
Abstract
Studies involving large observational datasets commonly face the challenge of dealing with multiple missing values. The most popular approach to overcome this challenge, multiple imputation using chained equations, however, has been shown to be sub-optimal in complex settings, specifically in settings with longitudinal outcomes, which cannot be easily and adequately included in the imputation models. Bayesian methods avoid this difficulty by specification of a joint distribution and thus offer an alternative. A popular choice for that joint distribution is the multivariate normal distribution. In more complicated settings, as in our two motivating examples that involve time-varying covariates, additional issues require consideration: the endo- or exogeneity of the covariate and its functional relation with the outcome. In such situations, the implied assumptions of standard methods may be violated, resulting in bias. In this work, we extend and study a more flexible, Bayesian alternative to the multivariate normal approach, to better handle complex incomplete longitudinal data. We discuss and compare assumptions of the two Bayesian approaches about the endo- or exogeneity of the covariates and the functional form of the association with the outcome, and illustrate and evaluate consequences of violations of those assumptions using simulation studies and two real data examples.
1 Introduction
Missing values are a common challenge in the analysis of observational data, especially in longitudinal studies.
This work is motivated by two research questions from the Generation R Study, 1 a large longitudinal cohort study from fetal life onward. Specifically, the questions are: (1) “How is gestational weight associated with maternal blood pressure during pregnancy?”, and (2) “How is gestational weight associated with body mass index of the offspring during the first years of life?”. Due to the observational nature of the study, there is a considerable amount of incomplete data, with the particular challenge that missing values do not only occur in the outcome but also in the baseline and time-varying covariates.
There are several well-established approaches to deal with incomplete data, the most popular being multiple imputation using chained equations (MICE), 2 which are readily available in standard statistical software. MICE has been shown to work well in many standard settings but may not be optimal in more complex applications, especially with longitudinal or other multivariate outcomes, which cannot be easily included in the imputation models for incomplete covariates in an appropriate manner. 3 Fully Bayesian approaches provide a useful alternative in such complex settings, due to their ability to jointly model multivariate outcomes and incomplete covariates. The most popular omnibus approach in the Bayesian framework postulates a full multivariate normal distribution. 4 Although this approach, as well as other approaches, is targeted towards a broad range of applications, in complex settings such as our two motivating research questions, the nature of the data requires careful consideration of the appropriateness of such standard methods and a more dedicated approach may be necessary. Especially with time-varying covariates, imputation and analysis become more demanding and, in order to obtain valid results, require additional considerations about the association between the time-varying covariates and the outcome. Specifically, endogenous covariates, i.e. covariates that are influenced by the outcome, and covariates that have non-standard functional relations with the outcome, can pose challenges that may or may not be adequately handled by standard methods, which usually assume linear associations and implicitly assume exogeneity of the covariates.
In the present paper, we focus on two approaches in the Bayesian framework to deal with covariates that are missing at random. The first approach is described by Carpenter and Kenward. 4 The basic idea is to assume a (latent) normal distribution for each incomplete variable and to connect them in such a way that the joint distribution is multivariate normal, which allows straightforward sampling to impute missing values. This approach is a common strategy to implement multiple imputation in longitudinal settings, where it can be used as the data generating step. The resulting data are then analyzed in a second step with a complete data method, not necessarily Bayesian. While the multivariate normality assumption creates a convenient standardized framework, it thereby also implies linear relations between the variables involved, which may not be the case.
The second approach factorizes the joint distribution of the data into a sequence of conditional distributions, where the first conditional distribution can conveniently be chosen to be the analysis model of interest, allowing simultaneous imputation and analysis within the same procedure. This approach has been described previously for time-constant covariates 3 and we will extend it in the present paper to handle exogenous as well as endogenous time-varying covariates. The specification of separate models for each incomplete covariate requires somewhat more consideration than the specification of a multivariate normal distribution, but makes this approach more flexible as well as capable of handling non-linear relationships. We will elucidate the capabilities and limitations of the two approaches with regards to different functional forms for, as well as endo- or exogeneity of, time-varying covariates and demonstrate how the use of an “off the shelf” approach may be problematic in settings that require a more tailored approach.
The remainder of this paper is structured as follows. We start with introducing the motivating dataset and describe in more detail the two research questions from the Generation R Study. In Section 3 we specify the linear mixed model for time-varying covariates and explore different functional forms as well as the issue of endo- and exogeneity. The two methods of interest are introduced in Section 4, where we will also discuss their implied assumptions about endo- or exogeneity of the covariates and their ability to handle different functional forms. We return to the Generation R data in Section 5, where we demonstrate how the two methods under investigation can be applied. A more formal evaluation of the methods follows in Section 6 where we perform a simulation study. Section 7 concludes this paper with a discussion.
2 Generation R data
The Generation R Study is a population-based prospective cohort study from early fetal life onward, conducted in Rotterdam, the Netherlands. 1 An important field of research within the Generation R Study is the exploration of how the mother's condition during pregnancy may affect her own health and that of her child. Especially weight gain during gestation is of interest as it is closely related to the development of the fetus, as well as to pregnancy comorbidities, such as gestational hypertension, that may adversely affect both mother and child (e.g. Tielemans et al. 5 ). Children's growth and body composition, as for instance measured by BMI, is an important determinant of health throughout childhood and later life. Therefore, current research is concerned with the two questions stated in Section 1, i.e. the associations between maternal weight (gain) during pregnancy with maternal blood pressure during pregnancy as well as with child BMI after birth.
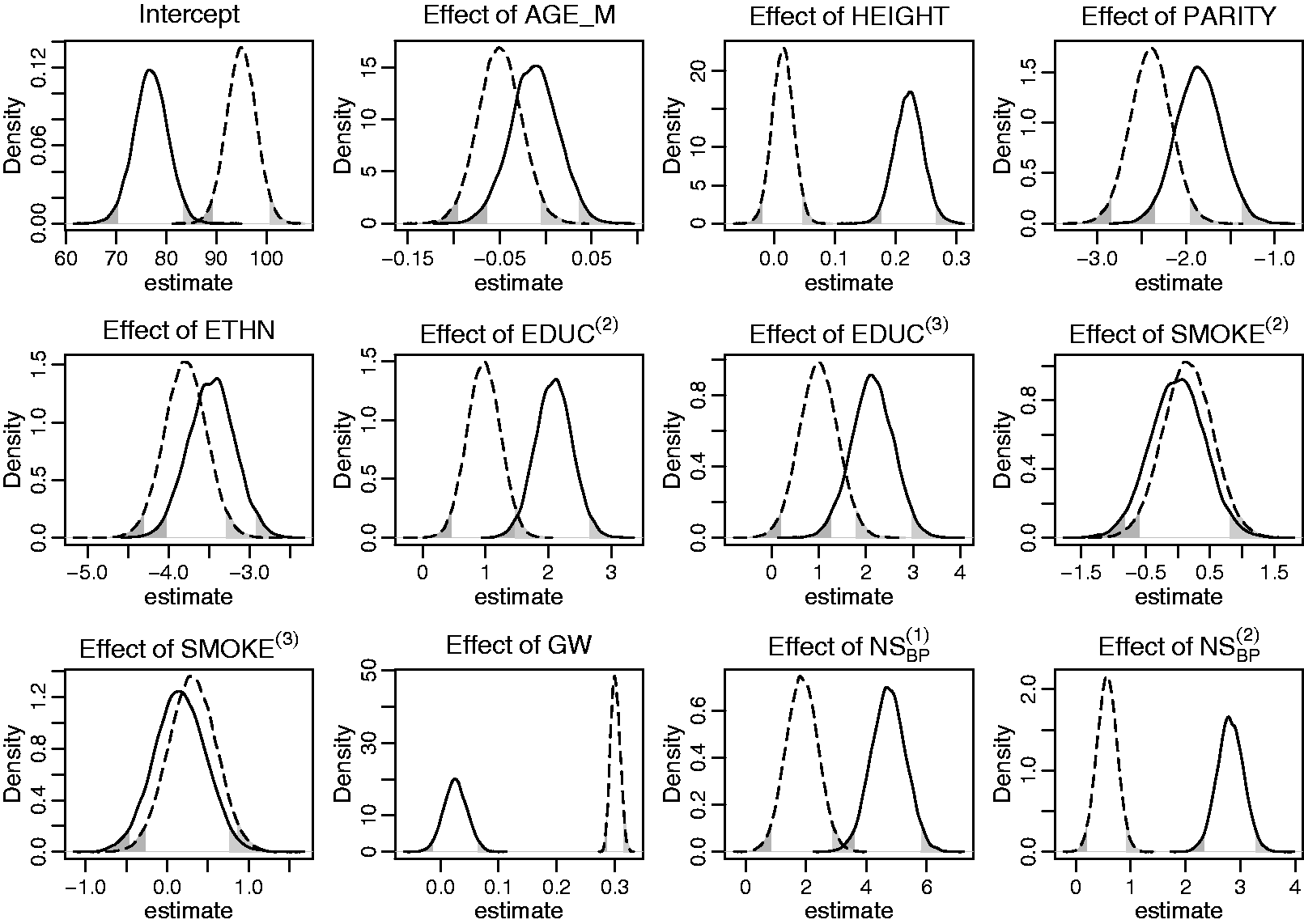
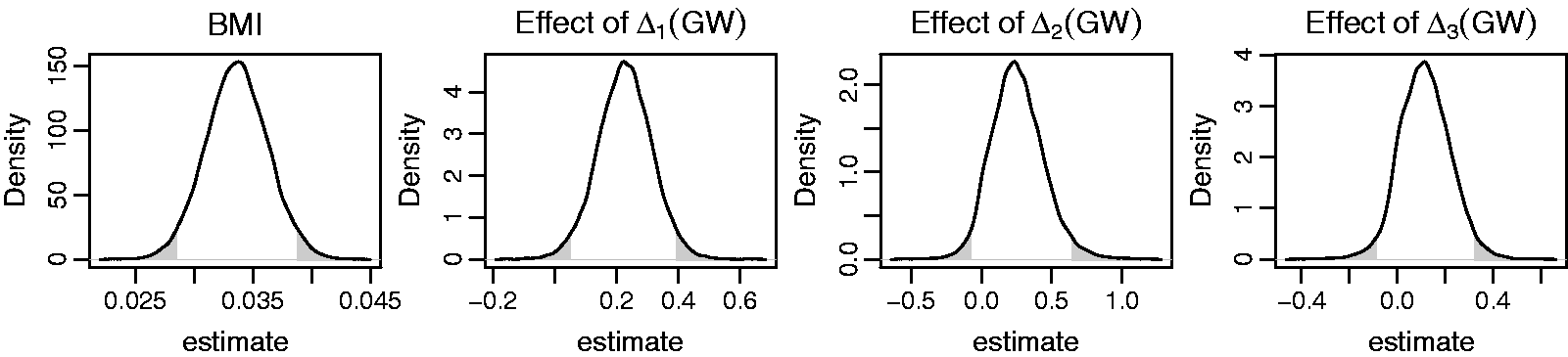
To investigate these two research questions, a subset of variables was extracted from the Generation R Study. The dataset contains information on 7643 mothers who had singleton, live births no earlier than 37 weeks of gestation, and their children. Each woman was asked for her pre-pregnancy weight (baseline) and to visit the research center once in each trimester, during which the weight ( Trajectories of maternal weight, maternal systolic blood pressure, and child BMI for a random sample of mothers and children from the Generation R data. Posterior distributions of the main regression coefficients in the first application, derived by the sequential approach. The solid (dashed) line represents the endogenous (exogenous) model. The shaded areas mark values outside the 95% credible interval. Posterior distributions of a selection of regression coefficients from the second application, derived by the sequential approach. The shaded areas mark values outside the 95% credible interval.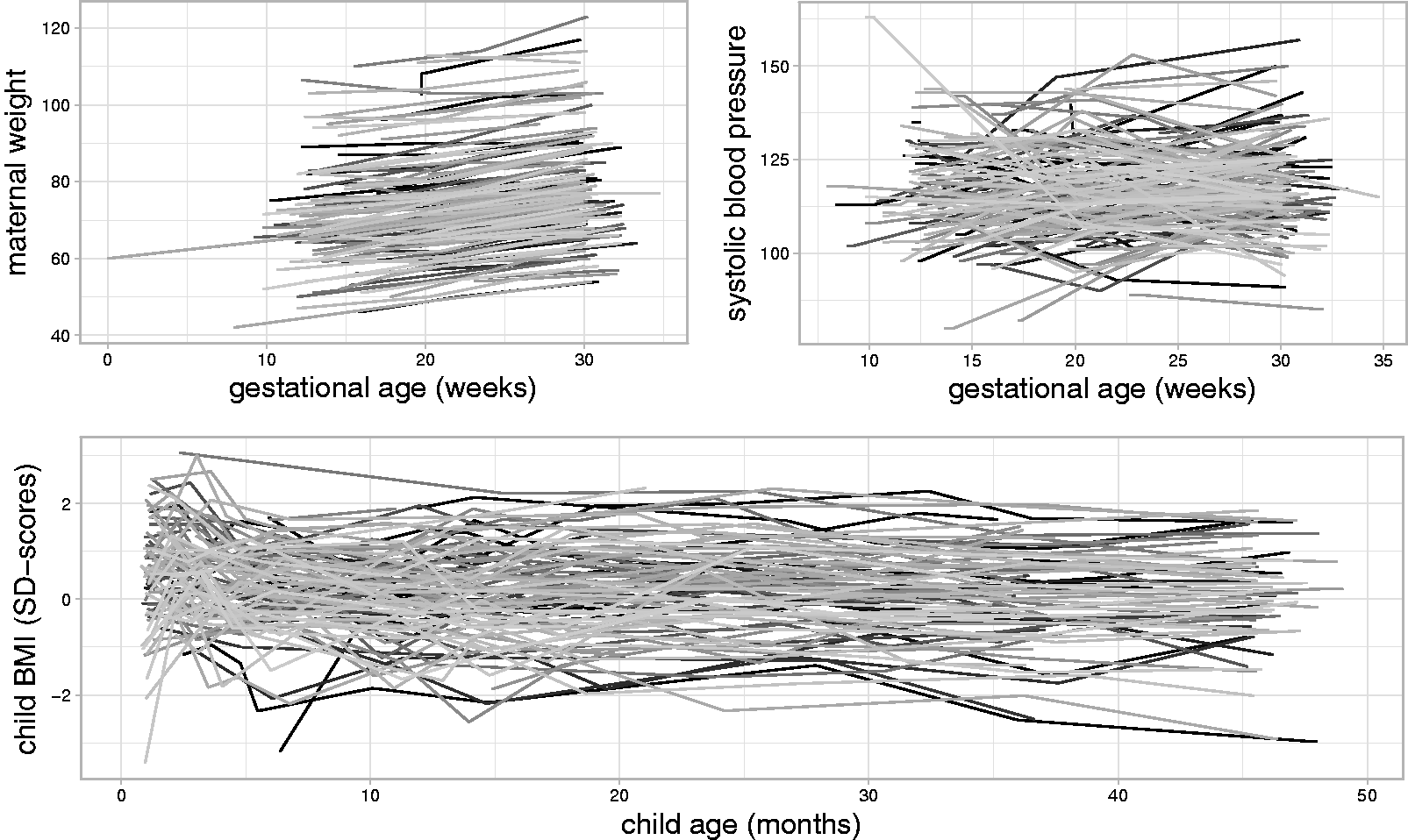
Logistic regression of the complete cases showed that missingness in the baseline covariates (except for
3 Modelling longitudinal data with time-varying covariates
3.1 Framework
A standard modeling framework for studying the relation between a longitudinal outcome and predictor variables is mixed effects modeling. As in our motivating case studies, often some of these predictors are time-varying. To facilitate exposition and also for notational simplicity, in the following we only consider a single time-varying covariate. In particular, for a continuous longitudinal outcome we postulate the following mixed model
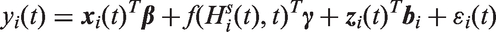
3.2 Functional forms for time-varying covariates
The choice of an appropriate functional form implies that the following two questions need to be addressed. Namely, how are


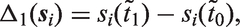
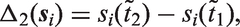
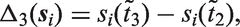
In other applications, it is likely that different functional forms will be more appropriate. Such functions may, for instance, represent cumulative effects or use estimates of random effects associated with the individual profiles of the time-varying covariate. In cases where there is not a specific functional form of interest or there is uncertainty about which functional form is most appropriate, multiple functional forms can be included and shrinkage priors used to reduce correlations between parameters or to select the best suited functional form. 6
3.3 Endo- and exogeneity
Another characteristic of the relation between a time-varying covariate and the outcome that needs to be considered is whether the time-varying covariate is exogenous or endogenous. Formally, exogeneity is defined by the following two conditions7,8
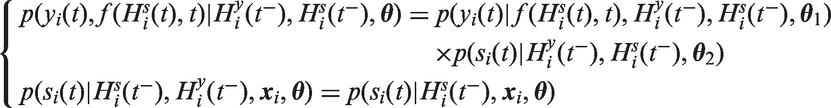
Most common methods for inference, like generalized linear (mixed) regression models, assume covariates to be exogenous. If that assumption is wrong and the covariate is in fact endogenous, estimates may be biased.8,9
4 Bayesian analysis with incomplete covariates
As introduced in Section 2, the motivating questions from the Generation R Study involve outcomes and covariates that are incomplete. This holds for both the baseline and time-varying covariates. Hence, to appropriately investigate the associations of interest, we need to account for missingness. In the Bayesian framework, missing values, whether they are in the outcome or in covariates, can be imputed in a natural and elegant manner. A common assumption, which we make here for the outcome as well as the covariates, is that the missing data mechanism is Missing At Random (MAR), i.e. the probability of a value being unobserved may depend on other observed values but not on values that have not been observed. In addition, the parameters of the analysis model are assumed to be independent of the missingness process. Under these assumptions, the missingness process is ignorable and does not need to be modeled. 10 Furthermore, this assumption entails that explicit imputation of the outcome is not necessary to obtain valid results and we will therefore focus on settings with incomplete covariates. In this section, we adapt and implement two popular Bayesian approaches for analyzing data with incomplete covariates, namely, the sequential approach,3,11 and the multivariate normal approach. 4 In particular, we extend the first approach to settings with time-varying covariates that may be exogenous or endogenous. Both approaches model the joint distribution of the complete data and draw imputations from the posterior full conditional distributions that result from it, but differ in the way the joint complete data distribution is specified. These differences influence how the two approaches can handle different functional forms as well as exo- vs. endogenous covariates.
We start with some additional notation. As in the motivating data, the time-varying covariate
4.1 Sequential approach
The sequential approach to impute missing baseline covariates in models with longitudinal outcomes was previously presented by Erler et al. 3 and will be extended here to incomplete time-varying covariates.
In our setting, the posterior distribution of interest (and associated joint distribution) is
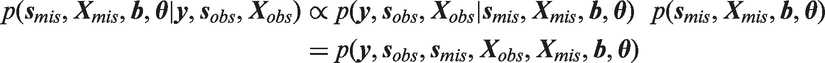
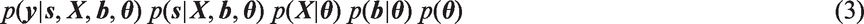
The first term in equation (3), i.e.
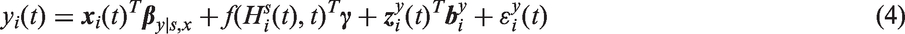

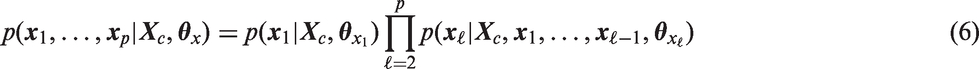
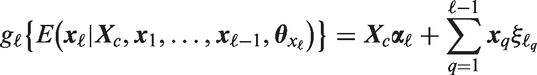
In the specification described above, the sequential approach implies exogeneity of
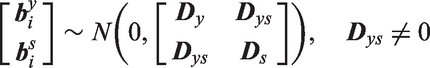
When
4.2 Multivariate normal approach
A popular alternative to handle missing covariates is the multivariate normal approach described in detail by Carpenter and Kenward.
4
The idea behind this approach is to assume (latent) normal distributions for all incomplete variables and the outcome, and to connect them in such a way that the resulting joint distribution is multivariate normal, which eases the sampling of imputed values. Specification of the joint distribution of the data is, hence, not based on a sequence but on a chosen multivariate distribution of known type. In our setting, the posterior distribution of interest can be written and factorized as
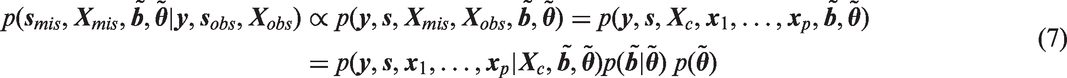
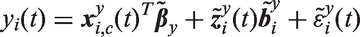
To produce the multivariate normal distribution, the models specified above are then connected through their random effects and error terms which are assumed to have a joint multivariate normal distribution
The error terms of the two longitudinal variables are assumed to be normally distributed as well, and may be modeled jointly as
The latent normal model for a binary or ordinal covariate
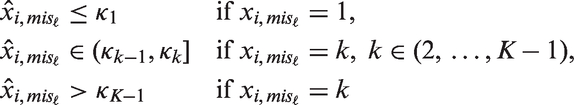
To keep the model identified, the variance of
As in the sequential approach, the use of variable specific random effects design matrices
Since
5 Analysis of the Generation R data
We now return to the Generation R data introduced in Section 2 and demonstrate how to use the two methods discussed above to investigate the two motivating research questions. As indicated earlier, the first question enables the investigation of the impact of mis-specifying the exo-/endogeneity assumption, while the second question requires the use of a non-standard functional form.
5.1 Association between blood pressure and gestational weight
Gestational hypertension is a known risk factor for various health outcomes in mothers as well as their children. One potentially influential factor for this condition is gestational weight, which will be investigated here. Whilst there are several papers exploring the relationship of gestational weight gain and the development of hypertensive conditions during pregnancy, the exact nature and functional form of the relation between these variables have yet to be explored in detail. Given the information available and the characteristics of the dataset at hand, a reasonable choice of functional form is to assume a linear relation between gestational weight (
Since both longitudinal variables in this application have non-linear evolutions over time, we modeled their trajectories using natural cubic splines with two degrees of freedom (df) for the effect of gestational age, in the formulas below represented by
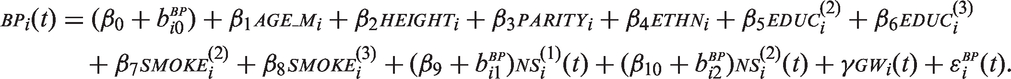
In the sequential approach, we used a linear mixed model to impute missing values of
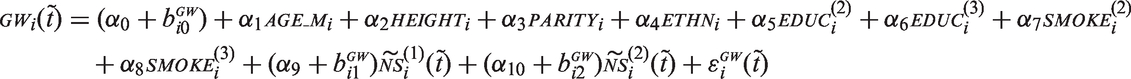
In the multivariate normal approach, the imputation models can be specified as
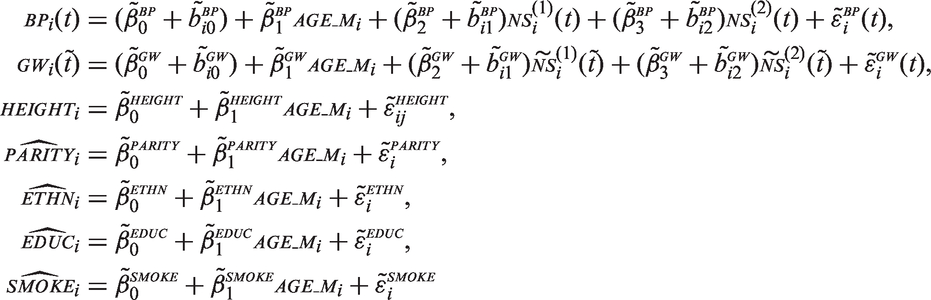
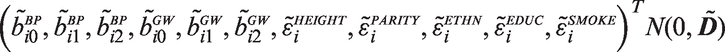
Using current versions of the software packages
A possible explanation for these differences is that in the exogenous model the correlation between
5.2 Association between gestational weight gain and child BMI
Fetal development follows a well researched course which is influenced by maternal health throughout pregnancy. Specifically the effect of gestational weight gain may vary between different periods of pregnancy, i.e. different periods of fetal development. Hence, the effect of trimester-specific weight gain is often a predictor of interest. How much weight gain is considered healthy varies with maternal BMI before pregnancy (
We calculated trimester-specific weight gain as the differences between weight before pregnancy, 14 weeks of gestation, 27 weeks of gestation and at (or right before) birth (
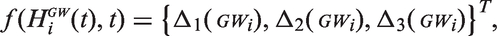

As in the first application, we assumed a non-linear evolution of
The analysis model for this research question can be written as
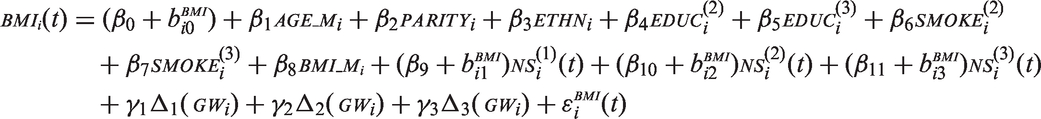
The analysis was again performed using the sequential approach, where imputation models for
Results from the analysis of this second research question are presented in Figure 3. Only the posterior distributions of the parameters relating to
6 Simulation study
To evaluate the performance of the two imputation approaches described in Section 4 with regards to mis-specification of the endo- or exogeneity of a time-varying covariate and the bias introduced by mis-specification of the functional form in a more controlled setting, we performed a simulation study in which we compared results from correctly specified models with those that are mis-specified, for data generated in a range of different scenarios and different missing mechanisms. Specifically, the key objectives were
to confirm that both approaches provide unbiased estimates when the models are correctly specified during imputation and analysis, to investigate how mis-specification of the endo- or exogeneity influences the results, and to explore bias due to mis-specification of the functional form, specifically
the bias introduced during imputation due to the implied linearity assumption of the multivariate normal approach when the true functional form is non-linear, and the bias introduced when the imputation model as well as the analysis model are mis-specified as linear.
6.1 Design
We simulated 200 datasets in each of six scenarios that differed in the endo-/exogeneity of the covariate, the functional form and the model (sequential or multivariate normal) that was used. Common to all scenarios was that 10 repeated measurements of a normally distributed time-varying covariate and a conditionally normal outcome variable, with measurements at the same, unbalanced time points, were created. Under the sequential approach, data were generated with a linear or a quadratic relation between covariate and outcome, where the covariate was either exogenous or endogenous. For the multivariate normal model (which always generates data with a linear relation between the outcome and an endogenous covariate), we considered two scenarios with regards to the correlation of the error terms, where in one scenario the error terms of outcome and covariate were independent and in the other correlated.
Missing values were created in the time-varying covariate according to two MAR mechanisms, in which the probability of the time-varying covariate being missing either only depended on the outcome at the same time point or on the outcome at the same time point as well as the covariate at the previous time point.
Details on the exact setup of the simulation study are given in Appendix C.1, available online.
6.2 Analysis models
Each of the datasets was analyzed using both approaches with different assumptions regarding the endo- or exogeneity of the covariate and the functional form, before values were deleted, and for both missing mechanisms. The complete dataset was analyzed using function
An overview of the assumptions and models used can be found in Table 2 in Appendix C.2, available online. The specific parameter values that were used are given in Tables 3 and 4 in Appendix C.3, available online.
6.3 Results
First, we found that the sequential approach provided unbiased estimates, when comparing the results from the analysis of the complete data to the true parameters that were used to generate the data. Second, in all scenarios, results were very similar for both MAR mechanisms and we will, hence, not distinguish them during the further description of the results.
Regarding our first objective, the comparison of the sequential and the multivariate normal approach when exo- or endogeneity and functional form were specified correctly, we found that both approaches were unbiased and their 95% credible intervals had the desired coverage. However, mis-specification of the error terms in the multivariate normal approach as independent had the overall largest impact on the results (estimates were on average half the value of the estimate from the analysis of the complete data and CIs had 0% coverage). Based on this finding, we excluded the multivariate normal approach with independent error terms from further comparisons. Moreover, we saw that mis-specification of an endogenous covariate as exogenous resulted in bias while mis-specification of an exogenous covariate as endogenous did not. This was the case for both approaches, and linear as well as quadratic (only for the sequential approach) functional form. With respect to our third objective, the simulation study showed that imputation with the multivariate normal approach (with correlated error terms) in a setting where the functional form was correctly assumed to be quadratic during the subsequent analysis had the second largest impact, with a relative bias of approximately 0.8, and resulted in CIs with coverage of close to 0%. The bias that was added due to mis-specification of the functional form as linear during imputation as well as analysis, as compared to the results from the analysis of the complete data under the same mis-specification, was small and overall comparable between the multivariate normal and the sequential approach. These findings were the same irrespective of the exo- or endogeneity of the covariate. Plots of the results from the simulation study as well as a detailed discussion of these results can be found in Appendix C.4, available online.
In summary, the results of this simulation study demonstrate the impact that imprudent acceptance of default assumptions, like exogeneity, linear relations between variables, or (conditioned on random effects) uncorrelated error terms may have. Plots of the results from the simulation study as well as a detailed discussion of these results can be found in Appendix C.4, available online.
7 Discussion
Motivated by two research questions from the Generation R study, we investigated two Bayesian approaches to handle missing covariate data in models with longitudinal outcomes and time-varying covariates. Specifically, we compared the multivariate normal approach, a widely known omnibus approach, to the more custom-designed sequential approach, which we extended to handle endogenous time-varying covariates. The focus of this comparison was on the ability to take into account different functional relations between such covariates and the outcome, and the suitability for exogenous as well as endogenous covariates.
The analysis of our real data applications illustrated the necessity for methods that allow for complex functional relations and endogenous covariates. Simulation studies confirmed that in our setting, methods that make the common assumption of exogeneity of a time-varying covariate provide biased estimates. The assumption of endogeneity during imputation and analysis, however, did not introduce any bias, which suggests to choose the endogenous specification, e.g., to model the random effects of the outcome and the time-varying covariate correlated, as a default. The simulation study also demonstrated that imputation with the multivariate normal approach in settings where the implied assumption of linear associations between variables is violated can be biased. Furthermore, great care should be taken when assumptions about the correlation structure of the error terms is made in the multivariate normal approach, as mis-specification may result in large bias. Results indicated that the sequential approach is more robust with regards to this type of mis-specification; however, future research is required to evaluate this further. Overall, the sequential approach performed well and proved to be a suitable method to impute and analyze longitudinal data with possibly endogenous time-varying covariates.
The ability of the sequential approach to handle various functional forms, and to provide estimates in settings with endogenous time-varying covariates, can be seen as its biggest advantages. Moreover, it can handle non-linear associations of baseline covariates and interaction terms involving incomplete covariates without the need of approximations like the ‘just another variable’ approach or passive imputation via transformation.12,22,23 Even in settings where there is no single functional form of interest, but several candidate functions, it may be applied in combination with shrinkage techniques which may help the decision which functional form is most appropriate.
In the present paper, we focused on a single time-varying covariate and ignorable missing data mechanisms; however, extensions of the sequential approach to accommodate more complex settings are possible. Multiple time-varying covariates can be added to the linear predictor of the analysis model. Imputation models for the time-varying covariates could either be specified assuming independence between different time-varying covariates, i.e. excluding them from each other's linear predictor, assuming joint multivariate distributions for their random effects and/or error terms, or by specifying a functional form of one time-varying covariate to be included in the linear predictor of another covariate, analogous to the specification of the analysis model described in Section 3. The second option may be a convenient choice if a linear relation between the time-varying covariates is a reasonable assumption. When the missing data mechanism is non-ignorable, this can be taken into account by extending the specification of the joint distribution with terms that either describe the selection mechanism (i.e. the missingness pattern given the data) or specify how the distribution of the data depends on the missingness pattern.2,4,9
A reason why the multivariate normal approach may be preferred in practice is its availability in software packages, as, for instance, the
When imputing and analyzing complex datasets, researchers need to deliberate if standard methods that are easy to apply meet the requirements of the application at hand, specifically, if the assumptions of those methods are met. It is our opinion that too often this is not the case and standard approaches are applied even when they are not adequate. Therefore, we plead for the use of methods that are flexible enough to be adapted to the specific characteristics of a problem. In the context of imputation and analysis of longitudinal data with possibly endogenous time-varying covariates, the sequential approach presented in this paper is such an approach.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the Netherlands Organisation for Scientific Research [VIDI grant 016.146.301].
Supplemental material
Supplemental material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.