model consist of different covariate effects, each providing unique clinical interpretations.
Existing estimating procedures for the MC model and the PHPH model usually involve updating the parameters via expectation-maximization (EM) algorithms to account for latent variables, for example, cure fraction, in the likelihood. However, these approaches could be computationally expensive in high-dimensional data or when the bootstrap method is used in variance estimation. Thus, estimating procedures such as the pseudo-observations approach that does not rely on the EM algorithm are more appealing for practical use. The concept of the pseudo-observations approach is to create pseudo values for the quantities of interest at individual levels using the analogy of leave-one-out cross-validation. These pseudo values are then treated as complete data where standard methods can be conveniently applied. Specifically, for subject , let be independent and identically distributed random variables and be a vector of covariates. The interest lies in modeling , where is a pre-specified transformation function of . Due to censoring, not all are observed. However, the observed or unobserved can be replaced by its pseudo-observations where is a consistent and (approximately) unbiased estimator for the expectation and is the estimator for using the remaining subjects, leaving subject out from the sample. The pseudo-observations approach was first proposed by Andersen et al.12 to model the transition probabilities in multi-state models. Since then, the pseudo-observations approach has been applied to many settings in survival analysis, including survival estimates,13 the restricted mean survival times,14 the cumulative incidence function,15 the relative survival function,16 the illness-death model with interval-censored data,17 and the causal inference for recurrent event data.18 Large sample properties have also been thoroughly investigated.19–21 However, the pseudo-observations approach has not been applied to the analysis of survival data with a cure fraction.
Regularization and variable selection are commonly used in high-dimensional data analysis, but it has been less studied for cure models. Regularized procedures minimize an objective function that consists of a penalty function to reflect sparsity. Some of the popular penalty functions are the least absolute shrinkage and selection operator (LASSO),22 adaptive LASSO (ALASSO),23 and smoothly clipped absolute deviation (SCAD).24 In the Cox MC models, Liu et al.25 used LASSO and SCAD penalties to select variables based on penalized likelihood functions. Masud et al.26 performed the variable selection based on the ALASSO penalty while considering the linear and nonlinear effects in both components. Masud et al.27 further utilized the ALASSO penalty to the Cox MC and the BCH models. In both works, an EM algorithm was adopted to estimate the parameters, and the bootstrap resampling procedure was used to obtain standard error estimates. Their works can be computationally intensive in high-dimensional data. The penalized BCH model of Masud et al.27 has limited application as it requires additional information on the latent carcinogenic cell counts, making their approach not applicable for survival data without similar biological interpretations. Moreover, the short-term covariate effect is not considered in their approach, limiting the understanding of the covariate impact on the timing of disease occurrence.
In this article, we develop new estimating procedures based on the pseudo-observations approach for both the MC and the BCH models. We further extend the proposed method by adopting the penalized generalized estimating equations (PGEE) approach28 to perform variable selection. The proposed work closes the gap on variable selection in cure rate models with pseudo-observations techniques. The proposed approaches are attractive in several aspects. First, pseudo-observations can be straightforwardly used as complete outcomes for the generalized linear model (GLM) without indication of censoring. Second, the proposed estimating procedures are computationally efficient and faster in running time than standard approaches that adopt the EM algorithm for estimation and bootstrapping for standard errors as the unknown regression parameters are estimated via the generalized estimating equations (GEE) approach with corresponding variance estimates obtained by sandwich estimators. Third, unlike the estimation and variable selection of regression parameters in the incidence and latency component of the MC model6,27 or the short-term and long-term effects of the BCH model11,27 are performed simultaneously within one model, our proposed methods using pseudo-observations can perform the estimation and variable selection separately in each component of the MC model or each effect of the BCH model. Specifically, once the pseudo-observations for the quantity of interest for each component of the MC model or each effect of the BCH model are generated for each subject, they can be modeled with standard methods like GLMs. The GEE and PGEE estimating methods can be applied for parameter estimation and variable selection. Finally, the proposed regression estimators can be easily implemented via standard statistical software.
The remainder of the article is organized as follows. The MC model and the BCH model are reviewed in Section 2. The construction of pseudo-observations is described in Section 3. Inference procedure, model diagnosis, and variable selection are presented in Section 4. Comprehensive simulation results are reported in Section 5. The analysis of two real datasets is provided in Section 6. Concluding remarks are given in Section 7. Asymptotic properties and additional simulation results are provided in the online Supplemental Materials.
2 The cure models
Let denote the cure status of a subject, where if the subject eventually experiences an event (uncured, susceptible), and if the subject is a survivor (cured, non-susceptible). Let be the survival time, where is the failure time if the subject is susceptible. In the presence of right censoring, we assume the observed data consist of independent replicates , , which are copies of , where , , is the censoring time, and and are vectors of covariates with dimensions and , respectively. We allow and to be completely distinct, overlapped, or identical. When , the subject experienced an event and . However, when , the cure status is not observed.
2.1 MC model
The MC model expresses the population survival function as
where is the uncured rate and is the conditional survival function of given . The incidence component is assumed to follow a logistic regression model
where is a scalar and is a -column vector. For the latency component, we model the conditional survival function via the Cox proportional hazards model
where is a -column vector of regression coefficients, and is the unspecified baseline hazard function with the cumulative function . Under models (2) and (3), the MC model is called the PHMC model.6
2.2 BCH model
Suppose is the cumulative hazard function of such that . Under the BCH model, the population survival function can be written as
where is a proper cumulative distribution function of a nonnegative random variable with and . As , one has which indicates the cure rate. The covariate effects can be assumed on the impact of the parameter with , where is a known function that relates a vector of regression coefficients to with an intercept term . This modeling strategy leads to the improper PH model,29 and the covariates have a long-term effect because describes the long-term survival probability.8 A common choice of is the exponential parameterization . Tsodikov8 extends the improper PH model by adding a short-term effect by incorporating covariates into or survival function . Specifically, the PHPH model of Tsodikov et al.11 has the form
where and is a -column vector of regression coefficients. To avoid overparameterization, we assume the coefficients do not contain an intercept term as suggested in Tsodikov et al.11When the cure fraction is the only parameter of interest, it makes no difference which model formulation (1) or (4) is chosen to estimate the cure rate nonparametrically. However, the two models become different when additional model assumptions are imposed on the cure rate and the latency distribution of in the MC model.
3 Pseudo-observations
3.1 Pseudo-observations for MC model
A common approach for constructing pseudo-observations is to generate those from a nonparametric estimator of the parameter of interest. The MC model has two parameters, uncured rate and the conditional survival function , to be estimated. There are two candidate estimators for the uncured rate . The first one is proposed by Maller and Zhou,30 in which the cure rate was estimated by , where is the KM estimator31 and is the maximum of the observed event times. The result implies that can be estimated by . Following the construction of pseudo-observations in Andersen et al.,12 one can define the pseudo-observations for subject by
where is the estimator for using the remaining subjects, leaving subject out from the sample. The second estimator is based on the estimation of in Tsodikov32 through the connection between models (1) and (4). To be specific, let be unique observed failure times, and let and . Let and be the number of failure times at time and the number of censored times in the interval , respectively. Under model (4), can be estimated by , where , , and . Consequently, can be estimated by , where is the estimated jump size at time . Instead of using the Lagrange multiplier method,32 we use the change of variables approach under the condition to obtain and . The estimating procedure is summarized in Web Appendix A. Since models (1) and (4) have the same cure rate, one could estimate by and create the pseudo-observations for by
where is the estimator of obtained when leaving subject out from the sample. Web Appendix B shows the behavior of pseudo-observations from (6) and (7) based on simulated data. One can see that these pseudo-observations are not necessary within the range [0,1].
To create the pseudo-observations for , one can express from model (1) and imply that can be estimated by . The pseudo-observations for can then be created by
where is the estimator for when leaving subject out from the sample.
3.2 Pseudo-observations for BCH model
Under model (4), we propose two approaches to create pseudo-observations for and , respectively. Since the cure rate can be nonparametrically estimated by , can be estimated by . Moreover, as mentioned in Section 3.1, can also be estimated by . Thus, the pseudo-observations for can be created by one of the following two approaches
Based on Tsodikov,8 can be consistently estimated by . As mentioned in Section 3.1, can also be estimated by . Thus, the pseudo-observations for can be created by one of the following two approaches,
where and (t) are estimators of when leaving subject out from the sample.
4 Statistical inference
The statistical inference of the pseudo-observations approach is based on the asymptotic unbiased property of the pseudo-observations for the parameter of interest.33 Following Jacobsen and Martinussen20 and Overgaard et al.,21 we present the proofs of the asymptotic unbiased property for proposed pseudo-observations in Web Appendix C of the online Supplemental Materials.
4.1 Estimation of parameters under MC model
Based on the pseudo-observations in Section 3.1, the parameters in the incidence component and in the latency component of the PHMC model with (2) and (3) can be estimated separately. To estimate , we consider the following GLM
where is the logit link function for a binary variable. The parameters can be estimated based on the GEE approach34 using pseudo-observations by solving the estimating equations
where is the pseudo-observations for , and is the working variance. Let and be the estimators from (14) as is replaced by and , respectively.
To estimate , the pseudo-observations for are evaluated at several time points and used as responses in the GLM for the covariate effects. Specifically, let be a set of distinct times between 0 and the maximum of observed event time, and let be the pseudo-observations (8) for subject at time for . We assume the GLM with
where is the intercept at time , is the regression parameters, and is a link function. Common choices for include the log-log function and log function . Model (15) becomes the Cox PH model (3) when and . We use the following GEE to estimate the unknown parameters and
where , , is a vector whose component equals , and is a working covariance matrix that accounts for the correlation inherent from the pseudo-observations.12We denote as the estimators obtained from solving (16).
4.2 Estimation of parameters under BCH model
Under PHPH model (5), the short-term and long-term covariate effects can be estimated separately. To estimate the long-term effect , we consider the following GLM
where , , are independent and identically distributed (i.i.d.) with mean zero, and is a link function. Possible choices of are the log link function and the log-log function . Of these, setting leads to the assumption of model (5), which motivates us to estimate the parameters based on pseudo-observations created by or via
where is the pseudo-observations for , and is a working variance of . Let and be the estimators obtained from (18) when is replaced by and in (9) and (10), respectively. Under the assumption , we have , where . We thus consider the GLM with
where , , , and , , are i.i.d. with mean zero. We consider the following GEE to estimate and
where , is the vector of pseudo-observations for calculated at for subject , is the -column vector whose component equals , and is a working covariance matrix. Let and be the estimators obtained from equations (20) while is replaced by and in (11) and (12), respectively.
4.3 Variance estimation and model diagnosis
All estimators obtained from solving estimating equations mentioned in Sections 4.1 and 4.2 can be using the geese function in the R package geepack.35 We adopt the approximate jackknife variance estimates,36 which is available in the geese function. Note that adopting a sandwich estimator might lead to inconsistent and upward biased results for variance estimation; however, this has an insignificant impact in practical applications.20 We follow the idea of pseudo-residuals33 to assess the goodness-of-fit for (13) and (15) for the PHMC model. Define the pseudo-residuals based on either or , and calculated at a given time . If the model fits the data well, no trend should be perceptible when plotting residuals against a covariate. Similarly, we consider pseudo-residuals or for model (17) and the pseudo-residuals or at a given time for model (19). The idea of pseudo-residuals is illustrated in the melanoma data in Section 6.1.
4.4 Variable selection
The proposed pseudo-observations approach allows variable selection and parameter estimation to be simultaneously implemented in each component of the PHMC model and the PHPH model by penalizing the corresponding GEEs.28Specifically, for the incidence component of the PHMC model, we penalize the GEE in (14) by
where for some vectors and , is a vector of penalty functions for some tuning parameter , , , and is the element-wise product of and . The intercept term is not penalized and has been left out of the penalty term in (21). Similarly, we consider the following PGEE for for the latency component of the PHMC model by extending (16)
where is the tuning parameter, and the intercept term, , is left out of the penalty term.
For the long-term effect of the PHPH model, we extend (18) to the following PGEE
where is the tuning parameter and the intercept term is not penalized.
Lastly, for the short-term effect of the PHPH model, we penalize (20) through
where is the tuning parameter and is not penalized. In the simulation studies and data analyzes, we illustrate the proposed procedure with the SCAD penalty24 and select the tuning parameters via five-fold cross-validation, where the data are randomly partitioned into five subsets of approximately equal sizes. For a given tuning parameter , we calculate the overall cross-validated prediction error where is the PGEE estimator based on data without the th subset, is the size of the th subset, is the number of pseudo-observations for subject , and are the pseudo-residuals as defined in Section 4.3 with covariates . We use the estimates obtained from the unpenalized GEEs as the initial values in the iteration of PGEEs and cross-validation.
5 Simulation
Simulation studies are conducted to assess the finite sample performance of proposed estimators. We first evaluate the performance under the PHMC model. Specifically, we generate the cure status according to the logistic model (2) with one covariate , generated from a Bernoulli(0.5) distribution. The regression coefficient is set at so that the treatment group (e.g. those with ) are more likely to be cured. The intercept is chosen to be , or to achieve the average cure rates of 10% (14.1% among those with ), 20% (26.7% among those with ) or 40% (52.3% among those with ), respectively. On the other hand, the survival times are generated from the Cox PH model (3), with , and generated from independent Bernoulli(0.5) and Uniform(0, 1), respectively. We set the regression coefficient in (3) at and generated the censoring times from Uniform(0, ), where is chosen to make 10% of the censored subjects susceptible. Throughout the simulations, the pseudo-observations are calculated at 10 time-points from the quantitles of observed event times between 0 and .
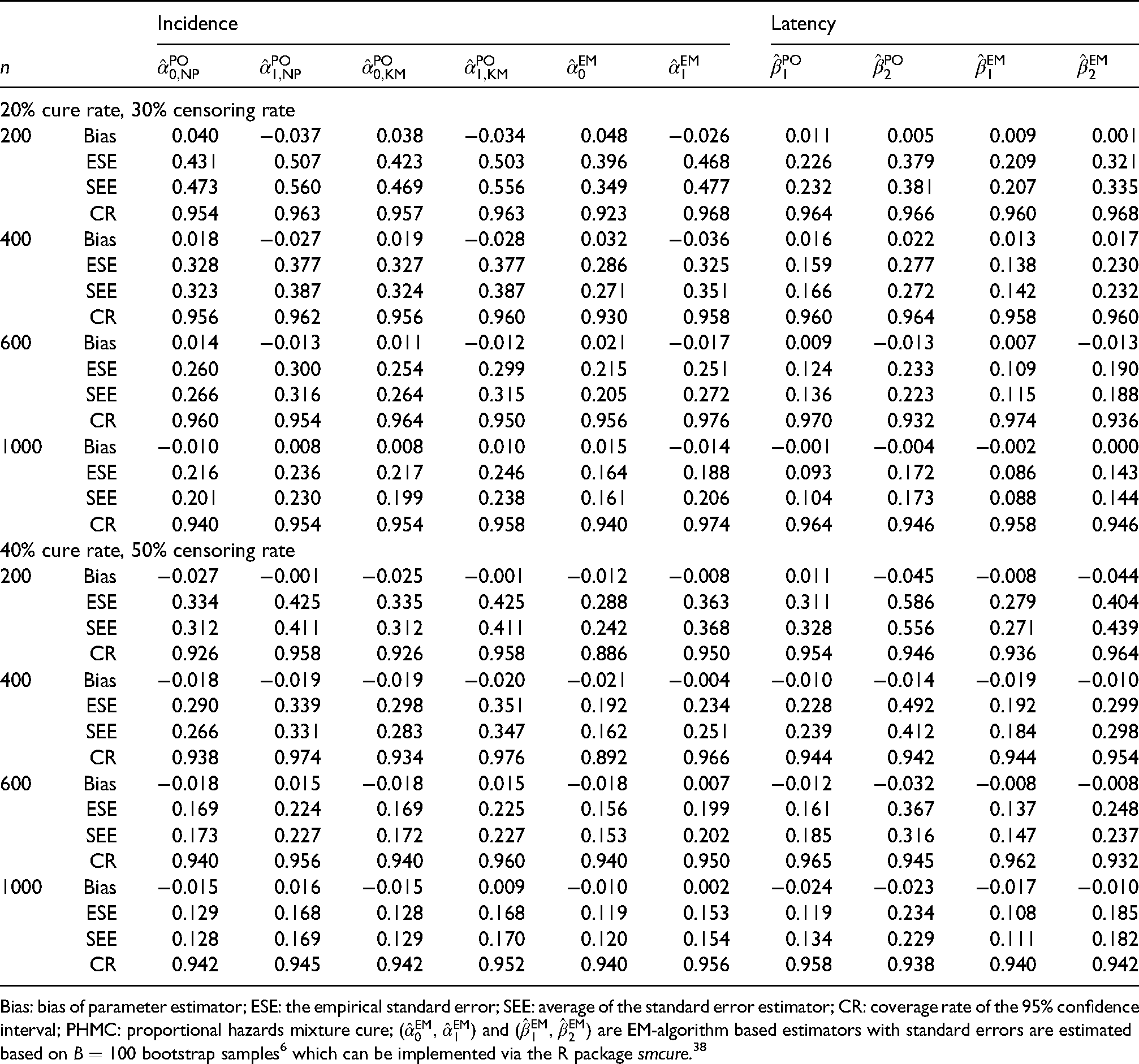
Table 1 summarizes the simulation results of 20% and 40% cure rates scenarios based on (14) and (16) with link functions , and . The scenario with 10% cure rate is presented in Table 1 in Web Appendix E. We only present the results with a working independence assumption among the pseudo-observations. Adopting a more complicated covariance structure provides no obvious improvement as presented in Klein and Andersen37 and Graw et al.19The proposed estimates are compared with the EM-algorithm estimators obtained from Peng and Dear6 with bootstrap samples for standard error estimation. For each estimator, we report the average bias (Bias), the empirical standard error (ESE), the average of the standard error estimator (SEE), and the empirical coverage rate (CR) of 95% confidence interval based on 500 replicates with sample size , and . Overall, the proposed estimators perform reasonably in all scenarios with Bias, ESE, and SEE all decreasing with increasing while CRs are close to the nominal level of 0.95. The estimators and have similar performance, indicating that pseudo-observations constructed by (6) or (7) are both appropriate. Compared to the estimates of Peng and Dear,6 our estimators have higher ESE and SEE under various sample sizes, indicating a loss of efficiency. Specifically, based on our simulation settings, the smallest relative efficiency loss for the latency component is around 12% with under the 10% cure rate scenario. The smallest relative efficiency loss for the incidence component is around 9% with under the 40% cure rate scenario. This loss efficiency situation is likely due to a discrete approximation to the baseline hazard function with a continuous time scale, for example, 10 selected time-points for the latency component in our approach. Note that the latency component yields smaller ESE and SEE under 10% cure rate compared to 20% and 40% cure rates scenarios as more noncured subjects contribute to the estimation of .
Simulation summaries under the PHMC model based on 500 replicates.
Incidence
Latency
20% cure rate, 30% censoring rate
200
Bias
0.040
−0.037
0.038
−0.034
0.048
−0.026
0.011
0.005
0.009
0.001
ESE
0.431
0.507
0.423
0.503
0.396
0.468
0.226
0.379
0.209
0.321
SEE
0.473
0.560
0.469
0.556
0.349
0.477
0.232
0.381
0.207
0.335
CR
0.954
0.963
0.957
0.963
0.923
0.968
0.964
0.966
0.960
0.968
400
Bias
0.018
−0.027
0.019
−0.028
0.032
−0.036
0.016
0.022
0.013
0.017
ESE
0.328
0.377
0.327
0.377
0.286
0.325
0.159
0.277
0.138
0.230
SEE
0.323
0.387
0.324
0.387
0.271
0.351
0.166
0.272
0.142
0.232
CR
0.956
0.962
0.956
0.960
0.930
0.958
0.960
0.964
0.958
0.960
600
Bias
0.014
−0.013
0.011
−0.012
0.021
−0.017
0.009
−0.013
0.007
−0.013
ESE
0.260
0.300
0.254
0.299
0.215
0.251
0.124
0.233
0.109
0.190
SEE
0.266
0.316
0.264
0.315
0.205
0.272
0.136
0.223
0.115
0.188
CR
0.960
0.954
0.964
0.950
0.956
0.976
0.970
0.932
0.974
0.936
1000
Bias
−0.010
0.008
0.008
0.010
0.015
−0.014
−0.001
−0.004
−0.002
0.000
ESE
0.216
0.236
0.217
0.246
0.164
0.188
0.093
0.172
0.086
0.143
SEE
0.201
0.230
0.199
0.238
0.161
0.206
0.104
0.173
0.088
0.144
CR
0.940
0.954
0.954
0.958
0.940
0.974
0.964
0.946
0.958
0.946
40% cure rate, 50% censoring rate
200
Bias
−0.027
−0.001
−0.025
−0.001
−0.012
−0.008
0.011
−0.045
−0.008
−0.044
ESE
0.334
0.425
0.335
0.425
0.288
0.363
0.311
0.586
0.279
0.404
SEE
0.312
0.411
0.312
0.411
0.242
0.368
0.328
0.556
0.271
0.439
CR
0.926
0.958
0.926
0.958
0.886
0.950
0.954
0.946
0.936
0.964
400
Bias
−0.018
−0.019
−0.019
−0.020
−0.021
−0.004
−0.010
−0.014
−0.019
−0.010
ESE
0.290
0.339
0.298
0.351
0.192
0.234
0.228
0.492
0.192
0.299
SEE
0.266
0.331
0.283
0.347
0.162
0.251
0.239
0.412
0.184
0.298
CR
0.938
0.974
0.934
0.976
0.892
0.966
0.944
0.942
0.944
0.954
600
Bias
−0.018
0.015
−0.018
0.015
−0.018
0.007
−0.012
−0.032
−0.008
−0.008
ESE
0.169
0.224
0.169
0.225
0.156
0.199
0.161
0.367
0.137
0.248
SEE
0.173
0.227
0.172
0.227
0.153
0.202
0.185
0.316
0.147
0.237
CR
0.940
0.956
0.940
0.960
0.940
0.950
0.965
0.945
0.962
0.932
1000
Bias
−0.015
0.016
−0.015
0.009
−0.010
0.002
−0.024
−0.023
−0.017
−0.010
ESE
0.129
0.168
0.128
0.168
0.119
0.153
0.119
0.234
0.108
0.185
SEE
0.128
0.169
0.129
0.170
0.120
0.154
0.134
0.229
0.111
0.182
CR
0.942
0.945
0.942
0.952
0.940
0.956
0.958
0.938
0.940
0.942
Bias: bias of parameter estimator; ESE: the empirical standard error; SEE: average of the standard error estimator; CR: coverage rate of the 95% confidence interval; PHMC: proportional hazards mixture cure; and are EM-algorithm based estimators with standard errors are estimated based on bootstrap samples6 which can be implemented via the R package smcure.38
On the other hand, Table 2 in Web Appendix E reports the average computing time in seconds for each estimator under the 10% cure rate scenario based on 500 replicates. For each fixed , our proposed estimators including variance estimation have smaller total computing times (summation of latency and incidence) than that of the EM-algorithm estimate6 using bootstrap samples for standard error estimation. Computing times increase as long as the sample size increases. Among our proposed estimators for the incidence component, the computing time for the KM estimator (6) is faster than that of the estimator (7). Note that all results of computing times are implemented in R and performed on a Linux machine with an Intel Core i7-8565U processor and 15.4 GB memory.
We next evaluate the performance of the proposed estimators under the PHPH model (5). For subject , two independent covariates and are generated from Bernoulli(0.5) and standard normal distribution, respectively. We set , and . It is not straightforward to simulate survival time from the improper survival function of model (5) as it has a positive mass at . We thus utilize the connection between the MC model (1) and the PHPH model (5) to generate survival times. The data generation algorithm is summarized in Web Appendix D. We set , with two different values of , and , which correspond to 20% and 40% cure rate, respectively. The censoring times are independently generated from Uniform(0,), where is chosen so that 10% of the censored subjects are susceptible. Tables 3 and 4 presented in Web Appendix E show the results of estimators and obtained from (18) and estimators and obtained from (20), respectively. A maximum likelihood estimator (MLE) is implemented for comparison. The proposed estimates are virtually unbiased. The SEE is reasonably close to the ESE, and the CR is close to the nominal level. The two constructions of the pseudo-observations yield a similar pattern, indicating that both approaches are feasible for constructing pseudo-observations. The proposed estimators have higher ESE and SEE than MLE under different sample sizes, indicating a loss of efficiency. For example, the relative efficiency losses are around 19% and 25% for long-term and short-term effects, respectively, under the scenario, , 40% cure rate, and 50% censoring rate.
To study the performance of variable selection under the PHMC model, we consider the covariate in which are independently generated from Uniform(0,1), and are independently generated from Bernoulli(0.5), and are generated from a multivariate normal distribution with and , for . We set the regression coefficients at , , and , and the baseline hazard function . Those configurations yield a cure rate of 30%. The censoring times are independently generated from Uniform, where is chosen so that either 10% or 30% of the censored subjects are susceptible. For each simulated data set, we fit the GEE full model that considers all covariates, the GEE Oracle model that only includes covariates with nonzero coefficients, the proposed PGEE model with SCAD penalty, and the PHMC model with LASSO and ALASSO penalties proposed by Masud et al.27
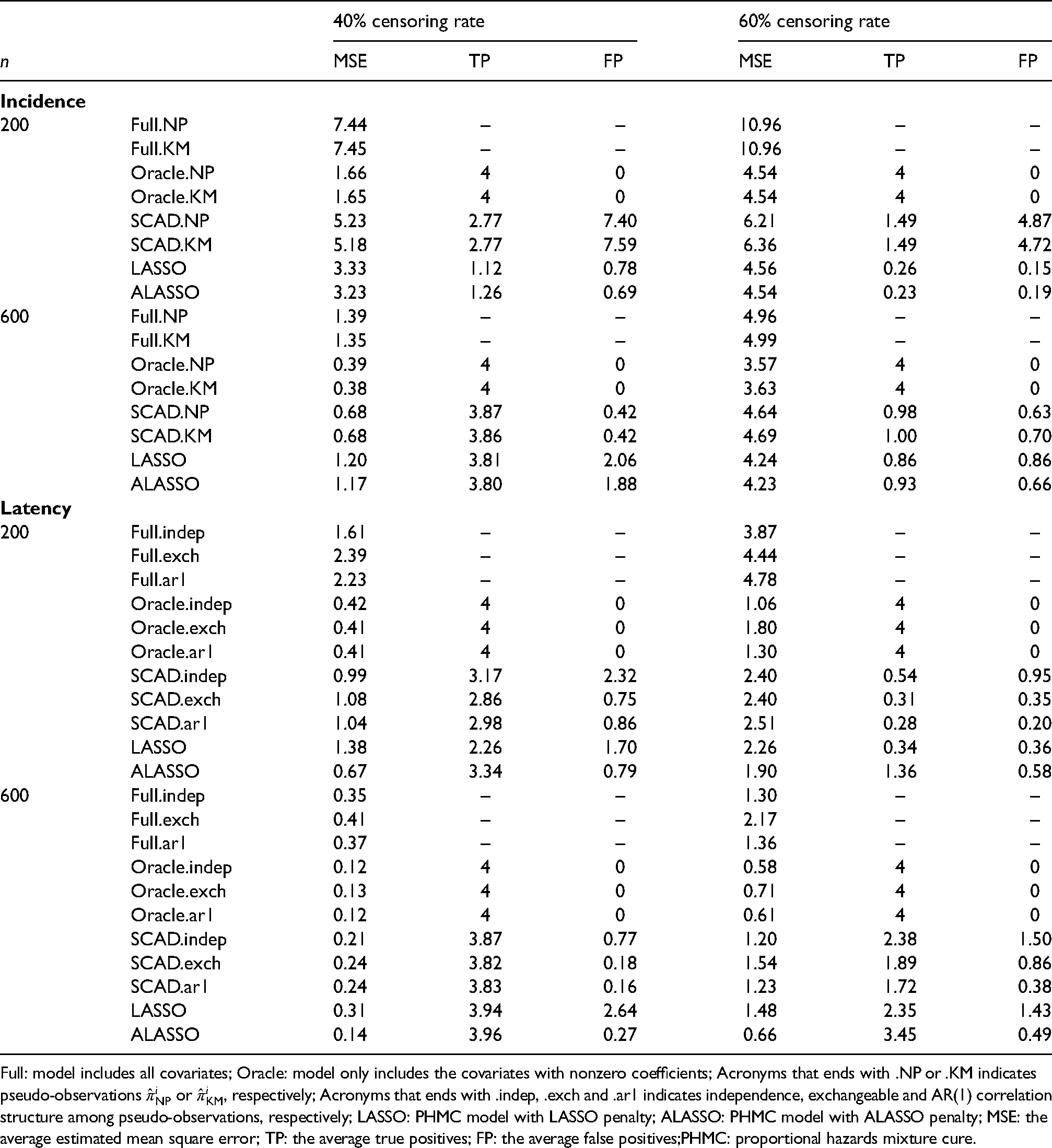
Table 2 summarizes the results for variable selection under the PHMC model with and 600. Based on 200 replicates, the average mean square error (MSE), true positives (TP), and false positives (FP) are reported. The MSE is defined as for incidence component and for latency component, where and are the estimators of and based on the th generated dataset. The TP and FP are calculated as the average number of selected covariates that have actual nonzero and zero coefficients, respectively. Five-fold cross-validation is used to determine the tuning parameter. For the incidence component, the two pseudo-observations approaches yield similar performances, making them practically identical. For all scenarios, the MSE of proposed PGEE approaches is smaller than that of the full model but is larger than that of the oracle model. However, it becomes closer to the MSE of the oracle model as increases. In addition, when the censoring rate is 40%, the proposed PGEE approaches behave closer to the oracle model, have TP closer to the number of nonzero covariates, and decreasing FP as increases. On the contrary, the FP of the LASSO and ALASSO estimators do not seem to decrease with increasing . For the latency component, we consider the proposed PGEE with three different correlation structures: independence, exchangeable, and AR(1). The results of PGEE with independent structure tend to have slightly higher TP and FP and lower MSE than that of the PGEE with exchangeable and AR(1) correlation structure. However, the performances are close when the sample size is large and with 40% censoring rate, indicating that little advantage gains while specifying complicated correlation structure among pseudo-observations for variable selection. When the censoring rate is 60%, the TP decreases and the MSE increases for all the presented methods. Compared to the results based on LASSO and ALASSO, our proposed PGEE performs reasonably in identifying important variables with . The results with and reveal a similar trend and are presented in Table 5 in Web Appendix E.
Simulation summaries for variable selection on the incidence and latency component of the PHMC model with 30% cure rate.
40% censoring rate
60% censoring rate
MSE
TP
FP
MSE
TP
FP
Incidence
200
Full.NP
7.44
–
–
10.96
–
–
Full.KM
7.45
–
–
10.96
–
–
Oracle.NP
1.66
4
0
4.54
4
0
Oracle.KM
1.65
4
0
4.54
4
0
SCAD.NP
5.23
2.77
7.40
6.21
1.49
4.87
SCAD.KM
5.18
2.77
7.59
6.36
1.49
4.72
LASSO
3.33
1.12
0.78
4.56
0.26
0.15
ALASSO
3.23
1.26
0.69
4.54
0.23
0.19
600
Full.NP
1.39
–
–
4.96
–
–
Full.KM
1.35
–
–
4.99
–
–
Oracle.NP
0.39
4
0
3.57
4
0
Oracle.KM
0.38
4
0
3.63
4
0
SCAD.NP
0.68
3.87
0.42
4.64
0.98
0.63
SCAD.KM
0.68
3.86
0.42
4.69
1.00
0.70
LASSO
1.20
3.81
2.06
4.24
0.86
0.86
ALASSO
1.17
3.80
1.88
4.23
0.93
0.66
Latency
200
Full.indep
1.61
–
–
3.87
–
–
Full.exch
2.39
–
–
4.44
–
–
Full.ar1
2.23
–
–
4.78
–
–
Oracle.indep
0.42
4
0
1.06
4
0
Oracle.exch
0.41
4
0
1.80
4
0
Oracle.ar1
0.41
4
0
1.30
4
0
SCAD.indep
0.99
3.17
2.32
2.40
0.54
0.95
SCAD.exch
1.08
2.86
0.75
2.40
0.31
0.35
SCAD.ar1
1.04
2.98
0.86
2.51
0.28
0.20
LASSO
1.38
2.26
1.70
2.26
0.34
0.36
ALASSO
0.67
3.34
0.79
1.90
1.36
0.58
600
Full.indep
0.35
–
–
1.30
–
–
Full.exch
0.41
–
–
2.17
–
–
Full.ar1
0.37
–
–
1.36
–
–
Oracle.indep
0.12
4
0
0.58
4
0
Oracle.exch
0.13
4
0
0.71
4
0
Oracle.ar1
0.12
4
0
0.61
4
0
SCAD.indep
0.21
3.87
0.77
1.20
2.38
1.50
SCAD.exch
0.24
3.82
0.18
1.54
1.89
0.86
SCAD.ar1
0.24
3.83
0.16
1.23
1.72
0.38
LASSO
0.31
3.94
2.64
1.48
2.35
1.43
ALASSO
0.14
3.96
0.27
0.66
3.45
0.49
Full: model includes all covariates; Oracle: model only includes the covariates with nonzero coefficients; Acronyms that ends with .NP or .KM indicates pseudo-observations or , respectively; Acronyms that ends with .indep, .exch and .ar1 indicates independence, exchangeable and AR(1) correlation structure among pseudo-observations, respectively; LASSO: PHMC model with LASSO penalty; ALASSO: PHMC model with ALASSO penalty; MSE: the average estimated mean square error; TP: the average true positives; FP: the average false positives;PHMC: proportional hazards mixture cure.
To investigate variable selection performance under the PHPH model, we generate the covariate vector following the PHMC model’s configuration to specify the short-term and long-term effects. In this case, we set , , , and the baseline function , resulting in a cure rate of 30%. The censoring times are independently generated from Uniform, where is chosen so that either 10% or 30% of the censored subjects are susceptible. Tables 6 and 7 in Web Appendix E depict the simulation results for long-term and short-term effects based on different sample sizes. The definition of the MSE for the long-term and short-term effects is similar to that of the incidence and latency components mentioned in the above paragraph. We observe that the two constructions of pseudo-observations yield similar results. For each sample size , the MSE of the PGEE is smaller than that of the full model but is larger than that of the oracle model. As increases, the MSE of the PGEE decreases and is close to that of the Oracle model. Also, the TP increases and the FP decreases. However, as expected, the MSE increases and the TP decreases when the censoring rate increases to 60%. Finally, based on our simulation results, we observe minimal performance gains when specifying complicated correlations among pseudo-observations. With the same simulation specifications, we observe an improvement in FP and a loss in TP (results not shown here) when a one-standard error rule is used to select the optimum tuning parameter.
6 Data analysis
6.1 The melanoma data
We apply the proposed method to a melanoma dataset from the Eastern Cooperative Oncology Group phase III clinical trial e1684,1 which is available from the R package smcure.38 The primary objective is to determine whether the high dose interferon alpha-2b (IFN) regimen in postoperative adjuvant therapy would lead to a significantly prolonged interval of relapse-free for melanoma. The event of interest is the relapse of melanoma. The interested covariates include treatment (0placebo, 1IFN), gender (0male, 1female), and age (centered to zero). After excluding missing data, a total of 284 subjects is included in the analysis. The overall censoring rate is 30.9%. Figure 1(a) shows the KM estimates stratified by treatment and gender. The KM estimates level off at the end of the study, suggesting a fraction of nonsusceptibility to the recurrence of melanoma. This observation is confirmed by the Maller-Zhou test30 with a -value of . Based on the KM curves, a male has a higher cure rate than a female in the treatment group, whereas it is reversed in the control group, implying an interaction between the treatment and gender. Thus, the interaction term is also considered in the data analysis.
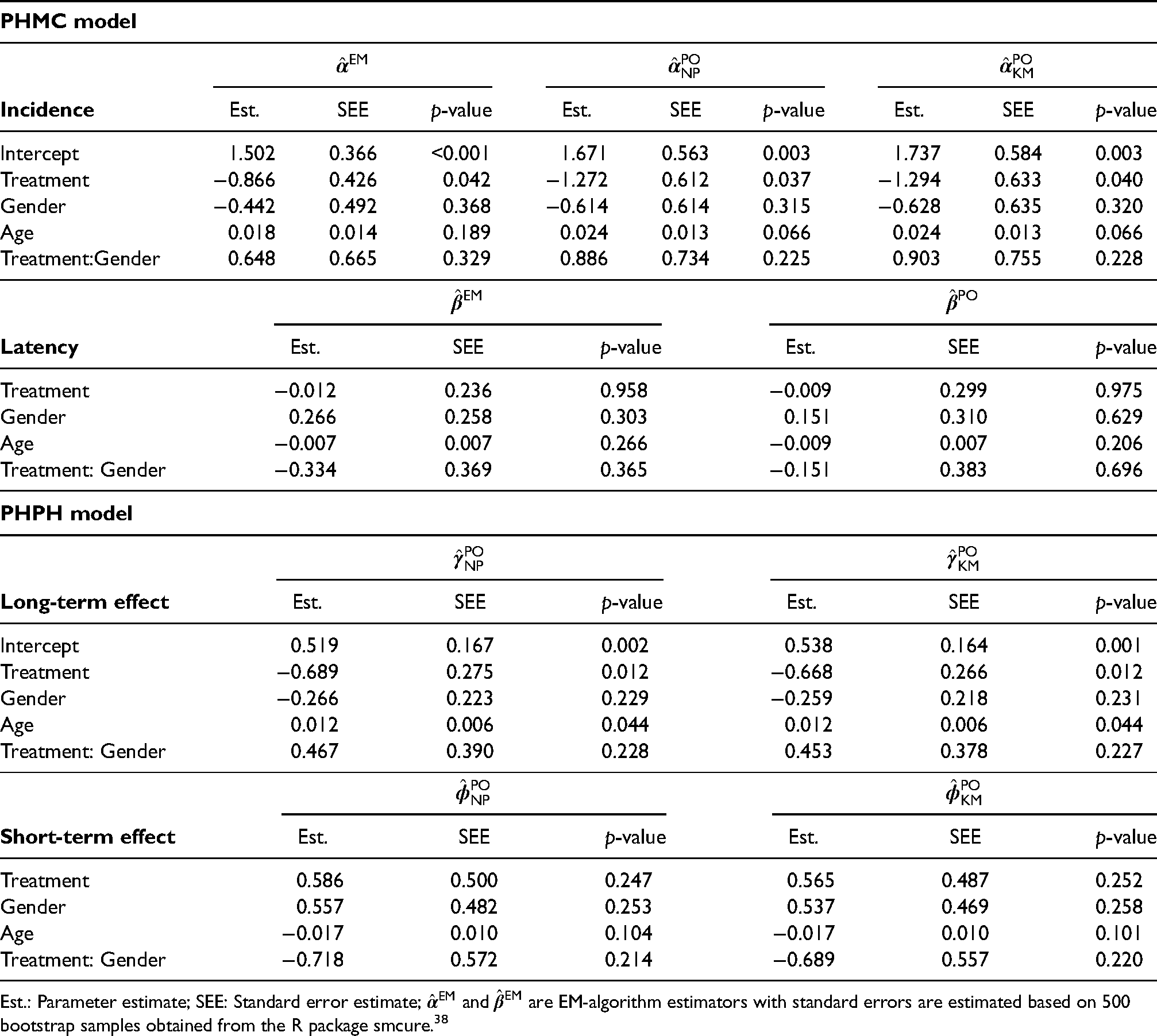
The top panel of Table 3 presents the results from the PHMC model obtained by (14) and (16) with , , and . The lower panel of Table 3 presents the results from the PHPH model obtained by (18) and (20) with , , and . For comparison, we included the estimator6 based on the EM-algorithm with standard errors obtained from 500 bootstrapped samples. The two constructions and of the pseudo-observations for yield similar patterns. For the incidence component, our proposed estimates and are similar to the estimate . The treatment has a significantly adverse effect on the susceptibility (noncured), which means the treatment substantially improves the relapse-free (cured) rate, especially for males. The positive age effect indicates that older patients tend to have a higher relapse rate of melanoma. In the latency component, none of the four covariates are significantly associated with the failure time if patients are susceptible. However, female patients tend to have a lower risk of recurring melanoma than male patients in the treatment group but higher in the control group.
Parameter estimates for the melanoma data.
PHMC model
Incidence
Est.
SEE
-value
Est.
SEE
-value
Est.
SEE
-value
Intercept
1.502
0.366
<0.001
1.671
0.563
0.003
1.737
0.584
0.003
Treatment
−0.866
0.426
0.042
−1.272
0.612
0.037
−1.294
0.633
0.040
Gender
−0.442
0.492
0.368
−0.614
0.614
0.315
−0.628
0.635
0.320
Age
0.018
0.014
0.189
0.024
0.013
0.066
0.024
0.013
0.066
Treatment:Gender
0.648
0.665
0.329
0.886
0.734
0.225
0.903
0.755
0.228
Latency
Est.
SEE
-value
Est.
SEE
-value
Treatment
−0.012
0.236
0.958
−0.009
0.299
0.975
Gender
0.266
0.258
0.303
0.151
0.310
0.629
Age
−0.007
0.007
0.266
−0.009
0.007
0.206
Treatment: Gender
−0.334
0.369
0.365
−0.151
0.383
0.696
PHPH model
Long-term effect
Est.
SEE
-value
Est.
SEE
-value
Intercept
0.519
0.167
0.002
0.538
0.164
0.001
Treatment
−0.689
0.275
0.012
−0.668
0.266
0.012
Gender
−0.266
0.223
0.229
−0.259
0.218
0.231
Age
0.012
0.006
0.044
0.012
0.006
0.044
Treatment: Gender
0.467
0.390
0.228
0.453
0.378
0.227
Short-term effect
Est.
SEE
-value
Est.
SEE
-value
Treatment
0.586
0.500
0.247
0.565
0.487
0.252
Gender
0.557
0.482
0.253
0.537
0.469
0.258
Age
−0.017
0.010
0.104
−0.017
0.010
0.101
Treatment: Gender
−0.718
0.572
0.214
−0.689
0.557
0.220
Est.: Parameter estimate; SEE: Standard error estimate; and are EM-algorithm estimators with standard errors are estimated based on 500 bootstrap samples obtained from the R package smcure.38
Under the PHPH model, the treatment has a significantly negative effect on the long-term effect, indicating that high dose IFN regimen increase the rate of relapse-free melanoma, especially for males. Older patients have a high possibility of recurring melanoma even though the effect is not statistically significant at the 5% nominal level. Those results are consistent with the findings in the incidence of the PHMC model. None of the four covariates are statistically significant at the 5% nominal level related to the short-term effect. The estimates indicate females are likely to have a more rapidly developing melanoma within the treatment group. However, the result is reversed in the control group, i.e., males are expected to experience melanoma sooner than females. Those findings are verified in Figure 1(a), where the KM estimate drops relatively faster for the females than for the males in the treatment group. In contrast, the KM estimates drop faster for the males than females in the control group.
To understand the covariate effect of cure rates in two models, we calculate the estimated cure rates in each group while holding the age variable at the average. The results presented in Table 6 of Web Appendix E suggests that there are higher cure rates among the treatment groups, echoing our finding that the treatment substantially improves the relapse-free (cured) rate. The estimated cure rates based on and under the PHMC model are close to that based on ; however, the results based on and under the PHPH model tend to have higher cure rate except for the female in the treatment group. This suggests that the PHMC model is more conservative in estimating cure rates. To assess the goodness of fit, Figure 2 in Web Appendix F presents the boxplots of pseudo-residuals for models (13) and (15) of the PHMC model. The top panel shows the boxplots of pseudo-residuals stratified by treatment and gender based on the pseudo-observations from (6) and its corresponding estimators. The pseudo-residuals fluctuate around zero, indicating the adequacy of the proposed GLM even though the pseudo-residuals have a larger variation in the Control/Male group. The bottom panel illustrates the boxplots of pseudo-residuals based on pseudo-observations calculated at four given time points chosen from the quantiles of observed event times. The residuals are symmetric around 0 at any given time point, which implies the proposed GLM model fits the data well even though the variation of the pseudo-observations increases in the Control/Male group as the time increases. The boxplots of pseudo-residuals stratified by treatment and gender based on GLMs (17) and (19) under the PHPH model are also presented in Figure 3 of Web Appendix F. The top panel shows the residuals calculated based on pseudo-observations and its resulting estimators, and the bottom panel presents the pseudo-residuals calculated based on pseudo-observations at four given time points. Compared to Figure 2 in Web Appendix F, the pseudo-residuals under the PHPH model tend to have more considerable variations. This result might suggest that the PHMC model fits the data better than the PHPH model.
6.2 The dental data
We apply the proposed PGEE approaches to a dental dataset from the Creighton University School of Dentistry.2The dataset contains dental records from 5336 patients with periodontal disease collected between August 2007 and March 2013. In this work, the outcome of interest is the time to the first tooth loss due to periodontal reasons for each patient, yielding a censoring rate of 74.1%. The data analysis includes a total of 44 risk factors, whose detailed descriptions can be found in Tables 3 and 4 in Calhoun et al.2 The length of the follow-up was 5.7 years, and the last event occurred at 5.37 years for both molar and non-molar groups. There were 35 and 20 teeth censored between the last event and the end of the study for the malor group and non-molars group, respectively. Figure 1(b) shows the KM survival curves stratified by the tooth type (3456 molars vs. 1880 non-molars) leveling off to nonzero probabilities, indicating a possible presence of a cured fraction in the population. This is also confirmed by the Maller-Zhou test30 with a -value of .
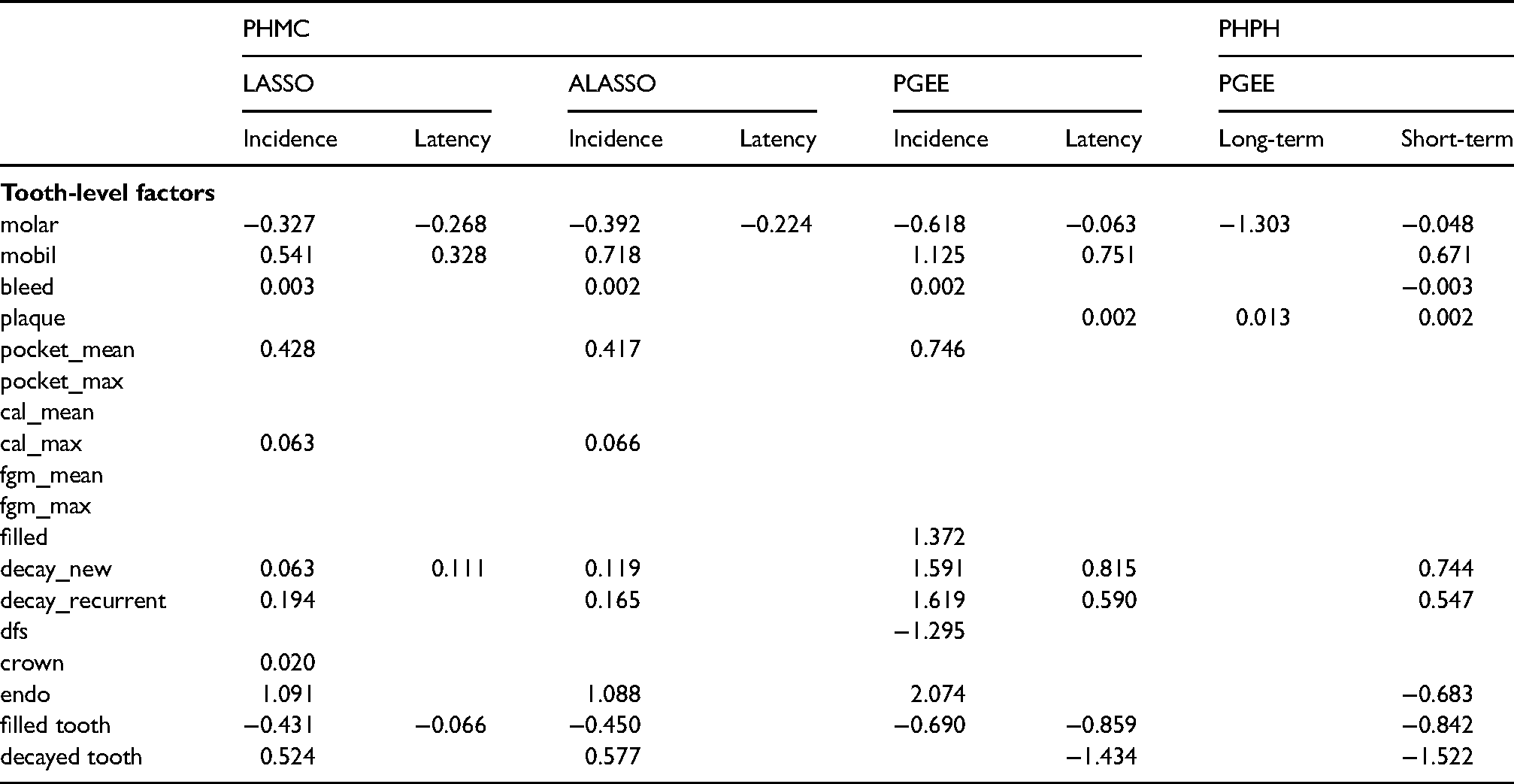
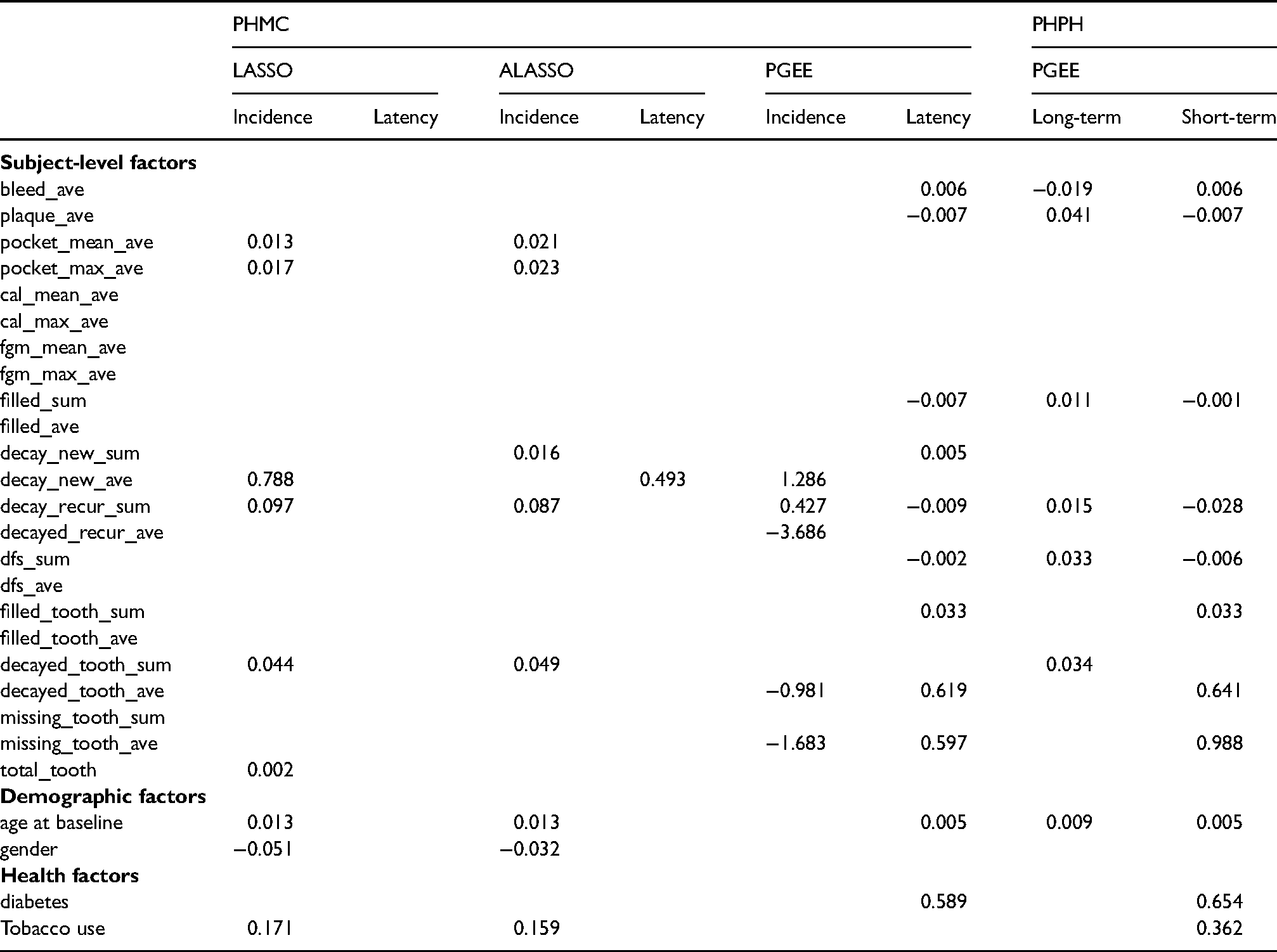
As the study aims to identify which factors are associated with tooth loss, the proposed PGEE provides a logical tool for risk factor screening. We perform the variable selection procedure in both the PHMC model and the PHPH model. Under the PHMC model, we apply the proposed PGEEs in (21) and (22) with pseudo-observations created by and , respectively. While under the PHPH model, we apply the proposed PGEEs in (23) and (24) with pseudo-observations created by and , respectively. In both the PHMC model and the PHPH model, a working independence correlation is incorporated for the ten pseudo-observations obtained from the quantitles of observed event times. The tuning parameters are selected via five-fold cross-validation. For comparison, we also fit the PHMC model with LASSO and ALASSO penalties proposed by Masud et al.27 implemented in the R package intsurv.39In the variable selection procedure, the molar variable’s coefficient is not penalized since the variable effect is the research of interest. Tables 4 and 5 present the variable selection results. Under the PHMC assumption, when predicting whether a tooth is cured, the LASSO and ALASSO selected more variables as we observed in the simulation studies; see Table 2 and Table 5 in Web Appendix E. The common selected factors based on presented methods include mobility score (mobil), bleeding on probing (bleed), periodontal probing depth (pocket_mean), decayed surfaces new (decayed_new), decayed surfaces recurrent (decayed_recurrent), endodontic therapy (endo), filled tooth (filled_tooth) and recurrent decayed surfaces (decay_recur_sum). Only the variable filled tooth increases the chance of cure while others decrease the chance of cure. In addition, for the latency, the PGEE tends to identify more risk factors in predicting tooth survival time. The mobility score (mobil), decayed surfaces new (decayed_new) and filled tooth (filled_tooth) are three common selected factors related to the tooth survival time based on PGEE and LASSO. Under the PHPH model assumption, our proposed PGEE approach suggests that factors plaque score (plaque), bleeding on probing (bleed_ave), plaque index (plaque_ave), filled surfaces (filled_sum), recurrent decayed surfaces (decay_recur_sum), decayed and filled surfaces (dfs_sum), number of decayed teeth (decayed_tooth_sum) and age at baseline (baseline_age) are importantly associated with the long-term effect. Moreover, 20 factors are identified in association with the short-term effect, indicating losing the tooth more rapidly. Interestingly, we observe that 15 variables are both selected by the PGEE in the latency component of the PHMC model and the short-term effect of the PHPH model even though covariates are interpreted differently in the two models.
Estimated coefficients based on different penalization approaches for the dental dataset.
PHMC
PHPH
LASSO
ALASSO
PGEE
PGEE
Incidence
Latency
Incidence
Latency
Incidence
Latency
Long-term
Short-term
Tooth-level factors
molar
−0.327
−0.268
−0.392
−0.224
−0.618
−0.063
−1.303
−0.048
mobil
0.541
0.328
0.718
1.125
0.751
0.671
bleed
0.003
0.002
0.002
−0.003
plaque
0.002
0.013
0.002
pocket_mean
0.428
0.417
0.746
pocket_max
cal_mean
cal_max
0.063
0.066
fgm_mean
fgm_max
filled
1.372
decay_new
0.063
0.111
0.119
1.591
0.815
0.744
decay_recurrent
0.194
0.165
1.619
0.590
0.547
dfs
−1.295
crown
0.020
endo
1.091
1.088
2.074
−0.683
filled tooth
−0.431
−0.066
−0.450
−0.690
−0.859
−0.842
decayed tooth
0.524
0.577
−1.434
−1.522
(Continuation of Table 4) Estimated coefficients based on different penalization approaches for the dental dataset.
PHMC
PHPH
LASSO
ALASSO
PGEE
PGEE
Incidence
Latency
Incidence
Latency
Incidence
Latency
Long-term
Short-term
Subject-level factors
bleed_ave
0.006
−0.019
0.006
plaque_ave
−0.007
0.041
−0.007
pocket_mean_ave
0.013
0.021
pocket_max_ave
0.017
0.023
cal_mean_ave
cal_max_ave
fgm_mean_ave
fgm_max_ave
filled_sum
−0.007
0.011
−0.001
filled_ave
decay_new_sum
0.016
0.005
decay_new_ave
0.788
0.493
1.286
decay_recur_sum
0.097
0.087
0.427
−0.009
0.015
−0.028
decayed_recur_ave
−3.686
dfs_sum
−0.002
0.033
−0.006
dfs_ave
filled_tooth_sum
0.033
0.033
filled_tooth_ave
decayed_tooth_sum
0.044
0.049
0.034
decayed_tooth_ave
−0.981
0.619
0.641
missing_tooth_sum
missing_tooth_ave
−1.683
0.597
0.988
total_tooth
0.002
Demographic factors
age at baseline
0.013
0.013
0.005
0.009
0.005
gender
−0.051
−0.032
Health factors
diabetes
0.589
0.654
Tobacco use
0.171
0.159
0.362
7 Conclusions
This article extends the pseudo-observations approach to the context of right-censored survival data with a cure fraction for two popular cure models, the MC model and the BCH model. Several estimators for the regression parameters related to the cure rate and the risk of experiencing the event are proposed under the PHMC model and the PHPH model. The proposed methods allow researchers to estimate the covariate effects separately and identify essential factors associated with the cure rate and the risk of failure. Simulation studies show that the proposed methods perform reasonably under finite sample sizes. We also demonstrate the proposed methodology on two real applications involving survival data with a cure fraction.
In this work, for the MC model, we propose two different incidence regression estimators and . For the BCH model, we consider two different regression estimators and for long-term effects and two different regression estimators and for short-term effects. In the simulation studies, each of the pairs of estimators performs similarly. However, from the computing time point of view, we recommend that researchers consider estimators based on KM estimator as its computing times is fast. On the other hand, as we showed in the simulation studies, our proposed estimators based on pseudo-observations under both MC and BCH models have larger ESE and SEE than those from the usual MC and BCH models. This efficiency loss is commonly seen in the pseudo-observations literature.12,40 As pointed out by a referee, the efficiency loss is a limitation for our proposed pseudo-observations approach on the cure models when the number of covariates is small, like our real data analysis in Section 6.1. However, modeling pseudo-observations constitutes a general and straightforward approach to simplify survival analysis. In our applications, the pseudo-observations approach brings several advantages. First, it is more flexible and feasible for parameter estimation and variable selection when the number of covariates is large. The estimating procedure can be performed separately for each component in the MC model and each effect in the BCH model. Second, the computing time based on the pseudo-observations approach is faster than standard approaches that use the EM algorithm for estimation and bootstrapping for standard errors. Finally, pseudo-residuals can be applied for model diagnosis via residual plots.
Our PHPH model links the short-term effect to the baseline survival function via a proportional hazard model. The proposed PHPH model can be extended to accommodate non-proportional hazard assumptions by considering an exponential transformation or an accelerated failure time model in the short-term effect.8On the other hand, we applied the pseudo-observations approach to the PHMC model. Another commonly used MC model is the accelerated failure time MC (AFTMC) model,7 in which the logistic regression model is considered to model the cure status in the incidence component and the AFT model, , is used to model the conditional survival function in the latency component, where is the error term with survival distribution . Under AFTMC model, our proposed pseudo-observations (6) and (7) using GEE approach can be directly applied to estimate the unknown parameters in the incidence component. For the latency component, we discuss the feasibility of using the pseudo-observations approach to estimate under AFT model in two folds. First, when the survival distribution is known; that is, a parametric AFT model, one can write and treat it as a GLM with link function . To estimate , one can create the pseudo-observations for with given time points based on KM estimator as we proposed in equation (8) and then the GEE approach can be applied to obtain the estimates for . However, one might need to program the estimating equation on their own because the geese function in the R package geepack35 only provides commonly seen link functions. Second, when the survival distribution is unknown in a semi-parametric AFT model, it may not be straightforward to use the pseudo-observations approach to estimate even though the pseudo-observations for can be created. The main issue is the unknown survival function , so is the inverse function . Further investigation is required and will be an interesting topic for future research.
We note some limitations of our proposed work for variable selection. Based on our simulation studies, the TP rate seems to be low for the incidence component of the MC model when . This results might be induced because only one time point is used to create the pseudo-observations for the cure rate. When applying our proposed approach to a small sample sizes like 200 in our simulation, researchers can investigate the stability of variable selection via the bootstrap approach proposed by Royston and Sauerbrei.41 In this work, we only report the selected coefficient estimates from the penalized approach for the dental data analysis. In practice, one might adopt a two-stage approach in which the inference is based on the selected model to obtain standard errors.27The validity of inferences based on the penalization and the goodness-of-fit assessments will be studied in future work.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802221108579 - Supplemental material for Analysis of survival data with cure fraction and variable selection:
A pseudo-observations approach
Supplemental material, sj-pdf-1-smm-10.1177_09622802221108579 for Analysis of survival data with cure fraction and variable selection:
A pseudo-observations approach by Chien-Lin Su, Sy Han Chiou, Feng-Chang Lin and Robert W Platt in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors would like to thank the editors, the associate editor, and three anonymous referees whose comments led to a substantial improvement of this paper. For this research work, Robert Platt acknowledges the support by the Natural Sciences and Engineering Research Council of Canada (NSERC) with grant numbers RGPIN-2016-06296 and RGPIN-2017-04363, the Canadian Institutes for Health Research (CIHR) with grant number FDN-143297 and the Albert Boehringer I Chair in Pharmacoepidemiology. Feng-Chang Lin acknowledges the support by the National Center for Advancing Translational Sciences (NCATS), National Institutes of Health, USA, through grant number UL1TR002489.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Center for Advancing Translational Sciences (NCATS), National Institutes of Health, through Grant Award Number UL1TR002489.
ORCID iDs
Chien-Lin Su
Sy Han Chiou
Feng-Chang Lin
Supplemental materials
The reader is referred to the online Supplemental Materials for asymptotic properties and additional simulation results. The R codes with examples for this work are deposited to a Github repository .
References
1.
KirkwoodJStrawdermanMErnstoffM, et al. Interferon alfa-2b adjuvant therapy of high-risk resected cutaneous melanoma: the eastern cooperative oncology group trial est 1684. J Clin Oncol1996; 14: 7–17.
2.
CalhounPSuXNunnM, et al. Constructing multivariate survival trees: the MST package for R. J Stat Softw2018; 83: 1–21.
3.
PengYYuB. Cure Models: Methods, Applications, and Implementation. New York: CRC Press, 2021.
4.
FarewellVT. The use of mixture models for the analysis of survival data with long-term survivors. Biometrics1982; 38: 1041–1046.
5.
PengYDearKDenhamJ. A generalized F mixture model for cure rate estimation. Stat Med1998; 17: 813–830.
6.
PengYDearK. A nonparametric mixture model for cure rate estimation. Biometrics2000; 56: 237–243.
7.
LiCSTaylorJMG. A semi-parametric accelerated failure time cure model. Stat Med2002; 21: 3235–3247.
8.
TsodikovA. Semi-parametric models of long-and short-term survival: an application to the analysis of breast cancer survival in Utah by age and stage. Stat Med2002; 21: 895–920.
9.
A, AsselainBBardouV, et al. A simple stochastic model of tumor recurrence and its application to data on premenopausal breast cancer. Biometrie et Analyse de Donnees SpatioTemporelles1993; 12: 66–82.
10.
SpostoR. Cure model analysis in cancer: an application to data from the children’s cancer group. Stat Med2002; 21: 293–312.
11.
TsodikovAIbrahimJGYakovlevAY. Estimating cure rates from survival data: an alternative to two-component mixture models. J Am Stat Assoc2003; 98: 1063–1078.
12.
AndersenPKleinJRosthøjS. Generalised linear models for correlated pseudo-observations, with applications to multistate models. Biometrika2003; 90: 15–27.
13.
KleinJLoganBHarhoffM, et al. Analyzing survival curves at a fixed point in time. Stat Med2007; 26: 4505–4519.
14.
AndreiACMurrayS. Regression models for the mean of the quality-of-life-adjusted restricted survival time using pseudoobservations. Biometrics2007; 63: 398–404.
15.
NicolaieMAVan HouwelingenJCDeWitteTM, et al. Dynamic pseudo-observations: a robust approach to dynamic prediction in competing risks. Biometrics2013; 69: 1043–1052.
16.
PavličKPermeMP. Using pseudo-observations for estimation in relative survival. Biostatistics2019; 20: 384–399.
17.
SabathéCAndersenPHelmerC, et al. Regression analysis in an illness-death model with interval-censored data: a pseudovalue approach. Stat Methods Med Res2020; 29: 752–764.
18.
SuCLPlattRPlanteJF. Causal inference for recurrent event data using pseudo-observations. Biostatistics2022; 23: 189–206.
19.
GrawFGerdsTSchumacherM. On pseudo-values for regression analysis in competing risks models. Lifetime Data Anal2009; 15: 241–255.
20.
JacobsenMMartinussenT. A note on the large sample properties of estimators based on generalized linear models for correlated pseudo-observations. Scandinavian J Stat2016; 43: 845–862.
21.
OvergaardMParnerEPedersenJ. Asymptotic theory of generalized estimating equations based on jack-knife pseudoobservations. Ann Stat2017; 45: 1988–2015.
22.
TibshiraniR. Regression shrinkage and selection via the lasso. J R Stat Soc B (Methodological)1996; 58: 267–288.
23.
ZouH. The adaptive lasso and its oracle properties. J Am Stat Assoc2006; 101: 1418–1429.
24.
FanJLiR. Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc2001; 96: 1348–1360.
25.
LiuXPengYTuD, et al. Variable selection in semiparametric cure models based on penalized likelihood, with application to breast cancer clinical trials. Stat Med2012; 31: 2882–2891.
26.
MasudAAYuZTuW. Variable selection and nonlinear effect discovery in partially linear mixture cure rate models. Biostat Epidemiol2019; 3: 156–177.
27.
MasudATuWYuZ. Variable selection for mixture and promotion time cure rate models. Stat Methods Med Res2018; 27: 2185–2199.
28.
WangLZhouJQuA. Penalized generalized estimating equations for high-dimensional longitudinal data analysis. Biometrics2012; 68: 353–360.
29.
TsodikovA. A proportional hazards model taking account of long-term survivors. Biometrics1998; 54: 1508–1516.
30.
MallerRAZhouS. Estimating the proportion of immunes in a censored sample. Biometrika1992; 79: 731–739.
31.
KaplanEMeierP. Nonparametric estimation from incomplete observations. J Am Stat Assoc1958; 53: 457–481.
32.
TsodikovA. Estimation of survival based on proportional hazards when cure is a possibility. Math Comput Model2001; 33: 1227–1236.
33.
AndersenPPermeMP. Pseudo-observations in survival analysis. Stat Methods Med Res2010; 19: 71–99.
34.
LiangKYZegerS. Longitudinal data analysis using generalized linear models. Biometrika1986; 73: 13–22.
35.
HalekohUHøjsgaardSYanJ. The R package geepack for generalized estimating equations. J Stat Softw2006; 15: 1–11.
36.
KleinJGersterMAndersenP, et al. SAS and R functions to compute pseudo-values for censored data regression. Comput Methods Programs Biomed2008; 89: 289–300.
37.
KleinJAndersenP. Regression modeling of competing risks data based on pseudovalues of the cumulative incidence function. Biometrics2005; 61: 223–229.
38.
CaiCZouYPengY, et al. smcure: an R-package for estimating semiparametric mixture cure models. Comput Methods Programs Biomed2012; 108: 1255–1260.
AndersenPSyriopoulouEParnerET. Causal inference in survival analysis using pseudo-observations. Stat Med2017; 36: 2669–2681.
41.
RoystonPSauerbreiW. Stability of multivariable fractional polynomial models with selection of variables and transformations: a bootstrap investigation. Stat Med2003; 22: 639–659.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.