
Abstract
Simulation offers a simple and flexible way to estimate the power of a clinical trial when analytic formulae are not available. The computational burden of using simulation has, however, restricted its application to only the simplest of sample size determination problems, often minimising a single parameter (the overall sample size) subject to power being above a target level. We describe a general framework for solving simulation-based sample size determination problems with several design parameters over which to optimise and several conflicting criteria to be minimised. The method is based on an established global optimisation algorithm widely used in the design and analysis of computer experiments, using a non-parametric regression model as an approximation of the true underlying power function. The method is flexible, can be used for almost any problem for which power can be estimated using simulation, and can be implemented using existing statistical software packages. We illustrate its application to a sample size determination problem involving complex clustering structures, two primary endpoints and small sample considerations.
1. Introduction
The sample size of a clinical trial is typically chosen with respect to its power, which is the probability of a statistically significant result conditional on the parameter of interest being equal to the minimal clinically important difference (MCID). 1 Since power will generally increase with sample size, a nominal power threshold (often 80% or 90%) is set and the smallest sample size which satisfies this is selected. For many sample size determination (SSD) problems, power can be calculated using a simple mathematical formula and the optimisation problem can be solved in a timely manner. When complexity in the trial design or the method of analysis mean such formulae are not readily available, we can estimate power using a Monte Carlo (MC) approximation.2,3 To do so, we simply simulate several hypothetical sets of trial data under the alternative hypothesis, analyse each of these, and calculate the proportion of analyses which reject the null hypothesis. The simplicity and flexibility of the simulation method has seen it used for a variety of statistical models and study designs, including problems involving hierarchical models,4,5 proportional hazards models, 6 logistic regression models, 7 individual patient data meta-analyses, 8 patient enrolment models, 9 stepped wedge designs10,11 and cluster randomised crossover designs. 12 Although calculating MC estimates of power can be computationally demanding, these SSD problems remain feasible because, as optimisation problems, they are quite simple. In particular, optimisation takes place over a single parameter (the sample size), subject to a single constraint (power), and with respect to a single objective to be minimised (the sample size again).
SSD problems, particularly those found in trials of complex interventions, are not always this simple. 13 There may be several dimensions to the trial’s sample size or, more generally, several quantitative parameters, which must be specified at the design stage and which influence the power of the trial. We will refer to these as design parameters. Several design parameters are common in, for example, trials with multilevel structures such as cluster randomised trials, where both the number of clusters and the number of participants in each cluster must be specified. Increasing the number of design parameters complicates the SSD problem by increasing the number of possible solutions to search. A second complication arises when there is more than one criterion we are interested in minimising, subject to the nominal power constraint. A cluster randomised trial will often have this property, as we would like to minimise both the total number of participants and the number of clusters. Given multiple conflicting objectives, there is no single ‘optimum’ solution but rather a range of solutions which offer different degrees of trade-off between the objectives. Seeking a set of good solutions, rather than a single optimum, further adds to the difficulty of the SSD problem.
Simple, simulation-based SSD problems can generally be solved in a feasible time with an exhaustive search,14,15though a bisection search, as proposed by Williams et al. 16 and refined by Jung, 17 may be more efficient. A more sophisticated algorithm was implemented in the SimSam package, 5 written for Stata (Stata Corporation, College Station, TX, USA). Although there is no such general framework for solving complex SSD problems, a number of methods have been proposed for specific applications. In some cases, these methods impose restrictions which reduce the complex SSD problem to a simple one in a single dimension. For example, approaches to simulation-based SSD for stepped wedge trials have focused on choosing one design parameter (such as the number of clusters randomised to each sequence) while keeping others (the number of participants per cluster and the number and arrangement of sequences) fixed.10,11 In other applications, including meta-analysis, 18 work has focussed on estimating power through simulation but has left the associated complex SSD problem unspecified. The complexity of SSD in multilevel designs has been addressed to some extent in the MLPowSim package, 15 although this is limited to performing a simple grid search over two design variables (the number of clusters, and the cluster size). Adaptive designs are another area where simulation is often used to estimate operating characteristics, and where the SSD problem is complex due to the large number of design parameters needed to describe stopping rules. Where these problems have been addressed, optimisation has remained feasible through some special structure of the problem being identified and exploited. For example, optimal multi-arm multi-stage designs can be found when the primary endpoint is normally distributed, since one can draw a single large sample from a multivariate normal distribution prior to optimisation and use transformations of these samples over the course of the search. 19 Together with an implementation in C++, this leads to feasible computation times.
In theory, a general approach to solving any complex SSD problem would be through using benchmark multi-objective optimisation algorithms such as NSGA-II, 20 robust implementations of which are freely available in statistical software such as R. 21 However, these so-called ‘greedy’ algorithms typically assume that evaluating any proposed solution to the problem is a very fast process, and consequently evaluate many thousands of solutions during the search. If these algorithms were applied to problems where evaluating solutions required computing an MC estimate of power, they would take an infeasibly long time to converge. Thus, if we are to extend simulation-based trial design to complex SSD problems, we require a more general framework employing more efficient optimisation algorithms.
Outwith the context of clinical trial design, a great deal of research has addressed optimisation problems where the evaluation of a solution is a computationally demanding, or expensive, operation. 22 , 23 One approach addresses the problem by substituting the expensive function with a mathematical approximation known as a surrogate model. The surrogate model is then used to make predictions about the true function for different values of design parameters, with these predictions informing which point should be evaluated next. The information obtained from this evaluation is used to update the surrogate model, thus improving the predictions available at the next iteration. One class of surrogate model is Gaussian process (GP) regression. Also known as Kriging and having its roots in geostatistics, 24 GP models are spatial interpolators that are computationally tractable 25 and can be fitted using robust and freely available software. 26 A GP surrogate model provides not only a prediction of the true function value at any point, but also a measure of uncertainty in this prediction. This property is exploited by the benchmark efficient global optimisation (EGO) algorithm, 27 allowing the next point in the search to be chosen in a way that formally balances the potential benefits of exploitation (searching around areas already known to be promising) and exploration (searching in areas of high uncertainty). Although EGO was originally proposed for unconstrained optimisation of expensive objective functions with deterministic output, various proposals have extended it to incorporate the expensive constraints, 28 multiple objectives 29 and stochastic outputs 30 that feature in complex SSD problems.
In this paper we will explore how GP regression models and a variant of the EGO algorithm can be used to solve complex SSD problems. We will describe a general method which can be applied to almost any SSD problem, providing the user can write a programme which simulates the data generating process and analysis of the trial at any given set of parameter values and for a given choice of sample size, returning a binary indicator denoting rejection or otherwise of the null hypothesis. By allowing user-written simulation programmes, we aim to provide a flexible method which can be applied to a wide range of trial design problems. This approach will also facilitate SSD for novel designs developed in the future and which cannot be anticipated now.
The remainder of the paper is structured as follows. A motivating example is described in section 2. In section 3, we provide the necessary background and notation regarding Monte Carlo estimation and multi-objective optimisation. In section 4, we describe Gaussian process regression, the efficient global optimisation algorithm, and a framework for its application to sample size determination. We return to the examples in section 5, illustrating how the method can be applied in practice, where we also conduct a simulation study. We conclude with a discussion of the implications and limitations of the proposed approach in section 6.
2. Motivating example – PACE
‘Pacing, graded activity and cognitive behaviour therapy; a randomised evaluation’ (PACE) 31 , 32 was a randomised controlled trial comparing adaptive pacing therapy, cognitive behavioural therapy, graded exercise therapy and specialist medical care as secondary care treatments for patients with chronic fatigue syndrome, with respect to two potentially correlated continuous primary endpoints (fatigue and disability). Participants were randomised to receive one of these four treatments, and we will henceforth refer to these randomised groups as ‘arms’ of the trial. The data had a complex multilevel structure, with three of the four arms including a therapy provided by different therapists (partially nested structure) and all arms including medical care from the same doctors (crossed structure), leading to the potential for treatment-related clustering. Here, we consider how we might have designed a pilot trial prior to the definitive PACE trial to provide a preliminary test of the potential efficacy of adaptive pacing therapy (APT) in comparison to specialist medical care (SMC).
We assume the pilot trial would have the same complex multilevel data structure as the main trial, where therapists are partially nested within interventions, doctors are crossed with interventions, and patients are cross-classified with therapists and doctors in the intervention arm and nested within doctors in the control arm. 33 This structure is illustrated in Figure 1. As in the original PACE trial, the primary analysis will fit a mixed effect model for each primary endpoint and use likelihood ratio tests to obtain a p-value in each case. By fitting separate models for each endpoint, as opposed to a joint model, misspecification will be a potential problem if there are correlations between the endpoints at the participant level, or between the random effects of therapists and doctors. Such model misspecification has been noted as a clear motivation for simulation-based power calculations, 3 which will allow an estimate of the true power, accounting for the effect of this misspecification, to be obtained.
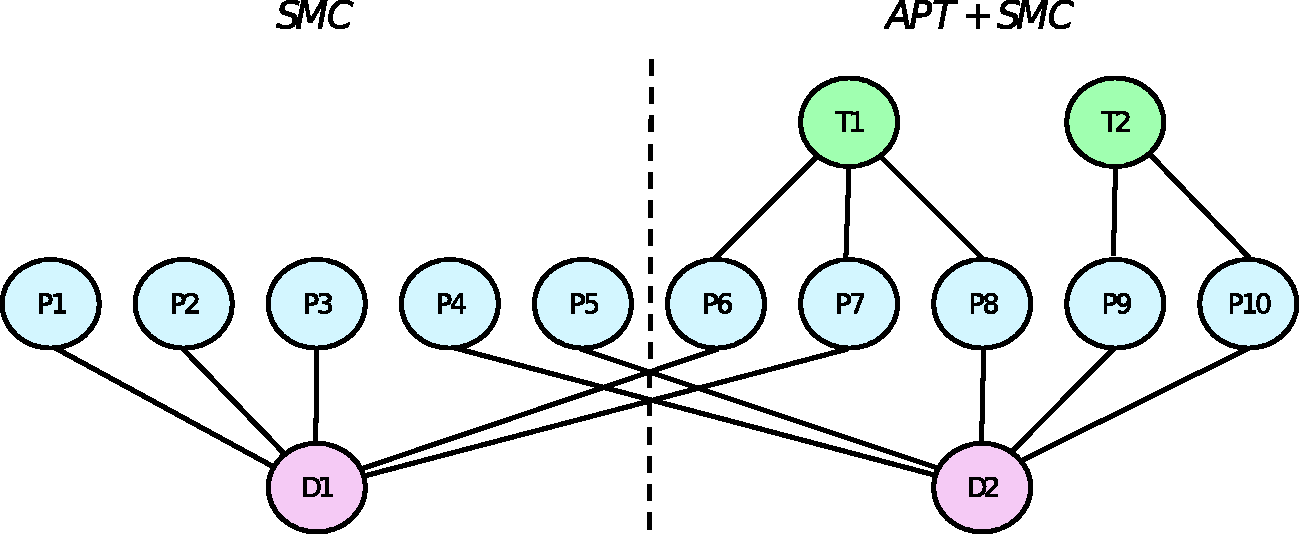
Multilevel structure of the SMC and APT arms of our example, where therapists (T) are partially nested within interventions, doctors (D) are crossed with interventions, and patients (P) are cross-classified with therapists and doctors in the intervention arm and nested within doctors in the control arm.
The results of the trial will be considered positive if either of the analyses show a statistically significant difference, leading to an inflated type I error rate under the null hypothesis of no effect on each endpoint.
34
This inflation, together with the small sample context, motivates the inclusion of the nominal type I error rate a as a design parameter in this problem. Together with a, we have four further design parameters: the total sample size in the APT arm, denoted n1; the number of APT therapists, k; the allocation ratio relating the total number of participants in each arm,
3. Background
3.1. Monte Carlo estimation
Monte Carlo methods can be used to numerically approximate expectations

The estimate is unbiased for all N and has variance equal to
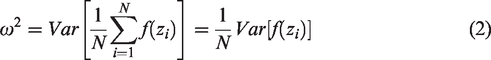
The standard error of the MC estimate will therefore reduce at a rate of
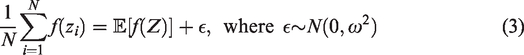
In the context of simulation-based trial design, if Z is the test statistic to be compared with an acceptance region Λ then the probability of acceptance under hypothesis H is Define the population model. This describes the underlying target population and should specify all population parameters and distributions under the hypothesis of interest. Define the sampling strategy. This should specify the numbers of patients, clusters or any other sampling units in the trial and how they will be drawn from the population. Define the method of analysis. For hypothesis testing, this will include defining the form of the test statistic Z and the acceptance region Λ.
Given each of the above elements, pseudo-random number generators can be used to simulate the recruitment, randomisation and primary outcome measure of patients under the hypothesis of interest, from which a test statistic zi can be calculated.
3.2. Multi-objective optimisation
A solution to the SSD problem consists of a vector of design parameters
An objective function
A constraint function
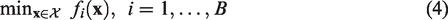
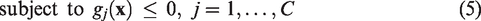
We denote by
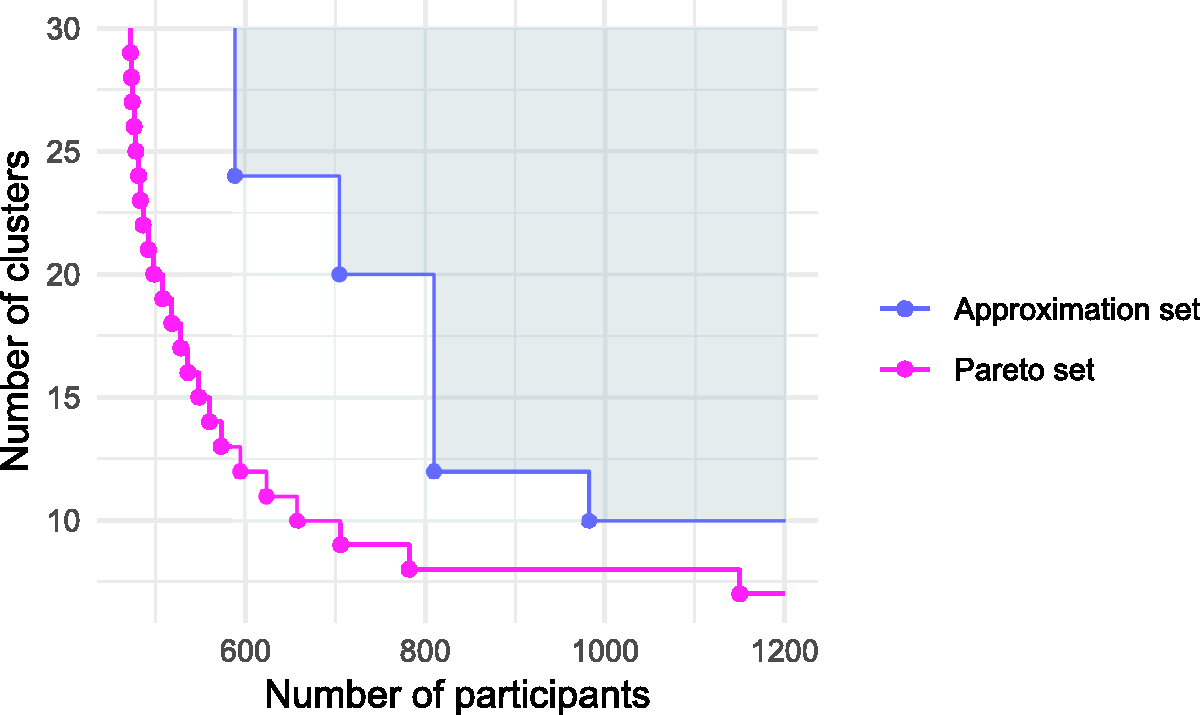
Example Pareto front
Multi-objective optimisation seeks to find a set of solutions that are close to the true Pareto set, with every member of the set non-dominated with respect to all other members. We will refer to these as approximation sets, denoted
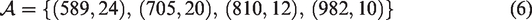
To understand the similarity between any approximation set
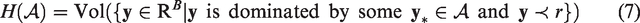
The specific choice of r is not important, providing it is larger than anticipated worst-case objective values. The largest possible hypervolume of any feasible approximation set
4. Simulation-based sample size determination
4.1. Overview
The proposed method is based on the efficient global optimisation algorithm.
35
For clarity, we will describe the algorithm in the context of an SSD problem with a single constraint function, denoted Algorithm 1 Efficient global optimisation
35
1: Compute MC estimates 3: Regress 4: Find 5: Compute MC estimate 6: Update the computational budget
The process of computing MC estimates used in steps (1) and (5) has already been described in section 3.1. In what follows we will first consider step (3), describing Gaussian process regression models and outlining how they can be fitted and used to make predictions. The notion of expected improvement in step (4) will then be defined for the constrained multi-objective problems we are concerned with. Finally, we cover the remaining aspects of implementation.
4.2. Gaussian process regression
Consider a set of points
In using a GP we assume that our belief regarding the values of g can be represented by a multivariate normal distribution. Prior to computing any estimates of g, we assume that the mean function of this multivariate normal is equal to zero.
a
We write the covariance matrix of the distribution as
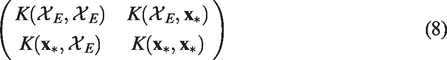
Given this prior distribution, we compute the MC estimates
The predictive distributions are influenced by the prior covariance matrix (8). The matrix is populated using a covariance function (or kernel),
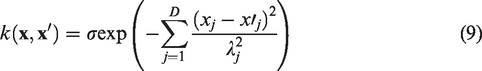
By using covariance functions of this form we will obtain a Gaussian process which is infinitely differentiable over
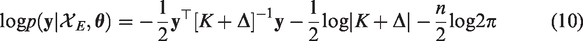
An illustration of a Gaussian process regression model of a power function in one dimension is given in Figure 3. The power of three different choices of sample size has been calculated and a GP model fitted to the results. The figure illustrates how the uncertainty in the model predictions (shaded area) increases the further we are from a point which has been evaluated. The GP prediction of power at a sample size of n = 190, shown as a dashed line, is normally distributed with mean 0.84 and standard deviation 0.035.
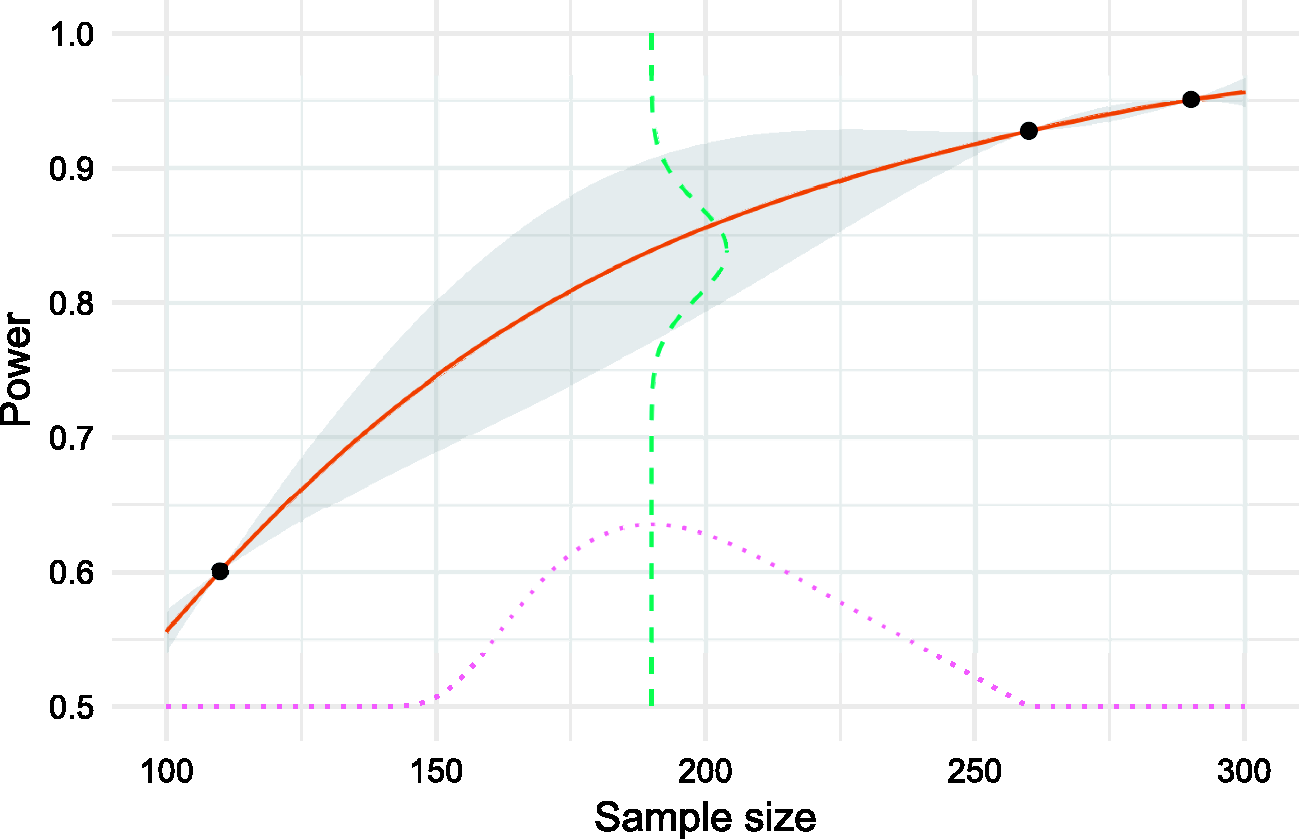
A Gaussian process model of a power function over a one-dimensional sample size (solid line) based on three evaluations. Uncertainty is shown as the shaded area. Expected improvement (dotted line) is maximised at a sample size of 190, where the predicted power is normally distributed around a mean estimate of 0.84 (dashed line).
4.3. Expected improvement
At any given point during the optimisation process we can obtain an approximation set

Prior to evaluation, we do not know if the point

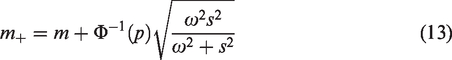

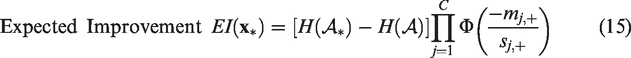
Note that we include a penalty term for all
An illustration of expected improvement for a single-objective problem is given in Figure 3. When choosing which sample size to evaluate next and aiming to find the lowest per-arm sample size with at least 80% power, we balance the potential improvement over the best current solution (a sample size of 260) with the probability of constraint satisfaction. In this case, we would choose to evaluate the sample size of 190, estimated by the GP model to have a power of 84%.
4.4. Fixed space-filling design
An alternative to the EGO algorithm is to evaluate a number of solutions chosen using a space-filling experimental design, and use these to construct an approximation set. Specifically, we construct a Sobol sequence (a low-discrepancy sequence which can be thought of as a quasi-random uniform distribution) and estimate the type II error rate at each of these solutions using N MC samples. For each point a confidence interval based on the MC error can then be calculated, and any points where the interval was not entirely below the nominal value discarded. Of those that remained, any dominated solutions are discarded to leave an approximation set. We will refer to this as the ‘fixed design’ method.
4.5. Implementation
To apply Algorithm 1 in practice we must first choose the initial set of points to be evaluated,
As the algorithm depends on GP regression models, it can be helpful to assess the fit of these models. One approach is to regularly plot the predicted mean and standard deviation in one or two dimensions, centred at the last evaluated point. Poor model fit could be identified if the mean function is not, for example, strictly increasing as expected. We can also contrast the predicted function values with the obtained function values at each iteration, halting the algorithm if a large and unexpected discrepancy in these values is observed.
We have implemented the proposed framework in R, partly due to the availability of robust and efficient R packages for fitting Gaussian process models (DiceKriging 26 ) and for global optimisation (pso 36 ). Using R also provides flexibility in terms of the user-written simulation routines by facilitating various complicated analysis procedures, e.g. multilevel modelling through lme4. 40 The implementation is provided in the supplementary material and online at https://github.com/DTWilson/Bayes_opt_SSD, where we show how it can be applied to solve a number of example SSD problems.
5. Illustration and evaluation
5.1. Application to a hypothetical example
We begin by showing how the proposed method can be applied to design a hypothetical two-arm cluster randomised trial with a continuous, normally distributed outcome, k clusters in each arm, and m participants in each cluster. The outcome of participant i in cluster j is modelled as



To apply the proposed method, we define k and
In Figure 4, we plot the 50 solutions evaluated over the course of the EGO algorithm, distinguishing between those in the initial design
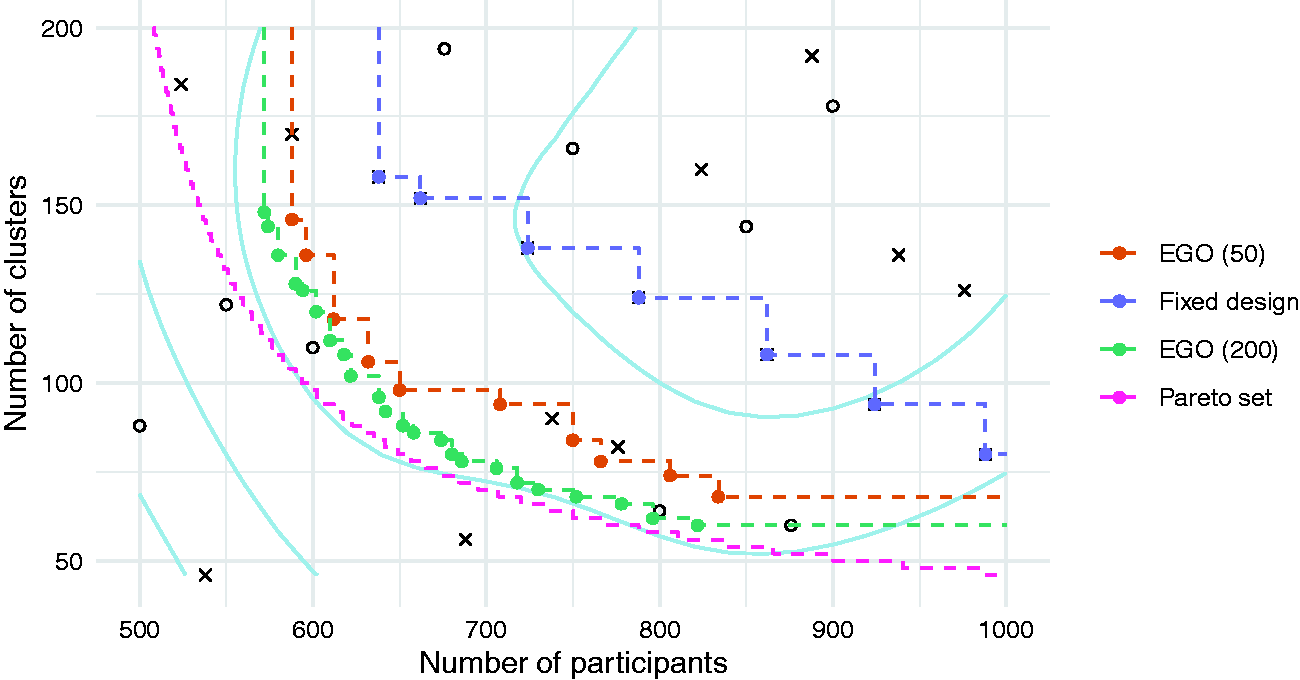
Objective values of solutions in the initial set
We find that the EGO algorithm leads to a much better approximation set than the comparator, for the same computation budget. For example, the fixed design method suggests that in order to limit the number of clusters to 80, a total of 988 participants will be required. In contrast, the EGO method shows that a total sample size of only 766 is needed. The true minimal sample size required for 80 clusters is 649 participants, showing that while the EGO algorithm can substantially improve upon the simpler alternative, it has still suggested an approximation set that is some distance from the Pareto set. As shown in Table 1, all the suggested solutions are adequately powered with a true type II error rate β less than the nominal 0.1. Increasing the computational budget by applying a further 150 iterations of the algorithm moves the approximation set closer to the Pareto set, as would be expected.
Approximation sets for the hypothetical example obtained using the EGO algorithm and the fixed design approach, with 50 evaluations each. Solutions are defined by the total number of participants, 2n, and the total number of clusters, 2k. The true type II error rate β is shown alongside with the estimate
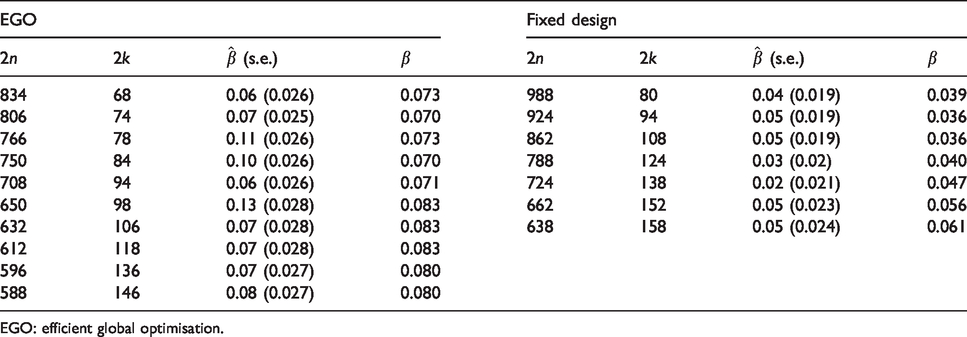
EGO: efficient global optimisation.
5.2. Simulation study
To understand the variability in performance of the proposed method, we conducted a simulation study based on the preceding hypothetical example in section 5.1. We applied the method as before, with 20 initial evaluations at points determined by a Sobol sequence, followed by 30 iterations of the algorithm. At each evaluation, N = 100 MC samples were used when estimating power. We repeated this process 500 times. For comparison, we also applied the fixed design approach by evaluating 50 solutions chosen by a Sobol sequence, discarding those with an estimated type II error rate greater than the nominal 0.1, and finding the approximation set from the remaining solutions. We repeated this process 500 times, again using
We plot the distribution of the dominated hypervolumes in Figure 5. Comparing the EGO and fixed design methods when each uses 50 evaluations in total, we find that the average dominated hypervolumes are 4824 and 3243, respectively. There is some overlap in the distributions. For example, 92% of EGO runs led to a dominated hypervolume greater than 4500, compared with 1% of fixed design runs. Increasing the number of evaluations in the fixed design improves the solution quality as expected, but to obtain an average performance similar to the EGO algorithm the number of evaluations must be increased to between 800 and 1000.
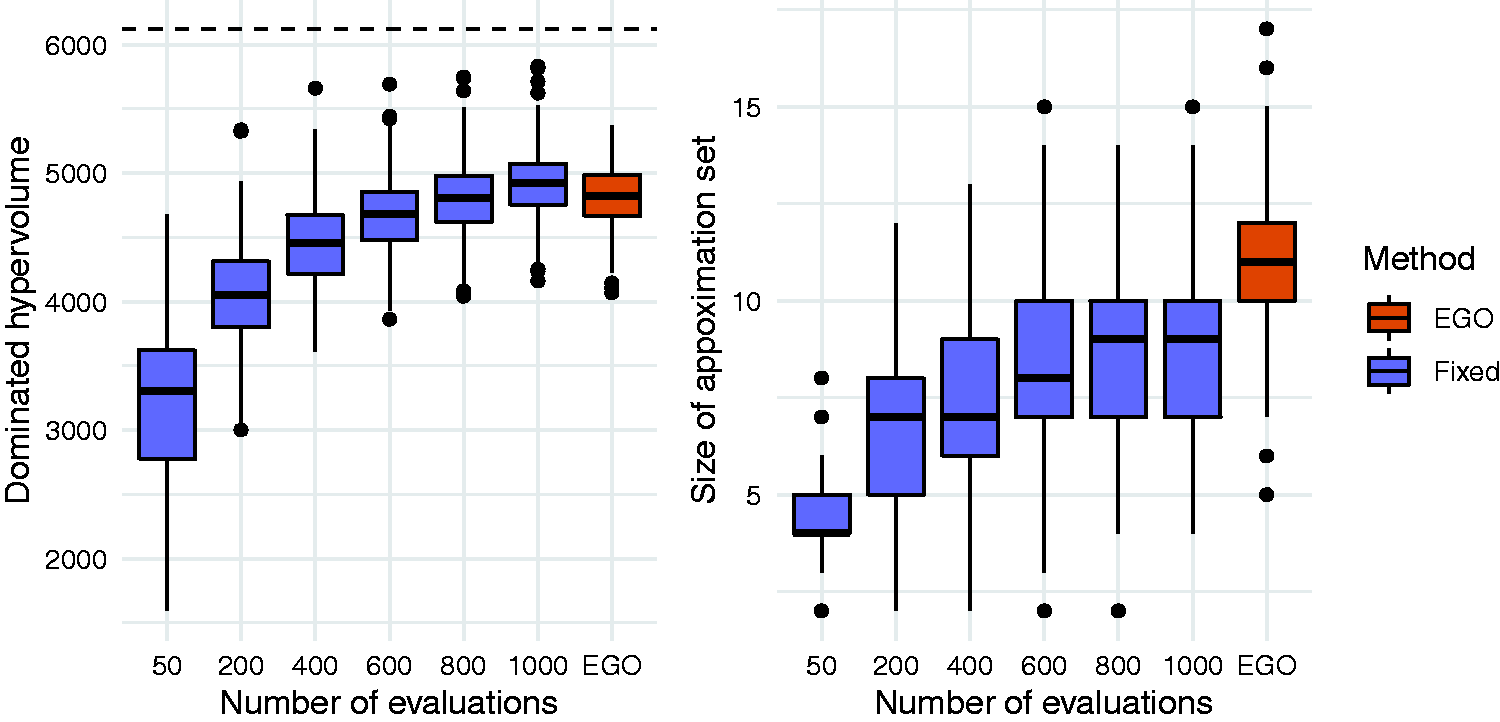
Distributions of dominated hypervolumes (left) and size (right) of approximation sets obtained using the EGO method and the fixed design method. The dashed horizontal line on the left hand plot indicates the dominated hypervolume of the true Pareto set.
Figure 5 shows that the approximation sets are typically larger than those obtained using fixed designs, with an average of 10.9 solutions. In comparison, a fixed design of size 50 had an average of 4.4. This suggests that as well as producing approximation sets of consistently higher quality, the EGO approach will also provide more choice for trading off the two conflicting objectives. The vast majority (98%) of EGO approximation sets contained only valid solutions with a true type II error rate of at most 0.1. For the fixed design method, this proportion was similar when 50 solutions were evaluated but decreased as the number of evaluations increased. For fixed designs of size 1000, 63% of approximation sets contained at least one invalid solutions, although there were at most three invalid solutions in any one approximation set.
We also investigated the effect of changing E, the number of solutions evaluated initially before the iterative part of the EGO algorithm. Keeping the total number of evaluations at 50, we considered E = 10 and 30 in addition to the case E = 20 already presented. As before, the algorithm was run 500 times and the dominated hypervolume of the final approximation set was recorded. We found little difference between setting E = 10 (mean 4823) and E = 20 (mean 4824). When the number of initial evaluations was increased to E = 30, we found a statistically significant decrease in the mean dominated hypervolume to 4761. We can therefore conclude that, in this example, the recommendations referenced in section 4.5 (setting E to ten times the dimensions of the solutions space and representing 30% to 50% of the total computational budget) work well.
5.3. Application to the motivating example
Recall that the PACE trial measured two primary endpoints, one relating to fatigue (denoted as F) and one to disability (denoted as D). Our model of the continuous response of the ith participant for endpoint 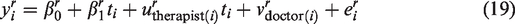
Correlation between the two endpoints is modelled by simulating bivariate residuals 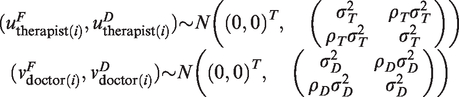
For the purposes of power calculations we must make some assumptions about the various nuisance parameter values. We set the second level variance components to
Our design parameters (together with the ranges considered) are the total sample size in the intervention arm, denoted n1 (50 to 100); the number of therapists, k (2 to 10); the allocation ratio relating the total number of participants in each arm,
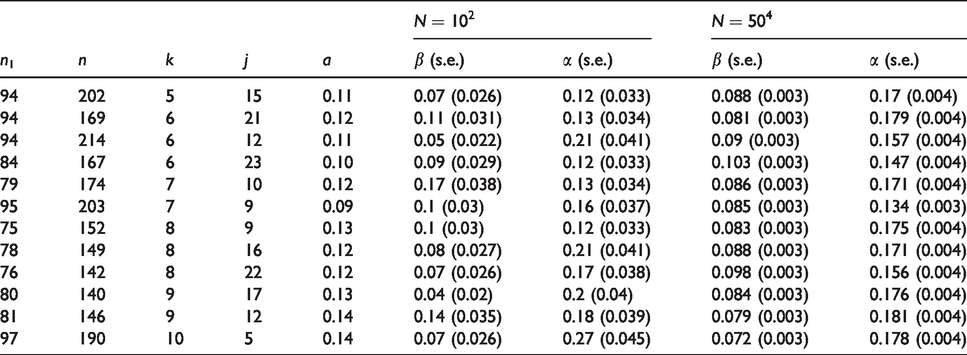
We initialised the algorithm by generating a Sobol sequence of size 50 and computing MC estimates of power for each point using N = 100 MC samples. After 150 iterations of the algorithm, an approximation set containing 12 solutions was obtained. The algorithm took 2 h and 36 min to run on a PC with a 2.60 GHz processor and 8GB RAM. The objective values of these solutions are illustrated in Figure 6, with full details provided in Table 2. The total number of participants ranged from 140 to 214; of therapists, from 5 to 10; and of doctors, from 5 to 23. Nominal type I error rates ranged from 0.09 to 0.14, all some way below the actual constraint value of 0.2. We calculated precise MC estimates (using
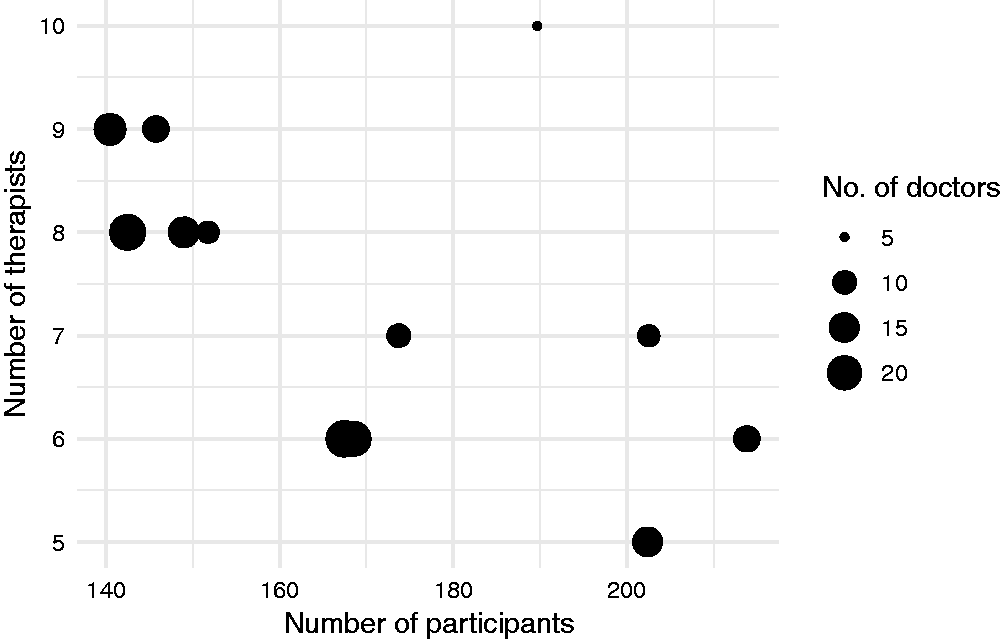
Objective values of the approximation set obtained following 50 iterations of the algorithm for the motivating example.
Approximation set after 50 iterations for the motivating example. Solutions are defined by the number of participants in the APT arm n1, the total number of participants across both arms n, the number of therapists k, the number of doctors j and the nominal type I error rates a. Both type I and II error rates are estimated using simulation using N samples, and are constrained at 0.2 and 0.1, respectively.
6. Discussion
Although simulation is often required for clinical trial sample size determination, related methodology has typically assumed that there is only one parameter which we are able to adjust (the sample size); that there is only one operating characteristic which must be estimated using simulation (the power of the trial); and that our goal is to minimise only one criterion (the sample size again). 3 , 5 In this paper, we have described a flexible approach to simulation-based SSD, which can be used for more general multi-parameter problems. The method draws on established global optimisation algorithms, which use statistical ‘surrogate’ models to solve design problems where there are several parameters to be chosen, several objectives to minimise, and several constraints to satisfy. We have illustrated how such problems arise in clinical trials of complex interventions.
The general optimisation framework we have suggested recognises that in many complex trials we are interested in minimising more than one quantity subject to constraints on operating characteristics. Problems of this sort are common in multilevel trial design, 42 but are typically approached by first reducing the multiple objectives down to a single objective. For example, in the design of a cluster randomised trial it is common to fix the number of participants per cluster and minimise the number of clusters, 43 or vice-versa.44,45 Alternatively, a function that specifies the cost of sampling at the cluster and the patient level could be specified, 46 and the overall cost could be minimised. 47 The latter approach has been suggested for both two-level 48 and three-level hierarchical trial designs.49,50 However, the a priori specification of such a cost function may not always be feasible, particularly when several stakeholders are involved. 51 The Pareto optimisation framework we have described leads to a more computationally challenging optimisation problem, but produces a set of good solutions enabling the available trade-offs between objectives to be seen and selected from.
As noted in section 1, related work in simulation-based design methodology has often focussed on a specific area of application. One advantage that brings is the relative ease with which the software can be used to solve a new problem within the same area. In contrast, our approach requires that the user provides a programme which simulates the data generation and analysis of their proposed trial design. Although some have argued that this requirement may be prohibitive in practice, 18 it allows the user to solve their specific problem rather than some related version of it. Moreover, prior to addressing the sample size issue, modelling and simulation can help inform many other aspects of trial design, such as the patient population or the choice of endpoint. 52 One way to assist users in writing their own simulations is to share example programmes for a range of problems, providing a starting point for the development of a new programme. We have provided some examples in the supplemental material.
When submitting a proposed design for approval by a funding body it is important that the sample size calculation is transparent and replicable. This may be achieved in the context of simulation-based SSD by supplying the simulation programme as part of the application. 5 Given this, any reviewer should be able to re-calculate the operating characteristics of the proposed design. However, a greater challenge for the reviewer is understanding the programme and ensuring it is an accurate representation of the model in question. This requirement has partly motivated our use of R. Although significantly slower than a compiled language such as C++, it has been argued that software written in R is more transparent. 52 Validation will be further facilitated if a simulation protocol of the sort described in Burton et al. 53 is provided alongside the code. Future work could develop an interface for alternative statistical software such as Stata or SAS, allowing a simulation programme to be written in them and connect with the R implementation of the optimisation algorithm.
We have followed the conventional approach to clinical trial design whereby constraints on operating characteristics are set and then a constrained optimisation problem is solved. In practice the constraints are not fixed in advance, but adjusted iteratively in response to the design requirements they produce. For example, an initial nominal power of 90% may require an infeasibly large sample size, leading to a revision down to 80%. Such an iterative procedure will increase an already substantial computational burden for simulation-based design. However, note that a change to a constraint does not mean starting the process again, since any previous MC estimates can still be used when fitting the GP model(s). The sequential nature of the optimisation algorithm suggests that an interactive routine could be developed, where the user pauses the algorithm in response to the sample size requirements which are being observed, adjusts the constraints, and then continues with the optimisation.
We have defined power in relation to a specific value of the parameter of interest, the so-called MCID, and specific point estimates of any nuisance parameters. Implicit in this formulation is an assumed monotonicity of the power function with respect to the parameter of interest. That is, we assume that if the power at this point is above the nominal constraint, then power at all larger values will also be above this level. When this assumption cannot be made, the method could be applied by setting further power constraints at other points in the parameter space. This approach could also be taken with respect to any nuisance parameters, helping to guard against any error in their estimation. This will, however, increase the computational burden by requiring more simulations at each iteration of the algorithm.
The examples have demonstrated that the time required to solve a sample size determination problem can be significant, of the order of hours. Given that the majority of computational effort is expended generating MC samples when evaluating solutions, it is important that these simulation programmes are as efficient as possible. We recommend making use of code profilers such as R’s ‘Rprof’ to identify the parts of the programme that are consuming the most resources. Further efficiencies could potentially be gained by using more sophisticated methods for surrogate modelling and efficient optimisation. For example, prior knowledge such as the power function being bounded or monotonic could be incorporated into the surrogate modelling process. 29
Numerous extensions to the proposed approach can be considered. One argument for simulation-based design is the ease with which sensitivity to model assumptions, such as the value of nuisance parameters, can be assessed. 3 Future work could consider how a systematic assessment of sensitivity to nuisance parameters could be conducted, given a proposed trial design. Such investigations fall under the heading of uncertainty quantification and can be carried out using GP regression and associated techniques. 54 A further extension could consider Bayesian approaches to trial design, including hybrid Bayesian-frequentist assurances, 55 fully Bayesian measures such as average coverage criterion 56 and decision-theoretic methods. 57 Aside from very simple cases involving only conjugate analyses, evaluating these Bayesian criteria will generally require simulation 55 and so optimal design may benefit from the efficient methods discussed here. Complex SSD problems are also common in the area of adaptive designs, which can aim to minimise the expected sample size under several different hypotheses and over a number of stopping rule parameters. 19 Extending the proposed methods to such problems would require using surrogate models to approximate the objective functions, as opposed to only the constraints.
In conclusion, efficient optimisation algorithms based on surrogate models of expensive operating characteristic functions can be used to solve complex clinical trial sample size determination problems. By using these methods we can avoid making unrealistic simplifying assumptions at the trial design stage, both in terms of the statistical model underlying the trial and of the nature of the design problem.
Supplemental Material
sj-zip-1-smm-10.1177_0962280220975790 - Supplemental material for Efficient and flexible simulation-based sample size determination for clinical trials with multiple design parameters
Supplemental material, sj-zip-1-smm-10.1177_0962280220975790 for Efficient and flexible simulation-based sample size determination for clinical trials with multiple design parameters by Duncan T Wilson, Richard Hooper, Julia Brown, Amanda J Farrin and Rebecca EA Walwyn in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Medical Research Council [grant number MR/N015444/1].
Supplemental Material
Supplemental material for this article is available online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.