
Abstract
In the statistical literature, the class of survival analysis models known as cure models has received much attention in recent years. Cure models seem not, however, to be part of the statistical toolbox of perinatal epidemiologists. In this paper, we demonstrate that in perinatal epidemiological studies where one investigates the relation between a gestational exposure and a condition that can only be ascertained after several years, cure models may provide the correct statistical framework. The reason for this is that the hypotheses being tested often concern an unobservable outcome that, in view of the hypothesis, should be thought of as occurring at birth, even though it is only detectable much later in life. The outcome of interest can therefore be viewed as a censored binary variable. We illustrate our argument with a simple cure model analysis of the possible relation between gestational exposure to paracetamol and attention-deficit hyperactivity disorder, using data from the Norwegian Mother, Father and Child Cohort Study conducted by the Norwegian Institute of Public Health, and information about the attention-deficit hyperactivity disorder diagnoses obtained from the Norwegian Patient Registry.
Keywords
1 Introduction
Perinatal epidemiological studies investigating the possible effects of some gestational exposure on a postnatal condition can roughly be split into two categories. Those where the condition is observable immediately after birth and those where it may take years before the condition is ascertained, if ever. This paper is concerned with the latter. Smoking and low birth weight; infant supine position and sudden infant death syndrome; and foetal alcohol spectrum disorders fall in the first category. The association between prenatal marijuana exposure on neuropsychological conditions 1 and the association between prenatal exposure to pharmaceuticals and neurodevelopmental disorders belong to the second category. The present study was motivated by the hypothesis linking gestational exposure to paracetamol and an increased risk of neurodevelopmental disorders, attention-deficit hyperactivity disorder (ADHD) in particular,2–5 hypotheses that are pertinent examples of the latter category.
From a statistical modelling perspective, the main difference between these two types of hypotheses is that the data in the latter are plagued by censoring. That is, the outcome in studies in the second category may be unknown at the time of study due to a lack of follow-up. Thus, for studies in the first category, standard regression analysis is a natural choice (e.g. linear, Poisson, logistic), while for the latter type of studies, the need to handle censoring often leads to survival analysis methods being employed (e.g. the Cox model). A consequence of opting for a survival analysis model is that the outcome is defined as the time to diagnosis, a convenient choice due to the availability of efficient survival analysis software, but that, we argue, can in many cases be an imprecise operationalisation of the outcome in view of the hypothesis being tested. The reason for this is that in perinatal studies belonging to our second group, the hypotheses often concern an exposure that is only present during pregnancy, and consequently the outcome of interest should be thought of as occurring when the effect of the exposure ceases to have an effect, that is, at birth. Think of a frailty model with hazard
In the statistical literature, cure models have received much attention in recent years.6–12 The name stems from medical applications where some patients never experience a relapse of the disease under study, and these patients are therefore considered cured. Cure models have also been proposed in the field of reproductive epidemiology to account for the possibility of some of the individuals under study being sterile. 13
It is worth noting that the motivation typically underlying cure models is rather different from the argument we put forward in this paper. Typically, cure models are solidly anchored in the survival analysis world, while our approach, which is focused on the probability of belonging to the susceptible group, is more akin to a misclassification- or missing data problem. In other words, in this paper, we are less interested in survival quantities such as hazard rates and survival functions per se, but view them as nuisance parameters that must be tended to in order to make inferences on the parameters determining whether a child is born susceptible or not. See Farewell 14 for an early paper advocating for cure models in a similar manner.
The article proceeds as follows. In Section 2, we provide a brief introduction to the cure model, and motivate this class of models in light of the hypothesis linking paracetamol and ADHD (hereafter referred to as the paracetamol–ADHD hypothesis). This section also contains some theoretical results on simple logistic and Cox models when such are fitted to data that contain a cure fraction. These results are illustrated with two small simulation studies. In Section 3, we fit different cure models to the data on gestational exposure to paracetamol and ADHD, and compare these with a logistic regression and a Cox regression model. The aim of this application is to investigate whether our reading of the paracetamol–ADHD hypothesis finds empirical backing, and illustrate the fact that all three classes of models are likely to lead to rather similar conclusions about the paracetamol–ADHD hypothesis.
2 The cure model and ADHD
In this section, we first, using the paracetamol–ADHD hypothesis as our example, elaborate on why we find the class of cure models appropriate for the perinatal studies discussed in this paper. Subsequently, we give a brief introduction to the standard mixture cure model.
2.1 The paracetamol–ADHD hypothesis
The use of cure models in perinatal epidemiological studies can be motivated by the directed acyclic graph (DAG) in Figure 1. In this DAG, x represents the gestational exposure, Y is a binary indicator representing the condition the child is born in, while u is a set of confounders. In perinatal studies belonging to our second category, we think of Y as an indicator of a being born susceptible (Y = 1) or nonsusceptible (Y = 0) to the condition in question, i.e. the variable Y indicates the incidence of, or vulnerability to, a particular disease or condition, or a lifetime free of the disease or condition under study.
14
The variable T is the minimum of the time at which the presence of the condition in the child is discovered and a censoring time, δ is an indicator taking the value 1 if the value Y = 1 is discovered before censoring and z is a set of postnatal variables influencing the time to an eventual diagnosis. The paracetamol–ADHD hypothesis suggests that gestational exposure to paracetamol is associated with ADHD. More precisely, it states that – all else equal during the gestational period – two children with the exact same gestational exposure to paracetamol should lead to the same conclusion about the effect of gestational exposure to paracetamol on the risk of ADHD, even though the two children were diagnosed at different ages. This entails that the exposure effectively ceases to have an effect once the child is born, which is the reason for there not being a direct arrow from x to
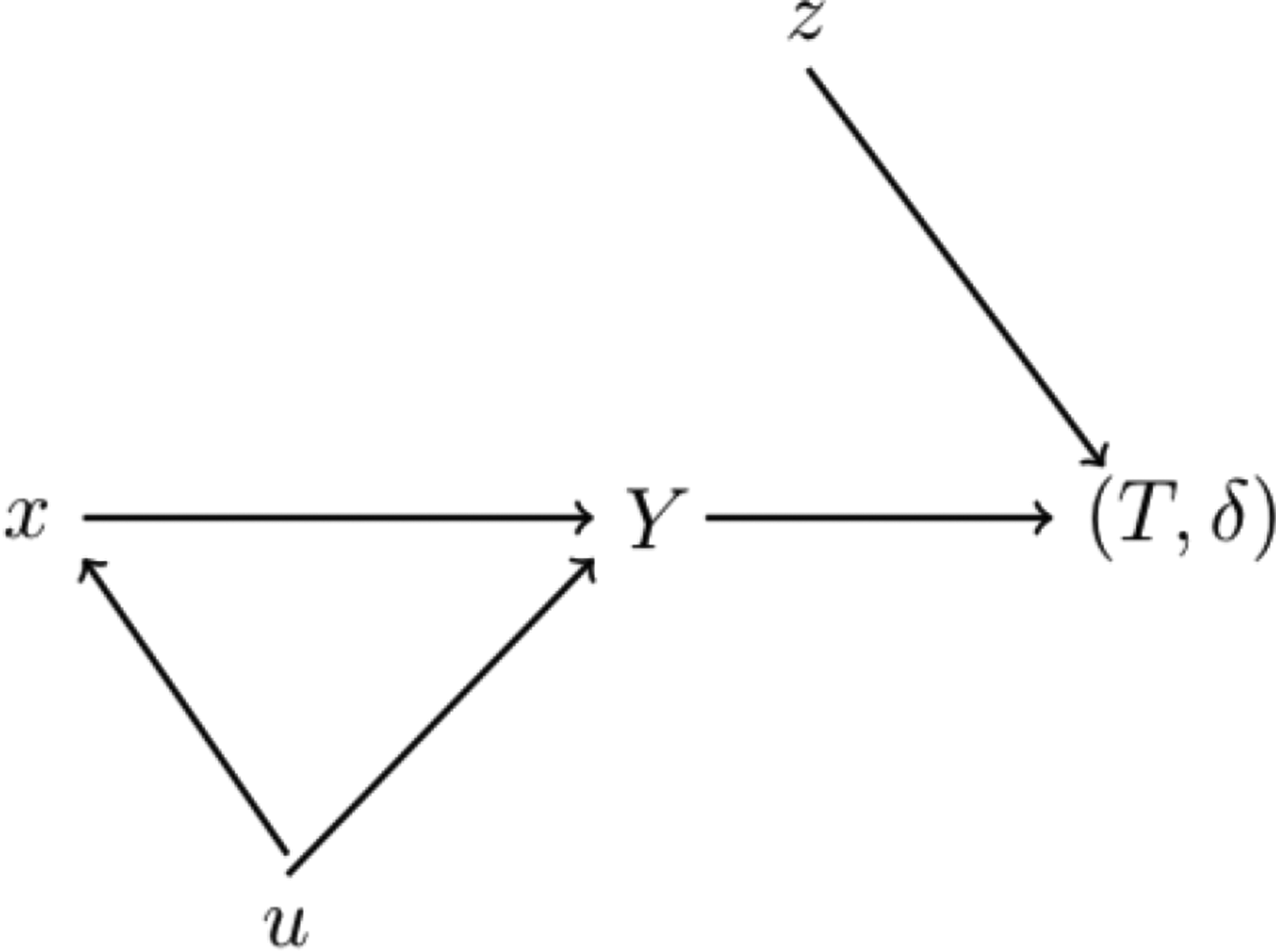
A DAG illustrating the data generating mechanism presented in Section 2.1. The exposure of interest (paracetamol) is x, Y is the latent susceptible/nonsusceptible indicator and u is a confounder of this relation. Given susceptibility (Y = 1), z is a postnatal covariate influencing the possibly right-censored time to diagnosis
The Y’s are, however, only partially observable so the
2.2 The standard cure model
As above, let Y be the indicator of susceptibility (Y = 1), or of a lifetime free of the condition (Y = 0), with π the probability of Y = 1. The time to diagnosis is a variable

Both π and S(t) are typically modelled as functions of covariates, common choices being a logistic function for the probability of being susceptible, and a proportional hazards model for the survival function of the susceptible group. That is, for the i’th individual
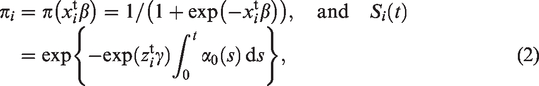
For the perinatal studies that are the object of this paper, two features of the model in equation (1) should be pointed out. First, by using this model, we are assuming that the nonsusceptible individuals are never diagnosed with the condition in question, that is, we assume that there are no false positives in the sample. In the case of ADHD, this assumption may be questioned. In the US, there is evidence of ADHD overdiagnosis in some communities, 15 meaning that the prevalence of ADHD is higher than the standard 3–5% prevalence estimate.16–18 In the data set we analyse in Section 3, only about 2.3% of the children are diagnosed with ADHD. Since this number is well below the standard prevalence estimates, it would lead one to believe that false positives are not a major issue in our data.
Notice that if δ = 1, then we know that Y = 1, while if δ = 0, we do not know whether the individual is susceptible or nonsusceptible. This brings us to the second point, if the data contain information on nonsusceptibility (e.g. a medical test that ascertains immunity to a certain disease), then this information ought to be taken into account. As it stands, the model in equation (1) cannot incorporate such information (see Remark 1 in Section 4 for further discussion).
The log-likelihood function of the model in equation (2) is
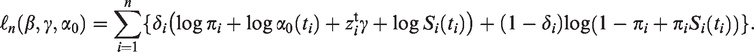
If
2.3 Fitting logistic and Cox models to cure data
In this section, we provide some insight on the bias incurred in the parameter estimates when the data stem from a cure model, but a logistic regression model or a Cox regression model, is chosen.
Suppose that the data
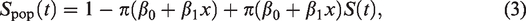
Consider fitting a logistic regression model to independent data
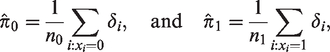
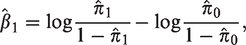
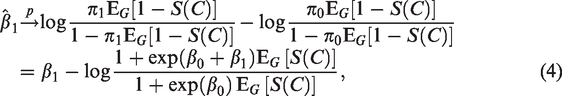
If S(t) rapidly approaches zero, which is the case if the condition under study is likely to be discovered early in life, then the bias term will be small. And, through its dependence on β0, we see that the bias of
Now, consider fitting a Cox regression model with hazard rate
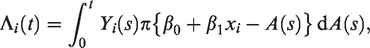
Let
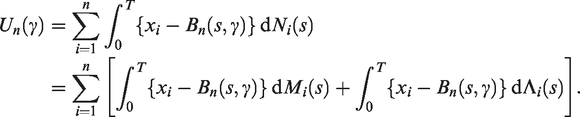
If the second term on the right is zero, which it is when the model
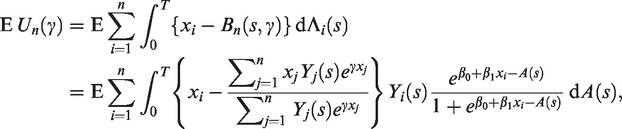
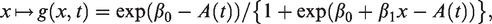
In summary, when it comes to estimating β1, the logistic model provides decent estimates when β0 is small or the cumulative hazard increases rapidly, while the Cox model only gives decent estimates when β0 is small.
To illustrate this, we performed two simulations studies with varying parameter values. In both, the data were simulated from a cure model of the form given in equation (3), with the parameter of interest set to
In the simulations reported in Figure 2, we set
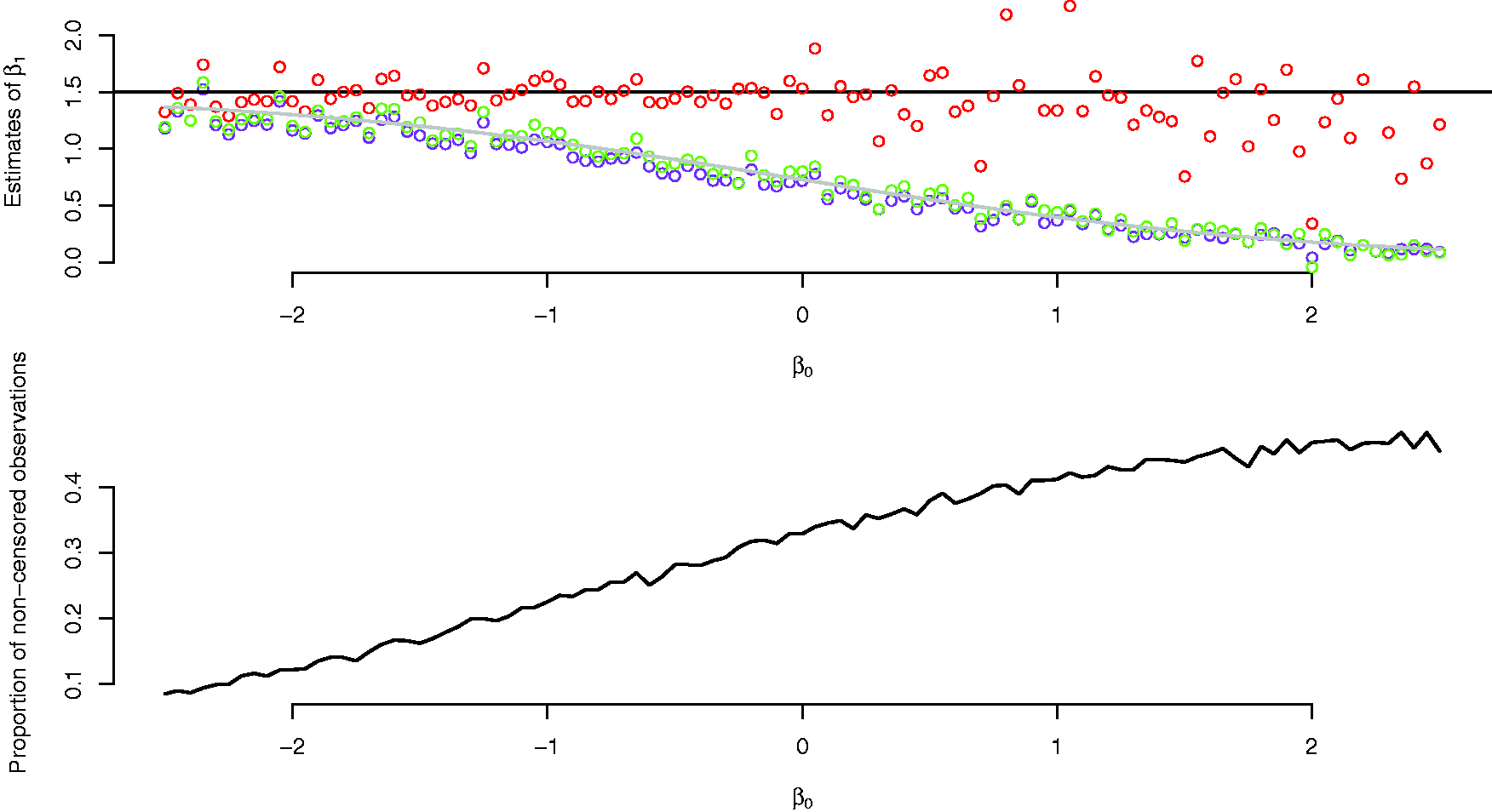
Upper panel: estimates of β1 from a semiparametric cure model (red dots), logistic model (green dots) and a Cox model (purple dots), with varying values of β0. The grey line overlapping the green and purple dots is the term on the right in equation (4) as a function of β0. The black line is the true parameter value of β1. Lower panel: Proportion of non-censored observations as a function of β0.
In the simulations reported in Figure 3, we set
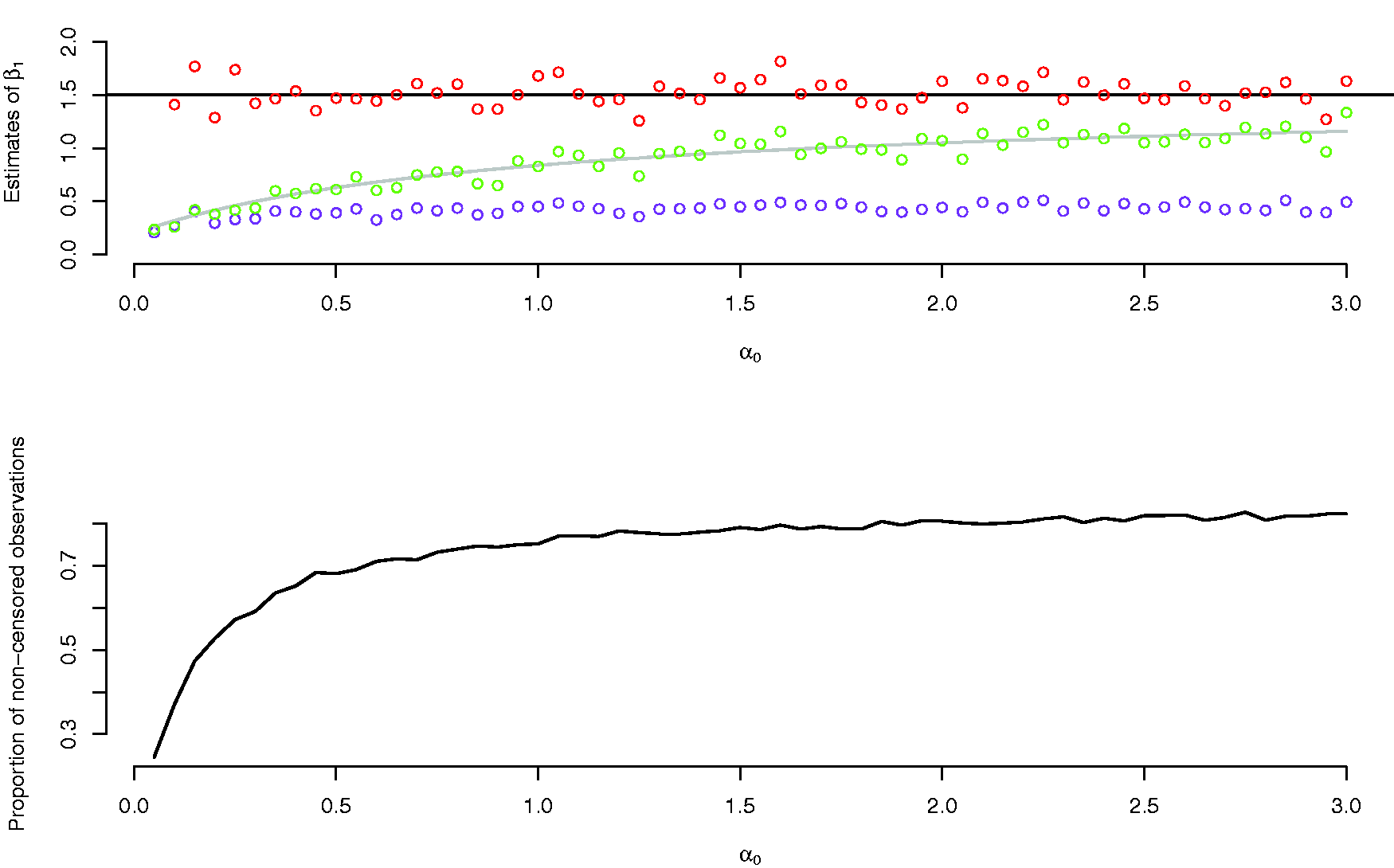
Upper panel: estimates of β1 from a semiparametric cure model (red dots), logistic model (green dots) and a Cox model (purple dots), with varying values of α0. The grey line is the term on the right in equation (4) as a function of α0. The black line is the true parameter value of β1. Lower panel: proportion of non-censored observations as a function of α0.
In the data set we analyse in Section 3, only
3 Data analysis
The cure models we fit to the paracetamol–ADHD data have population survival functions
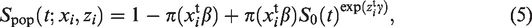
For comparison, we also fit a logistic model and a Cox model to the paracetamol–ADHD data. As elaborated on in Section 2.3, we have reason to expect a nominal similarity between the exposure estimates from these models to those of the corresponding cure models. This is because the prevalence of ADHD in the data is low, and because most children diagnosed with ADHD are diagnosed quite early in life.
The data used in this analysis stem from the Norwegian Mother, Father and Child Cohort Study (MoBa) conducted by the Norwegian Institute of Public Health. Information about the ADHD diagnoses was obtained from the Norwegian Patient Registry (NPR). The analyses of this section are motivated by and use essentially the same data as Ystrom et al., 2 and a more elaborate discussion of the MoBa and the NPR can be found therein.
After having removed observations with missing values, the sample consisted of
The 11 birth year cohorts included in the data, size of cohort and number of children within each cohort with a diagnosis of ADHD.
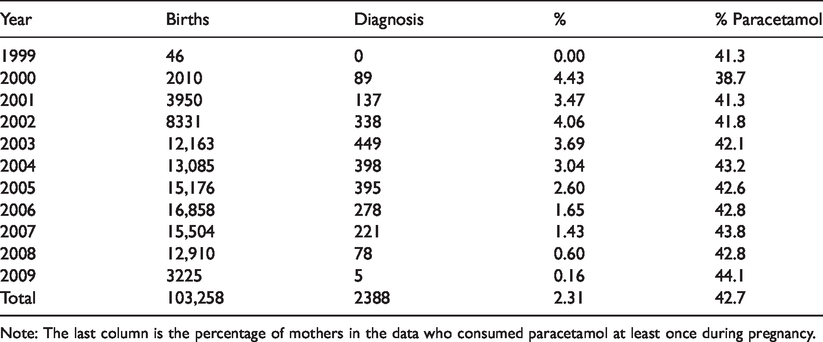
Note: The last column is the percentage of mothers in the data who consumed paracetamol at least once during pregnancy.
The cure models we fit have population survival functions of the form (equation (5)), with the baseline survival function being either nonparametric or that of a gamma distribution with density
Summary of covariates.

ADHD: attention-deficit hyperactivity disorder.
Note: All the covariates are binary (0–1). For an individual, a value of 1 means, respectively, that paracetamol was consumed at least once during gestation, the mother has higher education, the mother consumed alcohol at least once a month during gestation and that paracetamol has been consumed to alleviate fever.
We fitted three different cure models for each of the two specifications of the baseline survival function
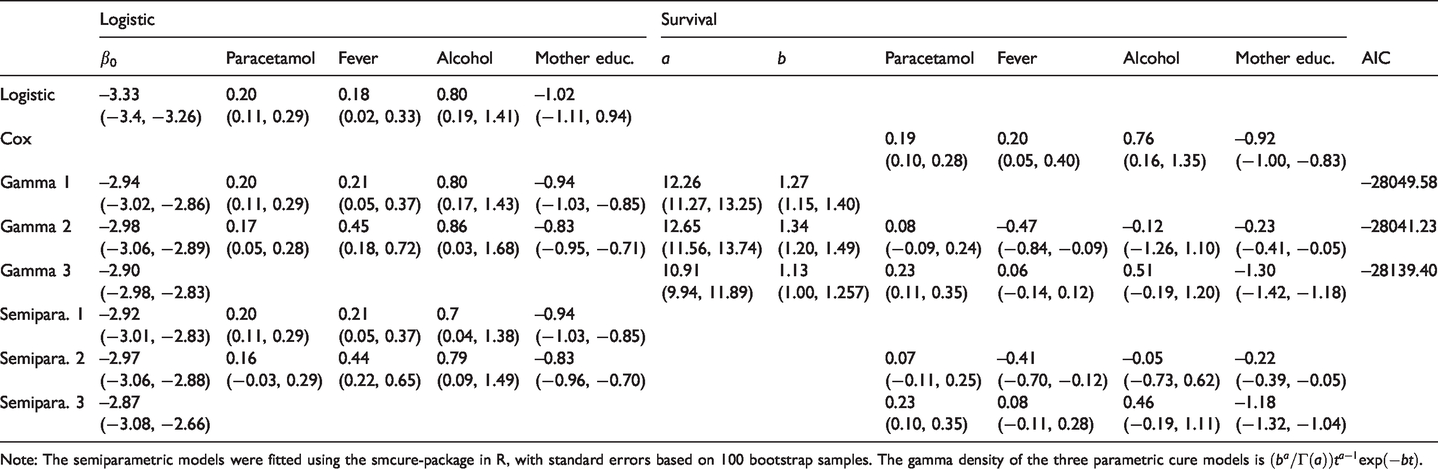
Table 3 reports the parameter estimates and estimated standard errors of these for all eight models. Figure 4 displays estimates of the proper survival functions (that is,
Estimates based on
Note: The semiparametric models were fitted using the smcure-package in R, with standard errors based on 100 bootstrap samples. The gamma density of the three parametric cure models is
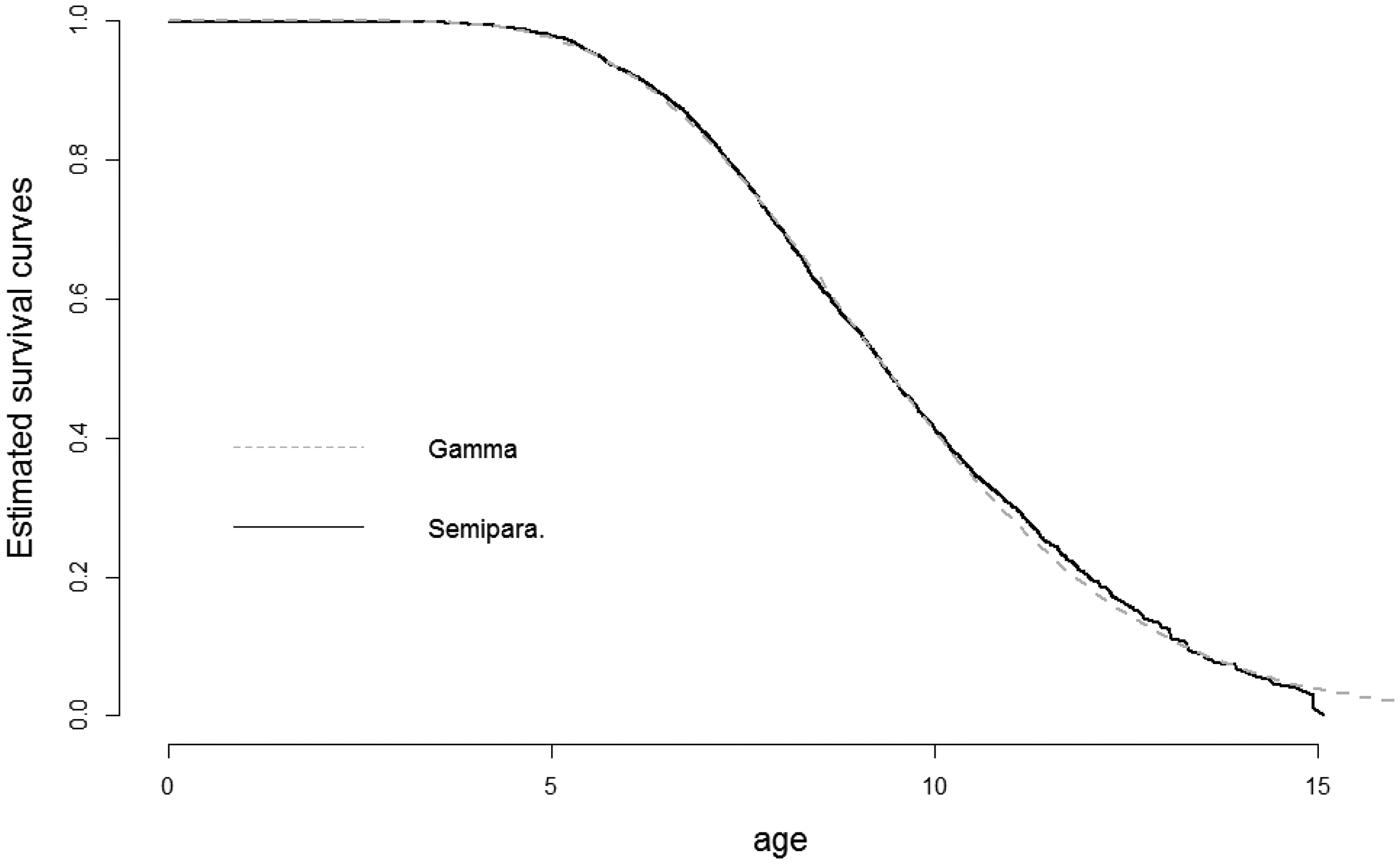
Estimates of the survival curve of the susceptible children, i.e. the proper survival functions S(t) in equation (5). The estimates are based on the model Semipara. 1 and Gamma 1 of Table 3.
In Table 3, the first thing to notice is that in the cure models that include covariates on both the logistic and the survival part (Gamma 2 and Semipara. 2), the estimated effects of paracetamol on the logistic part are significant at the
The results reported in Table 3 are interesting because they can be seen as corroborating the reading of the paracetamol–ADHD hypothesis expounded in Section 2.1, namely that gestational exposure to paracetamol determines whether or not a child is susceptible, while being unimportant for the time to diagnosis. In other words, given susceptibility the time to diagnosis appears to be independent of the exposure.
The important issue of identifiability of the semiparametric cure model should be pointed out. Loosely speaking, for the fraction of susceptible children to be accurately estimated, we must assume that the (covariate dependent) distribution function of the survival times of the susceptible individuals reaches unity before the distribution function of the censoring times. 12 In effect, for identifiability reasons, when we fit the semiparametric cure models, the survival functions are set to zero for all survival times above the largest observed diagnosis time. No such fix is demanded when fitting fully parametric cure models. See Section 4 for further discussion of these issues, and Amico and Van Keilegom 12 for a thorough discussion of identifiability in semiparametric cure models.
4 Discussion and concluding remarks
In this section, we briefly discuss the above findings and introduce some topics for possible future research.
The cure model was motivated by arguing that the scientifically interesting question in many perinatal studies is how the exposure relates to a partly unobservable variable indicating whether or not the child is susceptible to the condition or disease of interest.
The empirical analysis of the paracetamol–ADHD hypothesis of Section 3 indicates that the diagnosis times are independent of the exposure when susceptibility is accounted for. These findings have important implications for studies on most childhood long-term outcomes as there will always be a fraction of the children that is never diagnosed with the condition studied, and among these many should, for all practical purposes, be regarded as nonsusceptible to the condition in question. When a fraction of the offspring are nonsusceptible, conventional survival analysis methods will give biased effect estimates.
4.1 Remark 1
As discussed in Section 2.1, when using the cure model, we assume that we do not have data on the absence of the condition or disease, i.e. δ = 0 does not inform us on what the true value of Y is. Now, consider a different scenario, where one does indeed have data on the absence of a condition or disease. Then, one would want to model a positive probability of nonsusceptibility (Y = 0) being discovered. This motivates a model where the children born susceptible (Y = 1) have a hazard rate 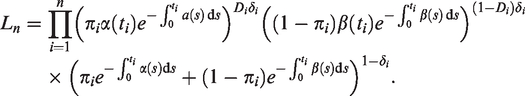
If π,
4.2 Remark 2
A class of survival models that can give estimates of continuous levels of susceptibility are so called first hitting time models.22,23 One example is the following. Consider a Wiener process Z(t) with drift μ and
4.3 Remark 3
We have argued that in the perinatal studies discussed in this paper, the quantity of scientific interest is π, the probability of being born susceptible, while parameters related to the distribution of the diagnosis times are nuisance parameters. Nevertheless, the model selection criterion employed in Table 3 is the AIC, a criterion that assesses general overall issues and goodness of fit aspects of the cure models, and not only how good the inference on π or related quantities is. Preferably, when the scientific question directs attention to one part of the cure model, the model selection criterion employed ought to reflect this. Therefore, a possible topic for future research is developing a focused information criterion (see Jullum and Hjort
25
and Claeskens and Hjort
26
) for comparing different parametric, as well as parametric and semiparametric cure models. The idea is to select the model that best estimates a focus parameter, say ψ, where the quality of the estimator is assessed by (an estimate of) the mean squared error
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work and Emil A Stoltenberg’s PhD is funded by The PharmaTox Strategic Research Initiative. Hedvig ME Nordeng and Eivind Ystrom are funded by the European Research Council Starting Grant ‘DrugsInPregnancy’, ERC-STG-2014 under agreement No. 639377.