
Abstract
Continuous growth models show great potential for analysing cancer screening data. We recently described such a model for studying breast cancer tumour growth based on modelling tumour size at diagnosis, as a function of screening history, detection mode, and relevant patient characteristics. In this article, we describe how the approach can be extended to jointly model tumour size and number of lymph node metastases at diagnosis. We propose a new class of lymph node spread models which are biologically motivated and describe how they can be extended to incorporate random effects to allow for heterogeneity in underlying rates of spread. Our final model provides a dramatically better fit to empirical data on 1860 incident breast cancer cases than models in current use. We validate our lymph node spread model on an independent data set consisting of 3961 women diagnosed with invasive breast cancer.
Keywords
1 Introduction
Since its popularisation in medical statistics, the multi-state Markov model has been the primary tool to model breast cancer progression using epidemiological or breast cancer screening data.1–5 In recent years, however, several research groups have developed alternatives based on continuous processes. Bartoszynski et al. 6 estimated tumour growth with an exponential growth function, explaining individual variation in growth rates with gamma distributed random effects. Plevritis et al. 7 described some extensions of the model. Both of these early models based inference on tumour sizes of breast cancer cases in non-screened populations. Weedon-Fekjaer et al.5,8 fitted a continuous tumour growth model to data collected from a screened population. They presented a parsimonious model, containing only four parameters, that described both tumour growth and screening sensitivity as continuous functions, enabling them to condition on screening history and mode of detection. An alternative approach that also uses screening data was described by Abrahamsson and Humphreys. 9 The approach is based on specifying three underlying processes: tumour growth, screening sensitivity, and symptomatic detection. The authors essentially extended the model of Bartoszynski et al. 6 and derived probability distributions for tumour sizes, conditioned on screening history and mode of detection. Isheden and Humphreys 10 derived a number of mathematical results that simplified and reduced the computational complexity of the model.
The Markov model requires many parameters when the number of disease states is large. As a consequence, the model is not well suited for quantifying the role of individual risk factors on breast cancer progression. Continuous growth models, on the other hand, have few parameters, and can easily be modified to estimate tumour progression at an individual level. For example, Abrahamsson et al. 11 modelled tumour growth rate as a function of BMI and time to symptomatic detection as a function of breast size, and Abrahamsson and Humphreys 9 and Isheden and Humphreys 10 have estimated screening sensitivity as a continuous function of tumour and mammographic image-based covariates. For data collected in the absence of screening, Plevritis et al. 7 extended the exponential growth model of Bartoszynski et al. 6 with two disease states, representing regional lymph node spread and metastatic spread. In the presence of screening, no model that we know of has modelled both tumour growth and tumour spread as continuous time processes. The aim of this article is to develop such a joint process, based on the literature on lymph spread modelling and lymph spread simulation.
In 2000, the U.S National Cancer Institute established a consortium, 12 consisting of six research groups from Georgetown University, University of Texas MDACC, Dana-Farber Cancer Institute, Erasmus MC, Stanford University, and University of Wisconsin, to develop simulation-based modelling approaches for investigating the impact of breast cancer interventions, with a focus on prevention, screening, and treatment. Each group models the natural history of breast cancer as part of their investigation, and the last three groups model breast cancer tumour growth as a continuous time growth process. All groups model localised tumour stages, regionally spread stages, and distant metastatic stages, but only the University of Wisconsin group models breast tumour spread as a continuous time process.
To model breast tumour spread, the Wisconsin group uses a model proposed by Shwartz,
13
which assumes that tumour volume V grows exponentially with an individually assigned growth rate, and that the instantaneous rate of additional lymph node spread at time t is equal to
Related tumour spread models have been proposed by Hanin and Yakovlev 14 and, as mentioned, by Plevritis et al. 7 Hanin and Yakovlev based their model on the model of Shwartz 13 and assumed that tumours grow exponentially and that the rate of additional lymph node spread is proportional only to tumour volume. They introduced a number of additional assumptions and provided a detailed mathematical description of the model. Plevritis et al. 7 described a simpler model. They assumed that the hazard of a localised tumour spreading to the lymph nodes is proportional to the volume of the tumour. They also relied on exponential tumour growth.
From the observations that: a) the CISNET University of Wisconsin group had to introduce additional assumptions to fit the Shwartz model to data and b) that the Shwartz model represents a generalisation of the models of Hanin and Yakovlev and Plevritis et al., we conclude that existing models can be improved upon. In this article, we back this claim by showing that the Shwartz model has two inherent weaknesses. The first weakness is that the model implies that slow growing tumours have a higher degree of lymph node spread, compared to fast growing tumours, and the second weakness is that the model implies either an unrealistically high degree of lymph node spread for large tumours or an unrealistically low degree of spread for small tumours. Based on these observations, there is a need for new statistical models of regional lymph node spread.
This article is structured in the following way. We present the models of Shwartz
13
and Hanin and Yakovlev,
14
and describe these weaknesses in detail. We then propose several models of regional lymph node spread. The first one is based on Shwartz
13
but does not suffer the first weakness. The second one is a new model that addresses both of the weaknesses mentioned above. The new model assumes that the instantaneous rate of additional lymph node spread at time t,
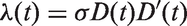
2 Traditional models of regional lymph node spread
Shwartz
13
described a joint process for tumour growth and regional lymph node spread. Given an inverse growth rate r (assumed to vary across individuals), he assumed that tumour volume grows exponentially from time t = 0

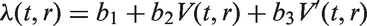
Based on the Poisson process proposed by Shwartz,
13
it follows that the intensity measure is given by
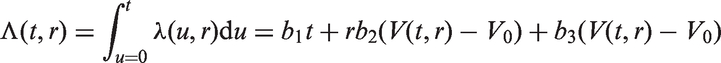
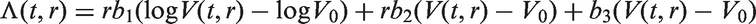
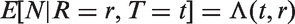
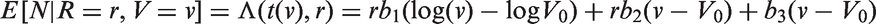
Hanin and Yakovlev
14
used the same tumour growth function, but assumed that the intensity function was given by

Both models, but especially the model of Hanin and Yakovlev, exhibit a second weakness. Namely, that the rate of additional lymph node spread increases enormously with increasing tumour volumes. We illustrate this by comparing the expected number of lymph nodes for tumours of diameters 5 mm and 30 mm. Plugging these diameters into equation (2), for fixed values of r and γ, we find that the expectation is more than 200 times larger for the bigger tumour. Such an extreme difference is not supported by clinical data. In our data the mean number of lymph nodes for 30 mm tumours (2.15) is less than nine times that for 5 mm tumours (0.25).
Shwartz 13 found that when simulating cohorts of symptomatic cancers based on his model, he produced too few affected lymph nodes in tumours with diameters smaller than 1 mm. The CISNET University of Wisconsin group also saw this when using their modified approach. They also found that the model generated too many lymph nodes in large tumours. Even though the second weakness, strictly speaking, does not have to apply to the Shwartz model, it clearly does, as the findings of the two groups show. Together, these weaknesses mean that new models of lymph node spread are needed.
3 Joint processes of tumour growth and lymph node spread
In this section, we present joint processes of tumour growth, time to symptomatic detection, and lymph node spread. The joint processes share the same models for tumour growth, variation in tumour growth, and time to symptomatic detection, but differ in their models of lymph node spread. All models are, however, based on the same general framework: an inhomogeneous Poisson process with intensity function dependent on tumour volume. The first, called model A, is a variation of Shwartz,
13
where we assume that the intensity function is proportional to the first derivative of tumour growth,
3.1 Shared processes and assumptions
We use the original tumour growth process that Schwartz 15 described in 1961, and adopt the other shared models from Bartoszynski et al., 6 Hanin and Yakovlev, 14 Plevritis et al., 7 Abrahamsson and Humphreys, 9 and Isheden and Humphreys. 10
We assume that the tumour is monoclonal and originates from a spherical cell of diameter


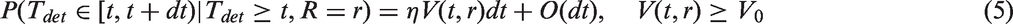
We begin with the two models of spread which we call A and B. We then work in a stepwise fashion, developing model B to a class of models and then showing how these can be extended to incorporate random effects.
In all models, we assume that spread occurs one cell at a time and that secondary tumours (in the lymph nodes) have the same cell reproductive rate as the primary tumour. We only model spread that eventually becomes clinically detectable, i.e. lymph node spread that is detectable by the physician once the primary tumour has been detected. Secondary tumours need to grow to size V0 to be clinically detectable (we could in theory use a volume different to V0 here). This means that between the time of tumour spread and the time at which the secondary tumour becomes a clinically detectable lymph node metastasis, there is a time lag of size t0. For a fixed inverse growth rate r, the time lag is defined by

3.2 Model A
The first lymph node spread model is an inhomogeneous Poisson process with intensity function
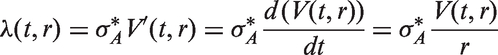
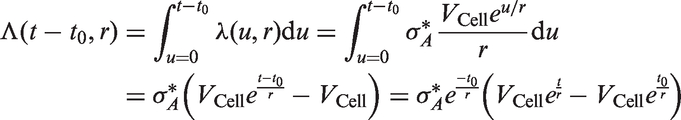
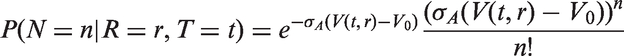
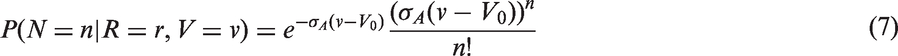
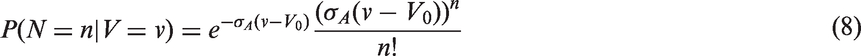
3.3 Model B
We now focus on deriving a biologically inspired model for lymph node spread. We base our model on two observations: A) lymphatic fluid is hostile to tumour cells; it contains little oxygen and nutrients, and tumour cells in the lymphatic system are under constant attack by the immune system. In order to survive, tumour cells entering the lymph system need to be highly mutated. B) Cell migration and cell proliferation share some common growth factors, such as the Hepatocyte Growth Factor/scatter factor. 16 Thus, the rate of cancer spread may be related to the rate of cell division.
Based on A) and B), we assume that the rate of lymph node spread is proportional to the average number of mutations in the cancer cells and the rate of cancer cell division. The first of these quantities is not observable, but assuming a constant rate of mutation during cell division, the average number of mutations in the cancer cells is proportional to the number of times the cells in the tumour has divided. In summary, the second spread model is an inhomogeneous Poisson process with intensity function
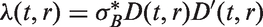
Assuming that cancer cells form a spherical and densely packed tumour, and that cancer cells resist cell death, the number of times the cells in the tumour has divided is calculated by describing tumour volume as a doubling process. We get the number of cell divisions from the following relation
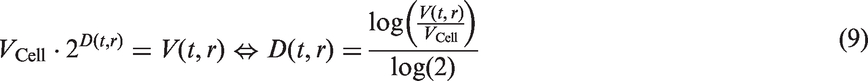
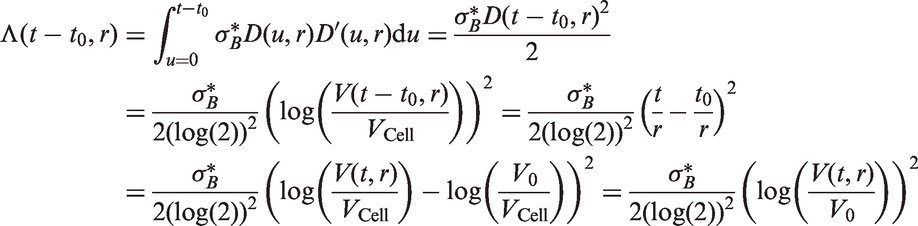
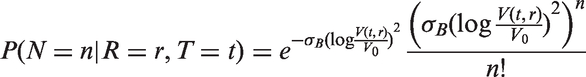
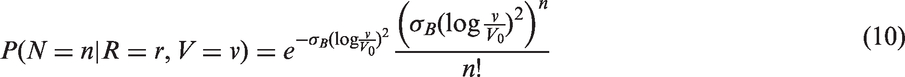
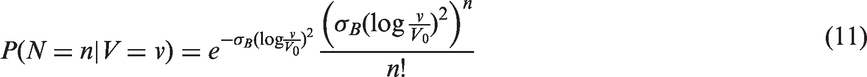
3.4 A new class of models for lymph node spread
Based on model B, we here define a class of mathematically tractable models for lymph node spread. We show that if the intensity function is assumed to be proportional to the kth power of the number of cell divisions in the tumour and the rate of cell division in the tumour, and if we make the same assumptions as in model B, we can derive closed forms for
We define the new model class, similarly to model B, by assuming that lymph node spread follows an inhomogeneous Poisson process with intensity function
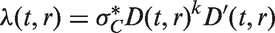
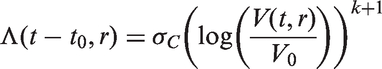
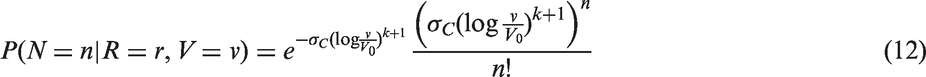
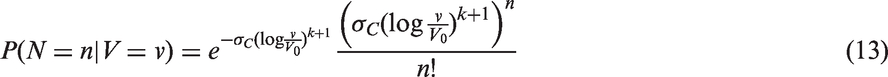
3.5 Random effects modelling of lymph node spread
So far we have concentrated on developing new models of the mean numbers of affected lymph nodes. Breast cancer is, however, a heterogeneous disease; just as tumours grow at different speeds for different women, it would seem reasonable that breast cancer lymph node spread will occur at different rates for different women. We derive here a Poisson process where the constant factor s is gamma distributed. As before, we assume that
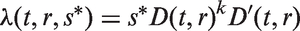
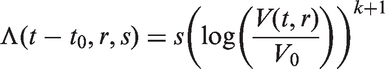

4 Likelihood for incident cases in the presence of screening
To jointly estimate the parameters of the processes, we derive a likelihood function for incident breast cancer cases, collected in the presence of screening. This approach requires a model for mammography screening test sensitivity.
A screening test depends primarily on two factors: tumour size and mammographic density. Mammographic density reflects the different tissues in the breast. Fatty tissue appears dark on a mammogram, whereas fibroglandular tissue is bright. Since tumours also appear bright, they can be concealed in fibroglandular regions. A widely used measure of mammographic density is percentage density, which is measured as the fraction of pixels within the breast region on the mammogram that have an intensity above a particular threshold. For screening sensitivity, we adopt a model from Abrahamsson and Humphreys.
9
We assume that the probability for a positive screening test, given a tumour in the breast, is equal to
We can use the model for screening sensitivity, along with the other models, to write the joint likelihood of tumour size and number of lymph nodes affected, conditioning on screening history and mode of detection. Under stable disease assumptions14,10 and assuming that tumour growth rate is independent of screening attendance, it has been shown that optimising this likelihood, using incident cases only, yields unbiased parameter estimation.
10
The stable disease assumptions are
The rate of births in the population is constant across calendar time, The distribution of age at tumour onset is constant across calendar time, and The distribution of time to symptomatic detection is constant across calendar time.
These assumptions manifest in a constant incidence of breast cancer in the population. We discuss these assumptions in the light of our analysis in section 7.
Pathologists tend to round small tumour diameters to the nearest mm, and larger tumour diameters to the closest 5 or 10 mm. Therefore, we divide tumour sizes into 24 different millimetre size intervals, A – There is a tumour in the woman's breast at time t. B0 – A tumour is screen detected at time t. C
i
– The tumour is in size interval i at time t. D – The tumour is symptomatically detected at time t. N
j
– The number of lymph nodes affected at time t is j.
The likelihood is treated somewhat differently for screen detected and symptomatically detected cancers. For the sake of clarity, we omit mammographic density from the likelihood calculations.
4.1 Likelihood for screen detected cases
Given that a tumour is screen detected, the probability of the tumour being in size interval i with j lymph nodes affected is

4.2 Likelihood for symptomatic cases
Given that a tumour is symptomatically detected, the probability of the tumour being in size interval i with j affected lymph nodes is

4.3 Calculating the likelihood
The likelihoods described in equations (18) and (19) are the joint probabilities of tumours belonging to size interval i and having j affected lymph nodes, conditioned on mode of detection, numbers and times of previous negative screens, and mammographic density (the latter is omitted from the likelihood expressions for simplicity, but is included in our calculations for the analyses presented in the next section). There are seven different quantities in the likelihood, which we express in terms of models (3) to (5), the screening sensitivity (17), and lymph node models (7) and (8), (10) and (11), (12) and (13), or (15) and (16).
The first quantity is
The second quantity is
The third quantity is
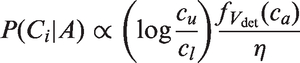
The fourth quantity is
The fifth quantity is
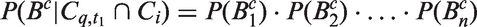
The sixth quantity is
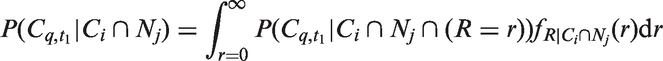
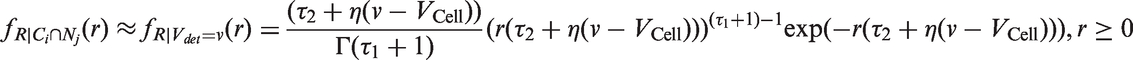
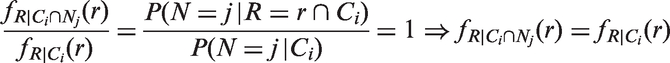
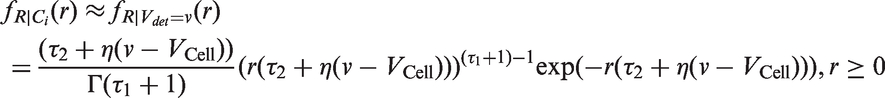
The seventh quantity is
For the four lymph node spread models described here, the likelihood is separable; we can separate into a size component and a nodes component. This can be seen, for example for the likelihood for screening cases, by writing
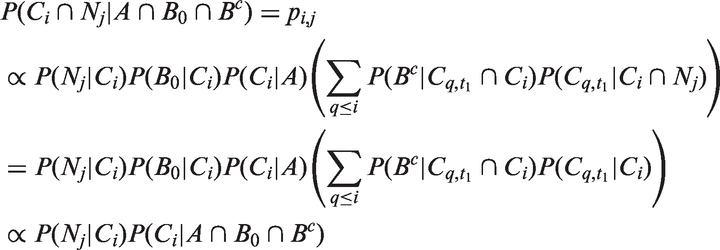
For the models of Hanin and Yakovlev
14
and Shwartz,
13
the likelihood calculation is not as straightforward. The quantity
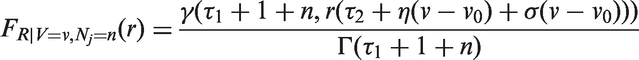
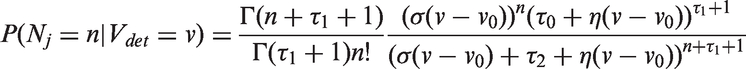
The likelihood that we describe in this section is complex. It relies on several approximations that are needed mainly to account for discretisation in the estimation procedure. To verify that we implemented the methods correctly, we performed a simulation study. The aim of the study was to show that we can accurately retrieve parameter estimates from the likelihood. The results are shown in Appendix 1.
5 Joint modelling of tumour size and lymph node spread – a study of incident invasive breast cancer in post-menopausal women
Comparison of screening and symptomatically detected cancers in CAHRES.
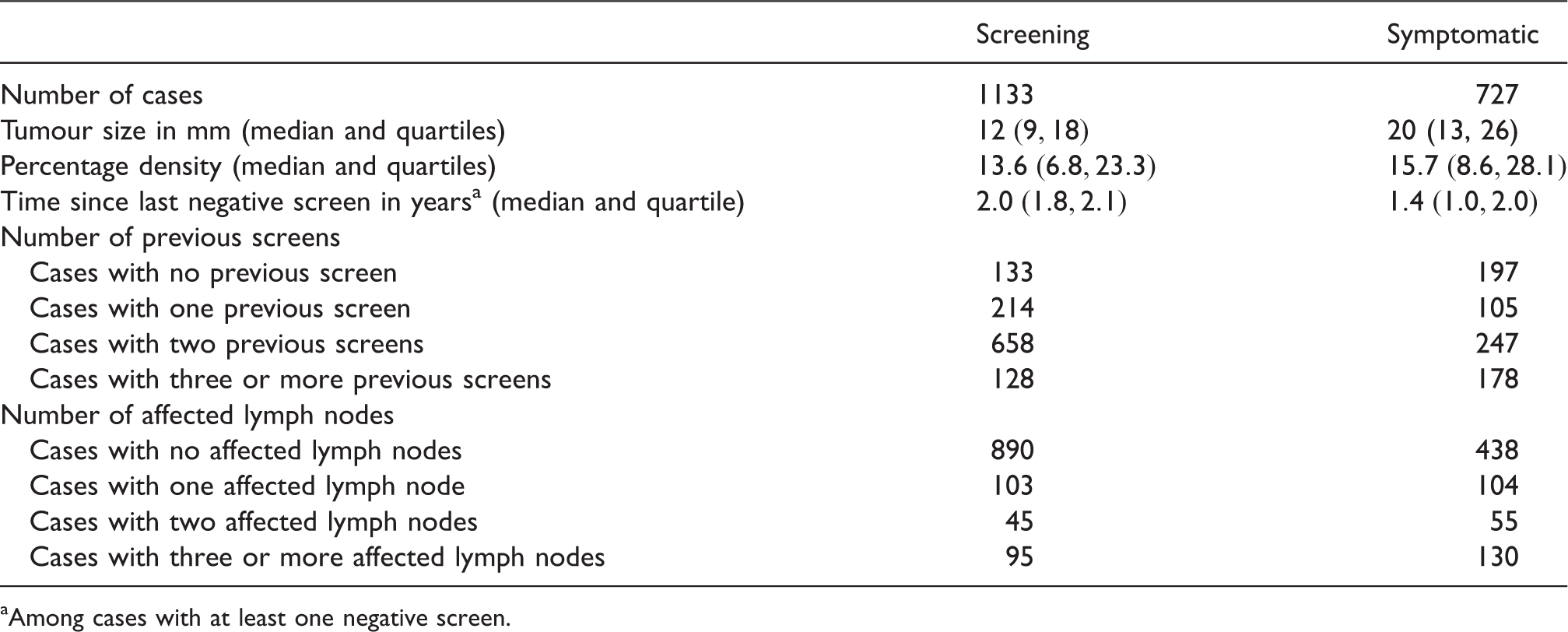
Among cases with at least one negative screen.
We fitted model A and model B by maximising the likelihood over parameters Model-based estimates of expected lymph node spread as a function of tumour size, based on CAHRES. Circles and bars represent averages and 95% confidence intervals of numbers of lymph nodes affected within each tumour size interval. Model A (dotted) produces excessive spread at large tumour sizes, while model B (solid) underestimates spread at large tumour sizes. Parameter estimates in joint models of tumour size and lymph node spread, together with bootstrapped 95% coverage intervals, based on 1860 post-menopausal breast cancer cases (CAHRES).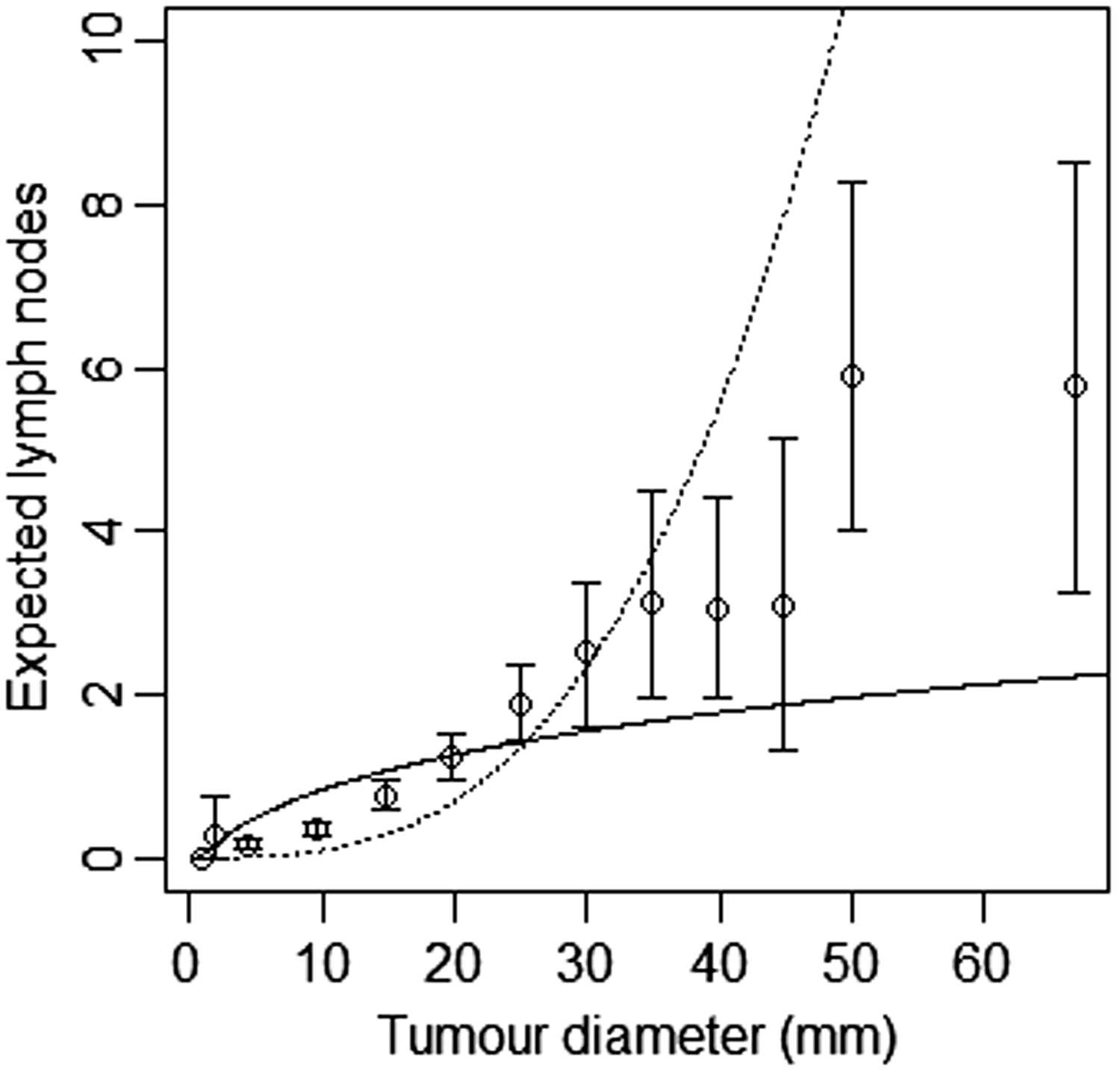
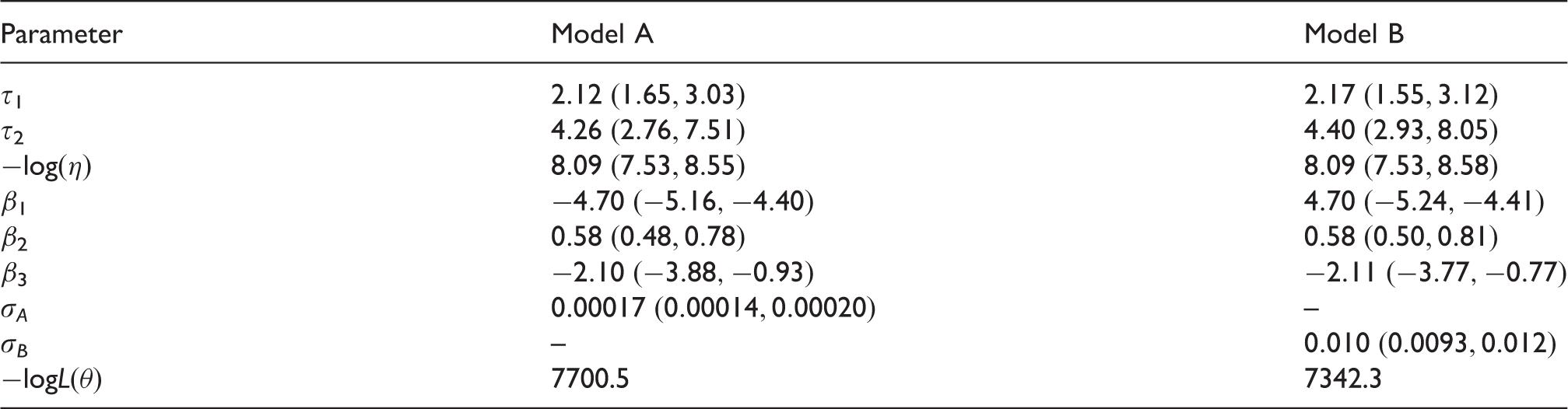
We attempted to jointly fit the tumour growth model with the lymph spread models of Hanin and Yakovlev, and Shwartz. In both cases, the models did not converge, and we were not able to retrieve parameter estimates. Their lymph spread models are not consistent with the data (see Section 2). If we would have been able to get the joint model to converge, we know that the lymph node models of Hanin and Yakovlev and Shwartz would have over-estimated the number of affected lymph nodes at large tumour sizes and underestimated the number of affected lymph nodes at small tumour sizes to the same extent as model A does. Although model B does underestimate the number of lymph nodes at larger tumour sizes, overall, it provides a better fit to the data than model A, and the models of Hanin and Yakovlev, and Shwartz.
Parameter estimates and log-likelihood values for different functional forms of the Poisson lymph node spread model (CAHRES).

Parameter estimates and log-likelihood values for different functional forms of the random effects lymph node spread model (CAHRES).

From the integer values, we achieved the best model fit for k = 5, with a log-likelihood difference of 296.1 compared to the spread component of model B (k = 1). Varying both σ
C
and k, we found the optimal value of k to be 4.75, with 95% confidence interval Model-based estimates of expected lymph node spread as a function of tumour size (CAHRES). Circles and bars represent averages and 95% confidence intervals of numbers of lymph nodes affected within each tumour size interval. The spread component of Model A (dotted) produces excessive spread in large tumours, whereas in terms of expected numbers of affected lymph nodes the spread model with k = 5 (solid) fits at all tumour sizes.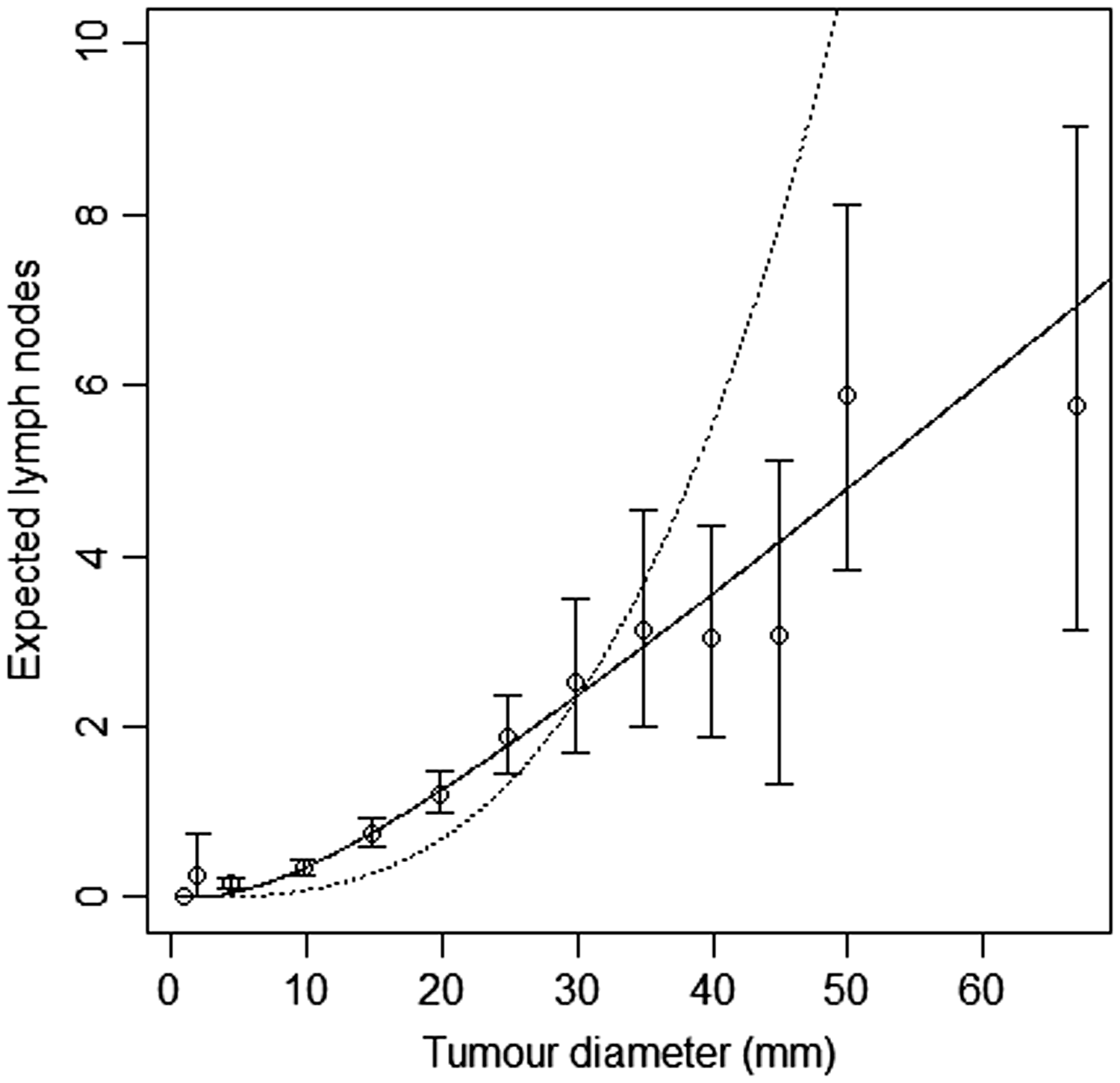
We fitted joint models of tumour size and lymph node spread, based on the random effects models described by equations (15) and (16), for
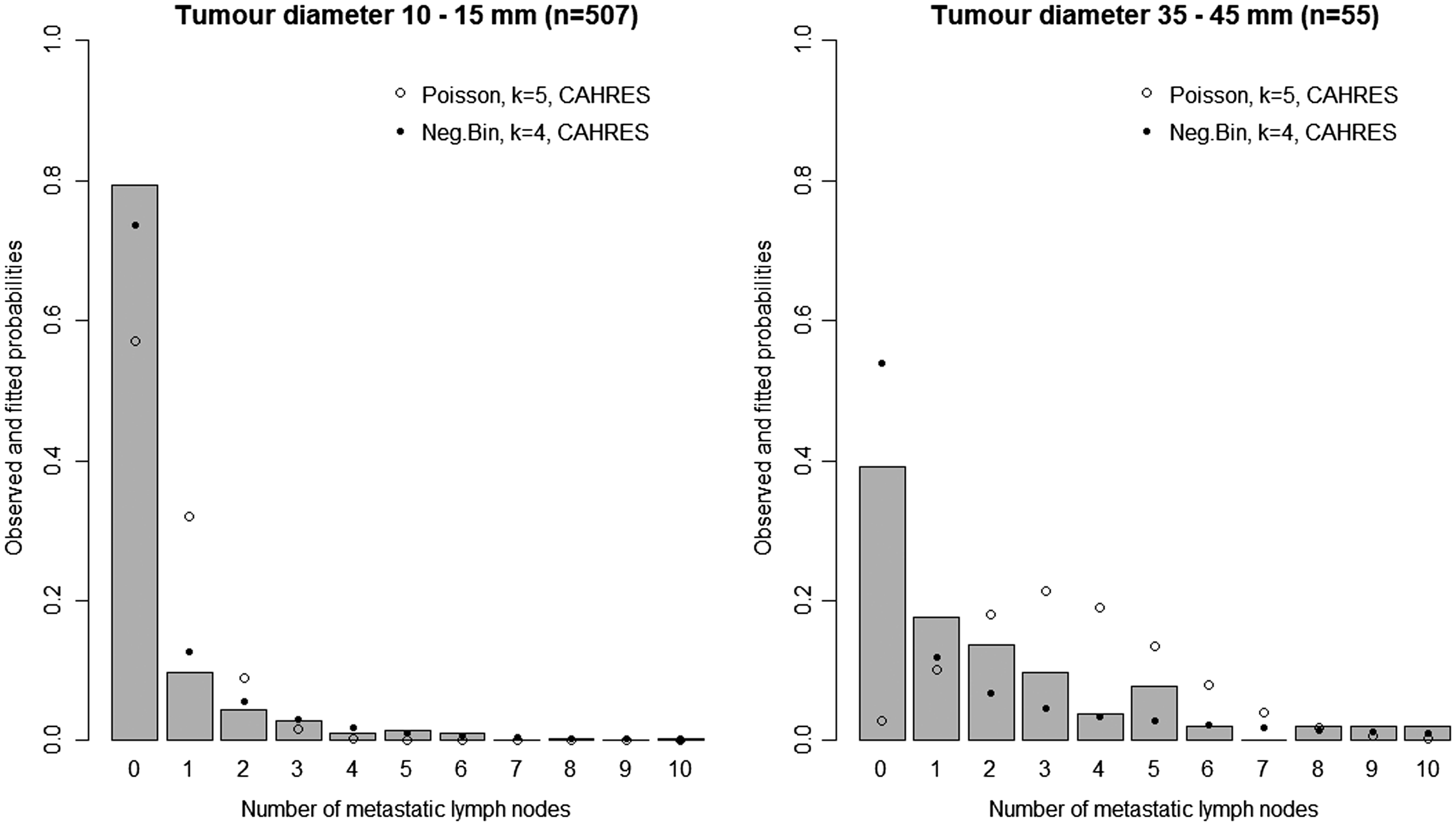
In Figure 3, we plot estimates of expected number of lymph nodes affected based on the random effects lymph spread model with k = 4. These estimates pass through all the 95% confidence intervals (except one, which comes very close). In Figure 4 we plot the observed numbers of lymph nodes (bars) within two size categories, along with the model predicted probabilities at the end points of the intervals. The random effects model accounts for overdispersion in relation to the Poisson model. We note that if we were to represent model A, allowing or not allowing for overdispersion, even in this plot, the prediction of the mean value of the number of lymph nodes would be overestimated for large tumour sizes.
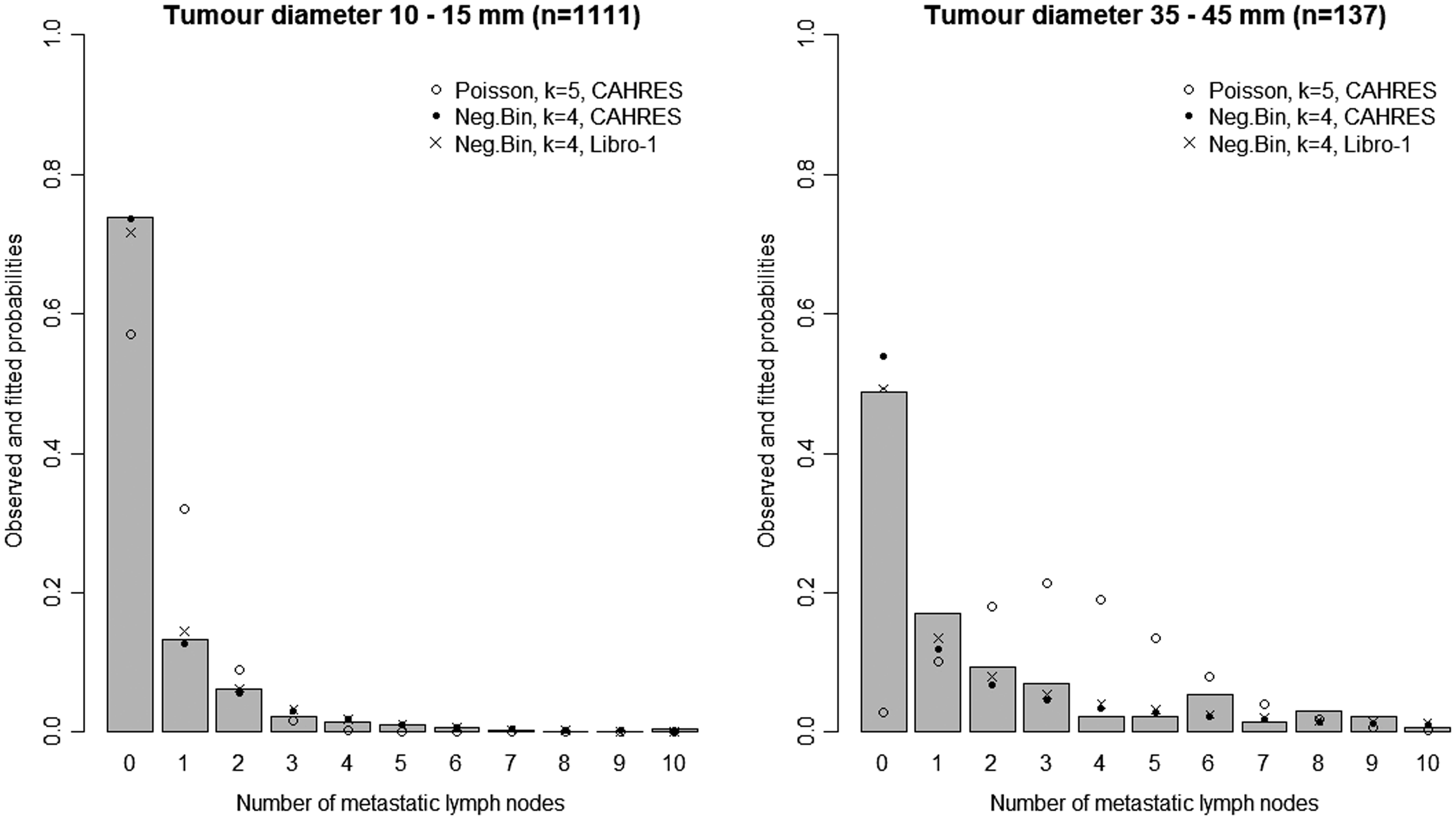
Model-based estimates of expected lymph node spread as a function of tumour size (CAHRES). Circles and bars represent averages and 95% confidence intervals of numbers of lymph nodes affected within each tumour size interval. The spread component of Model A (dotted) is plotted alongside the random effects spread model with k = 4 (solid). Observed and predicted numbers of affected lymph nodes (CAHRES). The bars represent the observed numbers of affected lymph nodes, within tumour size interval 10–15 mm (left) and 35–45 mm (right), in the CAHRES dataset. Circles represent predicted probabilities from the Poisson model with k = 5, estimated on the CAHRES data set, and dots represent predicted probabilities from the random effects Poisson model with k = 4, also estimated on the CAHRES data set.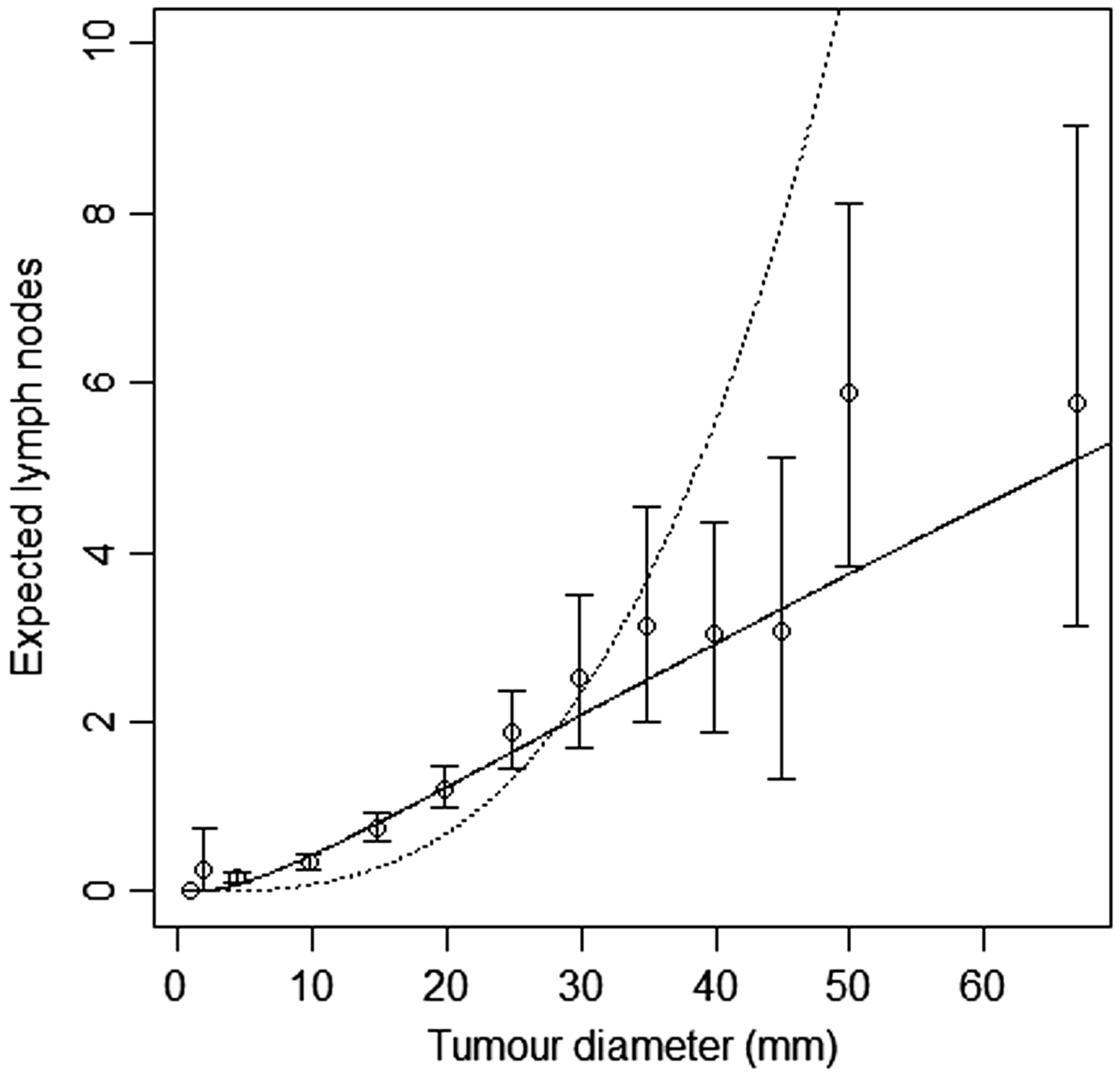
Finally for CAHRES, we divided the data set into screen detected cases and symptomatically detected cases, and plotted 95% confidence intervals for average number of affected lymph nodes, along with the model-based estimates obtained from fitting model A and the random effects Poisson model with k = 4; see Figure 5. Although the estimates based on our selected model intersect all but one of the confidence intervals, there is some suggestion (at large tumour sizes) that the model could be underestimating expected number of lymph nodes in symptomatic cases and overestimating the expected numbers in screening cases.
Model-based estimates of expected lymph node spread as a function of tumour size (CAHRES). To the left, circles and bars represent averages and 95% confidence intervals of numbers of lymph nodes affected within each tumour size interval for screen detected cancers, and to the right the corresponding quantities for symptomatically detected cancers. On both figures, the spread component of Model A (dotted) is plotted alongside the random effects spread model with k = 4 (solid).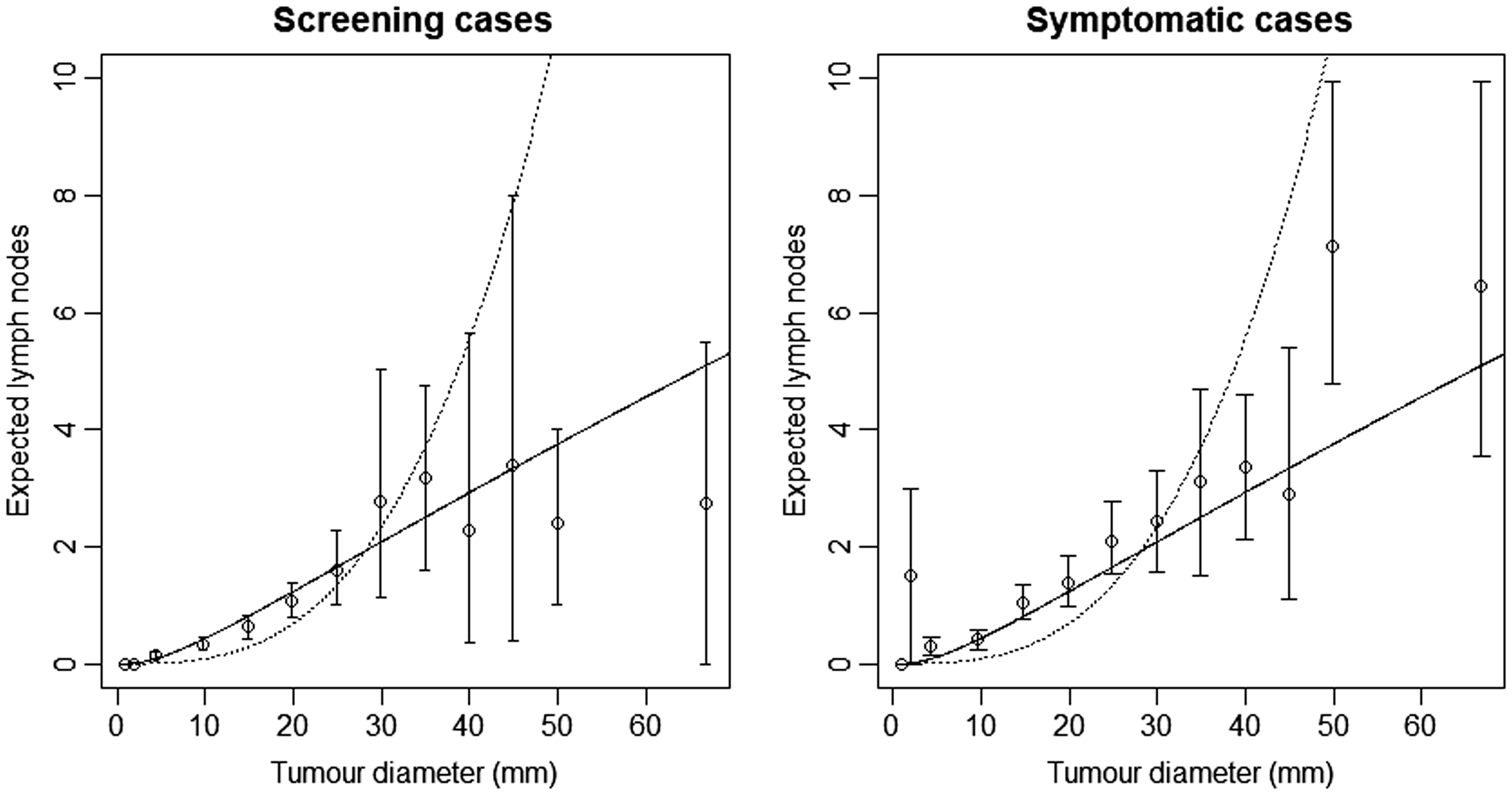
6 Validation study of the random effects lymph node spread model
We attempted to validate our lymph node spread model using an independent data set of women diagnosed with invasive breast cancer between January 1, 2001 and December 31, 2008 in the Stockholm-Gotland healthcare region in Sweden, known as Libro-1. These women were identified though the Regional Breast Cancer Register. Information on diagnosis and tumour characteristics were available, but not on time and number of screening rounds. Women were excluded if they were less than 50 years old, underwent diagnostic operations, were pre-operatively diagnosed with in situ breast cancer but pathology reports showed an invasive component, had incorrect dates of diagnosis, had more than 63 days between diagnosis and date of surgery, had missing tumour size, or missing lymph node status. In 2007, the registers changed the definitions and procedures for evaluating lymph node spread. To keep the data set comparable to the CAHRES data set, we excluded women that were categorised according to the new standard. The final data set consisted of 3961 women.
In Figure 6, we plot 95% confidence intervals of number of affected lymph nodes, within tumour size intervals, based on the Libro-1 data (bars), along with the expected number of lymph nodes, as a function of tumour diameter, based on the random effects model with k = 4, estimated from the CAHRES data. We also fitted the random effects model to the Libro-1 data with Model-based estimates of expected lymph node spread as a function of tumour size based on the random effects Poisson model (k = 4), estimated on CAHRES (dotted line) and Libro-1 (solid line), along with 95% confidence intervals of average lymph node spread obtained from Libro-1. Observed and predicted numbers of affected lymph nodes (Libro-1). The bars represent the observed numbers of affected lymph nodes, within tumour size interval 10–15 mm (left) and 35–45 mm (right), in the Libro-1 dataset. Circles represent predicted probabilities from the Poisson model with k = 5, estimated on the CAHRES data set, dots represent predicted probabilities from the random effects Poisson model with k = 4, also estimated on the CAHRES data set, and crosses represent estimated probabilities from the random effects Poisson model with k = 4, estimated on the Libro-1 data set. Parameter estimates and log-likelihood values for different functional forms of the random effects lymph node spread model (Libro-1).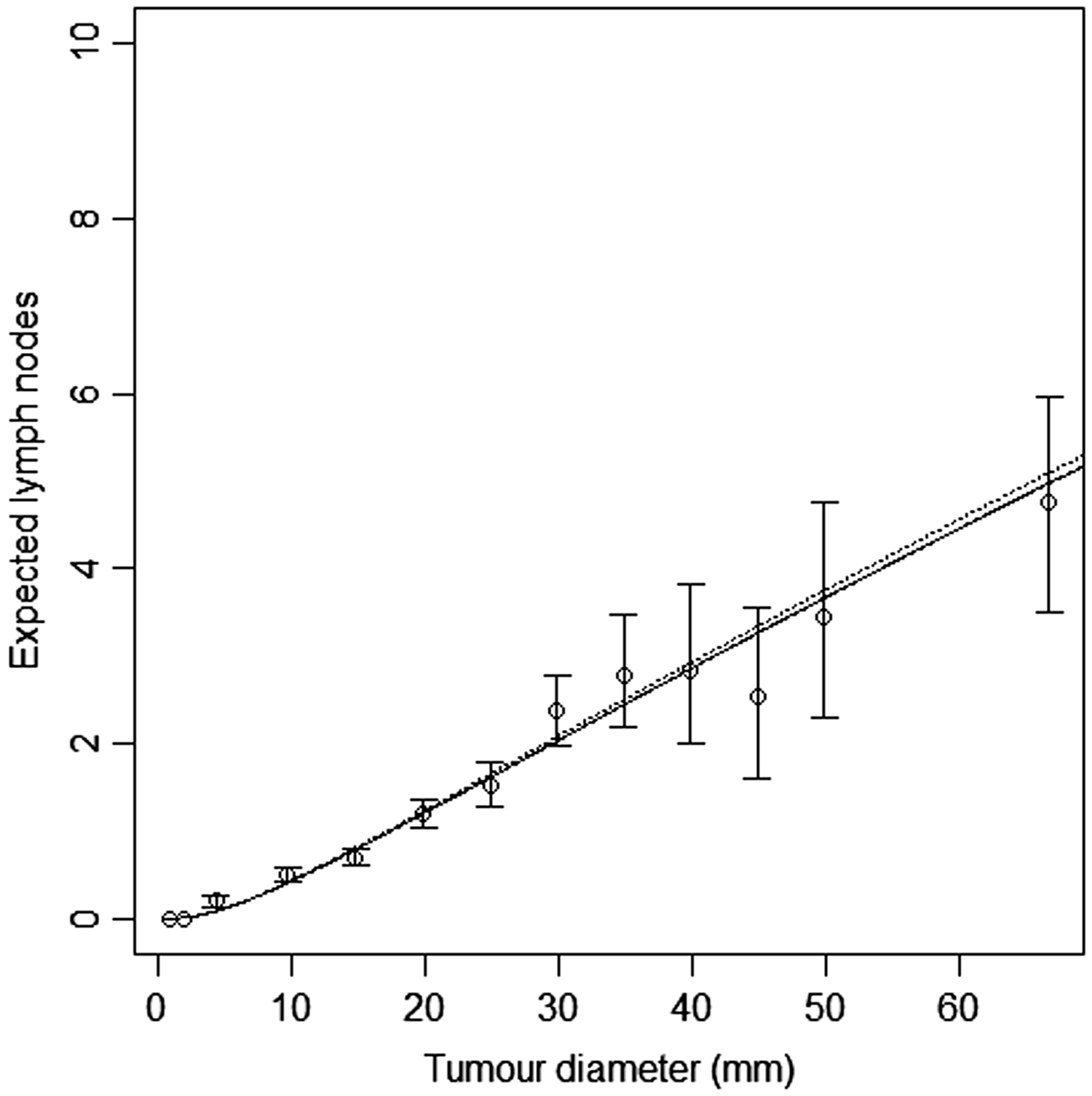

When estimating
7 Discussion
Continuous growth models offer an interesting alternative to multi-state Markov models for studying the natural history of breast cancer. Previously proposed continuous growth models have components for tumour growth, time to symptomatic detection, and screening sensitivity. The aim of this article has been to add an additional component for lymph node spread. We began this article by reviewing the literature of breast cancer lymph spread models. We identified two models, one from Hanin and Yakovlev, 14 and one from Shwartz, 13 which is also used by the CISNET University of Wisconsin group. Both models are Poisson processes with intensity functions dependent on tumour volume. In this paper, we show that these models have two weaknesses. The first is that slow growing tumours spread more quickly than fast growing tumours, and the second is that the rate of additional lymph node spread grows excessively with increasing tumour volume. In order to avoid these two weaknesses, we have improved upon the existing models and developed new models of lymph node spread in a step-by-step fashion. We focused first on modelling the mean structure and then extended the lymph node spread model to incorporate random effects.
The first step of the process was to construct a model A, which avoids an inverse relation between tumour growth rate and lymph node spread. This was done by removing the terms from the intensity function that contributed to the inverse relationship in Shwartz 13 model. We were able to estimate the parameters of model A jointly with the tumour growth models (see Table 2). This was not the case with the models of Hanin and Yakovlev, 14 or Shwartz. Since we were not able to make those models converge and since we were able to remove the inverse relationship between tumour growth rate and lymph node spread, we consider model A an improvement on Hanin and Yakovlev, and Shwartz.
In the second step, we created model B. At this step, we addressed the second weakness. Model A assumes a linear relationship between the expected number of lymph nodes affected and tumour volume. Because tumour growth is assumed to be exponential with time, this linear relationship implies that the number of affected lymph nodes grows exponentially with time. To decrease the rate of spread in the model, we introduce a logarithmic term. We assume that the intensity function depends on the number of cell divisions instead, which is equivalent to the tumour volume divided by the volume of a single cell. We found that model B was an improvement on model A, although it overestimated spread at small tumour sizes and underestimated spread at large tumour sizes.
Model B removes the exponential spread behaviour of previous models in the literature, and provides a basis on which to build further. We tested different shapes of the spread functions by introducing a class of lymph spread models. These models differ in their shape, defined by a factor k, with model B represented as a special case (k = 1). In this model class, we found that k = 5 provided good model fit. In terms of expected values, this model fitted well across all tumour volumes. By extending the lymph node spread models to allow for random effects, we were able to incorporate heterogeneity in rates of lymph node spread. This extension turned out to be extremely important, and corrected for overdispersion with respect to the classical Poisson models. In fitting the overdispersed random effects model, we obtained a point estimate of k = 4.11 using the CAHRES study data, and an estimate of k = 3.65 using the Libro-1 study data. The 95% confidence intervals for k, estimated on the two data sets, overlapped and included k = 4; this value provided good model fit in both data sets.
The analyses in this paper rely on the assumptions of a stable disease population and the assumption that screening attendance is independent of tumour growth rate. For the joint analysis of size and lymph node spread, we have worked with CAHRES, a nationwide cohort with 84% participation rate. The study invited all Swedish born women ages 50 to 74 that were diagnosed with invasive breast cancer in Sweden from October 1993 to March 1995. In the absence of screening, a population satisfying stable disease assumptions will exhibit a constant incidence of breast cancer. 10 Once a screening program has run for a number of years, we expect a constant incidence if the stable disease assumptions hold. Of the 26 counties in Sweden, 22 had implemented screening programmes by, and in many cases well before, 1990, 22 and incidence data from the Swedish Cancer Registry shows that breast cancer incidence was approximately constant between 1991 and 1997. 23 In the current study, all women were post-menopausal at diagnosis. It is unlikely that a large fraction of the women took part in extra surveillance for breast cancer, which means that the assumption that screening attendance is independent of tumour growth rate is likely to be reasonable.
The joint model of tumour growth and lymph node spread has two main areas of application. The first one is for evaluating screening programs, which can be done via microsimulation. Several research groups12,24 have used Markov models to simulate the natural history of breast cancer. As the number of disease states increases, these models become impractical, especially if the objective is to simulate screening options based on individual risk factors. For this, continuous growth models present a strong alternative. The second area of application is to study factors behind growth and spread. Abrahamsson et al. 11 used continuous growth models to regress BMI on the log inverse growth rate, and breast size on the log of the hazard proportionality constant in the model for time to symptomatic detection, and Isheden and Humphreys 10 studied in detail the relationship between mammographic density, tumour size, and screening sensitivity. For the new sub-model for lymph node spread, we are currently working on extensions of the model to study association with observable factors, both traditional breast cancer risk factors and tumour characteristics/subtypes.
As we have pointed out, our models assume several well known biological properties of cancer. The fact, however, that the k = 4 model fits better than the k = 1 model implies that there may be a degree of genomic instability as breast cancer cells divide. Finally, we point out that in our work we have not been able to specify a tractable model where fast growing tumours spread more rapidly than slow growing ones. It is possible that an alternative model with this characteristic will also provide a good fit to incidence data on tumour size and lymph node spread.
Footnotes
Acknowledgements
We are grateful to Wei He for assisting in data retrieval, to Mark Clements, Alexander Ploner, and Ola Hössjer for valuable discussions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Swedish Research Council (2016-01245), the Swedish Cancer Society (CAN 2017/287) and the Swedish e-Science Research Centre.