
Abstract
Background
The evaluation of Patient Reported Outcomes Measurement Information System (PROMIS) computerized adaptive test (CAT) in adults with systemic lupus erythematous (SLE) is an emerging field of research. We aimed to examine the test–retest reliability and construct validity of the PROMIS CAT in a Canadian cohort of patients with SLE.
Methods
Two hundred twenty-seven patients completed 14 domains of PROMIS CAT and seven legacy instruments during their clinical visits. Test–retest reliability of PROMIS was evaluated 7–10 days from baseline using intraclass correlation coefficient (ICC (2; 1)). The construct validity of the PROMIS CAT domains was evaluated against the commonly used legacy instruments, and also in comparison to disease activity and disease damage using Spearman correlations. A multitrait-multimethod matrix (MMM) approach was used to further assess construct validity comparing selected 10 domains of PROMIS and SF-36 domains.
Results
Moderate to excellent reliability was found for all domains (ICC [2;1] ranging from lowest, 0.66 for Sleep Disturbance and highest, 0.93 for the Mobility domain). Comparing seven legacy instruments with 14 domains of PROMIS CAT, moderate to strong correlations (0.51–0.91) were identified. The average time to complete all PROMIS CAT domains was 11.7 min. The MMM further established construct validity by showing moderate to strong correlations (0.55–0.87) between select PROMIS and SF-36 domains; the average correlations from similar traits (convergent validity) were significantly greater than the average correlations from different traits.
Conclusions
These results provide evidence on the reliability and validity of PROMIS CAT in SLE in a Canadian cohort.
Key Messages
1. The data from this SLE cohort demonstrate that the PROMIS CAT domains have moderate to excellent test–retest reliability and moderate to strong construct validity compared to all seven legacy instruments. 2. Using the multitrait-multimethod matrix, six a priori hypotheses were confirmed showing moderate to strong correlations between select PROMIS and SF-36 domains (convergent validity). 3. The PROMIS CAT instruments seem feasible for many clinical environments as the median time to completion of all 14 PROMIS CAT domains was 11.7 min without additional time needed to score.
Introduction
Systemic lupus erythematous (SLE) is a multi-organ autoimmune disease with significant impact on overall health-related quality of life (HRQoL).1–3 Studies have shown that physician assessments of disease burden do not always align with patient reports. 4 As a result, patient-reported outcome (PRO) measurement tools have become invaluable in clinical practice and are central to patient-centered care. PROs have the potential to increase participation of patients in their medical care and to facilitate earlier identification and access to mental health and social support. 2
Currently, there are multiple generic and SLE-specific questionnaires that have validity evidence in SLE to evaluate HRQoL called legacy instruments.5,6 Specifically, these instruments include the following: The Medical Outcomes Study Short-Form 36 Health Survey (SF-36), 7 Lupus Quality of Life (LupusQoL), 8 Beck Anxiety Inventory (BAI), 9 The Perceived Deficits Questionnaire (PDQ-20), 10 Beck Depression Scale-second edition (BDI-II),11,12 The Assessment of Chronic Illness Therapy Fatigue Scale (FACIT-F), 13 and Epworth Sleepiness Scale (ESS). 14 Often these legacy instruments are administered on paper, and scoring each separately can become cumbersome at point of care. 15
The Patient Reported Outcome Measurement Information System (PROMIS) was created by the National Institute of Health in 2004 to describe and evaluate physical, mental and social health.16–19 It purports to have widespread utility in both the general population and in individuals living with chronic conditions.16–18,20 PROMIS instruments have been shown to capture the experiences of patients across the broad continuum of symptoms and function, especially at low disease activity levels in a variety of rheumatological illnesses. 21
A derivative of PROMIS tools based on item response theory (IRT), computerized adaptive tests (CAT) have been shown to efficiently (i.e., feasibility), accurately (i.e., validity) and precisely (i.e., reliability) incorporate patient self-report of health into research, potentially reducing research costs.22,23 Administered on an iPad or computer platform, PROMIS CAT has the ability to incorporate multiple domains of health. Current literature suggests that CAT-based assessments have the ability to modify the number of questions based on previous answers leading to reductions in responder burden.21,22 PROMIS CAT instruments or domains incorporate patient self-report of health into research, allowing for reduced number of measurements and therefore, reduced research costs.23,24
Initial studies of the PROMIS CAT instruments provide promising measurement property evidence supportive of use in English speaking North American SLE populations. Kasturi et al. (2017) reported that in 204 patients with SLE, 10 PROMIS CAT domains had moderate to strong correlations (ρ = −0.49 to 0.86, p < 0.001) with SF-36, and LupusQoL-US version and moderate to good test-retest reliability (ICC were >0.7 across all domains). 25 Despite the supportive initial evidence, gaps in evidence exist and research is still needed to endorse the use of the PROMIS CAT instruments in SLE populations. No study to date has compared all 14 domains of PROMIS CAT with legacy instruments in patients with SLE in Canada. Furthermore, no study has used multitrait-multimethod (MMM) analysis as proposed by Campbell and Fiske to examine the validity of similar and different traits of PROMIS CAT and legacy instruments simultaneously for use in SLE. 26 Creating a multi-dimensional measurement model has the added benefit of further examining whether PROMIS actually measures the given traits it purports to evaluate. 26 Having more comprehensive reliability and validity evidence for a PRO tool to assist rheumatologists, the health care team and patients in the assessment and early identification of physical, mental, and social concerns is crucial for optimal disease management of patients with SLE.
Hence, this study aims to: (1) compare time to completion of the PROMIS CAT domains with legacy instruments; (2) assess intra-rater test–retest reliability of PROMIS CATs; (3) evaluate construct validity of PROMIS CATs compared to legacy PRO measures, in addition to SLE disease activity and organ damage metrics; and (4) evaluate convergent validity of PROMIS CAT in relation to SF-36 using an MMM analysis comparing similar and different traits.
Materials and methods
Study design
This was a prospective observational study whereby participants were asked to complete selected legacy instruments and the PROMIS CAT on a laptop or tablet in clinic or at home. Patients were also asked if they would complete the PROMIS CAT 7–10 days after baseline at home to study intra-rater test–retest reliability. Of 227 patients, 38% (n = 87) agreed to complete the PROMIS CAT again 7–10 days after baseline at home. This study was approved by the hospital-based research institutional ethics board.
Recruitment and sample
All consecutive English-speaking adults (≥18 years old) with SLE receiving care at a Toronto Lupus Center between July 2018 and Jan 2020 were screened for potential inclusion.
To be included in the study, recruited patients fulfilled at least four of the ACR revised criteria for the classification of SLE or three ACR criteria and a biopsy (lupus nephritis and cutaneous lupus). 27 Patients consented to participate at their regular appointments. Patients either agreed to complete the questionnaires in clinic on an iPad or computer or at home accessed through an email.
Measures
Patients completed the PROMIS CAT during their clinical visit and 7 days later at home (for test–retest intra-rater reliability) assessing 14 domains of health, specifically: Physical Function (V2.0), Applied Cognitive Abilities (V2.0), Applied Cognitive General (V2.0), Mobility (V2.0), Pain Behavior (V2.0), Pain Interference (V1.1), Ability to Participate in Social roles (V2.0), Satisfaction with Social Roles (V2.0), Sleep Disturbance (V1.0), Sleep Related Impairment (V1.0), Fatigue (V1.0), Anger (V1.1), Anxiety (V1.0), and Depression (V1.0).
The PROMIS CAT is scored using T score metrics where the mean ± standard deviation T score is 50 ± 10 in the US general population. Higher T scores reflect more of a particular domain. For some domains, a higher score is more desirable such as Physical Function, but for others it is less desirable such as Fatigue. The number of questions administered for each PROMIS CAT domain ranges from 4 to 12. Questions within domains are based on a 7-day recall period except for the physical and social health domains which do not specify a recall time frame.
Patients were also asked to complete: The SF-36, 7 LupusQoL, 8 Beck Anxiety Inventory (BAI), 9 The Perceived Deficits Questionnaire (PDQ-20), 10 Beck Depression Scale-second edition (BDI-II),11,12 The Assessment of Chronic Illness Therapy Fatigue Scale (FACIT-F), 13 and Epworth Sleepiness Scale 14 (see Supplement 1 for details on scores and recall periods for each). High scores on SF-36 in any domain indicate better health.7,19 Disease activity was quantified using the Systemic Lupus Erythematosus Disease Activity Index 2000 (SLEDAI-2K). 28 SLEDAI-2K ranges from 0 (no disease activity) to 105 (most organ involvement). SLE-related organ damage was quantified using Systemic Lupus International Collaborating Clinics (SLICC)/ACR Damage Index (SDI).27,29 SDI ranges from 0 (no organ damage) to 46 (most organ damage).
Statistical analysis
Sample characteristics. Study participants socio-demographic and disease related information was collected at baseline including: age at study enrolment, SLE disease duration at study enrolment, sex, self-identifying ethnicity and highest education at enrolment. The mean and standard deviation (SD) for continuous variables and frequency (percent) for categorical variables) was calculated. Differences between patients who agreed to participate (participants) and those who declined to participate (non-participants) were evaluated by examining clinical and socio-demographic characteristics using un-paired t-test for continuous variables, chi-square test for binary and Cochran–Armitage trend test for categorical variables. Baseline T scores for PROMIS domains are reported as mean ± SD.
Instrument interpretability and feasibility. Floor and ceiling effects for each instrument, an indicator of instrument score interpretability was determined by calculating the percentage of respondents with the minimum and maximum scores (i.e., floor and ceiling effects, respectively). Floor or ceiling effects were considered meaningful when >15% of respondents scored at extremes. 30 Median time to completion for each PROMIS domain and the legacy instruments were displayed in seconds and were used as an indicator of instrument feasibility or usability.
Intra-rater test–retest reliability. Test–retest reliability was evaluated with intra-class correlation coefficient (ICC (2; 1)) analysis of PROMIS CAT scores at baseline and 7–10 days after baseline. 31 ICC (2; 1) values were interpreted in the following way: < 0.5 was indicative of poor reliability, between 0.5 and 0.75 indicated moderate reliability, between 0.75 and 0.9 indicated good reliability, and >0.9 indicated excellent reliability. 31
Construct validity. PROMIS CAT 14 domains were evaluated against the seven commonly used legacy instruments (The SF-36, 7 LupusQoL, 8 Beck Anxiety Inventory [BAI], 9 The Perceived Deficits Questionnaire [PDQ-20], 10 Beck Depression Scale-second edition [BDI-II],11,12 The Assessment of Chronic Illness Therapy Fatigue Scale [FACIT-F], 13 and Epworth Sleepiness Scale, 14 ) in addition to SLEDAI-2K and SDI. We hypothesized that most legacy instruments would have at least a moderate correlation with corresponding PROMIS domain and that SLEDAI-2K and SDI would have a weak correlation with PROMIS domains.
Construct validity was also evaluated using the MMM approach comparing a similar construct using two different tools (in our case PROMIS-CAT and SF-36).32–34 10 PROMIS-CAT domain scores (Physical Function, Mobility, Pain Behavior, Pain Interference, Fatigue, Anger, Anxiety, Depression, Ability to Participate in Social Roles, Satisfaction with Social Roles) and SF-36 domains scores (Physical Function, Role Physical, Bodily Pain, Vitality, Role Emotional, General Health, Mental Health, Social Function) were compared. We hypothesized that similar traits (convergent validity) on average would have higher correlations than different traits between SF-36 and PROMIS-CAT domains (similar and different trait correlations are represented in Supplement 2). Using the MMM matrix, construct validity was also evaluated using additional six a priori hypotheses to explore the relationships of PROMIS-CAT domains with corresponding SF-36 domains. We hypothesized that the following associations with at least moderate strength in the same direction would be found (Spearman correlation ρ>0.3): (1) PROMIS-CAT Physical Function and the SF-36 domains of Physical Function and Role Physical; (2) PROMIS-CAT Pain Behavior and Pain Interference and the SF-36 domain Bodily Pain; (3) PROMIS-CAT Anger, Anxiety, and Depression with SF-36 Role Emotional scores; (4) PROMIS-CAT Ability to Participate in Social Roles and Satisfaction with SF-36 Social Roles; (5) PROMIS-CAT Fatigue with SF-36 Vitality; (6) PROMIS-CAT Depression, Anger and Anxiety with SF-36 Mental Health. The values were interpreted in the following way: ρ <0.3 was indicative of weak association, ρ = 0.3–0.7 was indicative of moderate correlation, and ρ > 0.7 was indicative of strong correlation. 35
Analytical software used in this project was SAS 9.3 (SAS Institute Inc., Cary, NC, USA.), and a p value <0.05 was regard as statistically significant.
Results
Sample characteristics
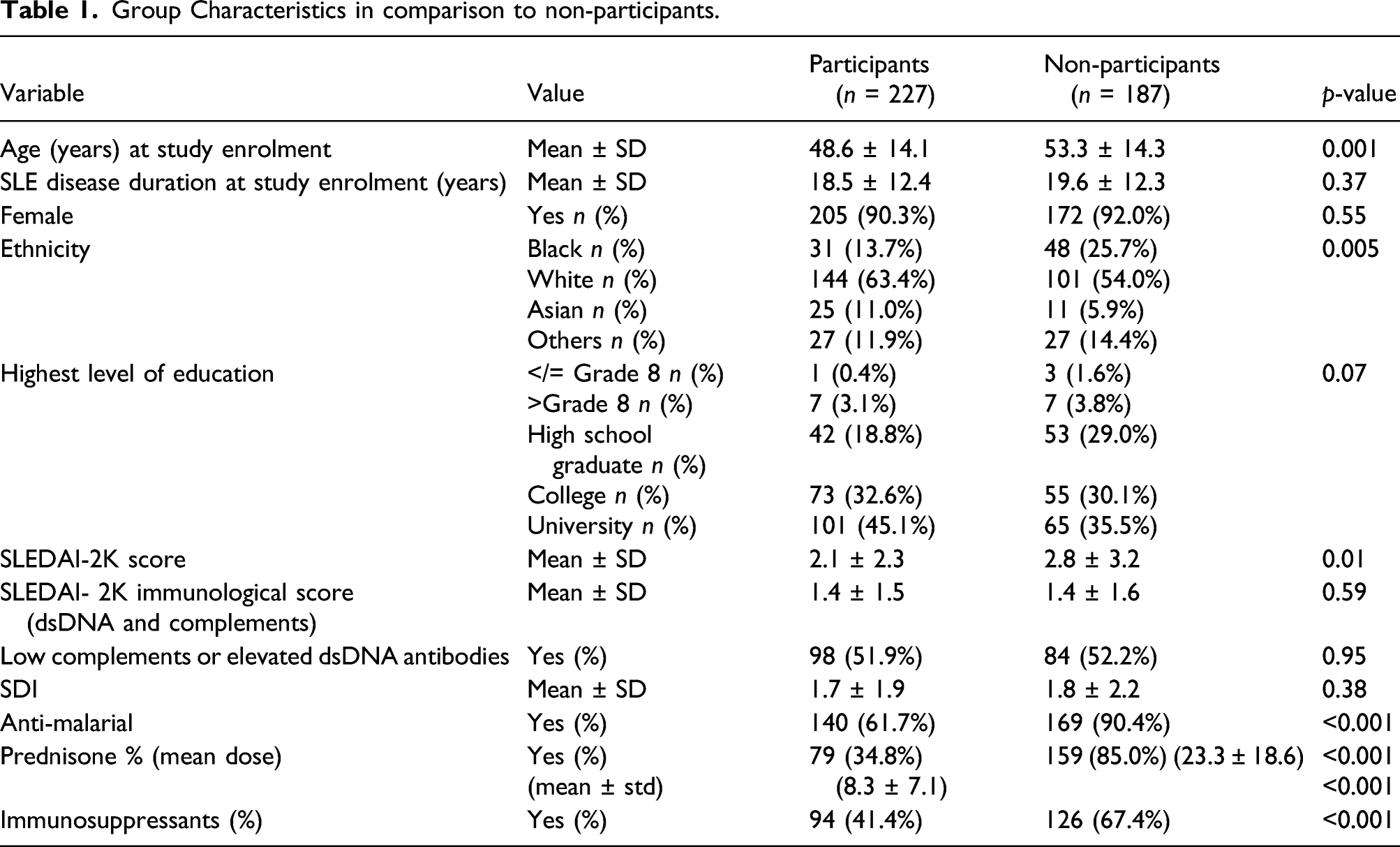
Group Characteristics in comparison to non-participants.
Instrument interpretability and feasibility
PROMIS CAT score distributions. a
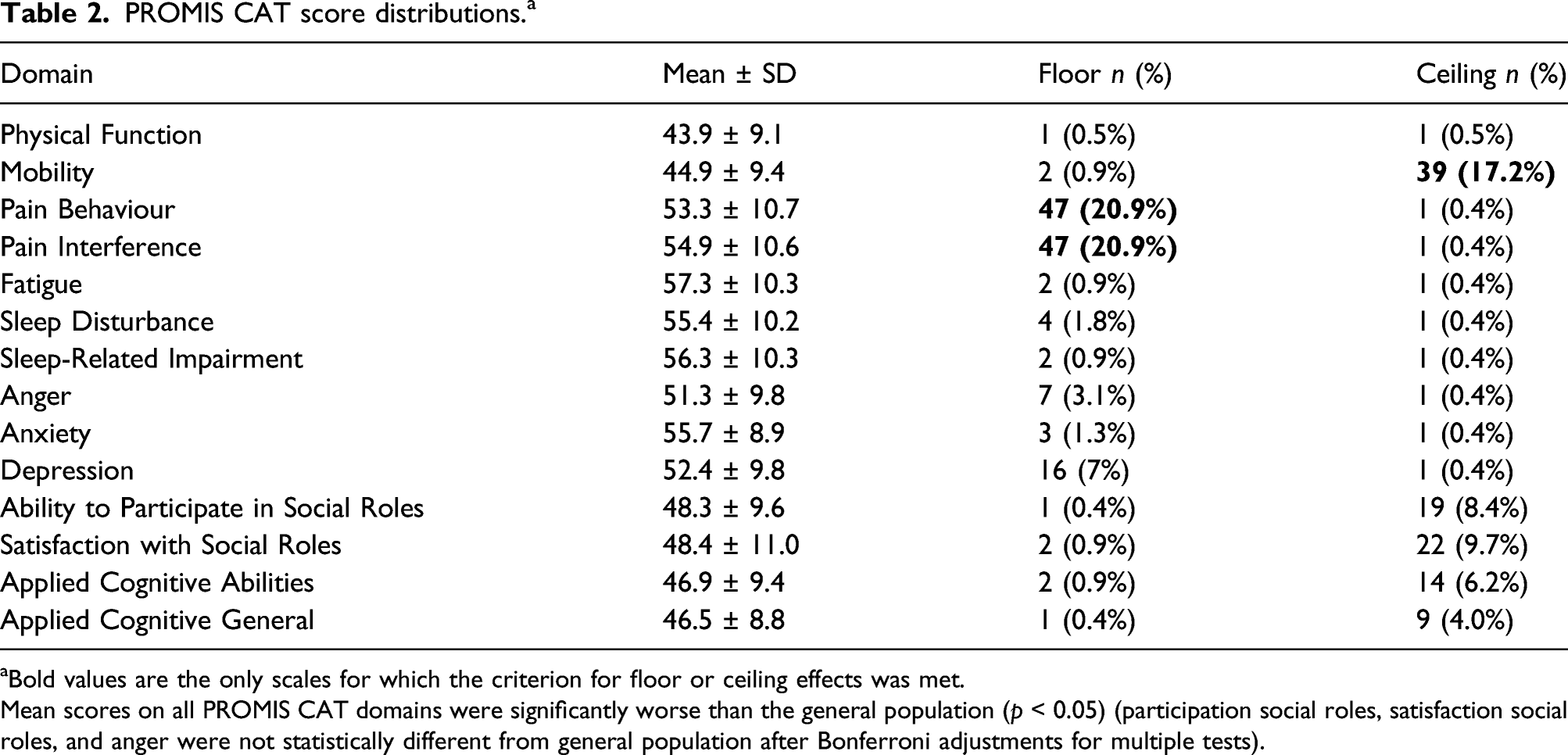
aBold values are the only scales for which the criterion for floor or ceiling effects was met.
Mean scores on all PROMIS CAT domains were significantly worse than the general population (p < 0.05) (participation social roles, satisfaction social roles, and anger were not statistically different from general population after Bonferroni adjustments for multiple tests).
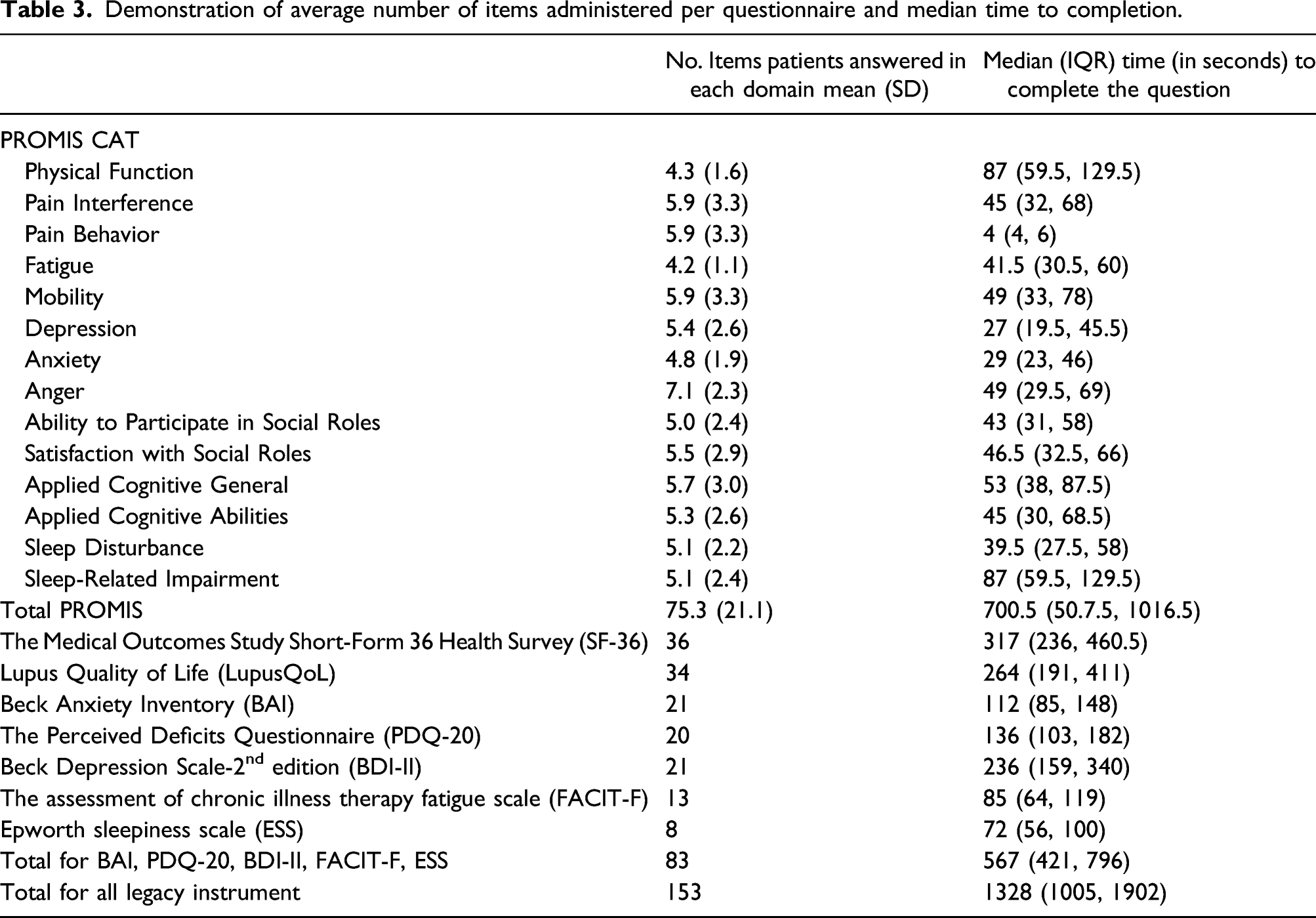
Demonstration of average number of items administered per questionnaire and median time to completion.
Test–retest reliability
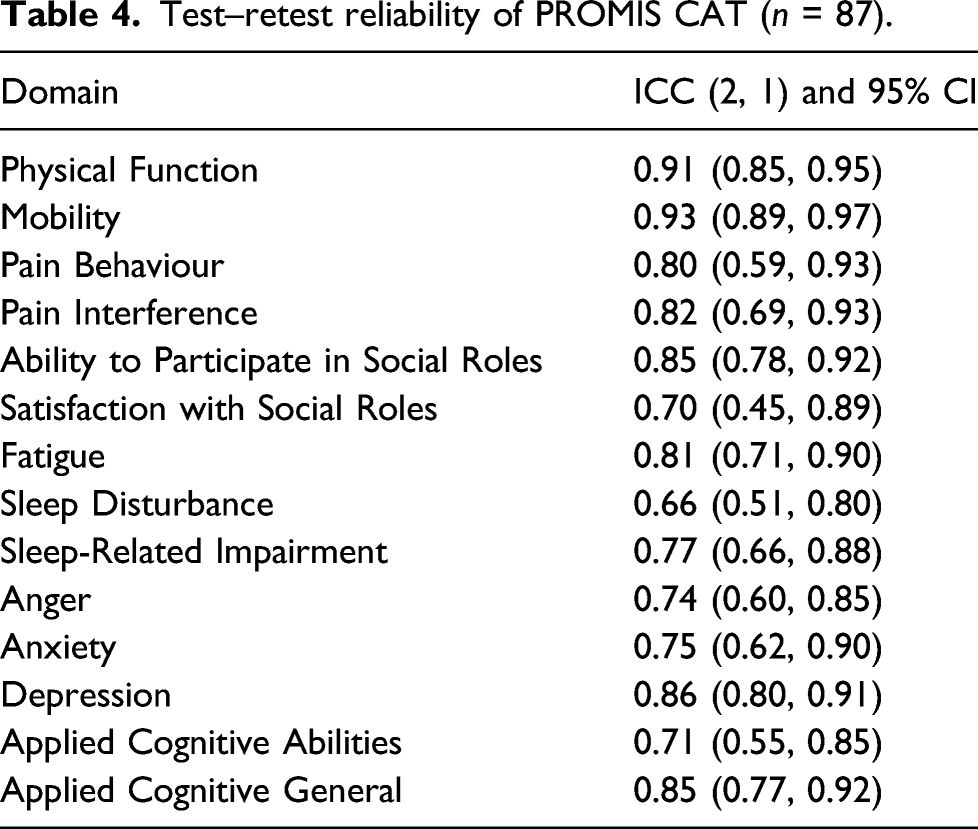
Test–retest reliability of PROMIS CAT (n = 87).
Construct validity
Spearman Correlation, ρ a between 14 domains of PROMIS CAT and seven legacy instruments in addition to SLEDAI-2K and SDI.
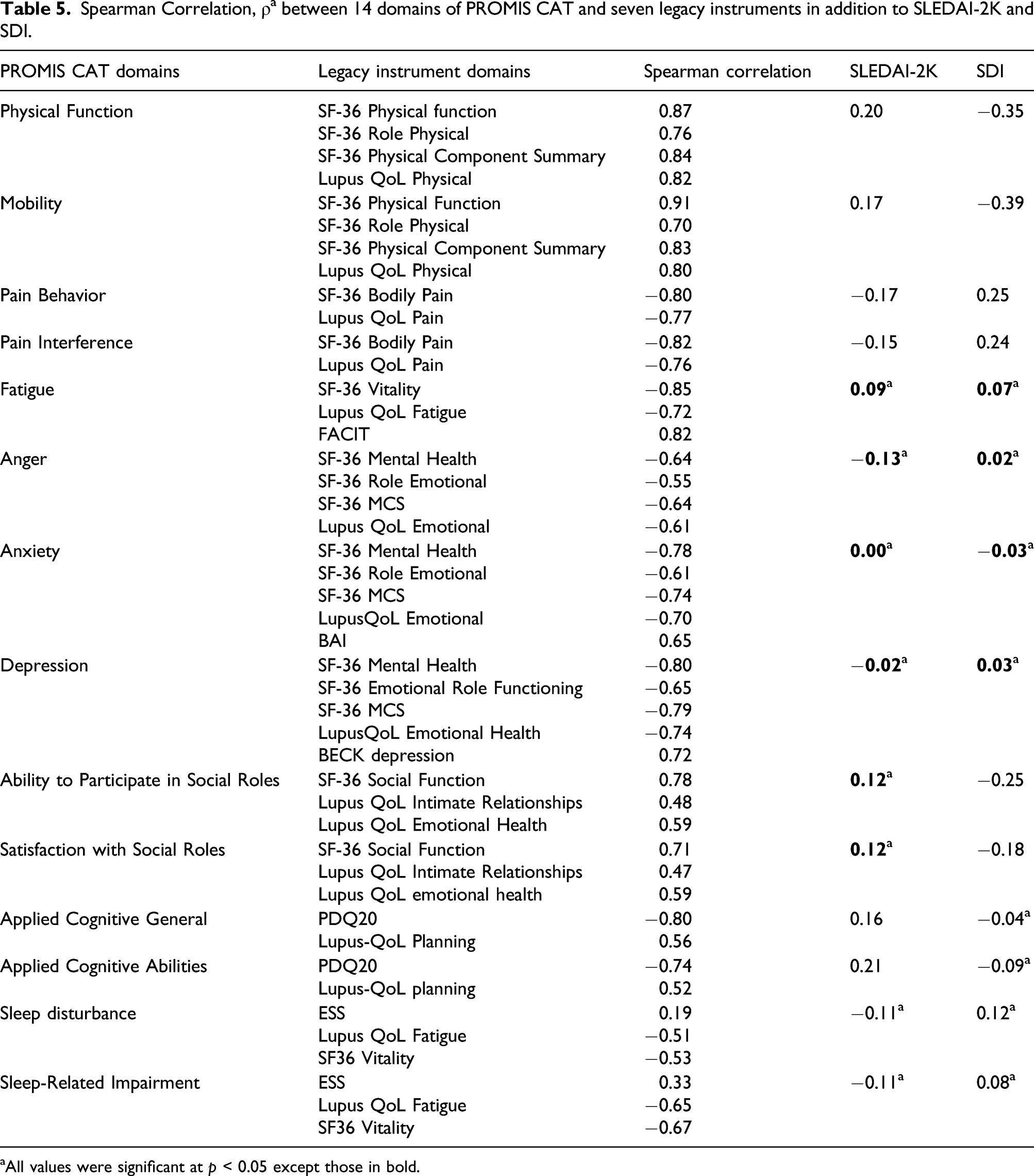
aAll values were significant at p < 0.05 except those in bold.
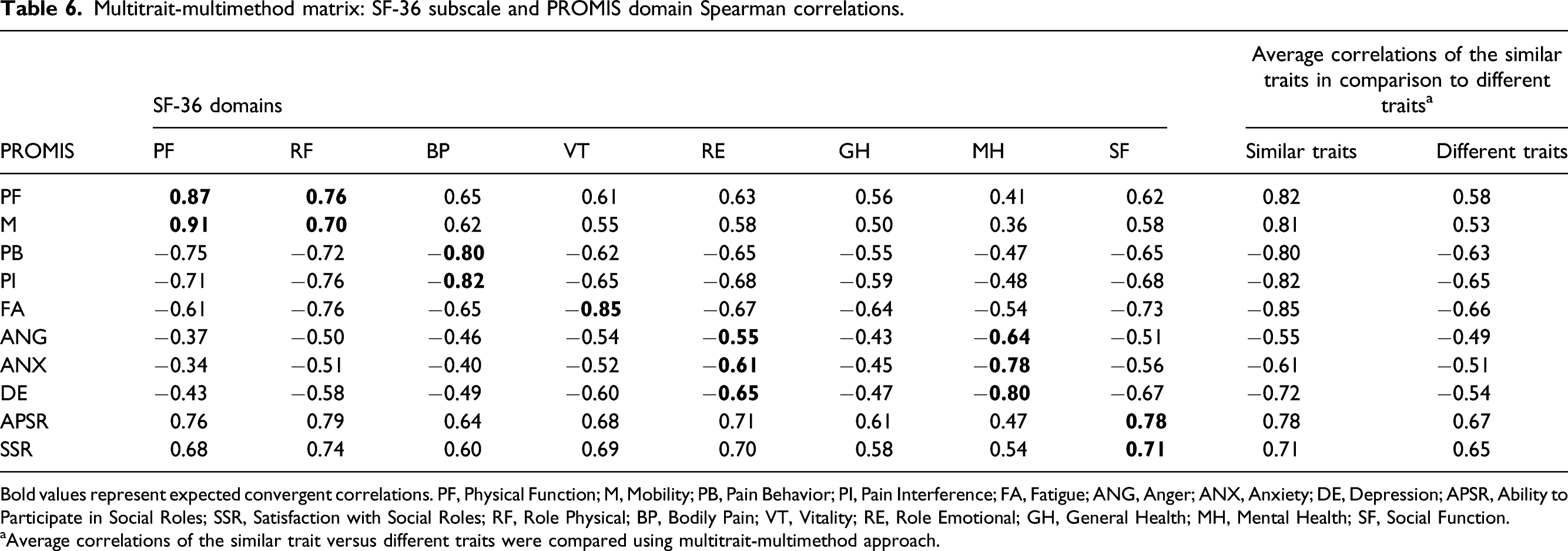
Using the MMM, construct validity was tested again. All a priori developed hypotheses in Supplement 2 were satisfied. As we hypothesized, PROMIS CAT demonstrated significant correlations with legacy instruments in comparable domains and weaker correlations with domains of different traits (Table 6). Furthermore, the average correlations of similar traits between the 10 domains of PROMIS CAT and SF-36 were greater than the average correlations from different traits confirming our hypotheses. All six a priori hypotheses were satisfied with moderate to strong correlations (Spearman correlation, ρ = 0.55–0.87) between PROMIS-CAT and most SF-36 domains. 1. Patients with lower Physical Function (PF) scores on PROMIS CAT also have lower Physical Function scores across the two related SF-36 domains (Physical Function (PF) and Role Physical (RF)) with at least a moderate correlation (ρ>0.3). PROMISPF/SF-36PF (ρ = 0.87, p < 0.0001) PROMISPF/SF-36RF (ρ = 0.76, p < 0.0001) 2. Patients that scored higher on Pain Behavior (PB) and Pain Interference (PI) on PROMIS CAT scored lower (worse) Bodily Pain (BP) on SF36 with at least a moderate correlation (ρ > 0.3). PROMISPB/SF-36BP (ρ = −0.80, p < 0.0001) PROMISPI/SF-36BP (ρ = −0.82, p < 0.0001) 3. Patients that scored higher on Anger (ANG), Anxiety (ANX), or Depression (DEP) on PROMIS CAT, rated a lower Role Emotional (RE) health on SF-36 with at least a moderate correlation (ρ > 0.3). PROMISANG/SF-36RE (ρ = −0.55, p < 0.0001) PROMISANX/SF-36RE (ρ = −0.61, p < 0.0001) PROMISDEP/SF-36RE (ρ = −0.65, p ≤ 0.0001) 4. Patients with lower scores on Ability to Participate in Social Roles (APSR) and Satisfaction with Social Soles (SSR) on PROMIS CAT also rated lower on Social Function (SF) on SF-36 with at least a moderate correlation (ρ > 0.3). PROMISAPSR/SF-36SF (ρ = 0.78, p = <0.0001) PROMISSSR/SF-36SF (ρ = 0.71, p = <0.0001) 5. Patients with higher Fatigue (FA) score on PROMIS CAT would have a lower Vitality (VT) score on SF-36 with at least a moderate correlation (ρ > 0.3). PROMISFA/SF-36VT (ρ = −0.85, p= < 0.0001) 6. Patients with a higher Depression (DEP), Anxiety (ANX), or Anger (ANG) score on PROMIS CAT would have a lower Mental Health (MH) score on SF-36 with at least a moderate correlation (ρ > 0.3). PROMISDEP/SF-36MH (ρ = −0.80, p < 0.0001) PROMISANX/SF-36MH (ρ = −0.78, p < 0.0001) PROMISANG/SF-36MH (ρ = −0.64, p < 0.0001) Multitrait-multimethod matrix: SF-36 subscale and PROMIS domain Spearman correlations. Bold values represent expected convergent correlations. PF, Physical Function; M, Mobility; PB, Pain Behavior; PI, Pain Interference; FA, Fatigue; ANG, Anger; ANX, Anxiety; DE, Depression; APSR, Ability to Participate in Social Roles; SSR, Satisfaction with Social Roles; RF, Role Physical; BP, Bodily Pain; VT, Vitality; RE, Role Emotional; GH, General Health; MH, Mental Health; SF, Social Function. aAverage correlations of the similar trait versus different traits were compared using multitrait-multimethod approach.
Discussion
The importance of PRO measurement tools has been previously emphasized in the literature. 2 The measurement evidence, including the interpretability, feasibility, reliability, and validity of the PROMIS Computerized Adaptive Tests (CAT), in a cohort of patient living with SLE in Canada was examined. This is the first study to use an MMM to evaluate construct validity and to test hypothesized relationships developed a priori. This study further provides evidence that PROMIS CAT can perform as well as legacy instruments, encompass many HRQoL domains, and will ultimately save time without the added work of individualized data management platform, grading, and paper forms.
To date, only one other study has examined the validity and reliability of PROMIS CAT in SLE. 25 Kasturi et al. (2017) examined 204 participants finding a moderate to good agreement for test–retest reliability in all their domains with ICC ranging between 0.72 (for Anger) and 0.88 (for Mobility and Sleep Disturbance). 25 In contrast, this study had excellent test–retest reliability for PROMIS CAT Mobility domain (ICC (2;1) 0.93; 95% CI: 0.89, 0.97) and Physical Function domain (ICC (2;1) 0.91; 95% CI: 0.85, 0.95), and moderate to good agreement for all other domains. It also had the lowest reliability for Sleep Disturbance (ICC (2;1) 0.66; 95% CI: 0.51, 0.80) and Satisfaction with Social Roles (ICC (2;1) 0.70; 95% CI: 0.45, 0.89), while Kasturi et al. (2017) found higher reliability in these domains. 25 This difference may be due to the time between the two measurements. This study allowed 7–10 days for test–retest, and Kasturi et al. (2017) allowed only 7 days. 25 Since these constructs are not very stable overtime, this increases the chances of variability with longer intervals. 36
Similar to this study, Kasturi et al. (2017) found moderate to strong correlations between two legacy instruments (LupusQoL and SF-36) and 10 corresponding PROMIS CAT domains. 25 However, this study encompassed seven legacy instruments and also examined a greater number of PROMIS CAT domains including Cognition and Sleep. 14 Kasturi et al. (2017) similarly found that the majority of the associations between disease activity and damage and PROMIS CAT were weak. 25 This finding highlights the importance of incorporating PROs in research and clinical settings as disease activity and damage do not cover the entire spectrum of SLE.
Using an MMM, construct validity of PROMIS CAT was further solidified by testing six a priori hypothesis. It was demonstrated that correlations of similar traits on average have higher correlations than correlations of different traits between SF36 and PROMIS CAT. The PROMIS domain Anger had the lowest correlation with SF-36 Role Emotional but still demonstrated a moderate correlation (ρ = −0.55).
Other studies have examined the time to completion of the PROMIS CAT domains in different rheumatic diseases. However, only one study has measured time to completion in PROMIS CAT in patients with SLE. Kasturi et al. (2017) noted that the average item per PROMIS CAT domain was four and the median time to completion of each PROMIS domain was 32 s. 25 For all 10 domains studied, they found the median time to completion was 7.4 min while for SF-36 it took 5.2 min and LupusQoL 4.6 min. 25 In this study, the average number of items per PROMIS CAT domain (total = 14 domains) was 5.4 (STD 2.5) and the median time to completion per domain was 50 s (IQR 36.3–72.6). It also took the participants about the same time, 5.2 min, to complete SF-36, 4.4 min, to complete Lupus QoL, and 22 min to complete all legacy instruments. In contrast, it took about 11.6 min to complete all 14 PROMIS domains. PROMIS CAT in this study included an additional four domains compared to Kasturi et al. (2017) which, combined with the higher number items per domain, explains the longer time to completion. 25 Overall, the 14 domains of PROMIS CAT take approximately 11 min less to complete than the legacy tests needed to assess the same domains, without the time needed for individualized grading.
PROMIS also provides static short forms ranging in length from four to eight items that can be used to assess different PROMIS domains as opposed to CAT. Multiple studies have evaluated PROMIS short forms (SF) in various rheumatologic conditions.37–39 These studies all found at least moderate correlations between the PROMIS short form and their corresponding legacy instruments, as well as good test–retest reliability.37–39
This study was able to undercover several limitations to PROMIS CAT. PROMIS CAT showed floor or ceiling effects for three domains. Importantly, there were floor effects in one domain: Mobility, which may demonstrate that appropriate functional status may not be captured by this tool. 8 Further, the legacy instrument ESS had weak associations with the PROMIS CAT domain Sleep Disturbance but a moderate association with Sleep Related Impairment. In a previous study comparing PROMIS Sleep Related Impairment and Sleep Disturbance with ESS, only Sleep Related Impairment and Sleep Disturbance correlated with active SLE, whereas ESS did not. 40 The less robust associations with ESS may also be due to differences in instrument content. The ESS assesses daytime sleepiness, which is only one aspect of Sleep Disturbance covered in the PROMIS Sleep Disturbance scale. The Sleep Disturbance scale measures sleep quality, which may or may not have an impact on daytime sleepiness.
Limitations of this study include that consecutive patients from one clinic completed PROMIS CAT only in English, limiting generalizability and internal validity. Secondly, although all participants were encouraged to participate, non-participants included a higher proportion of Black patients and those with higher levels of disease activity, greater use and higher doses of prednisone, and immunosuppressants. This shows that individuals with more severe burden of SLE disease activity, were less inclined to participate which should be considered when interpreting the measurement property evidence.
This study has four main strengths. First, this study collected data from a large number of patients. Second, this is the first study that examines PROMIS CAT in a Canadian cohort of patients with SLE, providing wider international evidence for instruments developed in the US. Third, the analysis used an MMM approach which can simultaneously measure correlations of similar and different traits. Lastly, it was able to compare seven legacy instruments with 14 domains of PROMIS CAT, allowing the incorporation of a wide range of HRQoL manifestations in this study.
Conclusions
This study provides further evidence that PROMIS CAT can be used as a PRO measurement tool for patients living with SLE to measure a wide range of domains associated with HRQoL. It has the capability of combining many different commonly assessed domains in an easy-to-use platform. In comparison to legacy instruments, it is able to perform well and has moderate to strong construct validity and moderate to excellent reliability for most domains. It takes approximately 11.6 min to complete PROMIS CAT with all its 14 domains without additional time needed for scoring. It can easily be incorporated as part of a regular outpatient clinic visit. The association between PROMIS CAT domains and disease activity and damage was mainly weak and non-significant. Future studies should focus on the responsiveness on PROMIS and score interpretability.
Supplemental Material
sj-pdf-1-lup-10.1177_09612033211051275 – Supplemental Material for Validity and reliability of patient reported outcomes measurement information system computerized adaptive tests in systemic lupus erythematous
Supplemental Material, sj-pdf-1-lup-10.1177_09612033211051275 for Validity and reliability of patient reported outcomes measurement information system computerized adaptive tests in systemic lupus erythematous by Mitra Moazzami, Patricia Katz, Dennisse Bonilla, Lisa Engel, Jiandong Su, Pooneh Akhavan, Nicole Anderson, Oshrat E. Tayer-Shifman, Dorcas Beaton and Zahi Touma in Lupus
Supplemental Material
sj-pdf-2-lup-10.1177_09612033211051275 – Supplemental Material for Validity and reliability of patient reported outcomes measurement information system computerized adaptive tests in systemic lupus erythematous
Supplemental Material, sj-pdf-2-lup-10.1177_09612033211051275 for Validity and reliability of patient reported outcomes measurement information system computerized adaptive tests in systemic lupus erythematous by Mitra Moazzami, Patricia Katz, Dennisse Bonilla, Lisa Engel, Jiandong Su, Pooneh Akhavan, Nicole Anderson, Oshrat E. Tayer-Shifman, Dorcas Beaton and Zahi Touma in Lupus
Footnotes
Contributorship
All authors contributed to the conception and design of the study. MM, DB, and NA collected the data. Material preparation and analysis and interpretation of data were performed by LE, JS, PA, NA, OTS, DB, and ZT. MM wrote the first draft of the manuscript. All authors reviewed and critically revised the manuscript. All authors read and approved the final manuscript as submitted and agree to be accountable for all aspects of the work.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MM was supported by the Lupus Foundation of America Gina M. Finzi Memorial Student Fellowship. This work was supported by donations from the Lou and Marrisa Rocca family, the Diana and Mark Bozzo Family, and the Kathi and Peter Kaiser family.
Ethical approval
This study was reviewed and approved by the University Health Network Research Ethics Board (UHN REB#18-5339) This study was performed in accordance with the ethical standards as laid down in the 1964 Declaration of Helsinki and its later amendments or comparable ethical standards. If doubt exists whether the research was conducted in accordance with the 1964 Helsinki Declaration and the Canadian Tri-Council Policy Statement Guidelines on research involving human subject, or comparable ethical standards.
Data availability
The dataset used and analyzed during the current study is available from the senior author on reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.