
Abstract
Correct classification of breast cancer subtypes is of high importance as it directly affects the therapeutic options. We focus on triple-negative breast cancer which has the worst prognosis among breast cancer types. Using cutting edge methods from the field of robust statistics, we analyze Breast Invasive Carcinoma transcriptomic data publicly available from The Cancer Genome Atlas data portal. Our analysis identifies statistical outliers that may correspond to misdiagnosed patients. Furthermore, it is illustrated that classical statistical methods may fail to identify outliers due to their heavy influence, prompting the need for robust statistics. Using robust sparse logistic regression we obtain 36 relevant genes, of which ca. 60% have been previously reported as biologically relevant to triple-negative breast cancer, reinforcing the validity of the method. The remaining 14 genes identified are new potential biomarkers for triple-negative breast cancer. Out of these, JAM3, SFT2D2, and PAPSS1 were previously associated to breast tumors or other types of cancer. The relevance of these genes is confirmed by the new DetectDeviatingCells outlier detection technique. A comparison of gene networks on the selected genes showed significant differences between triple-negative breast cancer and non-triple-negative breast cancer data. The individual role of FOXA1 in triple-negative breast cancer and non-triple-negative breast cancer, and the strong FOXA1-AGR2 connection in triple-negative breast cancer stand out. The goal of our paper is to contribute to the breast cancer/triple-negative breast cancer understanding and management. At the same time it demonstrates that robust regression and outlier detection constitute key strategies to cope with high-dimensional clinical data such as omics data.
1 Introduction
Triple-negative breast cancer (TNBC) represents 10% to 17% of all diagnosed breast tumors, 1 and has the worst prognosis amongst the different subtypes of breast cancer (BC). 2 TNBC is characterized by the lack of expression of targetable proteins like estrogen receptor (ER), progesterone receptor (PR), and human epidermal growth factor receptor 2 (HER2). 3 Based on this, the current standard of care treatment protocols for TNBC are limited to surgery, radiotherapy, and chemotherapy. 4 Since the BC subtype directly influences the therapeutic options, there is a high demand for the development of methods that not only accurately classify BC patients into BC subtypes but also identify relevant (target) genes that discriminate between TNBC patients and patients with other types of BC. The identification of genes that are either down- or up-regulated in TNBC is expected to play an important role in precision medicine, by providing a more in-depth knowledge on the cancer biology, but also yielding diagnostic, prognostic, and therapeutic markers that will ultimately improve patient outcomes. 5
The classification of BC into TNBC and non-TNBC is dependent on the absence/presence of ER and PR expression, and HER2 amplification. The ER, PR, and HER2 status is evaluated by immunohistochemistry (IHC), either in core biopsies and/or surgical resection specimens. Tumors are classified as either “positive” or “negative” based on the results obtained. However, preanalytic variables, thresholds for positivity, and interpretation criteria may generate inaccurate results. For example, it has been reported that up to 20% of ER and PR test results are false negative or false positive. 6 This is probably mostly related with the difficulty to apply the thresholds for positivity. Guidelines from the European Society of Medical Oncology and the American Society of Clinical Oncology/College of American Pathologists recommend the cut-off to define ER or PR-positive cases as ≥1% ER or PR-positive tumour cells, respectively.6,7 Tumours exhibiting <1% of tumour cells positive for ER or PR should be considered negative. 6
Oncogenic ERBB2 is overexpressed in 15–20% of primary breast cancers. 8 Determination of positivity for HER2 overexpression by IHC is dependent on the assessment of the intensity of the reaction product, the completeness of membrane staining, and the percentage of positive cells.8,9 An IHC score of 3+ is categorized as HER2 positive and is defined as strong complete reactivity seen in >10% of tumor cells. An IHC score of 2+ is classified as borderline reactivity (equivocal) and defined as weak to moderate complete membranous reactivity in >10% of tumor cells. IHC scores 0 and 1+ are considered HER2 negative. IHC 1+ is defined as faint, barely perceptible membranous reactivity in >10% of tumor cells. IHC 0 is defined as no reactivity or membranous reactivity in <10% of tumor cells. All equivocal cases, IHC 2+, must be evaluated by fluorescence in situ hybridization (FISH) or chromogenic in situ hybridization (CISH), where also a threshold for positivity is implied, based on average copy number/cell.
The clinical consequences of receptor status are extremely important. A patient given a wrong BC subtype classification will undergo inappropriate cancer treatment, either hormonal based or not, with severe consequences for cancer progression and survival. False negatives for ER and PR could benefit from endocrine therapy, and for false positives the hormonal therapy will fail. On the other hand, while a false positive HER2 assessment leads to the administration of potentially toxic, costly, and ineffective HER2-targeted therapy, a false negative HER2 assessment results in denial of anti-HER2 targeted therapy for a patient who could benefit from it. 8
In this context, statistical analysis of gene expression data for known BC cases may provide valuable insights. However, real data often contain one or more observations deviating from the main pattern of the data.10,11 For example, when considering gene expressions from TNBC data, inaccuracies may be due to variations in ER, PR, and HER2 testing, as mentioned above. Wrong TNBC class labels may result from inconsistencies between the IHC and FISH testing technologies. Unfortunately, classical results are highly influenced by these suspicious observations. The effect of outliers may be such that classical statistical techniques no longer detect them. This phenomenon is known as masking in statistics literature. 12 Moreover, outlying observations may even influence classical statistics so much that regular observations are flagged as outliers, a phenomenon known as swamping. 13 In regression models, these observations may compromise the predictive performance. Due to the high dimensional nature of the data, typical regression techniques are no longer valid. For example, the classical least squares fit cannot be computed when there are fewer observations than variables. Therefore, one uses sparsity-inducing methods to select relevant subsets of the original variables. However, these sparse methods might also be impacted by outliers, leading to relevant variables being neglected and irrelevant variables being selected. 14 Moreover, detecting interesting anomalous cases (e.g. a normal patient with deviating expressions of specific genes) may be of particular interest.
The importance of detecting outlying patients is therefore twofold. Outliers corresponding to errors in the labeling must be detected and treated accordingly in order to achieve accurate model predictions. Correctly diagnosing patients is of utmost interest as wrongly diagnosed patients may receive ineffective, expensive, and potentially harmful treatment. Secondly, outliers which are not errors reveal hidden information on the covariates that might play a role in the definition of new therapies based on target genes revealed by outlier analysis.
The remainder of the paper is structured as follows. In the next section, we discuss TNBC data construction from RNA-Seq and clinical data from Breast Invasive Carcinoma (BRCA). We then discuss logistic regression as a tool to decide BC class membership. Due to the high dimensionality of the data and the concern for outliers, we then turn to robust sparse logistic regression which selects relevant variables and flags outlying cases. Also the DetectDeviatingCells (DDC) method 15 is applied, and its results are linked to those of the robust logistic regression which brings new insights. The paper concludes with a discussion of results and model diagnostics along with the biological interpretation of the selected gene set.
2 Data description
The BRCA data set is publicly available from The Cancer Genome Atlas (TCGA) Data Portal 16 and contains genomic and clinical data from BC patients. The RNA-Seq Fragments Per Kilo base per Million (FPKM) data were imported using the “brca.data” R package. 17 The BRCA gene expression data is composed of 57,251 variables for a total of 1222 samples from 1097 individuals. From those samples, 1102 correspond to primary solid tumor, 7 to metastases, and 113 to normal breast tissue. Only samples from primary solid tumor were considered for analysis.
The TNBC gene expression data set was built based on the BRCA RNA-Seq data set available from TCGA. A subset of 19,688 variables, including the three TNBC-associated genes ESR1 (ENSG00000091831), PGR (ENSG00000082175), and ERBB2 (ENSG00000141736), hereafter designated as ER, PR and HER2, was considered, corresponding to the protein coding genes reported from the Ensemble genome browser 18 and the Consensus CDS 19 project. The response variable Y, corresponding to the clinical type, is a binary vector coded with “1” for TNBC individuals and “0” for non-TNBC. This vector was built based on the BRCA clinical data available from TCGA, regarding the individuals’ label for ER, PR, and HER2 (either “positive”, “negative”, or “indeterminate”). When a “negative” label is recorded for all three genes the response is set to “1” (TNBC), whereas in all other cases the status is “0” (non-TNBC). However, for assessing the HER2 label, three variables are available from the clinical data: two from the IHC analysis, the HER2 level and status, and another corresponding to the HER2 status obtained by FISH. The IHC status was considered, since it was measured for a larger number of individuals. Whenever both IHC status and FISH status were available for a given patient, the FISH status was considered instead, as FISH is a more accurate test for classifying individuals into HER2 “positive” or “negative”. Having the final status of samples for ER, PR, and HER2 expression, the Y response vector was then built as explained above. Samples showing at least one “negative” label for any of the three genes and the remaining genes’ labels set to “indeterminate” were excluded from the dataset, yielding a total of 1019 samples (160 TNBC and 859 non-TNBC) accounted for further data analysis.
A total number of 28 individuals were marked as suspect when no concordance existed between the HER2 IHC level and status, and between the HER2 IHC status and FISH status. Special attention will be given to individuals for whom non-concordance between lab testing exists and the choice of one or another determines the final label (TNBC vs. non-TNBC). These suspect individuals are potentially mislabeled and are therefore potentially outliers. We will verify whether they belong to the list of outlying individuals detected in this study. The age and race of the variables were also included as explanatory variables, since they were statistically significant in separate univariate logistic regressions to predict the individuals’ status. The final dataset consisted of 924 samples (153 TNBC and 771 non-TNBC), after excluding samples with no age and/or race records. This data set will be referred to as the training data with the remaining 95 samples being the test set.
3 Methods
Let
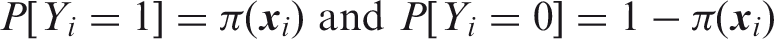
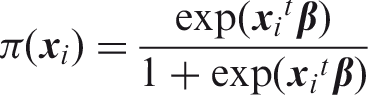
Typically, the regression coefficients
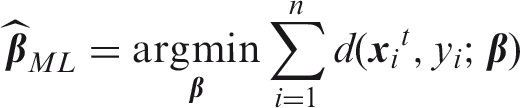
However, when the number of variables p is large, standard maximum likelihood estimators can be very difficult to interpret. Also the predictive power of a model may be impacted when including too many variables.20,21 Moreover, when p > n the maximum likelihood estimator cannot even be computed because there are more unknowns
3.1 Sparse logistic regression
One of the first shrinkage estimators in the literature is ridge regression.23,24 The estimator for
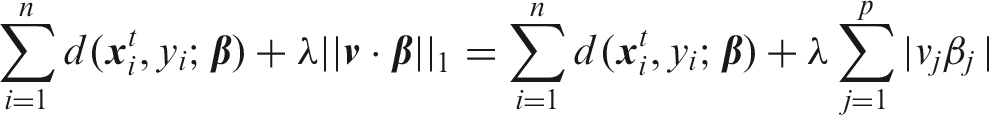
Here ċ stands for the elementwise product. The tuning parameter
A downside of ridge regression is that it cannot shrink coefficients exactly to zero, thus all variables will be retained in the selected model.20,21,25 The LASSO estimator,
21
which employs an l1 penalty instead of the l2, may be used to solve this problem. It performs variable shrinkage and variable selection at the same time. The LASSO estimate of
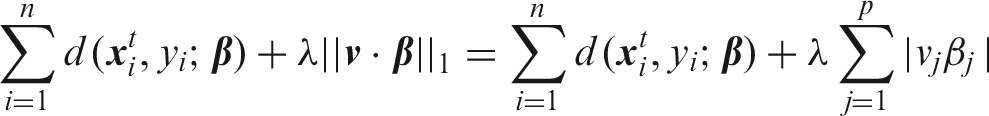
Again the tuning parameter
The elastic net procedure proposed by Zou and Hastie
26
tries to overcome the downsides of both ridge regression and the LASSO. It shrinks the variables and performs variable selection while being able to select groups of correlated variables. The sparse estimate for
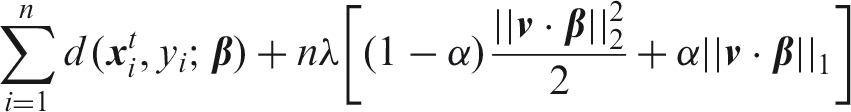
The parameter α controls the mixing between the ridge and LASSO penalty and should be chosen in the interval
In the next subsection, we discuss how the elastic net procedure may be modified to make it robust to outliers. We will first discuss a robustification of the non-sparse maximum likelihood technique before turning our attention to a robust sparse procedure.
3.2 Robust sparse logistic regression
The maximum likelihood estimator is highly susceptible to outliers because both outliers in the predictor space and outliers in the response variable may have an unbounded effect on the log-likelihood. As a possible alternative, more robust procedures have been proposed. For an outlier-contaminated data set they provide a solution that is close to the one that would be obtained on an outlier-free data set using classical methods. One of the ways to achieve robustness is to use a trimmed log-likelihood function. For linear regression the resulting estimator is called the Least Trimmed Squares (LTS) estimator.29,30
For logistic regression the LTS estimator is defined by
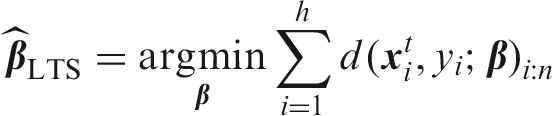
The ideas of LTS regression were adapted for sparse robust logistic regression by Kurnaz et al.
31
and were implemented in the R
27
software package enetLTS.
32
They defined the enetLTS logistic estimator which combines the sparsity of the elastic net procedure with the robustness of LTS regression. In that sense their work is an extension of sparse LTS linear regression
14
that combines the LTS estimator for linear regression with the LASSO penalty. The enetLTS estimator is defined by
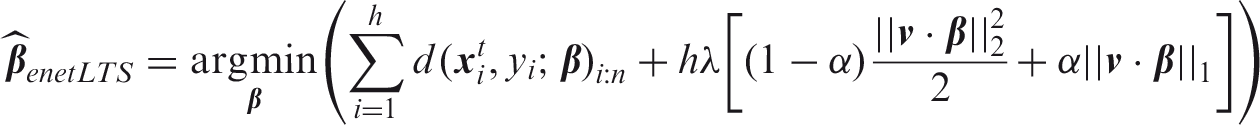
To increase efficiency, LTS regression usually includes a reweighting step.
10
Generally speaking, the reweighting step identifies outliers according to the above fitted robust LTS model. These are then downweighted before fitting a classical model using these weights. Consider the Pearson residuals
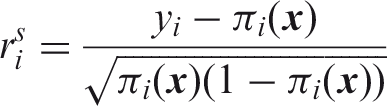
Under the logistic model these are known to be approximately normally distributed. Each observation i then receives a weight wi of 1 when
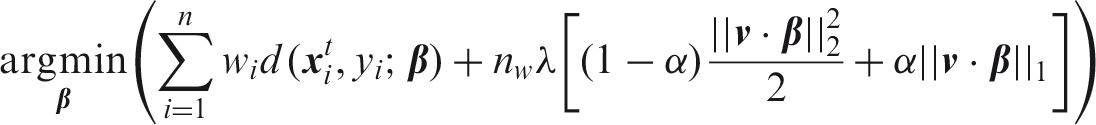
3.3 Detecting deviating data cells
Let
Figure 1 illustrates these two different paradigms. The left panel indicates three rowwise outliers in the data. The right panel identifies several contaminated cells in the data matrix. Even though many rows have one or more outlying cells, they still contain valuable information in their remaining cells.
Illustration of the cellwise outlier paradigm versus the typical outlier paradigm.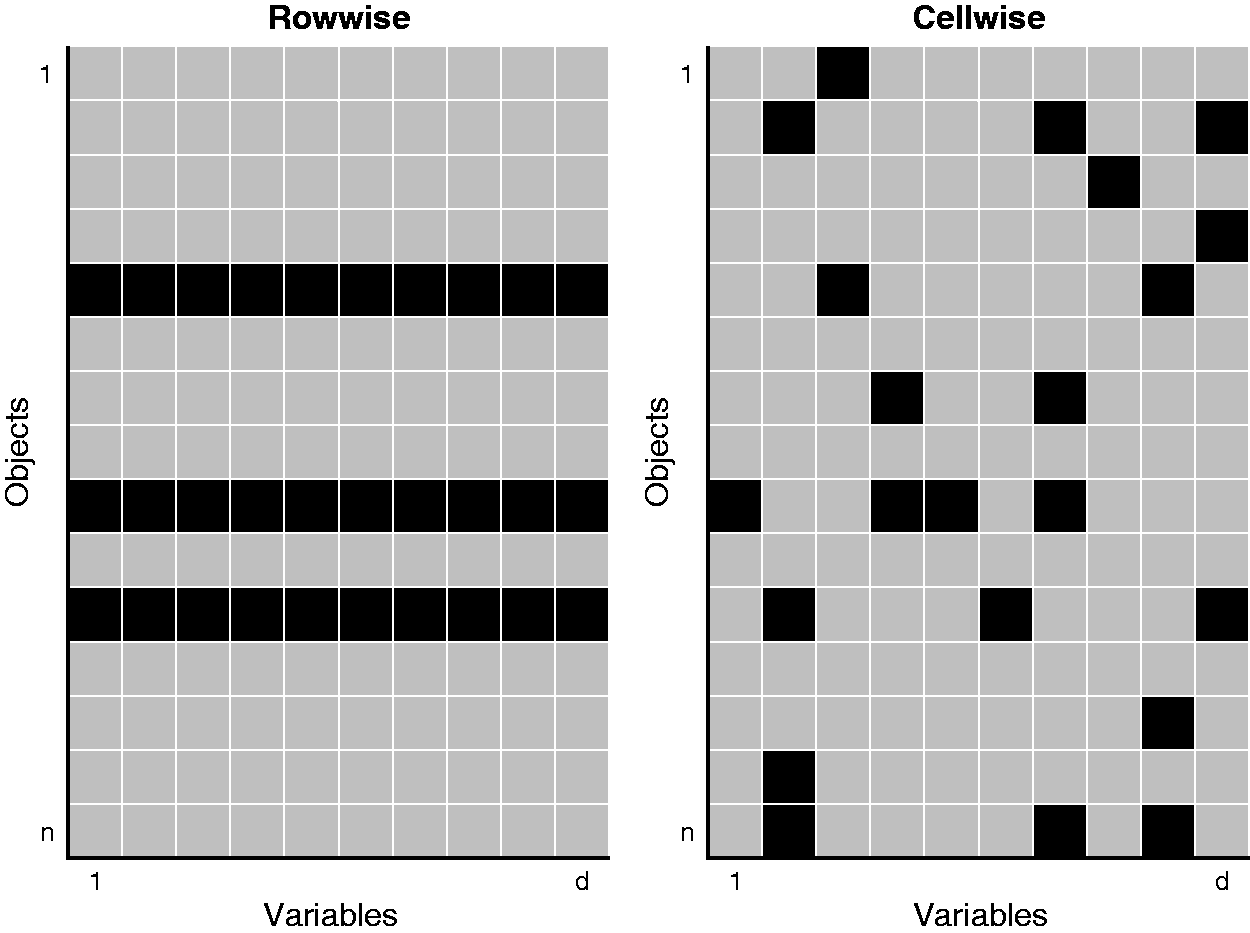
After applying robust sparse logistic regression, we analyze the selected genes (variables) using the DDC method recently proposed by Rousseeuw and Van den Bossche 15 as a second step. This will provide us with additional insight in the role of the selected genes and the nature of flagged outliers.
The DDC procedure uses bivariate correlations between the different variables. It then computes a predicted value for each cell, based on the values of other cells in the same row. Next, it compares the predicted and observed value of each cell. When this robustly standardized difference exceeds a certain cutoff, the cell is flagged. Cells for which the observed value is much lower than the imputed value are colored blue. When the observed value is much higher than the imputed value, the cell is colored red.
4 Results and discussion
We analyzed the TNBC data set using both the sparse logistic and the robust sparse logistic procedures discussed above. In both instances, the parameters α and λ were selected using fivefold cross-validation evaluating the mean of the deviances in the fold. To eliminate randomness in the selection of the folds, the cross-validation was averaged over 10 runs. For the robust sparse logistic regression method, the parameter h was selected as
Summary of the fitted models for the robust and non-robust sparse logistic regression methods.
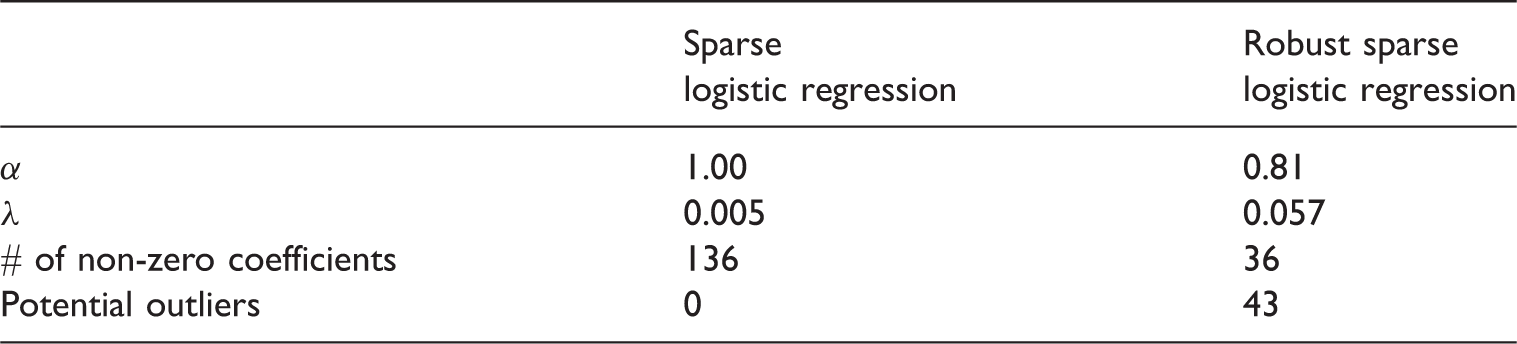
The results in Table 1 show that the cross-validation leads to different parameter choices for α and λ between the robust and non-robust sparse logistic regression method. The classical method selects roughly four times as many coefficients (genes) as the robust method. Moreover, only three of the 136 genes selected by the classical method are also selected by the robust method, namely ER, HER2, and PPP1R14C. While the non-robust method fails to identify outlying observations, due to the masking effect described in the Introduction, the robust procedure indicates 43 observations as potential outliers, 12 in common with the set of 24 outliers identified by ensemble outlier detection technique in the study of Lopes et al. 38 It is important to note that all 43 outliers flagged by the robust method are marked as non-TNBC patients in the data, but are predicted to be TNBC according to the fitted model. If indeed true, these patients would receive ineffective, costly, and potentially toxic therapies. It is therefore important to detect all such cases.
The observed differences between the classical sparse logistic regression and its robust counterpart are in concordance with the simulation study performed by Kurnaz et al. 31 They compared the performance of both estimators using clean and contaminated simulated data by several performance measures including the false positive rate (or the proportion of non-informative variables that are incorrectly included in the model) and the false negative rate (or the proportion of informative variables that are incorrectly excluded from the model). Their results indicate that for contaminated data classical sparse logistic regression suffers from a high false negative rate up to almost a 90%. This means that most of the informative variables are excluded from the selection. The number of potential outliers found by the robust procedure provides a strong indication that we are in such a contaminated data case. This explains why there is only a small overlap between the selected genes by the two methods. To compensate for leaving out these informative genes, a larger set of less informative genes is picked up by the classical method. For a more detailed discussion, see Kurnaz et al. 31
As neither model selects the variables age and race, the 95 observations that were initially left out of the analysis due to missing values for either of these variables may be used for out-of-sample testing. The prediction of TNBC occurrence does not match with the data in 4 out of 95 cases for the classical method and in 6 of the 95 cases for the robust method. These observations may be considered to be discordant cases for which two are predicted differently from the observed response by both the classical and robust procedure. Correspondingly, from the four discordant cases by the classical method, two are only discordant for the classical method, whilst for the robust procedure four out of six cases are only discordant for the robust procedure. Both methods find two additional outliers in the test set corresponding to patients who were attributed a non-TNBC status in the data. From the six cases who did not match according to the robust method, two were borderline cases with a predicted TNBC probability of 0.53 and 0.57, respectively. Even though the robust model selects only a handful of genes compared to the classical method, its out of sample performance is comparable to traditional methods.
4.1 Detailed discussion of identified outliers
Summary of the 43 individuals identified as outliers by robust sparse logistic regression regarding ER, PR, and HER2 gene expression and corresponding clinical label (within parentheses).
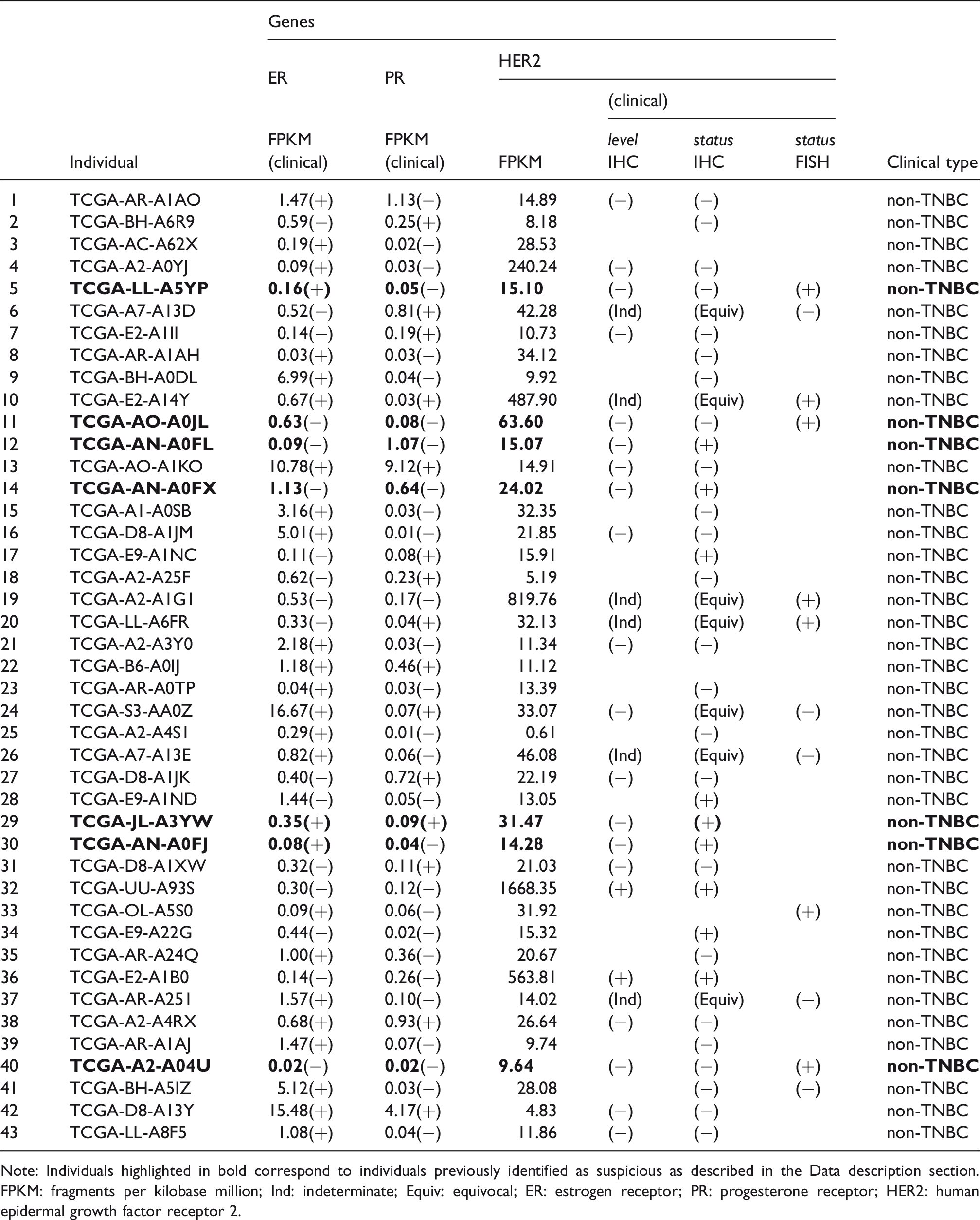
Note: Individuals highlighted in bold correspond to individuals previously identified as suspicious as described in the Data description section. FPKM: fragments per kilobase million; Ind: indeterminate; Equiv: equivocal; ER: estrogen receptor; PR: progesterone receptor; HER2: human epidermal growth factor receptor 2.
All observations flagged as outliers are originally labeled as non-TNBC individuals, based on ER and/or PR expression, and/or HER2 amplification. From the list of 43 outliers detected, 7 belonged to the group of 28 observations that were previously identified as suspect, i.e. individuals for whom there is no concordance between lab methods for the HER2 determination (see section 2). This is particularly critical for individuals ER and PR “negative” and for which the HER2 label determines the final TNBC vs. non-TNBC label, like for example individuals 12, 34, and 40.
Several inconsistencies between clinical labeling and gene expression can be also observed for ER and PR. An ER expression value of 0.03, for example, has corresponding positive label for individual 8, while an ER value of 0.63 is translated into a negative label for individual 11. Regarding PR labeling, the same PR expression value of 0.03 corresponds to a negative label for individual 8 and to a positive label for individual 10. Similarly, individual 2 with a PR expression value of 0.25 has a positive PR label, while individual 36 with a PR expression value of 0.26 has a negative PR label. This can be justified by the fact that the clinical threshold for ER and PR positivity is >1% of positive cells within the tumor. Not only IHC scoring has inherent subjectivity, but also receptors positivity can be achieved at very different levels of gene expression. The same happens for HER2. Individual 5 was labeled negative with an HER2 expression value of 15.1, and for the same expression value individual 12 was labeled as HER2 positive. Wrong labeling in one or more variables clearly impacts final labeling of individuals into TNBC and non-TNBC, with serious consequences in clinical decision and prognosis.
For other individuals, however, the outlyingness cannot be explained by mislabeling of the three TNBC-associated gene expressions, as they seem to have concordant gene expression and label (see e.g. individuals 32, 36, and 42). This suggests that these individuals are correctly classified but might exhibit abnormal expression values for some of the measured genes.
4.2 Discussion of selected genes with relation to outlier identification
To gain more insight, we ran the DDC algorithm on the 36 selected genes only, without telling DDC anything about the clinical response variable or which rows were flagged as outliers. The result is a cell map with over 1000 rows, which is hard to visualize. Therefore, Figure 2 instead shows (from top to bottom) the first 30 non-TNBC patients, 30 TNBC patients, and the 43 outliers found by the robust logistic fit. The indices of the outliers correspond to the row numbers in Table 2. A blue cell in Figure 2 indicates an unexpectedly low gene expression value whereas a red cell indicates an unexpectedly high value, relative to the other cells in its row and using the correlations between the columns. We see that the overall pattern detected by the DDC algorithm for the patients flagged as potential outliers (all originally labeled as non-TNBC) matches the pattern observed for the TNBC patients. This is a very strong indication that indeed these patients have an erroneous label in the data.
Cellwise outlier map. The columns correspond to the genes selected by the robust sparse logistic model. The rows correspond to 30 non-TNBC patients (label nT), 30 TNBC patients (label T), and the 43 outliers found by the robust fit.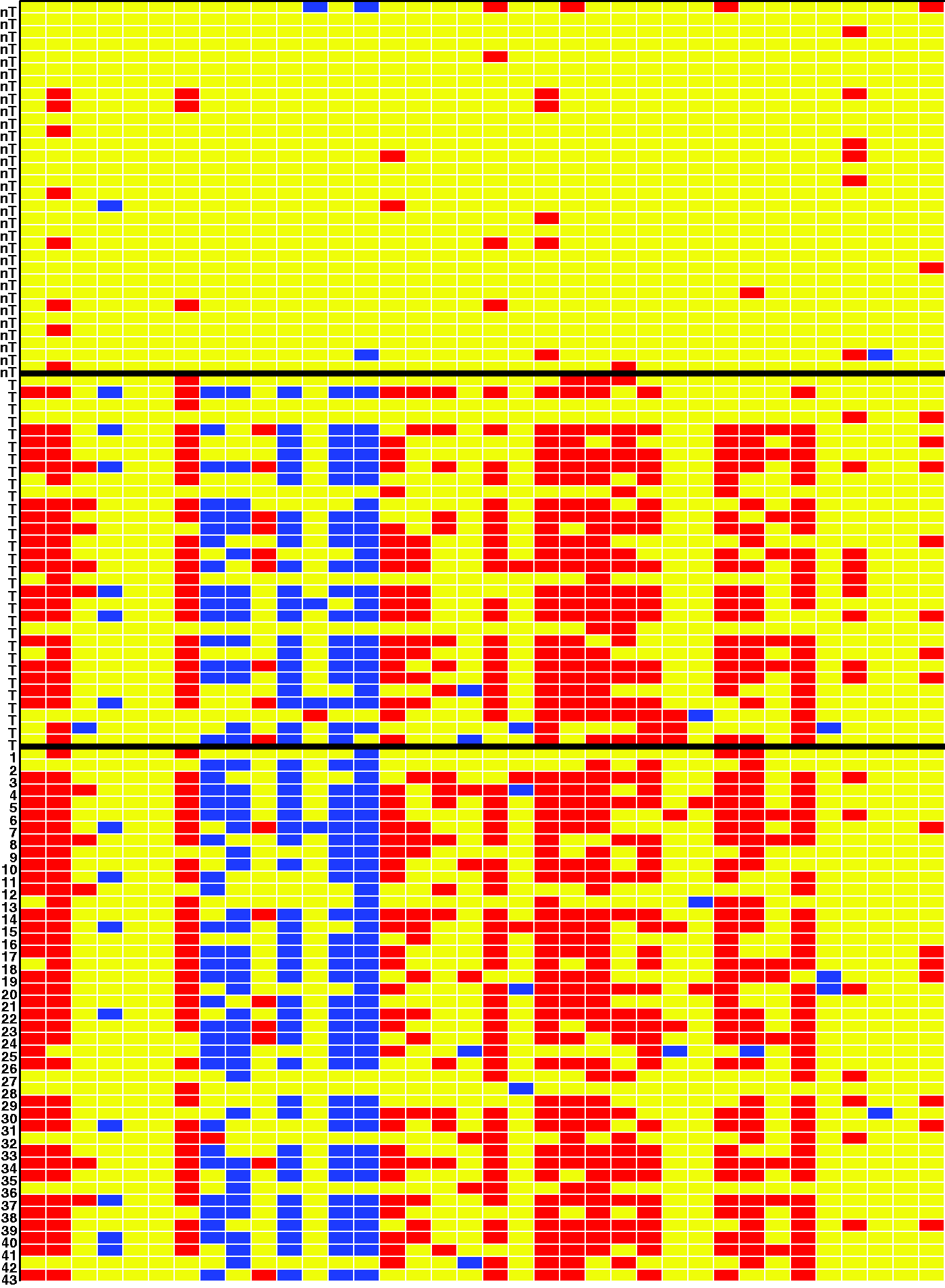
Genes for which most of the cells of the TNBC patients are colored are of particular interest. Additional evidence for their role in classifying TNBC patients is provided by the sign and size of their coefficients in the robust sparse logistic model. Figure 3 depicts the coefficient in the robust sparse logistic model for each of the genes, using the same color coding as in the DDC map. The coefficients of the ER, PR, and HER2 genes have been colored black. We indeed see that the genes standing out in the DDC map are mostly those genes with higher coefficients, in absolute value, in the model. The red-colored genes turn out to get positive coefficients, the blue genes get negative coefficients, and the yellow ones get coefficients closer to zero. The selected genes may thus be of particular biological and medical interest for the understanding and diagnosis of TNBC.
Interpretation of genes selected in the robust sparse logistic model. The color coding corresponds to the color determined by the DDC map.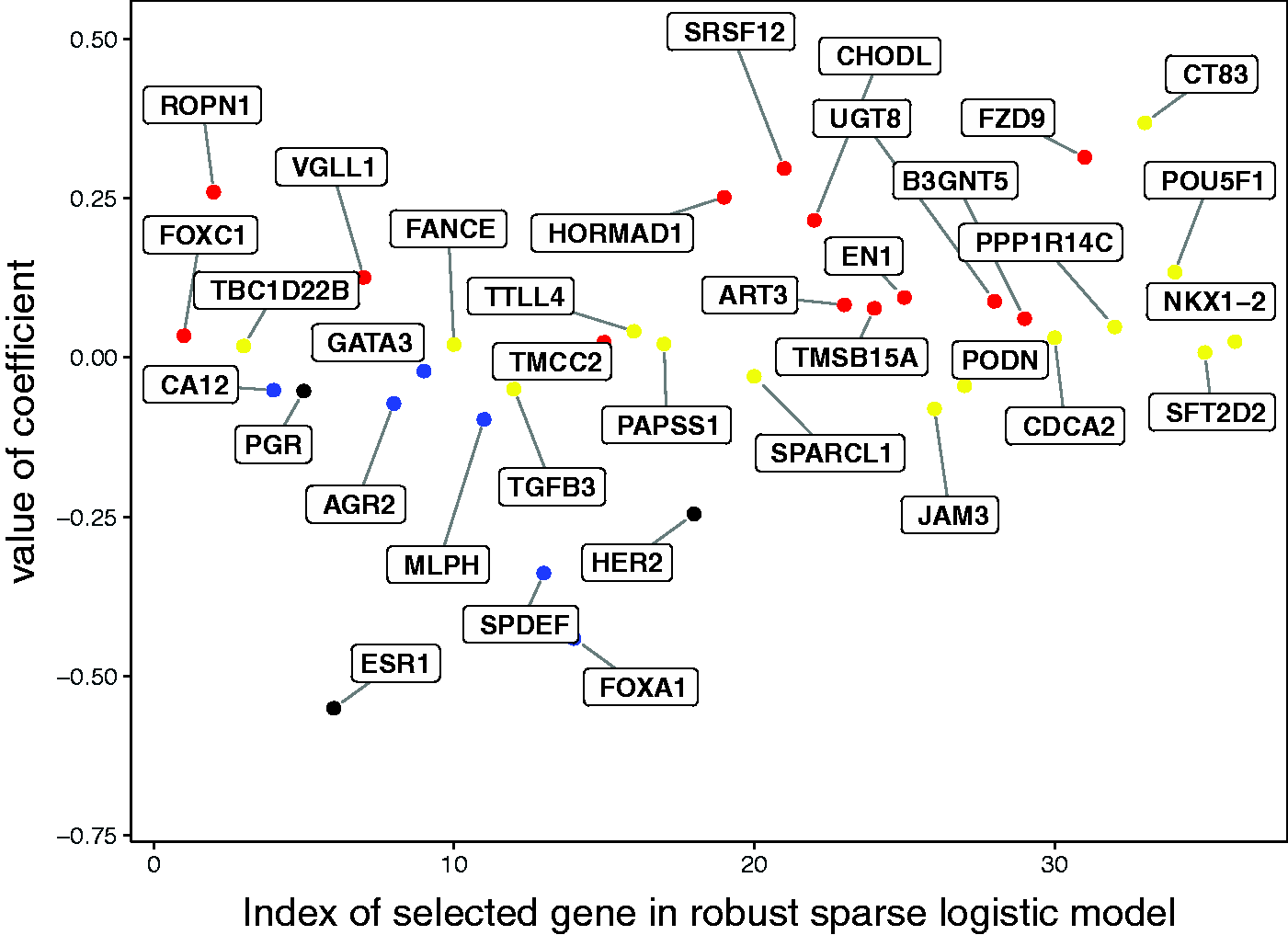
Genes selected by the robust sparse logistic method, corresponding coefficients (rounded to 3 digits) and their color coding.
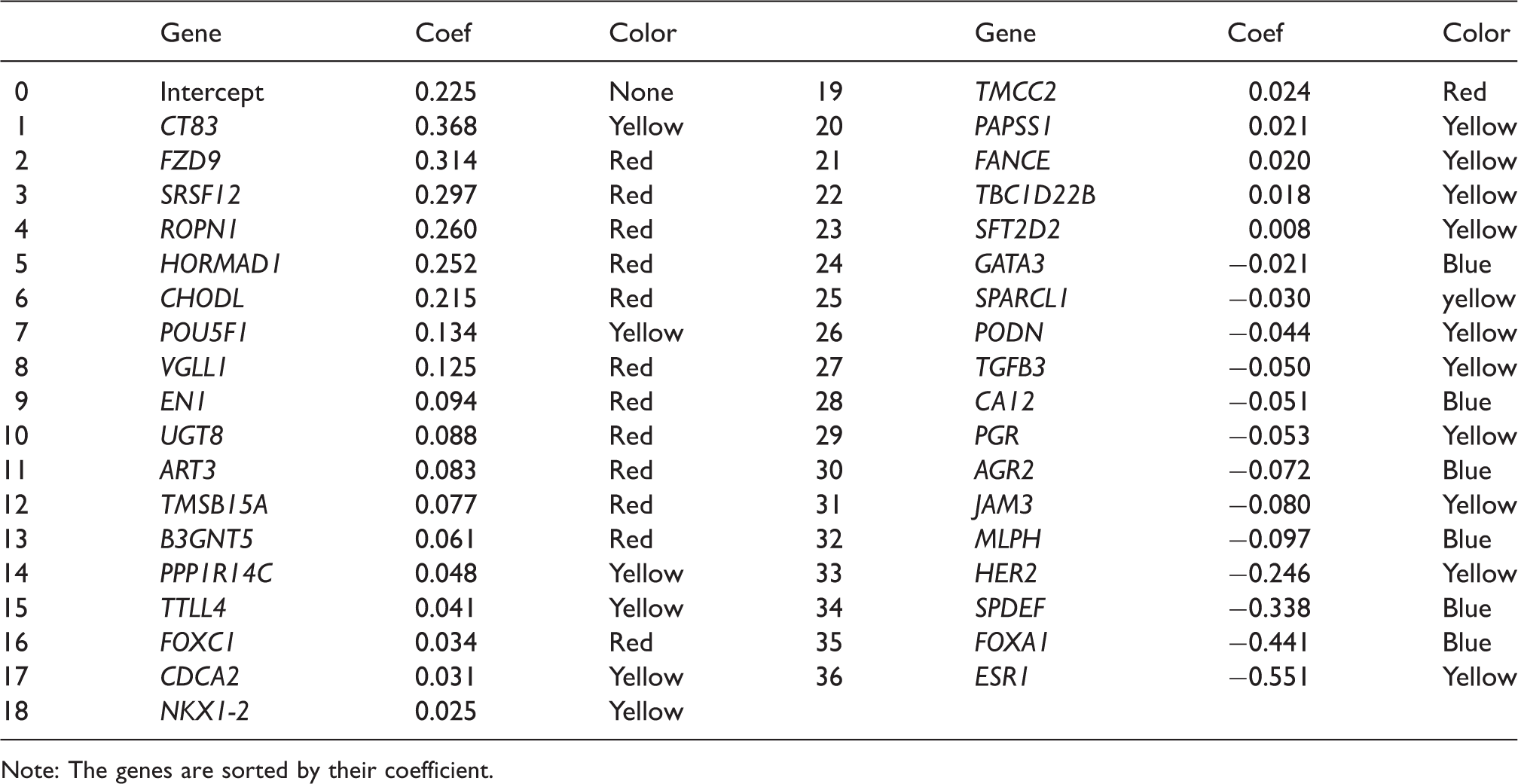
Note: The genes are sorted by their coefficient.
4.3 Biological interpretation of selected genes and correlation structures
Among the 36 genes listed in Figure 3, 13 (36.1%) were down-regulated in TNBC and 23 (63.9%) were up-regulated. The majority of genes found to be down-regulated in TNBC (11/13) were previously reported to be down-regulated in this particular subtype of BC or overexpressed in ER+/HER2+ breast tumors. These include ESR1, PGR, and HER2, but also AGR2, 39 CA12, 40 FOXA1, 41 GATA3,42,43 MLPH,44,45 SPDEF, 46 SPARCL1, 47 and TGFB3. 48 Also 11 of the 23 genes up-regulated in TNBC were previously described as such, namely ART3, 49 B3GNT5, 50 EN1,51,52 FOXC1, 53 FZD9, 54 HORMAD1, 55 POU5F1, 56 ROPN1, 57 TMSB15A, 58 UGT8, 59 and VGLL160.
Our analysis has led to the identification of 14 genes that were not previously reported as specifically involved in TNBC or (breast) cancer overall, therefore contributing to the search for new interest biomarkers to further validate and functionally study. These include JAM3 and PODN, down-regulated in TNBC; and SFT2D2, CDCA2, CHODL, CT83, FANCE, NKX1-2, PPP1R14C, SRSF12, TBC1D22B, TMCC2, TTLL4, and PAPSS1, up-regulated in TNBC. JAM3 has been previously identified as a biomarker for cervical cancer 61 and was found to be up-regulated and associated with higher cancer risk in the offspring from mice with high-fat diet intake during pregnancy. 62 Amongst the up-regulated genes, SFT2D2 was previously described as down-regulated in a bone (specific) metastasis-related gene set. 63 PAPSS1, involved in estrogen metabolism, was not directly implicated in TNBC before but found to be overexpressed in breast tumor tissues in comparison to adjacent normal tissue, independently of ER status. 64
Finally, we consider a graphical representation of the correlation-based network structure between the selected genes depicted in Figure 4. For clarity, only correlations above 0.6 in absolute value are shown. The thickness of the connecting lines represents the strength of the correlation, whereas green represents a positive correlation and red signals a negative correlation. Figure 4(a) shows the correlation plot for the non-TNBC individuals, whereas Figure 4(b) is the plot for TNBC individuals. The patterns in the left and right panels are strikingly different.
Representation of the correlation between the genes selected by the robust sparse logistic model. The color coding corresponds to the color determined by the DDC map. (a) Correlations for non-TNBC patients. (b) Correlations for TNBC patients.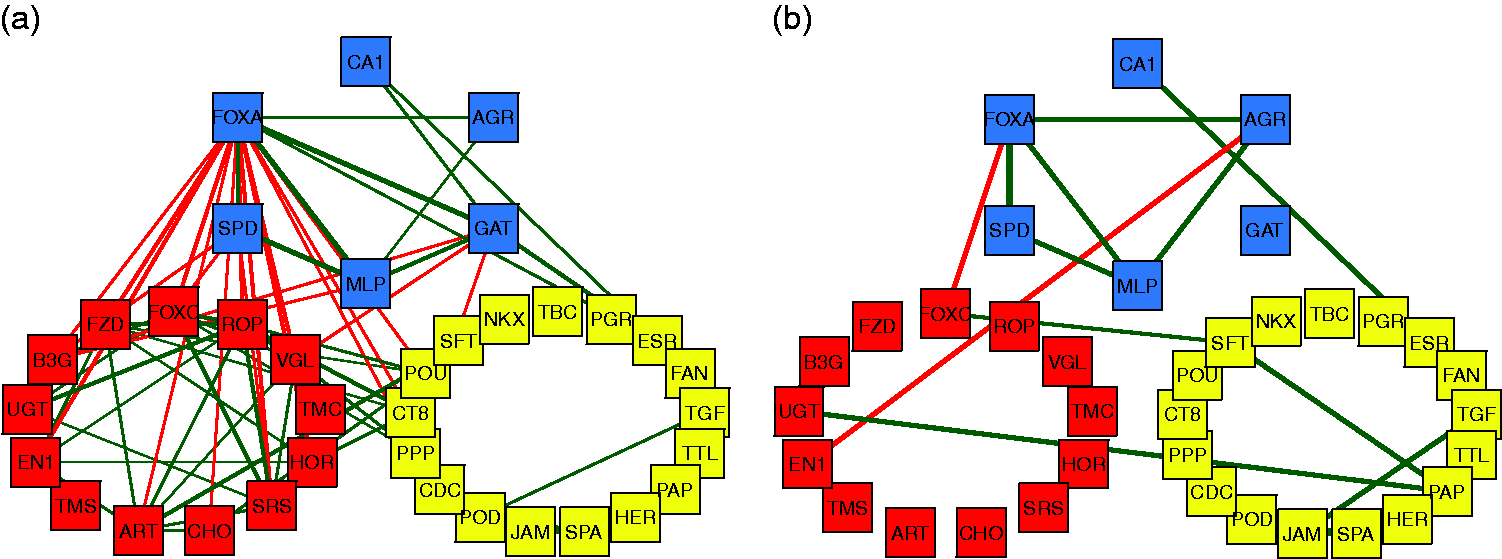
The proto-oncogene AGR2 (anterior gradient homology 2) is among the down-regulated genes in TNBC, and a strong correlation between AGR2 and FOXA1 was found in TNBC. Moreover, AGR2 was correlated with other genes, suggesting a particular relevance for this gene. AGR2 is a known biomarker of poor prognosis in ER+ BC. 65 Accordingly, different studies have reported that expression of the proto-oncogene AGR2 is induced by estrogen and tamoxifen in BC cells, 66 and that AGR2 is required for the growth and migration of ER+ cells. The transcription factor FOXA1 is implicated in the regulation of many ERα-target genes, including AGR2. This justifies the multiple correlations we found between FOXA1 and other genes in non-TNBC. However, in tamoxifen-resistant cells, the expression of AGR2 occurs in a constitutive manner, requiring FOXA1, but loses its dependence on ER, suggesting a mechanism where changes in FOXA1 activity obviate the need for ER in the regulation of this gene. 67 It is hypothesized that AGR2 may be involved in the folding of the extracellular domains of proteins that influence cell growth and survival, and that AGR2 may represent an important biomarker and therapeutic target in BC. 68 It thus appears that the FOXA1–AGR2 link in TNBC may be of particular relevance and deserves further study.
The fact that the biological role in TNBC of approximately 60% of the selected genes has been previously reported strengthens our analysis and fosters investigation on the potential role of the remaining selected genes in BC and in particular TNBC.
5 Conclusion
This work shows that robust sparse logistic regression can be a powerful tool in precision medicine. It enables accurate prediction of the BC subtype, irrespective of the possible presence of outliers situated in either the clinical label or in the gene expression data. In contrast, classical sparse logistic regression methods are severely affected by the outliers in the data. At the same time, robust methodology allows to inspect the detected outliers which may lead to the correct status of the patient and the prescription of the appropriate treatment. Due to the sparse nature of this robust regression, genes included in the model may be highly relevant to the understanding of TNBC. While 60% of the selected genes were previously reported to be related to TNBC or BC, the remaining identified genes deserve further attention as potential biomarkers for the disease. Among the selected genes, biologically relevant gene networks could be identified both for TNBC and non-TNBC patient data, particularly the strong FOXA1–AGR2 link in TNBC. These results are intended to contribute to BC/TNBC understanding, the definition of new therapies and ultimately more effective TNBC management.
Footnotes
Acknowledgments
The authors thank André Veríssimo and Eunice Carrasquinha for insightful discussions during problem identification and data processing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the International Funds KU Leuven (grant C16/15/068); the European Union Horizon 2020 research and innovation program (grant no. 633974 (SOUND project)), and the Portuguese Foundation for Science & Technology (FCT), through projects UID/EMS/50022/2013 (IDMEC, LAETA), UID/CEC/50021/2013 (INESC-ID), PTDC/EMS-SIS/0642/2014, and IF/00653/2012. The computational resources and services used in this work were provided by the VSC (Flemish Supercomputer Center), funded by the Flemish Research Foundation (FWO) and the Flemish Government, department EWI.