
Abstract
The growing demand for spatially detailed data to advance the Sustainable Development Goals agenda of ‘leaving no one behind’ has resulted in a shift in focus from aggregate national and province-based metrics to small areas and high-resolution grids in the health and development arena. Vaccination coverage is customarily measured through aggregate-level statistics, which mask fine-scale heterogeneities and ‘coldspots’ of low coverage. This paper develops a methodology for high-resolution mapping of vaccination coverage using areal data in settings where point-referenced survey data are inaccessible. The proposed methodology is a binomial spatial regression model with a logit link and a combination of covariate data and random effects modelling two levels of spatial autocorrelation in the linear predictor. The principal aspect of the model is the melding of the misaligned areal data and the prediction grid points using the regression component and each of the conditional autoregressive and the Gaussian spatial process random effects. The Bayesian model is fitted using the INLA-SPDE approach. We demonstrate the predictive ability of the model using simulated data sets. The results obtained indicate a good predictive performance by the model, with correlations of between 0.66 and 0.98 obtained at the grid level between true and predicted values. The methodology is applied to predicting the coverage of measles and diphtheria-tetanus-pertussis vaccinations at 5 × 5 km2 in Afghanistan and Pakistan using subnational Demographic and Health Surveys data. The predicted maps are used to highlight vaccination coldspots and assess progress towards coverage targets to facilitate the implementation of more geographically precise interventions. The proposed methodology can be readily applied to wider disaggregation problems in related contexts, including mapping other health and development indicators.
Keywords
1 Introduction
The launch of the Sustainable Development Goals (SDGs) in 2015 1 with the central focus of ‘leaving no one behind’ has prompted a call for spatially detailed data to improve the evaluation and monitoring of key health and development measures within countries. High-resolution maps of development and health indicators are useful tools for determining the geographical variation and inequities in these indicators to better inform decision making, policy and targeting of interventions. Maps built on geolocated household survey data integrated with geospatial covariates have grown in popularity in recent years2–5 due to their advantages over small area estimation,6–8 including flexibility for use in monitoring progress towards development goals at more operationally relevant spatial scales and non-reliance on additional data from censuses or other administrative sources. Central to their production are data obtained from national household surveys, such as the Demographic and Health Surveys (DHS), 9 which are typically conducted every 3–5 years in low- and middle-income countries to provide data on a wide range of relevant indicators. Many DHS surveys (as well as surveys from other programs) are now geolocated, and the increasing availability of the global positioning system (GPS) coordinates of survey clusters have facilitated the integration of cluster-level data with geospatial covariate layers, often in a model-based framework, to map these indicators. Geostatistical models which characterize spatial dependence via parametric covariance functions, 10 and generalized additive models 11 utilizing smooth functions of the cluster coordinates to model spatial autocorrelation, are commonly used approaches. However, the feasibility of these approaches rely on the availability of GPS-located cluster centroid data.
In some cases, access to national survey data sets with GPS cluster location data can be limited, due to various reasons including security, confidentiality and political concerns. Therefore, in certain countries, data from these surveys can at best be obtained at an aggregate level, typically at the first administrative level (i.e. provinces). Consequently, high-resolution mapping methods which are designed for point-referenced data cannot be applied. Providing local-scale subnational estimates to better guide health interventions,11,12 therefore, requires alternative methods for dealing with the problem of spatial misalignment that exists between the accessible subnational (or areal) data and the grid points at which predictions are required.
Spatial misalignment or change of support problems is well-studied in the statistical literature.13,14 Four types of misalignment are often encountered in practice: (i) area-to-area (also known as modifiable areal unit problem),15,16 (ii) area-to-point,17,18 (iii) point-to-point and (iv) point-to-area. These misalignment problems represent many contexts where data are available at a given spatial scale (or multiple scales), whereas inference or predictions are required at another scale that represents a completely different spatial configuration.18,19 Methods for point-to-point and point-to-area misalignment constitute the crux of geostatistical studies. 10 Many model-based approaches, some of which are tailored to certain applications, have also been developed for dealing with other misalignment problems.13,14 These are mostly implemented in a Bayesian framework using Markov chain Monte Carlo (MCMC) methods, although the Integrated Nested Laplace Approximations (INLA) method 20 is becoming popular recently. Nevertheless, methods for area-to-area and area-to-point misalignment, especially with non-Gaussian outcomes, are less frequently studied and most existing approaches are not available in commonly used software packages.
The primary objective of this paper is to develop a novel approach to the area-to-point disaggregation problem, focusing on high-resolution mapping of childhood vaccination coverage using areal survey data. The proposed approach is a joint model that combines a conditional autoregressive (CAR) model for the observed areal data and a Gaussian process model for the prediction grids, whilst intrinsically adjusting for the misalignment in the covariates included in the model. A key aspect of our hierarchical modelling strategy is the linking of the areal observations and the prediction grids using these latent processes and the regression component. The Bayesian model is fitted using the INLA method. INLA is a deterministic algorithm that utilizes both analytical approximation and numerical integration to perform approximate Bayesian inference for the class of latent Gaussian models, which includes spatial and spatiotemporal models. As a faster and accurate alternative to simulation-based MCMC methods, the INLA approach has gained popularity among researchers partly due to the availability of the R-INLA package for its implementation.21,22 To implement the INLA approach for point-referenced data, it is often combined with the stochastic partial differential equation (SPDE) approach proposed by Lindgren et al. 23
The remainder of this paper is structured as follows. The data sets analyzed – vaccination coverage data and the prediction covariates – are discussed and displayed in Section 2. The proposed model and the accompanying Bayesian inferential procedure using the INLA-SPDE approach are discussed in Section 3. In Section 4, a simulation study is carried out to examine the predictive performance of the model under different scenarios. An application to high-resolution mapping of vaccination coverage in Afghanistan and Pakistan is presented in Section 5. As a further validation exercise, in Section 6, predicted maps produced using the proposed methodology are compared with those obtained via geostatistical approaches that utilize geolocated cluster level data, based on parallel data sets containing both areal and geolocated cluster level information. We conclude with some discussion in Section 7.
2 Data
Subnational vaccination coverage data for Afghanistan and Pakistan were obtained from the most recent DHS surveys conducted in 2015 and 2013, respectively, in both countries.24,25 For Afghanistan, the subnational areas were the 34 provinces of the country whereas for Pakistan, these were the eight administrative level 1 areas (although the survey excluded Azad Kashmir and Federally Administered Tribal Areas (FATA)). When obtaining aggregate summaries of DHS data, it is required that sampling weights are applied to account for the survey design. 26 Hence, the subnational data used here were weighted to adjust for the selection probabilities and non-response. Other information related to the surveys including the population sizes of the subnational areas can be found in the relevant DHS reports.24,25
For each area in both countries, data on measles and diphtheria-tetanus-pertussis (DTP) vaccinations were extracted and matched to the corresponding boundaries obtained from DHS spatial data repository. 27 The data for measles vaccination coverage, by definition,24,25 refer to coverage with at least the first dose of measles containing vaccine (MCV1), which is usually administered from age 9 months. For DTP, the coverage of each of the three doses: DTP1, DTP2 and DTP3, recommended at 6, 10 and 14 weeks, respectively, was obtained separately. For each vaccination type, the data comprised of the numbers of children aged 12–23 months (a standard age group for assessing vaccination coverage, see literature24,25) surveyed and the numbers that were vaccinated at any time prior to the survey. Whether or not a child was vaccinated was determined during the surveys either from the child's vaccination card or through parental recall. We note that there is a potential for information bias associated with determining vaccination status through parental recall in the absence of vaccination cards. However, analysis of cards only data is constrained by sample size issues due to high proportions of children without vaccination cards in both countries (≈67% in Pakistan).24,25
Overall, the weighted data comprised of 5704 children in Afghanistan, of which 3443 (60.4%), 4166 (73.0%), 3875 (67.9%) and 3293 (57.7%) had received measles and DTP 1, 2, 3 vaccinations, respectively. For Pakistan, out of 2074 children, 1274 (61.4%), 1633 (78.7%), 1508 (72.7%) and 1352 (65.2%) had received the respective vaccinations. The province of Zabul in Afghanistan was excluded from all the summary tables of indicators produced following the 2015 DHS survey 24 due to poor accessibility during the survey. This area and the excluded provinces in Pakistan were treated as missing data in the analysis.
Geospatial socioeconomic, demographic, environmental and physical factors play an important role in determining the spatial patterns and geographic inequities in vaccination coverage. 12 As such, these have been used in previous research to map vaccination coverage at fine spatial scales. To inform our disaggregation model, we selected two covariates from a suite of geospatial covariate layers available for both countries through the WorldPop project (www.worldpop.org.uk). These were: travel time to major cities of at least 50,000 people 28 and population density. 29 This number of covariates was chosen deliberately to guard against the possibility of overfitting. The selected covariate layers were each preprocessed and resampled to match the administrative boundary shapefiles of both countries and the 5 km prediction grids using ArcGIS v10.4.
In Figure 1, we show the observed vaccination coverage data for measles and DTP3 for both countries. Similar maps for DTP1 and DTP2 and the maps of the covariate layers are displayed in online Supplemental Figures S1 and S2, respectively.
Maps of observed measles and DTP3 vaccination coverage for Afghanistan in 2015 (left panel) and Pakistan in 2013 (right panel) at administrative level 1.
3 Methods
3.1 The disaggregation model
The disaggregation model used in this work is formalized as follows. Let
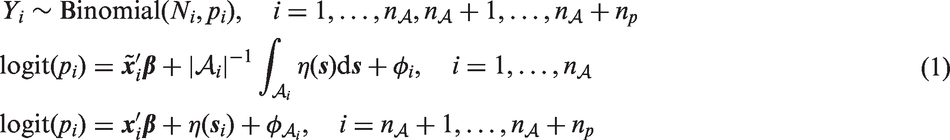
In equation (1),
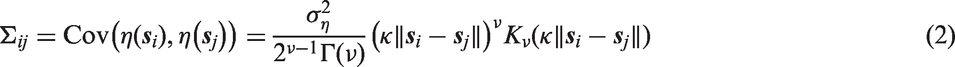
The second set of spatial random effects
3.2 Bayesian inference using the INLA-SPDE approach
We propose to fit the model in equation (1) using the INLA-SPDE approach.20,23 Let
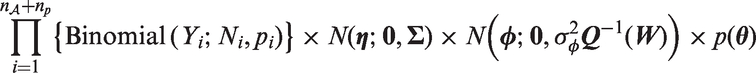
The SPDE approach is particularly required for the estimation of the latent Gaussian field,

The R code for the analysis is provided in the online Supplemental materials.
4 Simulation study
The purpose of this simulation study is to demonstrate the predictive ability of the proposed model in scenarios depicting the intended applications. Data were generated using the unit (i.e. Plots of the grid (
The true values of the parameters of model (1) used in generating the data are described as follows. For the spatial process
To evaluate the predictive performance of the model, we computed the correlations between the observed and predicted probabilities at both the grid and area levels, as well as the root mean square error (RMSE = One of the simulated data sets for spatial range r = 0.7. Plotted are true simulated probabilities and the corresponding predictions (mean) and their standard deviations for 
Results of the simulation study.
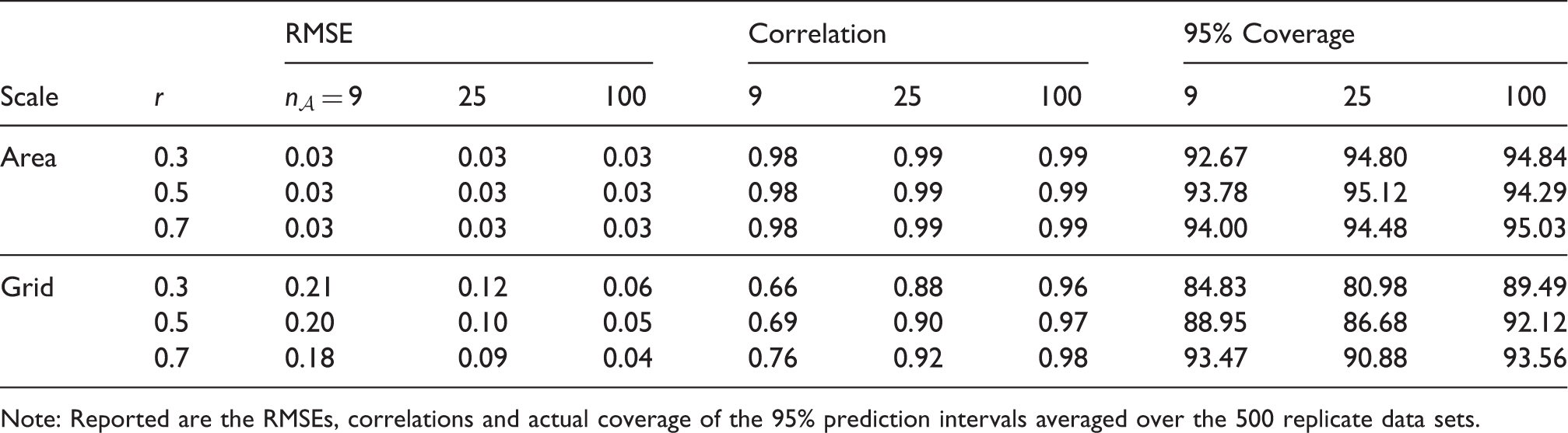
Note: Reported are the RMSEs, correlations and actual coverage of the 95% prediction intervals averaged over the 500 replicate data sets.
5 Mapping the coverage of measles and DTP1, 2 and 3 vaccinations in Afghanistan and Pakistan
We now apply the proposed methodology to predict vaccination coverage in the study countries at
Posterior estimates of the parameters of the fitted models for measles and DTP 3.
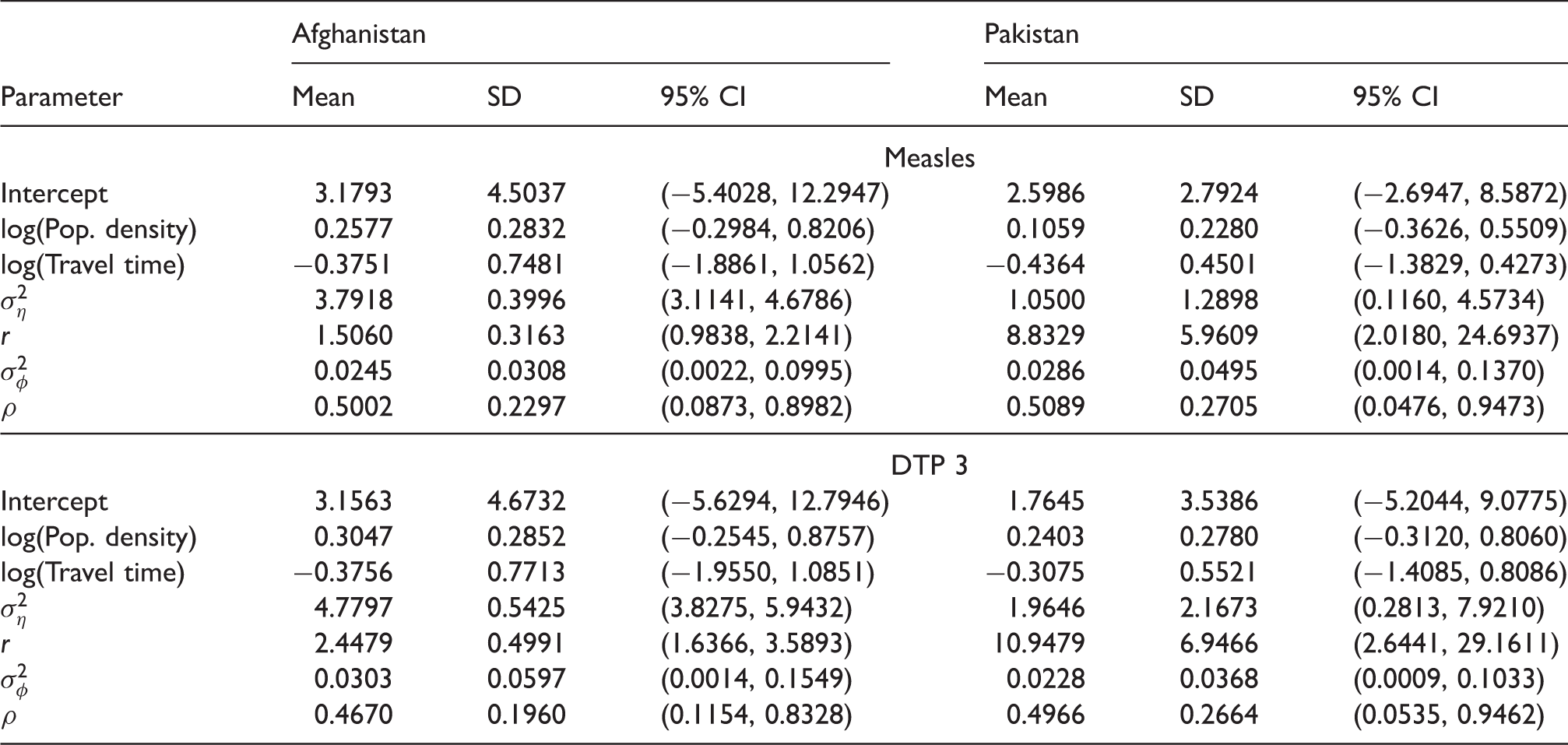
The estimates of vaccination coverage for areas with missing data as identified in Section 2 are reported in online Supplemental Table S3. In all cases, the estimated areal values for the areas with observations had very high correlations (>0.97) with the observed values. Also, the RMSEs of the areal predictions for Afghanistan were <0.03 while those of Pakistan were <0.04. These statistics confirm the accuracy of the predictions for the missing areas; however, it should be noted that the model does not account for other conditions, such as security issues, which could affect vaccination coverage levels in these areas.
The predicted vaccination coverage levels at Predicted measles and DTP3 vaccination coverage at 5 × 5 km2 (left panel) in children aged 12–23 months for Afghanistan in 2015, with the associated standard deviation maps (right panel). Predicted measles and DTP3 vaccination coverage at 5 × 5 km2 (left panel) in children aged 12–23 months for Pakistan in 2013, with the associated standard deviation maps (right panel).
Of significant epidemiological interest in the evaluation of measles vaccination coverage is the identification of ‘coldspots’.
11
Coldspots are low coverage areas that foster and accelerate disease circulation, and should thus be designated as priority areas when planning immunization and disease elimination programmes. In Figure 6 (right panel), we define coldspot areas using flexible thresholds pertaining to the overall coverage levels within each country. These are: the lowest 20%, lowest 50% and lowest 80% coverage areas, corresponding to cutpoints of 0.33, 0.55 and 0.70 for Afghanistan, and 0.35, 0.47 and 0.67 for Pakistan, respectively. These maps show that significantly large areas of both countries, as explained previously, are coldspots of low vaccination coverage, especially when considering the 80% threshold within each country. However, for effective planning using these maps, the identified coldspots must be combined with maps of population estimates to determine whether significant numbers of unvaccinated children exist in these areas (see Takahashi et al.
11
).
Maps of Afghanistan (top) and Pakistan (bottom) showing: (a and c) coldspot areas for measles vaccination defined as the lowest 20%, lowest 50% and lowest 80% coverage areas and (b and d) the districts attaining the WHO Global Vaccine Action Plan (GVAP) threshold of 80% coverage (in green colour) with DTP3 vaccination for Afghanistan in 2015 and Pakistan in 2013.
The WHO Global Vaccine Action Plan (GVAP) has set a target of attaining 80% coverage with all vaccines in all countries by 2020. 37 We illustrate the evaluation of progress towards this target using DTP3 vaccination coverage maps. (Given that this target was set at the district level, this evaluation would not have been possible using the areal data in Figure 1.) For each country, the 5 × 5 km2 predictions were aggregated to the district level by averaging the predictions over the grid cells within each district – this is a standard approach used in geostatistics. The maps in Figure 6 (right panel) show that for Afghanistan in 2015 and Pakistan in 2013 only 8% and 19% of districts had attained these targets, respectively. In Pakistan, in particular, these districts are mostly located in the province of Punjab, matching findings elsewhere. 38
6 Predictive performance comparisons with high-resolution maps obtained using geolocated cluster level data
High-resolution maps of vaccination coverage have been produced in previous research using geolocated survey data.11,12 Here, we undertake additional data analyses to compare maps of measles vaccination coverage in children aged 12–23 months produced using the proposed methodology which utilizes weighted areal data (see, e.g. Section 2) with equivalent maps obtained using geolocated cluster level data, in settings where both data sets were available. The countries considered in this analysis were Cambodia, Mozambique and Nigeria, for which the most recent DHS surveys were conducted in 2014, 2011 and 2013, respectively. For the analysis with areal data, we used the most detailed administrative (admin) level at which the surveys were deemed representative. These were the 19 regions (as groups of admin level 1 areas) of Cambodia, the 11 admin level 1 areas of Mozambique and the 37 states (including the capital) of Nigeria. Combining weighted vaccination coverage data for these areas with some covariate data identified in a previous modelling exercise in Utazi et al.
12
(see online Supplemental materials for details) model (1) was applied to predict vaccination coverage on a
To obtain vaccination coverage maps using geolocated cluster level data, we modified model (1) by replacing the areal data with cluster level data and removing the areal random effect, φ, yielding
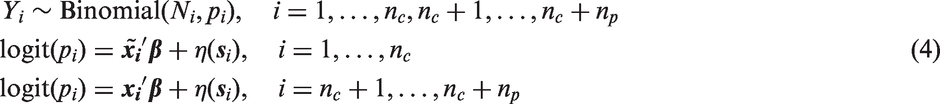
The resulting coverage maps and associated uncertainties are shown in online Supplemental Figures S8 to S10 for all three countries, alongside the differences between the two approaches. A visual inspection of the maps shows that while the two approaches are mostly similar in predicting high and low coverage areas together with the associated uncertainties, some differences are apparent in some areas. However, the average differences of 0.04 (interquartile range (IQR) = 0.08), 0.05 (IQR = 0.09) and 0.05 (IQR = 0.13) for Cambodia, Mozambique and Nigeria, respectively, as reported in online Supplemental Table S5 indicate that, in general, strong similarities exist between the two approaches.
In Figure 7(a), we compare for each country, the distributions of the (a) Distributions of proportions of children aged 12–23 months vaccinated against measles and (b) percentage differences in national estimates of numbers of under 5 year olds unvaccinated between DHS admin estimates and each of the 5 × 5 km2 estimates from area-to-grid and cluster-to-grid approaches. Vaccination coverage in children aged 12–23 months was used as a proxy for coverage levels in under 5s in (b).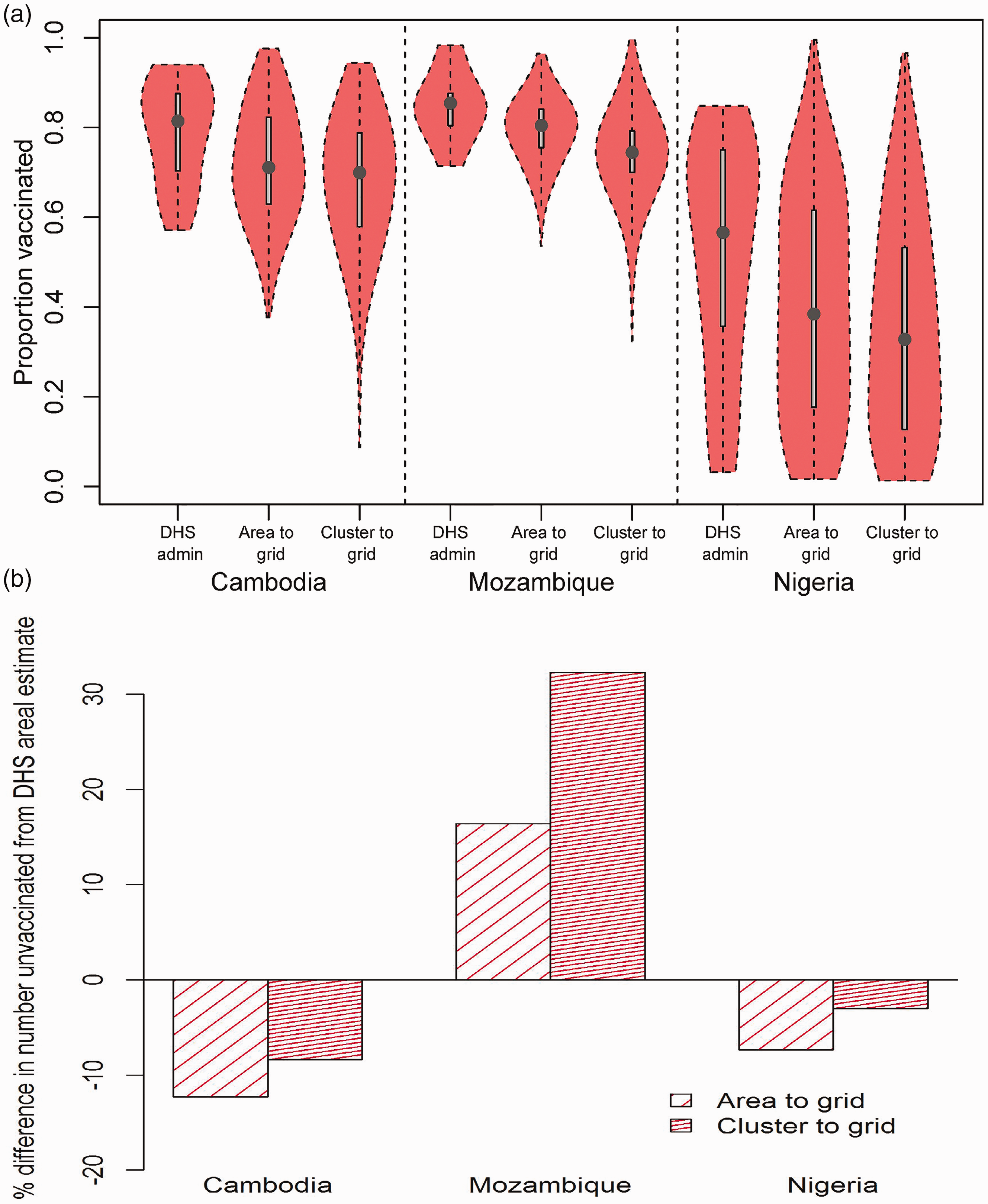
7 Discussion
Spatially detailed data is key in the era of the SDGs with the central focus of ‘leaving no one behind’ and the push for precision public health 39 as a strategy for achieving disease elimination and allocating scarce resources. In resource poor settings, high-resolution maps of key health and development metrics are increasingly derived from geolocated cluster level survey data through spatial interpolation methods. Here, we have developed a methodology for producing high-resolution maps from areal survey data where geolocated cluster level information is unavailable, focusing on binomial responses arising from the application to vaccination coverage mapping. The areas and the high-resolution grids were linked in the proposed model using the regression component and both of the spatial random effects in a hierarchical Bayesian framework. The INLA-SPDE approach provided a fast and computationally efficient method for implementing the model. A simulation experiment demonstrated the predictive ability, and high-resolution mapping of measles and DTP vaccination, the applicability of the methodology. The value of the high-resolution maps of vaccination coverage produced is illustrated through the identification of coldspots of low coverage and an assessment of progress toward vaccination targets. These output maps, when combined with population estimates, as demonstrated in Section 6, can be used to generate estimates of numbers of unvaccinated children, particularly those living in coldspot areas, as well as estimates of numbers children who have received the first dose of a vaccine but not the latter dose(s) to help with the planning and implementation of vaccination programmes, and other disease eradication and health improvement efforts (see Takahashi et al. 11 ).
While geolocated cluster-level survey data are ideal for geostatistical mapping of development indicators due to their level of spatial detail and availability of ready-to-use methodological approaches, there are however some advantages to modelling using area level data. First, areal summaries are unaffected by the displacement of survey cluster coordinates often carried out to protect respondents' confidentiality. 2 Secondly, most surveys such as those undertaken as part of the DHS program are designed to be representative at the area level. This facilitates the application of sampling weights to areal summaries to account for the survey design. Currently, we are not aware of any appropriate technique for accounting for the survey design when producing high-resolution maps from cluster-level data using geostatistical approaches, although it has been noted that these may not substantially change the predicted maps. 40 Thirdly, areal data being aggregates of cluster-level data are, in principle, unlikely to be affected by sample size issues often encountered when using cluster-level data in binomial models. 12 Most importantly, the comparisons undertaken in Section 6 have shown that maps produced using areal data through the proposed methodology are highly comparable to those produced using cluster level data, notwithstanding the fact that weighted areal data were used in these comparisons.
There are limitations in this work in terms of predictive accuracy relating to the number and size of the input areal units. In the data sets analysed, this limitation is particularly evident in Pakistan where observed vaccination coverage levels correspond to large, sparse administrative units. Since predictive accuracy (see Section 4) increases as
In the vaccination coverage mapping application, the geospatial covariates used did not include some variables that are known to influence access to and acceptance of vaccines such as health facility access,
41
maternal literacy
38
and vaccine stocks. The inclusion of these variables in the analyses, where their spatial surfaces exist, could further improve the predicted maps. In addition, the selected covariates used in the applications were based on previous studies as pointed out in Section 2. In situations where there is no prior information on the relationships between the variable of interest and available covariates, the observed areal data could be used to perform covariate selection. The no-covariate case is not of interest in this work as a previous study
18
has shown that predictive performance decreases in this case. On a related note, the specification of uniform regression coefficients for all the areas in the model has the potential to obscure area-specific variations in the relationships between the covariates and vaccination coverage. For example, an overall positive relationship between vaccination coverage and population density implies that anti-vaccine populations cannot be accounted for by the model. Lastly, in the simulation study in Section 4, the effects of different values of
We envisage future work in several directions. Here, we focused on binomial responses. However, the methodology is easily extensible to other outcome distributions and can be used to model many other health and development indicators. Vaccination coverage is known to vary by age,11,12 with age-specific coverage levels providing valuable information and insights. Although the 12 to 23-month age group analysed here is a standard age group used for evaluating the effectiveness of vaccination programmes, we plan to explore coverage mapping for other age groups of under 5s in the countries studied. Extensions to other childhood vaccinations and more countries without geolocated survey data will also be considered. Lastly, as demonstrated in Moraga et al., 18 it is straightforward to introduce point-level data in the proposed methodology (by combining equations (1) and (4)) to form a fusion model. This modelling framework could be used to adjust for the survey design (through the areal data) in geostatistical mapping of development indicators using geolocated survey data.
Supplemental Material
Supplemental material for A spatial regression model for the disaggregation of areal unit based data to high-resolution grids with application to vaccination coverage mapping
Supplemental material for A spatial regression model for the disaggregation of areal unit based data to high-resolution grids with application to vaccination coverage mapping by CE Utazi, J Thorley, VA Alegana, MJ Ferrari, K Nilsen, S Takahashi, CJE Metcalf, J Lessler and AJ Tatem in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: AJT is supported by funding from the Bill & Melinda Gates Foundation (OPP1106427, OPP1134076, OPP1182408, OPP1117016), the Clinton Health Access Initiative, National Institutes of Health, a Wellcome Trust Sustaining Health Grant (106866/Z/15/Z), and funds from DFID and the Wellcome Trust (204613/Z/16/Z). CJEM, JL and MF are supported by Bill & Melinda Gates Foundation Grant (OPP1094793).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.