
Abstract
For semi-continuous data which are a mixture of true zeros and continuously distributed positive values, the use of two-part mixed models provides a convenient modelling framework. However, deriving population-averaged (marginal) effects from such models is not always straightforward. Su et al. presented a model that provided convenient estimation of marginal effects for the logistic component of the two-part model but the specification of marginal effects for the continuous part of the model presented in that paper was based on an incorrect formulation. We present a corrected formulation and additionally explore the use of the two-part model for inferences on the overall marginal mean, which may be of more practical relevance in our application and more generally.
1 Introduction
In Su et al., 1 we described a two-part marginal model for longitudinal semi-continuous data that are a mixture of true zeros and continuously distributed positive values. Our likelihood-based model had an underlying two-part mixed model, where, in the random effects logistic regression for the first part (i.e. the binary part), the random intercept was assumed to follow the bridge distribution of Wang and Louis. 2 A zero-mean normal random intercept was included into the linear mixed modelling structure of the second part (i.e. the continuous part).
Our primary focus was to ensure that the regression parameters in the binary part of the two-part marginal model were interpretable after integration over the random effects distribution. Marginal covariate effects on the expected value of the response for the population of observed non-zero responses may, however, also be of interest. These arise directly from the approaches in Moulton et al., 3 Lu et al., 4 Hall and Zhang 5 and Yang and Simpson 6 and involve well-defined integrations (see refs7,8).
However, when discussing the continuous part of our model, we assumed, as did Tooze et al., 9 that integrating out the random effects was straightforward, and that the form of the relationship between covariates and the marginal mean of the response, given that it is positive, was the same as the conditional mean given a positive response and random effects. Unfortunately, this is not the case. This paper rectifies this error and explores the use of the proposed model when the target of inference is the overall marginal mean, which may be of most practical relevance.
2 Marginal inference from two-part models
2.1 Model
Our two-part marginal model 1 is based on the original two-part mixed modelling framework introduced in Olsen and Schafer 10 and Tooze et al. 9 and the random effects specifications in Lin et al. 11
Briefly, let Yij be a semi-continuous variable for the ith (
Yij can be represented by two variables, the occurrence variable
The distribution of Yij is formulated by assuming, firstly, that Zij is specified by a random effects logistic regression with
2.2 Marginal covariate effects
The main benefit of the bridge density, stressed in Su et al.,
1
is that after integration over the random intercepts,
However, although in Su et al.
1
we claimed that the marginal mean of

As the integral given by
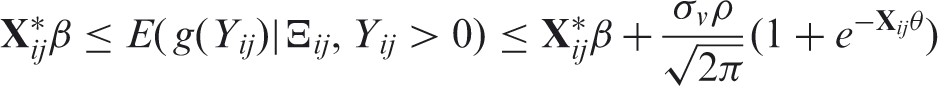
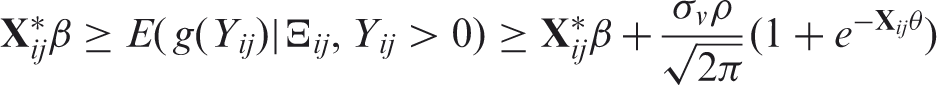
Although an exact analytical expression is not available, numerically solving (1) at the maximum-likelihood estimates is straightforward as only a single integral is involved. This integral can be evaluated using adaptive Gaussian quadrature techniques. The estimation of the parameters
2.3 Interpretation of the marginal effects in the continuous part
As noted earlier and in Su et al.,
1
the interpretation of θ is straightforward as these parameters are simply (population-averaged) log-odds ratios. In contrast, assessment of the impact of a covariate on the marginal mean (given being positive),
In such a case, the impact of a covariate could be assessed through plotting the relationship between this covariate and
2.4 Overall marginal mean
When
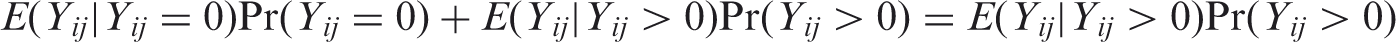
From Section 2.2, bounds on the overall marginal mean can be obtained as
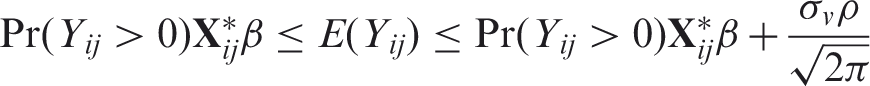
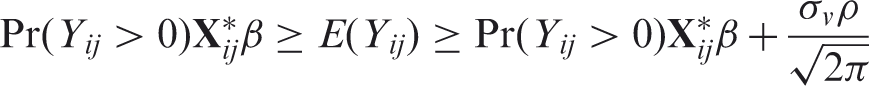
3 The HAQ data revisited
In this section, we revisit the HAQ data described in Su et al. 1 The objective is to examine the association between alleles that code for human leukocyte antigen (HLA) proteins and disability level in a psoriatic arthritis (PsA) patient cohort. R code for this new analysis is located in the Supplementary Material.
Table 2 of Su et al. 1 presented results from fitting the two-part mixed model to the data, where the third column shows the conditional covariate effects in the continuous part. As noted earlier, the corresponding marginal covariate effects are generally not equal to these conditional effects.
In this particular application, it is perhaps more natural to examine the association between the HLA alleles and the overall expected disability level of the patients over the study period, instead of the association when some disability is present. This is because disability, as measured by HAQ, for patients can vary over time and, for example, at one visit a patient can have mild disability, but at the next visit his/her situation may be improved resulting in a zero value of HAQ. We conjecture that it will often be felt to be clinically more informative to present the marginal covariate effects on the overall expected disability level together with the marginal covariate effects on the probability of having any level of disability.
For the HAQ example, we sample from the asymptotic distribution of the parameters based on the estimates in Table 2 of Su et al. 1 and calculate the contrasts of overall expected HAQ with and without specific HLA alleles, controlling for other covariates. For presentation purposes, we fix the age at PsA diagnosis at 35 years and disease duration at 15 years, which correspond to zero values in standardized versions of the two variables. These contrasts represent the effects of HLA alleles on the overall expected disability level (controlling for other covariates) in the PsA patient cohort.
The top panels of Figure 1 show the HLA-B27 effects given other alleles, sex, age at diagnosis and disease duration. Because the overall mean of HAQ is not directly parametrized in the fitted model, the corresponding covariate effects are not the same for all values of the other variables. However, the HLA-B27 effects are approximately the same across different combinations of other covariates, and the 95% confidence intervals do not include zero. This demonstrates a significant association between HLA-B27 and overall expected HAQ.
Contrasts (with 95% confidence intervals) of overall mean of HAQ for different combinations of the covariates (controlling for being 35 years old at PsA diagnosis and having a disease duration of 15 years).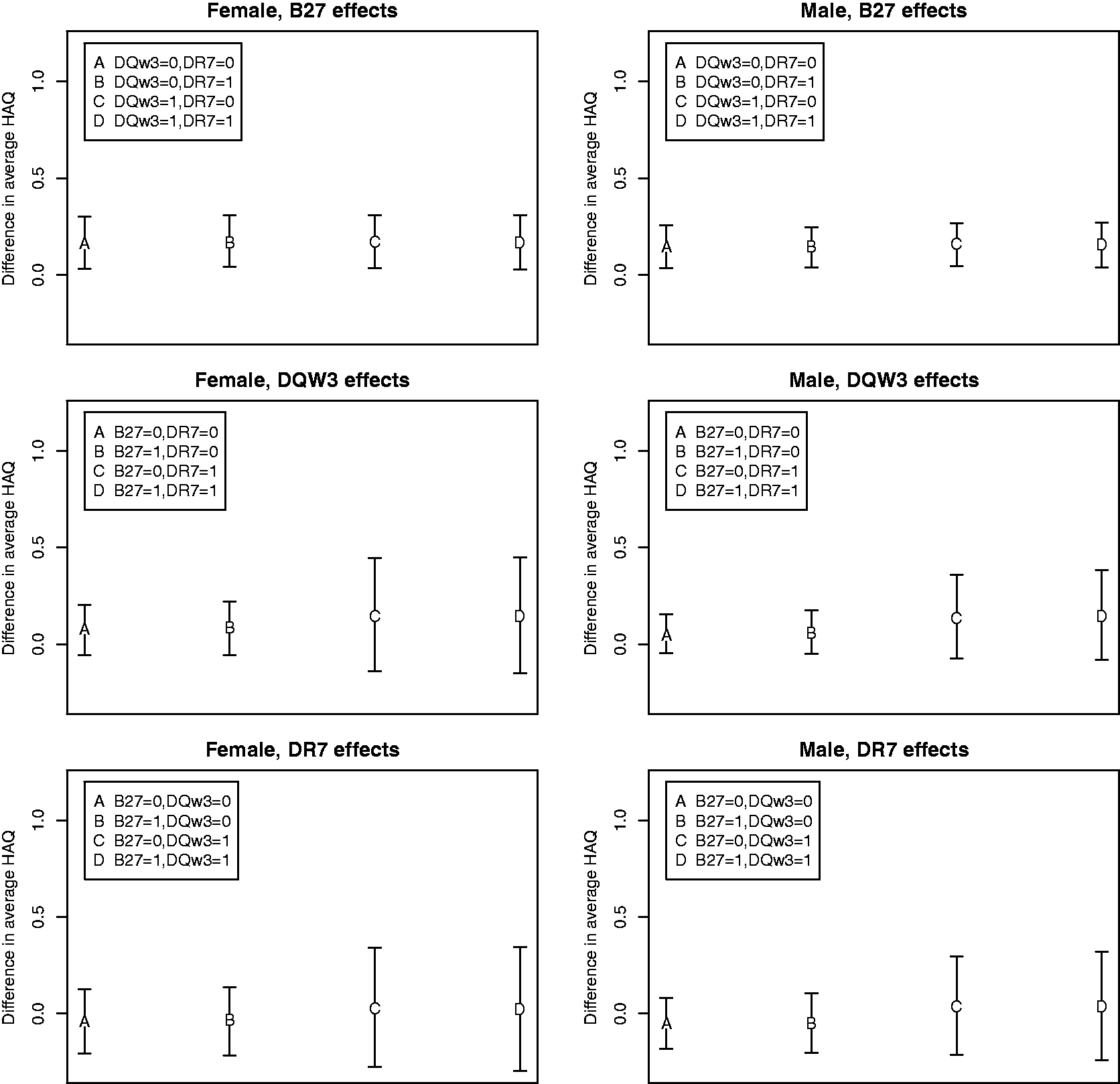
In Su et al.,
1
we found a significant interaction between the effects of HLA-DQW3 and HLA-DR7 in the binary part of the two-part mixed model (
The middle and bottom panels of Figure 1 reflect the possible interaction between HLA-DQW3 and HLA-DR7 on the overall marginal mean of HAQ stratified by gender and absence/presence of the HLA-B27 allele. Age at PsA diagnosis is fixed at 35 years and disease duration at 15 years.
For illustrative purposes, considering the left middle (or bottom) panel of Figure 1 for females with the presence of HLA-B27, we estimate that the difference in the HLA-DQW3 (or, alternatively, HLA-DR7) effects on the overall marginal mean of HAQ between those with the presence of HLA-DR7 (or HLA-DQW3) allele and those with it absent (i.e. contrast D–B in figure) is 0.0564 with 95% confidence interval [–0.2062, 0.3232]. For females with HLA-B27 absent, the estimate of this difference in the HLA-DQW3 (or, alternatively, HLA-DR7) effects on the overall marginal mean of HAQ between those with and without the HLA-DR7 (or HLA-DQW3) allele (i.e. contrast C–A) is 0.0648 with 95% confidence interval [–0.1971, 0.3158]. These estimates of the HLA-DQW3 and HLA-DR7 interaction for females, with and without HLA-B27 present, are similar and both non-significant statistically. Conclusions based on these results are similar to those found for the continuous part in the two-part marginal model (data not shown).
4 Discussion
In this article, we have corrected the formulation for the continuous part of the two-part marginal model presented in Su et al.
1
We show that the (marginal) mean of
In some contexts, the logit may not be the preferred link function in the binary part. For example, in dilution and serological studies the cloglog link may be more appropriate. In psychometrics, the probit may be more convenient. For either of these alternatives, a two-part marginal formulation can be derived. For instance, if the logit link is replaced with the probit and Bi is assumed
In conclusion, care should be taken when using two-part models for semi-continuous data that are longitudinal or otherwise clustered. Both the specification of random effects structures, as discussed in Su et al., 14 and the interpretation and calculation of marginal effects, as discussed in this paper, require careful attention to assumptions.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Medical Research Council (Unit Programme number U105261167).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.