
Abstract
A typical problem in causal modeling is the instability of model structure learning, i.e., small changes in finite data can result in completely different optimal models. The present work introduces a novel causal modeling algorithm for longitudinal data, that is robust for finite samples based on recent advances in stability selection using subsampling and selection algorithms. Our approach uses exploratory search but allows incorporation of prior knowledge, e.g., the absence of a particular causal relationship between two specific variables. We represent causal relationships using structural equation models. Models are scored along two objectives: the model fit and the model complexity. Since both objectives are often conflicting, we apply a multi-objective evolutionary algorithm to search for Pareto optimal models. To handle the instability of small finite data samples, we repeatedly subsample the data and select those substructures (from the optimal models) that are both stable and parsimonious. These substructures can be visualized through a causal graph. Our more exploratory approach achieves at least comparable performance as, but often a significant improvement over state-of-the-art alternative approaches on a simulated data set with a known ground truth. We also present the results of our method on three real-world longitudinal data sets on chronic fatigue syndrome, Alzheimer disease, and chronic kidney disease. The findings obtained with our approach are generally in line with results from more hypothesis-driven analyses in earlier studies and suggest some novel relationships that deserve further research.
Keywords
1 Introduction
Causal modeling, an essential problem in many disciplines,1–6 attempts to model the mechanisms by which variables relate and to understand the changes on the model if the mechanisms were manipulated. 7 In the medical domain, revealing causal relationships may lead to improvement of clinical practice, for example, the development of treatment and medication. Slowly but steadily, causal discovery methods find their way into the medical literature, providing novel insights through exploratory analyses.8–10 Moreover, data in the medical domain are often collected through longitudinal studies. Unlike in a cross-sectional design, where all measurements are obtained at a single occasion, the data in a longitudinal design consist of repeated measurements on subjects through time. Longitudinal data make it possible to capture change within subjects over time and thus gives some advantage to causal modeling in terms of providing more knowledge to establish causal relationships. 11 As emphasized in Fitzmaurice et al., 12 there is much natural heterogeneity among subjects in terms of how diseases progress that can be explained by the longitudinal study design. Another advantage is that in order to obtain a similar level of statistical power as in cross-sectional studies, fewer subjects in longitudinal studies are required. 13
To date, a number of causal modeling methods have been developed for longitudinal (or time series) data. Some of the methods are based on a Vector Autoregressive (VAR) and/or Structural Equation Model (SEM) framework which assumes a linear system and independent Gaussian noise.14–18 Some other methods, interestingly, take advantage of nonlinearity,19–21 or non-Gaussian noise,20,22 to gain even more causal information. Most of the aforementioned methods conduct the estimation of the causal structures in somewhat similar ways. Bessler and Lee, 15 Demiralp and Hoover, 16 Moneta, 17 Peters et al., 20 Hyvärinen et al. 22 use the (partial correlations of the) VAR residuals to either test independence or as input to a causal search algorithm, e.g., LiNGAM (linear non-Gaussian acyclic model), 23 PC (“P” stands for Peter, and “C” for Clark, the authors). 24 In general, these causal search algorithms are solely based on a single run of model learning which is notoriously unstable small changes in finite data samples can lead to entirely different inferred structures. This implies that some approaches might not be robust enough to correctly estimate causal models from various data, especially when the data set is noisy or has small sample size.
In the present paper, we introduce a robust causal modeling algorithm for longitudinal data that is designed to resolve the instability inherent to structure learning. We refer to our method as S3L, an abbreviation for stable specification search for longitudinal data. It extends our previous method, 25 here referred to as S3C, which is designed for cross-sectional data. S3L is a general framework which subsamples the original data into many subsets, and for each subset, S3L heuristically searches for Pareto optimal models using a multi-objective optimization approach. Among the optimal models, S3L observes the so-called relevant causal structures, which represent both stable and parsimonious model structures. These steps constitute the structure estimation of S3L which is fundamentally different from the aforementioned approaches that mostly use a single run for model estimation. For completeness, detail about S3C/L is described in Section 2. Moreover, in the default setting S3L assumes some underlying contexts: independent and identically distributed (iid) samples for each time slice (lag), linear system, additive independent Gaussian noise, causal sufficiency (no latent variables), stationary (time-invariant causal relationships), and fairly uniform time intervals between time slices.
The main contributions of S3L are:
The causal structure estimation of S3L is conducted through multi-objective optimization and stability selection
26
over optimal models, to optimize both the stability and the parsimony of the model structures. S3C/L is a general framework which allows for other causal methods with all of their corresponding assumptions, e.g., nonlinearity, non-Gaussianity, to be plugged in as model representation and estimation. The multi-objective search and the stability selection part are independent of any mentioned assumptions. In the default model representation, S3L adopts the idea of the “rolling” model from Friedman et al.
27
to transform a longitudinal SEM model with an arbitrary number of time slices into two parts: a baseline model and a transition model. The baseline model captures the causal relationships at baseline observations, when subjects enter the study. The transition model consists of two time slices, which essentially represent the possible causal relationships within and across time slices. We also describe how to reshape the longitudinal data correspondingly, so as to match the transformed longitudinal model which then can easily be scored using standard SEM software. We provide standardized causal effects which are computed from Intervention-calculus when the DAG (directed acyclic graph) is Absent (IDA) estimates.
28
We carry out experiments on three different real-world data of (a) patients with chronic fatigue syndrome (CFS), (b) patients with Alzheimer disease (AD), and (c) patients with chronic kidney disease (CKD).
Some relevant methods have attempted to make use of common structures to infer causal models. Causal stability ranking (CStaR),
29
originally designed for gene expression data, tries to find stable rankings of genes (covariates) based on their total causal effect on a specific phenotype (response), using a subsampling procedure similar to stability selection and IDA to estimate causal effects. As CStaR only focuses on relationships from all covariates to a single specific response, it seems to be difficult to generalize it to other domains where any possible causal relationship may be of interest. Moreover, another approach called group iterative multiple model estimation (GIMME),
30
originally developed for functional magnetic resonance imaging (fMRI) data and essentially an extension of extended unified SEM (combination of VAR and SEM),
31
aims to combine the group-level causal structures with the individual-level structures, resulting in a causal model for each individual which contains common structures to the group. Such subject-specific estimation may be feasible given relatively long time series (as in resting state fMRI), but likely too challenging for the typical longitudinal data in clinical studies with a limited number of time slices per subject. Still in the domain of fMRI, there is a method called independent multiple-sample greedy equivalence search (IMaGES).
32
The method is a modification of GES (described in the following paragraph), and designed to handle unexpected statistical dependencies in combined data. Since IMaGES was developed mainly for combining results of multiple data sets, we do not consider it further.
Having both the transformed longitudinal model and the reshaped data, we can run other alternative approaches which are designed for cross-sectional data and conduct comprehensive comparisons. Here, for evaluation of S3L, we generate simulated data and compare with some advanced constrained-based approaches such as PC-stable, 33 conservative PC (CPC), 34 CPC-stable,33,34 and PC-Max. 35 All of these methods are extensions of the PC algorithm which in principle consists of two stages. The first stage uses conditional independence tests to obtain the skeleton (undirected edges) of the model, and the second stage orients the skeleton based on some rules, resulting in an essential graph or Markov equivalence class model (described in Section 2.1; for more details, see Chickering 36 ). We also compare with an advanced score-based algorithm called fast greedy equivalent search (FGES). 37 It is an extension of GES which in general starts with an empty (or sparse) model, and iteratively adds an edge (forward phase) which mostly increases the score until no more edge can be added. Then GES iteratively prunes an edge (backward phase) which does not decrease/improve the score until no more edge can be excluded.
The rest of this paper is organized as follows. All methods used in our approach are presented in Section 2. The results and the corresponding discussions are presented in Section 3. Finally, conclusion and future work are presented in Section 4.
2 Methods
2.1 Stable specification search for cross-sectional data
In Rahmadi et al. 25 , we introduced our previous work, S3C, which searches over structures represented by SEMs. In SEMs, refining models to improve the model quality is called specification search. Generally, S3C adopts the concept of stability selection 26 in order to enhance the robustness of structure learning by considering a whole range of model complexities. Originally, in stability selection, this is realized by varying a continuous regularization parameter. Here, we explicitly consider different discrete model complexities. However, to find the optimal model structure for each model complexity is a hard optimization problem. Therefore, we rephrase stability selection as a multi-objective optimization problem, so that we can jointly run over the whole range of model complexities and find the corresponding optimal structures for each model complexity.
In more detail, S3C can be divided into two phases. The first phase is search, performing exploratory search over SEMs using a multi-objective evolutionary algorithm called Non-dominated Sorting Genetic Algorithm II (NSGA-II). 38 NSGA-II is an iterative procedure which adopts the idea of evolution. It starts with random models, and in every generation (iteration), attempts to improve the quality of the models by manipulating (refining) good models (parents) to make new models (offsprings). The quality of the models is characterized by scoring that is based on two conflicting objectives: model fit with respect to the data and model complexity. The model manipulations are realized by using two genetic operators: crossover that combines the structures of parents and mutation that flips the structures of models. Moreover, the composition of model population in the next generation is determined by selection strategy. One of the key features of NSGA-II is that in every iteration, it sorts models based on the concept of domination, yielding fronts or sets of models such that models in front l dominate those in front l + 1. The domination concept states that model m1 is said to dominate model m2 if and only if model m1 is no worse than m2 in all objectives and the model m1 is strictly better than m2 in at least one objective. The first front of the last generation is called the Pareto optimal set, giving optimal models for the whole range of model complexities. Details of the NSGA-II algorithm are described in Deb et al. 38
Based on the idea of stability selection,
26
S3C subsamples N subsets from the data D with size
The second phase concerns visualization, combining the stability graphs into a graph with nodes and edges. This is done by adding the relevant edges and orienting them using prior knowledge (described in Section 2.2.2) and the relevant causal paths. More specifically, we first connect the nodes following the relevant edges. Then we orient these edges based on the prior knowledge. And finally, we orient the rest of the edges following the relevant causal paths of length one. The resulting graph consists of directed edges which represent causal relationship and possibly with additional undirected edges which represent strong association but for which the direction is unclear from the data. Furthermore, following Meinshausen and Bühlmann, 26 for each edge in the graph we take the highest selection probability it has across different model complexities in the relevant region of the edge stability graph as a measure of reliability and annotate the corresponding edge with this reliability score. The reliability score indicates the confidence of a particular relevant structure. The higher the score, the more we can expect that the relevant structure is not falsely selected. 26 In addition, each directed edge is annotated with a standardized causal effect estimate which is explained in Section 2.2.3. The stability graphs are considered to be the main outcome of our approach where the visualization eases interpretation.
2.2 S3L
S3L is an extension of S3C. In principle, as illustrated in Figure 1, S3L applies S3C on transformed longitudinal models, called baseline and transition models (explained in Section 2.2.1). Furthermore, in order to see to which extent a covariate would cause a response, S3L provides standardized total causal effect estimates which are intrinsically computed from estimates from IDA
28
(described in Section 2.2.3). In the following subsections, we first describe how we transform a longitudinal model and reshape the data accordingly, and then we discuss the implication of allowing prior knowledge in our S3C structure learning.
Given a longitudinal data set, S3L uses the baseline observations to infer a baseline model, and reshapes the whole data set to infer a transition model. Both baseline and transition models are annotated with a reliability score α and a standardized causal effect β.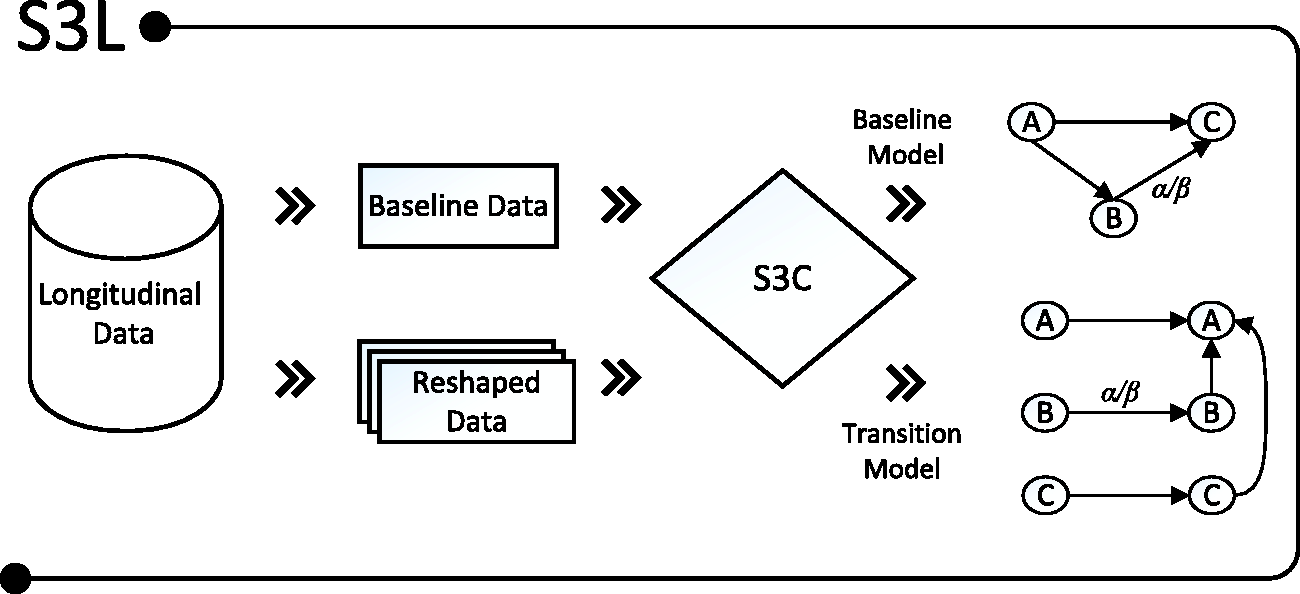
2.2.1 Longitudinal model and data reshaping
Based on the idea of a “rolling” network in Friedman et al.
27
, we transform a longitudinal SEM with an arbitrary number of time slices (e.g., Figure 2(c)) into two parts: a baseline model (Figure 2(a)) and a transition model (Figure 2(b)). In the original paper, the authors treat these models as probabilistic networks, here we treat them purely as SEMs. The baseline model essentially represents the causal relationships between variables that may happen at the initial time slice t0, for instance, causal relationships that occur before a medical treatment started. Moreover, the baseline model may also represent relationships of the unobserved process before t0.
27
The transition model constitutes the causal relationships between variables across time slices (a) The baseline model which is used to capture causal relationships at the initial time slice, e.g., before medical treatment. (b) The transition model which is used to represent causal relationships within and between time slices, e.g., during medical treatment. (c) The corresponding “unrolled” longitudinal model.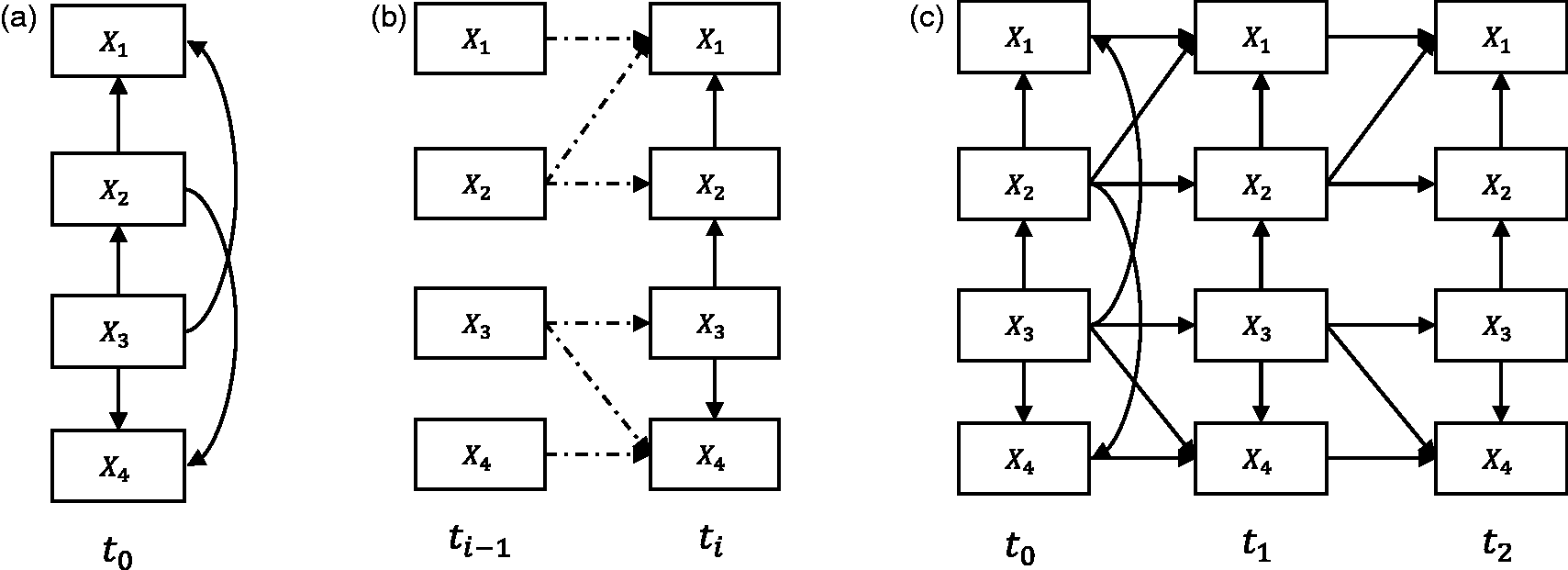
From the transition model, we distinguish two kinds of causal relationships, namely intra-slice causal relationship (e.g., solid arcs in Figure 2(b)) and inter-slice causal relationship (e.g., dashed arcs in Figure 2(b)). The intra-slice causal relationship represents relationships within time slice ti. Accordingly, the inter-slice causal relationship represents relationships between time slices
Moreover, in order to score the transformed models, we reshape the longitudinal data accordingly. Figure 3 shows an illustration of the data reshaping. Suppose we are given longitudinal data with s instances, p variables, and i time slices, we assume that the original data shape is in a form of a matrix D of size s × q, with D is a matrix representing the original data shape which consists of s instances, p variables, and i time slices. 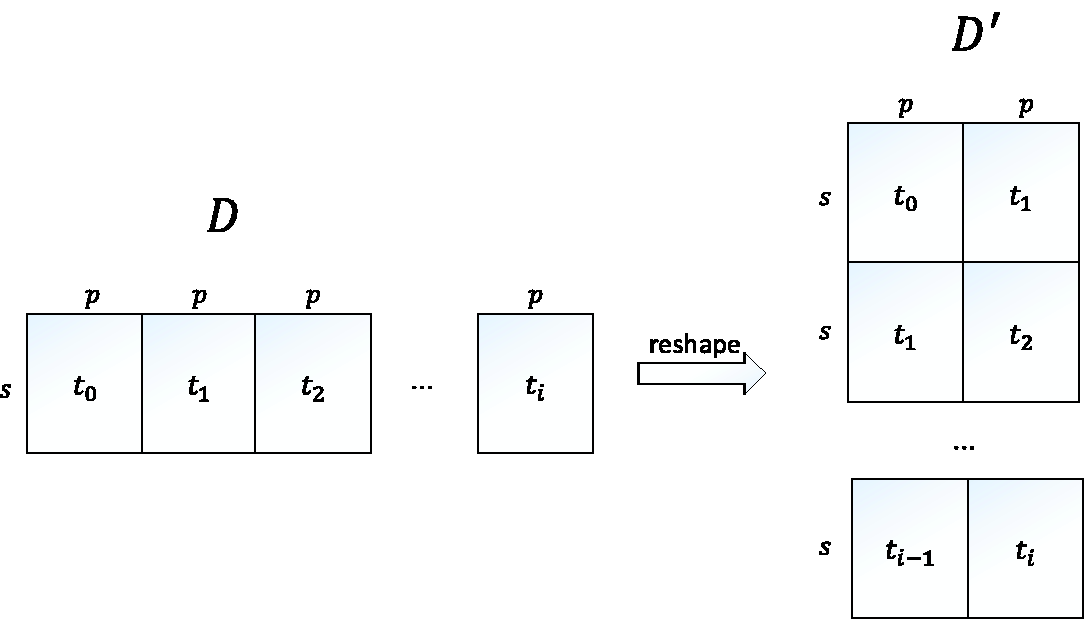
2.2.2 Constrained SEM
In practice, we are often given some prior knowledge about the data. The prior knowledge which may be, e.g., results of previous studies, gives us some constraints in terms of causal relations. For example, in the case of, say disease A, there exists some common knowledge which tells us that symptom S does not cause disease A directly. In terms of a SEM specification, the prior knowledge can be translated into a constrained SEM in which there is no directed edge from variable S (denotes symptom S) to variable A (denotes disease A); this still allows for directed edges from A to S or directed paths (indirect relationships) from S to A, e.g., a path
Model specifications should comply with any prior knowledge when performing specification search and when measuring the edge and causal path stability. Recall that in order to measure the stability, all optimal models (DAGs) are converted into their corresponding equivalence class models (CPDAGs). This model transformation, however, could result in CPDAGs that are inconsistent with the prior knowledge. For example, a constraint
2.2.3 Estimating causal effects
We employ IDA
28
to estimate the total causal effects of a covariate Xi on a response Y from the relevant structures. This method works as follows. Given a CPDAG
Causal effects can be computed using the so-called intervention calculus,
39
which aims to determine the amount of change in a response variable Y when one would manipulate the covariate Xi (and not the other variables). Note that this notion differs from a regression-type of association (see IDA paper for illustrative examples). Given a DAG Gj, the causal effect θij can be computed using the so-called back-door adjustment, which takes into account the associations between Y, Xi and the parents
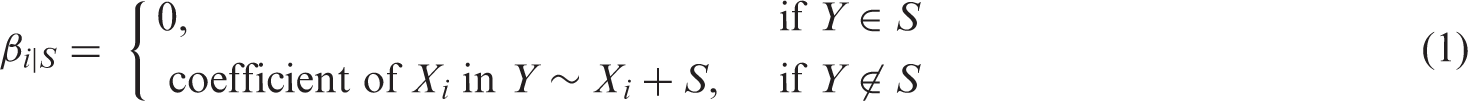
IDA works for continuous, normally distributed variables and then only requires their observed covariance matrix as input to compute the regression coefficients. Following Drasgow, 42 we treat discrete variables as surrogate continuous variables, substituting the polychoric correlation for the correlation between two discrete variables and the polyserial correlation between a discrete and a continuous variable.
Our fitting procedure does not yield a single CPDAG, but a whole set of CPDAGs to represent the given data. We therefore extend IDA as follows. We gather
To represent the estimated causal effects from X to Y, we compute the median

3 Results and discussion
3.1 Implementation
We implemented S3C and S3L as an R package named
3.2 Parameter settings
For application to simulated data and real-world data, we subsampled 50 and 100 subsets from the data with size
When using multi-objective optimization we minimize both the
3.3 Application to simulated data
3.3.1 Data generation
We generated data sets from a longitudinal model containing four continuous variables and three time slices (depicted by Figure 4). For each of sample sizes 400 and 2000, we generated 10 data sets with random parameterizations and made those publicly available (https://tinyurl.com/smmr-rahmadi-dataset).
The longitudinal model with four variables and three time slices, used to generate simulated data.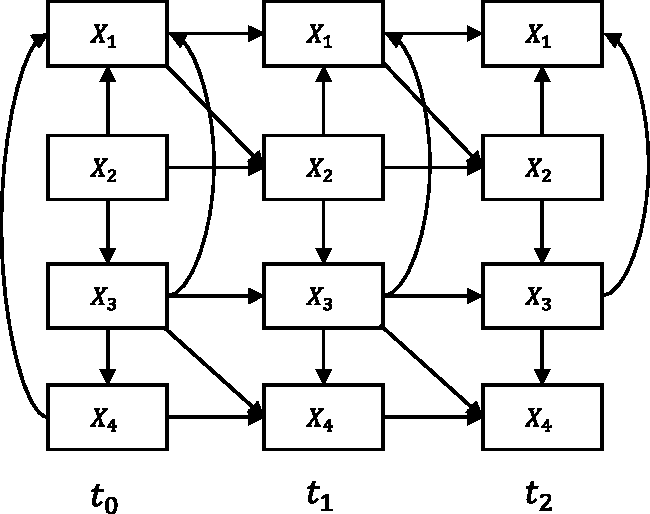
3.3.2 Performance measure
We conducted comparisons between S3L with FGES, PC-stable, CPC, CPC-stable, and PC-Max in two different scenarios: with and without prior knowledge about part of the causal directions. Here, the comparisons focus more on the transition model, because in our previous paper
25
we already conducted experiments on the baseline model. In the case of prior knowledge, we added that variable X1 at ti cannot cause variables X2 and X3 at ti directly. This prior knowledge translates to constraints that the various methods can use to restrict their search space. In addition to both scenarios, we also added longitudinal constraints to the models of FGES, PC-stable, CPC, CPC-stable, and PC-Max the same as those used in the transition model of S3L, i.e., there is no intra-causal relationship from time
The parameters of FGES, PC-stable, CPC, CPC-stable, and PC-Max used in this simulation are set following some existing examples.28,46,47 For FGES, the penalty of BIC score is 2 and the vertex degree in the forward search is not limited. For PC-stable, CPC, CPC-stable, and PC-Max, the significance level when testing for conditional independence is 0.01, and the maximum size of the conditioning sets is infinite.
Moreover, as the true model is known, we measure the performance of all approaches by means of the receiver operating characteristic (ROC) 48 for both edges and causal paths. We compute the true positive rate (TPR) and the false positive rate (FPR) based on the CPDAG of the true model. As for example, in the case of edge stability, a true positive means that an edge obtained by our method or the other approaches is present in the CPDAG of the ground truth.
To compare the ROC curves of our method and those of alternative approaches, we employed three significance tests. The first two tests, as introduced in DeLong et al. 49 and in Robin et al., 50 compare the area under the curve (AUC) of the ROC curves by using the theory of U-statistics and bootstrap replicates, respectively. The third test, Venkatraman and Begg, 51 compares the actual ROC curves by evaluating the absolute difference and generating rank-based permutations to compute the statistical significance. The null hypothesis is that (the AUC of) the ROC curves of our method and those of alternative approaches are identical.
Furthermore, we computed the ROC curves using two different schemes: averaging and individual. Both schemes are applied to all methods and to all data sets generated. In the averaging scheme, the ROC curves are computed from the average edge and causal path stability from different data sets, and then the statistical significance tests are applied to these ROC curves. On the other hand, in the individual scheme the ROC curves are computed from the edge and causal path stability on each data set. We then applied individual statistical significance tests on the ROC curves for each data set and used Fisher’s method,52,53 to combine these test results into a single test statistic.
The experimental designs (with and without prior knowledge) and the ROC schemes (averaging and individual) are aimed to show empirically and comprehensively how robust the results are of each approach in various practical cases as well as against changes in the data.
3.3.3 Discussion
We first discuss the result of our experiments on the data set with sample size 400. Figure 5 shows the ROC curves for the edge stability (panels (a) and (c)) and the causal path stability (panels (b) and (d)) from the averaging scheme. Panels (a) and (b) represent the results without prior knowledge, while panels (c) and (d) represent the results with prior knowledge. Table 1 lists the corresponding AUCs.
Results from simulation data with sample size 400: ROC curves for (a) the edge stability and (b) the causal path stability (without prior knowledge), and (c) the edge path stability and (d) the causal path stability (with prior knowledge), for different values of AUCs for the edge and causal path stability for each method, from simulation on data with sample size 400, with (yes) and without prior knowledge (no). AUC: area under the curve; CPC: conservative PC; FGES: fast greedy equivalent search; S3L: stable specification search for longitudinal data.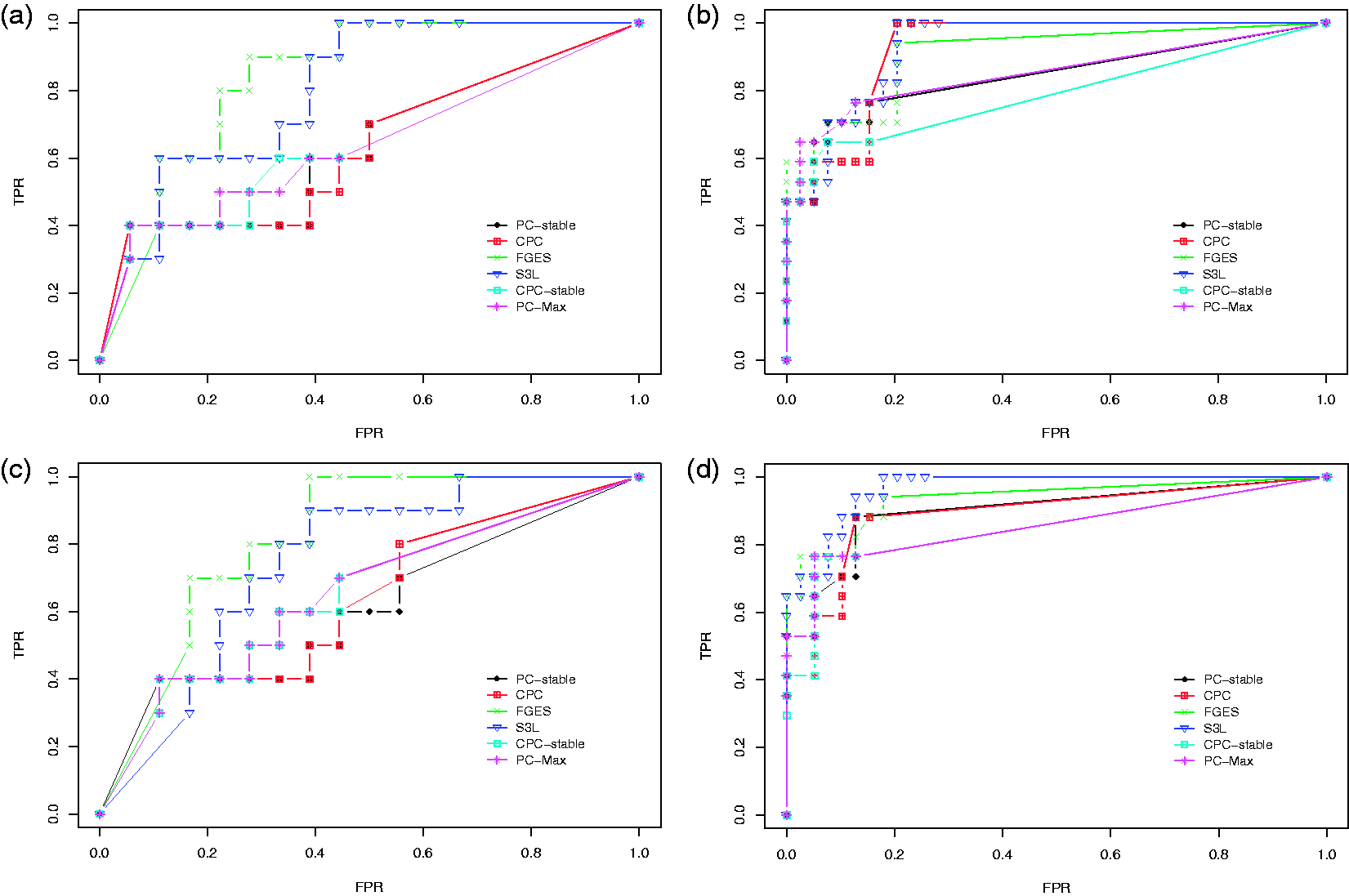

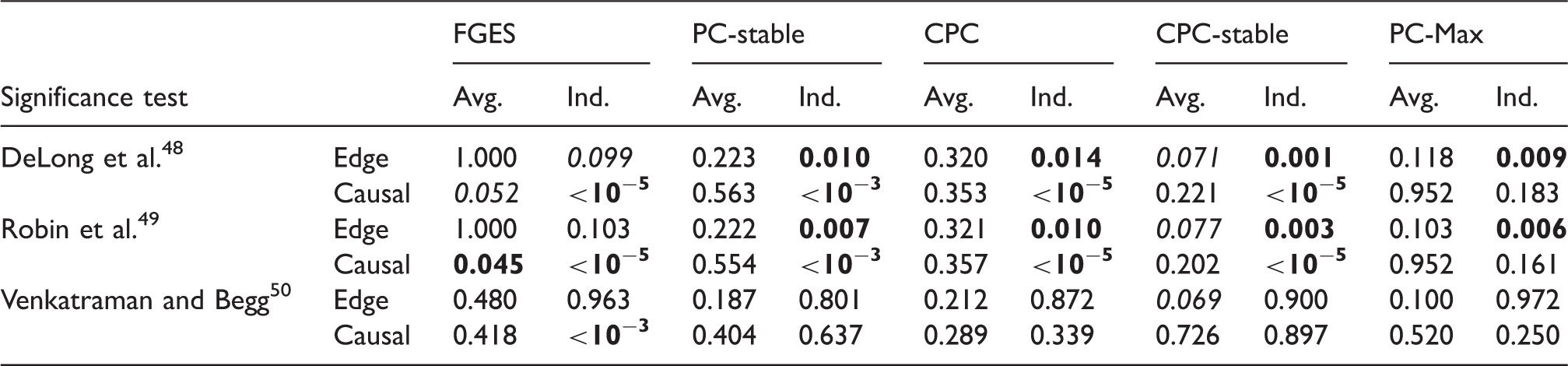
p-Values from comparisons on data set with sample size 400 between S3L and alternative approaches without prior knowledge.
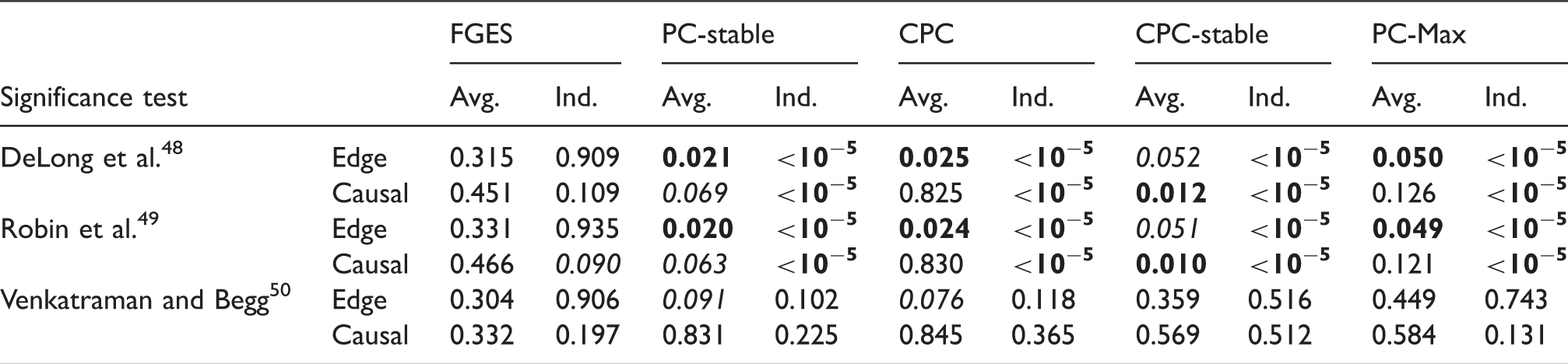
Note: The null hypothesis is that (the AUC of) the ROC curves of S3L and those of alternative approaches are equivalent. For each significance test, we compared the ROC of the edge (Edge) and causal path (Causal) stability (see Figure 5(a) and (b)) on both averaging (Avg.) and individual (Ind.) schemes.
AUC: area under the curve; CPC: conservative PC; FGES: fast greedy equivalent search; ROC: receiver operating characteristic.
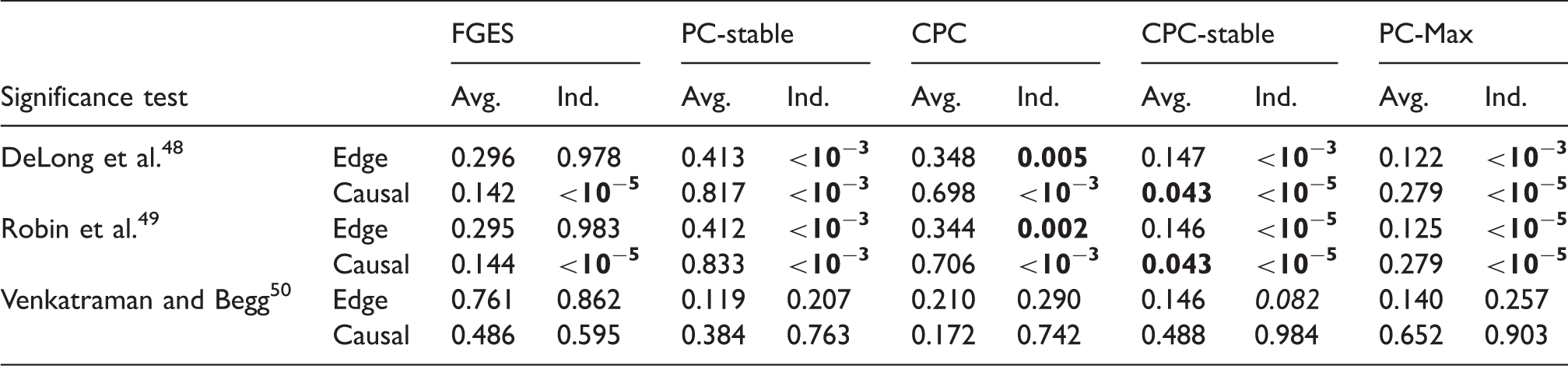
p-Values from comparisons on data set with sample size 400 between S3L and alternative approaches with prior knowledge.
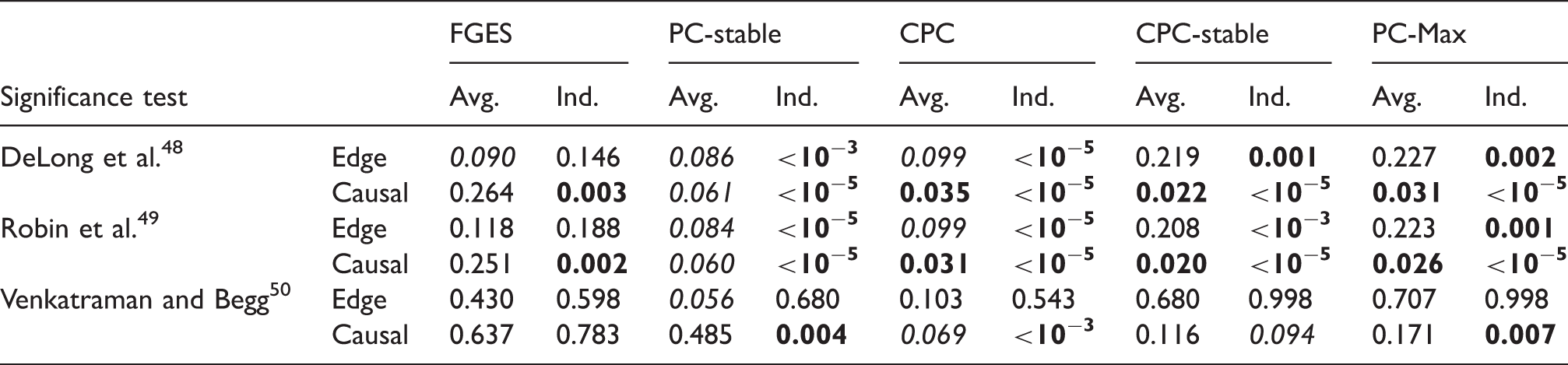
Note: The null hypothesis is that (the AUC of) the ROC curves of S3L and those of alternative approaches are equivalent. For each significance test, we compared the ROC of the edge (Edge) and causal path (Causal) stability (see Figure 5(c) and (d)) on both averaging (Avg.) and individual (Ind.) schemes.
AUC: area under the curve; CPC: conservative PC; FGES: fast greedy equivalent search; ROC: receiver operating characteristic.
Next we discuss the result of our experiments on the data set with sample size 2000. Figure 6 shows the ROC curves and Table 4 lists the corresponding AUCs. Tables 5 and 6 list the results of the significance tests for both the averaging and individual schemes in the experiment with and without prior knowledge, respectively. In the case without prior knowledge, generally the AUCs of the edge and the causal path stability of S3L are better than (p-value Results from simulation data with sample size 2000: ROC curves for (a) the edge stability and (b) the causal path stability (without prior knowledge), and (c) the edge path stability and (d) the causal path stability (with prior knowledge), for different values of AUCs for the edge and causal path stability for each method, from simulation on data with sample size 2000, with (yes) and without prior knowledge (no). AUC: area under the curve; CPC: conservative PC; FGES: fast greedy equivalent search; S3L: stable specification search for longitudinal data. p-Values from comparisons on data set with sample size 2000 between S3L and alternative approaches without prior knowledge. Note: The null hypothesis is that (the AUC of) the ROC curves of S3L and those of alternative approaches are equivalent. For each significance test, we compared the ROC of the edge (Edge) and causal path (Causal) stability (see Figure 6(a) and (b)) on both averaging (Avg.) and individual (Ind.) schemes. AUC: area under the curve; CPC: conservative PC; FGES: fast greedy equivalent search; ROC: receiver operating characteristic. p-Values from comparisons on data set with sample size 2000 between S3L and alternative approaches with prior knowledge. Note: The null hypothesis is that (the AUC of) the ROC curves of S3L and those of alternative approaches are equivalent. For each significance test, we compared the ROC of the edge (Edge) and causal path (Causal) stability (see Figure 6(c) and (d)) on both averaging (Avg.) and individual (Ind.) schemes. AUC: area under the curve; CPC: conservative PC; FGES: fast greedy equivalent search; ROC: receiver operating characteristic.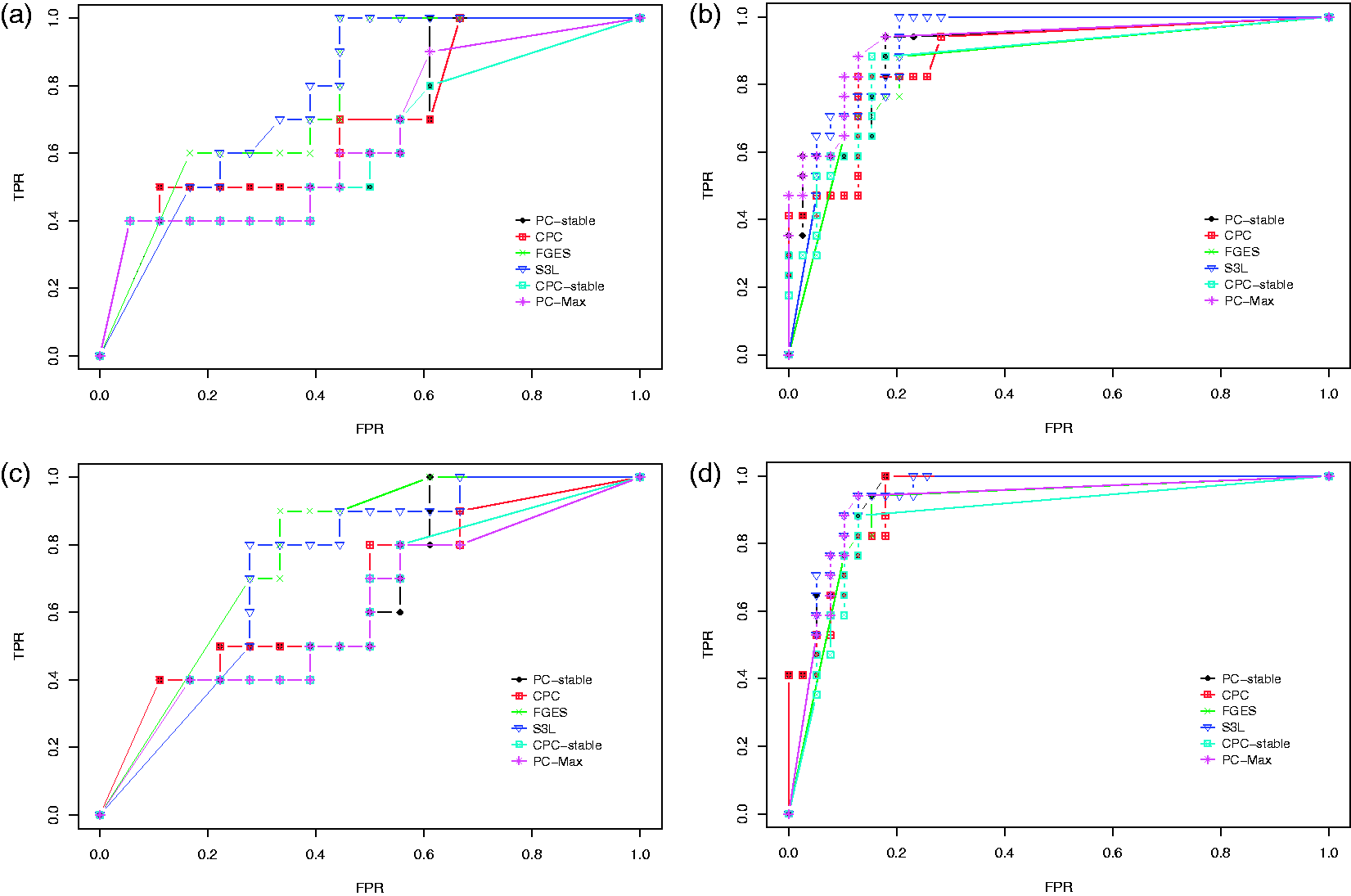

To conclude, we see that in general S3L attains at least comparable performance as, but often a significant improvement over, alternative approaches. This holds in particular for causal directions and in the case of a small sample size. The presence of prior knowledge enhances the performance of the S3L.
3.4 Application to real-world data
Here the true model is unknown, so we can only compare the results of S3L with those reported in earlier studies and interpretation by medical experts. We set the thresholds to
The model assumptions in the application to real-world data follow from the assumptions of S3L in the default setting. The assumptions include iid samples on each time slice, linear system, independent Gaussian noise, no latent variables, stationary, and fairly uniform time intervals between time slices.
Moreover, there is an important note related to the visualization of the stability graphs. A DAG without edges will always be transformed into a CPDAG without edges. A fully connected DAG without prior knowledge will be transformed into a CPDAG with only undirected edges. However, if prior knowledge is added, a fully connected DAG will be transformed into a CPDAG in which the edges corresponding to the prior knowledge are directed. From these observations, it follows that in the edge stability graph all paths start with a selection probability of 0 and end up in a selection probability of 1. In the causal path stability graph when no prior knowledge has been added, all paths start with a selection probability of 0 and end up in a selection probability of 0. However, when prior knowledge is added, some of the paths may end up in a selection probability of 1 because of the added constraints.
3.4.1 Application to CFS data
Our first application to real-world data considers a longitudinal data set of 183 patients with CFS who received cognitive behavior therapy (CBT). 54 Empirical studies have shown that CBT can significantly reduce fatigue severity. In this study, we focus on the causal relationships between cognitions and behavior in the process of reducing subject’s fatigue severity. We therefore include six variables namely fatigue severity, the sense of control over fatigue, focusing on the symptoms, the objective activity of the patient (oActivity), the subject’s perceived activity (pActivity), and the physical functioning. The data set consists of five time slices where the first and the fifth time slices are the pre- and post-treatment observations, respectively, and the second until the fourth time slices are observations during the treatment. The missing data are 8.7%, and to impute the missing values, we used single imputation with expectation maximization (EM) in SPSS. 55 As all of the variables have large scales, e.g., in the range between 0 and 155, we treat them as continuous variables. We added prior knowledge that the variable fatigue at t0 and ti does not cause any of the other variables directly. This is a common assumption made in the analysis of CBT in order to investigate the causal impact on fatigue severity.54,56
First we discuss the baseline model, which only considers the baseline causal relationships. The corresponding stability graphs can be seen in Figure 7(a) and (b). As mentioned before, The stability graphs of the baseline model in (a) and (b) and the transition model in (c) and (d) for chronic fatigue syndrome, with edge stability in (a) and (c), and causal path stability in (b) and (d). The relevant regions, above (a) The baseline model and (b) the transition model of chronic fatigue syndrome. The dashed line represents a strong relation between two variables but the causal direction cannot be determined from the data. Each edge has a reliability score (the highest selection probability in the relevant region of the edge stability graph) and a standardized total causal effect estimation. For example, the annotation “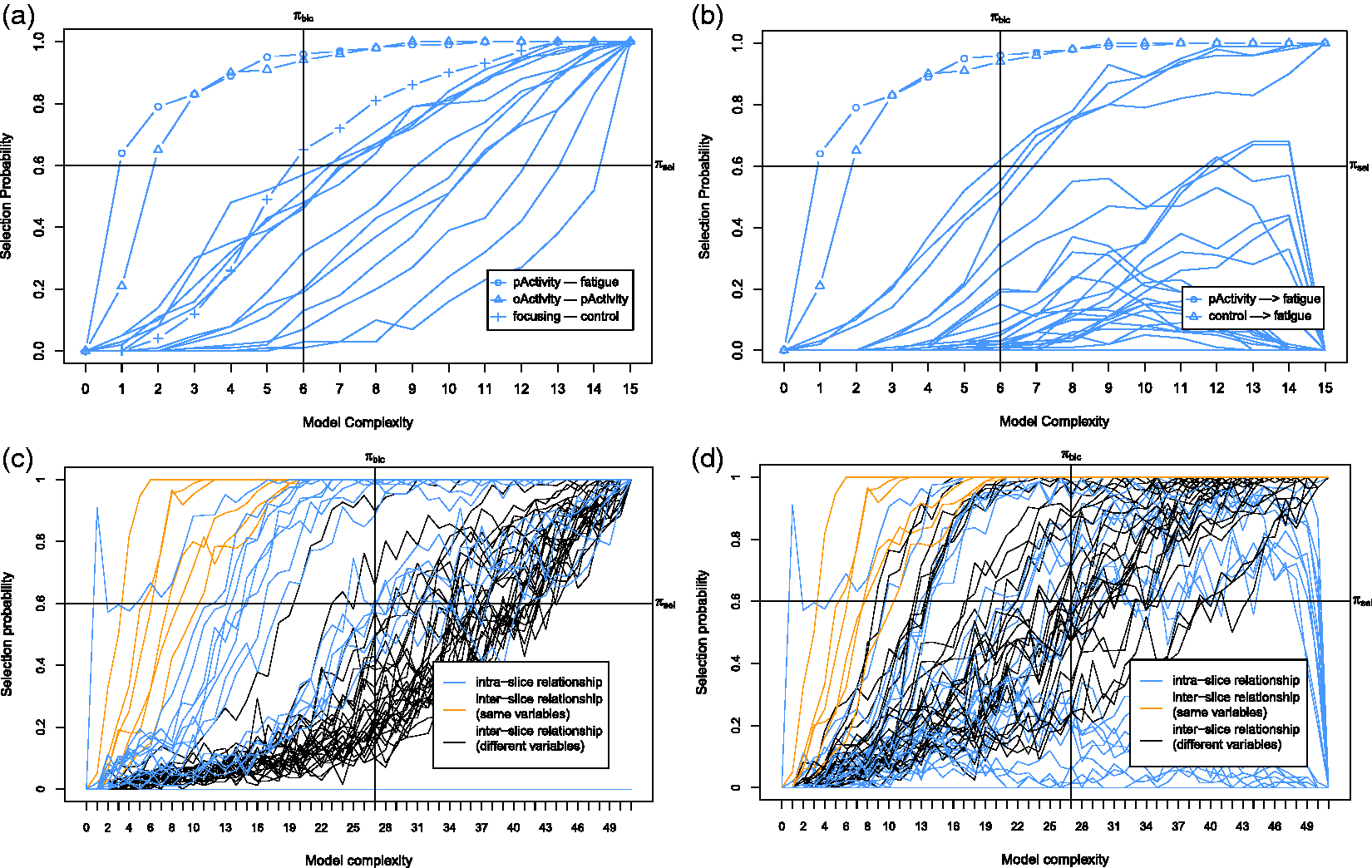
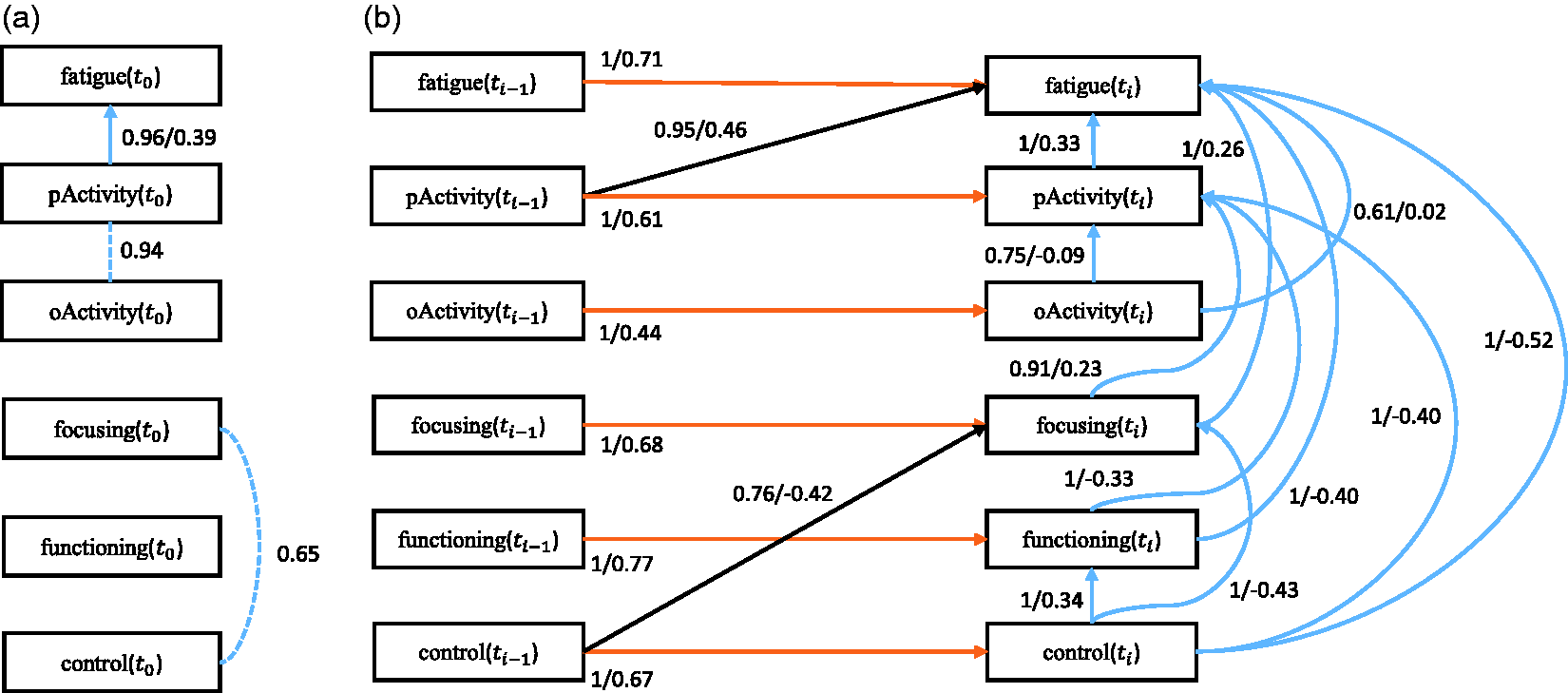
Next we discuss the transition model, which considers all causal relationships over time slices. The corresponding stability graphs are depicted in Figure 7(c) and (d). We set
3.4.2 Application to AD data
For the second application to real-world data, we consider a longitudinal data set about AD, which is provided by the Alzheimer’s Disease Neuroimaging Initiative (ADNI),
58
and can be accessed at
In the present paper, we focus on patients with MCI, an intermediate clinical stage in AD. 59 Following Haight and Jagust 60 we include only the variables: subject’s cognitive dysfunction (ADAS-Cog), hippocampal volume (hippocampal_vol), whole brain volume (brain_vol), and brain glucose metabolism (brain_glucose). The data set contains 179 subjects with four continuous variables and six time slices. The first time slice captures baseline observations and the next time slices are for the follow-up observations. The missing data are 22.9%, and as in the application to CFS, we imputed the missing values using single imputation with EM. We added prior knowledge that the variable ADAS-Cog at t0 and ti does not cause any of the other variables directly. We performed the search over 100 subsamples of the original data set.
First we discuss the baseline model which only considers the baseline causal relationships. The corresponding stability graphs are shown in Figure 9(a) and (b). The stability graphs of the baseline model in (a) and (b) and the transition model in (c) and (d) for Alzheimer’s disease, with edge stability in (a) and (c), and causal path stability in (b) and (d). The relevant regions, above (a) The baseline model and (b) the transition model of Alzheimer’s disease. The dashed line represents a strong relation between two variables but the causal direction cannot be determined from the data. Each edge has a reliability score (the highest selection probability in the relevant region of the edge stability graph) and a standardized total causal effect estimation. For example, the annotation “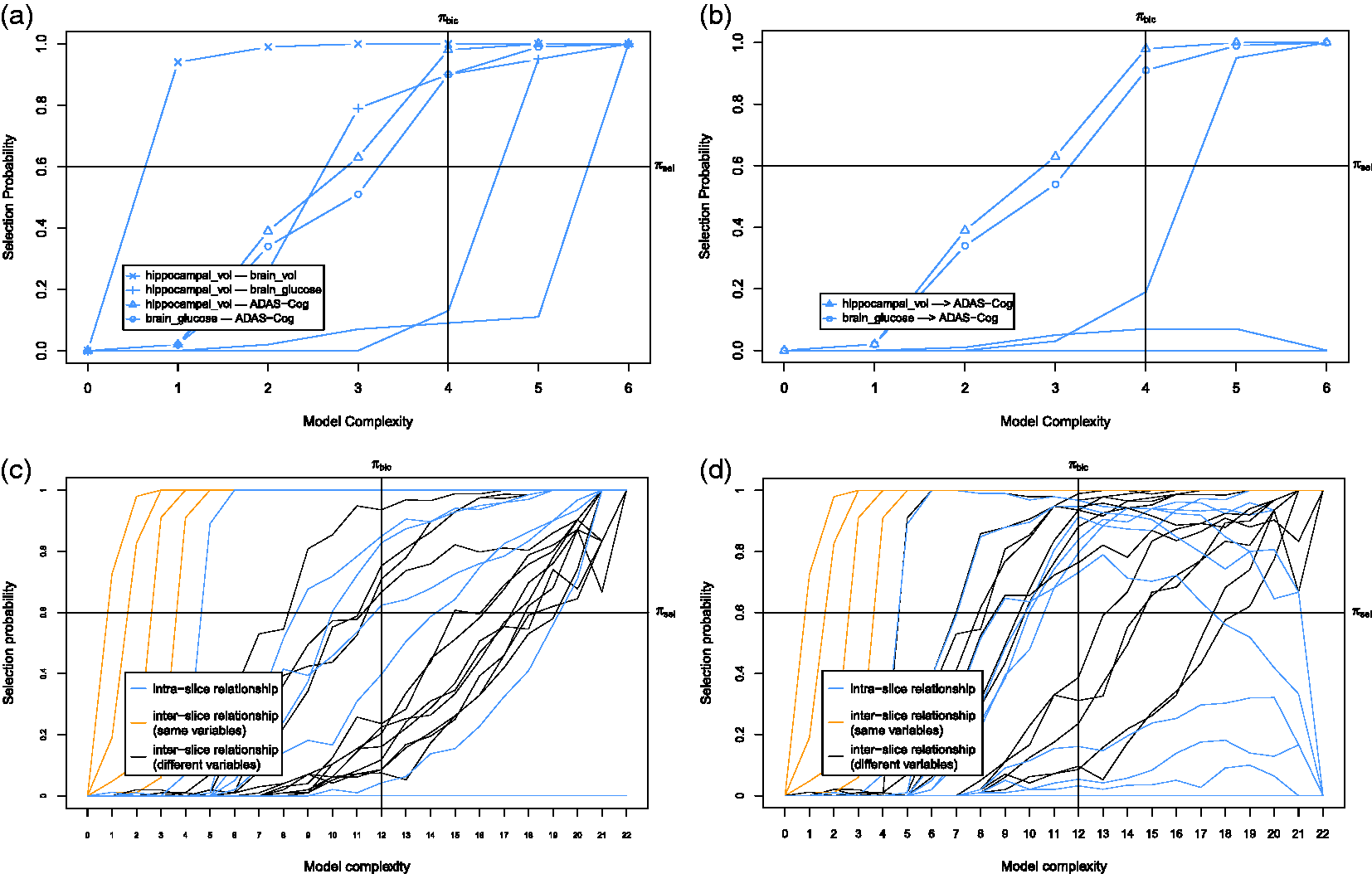
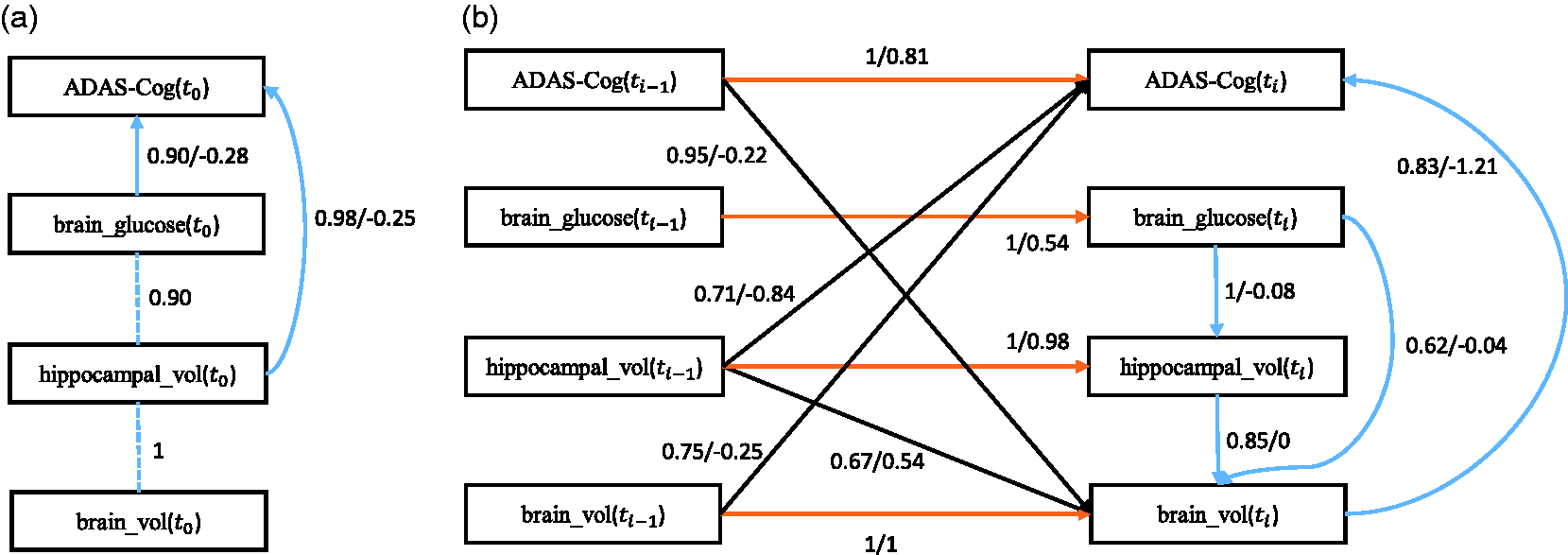
Next we discuss the transition model which considers all causal relationships across time slices. We set
3.4.3 Application to CKD data
For the third application to real-world data, we consider a longitudinal data set about CKD, provided by the MASTERPLAN Study Group. 61 The MASTERPLAN study was initiated in 2004 as a randomized, controlled trial studying the effect of intensified treatment with the aid of nurse practitioners on cardiovascular and kidney outcome in CKD. This intensified treatment regimen addressed 11 possible risk factors for the progression of CKD simultaneously. The study previously showed that this intensified treatment resulted in fewer patients reaching end-stage kidney disease compared to standard treatment. 61
Here we focus on the potential causal mediators for the protective effect incurred by the intensified treatment with the aid of nurse practitioners. In other words, we aim to identify which of the treatment targets contributed to the observed overall treatment effect. In the present analysis, we include only variables of interest, being treatment status, either nurse practitioner aided care or standard care, as allocated by the randomization procedure (treatment), estimated glomerular filtration rate (gfr—a marker for overall kidney function), and a variable indicating informative censoring (inf_cens). Informative censoring occurred when patients reached end-stage kidney disease requiring renal replacement therapy, such as dialysis or a kidney transplantation, or when they died. Furthermore, we considered treatment targets that were previously hypothesized to contribute most to the overall treatment effect: systolic blood pressure (sbp), LDL-cholesterol (ldl) and parathyroid hormone (pth) concentrations in blood, and protein excretion via urine (pcr). In total, there are 497 subjects with 7 variables (both continuous and discrete) over 5 time slices. The first time slice contains the baseline observations taken before treatment, and the next time slices are the follow-up observations during treatment. Particularly, we set the variable treatment only at
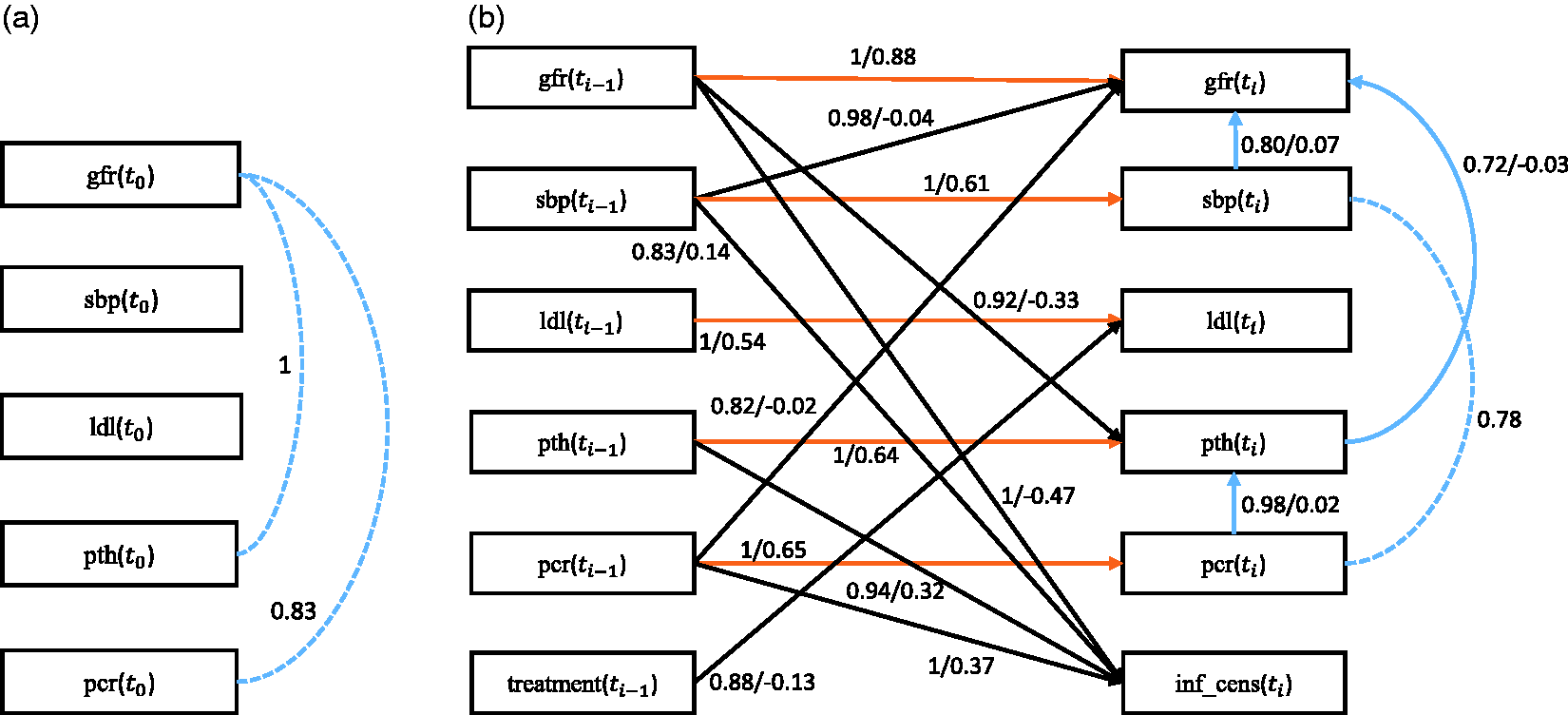
First we discuss the baseline model, which only considers the baseline causal relationships. Figure 11(a) and (b) depicts the corresponding stability graphs. As in applications to CFS and ADNI data, πsel is set to 0.6 and based on the search phase of S3L we found that
Next we discuss the transition model, which takes into account all causal relationships across time slices. We set The stability graphs of the baseline model in (a) and (b) and the transition model in (c) and (d) for chronic kidney disease, with edge stability in (a) and (c), and causal path stability in (b) and (d). The relevant regions, above (a) The baseline model and (b) the transition model of chronic kidney disease. The dashed line represents a strong relation between two variables but the causal direction cannot be determined from the data. Each edge has a reliability score (the highest selection probability in the relevant region of the edge stability graph) and a standardized total causal effect estimation. For example, the annotation “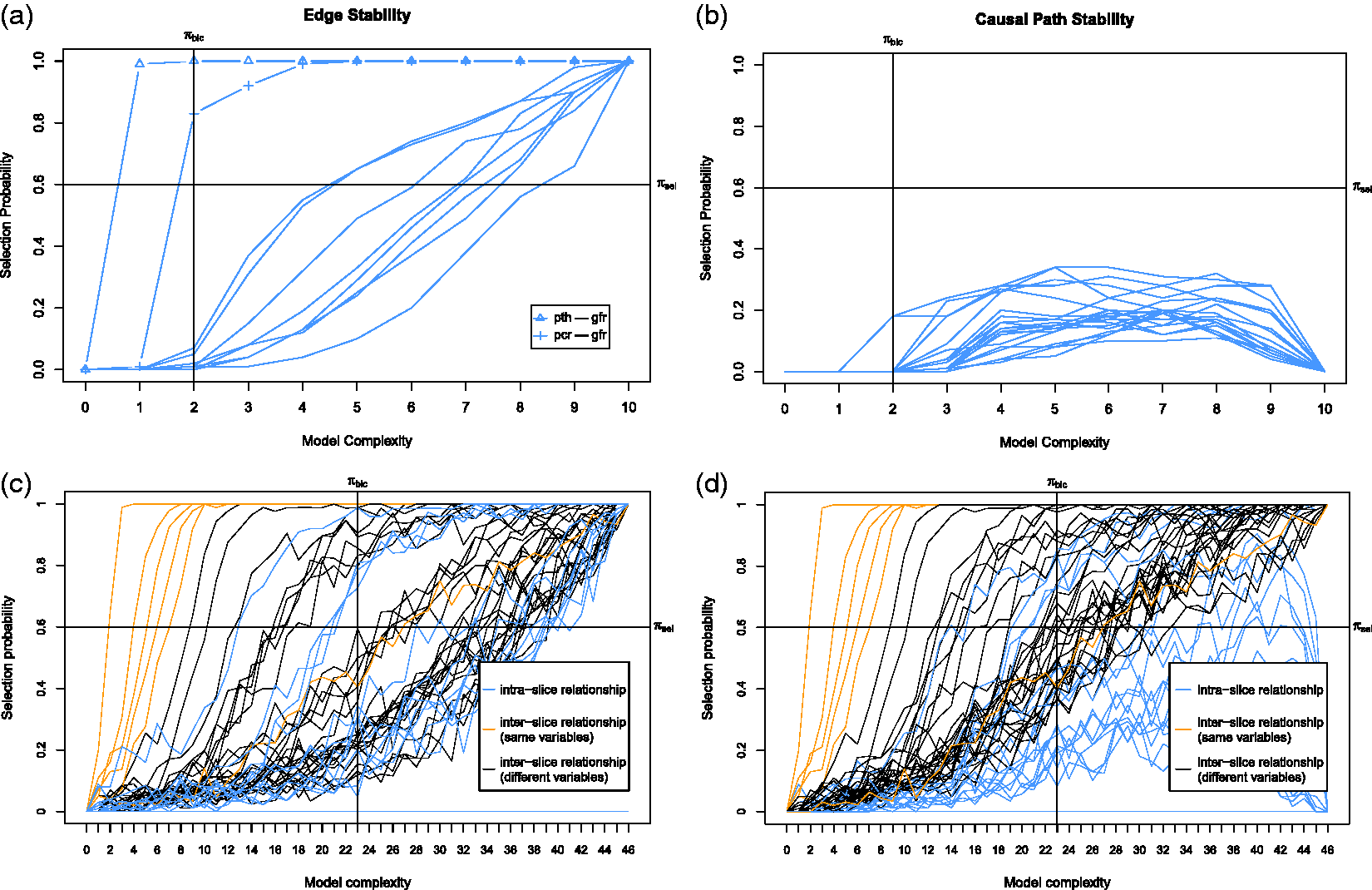
4 Conclusion and future work
Causal discovery from longitudinal data turns out to be an important problem in many disciplines. In the medical domain, revealing causal relationships from a given data set may lead to improvement of clinical practice, e.g., further development of treatment and medication. In the past decades, many causal discovery algorithms have been introduced. These causal discovery algorithms, however, have difficulty dealing with the inherent instability in structure estimation.
The present work introduces S3L, a novel discovery algorithm for longitudinal data that is robust for finite samples, extending our previous method 25 on cross-sectional data. S3L adopts the concept of stability selection to improve the robustness of structure learning by taking into account a whole range of model complexities. Since finding the optimal model structure for each model complexity is a hard optimization problem, we rephrase stability selection as a multi-objective optimization problem, so that we can jointly optimize over the whole range of model complexities and find the corresponding optimal structures. Moreover, S3L is a general framework that can be combined with alternative approaches, without modifying their original assumptions, e.g., linearity, non-Gaussian noise, etc.
The comparison on the simulated data shows that S3L achieves at least comparable performance as, but often a significant improvement over alternative approaches, mainly in obtaining the causal relations, and in the case of small sample size. Moreover, the results of experiments on three real-world data sets are corroborated by literature studies.54,56,57,60,62,64–67
However, the current method considers only longitudinal data with observed variables and cannot handle missing values (other than through imputation as a preprocessing step). We also still assume that the time intervals between time slices are fairly uniform between subjects. Some existing approaches called random-coefficient models, also termed multi-level or hierarchical regression models,68,69 are flexible to handle unequal intervals between time slices within a subject and/or across subjects. Future research will aim to account for these aforementioned issues.
Footnotes
Acknowledgements
The authors wish to thank Thaddeus J Haight, Falma Kemalasari, Joseph Ramsey, and two anonymous referees for their valuable discussions, comments, and suggestions.
The OPTIMISTIC Consortium comprises:
The MASTERPLAN Study Group comprises: Arjan D van Zuilen, Peter J Blankestijn, Department of Nephrology, University Medical Center Utrecht, Utrecht. Michiel L Bots, Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht. Marjolijn van Buren, Louis-Jean Vleming, Department of Internal Medicine, Haga Hospital, The Hague. Marc AGJ ten Dam, Department of Internal Medicine, Canisius Wilhelmina Hospital, Nijmegen. Karin AH Kaasjager, Department of Internal Medicine, Rijnstate Hospital, Arnhem, Gerry Ligtenberg, Dutch Health Care Insurance Board, Diemen. Yvo WJ Sijpkens, Department of Nephrology, Leiden University Medical Center, Leiden. Henk E Sluiter, Department of Internal Medicine, Deventer Hospital, Deventer, Peter JG van de Ven, Department of Internal Medicine, Maasstad Hospital, Rotterdam. Gerald Vervoort, and Jack FM Wetzels, Department of Nephrology, Radboud University Nijmegen Medical Centre, Nijmegen.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the DGHE of Indonesia as well as by the European Community’s Seventh Framework Programme (FP7/2007–2013) under grant agreement no. 305697. The collection and sharing of brain imaging data used in one of the applications to real-world data was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai, Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer, Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (![]() ). The Grantee Organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Disease Cooperative Study at the University of California, San Diego. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
). The Grantee Organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Disease Cooperative Study at the University of California, San Diego. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.