
Abstract
Background
Recent literature on the comparison of machine learning methods has raised questions about the neutrality, unbiasedness and utility of many comparative studies. Reporting of results on favourable datasets and sampling error in the estimated performance measures based on single samples are thought to be the major sources of bias in such comparisons. Better performance in one or a few instances does not necessarily imply so on an average or on a population level and simulation studies may be a better alternative for objectively comparing the performances of machine learning algorithms.
Methods
We compare the classification performance of a number of important and widely used machine learning algorithms, namely the Random Forests (RF), Support Vector Machines (SVM), Linear Discriminant Analysis (LDA) and k-Nearest Neighbour (kNN). Using massively parallel processing on high-performance supercomputers, we compare the generalisation errors at various combinations of levels of several factors: number of features, training sample size, biological variation, experimental variation, effect size, replication and correlation between features.
Results
For smaller number of correlated features, number of features not exceeding approximately half the sample size, LDA was found to be the method of choice in terms of average generalisation errors as well as stability (precision) of error estimates. SVM (with RBF kernel) outperforms LDA as well as RF and kNN by a clear margin as the feature set gets larger provided the sample size is not too small (at least 20). The performance of kNN also improves as the number of features grows and outplays that of LDA and RF unless the data variability is too high and/or effect sizes are too small. RF was found to outperform only kNN in some instances where the data are more variable and have smaller effect sizes, in which cases it also provide more stable error estimates than kNN and LDA. Applications to a number of real datasets supported the findings from the simulation study.
Keywords
1 Background
Recent advances in genomic, proteomic, neuroimaging and other high-throughput technologies have led to an explosion of high-dimensional data requiring development of novel methods or modification of existing statistical and machine learning techniques to maximise the information gain from such data. An increase in the number of available methods has logically necessitated method comparisons in order to find the best one in a particular situation resulting in numerous publications focusing on comparative studies in the recent bioinformatics and computational biology literature. A large body of such studies have compared supervised statistical and machine learning methods for subject classification predominantly based on microarray gene expression or high-dimensional mass spectrometry data.1–10
Recent literature11–15 on the subject has raised questions about the neutrality, unbiasedness, utility and the ways most of these comparisons are performed as there is little consensus between the findings of such studies. A review by Boulesteix et al. 11 indicated a tendency in some comparative studies to demonstrate the superiority of a particular method using datasets favouring the chosen method. Similar concerns were echoed in a recent Bioinformatics paper by Yousefi et al. 15 suggesting (i) reporting of results on favourable datasets and (ii) the so-called multiple-rule bias where multiple classification rules are compared on datasets purporting to show the advantage of a certain method, as the major sources of bias in such comparisons.
There are comparative studies where the objectives are not to demonstrate one particular method as better than the others. Several such studies, the so-called neutral comparisons, are cited by Boulesteix et al. 11 One limitation of these studies is that the comparisons are mainly based on real datasets, and a problem with comparing classification performance estimated on real datasets is the sampling error or noise in the estimated performance measures. Due to the fact that performance estimates are subject to sampling variability,12,15 the best performance in one or a few instances does not necessarily imply so on an average or on a population level.
Three alternative routes can potentially be explored for a more robust and objective comparison: (i) using statistical test to take account of the sampling variability or noise in the performance estimates, (ii) comparing analytically based on the distribution theory of the performance estimates and (iii) repeatedly estimating the performance measure on a large number of simulated/synthetic data to average out the sampling variability or noise from the estimated performance criterion. Hanczar and Dougherty 14 investigated the possibility of using statistical tests for performance comparison and concluded that direct comparison based on statistical test is unreliable and can often lead to wrong conclusions. Analytic comparison would be an elegant approach but requires finding the sampling distribution of the performance estimates based on the joint distribution of feature and class variables. Due to the fact that many of the modern machine learning algorithms are complex (the so-called black-box techniques) and often are not based on any underlying statistical model, working out the analytic distributional properties of performance estimates is not possible except for some classical statistically motivated discrimination methods such as the Linear Discriminant Analysis (LDA 16 ). As indicated by Hua et al., 17 this leaves open the simulation route as a feasible and viable means of objectively studying the characteristics of performance measures based on learning algorithms of a wide range of complexities and forms. This has been realised in other studies in the literature such as Hanczar and Dougherty, 14 which concluded that ‘the classification rule comparison in real data is worse than in the artificial data experiments. … strongly suggest that researchers make their comparative studies on synthetic datasets’.
We also think that simulation studies are a viable and practical way of figuring out ‘which method performs better in what circumstances’. The truth is always known in simulated data and therefore it is easy to investigate bias, the closeness of an estimate to the truth, which is not easy with real data. Synthetic data also make it possible to study the properties of an estimator at varying levels of different data characteristics such as variability, sample size, effect size, correlation, etc. However, the role of real data is also important and should be used to complement the simulation-based investigation as the patterns and structures in real data are generally much more complex and no simulation model can fully capture the patterns, dimensions and sources of variability in data generated from a real biological system.
In this study, we undertake an extensive simulation experiment to compare the classification performance of a number of important and widely used machine learning algorithms ranging from the most classical LDA
16
to modern methods such as the Support Vector Machines (SVM18–20). Although comparisons in the literature have mostly been on real data, synthetic data have also been considered to some extent previously.3,6,7,14 However, simulation studies previously used were limited in terms of the number of data characteristics and their coverage (parameter space) considered. The utilities of multi-factorial designs for simulation experiments were discussed by Skrondal
21
in the context of Monte Carlo experiments. Simultaneous investigation of multiple factors each at multiple levels helps improve the external validity, the extent to which the results can be gerneralised to other situations and to the population, of the conclusions from the simulation study. Using massively parallel processing on high-performance supercomputers (Edinburgh Compute and Data Facility, ECDF, and NIHR Biomedical Research Centre for Mental Health Linux Cluster), we evaluate and compare generalisation errors (leave-one-out cross-validation (CV) errors) for a large number of combinations of the following seven factors: number of variables (p), training sample size (n), biological (or, between-subjects) variation (
2 Methods
2.1 Classification methods
We compare classification performance of a number of widely used classification methods based on a diverse range of algorithms and architecture, namely the decision tree and resampling based method, Random Forests, RF 23 ; kernel-based learning algorithm, SVM18–20; statistically motivated classical method, LDA24–26; and instance-based (closest training examples) algorithm k-Nearest Neighbour, kNN.27,28
2.2 Optimising tuning parameters
Most classification algorithms have their own tuning parameters, which ideally require optimisation on each dataset the methods are applied to. We optimise important user customisable parameters for each method on every simulated dataset using a grid search over supplied parameter spaces. Our search spaces for tuning parameters always included the software default values for the respective parameters to ensure that the performance estimates at optimised parameters are at least as good as that at the default choices.
The RF method is suggested to be quite robust with respect to the variation of its tuning parameters. Leo Breiman (in the manual of original FORTRAN program of RF) suggested that mtry (number of variables to be used as candidates at each node) is the only parameter that requires some judgment to set. We optimise mtry using a grid search over a random sample of size 5, inclusive of the default value (
We evaluated SVM with linear, polynomial and radial basis function (RBF) kernels and chose RBF for all calculations as it was found to be less biased than the polynomial kernel in our simulation and also because it is more general than the linear kernel. This is chosen by using the kernel argument (kernel = ”radial”) of the R function svm. The performance of SVM with RBF kernel may depend on the cost (the C-constant of the penalty term in the Lagrange multipliers) and gamma (the inverse-width parameter of RBF kernel function). The cost parameter controls the margin of the support vectors – a smaller value relaxes the penalty on margin errors (ignores penalising points close to the boundary) and hence increases the margin of classification. The value of gamma controls the curvature of the decision boundary – higher values make the decision boundary more flexible (non-linear). We optimise the cost and gamma parameters using grid search over the spaces consisting of uniform samples of size 5 (inclusive of the default values) from the ranges (1/10, 10) and (
2.3 Performance estimators
We compare performance of the methods in terms of classification error, sensitivity and specificity. We use leave-one-out cross-validation for estimating these performance measures. This choice was based on evaluation and comparison of several estimators, namely the leave-one-out CV, 10-fold CV, bootstrap and 0.632 plus bootstrap30 estimators. The estimators were compared in terms of bias and variability using simulations for training samples of various sizes. We consider training sample sizes (n) ranging from 10 to 250, but all four estimators could not be compared for the entire range as bootstrap and 0.632 plus bootstrap estimators often lead to computational problems for smaller n due to the extremely unbalanced nature of resampled data. In order to keep bootstrap-based estimators in the comparison, we restricted the sample size to be at least 50 and a comparison based on average performance over 10 different training sample sizes (
2.4 Example datasets
We evaluated the performance of the methods on a number of real datasets generated from a range of high-throughput platforms such as gene expression data from DNA microarrays, neuroimaging data from high-resolution MRI system and ERP data measuring brain activity derived from EEG system.
2.4.1 Bipolar gene expression data
This dataset is based on a microarray gene expression study 31 of adult postmortem brain tissue (dorsolateral prefrontal cortex) from subjects with bipolar disorder and healthy controls. Affymetrix HG-U133A GeneChips platform was used to determine the expression of approximately 22,000 mRNA transcripts of 61 subjects (30 bipolar and 31 controls). Preprocessed RMA normalised data of this experiment are obtained from GEO (http://www.ncbi.nlm.nih.gov/geo/), accession number GSE5388..
2.4.2 MRI brain imaging data
The brain imaging data were downloaded from the Alzheimer’s disease Neuroimaging Initiative (ADNI) database (www.loni.ucla.edu/ADNI, PI Michael M Weiner). ADNI was launched in 2003 by the National Institute on Aging (NIA), the National Institute of Biomedical Imaging and Bioengineering (NIBIB), the Food and Drug Administration (FDA), private pharmaceutical companies and non-profit organisations, as a $60 million, five-year public–private partnership. The primary goal of ADNI has been to test whether serial MRI, PET and other biological markers are useful in clinical trials of MCI and early Alzheimer’s Disease (AD). Determination of sensitive and specific markers of very early AD progression is intended to aid researchers and clinicians to develop new treatments and monitor their effectiveness, as well as lessen the time and cost of clinical trials. ADNI subjects aged 55 to 90 from over 50 sites across the United States and Canada participated in the research and more detailed information is available at www.adni-info.org. 1.5-T MRI data were downloaded from the ADNI website (www.loni.ucla.edu/ADNI). The description of the data acquisition of the ADNI study can be found at www.loni.ucla.edu/ADNI/research/Cores/index.shtml. Briefly, data from 1.5-T scanners were used with data collected from a variety of MR systems with protocols optimised for each type of scanner. Full brain and skull coverage was required for the MRI datasets and detailed quality control carried out on all MR images according to previously published quality control criteria.32,33 We applied the Freesurfer pipeline (version 5.1.0) to the MRI images to produce regional cortical thickness and volumetric measures. All volumetric measures from each subject were normalised by the subject’s intracranial volume, while cortical thickness measures were not normalised and were used in their raw form. 34
2.4.3 Electroencephalographic data
EEG signals measure voltage fluctuations recorded from electrodes on the scalp, providing an index of brain activity. These data were obtained from 41 adults with a current diagnosis of ADHD (attention deficit hyperactivity disorder) and 47 individuals with no mental health problems.
35
EEG was recorded during a 3-min resting condition (eyes open) and a cued continuous performance task (CPT-OX; described in detail in McLoughlin et al.
36
). EEG montage and recording, as well as re-referencing, downsampling and ocular artefact rejection procedures were equivalent to those outlined in Tye et al.
37
Trials with artefacts exceeding 200
2.5 Simulation
2.5.1 Main simulation
Classification problems based on high-dimensional data are predominantly demonstrated using microarray gene expression data. We therefore design our simulation model to generate realistic gene expression data where we can systematically vary different data characteristics (variability, effect size, correlation, etc.) in order to investigate the effects of such data characteristics on the performance of classification algorithms. To make our simulated data as realistic as possible, we base our simulation study on a real microarray dataset. We define a set of base expressions (μ) by averaging normalised

Independence is rarely a realistic assumption for any multidimensional data including gene expressions where groups of genes operate together in an orchestrated fashion forming network relationships to perform certain biological functions. Variables within such groups or networks are generally highly correlated within themselves but are likely to exhibit negligible correlations with variables from another group. We consider a block-diagonal correlation matrix to model such network relationships using the hub-Toeplitz
39
correlation structure for the hth block:

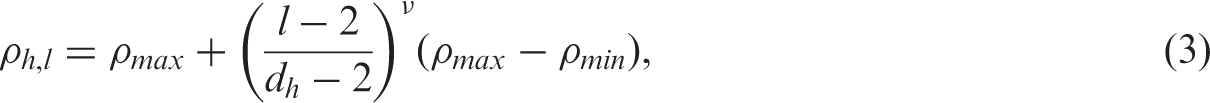
We set the number of blocks (H) to 1 for
We use Cholesky root transformation to impose the block-diagonal hub-Toeplitz structure

In order to introduce a systematic source of variation (namely the group difference), we divide the training sample into two groups, G1 and G2, of sizes
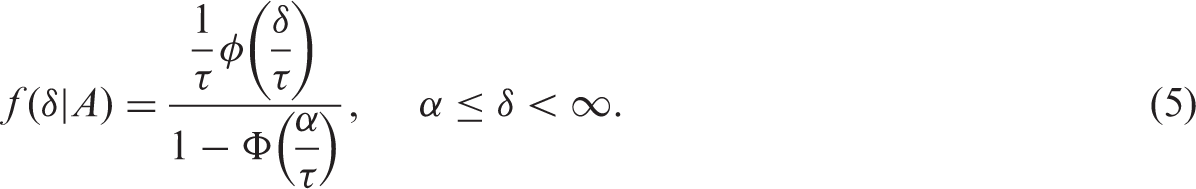

The values of training sample size (n), biological variation (
2.5.2 Non-normal data
We perform a sensitivity analysis to investigate possible consequences of departure from normally distributed data. We simulated data from the Poisson family for this sensitivity analysis. Poisson data differ from its Gaussian counterpart in several respects: (i) Poisson is a discrete distribution which generates integer valued data rather than interval scaled (Gaussian like) data, (ii) mean–variance relationship for Poisson data is more restricted than that for Gaussian data as they are identical to the intensity rate parameter (λ) and (iii) Poisson data are generally positively skewed, particularly for smaller λ. It is not possible to exactly match the mean and variance of Poisson data with their Gaussian counterparts, but we maintained similar (hub-Toeplitz) block diagonal covariance structure between variables as that for the Gaussian data and conducted the simulation at various combinations of training sample and feature set sizes (
3 Results and discussion
3.1 Results on main simulation
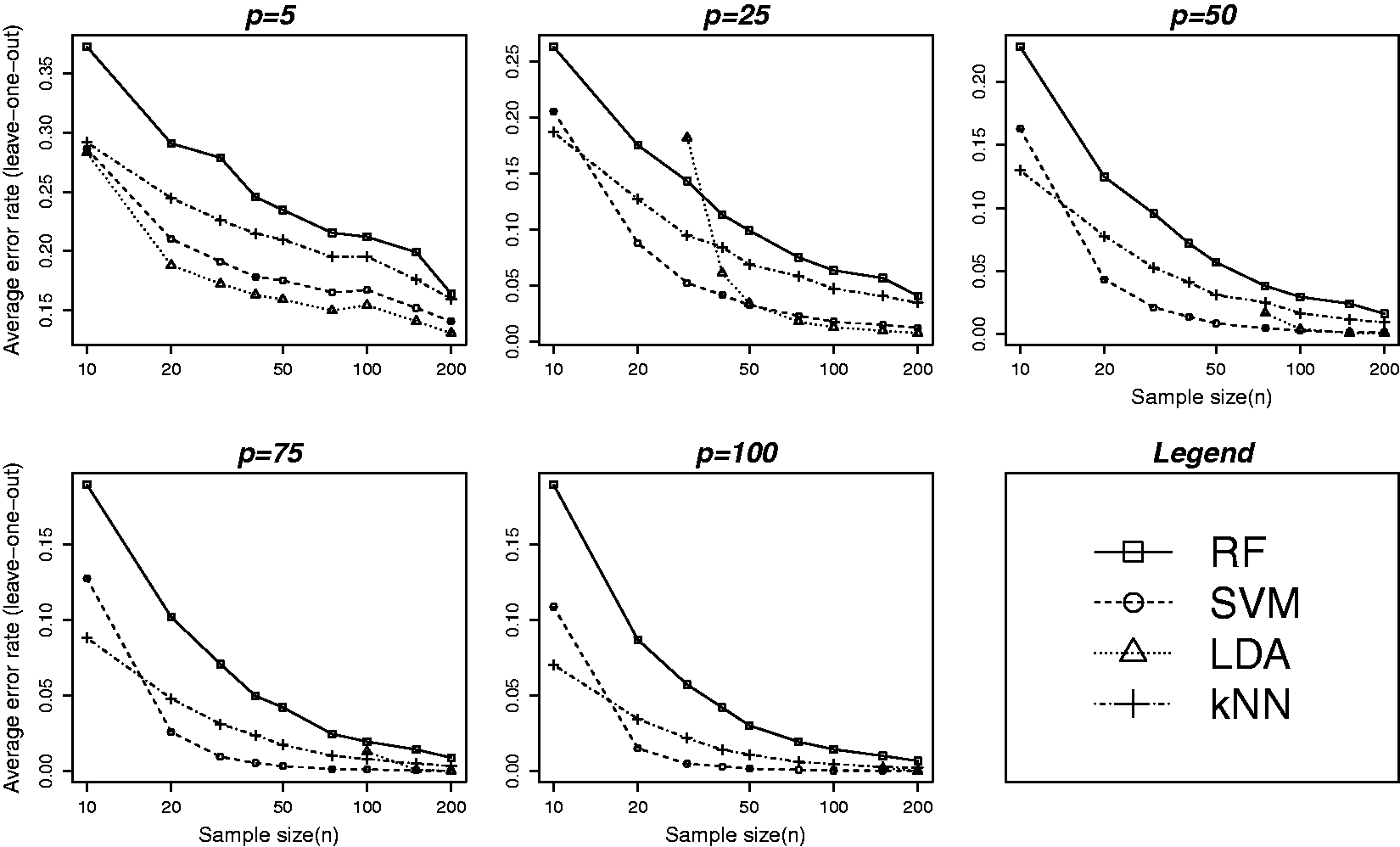
Average leave-one-out cross-validation estimate of classification error over the 500 replications of simulated datasets for all the four methods (RF, SVM, LDA and kNN) are plotted against the values of the various data characteristics in Figures 1 and 2. Top and bottom panels in Figure 1 are based on ( Average leave-one-out cross-validation error at varying levels of different data characteristics: biological variability ( Average leave-one-out cross-validation error at varying levels of training sample and feature set sizes. Error rates are plotted against nine different values of n as given in Table 1. The five plots correspond to five different values of p (feature set size): 5, 25, 50, 75 and 100, respectively. All other parameters are set to fixed values: (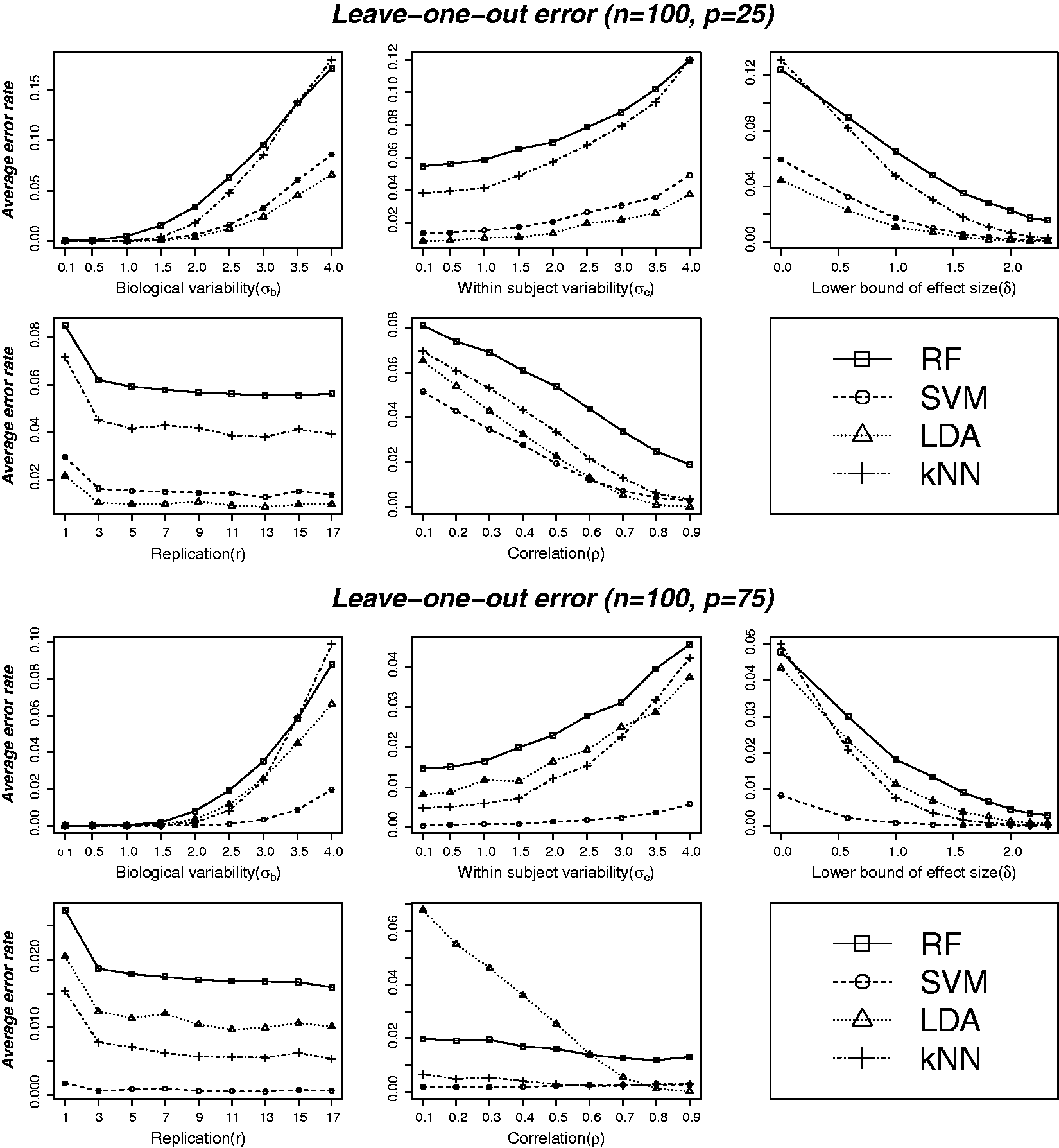
Corresponding plots for sensitivity and specificity are presented in supplementary Figures S4 and S5. The performances of all the studied methods were found to be symmetric in terms of sensitivity and specificity, which is expected to be the case for balanced and symmetrically distributed data. The patterns and order of performance in terms of sensitivity and specificity were found to be similar to that of overall classification error.
Figure 2 shows error rates plotted against nine different values of n as given in Table 1. The five plots correspond to five different values of p (feature set size): 5, 25, 50, 75 and 100, respectively. Although SVM was found to perform better than the other methods (see Figure 1) for larger training samples and feature sets, the method does not perform well for smaller (
To better understand the patterns of classification performance and for the ease of visual comparisons, three-dimensional plots of average leave-one-out cross-validation error as a joint function of feature set size and biological variation are displayed in Figure 3. All the plots correspond to n = 100 and the feature set size (p) ranges between 5 and 100 inclusive. The figure shows the error rate as a joint function of ( Three-dimensional plot of average leave-one-out cross-validation error as a joint function of feature set size (number of variables) and biological variation. All the plots corresponds to n = 100 and the five different feature set size (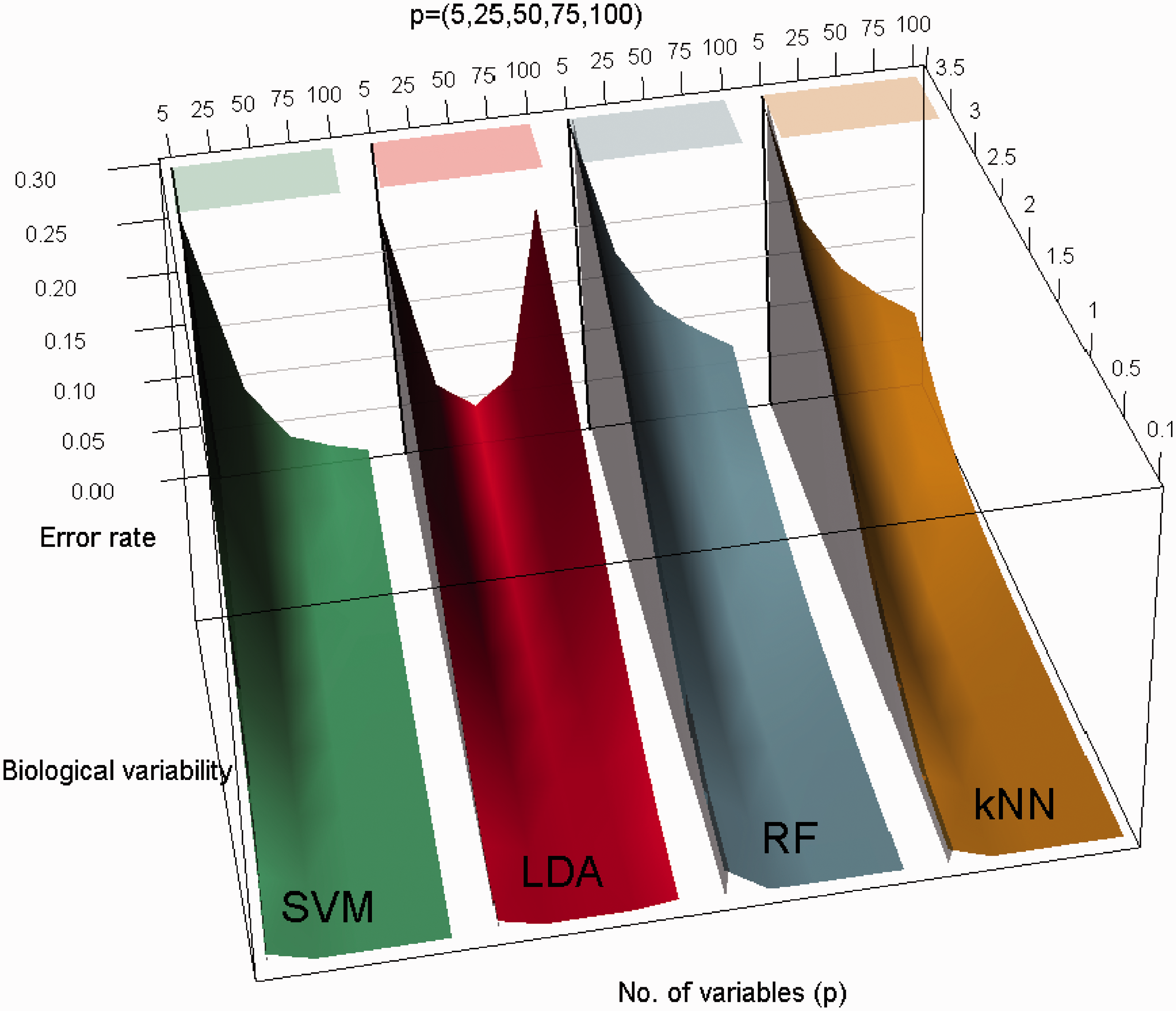
The standard errors (SE) of leave-one-out cross-validation error estimates at varying levels of different data characteristics are plotted in supplementary Figure S3. The SEs of error estimates appear to follow very similar patterns to that of average error estimates. For example, SVM provides the most stable (lowest SE) estimates of leave-one-out error in situations where the feature sets are larger than half the size of training samples (
3.1.1 Results on non-normal data
This section presents the results for simulation based on non-normal (Poisson) distributions as described in the simulation section. Supplementary Figure S6 shows average leave-one-out cross-validation estimate of classification error over the 500 replications of simulated data for all the four methods (RF, SVM, LDA and kNN) at various combinations of feature set and training sample size. The patterns and order of performance for Poisson data look very similar to that we observed for Gaussian data (Figure 2). For example, like Gaussian data, SVM is seen not to perform well for smaller samples (
3.2 Results on real data
Real life data are generally much more complex than the simulated data in terms of patterns and sources of variability. In order to be able to generalise the conclusions, it is important to investigate whether the findings on simulated data are supported by that from real data. We therefore compare the performance of the methods on several real datasets generated from various high-throughput technologies such as gene expression data from DNA microarrays, neuroimaging data from high-resolution MRI system and ERP data measuring brain activity derived from EEG system. Our example datasets are mainly from studies in mental health research, but the findings should be generalisable to any other disease or condition.
3.2.1 Bipolar gene expression data
This dataset is based on a microarray gene expression study
31
of adult postmortem brain tissue (dorsolateral prefrontal cortex) from subjects with bipolar disorder and healthy controls. More details can be found in the methods section. We select top 25 markers based on the p-values of the Empirical Bayes test
41
for differential expression between the bipolar and control groups for classification analysis. This selection is made in order to avoid using variables that are just noise and have no class discriminatory signals. The same approach is used for all other example datasets we used in this paper. The summary characteristics of bipolar gene expression data based on the selected markers are given in Table 2. Estimated leave-one-out cross validation errors for bipolar versus control classification based on the top 25 markers are displayed in Figure 4.
Leave-one-out CV errors for classifying 61 patients into Bipolar and Control groups based on top differentially expressed genes from the bipolar gene expression data.
31
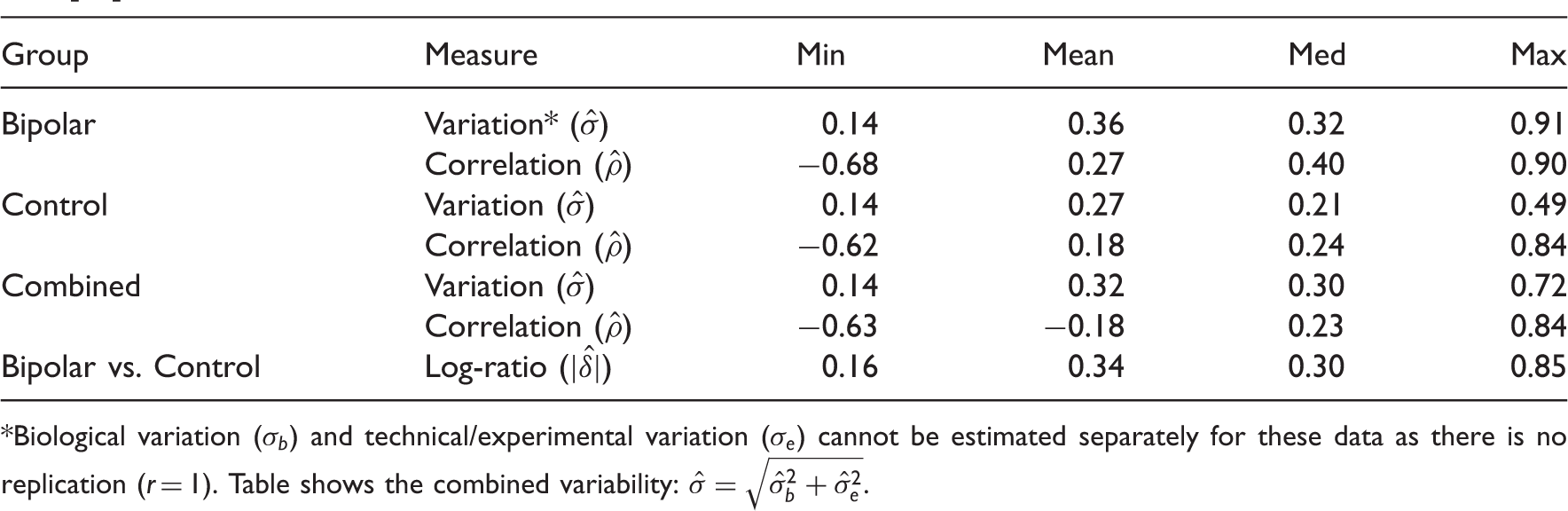
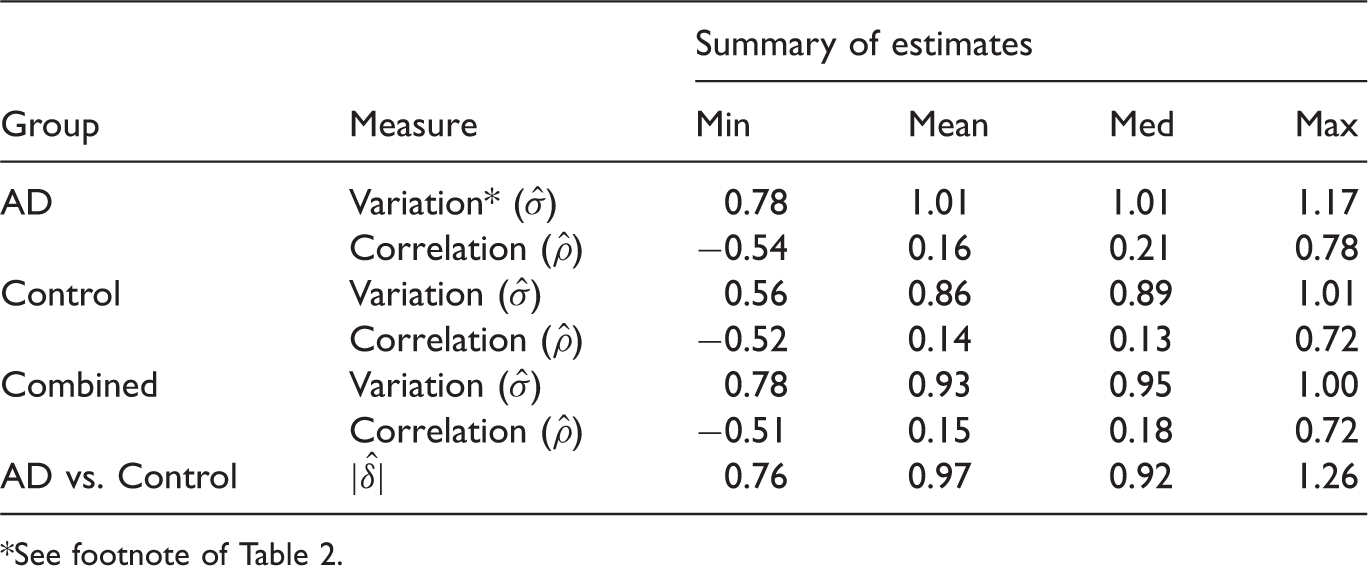
Summary of estimated data characteristics for a subset of top 25 markers from the bipolar gene expression data [31]. Biological variation (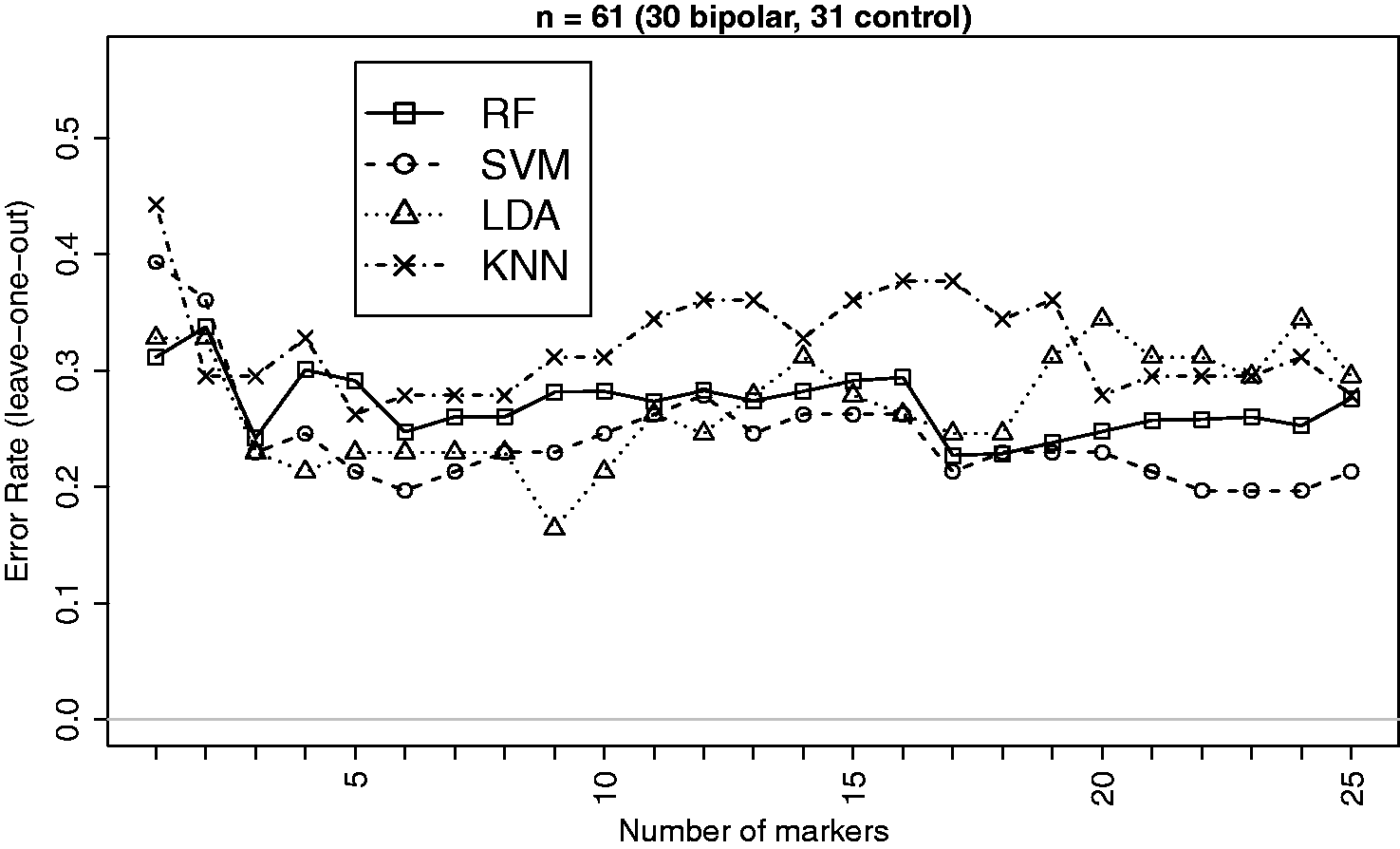
Effect sizes are not that big for this dataset and the classification performance does not appear to improve as the number of markers grows beyond around 5. However, in terms of comparative performance SVM appears better (closely followed by LDA) in most instances which is consistent with the findings on simulated data. It may be noted that the performance of LDA started to deteriorate when the number of markers exceeded 18 which is much smaller than the threshold (
3.2.2 Brain imaging data of Alzheimer’s and control patients
Recent advances in neuroimaging technologies such as the high-resolution MRI system have made it possible to effectively measure brain-wide regional cortical thickness and regional volume using automated atlas-based neuroimage segmentation scheme. Such measures are commonly used for linking Alzheimer’s disease to the physical changes in different brain regions, e.g., hippocampus and entorhinal cortex. In this study, we consider brain imaging data from the US-based ADNI study (www.loni.ucla.edu/ADNI) for classifying patients on the basis of their regional cortical thickness and volume measures. Further information on the data and the protocols for generating such measures can be found in the method section. We select the top 25 measures on a sample of 418 (186 AD, 222 Controls) patients based on the p-values of the Empirical Bayes test
41
for difference in means between the AD and control (CTR) groups for classification analysis. The summary characteristics of imaging data based on the selected markers are given in Table 3. The classification performances of the four methods (RF, SVM, LDA and kNN) for the AD versus CTR classification are displayed in Figure 5. Effect sizes (δ) are higher for this dataset and the performances of the methods appear very close to each other. This is expected and supported by the findings from simulation (e.g., Figure 1) indicating that the performance differences gets narrower as the effect size increases. Overall, SVM and LDA seem to have performed better in most instances as supported by the general patterns observed in simulation.
Leave-one-out CV errors for classifying 408 patients into AD and Control groups based on top imaging measures. There is very little differences between the performances of the methods, which is expected due to larger effect sizes and is supported by the findings from simulation indicating that the performance differences gets narrower as the effect size increases. Summary of estimated data characteristics for a subset of top 25 brain imaging markers from the ADNI study. See footnote of Table 2.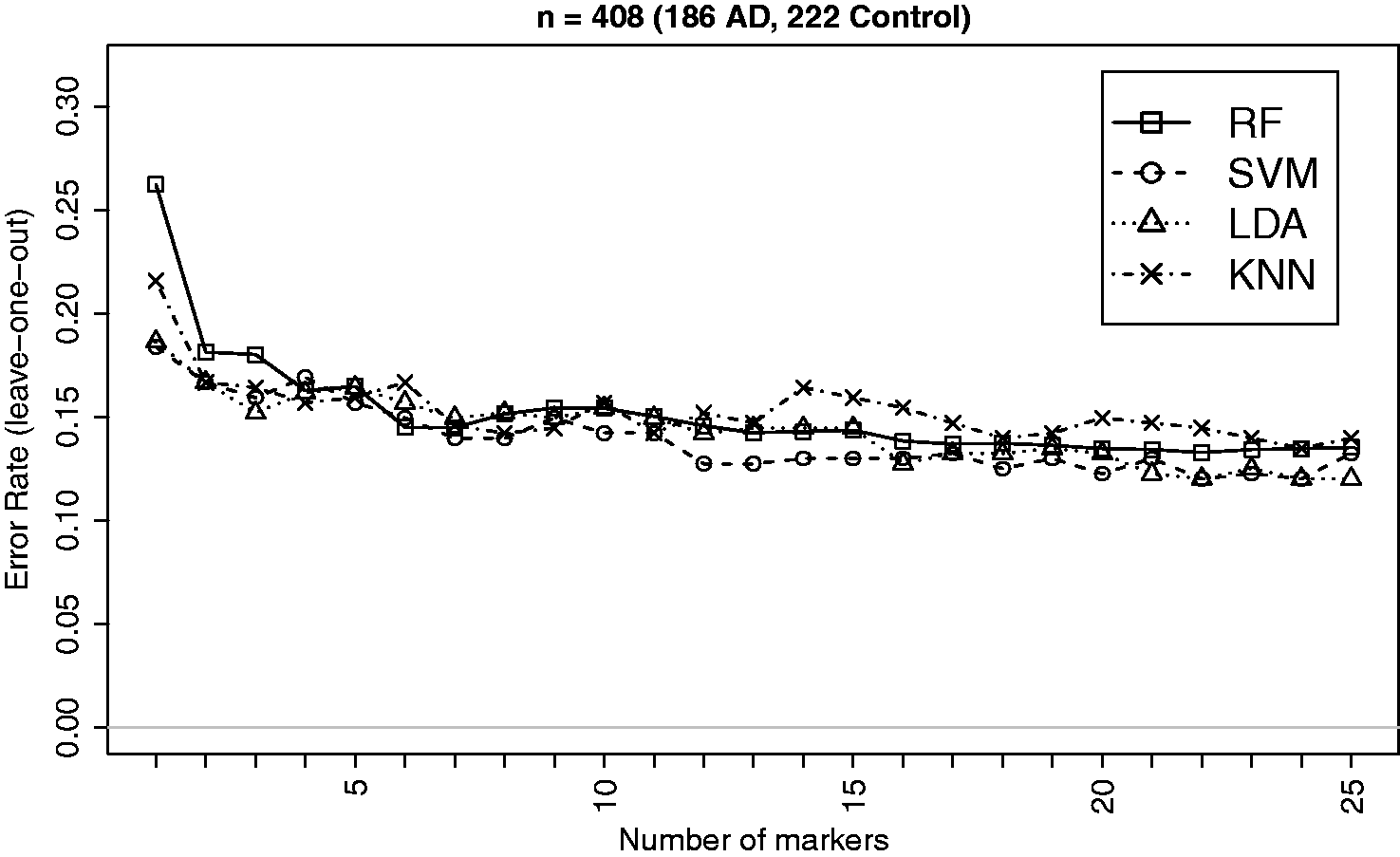
3.2.3 Electroencephalographic data
EEG signals measure voltage fluctuations recorded from electrodes on the scalp, providing an index of brain activity. EEG data for this example were obtained from 41 adults with a current diagnosis of ADHD (attention deficit hyperactivity disorder) and 47 individuals with no mental health problems. 35 More detail data description is in the method section. Out of 63 measures, only few were significantly different between case and control groups. We, however, select the top 25 measures based on the p-values of the Empirical Bayes test 41 for classification analysis.
The summary characteristics of EEG data based on the selected measures on 86 subjects (two ADHD cases excluded due to missing values in some of the selected variables) are given in Table 4. The classification performances of the four methods (RF, SVM, LDA and kNN) for the ADHD versus Control classification are displayed in Figure 6.
Leave-one-out CV errors for classifying 86 patients into ADHD and Control groups based on top EEG measures. This is an example where the effect size is very small and therefore the error rate does not show a steady declining pattern as the number of variables grows. This however supports the observation from simulation regarding the strengths of RF in dealing with data having weaker signal and higher noise as RF is seen to outperform LDA and kNN in this example. Summary of estimated data characteristics for a subset of top 25 features from the EEG data. See footnote of Table 2.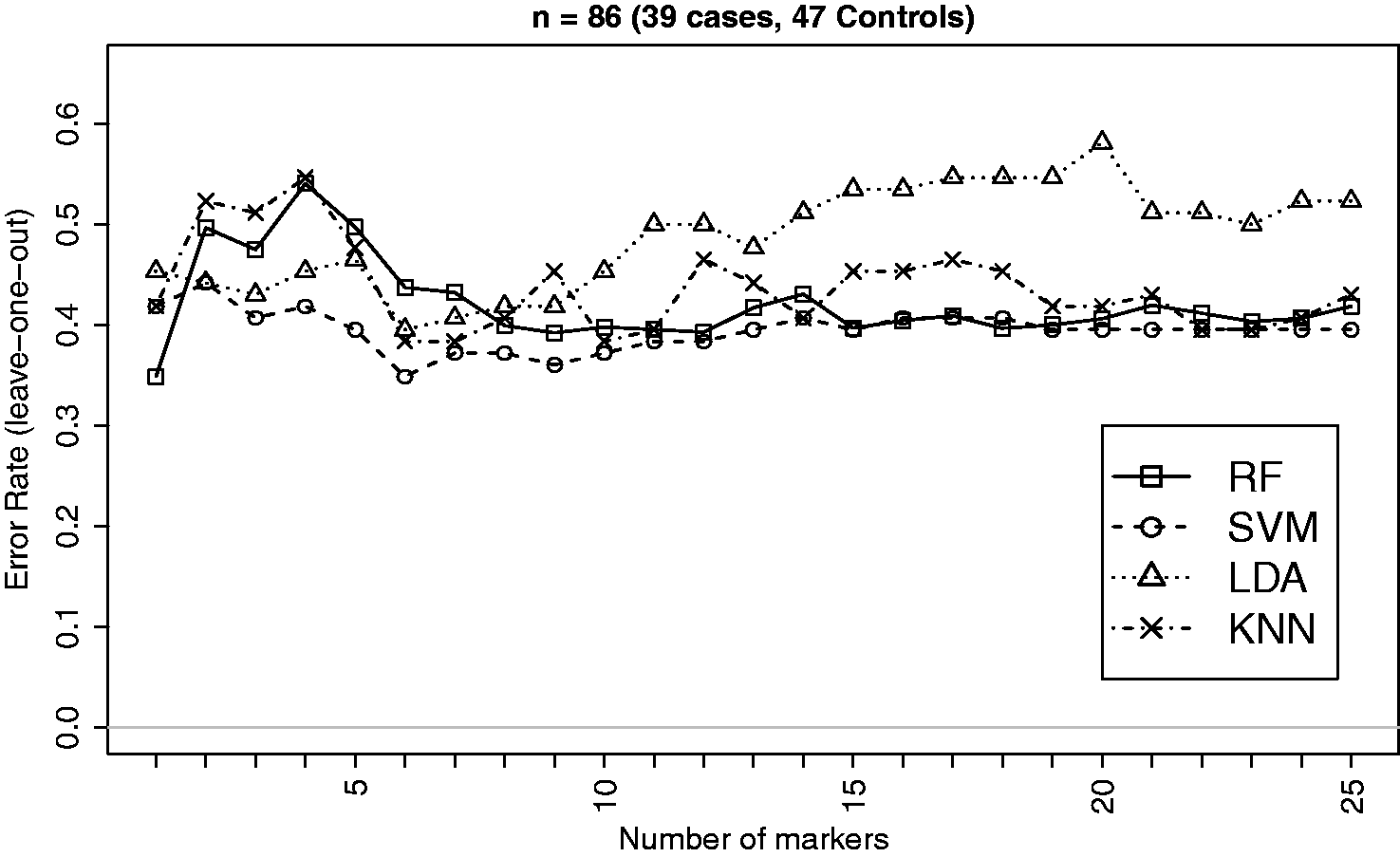
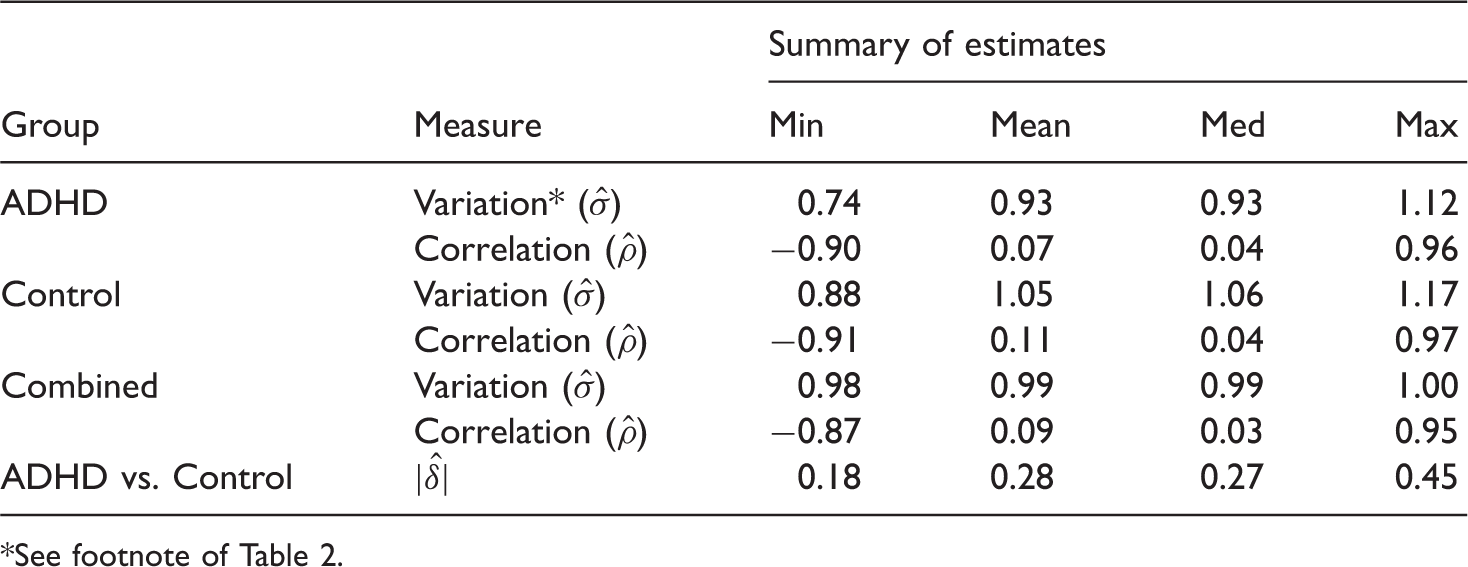
Of the three example datasets, EEG data have the smallest signal (mean
4 Conclusions
We performed an extensive simulation study in order to objectively compare classification performance of a number of widely used machine learning or statistical algorithms in terms of generalisation errors, sensitivity and specificity for supervised classification problems. The main focus of our study was to investigate ‘which method performs better in what circumstances’ by comparing performances at various combinations of levels of multiple factors (data characteristics). Results of our simulation study and subsequent examples on multiple real datasets from various high-throughput technology platforms led to the following conclusions:
For smaller number of correlated features, number of features not exceeding approximately half the sample size, LDA was found to be the method of choice in terms of average generalisation errors as well as stability (precision) of error estimates. The region of strength of LDA appears to be As the feature set gets larger ( The performance of kNN also improves as the feature set size grows and outplays that of LDA and RF unless the data variability is too high and/or effect sizes are too small. RF was found to outperform only kNN in some instances where the data were more variable and had smaller effect sizes, in which cases it also provided more stable error estimates than kNN and LDA. All methods showed a tendency to perform better at higher correlation, but RF appears to have comparatively worse performance when the variables are very highly correlated. Performances of all the studied methods were found to be symmetric in terms of sensitivity and specificity, which is expected to be the case for balanced and symmetrically distributed data.
None of the methods studied (except LDA) require the data to follow any particular probability distribution and the simulation results should be robust against departures from normality assumption. We demonstrated this by simulating from non-normal (Poisson) distribution which indicates that LDA is robust against some departure from normality and the other methods perform similarly on normal and non-normal data.
Footnotes
Acknowledgements
We thank Prof. Andrew Pickles and the anonymous reviewers for helpful comments on an earlier draft which helped to improve the paper. We thank Dr. Gráinne McLoughlin and Prof. Philip Asherson for providing the EEG data and Division of Pathway Medicine (Edinburgh University) for the base gene expression data.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MK, RD and AS receive salary support from the National Institute for Health Research (NIHR) Mental Health Biomedical Research Centre at South London and Maudsley NHS Foundation Trust and King’s College London. The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR or the Department of Health. This work has made use of the resources provided by the ECDF (http://www.ecdf.ed.ac.uk/), and the NIHR Biomedical Research Centre for Mental Health Linux Cluster (http://compbio.brc.iop.kcl.ac.uk/cluster/). The ECDF is partially supported by the eDIKT initiative (http://www.edikt.org.uk). The collection and sharing of brain imaging data used in one of the examples of this study was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: Abbott; Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Amorfix Life Sciences Ltd.; AstraZeneca; Bayer HealthCare; BioClinica, Inc.; Biogen Idec Inc.; Bristol-Myers Squibb Company; Eisai Inc.; Elan Pharmaceuticals Inc.; Eli Lilly and Company; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; GE Healthcare; Innogenetics, N.V.; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Medpace, Inc.; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Servier; Synarc Inc.; and Takeda Pharmaceutical Company. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private Rev November 7, 2012 sector contributions are facilitated by the Foundation for the National Institutes of Health (![]() ). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Disease Cooperative Study at the University of California, San Diego. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of California, Los Angeles. This research was also supported by NIH grants P30 AG010129 and K01 AG030514.
). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Disease Cooperative Study at the University of California, San Diego. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of California, Los Angeles. This research was also supported by NIH grants P30 AG010129 and K01 AG030514.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.