
Abstract
We compare two multi-state modelling frameworks that can be used to represent dates of events following hospital admission for people infected during an epidemic. The methods are applied to data from people admitted to hospital with COVID-19, to estimate the probability of admission to intensive care unit, the probability of death in hospital for patients before and after intensive care unit admission, the lengths of stay in hospital, and how all these vary with age and gender. One modelling framework is based on defining transition-specific hazard functions for competing risks. A less commonly used framework defines partially-latent subpopulations who will experience each subsequent event, and uses a mixture model to estimate the probability that an individual will experience each event, and the distribution of the time to the event given that it occurs. We compare the advantages and disadvantages of these two frameworks, in the context of the COVID-19 example. The issues include the interpretation of the model parameters, the computational efficiency of estimating the quantities of interest, implementation in software and assessing goodness of fit. In the example, we find that some groups appear to be at very low risk of some events, in particular intensive care unit admission, and these are best represented by using ‘cure-rate’ models to define transition-specific hazards. We provide general-purpose software to implement all the models we describe in the
1 Introduction
For emerging infectious diseases such as coronavirus disease 2019 (COVID-19), the severe acute respiratory illness following infection with the SARS-CoV-2 virus, a prompt understanding of disease severity and healthcare resource use are essential to informing government response. Of particular interest are the probability that a person just admitted to hospital will be admitted to an intensive care unit (ICU), the probability of death in hospital before or after ICU admission, and the predicted length of stay in hospital, or average times between these events. Accurate estimates of these quantities are required both for direct policy-making, and to include in larger models that combine these estimates with other sources of data (e.g. on transmission and risk of hospitalisation) to predict outcomes for wider populations.1,2
These quantities can typically be estimated from data on people hospitalised with the infection. These data usually consist of dates of admission, discharge, and in-hospital events such as admission to ICU. The follow-up is commonly incomplete, i.e. it ends while patients are still in hospital, and even during follow-up, the occurrence of events and their dates may be incompletely recorded. This form of data is generally described as multi-state data, in which a set of individuals, sharing the same starting state, are followed up through time. For each individual, we might observe the time and state of their next transition, or observe that they have remained in the same state up to a particular time. In the latter case, the time of the next transition is right-censored and the state they next move to is unknown. After a transition is observed, there may be onward transitions to further states observed in the same manner.
Two different modelling frameworks have been used to represent this kind of data. The most commonly used method to represent transitions in multi-state data is based on cause-specific hazards of competing risks.3–5 These models are defined by hazards or intensities
A less common approach is based on mixture models. This was used by Ghani et al.
9
and Donnelly et al.
10
in a context that is similar to our application, to estimate probabilities of death and recovery, and times to these events, for people with an infectious disease. Each individual’s next state is assumed to be
These approaches to competing risks were contrasted by Cox 13 (with two events and exponentially-distributed times) who suggested either approach could be used to construct an arbitrarily flexible model. However they have not been compared in practice in the context of general fully parametric multi-state models. Lau et al. 14 advocated mixture models, compared to semiparametric proportional cause-specific hazard models, for describing the associations of covariates with the risk of competing outcomes, but did not consider fully-parametric cause-specific hazard models. In our application, we focus on parametric models, to stabilise estimation in periods where the data are sparse, enable short-term extrapolation beyond the end of the data, and to provide explicitly parametric inputs for epidemic models, based on Bayesian evidence synthesis, that are designed to inform policy for wider populations.1,2
In this paper, we compare the practical use of these two different frameworks for fully-parametric multi-state modelling, in the context of an application to COVID-19 hospital admissions. We consider their interpretation, the ease of model specification, their computational efficiency, implementation in software, and assessing their goodness of fit to the data. A novel modification to the likelihood in both frameworks was required to represent partially observed final outcomes, where patients are known to be alive but with unknown hospitalised status. We develop the first general-purpose software implementation of the mixture multi-state model, in the
A feature of our data is that there are subsets of patients who appear to be at very small risks of particular events. These are handled naturally by the mixture model, which is parameterised by probabilities of events. To characterise these data within the cause-specific hazards framework, we use cure (also known as mixture cure) distributions to represent one or more of the latent event times
In Section 2, we describe the motivating COVID-19 hospital admissions dataset. Section 3 sets out the theoretical definitions of the two alternative multi-state modelling frameworks and how the quantities of interest are defined and computed. The models are applied to the COVID-19 hospital data in Section 4, and the fit and interpretations of the best of both types of parametric model are compared. While the mixture model is simpler to interpret and involved less computation to obtain the quantities of interest, the fit in the COVID-19 example was best for the cause-specific hazards model with mixture-cure distributions. Section 5 concludes the paper with a discussion of the merits of the two frameworks and the open issues.
2 CHESS: Hospital admissions data from COVID-19 patients
Data were extracted from the COVID-19 Hospitalisation in England Surveillance System (CHESS), established and managed by Public Health England (PHE). 20 CHESS began in mid-March 2020 and aims to monitor the impact of severe COVID-19 infection on the population and on health services and provide real-time data to forecast and estimate disease burden and health service use. CHESS is a mandatory data collection system 21 and captures individual-level data on all patients admitted to ICU or HDU (high dependency unit) with COVID-19 at National Health Service (NHS) Trusts in England, in addition to data from all hospital admissions with COVID-19 from the 22 out of 107 trusts that were designated as ‘sentinel’ trusts, representing 26% of hospital admissions. Collected data include patient demographics, risk factors, clinical information on severity, and outcome. CHESS data covering the period from 15 March to 2 August 2020 were extracted at PHE and linked using NHS number to the Office for National Statistics (ONS) deaths register to obtain complete information for deaths occurring both within and outside of hospital.
There are 5544 hospital admission records from sentinel trusts in CHESS from people known to have tested positive for COVID-19 infection up to 2 days after admission, who are assumed to have been infected outside hospital. People who were infected with COVID-19 while in hospital for another condition are excluded, as there is insufficient information to determine how much of their hospital stay was due to COVID-19. From the 5544 records, we excluded 74 patients, including those with missing or inconsistent dates of ICU admission, or missing information on age or gender, leaving 5470 hospital admissions. The final outcomes from these patients, and whether they were admitted to ICU, are counted in Table 1. In around 10% of cases, whether the patient died in hospital care, or was discharged, is not yet observed or unknown, noting that people recorded as ‘transferred’ are still in hospital care. The people with ‘unknown’ final outcome are known to be still alive, and it is assumed that if they went to ICU then this was recorded, but it is not known whether they are still in hospital at the date of data extraction.
Summary of events in CHESS data.

The data on the next event following hospital admission are illustrated further by age and gender in Figures 1 and 2. Figure 1 illustrates the proportions experiencing each next event, while Figure 2 shows the distribution of the times to each kind of observed event after admission, the times to right-censoring for those known to be still in hospital, and the times from admission to data extraction for those with unknown outcome. Note that a substantial number of people are still in hospital care after around 50 days in hospital, which is extreme compared to the distributions of the times to the observed events. The probabilities and average times of events could be inferred directly from these summaries, but the estimates would be biased as they would ignore the information from the censored times, which indicate longer hospital stays, and people with unknown outcome. Therefore likelihood-based statistical models are constructed.
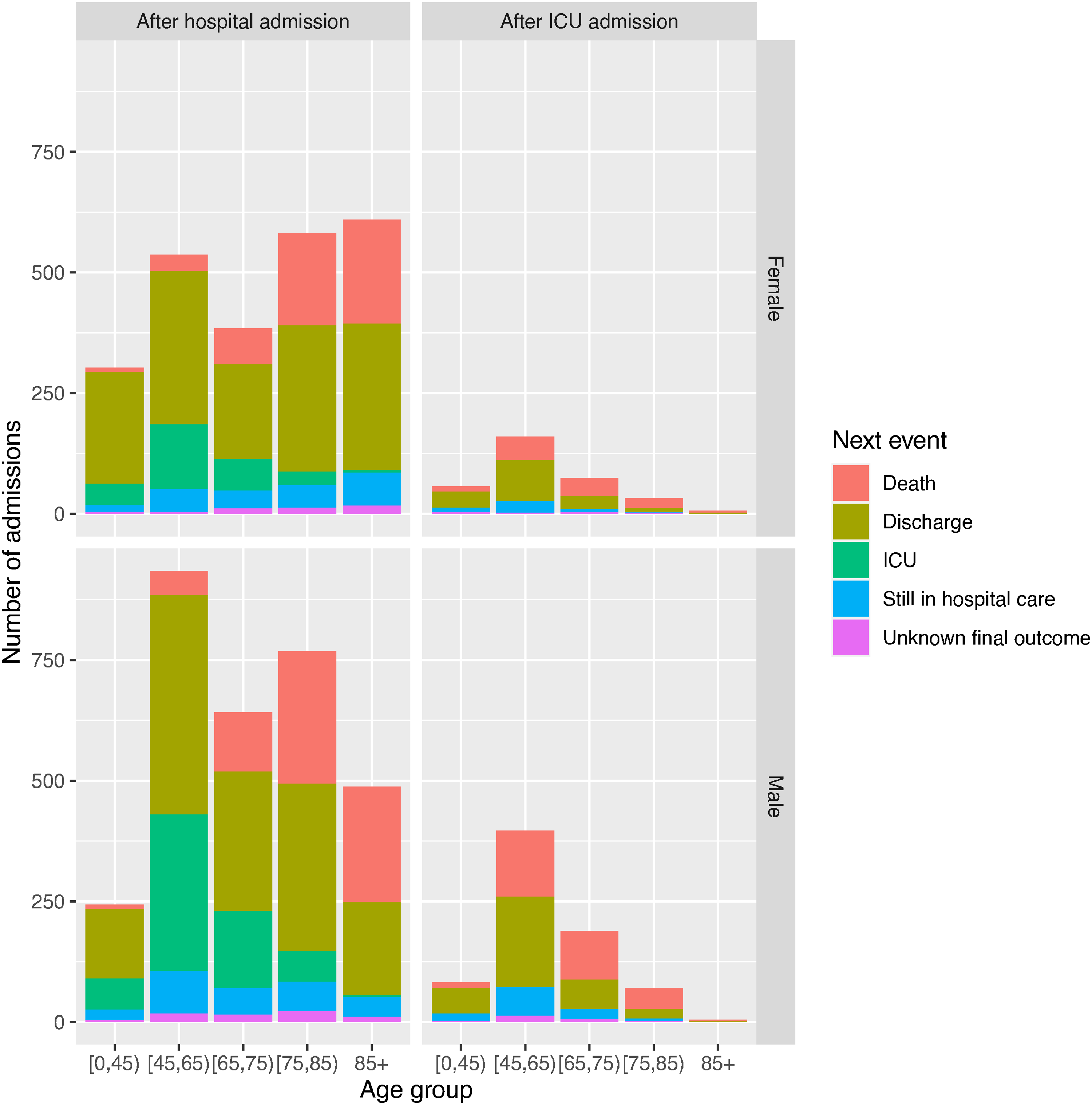
Distribution of next event following hospital admission, or following ICU admission, by age group and gender, as a simple summary of the data.
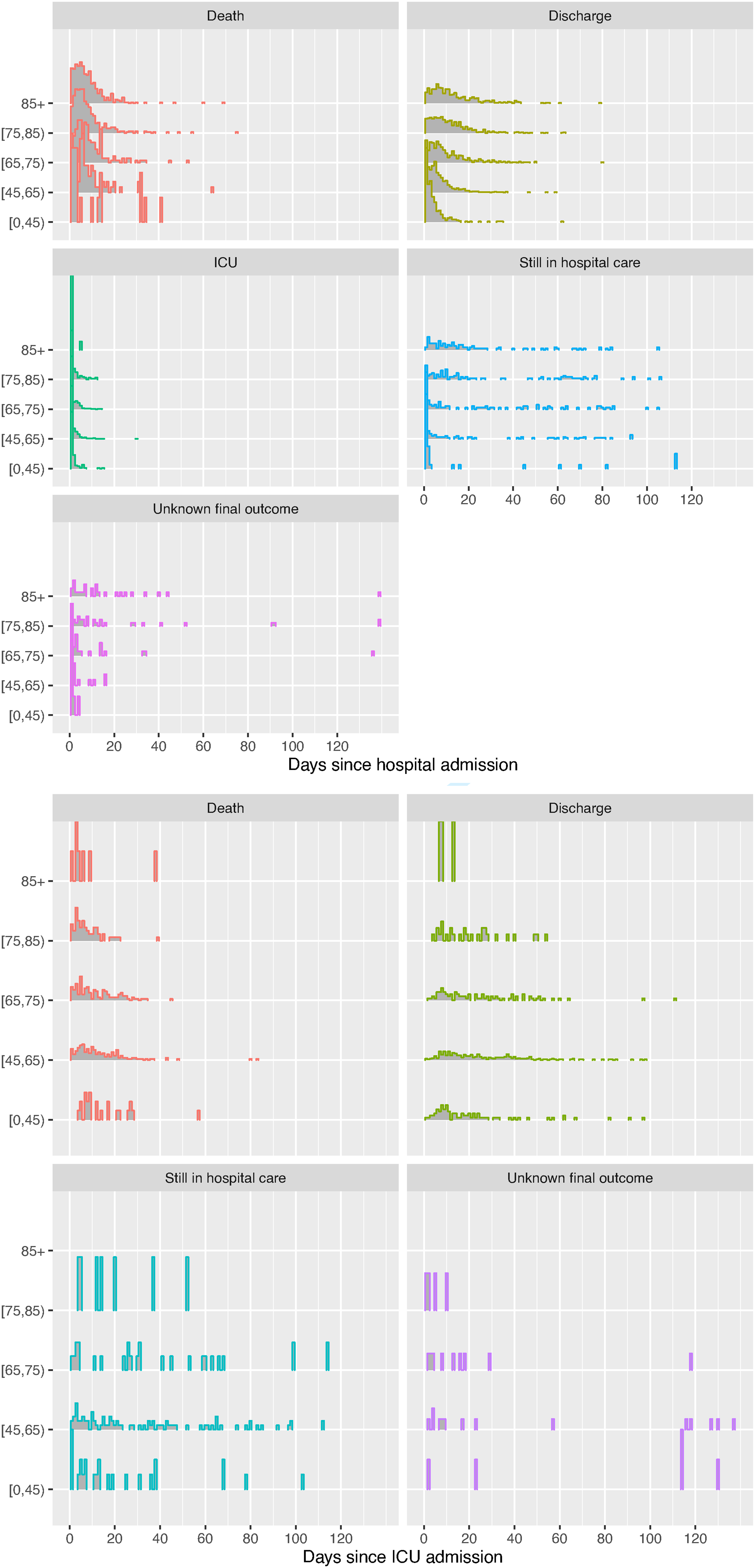
Distribution of times to next event following hospital or ICU admission, by age group, as a standard histogram of the data, including times to right-censoring for those still in hospital, or times to data extraction for those with unknown outcome.
3 Multi-state modelling frameworks
A parametric, continuous-time, semi-Markov multi-state model is used with four states, represented in Figure 3. This comprises two submodels representing ‘competing risks’ of the next event: one for the event following hospital admission, and another for the event following ICU admission. Note that in practice, individuals will be discharged from ICU to a hospital ward, but since dates of leaving ICU are only partially recorded in this dataset, we simply combine the ICU state with the state of being in a hospital ward after leaving ICU, so the ‘ICU’ state represents ‘in hospital, and has been admitted to ICU’, rather than ‘in hospital and currently in ICU’. Individual
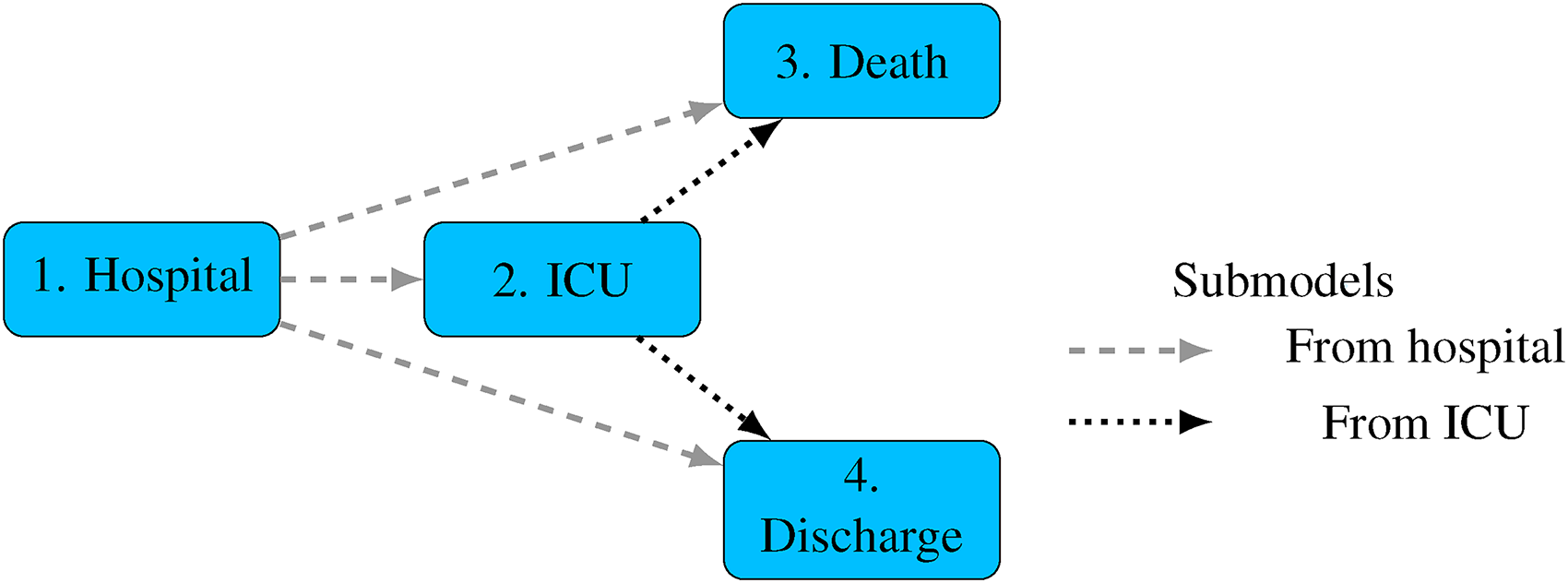
Multi-state model. Permitted instantaneous transitions between states indicated by arrows.
The next-state probability The distribution of the conditional length of stay The ultimate-outcome probabilities The distribution of the conditional time to ultimate outcome
In general, any summary of the distribution of state transitions and times to events can be computed by simulation, but some quantities will be available analytically.
3.1 Cause-specific hazards model
In a competing risks model specified through cause-specific hazards3,5,6 at time
Conditional length of stay
This is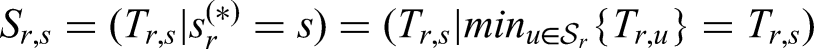
Next-state probabilities
In the COVID-19 example, we have probabilities
Ultimate outcomes
Similarly, the ultimate-state probabilities are determined from the transition probabilities of the full multi-state model as
Computation of quantities of interest
The next-state probabilities are calculated as follows. The transition probabilities for the two sub-models are related to the transition intensities through the Kolmogorov forward equation:
The distribution of the conditional lengths of stay
3.2 Mixture multi-state model
In the ‘mixture’ competing risks model,
11
extended here to a general multi-state model, each individual 
3.3 Data and likelihoods
Observations of the event times or censoring times from individual
exact transition time: right censoring partially-known outcomes
Cause-specific hazards model
We use the likelihood as in Prentice et al.,
3
extended to handle partially known outcomes. To construct this, first write the
For exact transition times, The first term represents the transition that was observed at For observations of right-censoring, For individuals with partially-known outcomes, where it is known they are alive and it is known whether they went to ICU or not, the times to death or discharge are right-censored. Since we do not know whether they have been discharged before time
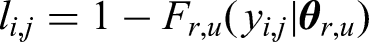
The full likelihood is 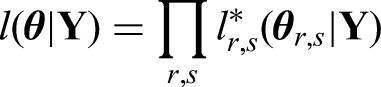
This is possible since, for each
Mixture multi-state model
The likelihood presented by Larson and Dinse
11
for competing risks can be extended easily to a full multi-state model. Firstly define again 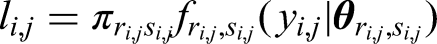
For observations 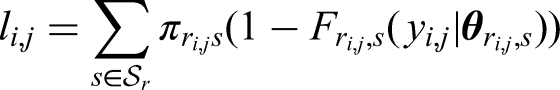
For patients with partial outcomes, the likelihood is as for right-censoring, except that the term for
The full likelihood is
3.4 Parametric distributions and implementation
The cause-specific hazards models can be fitted in standard survival modelling software. We use the
Each model formulation requires the choice of a parametric model for the time to an event. A wide range of flexible distributions are used in practice and are available in 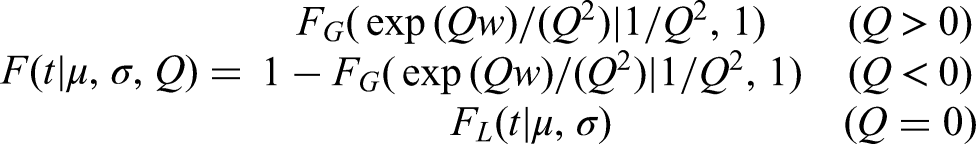
For the data in this example, we also use mixture cure distributions.
16
These are defined by extending a standard parametric time-to-event distribution 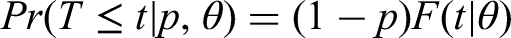
This model may be extended to include covariates that explain the ‘cure’ probability
3.5 Model selection
For both the mixture model and the cause-specific hazards/competing risks model, a well-fitting parametric model was selected by the following procedure, on the basis of Akaike’s information criterion (AIC).
In the mixture models, all models included age group and gender as additive covariate effects on the (multinomial) logit component membership probability. The component-specific time-to-event model was selected by starting with a generalised gamma distribution with constant parameters, then comparing against simpler gamma, Weibull and log-normal models, and against more complex models where one or more of the generalised gamma parameters also depended on age and gender.
In the cause-specific hazards models, we started with generalised gamma distributions for each cause-specific hazard, with a location parameter that depended on age and gender. This model was then compared with simpler gamma, Weibull and log-normal models, and more complex models where the second or third parameter of the generalised gamma also depended on age and gender. Models with a ‘cure fraction’ (potentially depending on age and gender) were also investigated to describe a proportion of people at negligible risk of ICU admission or death. A cure fraction for discharge as well was judged to be implausible, so that while some people will never go to ICU or die from their current infection, all survivors are assumed to eventually leave hospital.
Interactions between age and gender were also investigated in both frameworks.
4 Application of the models to the COVID-19 hospital data
4.1 Model checking
The best-fitting among the mixture models and cause-specific hazards models, judging from AIC, are described in Table 2. The best fitting cause-specific hazards model has a lower AIC compared to the best-fitting mixture model, which is driven by the better fit of the cause-specific model for the events following hospital. After investigating for interactions, effects of age and sex were included as additive in all models.
The fit of the models can also be compared for specific subgroups of the data. Table 3 shows the difference between the log-likelihood of the cause specific hazards model and the likelihood of the mixture model, for each age/sex subgroup of the data, and for the hospital and ICU-specific submodels and both combined. The better fit of the cause-specific hazards model overall is due to its better fit in the hospital-specific submodel, while the two models fit similarly well for transitions from ICU. In the hospital submodel, within each subgroup, the log-likelihood of the cause-specific hazards model is greater, showing better fit. While these subgroup-specific comparisons do not account for the difference in model complexity (as in AIC), there is no evidence that the mixture model should be preferred for describing any particular age/sex subgroup.
Selected parametric assumptions for the cause-specific hazards and mixture multistate models. All mixture multistate models also include age and gender covariates on the probabilities

Relative fit of the cause-specific hazards model compared to the mixture model, defined as the log likelihood of the cause-specific hazards model minus the log likelihood of the mixture model, by age/sex subgroup, for the hospital submodel, the ICU submodel and both combined. Positive values indicate better fit for the cause-specific hazards model.

The fit of the models can be checked against nonparametric estimates in various ways. Note that nonparametric estimates are only available up to the maximum observed follow-up in the data, while the parametric models allow extrapolation beyond that time.
Checking mixture and cause-specific hazard models together
The goodness-of-fit of all of the parametric models can be checked by comparing estimates of the continuous-time transition probability (or ‘cumulative incidence’)
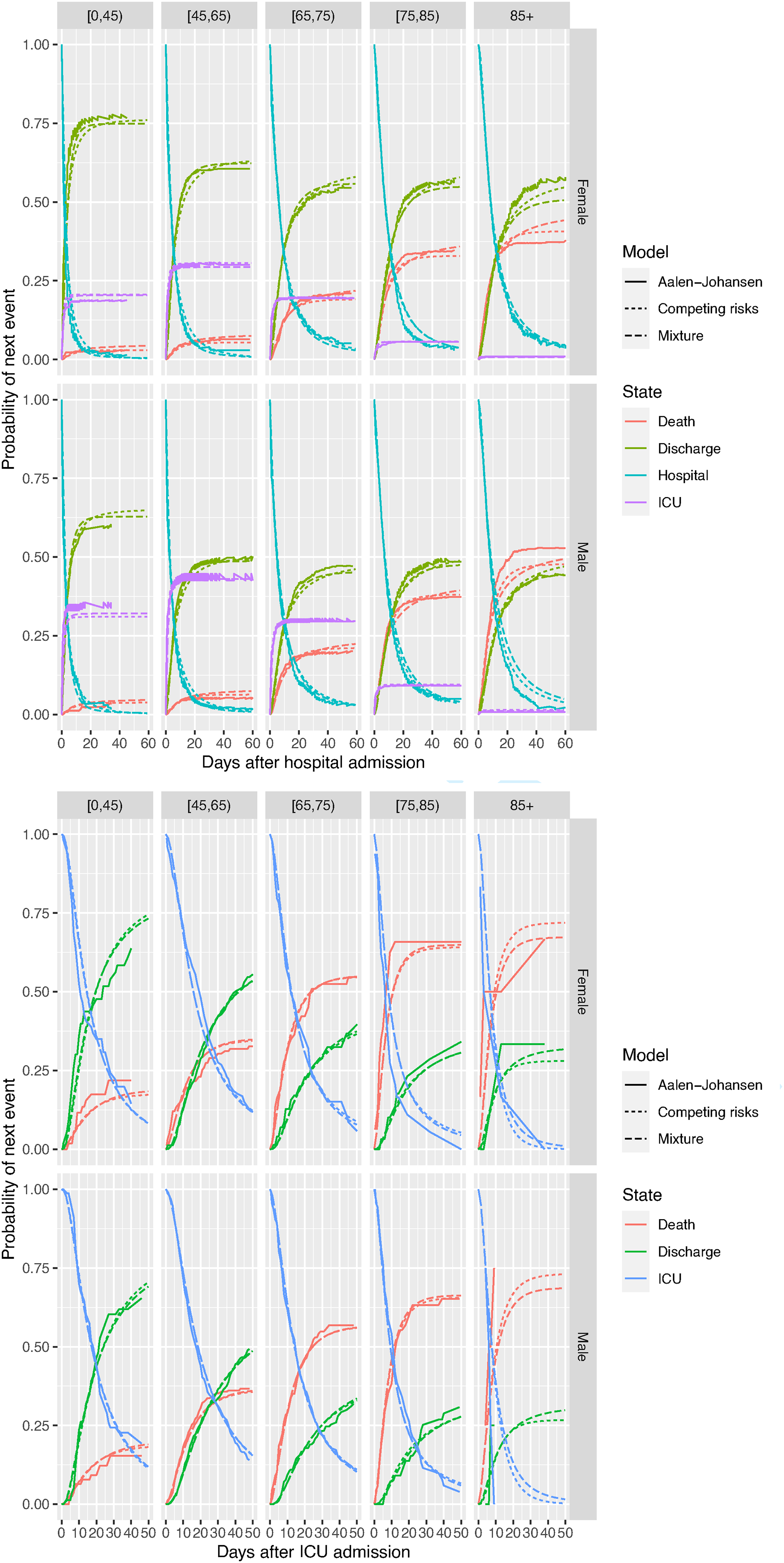
Probabilities of having experienced each competing next state following hospital admission, against time since admission, by age group and gender, comparing non-parametric (Aalen-Johansen) and two alternative parametric models. Top: events following hospital admission, bottom: events following ICU admission.
Check of cause-specific hazard models
The cause-specific hazard models can be checked against Kaplan-Meier estimates of the distribution of the time to each latent competing event, since they are standard parametric survival models for the time to the cause of interest, with the occurrence of other causes treated as censoring (Figure 5).
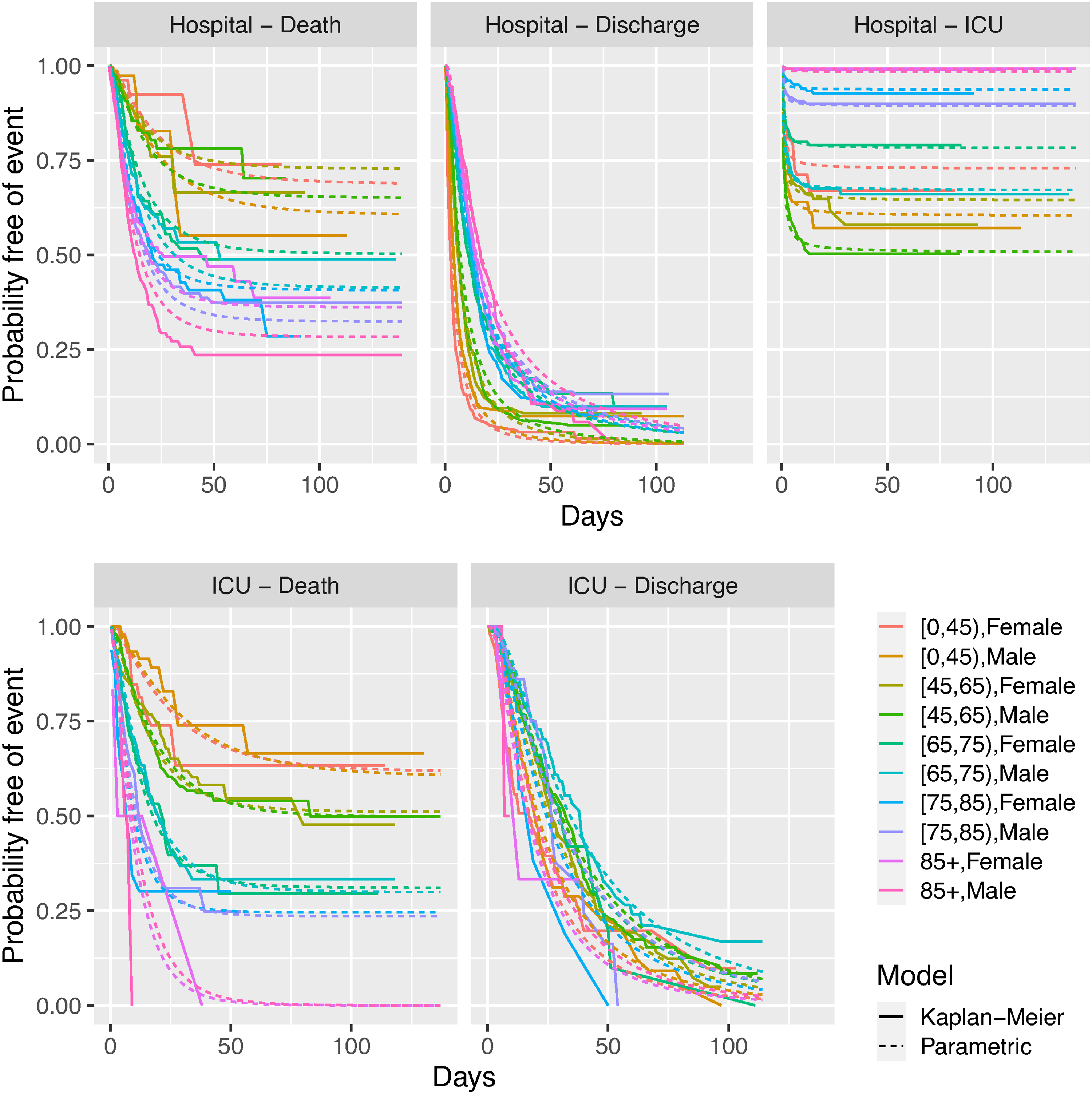
Check of cause-specific hazard models against Kaplan-Meier estimates of the distribution of the time to each latent competing event, by age and gender.
The Kaplan-Meier estimates show a characteristic flattening out for the time from hospital admission to death and ICU admission, implying that only a proportion of patients experience these events by a certain time, after which the hazard of those events becomes small. This pattern is consistent with the ‘cure’ models that provided the best fit among the cause-specific models for these events.
For the times from hospital to discharge, the Kaplan-Meier estimates show that the majority of (‘latent’) discharge times have occurred by around 50 days, if deaths and ICU admissions are considered as right-censoring for these ‘latent’ times. We disregarded ‘cure’ models for this transition, assuming that the survival curve for time to discharge will eventually decrease to zero. However there is a tail of people who have been in hospital for very long periods, particularly from the older age groups (see also Figure 2). Therefore we might expect some uncertainty in estimating the upper tail of the distribution of the length of stay.
Check of mixture models
In the mixture models, the fit of the distribution of the time to each event conditionally on that event occurring can be checked, to some extent, against histograms of the observed times. This ignores the contribution of the censored data to the fitted models, which comprise 10% of the observations and include people with longer hospital stays. Figure 6 shows these comparisons for the model for events following hospital admission, by age and gender. Estimated densities are overlaid on histograms of the times to each event for people who were observed to have that event. The shapes of the fitted densities for beyond 50 days of observed follow-up are influenced by the parametric model form, and are difficult to check against the censored and incomplete data (shown in Figure 2, but not in Figure 6) that contribute to the estimates for these times.
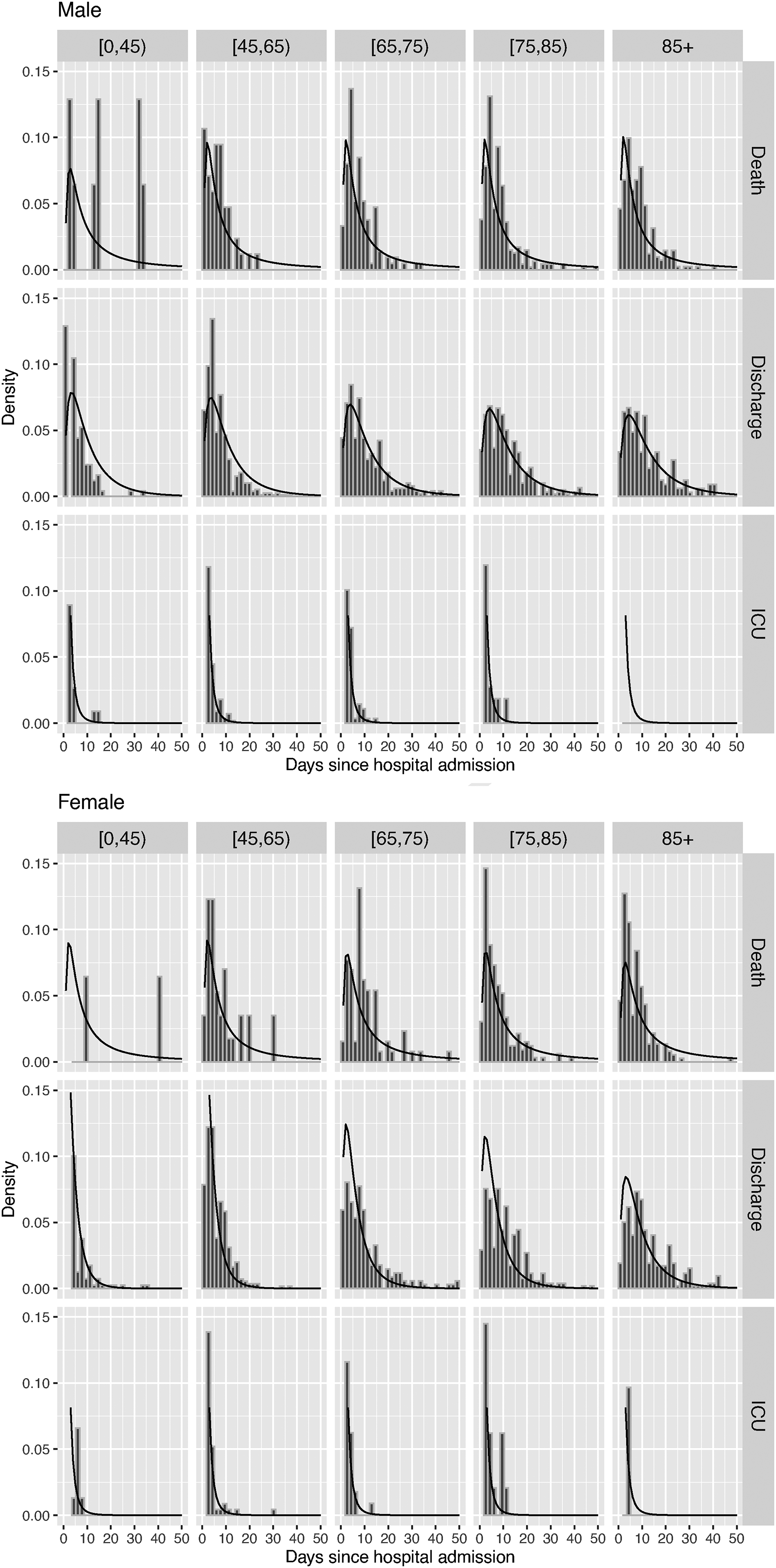
Check of fitted time-to-event densities from the mixture model against histograms of observed times to each alternative next event following hospital admission, by gender and age group.
4.2 Estimated probabilities and times of next events
Figure 7 shows the probabilities governing the next event following hospital admission, compared between the two parametric models. There are only moderate differences between the estimates from the mixture and cause-specific hazards models. The mortality rates, both before and after ICU admission, increase with age and are higher for men. Rates of ICU admission are higher for younger people, which is largely a consequence of hospital policy rather than disease severity.
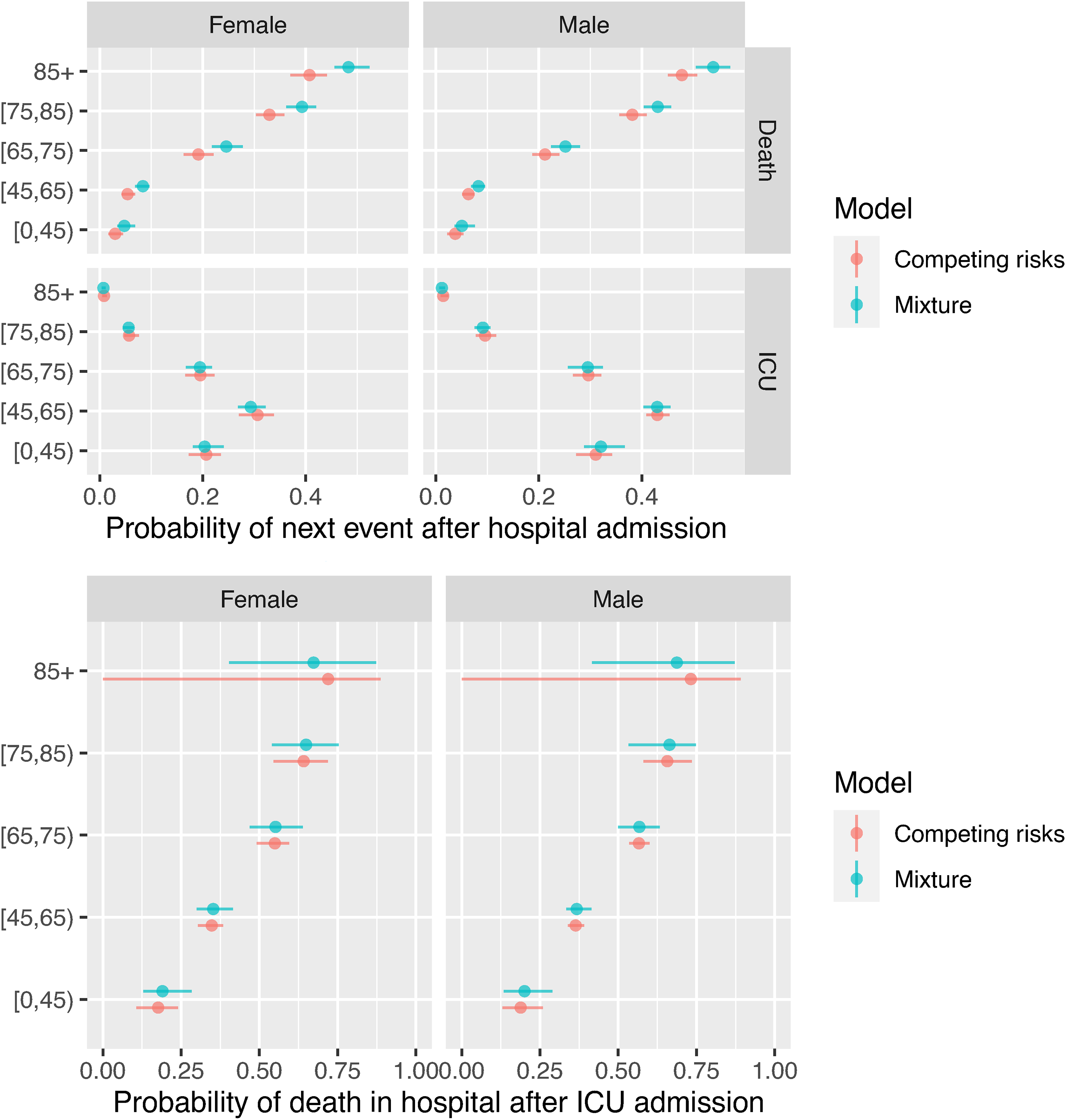
Probabilities of next event after hospital or ICU admission, estimated from mixture and competing risks models.
Figure 8 shows the mean times to events (in red) with 95% confidence intervals (representing uncertainty) and the median and 90% quantile intervals (in blue, representing between-person variability) for the time-to-event distributions, under both models. These confidence intervals, and all others presented, are obtained by simulating a sample of alternative parameter values from the asymptotic normal distribution of the maximum likelihood estimates. 28 Note that some of the confidence intervals around the means are too narrow to be seen. The estimated medians agree between the models, however the estimated upper tails of the distributions are sensitive to the model choice. The mixture models estimate longer mean times to death (and upper quantiles of this distribution) for those who die in hospital without going to ICU. This is a plausible consequence of using a cure distribution for time to death in the cause-specific hazard models – where if a person survives longer than a certain time, the model infers that they belong to the ‘cured’ fraction who will never die in hospital. Whereas under the mixture models, those observed to be still in hospital are estimated to be still at non-zero risk of death, so that longer, but finite, times to death are more plausible under the mixture models considered here.
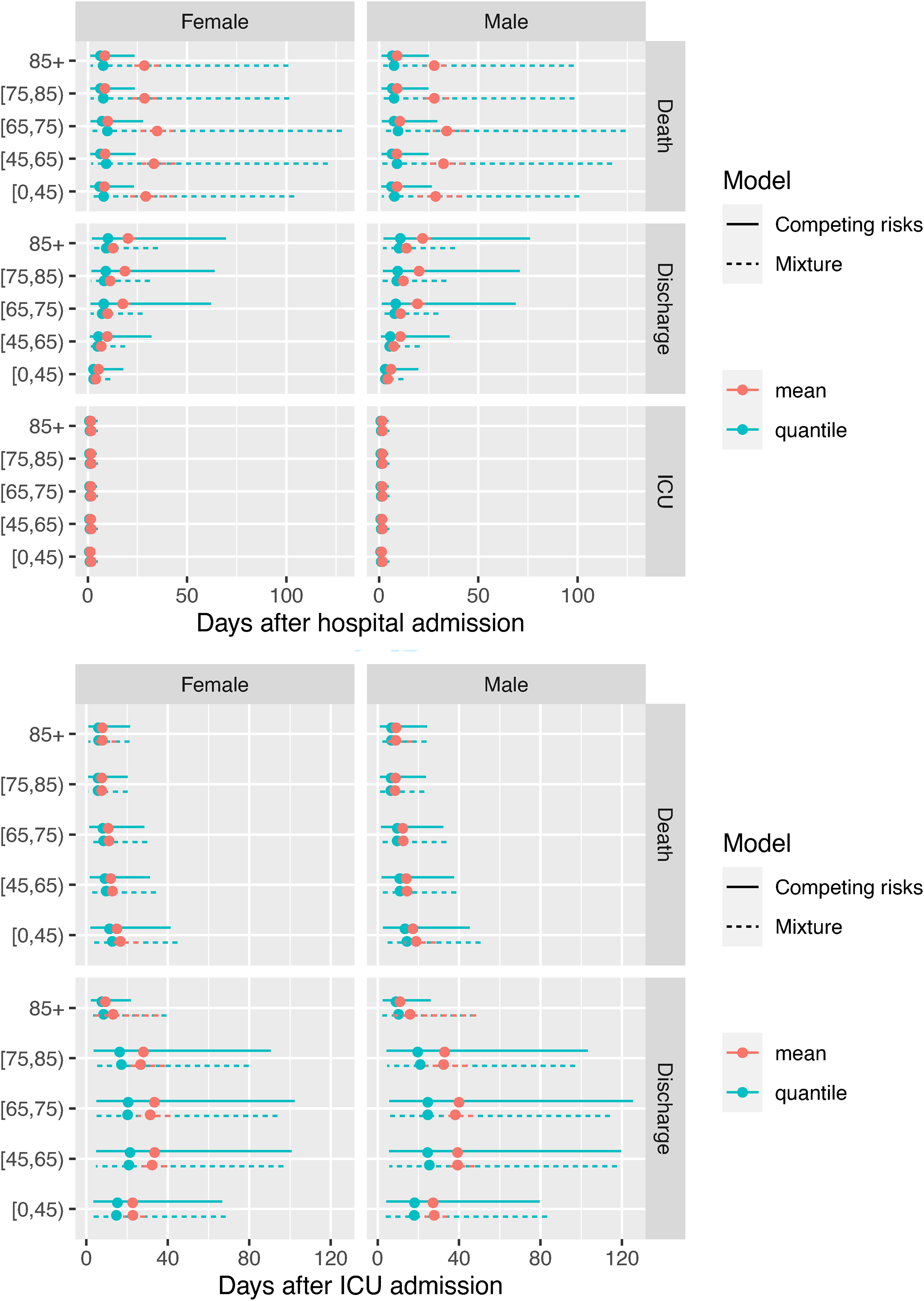
Times to the next event after hospital admission and the next event after ICU admission: means and 95% confidence intervals in red, and median and 90% quantile intervals (in blue).
Estimated times to discharge are slightly higher under the cause-specific hazards models, which could be explained by artefacts of how the different parametric assumptions extrapolate the time of the eventual event for those who are still in hospital (see also the Kaplan-Meier plots of time from hospital to discharge in Figure 5). The models both agree on the time from hospital to ICU admission being distributed tightly around a mean of about 2 days, and on the distributions of the times to events following ICU admission.
4.3 Estimates for ultimate events after hospital admission
The models for the events following hospital admission and events following ICU admission can be coupled to provide predictions of the probability that a person just admitted to hospital will die in hospital, and the distributions of the time to death in hospital or discharge alive (Figure 9). The estimated probabilities are again slightly different between the two models, but both show the same increasing trend with age, and higher mortality for men, from around 0.07 for men and women aged under 45 to 0.4 for women over 85 years of age, and 0.5 for men over 85.
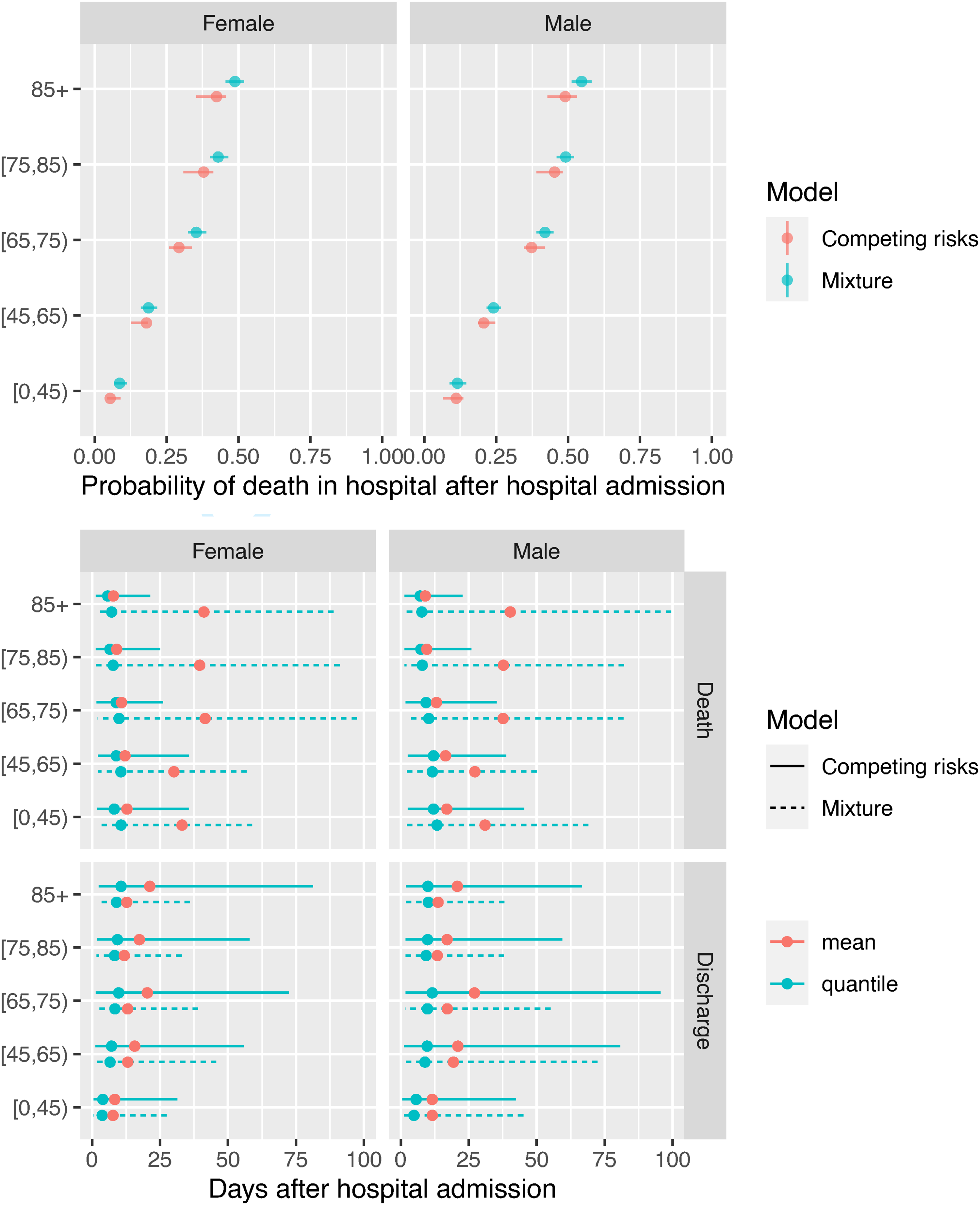
Probabilities of death in hospital, and times from hospital admission to death in hospital or discharge, averaged over people who are admitted to ICU and people who aren’t.
The differences between models in the estimated distribution of times to ultimate events reflect the differences seen in Figure 8, with medians that agree between the models (at around 10 days for times to death and discharge), but longer mean times to death under the mixture model, and longer mean times to discharge under the competing risks model.
While the cause-specific hazards model fitted the observed data better overall (judging by AIC), inference from the fitted mixture model is more computationally efficient. Computing the quantities of interest is practically instant given the fitted mixture model. Computing them given the competing risks model requires two levels of simulation: over
5 Discussion and comparison of modelling frameworks
We have obtained estimates of probabilities of events following hospital admission, and estimates of the distribution of times to those events, for people admitted to hospital with COVID-19 infection, using two different frameworks for multi-state modelling. The estimates of event probabilities and median times to events did not depend substantially on the model assumptions. However, due to limited follow up, and despite the fact that only about 10% of event times were censored, some uncertainty remained in the upper tails of the distributions of the times to death and discharge. The parametric assumptions can only be checked against the data observed in the follow-up period, where a cause-specific hazard model with ‘cure’ fractions was found to fit best, based on AIC and comparisons with nonparametric estimates. To make longer-term predictions we must make substantive assumptions about what will happen after the end of follow up. In this example, we assumed ‘cure’ fractions for ICU and death were plausible in the cause-specific hazards model, that is, a proportion of people never experience these events, but everyone will eventually be discharged from hospital.
Both mixture modelling and cause-specific hazards are useful frameworks for fully parametric multi-state modelling. With the
As discussed by Cox,
13
in theory, either model framework can represent the exact mechanism if the transition-specific parametric distributions are specified correctly. A third framework, ‘vertical’ modelling, was also proposed by Nicolaie et al.,
29
based on modelling
Either model framework might be used in situations where some people are at negligible risk of particular events, as in ‘cure’ models where a fraction of people do not die from a disease. We clarified the difference between the ‘mixture cure’ distributions of Boag 16 and the ‘mixture competing risks’ models of Larson and Dinse 11 – in the former, the ‘cure’ event that competes with death is not observable, and in the latter, it is. We extended the mixture competing risks model to a full multi-state model, and developed accessible software to implement it, while we used the mixture cure distribution to define cause-specific hazards in the competing risks framework. This provided the best fit to the COVID-19 hospital data, judging by AIC. This might have been because the ‘mixture competing risks’ model does not assume that a person in one mixture component is ‘immune’ from the events defining the other components – because the components are simply defined by which event among a set of competing events will occur before the others. In our application, the cause-specific cure model, where a proportion of people are at zero risk of ICU admission and death in hospital, fitted better than the mixture model where everyone still in hospital is assumed to be still at risk of these events.
In our application, policy-makers required estimates of average outcomes for mixed populations defined by age groups and gender. Therefore there were only two categorical covariates in our model. Models with more covariates, including continuous covariates, would be required to determine predictors of outcomes for individuals, or to investigate disease aetiology. Under the mixture model, covariate effects on probabilities of, or times to, observable events can be estimated directly, for example, as log odds ratios, hazard ratios or time acceleration factors. While hazard ratios from a cause-specific hazard model can be argued to more closely represent the mechanisms of how risks of events are determined at the biological level, compared to effects on probabilities,
32
they are harder to interpret in terms of average outcomes compared between populations. Non-proportional hazards, or other flexible models for covariate dependencies, are available in software (e.g.
In routinely collected data on people hospitalised with an infection, other challenges might arise, such as more severe kinds of incomplete observation. Addressing these challenges would be important for decision-making at the start of an epidemic, where data are sparser. In earlier versions of the dataset that we studied, final survival status and ICU admission histories were missing for substantial numbers of patients, and many event dates were interval-censored over wide ranges. Such partial observations are hard to handle without strong assumptions such as the Markov assumption and piecewise-constant hazards, 35 and even with a flexible model, untestable assumptions about whether missingness is informative may be required. Routinely collected data are also subject to selection biases which may make inference for wider populations difficult. These challenges further emphasise the need for strong infrastructures for data collection in preparation for future public health emergencies.
Code to implement the analyses in the paper is included as an online supplementary document in R Markdown format, together with a simulated dataset of the same form as the data used in the paper.
Supplemental Material
sj-rda-1-smm-10.1177_09622802221106720 - Supplemental material for A comparison of two frameworks for multi-state modelling, applied to outcomes after hospital admissions with COVID-19
Supplemental material, sj-rda-1-smm-10.1177_09622802221106720 for A comparison of two frameworks for multi-state modelling, applied to outcomes after hospital admissions with COVID-19 by Christopher H Jackson, Brian DM Tom, Peter D Kirwan, Sema Mandal, Shaun R Seaman, Kevin Kunzmann, Anne M Presanis, and Daniela De Angelis in Statistical Methods in Medical Research
Supplemental Material
sj-Rmd-2-smm-10.1177_09622802221106720 - Supplemental material for A comparison of two frameworks for multi-state modelling, applied to outcomes after hospital admissions with COVID-19
Supplemental material, sj-Rmd-2-smm-10.1177_09622802221106720 for A comparison of two frameworks for multi-state modelling, applied to outcomes after hospital admissions with COVID-19 by Christopher H Jackson, Brian DM Tom, Peter D Kirwan, Sema Mandal, Shaun R Seaman, Kevin Kunzmann, Anne M Presanis, and Daniela De Angelis in Statistical Methods in Medical Research
Footnotes
Acknowledgements
This work was supported by the Medical Research Council programmes MRC_MC_UU_00002/11, MRC_MC_UU_00002/10 and MRC_MC_UU_00002/2. We are grateful to the Joint Modelling Cell and Epidemiology Cell at Public Health England for providing and discussing the CHESS data.
Author's note
The organization, Public Health England, provided in the second affiliation has just changed its name and restructured itself after submission of this article. Hence, Public Health England's new name is UK Health Security Agency.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.