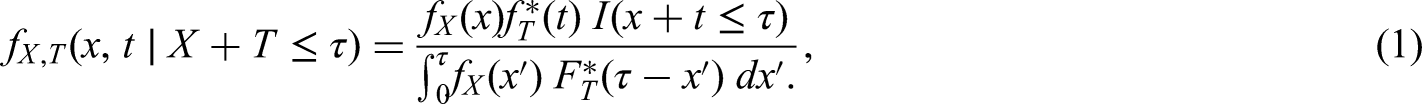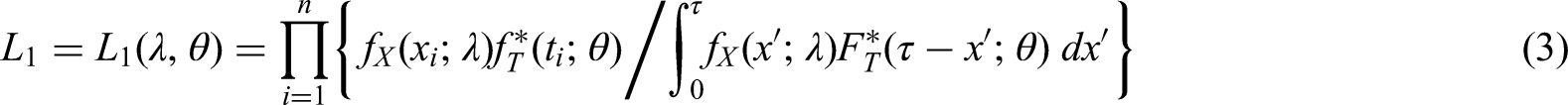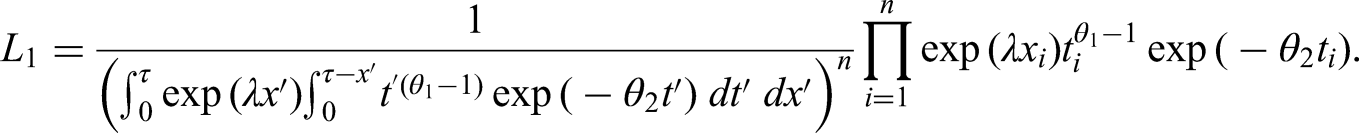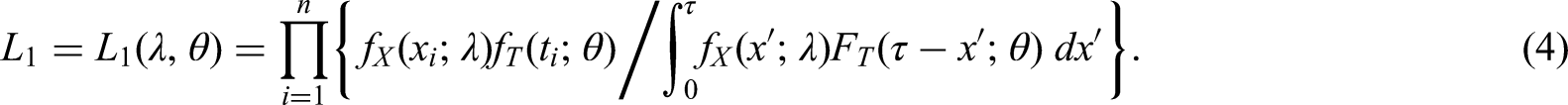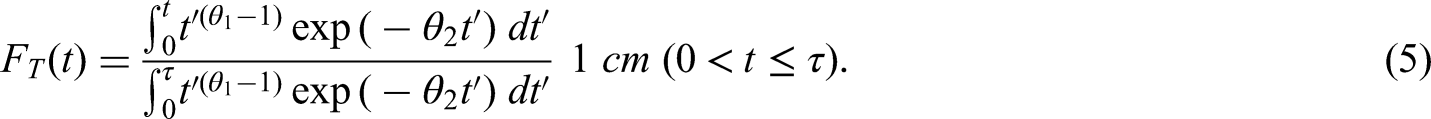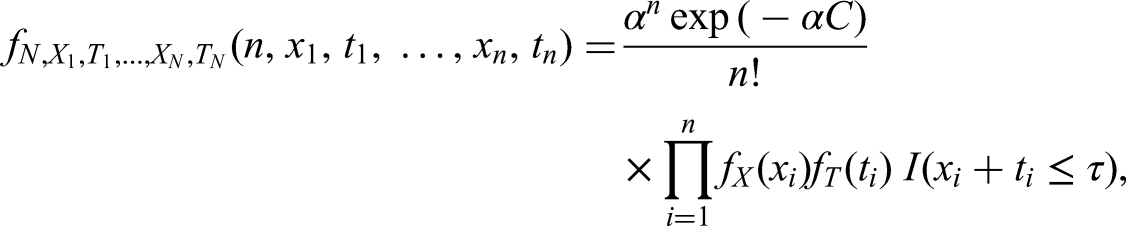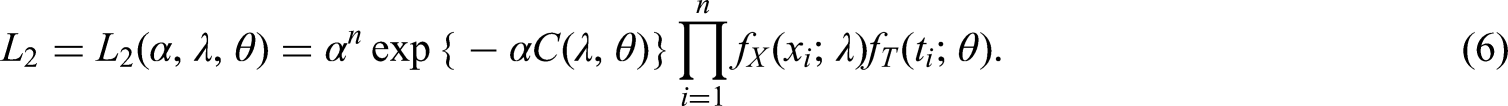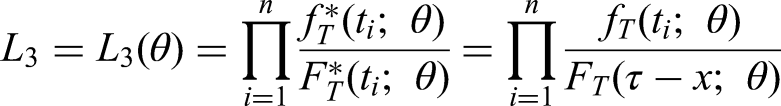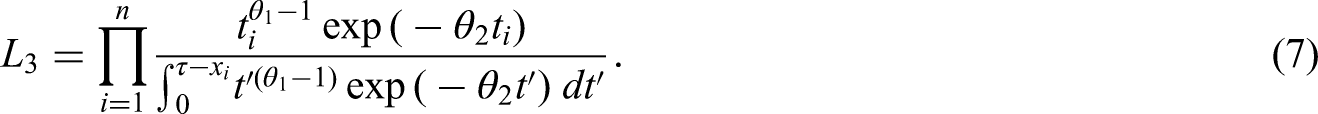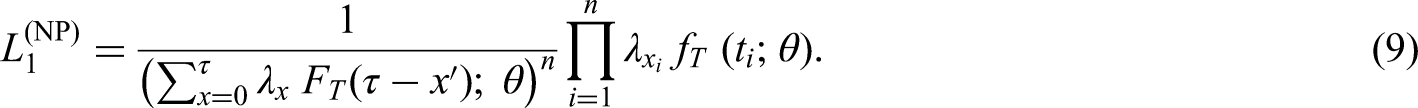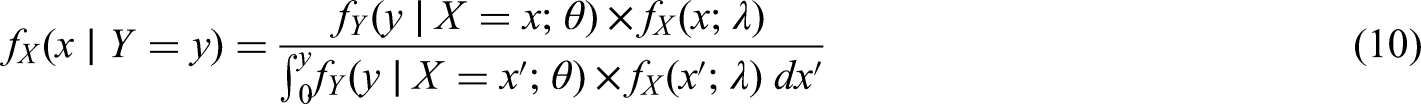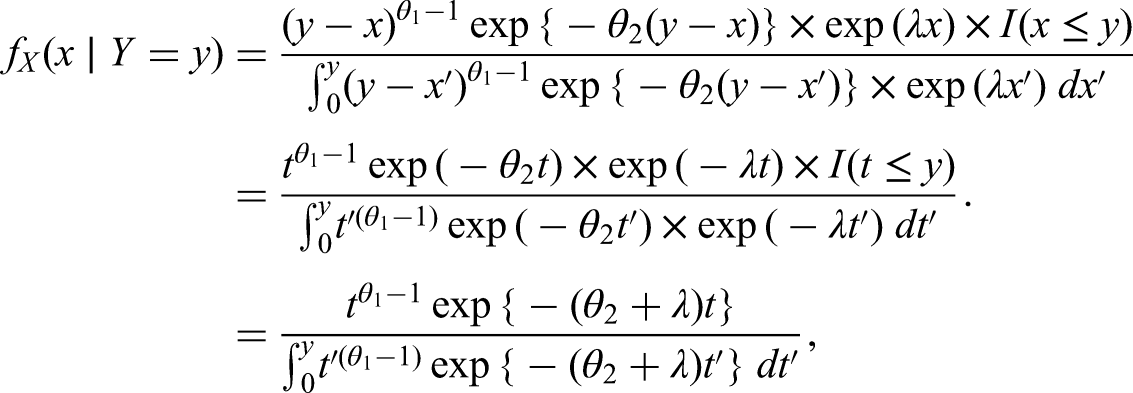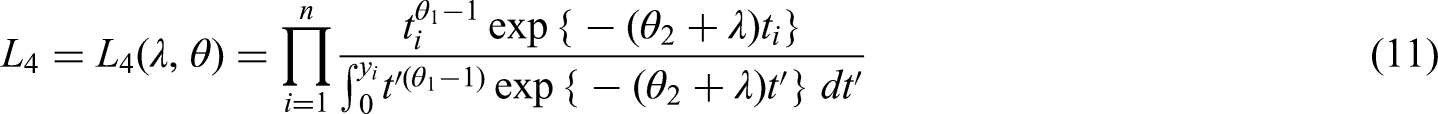Time-to-event data are right-truncated if only individuals who have experienced the event by a certain time can be included in the sample. For example, we may be interested in estimating the distribution of time from onset of disease symptoms to death and only have data on individuals who have died. This may be the case, for example, at the beginning of an epidemic. Right truncation causes the distribution of times to event in the sample to be biased towards shorter times compared to the population distribution, and appropriate statistical methods should be used to account for this bias. This article is a review of such methods, particularly in the context of an infectious disease epidemic, like COVID-19. We consider methods for estimating the marginal time-to-event distribution, and compare their efficiencies. (Non-)identifiability of the distribution is an important issue with right-truncated data, particularly at the beginning of an epidemic, and this is discussed in detail. We also review methods for estimating the effects of covariates on the time to event. An illustration of the application of many of these methods is provided, using data on individuals who had died with coronavirus disease by 5 April 2020.
Data on time to an event are said to be right truncated if they come from a set of individuals who have been randomly sampled from a population using a sampling mechanism that selects only individuals who have experienced the event by a given time, called the truncation time. An example is data on the time from onset of coronavirus disease (COVID-19) symptoms to death collected from a sample of individuals who all developed symptoms and died by 5 April 2020. Among individuals in the population whose symptoms began on, say, 20 March, only those whose time from symptom onset to death was less than 16 days could be included in the sample. For these people, the truncation time is 16 days. Likewise, among those whose onset was on 31 March, only those whose time to death was less than 5 days could be included. Their truncation time is 5 days. Among the sampled individuals, the proportion whose time to death is less than days (e.g. days) will be greater than the proportion in the population of people who (eventually) die with COVID-19. So, a naive estimate of the distribution of time to death in this population will be biased. Moreover, the average time to death in sampled individuals whose symptom onset was on 31 March will be shorter than the average time in those whose onset was on 20 March, even if time to death is independent of onset time in the population.
Ideally, we would have a random sample of individuals who experience an initial event (e.g. onset of COVID-19 symptoms) that places them at risk of a final event of interest (e.g. death with COVID-19) and follow them to see how many experience the final event and the times from initial to final event. However, this is not always feasible. For example, in the case of COVID-19 many people will have experienced symptoms but never reported them. Another example is HIV/AIDS, where many people will not have discovered they are infected with HIV (the initial event) until they were diagnosed with AIDS (the final event).
The analysis of right-truncated data requires statistical methods that account for the fact that each of the sampled individuals must have experienced the final event by their truncation time. The purpose of this article is to review such methods in the context of an infectious disease epidemic, like COVID-19.
Much of the statistical methodology for right-truncated data was developed in the 1980s and early 1990s in the context of the HIV/AIDS epidemic (e.g. 1,2). However, some of it predated the 1980’s. For example, some methods described in this article involve the idea of reversing the time axis, that is, counting backwards in time from the final event to the intial event. This reversal has the effect of making right-truncated data left-truncated. The Lynden-Bell3 estimator is the extension of the original Kaplan-Meier estimator to handle left truncation. Some of the other methods are based on Turnbull’s general algorithm for estimating a distribution function under general patterns of censoring or truncation 4. Recently, the emergence of COVID-19 has highlighted the need for methods that handle right truncation. Data from early in the epidemic have been used to estimate the distributions of time from infection to symptom onset, symptom onset to hospitalisation, symptom onset to death, and hospitalisation to death. Although many researchers have accounted for the right truncation of the data (e.g. 5–7 some have not done so or it is unclear whether they have (e.g. 8–10).
An important issue when estimating the distribution of time to event using right-truncated data is that of identifiability. When the maximum truncation time that can be observed in the sample is less than the maximum time to event in the population, the time-to-event distribution can only be estimated up to a constant of proportionality. In the article, we shall pay particular attention to this issue.
The structure of the article is as follows. In the section ‘Estimating marginal distribution of time to event’ we look at methods that estimate the marginal distribution of time from onset to death in the population of people who (eventually) die from the infection. Some of these methods model both time of onset, and hence truncation time, and time from onset to death, whereas others model only the time from onset to death. Some methods are parametric; others, non-parametric. We review these methods and investigate their asymptotic relative efficiency (ARE) for estimating the mean time from onset to death. Section ‘Estimating and testing covariate effects’ looks at methods for estimating the effect of covariates on the distribution of time to death, and for testing independence between covariates and time to death. These include parametric and semi-parametric methods. An illustration of the application of some of these methods to COVID-19 deaths is described in the section ‘Application to COVID-19’. Section ‘Discussion’ contains some practical recommendations and a brief discussion of more general truncation patterns and of censoring.
Estimating marginal distribution of time to event
Let and denote the times of an individual’s initial and final events, respectively, with . These two events could be, respectively, onset of COVID-19 symptoms and death from COVID-19. Alternatively, they could be, for example, infection with COVID-19 and hospitalisation, or HIV seroconversion and AIDS diagnosis. Let denote the individual’s time from initial to final event; we call this the ‘delay’. We assume that the support of includes zero and that and are either both continuous or both discrete variables; if they are discrete, we suppose, without loss of generality, that they take integer values and we interpret integrals as sums. Unless stated otherwise, we shall assume is independent of . Let and denote, respectively, the probability density (or mass) function of and the distribution function of .
We obtain an i.i.d. sample, , from the probability distribution of given for some , that is, from
where denotes the conditional probability density (or mass) function of given , and denotes the indicator function. If and are discrete, we shall assume, again without loss of generality, that is an integer. We should like to estimate , but first we need to discuss whether this is possible.
Identifiability
The maximum truncation time in the sample is . If this is greater than the maximum delay in the population, then and can be estimated from the data. If, on the other hand, the maximum truncation time is less than the maximum delay in the population, then and is only (non-parametrically) identified up to a constant of proportionality. This is because the sampling mechanism does not allow us to observe values of greater than , and so the data do not tell us what proportion, , of individuals in the population have . This lack of identifiability is manifest in equation (1): if and the probability density (or mass) function and distribution function of are instead and (), then the joint distribution of and given is
which is still equal to the right-hand side of equation (1), because the two terms in (2) cancel out.
Unlike and , the functions and are identifiable from the data . They are, respectively, the conditional probability density (or mass) function and conditional distribution function of given .
In the absence of other information or assumptions, (or equivalently ) is all we can estimate. Obviously, if we know from other information that , then estimating is the same as estimating . Likewise, if we know that, for example, , then , and so we can estimate . Alternatively, if we assume a parametric model for and fit this model to the data, then (and hence for all ) will be estimated, because is a deterministic function of the model parameters. However, as we shall now illustrate, this estimate of relies on extrapolation of the parametric model beyond the range of the data.
Parametric modelling of joint distribution of and
A joint-conditional likelihood
We can estimate by parameterising the distributions of and in terms of distinct parameters and , respectively, and maximising the likelihood function corresponding to equation (1), viz.
For example, if we assume and , then
We might call the ‘joint-conditional’ likelihood, because it is based on the joint distribution of and and is conditional on the final event occurring by time .
Notice that equation (3) can be equivalently written as
This highlights that depends on the distribution of only through , its conditional distribution given . In the example given immediately above, this distribution is
Any distribution for which equation (5) describes would yield the same likelihood . Thus, the data do not distinguish between and, for example, . In the former case, ; in the latter case, . Another possibility is that , in which case . In short, could theoretically be anywhere between 0 and 1 and only is non-parametrically identified.
In practice, we might believe that the parametric model accurately describes the whole of the delay distribution, or we might have additional information that makes us confident that , or the data themselves might suggest that equals 1 or is close to 1. The latter might be the case if there were a reasonably large number of sampled individuals with truncation times close to and all or almost all of these individuals had delays that were far less than . The absence of any longer delays among these people who could have been sampled even if their delays had been longer might lead one to conclude that longer delays are rare. However, caution is warranted, because there remains a possibility that the distribution of delays is bimodal, with a fraction of the population having much longer delays than the rest. For example, this might be the case for COVID-19 if some very seriously ill patients are kept alive on ventilators for a long period of time.
We should be careful not to be misled by a good fit of the parametric model to the data. We can assess the fit on this parametric model only over the range . In all three examples of distributions that give rise to equation (5), this fit is perfect. In particular, if the proportion, , of the probability mass of the distribution that lies in the interval is far from 1, then we are only judging the fit of the model in the early part of the distribution. Note that while it is common in time-to-event studies (without right truncation) for administrative censoring to prevent assessment of the fit of a parametric model in the tail of the distribution, this censoring prevents from being (non-parametrically) identified only for times after the censoring time.
An equivalent likelihood.
So far, we have assumed the data represent a sample from the population and that the sample size is fixed. An alternative framework involves assuming that initial events are generated from a (non-homogeneous) Poisson process with rate at time , the delays are independent of the initial event times, and we observe all individuals for whom 2. Now is a random variable with , where and Also, conditional on , are i.i.d. with distribution given by equation (1) with . Hence the joint distribution of is
which gives rise to the likelihood function
Kalbfleisch and Lawless2 show that the maximum likelihood (ML) estimates and observed and estimated Fisher Information for are the same whether they are obtained from or . Thus, (and ) can be estimated from whichever of these likelihoods is most computationally convenient, even if the assumption that the initial events are generated from a Poisson process does not hold (as might be the case, for example, if the initial events occur in clusters).
Applications.
Kalbfleisch and Lawless2 illustrate the use of . They estimate the distribution of time from infection to onset of AIDS in blood transfusion patients. A common assumption is that at the beginning of an epidemic, cases arise from a Poisson process with rate . This means that and . Kalbfleisch and Lawless make this assumption and assume that has a Weibull distribution. They obtain the ML estimate of using a Fisher scoring algorithm. Another example of the use of is given by Cox and Medley,11 who estimate the distribution of the time taken for an AIDS diagnosis to be reported to the Communicable Disease Surveillance Centre. They allow the rate of AIDS diagnoses to be increasing sub-exponentially, by using , and test the null hypothesis that . They consider several parametric models for the distribution of the reporting delay .
Salje et al.7 use equation (1), the basis of the likelihood , to estimate , but do not use ML. In their application, is the time from hospitalisation with COVID-19 to death. They assume , the distribution of hospitalisation times in the population, is known and model as a mixture of an exponential distribution and a log normal distribution. They estimate the parameters of this mixture distribution by finding the values that minimise the sum of squared differences between the distribution of implied by equation (1) and the observed distribution of delays in the sample.
Modelling the distribution of
Parametric modelling.
A third likelihood function that can be used to estimate comes from factorising as and using only the second factor. This yields the likelihood
For example, if we assume , then
We might refer to as the ‘conditional-on-initial (event time)’ likelihood. The issues regarding the identifiability of that were discussed in section ‘Parametric modelling of joint distribution of and ’ continue to apply when , rather than , is used.
Non-parametric modelling
is also the basis of a non-parametric estimator, , of . This estimator is obtained by applying the familiar Kaplan-Meier estimator in reverse-time, that is, to . By reversing time, right truncation of (i.e. must be ) becomes left truncation of (i.e. must be ). Left truncation (or ‘late entry’) is easily handled by the original Kaplan-Meier estimator (or more accurately, the Lynden-Bell3 estimator, which extends the Kaplan-Meier estimator to handle left truncation). For simplicity, we shall now describe the estimator for discrete ; Lagakos et al.12 describe the corresponding estimator for continuous .
Let be the number of delays observed to equal (), and let be the number of delays observed to be at most in those individuals whose truncation time is such that a delay of would have been observed. Let , which is a consistent estimator of , the hazard in reverse time (the usual hazard in forward time is ). Since ,
is a consistent estimator of . is asymptotically normally distributed and its variance can be consistently estimated using the following adaptation of the Greenwood formula for the variance of the Kaplan-Meier estimator 12: 95% confidence limits for can be calculated as where and This guarantees that the confidence interval lies within the interval .
An alternative way to calculate the same estimator is to define (for ; ) as the number of sampled individuals with and and fit the model . Now , where is the ML estimate of 1. Obtaining an estimate of the variance of this way is, however, more difficult.
The non-parametric estimator can be used to check the fit of a parametric model for . When doing this, it is important to compare with the parametric estimate of , rather than of . For example, if we maximise the likelihood given by equation (7), we obtain both an estimate of , the distribution function of a gamma distribution, and an estimate of , the distribution function of a truncated gamma distribution. should be compared with the latter.
It is important to notice that only the individuals with , and hence a truncation time of , contribute to the calculation of . Therefore, if is small, will have large variance, which causes also to have large variance not just for but for all values of . In this case, it is advisable to choose a value such that is reasonably large and replace the estimator of by , which is an estimate of .
Relative efficiency of likelihoods and
Unlike (or equivalently ), does not require a model to be specified for the distribution of the initial event times. This eliminates the risk that such a model may be misspecified. However, it has the disadvantage that some of the information in the data is being discarded, which makes less efficient than , especially when is small. Brookmeyer and Gail13 found that the ML estimator of based on could be considerably less asymptotically efficient that the estimator based on when the density of is known. Jewell14 and Kalbfleisch and Lawless2 also comment that the loss of efficiency from using can be considerable. In section ‘Study of ARE of estimators’ we carry out a more extensive study of relative efficiency, comparing: (i) treating the distribution of as known; (ii) treating this distribution as unknown; (iii) ; and (iv) the likelihood described in section ‘Modelling the distribution of given ’.
A simple example illustrates the information that uses but does not. Suppose and are discrete, with equal to either 0 or 1 and equal to either 0 or 1, and . We observe 10 individuals with , 10 individuals with , and no individuals with . If we use , we would estimate . Now suppose that we know that . Unlike , uses this information. Since we have only observed individuals with , it seems likely that there are quite a few individuals with whom we have not observed. Since we have not observed them, they must all have . This suggests that .
In section ‘Parametric modelling of joint distribution of and ’, we considered the use of only with parametric models. If and are discrete variables (possibly formed by discretising continuous variables), the distribution of can instead be modelled non-parametrically. Writing , with , then becomes
Here, can be a non-parametric or parametric model. Kalbfleisch and Lawless2 show that the ML estimate of obtained from is identical to that obtained from . This is true whether is modelled parametrically or non-parametrically and regardless of how finely time (if continuous) is discretised. This shows that when is more efficient than , this greater efficiency comes from the modelling assumptions makes about the marginal distribution of .
Modelling the distribution of given
Verity et al.5 proposed a fourth likelihood function, which arises from factorising as where , and using only the second factor. This factor can be written as
They assume that the initial events follow a Poisson process with rate and that . Equation (10) then becomes
which is the density of a truncated gamma distribution with shape , rate and truncated to . This gives the likelihood
We might refer to as the ‘conditional-on-final (event time)’ likelihood. It is evident from equation (11) that only and are identified. Practical use of therefore requires that be known.
Verity et al.5 analysing data on 24 COVID-19 deaths that occurred in China very early in the epidemic, assumed per day and estimated that the mean time from onset of symptoms to death was 19 (95% CI 16–50) days. They did not explain why they used , rather than . In view of the small sample, it was probably impractical to estimate both and . However, could have been used instead, also with fixed at 0.14. The appeal of may have been ease of use: it is just the likelihood of a truncated gamma distribution. Another advantage of relative to , which may have been relevant, is that the former is a valid likelihood no matter how individuals are sampled, provided that the sampling probabilities depend only on . Validity of as a likelihood requires a simple random sample of individuals with .
Equation (11) is derived from the assumptions that and has a gamma distribution. The ‘conditional-on-final’ likelihood could also be derived from other assumed distributions for and , but would not have the form of a truncated gamma distribution.
Study of ARE of estimators
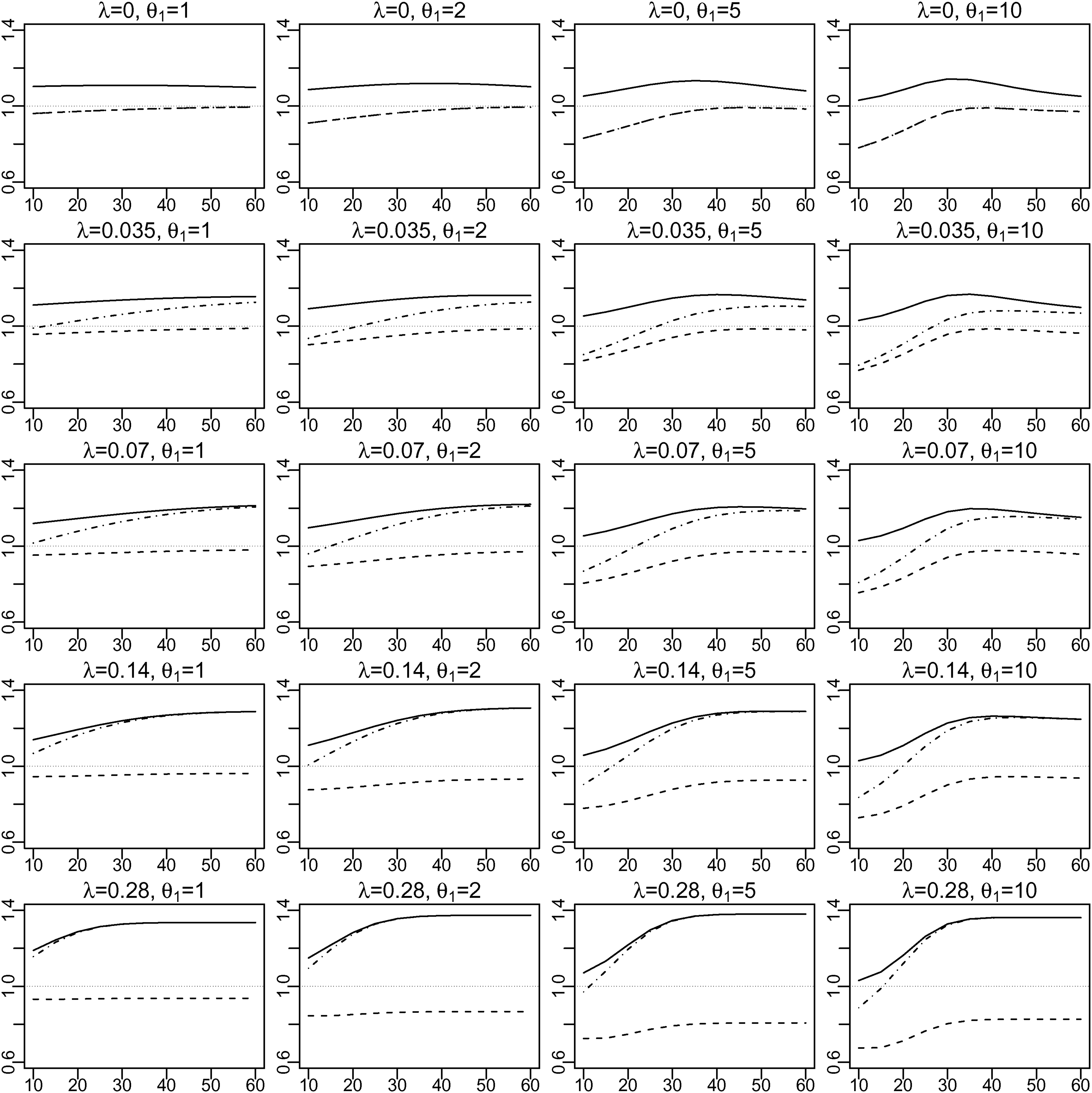
We carried out a study of the AREs of the ML estimators of the expected delay, , based on (i) with known (‘’), (ii) , and (iii) (with known ), all relative to the ML estimator based on (iv) with unknown (‘’). We assumed and , and considered multiple scenarios defined by different combinations of values of , , and . For the distribution of , we used , 0.035, 0.07, 0.14 and 0.28. For the distribution of , we used , 2, 5 and 10, and set , so that has mean . The mean of 19 (days) was chosen because it was the estimate calculated by Verity et al. (2020) early in the COVID-19 pandemic. was varied from to . Note that the AREs are invariant to the choice of , in the sense that they do not change if and are both multiplied by some constant and is divided by the same constant (keeping unchanged).
To calculate an ARE, we first calculated the asymptotic variance of each of the four ML estimators of . Then we obtained the corresponding asymptotic variance of each of the four ML estimators of using the Delta Method. The ratio of the asymptotic variances of two estimators of is their ARE. The formulae used for these calculations are given in the Supplemental Materials.
Figure 1 shows the results. Each row corresponds to a different value of ; each column, to a different value of . The -axis of each graph represents and the -axis represents the ARE. The ARE of (relative to ) varies from slightly over 1.0 to about 1.4. It increases with ; it also increases with , at least when . The ARE of (relative to ) varies from 0.67 to almost 1. It decreases with increasing or , and mostly increases with . In particular, it is close to 1 when is uniformly distributed ( and is exponentially distributed (), and is 0.67 when , and . When is uniformly distributed (), has exactly the same efficiency as (see Supplemental Material for proof). However, as increases, becomes relatively more efficient, and approaches the efficiency of , especially for larger values of .
For each of five values of and of four values of , graph shows the asymptotic relative efficiency (ARE) of the estimator of based on (i) (solid line), (ii) (broken line) and (iii) (dot-dash line) all compared to (iv) . The -axis of each graph is and the -axis is the ARE.
We also calculated the AREs for the ML estimators of the median of . These were almost identical to the AREs for the expectation, (see Supplemental Material).
Estimating and testing covariate effects
Let be a covariate or vector of covariates. We assume, unless stated otherwise, that is independent of . We may be interested in testing whether is independent of and/or estimating the effect of on .
Parametric models
A parametric model can be specified for the distribution of given . For example, might be assumed to have a gamma distribution with and shape parameter . Then can be estimated by maximising , or . Just as in the case with no covariates (section ‘An equivalent likelihood’), the ML estimate and Fisher information for obtained from and are identical. 2If is a function of , this same method can still be applied using either or . A likelihood ratio test or Wald test can be used for the null hypothesis that one or more elements of the vector equal zero.
Kalbfleisch and Lawless2 give an example of using with a Weibull regression model for the effect of age on time from HIV infection to AIDS diagnosis.
Semi-parametric models
Brookmeyer and Liao15 propose a generalisation of the discrete-time estimator to estimate covariate effects. Fit the binomial regression models () simultaneously, where is a specified link function. Let and denote the resulting estimates. Then calculate . In the absence of covariates, this is equivalent to . Brookmeyer and Liao recommend using the complementary log link, , because the model then implies , which provides an interpretation of . The null hypothesis that (or a subvector of a vector ) equals zero can be tested using a likelihood ratio test or Wald test. This method can also be used when is a function of .
Kalbfleisch and Lawless16 extend the method of Brookmeyer and Liao to continuous time and derive score tests of the null hypothesis that . Following a similar approach, Lagakos et al.12 had earlier described a log rank test for testing independence of and a binary covariate .
The Poisson regression approach to calculating , described in section ‘Non-parametric modelling’, is extended by Brookmeyer and Damiano1 to perform a likelihood ratio test of the global null hypothesis that . This is done by including interaction terms in the Poisson model. This approach is less useful, however, for testing whether a set of covariates is conditionally independent of given another set of covariates or for estimating covariate effects. 15
Proportional hazards models
A common assumption in both parametric and semi-parametric models for a time-to-event outcome is that hazards are proportional. Brookmeyer and Liao’s15 semi-parametric model, described in section ‘Semi-parametric models’, assumes proportional hazards, but in reverse time. This differs from the usual proportional hazards assumption, which is in forward time and states that hazard ratios are constant over time and . Brookmeyer and Liao’s model implies that when (respectively, ), the (forward-time) hazard ratio comparing to is initially greater (less) than one and decreases (increases) monotonically over time, becoming equal to one at time .
Finkelstein et al.17 show that the (forward-time) proportional hazards assumption suffices to identify , provided that the hazard ratios of the covariates in the model do not all equal zero. When the hazard ratios all equal zero, is not identified, just as in the non-parametric case with no covariates. Finkelstein et al. describe how to fit the semi-parametric proportional hazards model by ML. Provided that the hazard ratios of the covariates do not all equal zero, this provides estimates of the hazard ratios and . Unfortunately, the identification of relies entirely on the proportional hazard assumption. If this does not hold, the estimate of can be heavily biased. Moreover, if there is only one covariate in the model, its hazard ratio is estimated very imprecisely. Finkelstein et al. discourage the use of their method for estimating or the hazard ratio of a single covariate. When there are multiple covariates with non-zero hazard ratios in the model (and possibly additional covariates with zero hazard ratio), Finkelstein et al. find that these hazard ratios can be estimated more precisely. However, it is unclear how big might be the effect of a small violation of the proportional hazards assumption on the bias of these estimates when . Alioum and Commenges18 suggest that when there is only one covariate, its hazard ratio could be estimated twice, once with fixed at its lowest value considered plausible, and once at its highest plausible value. However, the resulting range of hazard ratios in their example is very wide.
Perhaps the main use of Finkelstein et al.’s method is for hypothesis testing with multiple covariates. Brookmeyer and Liao (1990), Lagakos et al. (1988) and Brookmeyer and Damiano (1989) described simpler hypothesis testing methods. However, if one wants to test whether one set of covariates is independent of given another set of covariate, then Lagakos et al.’s log rank test cannot be used, and although the binomial regression model of Brookmeyer and Liao or the Poisson model of Brookmeyer and Damiano could be used, the parameters in these models do not have interpretations as standard hazard ratios, whereas those in Finkelstein et al.’s model do.
Finkelstein et al.’s method involves estimating the baseline hazard. Vakulenko-Lagun et al.19 propose a simpler Cox regression approach with inverse probability weighting. This uses a modification of the Cox partial likelihood, which does not depend on the baseline hazard. This method involves weighting the observed individuals so that they represent both themselves and those individuals who were not observed because of the right truncation. The method requires either that or that is known. If is unknown, a sensitivity analysis can be performed, analysing the data using a range of plausible values of . This method can be applied using the R package coxrt. We are not aware of software being available for implementing Finkelstein et al.’s method.
Application to COVID-19
The first case of COVID-19 in the UK was reported on 30 January 2020. Public Health England (PHE) receives reports every day of COVID deaths from National Health Service England, the Demographics Batch Service (DBS) and Health Protection Teams (HPT). DBS and HPT also report date of symptom onset, when available, for these deceased individuals. Here we illustrate some of the methods discussed above using data available early in the epidemic, specifically at 9 April. We estimate the distribution of time (‘delay’) from symptom onset to death and investigate the effects of sex and age on this distribution. This is intended only as a simple illustration of methods; results should be interpreted with caution.
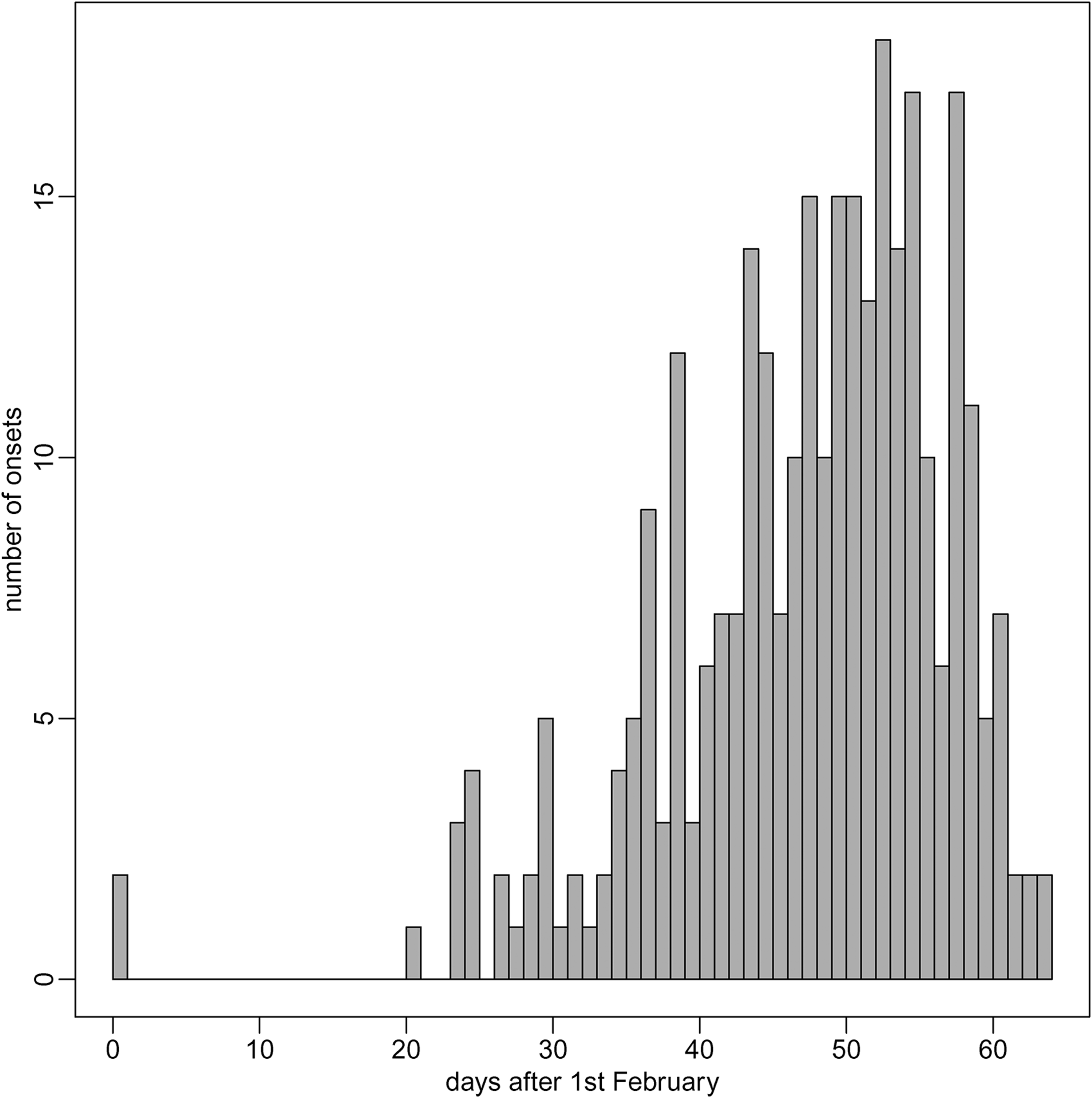
To allow for reporting delays, we exclude deaths occurring between 6 and 9 April; around 80% of deaths are reported within 4 days. 20Of the remaining 7415 deaths, the symptom onset date was known for 316 (4.3%). Of these 316, we excluded 12 because of missing sex or age. The remaining 304 constitute the sample we shall use. 180 were male and 124 female; 25 were aged under 65, 33 aged 65–74, 100 aged 75–84, and 146 were aged over 85. Figure 2 shows the distribution of onset times . The distribution is skewed, with most onsets being in the second half of March. This reflects exponential growth in the early phase of the epidemic. The earliest observed onset date was 1 February (time zero); the two individuals with onset on that day have the maximum truncation time of days. Only 13 other individuals have onsets before 2 March (time 30), and so truncation times greater than 34 days; most truncation times are less than 20 days.
Distribution of symptom onset times in the sample of 304 individuals.
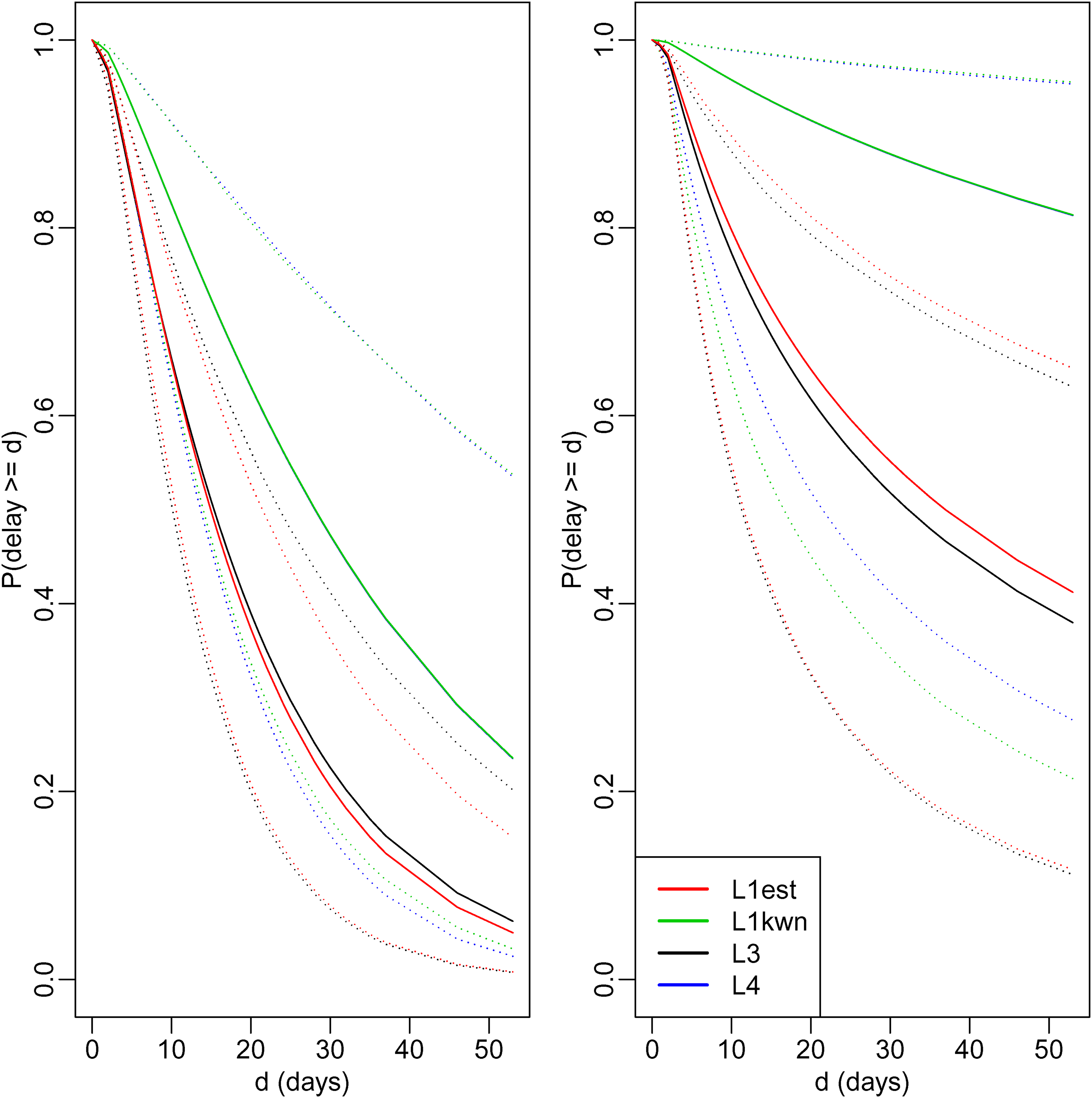
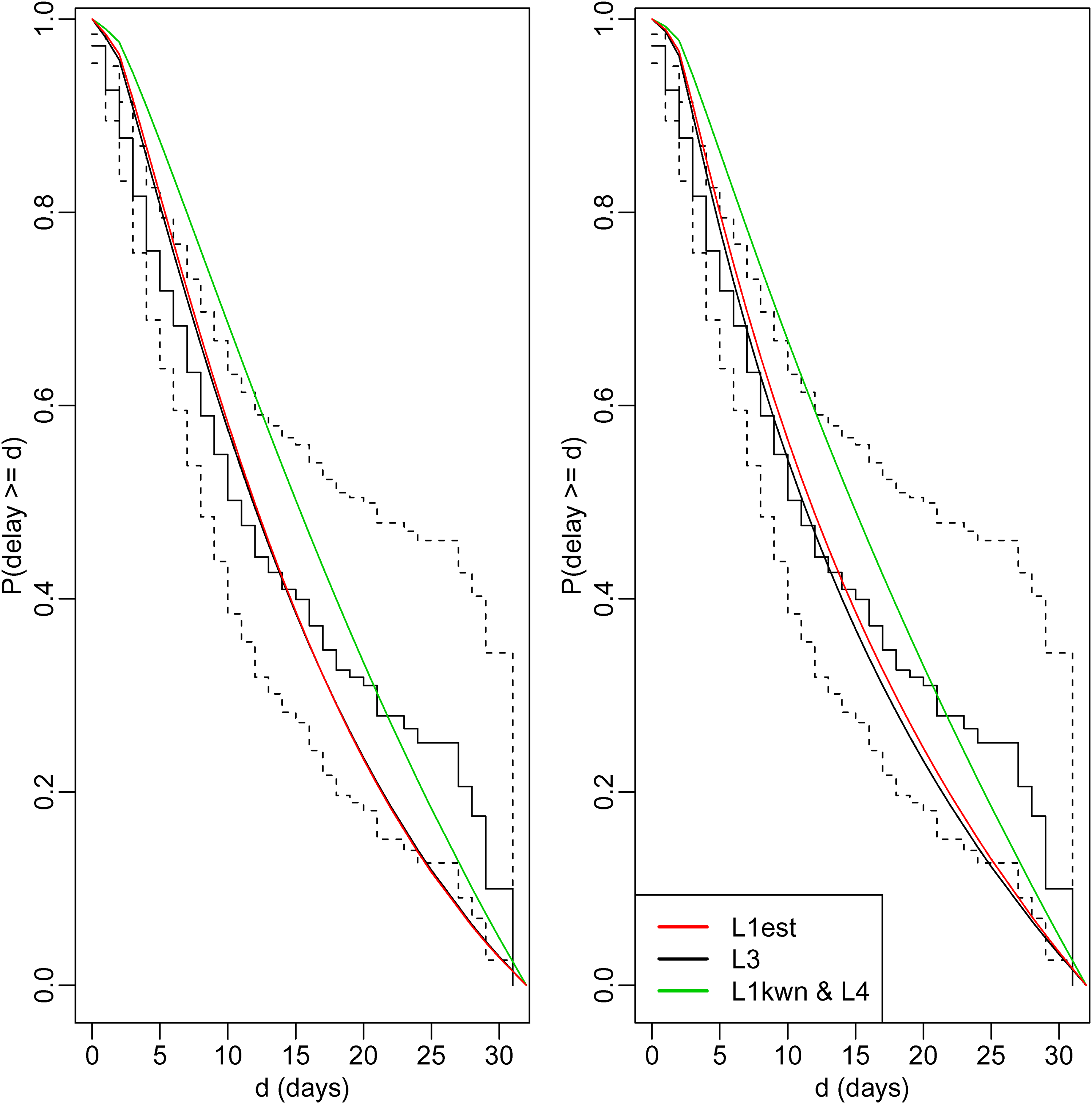
The mean delay in the sample is 7.1 days (range: 0–52 days). As only those who die by 5 April can be included in the sample (right truncation), the mean in the population could be much greater. Using the R package flexsurv, 21 we estimated the distribution of delays in the population by fitting two parametric models: a gamma distribution and a log normal distribution. Each was fitted in four ways: by maximising with unknown (‘’), with known (‘’), and . For and , we assumed , the estimate calculated early in the epidemic by Verity et al.5. Figure 3 shows the estimates of the survival distribution (i.e. ). These are quite diverse. For example, estimated survival at 30 days varies from 0.21 to 0.88. However, as expected, these estimates are all greater than the proportion (0.02) of the sample who have delays greater than 30 days. The estimates from the log normal model are systematically greater than those from the gamma model, and all estimates have wide associated confidence intervals. For a given model, the estimates from and are similar to one another, and those from and are almost identical to one another. This is perhaps not surprising, given our findings in section ‘Study of ARE of estimators’ for the gamma distribution. There we found that: (1) when , and have similar asymptotic efficiency, unless is small compared to the mean delay ; and (2) and have similar asymptotic efficiencies when and the shape parameter of the gamma distribution equals 1. For the COVID data, the estimates of from the gamma model varied from 19 for or to 36 for or , and the estimates of the shape varied from 1.16 to 1.24.
Estimated survival curves from the gamma model (left) and log normal model (right), obtained using likelihoods , , and . Dotted lines represent 95% confidence intervals (Estimates using and are so close they may be hard to distinguish.).
For both the gamma and log normal models, the estimates of from were 0.11 (95% CI 0.09–0.12). The difference between this estimate and the assumed value of used by and may explain why the estimates of survival from and are lower than those from and . Compared to , implies a later average onset time, , in the population, and hence a higher proportion of people in that population that have delays too long to be sampled (). This implied greater extent of right truncation implies a greater difference between the mean delay in the sample and the mean delay in the population.
We used the non-parametric estimate of survival conditional on , that is, , to assess the fit of the parametric models. To avoid having wide confidence intervals for , we used . This ensures that at least individuals had truncation times of days. Figure 4 compares with the corresponding parametric estimates of survival conditional on , that is, with the estimates of . The fit of the models using and is reasonable during the first 15 days, but less good thereafter. The fit when or is used is considerably worse, presumably because the data do not support the choice of . Note that the difference between the conditional (on ) survivor curves estimated from the gamma model and the corresponding estimates from the log normal model is much less obvious than the differences between the corresponding unconditional survivor functions (shown in Figure 3). This illustrates the point made in sections ‘Identifiability’ and ‘A joint-conditional likelihood’ that two models can give similar estimates of and yet very different estimates of .
Comparison of non-parametric estimate (step function) of survival conditional on delay being less than 31 days with corresponding estimates from the gamma model (left) and log normal model (right). Dotted lines represent 95% confidence intervals for the non-parametric estimate. Estimates using and are so close that they are shown by a single line, and estimates using and are so close that they may be difficult to distinguish.
Next we fitted the gamma and log normal models with sex and age group (0–64, 65–74, 75–84 and ) as covariates, again using the R package flexsurv. This was done using the likelihood ; flexsurv does not currently allow or to be used with covariates. The gamma (respectively, log normal) model assumes that the log rate (respectively, mean of the log delay) is a linear function of the covariates. Delays were estimated to be longer for males than females and for younger than for older people. Both effects were borderline-significant in the gamma model. Neither was significant in the log normal model, although age was found to be significant when a trend test was used (see Supplemental Materials).
If the gamma or log normal model is misspecified, tests of covariate effects may not be valid. Brookmeyer and Liao’s method allow tests that do not depend on parametric assumptions. Using this method, we found again that delays are longer for males and younger people. Neither effect reached statistical significance, although age was significant when a trend test was used (see Supplemental Materials).
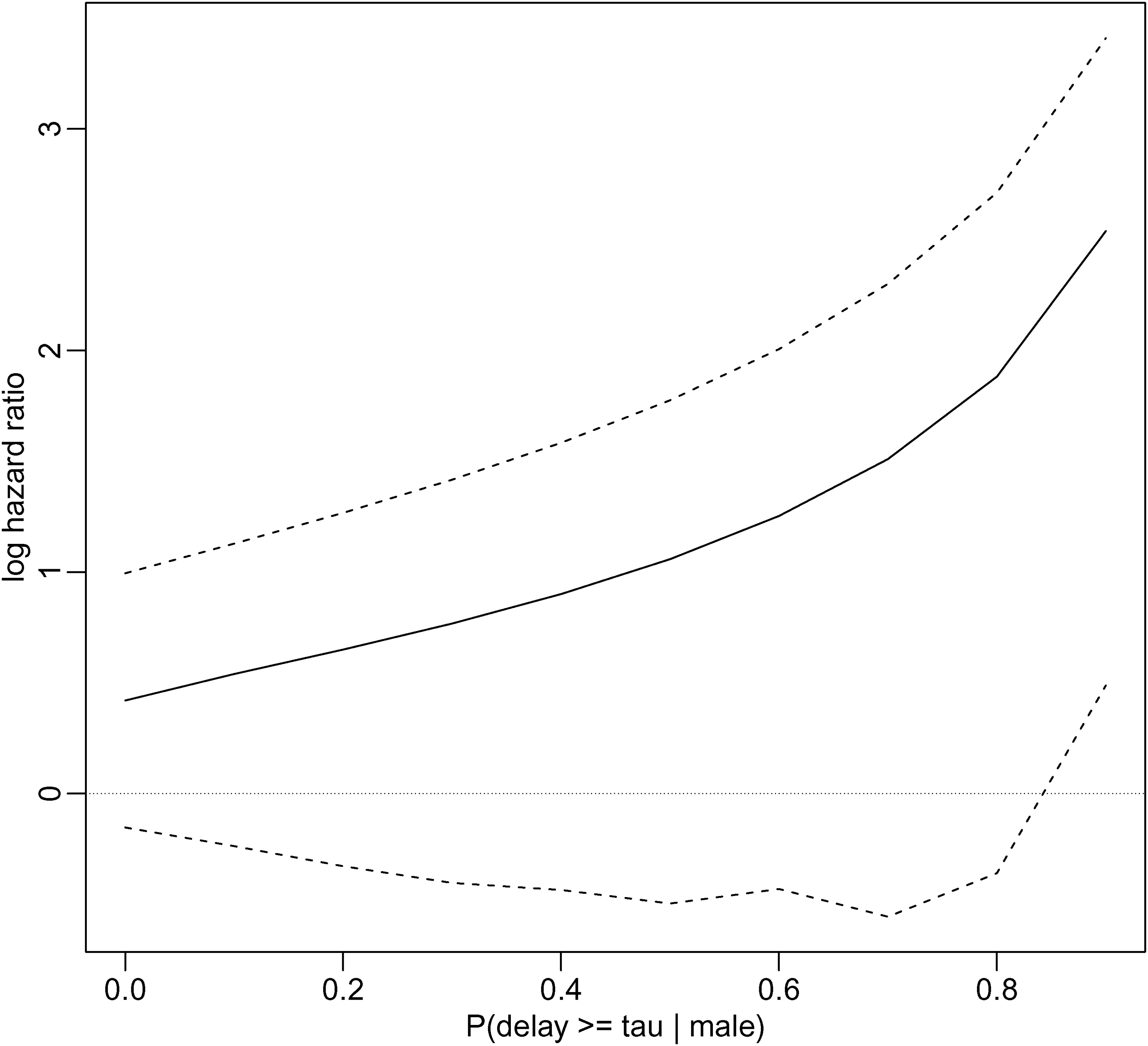
Finally, we used Vakulenko-Lagun’s et al.’s Cox regression method. This requires that either or we specify a value for . Figure 3 suggests it is unlikely that is close to 1. Using the R package coxrt, we fitted the model that included the covariate sex, varying over the full range from 1.0 to 0.1, where here means male. The method uses inverse probability weighting to account for the right truncation, with the weights being functions of a Kaplan-Meier estimate of the truncation time distribution. As explained in the Supplemental Materials, this Kaplan-Meier estimate could not be calculated for our data set, until we excluded the 12 individuals with onset times before 1 March. This makes 1 March the new time zero, and so now equals 36. Figure 5 shows how the estimated log hazard ratio associated with being female changes as changes. Females are estimated to have a greater hazard than males (and hence shorter mean delay) and the estimated log hazard ratio increases as increases. However, the confidence intervals, calculated using 1000 bootstrap samples, indicate that this effect is not significant, at least not until . There were convergence problems: the percentage of bootstrap samples for which convergence was not achieved was 0.0% when is 0.2 or less, 0.3% when it is 0.3, 1.4% when it is 0.5, 3.1% when it is 0.7, and 7.9% when it is 0.9. This may make the estimated confidence intervals unreliable for the largest values of . We also tried to fit the model with age group, both as a four-level unordered categorical variable and an ordinal categorical variable with linear effect, but the fitting algorithm did not converge. We could, however, fit the model with age as a binary variable, although again with some convergence problems in the bootstrap samples (see Supplemental Materials).
Estimate of log hazard ratio associated with sex=female as a function of . Dotted lines indicate 95% confidence limits calculated by bootstrap; these may be unreliable when is large (see text).
Discussion
We have considered ML estimation of the marginal distribution of the delay , using four likelihoods. Likelihoods and are based on the joint distribution of and the time of the initial event ; on the distribution of given ; and on the distribution of given the time of the final event . Estimates from and are identical. has the advantage of not requiring a model for but the disadvantage of yielding the least efficient estimates. requires to be known exactly. When is known, is more efficient than . also has the advantage over that it can be used when is a function of unknown parameters. However, has the advantage that, unlike and , it yields valid estimates even when the sampling probabilities depend on the actual values of , rather than only on whether .
In our study of asymptotic efficiency, we found the ARE of relative to varied between 0.67 and 1 when was unknown. Because does not use information on , these AREs became more marked when was known, varying between 0.58 and 0.92. AREs of 0.67 and 0.58 correspond to reductions in sample size of 33% and 42%, respectively. These AREs were calculated assuming a gamma distribution for the delay and exponential growth over time in the number of initial events. In the early phase of an epidemic, the assumption of exponential growth may be tenable, but it is unlikely to hold later on. More research on the AREs when and have other distributions is warranted, as well as on finite-sample relative efficiencies.
The non-parametric estimator, , of the delay distribution has the attraction of not requiring distributional assumptions. It does, however, only estimate the distribution of conditional on ; the unconditional distribution of is estimable only by using parametric assumptions. One use of is to assess the fit of parametric models over the range . However, the confidence intervals associated with may be very wide at the beginning of an epidemic, when the numbers of sampled individuals with large truncation times may be small.
To estimate the effects of covariates on the delay, and to test whether these effects are non-zero, or can be used with parametric models. Brookmeyer and Liao’s (1990) semi-parametric model can also be used, particularly for the purpose of testing whether the effect of a single covariate is zero. The semi-parametric Cox regression method of Vakulenko-Lagun et al. (2019) allows hazard ratios of covariates to be estimated under a standard proportional hazards assumption. However, it does assume that the covariates are independent of the truncation time , and hence of . Moreover, it requires that be equal to one or that an interval can be specified within which is believed to lie. As this interval becomes wider, the uncertainty in the hazard ratios increases. We also had some convergence problems when fitting these models to the COVID-19 data (section ‘Application to COVID-19’).
The R package flexsurv can be used to fit parametric models using , and , and also to calculate . Brookmeyer and Liao’s (1990) method can be applied using any software for fitting generalised linear models. The R package coxrt applies the method of Vakulenko-Lagun et al. (2019). We have focussed on ML estimation, but also Bayesian analyses can be carried out using the likelihoods , , and . Indeed, the analysis of Verity et al. (2020) was Bayesian, using with informative priors.
In addition to being right-truncated, may be censored. This is easily handled in parametric models by replacing in and by , where is the interval within which individual ’s delay is known to lie. If individual is left-censored, ; if right-censored, . The estimator is easily extended to allow left censoring of . 22The non-parametric estimator of under general censoring of both and and right truncation of is described by Sun.23Alioum and Commenges (1996) generalise Finkelstein et al.’s (1993) method to allow interval censoring of . Double truncation (i.e. simultaneous left and right truncation) of is addressed by, among others.4,24,25,18,23,26,27The R package DTDA28 can be used to calculate the non-parametric estimator of when is double truncated (it can also be used when is only right-truncated, but calculating using equation (8) is faster). Brookmeyer and Gail13 showed that when is double-truncated and the distributions of and are modelled parametrically, the efficiency gain from using rather than to estimate could be considerably greater than the efficiency gains we showed in section ‘Study of ARE of estimators’. In the Supplemental Materials, we extend our study of ARE to double-truncated data and replicate Brookmeyer and Gail’s finding.
and describe the distribution of in the population of individuals who will (eventually) experience the final event. They do not describe what proportion of the population will never experience the final event. An alternative sampling mechanism randomly samples individuals who experience any one of a number of mutually exclusive types of final event by time . For example, one might have a random sample from the population of individuals who develop COVID-19 symptoms and go on to die or recover by time . This situation of competing risks and right truncation is discussed by Hudgens et al.29 and de Una-Alvarez,30 who describe how to estimate cumulative incidence functions. These functions describe what proportion of individuals who die or recover by time will die by time and what proportion will recover by time ().
In addition to the problems of right-truncation, censoring and competing risks, other issues can complicate the estimation of a time-to-event distribution early in an epidemic. Overton et al.31 describes some of these, which include the possibility that some individuals who experience the final event leave the country before being detected, changes over time in the definition of the final event or in the format of the data being collected, and delays in reporting the final event.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802211023955 - Supplemental material for Estimating a time-to-event distribution from right-truncated data in an epidemic: A review of methods
Supplemental material, sj-pdf-1-smm-10.1177_09622802211023955 for Estimating a time-to-event distribution from right-truncated data in an epidemic: A review of methods by Shaun R Seaman, Anne Presanis and Christopher Jackson in Statistical Methods in Medical Research
Footnotes
Acknowledgements
This work was funded by UKRI Medical Research Council (Seaman: MC_UU_00002/10 and Presanis, Jackson: MC_UU_00002/11) and via a grant from the MRC UKRI / DHSC NIHR COVID-19 rapid response call (Presanis, grant ref: MC_PC_19074), and was supported by the NIHR Cambridge BRC. We acknowledge the support of the Public Health England (PHE) Epidemiology and Modelling Cells in providing and discussing the data used. The views expressed are those of the authors and not necessarily those of PHE, the NHS, the NIHR or the Department of Health and Social Care.
Data availability
Data used in the analyses of this paper are available upon the signing of a data-sharing agreement with Public Health England.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Shaun R Seaman
Christopher Jackson
Supplemental material
Supplemental material for this article is available online.
References
1.
BrookmeyerRDamianoA. Statistical methods for short-term projections of AIDS incidence. Stat Med1989; 8: 23–34.
2.
KalbfleischJDLawlessJF. Inference based on retrospective ascertainment: An analysis of the data on transfusion-related AIDS. J Am Stat Assoc1989; 84: 360–372.
3.
Lynden-BellD. A method of allowing for known observational selection in small samples applied to 3CR quasars. Mon Not R Astron Soc1971; 155: 95–118.
4.
TurnbullBW. The empirical distribution function with arbitrarily grouped, censored and truncated data. J R Stat Soc, Ser B1976; 38: 290–295.
5.
VerityROkellLCDorigattiI, et al. Estimates of the severity of coronavirus disease 2019: a model-based analysis. Lancet Infect Dis2020; 20: 669–677.
6.
PellisLScarabelFStageHB, et al. Challenges in control of COVID-19: short doubling times and long delay to effect of interventions. 2020; MedRxiv, https://doi.org/10.1101/2020.04.12.20059972(11/06/2020).
7.
SaljeHKiemCTLefrancqN, et al. Estimating the burden of SARS-CoV-2 in France. Science2020; 369: 208–211.
8.
BackerJAKlinkenbergDWallingaJ. Incubation period of 2019 novel coronavirus (2019-nCoV) infections among travellers from Wuhan, China, 20–28 January 2020. Eurosurveillance2020; 25: 1–6.
9.
LauerSAGrantzKHQifangB, et al. The incubation period of coronavirus disease 2019 (COVID-19) from publicly reported confirmed cases: Estimation and application. Ann Intern Med2020; 172: 577–582.
10.
WuJTLeungKBushmanM, et al. Estimating clinical severity of COVID-19 from the transmission dynamics in wuhan, China. Nat Med2020; 26: 506–510.
11.
CoxDRMedley GF. A process of events with notification delay and the forecasting of AIDS. Philos Trans R Soc London1989; 325: 135–145.
12.
LagakosSWBarrajLMDe GruttolaV. Nonparametric analysis of truncated survival data, with application to AIDS. Biometrika1988; 75: 515–523.
13.
BrookmeyerRGailMH. A method for obtaining short-term projections and lower bounds on the size of the AIDS epidemic. J Am Stat Assoc1988; 83: 301–308.
14.
JewellNP. Some statistical issues in studies of the epidemiology of AIDS. Stat Med1990; 9: 1387–1416.
15.
BrookmeyerRLiaoJ. The analysis of delays in disease reporting: Methods and results for the acquired immunodeficiency syndrome. Am J Epidemiol1990; 132: 355–365.
16.
KalbfleischJDLawlessJF. Regression models for right truncated data with applications to AIDS incubation times and reporting lag. Stat Sin1991; 1: 19–32.
17.
FinkelsteinDMMooreDFSchoenfeldDA. A proportional hazards model for truncated AIDS data. Biometrics1993; 49: 731–740.
18.
AlioumACommengesD. A proportional hazards model for arbitrarily censored and truncated data. Biometrics1996; 52: 512–524.
19.
Vakulenko-LagunBMandelMBetenskyRA. Inverse probability weighting methods for cox regression with right-truncated data. Biometrics2019; 76: 484–495.
JacksonCH. Flexsurv: a platform for parametric survival modeling in R. J Stat Softw2016; 70: 1–33.
22.
CuiJ. Nonparametric estimation of a delay distribution based on left-censored and right-truncated data. Biometrics1999; 55: 345–349.
23.
SunJ. Estimation of a distribution function with truncated and doubly interval-censored data and its application to AIDS studies. Biometrics1995; 51: 1096–1104.
24.
FrydmanH. A note on nonparametric estimation of the distribution function from interval-censored and truncated observations. J R Stat Soc, Ser B1994; 56: 71–74.
25.
EfronBPetrosianV. Nonparametric methods for doubly truncated data. J Am Stat Assoc1999; 94: 824–834.
26.
MandelMÁlvarez de UñaJSimonDK, et al. Inverse probability weighted Cox regression for doubly truncated data. Biometrics2018; 74: 481–487.
27.
RennertLXieSX. Cox regression model with doubly truncated data. Biometrics2018; 74: 725–733.
28.
MoreiraCÁlvarez de UñaJCrujeirasRM. An R package to analyze randomly truncated data. J Stat Softw2010; 37: 1–20.
29.
HudgensMGSattenGALonginiIM. Nonparametric maximum likelihood estimation for competing risks survival data subject to interval censoring and truncation. Biometrics2001; 57: 74–80.
30.
Álvarez de UñaJ. Nonparametric estimation of the cumulative incidences of competing risks under double truncation. Biom J2020; 62: 852–867.
31.
OvertonCEStageHBAhmadS, et al. Using statistics and mathematical modelling to understand infectious disease outbreaks: COVID-19 as an example. Infect Dis Model2020; 5: 409–441.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.