
Abstract
Improving the quality of care that patients receive is a major focus of clinical research, particularly in the setting of cardiovascular hospitalization. Quality improvement studies seek to estimate and visualize the degree of variability in dichotomous treatment patterns and outcomes across different providers, whereby naive techniques either over-estimate or under-estimate the actual degree of variation. Various statistical methods have been proposed for similar applications including (1) the Gaussian hierarchical model, (2) the semi-parametric Bayesian hierarchical model with a Dirichlet process prior and (3) the non-parametric empirical Bayes approach of smoothing by roughening. Alternatively, we propose that a recently developed method for density estimation in the presence of measurement error, moment-adjusted imputation, can be adapted for this problem. The methods are compared by an extensive simulation study. In the present context, we find that the Bayesian methods are sensitive to the choice of prior and tuning parameters, whereas moment-adjusted imputation performs well with modest sample size requirements. The alternative approaches are applied to identify disparities in the receipt of early physician follow-up after myocardial infarction across 225 hospitals in the CRUSADE registry.
Keywords
1 Introduction
Clinical studies frequently seek to improve the quality of care provided to patients by identifying discrepancies between providers. Provider units may be individual physicians, clinics, or hospitals. The first step is to establish that systematic variation exists and is of sufficient magnitude to justify a detailed investigation. Wide variation in outcomes supports the hypothesis that institutional factors play a role in affecting outcomes. Variation in treatment patterns suggests that the quality of care may be improved by identifying the practices of best performing institutions and adopting them widely. If the discrepancies between providers are small, improvement in quality will most likely come from new developments in care, rather than existing models. Consequently, recent publications emphasize conclusions about the magnitude in variation across providers: “the degree of variability in clinical practice we observed represents a potential quality improvement opportunity”; 1 “in-hospital major bleeding rates varied widely across hospitals”; 2 and “ICU admission rates for heart failure (HF) varied markedly across hospitals”. 3
These data arise hierarchically, with a sample of providers, and within them, a sample of patients who experience a binary treatment or outcome. The goal is to quantify variation at the provider level in the proportion of patients who experience the outcome. Such data are commonly modeled by hierarchical logistic regression with a Gaussian random effect for provider whereby the provider-level variance can be estimated. This variance, measured on the log-odds scale, has limited the clinical interpretability, and the investigators prefer to visualize the variation in provider probabilities on an absolute scale. Therefore, numerous examples in the cardiovascular literature include a histogram of provider-specific sample proportions.3–5 For example, Hess et al.
5
sought to identify disparities in the receipt of early follow-up (within seven days) with a physician after myocardial infarction. Across 225 hospitals enrolled in the CRUSADE registry, the hospital-specific sample proportions of early follow-up ranged from 2.6% to 51.6% (interquartile (IQR) range: 17.7%–29.1%). Such observed variation in sample proportions is predictably larger than underlying variation in provider probabilities, as each sample proportion is subject to sampling error. To address this, the authors followed a common convention of excluding sites with less than 25 patients.3–5 The convention is not sufficient. As an illustration, Figure 1(a) shows a hypothetical distribution of proportions from 225 hospitals in which the probability of receiving treatment is randomly generated and ranges between 20% to 33%, with an interquartile range of 3%. Figure 1(b) shows raw proportions that are observed if patient outcomes are sampled from these hospitals, with the number of patients-per-hospital randomly selected from the observed hospital sizes in the CRUSADE registry. As can be seen by comparing Figure 1(a) and (b), the raw proportions overstate the variation by nearly three-fold.
Comparison of distributions across providers. (a) Simulated distribution of true proportions from 225 hypothetical hospitals in which the true probability of receiving treatment ranges between 20 to 33%. (b) Simulated distribution of hospital-specific sample proportions, from the same hospitals, where the number of patients-per-hospital is randomly selected from the observed hospital sizes in the CRUSADE registry.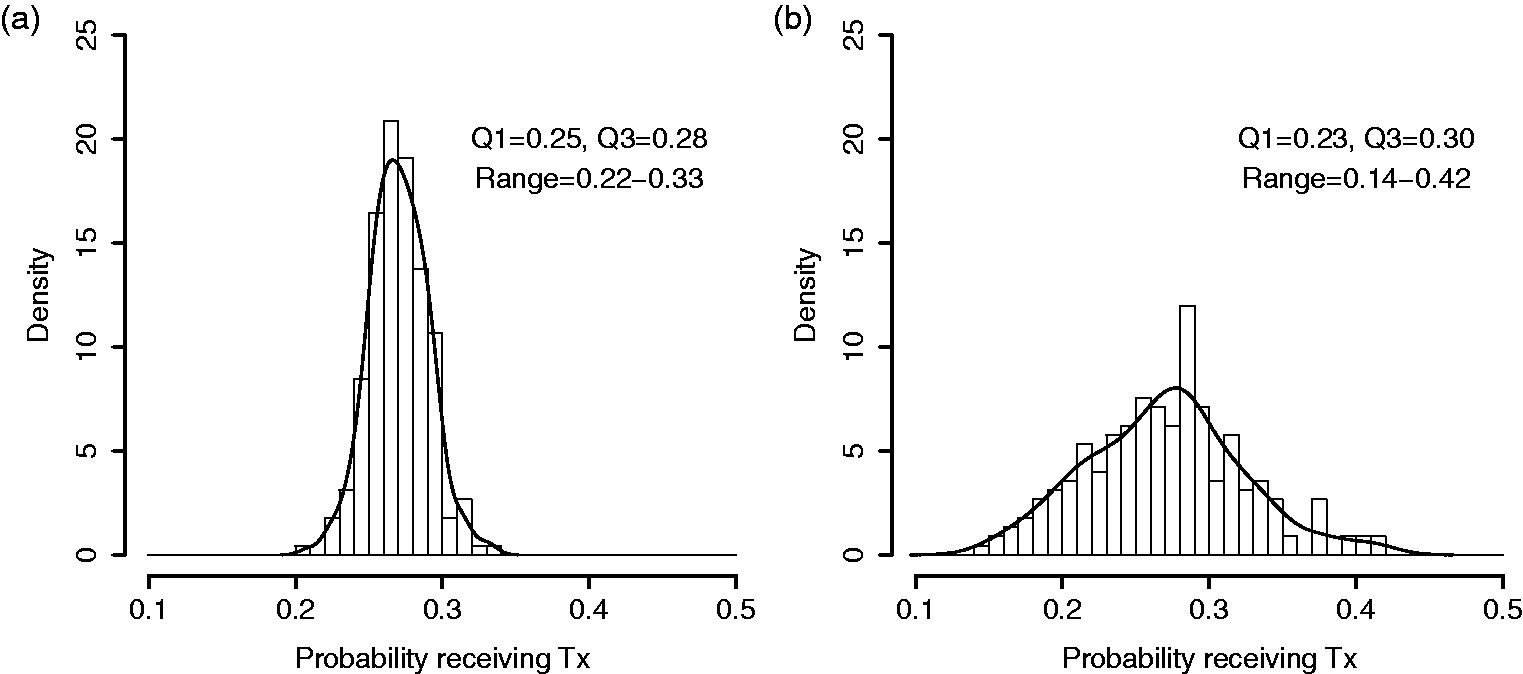
There is a large body of literature on methods for hospital monitoring and profiling,6,7 including recent recommendations from a panel of experts commissioned by the Committee of Presidents of Statistical Societies. 8 These sources review, in detail, the alternative methods for profiling individual hospitals. Hierarchical models and shrinkage estimators are advocated as a strategy to remove the excessive sampling error in estimates for small sites and are widely used in the medical literature.6–8 However, the objective of making predictions for individual sites differs from the specific goal of estimating the magnitude of variation across sites. For the latter objective, estimating potentially hundreds of nuisance parameters (the performance of each hospital) and then pulling them back together to form a distribution results in more error than is necessary, in the form of either over-dispersion (exhibited in the raw proportions above) or shrinkage toward the mean. Although provider-specific sample proportions are over-dispersed, the distribution of shrinkage estimators is too narrow relative to the distribution of true provider performance.8–10
The fact that naive methods remain common in provider-variation studies may reflect that (1) the magnitude of the problem is not well appreciated and (2) the relative advantages and/or limitations of alternative methods are not clear in this context. Although several approaches for estimating and illustrating cluster-level variability in hierarchical data have been proposed, prior studies have focused on different targets of inference,11,12 continuous outcomes,11,13–16 or large cluster sizes.12,13
We consider three existing methods for binary outcomes: (1) Gaussian hierarchical models (GHM), (2) Bayesian semi-parametric beta-binomial model with a Dirichlet process (DP) prior, 17 and (3) non-parametric empirical Bayes (EB), smoothing by roughening (SBR). 13 Alternatively, we propose that a recently developed method for density estimation in the presence of measurement error, moment-adjusted imputation (MAI), can be adapted for this problem. 18 In Section 2, we describe the methods under consideration. In Section 3, the methods are evaluated by simulation across a range of conditions that are motivated by clinical examples. Finally, the methods are applied and interpreted in the CRUSADE example of early physician follow-up.
2 Methods
For clarity of exposition, suppose we are interested in studying treatment variation across hospitals. Other binomial outcomes of clusters could easily be substituted. Let

The hospital-specific parameter pi comes from a population distribution, Fp, that depends on parameters
As noted by Paddock and Louis,
19
there are applications where the observed N hospitals constitute the full population of interest. In that case, one is interested in the finite probabilities
2.1 Raw proportions
As described above, a standard approach to this problem is to obtain sample proportions for each hospital as
2.2 Gaussian hierarchical model
The generic two-stage model for Yi is provided in Equation (1). Here, we focus on the Gaussian, logistic model by adding parametric assumptions. The model assumes:

For the current application, we are not interested in the individual pi, but in describing their distribution. Given that logit(p) is assumed to follow a normal distribution, Normal
Clearly,
2.3 Semi-parametric Bayesian density estimation
Bayesian methods offer flexibility in the specification of hierarchical models and density estimation. Rather than specifying a parametric prior distribution for cluster-specific probabilities, the Dirichlet process (DP) prior has been widely used for parametric mixture modeling.11,12,14,15,17,23 Numerous options and software are reviewed by Jara et al.
23
The DPs mixture can approximate many smooth distributions by estimating the number of mixture components according to the data. One such model, based on the methods of Escobar and West
14
and Liu,
17
is implemented by the DPbetabinom function in R DPpackage.
23
The function fits a semi-parametric version of the beta-binomial model
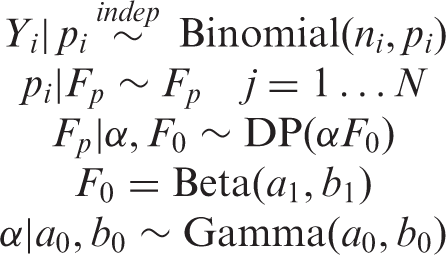
For this study, we assume
In preliminary studies, we evaluated potential values for the hyper-parameters a0 and b0 or the prior parameter α (removing the hyper-prior). Plausible values for α range from
2.4 Smoothing by roughening
Rather than specifying a parametric prior distribution for the provider-specific parameters, Laird24,25 developed a non-parametric maximum likelihood (NPML) estimator of the prior, Fp. Despite numerous advantages, this approach yields discrete priors with too narrow support and under-dispersion,
13
motivating the adaptation of a non-parametric EB alternative called “smoothing by roughening” (SBR).13,26 The process starts with a smooth prior distribution, that is not necessarily correct, and uses the EM algorithm to update it in the direction of the NPML. Fewer iterations results in a more smooth distribution, while increasing iterations are successively closer to the NPML. To speed up computation, the initial smooth density is discretized at a large number of mass points
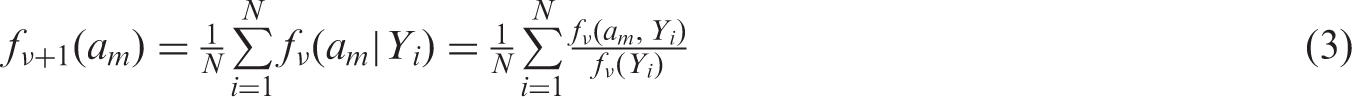

When iterated to convergence, the SBR algorithm produces the NPML estimate; however, the goal of SBR is to produce a smooth distribution by the selection of finite νN. The appropriate choice of νN is unclear, though Shen and Louis
13
provide some guidance. They suggest that “There is no need to be too strict on the exact value of νN, as long as for large N, νN is of order log N, … For small or moderate samples, we recommend
2.5 Moment-adjusted imputation
By viewing this as a measurement error problem, additional options become available. Thomas et al.
18
introduced moment-adjusted imputation (MAI) which replaces mis-measured data, W, with estimators that have asymptotically the same distribution as a latent variable of interest, X, up to some finite number of moments. They show that MAI is related to other measurement error methods but has superior performance in many settings. MAI is applicable whenever the error in W is due to added noise; Wi = Xi + Ui, where Ui is normally distributed random error with mean 0 and variance
The details of MAI have been described previously, with application to a broad variety of problems.
18
Here, we review a special case of MAI that is applicable to the current focus on cluster-specific proportions. For the clarity of exposition, we use general MAI notation in this section and refer to X and W. The objective is to construct-adjusted versions of the Wi, say
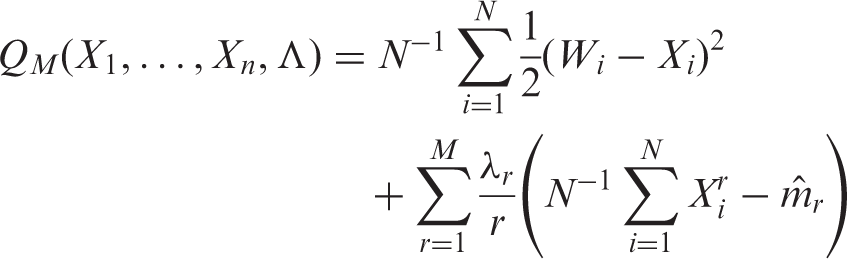
The adjusted data are obtained by taking the derivative of QM with respect to
For the current application, MAI can be applied directly to the “mis-measured”
Thomas et al. 18 provide an extensive simulation study of MAI, with application to kernel density estimation. They recommend matching an even number of moments (two or four). When p has a normal distribution, it is adequate to match two moments, when p has a Chi-square or bi-modal distribution, it is necessary to match four moments in order to capture unique features. The tradeoff between matching two versus four moments is a bias-variance tradeoff. Higher order moments are estimated with less precision, and MAI uses estimated moments. Matching higher moments reduces bias but adds variation. Thomas et al. 18 show that matching four moments strikes a good balance in many reasonable scenarios. As the advantage of MAI is the flexible handling of non-normal distributions, a general recommendation is to match four moments.
2.6 Small sites
From a subject matter standpoint, excluding hospitals with very few eligible patients is clinically reasonable; researchers do not expect to characterize a hospital based on a handful of patients. The ad hoc convention is to exclude ni < 25. Although this exclusion is insufficient, it can be relaxed when the methods considered here are employed. However, there is a limit to the feasibility of recovering fp when hospital sizes become small. Effectively, the ratio of noise to signal becomes very large; a scenario in which fp cannot be identified without strong parametric assumptions.
27
Thus, we do not expect good performance of non-parametric or semi-parametric methods for the estimation of fp with extremely small hospital sizes. Preliminary simulations indicate that a minimum
3 Simulation studies
In this section, we compare the preceding methods by simulation across a range of conditions, including (1) number of providers N: 100, 300, and 500; (2) number of patients per provider ni: 20, median
3.1 Illustration
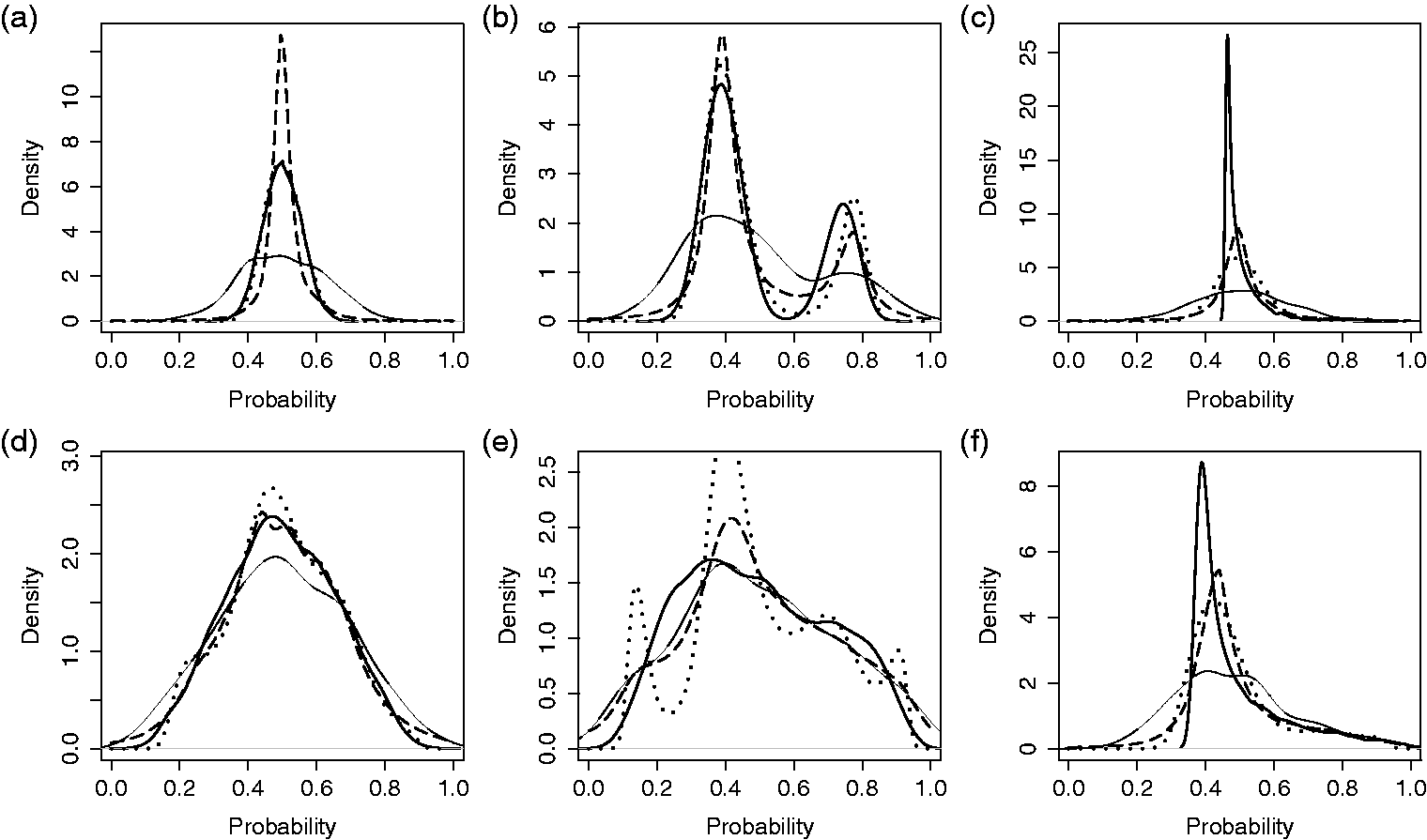
In Figures 2 and 3, the simulation settings are demonstrated along with select results for single simulated data sets. For this illustrative example, we fix the number of providers at 300 and the number of patients per provider at 20. Densities Comparison of methods for estimating the distribution of probabilities across providers. Results from a single, simulated data set for three provider probability distributions and two magnitudes of provider variation: (a-c) small underlying variation, Comparison of methods for estimating the distribution of probabilities across providers. Results from single, simulated data sets with three provider probability distributions and two magnitudes of provider variation: (a-c) small underlying variation, 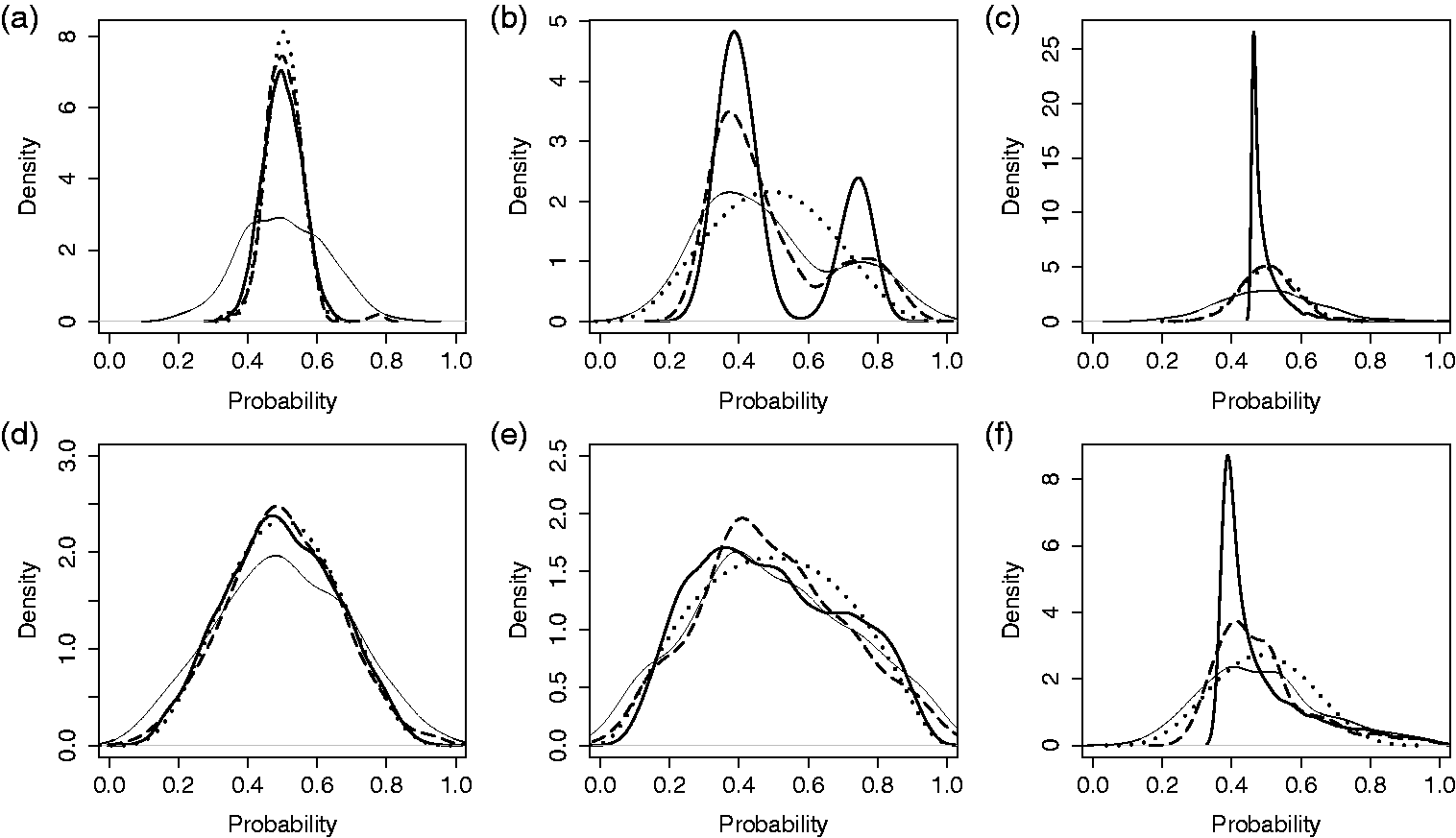
3.2 Monte Carlo simulation
In B = 1000 simulated data sets, a sample of N providers is drawn, with probabilities of outcome generated according to the distributions for logit(p) described above. For each data set and method, we obtain estimates of Cluster-level variance estimate; averaged over 1000 simulated data sets and plotted on the log scale, as a ratio, relative to the true variance, 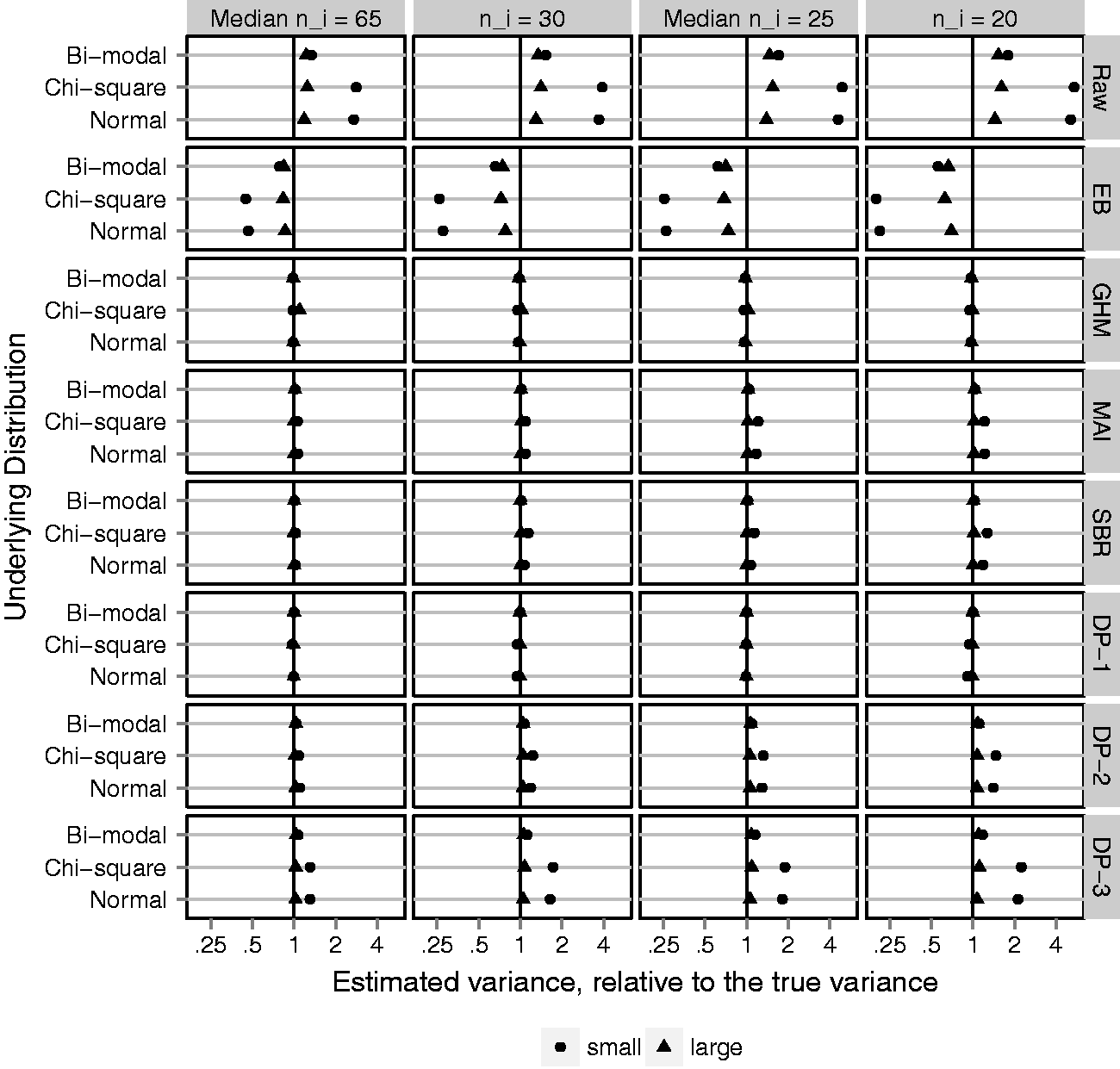
Figure 4 shows the MC average provider-level variance estimates plotted as a ratio, relative to the true variance, on the log scale. The ratio is taken so that different underlying distributions and magnitudes of variance can be plotted on a common scale. Ratios less than 1 reflect estimators that under-estimate the variance, whereas ratios greater than 1 reflect estimators that over-estimate the variance. The log scale is used so that a 50% under-estimate is the same distance from 1 as a 200% over-estimate. Figure 4 shows that the naive method, based on raw proportions, substantially over-estimates the variance. As expected, the Gaussian EB predictions are just as bad, in the opposite direction. The candidate adjustment methods, GHM, MAI, SBR, and DP-1, are almost perfectly unbiased. Of note, the GHM variance estimator is unbiased even when the underlying distribution is chi-square or bi-modal and the Gaussian assumption is incorrect. However, the Bayesian semi-parametric method is sensitive to the specification of prior parameters; priors DP-2 and DP-3 slightly over-estimated the cluster-specific variance, particularly when the underlying variation is small. Results for the MSE track closely with bias and are reported in online Supplemental Appendix C. Adjustment methods reduced the MSE, relative to raw proportions, by 60% to 99%.
The ED provides a global measure of closeness between the estimated distributions and their target. Figure 5 shows the average over simulated data sets of ED-CDF for each adjustment method, plotted as a percent reduction relative to the average ED-CDF for raw proportions. The goal is to quantify improvement in estimating Fp compared to taking a naive approach. MAI is the only adjustment method that reduces the ED-CDF in all scenarios. As expected, GHM does best when the underlying distribution function is Gaussian, but poorly otherwise. SBR performs similar to MAI, but in a few cases increases the ED-CDF. Investigation of individual data sets (online Supplemental Appendix D) reveals that this can be attributed to SBR identifying too many peaks or multiple modes when the target distribution is smooth. Among the DP methods, DP-2 and DP-3 perform better than DP-1. This makes sense considering that DP-2 and DP-3 favor a smooth distribution, whereas DP-1 identifies too many peaks and modes rather than a smooth distribution (online Supplemental Appendix D). The many peaks have minimal impact on the variance estimate but matter with respect to estimating Fp.
Euclidean distance between estimated distribution functions and the underlying distribution of cluster-level probabilities, Fp (ED-CDF); average over 1000 simulated data sets and plotted on the log scale as a percent reduction relative to the ED-CDF for raw proportions (naive method). Black vertical line represents no difference. Gray vertical lines represent 50% improvement (left) and 200% worse (right). Fixing N = 300 clusters and varying (1) four cluster sizes, ni: 20, mixture with median 25, 30, and mixture with median 65; (2) underlying variation: small and large with Euclidean distance between estimated density function and the underlying distribution of cluster-level probabilities, fp (ED-PDF); average over 1000 simulated data sets and plotted on the log scale as a percent reduction relative to the ED-PDF for raw proportions (naive method). Black vertical line represents no difference. Gray vertical lines represent 50% improvement (left) and 200% worse (right). Fixing N = 300 clusters and varying (1) four cluster sizes, ni: 20, mixture with median 25, 30, and mixture with median 65; (2) underlying variation: small and large with 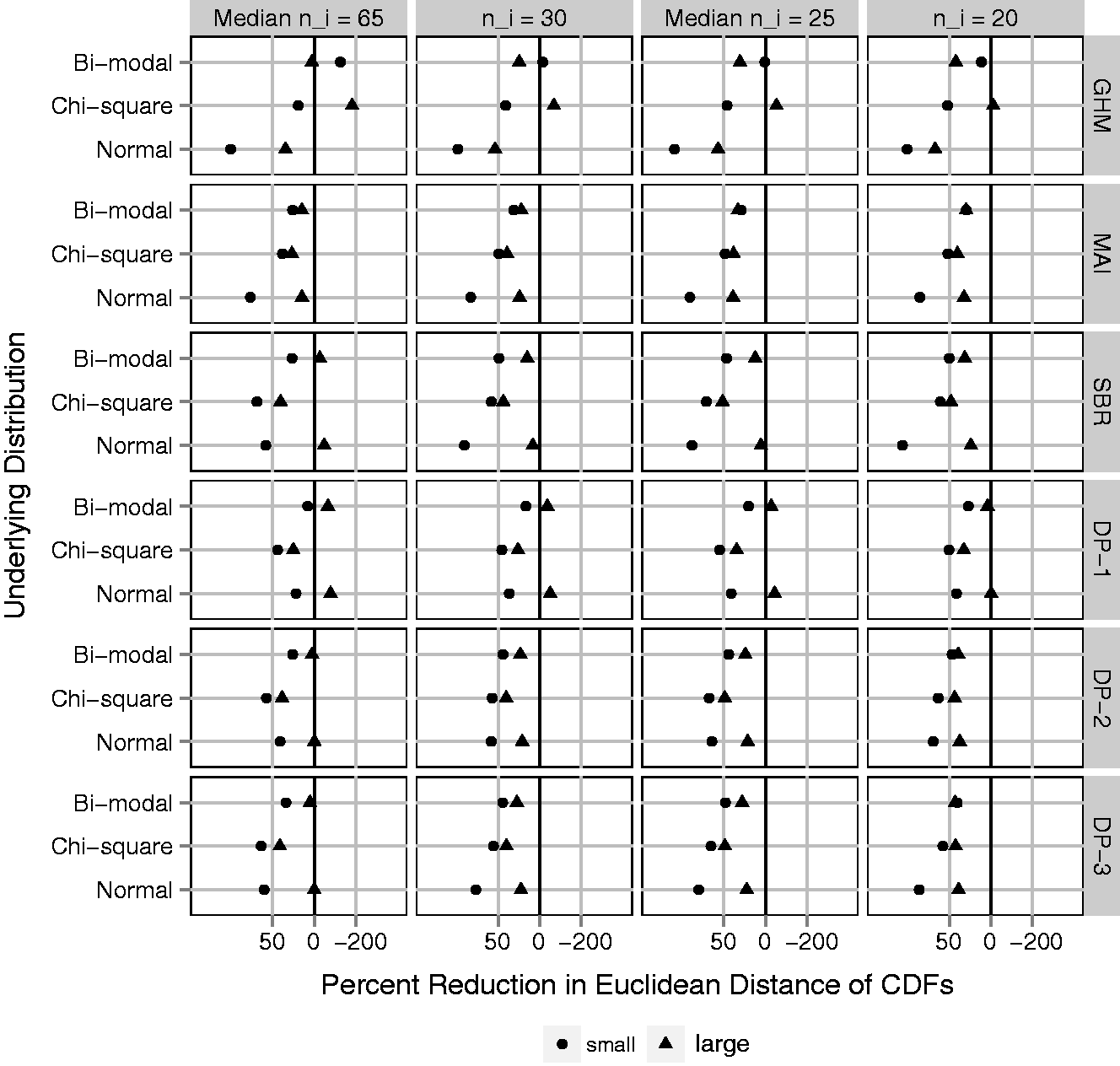
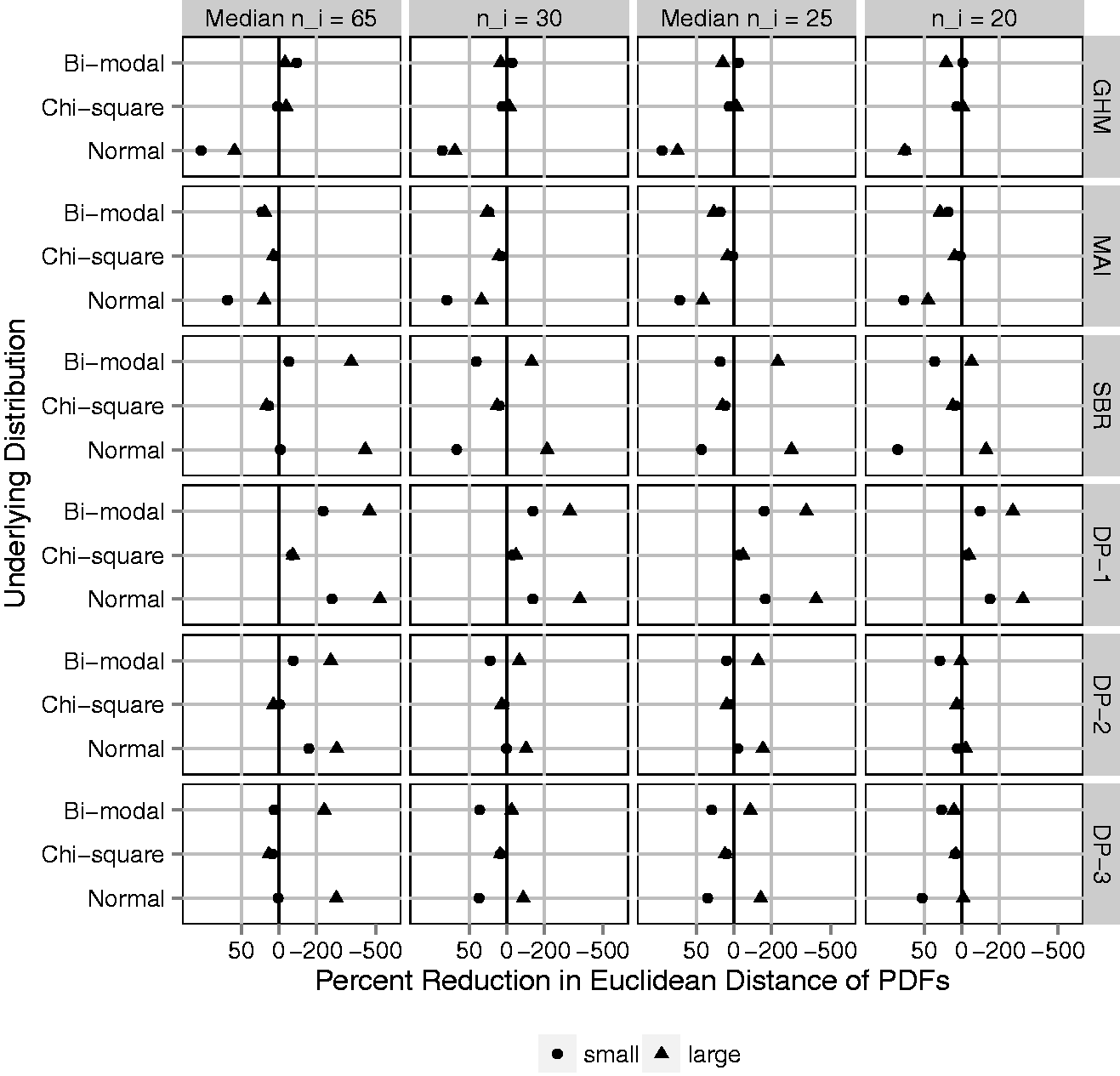
The ED-CDF metric does not tell the full story. Provider variation is frequently illustrated by plotting a density estimate, which may also be of interest. Even if the primary goal focuses on variation, a density estimate with multiple modes or unique skew is likely to attract attention. Therefore, accuracy for density estimation is important. Figure 6 shows the average over simulated data sets of ED-PDF, plotted as a percent reduction relative to the average ED-PDF for raw proportions. On this metric, improving density estimation relative to raw proportions is not guaranteed by any adjustment method. As expected, the GHM provides large improvements only if the underlying distribution is Gaussian. Otherwise it is generally worse. MAI improves the ED-PDF as much as 25% to 75% when the underlying distribution is normal or bi-modal, though very little when the underlying distribution is Chi-square. In online Supplemental Appendix D, MAI produces a rare outlier in the case of small ni and small, chi-square provider variation. The outlier was easily recognizable for having mass on a few discrete points and may have skewed the average performance in this scenario. This never occurred with larger ni (
4 Analysis of early physician follow-up
To demonstrate these methods, we revisit the example of early physician follow-up described in Section 1. Using the raw proportions, calculated within each provider, Hess et al.
5
saw wide variation in early follow-up with a physician after MI (Figure 7(a)). In Figure 1, we re-analyze the CRUSADE data and directly estimate the density of the provider-specific proportion of patients receiving early follow-up using a GHM, MAI, SBR, and DP methods. In Figure 7(c), SBR is displayed for Variation in early follow-up across providers. (a) Density of raw proportions. (b) Estimated densities by GHM and MAI. (c) Estimated densities by SBR. (d) Estimated densities by DP priors. DP: Dirichlet process; GHM: Gaussian hierarchical model; MAI: moment-adjusted imputation; SBR: smoothing by roughening.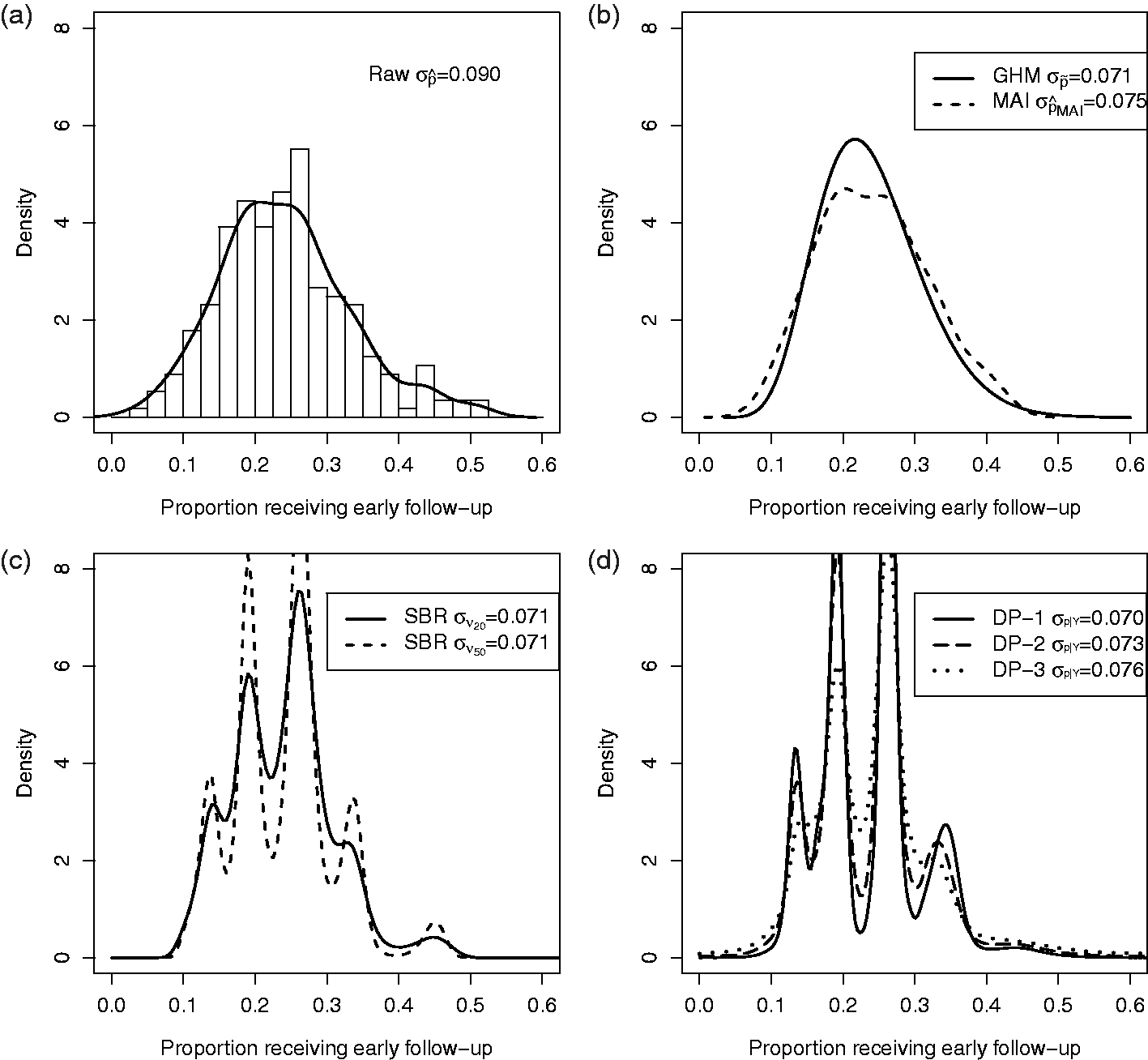
Comparing Figure 7(a) with 7(b) to (d), the standard deviation is smaller when chance variations are removed. The adjusted distributions in Figure 7(b) to (d), have nearly identical spread. Compared to GHM, MAI preserves some unique features of the raw distribution, such as slight bi-modality near the peak, whereas SBR and DP methods create clusters of provider probabilities. Our simulation studies suggest that those clusters may be false and occur even if the underlying distribution of provider probabilities is smooth. Figure 7(b) to (d) conveys the same essential information that the wide variation in the use of early follow-up observed by Hess et al. 5 was largely reflective of real variation.
5 Discussion
When the goal of an analysis is to estimate the magnitude of systematic differences among providers, the random variation associated with observed rates muddies the picture. We illustrate the use of existing methods for this purpose and assess their merits under settings that are representative of hospital variation studies, including smaller cluster sizes than have previously been evaluated. Further, we demonstrate a novel application of MAI. Our results emphasize that each has limitations. The choice of methods should be guided by the priorities of a given study and the available data.
When the goal is to quantify cluster-level variation and flexible density estimation is not a priority, the GHM performs well; its variance is unbiased regardless of whether the underlying distribution is Gaussian. This result does not depend on the number of hospitals, N, or hospital sizes, ni. The GHM is particularly useful if the number of providers is small (
Although DP-1, DP-2, and DP-3 reduce bias in the estimation of provider-level variability, the resulting densities are not accurate. Given that our motivating applications seek to illustrate variability via a density estimate, this method could be misleading. The current analysis is based on a mixture of DPs that has been proposed for the purpose of flexible density estimation and incorporated into software that is apparently straightforward to use.14,17,23 Our specification of hyper-prior parameters is consistent with the previous literature, 15 and DP-1 is similar to fixing α = 1, which is default in the documentation of DPbetabinom(). However, the problems we observe are not easily resolved by modifying the hyper-prior parameters. We explored a large number of hyper-prior parameters prior to focusing on DP-1, DP-2, and DP-3. Alternatives were not superior. Therefore, our results are likely representative of a typical application of this software. This does not implicate all Bayesian methods; a Bayesian analysis with Gaussian prior would be nearly identical to the GHM. However, the Bayesian semi-parametric model based on a DP prior was frequently worse than naive methods at estimating the provider-level density. This method does not appear suitable to hospital variation studies that are similar to the settings we evaluate.
SBR exhibits some of the same problems as DP methods. Even with a large number of hospitals and many patients per hospital, the SBR density estimate is often worse than the naive method, with false multi-modality. Shen and Louis 13 noted that the SBR estimate of Fp behaves similarly to the one based on the DP hyper-prior, depending on the number of iterations νN. SBR converges to the nonparametric maximum likelihood estimator (NPML) as the number of iterations increases. The NMPL has been criticized for being discrete, and frequently under-dispersed. Therefore it is not surprising that SBR would exhibit similar features at some number of iterations. Using fewer iterations of SBR is an option. Smaller νN will create more smoothing and avoid multi-modality. However, the tradeoff, at least with an uninformative prior, is that the results remain over-dispersed. This phenomenon can be seen in Supplemental Appendix E.
These problems observed with DP and SBR methods were not observed in previous studies that focused on continuous outcomes, larger cluster sizes and estimation of CDFs. In these cases, where there is more information in the data, results would not be as sensitive to choice of prior parameters or iterations. In addition, focusing on the CDF (Figure 5) does not emphasize a problem because the ED-CDF (Figure 5) is insensitive to false modes, since it is primarily driven by differences in center and spread. One advantage to SBR is that it is easy to investigate the sensitivity of results to the choice of νN. By saving the output at each step, one can plot the results across a range of νN. If the results were insensitive that might provide an additional level of confidence. In our settings, the results were very sensitive. Therefore, there is a high risk of inaccurate results or the potential to pick and chose among them.
Compared to the DP and SBR methods, MAI does not involve decisions regarding hyper-prior or tuning parameters. MAI does not directly target density estimation but “adjusts” the observed data to have unbiased moments up to a fixed number. However, the choice of how many moments to match is analogous to a tuning parameter. We implemented MAI, as proposed by Thomas et al., 18 by fixing the number of unbiased moments at four (mean, variance, skewness, and kurtosis). If the number of moments matched were increased, the results would vary. For our purpose, MAI may be preferable because the decision regarding moments is easily interpreted and related to the goals. In order to visualize variability across providers, without any strong parametric assumptions, it may be adequate to have unbiased mean, variance, skewness, and kurtosis. Indeed, this approach performed well across a range of scenarios.
There are a variety of opportunities for extensions and future research. For clarity, we have focused on the example of variation in early follow-up across hospitals, but the same issues and methods apply to any binary outcome and across different types of provider-based clusters (site, region, and physician). Occasionally, the goal is to describe variation across providers, after adjusting for patient characteristics. It is relatively simple to adapt MAI to allow for case-mix adjusted rates, as MAI starts with a set of noisy estimates (potentially adjusted) and removes the noise. However, there are a lot of ways in which adjustment can be defined in terms of the target of inference. This is more complicated because the variation in proportions depends on the mean; different methods of adjustment that alter the center of the distribution may target different variance parameters. In addition, one might consider whether fixed provider-level information could be used to augment the adjustment process. Provider volume, for example, is often of interest. MAI was developed to target the joint distribution of multiple variables including mis-measured and error-free variables. Moments and cross-products can be targeted to achieve this end. MAI could be adapted to remove measurement error in a volume-specific way; preserving the joint distribution between site-specific performance and volume. These extensions are an important avenue for future research.
Quality improvement studies involve many objectives that are not considered here and excellent resources are available.6–8 Different objectives within the same study may require different methods. Here, we provide methods that may complement other analyses. Whenever the magnitude of variability is a key finding, it should be estimated and illustrated unbiasedly.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded, in part, by the Patient-Centered Outcomes Research Institute (PCORI) grant
Supplemental material
Supplemental material is available online for this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.