
Abstract
Many studies measure the same type of information longitudinally on the same subject at multiple time points, and clustering of such functional data has many important applications. We propose a novel and easy method to implement dissimilarity measure for functional data clustering based on smoothing splines and smoothing parameter commutation. This method handles data observed at regular or irregular time points in the same way. We measure the dissimilarity between subjects based on varying curve estimates with pairwise commutation of smoothing parameters. The intuition is that smoothing parameters of smoothing splines reflect the inverse of the signal-to-noise ratios and that when applying an identical smoothing parameter the smoothed curves for two similar subjects are expected to be close. Our method takes into account the estimation uncertainty using smoothing parameter commutation and is not strongly affected by outliers. It can also be used for outlier detection. The effectiveness of our proposal is shown by simulations comparing it to other dissimilarity measures and by a real application to methadone dosage maintenance levels.
1 Introduction
Clustering sets out to find groups of subjects based on several different characteristics, where subjects within a cluster are considered to be similar based on the given characteristics. The degree of similarity and dissimilarity can be defined in many ways, and there are many clustering methods, including hierarchical clustering, k-means, DBSCAN, etc. Berkhin 1 gives an overview of both partition-based and hierarchical clustering methods, Bouveyron and Brunet-Saumard 2 review popular partition-based methods for high-dimensional data, and Murtagh and Contreras 3 review several hierarchical clustering algorithms, see also Hennig et al. 4 A bottom-up hierarchical method does not require any statistical model assumption, rather only a linkage method by which two clusters are merged at each step of the hierarchical agglomerative process. This process can be displayed by a dendrogram from which clusters are obtained. However, once merged, clusters cannot be separated at the next step. Partition-based methods, in contrast, partition subjects into a desired number of clusters, which needs to be specified. The cluster assignment of subjects for one number of clusters for these methods does not restrict cluster assignments for other numbers of clusters.
In many situations, the same type of information on the same subject is measured at multiple time points. To cluster such data, one should take into account the data format and the temporal order structure. Data of each subject are often collected at unequally spaced time points. As a result of aligning records into a conventional ‘variable-by-variable’ format, there are many ‘empty’ records at regular time points. Those empty records can be regarded as a kind of ‘missing’ value. In addition, even if all subjects were observed at the same time points, conventional clustering fails to take into account the temporal order structure of variables, on which adjacent measurements for the same subject are expected to have similar values. Functional data clustering exists for grouping such data. Three major categories for functional data clustering are dissimilarity-based methods, decomposition-based methods and model-based methods.
Dissimilarity-based methods, using pointwise dissimilarities between pairs of subjects, are the most straightforward approach.5–7 These methods often take care of data format and time coordinates by certain curve smoothing or imputation techniques, and subsequently dissimilarities between subjects are computed to which the conventional dissimilarity-based methods can be applied. Little attention, however, has been paid to the uncertainty of smoothing or imputation. To the best of our knowledge, the only two exceptions are (a) a prediction-based approach of Alonso et al. 8 that was modified by Vilar et al., 9 and (b) a hypotheses-testing-like approach of Maharaj. 10 The former is computationally intensive and the latter is designed for invertible ARMA processes, which restricts their application.
Decomposition-based methods overcome the issue of smoothing and sequential order by transforming the observed data into a finite series of common features. These procedures deal with the uncertainty of smoothing implicitly. For example, Abraham et al. 11 used spline basis functions, James et al. 12 used functional principal component analysis, and Warren Liao 13 reviewed more sophisticated ‘feature-extraction’ algorithms. These approaches define common features for all groups and then assign weights to features by which groups are identified. Each group has different weights on those features, and each group can be interpreted according to its lower-dimensional projection on features. Features extracted from certain transformations of data are also popular, such as spectral densities, 14 periodograms15,16 and permutation distributions. 17 Nonetheless, in reality, not all groups share the same number of features, and it is not easy to determine an appropriate number of dimensions.
In light of the difficulties encountered by the first two methods, many researchers suggest the third alternative: various model-based frameworks. They estimate individual underlying curves and cluster subjects simultaneously, and then statistical inference can be made based on the working models for clusters, such as measuring the uncertainty for cluster assignment and ‘within-cluster’ variation. Unfortunately, these approaches encounter other challenges. Purely parametric functional forms as used in Jones and Nagin 18 may not be realistic, and its assumption of subjects sharing the same ‘underlying’ curve within a group can be too restrictive. Applying semi- or non-parametric methods usually requires some dimension reduction within each group (e.g. FCM, 19 funHDDC, 20 Funclust 21 and K-centre 22 ), which encounters a similar problem as decomposition-based methods. A pure likelihood-based framework (without dimension reduction) called longclust is proposed by McNicholas and Murphy. 23 This method is limited to short time series and breaks down easily due to the curse of dimensionality. Even worse, the notion of distribution for random functions is not well-defined as curves could have infinite dimensions. 24
We have reviewed the strengths and weaknesses of the existing functional data clustering methods. Moreover, it is worth mentioning the dilemma resulting from curve variability. Clustering curves can be a difficult ‘chicken-and-egg’ problem between (a) how to determine the within-cluster variations before identifying subgroups, and (b) how to separate subgroups when within-cluster variations are unknown. This dilemma is related directly to the smoothing uncertainty problem in dissimilarity-based approaches. Decomposition- and model-based approaches estimate such variability with necessity, but the magnitude of the estimate is often distorted when outliers occur. A two-step strategy exploiting relative merits of different methods seems reasonable: initially separate potential outliers based on an ‘outlier-invariant’ pairwise dissimilarity, and then form main clusters with another appropriate clustering method. For such a strategy, a dissimilarity measure concerning the variability of curve estimation or feature selection is crucial.
In this article, we develop an easily implementable and practically advantageous dissimilarity measure between subjects. The curve smoothing used here is based on the technique of smoothing splines, which is completely determined by the chosen smoothing parameter. With an infinite smoothing parameter, the curve is estimated as a straight line, while the curve interpolates the observed data with a zero smoothing parameter. The innovation of our method is to measure the dissimilarity between subjects based on pair-by-pair varying curve estimates for a subject. The concepts are that (a) smoothing parameters of smoothing splines reflect the inverse of the signal-to-noise ratios and (b) the estimated curves for two similar subjects are expected to be close if an identical smoothing parameter is applied to both sets of observations. Specifically, if the unobserved true curves of subjects i and j are similar, their curve estimates should resemble with each other, no matter whether we use a smoothing parameter primarily for the i-th or the j-th subject. Our dissimilarity is then calculated through commuting between the smoothing parameters for a pair.
The rest of the article is organized as follows. Section 2 describes the proposed Smoothing Parameter Commutation dissimilarity and some of its properties. Its effectiveness is shown through simulations comparing to other dissimilarity measures in Section 3. An example of its application to methadone dosages observations is given in Section 4, where we also identify outliers with a simple but efficient method. Finally, Section 5 provides some concluding remarks and discussion concerning future directions.
2 Method
2.1 Smoothing splines
We utilize the smoothing spline to estimate curves of subjects. Assume that the curve of the i-th subject is observed as a set of measurements
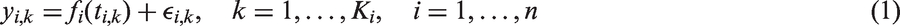
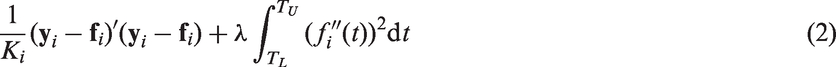

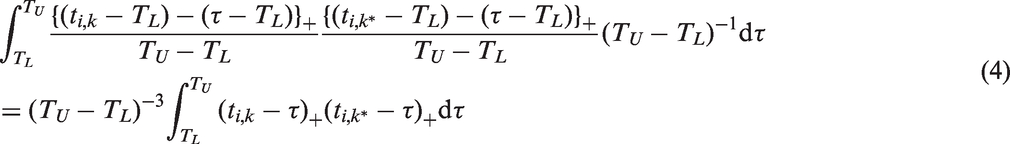
For any given
2.2 Smoothing Parameter Commutation dissimilarity
The concept of our method is that if the ‘true’ fi and fj are similar, it is expected that
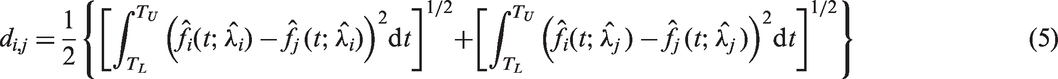
Due to the roles of
Our proposal has several advantages. First, data observed at irregular time points can be handled directly, because of the nature of smoothing splines. Second, the dissimilarity also serves as a useful tool for outlier detection (see Section 4). Third, the implementation is handy since subroutines for smoothing splines and numerical integration are widely available. Although the computational burden for (5) seems heavy at first glance, it can be done quite efficiently among n subjects. Given λ, a fast
3 Simulation study
We conduct a simulation to investigate whether our proposed Smoothing Parameter Commutation measure is more capable than other dissimilarity measures when observations are contaminated with (independent or dependent) noises. If an analyst is interested in the relative shape patterns of curves, regardless of shift, shrinkage, expansion or magnitude, then several alignment, normalization and warping tools can be applied in preprocessing.32–34 In order to not lose focus, we do not consider dissimilarity measures engaging with the preprocessing.
We consider the following four random curve models over
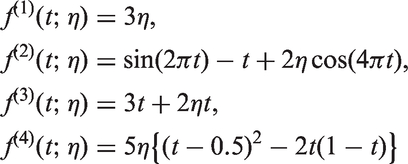
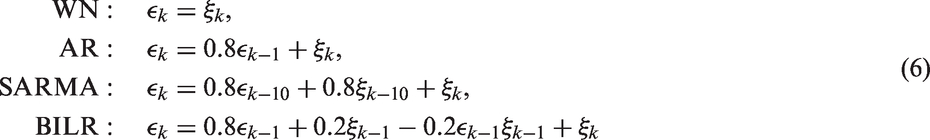
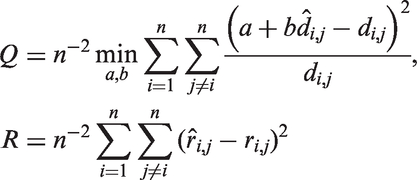
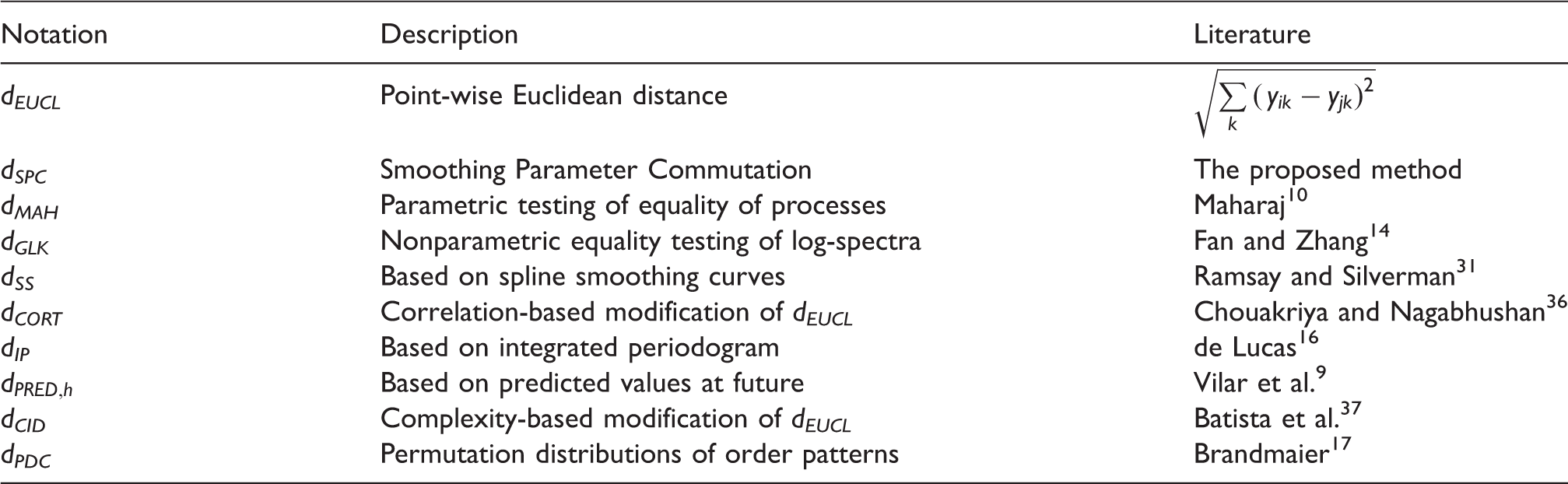
Dissimilarity measures to be compared.
Averaged Q-values over 200 simulated replicates among 10 dissimilarity measures for each combination of f and εk (with 10 random curves), and all the 160 curves.
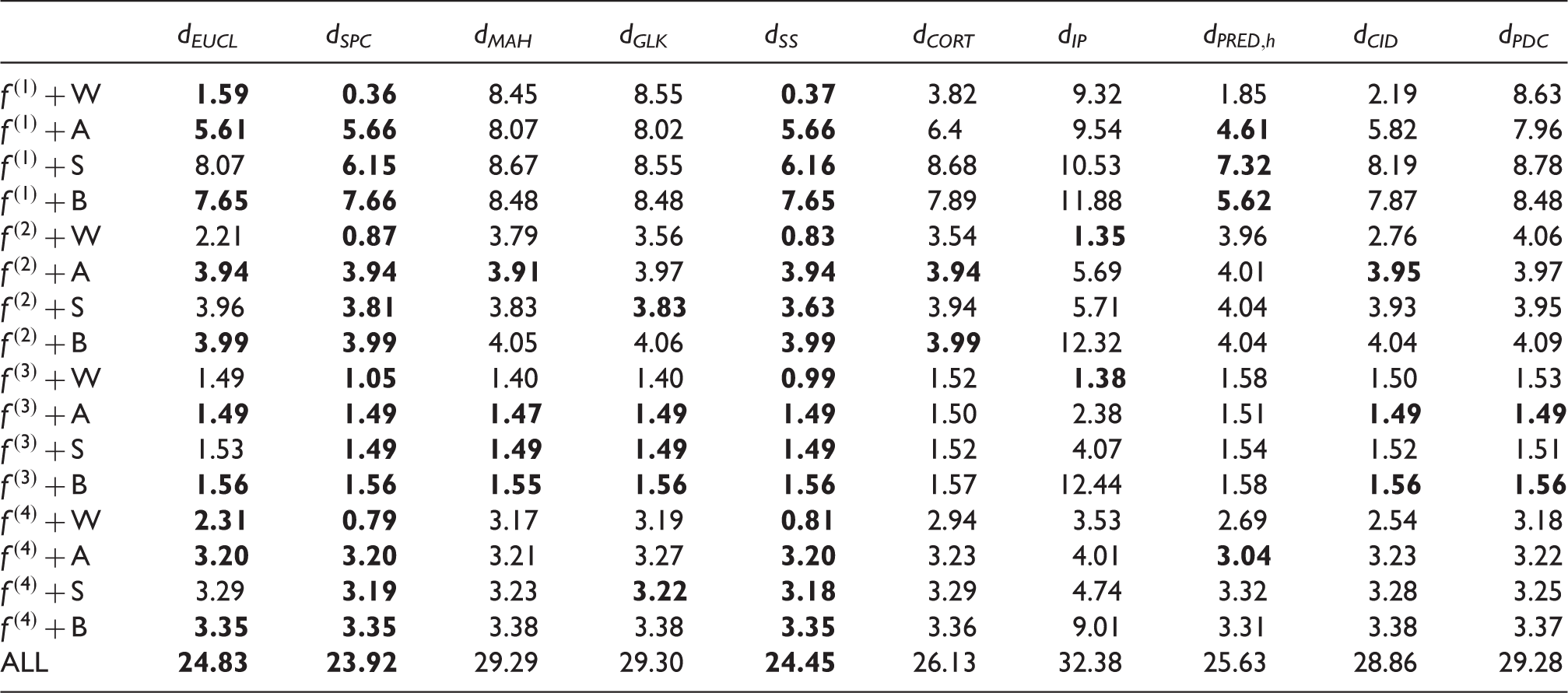
W, A, S and B in the first column stand for WN, AR, SARMA and BILR in (6), respectively. Bold digits are the best 3 within each row.
Averaged R-values over 200 simulated replicates among 10 dissimilarity measures for each combination of f and εk (with 10 random curves), and all the 160 curves.
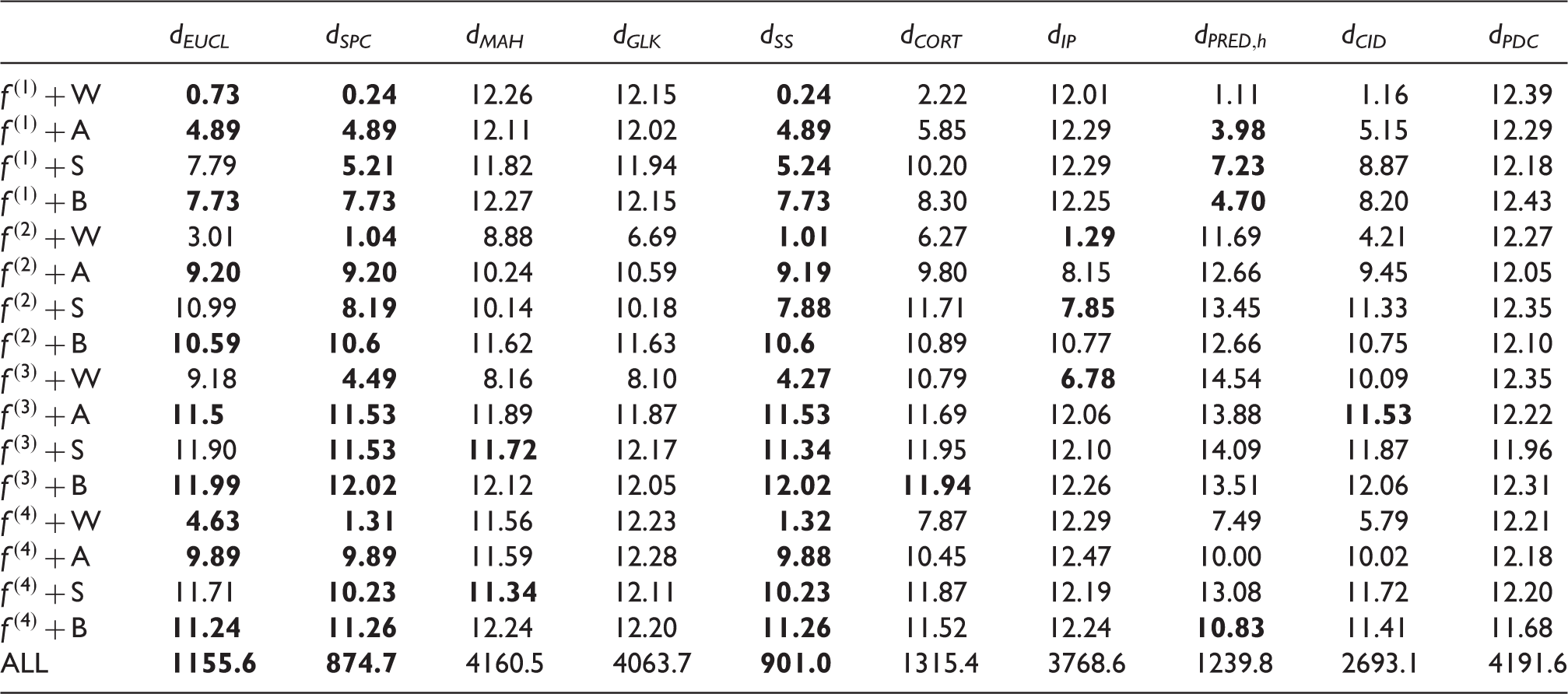
W, A, S and B in the first column stand for WN, AR, SARMA and BILR in (6), respectively. Bold digits are the best 3 within each row.
The Q value is a loss function based on the best affine approximation, which measures how close optimally linearly transformed dissimilarity measures are to the true dij. Obviously, this would be a good feature for a dissimilarity measure in such cases, but one may argue that achieving this is not the aim of some of the measures listed in Table 1, so we propose alternative measures, see below. Q favours Euclidean distance based dissimilarities. R measures by and large the same feature but does not rely on metric approximation. Note that in areas of high density of curves small changes in the metric approximation quality can lead to much larger changes in ranks, so that differences in R are often much clearer than differences in Q. In any case, the two comparison criteria are highly coherent in that they almost always detect the same best and worst measures. As expected, without missing data, dEUCL is often among the best measures and it looks unbiased for estimating the true distance between curves in many situations. But it does not do well enough if the signal or noise is periodic (
Averaged measures over 200 simulated replicates among 10 dissimilarity measures for four groups of f among all the 160 curves.

Digits in parentheses are the standard errors.
4 Real data application with outlier detection
We apply dSPC defined in (5) to a methadone maintenance therapy dataset analysed in Lin et al. 41 Daily methadone dosages in milligrams (mg) for 314 participants between 01 January 2007 and 31 December 2008 were collected. Dosage records for each patient from day 1 to 180 were used for clustering. Lin et al. 41 categorized the dosages into seven levels, one of which is for missing values, and proposed a dissimilarity measure for clustering such ordinal data with extra missingness category. The ordering of time coordinates, however, was ignored in their approach. In this example, we use the daily dosage taken by patients, and do not recode missing values separately. Smoothing splines take care of the irregular follow-up time points of patients automatically, which may not be an easy task for some other measures listed in Table 1.
Real data, inevitably, are prone to have outliers. Garcia-Escudero et al. 42 give an overview of the impact of outliers on clustering and some approaches to deal with them. A clustering procedure with outlier removal consists of three steps: (a) calculating the dissimilarity matrix, (b) detecting and removing outliers and (c) grouping the remaining subjects into a desired number of clusters. An outlying curve in functional data is not only one with a few unusual high or low measurements, but also one that has an overall atypical magnitude or shape. Hubert et al. 43 distinguish the former as ‘isolated outlier’ and the latter as ‘persistent outlier’. Among ‘persistent outliers’, Hyndman and Shang 44 call curves lying outside the range of the vast majority of the data ‘magnitude outliers’ and call those having a very different shape from other curves ‘shape outliers’. Much research has been done on detection of persistent outliers.
Some work exploits the notion of data depth for sorting subjects into layers with a more outward layer more likely to be atypical (first proposed by Tukey 45 ; see Gervini 46 and Hubert et al. 43 for an overview in the functional setting), often equipped with a functional boxplot as a visualization tool. Some methods rely on robust functional principal components,47,48 which brings about various visualization tools such as bagplots and highest-density-region boxplots. 44 While most of the above focus on magnitude outliers, Arribas-Gil and Romo 49 propose the ‘outliergram’ to detect shape outliers as well as magnitude outliers. Other methods deal with phase heterogeneity relating to warping and alignment preprocessing,50,51 which is beyond the scope of this work.
The aforementioned methods regard outliers as subjects that are very different to the majority. Alternatively, Ramaswamy et al. 52 propose a dissimilarity-based outlier detection method considering the dissimilarity to nearest neighbours. Their outlier definition is that outliers are those with no or only so few subjects nearby that these could not be interpreted as forming a relevant cluster. This method has been shown to be effective in the pattern recognition literature.53,54 The difficulty in applying it to functional data is the construction of an appropriate dissimilarity, which is the main theme of the present study. By virtue of the good performance of dSPC in the previous section, we consider a dissimilarity-based outlier detection method similar to Ramaswamy et al. 52 We obtain a pairwise dissimilarity matrix based on (5), and calculate the average dissimilarity of each participant to their k nearest neighbours. The minimum size of clusters to be meaningful (k should be this size minus one) in principle depends on the application and the size of the dataset. Averaging the dissimilarities to the nearest neighbours implies that a collection of up to k subjects needs to be further away from the remaining subjects in order to be considered outliers than a single isolated subjects, because a single isolated outlier forms an even less relevant pattern. Note that in cluster analysis with outliers, there is an essential ambiguity about whether a small group of atypical subjects is a cluster on its own, or rather a group of outliers, see Garcia-Escudero et al. 42 Therefore, outlier detection methods in clustering will always require some tuning of this kind.
Two participants had average dSPC values to the three nearest neighbours as 498 and 989, while the others had values between 34 and 282. The two participants were, therefore, considered as potential outliers. We assess the outlyingness of observations visually, using boxplots, without the need of involving formal model assumptions. Figure 1 shows the average dissimilarities to k nearest neighbours, where Distribution of the averaged dissimilarity dSPC to the nearest k neighbours, where 
Hennig and Lin
55
used a flexible parametric bootstrap method to assess the number of clusters for the data in Lin et al.
41
The PAM solutions between 2 and 20 clusters were compared regarding the average silhouette width
40
and the prediction strength.
56
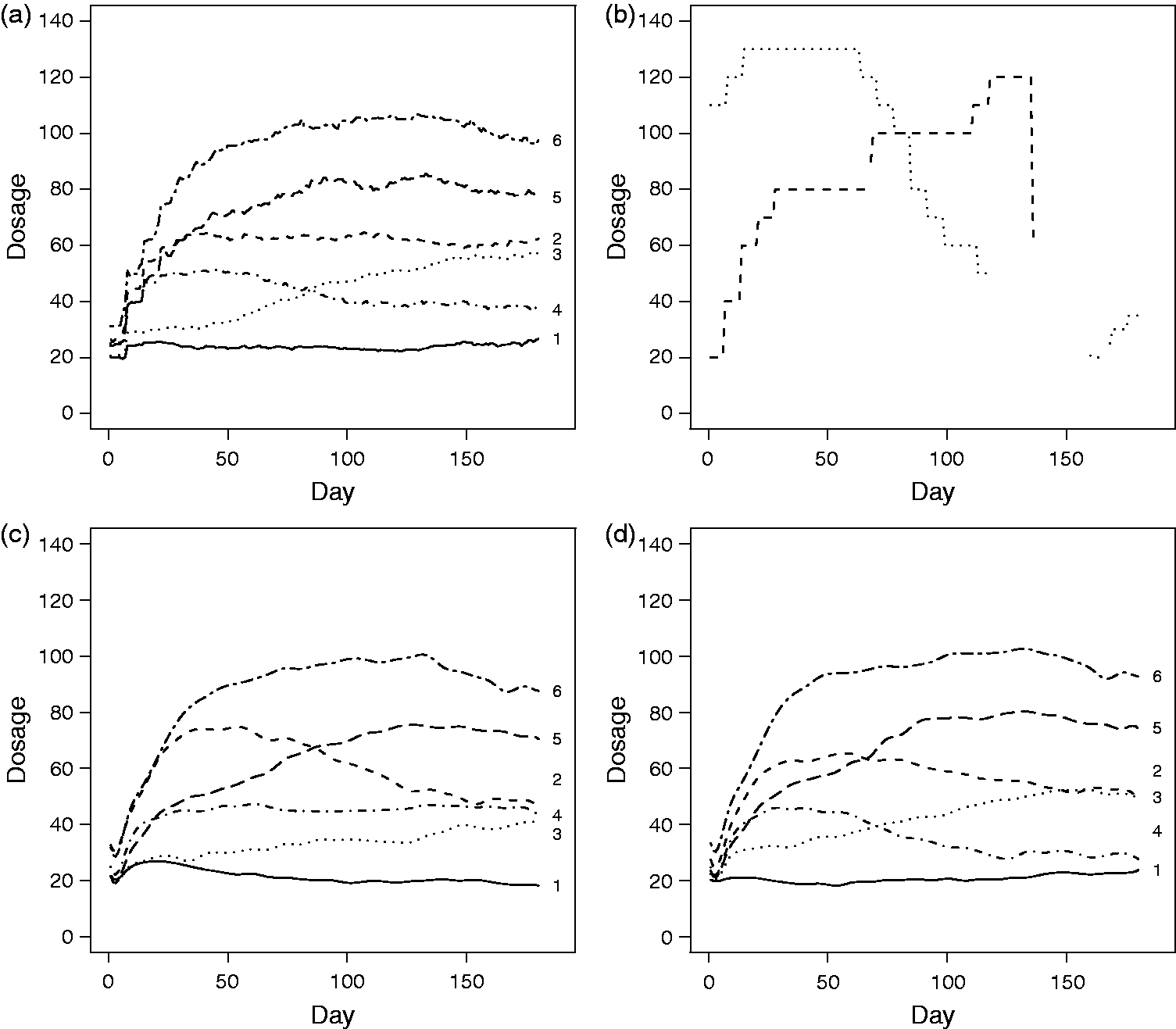
This suggested either five or six clusters. We use PAM with six clusters and use the adjusted Rand index to measure the similarity between clusters found in our study. We excluded the two outlying participants and applied PAM with six clusters to the pairwise dSPC matrix of the 312 participants. Figure 2 shows the clustering result. Each horizontal line represents a dosage curves from day 1 to 180. Figure 3(a) shows the average dosage of each cluster. As seen, Groups 1 and 2 are more stable, remaining at dosages in [10,40] and [40,80], respectively. Group 3 has an upward trend while Group 4 has a downward trend, and their average dosages represented by the two curves cross around day 85. Group 5 goes up quickly and stays at dosage of around 80 mg. Although Group 6 has a similar trend to Group 5, it fluctuates heavily over a larger range and looks less stable. Overall, these figures indicate that a patient with early higher dosage taken (roughly above 60 mg before day 45) does not tend to reduce the level afterwards, and a monitoring between the second and third month can be critical.
Subgroups from PAM clustering of the 312 patients in methadone maintenance therapy. (a): Curves of average dosage of the six groups obtained from PAM and the pairwise dissimilarity matrix in Figure 2; (b) dosage profiles of the two potential outliers; (c) mean profiles of a model-based clustering method including outliers; (d) mean profiles of the model-based clustering method excluding outliers.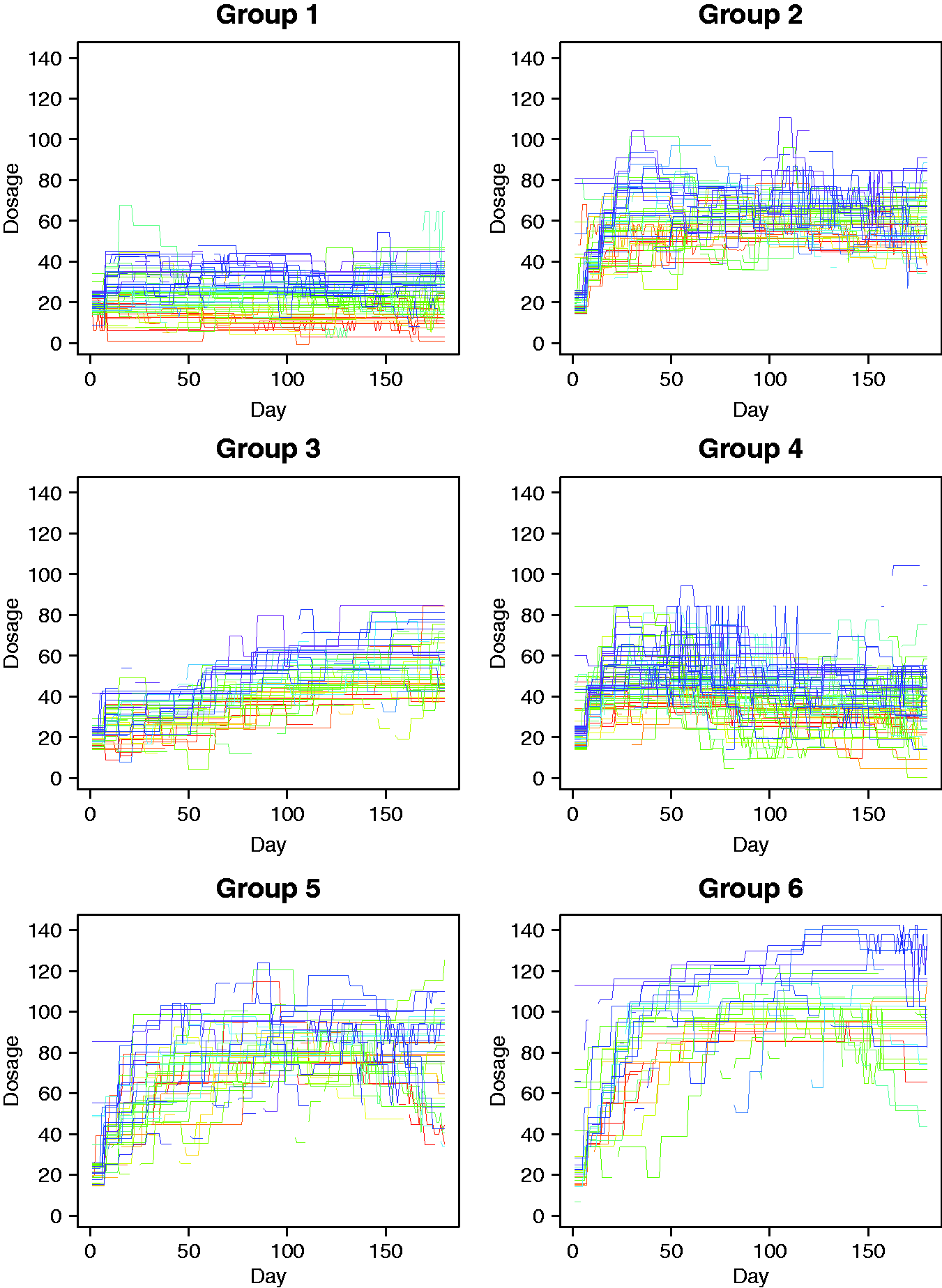
Results based on \a model-based functional data clustering are also given for reference. We used the ‘funcit’ function in the ‘funcy’ package 57 on the Comprehensive R Archive Network (CRAN; R Core Team 58 ). The model option of ‘funcit’ is set to be ‘iterSubspace’, i.e. an implementation of the algorithm in Chiou and Li. 22
The ‘funcy’ package integrates several model-based clustering methods for functional data, but most of them require regular measurements and do not fit the methadone dosage example with many missing values. The only two methods of the package allowing irregular measurements are ‘fitfclust’ and ‘iterSubspace’, and we used the latter because of the length of time and amount of memory needed to run one iteration.
Profiles of the two aforementioned potential outliers are shown in Figure 3(b). The theoretical mean profiles of clusters obtained from the model-based clustering with and without outliers are shown in Figure 3(c) and (d), respectively. Excluding the two outliers improved the model-based method in the sense that the average dissimilarity to the mean profile was reduced by 7.6% from 166.7 to 154.9, which yielded more compact clusters. It seems inappropriate to assign the two outlying curves into the found groups. Enforcing their inclusion will exaggerate the within-group variation, no matter which groups they are assigned to. Then the boundaries of groups are more blurred, and the mean profiles are less representative of their groups.
We also applied the outliergram
49
for outlier detection. Five outliers were detected. Two of them were the same participants as identified by our method shown in Figure 3(b), confirming their outlyingness. The two grey curves in Figure 4 were clustered as Group 4 in Figure 2 but are detected as outlier by the outliergram because of an atypical downward trend, and the black solid curve was in Group 6. For applications where both magnitude and shape heterogeneities are important, our method taking into account both is preferred. In situations where separation is important, the outliergram may be more suitable.
Dosage profiles of the five potential outliers identified by using outligram.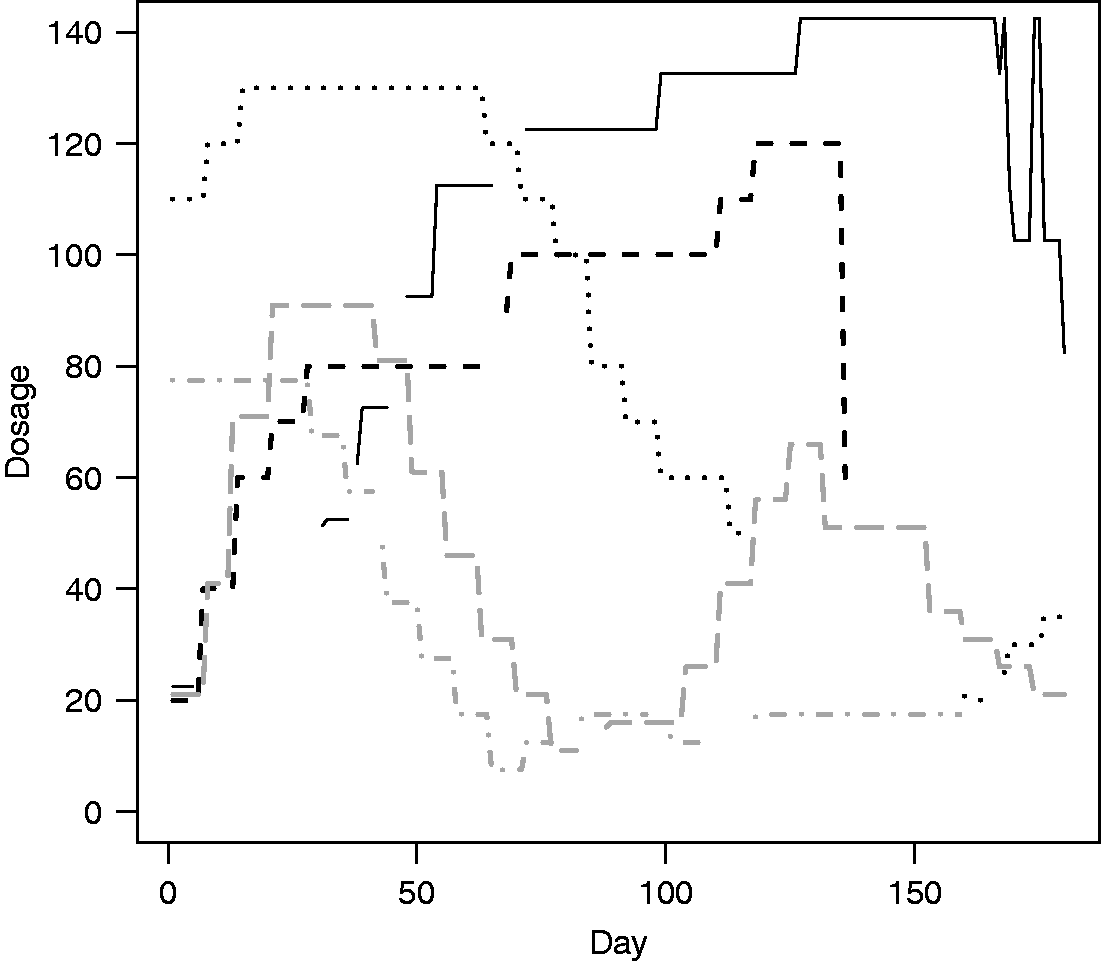
Identifying outliers in model-based clustering is hard, because the assessment of outlyingness depends on the model fit, which in turn is based on the outlying subjects (see Garcia-Escudero et al. 42 for various iterative approaches for doing this, which depends on some initialization). In contrast, in dissimilarity-based clustering, outliers can be identified based on the dissimilarities alone, without having to rely on knowing the clusters. The simulations above show a strong and stable performance of the proposed dissimilarity. It can also be used for a beneficial pre-cleaning step for model-based clustering.
5 Conclusion and discussion
We have shown that the proposed Smoothing Parameter Commutation dissimilarity is good at reproducing the true distances between noiseless curves that change gradually. On the real dataset, dissimilarity-based clustering on smoothed data is superior to model-based clustering under specific time series assumptions. The concept of the proposed dissimilarity measure is simple and easy to implement. We also demonstrated a simple method for outlier detection that helps model-based functional data clustering to form more compact subgroups.
There are many nonparametric regression methods other than smoothing splines, e.g. local polynomial regressions and wavelet analysis. Different techniques stand out in different situations. It is of interest to study whether there exist analogous parameter commutation operations and with similar advantages when applying other nonparametric regressions. This direction is left as a future work.
Footnotes
Acknowledgements
The authors thank the two anonymous reviewers and the editor for their helpful comments on improving the paper. The authors also thank Dr. Chieh-Liang Huang in China Medical University Hospital for permission to use the methadone dosage data.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: ST was supported in part by Taiwan Ministry of Science and Technology grant MOST103-2118-M-001-007-MY3. CH was supported by Engineering and Physical Sciences Research Council Grant EP/K033972/1. Y-FL was supported in part by China Medical University (grant CMU105-S-49) and Taiwan Ministry of Science and Technology (grant MOST 104-2314-B-039-037). CL was supported by Medical Research Council (grant number MC_UP_1302/4) and Cancer Research UK (grant number C48553/A18113).