
Abstract
Statistical approaches for estimating treatment effectiveness commonly model the endpoint, or the propensity score, using parametric regressions such as generalised linear models. Misspecification of these models can lead to biased parameter estimates. We compare two approaches that combine the propensity score and the endpoint regression, and can make weaker modelling assumptions, by using machine learning approaches to estimate the regression function and the propensity score. Targeted maximum likelihood estimation is a double-robust method designed to reduce bias in the estimate of the parameter of interest. Bias-corrected matching reduces bias due to covariate imbalance between matched pairs by using regression predictions. We illustrate the methods in an evaluation of different types of hip prosthesis on the health-related quality of life of patients with osteoarthritis. We undertake a simulation study, grounded in the case study, to compare the relative bias, efficiency and confidence interval coverage of the methods. We consider data generating processes with non-linear functional form relationships, normal and non-normal endpoints. We find that across the circumstances considered, bias-corrected matching generally reported less bias, but higher variance than targeted maximum likelihood estimation. When either targeted maximum likelihood estimation or bias-corrected matching incorporated machine learning, bias was much reduced, compared to using misspecified parametric models.
Keywords
1 Introduction
Health policy makers require unbiased, precise estimates of the effectiveness and cost-effectiveness of health interventions.1–3 When observational studies are used to estimate average treatment effects (ATEs), it is vital to address potential bias due to confounding. Most studies use methods that assume there is no unmeasured confounding. 4 Under this assumption unbiased estimates can be obtained after controlling for observed characteristics, for example with parametric regression, propensity score (PS) or double-robust (DR) methods, provided either the PS or the endpoint regression model is correctly specified.
In studies that rely on regression methods alone, the estimated ATEs can be highly sensitive to the choice of model specification. 5 When evaluating health care interventions, correctly specifying a regression model can be challenging. For example, health-related quality of life (HRQoL) data are often semi-continuous, with non-linear covariate–endpoint relationships. 6 Instead, PS approaches may be preferred such as matching or inverse probability of treatment weighting (IPTW), but these rely on the correct specification of the PS. Most medical applications use a PS estimated with logistic regression models that only include main effects, which raises the concern of model misspecification.7,8
DR methods9,10 are consistent if either the endpoint regression or the PS is correctly specified. However, in practice both the regression function and the PS may be misspecified, and also, poor overlap can lead to the estimated PSs close to 0 and 1. 11 Here, DR methods such as weighted regression may not protect from bias.12,13 A recently proposed DR method, targeted maximum likelihood estimation (TMLE),14,15 can be less biased and more efficient than conventional DR methods when there is poor overlap16–18 by respecting known bounds on the endpoint. Another approach which can exploit information from the PS and the endpoint regression is bias-corrected matching (BCM).19,20 This method aims to reduce residual bias by adjusting the matching estimator with regression predictions of the endpoint. BCM is relatively robust under misspecification, for example, unless the functional form relationship between the covariates and the endpoint is highly non-linear; adjustment using a linear regression for the endpoint can reduce most of the residual bias from imbalance in the matched data.20–23 However, an outstanding concern with TMLE and BCM that use fixed, parametric models is that there may be residual bias due to functional form misspecification of both the PS and endpoint regressions.
In order to minimise bias due to functional form misspecification, both methods can exploit machine learning techniques. Unlike fixed, parametric models, where the functional form is chosen by the analyst, these methods use an algorithm to find the best fitting model. Machine learning estimation approaches for estimating the PS8,24,25 and the endpoint regression function 26 have been shown to reduce bias due to model misspecification. However, few studies have investigated machine learning for DR approaches.16,27 No previous study has considered machine learning for BCM.
This paper aims to compare TMLE and BCM and to combine both methods with machine learning for estimating the PS and the endpoint regression function. The methods are contrasted for estimating the ATE of a binary treatment, with a focus on dual functional form misspecification of the PS and the endpoint regression. We also compare TMLE and BCM to other commonly applied DR, 12 PS matching28,29 and regression 6 approaches.
We illustrate the methods in a motivating case study and in a simulation study. The case study considers the relative effectiveness of alternative types of total hip replacement (THR) on post-operative HRQoL for patients with osteoarthritis. We exploit a large UK survey, which collects patient reported outcome measures (PROMs),30,31 before and after common elective surgical procedures. This case study exemplifies the challenge of correctly specifying the endpoint regression function. The simulation study was grounded in the case study and compared the relative performance of the methods for a range of data generating processes (DGPs). We compare the relative performance of the methods according to bias, root mean squared error (RMSE) and coverage rates of nominal 95% confidence intervals (CIs).
In the next section, we outline the statistical methods under comparison. Section 3 presents the motivating example. Section 4 reports the design and results of the simulation study. The last section discusses the findings and suggests areas for further research.
2 Statistical methods
The parameter of interest is the ATE of a binary treatment A, defined as
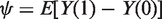
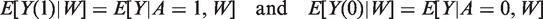
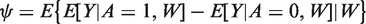
2.1 Regression estimators
We consider a general regression estimator, the G-computation estimator,
35
which uses estimates of the expected potential outcomes, conditional on observed characteristics, defined as
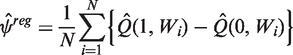
2.1.1 Machine learning estimation of the regression function
In general, machine learning covers a wide range of classification and prediction algorithms.8,26 Unlike approaches that assume a fixed statistical model, for example a GLM with a log link, machine learning aims to extract the relationship between the endpoint and covariates through a learning algorithm. 24 Machine learning approaches for estimating the endpoint regression can reduce bias which results from model misspecification. 26 Here we consider the ‘super learning’ algorithm, 38 which uses cross-validation to select a weighted combination of estimates given by different prediction procedures. 39 The range of prediction algorithms is pre-selected by the user, potentially including parametric and non-parametric regression models. Asymptotically, the super learner algorithm performs as well as the best possible combination of the candidate estimators. 40
2.2 PS methods
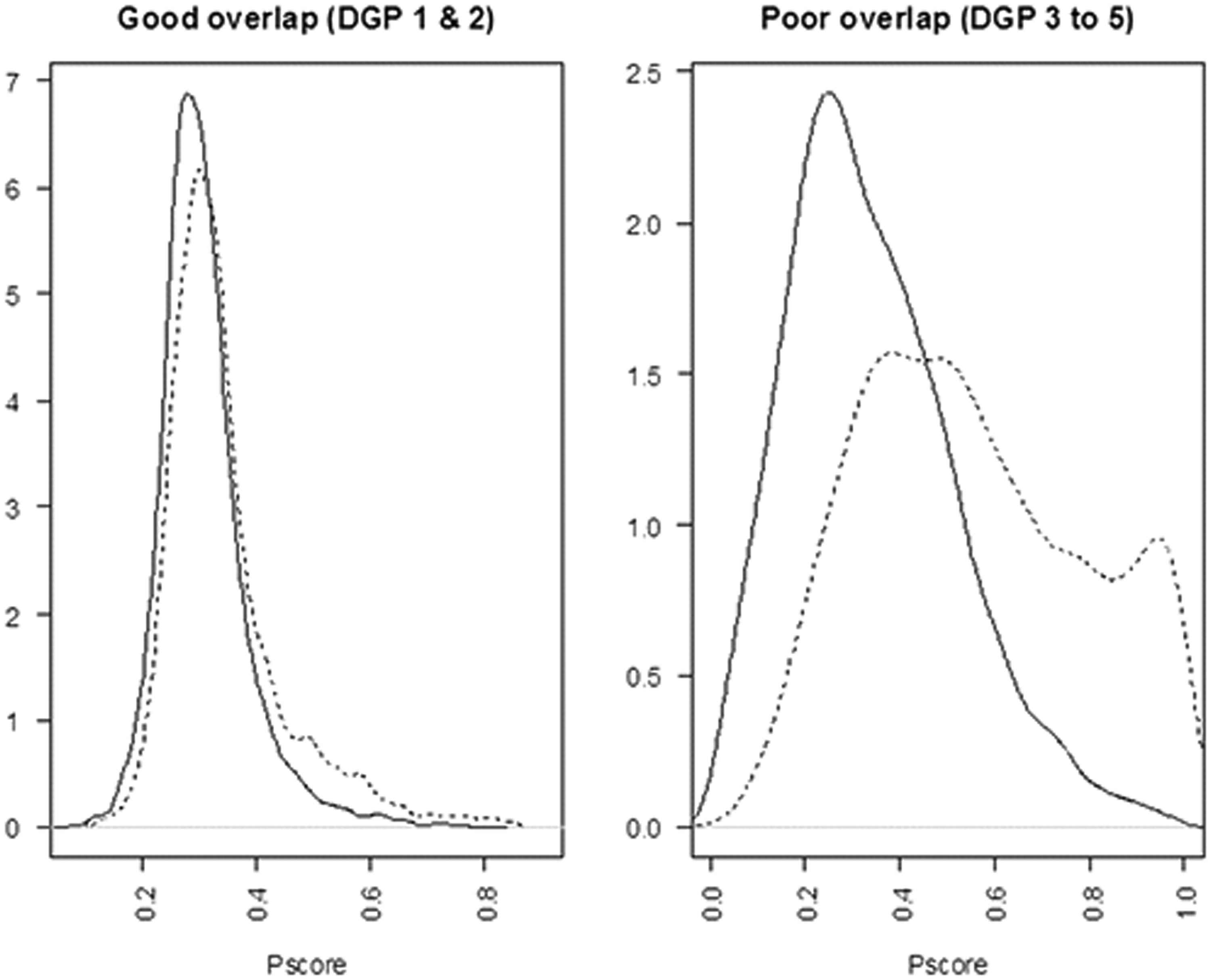
The PS, defined as the conditional probability of treatment assignment given W,
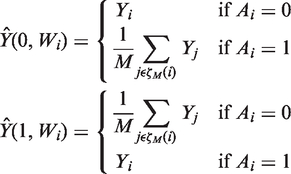
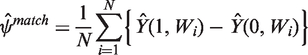
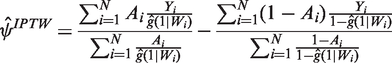
2.2.1 Machine learning estimation of the PS
Instead of estimating the PS with a fixed parametric model, flexible approaches have been proposed to help correctly specify
2.3 DR methods
DR methods9,52 combine models for
In realistic settings such as when there is poor overlap and dual misspecification, weighted regression can report biased and inefficient estimates of ATEs.12,13,16,54 An ongoing debate discusses the relative merits of different DR estimators in these circumstances.10,16,55 One recommendation is to use machine learning methods to estimate g(ċ). 27 A further suggestion is that DR estimators should have a ‘boundedness property’: they should respect the known bounds of the endpoint – for example that an HRQoL endpoint ranges from the value for the worst imaginable health state (−0.59) to that for full health, 156 – so that the estimated parameter will always fall into the parameter space.10,57 This property can reduce bias and increase precision when the PS is used as weights, where large weights can lead to estimated values of the endpoint falling outside of a plausible range. 18 Below we discuss a DR estimator, TMLE, that can have this boundedness property 57 and is therefore appealing when overlap is poor.18,58
2.3.1 TMLE
While standard maximum likelihood estimation aims to find parameter values that maximise the likelihood function for the whole distribution of the data, TMLE focuses on the portion of the likelihood required to evaluate the parameter of interest.15,59 This is achieved by using information in the PS to update an initial outcome regression, as described in the next section. The TMLE solves the efficient influence curve estimating equation, where an influence curve describes the behaviour of an estimator under slight changes of the data distribution. 60 This results in the property of double robustness, and if both Q(ċ) or g(ċ) are correct, in semi-parametric efficiency. 14
Performing TMLE involves two stages,
61
which, for estimating the ATE, are
Obtain an initial estimate of the conditional mean of Y given A and W, by using regression to predict the potential outcomes Q(1,W) and Q(0, W). Fluctuate this initial estimate,
Here, the fluctuation corresponds to extending the parametric model for
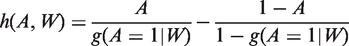
To ensure the boundedness of the TMLE, for continuous endpoints it is recommended that known bounds of the endpoint are exploited by rescaling Y to between 0 and 1.18,58 The rescaled endpoint is defined as
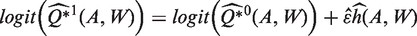
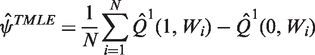
2.3.2 BCM
It is generally recommended that matching methods are followed by regression adjustment.19,22,44 The idea is similar to regression adjustment in randomised trials: regression is used to ‘clean up’ residual imbalances between treatment groups after matching.
51
BCM20,62 adjusts the imputed potential outcome with the difference in the predicted endpoint that can be attributed to covariate imbalance between the matched pairs. These predictions are obtained using a regression of the endpoint on covariates, stratified by treatment assignment. The bias-corrected predictions of the potential outcomes are obtained as follows
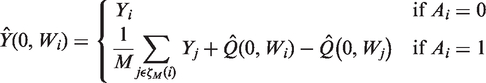
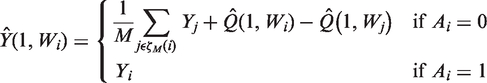
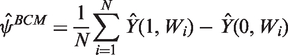
3 Motivating case study
3.1 Overview
We consider the methods in a case study that evaluates the effect of alternative hip prosthesis types on the HRQoL of patients with osteoarthritis using an observational database on patients with THR. THR is one of the most common surgical procedures in the UK, with over 50,000 hip procedures performed in the National Health Service (NHS) in England and Wales in 2011; 64 health care decision makers have a considerable interest in evaluating the effectiveness of different prosthesis types in routine care. 64 A large-scale survey that collects PROMs on all patients who undergo elective surgery in the NHS provides a key data source for this evaluation. The resulting observational dataset includes pre- and post-operative HRQoL for patients with THR procedures.30,31
The dataset measures the HRQoL endpoint as EQ-5D-3L scores. 65 The EQ-5D-3L is a generic instrument with five dimensions of health (mobility, self-care, usual activities, pain and discomfort, anxiety and depression) and three levels (no problems, some problems, severe problems). The EQ-5D-3L profiles were combined with health state preference values from the UK general population to give utility index scores on a scale ranging from 1 (perfect health), through 0 (death) to the worst possible health state, −0.59. 56 This results in a bounded, semi-continuous distribution of the endpoint that exhibits a point mass at 1, posing a challenge for the specification of the regression model. 6
A previous analysis of this dataset 66 reported the relative effectiveness of common prosthesis types, such as cemented, cementless and ‘hybrid’ prostheses. The analysis used multivariate matching and linear regression to adjust for confounding and found a small but statistically significant advantage of hybrid compared to cementless prostheses.
For this motivating example, we estimate the ATE on EQ-5D-3L, 6 months after THR in males patients, aged 65–74 (n = 3583) who received hybrid versus cementless hip prostheses. We illustrate the use of TMLE and BCM with fixed parametric models and then machine learning estimation techniques, and compared to regression, matching, IPTW and WLS.
3.2 Statistical methods in the case study
Potential confounders include patient characteristics such as age, sex, body mass index, pre-operative health status (‘Oxford Hip score’ and HRQoL), comorbidities, disability, index of multiple deprivation and characteristics related to the intervention, such as surgeon experience (senior surgeon or not) and hospital type (NHS, private sector hospital or treatment centre). Of the 3583 patients included in the analysis, 70% had a missing value on at least one variable, with 46% having missing values for more than one covariate. Thirty-two per cent were missing data on post-operative HRQoL and 39% on BMI. Other covariates were complete for over 90% of the sample. Multiple imputation using chained equations was applied to impute missing covariate and endpoint values.
66
Following recommendations,
67
five multiply imputed datasets were created, and the analysis described below was performed on each dataset. Point estimates and variances were combined using Rubin’s formulae.
68
Fixed parametric approaches for estimating
For machine learning estimation of
We applied WLS with IPT weights obtained from the logistic model and also from the boosted CARTs. TMLE used the known minimum and maximum values of the endpoint as bounds, −0.59 and 1. 56 Standard errors and 95% CIs were calculated using the sandwich estimator for IPTW and WLS, and using the influence curve 14 for TMLE. For the matching methods, estimated standard errors took into account the matching process, but were conditional on the estimated PS, hence did not account for the uncertainty in the process of estimating the PS.20,44 For the two-part model and the super learning regression estimator, standard errors were estimated with the non-parametric bootstrap. 75
3.3 Case study results
Balance on pre-operative characteristics, means and % standardised mean differences.
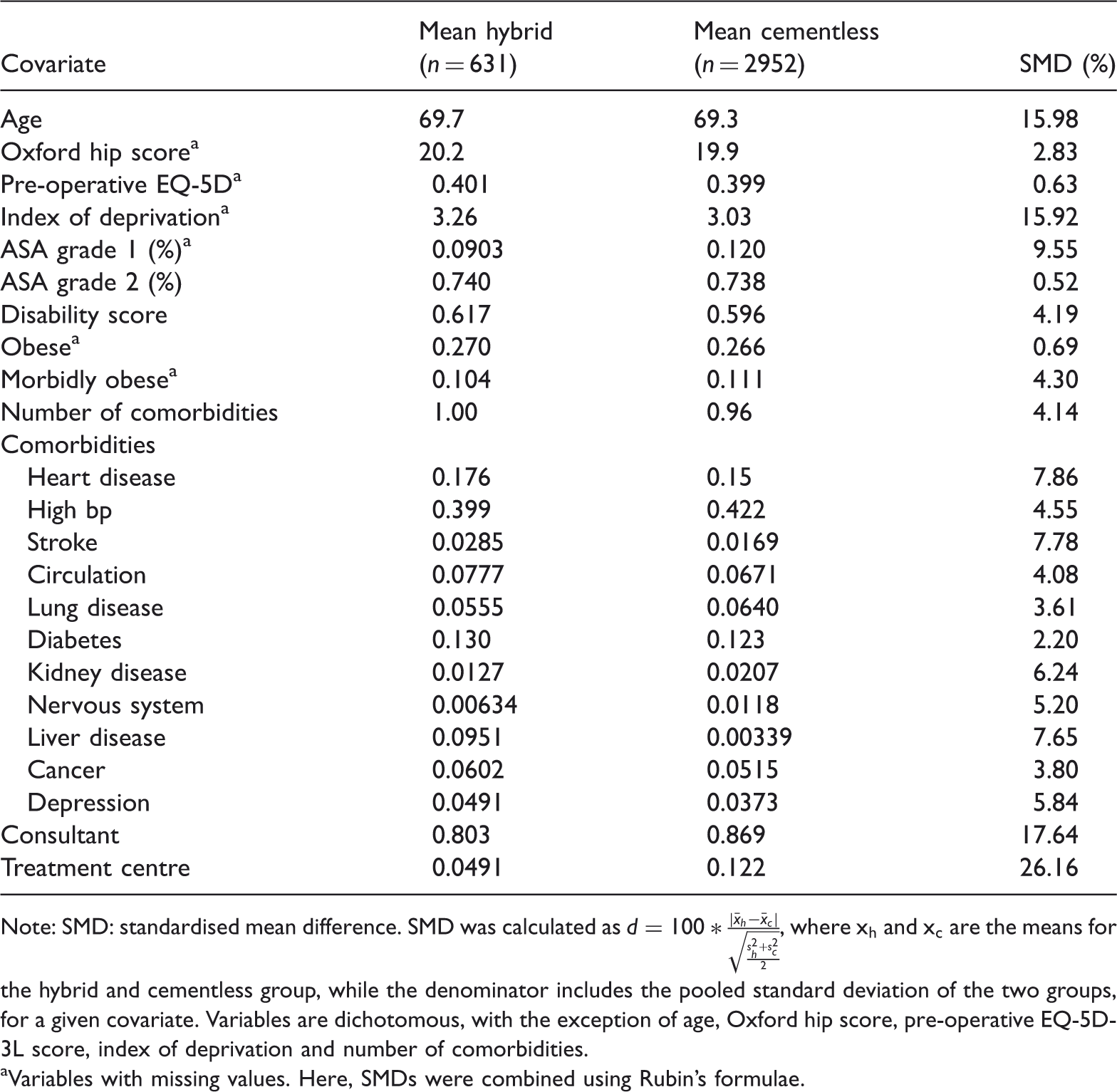
Note: SMD: standardised mean difference. SMD was calculated as
Variables with missing values. Here, SMDs were combined using Rubin’s formulae.
There was good overlap between the densities of the estimated PSs for the hybrid and cementless groups, when Densities of the estimated PS using logistic regression, hybrid versus cementless THR. Hybrid (dashed line) versus cementless (black line).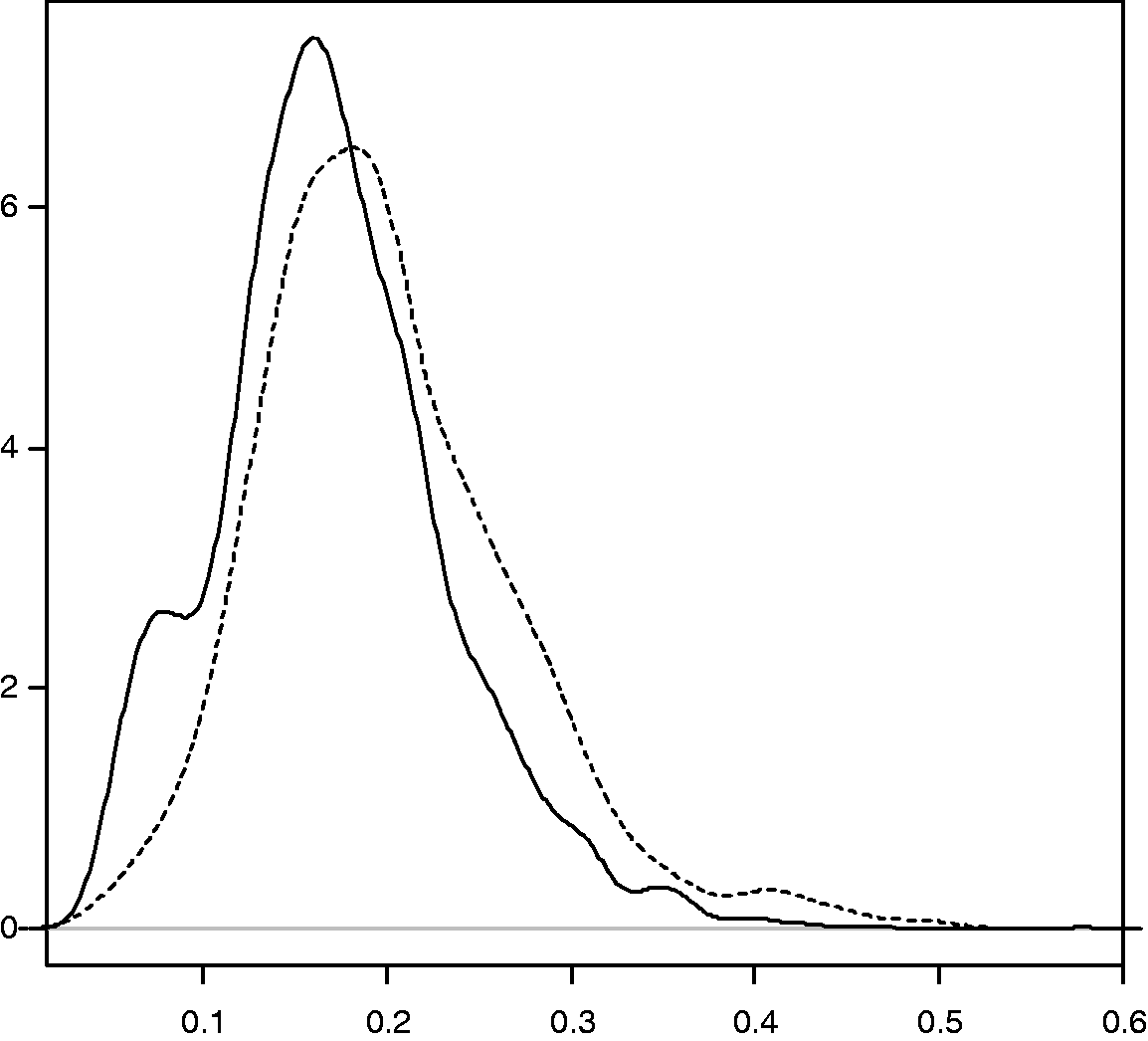
Figure 2 shows the point estimates and 95% CIs after combining the estimates obtained for the imputed datasets. All methods reported a small positive advantage in mean EQ-5D-3L scores for hybrid versus cementless prostheses, but with CIs that included zero.
Point estimates and 95% CIs of ATE in terms of EQ-5D-3L score, hybrid versus cementless THR, across statistical methods. SL: super learner.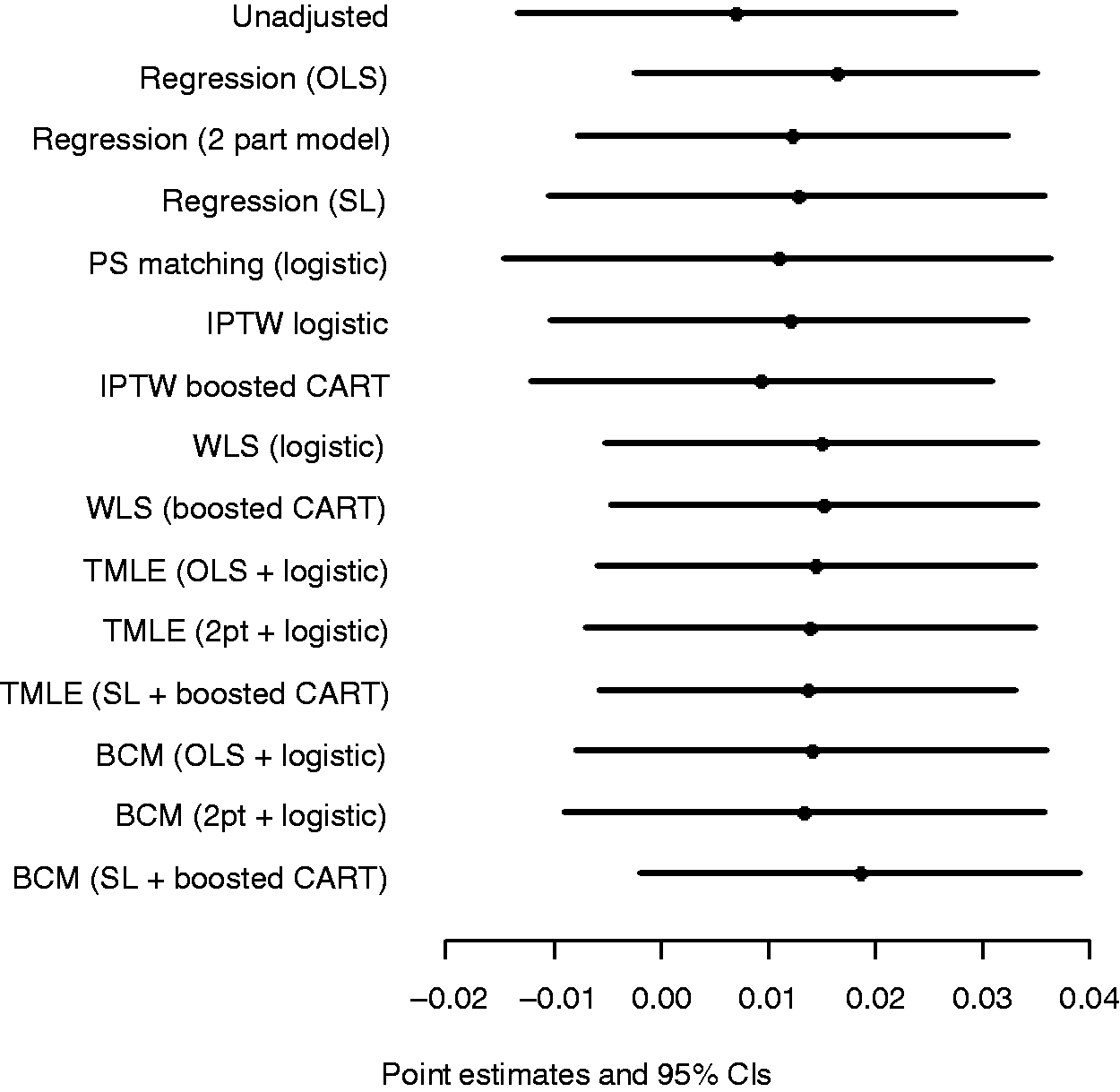
4 Simulation study
4.1 Overview
The simulation study compares the performance of BCM and TMLE, in estimating the ATE of a binary treatment on an endpoint with a non-linear response surface. As in the case study, we compared these methods to regression, PS matching, IPTW and WLS, and for each method, we considered fixed parametric models and machine learning estimation for Reweighting methods are anticipated to outperform BCM when overlap is good.
21
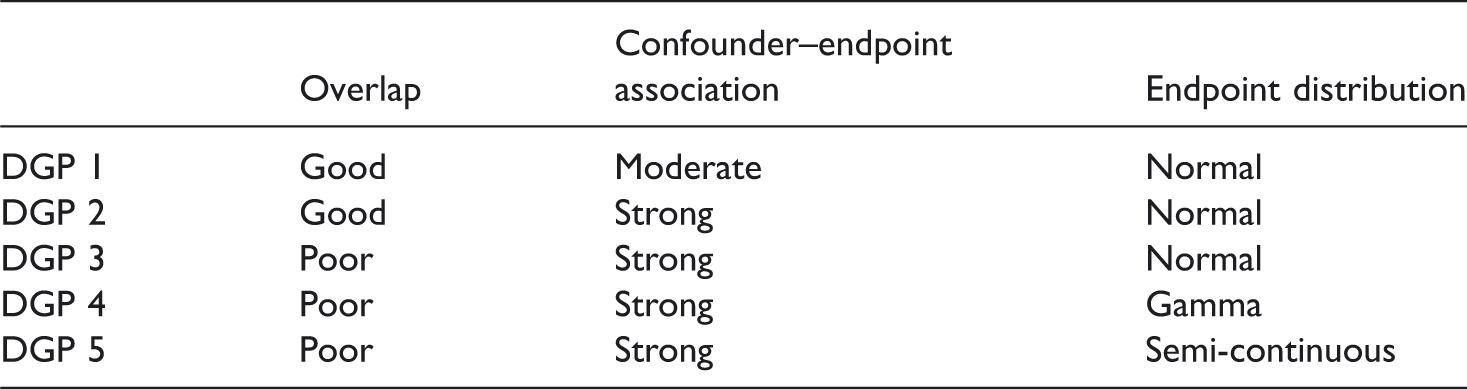
In such scenarios, TMLE is expected to outperform BCM in terms of bias and efficiency. When overlap is poor, BCM is expected to outperform TMLE, because matching can be less sensitive than weighting to extreme PS values and to the misspecification of Using appropriate machine learning methods is anticipated to reduce bias compared to using misspecified parametric models for Summary of DGPs used in the simulation study.
We assumed a PS mechanism that generated good overlap of the densities of the true PS (DGP 1 and 2) and one that generated poor overlap (DGP 3–5). We considered moderate (DGP 1) and strong (DGP 2–5) association between the confounders and the endpoints. DGPs 1–3 considered a normal endpoint with an identity link function between the linear predictor and the endpoint, DGP 4 considered an endpoint which followed a gamma distribution with a log link, while DGP 5 considered a semi-continuous distribution, with a mixture of a beta-distributed random variable and values of 1.
For each DGP, five scenarios were considered: (a) when fixed parametric models were used for both the PS and the endpoint regression, and these were correctly specified, (b and c) when one of the two was misspecified and (d) when the correct specification for both models was unknown. Scenario (d) had two sub-scenarios, differentiated by the implementation of the methods: in scenario (d1), we considered misspecified, fixed parametric models, while for scenario (d2) we considered machine learning estimates of
Bias, variance, RMSE and the coverage rate for nominal 95% CIs of the estimated ATEs were obtained. Relative bias was calculated as the percentage of the absolute bias of the true parameter value, where absolute bias is the difference between the true parameter value and the mean of the estimated parameter. The RMSE was taken as the square root of the mean squared differences between the true and estimated parameter values.
4.2 DGPs
For each DGP, we generated 1000 datasets of n = 1000, with binary (W1 to W5) and standard normally distributed covariates
For DGP 1, the PS model resulted in a good overlap of the true PS (see Figure 3)
Densities of the true PS in the simulations for a typical sample (n = 10,000). Treated (dashed line) versus control (black line). (a) Good overlap (DGP 1 and 2), (b) poor overlap (DGP 3–5).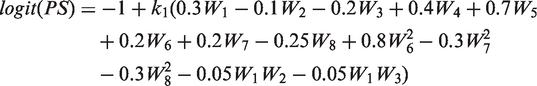
The treatment variable A was drawn from a Bernoulli distribution, using the PS as the parameter of success probability. The endpoint was drawn from a normal distribution with mean
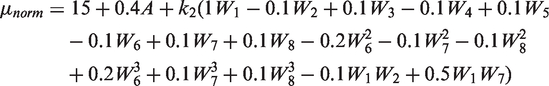
In DGP 2, setting
In DGP 4, the endpoint was drawn from a gamma distribution, with a log link, shape parameter of 100 and a scale parameter of 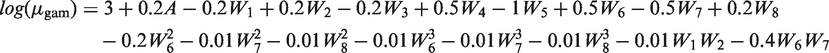
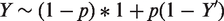
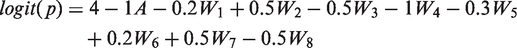
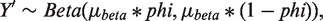
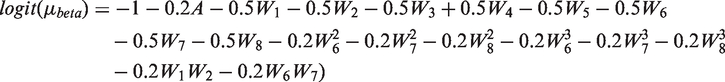
4.3 Implementation of the methods
Correct specification was defined as applying a fixed parametric model according to the known features of the true DGP, such as the link function, the functional form between the covariates and the linear predictor, and the error distribution. For each DGP, the misspecified parametric
4.4 Simulation study results
Tables 3 to 5 report the relative bias (%), variance, RMSE and 95% CI coverage for the estimators considered, and Figure 4 presents the distribution of the estimated ATEs with box plots.
Estimated ATEs in the simulations. The boxplots show bias and variation, as median, quartiles and 1.5 times interquartile range for the estimated ATEs across 1000 replications. The dashed lines are the true values. The left panel provides results for when the PS model and endpoint were estimated with misspecified fixed parametric methods (d1), the right panel for when machine learning estimation (d2) was used. (a) DGP 3, (b) DGP 4, (c) DGP 5. Simulation results for DGP 1, over 1000 replications: normal endpoint, moderate association confounder–endpoint association, good overlap. Note: In DGP 1 the true ATE was 0.4 and the bias using a naive estimator based on the mean difference was 20%. WLS is implemented as main terms only in regression; hence it is reported as a misspecified estimator. Simulation results for DGP 4 and 5, over 1000 replications: Normal and gamma endpoints, strong confounder–endpoint relationship, poor overlap. Note: In DGPs 4 and 5, the true ATE was 9.98 and 0.062, respectively. The bias using a naive estimator based on the mean difference was 170 and 150%, respectively.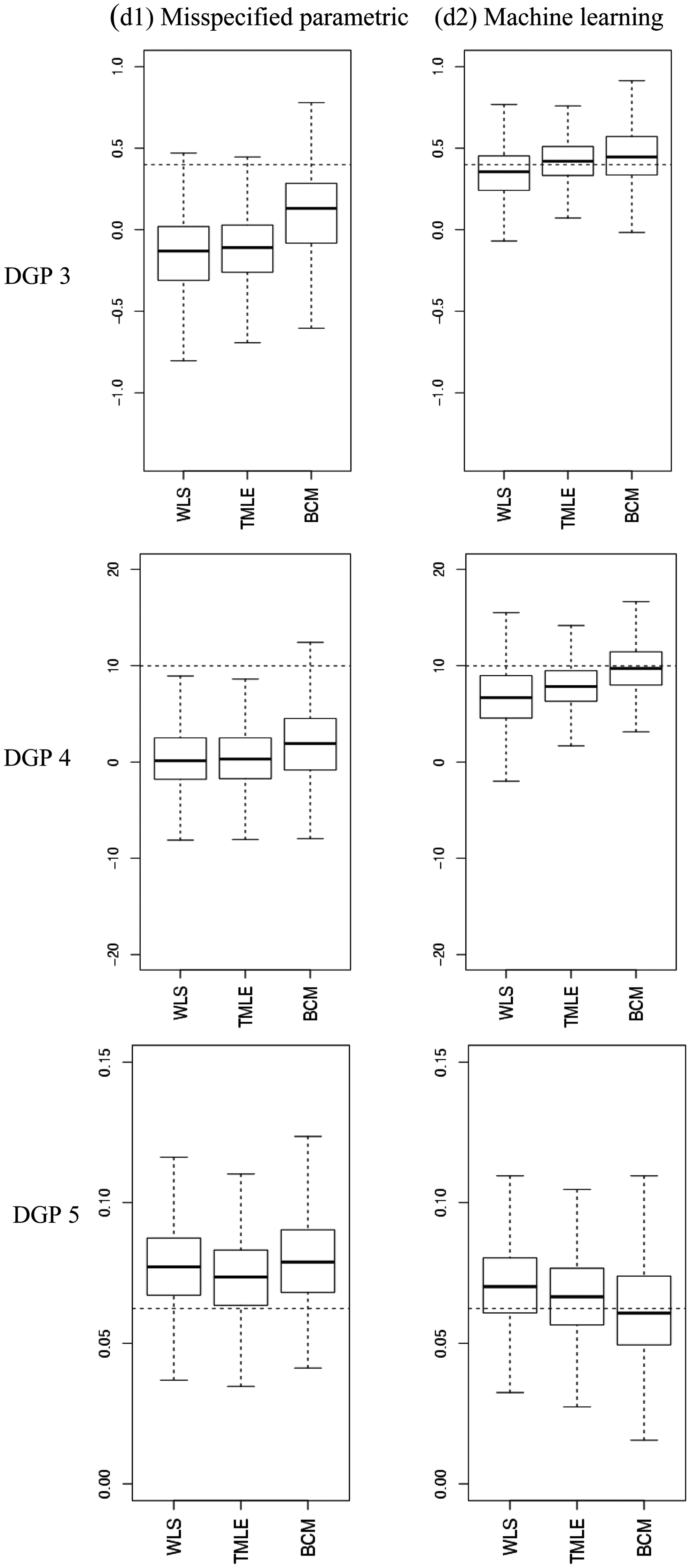
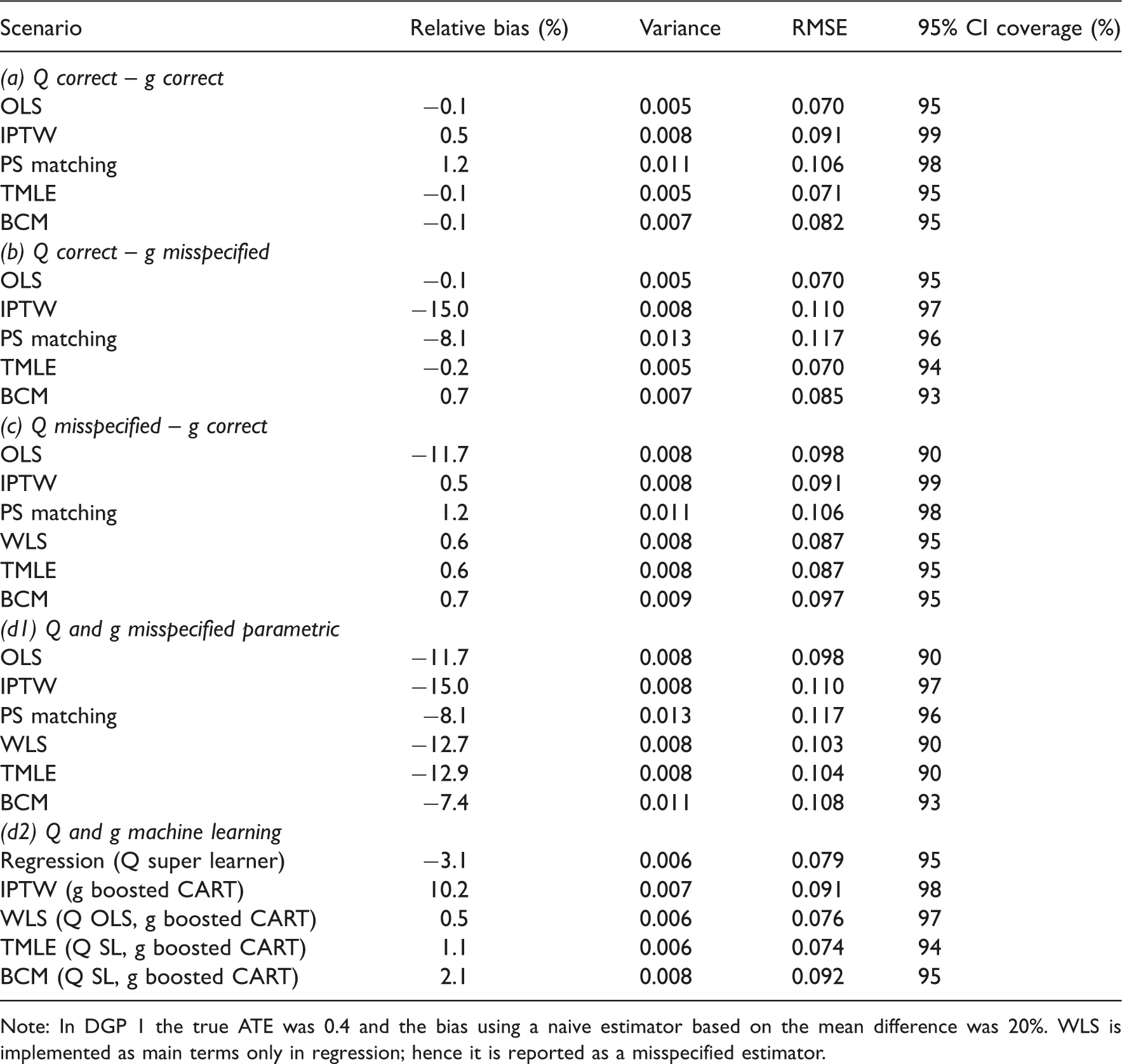
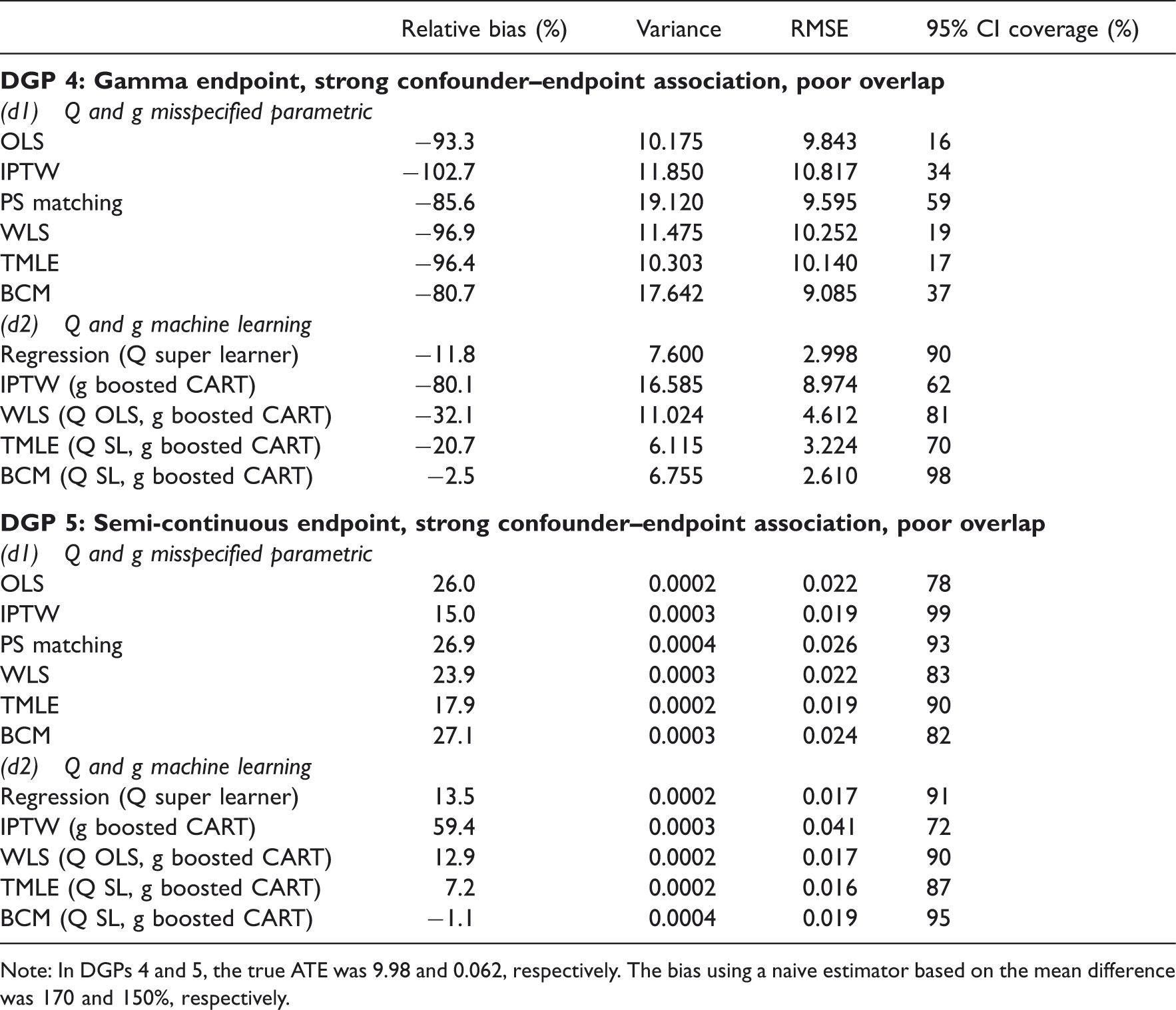
Table 3 reports results for DGP 1, when there was good overlap, with a moderate association between the confounders and a normally distributed endpoint. When both
Simulation results for DGP 2 and 3, over 1000 replications: normal endpoint, strong confounder–endpoint association, good and poor overlap.
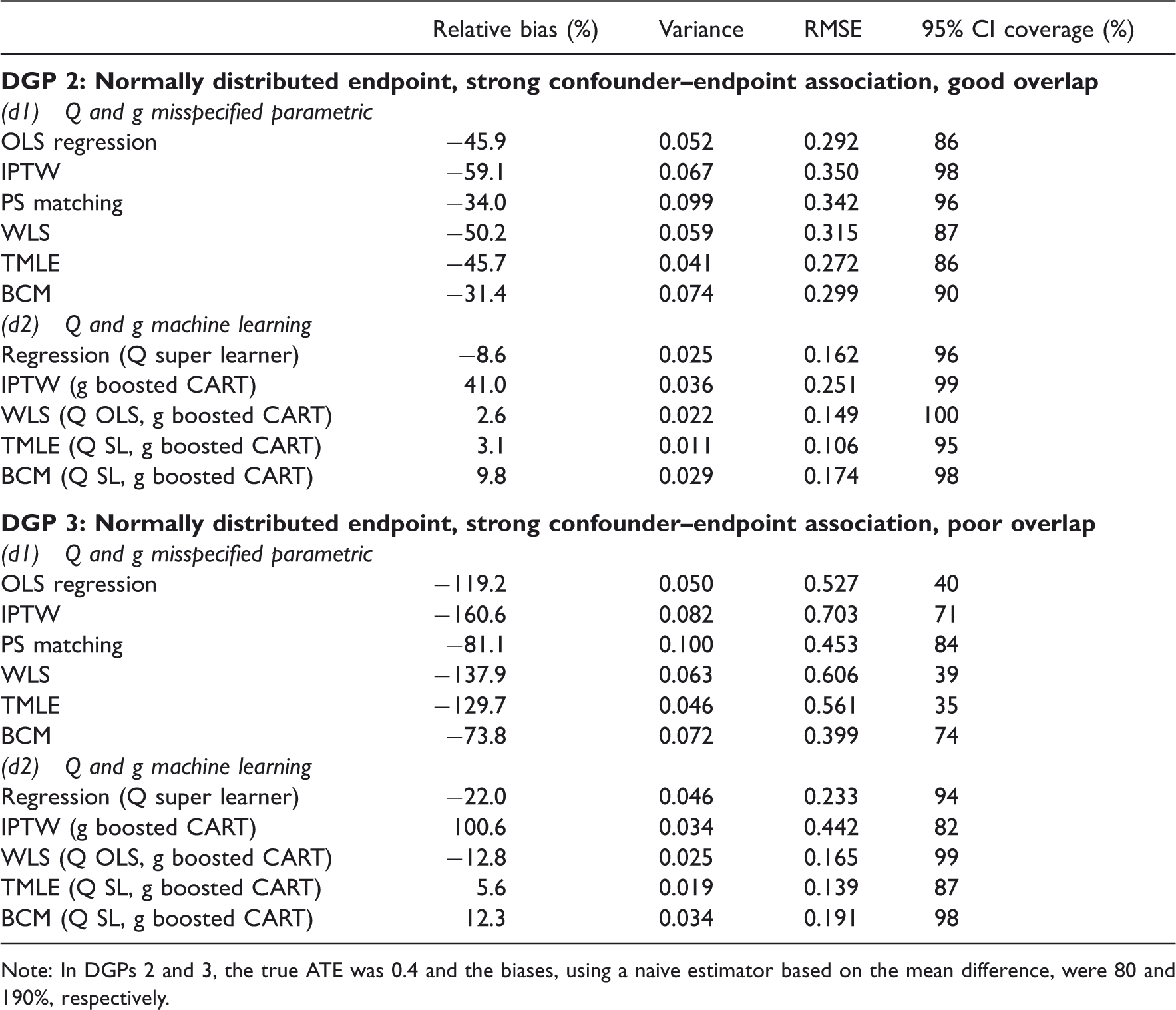
Note: In DGPs 2 and 3, the true ATE was 0.4 and the biases, using a naive estimator based on the mean difference, were 80 and 190%, respectively.
IPTW using machine learning weights often reported high bias: for example for DGP 5, it reported higher bias than using a misspecified, fixed logistic regression. This indicated that using boosted CARTs for estimating the PS was insufficient to eliminate bias. For DGPs 3–5, where overlap was poor, truncating the weights for IPTW and TMLE for either the logistic or the boosted PS models did not change the results.
5 Discussion
This paper finds that in circumstances when the parametric models for both the endpoint regression function and PS are misspecified, both TMLE and BCM can reduce bias when coupled with machine learning methods.
We considered these methods, alongside more traditional PS, regression and DR methods in a case study that evaluated the effect of alternative types of THR for patients with osteoarthritis. This study illustrates a general challenge which is to specify a regression model for a non-normal endpoint (HRQoL), with a non-linear response surface. In the simulation studies, grounded in the case study, we generated endpoints data with normal, skewed and semi-continuous distributions, with non-linear covariate–endpoint relationships. In the simulated scenarios, where there was dual misspecification, and machine learning techniques were used to estimate the endpoint regression function and the PS, both TMLE and BCM could greatly reduce bias, in contrast to the high bias where misspecified fixed parametric models were used.
We found that the relative advantage of TMLE versus BCM was dependent on the features of the DGPs considered. In favourable settings such as good overlap and moderate association between the confounder and the endpoint, TMLE outperformed BCM in terms of bias and precision. This result corresponds to previous work that found that reweighting estimators outperformed BCM under good overlap. 21 In a more challenging setting, when overlap was poor, and there was a strong association between the confounders and the endpoint, we found a bias–variance trade-off between the methods under comparison: for non-normal endpoints, BCM showed less bias, but was more variable than TMLE. We followed recent recommendations when reporting CIs for matching estimators, 44 and like previous studies, we found that they reported somewhat higher than nominal coverage. 20
Our work extends the previous literature in several aspects. First, this is the first paper that compares the relative performance of BCM and TMLE, and also compares these methods to traditional approaches. Second, while BCM has been proposed with flexible approaches for estimating the endpoint regression function, previous studies used OLS for adjustment.20,21 This study considers super learning, a machine learning method for bias correction, and finds that when matching is based on a PS that was also estimated using machine learning (boosted CARTs), the bias due to model misspecification was greatly reduced. We find this result across a range of DGPs including highly non-linear response surfaces. Third, unlike previous studies that used machine learning only for selected combined methods such as TMLE, 16 this paper took a systematic approach and evaluated the impact of using machine learning estimation for single methods, such as regression and IPTW, and for combined methods, such as TMLE and BCM.
Similarly to Kang and Schafer (2007),12 we find that combining the PS and endpoint regression from misspecified fixed parametric models does not reduce bias compared to using these models in single methods such as IPTW. In the scenarios considered in this study, it was the combined use of machine learning approaches for estimating the endpoint regression and the PS that helped eliminate most of the bias due to observed confounding.
This work has some caveats. The methods considered and the simulation settings all assume ‘no unobserved confounding’. Machine learning methods can augment but not necessarily replace subject-matter knowledge when selecting the set of confounders that need to be controlled for. 76 In the case study, while we used a rich set of measured cofounders suggested by previous literature and clinical expert opinion, 66 some unobserved confounders such as unobserved patient preferences for prosthesis types may prevail. The scope of this paper did not extend to comparing alternative machine learning approaches. We found that boosted CARTs for estimating the PS, a method that has been found to outperform logistic regression and alternative machine learning approaches, 24 did not consistently reduce bias compared to misspecified logistic regression. Further machine learning approaches may be considered for the PS, such as random forests 24 or neural networks. 8 These approaches also have promising application for estimating the endpoint regression function. 26 Any machine learning method relies on subjective choices of the user. For boosted CARTs, tuning parameters such as the shrinkage parameter needs to be selected. 50
For estimating the outcome regression, we demonstrated the use of the super learner. 38 A distinguishing feature of this ensemble prediction approach compared to other model selection approaches is that it combines many estimators, by selecting a combination of predictions from alternative prediction algorithms. That is, the super learner aims to provide a better fit to the data than relying on any one prediction algorithm. In the simulation study, in order to mimic a situation where the investigator does not know the true DGP, we required the super leaner to consider the same, restricted range of prediction algorithms (including GLMs, generalised additive models and multivariate adaptive polynomial spline regression) for each DGP. In practice, we recommend that the analyst requires the super learner to consider a richer set of prediction algorithms; a wide range of models and prediction algorithms should be proposed according to subject-matter knowledge to encourage the consistent estimation of the regression function albeit at the expense of increased computational time. 39 These prediction algorithms can include advanced model selection methods such as fractional polynomials 77 or penalised model selection approaches. 78
This paper considered continuous and semi-continuous endpoints motivated by the case study. The approaches presented are in principle applicable to binary, count or survival outcomes and other parameters such as the odds ratio, risk ratio or hazard ratio. TMLE has been demonstrated to have good finite sample performance for binary and survival endpoints.17,59 While matching estimators have also been proposed for estimating risk ratios and odds ratios,46,79 BCM estimators for these parameters have not yet been developed.
In the simulations, each method is adjusted for the observed covariates known to be predictive of both treatment assignment and of the outcome. In practice, this feature of the DGP is not known, and subject-matter knowledge should be used to select for adjustment of those potential confounders that are measured before treatment, and are both predictive of treatment selection and the endpoint. 1 The inclusion of those covariates which influence treatment assignment, but not the endpoint in the PS can lead to estimates that are statistically inefficient.80–82
This work also opens up areas for future research. In the common settings of poor overlap, an extension of TMLE, collaborative maximum likelihood estimation (C-TMLE)55,83 can outperform TMLE. C-TMLE uses machine learning to select a sufficient set of covariates for inclusion in
We conclude that both TMLE and BCM have the potential to reduce bias due to observed confounding, in common settings of dual misspecification, if coupled with machine learning methods for estimating the PS and the endpoint regression function. TMLE is implemented as a readily available software package. 61 For BCM, the available packages currently allow for regression adjustment using OLS only.62,84 In order to facilitate the uptake of the methods, the Supplementary Appendix provides code for the implementation of TMLE and BCM with machine learning.
Footnotes
Acknowledgements
We thank Jan vanderMeulen and Nick Black (LSHTM) for access to the PROMs data and the Department of Health for funding the primary analysis of the PROMs data. We are grateful to Mark Pennington (LSHTM) for advice on the motivating case study. We thank Rhian Daniel, Karla Diaz-Ordaz (LSHTM) and Adam Steventon (Nuffield Trust) for valuable comments on the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: NK, RR and RG were funded by the Economic and Social Research Council (Grant no. RES-061-25-0343).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.