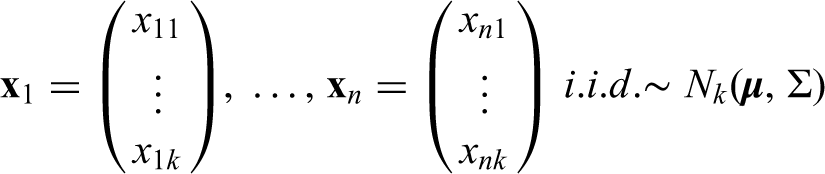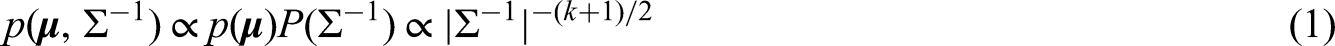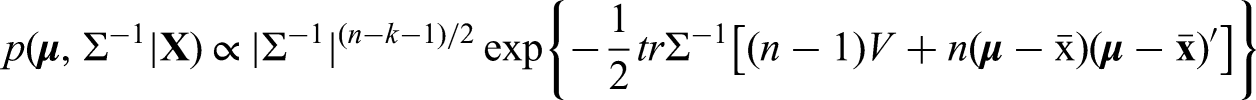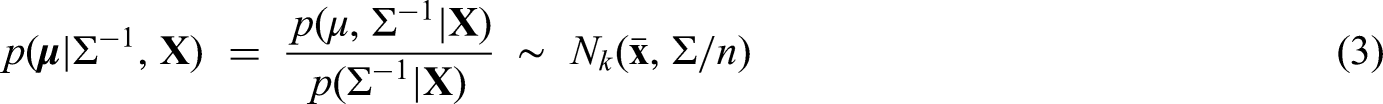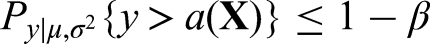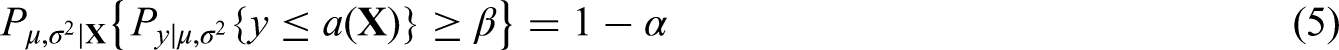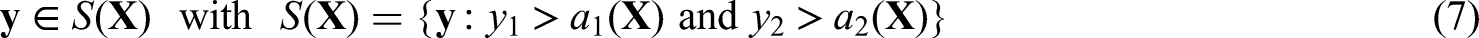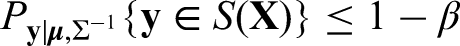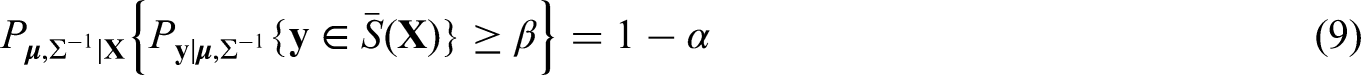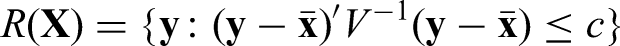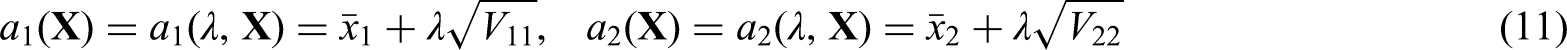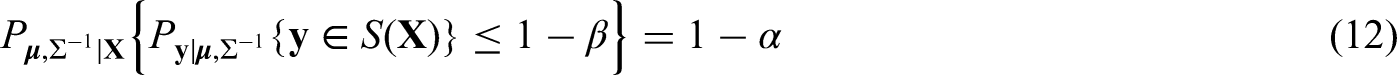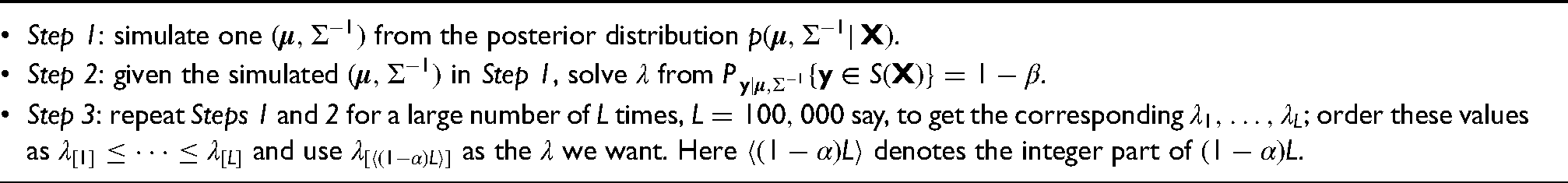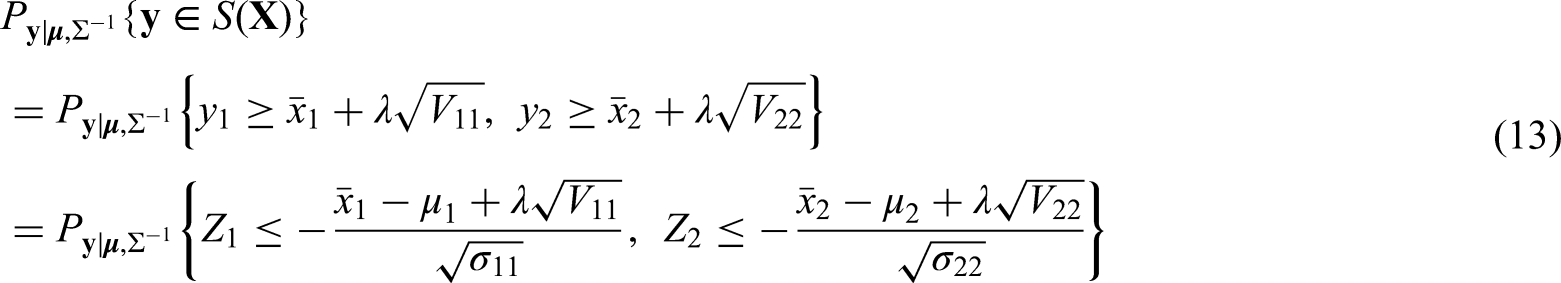The growth hormone-2000 biomarker method, based on the measurements of insulin-like growth factor-I and the amino-terminal pro-peptide of type III collagen, has been developed as a powerful technique for the detection of growth hormone misuse by athletes. Insulin-like growth factor-I and amino-terminal pro-peptide of type III collagen are combined in gender-specific formulas to create the growth hormone-2000 score, which is used to determine whether growth hormone has been administered. To comply with World Anti-Doping Agency regulations, each analyte must be measured by two methods. Insulin-like growth factor-I and amino-terminal pro-peptide of type III collagen can be measured by a number of approved methods, each leading to its own growth hormone-2000 score. Single decision limits for each growth hormone-2000 score have been introduced and developed by Bassett, Erotokritou-Mulligan, Holt, Böhning and their co-authors in a series of papers. These have been incorporated into the guidelines of the World Anti-Doping Agency. A joint decision limit was constructed based on the sample correlation between the two growth hormone-2000 scores generated from an available sample to increase the sensitivity of the biomarker method. This paper takes this idea further into a fully developed statistical approach. It constructs combined decision limits when two growth hormone-2000 scores from different assay combinations are used to decide whether an athlete has been misusing growth hormone. The combined decision limits are directly related to tolerance regions and constructed using a Bayesian approach. It is also shown to have highly satisfactory frequentist properties. The new approach meets the required false-positive rate with a pre-specified level of certainty.
As a powerful anabolic agent of considerable therapeutic value, growth hormone (GH) is misused in sport to enhance performance.1 To preserve the fairness of competition, its use is prohibited by the World Anti-Doping Agency (WADA).2–5 Two methods for the detection of GH misuse are currently available and approved by WADA: the isoform test developed by Bidlingmaier et al.6 (see also WADA2,3) and the GH-2000 biomarker test developed by the GH-2000 and GH-2004 projects.7 The latter method depends on the measurements of two GH sensitive biomarkers, the insulin-like growth factor-I (IGF-I) and the amino-terminal pro-peptide of type III collagen (P-III-NP), both of which rise in response to exogenous GH administration.8,9 The measured concentrations of the two biomarkers are combined in sex-specific and age-adjusted discriminant functions10,11,7,12 to allow the calculation of a score, the GH-2000 score. It is possible that the score may take a negative value.
The measurements of IGF-I and P-III-NP are carried out by choosing two specific assays. As the measured results differ slightly from one assay to another, each assay pair generates an assay-specific GH-2000 score, which differs from other GH-2000 scores generated by different assays. These are the basis of the data generating process. Currently, there are three IGF-I assays and two P-III-NP assays approved by WADA. The IGF-I assays are a mass spectrometry (MS)-based approach, Immunotech A15729 IGF-I IRMA (Immunotech SAS, Marseille, France), and Immunodiagnostic Systems iSYS IGF-I (Immunodiagnostics Systems Limited, Boldon, UK). The P-III-NP assays are UniQ P-III-NP RIA (Orion Diagnostica, Espoo, Finland) and Siemens ADVIA Centaur P-III-NP (Siemens Healthcare Laboratory Diagnostics, Camberley, UK). For more details and background on these assays, see Holt et al.7 As any GH-2000 score requires a pair of IGF-I assay and P-III-NP assay, there are six possible GH-2000 scores. Depending on the available technology, laboratories choose the appropriate GH-2000 scores for evaluating their samples, and a decision limit based on one single GH-2000 score has been developed in Holt et al.7 and Böhning et al.13 by assuming that a GH-2000 score from an athlete without GH misuse has a normal distribution.
As stated in Holt et al.,7 a result will be declared as an adverse analytical finding (i.e. indicative of doping) only if the confirmation procedure results in GH-2000 scores greater than the decision limits for two pairs of analytes. These decision limits are constructed on the basis of the univariate normal distributions of the associated GH-2000 scores. Erotokritou-Mulligan et al.11 with further details in Holt et al.,7 construct combined decision limits on the basis of a bivariate normal distribution. The idea is motivated by the intuition that a reduced correlation between the two GH-2000 scores could lead to reduced decision limits, and thus increase the sensitivity of GH misuse detection. We describe details of this method in Section 3.3.
The purpose of this paper is to provide a valid construction method of combined decision limits when two GH-2000 scores, based on two different pairs of IGF-I and P-III-NP assays, are used jointly in assessing the compliance of a sample. It is shown here how the combined decision limits are directly related to a particular tolerance region, and can be constructed so that the false positive rate (FPR) is controlled at a pre-specified level , say 1 in 10,000, with a pre-specified confidence or belief , for example, , about the possible value of , assuming the two GH-2000 scores have a bivariate normal distribution . This is in contrast to the previously mentioned method discussed in Erotokritou-Mulligan et al.,11 where such a property is assumed to hold bona fide.
A Bayesian approach is adopted in this paper since a frequentist solution is much harder to construct and not available thus far (see Section 3.2 for more details). The frequentist property of the Bayesian combined decision limits is also assessed by simulation, which shows that the Bayesian combined decision limits can also be interpreted as frequentist combined decision limits.
The paper is organized as follows. Section 2 collects some known distributional results that will be used in Section 3. Section 3 considers the construction of decision limits. A very brief review of the construction of a single decision limit for one GH-2000 score is given in Section 3.1. Section 3.2 constructs Bayesian combined decision limits for two GH-2000 scores. The method is then illustrated with a real data set in Section 3.3. A simulation study is presented in Section 3.4 to assess the frequentist property of the Bayesian combined decision limits given in Section 3.3. Finally, the paper closes with a brief discussion in Section 4.
Preliminary distributional results
In this section, we collect some known distributional results, which are used in Section 3 for the construction of decision limits. More details about these results can be found in Guttman,14 Box and Tao15 and Anderson.16
Following Holt et al.7 and Böhning et al.,13 we assume that the GH-2000 scores from an athlete without GH misuse have a -variate normal distribution , with both and unknown. For the problem considered in this paper, we are only interested in the case of since only two GH-2000 scores are involved.We assume further that we have observed a random sample from the population :
Denote , , and .
In this paper, the non-informative reference prior distribution of given by
is used since the sample is all we have. An additional incentive for using the non-informative reference prior is that the Bayesian decision limit for the special case of is also the frequentist decision limit; see Section 3.1 below.
The posterior distribution of based on the observed data is then given by
where denotes the trace of matrix . Integrating out gives the posterior distribution of
in the notation of Box and Tao,15 and the posterior conditional (on ) distribution of is
Decision limits
In this section, we consider the construction of decision limits. In Sction 3.1, we provide a very brief review of the construction of decision limit for one single GH-2000 score, that is, for the case of , which helps the understanding of Section 3.2. Section 3.2 studies the construction of combined decision limits based on two GH-2000 scores, that is, for the case of . Section 3.3 illustrates the computation of the decision limits by using the dataset on GH-2000 scores given in Holt et al.7 Section 3.4 presents the results of simulation studies.
3.1 Decision limit for one GH2000 score
Let denote the decision limit for one GH-2000 score. Hence a future sample observation is declared to be positive if and only if is larger than . To control the FPR at the pre-specified level , it is desirable to have
which is equivalent to
under the assumption that is from the population distribution . Here the probabilities are calculated with respect to the distribution of conditional on . Note that the probability in (4) depends on the value of , for which we have only the posterior distribution after observing the data . Hence this probability cannot be guaranteed to be at least for every possible value of and, instead, we guarantee with a pre-specified (close to one) belief (or confidence) with respect to possible values of that the probability in (4) is at least , that is,
One recognizes this is the defining equation of that is a Bayesian confidence and content upper tolerance interval for the population . Bayesian tolerance intervals were first introduced in Aitchison17 and Guttman14,18 are excellent references on the topic.
Following Guttman14, the that solves equation (5) under the non-informative prior for given in (1) with is given by
where denotes the quantile of the standard normal distribution , and denotes the quantile of the non-central distribution with degrees of freedom and non-centrality parameter . This Bayesian confidence and content upper tolerance interval is also the frequentist confidence and content upper tolerance interval (cf. Guttman14). This is the additional incentive for using the non-informative reference prior in this paper.
3.2 Combined decision limits
In this subsection, we have . Hence a future sample observation is declared to be positive if and only if both and as stated in Holt et al.,7 that is,
To control the FPR at the pre-specified level , it is desirable that
which is equivalent to
under the assumption that is from the population distribution , where the probabilities are calculated with respect to the distribution of conditional on , and denotes the complement of . As in the case of in Section 3.1, the probability in (8) depends on the value of , for which we have only the posterior distribution after observing the data . Hence this probability cannot be guaranteed to be at least for every possible value of from the posterior distribution , and we guarantee with a pre-specified belief (or confidence) about the possible values of that the probability in (8) is at least , that is,
One recognizes immediately that is a Bayesian confidence and content tolerance region for the population . But this particular tolerance region has not been considered before to the best of our knowledge.
Under the frequentist framework, tolerance intervals/regions were introduced first by Wilks.19 Guttman,14,18 Hahn and Meeker,20 Krishnamoorthy and Mathew21 and Meeker et al.22 are excellent references on tolerance intervals/regions. The R package tolerance23 allows the computation of many tolerance intervals/regions. Until very recently, the only available frequentist content and confidence tolerance region specifically for multivariate normal distribution is of the ellipsoidal form
where is the critical constant that needs to be determined so that
where the probability is calculated with respect to the random variable conditional on , and is calculated with respect to . The central ellipsoidal tolerance region of Dong and Mathew,24 also of the form above but with a larger , is conservative, that is the probability on the left side of the equation in (10) is strictly larger than .
One key factor in the choice of the above is that the probability in (10) does not depend on the unknown parameters . But even in this case the computation of is very challenging and only approximation methods are available; see, for example, Krishnamoorthy and Mathew,25 Krishnamoorthy and Mondal,26 and Mbodj and Mathew.27 If is replaced by then the corresponding probability expression depends on the unknown in a complicated manner and so the computation of tolerance regions of forms different from is much harder.
But most recently, rectangular (including one-sided or mixed-sided) tolerance regions of content and confidence, specifically for multivariate normal distribution, have been constructed in Lucagbo28 (Section 4.7) by using a parametric bootstrap. These tolerance regions are of different forms from the tolerance region in (9) considered in this paper.
For nonparametric rectangular (including one-sided or mixed-sided) tolerance regions, the reader is referred to Young and Mathew29 and Lucagbo28 (Sections 5.6 and 5.7) for the latest development.
In the Bayesian framework, there is no published work on confidence and content tolerance region of the form for even with . The reader is referred to Chen30 (Chapter 3) for the latest development on the construction of nonparametric Bayesian tolerance regions.
To determine of in (7) from the only constraint in (9), we set
where is the th element of , is the th diagonal element of , , and is the critical constant that needs to be determined from (9). These two expressions of are sensible if one compares them with the decision limit in (6) for the case of one GH-2000 score. Hence and is solved from
which is equivalent to (9).
For computing by simulation for given
Step 1: simulate one from the posterior distribution .
Step 2: given the simulated in Step 1, solve from .
Step 3: repeat Steps 1 and 2 for a large number of times, say, to get the corresponding ; order these values as and use as the we want. Here denotes the integer part of .
We use a simulation method, given by Algorithm 3.2, to compute the from (12). It is well known that the sample quantile in Algorithm 3.2 converges almost surely to the population quantile that solves (9) as . Hence can be regarded as accurate so long as the number of simulations is large enough. The computation results given in (the penultimate paragraph of) Section 3.3 below show that is sufficiently large for the problem considered in this paper.
Now Step 1 can be implemented by using the distributional results in (2) and (3) in the following way. We first simulate one from and then one from to generate one . To simulate one from , we use the Bartlett decomposition (see Smith and Hocking31 and the references therein) in the following way. Step (a): generate independent random variables , and to form matrix . Step (b): set which has the required Wishart distribution. This simulation method for works for a general . Alternatively one can directly use, for example, the R package rWishart.
For Step 2, we have from (7) and (11) that
where and have distribution , with and . The probability in (13) can be computed directly by using the function pmvnorm of the R package mvtnorm; see Genz and Bretz32 and Genz et al.33 for more details. Furthermore, note that this probability is monotone decreasing in . Hence the unique solution of can be easily computed by using a numerical searching algorithm, for example, the bisection method is used in our coding. From our experience, the computation of one in Step 2 takes only a small fraction of a second on an ordinary personal computer (PC); see more details in the next subsection.
If one uses, in Step 2, an inner loop of simulation to compute an approximation to , similar to an idea used in, for example, Krishnamoorthy and Mathew25 to construct the frequentist ellipsoidal tolerance region , then the computation is much more time-consuming and the resultant is much less accurate. Hence, this is not recommended for computing .
3.3 Applications to the dataset on GH-2000 scores
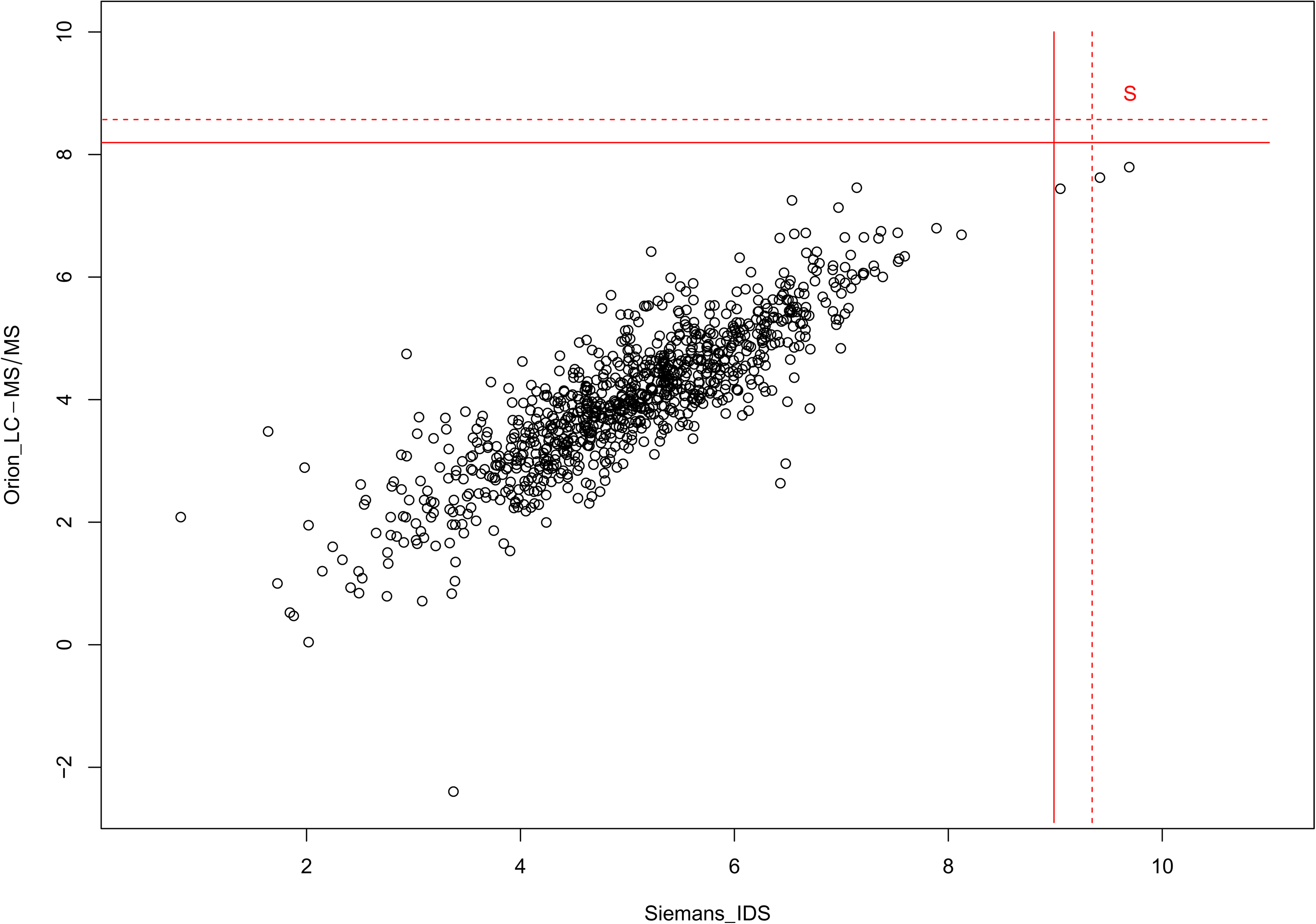
In this subsection, we compute the decision limits given in the last two subsections using the available sample observations on GH-2000 from Holt et al.7 For the purpose of illustration, we focus on the following two GH-2000 scores: (1) Siemens IDS generated by using the P-III-NP assay Siemens ADVIA Centaur and IGF-I assay Immunodiagnostic Systems iSYS IGF-I and (2) Orion liquid chromatography-tandem mass spectrometry (LC-MS/MS) generated by P-III-NP assay UniQ P-III-NP RIA and IGF-I assay LC-MS/MS. These two GH-2000 scores are available for a sample of female athletes and plotted by the 917 dots in Figure 1. There were 932 female athletes in the sample originally. But some had Siemens IDS readings missing, and some had Orion LC-MS/MS readings missing. Hence, only the female athletes having both readings available are used in the analysis below.
Plots of the single and combined decision limits based on the observed data. Single decision limits are given by the dotted lines. Combined decision limits are given by the upper-right quadrant bounded by two solid lines.
We set FPR and confidence level , which are currently adopted by WADA. If one wants to use the GH-2000 score Siemens IDS () only to decide whether a future female athlete with reading is positive on GH misuse, then the single decision limit is computed from the formula in (6) and given by . It is depicted by the vertical dotted line in Figure 1. Hence, a future female athlete is judged to be positive if and only if . If one wants to use the GH-2000 score Orion LC-MS/MS () only to decide whether a future female athlete is positive, then the single decision limit is computed again from the formula in (6) and given by . It is depicted by the horizontal dotted line in Figure 1. Hence, a future female athlete is judged to be positive if and only if .
On the other hand, if one wants to use both the GH-2000 scores Siemens IDS and Orion LC-MS/MS to decide whether a future female athlete with reading is positive, then the combined decision limits in (11) are used and computed by using Algorithm 3.2. By using simulations, is calculated to be 3.5578, which gives and . These two decision limits are depicted by the two solid lines, respectively, in Figure 1, and the set is given by the upper-right quadrant formed by these two solid lines and indicated by the letter in the figure. Hence, a future female athlete is judged to be positive if and only if both and .
The decision limits constructed according to the property in (9) or (12) have the following interpretation. With belief or confidence about the possible value of that, the FPR is no more than 1 in 10,000 that a future athlete, whose GH-2000 reading follows the distribution , is wrongly judged to be positive.
The computation of based on simulations takes about 210 s on an ordinary Window’s PC (Intel(R) Core(TM) i5-6600 CPU 3.30GHz, RAM 8.0 GB). We have tried five different random seeds for the random number generator, which give the corresponding -values: 3.5572, 3.5574, 3.5567, 3.5594, and 3.5579. This indicates that the value computed using is likely to be accurate to the second decimal place at least. Indeed, one computation we have done using simulations produces and takes about 2210 s (37 min). Hence, the computation method proposed is fast and accurate enough for practical purposes with .
It is valuable to compare the proposed combined decision limits with the combined decision limits of Erotokritou-Mulligan et al.11 and Holt,7 which is mentioned in Section 1. They are given by and , and so of similar form as the new combined decision limits given in (11). However, the critical constant is given by with being solved from , where has distribution with being the usual sample correlation coefficient between the two GH-2000 scores and based on the sample . For the case considered in this subsection, it is computed that , , , , and .
While and are quite close to and , respectively, for the specific sample observed, the construction of and does not guarantee that forms a confidence and content tolerance region for the population . Indeed a simulation study in the next subsection shows that the true probability of covering content of the population could deviate from the nominal level in both directions.
3.4 Simulation studies
In this subsection, a simulation study is carried out to assess whether the Bayesian confidence and content tolerance region in Section 3.3 is also a frequentist confidence and content tolerance region for . Specifically, we assess whether
holds for all possible values of and ; here the probability is calculated with respect to conditional on the sample mean and covariance matrix , and is calculated with respect to which depends on the random sample from .
It can be shown that does not depend on . Hence, it is only necessary to assess whether (14) holds for all possible values of with . From the observed sample on GH-2000 scores in Section 3.3, the 99% confidence intervals for , and are given, respectively, by , and . So the following three values are used for , for , and for in the simulation study, with a total of 27 combinations of . The range of these 27 combinations cover the likely true value of . Furthermore, FPR , confidence level and sample size are used as in Section 3.3.
For computing the (outer) probability in (14) by simulation
Step 1: simulate one sample from .
Step 2: use the sample to compute the region by using Algorithm 3.2; the number of simulations used to compute is .
Step 3: compute by using an expression similar to (13) with for , and the R function pmvnorm.
Step 4: repeat Steps 1 to 3 for a large number, say , times; the proportion of times that is used as the required probability.
The (outer) probability in (14) is approximated by a proportion using Algorithm 3.4. It takes about 60 h to compute each probability in Table 1 on the same computer as mentioned in Section 3.3, with most computation time spent on computing the -values in the repetitions.
The probability in (14) for given .
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.951
0.953
0.953
0.953
0.953
0.953
0.953
0.953
0.953
0.953
Table 1 presents the simulation results on the probability in (14). It is clear from Table 1 that the probabilities are very close to for all the 27 configurations of and . Since the range of these 27 configurations most likely covers the true value of , it follows therefore that it is most likely the inequality in (14) holds for the unknown true value of . Hence the Bayesian combined decision limits can also be interpreted as the frequentist combined decision limits of approximate confidence.
The results in Table 1 seem to indicate that the probability in (14) depends on , that is, and , only through . But this is difficult to prove analytically since the critical constant of depends on in a complicated manner in Step 1 of Algorithm 3.2. We have done further simulation study on the probability in (14) with and various values of in the wider range . The results are given by Prob (new) in Table 2.
The probability in (14) for given with .
0
0.949
0.950
0.950
0.950
0.949
0.950
0.950
0.951
0.950
0.950
0.998
0.995
0.986
0.975
0.963
0.956
0.953
0.952
0.949
0.948
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0.955
0.950
0.950
0.953
0.958
0.961
0.954
0.950
0.951
0.945
0.940
0.939
0.941
0.948
0.950
0.950
0.943
0.946
The results on Prob (new) in Table 2 indicate that, if the probability in (14) does depend on only through , then this probability seems to be quite close to across the wide range of -values.
Finally, we have carried out a simulation study to assess the probability corresponding to the probability in (14) but for the combined decision limits and of Erotokritou-Mulligan et al.11 and Holt.7 It is clear that this probability depends on only through , and the simulation results on this probability are given by Prob (old) in Table 2. As pointed out in the last subsection, its construction does not guarantee that is a confidence and content tolerance region for the population . From the results in Table 2, it can be seen that the probability of covering content of the population tends to be a bit smaller than the nominal level when the true value of is around 0.7. Strong deviations from the nominal level occur for smaller than . In practice, negative correlations between two GH-2000 scores are unlikely to occur. But in other applications where the two scores have a large negative correlation, the method of Erotokritou-Mulligan et al.11 and Holt7 will produce and that are larger than necessary. In contrast, with the new combined decision limits, the probabilities Prob(new) are consistently close to the nominal level across the range of values.
Discussion
Decision limits based on the GH-2000 scores produced by the various pairs of analytical assays employed have been published. These scores are used individually but scores for two pairs of assays must be exceeded before an athlete has to answer a case for the misuse of GH. In other words, WADA mandated the measurement of each analyte by two methods which meant that each sample had two GH-2000 scores. Hence, it is natural to use the correlation structure involved in the two scores to develop naturally decreased decision limits which would increase the sensitivity of the biomarker method. The biomarker test then would be more sensitive the lower the correlation between the two GH-2000 scores under consideration would be.
While combined decision limits have their benefits there are some drawbacks. First, depending on which of the other pair of assays was used, the decision limit for one assay pair could change and that could lead to confusion. Ideally, for a given GH-2000 score one would like to have a unique decision limit and not one that depends on which other GH-2000 score is used in the pair. Secondly, it became possible to measure IGF-I by mass spectrometry as the preferred choice to measure IGF-I. WADA does not mandate measurement by a second assay when an analyte is measured by mass spectrometry because of the greater reliability and traceability of the method compared with immunoassays. Hence, using the same assay for IGF-I in two GH-2000 scores leads to an increase in the correlation and the potential for an increased sensitivity of the biomarker test diminishes. On the other hand, it might be that in the near future two mass spectrometric methods for IGF-I (intact and digest) will be available with a potential of a decrease in the correlation of two GH-2000 scores involved in the pair.
Having said that, it is valuable nevertheless to have a statistical theory for constructing combined decision limits. These combined decision limits should have the same pre-specified confidence and FPR as the single decision limit. A Bayesian approach is used in this paper to construct the combined decision limits. Our simulation study in Section 3.4 shows that the Bayesian combined decision limits also have satisfactory frequentist properties and so can be regarded as frequentist combined decision limits too. The R code available from the authors allows the method ready to be used.
Combined decision limits of other forms are worth investigating too in future. For example, it seems also sensible to use combined decision limits of the form with and of the forms in (11). That is, a future athlete is judged to be positive if either of the two readings is too high. The corresponding becomes a one-sided rectangular tolerance region for a bivariate normal distribution considered recently in Lucagbo28 (Section 4.7). It would be interesting to compare the tolerance region constructed using the Bayesian method as in this paper with the tolerance region constructed using parametric bootstrap of Lucagbo.28
The computation method of Section 3.2 can potentially be explored in the construction of a frequentist tolerance region of the ellipsoidal form in (10) for at least, which is probably the most useful case in applications of tolerance regions. Furthermore, the construction of the Bayesian tolerance region of the ellipsoidal form can also be investigated, even though it is not of direct interest to GH misuse detection.
While the GH misuse detection motivates this work, one can envisage other potential applications of the methodology developed in this paper. For example, suitable decision limits can be constructed to trigger an alert on whether a child of a given age is over/underweight or over/underheight.
For nonparametric tolerance regions, the reader is referred to Young and Mathew,29 Lucagbo28 (Chapter 5) and Chen30 (Chapter 3) for the latest development.
Footnotes
Acknowledgements
We thank the referees for constructive comments.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Dankmar Böhning
Yang Han
References
1.
HoltRIG. Is human growth hormone an erotogenic aid?Drug Test Anal2009; 9: 412–418.
BidlingmaierMWuZStrasburgerCJ. Test method: GH. Baillieres Best Pract Res Clin Endocrinol Metab2000; 14: 99–109.
7.
HoltRIGBanningWGurkhaN, et al. The development of decision limits for the GH-2000 detection methodology using additional insulin-like growth factor-I and amino-terminal pro-peptide of type III collagen assays. Drug Test Anal2015; 7: 745–755.
8.
LongboardSKeayNEhrnborgC, et al. Growth hormone (GH) effects on bone and collagen turnover in healthy adults and its potential as a marker of GH abuse in sports: a double blind, placebo-controlled study. The GH-2000 study group. J Clun Endocrinol Metab2000; 85: 1505–1512.
9.
DallRLongboardSShernborneC, et al. The effect of four weeks of supra physiological growth hormone administration on the insulin-like growth factor axis in women and men. GH-2000 study group. J Clin Endocrinol Metab2000; 85: 4193–4200.
10.
CowrieJKBassettEERosenT, et al. Detection of growth hormone abuse in sport. Growth Horn IGF Res2007; 17: 220–226.
11.
Erotogenous-MulliganIGuhaNStowM, et al. The development of decision limits for the implementation of the GH-2000 detection methodology using current commercial insulin-like growth factor-I and amino-terminal pro-peptide of type III collagen assays. Growth Horm IGF Res2012; 22: 53–58.
12.
BöhningDBöhningWGuhaN, et al. Statistical methodology for age-adjustment of the GH-2000 score detecting growth hormone misuse. BMC Med Res Methodol2016; 16: 147.
13.
BöhningDLiuWHoltRIG, et al. Exact statistical calculation of the uncertainty term in the decision limits based on the GH2000 score for growth hormone misuse detection (doping). Stat Methods Med Res2019; 28: 928–936.
14.
GutmanI. Statistical tolerance regions: Classical and Bayesian. London: Griffin, 1970.
15.
BoxGEPTaoGC. Bayesian inference in statistical analysis. New York: Wiley, 1992.
16.
AndersonTW. An introduction to multivariate statistical analysis. 3rd ed.New York: Wiley, 2003.
17.
AitchisonJ. Bayesian tolerance regions. J R Stat Soc Ser B1964; 26: 161–175.
18.
GutmanI. Tolerance regions. In: KotzS (eds) Encyclopedia of statistical sciences, 2nd ed.New York: Wiley, 2006, pp. 8644–8659.
19.
WilksSS. Determination of sample sizes for setting tolerance limits. Ann Math Stat1941; 12: 91–96.
20.
HahnGMeekerWQ. Statistical intervals: A guide to practitioners. New York: Wiley, 1991.
21.
KrishnamurthyKMathewT. Statistical tolerance regions – theory, applications, and computation. New York: Wiley, 2009.
22.
MeekerWQHahnGJRescobieLA. Statistical intervals: A guide for practitioners and researchers. 2nd ed.New York: Wiley, 2017.
23.
YoungDS. tolerance: An R package for estimating tolerance intervals. J Stat Softw2010; 36: 1–39.
24.
DongXMathewT. Central tolerance regions and reference regions for multivariate normal population. J Multivar Anal2015; 134: 50–60.
25.
KrishnamurthyKMathewT. Comparison of approximation methods for computing tolerance factors for a multivariate normal population. Technometrics1999; 41: 234–249.
26.
KrishnamurthyKMondalS. Improved tolerance factors for multivariate normal distributions. Commun Stat Simul Comput2006; 35: 461–478.
27.
MbodjMMathewT. Approximate ellipsoidal tolerance regions for multivariate normal populations. Stat Prob Lett2015; 97: 41–45.
28.
LucagboMD. Rectangular statistical regions with applications in laboratory medicine and calibration. PhD Thesis, University of Maryland, Baltimore County, USA, 2021.
29.
YoungDSMathewT. Nonparametric hyperrectangular tolerance and prediction regions for setting multivariate reference regions in laboratory medicine. Stat Methods Med Res2020; 29: 3569–3585.
30.
ChenX. Prediction sets via parametric and non-parametric Bayes: With applications in pharmaceutical industry. PhD Thesis, Leiden University, The Netherlands, 2021.
31.
SmithWBHockingRR. Algorithm AS 53: Wishart variate generator. J Roy Stats Scio Series C1972; 21: 341–345.
32.
GenzABretzF. Computation of multivariate normal and t probabilities (Lecture Notes in Statistics). New York: Springer, 2009.