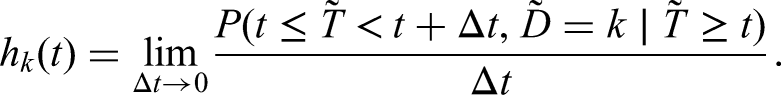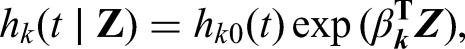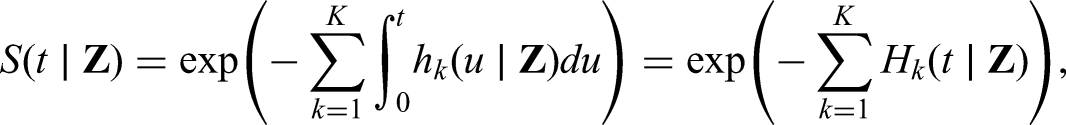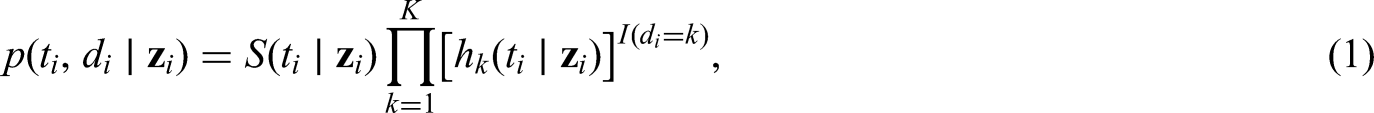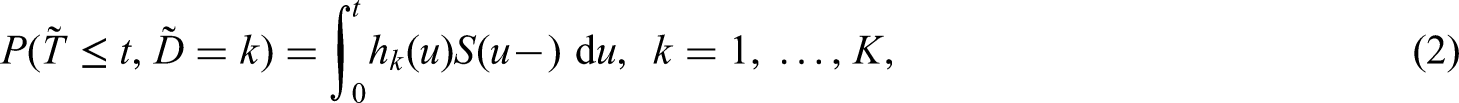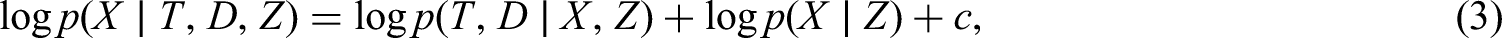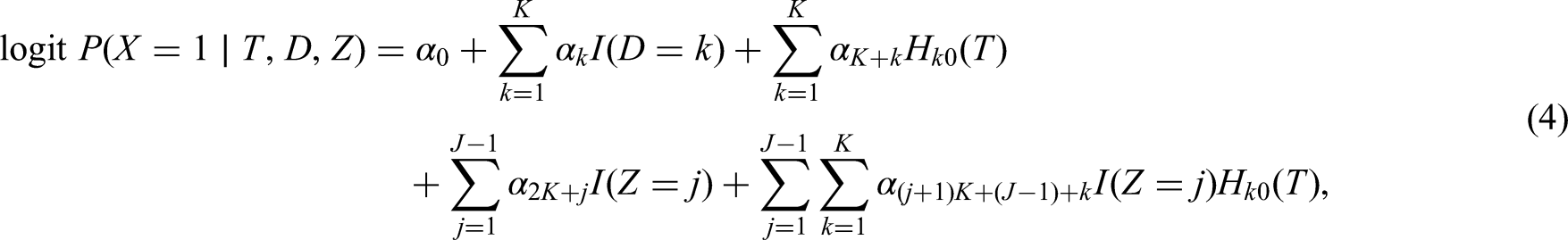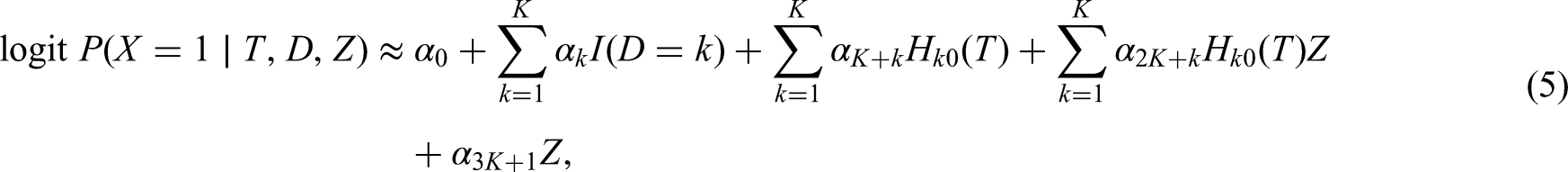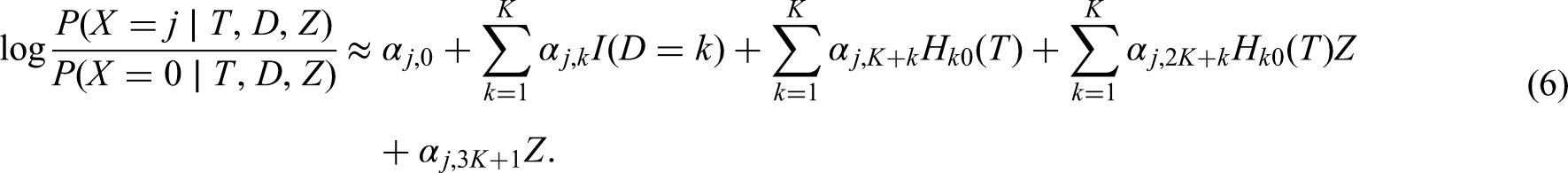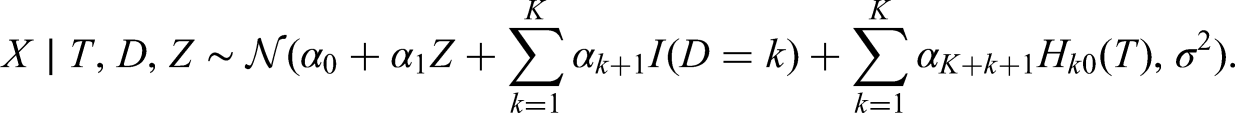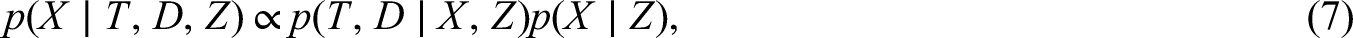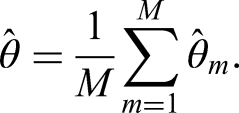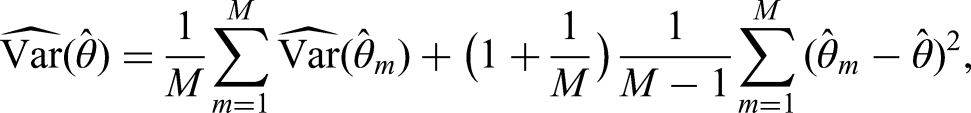In studies analyzing competing time-to-event outcomes, interest often lies in both estimating the effects of baseline covariates on the cause-specific hazards and predicting cumulative incidence functions. When missing values occur in these baseline covariates, they may be discarded as part of a complete-case analysis or multiply imputed. In the latter case, the imputations may be performed either compatibly with a substantive model pre-specified as a cause-specific Cox model [substantive model compatible fully conditional specification (SMC-FCS)], or approximately so [multivariate imputation by chained equations (MICE)]. In a large simulation study, we assessed the performance of these three different methods in terms of estimating cause-specific regression coefficients and predicting cumulative incidence functions. Concerning regression coefficients, results provide further support for use of SMC-FCS over MICE, particularly when covariate effects are large and the baseline hazards of the competing events are substantially different. Complete-case analysis also shows adequate performance in settings where missingness is not outcome dependent. With regard to cumulative incidence prediction, SMC-FCS and MICE are performed more similarly, as also evidenced in the illustrative analysis of competing outcomes following a hematopoietic stem cell transplantation. The findings are discussed alongside recommendations for practising statisticians.
Missing covariate data are of perennial concern in observational studies in medicine.1 The backbone of such studies are clinical registries, which collect patient data potentially spanning many countries and centres over long periods of time. These and other data management complexities can lead to various patterns of (possibly informative) missingness. Furthermore, these registries are often set up for multiple purposes leading to multiple studies where different potentially exclusive survival outcomes could be considered. Consequently, competing risks outcomes are frequently investigated. This refers to a setting in which individuals can only experience one of several mutually exclusive events.
In studies considering competing risk outcomes, interest can lie in both the probabilities of events occurring over time and the effect of covariates on the different competing events. Appropriate handling of missing data is then of central concern in view of avoiding potential bias and/or loss of power when estimating these quantities, as could be expected when using simple methods such as complete-case analysis (CCA).2
A more principled approach to handling missing covariate data is to use multiple imputation (MI), where a set of complete data sets is generated using samples based on an imputation model to fill in the missing values.3 A substantive model is then run on each of these data sets, before combining the estimates using rules that adequately reflect the uncertainty in the imputation procedure.4 The imputation model and the substantive model should ideally be compatible, that is, deriving from a joint model under which both models are conditionals. If data are missing across multiple covariates, the fully conditional specification approach can be used.5 This involves specifying an imputation model for each variable with missing values, fully conditional on the other variables, including the outcome. The procedure is better known under its more popular name ‘multivariate imputation by chained equations’ (MICE).6
In time-to-event analysis, a popular choice of substantive model is the Cox proportional hazards model. White and Royston7 showed that when using MICE in the context of a Cox model (in absence of competing events), for each covariate with missing data, the corresponding imputation model should include the remaining covariates, the event indicator, and the cumulative baseline hazard. To implement this model, the cumulative baseline hazard can be approximated by the marginal Nelson–Aalen estimate of the cumulative hazard. Moreover, depending on the type of covariate, the imputation model is simplified with a Taylor approximation for the non-linear terms from the Cox likelihood. In view of this approximate compatibility between the substantive and imputation model, Bartlett et al.8 proposed a variant of MICE called ‘substantive model compatible fully conditional specification’ (SMC-FCS). The approach ensures full compatibility between the imputation model and the substantive model by imputing missing covariate values in a rejection sampling procedure.
In competing risk settings, where the analysis model of interest is often a cause-specific Cox proportional hazards model, there has been little research addressing the appropriate use of MI when imputing missing covariate data.9 The most prominent work is that of Bartlett and Taylor, where the SMC-FCS approach was extended for cause-specific Cox models.10 In a simulation study as part of their work, Bartlett and Taylor compared SMC-FCS to an approximate MICE procedure proposed by Resche-Rigon et al.11 The proposal was an extension of the work of White and Royston for cause-specific Cox models. Simulation results suggested using SMC-FCS generally leads to estimates with little bias and nominal coverage.10 In contrast, the approximate MICE approach was often biased, with some mitigation using interaction terms in the imputation model.
Importantly, we remark that the algebraic motivation behind the approximate MICE approach is currently unpublished. Moreover, the work of Bartlett and Taylor is to our knowledge the only empirical comparison of this approximate MICE approach with the SMC-FCS approach. Thus, questions regarding the performance of both methods in a wider range of situations still remain. In addition, the question of how both the approaches perform with regard to predicted cumulative incidence functions is hitherto unexplored.
The aim of the present research is thus threefold. First, we aim to formally extend the work of White and Royston for cause-specific Cox models. Specifically, we will derive the approximately compatible imputation models for continuous, binary and multi-level categorical missing covariates. This extension was originally initiated by one of the authors of the current manuscript and shared as part of an oral presentation.11 Second, we aim to replicate and extend the simulations of Bartlett and Taylor; additionally manipulating the shape of the competing baseline hazards and the strength of missingness mechanisms, among other extensions. Third, we will explore how biases in cause-specific Cox models affect predicted cumulative incidence functions for patterns of reference covariate values. Simulation results will be interpreted alongside an illustrative analysis using a data set from the field of allogeneic hematopoietic stem cell transplantation (alloHCT).
In the Section 2, we present the motivating data set, and in the Section 3 we introduce notation for cause-specific competing risks analysis. In the Section 4.1 section, the algebraic motivation behind the imputation model for a cause-specific Cox analysis model is shown. The simulation study is presented in the Section 5, followed by an illustrative analysis in the Section 6. Findings are discussed alongside recommendations for practice in the Section 7.
Motivating example
Schetelig et al.12 assessed long-term outcomes of patients with myelodysplastic syndromes (MDS) or secondary acute myeloid leukemia (sAML) after an alloHCT. MDS is characterised by the production of deficient clonal blood cells in the bone marrow and can rapidly progress to more severe sAML.13 AlloHCT is the only treatment that can offer long-term remission of the disease. Therefore, alloHCT is recommended for disease stages at high risk of transformation into acute myeloid leukemia (AML) or death from other complications. However, this procedure is associated with a high risk of adverse outcomes, either due to relapse of MDS or sAML, or due to side effects of the (pre-)treatment. This leads to the competing risks outcomes relapse and non-relapse mortality.
The data set contains 6434 patients transplanted between 2000 and 2012, and registered with the European Society for Blood and Marrow Transplantation (EBMT). Several possible predictors measured at the time of transplantation have a substantial amount of missing values. Some examples of variables with missing values are cytogenetic classification (62.2% missing), comorbidity index (59.9% missing) and the Karnofsky performance score (32.8% missing). A cause-specific model for relapse with the aforementioned three variables as predictors, performed on complete cases only, makes use of a mere 20% of the full data set. The immediate lack of efficiency here prompted an investigation as to the performance of MI for such examples.
Cause-specific competing risks analysis
In a competing risks setting, we assume that individuals can ‘fail’ from only one of distinct events. We denote that failure time as , and the competing event indicator as . In practice, individuals are subject to some right-censoring time , which is assumed to be independent of and , possibly given covariates. We thus only observe realisations of and , where indicates a right-censored observation.
If we view competing risks as a multi-state process, with a single (event-free) initial state and absorbing states, interest often lies in the cause-specific hazard, defined for a single event as
This hazard function can be interpreted as the instantaneous force of transition, or intensity, of moving between the initial state and state .14,15 A model can then be specified, conditional on a covariate vector . A Cox model is a common choice, defined for a failure cause as
where is the cause-specific baseline hazard, and represents the effects of covariates on the cause-specific hazard. We note that in what follows, we use ‘effect’ to refer to the impact of a covariate in a multivariable model where there may be non-negligible additional confounding, and this should hence not be interpreted as a fully causal quantity. Furthermore, the hazard functions define the failure-free survival probability:
where is the cause-specific cumulative hazard for cause . Assuming conditional non-informative censoring, the likelihood contribution of an individual with observations is then
where is the indicator function. The covariate effects on the cause-specific hazard can then be estimated by optimising the partial likelihood.16 This follows from the observation that the above expression factorises into separate factors for each cause , which each corresponding to a standard Cox likelihood function where events from all other causes are treated as censored observations.17
Cumulative incidence functions
Beyond assessing covariates, cause-specific hazards can also be used to estimate the so-called cumulative incidence functions, defined as
where is the failure-free survival probability just prior to .18 This cumulative incidence function, or transition probability, is the probability of experiencing event before or at time . It is also known as the absolute, or crude risk. It can be computed either non-parametrically, or semi-parametrically if Cox models are specified for the . In the latter case, the cumulative hazards derived from the Breslow estimator of the cumulative cause-specific baseline hazards are used as ingredients for estimating the cumulative incidence for cause .
This implies that we do not need to model the cumulative incidence function directly in order to obtain these predicted probabilities, as is done when using the Fine-Gray model.19 This is helpful given that in observational studies, interest is seldom in prediction alone: predictions are often presented after first reporting and interpreting model coefficients. The cause-specific hazards framework provides a more natural scale on which to interpret covariate effects and allows to obtain predicted patient-specific cumulative incidence functions for all causes.
Methods
In this section, we provide a framework for using MICE and SMC-FCS for both estimation of cause-specific regression coefficients and cumulative incidence functions. Throughout, we assume that data are missing according to a missing (completely) at random mechanism, hereafter abbreviated as M(C)AR.
Fully conditional approach (MICE)
We introduce as a single, partially observed covariate, and as a fully observed covariate. We note that could also represent a vector of complete covariates. Appropriate use of MICE for cause-specific competing risks analysis requires the specification of an imputation model, from which a number of imputed data sets are generated. Detailed derivations for are provided in appendix A, which we summarise in the present subsection.
To begin with, we note that by Bayes’ Theorem,
where is a constant term that does not depend on . For , a cause-specific Cox proportional hazards model for each failure cause is specified as . In case of binary or continuous and , and are scalars; for categorical or with two or more levels, and are vectors and and represent dummy codings for the levels of the covariates. To impute from the fully conditional distribution in Equation (3), we also need to specify a model for the missing data, . This model will generally vary depending on the covariate type of .
Binary X
If is binary, we could assume . If is categorical with levels (without loss of generality assuming that takes values in ), we can write
which implies that for categorical we can impute missing values using a logistic regression with (as a factor variable), the cumulative baseline hazards for all causes of failure, (as a factor variable), and the complete interactions between the cumulative baseline hazards and . For continuous , results are no longer exact. Using a first-order Taylor approximation for the term, we can write
which is valid if is small. This approximate imputation model thus uses , , all and the interactions between all and as predictors in a logistic regression. Note that the parameters used above and in the next subsections represent the imputation model coefficients, and are themselves functions of other (substantive and missing data model) parameters. Therefore, these will vary depending on the covariate types of and , and the parametrisation of the substantive model (i.e. whether each cause-specific model has the same predictors, and their functional forms).
Nominal categorical X
If is a categorical covariate with levels and , we can specify different imputation models depending on whether is ordered or not. In the unordered (nominal) case, we can specify a multinomial logistic regression for , yielding
This comes as a result of generalising to , and holds for continuous as in (5). For categorical or no , where for the former should be used as in equation (4), the expression for the fully conditional distribution is exact as in the binary case. The predictors to be included in the imputation model are exactly the same as for binary .
Ordered categorical X
For ordered categorical , a proportional odds model could be assumed as . This however implies that the fully conditional distribution requires specifying , which does not have a standard proportional hazards density. Instead, it has a weighted sum of proportional hazards densities. Thus, the expression for does not extend from the binary case in any simple form. Nevertheless, a proportional odds model including , and all could still be used to impute the missing values, though the properties of such a model are not currently well known. We refer the reader to the book written by McCullagh and Nelder for a detailed description of both the multinomial logistic regression and proportional odds models.20
Continuous X
If is a continuous covariate, we could assume it to be normal conditional on (possibly after transformation), as . The implied expression for is not normal due to the term, and so a bivariate Taylor approximation is used around the sample means and . To the first degree, the approximate fully conditional density is expressed as
This suggests a model for imputing continuous should be a linear regression with , and all again as predictors. With a quadratic approximation for , the accuracy of the above model can be improved by additionally including the interactions between all and . The approximations are valid under the assumption of small .
We note that the above models, like in the simple time-to-event settings, cannot be implemented without a working estimate of – whose true values we will assume are unknown. For the competing risks setting, we can use the marginal Nelson–Aalen estimate of the cumulative cause-specific hazard (which requires treating all events other than as censored) as an approximation for . As explained by White and Royston, this approximation becomes poorer with larger true covariate effects.7 We may then expect the estimated covariate effects after the imputation procedure to be biased.
Substantive model compatible approach
We refer the reader to the work of Bartlett et al.8 for a detailed introduction of the SMC-FCS method, and to the work of Bartlett and Taylor10 for its specific extension to cause-specific Cox proportional hazards models. Briefly, the SMC-FCS method (in the current setting) is based on the application of Bayes’ theorem,
which was already introduced on the logarithmic scale in Equation (3). The parameters associated with both and are omitted for readability. In essence, the procedure involves choosing as a proposal density and using rejection sampling to draw possible values for missing from a density proportional to . This is under the assumption that is simple to sample from, as is the case if we specify a model for it, e.g. a linear regression of conditional on . The imputation model is then compatible with the substantive model in the sense that a joint distribution exists which contains both the substantive model and the imputation model as its conditional distributions. If multiple covariates have missing data, it is still possible to specify mutually incompatible models for , but each fully conditional distribution will be compatible with the substantive model.
In contrast to MICE, the SMC-FCS approach does not require any approximations – neither for the non-linear terms nor for the cumulative baseline hazard. Of course, the cumulative baseline hazard still needs to be evaluated in order to draw from (7). In order to do so, the Breslow estimate is used and is updated at each iteration of the imputation procedure conditional on the most recent draws from the posterior distribution of the regression coefficients.
Regression coefficients
Both the MICE and SMC-FCS procedures result in imputed data sets. In each of these data sets, the cause-specific Cox model for one or more of the causes of failure is fitted. Let denote a cause-specific regression coefficient of interest, and let and , respectively denote the estimate and associated variance of this coefficient in the th imputed data set. We can combine these estimates using Rubin’s rules, with estimator
The associated variance estimator is
which combines estimates of within and between imputation variance.4 The estimate of the standard error is then readily obtained as .
Predicted probabilities
To obtain the predicted cumulative incidence functions for an individual with fully observed covariates after an MI procedure, there are at least two possible options. The first is to pool the regression coefficients and baseline hazards separately, and use those to produce a single predicted curve. The second approach is to use the substantive models fitted in each imputed data set to create imputation-specific predictions, and then pool those (possibly after transformation) using Rubin’s rules. The articles by Wood et al.21 and Mertens et al.22,23 recommend the second approach, which is the one we employ in the present paper.
Simulation study
We designed a simulation study with the aim of comparing the performance of CCA, MICE and SMC-FCS in the presence of missing baseline covariate values for cause-specific Cox proportional hazards models with two competing events. We assessed performance with respect to estimated regression coefficients and predicted cumulative incidence functions.
Data-generating mechanisms
We generated data sets containing individuals, with one record each containing both predictor and outcome information.
Covariates
Two covariates and were generated in each data set. We varied the covariate type of as either continuous or binary, and was fixed as continuous. When both covariates were continuous, they were generated from a bivariate standard normal distribution , with means , variances and correlation .
When was binary, we assumed and , with a point-biserial correlation between the two variables of . We can generate observations in this way by first generating and from a bivariate standard normal distribution with correlation , and then dichotomising at 0 (the value of the standard normal quantile function for a probability of 0.5) to produce . We refer the reader to the work of Demirtas and Hedeker for a description of this well-established procedure.24
Competing event times
We based our simulation of event times on the motivating alloHCT example described in the Section 2 section, focusing on the two competing events relapse (REL) and non-relapse mortality (NRM) over a 10-year follow-up period. To generate the failure times for the competing events, we made use of latent failure times, denoted for REL and NRM, respectively.25
Typically in alloHCT studies, patients are at very high risk of both relapse and NRM in the initial period after alloHCT, with this risk gradually decreasing thereafter as they survive longer. For this reason, generating failure times from a distribution with a decreasing hazard function is appropriate. The Weibull distribution, with probability density function , with shape and rate , accommodates decreasing hazards for . This is the parametrisation used in the text by Klein and Moeschberger.26
We thus generated both latent failure times from independent Weibull distributions, assuming cause-specific proportional hazards conditional on and . We furthermore generated independent censoring times from an Exponential distribution. In summary:
where is the censoring rate, and and are the baseline hazard rates for REL and NRM, respectively. We then defined , with an associated factor variable , where if REL occured first, and otherwise. The generated observed (event or censoring) time was then defined as , with corresponding indicator .
We used estimates from cause-specific marginal accelerated failure time (AFT) models on the motivating data set to fix the parameters values of the baseline shape and hazard rates for the latent failure times. Weibull AFT models for both causes of failure led to fixing , , , and . An exponential AFT model for the censoring distribution motivated setting . Since the baseline hazards for both competing events were estimated to be very similar, we decide to also vary , such that REL had a steadily increasing hazard. Both these ‘similar’ and ‘different’ baseline hazard configurations lead to comparable marginal 10-year cumulative incidences of both events, in the 35–45% range. Regarding cause-specific regression coefficients, we varied , and fixed , and .
Missing data mechanisms
was conserved as a complete covariate, and missingness was induced in . Let indicate whether elements of were missing () or observed (). We varied the proportion of missing values as either ‘low’ with 10% missing, or ‘high’ with 50%. We defined four separate missingness mechanisms:
Missing completely at random (MCAR), defined as or .
Missing at random (MAR) conditional on , which was defined as .
Outcome-dependent MAR (MAR-T), which was defined as . is , standardised to have zero mean and unit variance. Note that was the observed (event or censoring) time; if missingness depended on the true event time, this would lead to a missing not at random mechanism.
Missing not at random (MNAR) conditional on , which was defined as .
For mechanisms (2)–(4), represented the strength and direction of the missingness mechanism. For example, if in the MAR mechanism, observations with smaller values of the had a larger probability (increasing with more extreme ) of the corresponding being missing. In the present study, we varied , representing ‘weak’ and ‘strong’ mechanisms, respectively. In this context, the MAR-T mechanism could reflect a measurement that is only collected if a subject survives long enough into a study and is in follow-up, as may be the case with a genetic test. Although this kind of measurement is collected or only available at a later point in time, it can still be considered as baseline information and does not constitute conditioning on the future.
The value of was chosen (in each simulated data set) such that the average missingness probability was equal to either 0.5 or 0.1. This was done via standard root-solving for a fixed value of .
Design
The simulation study is chosen to follow a partially factorial design, where the parameters outlined above are varied systematically. A full factorial design would result in 4 (missingness mechanisms) 2 (mechanism strengths) 2 (proportions missing data) 2 (covariate types for ) 2 (baseline hazard parametrisations) 2 (effects magnitudes of on cause-specific hazard of REL) scenarios. However, the strength of the missingness mechanism cannot be varied for MCAR settings by definition, leaving scenarios in total.
Estimands
The analysis models of interest are the cause-specific Cox proportional hazards models for REL and NRM, for . We then have two main sets of estimands of interest:
, which are the data-generating regression coefficients from both cause-specific Cox models.
, which is a vector containing the REL and NRM probabilities (cumulative incidences) for a set of reference patients at 6 months, 5 years and 10 years after baseline.
These reference patients were defined by all combinations of with for continuous , and for binary . Since the data-generating coefficients for both competing events had a positive effect on the cause-specific hazards, one could for example refer to as a ‘high risk’ individual, and ‘low risk’ for .
Methods
Five missing data methods were compared in each simulation scenario:
– an analysis run on a data set after listwise deletion.
– MI with imputation model predictors including , the event indicator solely for event one i.e. , and the cumulative hazard for REL (at the end of follow-up for each individual), based on the Nelson–Aalen estimator, as an approximation of the cumulative baseline hazard .
– MI with imputation model predictors including , the event indicator as a three level factor variable, and the cumulative hazards for both events and ; outlined in the ‘Fully conditional approach (MICE)’ section.
– identical to the , with the addition of the interactions and ; outlined in the Section 4.1.
SMC-FCS – the approach outlined in the Section 4.2, using as sole predictor in the model (default setting).
The method corresponds to the ‘FCS survival’ method explored in the simulation study by Bartlett and Taylor, where failures other than cause one are treated as censored and the cumulative hazard of cause two is omitted from the imputation model. It corresponds to a direct application of the White and Royston results7 to the cause-specific Cox model for cause one, which may present itself as intuitive when interest lies in a single failure cause.
Additionally, the model was also fitted on the complete data set prior to any missingness being induced in . For the imputation methods, the number of imputed data sets was varied as . We set since no substantial reduction in empirical standard errors was observed over trial runs with . We also note that for , the imputations were not re-run independently. Results were instead pooled across the first 5, 10 or 25 imputed data sets from the original 50.
When was continuous, the imputation model was linear regression. For binary , the imputation model was logistic regression. We note that since there was only one partially observed covariate, chained equations were not needed. Nevertheless, we still refer to methods , and under the general umbrella term ‘MICE’ methods when reporting the results.
Performance measures
For , we recorded the point estimates, empirical and estimated standard errors, absolute bias and coverage probabilities. As our primary measure of interest was bias, we based the number of simulation replications per scenario on a desired Monte–Carlo standard error (MCSE) of bias. As per Morris et al.,27 this is defined as . We assumed that (largest empirical standard error to be expected with binary , based on small trial run), and we deemed a to be appropriate. We thus required replications per scenario, which we rounded up to . We thus generated 160 independent data sets per simulation scenario.
For , we recorded the point estimates, empirical standard errors, absolute bias, coverage probabilities and root mean square error (RMSE). We focus primarily on reporting bias and RMSE. Based on trial runs, we assumed , which for 160 replications would result in a . We thus proceeded with the same number of simulated data sets.
Software
All analyses were performed using R version 3.6.228. The substantive model compatible imputation was performed using the SMC-FCS package version 1.4.1,29 and MICE was performed using the mice package version 3.8.0.30 The cause-specific Cox models were run and subsequent predicted cumulative incidences were obtained using the mstate package version 0.2.12.31
Results
We focus primarily on (the regression coefficient for in the cause-specific REL model) and the 5-year probabilities of REL and NRM. For the imputation methods, we present results only with . Full results are reported in the Supplemental materials, linked at the end of the present text.
Regression coefficients
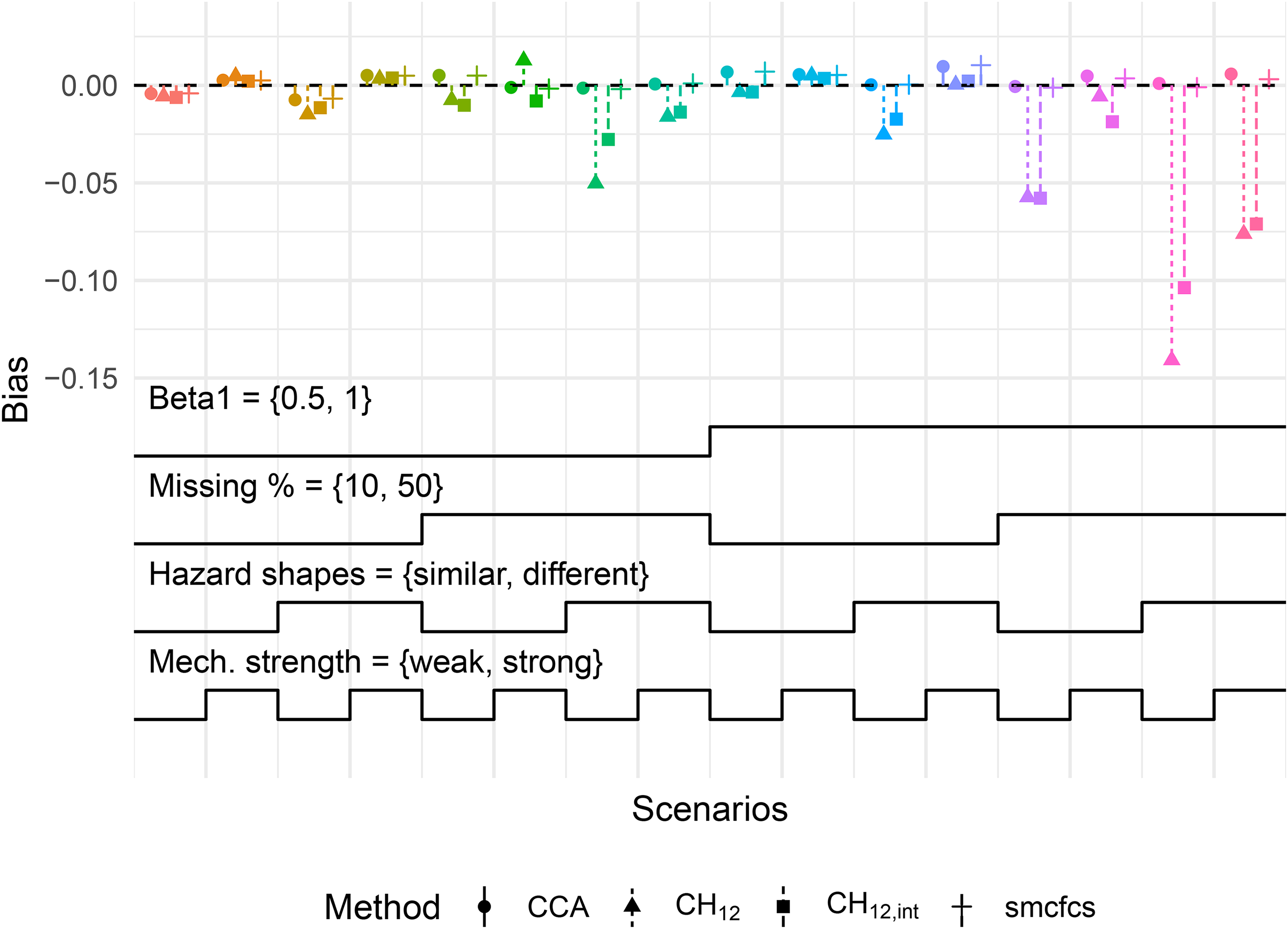
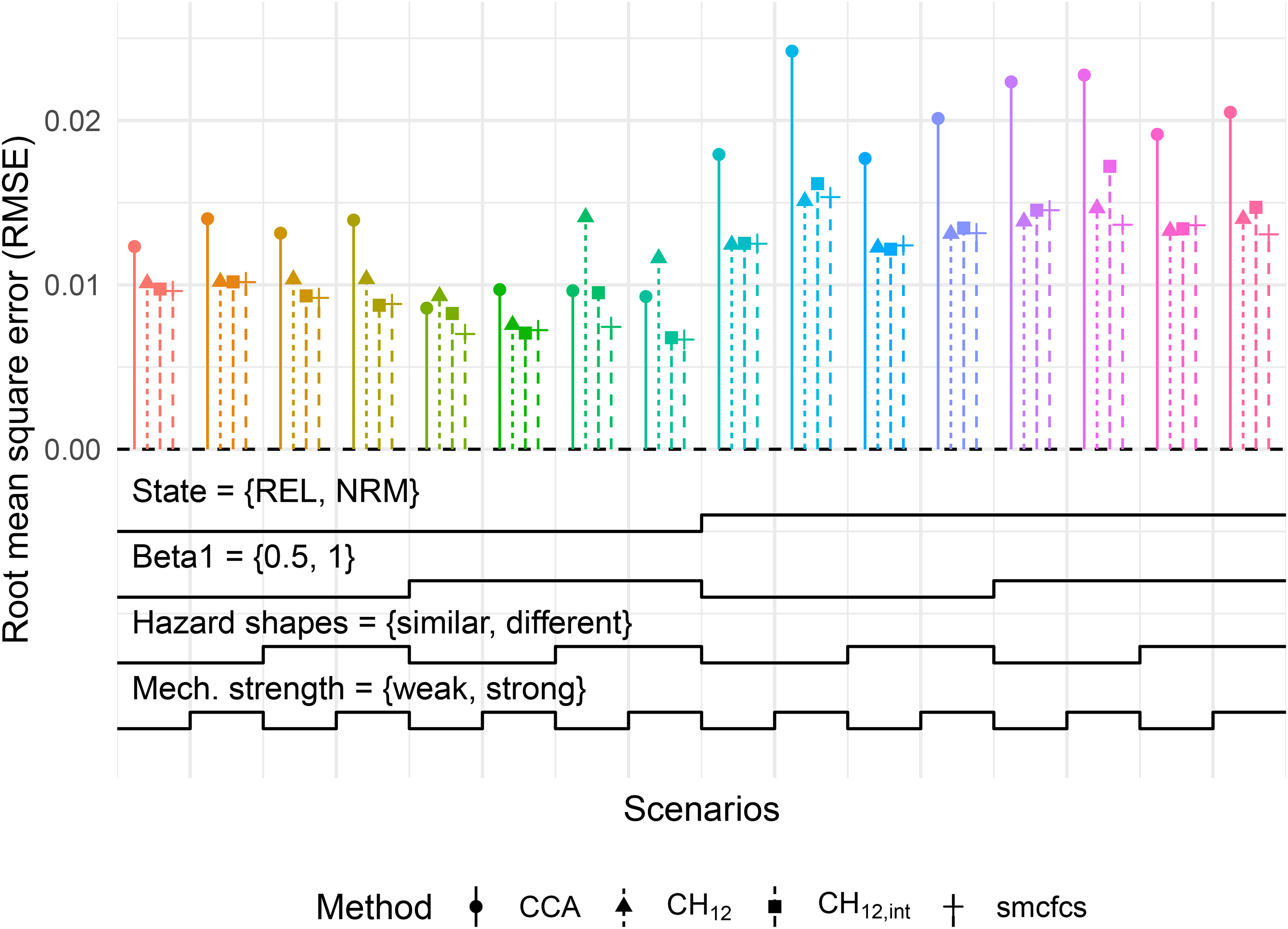
Figure 1 summarises the results with regard to bias in the estimation of with a MAR mechanism induced on continuous . The plot is a variant of a nested-loop plot, where each colour-cluster of points represents a scenario defined by the step functions at the bottom of the plot.32 For example, the left-most bin in the plot corresponds to a scenario with data-generating , 10% missing data, similar hazard shapes and a weak missingness mechanism. For readability, the method and the analysis ran on the full data set prior to inducing missing data are omitted from the Figure.
Bias in for MAR mechanism with continuous . Each cluster of points corresponds to a scenario defined by the step functions at the bottom of the plot. Each step represents a level of a factor being varied and is read from left to right (e.g. for Hazard shapes, the first step is ‘similar’ while the second is ‘different’). Monte-Carlo standard errors of bias for all scenarios were below 0.008. Mech.: missingness mechanism; MIR: missing at random.
First, we note that in the 16 scenarios depicted, both and SMC-FCS showed little to no bias in the estimation of . For , no bias was expected given that this was a case of covariate-dependent MAR, and results for SMC-FCS were in line with the simulations of Bartlett and Taylor.10 Second, the MICE methods showed varying amounts of bias depending on the scenario. With increasing true covariate effects and a higher proportion of missing values, the bias was larger. This was to be expected in light of the approximations employed in the Section 4.1, which are valid for small covariate effects. Moreover, the magnitude of the bias was also larger when the baseline hazard shapes were different. Last, adding the interaction terms in the imputation model did not significantly reduce bias, except when the missingness mechanism was weak, and the baseline hazard shapes were different.
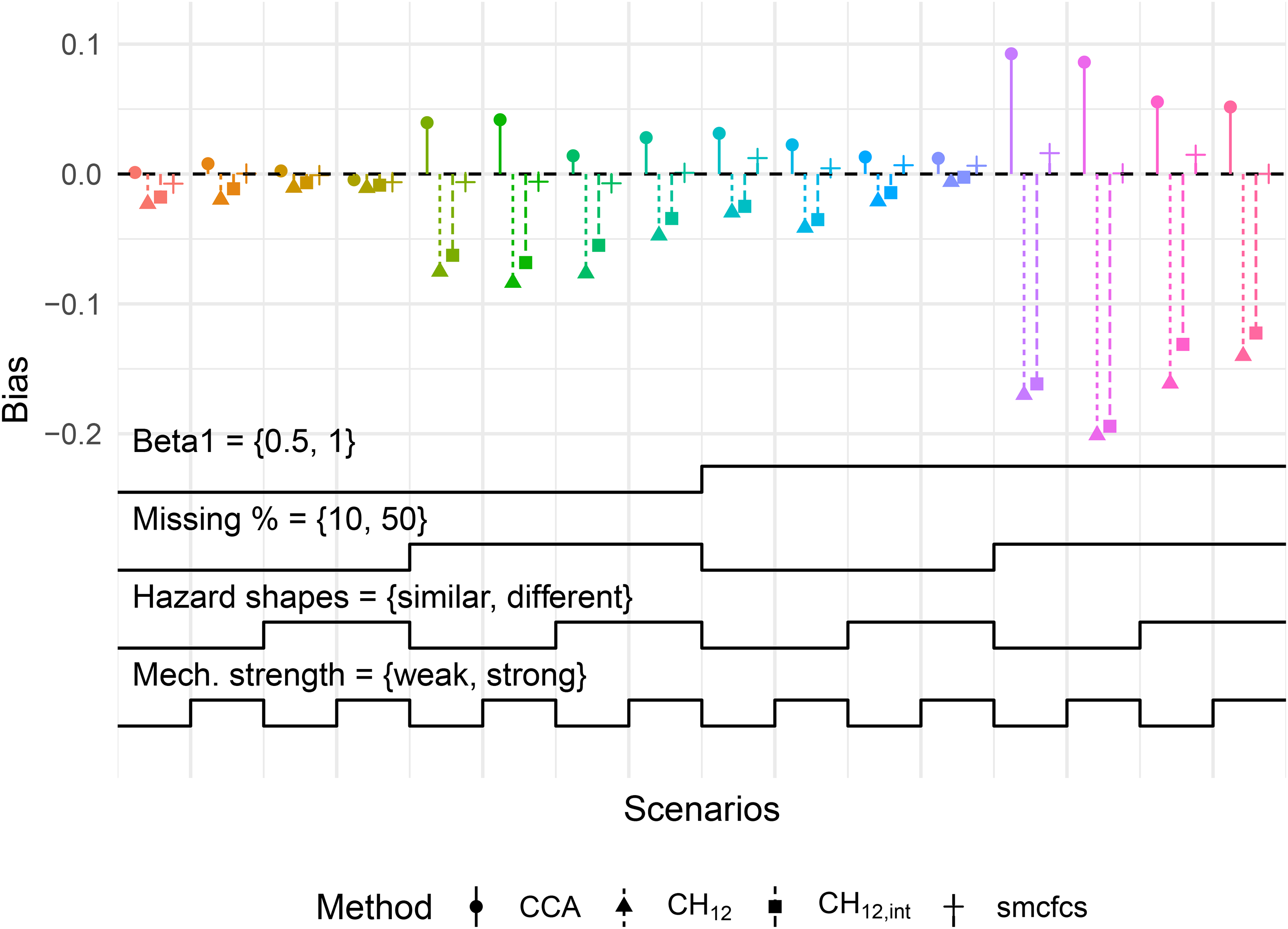
In contrast, we also present the results for with a MAR-T mechanism in Figure 2, again with continuous . In this case, was consistently biased, as is expected when missingness is dependent on the outcome. Particularly for a high proportion of missing values, the bias in both MICE methods was even more severe than that of , reaching close to 20% (relatively). Conversely, SMC-FCS was consistently unbiased across the depicted scenarios.
Bias in for MAR-T mechanism with continuous . Monte-Carlo standard errors of bias for all scenarios were below 0.008. Refer to Figure 1 for a description on how to read this type of plot. Mech.: missingness mechanism; MAR-T: outcome-dependent missing at random.
We also briefly summarise some of the more general findings across the simulations reported in the Supplemental material. First, efficiency gains (in the form of smaller estimated standard errors) were mainly observed for and . Second, the method yielded the largest biases and lowest coverage probabilities of all methods. This was unsurprising, as corresponded to imputing as if competing outcomes were considered as censoring. Third, the findings with MCAR missingness were largely analogous to those of the MAR reported above; and in presence of MNAR, all imputation methods (including SMC-FCS) showed appreciable bias. Last, in scenarios with binary , the overall bias in the MICE methods was lower with respect to scenarios with continuous . This could be attributed to the different terms that are being approximated in the imputation models. In addition to the cumulative baseline hazards, only is being approximated in the case of binary , whereas in the continuous case a fuller is being approximated.
In terms of RMSE, which summarises both bias and variance, the differences in performance between the methods in M(C)AR scenarios wwere smaller, aside from when missingness was high and the baseline hazard shapes were different (see for example Figure 2.1.2 of the Supplemental material on regression coefficients).
Predicted probabilities
Concerning predicted probabilities, we focus on the estimation of 5-year REL and NRM probabilities for a ‘low-risk’ individual, i.e. with continuous . Figure 3 summarises the RMSE of these probabilities under a MAR mechanism where 50% of values are missing.
RMSE of 5-year REL and NRM probabilities with for MAR with 50% missing values. Monte-Carlo standard errors of RMSE for all scenarios were below 0.002. Refer to Figure 1 for a description on how to read this type of plot. Mech.: missingness mechanism; RMSE: root mean square error; REL: relapse; MAR: missing at random; NRM: non-relapse mortality.
We point the reader to the -axis of the plot, where results are now on the probability scale. The largest RMSE reported in the plot was just under 2.5%, with most RMSE values for the imputation methods being under 1.5%, with little to no difference between them. In these scenarios, the imputation methods outperform , but with the finest of margins. This is part of a general finding across the simulations: the predicted probabilities when using the imputation methods overall had very little bias, and little reduction in variability was observed beyond imputations. We note that since all methods were similarly biased under M(C)AR (as seen for example in Figure 1.2.1 of the Supplemental material on predictions), the RMSE for is expected to be a factor of larger than for the imputation methods when missingness was ‘high’, given that used half as much data.
We propose various explanations for this behaviour. First, we note that the prediction results for (with continuous or binary) can be taken as a proxy for how precisely the cause-specific baseline hazards are estimated. For all non-MNAR scenarios, little to no bias was found in the predicted probabilities for these reference patients. This may be additionally linked to the fact that and are centred and normal, which could imply that is adequately approximated by the Nelson–Aalen estimator. Second, regarding regression coefficients, bias was primarily observed in and , with the former showing more extreme bias when data-generating . Estimates of and however generally only exhibited biases of up to 5% in the MAR scenarios, and slightly higher for in MAR-T scenarios. Well-estimated cause-specific baseline hazards in tandem with close to unbiased estimates of could then explain the small bias in the predictions, since bias in the linear predictor as a whole () only reached 10% in the most extreme cases, and was mostly below the 5% mark otherwise.
Additional simulations
In Supplemental material I (available online), we performed two additional simulation studies. The first investigated the use of the Breslow estimates of the cumulative baseline hazards in the imputation model, updated at each iteration of the imputation procedure. Consistent with earlier results in the standard survival setting, MICE using intra-iteration updates of the Breslow estimates performed no better than using the marginal cumulative hazards in the imputation model.7 The second study assessed the performance of the MI methods in the presence of competing events. In this setting, SMC-FCS remained unbiased, while the MICE methods including additional interaction terms performed slightly better than those without.
Illustrative analysis
We used the motivating alloHCT data set introduced in the Section 2 illustrate the methods described in the simulation study. Cause-specific Cox proportional hazards models were fitted for both REL and NRM, conditional on a set of baseline predictors chosen on the basis of substantive clinical knowledge. An overview of these predictors, including their names, descriptions and proportion of missing values, can be found in Appendix B. The same predictors were used in the models for REL and NRM.
We used the , and SMC-FCS methods to handle the missing baseline covariate data, which we assumed to be MAR. Given that did not show much improvement over in the simulation study, we decided to use the more parsimonious latter. Therefore, the imputation model for a partially observed covariate using contained as predictors the remaining fully and partially observed covariates from the substantive model, and the marginal cumulative hazards for both events. For SMC-FCS, the imputation model similarly contained the remaining fully and partially observed covariates from the substantive model, which is the default setting. Continuous covariates were imputed using linear regression, binary covariates using logistic regression, ordered categorical using proportional odds regression and nominal categorical using multinomial logistic regression. Since missingness spanned multiple covariates, chained equations were required.
To motivate the choice of for and SMC-FCS, we used von Hippel’s quadratic rule based on the fraction of missing information (FMI) rather than the proportion of complete cases.33,34 We first ran a set of imputations, with iterations. After pooling, the coefficient with largest FMI was that of donor age in the model for NRM, with a value of approximately 0.49. Based on an 95% upper-bound for this FMI, and for a desired coefficient of variation of 0.05, we would require approximately imputed data sets. We rounded this upwards, and performed our final analysis with . We conserved as convergence was generally observed from 10 iterations onwards.
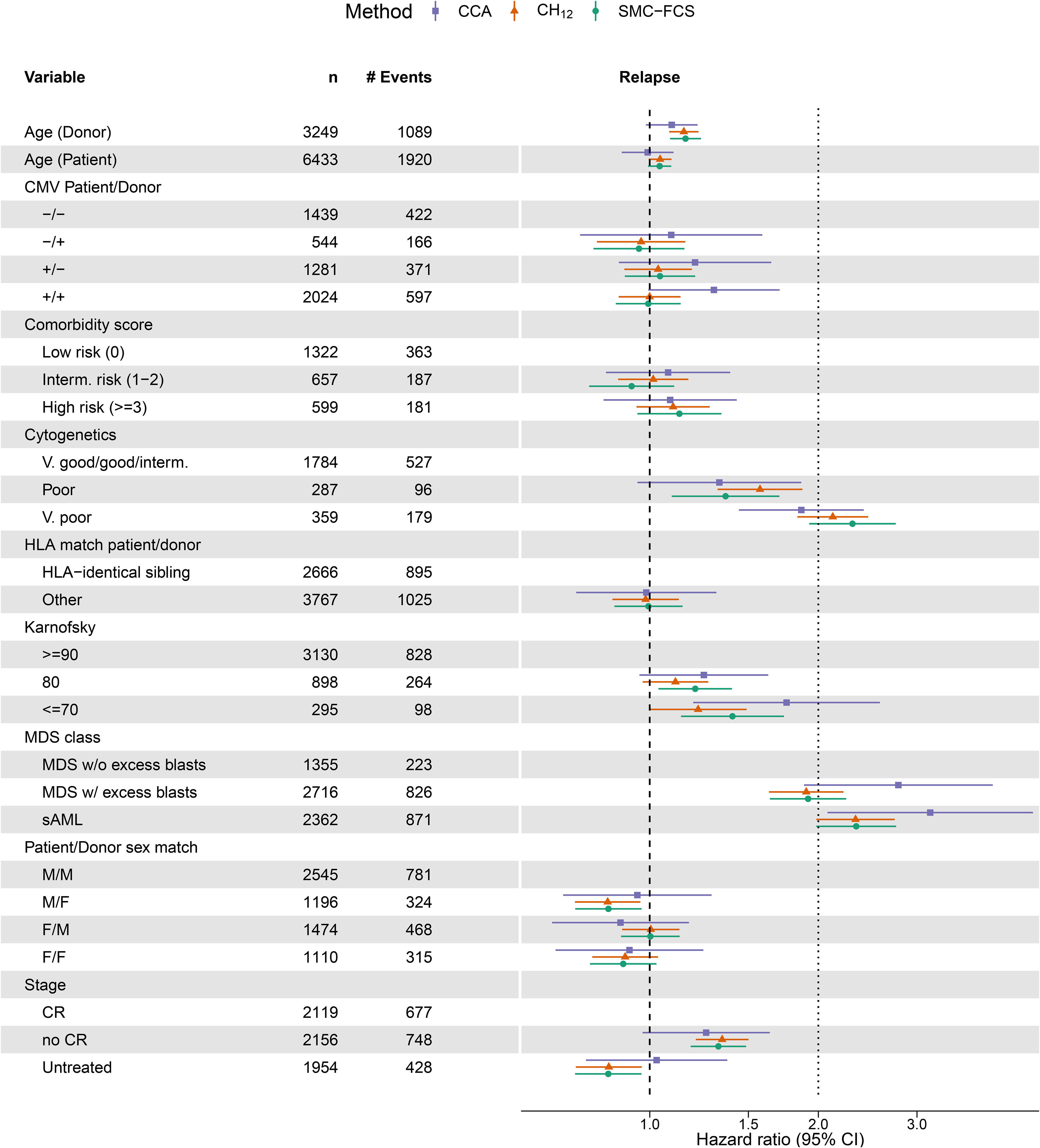
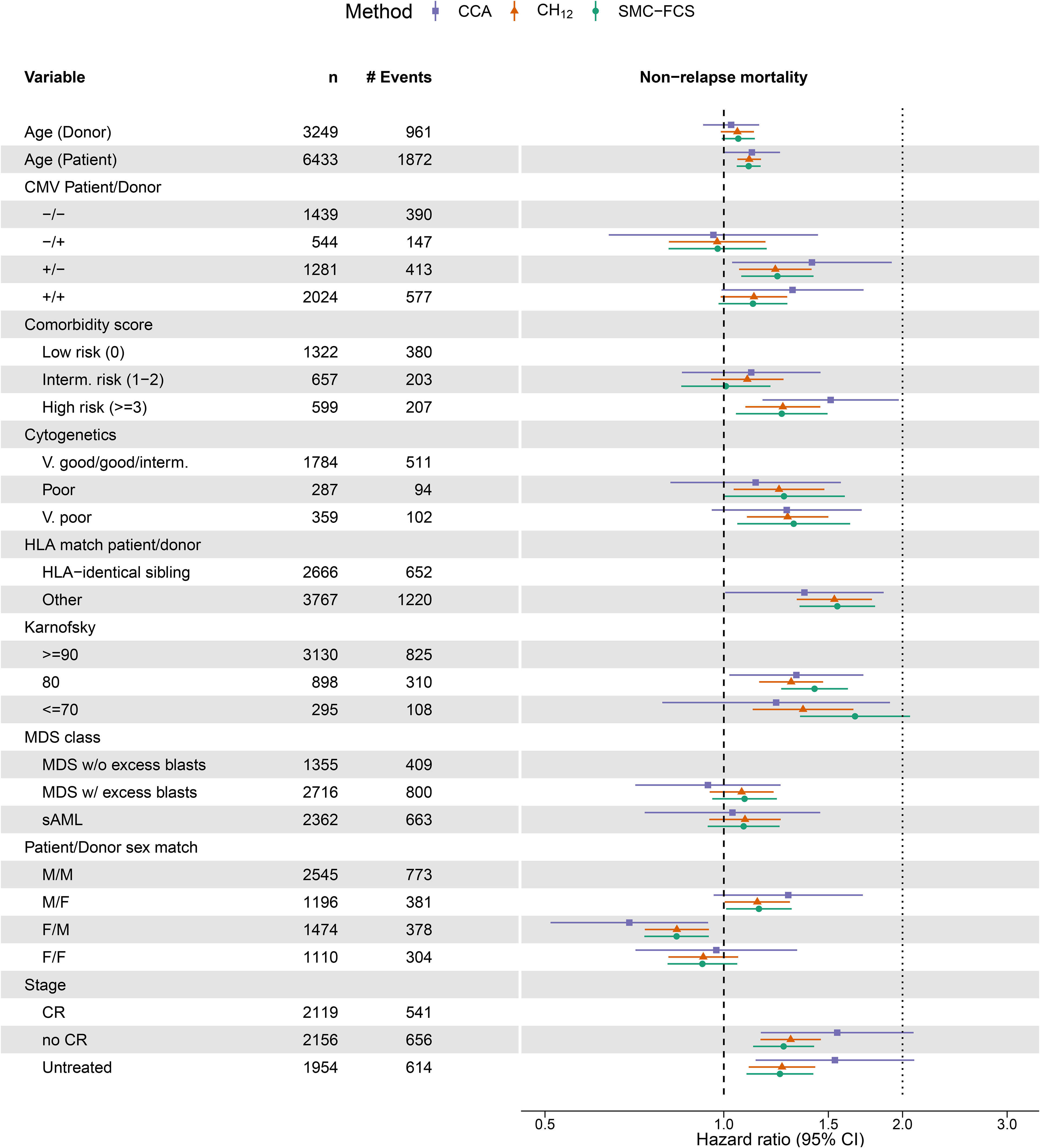
Figure 4 summarises the exponentiated point estimates (hazard ratios, HR) and associated 95% confidence intervals (CI) from the cause-specific model for REL. The CIs for and SMC-FCS are based on the pooled standard errors and the -distribution. First, we observed a clear gain in efficiency across all coefficients for both imputation methods relative to . Second, there was general agreement between the estimates obtained from both and SMC-FCS; a finding which was also reported in the illustrative analysis in the work by Bartlett and Taylor.10 Third, we did note some differences between and the imputation methods for certain variables, such as remission status or Karnofsky score. The most surprising case of this was with the MDS class of the patient, which was completely observed. In the model for REL, the HR for the sAML category estimated with is just above three, whereas the imputation methods estimate it much closer to two. This also raises the point that for categorical variables, differences in methods can be seen on the category level rather than on the variable level as a whole – as also evidenced by the estimated HRs for the cytogenetics variable. Results for the cause-specific NRM model are summarised in Figure 5.
Forest plot with point estimates and 95% confidence interval for the cause-specific Cox model for Relapse. On the -axis are the hazard ratios, which is plotted on the log scale where the confidence intervals are symmetric. Variables and their descriptions can be found in the data dictionary. Per level of factor and for continuous variables, we show the observed counts () and the number of relapse events (# Events) in the full data set.
Forest plot with point estimates and 95% confidence interval for the cause-specific Cox model for non-relapse mortality (NRM). On the -axis are the hazard ratios, which is plotted on the log scale where the confidence intervals are symmetric. Variables and their descriptions can be found in the data dictionary. Per level of factor and for continuous variables, we show the observed counts () and the number of NRM events (# Events) in the full dataset.
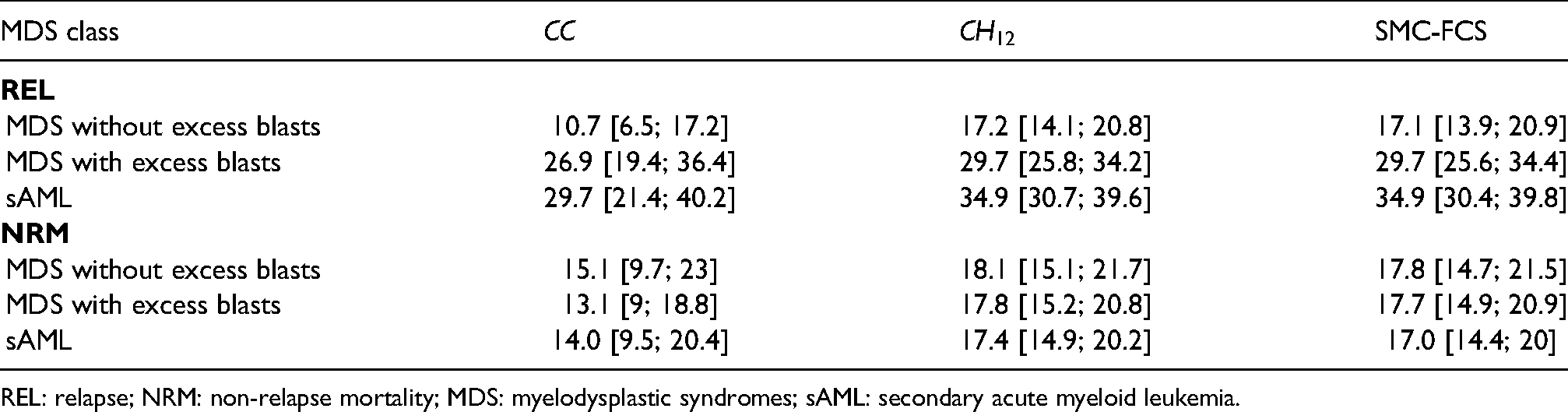
Furthermore, we computed the predicted 5-year cumulative incidences of REL and NRM for a set of three reference patients. These corresponded to the three MDS classes, all with the median patient and donor ages at transplant, and with reference levels for the remaining categorical covariates. Table 1 summarises the point estimates, and corresponding 95% CIs. For the imputation methods, the variances of the predicted probabilities were obtained with the Aalen estimator.35 Subsequently, the 95% CIs were constructed after transformation on the complementary log-log scale, as described in the work of Morisot and colleagues.36 For comparability, the CIs for were also constructed on the complementary log–log scale. In line with the results from the estimated regression coefficients, both imputation methods yielded quasi identical results. By contrast, yielded cumulative incidences that were generally lower by approximately 3–7 percentage points, with CIs that were up to twice as wide.
Predicted cumulative incidence (%) of both REL and NRM at 5-years for three reference patients with different MDS classes, reference levels for categorical covariates and sample median values for continuous covariates. The 95% confidence intervals were constructed based on a complementary log-log transformation.
Such differences between the MI methods and do question the validity of the M(C)AR assumption made. In the EBMT registry, many missing values can be considered MCAR, for reasons relating to data management. Variables such as comorbidity score, cytogenetic classification and donor age became more frequently collected over time as their clinical relevance grew clearer. Missingness may also be related to the transplant centre, i.e. particular measurements not being recorded in certain clinics. In the current analysis, both calendar date and transplant centre (categorical, large number of levels) were not included in the imputation model for simplicity. An option would have been to include them as auxiliary variables (added as predictor to , but not to substantive model), however, the use of auxiliary variables was not a focus of this manuscript, and both MICE and SMC-FCS make different assumptions with respect to the inclusion of these variables in the imputation model. Specifically, SMC-FCS would assume independence of centre and outcome given the covariates in the substantive model – an assumption which likely does not hold in the registry.37
Discussion
In this paper, we assessed the performance of currently implemented MI methods, MICE and SMC-FCS, that deal with missing baseline covariate data when the analysis model of interest is a cause-specific Cox proportional hazards model. For the MICE approach, we provided motivation for the imputation models to be used for continuous, binary, multi-level nominal and ordered categorical covariates with missing values. This is an extension of the work of White and Royston on Cox proportional hazards models for standard survival outcomes.7
We covered a wide range of scenarios in our simulation study, also investigating parameters commonly not addressed in simulation studies for this or similar problems, such as the shape of the baseline hazard and strength of association in the missingness model. Our results confirm the findings of the earlier work of Bartlett and Taylor.10 Namely, in terms of estimating regression coefficients, SMC-FCS categorically outperforms MICE across all investigated non-MNAR scenarios. Adding the interactions in the imputation model improves performance somewhat, but the substantial bias remains. When using MICE, bias grows more extreme as both covariate effects and the proportion of missing values increase and seems also affected by the shape of the baseline hazards and the strength of the missingness mechanism. Interestingly, in scenarios where missingness was outcome-dependent, the MICE approach produced biases even larger than those with CCA, which is expected to be biased in these scenarios. Although this is clearly concerning, we do acknowledge that given the longitudinal nature of survival data, a missingness mechanism that depends on the observed event time may be rare.
To the best of our knowledge, our work is the first systematic assessment of the performance of MI for missing covariates with regard to the prediction of cumulative incidences. In this respect, the imputation methods performed comparably, which may be attributed to a solid estimation of both the baseline hazards and of the regression coefficients from the complete covariates. The low biases found are consistent with those reported in the work by Mertens et al.22 on MI and prediction in the context of logistic regression. Furthermore, empirical standard errors did not become smaller beyond around imputed data sets. If interest lies in reducing the variability of individual predictions between replications of an MI procedure, or replications of a particular study, a choice of in the order of hundreds will likely be required, as suggested by the same work by Mertens and colleagues. We also emphasise that since we are predicting for reference patients (for which we have true data-generating probabilities over time), the assessment of the estimated probabilities is not hindered by any optimism that we would need to correct for, using for example a cross-validation procedure.
There are various limitations to the present work. First, we remark that the explored scenarios are naturally limited as a result of the vast possible parameter space for simulation studies in the field of missing data. For example, missingness was only induced in a single variable. Naturally, more realistic data will be subject to missingness across multiple variables, among which could be interactions in the substantive model. Second, the imputation of covariates with more complex distributions (conditional on other variables) fell outside of the scope of this work. There is a clear need for research and guidance on how to properly impute such variables, particularly for continuous measurements which are heavily skewed.38 This may in turn prevent unnecessary categorisation of these variables, and thus further loss of power. Last, we note that in the illustrative analysis, various multi-level nominal and ordinal categorical variables were multiply imputed. These covariate types were not investigated in the simulation study, but are pertinent for further research. Avenues for further exploration could include issues like category inbalance, and comparisons between imputing with proportional odds, multinomial logistic and even a latent normal model.39,40
Furthermore, a noteworthy difference between the MICE and SMC-FCS approaches in the present context lies in the treatment of cumulative cause-specific baseline hazards functions . While the SMC-FCS approach updates at each iteration of the imputation procedure using the Breslow estimate, the MICE approach approximates once using the Nelson–Aalen estimate and keeps them fixed throughout the imputation procedure. Updating iteratively with MICE was investigated in the single event setting by White and Royston, with simulations failing to justify its use over the inclusion of the Nelson–Aalen estimates in the imputation model.7 The additional simulation study reported in Supplemental material I of the present work appears to show that these earlier results do extend to the competing risk setting. This in turn suggests that the differences in performance between MICE and SMC-FCS could almost entirely be attributed to the functional form of the imputation model, rather than to any error in estimating .
For practising statisticians, our work in combination with that of Bartlett and Taylor10 shows that SMC-FCS should be the current standard when applying MI in the cause-specific competing risks setting. Although in many controlled situations differences between MICE and SMC-FCS may be small (as in our alloHCT example), the latter seems to be the safest choice given the inherent lack of knowledge regarding the true underlying missingness mechanism. Naturally, SMC-FCS can still be biased, and so the researcher is encouraged to think meticulously about the assumptions underlying their data. We also recommend that a CCA still be a starting point before performing MI, as it will be unbiased when M(C)AR and covariate-dependent MNAR hold. When biases occur, they may not be as extreme as expected, particularly when the proportion of incomplete cases is low. However, in applications where the proportion of incomplete cases is very high and the M(C)AR assumption is deemed plausible, efficiency gains can be substantial when using MI. This was particularly the case in our alloHCT example, where smaller standard errors were observed with the MI methods for both regression coefficients and predicted cumulative incidence.
The present findings add to a broader literature concerning missing covariates in the context of Cox models.41–43 Studies investigating methods for dealing with missing covariates for a substantive Fine-Gray model remain scarce. For the Fine-Gray model, MI has predominantly been assessed in the context of missing or interval-censored outcomes.44,45 We conclude by remarking that likelihood-based and fully Bayesian approaches have also not yet been explored or implemented in the context of competing risks, despite already showing promise in other applications.46
Supplemental Material
sj-pdf-1-smm-10.1177_09622802221102623 - Supplemental material for Multiple imputation for cause-specific Cox models: Assessing methods for estimation and prediction
Supplemental material, sj-pdf-1-smm-10.1177_09622802221102623 for Multiple imputation for cause-specific Cox models: Assessing methods for estimation and prediction by Edouard F Bonneville, Matthieu Resche-Rigon, Johannes Schetelig, Hein Putter and Liesbeth C de Wreede in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors would like to thank EBMT for the use of the MDS long-term data set, as well as the patients and centres involved in the original study. We thank Linda Koster (EBMT Leiden Study Unit) for the continued support with the data set. We also acknowledge Jacques-Emmanuel Galimard (EBMT Statistical Unit, Paris Team) for his input regarding the interpretation of simulation results, and Bart Mertens (Leiden University Medical Center) for his help concerning design of the simulation study and choice of missingness mechanisms.
Declaration of conflicting interests
The authors declare that there is no conflict of interest.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Edouard F Bonneville
Matthieu Resche-Rigon
Hein Putter
Supplemental Material
There are two supplements to the present manuscript. The first, Supplemental material I, is available alongside the manuscript. It presents two additional simulation studies, the non-parametric cumulative incidence curves from the alloHCT data and additional simulation results referred to in-text. Supplemental material II is an online supplement, hosted at . It contains full code, simulation data and results, in addition to a synthetic version of the illustrative analysis data set.
Appendix A
References
1.
CarrollOUMorrisTPKeoghRH. How are missing data in covariates handled in observational time-to-event studies in oncology? A systematic review. BMC Med Res Methodol2020; 20: 134.
2.
WhiteIRCarlinJB. Bias and efficiency of multiple imputation compared with complete-case analysis for missing covariate values. Stat Med2010; 29: 2920–2931.
3.
MurrayJS. Multiple imputation: A review of practical and theoretical findings. Stat Sci2018; 33: 142–159.
4.
RubinDB. Multiple Imputation for Nonresponse in Surveys. New York: Wiley, 1987.
5.
van BuurenSBrandJPLGroothuis-OudshoornCGMet al. Fully conditional specification in multivariate imputation. J Stat Comput Simul2006; 76: 1049–1064.
6.
van BuurenSOudshoornKPreventie en GezondheidTNO. Flexible Multivariate Imputation by MICE. Technical report, TNO, 1999.
7.
WhiteIRRoystonP. Imputing missing covariate values for the cox model. Stat Med2009; 28: 1982–1998.
8.
BartlettJWSeamanSRWhiteIRet al. Multiple imputation of covariates by fully conditional specification: Accommodating the substantive model. Stat Methods Med Res2015; 24: 462–487.
9.
LauBLeskoC. missingness in the setting of competing risks: From missing values to Missing potential outcomes. Curr Epidemiol Rep2018; 5: 153–159.
10.
BartlettJWTaylorJMG. Missing covariates in competing risks analysis. Biostatistics2016; 17: 751–763.
11.
Resche-RigonMWhiteIChevretS. Imputing missing covariate values in presence of competing risk. In International Society for Clinical Biostatistics Conference. Bergen, Norway, 19–23 August 2012, P22.10.
12.
ScheteligJde WreedeLCvan GelderMet al. Late treatment-related mortality versus competing causes of death after allogeneic transplantation for myelodysplastic syndromes and secondary acute myeloid leukemia. Leukemia2019; 33: 686–695.
PrenticeRLKalbfleischJDPetersonAVet al. The analysis of failure times in the presence of competing risks. Biometrics1978; 34: 541–554.
18.
AndersenPKAbildstromSZRosthøjS. Competing risks as a multi-state model. Stat Methods Med Res2002; 11: 203–215.
19.
FineJPGrayRJ. A proportional hazards model for the subdistribution of a competing risk. J Am Stat Assoc1999; 94: 496–509.
20.
McCullaghPNelderJ. Generalized Linear Models, Second Edition. Chapman and Hall/CRC Monographs on Statistics and Applied Probability Series, Chapman & Hall, 1989. ISBN 978-0-412-31760-6.
21.
WoodAMRoystonPWhiteIR. The estimation and use of predictions for the assessment of model performance using large samples with multiply imputed data. Biom J2015; 57: 614–632.
22.
MertensBJABanzatoEde WreedeLC. Construction and assessment of prediction rules for binary outcome in the presence of missing predictor data using multiple imputation and cross-validation: Methodological approach and data-based evaluation. Biom J2020; 62: 724–741.
23.
MertensB. Calibration of prediction rules for life-time outcomes using prognostic Cox regression survival models and multiple imputations to account for missing predictor data with cross-validatory assessment. ArXiv Preprint ArXiv:2105.01733. 2021.
24.
DemirtasHHedekerD. Computing the point-biserial correlation under any underlying continuous distribution. Commun Stat - Simul Comput2016; 45: 2744–2751.
25.
BeyersmannJLatoucheABuchholzAet al. Simulating competing risks data in survival analysis. Stat Med2009; 28: 956–971.
26.
KleinJPMoeschbergerML. Survival Analysis: Techniques for Censored and Truncated Data. Springer Science & Business Media, 2006. ISBN 978-0-387-21645-4.
27.
MorrisTPWhiteIRCrowtherMJ. Using simulation studies to evaluate statistical methods. Stat Med2019; 38: 2074–2102.
28.
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2020.
29.
BartlettJKeoghR. Smcfcs: Multiple Imputation of Covariates by Substantive Model Compatible Fully Conditional Specification, 2020.
30.
van BuurenSGroothuis-OudshoornK. Mice: Multivariate imputation by chained equations in R. J Stat Softw2011; 45: 1–67.
31.
de WreedeLCFioccoMPutterH. Mstate: An R package for the analysis of competing risks and multi-state models. J Stat Softw2011; 38: 1–30.
32.
RückerGSchwarzerG. Presenting simulation results in a nested loop plot. BMC Med Res Methodol2014; 14: 129.
33.
von HippelPT. How many imputations do you need? A two-stage calculation using a quadratic rule. Sociol Methods Res2020; 49: 699–718.
34.
Madley-DowdPHughesRTillingKet al. The proportion of missing data should not be used to guide decisions on multiple imputation. J Clin Epidemiol2019; 110: 63–73.
35.
de WreedeLCFioccoMPutterH. The mstate package for estimation and prediction in non- and semi-parametric multi-state and competing risks models. Comput Methods Programs Biomed2010; 99: 261–274.
36.
MorisotABessaoudFLandaisPet al. Prostate cancer: Net survival and cause-specific survival rates after multiple imputation. BMC Med Res Methodol2015; 15: 54.
37.
SnowdenJASaccardiROrchardKet al. Benchmarking of survival outcomes following haematopoietic stem cell transplantation: A review of existing processes and the introduction of an international system from the european society for blood and marrow transplantation (EBMT) and the joint accreditation committee of ISCT and EBMT (JACIE). Bone Marrow Transplant2020; 55: 681–694.
38.
LeeKJCarlinJB. Multiple imputation in the presence of non-normal data. Stat Med2017; 36: 606–617.
39.
FalcaroMNurURachetBet al. Estimating excess hazard ratios and net survival when covariate data are missing: Strategies for multiple imputation. Epidemiology2015; 26: 421–428.
40.
QuartagnoMCarpenterJR. Multiple imputation for discrete data: Evaluation of the joint latent normal model. Biom J2019; 61: 1003–1019.
41.
MarshallAAltmanDGHolderRL. Comparison of imputation methods for handling missing covariate data when fitting a cox proportional hazards model: A resampling study. BMC Med Res Methodol2010; 10: 112.
42.
ShahADBartlettJWCarpenterJet al. Comparison of random forest and parametric imputation models for imputing missing data using MICE: A CALIBER study. Am J Epidemiol2014; 179: 764–774.
43.
KeoghRHMorrisTP. Multiple imputation in cox regression when there are time-varying effects of covariates. Stat Med2018; 37: 3661–3678.
44.
DelordMGéninE. Multiple imputation for competing risks regression with interval-censored data. J Stat Comput Simul2016; 86: 2217–2228.
45.
BakoyannisGSiannisFTouloumiG. Modelling competing risks data with missing cause of failure. Stat Med2010; 29: 3172–3185.
46.
ErlerNSRizopoulosDvan RosmalenJet al. Dealing with missing covariates in epidemiologic studies: A comparison between multiple imputation and a full Bayesian approach. Stat Med2016; 35: 2955–2974.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.