
Abstract
We develop a new age-period-cohort model for cancer surveillance research; the theory and methods are broadly applicable. In the new model, cohort deviations are weighted to account for the variable number of periods that each cohort is observed. Weighting ensures that the fitted rates can be naturally expressed as a function of age × a function of period × a function of cohort. Furthermore, the age, period, and cohort deviations are split into orthogonal quadratic components plus higher-order terms. These decompositions enable powerful combination significance tests of first- and second-order age, period, and cohort effects. The regression parameters of the orthogonal quadratic polynomials (global curvatures) quantify how fast on average the trends in the rates are changing. Importantly, the global curvature for cohort determines the least squares slope of the expected annual percentage changes by age group versus age (local drifts), thereby providing a powerful one-degree-of-freedom test of age-period interactions. We introduce new estimable functions, including age gradients that quantify the rate of change of the longitudinal and cross-sectional age curves at each attained age, and gradient shifts that quantify how the cross-sectional age trend varies by period. We illustrate the new model using nationally representative multiple myeloma incidence. Comprehensive proofs are given in technical appendices. We provide an R package.
1 Introduction
Cancer surveillance research is an observational science of cancer-related rates and risks ascertained in population-based cohorts, notably cancer registries. 1 In this field, a standard age-period-cohort (APC) model is now well accepted. 2 APC models are used to track cancer burden, reveal disparity, provide etiological clues, gauge real-world effectiveness of screening and therapy, quantify natural history and its evolution, and forecast cancer incidence and burden. 3
Our experience analyzing cancer registry data motivated us to develop a next-generation APC model that retains all the good features of the standard model, yet provides new and improved estimable parameters and functions; a natural decomposition of fitted rates into age, period, and cohort effects; and more powerful statistical tests.
In the standard categorical APC model, the age, period, and cohort “deviations” are ensembles of parameters that together measure departures from the overall log-linear temporal trends. 4 Our new model incorporates two key innovations. First, cohort deviations are weighted to account for the variable number of periods that each cohort is observed. Because of this modification, the fitted rates can be decomposed into a function of age × a function of period × a function of cohort, without invoking any additional assumptions or constraints. Second, in the new model, the age, period, and cohort deviations are partitioned into orthogonal quadratic components plus higher-order terms. As we will show, the three new “global curvature” parameters corresponding to the quadratic terms for age, period, and cohort, respectively, are intimately connected with fundamental rate patterns and signals that may not be clearly seen when the data are analyzed with the standard model.
We illustrate the new model using cancer incidence data for multiple myeloma (MM) among Black men ascertained through the National Cancer Institute's Surveillance, Epidemiology, and End Results (SEER) program (https://seer.cancer.gov/). SEER is the authoritative source for cancer statistics in the United States (https://seer.cancer.gov/about/). Comprehensive derivations and proofs are presented in technical appendices. We provide an R package.
2 Event rates on a Lexis diagram
APC models parameterize age-specific event rates over time. Formally, the event rates are assumed to be a realization of a Poisson point process over a Lexis diagram, which is a rectangular field with attained age along one axis and calendar period along the other.
5
Our convention is the attained age runs along the y-axis and calendar period along the x-axis, to be consistent with outputs from the popular SEERSTAT programs (https://seer.cancer.gov/seerstat/). Individual events and corresponding person-years at risk are summed within a grid of cells defined by equal-width age and period intervals. For any given dataset, we denote the corresponding Lexis diagram as Lexis diagram for the myeloma data, displayed as a heat map of observed rates binned into two-year age groups and two-year calendar periods (a). Canonical plot of age-specific rates by birth cohort (b); for each age group, the first point in series corresponds to the earliest period of observation (1992–1993) and last point to the latest year (2013–2014).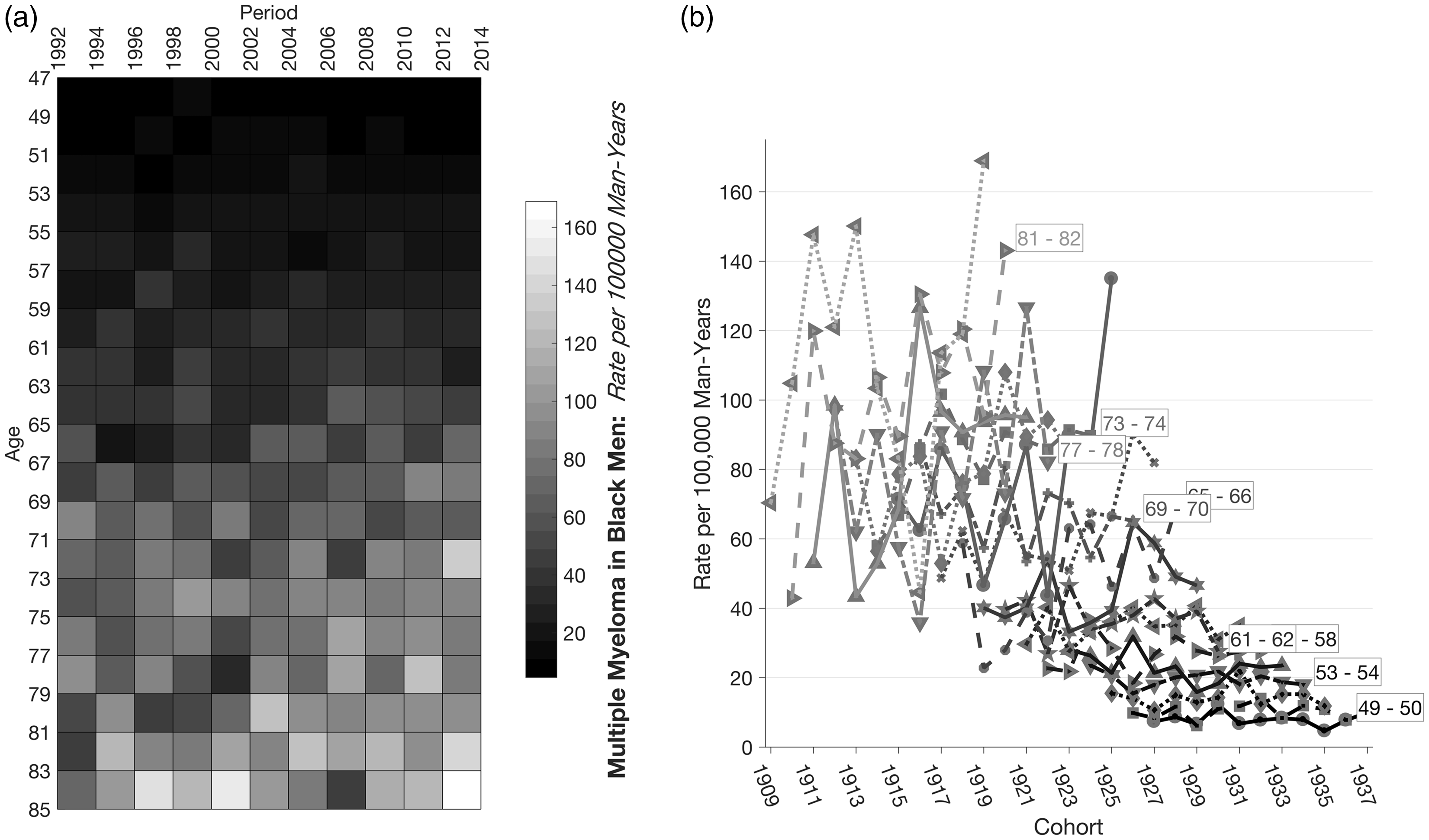
For purposes of modeling, cells along diagonals with slope
Each cell can be referenced by values or by indices. Values equal the midpoints of the cell's defining age and period intervals, while indices equal the corresponding sequence number within the Lexis diagram's A consecutive age groups and P consecutive calendar periods.
Thus, values, denoted with subscripted *'s, and indices are related as follows
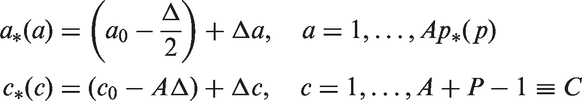
Different cohorts are followed at variable ages and in different periods. The number of cells per cohort is
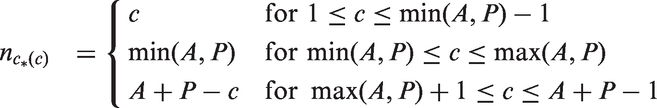
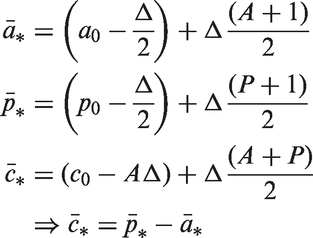
Estimable functions of age-period-cohort model parameters.

Estimable functions can be conditioned on any reference values of age, period, or cohort that occur in the Lexis diagram. To define all estimable functions with respect to the same reference cell, set the cohort index to
3 The standard APC model
For each cell in the Lexis diagram, the expected log rate per 1 person-year is
6
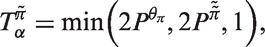
This is a longitudinal representation when we hold 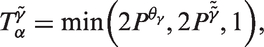
To fit the standard model, we impose six identifiability constraints, two for age, two for period, and two for cohort, in order to make the deviations orthogonal to the intercept and the corresponding log-linear trends. Importantly, in our set-up we impose the constraints over all cells in the Lexis diagram, and not simply over the sequence of A age deviations, P period deviations, and C cohort deviations, which implies that the constraints on the C unique cohort deviations
As described subsequently, this approach insures that the fitted rates can be consistently decomposed into a function of age × a function of period × a function of cohort. We call the quantity
4 Example: MM in Black men
MM is the most common hematological malignancy among African-American (Black) men, with an estimated lifetime risk of 1.25%. 10 We extracted MM incidence from the SEER 13 Registries Database (2015 release) 11 for Black men aged 47–84 during calendar years 1992–2013. We tabulated events and man-years within 19 two-year age groups (47–48 through 83–84) and 11 two-year calendar periods (1992–1993 through 2012–2013), which cover 29 nominal birth cohorts centered on birth years 1909 through 1965. In all, there were 3747 incident cases in 10,602,515 man-years.
In a “canonical” plot of age-specific incidence rates by birth cohort
12
(Figure 1(b)), there is a suggestion that incidence is rising in older age groups but has remained comparatively stable in younger age groups. However, the observed rates are “noisy” and simple inspection does not to us suggest any firm conclusions. Outputs from the standard APC model
6
(Figure 2) are also quite variable. The net drift of 0.89% per year (95% Confidence Interval [CI]: 0.36–1.42 %/year) is statistically significant (p = 0.001), hence, on average, the rates in Figure 1(b) and the Period and Cohort Rate Ratios in Figure 2(e) and (f) are increasing significantly over birth cohorts and calendar periods, respectively. The LAT of 8.0% per year (95% CI: 7.3–8.7%/year) is highly significant (p ≈ 0). Also, there appears to be some “deceleration” In the cohort deviations circa 1943 (Figure 2(c)) such that incidence increases in successive cohorts through circa 1943 and then decreases (Figure 2(e)), a pattern which is consistent with Figure 1(b). Formally, however, the cohort deviations are not statistically significant (p = 0.499). Overall, our impression is results from the standard model are too noisy to make firm conclusions about temporal effects; it would be appealing to incorporate additional smoothness in the model parameters.
Estimable functions from the standard APC model fitted to the myeloma data. The reference values are 66 years for age, 2003 for period, and 1937 for birth cohort.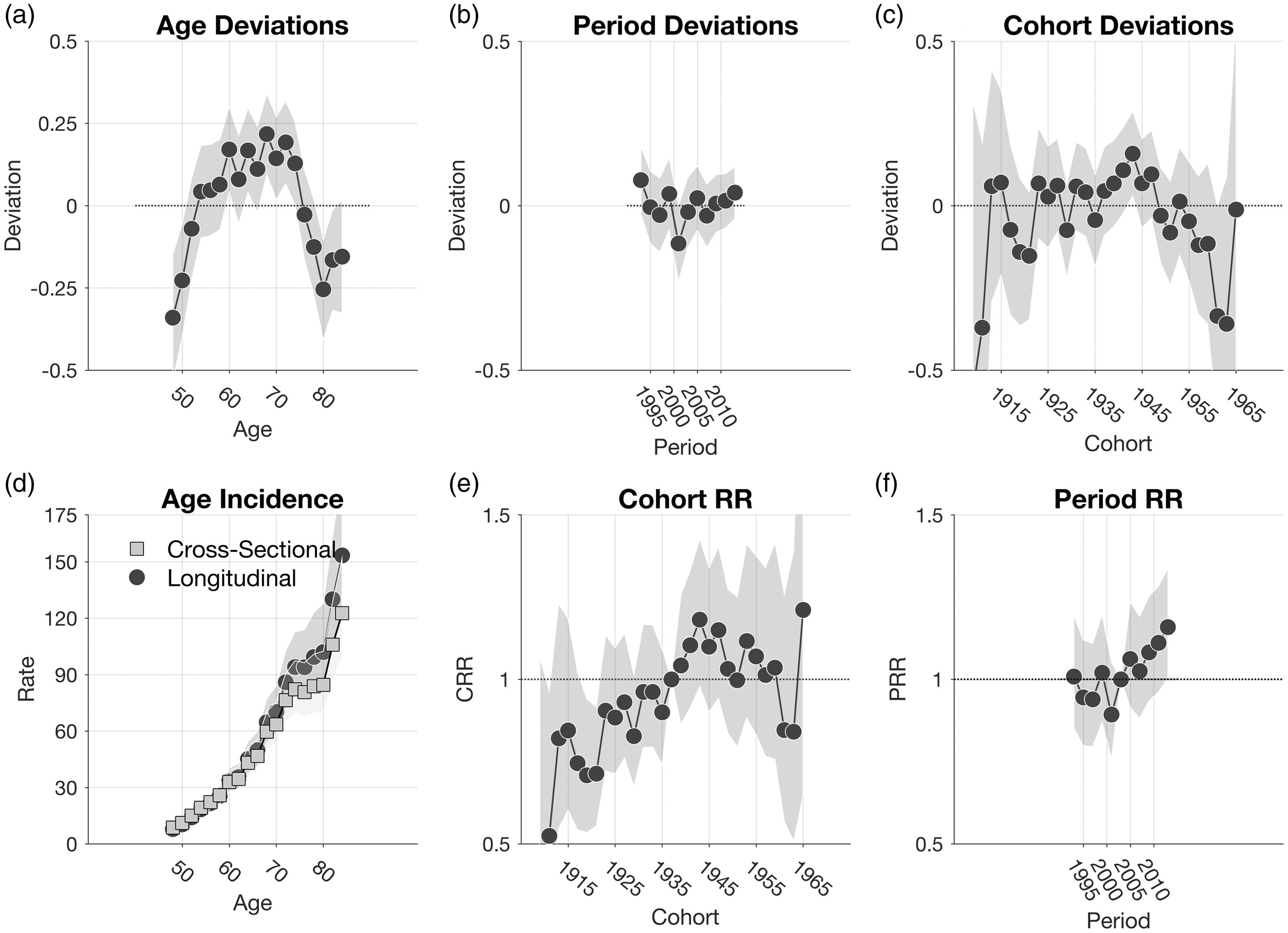
5 The new APC model
The basic idea is we split the complete deviations 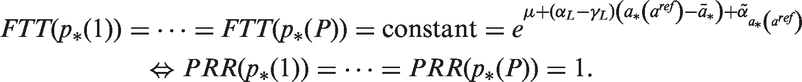
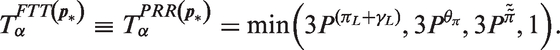
The functions
In Appendix A.2 we show that the orthogonal quadratic polynomial for age equals
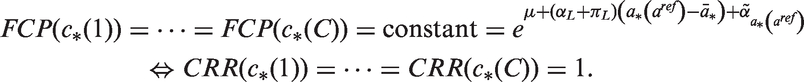
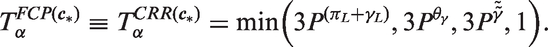
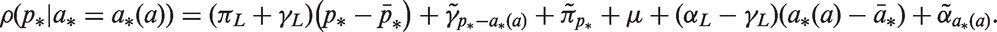
Each function is completely determined by characteristics of the corresponding Lexis diagram
For the myeloma data, Figure 3 shows the decomposition of the complete deviations for age, period, and cohort into constituent quadratic components plus higher-order terms. Global curvature for age (Figure 3(b)) and cohort (Figure 3(h)) but not period (Figure 3(e)) is statistically significant; the higher-order deviations for age (Figure 3(c)), period (Figure 3(f)), and cohort (Figure 3(i)) are not statistically significant. Hence, most of the variation in myeloma incidence around the intercept μ can be explained by just four of the model's 56 parameters, the two slope parameters Decomposition of complete age, period, and cohort deviations into orthogonal quadratic components plus higher-order terms.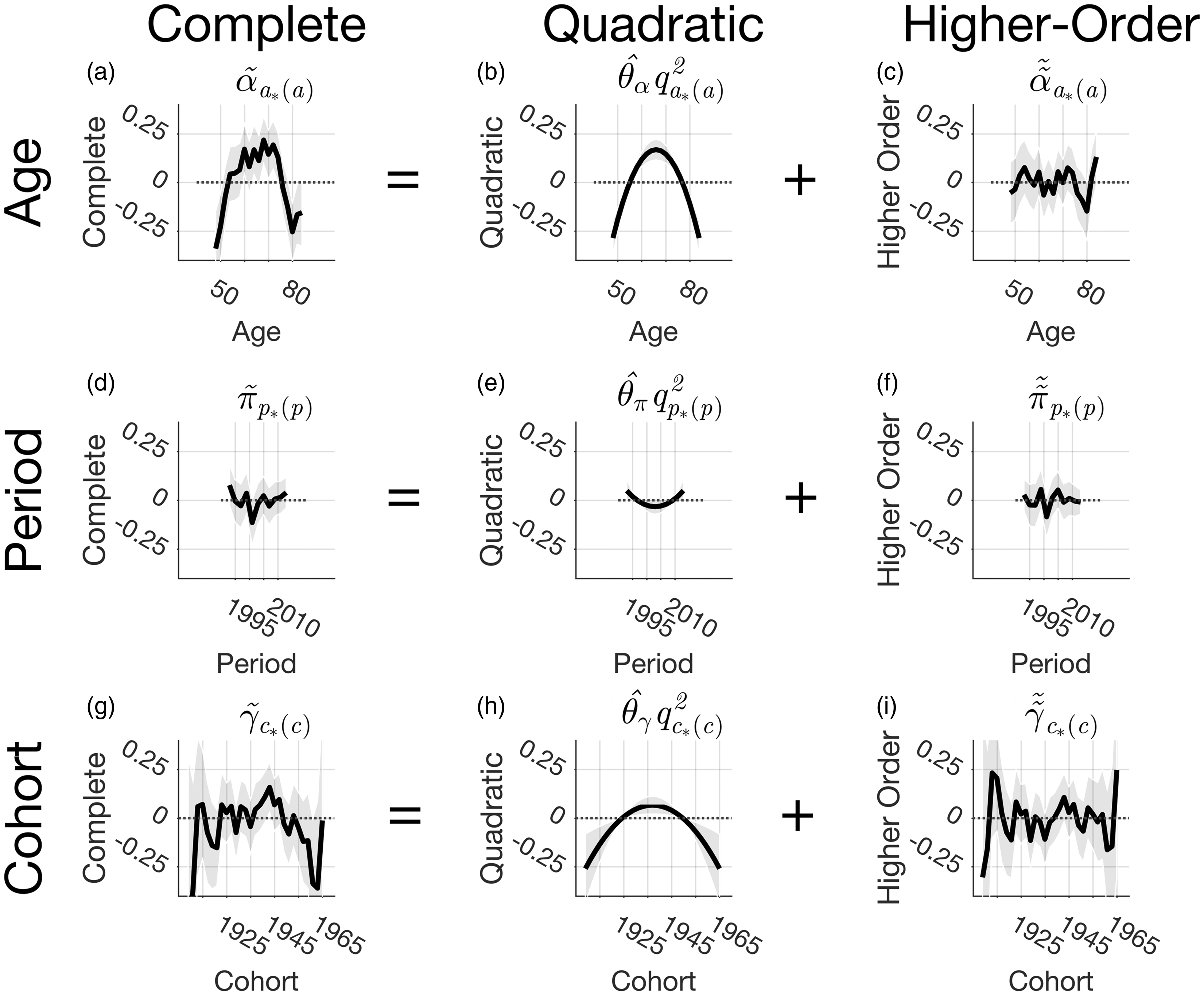
As shown in Appendix A.2, the locations of the roots of the orthogonal quadratic terms are a fixed property of the Lexis diagram. Hence, as shown in Figure 3, panels B, I, and H, the corresponding confidence bands must shrink to 0 at the roots.
6 Estimable functions and the fundamental decomposition principle
Estimable functions are log-linear combinations of identifiable APC coefficients. Estimable functions have been prominently deployed in cancer surveillance studies. In Table 1, we present popular estimable functions of age, period, and cohort, here defined using parameters of the new APC model.
Fundamental decompositions of age-period-cohort fitted rates.

The expected rates can be expressed in terms of any reference value of age, period, or cohort that occurs in the Lexis diagram. To define all of the equations in terms of the same reference cell, set the cohort index to
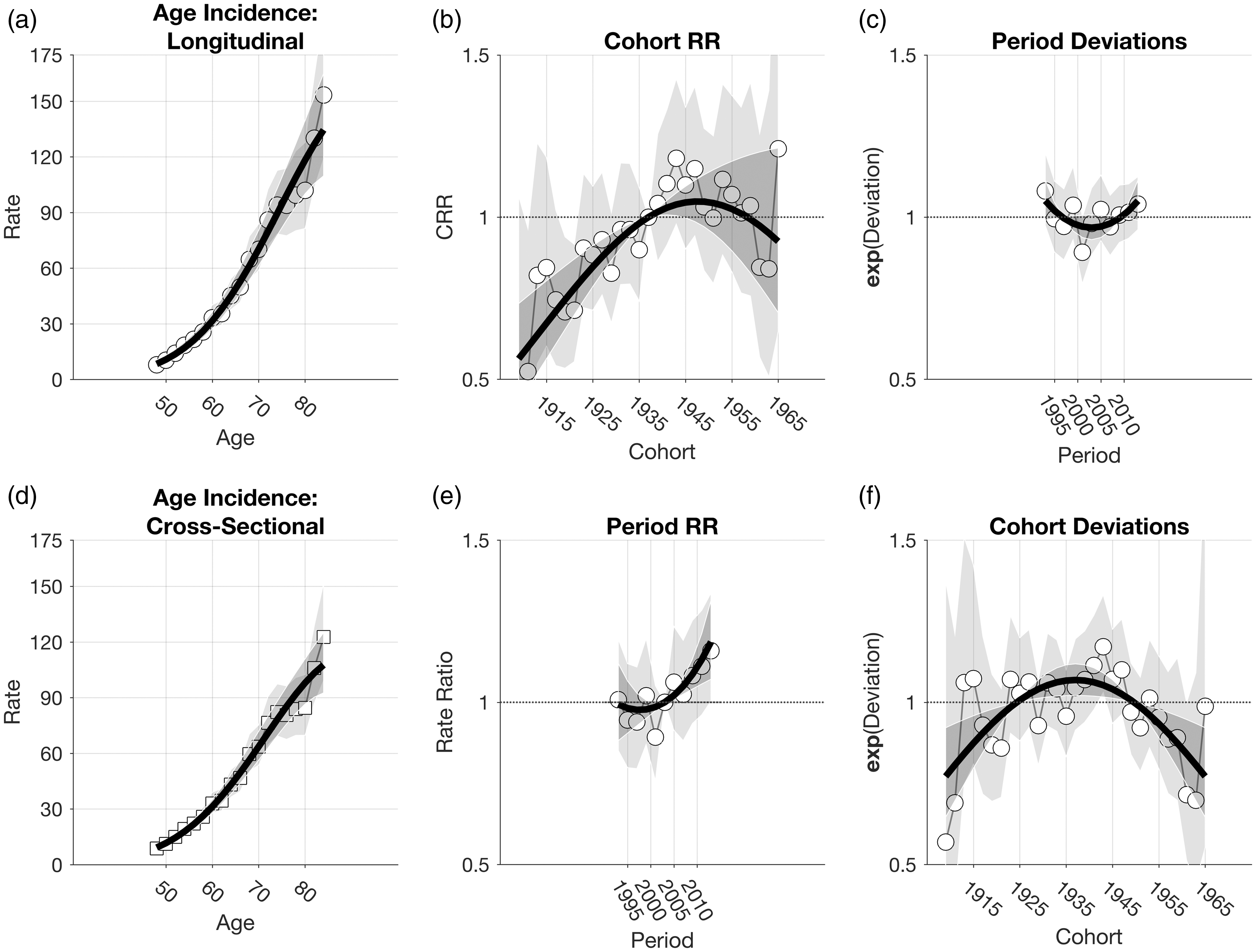
Estimable functions of the myeloma data based on new APC model. The bold curve in each panel shows the contributions of the linear and quadratic terms. The reference values are 66 years for age, 2003 for period, and 1937 for birth cohort.
Other useful estimable functions involve finite first and second derivatives of the deviations and estimable functions shown in Table 1. Let
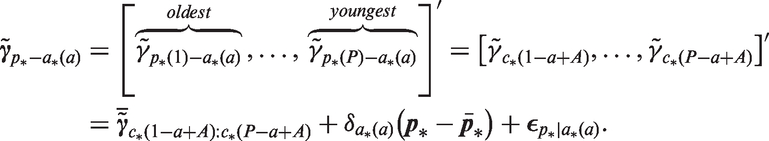
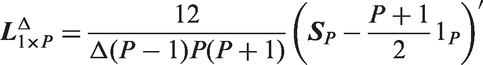
In the literature, there has been considerable interest in second differences of cohort deviations.14,15 These can be extracted from
7 Combination hypothesis tests of period and cohort deviations
A fundamental question is whether period or cohort effects influence the rates over and above log-linear influences captured through the net drift parameter 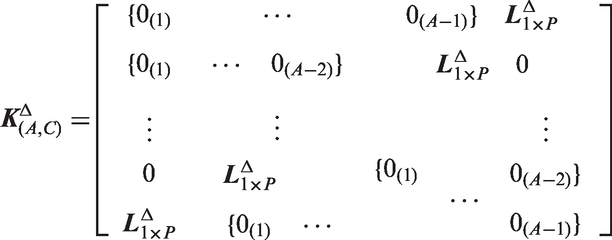
Similarly, we propose a new p-value combination test for the complete cohort deviations
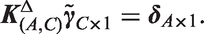
For the myeloma data, the standard Wald test for period deviations is
8 Combination hypothesis tests of period and cohort rate ratios
A related question is whether there is any association whatsoever of the rates with calendar period. Using the estimable functions defined in Table 1, under 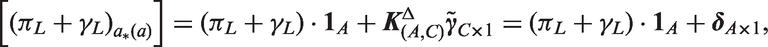
a p-value combination test of this hypothesis based on Tippett's method is
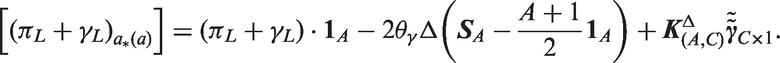
Similarly, under 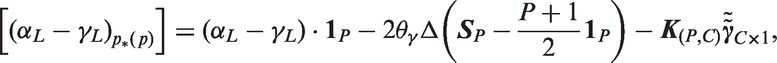
a p-value combination test for this hypothesis is
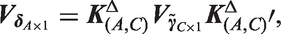
For the myeloma data, the standard Wald test for period rate ratios is
9 Power of Wald tests versus combination tests: simulation study
We carried out a simulation study to confirm the level-correctness of our tests and to gauge the potential real-world power gains (if any) obtainable using the new combination tests. We used point estimates from the myeloma data's APC model to define a baseline scenario, and simulated Poisson counts under the baseline and alternative scenarios.
We set
For cohort effects (Figure 5(a) and (b)), both the Wald tests and the combination tests are level correct for both Simulation results assessing Type-I error rates and power of Wald versus combination tests of complete cohort deviations (a); cohort rate ratios (CRR) (b); complete period deviations (c); period rate ratios (PRR) (d). See text for details.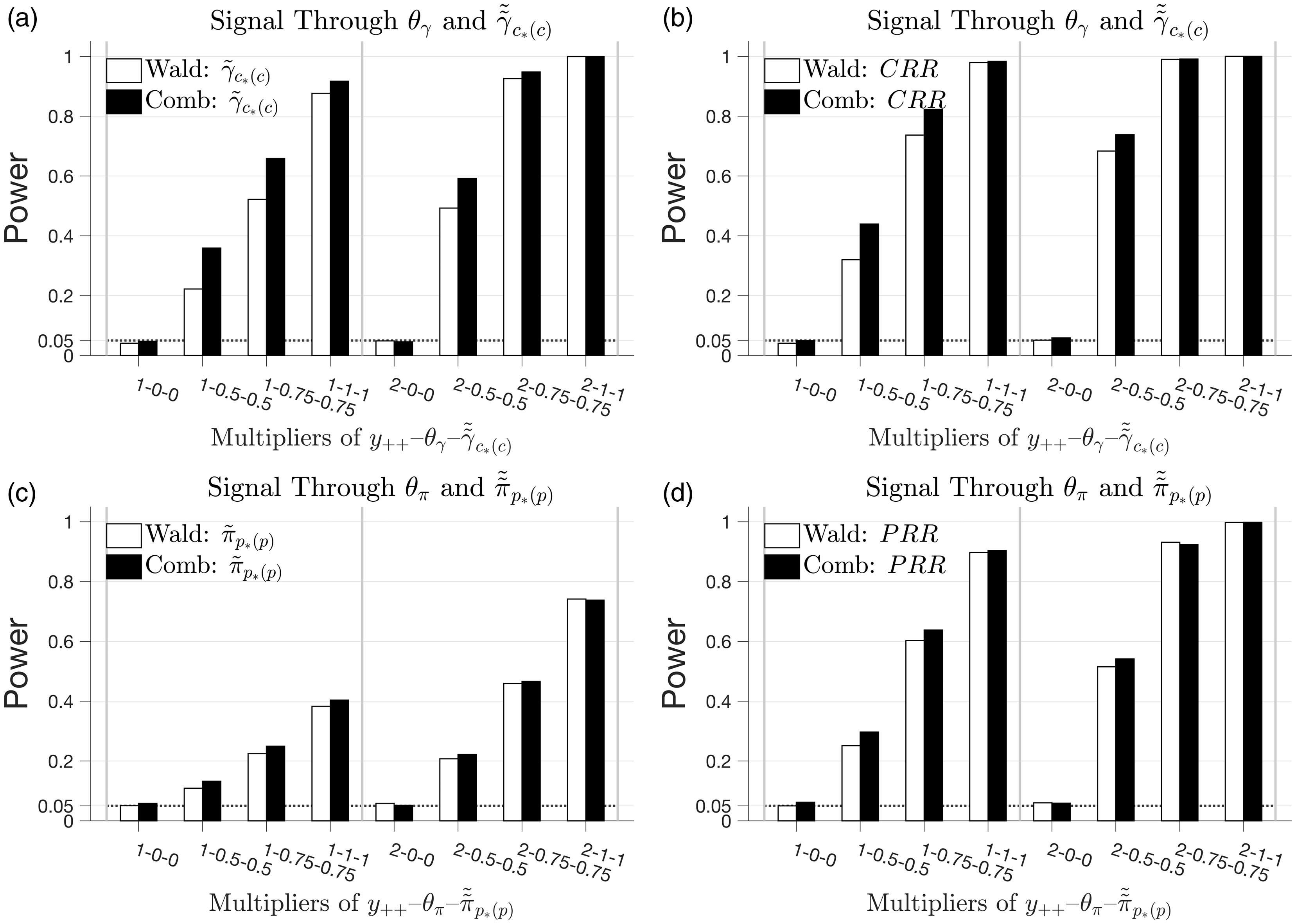
10 Local drifts
Local drifts are model-based estimates of annual percentage changes by age group. 6 Departures of local drifts from the overall net drift are a consequence of cohort deviations, hence local drifts quantify the heuristic that cohort effects represent an age interaction over time. Local drifts can be constructed by sliding a window of bandwidth P through the cohort deviations and extracting the least squares slopes, and then adding these “deflection” terms to the overall net drift.
Formally, the cross-sectional age-specific rates over time equal
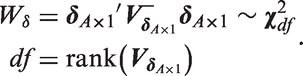
The sub-vector of P complete cohort deviations belonging to age group 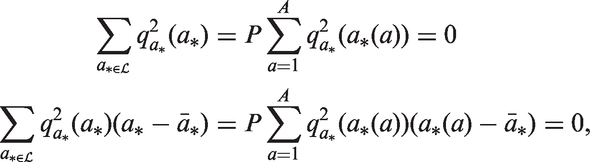
As we move from one age group to the next, we slide along by one birth cohort. We can calculate the ensemble of A deflections 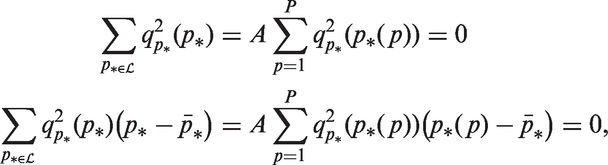
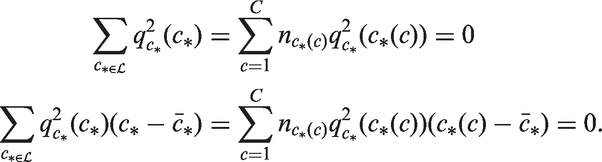
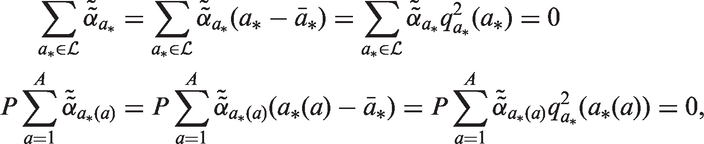
As shown in Appendix A.5, under the standard model the local drifts equal
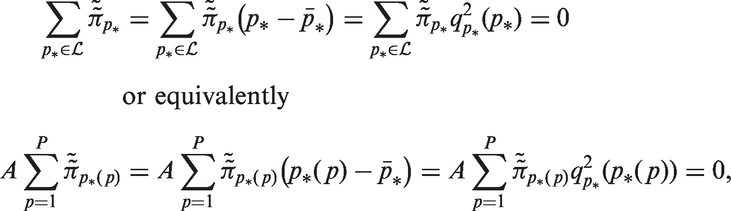
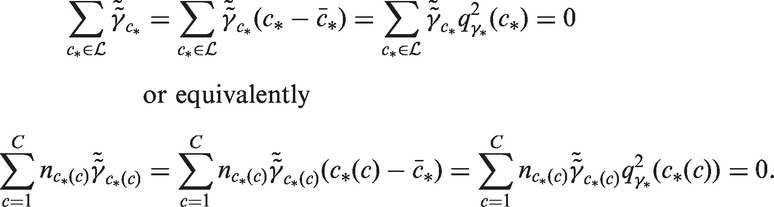
Thus, the least squares slope of the local drifts with respect to age is determined by the global curvature for cohort. When
Figure 6 presents local drifts for the myeloma data. For context, canonical plots of age-specific rates over time (Figures 6(a) and 1(b)) suggest that perhaps the rates are increasing in older age groups and are stable or perhaps decreasing in younger age groups. Local drifts from the standard model support this conclusion (Figure 6(b)), but the estimates are uncertain. The new model (Figure 6(c)) confirms that the Local drifts indeed increase consistently with age. On average across ages 45–84, the net drift increases by Local drifts of the myeloma data. (a) Canonical plot of age-specific rates over time (age binned into eight-year groups); (b) estimated annual percentage change per calendar year by age group (local drifts) estimated using standard APC model; (c) local drifts estimates from new APC model.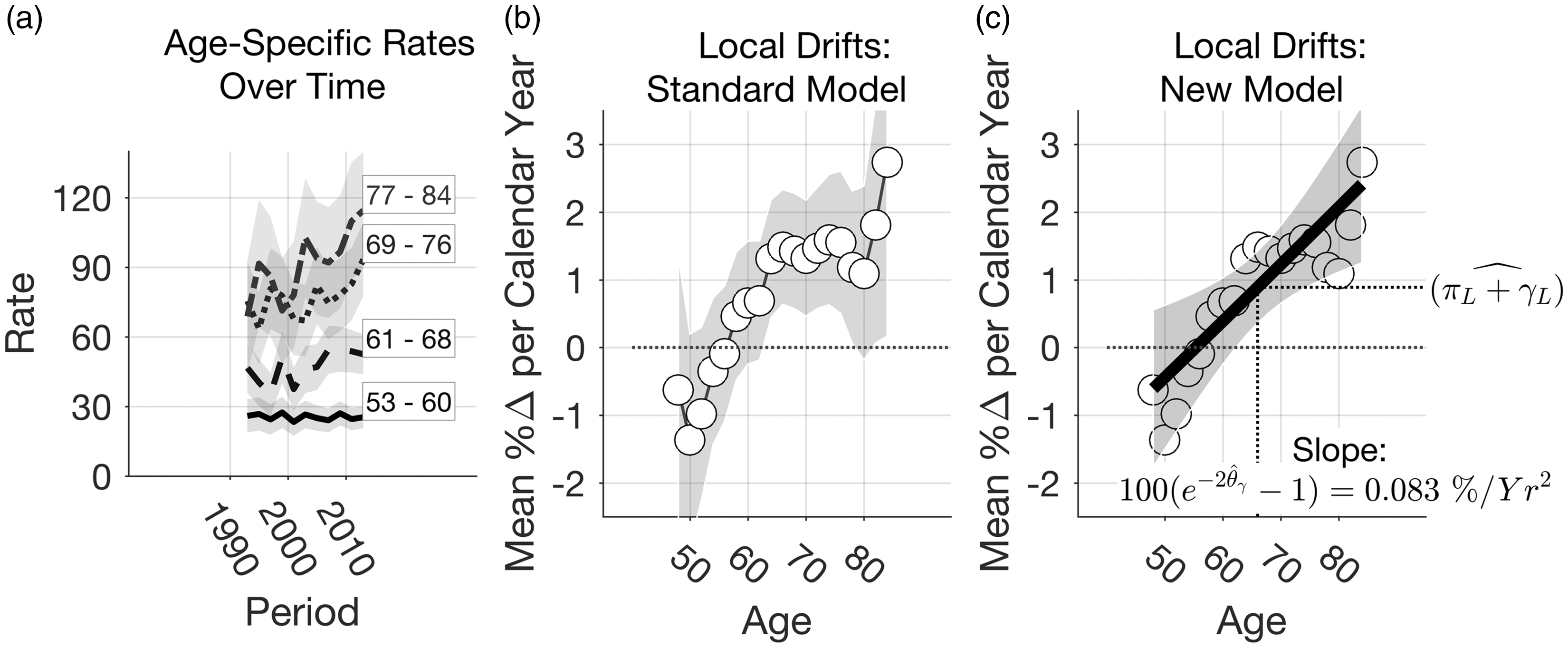
An important point is local drifts are cross-sectional quantities, and the same cross-sectional values hold whether we condition on age and examine the rates over calendar periods or we condition on calendar periods and examine the rates across age groups. In Appendix C, we show that the log-linear slopes of the cross-sectional age-specific rates within calendar periods equal
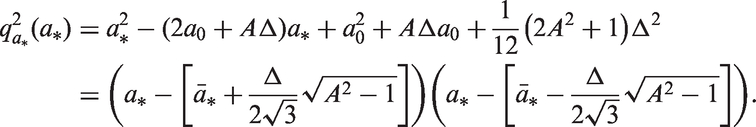
11 Local drifts tests
When testing for significance of the local drifts using the standard model, we often rely on an omnibus Wald statistic. The null hypothesis is that all local drifts are equal to the overall net drift, which is true if and only if 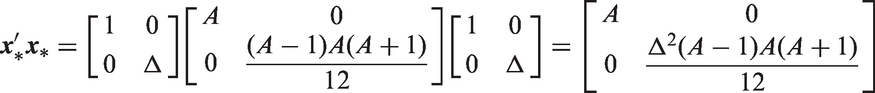
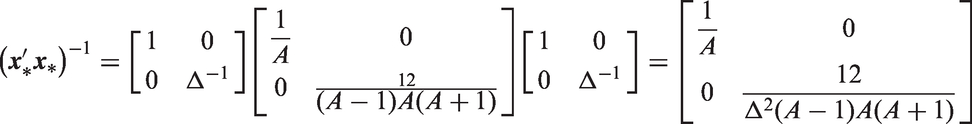
As shown in Appendix A.5, when the Lexis diagram is rectangular
The new model offers a 1-degree-of-freedom test. Clearly, if
In principle, one could construct a combination test
For the myeloma data, the Omnibus Wald Test is
12 Power of local drifts tests: simulation study
We carried out a simulation study of our new 1- degree-of-freedom (1-df ) and combination tests of local drifts, versus the standard Omnibus test. Our aim was to assess the level-correctness of our tests and to gauge the potential real-world power gains (if any) obtainable using the new tests, when the local drift signals arise from quadratic or higher-order cohort effects alone or simultaneously. As before, we used point estimates from the myeloma data's APC model to define a baseline scenario.
To assess the performance of the drifts tests, we considered three situations. First,
As shown in Figure 7(a), all three tests are level correct. The 1-df test is much more powerful than the Omnibus test; as one would expect (since in this situation the signal arises from cohort curvature alone) the combination test is slightly less powerful. The 1-df test has substantially higher power than the Omnibus test, 36% versus 9%, 87% versus 32%, and 99% versus 77% in the three non-null situations shown in Figure 7(a). In contrast, when the signal is entirely due to higher-order cohort effects (situation 2, Figure 7(b)), the 1-df test remains level correct. Here the Omnibus test is quite sensitive (59% power for the baseline case, 100% when the sample size is increased four-fold). The combination test is somewhat less powerful. In situation 3 (Figure 7(c)), even when there is signal from both sources, the 1-df test is more powerful or as powerful as the Omnibus test. In some situations, the combination test is more powerful than the 1-df test, and in some less. On balance, the combination test appears to be a useful compromise test.
Simulation results assessing Type-I error rates and power of Omnibus test, 1-df test, and combination test for assessing significance of local drifts. See text for details.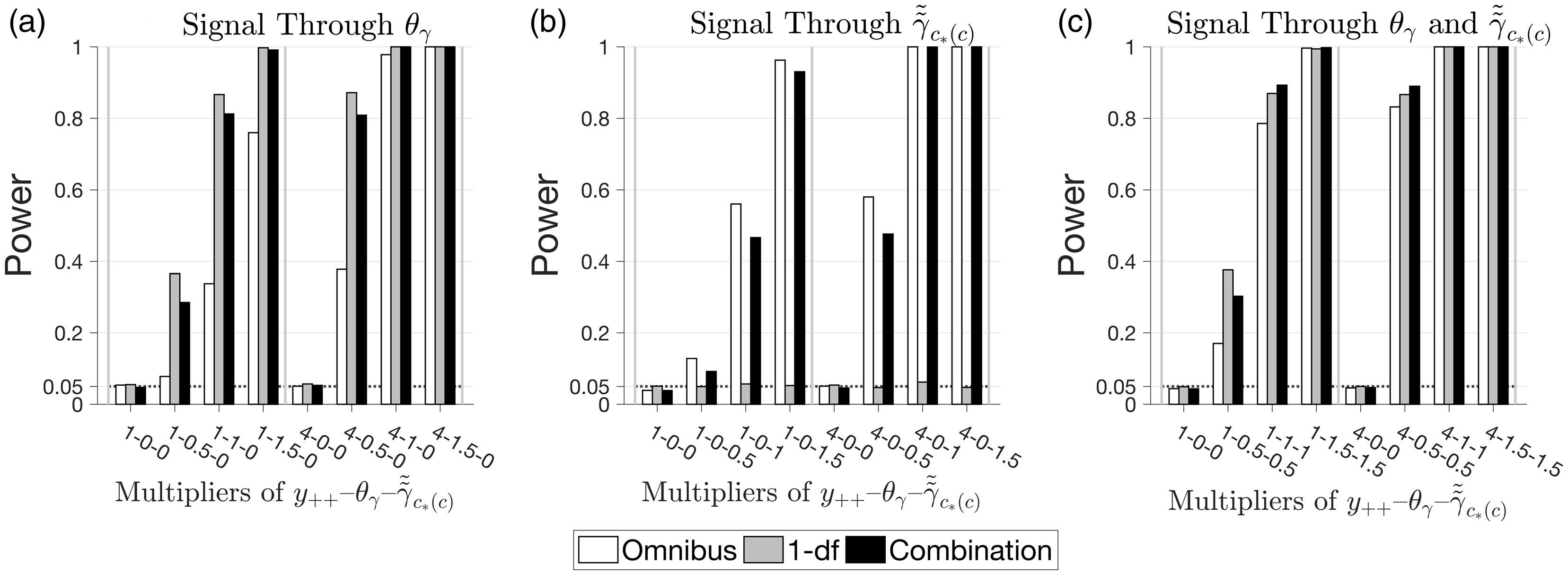
13 Discussion
We developed our new APC model with applications to cancer surveillance research in mind. Our methods are equally appropriate for many other health-related events. For example, using APC analysis, Shiels et al. 17 analyzed all-cause premature mortality in the US, and Best et al. 18 analyzed premature mortality from cancer, heart disease, accidents, suicide, and chronic liver disease/cirrhosis.
Our new APC model partitions age, period, and cohort deviations into orthogonal quadratic components plus higher-order terms. Other investigators have developed spline-based methods which include quadratic terms along with other polynomials.13,19 These approaches provide appealingly smooth estimable functions, but the regression parameters themselves provide little insight. In contrast, the global curvature parameters
We recently developed a random effects model for simultaneous analysis of multiple sets of rates ascertained from multiple population strata over the same Lexis diagram.
20
In that paper, we also present a quadratic model. A key innovation in this report is we use orthogonal polynomials that are characteristic of the underlying Lexis diagram, and demonstrate the surprisingly large utility of doing so. Going forwards, our random effects methods could use the orthogonal parameterization presented here to investigate the heterogeneity of local drifts and local drift trends (i.e. the quantity
Three theoretical points are worth emphasizing. First, all of the parameters and functions described here are identifiable. This is illustrated for example in Figure 3. Second, our new hypotheses tests are level correct, and can be more powerful than the usual global tests.
21
Third, the weighted cohort deviations described here are very useful, notwithstanding that unweighted deviations
Our new model opens avenues of future methodological research, including comparative analysis, power calculations, and forecasting. 3 For pairwise comparison of from 2 through around 10 strata (for example, 9-registry SEER analyses), we expect our new model will enable more powerful combination tests of log-parallelism and proportionality. 23 These methods would complement the random effects models that work best when the number of strata is around 10 or more. 20 Asymptotically, the Wald tests have non-central Chi-square distributions, which permits analytical power calculations.
One of the main limitations of the new model is shared by the old: currently, methods are limited to assess goodness-of-fit. One approach that might prove useful would use a smooth Gaussian process to model any residual departures after fitting the usual age, period, and cohort effects. 24 Another important topic is fitting models that incorporate external information, for example, data on established cancer risk factors or screening.
Because our new APC model subsumes a standard APC model yet provides serious advantages, we propose it be considered a new standard. In particular, we believe the value of estimating
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.