
Abstract
Longitudinal data can be used to estimate the transition intensities between healthy and unhealthy states prior to death. An illness-death model for history of stroke is presented, where time-dependent transition intensities are regressed on a latent variable representing cognitive function. The change of this function over time is described by a linear growth model with random effects. Occasion-specific cognitive function is measured by an item response model for longitudinal scores on the Mini-Mental State Examination, a questionnaire used to screen for cognitive impairment. The illness-death model will be used to identify and to explore the relationship between occasion-specific cognitive function and stroke. Combining a multi-state model with the latent growth model defines a joint model which extends current statistical inference regarding disease progression and cognitive function. Markov chain Monte Carlo methods are used for Bayesian inference. Data stem from the Medical Research Council Cognitive Function and Ageing Study in the UK (1991–2005).
Keywords
1 Introduction
The Medical Research Council Cognitive Function and Ageing Study (MRC CFAS 1 ) has longitudinal information on progression of cardiovascular diseases and information on cognitive function as measured by the Mini-Mental State Examination (MMSE 2 ). One of the interests is to evaluate whether cognitive function can be identified as a risk factor for cardiovascular diseases.
With regard to cardiovascular diseases, we use data on stroke. Occasion-specific cognitive function is modelled as a latent variable and its effect as a risk factor for stroke investigated by combining a multi-state model for stroke and survival with a growth model for cognition. The relevance of this joint model will be illustrated by addressing the survival after a stroke, given various trends in cognitive decline, and by estimating the probability of having a stroke in a specified time interval conditional on an MMSE score at the start of the interval and survival up to the end of the interval. In both these cases, the change of cognitive function has an effect and thus illustrates the importance of modelling cognitive function jointly with the multi-state process.
The Bayesian framework is used for statistical inference. It allows individual-specific parameters for cognitive function to be estimated using information from both the multi-state data and the longitudinal MMSE data. Combining the growth model for latent cognitive function with a multi-state model has not been described before, and seems a promising way to handle questionnaire data and related latent variable information in an investigation of a multi-state process.
A continuous-time multi-state model can be used to describe the disease progression over time. If one of the states is the death state, the model is called an illness-death model. In the analysis of the CFAS data, individuals are classified in state one if they never had a stroke, and in state two if they experience one or more strokes. State three is the death state. An intensity (hazard) of a transition from one state to another can be linked via a regression equation to risk factors for the transition such as age or sex. We will investigate the effect of cognitive function by modelling it as a risk factor for the transitions in the three-state model for stroke.
Frequentist continuous-time multi-state models can be found in Kalbfleisch and Lawless 3 and Jackson et al. 4 Bayesian inference for parametric multi-state models is discussed in Sharples, 5 Welton and Ades, 6 Pan et al. 7 and Van den Hout and Matthews. 8 Semi-parametric Bayesian methodology can be found in Kneib and Hennerfeind. 9
When risk factors are manifest and time-dependent, and a piecewise-constant approximation of the values seems reasonable, frequentist multi-state models can be fitted using existing methodology. Jackson
10
provides an
Specific to the application, cognitive function is a latent time-dependent risk factor and we assume that changes in the function over time can be described by a random-effect linear growth model. Typically, the MMSE response data consist of dichotomous and polytomous item scores. Therefore, a generalized item response theory (IRT) model will be used for the mixed-response type longitudinal MMSE data. The longitudinal item-based MMSE data are used to measure individual continuous-valued cognitive function scores.
An IRT model 11 assumes that certain observed discrete values are manifestations of an underlying latent construct. With regard to the MMSE, the discrete values are responses to a series of binary questions and one question with five ordered categories, and represent aspects of cognitive functioning. The time-dependent IRT model for longitudinal MMSE data relates the probability of the discrete values to the underlying occasion-specific cognitive function to explain MMSE performance.
Traditionally, the MMSE sum score is used as an estimate of cognitive function. However, using IRT has several advantages. First, item response data contain more information than sum scores and this allows the IRT model to parameterize the items individually. Second, the IRT model is better equipped to handle missing data. Third, IRT is more flexible with regard to incomplete designs and different number of items.
A specific problem with the MMSE sum score is that there is often a ceiling effect: many observed sum scores are close to the upper bound. Hence, the standard assumption that the conditional distribution of the observed response in the related growth model is normal is problematic. When cognitive function is assessed using IRT, the ceiling effect is less of a problem since cognitive function is modelled as a latent variable on a continuous scale.
Fox and Glas 12 defined a multilevel population model for a latent variable to account for the nesting of students in schools. This multilevel IRT measurement model is here extended to account for the nesting of time-dependent measurements within subjects and to account for mixed response types (dichotomous and polytomous items).
To summarize, a joint model is proposed for the multi-state data and the MMSE data, where cognitive function is the continuous latent variable that explains variation in the longitudinal MMSE scores and – potentially – variation in the transitions between the states.
For Bayesian inference, Markov chain Monte Carlo (MCMC) methods are used to sample values from the posterior density of the overall model that includes the multi-state model and the IRT growth model. The sampled values are used to compute posterior means, credible intervals (CIs) and other posterior quantities of interest.
The overall approach is very flexible and can therefore be used in other applications as well. Because MCMC is applied, random effects are estimated along with population parameters and dealing with missing MMSE item scores is relatively straightforward. In addition, in the estimation of the parameters, it is possible to specify the information flow: in our joint model, the parameters for the covariate process are sampled using multi-state data. Both for the growth model and the multi-state model, the number of observations and the times of interview can vary within and between individuals.
This article is organized as follows. Section 2 introduces the CFAS data and presents some basic descriptive statistics. Section 3 discusses the methods for data analysis: the multi-state model, the IRT linear growth model, model identification and prior densities. In Section 4, the handling of missing MMSE scores is explained. Section 5 briefly discusses the MCMC that is used for Bayesian inference. The data analysis can be found in Section 6. Section 7 concludes this article. The MCMC in Section 5 is detailed in the appendix.
2 Data
The MRC CFAS is a UK population-based study in which individuals have been followed from baseline 1991–1992 (www.cfas.ac.uk) 1 up to the last interviews in 2004. All participants are aged 65 years and above, and all deaths up to the end of 2005 have been included.
The three-state model for stroke is defined as follows. State 1 is the healthy state (no history of stroke), individuals in state 2 have had one or more strokes and state 3 is the death state. Transitions from 1 to 2 are interval-censored (exact times of strokes are not available), but death times are known. By definition, transitions from state 2 to state 1 are not possible.
Cognitive impairment was measured using the MMSE with sum scores in the range 0–30. There are 25 binary questions and one which has a scale from 0 up to 5. The latter is about counting backwards, where a score of 5 is given if the counting is flawless. This question is considered as an important item in the MMSE. Note that when working with sum scores, the question can add 5 points to a scale with a total range of 0 up to 30. To simplify the model slightly, we take scores 0 and 1 together in category 1, resulting in ordered scores 1, 2, 3, 4 and 5. An alternative would be to dichotomize the scale but that would mean that the relative importance of the question is lost.
In this article, we describe and analyse the data for men in Newcastle. The sample size is 925 and in total, there are 2810 observations (total number of interviews, right-censored states and observed deaths). In this data set, the median age at baseline is 73. Time between interviews varies between and within individuals. The median length of the time between two consecutive interviews is 26 months. The median number of interviews is 2.
For men in CFAS data from Newcastle, frequencies of number of times each pair of states was observed at successive observation times
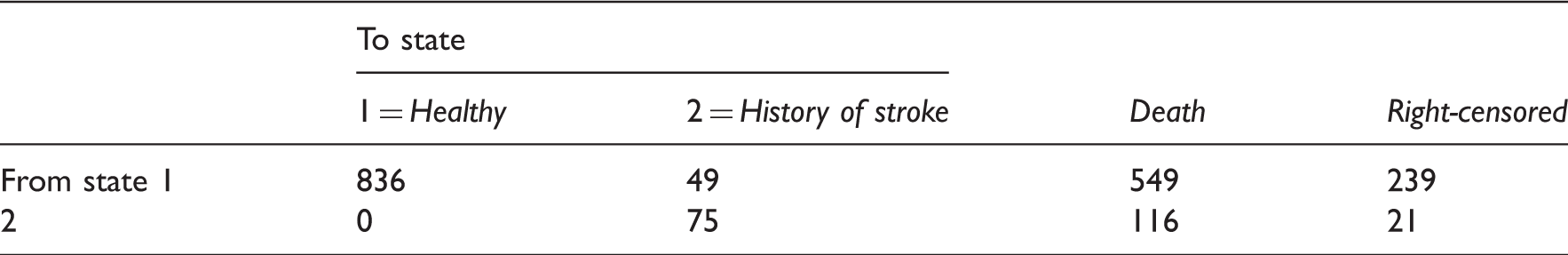
Originally, the MMSE was designed to screen for dementia. It contains questions on memory, language and orientation. Most of the questions are relatively easy for individuals with average cognition. MMSE sum scores below 10 are indicative of dementia. Individuals with scores in the range 25–30 are said to have normal cognitive functioning. Currently, the MMSE is also widely used to measure overall cognitive function. When the MMSE is applied in a population-based study such as CFAS, a large proportion of the observed MMSE sum scores will be in the range 25–30. In the data for men in Newcastle, the median of the MMSE sum score at baseline is 27.
MMSE scores are not always observed. There are 298 missing binary item scores in the records of 28 men. Nine men have a missing score for the five-category question.
3 Methods
In this section, the joint modelling framework is presented for latent growth trajectories and multi-state processes. First, the multi-state model is discussed, followed by the latent growth model part. The derivation of the joint posterior distribution concludes this section.
3.1 The multi-state model
This section presents the likelihood of the continuous-time multi-state model. The basic ideas can be found in Kalbfleisch and Lawless 3 and Jackson et al. 4 The formulation of the likelihood is different from that in Van den Hout and Matthews, 8 where an approximation with regard to exact death times was used. Transition probabilities in the likelihood are conditional on the current state and current values of risk factors. Commenges 13 uses the term partial-Markov to denote this kind of multi-state model since using the time-dependent risk factors implies that the process is not first-order Markov.
Let the interval-censored multi-state data be given by
Let (t, u] denote a generic time interval. For a continuous-time multi-state model, transition probabilities p
rs
(t, u) = P(x
u
= s|x
t
= r) are the entries of transition matrix
We assume a piecewise-constant multi-state model, where individual trajectories through the states are conditionally independent. For individual i, the likelihood contribution is
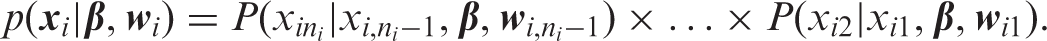
As implied by the above, we assume that given the current state and the current values of the risk factors, the distribution of the next state does not depend on the states visited before the current state. In addition, we assume that factor values are constant between consecutive observation times. Within each individually observed time interval (t ij , ti,j+1], this defines a time-homogeneous process. Using age as a piecewise-constant time-dependent risk factor, possible dependence of transition intensities on changing age is taken into account. 15
If there are no other risk factors besides age, the model for the intensities is given by log[q rs (t ij )] = βrs.1 + βrs.2Age(t ij ). This can also be formulated as q rs (t ij ) = λ rs exp[γ rs Age(t ij )], for λ rs > 0, which shows that the change of the intensities over time follows a Gompertz model with age as the time-scale.
3.2 Linear growth model for latent cognitive function
In our modelling, cognitive function is a latent time-dependent risk factor in the multi-state model. We assume that cognitive function is continuous and that the time-dependency can be described by a linear growth model. In the growth model, the function is represented by the variable θ.
For individual i with observation times ti1,…, t
in
i
, let 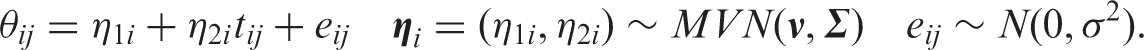
Cognitive function is a latent variable as it cannot be observed directly but is measured by the MMSE. At every observation time, the MMSE consists of K = 25 binary items (questions) and one item with five ordered answer categories. IRT models are used to link the observed discrete values to latent function
For individual i, the data for the binary response IRT model are given by 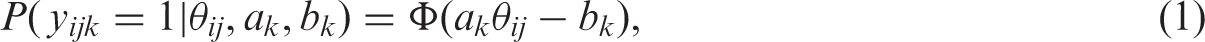
For k = 1,…, K, parameter a k is called a discrimination parameter and is the effect of a unit change in cognitive function θ on the success probability for item k. Parameter b k is a difficulty parameter and is the effect on the success probability when θ = 0. Note that a large negative value of b k corresponds to a relatively easy question.
Time-specific response data are assumed to be independent given time-specific cognitive function. This makes it possible to factorize the likelihood and we obtain
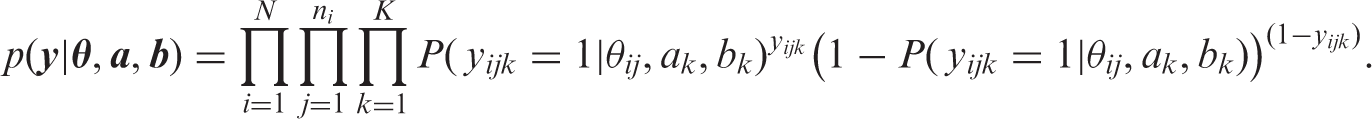
For the item with the five ordered response categories, we use the graded response model.
16
Let 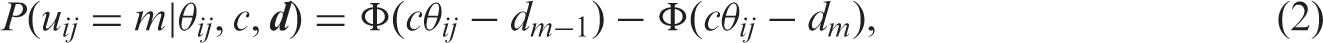
Fox
17
formulates this model for cross-sectional data, but – as above – given the conditioning on θ
ij
, the same model can be used for longitudinal data. The likelihood is
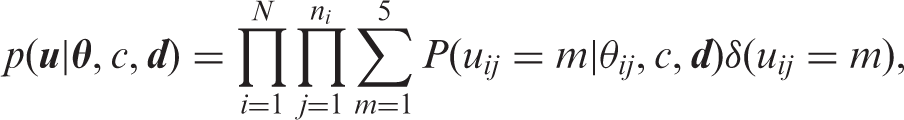
Analogous to the standard cross-sectional IRT model, we identify the growth model by fixing the scale of cognitive function
3.3 Posterior and prior densities
Bayesian inference is based on the posterior density of the model parameters. The posterior density is proportional to the likelihood of the data times the prior density of the model parameters. Ignoring manifest risk factors in the notation, the posterior of our model is given by
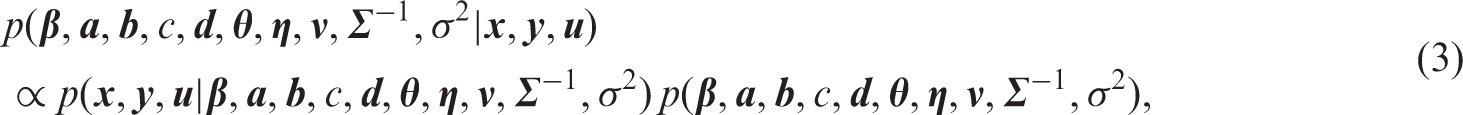
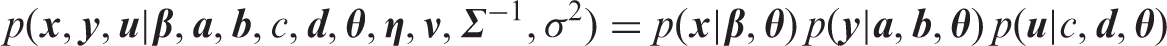
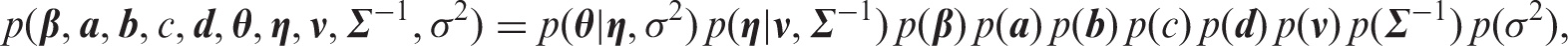
For the parameter 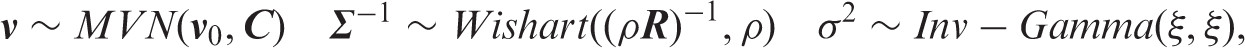
4 Missing scores on test items
In CFAS, not all the MMSE questions are answered by all the individuals. Missing values are ubiquitous in statistical analysis, and we are not the first to point out that the Bayesian framework is very suitable for dealing with certain forms of missingness.
We will assume that values are missing at random,
19
i.e. the missingness does not depend on the missing value itself, but may depend on observed data. It will further be assumed that the parameters for the distribution of
This flexible structure with respect to missing values is one of the reasons why we prefer to use an IRT model instead of using observed sum scores. The definition of a sum score is problematic when one or more item scores are missing.
Although we can estimate the model by ignoring the missing item scores, the MCMC method in the next section is easier to implement when we sample the scores along the way. In the MCMC algorithm, the missing scores are sampled first, after which the sampling of the model parameters proceeds as in the complete data case.
We illustrate the procedure for the binary response data. Given the probit model, latent cognitive function
For a missing values of polytomous u
ij
, values are sampled in a similar way using the multinomial distribution and parameters c and
5 Bayesian inference
MCMC methods are used to sample from the posterior distribution over the unknown parameters. The algorithm we use is a Gibbs sampler, 21 where each parameter is sampled conditional on the other parameters and the data. In case there is no closed form of the conditional probability distribution, Metropolis 22 or Metropolis–Hasting sampling 23 is undertaken. This scheme is sometimes known as Metropolis-within-Gibbs although some authors dislike this term, see the discussion in Carlin and Louis, 24 (sec. 3.4.4).
To summarize, data of individual i at time t
ij
consist of observed states x
ij
, binary response y
ijk
for item k and polytomous response u
ij
. Latent cognitive function is denoted as θ
ij
. The parameter vector for the three-state model is
Sampling the parameters of the IRT model for the dichotomous response is undertaken using an auxiliary variable
An innovative step in our Gibbs sampler is the sampling of
Here, we enumerate the main steps of the Gibbs sampling, where conditioning on all other parameters is indicated by three dots, e.g., p( Sample missing binary scores
Sample missing polytomous scores
Sample Metropolis sampling of Sample Sample Sample c from p(c|…) ∝ p( Sample Sample Sample
Posterior inference with regard to means, CIs and other derived quantities is based upon two chains, each with a burn-in of 5000 and an additional 15 000 updates. Convergence of the chains for the item parameters and the parameters for the growth model are assessed by visual inspection of the chains and by diagnostics tools provided in the
To compare models, we used the deviance information criterion.
28
The DIC comparison is based on a trade-off between the fit of the data to the model and the complexity of the model. Models with smaller DIC are better supported by the data. The deviance of interest is the deviance of the multi-state model given by
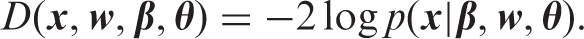
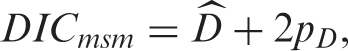
6 Application
The longitudinal MMSE data and multi-state data from the 925 men in CFAS in Newcastle will now be analysed. As stated before, in the three-state model, state 1 is the healthy state (no history of stroke), individuals in state 2 have had one or more strokes and state 3 is the death state. In the MMSE, there are 25 binary questions and one which is scored from 1 up to 5.
6.1 Estimation
Although the focus of the analysis is the three-state model, we briefly discuss the inference for the growth model for the MMSE data.
The choice of the hyper-parameters for the prior densities is
Posterior inference for model parameters with 95% CIs in parentheses
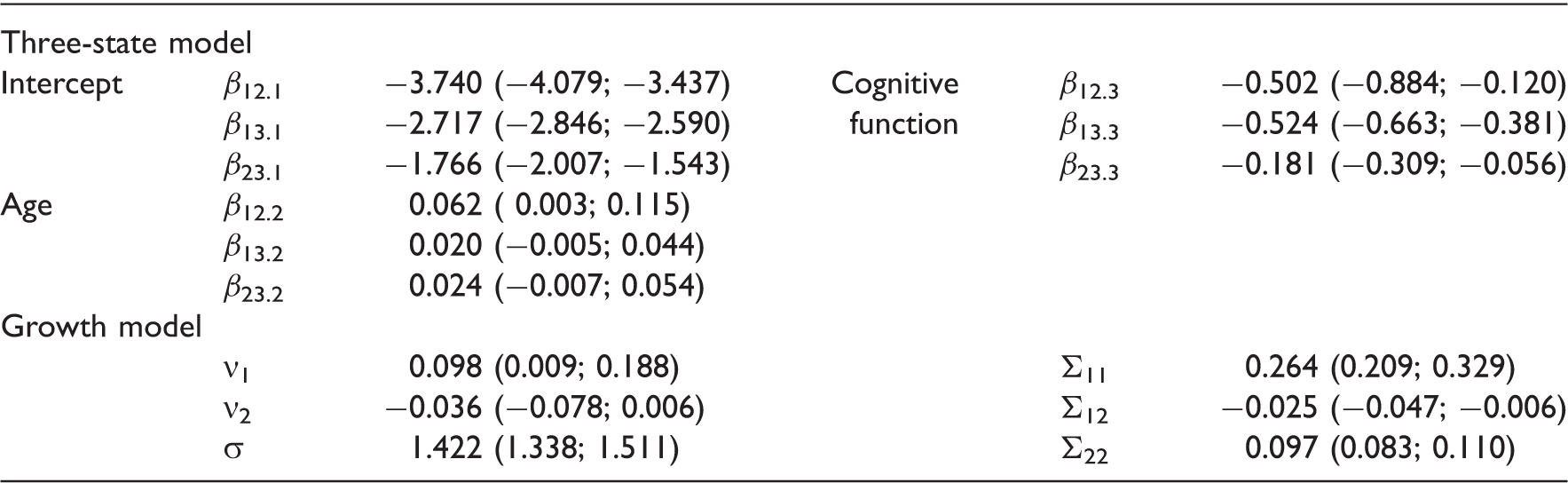
We do not aim to investigate the effect of the individual items in the MMSE. Nevertheless, it is interesting to see that there is indeed variation in the item-specific characteristics. For the parameters for the binary items, see Figure 1. This illustrates why we are using an IRT model in the first place: assuming for instance that all questions are equally difficult is clearly incorrect (bottom part of Figure 1). Note that all difficulty parameters have a posterior mean smaller than zero. This reflects that for most people, the MMSE items are easy. And this is as expected since the MMSE is originally constructed to screen for dementia and the questions are relatively easy for the majority of the individuals in CFAS. The variation in the discrimination parameters (top part of Figure 1) shows that some items are better at discriminating individual cognitive function than others.
Posterior inference for item parameters using boxplots. Discrimination parameters 
For the graded response model, the sampling of the threshold parameters d1, d2, d3 and d4 is depicted in Figure 2. The best way to sample threshold parameters has been a topic in the literature, (see sec. 4.3.4)
17
and the references therein. We used truncated normal distributions to generate new candidates in the Metropolis–Hasting step for Monte Carlo Markov chains for the difficulty parameter vector 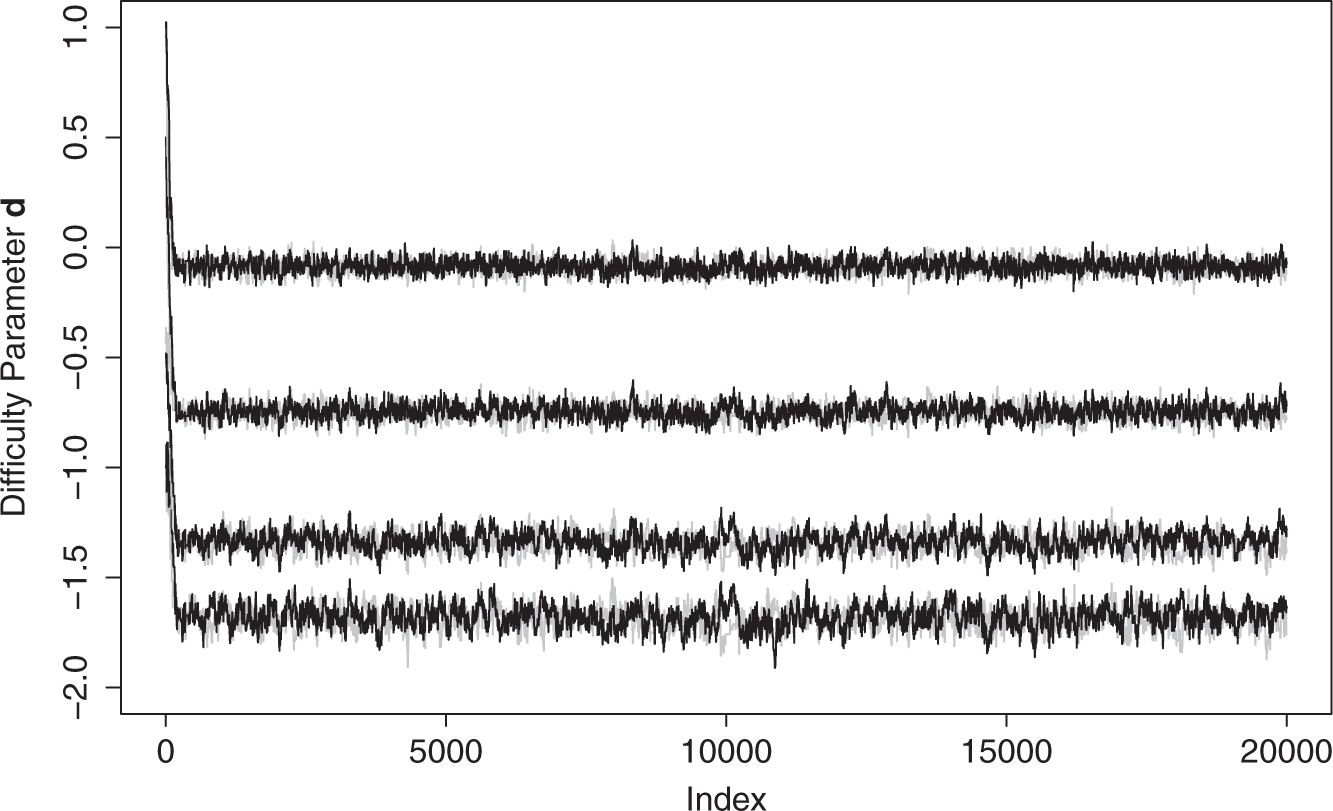
We now turn to the three-state model for stroke. The intensities are linked to age and cognitive function via the log-linear regression model given by
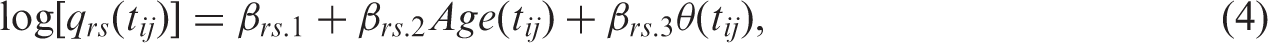
We start by examining whether adding age and cognitive function as risk factors provides a better model than the intercept-only model. The latter has DIC
msm
= 4825. The model with age but without cognitive function has DIC
msm
= 4777. Clearly, we get a better model by adding age. The final model, i.e. (4) with no restrictions, has DIC
msm
= 4680 which shows that taking cognitive function into account is worthwhile. Posterior inference for
The sign of the estimated effects of risk factors age and cognitive function are as expected: positive for age (getting older increases the risk of a transition) and negative for cognitive function (higher function is associated with a lower risk). Direct interpretation of the numerical results for the estimated effects is of limited use, see Section 6.4 for interpretation using estimated survival.
6.2 Goodness of fit
Model validation is undertaken by a posterior predictive model check. 29 Validation is hampered by the interval censoring of the transitions between the healthy state and the state defined by a history of stroke. Death times are, however, observed during the follow-up. We propose to validate the model by comparing the deaths observed during follow-up with simulated deaths given the posterior distribution of the parameters. This does not capture all aspects of the three-state model, but nevertheless gives an idea of goodness of fit: if the simulated deaths differ significantly from observed deaths, then the model cannot be trusted.
We use a test statistic that depends both on observed deaths (say data
In the model check, given sampled
We used 500 random samples from the MCMC for Posterior predictive model check. Comparing
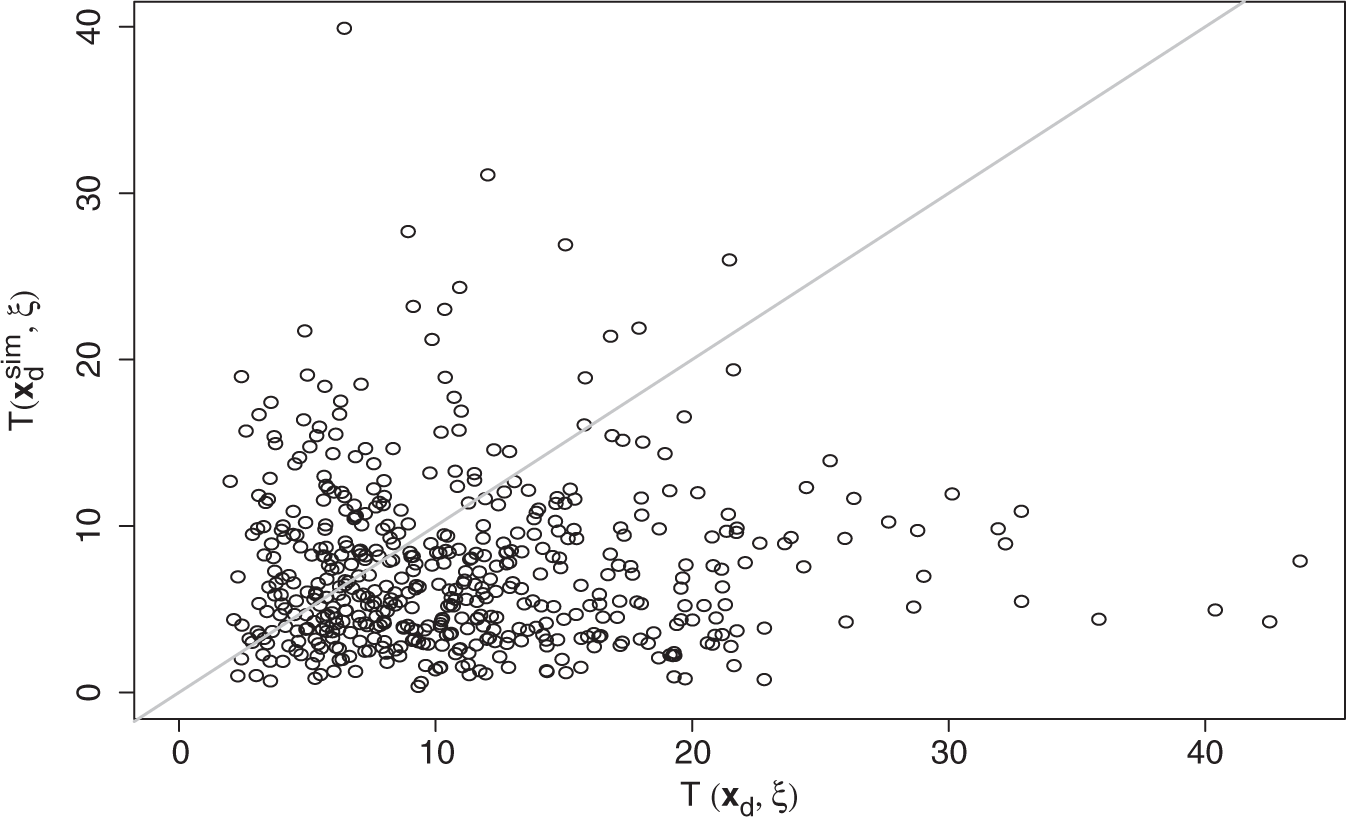
6.3 Prediction
Although posterior means for
Consider the case of A who has had a stroke in the past. What is his survival curve (probabilities of not dying) for the next 15 years? According to our model, this depends on current and future cognitive functions. Assume that his current function is equal to the estimated population mean (ηA1 = ν1). We consider baseline ages 65, 75 and 85. For each choice of baseline age, Figure 4 shows two survival curves conditional on assumptions with regard to the slope parameter in the growth model. For A, we assume that the slope is equal to the mean of its population distribution plus one standard deviation of that distribution (
Prediction for men in state 2 at baseline, aged 65, 75 and 85 years old. Solid lines for survival if slope in growth model is equal to population mean plus one standard deviation, dashed lines for slope equal to population mean minus one standard deviation (thin lines for 95% CIs). Prediction of survival for selected individual who is in state 1 at baseline, aged 69 (grey lines if baseline state would have been 2).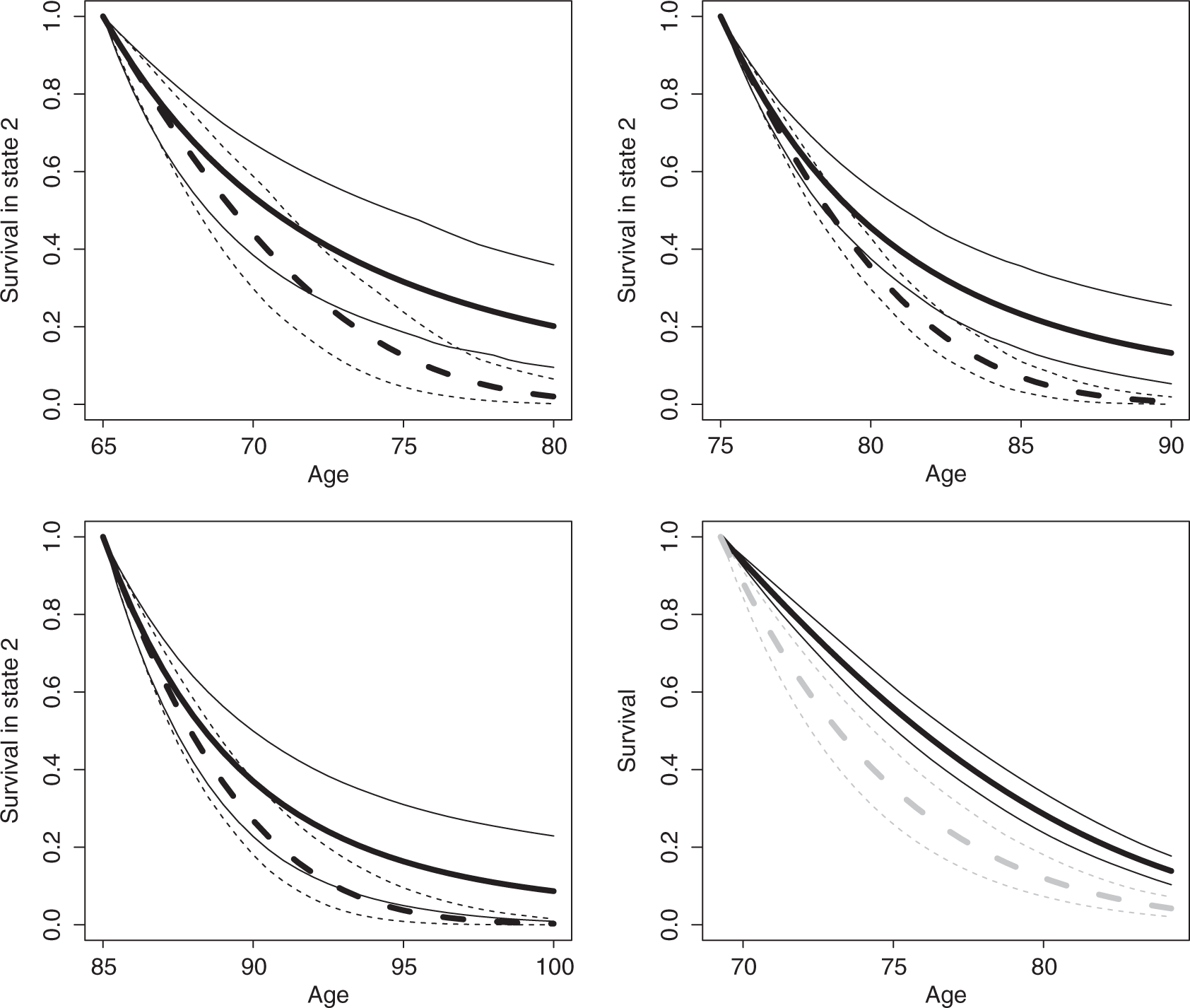
When it comes to prediction in practice, we would like to predict survival conditional on observed MMSE scores at baseline. Individual C has baseline scores 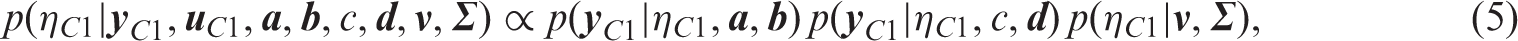
C is an actual man in the data set. At baseline, he is 69 years old, has an MMSE sum score of 23 and has no history of stroke. The MAP estimate of baseline function is −0.670 which is in the lower part of the estimated population distribution with mean ν1. Given baseline state 1 and assuming that the C's slope for the trend of cognitive function is the estimated mean ν2 for the population, we can estimate the survival. The bottom right graph in Figure 4 depicts this survival.
We consider possible transition from state 1 to state 2. For C, the probability that he will be in state 2 after 15 years (estimated at 0.047) is less interesting than the probability of being in state 2 conditional on being still alive after 12 years. The latter is estimated at 0.047/(1 − 0.862) = 0.341 with 95% CI (0.244; 0.521), where the uncertainty is with regard to the posterior distribution of 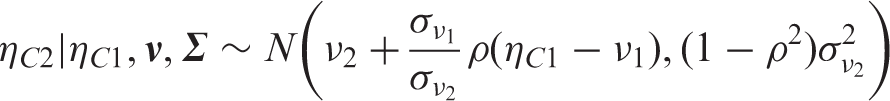
7 Conclusion
This article presented an application, where a three-state model for stroke and survival encompasses a latent growth model for time-dependent cognitive function using longitudinal MMSE data. The cognitive function was included in the joint analysis as a time-dependent risk factor for transitions in the three-state model.
Adding the MMSE sum score as a non-deterministic time-dependent risk factor is not a problem with respect to the estimation of a multi-state model when we assume that the piecewise-constant approximation is reasonable. However, for prediction, we need a model for the time-dependent risk factor. A growth model with the MMSE sum score as response variable is problematic because the conditional distribution of the sum score is not normal, as the scale is discrete and there are ceiling effects. The binomial distribution is an alternative for the response distribution, but this distribution does not distinguish between the items (questions) that make up the sum score. It is only when IRT models are used that both the discrete nature of the MMSE and the item-specific characteristics are taken into account.
The presented growth model is an extension from the one introduced by Douglas. 32 Our model can deal with variation in time intervals between interviews and is more flexible due to the random-effects structure.
Both within the three-state model and the growth model, we have used assumptions that are commonly made. In the multi-state process, the transition probabilities are conditional on the current state and current values of risk factors. Using the time-dependent risk factors implies that the process is not first-order Markov. The process is also not semi-Markov because time spent in the current state is not taken into account. Another important assumption is that the piecewise-constant approximation captures the essential part of time-dependent risk factors. The IRT for cognitive function in the growth model assumes local independence (given the item parameters, scores are independently distributed) and time-independent item parameters. A posterior model check was used to validate the model in the application.
In the three-state model for the history of stroke, each individually observed interval (say (t ij , ti,j+1] for individual i) is modelled in the likelihood as a homogenous process, where values of risk factors at time t ij are used to determine the distribution of the states at time ti,j+1. It is because of this that we can say lower cognitive function is associated with a higher risk of stroke. Due to the piecewise-constant approximation, the model is not invalidated by the fact that a stroke often causes a drop in cognitive function. For example, if a stroke occurred within (t ij , ti,j+1] and there is a drop in function, then the decreased function will only play a role in the modelling of the next interval (ti,j+1, ti,j+2].
The use of MCMC methods ensures proper propagation of the uncertainty at the various levels of the model. Using a random-effects growth model, individual heterogeneity is taken into account. Given the general structure of the model, it can be extended easily, for example, with additional covariates in the growth model or in the multi-state model. Possible sub-models may also be of interest. For example, if there is no MMSE information available, the growth model can be dropped from the overall model, and θ ij can take the role of a frailty which takes into account unobserved heterogeneity with regard to the risk of ill-health or death.
Footnotes
Acknowledgements
MRC CFAS is supported by major awards from the UK Medical Research Council and the Department of Health (grant MRC/G99001400). A. van den Hout is funded by the Medical Research Council grant no. UC US A030 0013. The collaboration was supported by a grant from the British Council and Platform Beta Techniek (![]() ).
).