
Abstract
This article presents a new taxonomy of privacy in library and information science (LIS). Current treatment of the concept often overlooks its diverse character within the LIS profession and neglects its heterogeneity within wider discourse. This study, by contrast, presents a taxonomy, connecting privacy in LIS with wider literature to improve understanding of the concept within professional practice. A structured literature search samples conceptions of privacy across LIS, paving the way for descriptive conceptualisation of the concept. The argument is presented in four stages. First, it is argued that privacy is a heterogenous concept within LIS which can be discussed in an abstract, ethical or practical context. Second, 10 conceptions of privacy in wider literature build a case for this diversity and form a theoretical backdrop for understanding the concept. Third, a structured search of literature reveals a range of views across the LIS profession. Constructivist grounded theory builds an informative taxonomy with four categories: conceptual, normative, contextual, and remedial, with the relationships between categories depicted via four ‘meta-categories’: theoretical, practical, descriptive and value-based. Fourth, the taxonomy’s benefit is twofold. First, to provide a template of comparison between LIS and wider literature and, second, to act as a tool within professional practice, asking what, where, why, and how the concept interacts with ethical situations. This, in turn, provokes a more thorough appreciation of privacy problems. This depth, it is argued, builds support for a re-orientation of core value in LIS as a manifestation of professional virtue.
Introduction
Privacy is a core, yet contested, value within Library and Information Science (LIS). To date, conceptions within LIS have not been mapped holistically, a perspective lacking in previous research. This study, building on two studies that provided a holistic understanding of neutrality and intellectual freedom, presents a new taxonomy of privacy, deepening understanding of the concept within LIS (see Macdonald, 2022, 2024). The argument unfolds in four stages. First, privacy is an elusive concept within LIS with a range of presentations that are abstract (Alfino, 2001; Sutlieff and Chelin, 2010), ethical (Buschman, 2014; Pekala, 2017) or focussed on practical issues within professional practice (Klinefelter, 2007; Prindle and Loos, 2017). Second, 10 conceptions of privacy are identified within wider literature: three descriptive, four normative and three contextual. These conceptions support Solove’s (2002) analysis of privacy as a dynamic concept that lends itself to a ‘family resemblance’ conceptualisation (p. 1088). Third, this approach is transposed to LIS where a structured literature review identifies 103 papers charting privacy’s dynamic character. Constructivist grounded theory develops a taxonomy that caters for this diversity. Four categories – conceptual, normative, contextual and remedial – are related using four ‘meta categories’: theoretical, practical, descriptive and value-based. The taxonomy links LIS with wider literature and provides a heuristic tool for practical decision making. Rather than record an objective truth, therefore, it builds an informative map of the concept to deepen understanding, acting as a gateway of comparison between LIS and wider discourse. Finally, it is suggested that the concept’s heterogeneity builds support for a re-orientation of core value in LIS.
Privacy: A core value in library and information science
Privacy’s prominence as a core value in LIS is reflected in ethical codes. The International Federation of Library Association’s (IFLA, 1999) Statement of Libraries and Intellectual Freedom supports ‘privacy and anonymity’ whilst its Statement on Privacy in the Library Environment guards against ‘interference with [user] privacy’ (IFLA, 2015). This commitment is crystallised in IFLA’s Code of Ethics for Librarians and other Information Workers, respecting ‘personal privacy and the protection of personal data’ (IFLA, 2012).
The American Library Association (ALA) adopted privacy at the turn of the 20th century (Witt, 2017: 644), with ‘confidentiality of patron transactions’ enshrined in its inaugural 1939 code (p. 645). The initial wording – ‘an obligation to treat as confidential any private information’ (ALA 2011 cited in Cyrus and Baggett, 2012: 286) – was broadened in 1995 to ‘protect . . . users’ right to privacy and confidentiality’ (ALA, 2021), reflecting a ‘realisation that erosion of . . . privacy rarely starts within the library’ (Cyrus and Baggett, 2012: 287). In Privacy: An Interpretation of the Library Bill of Rights, privacy has a ‘chilling effect on users’ selection . . . of . . . resources’ (ALA, 2019) and libraries should not ‘monitor . . . beyond operational needs’ (ALA, 2019). In 2022, the ALA launched its Privacy Field Guides, with ‘practical, hands-on exercises’ on issues ranging from ‘digital security’ to third party vendors (ALA, 2022); these sit alongside ‘privacy checklists’ with recommended best practice (ALA, 2020).
Privacy is a prominent feature of other national library associations. The UK’s Library and Information Association (CILIP) supports the ‘right to the privacy and confidentiality of. . . personal information’ (2018b) ensuring ‘personal data . . . [is] protected’ and helps ‘users . . . [with] . . . issues, trade-offs and risks concerning data’ (CILIP, 2018b). Confidentiality is a core value, promoting ‘the right of all individuals to privacy’ (CILIP, 2018a), based on Article 8 of the European Convention of Human Rights, where it underpins ‘dignity. . .freedom of association and . . . speech’ (CILIP, 2022). Similarly, France’s ABF (2003) and Italy’s AIB (2014) ‘guarantee the confidentiality of users’, a commitment affirmed by the Netherland’s Professional Charter for Librarians in Public Libraries which ‘safeguards . . . the privacy of users at all times’ (NVB, 2001), and Spain’s SEDIC, which respects ‘privacy. . . personal and family intimacy’ (SEDIC, 2013).
In sum, privacy and confidentiality are core values within LIS, represented nationally and internationally as a commitment to safeguard user data (ABF, 2003; AIB, 2014), and promote user education (CILIP, 2018b). Despite statements of core value, however, the right to privacy is largely asserted without exploration of its meaning which is widely contested within wider literature.
Privacy in library and information science: One or many values?
Put another way, this shortcoming neglects privacy’s heterogeneity. This section, by contrast, draws attention to this diversity through three distinctions that provide a flavour of the problem the study addresses. First, privacy can be viewed abstractly. This abstract dimension discusses privacy’s meaning. For Sutlieff and Chelin, privacy represents control where, ‘information . . . is unavailable to others’ (Bowers, 2006: 377 cited in Sutlieff and Chelin, 2010: 164). Alfino (2001), by contrast, switches emphasis to the mind-set of the agent, equating loss of privacy with known observation (p. 7). Second, privacy has ethical dimension where it is evaluated as a ‘social good’ (Buschman, 2014: 45). Asher, by contrast, questions the concept’s value, arguing user data helps ‘libraries provide better services’ (2017, p. 45). Third, privacy can also be viewed in the context of professional practice, evolving with technological and legal challenge. Prindle and Loos (2017) note how ‘big data’ (p. 22) improves decision making in the context of learner analytics (Jones et al., 2020: 570), Klinefelter (2007) observes libraries hamstrung by federal legislation, and Garoogian (1991) cites the US constitution as a foundation for library privacy.
Rather than examining positions within each category, the current section illustrates privacy’s conceptual diversity. Abstract debates define privacy, ethical problems discuss value and, third, it may be seen as a practical issue in the context of professional practice. This heterogeneity is well documented within wider literature, notably by Solove, who argues that ‘privacy is a plurality of different things’ (2008, ix), ‘entangled in competing and contradictory dimensions’ (Post, 2001: 2087, cited in Solove, 2008: 2). In response to this entanglement, Solove constructs a descriptive taxonomy based on Ludwig Wittgenstein’s ‘family resemblances’ where instantiations of a concept are related by a ‘pool of similar elements’ rather than a ‘single common characteristic’ (p. 9). This approach, explored by the current author in two previous studies focussing on neutrality and intellectual freedom (Macdonald, 2022, 2024), provides a template for the current study.
Before exploring Solove’s method, however, it is necessary to explore conceptions of privacy within wider literature, integral to understanding its place within LIS. Current literature, by contrast, often overlooks this connection, creating an insular discussion of the concept. For the present study, it provides a theoretical bedrock for subsequent discussion by recognising LIS’s connection to wider society.
Privacy: Historical roots
This section begins examination of wider literature by exploring the concept’s origin. Privacy was first introduced by Aristotle to differentiate between ‘domestic and political society’ (Gobetti, 1992: 13). The public domain – known as the polis – constitutes ‘family connections, brotherhoods [and] amusements’ (Davis, 2007: 62). The private domain, by contrast, enshrines family and property in a ‘private sphere’ (Gobetti, 1992: 13). The distinction between the polis and the private exposes three contrasts. First, privacy signifies the dominance of men over household dependents (Gobetti, 1992: 14). Second, a duality of ‘individual and common good’ is tolerated in the polis whilst, in private, dependents are subordinate (Gobetti, 1992: 15). Third, the contrast between the polis and private enables man to achieve a full complement of virtue by ‘being alternatively a ruler and a subject’ (p. 15). This is not possible within the private sphere where ‘politics . . . [is] banned from domestic association’ (p. 15). Swanson, however, contests this patriarchal characterisation, arguing privacy extends beyond the household, representing, ‘activities that cultivate virtue and discount common opinion’ (2019, p. 2). For Swanson, Aristotle’s privacy constitutes choice – rejecting societal norms – by turning ‘away in order to achieve excellence’ (p. 3).
Two further lines of origin are found in John Locke. The first entwines privacy with property rights; agents who mix their labour with natural resources or, ‘joined to it something that is his own . . . directly makes it his property’ (Locke, 1988: 277–288 cited in Richardson, 2016: 82). Put simply, when man mixes his labour with natural resources, the result is his property or, characterised by Solove, ‘one gains a property right . . . when it emanates from oneself’ (2002, p. 1112). The labour theory of value grants property under a ‘pareto based proviso’ where ‘there is enough and as good left for others’ (Locke, 1952: 57 cited in Moore, 1997: 93).
Moore (1997) grounds intellectual property rights upon this Lockean proviso – ‘if no-one’s situation is worsened, then no one can complain about . . . appropriation’ (Moore, 1997: 94). He distinguishes between types and tokens. Types refer to intellectual property, whilst tokens refer to ‘concrete embodiments’ of types. Original types ‘better our lives by creating intellectual works’ whilst those attaining tokens illegitimately commit theft, leaving those who create intellectual property (types) worse off (1997, p.107).
Despite its influence Locke’s theory has been criticised. First, by questioning the link between labour and value; ‘one does not create 99% of the value of an apple by picking it’ (Hettinger, 1989: 37). Second, intellectual property builds on the work of others, making ‘intellectual products . . . social products’ (p. 38). Third, value is dictated by market forces which differ ‘greatly with variations in . . .social factors’. Given this, labour cannot lead to natural entitlement (p. 39).
It could be argued, however, that this portrayal of value – construed ‘in purely economic terms’ – is too narrow (Mossoff, 2012: 284). Mossoff argues that Locke presents a broader ‘human flourishing’. On this interpretation, productive labour is a moral activity. In this guise, Locke presents a normative theory where labour is ‘the means . . . to live a flourishing life’ (2012, p. 297). Instead of making a descriptive claim about the economic value, therefore, Locke makes a normative claim that agents are entitled to the fruits of labour as a condition for flourishing. Rather than evaluate each argument, however, the present argument charts Locke’s thought in the conceptual development of privacy.
Privacy also extends to a second ontological strand of Locke’s thought. Richardson (2016), drawing upon Coleman, cites Locke’s claim that ‘we have a duty to God to maintain . . . our identity over time’ (Locke, 1975, XXVII, cited in Richardson, 2016: 91). This is achieved by the preservation of a sense of self, held together ‘through . . . memory of what we have thought and done’ (p. 91). These ‘inalienable and subjective thoughts’ preserve identity through a sacrosanct ‘inner self’ (Richardson, 2016: 91), with ramifications for digital privacy; in a world where ‘actions are . . .recorded [through] computer mediated communication’ tech companies possess, ‘a better memory of our actions than we do’ (p. 98). This pool of information, collected by Google and Amazon, threatens our identity and self-development. If others know more about us, our place as master of our ‘inner self’ becomes threatened (p. 98).
Privacy can also be traced through the utilitarian tradition. Mill distinguishes between ‘self-regarding’ and ‘other regarding’ activities, arguing that the former should be shielded from public scrutiny, allowing ‘experiments in living’ and ‘social progress’ (Richardson, 2016: 55). In On Liberty, the no harm principle – “the only purpose for which power can be rightfully exercised . . . is to prevent harm to others’ (Mill, 19753 cited in Johnson, 1989: 20) – also justifies privacy by ringfencing ‘self-regarding’ activities (p. 20), epitomised by Mill’s assertion in Political Economy; ‘there is a circle around every individual . . . which no government. . . ought to overstep’ (Mill, 1965: 938 cited in Fuchs, 2011: 223).
To summarise, privacy has a rich and varying foundation within the Western philosophical tradition as an enabler of virtue (Aristotle), a right derived from labour or identity (Locke) and a wider public good (Mill). These disparate strands underlie the concept’s evolving and, at times puzzling, nature. The next section resumes its journey, charting the birth of the modern concept.
Warren, Brandeis and Prosser: The birth of modern privacy
The modern concept’s origin is widely attributed to Warren and Brandeis’s 1890 The Right to Privacy where privacy as a distinct legal concept – ‘disentangled from property’ – was born (Post, 1991: 648). Their influential article puts forward two claims. First, privacy represents ‘inviolate personality’ – a principle that operates tacitly within law, providing a legal basis for claims of harm that stem from intrusion (Kramer, 1990: 711); ‘the right to an inviolate personality, afford alone . . . the protection which the. . . demands may be rested’ (Warren and Brandeis, 1890: 211).
Second, privacy’s reach is based on ‘forms of respect in a common community’, underpinned by four limitations (Post, 1991: 651). First, where ‘publication . . . is of public . . . interest’, second, communication reported in courts, third, oral communication and, finally, the consensual release of information (Warren and Brandeis, 1890: 216). From Warren and Brandeis, the concept was developed by Prosser whose four torts ‘systematised and organised the law’ (Richards and Solove, 2010: 1888). First, ‘intrusion upon . . . seclusion or solitude’ (Prosser, 1960: 389–390); second, ‘disclosure of embarrassing private facts’ (p. 391); third, ‘publicity which places the plaintiff in a false light’ (p. 398) and, finally, ‘appropriation . . . of . . . likeness’ (p. 401).
The privacy of Warren, Brandeis and Prosser casts an elusive concept covering a range of cases. This ad hoc characterisation – a theme that runs throughout literature – is now explored.
Conceptions of privacy within wider literature
Having characterised the concept’s initial development, this section attempts to untangle conceptions of privacy within wider literature. Ten conceptions of privacy illustrate its diversity. To emphasise this plurality, each conception is labelled conceptual, normative, or contextual in Table 1. Conceptual conceptions debate privacy’s meaning whilst normative conceptions debate its value. Contextual conceptions, by contrast, discuss the concept as a practical issue in specific contexts. Rather than outlining a static ‘theory of privacy’, the purpose of this presentation is to lay the bedrock for a comparison that exposes the connection between LIS and wider literature by showing privacy as a heterogenous concept that can be viewed from a variety of different perspectives. Crucially, the presentation of 10 conceptions is not intended to be exhaustive, nor is it claimed that privacy cannot be conceived differently. Rather than advocate a particular conception of privacy, it illustrates the need for a new taxonomy by exposing the concept’s diversity – a feature, it is argued, often overlooked within LIS. Table 1 provides a snapshot of conceptions identified in literature, fully elucidated in the current section.
Conceptions of privacy within wider literature.
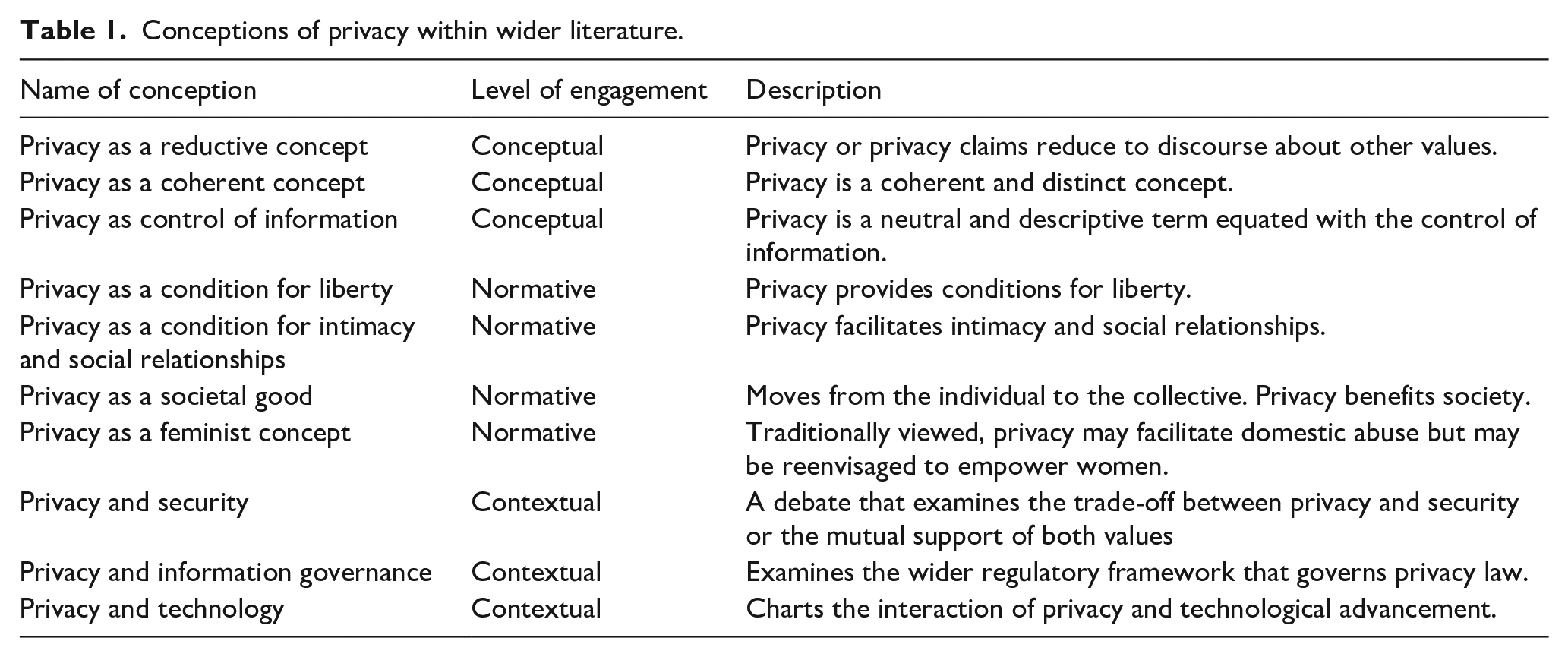
Conception one (Conceptual): A reductive concept
The reductive approach argues that privacy claims reduce to other rights, negating the need to delineate privacy as a distinct concept. Thomson (1975) argues that privacy is ‘analogous to rights . . . over . . . property’ (p. 304) or ‘the cluster of rights which the right over the person consists in and . . . the cluster of rights which owning property consists in’ (p. 306). She states, ‘I don’t have a right not be looked at because of . . . privacy . . . it is because I have these rights that I have a right to privacy’ (p. 312). Privacy, therefore, ‘can be explained without mentioning it’ (p.313).
For Posner, privacy claims reduce to ‘the efficiency of the marketplace’ (1981, p. 407) where consumers ‘sell themselves’, adopting ‘high standards of behaviour to induce others to engage in advantageous . . . dealings’ (1983, p. 388). Seen this way, agents ‘manipulate the world around them by selective disclosure of facts’ (p. 234). This selective disclosure – a form of privacy – hinders market efficiency. Second, this market-based rationality applies to nonmarket behaviour, regulating ‘personal relationships’ (p. 237). Within this paradigm, the written press – constituted by the “gossip column” – provides information, supplanting need for ‘personal surveillance’ (p. 237). Third, privacy protects commercial information, incentivising its creation and ‘investment in obtaining information vital to the . . . adjustment of markets’ (p. 244). Likewise, within the personal sphere, ‘eavesdropping’ undermines traditional channels of communication, leading to social inefficiency. In sum, privacy reduces to economic efficiency.
Finally, privacy is questioned within US law. Bork traces the concept’s development to Griswold v. Connecticut, where a reversed ban on contraceptives delineated a ring of privacy within the marital bedroom (2009, p. 116). This ring of privacy was extended to the landmark Roe versus Wade ruling, reversing laws prohibiting abortion and setting ‘severe limitations upon . . . power to regulate the subject’ (p. 118). Despite this, Bork argues that privacy – an “invented right” – has no legal foundation and, instead, represents an independent moral argument (p. 126). If privacy were sacrosanct, agents could do as they please or, put concisely, ‘there would be no law’ (p. 126).
For the first conception, therefore, privacy is a reductive concept. It has no independent explanatory value, reducing to rights over ‘person . . . and . . . property’ (Thomson, 1975: 306), economic utility (Posner) or invention within the US constitution (Bork, 2009).
Conception two (Conceptual): A coherent concept
A second conception of privacy argues it is a coherent concept. For Scanlon, it represents an invasion within a ‘conventionally defined zone’ (1975, p. 315). Viewing an item belonging to another person does not reduce to intrusion based on ownership – ‘there is a right which is violated . . . whether or not the object is mine’ (p. 318). Privacy is a distinct concept, representing a ‘zone . . . immune from specified interventions’ (p. 319).
Second, Doyle questions the fairness of Posner’s reduction; if companies’ profile workers, they ‘have an . . . interest in not hiring [those who] might add to . . . healthcare costs’ (2013, p. 150). Second, Posner ‘exaggerates the extent to which people withhold information to mislead or manipulate’, failing to account for ‘justified . . . cases of concealment’ (p. 151). In summary, Posner presents a one-dimensional and, perhaps naïve, account of human motivation that begs the question; ‘it is at least an open question whether . . . the market [should] trump privacy’ (p. 155).
Third, Johnson argues privacy does stem from the US constitution, as all legal interpretation involves ‘normative judgements’ (1994, p. 169). He defends a ‘constructivist interpretation of the constitutional right to privacy’ that best accounts for established legal practice (p. 190). Acknowledging we do not have an ‘all-purpose right to be “let alone”’, there are personal spaces including ‘home . . . luggage, or body’ protected ‘by the traditions of our people and our law’ (Lockner v. New York, 1905, cited in Johnson, 1994: 178).
To summarise, the coherent conception draws attention to rejoinders of the reductive position. For Scanlon, privacy represents intrusion in a defined zone. Second, Posner’s reduction overlooks issues that transcend the economic paradigm. Third, a constructivist legal interpretation grounds privacy within the US constitution. Whilst disparate, it grounds privacy as a coherent value.
Conception three (Conceptual): Privacy as control of information
A third conception grounds privacy in control of information, becoming a technical term equated with access. This is epitomised by Parent (1983) who argues that ‘privacy is the condition of not having . . . knowledge about one possessed by others’ (p. 269). This personal knowledge – constituting ‘facts about a person’ (p. 269) – ‘isolates’ privacy’s ‘distinct and unique meaning’ (p. 271). This ‘neutral and descriptive’ understating of privacy is underlined by Gavison (1980) who – distinguishing between the ‘concept and . . . value of privacy’ (p.424) – argues that it is restricted to ‘concern over accessibility to others’ (p. 423), and further emphasised by Moore, who arrives at a definition where privacy represents ‘access and personal information control’ (2003, p. 216). This is backed up by Bok (1989), who argues that privacy is ‘the condition of being protected from unwanted access by others’ (p. 10). For this conception, emphasis focuses on a neutral understanding of privacy as control of information, understood as ‘knowledge about one possessed by others’ (Parent), ‘accessibility over others’ (Gavison) and ‘unwanted access’ (Bok).
Conception four (Normative): Privacy as a condition for liberty
A fourth conception represents privacy as liberty, crystallised by Schoeman (1984), who states that privacy ‘limits the control of others over our lives’ facilitating a web of social relationships (p. 1); ‘the privacy norms that promote self-expression . . . involve those that involve people as fully engaged’ (p. 18).
Allen (2011) argues that ‘unpopular privacy’ should be protected as a ‘foundational’ human good’ (p. 13), preserving liberty and the ability to ‘live . . . with nonconforming preferences’ (p. 16). Privacy should be mandated as a ‘responsibility of self-care’ (p. 26). Reiman (1995) illustrates how privacy protects extrinsic loss of freedom – ‘unpopular or unconventional actions may be subject to social pressure’ (p.35) – and intrinsic loss of freedom that restricts ‘important choices’ (p. 37). Privacy promotes independent thought whilst loss of privacy, by contrast, threatens liberty symbolically by insulting the subject. This is affirmed by Bloustein and Pallone (2017), who link liberty to dignity – ‘privacy threatens our liberty. . . just as an assault . . . battery or imprisonment . . . does’ (p. 56).
To summarise, the fourth conception argues privacy protects liberty, preventing intrusion and enabling a web of social relations. Second, it is a mandated ‘foundational human good’, and third, a value that protects dignity and independent thought.
Conception five (Normative): Privacy as a condition for intimacy and social relationships
Closely connected with the protection of liberty, Rachels argues that privacy enables intimacy facilitating ‘patterns of behaviour’ which allow a ‘variety of relationships with other people’ (1975, p. 326). For Inness (1996), privacy protects ‘choice with respect to intimacy’ (1996, p. 104). Its value derives from ‘a respect for persons as emotional choosers’ facilitating ‘autonomous beings with the capacity for love, care and liking’ (p.112). Gerstein (1978) argues that observation alters intimate acts; ‘when we feel the eye of the outsider upon us . . . sexuality is . . . uprooted from the wholeness of intimacy’ (p. 80). Seen this way, ‘excluding outsiders . . . [is an] essential part of [intimacy]’ (p. 81).
Conception six (Normative): Privacy as a societal good
A sixth conception emphasises privacy’s collective value ‘to society in general’ (Regan, 2015: 50). Privacy is a common value that creates ‘a certain type of society’ (1995, p. 222) strengthening ‘the democratic political system’, by allowing individuals to participate ‘actively and independently . . . in . . . decisions’ (p. 225). In a modern context, this privacy erosion can be seen by political parties who analyse personal data to target voters with homogenous messaging (2015, p. 61). Public value is also underlined by Solove (2008), arguing privacy protects against ‘strife and violence’ (p. 98).
Regan argues that privacy is a communal value with an importance that precedes economic utility. This value – akin to ‘clean air and national defence’ – cannot be supplied by market forces (1995, p. 228). Despite this, however, she argues that modern ‘economy and society’ are dependent on this privacy to provide consumer confidence (p. 230). The ‘societal good’ conception turns away from the individual to societal benefit. Privacy is a common value that fosters individuality and diversity. More broadly, the shift from individual to collective sees privacy as ‘an attribute of social relationships and information systems’ (p. 230).
Conception seven (Normative): Feminist conception of privacy
Seventh, privacy can be seen from a feminist perspective, epitomised by Mackinnon who argues that the ‘public/private’ distinction ignores oppression of women. She argues that ‘the private sphere is the distinctive sphere of intimate violation and abuse’ (1989, p. 168). The right to abortion frees ‘male sexual aggression’. Schneider (2017) tempers this sentiment, arguing that the concept should be reconstructed to recognise ‘the affirmative role that privacy can play for battered women’ (p.287). Whilst passive privacy ‘justifies the refusal of the state to intervene’ (p. 287), the concept’s affirmative qualities – characterised by bodily integrity – ‘makes abuse impermissible’ (p. 289). Put another way, ‘conceived differently, privacy could . . .keep women safe, not battered’ (p. 289). This path of reconstruction is affirmed by DeCew (2015) who argues that the concept should ‘reject the public/private distinction as it has been understood in the past’ (p. 92). Instead, privacy should be regulated through contextual integrity whereby ‘norms of appropriate behaviour in the family . . . justify external intervention from government’ (p. 99). Here, privacy is broken by behaviour that transcends reasonable norms and expectations, creating a middle ground between arguments in favour or against the value in a domestic setting.
Conception eight (Contextual): Privacy or security?
The eighth conception of privacy charts its interaction with security, representing nuanced arguments that prioritise a value under given constraints. Himma (2016) argues that security should be prioritised ‘in . . . direct conflict’ (p. 145) with the value of life having ‘vital intrinsic importance’ (p. 154). Privacy, by contrast, is merely instrumental ‘as a means of securing other goods’ (p.155). Himma puts forward a utilitarian justification where utility – defined as ‘well-being’ – prioritises security in direct conflict. Likewise, Newell (2016) prioritises state surveillance with inbuilt protections. Drawing on a neo republican conception of freedom, it should be regulated by laws empowering ‘oversight by journalists and . . . citizens’ (p. 203).
Moore (2016) argues the ‘privacy versus security’ debate is a false dichotomy. Distinguishing between security provided state and security from the state, he compares the ‘mischief associated with criminals and terrorists’ with that ‘perpetrated with governments’ (p. 176). Building on this, he argues encryption boosts both values. This symbiosis is underlined by Esposti et al. (2017) who argue an ‘antagonistic’ relationship between both values prevents a deeper understanding of ‘individual privacy concerns, security attitudes and public [attitudes]’ (p. 71). Instead, both form part of a broader ‘human security’ with privacy as important as ‘protection from violence’ (p. 88). They argue for a transition to ‘a win-win security paradigm’ (p.88).
Pavone and Esposti further deconstruct the ‘privacy versus security’ relationship, noting a contrast in attitudes between feeling that ‘security measures may be used for . . . illegitimate purposes’ (2012, p. 561) and those who support protection against ‘terrorism [and] organised crime’ (p.557). This is epitomised by attitudes towards security cameras, viewed as both a safety measure and privacy threat (p. 564). This dimension brings a fresh take on the trade-off which becomes a product of trust towards the state.
In summary, conception eight charts the interaction between security and privacy. First, Himma (2016) argues that an instrumental privacy should give way to an intrinsic security whilst Newell (2016) supports security with structured regulation. Second, Moore (2016) questions the trade-off model, arguing privacy is part of a wider ‘human security’ (Esposti et al., 2017). The trade-off model is also challenged for its subjectivity, representing trust in government (Pavone and Esposti, 2012).
Conception nine (Contextual): Privacy and information governance
A further contextual conception focuses on privacy within regulatory frameworks. This is epitomised by Newman (2008) who distinguishes between comprehensive regimes that ‘cover both the public and private sectors’ and limited regimes that ‘do not impose principles on. . . the private sector’ (p. 23). The comprehensive approach is typified by countries across the European Union, beginning with the 1995 directive (p. 35) and subsequent GDPR regulation (Schwartz, 2012: 1966). Here, privacy protects against the ‘interests of companies and bureaucracies’ (Newman, 2008: 26). For comprehensive regimes, privacy takes priority over business activity, with regulation from an independent information commission (pp. 27–29).
Limited regimes, typified by the United States, permit ‘the collection and transfer of personal information’, relying on ‘self-regulation’ (p. 30) with emphasis on economic opportunities and absence of legislation regulating ‘exports of information to other countries’. (Schwartz, 2012: 1977). For this laissez-faire approach, government only addresses systemic ‘market failure’ (Movius and Krup, 2009: 174).
In sum, the information governance conception switches focus to the broad framework that legislates privacy’s importance with a wider regulatory framework. Rather than provide a detailed characterisation, the current argument sketches the context in which privacy operates – as comprehensive or limited – to demonstrate the concepts’ heterogeneity in philosophical, economic and legal debate.
Conception ten (Contextual): Privacy and technology
A final conception concerns its interaction with technology and its ability to ‘generate sensitive data’ (Alt and von Zezschwitz, 2019: 189). This close connection is epitomised by Zuboff’s (2019) ‘surveillance capitalism’ concealed ‘within the Trojan Horse of Technology’ (p. 11). She charts its evolution, showing how big tech companies repurpose behavioural data to maximise economic value (p. 13). This ‘behavioural surplus’, accrued from analysing user behaviour, sees users become ‘free raw material’ and a ‘means to profit’ (p.13). Understood this way, big tech marketizes human behaviour which, by encroaching privacy, is monetised within the ‘surveillance economy’ (p. 16).
The surveillance economy also predicts and shapes behaviour. This drive towards ‘prediction’ ‘violates the inner sanctum, as . . . algorithms decide the meaning of your sighs, blinks and utterances’ (p. 17). Further intervention – coined the ‘economies of action’ – represents interference ‘in the real world among real people and things’ (p.17). This modification, inserting prompts into our everyday lives, erodes personal autonomy by targeting ‘commercial results for surveillance customers’ (p. 18). This interference covertly automates human behaviour, eroding ‘democratic society’ (p. 19).
This danger is affirmed by Aho and Duffield (2020) who describe a ‘surveillance capitalism’ where all electronic interactions are ‘analysed, operationalised and deployed to shape or modify behaviour’, leading from an understanding of privacy as ‘intimate or sensitive’ to the acceptance of big data (p. 122). In response, Austin (2003) builds a conception of privacy as ‘respite from the public gaze’, where ‘individuality’, provides space to cultivate thoughts and ideas, facilitating an ‘authentic inner life’ and ‘intimate relationships’ (p. 147).
The interaction between privacy and technology charts a fast paced and changing relationship. Moore (2000) discusses IT monitoring in the workplace, distinguishing between ‘thin’ and ‘thick’ consent (p. 702). The former is consent ‘in name only’, whilst the latter represents autonomous choice. Alterman (2003) switches emphasis to biometric identification, including ‘digital fingerprints, retinal scans and facial characteristics’ (p. 139), arguing it reduces the body to a means of identification. Privacy includes the ‘right to control . . . biometric images of ourselves’ (p.144). Bright et al. focus on social media’s role in ‘surveillance capitalism’, including advertising using ‘geolocation tracking’ and ‘retargeting’ through personal data (2022, p. 128). This is epitomised by a range of cases including Zoom’s ‘undisclosed data mining during . . . meetings’, ‘Google’s collection of biometric data from children’ and Cambridge Analytica’s ‘unlawful use of Facebook user data’ (p. 129). De Wolf (2020) argues this pervasiveness creates ‘networked defeatism’ – a state of mind that constitutes a fatalistic attitude ‘towards. . . controlling information in a networked social environment’ (p. 1059).
The interaction between privacy and technology continues to evolve. Abdulsalam and Hedabou (2022) chart privacy dangers within cloud computing – the migration of data or services to a third-party provider. Dangers include ‘unauthorised secondary usage, trans-border flow [and] data retention’ (p. 2), a finding affirmed by Sun (2020) who adds ‘insider threat’ – a data breach from within – and a malicious ‘advanced persistent threat’ (p. 4). Khan et al. (2019) discuss the dangers of 5G networks that facilitate ‘smart and data-intensive on-demand services’ (p. 226). Threats include location tracking, identity theft and unauthorised data access (p. 227). They propose regulatory checks including a consensus in ‘global market privacy regulations’ and greater accountability (pp. 227–228). Rather than engage in a substantive discussion about privacy’s interaction with technology, the current argument characterises an evolving contextual understanding of privacy.
Methodology: Descriptive conceptualisation
The argument thus far lays the foundation for a descriptive understanding of privacy. Ten conceptions of privacy in wider literature chart an elusive and fragmented concept with contested meaning. The purpose of this presentation is to illustrate the concept’s diversity and underline its relative underdevelopment within LIS. This heterogeneity echoes Solove’s understanding that ‘there is no overarching conception of privacy’; instead, it should be ‘mapped like terrain’ (2008, p.ix). Solove relies on Ludwig Wittgenstein’s ‘family resemblances’ where a concept is not defined by one ‘common characteristic’ but draws from a ‘pool of similar elements’ (p. 9). For descriptive conceptualisation, emphasis shifts from an abstract specification of concepts to an appreciation of language as a ‘temporal and spatial phenomena’ where conceptual understanding represents language use in context (Wittgenstein, 1953, PI 108). The Wittgensteinian approach, therefore, rejects a ‘theoretical attitude’ in favour of a ‘grammatical investigation’ that examines ‘language embedded in its everyday context’ (Hacker, 2004: 17 cited in Macdonald, 2022: 582).
This approach echoes two separate studies that examine neutrality and intellectual freedom in LIS. Like privacy, neutrality is a heterogeneous concept understood as a ‘core value’, a ‘subservient value’, or a concept that generates ambivalence (Macdonald and Birdi, 2020: 342). Similarly, intellectual freedom within LIS may represent negative liberty, or an interventionist concept where LIS professionals facilitate access. It may be seen as a concept that empowers library users to make autonomous decisions, a concept that promotes democracy or a normative concept that protects social responsibility (Macdonald, 2024: 720). By employing a descriptive conceptualisation, both concepts can be seen holistically, enabling ‘a more productive discussion’ between parties with different viewpoints (2022, p. 581).
In this spirit, the present study develops a descriptive taxonomy of privacy using three of Solove’s guiding criteria. First, the taxonomy strikes a balance between abstract understanding and practical guidance, providing generality that informs professional practice. (Solove, 2008: 40). Second, it caters for variability, allowing for change and dynamism (p. 41). In this spirit, the present study provides a taxonomy that accommodates the concept’s evolution. Finally, a taxonomy must have focus. Solove investigates ‘concrete problems’ (41), leading to a taxonomy that encompasses four ‘groups of harmful activities’: ‘information collection’, ‘information processing’, ‘information dissemination’ and ‘invasion’ (p.p. 103). The current study, by contrast, presents a taxonomy of privacy with two points of focus. First, to bridge the gap between LIS and wider literature and, second, to improve ethical decision making within professional practice.
Methodology: Structured literature search
To do this, a structured literature search identified peer reviewed sources that discussed privacy within LIS. The term ‘structured’ is used instead of ‘systematic’, in keeping with Grant and Booth’s interpretation of a structured or systematised review as including only ‘elements of a systematic review’ (2009, p. 94). A systematic review, by contrast, is a ‘replicable scientific and transparent process’ that minimises ‘bias through exhaustive searches . . . decisions, procedures and conclusions’ (Tranfield et al., 2003: 209 cited in Linnenluecke et al., 2020: 175). This is affirmed by Ferreras-Fernández et al. (2016) who note the importance of an ‘explicit reproducible methodology’ (p. 291). The systematic criteria work in tandem with question selection that is ‘well defined and focussed’ (Aveyard, 2014: 19).
The current study, by contrast, takes a structured approach with the pragmatic aim of finding the fullest sample possible conducive to the development of a taxonomy. The search process constituted five stages. First, full-text searches in Dialogue ProQuest and Library and Information Science Abstracts (LISA) used the search string: (AB(LIS) OR AB (‘library and information science’) OR AB(librarianship)) AND (AB(privacy) OR AB(confidentiality)). To provide a clearer focus, results were filtered to peer reviewed material. The total number of sources retrieved across both databases was 357. There were 35 duplicates. Second, a title and abstract scan preliminarily retained 87 papers for selection based on two broadly construed inclusion criteria.
Literature that addresses the concept of privacy in relation to library and information science in a substantive way (cited in the title or abstract or forms part in the focus of the text.) The term Library and Information Science (LIS) was construed to include literature focussing on the administration and professional practice of libraries. At times, however, literature that discussed the philosophical understanding of privacy within information related disciplines was included, with the pragmatic aim of facilitating connections between LIS and wider literature.
Peer reviewed journal articles or book chapters.
Third, supplementary searching added 69 sources, giving total of 156. Finally, a full-text scan excluded a further 53, providing a final sample of 103 sources. Figure 1 reports the search process using a modified PRISMA flow diagram.
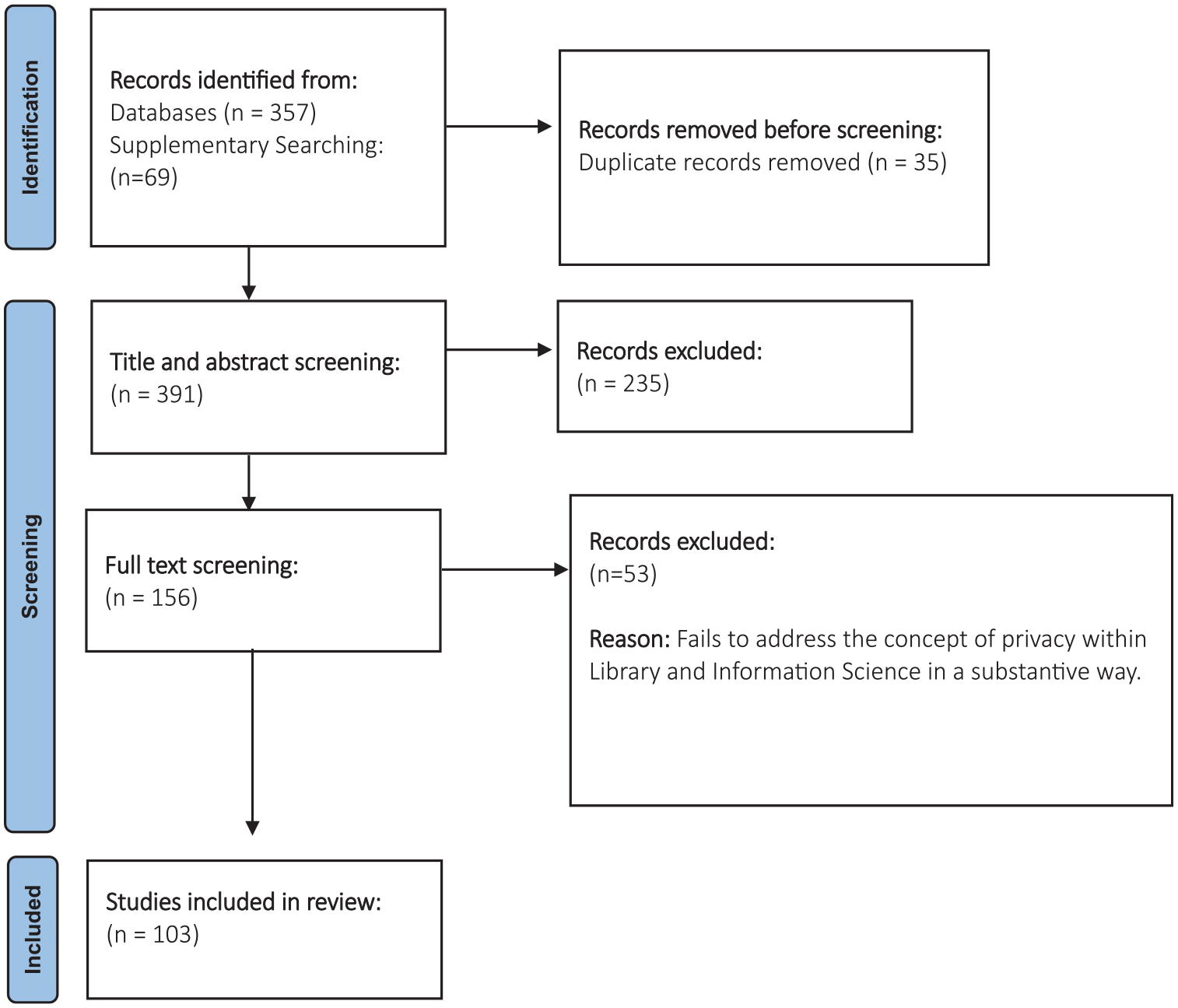
PRISMA flow chart reporting identification and screening process (see PRISMA, 2024).
To reiterate, the open and subjective inclusion criteria further underline the difference between a systematic and structured approach, with reviewer judgement used to delineate the boundary between LIS and wider literature and second, evaluate privacy’s relevance within each source. The lack of a systematic search should be seen as consequence of the subject matter, which is open and undefined. Put another way, a structured search focuses on exploration rather than reproducibility, giving the fullest possible representation of privacy.
Analysis: Constructivism, grounded theory and abduction
To enhance value and transparency, literature was analysed using grounded theory (Wolfswinkel et al., 2013). Grounded theory has four features: ‘minimal preconceptions’, ‘simultaneous data collection and analysis’, the use of ‘various interpretations for data’ and the construction of theory from research (Flick, 2018: 2). This traditional interpretation – requiring ‘minimal preconceptions’ – is problematic for the current study, which builds a descriptive taxonomy based on a pre-studied wider literature. Engaging with literature, however, has precedent, as affirmed by Dunne (2011) who argues it ‘contextualise[s] the study’ and ‘gauge[s] theoretical sensitivity’ (p.p. 116). The expectation of a research in a theoretical vacuum is unrealistic; instead, focus should be on making ‘use of previous knowledge’ (p. 117).
Building on this stance, the current study adopts constructivist grounded theory where the research process represents ‘historical, social and situational conditions’ (Charmaz, 2017: 35). Rather than record an objective truth, it discovers ‘an order which fits surprising facts . . . and solves practical problems’ (Reichertz, 2007: 9). Construction is achieved through abduction – a middle ground between induction and deduction – where patterns in data are brought together. First, common features within data are explained by deductive rules. Second, categories are inductively tested to ensure consistency (p. 222). Seen this way, the current study presents a taxonomy that acknowledges preexposure to wider literature and places emphasis on creativity that enables ‘the researcher to aptly name categories [and] let the mind wander [to generate] comparison’ (Strauss and Corbin, 1990: 27 cited in Reichertz, 2007: 13).
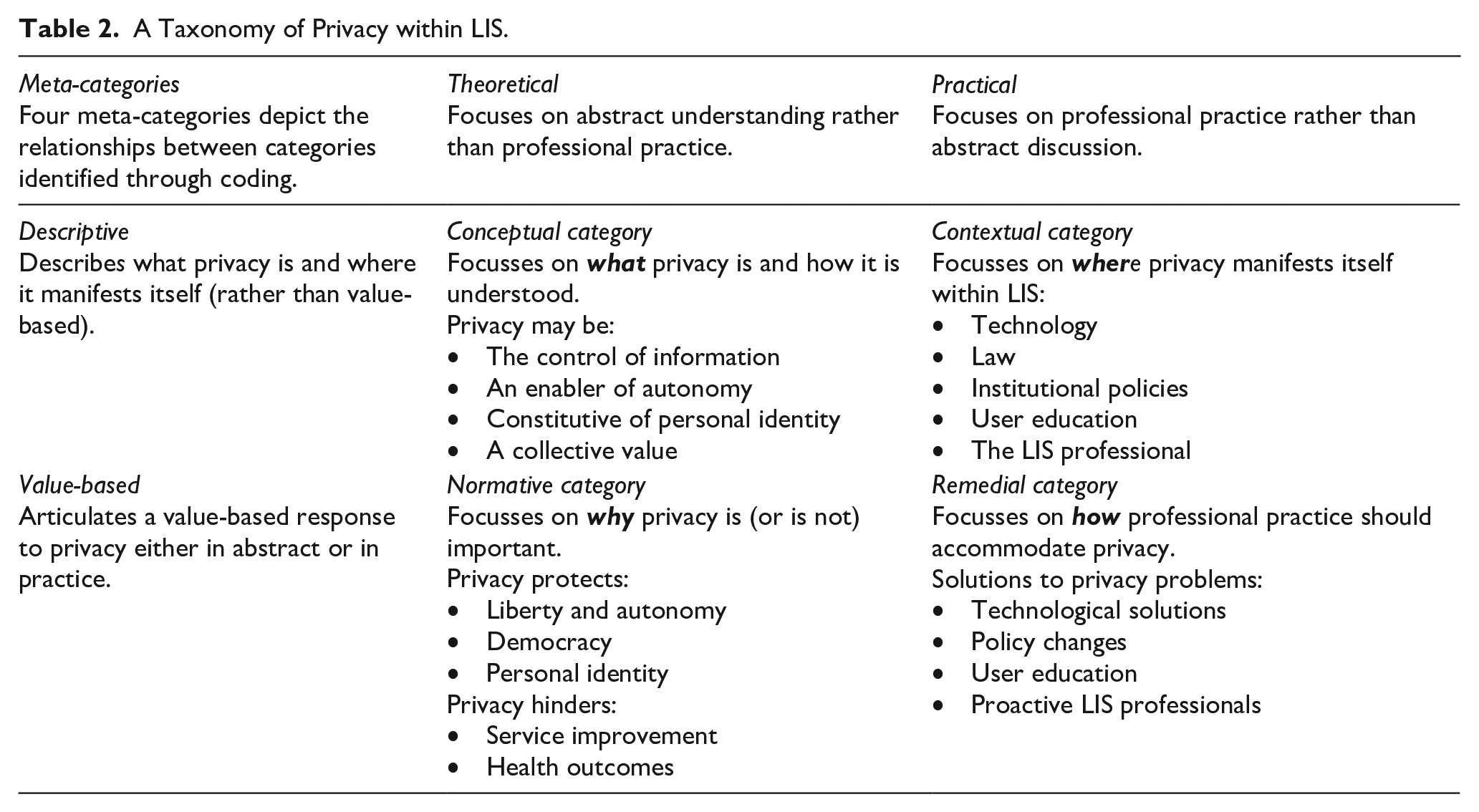
Data was coded using a threefold process. Categories will be fully explained in the results section. First, open coding grouped data together into broad categories providing a ‘bird’s eye image of the study’s findings’ (Wolfswinkel et al., 2013: 50). The ‘conceptual category’, for example, represents the meaning of privacy, whilst the ‘normative category’ switches emphasis to privacy’s prioritisation over other values. Second, axial coding identified ‘subcategories’ and exposed the ‘interrelations between [and within] categories’ (p. 50). The ‘conceptual category’, places differing emphasis on the ‘what’ question, where privacy is understood either as control of information, autonomous behaviour, personal identity or a collective value. Finally, selective coding was used to ‘integrate and refine’ relationships between categories (p. 51). This gave rise to four ‘meta-categories’: ‘theoretical’, ‘practical’, ‘descriptive’ and ‘value-based’. Table 2 shows relationships between categories. The ‘theoretical/practical’ divide represents contrast between two categories that discussed privacy in a theoretical or conceptual context, and the latter two which discussed privacy within professional practice. The ‘descriptive/value-based’ divide represents the contrast between the conceptual and contextual categories and the normative and remedial categories.
A Taxonomy of Privacy within LIS.
Rather than report an objective reality, validity and integrity was maintained through reflexivity – ‘an awareness of the ways in which the researcher . . . with a particular social identity and background, has an impact on the research process’ (Robson, 2002: 22 cited in McGhee et al., 2007: 335). This approach – which Charmaz refers to as ‘methodological self-consciousness’ – acknowledges researcher ‘worldviews . . . [and] . . . unearned privileges’ and their influence within the research process (2017, p. 36). In this vein, the current study both acknowledges the subjectivity of a constructivist taxonomy (a sole researcher with a pre-existing understanding of wider literature) and the possibility that a different taxonomy could be constructed under different research conditions. Rather than construe an objective reality, it has the modest aim of producing an informative taxonomy, building a bridge between LIS and wider literature to inform professional practice.
Results
Four categories – two theoretical and two practical – constitute the taxonomy. Each represents a way privacy may be understood. Table 2 provides a breakdown of categories and their interaction. Importantly, the taxonomy acknowledges that privacy may be understood in different ways which can be mutually supporting. In this vein, the same subject matter may be represented in more than one category, underlining its messy and complex character. The taxonomy embraces this ambiguity, arguing that it provides a full and informative exposition of the concept.
Category one: Conceptual category
The first category addresses what privacy is, focussing on the meaning of the concept. Seen this way, the conceptual category mirrors conceptual conceptions identified in wider literature. It breaks down into four sub-categories. The first represents control of information or data, summed up by Ard (2013) who argues that privacy shelters users ‘from . . . data collection or usage’ (p. 11; see also Ayre, 2017). Sutlieff, argues that ‘privacy means . . . information about an individual is unavailable to others’ (Bowers, 2006: 377 cited in Sutlieff and Chelin, 2010: 164). In a wider context, Bates (2018) describes privacy as ‘data friction’ where ‘socio-material factors . . . coalesce to . . . restrict data . . . movement’ (p. 412).
The control of information sub-category has three broad variables. First, data may be collected within the library ‘for educational purposes’ or externally for third-party vendors (Ashman et al., 2014: 828). Second, privacy may relate to personally identifiable information (PII), ‘used to distinguish or trace an individual’s identity’ (Prindle and Loos, 2017: 23), or anonymised information. This distinction is picked up by Macken and Iakovakis (2021) who distinguish between ‘information privacy’ referring to personal information and an ‘autonomy privacy’ that refers to a ‘right to conduct . . . activities without being surveilled’ (p. 89). Third, information may be collected for basic library administration or for improving library services. The latter is underlined by Asher (2017) who argues that libraries should incorporate ‘large-scale data into their assessment activities’ with ‘learner analytics’ enhancing ‘academic success, and engagement’ (p. 43).
Examples in the ‘control of information’ sub-category sit within each variable. Bradley and Staines refer to third party PII collection for research and marketing (Bradley and Staines, 2021: 5). Likewise, Salo (2021) refers to surveillance that captures ‘data on patron use of library-purchased electronic resources’ (p. 20) and Burkell and Fortier (2013) note ‘concerns . . . focussed on the collection . . . of . . . (PII) . . . provided by users . . . accessing online information’ (p. 1). Students are unaware of applications that track location, personalise advertising (Havelka, 2021: 49) or track browsing behaviour (Gardner, 2021: 70). PII may also be collected for internal business intelligence using learning analytics – ‘the measurement, collection, analysis and reporting of data about learners . . . for . . . optimising learning’ (Long and Siemens, 2011: 34 cited in Currier, 2021: 119), with Currier calling for the responsible stewardship of ‘data sets that contain [PII]’ (p. 126). Data may also be collected for essential library administration, epitomised by Noh (2017) who describes a ‘One-Card’ system enabling borrowing across multiple sites (p. 54). Rather than focus on PII, Jones and VanScoy shift emphasis to anonymised ‘clickstream’ data that ‘students leave in system logs’ which, combined with ‘demographic, biographic . . . and academic data’, create ‘visualisations of student behaviours’ (2019, pp. 4–5).
To summarise, the control of information conception represents a broad understand of privacy as the control of information or data depicted on three continuums of variation. First, information may constitute PII (Burkell and Fortier, 2013; Noh, 2017) or be anonymised (Jones and VanScoy, 2019); be collected within the library (Currier, 2021; Jones and VanScoy, 2019) or by third parties (Gardner, 2021; Salo, 2021) and may either be for essential library administration (Noh, 2017) or research and marketing (Havelka, 2021; Salo, 2021).
The second sub-category equates privacy with autonomous behaviour. Alfino argues privacy hinges on an ‘awareness . . . [of]..being observed’ (Alfino, 2001: 8). This awareness, a breach of privacy, impairs cognitive function (p. 8) – a link underlined by Jones and VanScoy where privacy enables agents to ‘conceive their actions as . . . their own’ (Rubel and Jones, 2016: 148 cited in Jones and VanScoy, 2019: 1334). For an autonomy understanding, therefore, privacy hinges on an agent’s mental state.
Third, Floridi’s ontological interpretation, understanding privacy as ‘a function of the ontological friction in the infosphere’, grounds the concept in personal identity (2006, p. 110). The infosphere represents ‘all informational entities . . . their properties, interactions, processes, and mutual relations’ (2007, p. 176). Information exchange, construed as ‘ontological friction’, represents flows of information. The example of a hospital ward illustrates; a ward with rooms for only one patient has a higher friction and reduced information exchange. This friction is enhanced or thwarted by evolving technology that ‘re-ontologizes’ the infosphere (2006, p. 110). Crucially, ‘one’s informational sphere and one’s personal identity are co-referential’ where ‘anything done to your information is done to you’ (p. 111). Seen this way, privacy is entwined with personal identity, making it a ‘fundamental and inalienable right’ (p. 111). Floridi, therefore, provides a conception of privacy based on an ontological understanding of information.
Finally, privacy may also be seen as a collective value. Buschman (2016) argues that philosophical definitions neglect the concept within professional practice (pp. 420–421), advocating a shift towards ‘collective privacy protections . . . built into . . . contracts’ and ‘easy-to-implement resources to assist in the protection of privacy’ (p. 428). This is achieved by collaborative working within a ‘rational community’ (p. 428). For Buschmann, privacy is a practical issue that interacts with professional challenge.
In sum, the conceptual category focusses on privacy’s meaning. First, privacy is seen as the control of information, understood via three continuums of variation: the kind of data collected (PII or anonymised data); who collects it (within the library or by external parties) or, third, the purpose of collection (essential administration or wider research and marketing purposes). Second, privacy may also be understood as autonomy, third, akin to personal identity and, finally, a collective value.
Category two: Normative category
The normative category switches emphasis to privacy’s importance as value, often expressed as a form of liberty equated with intellectual freedom that allows users to ‘access information without fears, judgements or punishments’ (Affonso and Sant’Ana, 2018: 171). Seen this way, it is closely related to normative conceptions outlined in wider literature. Pekala (2017), argues that intellectual freedom ‘necessarily requires privacy’ (p. 50). Kritikos and Zimmer (2017) note privacy ‘forms the bedrock for an individual’s right to read and . . . receive information’ (p. 24), illustrated by Lamdan (2013), who describes a patron’s fear viewing proceedings from the ‘Soviet Communist Party Congress’ (p. 137).
Privacy’s role in the protection freedom is threefold. First, it embodies positive liberty – understood as an agent’s ability ‘to assert control over their lives’ – protecting us from ‘chilling’ psychological fear and ‘self-limiting anxiety’ (Rubel and Zhang, 2015: 431). This ‘chilling’ effect is more likely to affect minority groups who ‘will always be more visible . . . and . . . easier to . . . identify’ (Asher, 2017: 48) resulting in fear of disclosure (Campbell and Cowan, 2016: 498). Privacy, by contrast, affords the ‘capacity for self-disclosure’ (p. 501).
Second, liberty facilitates autonomy. Jones and VanScoy (2019) link lack of privacy to ‘the degree to which one acts or thinks for oneself’ (Rubel and Jones, 2016:148 cited in Jones and VanScoy, 2019: 1335), thwarting a capacity to ‘generate and express ideas’ (p. 1335) and altering user behaviour (Anderson and Whalley, 2015: 526). Third, privacy promotes democracy through engagement ‘with controversial ideas’ (Ard, 2013: 6) and ‘the cultivation of ideas important to political debate’ (p. 9). Librarians should promote ‘private reading’, and protect ‘reference requests, circulation records and similar materials created through interactions with patrons’ (p. 18). This is echoed by Irvin (2021), who describes ‘intellectual freedom as sacred’ in a ‘fact-based’ society (p. 40).
In sum, privacy as a condition for liberty – expressed as intellectual freedom – represents a cluster of positions with a common substratum, enabling autonomy, and preserving democracy.
The normative category also links privacy to identity, building on Floridi’s notion of friction within the infosphere where ‘one’s informational sphere and one’s personal identity are co-referential’ (2006, p. 111) and epitomised by Garoogian (1991) who, drawing on Goffman, states that ‘privacy plays a key role in self-identity and personhood’ (p. 220). It also contains conceptions that limit the concept within professional practice, hindering service improvement. Asher (2017) notes the benefit of analysing ‘large library usage datasets’ leading to ‘more efficient use of funds’ and identifying ‘students at risk of dropping out’ (p. 45). Fortier and Burkell (2015) note the benefits of website ‘tracking mechanisms’ which ‘enhance user experience’ and promote ‘efficiency’ (p. 61), whilst Jones et al. (2020) observe librarians who collect data ‘to curry more favour when budget requests are due’ (p. 579). Privacy may also conflict with wider societal good. This theme, a facet of health librarianship, notes how electronic health records ‘improve healthcare delivery’ (Gariépy-Saper and Decarie, 2021: 77). Despite potential to ‘improve health outcomes’, however, Gariépy-Saper and Decarie note that electronic data could undermine patient confidence (p. 78).
Rather than characterise the totality of arguments within the normative category, the present argument highlights the way privacy is understood, with emphasis switching from what privacy is to why it is important. The largest sub-theme represents privacy as an enabler of liberty or intellectual freedom, facilitating a positive liberty that thwarts fear of observation. This freedom encourages a pluralism that hallmarks democracy. The normative category also places limitations on the concept which may hinder service improvement or conflict with wider public good.
Category three: Contextual category
The third category moves focus away from a theoretical understanding towards the contexts where privacy manifests itself, bridging the gap between theory and practice. It closely mirrors the contextual understanding of privacy identified within wider literature. The largest theme charts privacy and technology, epitomised by ‘big data’ – ‘large data sets that . . . reveal patterns, trends and associations’ (Bid Data, 2013 cited in Prindle and Loos, 2017: 22). The first sub-theme represents learner analytics – ‘the measurement, collection, analysis and reporting of data about learners and their contexts’ (Jones et al., 2020: 570). This involves analysis of ‘clickstream data’ – ‘timestamped “digital trails” students leave in system logs when they interact with learning management systems’ – which allow ‘institutions [to] . . . make comparisons among students’ (Jones and VanScoy, 2019: 1335). Jones et al. (2020), highlight four inter-related problems relating to libraries and LA ethics. Retention concerns check outs or ‘database usage’ (p. 577). Second, informed consent is affirmed by Ashman et al. (2014) who note how app personalisation is ‘subject to use and abuse without the knowledge or consent of the subjects’ (p. 822) and Jones and VanScoy (2019) who state only ‘10% of studies’ concerning analytics ‘explicitly mention consent’ (p. 577). Third, possibility of reidentification in large datasets risks ‘identity theft’ (Prindle and Loos, 2017: 29). Libraries should consider how data could be ‘connected to reveal the kind of PII needed for identity theft and data mining’ (Dennedy, 2014: 18 cited in Prindle and Loos, 2017: 29). Anonymisation procedures are often inadequate – disclosing information, such as age, may lead to identification through obvious ‘outlier[s]’ (p. 27). Fourth, analytics may also nudge students towards action, threatening autonomy (Jones and VanScoy, 2019: 1339).
Analytics from third-party vendors is emphasised by Gardner (2021) who discusses ‘third-party tracking’ to maximise revenue in the context of public libraries (p. 70). This is underlined by Ard (2013), who notes a shift towards ‘private entities with an interest in exploiting readers’ data’ (p. 3) and illustrated by Amazon who facilitate ‘e-book borrowing’ and data collection ‘for marketing purposes’ (p. 30) instead of ‘[enhancing] user experience’ (Fortier and Burkell, 2015: 61). Lambert et al. (2015) argue vendor privacy policies do not meet ‘the . . . standards of the library profession’ (p. 6; see also Magi, 2010: 267), whilst Kritikos and Zimmer (2017) examine ‘BiblioCommons’ – ‘a . . . cloud-based software solutions [company] for public libraries’ (p. 27) – noting that libraries have an ‘uneven approach to ensuring that . . . policies reflect . . . technological changes’ (p. 33). Consequently, ‘digital content vendors’ threaten ‘privacy and intellectual freedom’ (p. 26). Gardner (2021) argues that ‘unsecured HTTP’ is akin to allowing ‘interlopers to stand near a circulation desk’ (p. 71) and Childs (2017) underlines the need to switch to HTTPS. In response, Fortier and Burkell argue that libraries should ‘identify and review website privacy policies’ (2015, p. 65) and Becker (2021) argues that ‘libraries should work together to ensure that licence agreements . . . keep patron data confidential’ with ‘recourse . . . against the vendor . . . in the event that patron data [is] compromised’ (p. 9).
The technology subtheme also encompasses Radio Frequency Identification (RFID), consisting of electronic tags, ‘sensors to query tags’ and software that displays information about scanned items (Shahid, 2005: 1–2). Butters (2007) argues that reduced RFID security, exploited ‘in a covert manner to read data from tagged library items carried by the individual’ threatens the ‘privacy of the borrower’ (p. 432). He illustrates profiling where a scanner correlates ‘specific types of library material with . . . demographic, ethnographic or religio-political information’ (p. 433). This threat to the reader is affirmed by Ferguson et al. (2015) who discusses ‘hot listing’ where ‘dangerous’ books are cross referenced against borrowers (p. 118).
A distinct theme within the contextual category focuses on legal issues. Framed in a US context, Garoogian (1991) discusses privacy’s derivation from the first and fourth amendments, protecting ‘freedom of press, speech, and peaceful assembly’, and ‘unreasonable searches and seizures’. A right to ‘shield individuals from . . . [testifying] against themselves’ is guaranteed by the fifth and fourteenth amendments (p. 221), providing a ‘legal basis for protecting the confidentiality of patron library records’ (p. 223). This focus on US law is emphasised by Klinefelter (2007) who notes that the ‘Family Education Rights and Privacy Act (FERPA)’ – applicable to recipients of government funding (Nichols Hess et al., 2015: 109) – prevents staff sharing user records (Klinefelter, 2007: 258). Conversely, legislation may also diminish right to privacy. Lamdan (2013), outlines the Freedom of Information Act (FOIA) which charts procedures for requesting federal information (p. 132). Disclosing requestors’ PII undermines intellectual freedom and draws parallels with library patrons scrutinised by law enforcement (p. 137).
This legal context also influences policy, epitomised by the American Library Association’s 1971 adoption of its ‘Confidentiality of Library Records’ policy in reaction to borrower information requests by the US ‘Internal Revenue Service’ (Magi, 2007: 457). Lund outlines how US public libraries approach to ‘data privacy and computer filtering policy’ is often a reaction to ‘legislation, the Library Bill of Rights or published research’ (2021, p. 105). He argues that policy should offer ‘extensive detail and optimal freedom for users’ (p. 105).
Privacy also manifests itself in the context of user education. Ray and Feinberg (2021) incorporated privacy instruction into a ‘UNF library elective one-credit course’ that encouraged students to think critically about social media tools and develop ‘a better understanding of “data privacy”’ by considering how it ‘affects . . . everyday information needs’ (p. 65). This emphasis on education is affirmed by Cyrus and Baggett (2012), who argue that ‘libraries . . . might benefit from designating a “privacy expert”’ (p. 294). Hartman-Caverly and Chisholm (2020) surveyed privacy literacy practices in US academic libraries, including ‘filter bubbles; echo chambers . . . censorship and . . . targeted advertising’ (p. 312). Despite this, they found a high rate of dissatisfaction – a finding supported by Jones and VanScoy (2019) who found a ‘scarcity of privacy in the studied corpus’ in the syllabi of 8302 LIS courses (2019, p. 1349).
An often-overlooked context shifts to the LIS professional themselves. Zimmer reports the US Office for Intellectual Freedom’s survey where ‘80%’ of ‘librarians and allied professions’ do ‘all they can to prevent unauthorised access to . . . personal information’ and ‘88% . . . [believe] they have an important role to play in educating the public about privacy risks’ (2014, p. 124) with a ‘high level of concern among respondents’ (p. 126). Mon and Harris (2011), by contrast, examine the privacy of the LIS professional themselves, arguing that ‘anonymous’ librarians, with ‘impersonal prewritten “scripts”’, are received negatively by users who respond positively to ‘personal answers’ and the idea of ‘real’ people (p. 359).
In sum, the contextual category provides a flavour of the contexts in which privacy manifests itself. Once again, the purpose is not to provide an exhaustive account of contextual issues (beyond the scope of the current argument), but to characterise the way that privacy is understood. The contextual dimension turns away from a theoretical or value-laden understanding, towards a descriptive, yet practical, discussion of professional practice. Within literature, the largest theme focuses on technology – a messy cluster of problems, with an emerging incongruity between ethical standards in LIS and external vendors. It divides into three sub-themes: learner analytics, third-party vendors and RFID. Legal issues also interact and shape library privacy policy and, third, privacy is discussed from the perspective of user education, with a small body of literature considering LIS professionals.
Category four: Remedial category
The Remedial Category focusses on solutions to privacy problems, sharing the contextual category’s focus on professional practice and the normative category’s value. This category, a strong theme during analysis, closely mirrors practical solutions to privacy problems within wider literature, (although not depicted as a level of engagement in Table 1), and further illustrates the plurality of ways privacy may be conceptualised. Like the Contextual Category, the Remedial Category focuses on technology. For learner analytics, Currier (2021) argues for mitigation ‘requiring informed consent . . . establishing protocols for the collection . . . of [PII] . . . and advocating privacy rights’ (p. 117), where consent involves understanding ‘the types of data collected [and] . . . [its] use’ (p. 133). Protocols should ensure that data is ‘anonymised if . . . .necessary’ and libraries should advocate privacy rights in negotiations with third party vendors (p. 133). In the context of third-party tracking, Fortier and Burkell (2015) argue that users should ‘manage HTTP cookies’ (p. 63) and Klinefelter (2007) advocates ‘opt-in for customised Internet site access or opt-out e-mail reminders for checked-out materials’ (p. 271). Pekala (2017) promotes library engagement in the design of ‘library discovery tools’ to preserve privacy and incorporate ‘personalisation’ (p. 54).
Butters outlines safeguards to protect against RFID tags, including lobbying to improve security (p. 437). For Molnar and Wagner (2004), bibliographic information should not be stored ‘on library RFID tags’; they point towards ‘cryptography’ to enhance security (p. 218). More broadly, Ferguson et al. push for a ‘more proactive role for professional associations in . . . new technologies’ (p. 128) with librarians taking a central place in consideration of ‘ethical issues’ (p. 128). Campbell and Cowan (2016) argue for more effective cataloguing practices that enable minority uses to find resources without ‘divulging . . . information needs’ (p. 506). They advocate ‘up-to-date collection management and accurate . . . bibliographic control’ (p. 505), using RDA to ‘help queer users . . . know what they would like to know’ (p. 506).
A further theme within the Remedial Category focuses on policy. Carter (2002) argues that libraries should establish a ‘statement of patron rights . . . [reaffirming] . . . commitment to patron privacy’ and ‘establish a schedule for deleting patron identification information from machine logs’ with staff trained to understand the seriousness of privacy breaches (pp. 41-42). Similarly, Kritikos and Zimmer (2017) argue that libraires should ‘adjust their privacy policies to reflect . . . third-party cloud service providers and provide details on how . . . information . . . [is] . . . shared’ (p. 33). This importance is underlined by Magi (2008) who encourages library directors to conduct ‘an audit of their day-to-day operations’ to root out bad practice (p. 754) and Buschman (2016) who advocates collective negotiation (428).
The Remedial Category also addresses user education. Havelka promotes ‘collaborative . . . dialogue between tech companies . . . library sciences, and interdisciplinary research’ to improve ‘mobile privacy education and awareness’ (2021, p.p. 55). Jones and VanScoy (2019) argue that ‘instructors in all roles . . . need professional development on information privacy in an age of learning analytics’; they encourage peer discussion and the empowerment of ‘students to consider their rights and responsibilities’ (p. 1352). This commitment is affirmed by Anderson (2022), who argues that libraries should provide ‘instruction, workshops and training’ (p. 9) which Maceli argues could be ‘disseminated through continuing education or professional development opportunities’ (2018 p. 201).
The Remedial Category also focuses on the LIS professional. Pekala (2017) states that librarians have ‘ethical obligations that should require them to . . . understand how . . . user data is captured by library discovery tools’ (p. 51) and Anderson (2022) focuses on LIS professionals’ personal privacy, stating that ‘one’s own digital privacy can also be passed on to . . . patrons’ (p. 10). In contrast, Mon and Harris (2011) argue that librarians ‘should step out of the shadows of anonymity’ (p. 362); personal touches, such as ‘exchanging names’, provide a ‘personal connection’ encouraging students to find support (p. 358).
Rather than delve into detail, the Remedial Category characterises the way that privacy is understood as practical solutions to problems within professional practice. It is both practical and value-laden, offering real and workable solutions to privacy problems based on a normative position that views privacy as either beneficial or problematic.
Benefits of a taxonomy: Connection between LIS and wider literature
Thus far, the present argument has constructed a new taxonomy of privacy within LIS. Four categories: conceptual, normative, contextual, and remedial focus on a different aspect of the concept, underlining what, why, where, and how the concept interacts with professional practice. Whilst the constructivist methodology is consistent with the possibility of other taxonomies, the current argument builds a dynamic and open-ended framework that captures privacy’s heterogeneity using three of Solove’s criteria. Generality represents four categories that provide a static framework whilst variability is achieved through an openness that invites responses to what, why, where and how the concept interacts with professional practice and a structure that accommodates conceptual change. Third, the taxonomy’s focus lies in its ability to bridge the gap between LIS and wider literature. By mapping the terrain of privacy, it has potential to deepen understanding and embed privacy problems in LIS within the context of wider debate. This connection can be seen by examining families of conceptions examined in Table 1 (conceptual, normative and contextual) and their corresponding category within the taxonomy. Whilst the Remedial Conception, (not listed in Table 1), was a strong theme within LIS, strong parallels emerge between both literatures. The presentation here is not exhaustive, nor claims that all LIS literature has a strong grounding in wider literature. Instead, it draws these parallels to provide a flavour of the taxonomy’s benefit.
Category one: Conceptual category
For the conceptual category, there is parallel between four facets identified within the taxonomy. The first represents privacy as control of information, represented by ‘privacy rules’ that shelter ‘uses from . . . data collection or usage’ (Ard, 2013: 11) or ‘access to library data’ (Ayre, 2017: 2). In wider literature, this chimes closely with Parent’s characterisation of privacy as ‘the condition of not having undocumented personal knowledge about one possessed by others’ (1983, p. 269) and the descriptive sentiment of Gavison (1980) where privacy is restricted to ‘concern over accessibility to others’ (p. 423), and further emphasised by Moore’s characterisation of privacy as ‘access and personal information control’ (2003, p. 216).
Second, privacy is seen as a form of positive liberty that hinges on an ‘awareness of observation’ (Alfino, 2001: 8) or ‘the degree to which one acts or thinks for oneself’ (Rubel and Jones, 2016:148 cited in Jones and VanScoy, 2019: 1334). Within wider literature, this is closely aligned with Reiman’s understanding of privacy as the protection of freedom to pursue ‘unconventional actions . . . subject to social pressure’ (1995, p. 30). A sentiment underlined by Bloustein and Pallone (2017) where intrusion ‘threatens our liberty . . . [akin to] . . . battery or imprisonment’ (p. 56).
The third parallel constitutes a discussion of personal identity. Within LIS, Floridi’s (2006) ontological interpretation of information ensures ‘one’s informational sphere and one’s personal identity are co-referential’ where ‘anything done to your information is done to you’ (p. 111). Consequently, privacy becomes a ‘fundamental and inalienable right’ (p. 111). Within wider literature, this ontological understanding is found in Locke where privacy protects a sacrosanct ‘inner self’ made up of ‘inalienable and subjective thoughts’ (Richardson, 2016: 91). Both advocate the protection of properties that constitute identity. For Floridi, this represents information encompassing ‘properties, interactions, processes, and mutual relations’ (2007, p. 176) whilst, for Locke, it represents private inner thought. Fourth, both literatures also depict privacy as a collective, epitomised by Buschman (2016) who advocates the collective negotiation of contracts (p. 428). In wider literature, this chimes with Regan’s (2015) assertion that ‘privacy is not only of value to the individual but also to society in general’ (p. 50).
Category two: Normative
For the normative category, there is a close alignment between literatures, beginning with protection of liberty which, within LIS, prevents self-limiting anxiety that occurs when ‘browsing and borrowing records are monitored’ (Rubel and Zhang, 2015: 431) – an effect amplified for minority groups (Asher, 2017: 48). This is closely aligned with Schoeman’s (1984), assertion that privacy ‘limits the control of others over our lives’ (p. 1) enabling expression within social relationships. A commitment to democracy spans both literatures; within LIS, this represents Ard’s (2013) argument that ‘private enquiry’ enables ‘the cultivation of ideas important to political debate’ (p. 9) – a theme affirmed by Irvin (2021), who argues that librarians’ should defend a ‘fact-based’ society (p. 40). Within wider literature, Regan (2015) argues that privacy develops a ‘a certain type of society’ (p. 222) strengthening ‘the democratic political system’ (p. 225). Identity also spans literatures, albeit with a differing emphasis. Within LIS, this is reflected in Garoogian’s assertion that ‘privacy plays a key role in self-identity and personhood’ (1991 p. 220) and, within wider literature, Locke’s ontological argument that lack of privacy may compromise self-defining ‘identity through recall’ (Richardson, 2016: 100).
Second, there is also a shared understanding of how privacy hinders service improvement, epitomised by Asher (2017) who notes the benefit of ‘large library usage datasets’ which ‘identify students at risk of dropping out’ (p. 45) and Fortier and Burkell (2015), who describe ‘tracking mechanisms’ that ‘enhance user experience’ (p. 61). Within wider literature, this is echoed by limited regimes where information presents economic opportunity (Schwartz, 2012: 1977).
Category three: Contextual
For the contextual category, there is parallel with wider societal issues. Technology in LIS represents three sub-themes: learner analytics, third party vendors, and RFID. Within wider literature, this is documented by Aho and Duffield’s ‘surveillance capitalism’ (2020, p. 189), concerns including IT monitoring and informed consent (Moore, 2000: 702), and the dangers of cloud computing in the context of third-party providers (Abdulsalam and Hedabou, 2022: 2).
Second, legal themes are echoed across both literatures. Within LIS, Garoogian (1991) discusses privacy’s derivation from the US constitution and Klinefelter (2007) charts federal law’s effect on policy. The legal context is often cited by other library associations, affirmed by CILIP’s Clarifying Notes, where Article 8 of the European Convention of Human Rights underpins ‘human dignity . . . freedom of association and freedom of speech’ (CILIP, 2022). Within wider literature, the legal context can be seen as the juxtaposition between limited and comprehensive regimes. The latter typified by the European Union’s 1995 directive (Newman, 2008: 35) and subsequent GDPR regulation (Schwartz, 2012: 1966), whilst the former grant the private sector ‘wide latitude’, permitting the collection and transfer of personal information” (Newman, 2008: 30).
Category four: Remedial
The Remedial Category in LIS closely mirrors solutions privacy problems presented in wider literature, with emphasis on the technological and legal dimension. Within LIS, Currier argues that learner analytics can be mitigated by ‘informed consent . . . protocols for [data] collection’ and awareness of privacy rights (Currier, 2021: 117–133). Whilst Fortier and Burkell (2015) argue that users should learn how to ‘manage HTTP cookies’ (p. 63). In wider literature, by contrast, Khan et al. (2019) discuss solutions to problems posed by 5G networks, including a consensus in ‘global market privacy regulations’ and greater ‘accountability and responsibility’ for stakeholders (pp. 227–228).
Second, there are parallels within policy. Carter (2002) argues that libraries should establish privacy statements and train staff to understand the seriousness of privacy breaches (pp. 41–42), with policies to cater for ‘third-party cloud service providers’ (p. 33). Whilst in wider literature, Newell argues that surveillance should be regulated by laws empowering ‘oversight by journalists and . . . citizens’ (2016, p. 203). Magi (2008) encourages library directors to conduct ‘an audit of their day-to-day operations’ (p. 754) and Buschman promotes collective negotiation (p. 428). In wider literature, by contrast, DeCew (2015) argues that regulation constitutes contextual integrity whereby ‘norms of appropriate behaviour’ shield the public from governmental scrutiny (p. 99).
The current section, therefore, demonstrates the benefit of a descriptive taxonomy by showing how it facilitates comparison between LIS and wider literature. Rather than present a detailed analysis, each category acts as an entry point for exploring the similarities between literatures and instead of claiming that there is a ‘correct’ conceptualisation of privacy, it examines the messy and overlapping connections within each category. By doing this, the current argument acknowledges that different privacy debates may span more than one category. Seen this way, the brief comparison presented here may act as a starting point for wider discussion, moving emphasis away from insular discussion by promoting exchange of ideas between LIS and wider literature.
Benefits of a taxonomy: A heuristic tool for professional practice
Having demonstrated the taxonomy’s ability to facilitate connections between literatures, this section illustrates its use as a framework for working through ethical dilemmas within professional practice. In addition to pointing towards connections between literatures, the taxonomy can be seen as a heuristic tool used to work through privacy problems as they emerge. Used as a template, the taxonomy asks series of open questions, deepening understanding of practical ethical problems. The below example outlines how this might be approached within professional practice.
Problem: ‘Institution A’s’ library management system is compromised, exposing user borrowing history.
Solution: The taxonomy serves as a framework for working through the problem and gauging a response. Starting with the contextual category and working anticlockwise (see Table 2), the institution gets a feel for the problem and develops a deeper understanding of salient considerations.
Where (Contextual) – The issue is technological, involving the interaction between the institution’s IT department and third-party vendors. Second, the context is also legal, with a breach of data protection legislation and the institution’s internal policy.
What (Conceptual) – The institution clarifies what privacy means in this context. The most salient understanding is privacy as the control of information, with both the institution and third party losing the control expected by users and regulatory frameworks. In this context, privacy may also be thought of as a collective attribute of the library management system, rather than an individualised value.
Why (Normative) – The institution considers privacy’s normative significance. Rather than rely on frameworks or legislation, it comes to an autonomous understanding of privacy’s importance, safeguarding liberty and personal identity, with a particular emphasis on how minority groups, or those with unusual borrowing behaviour, may be disproportionately affected.
How (Remedial) – Moving forward, the institution minimises the risk of repetition through a range of measures. First, examining technological solutions, it works with the third party to enhance encryption. Second, it changes internal policy documents to make a repeat less likely. Finally, it considers user education, holding a series of workshops that highlight the importance of privacy and raise awareness of internal procedure.
The preceding sketch shows how the taxonomy may have a direct impact on professional practice. Instead of prescribing a ‘ready-made’ understanding of the concept, the taxonomy’s open structure facilitates exploration. Its content serves the practical purpose of deepening understanding of privacy within the LIS profession and facilitates an appreciation of how the meaning and value of the concept fluctuates in different contexts.
Conclusion: Privacy as professional virtue?
The present argument constructed a taxonomy of privacy within LIS, connecting LIS literature with wider literature to inform practical professional practice. The argument unfolded in three phases. First, an exploration of wider literature sketched 10 distinct ways of understanding privacy, categorised as conceptual, normative, or contextual (see Table 1). Second, this presentation laid the foundation for a descriptive conceptualisation within LIS. Drawing upon two other studies that built a descriptive understanding of neutrality and intellectual freedom (see Macdonald, 2022, 2024), a structured literature search and constructivist grounded theory built a taxonomy of four categories: conceptual, normative, contextual, and remedial, charting, what, why, where and how the concept interacts with professional practice. Four ‘meta-categories’–‘theoretical’, ‘practical’, ‘descriptive’ and ’value-based’– depict the relationships between categories (see Table 2). Finally, emphasis shifts to the taxonomy’s practical benefit, demonstrating its ability to deepen understanding of the concept within LIS by facilitating connections with wider literature and its use as heuristic tool to improve ethical decision making.
More broadly, however, the present argument emphasises the complexity of privacy within the LIS profession which, in turn, may facilitate a more granular understanding of its problems in specific situations. By using the taxonomy as a tool for decision making, LIS professionals must look afresh about the very meaning of privacy within practical contexts, working through the morally salient features of each situation. This fresh understanding requires a re-orientation of core value within the profession. A promising avenue of exploration, sketched by the current author, is an understanding of core value as a manifestation of professional virtue (see Macdonald, 2023). Understood this way, invariant moral principles, such as privacy, neutrality and intellectual freedom, are replaced by a particularist reading where principles manifest themselves with a different moral weight in individual situations. Instead of representing invariant moral principles, core values are understood as professional virtues, retaining an esteemed place within the profession whilst allowing the contextual malleability demanded by a complex conceptual landscape. Whilst beyond the scope of the current argument, the presentation of privacy presented here points towards the need for a conceptual re-orientation of value within the LIS profession.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Ethical considerations
Not applicable
Consent to participate
Not applicable
Consent for publication
Not applicable