
Abstract
This study has developed a combined indicator to evaluate the performance of different search engines. Documentary analysis, survey, and evaluative methods are employed in the present study. The research was conducted in two stages. First, a combined indicator was designed to measure search engines. To this end, 72 criteria for measuring the performance of search engines were identified, out of which 22 criteria were selected. Accordingly, 10 criteria were selected in six general classes through a survey of subject matter experts. Validation of our proposed combined indicator was obtained by Delphi method and using the opinions of experts in the fields of information science and information system. Second, web search engines were evaluated based on the proposed combined indicator. The statistical population of this part of the research consisted of two categories: (1) general web search engines, and (2) general subjects. The sample size of the first category contained four search engines Yahoo, Google, DuckDuckGo, and Bing, and the second category involved 40 search terms under 10 general categories. The results showed that the combined indicator had six general criteria: (1) relevance, (2) ranking, (3) novelty ratio, (4) coverage ratio, (5) ratio of unrelated documents, and (6) proportion of duplication hits. According to this indicator, Google is at the top, followed by Bing. This study proposes a new indicator for evaluating search engine performance, which can measure the efficiency of search engines. Therefore, its use to measure the performance of search engines is recommended to researchers and search engine developers.
Introduction
Since there are many general search engines with different indexing and ranking algorithms and hence different search results, it is necessary to evaluate the performance of search engines to determine which one is the best (Ali and Beg, 2011: 836) as users are very sensitive to their time and effort to search (Silverstein et al., 1998).
Evaluation is the process of measuring the efficiency of a system. In particular, evaluation determines which goals and objectives of the system have been achieved (Ali and Beg, 2011). Evaluation means judging value or worthiness. When evaluating an information retrieval system, subjects, and performance are considered and assessed. Evaluation is essential in solving information systems problems (Pao, 1989). Saracevic (1995) posited that evaluation essentially affects the study, development, and use of information retrieving sytems. Baeza-Yates and Ribeiro-Neto (1999) described two overall dimensions of “functional analysis” and “system performance evaluation.” In studies like Hjørland (2010), Huang and Soergel (2013), Saracevic (2015), and Zeynali-Tazehkandi and Nowkarizi (2020, the methods for assessing information retrieval efficiency are: “1) system-oriented approach, 2)user-oriented approach, and 3) hybrid-oriented approach (system-user-oriented approach).”
Search engine is a system of retrieving information. In recent years, search engine evaluation has received much attention and has been implemented using different approaches. In Lewandowski and Hochstotter (2008), search engine quality assessment has four components: “index quality, results quality, search features quality, and search engine usability.”
“How can search engine evaluation be performed? What metrics and approaches might be used? As an answer, it can be done by manual and automatic evaluation approaches. Azimzadeh et al. (2016) posited that, “evaluation of search engines can be done in two different ways; either manually using human arbitrators or automatically using automatic machinery approaches which do not use human arbitrators and their judgments.” Ali and Beg (2011) offered “testimonials” and “shootouts” categories to evaluate search engines.
Besides, based on the literature, search engine performance has been evaluated by over 72 criteria/metrics (Appendix 2) as well as various frameworks (e.g. Cranfield model and AWSEEM (Can et al., 2004)). Moreover, in evaluating search engines performance, there are problems such as uncertainty in choosing the appropriate criteria for search engine evaluation, consideration of only one or just a number of specific aspects of performance evaluation and inconsistencies in evaluations. When it comes to evaluating search engine performance, the question is: “which metrics should be used?” Due to the fact that one criterion alone cannot be used to evaluate search engines (none of the criteria is comprehensive enough to evaluate search engines thoroughly), a series of criteria for evaluating performance should be considered. It is necessary to create a set of standard tools for evaluating web search engines, so that in the future a better comparison between search engines can be made and changes in the performance of each particular search engine can be tracked over time (Oppenheim et al., 2000: 190). Therefore, in this study, we first introduce a new search engine performance index, which is a combined indicator, and then use this index to evaluate the performance of four search engines Google, Yahoo, DuckDuckGo, and Bing.
Related research
The first major attempt to evaluate and examine search engines was made by Cyril Cleverdon, one of the leading researchers in the field of information retrieval, who conducted two initial series of experiments in 1957, the results of which were published in 1962 (Pao, 1989). The Cranfield model represents a standard for evaluating the efficiency and performance of information retrieval systems, using six criteria: (1) coverage, (2) time delay, (3) recall, (4) precision, (5) method of presenting to the user, and (6) user effort to search. Of these six criteria, recall and precision are the most common in evaluating information retrieval systems (Cleverdon and Keen, 1966).
Most studies on search engine performance evaluation (Chu and Rosenthal, 1996; Clarke and Willett, 1997; Ding and Marchionini, 1996; Gauch and Wang, 1996; Tomaiuolo and Packer, 1996) are based on some relevance concepts and are referred to as Cranfield designs (Harter and Hert, 1997).
In general, studies in the field of search engine performance evaluation can be divided into seven categories as follows.
Ali and Beg (2011) classified the different methods for the evaluation of Web search systems into eight categories: (1) relevance-based evaluation, (2) ranking-based evaluation, (3) user satisfaction-based evaluation, (4) size/coverage of the Web-based evaluation, (5) dynamics of Search results based evaluation, (6) few relevant/known item based evaluation, (7) specific topic/domain-based evaluation, and (8) automatic evaluation. Azimzadeh et al. (2016) investigated manual and automatic approaches of search engine evaluation, suggesting “a framework for selecting the best pertinent method for each evaluation” (p. 78). Sanderson (2020) re-considered a set of research on measuring search engine performance from the 1990s, which have been largely neglected by subsequent researchers and research communities.
In 2000–2009, search engines have been variously examined using different metrics/indicators. Sroka (2000) evaluated five search engines based on the criteria of precision, the overlap of retrieved documents, and response time. The results show that Polski, Infoseek and Onet.pl perform better on the precision criteria. Hawking et al. (2001) evaluated 20 search engines based on several measures such as TSAP, MRR1, P@1, P@5, P@1–5, and coverage. Boudry (2002) examined eight search engines (Bioview, Scirus, Search4-science, Altavista, Google, Copernic, Infomine, and Open Directory Project) based on three criteria (precision, relative coverage, and proportion of dead/out of date links) and found that “the use of non-specialized search engines and meta-engines seems preferable over specific search engines in the field of biology” (p. 1112). Goh and Ang (2002) evaluated the retrieval effectiveness of Google and Overture based on precision and the distribution of relevant documents over the number of documents retrieved. The results showed that Google performed better in both aspects. Muh-Chyun and Ying (2003) investigated the applicability of three user-effort-sensitive evaluation measures (the first 20 full precision, search length, and rank correlation) on Google, AltaVista, Excite, and Metacrawler search engines. The results showed greater consistency between the first 20 full precision and search length. Meng et al. (2007) evaluated new Microsoft search engine (MSE) performance based on the average user response time, average process time for a query reported by MSE itself, and the number of pages relevant to a query. They found that “the MSE performs well in speed and diversity of the query results, while weaker in other statistics” (p. 17). Sakai (2007) compared “14 information retrieval metrics based on graded relevance, together with 10 traditional metrics based on binary relevance” (p. 532). Lu et al. (2007) assessed Yahoo, Copernic, Archivarius, Google, and Windows based on recall and precision averages, document level precision and recall, and exact precision and recall. Deka and Lahkar (2010) evaluated and compared Google, Yahoo, Live, Ask, and AOL based on coverage, relevance, duplicate links, and bad links measures. The overall results reveal the superiority of Google over the other four search engines.
Since 2010, corresponding to the volume of research on search engine evaluation, novel metrics/indicators have been exploited to asses search engines. Zhuhadar and Nasraoui (2010) “investigated the efficiency of ranking the documents using precision and the usability of the visual search engine” (1). Foo (2011) studied the retrieval efficiency of English-Chinese (EC) “cross-language information retrieval” using recall and precision for 4 search engines, indicating Google supercmacy over Yahoo. Bilal and Ellis (2011) explored “Google, Yahoo!, Bing, Yahoo Kids!, and Ask Kids” using overlap across and relevance rankings. Teixeira Lopes and Ribeiro (2011) comparatively evaluated general search engines (such as Bing, Google, Sapo, and Yahoo) and health-specific search engines (such as MedlinePlus, SapoSaude, and WebMD) in health information retrieval using six different measures (graded average precision (GAP), average precision (AP), gap@5, gap@10, ap@5, and ap@10). They found that general search engines surpass the precision of health-specific engines. Zhang et al. (2013) examined the efficiency of “Google, Google China, and Baidu” by searching title, basics, exact phrase, PDF, and URL, indicating the supremacy of Google over the other engines. Ali and Gul (2016) examined the “relative recall” and “precision” of Yahoo and Google via navigational, informational, and transactional queries, showing Google supremacy in these two criteria. Balabantaray (2017) also reported the supremacy of Google over Ask, Yahoo, AOL, and Bing in terms of results ranking and its characteristics. Hussain et al. (2019) evaluated the retrieval effectiveness of Google Images, Yahoo Image Search, and Picsearch in terms of their image retrieval capability based on precision and relative recall ratios. They found that Yahoo Image Search has better performance than two others in both two measures. CheshmehSohrabi and Abassi-Dashtaki (2019) evaluated the Ask search engine performance based on the three types of keyword, phrase, and question queries using recall and precision measures. The results indicate an average of less than 50% for recall and precision, respectively. Gul et al. (2020) assessed the retrieval performance of Google, Yahoo, and Bing using precision and relative recall measures in the fields of life science and biomedicine. The results showed the superiority of Google in both measures. Using various query set classes, Jatwani et al. (2020) measured Google, DuckDuckGo, and Bing in terms of “cumulative gain, discounted cumulative gain, ideal discounted cumulative gain, and normalized discounted cumulative gain” and reported the outperformance of DuckDuckGo in understand human intention and retrieving more related results. Zeynali Zeynali-Tazehkandi and Nowkarizi (2021) evaluated the effectiveness of Google, Parsijoo, Rismoon, and Yooz based on precision, recall, and NDCG measures. The results showed that these four search engines have significant differences in these three metrics. CheshmehSohrabi and Sadati (2022) evaluated the performance of four Image General Search Engines (Google, Yahoo, DuckDuckGo, and Bing), and three Image Specialized Search Engines (Flicker, PicSearch, and GettyImages) in image retrieval. The results showed that the Image General Search Engines have a higher recall and precision average. Bokhari et al. (2021) assessed the retrieval performance of Google, Bing, and Newslookup using vector space, Okapi BM25, and latent semantic indexing models, indicating the Google supremacy over the other systems. Soni and Roberts (2021) reported that TREC-COVID had a better retrieval efficiency than the commercial deep-learning-based Google and Amazon on the metrics of “5 P@5, P@10, NDCG@10, MAP, NDCG, and bpref.”
Table 1 shows the categorization of research conducted in the field of search engine performance evaluation.
Distribution of research conducted in the field of search engine performance evaluation according to the proposed classifications.

A review of the literature shows that after the Cranfield model in 1960, researchers like Van Rijsbergen (1979), Leighton and Srivastava (1999), Gwizdka and Chignell (1999), and Järvelin and Kekäläinen (2002) sought to address the shortcomings of previous criteria and proposed new criteria; however, these criteria were later criticized and replaced by other criteria. Some researchers (such as Sakai, 2004) even demonstrated the disadvantages of their own criteria hence offering an alternative, more comprehensive criterion, and some are still seeking research on a specific criterion (e.g. Bar-Ilan, 1998) related to search engine stability.
The trend of research in the field of evaluation of search engines performance is more inclined toward the development of criteria that consider only certain aspects of search engines. In other words, by examining the new criteria presented by the researchers, it appears that each of them has evaluated the search engines from a specific aspect. Accordingly, the existing formulas in the field of relevance have some demerits as follows. These formulas address only one aspect of performance evaluation (relevance). Besides, some of these formulas are complex and some are used in specific situations, such as ambiguous and diverse searches, for example, Agrawal et al. (2009) and Sakai et al. (2010) or for evaluations in incompletely proportional conditions, for example, Sakai and Kando (2008). In this context, Oppenheim et al. (2000), Chu and Rosenthal (1996), Su (2003), and Al-Maskari et al. (2007) proposed more comprehensive studies and more complete criteria. Oppenheim et al. (2000) recognized that much of the research is methodologically inconsistent and that an urgent need is felt for a series of criteria to evaluate search engines. Accordingly, they proposed some criteria.
Research methodology
Research method
The present study seeks to solve the problem of the non-exhaustivity of criteria in search engine evaluation. Documentary, Delphi and evaluative methods were used in this study. In parts of the research in which the criteria for evaluating the performance of search engines were identified based on texts, the method of documentary analysis was used and the studies were conducted qualitatively. Then, the survey method was used to investigate the views of subject matter experts on the identified criteria, as well as the prioritization and validation of these criteria. Finally, a quantitative evaluation research method was used to evaluate the performance of the search engines under study.
Statistical population and sample
The statistical population of this research had two categories: (1) general web search engines, and (2) general subjects. The sampling method was purposeful in both statistical populations. To select the search engines, we referred to sites like www.netmarketshare.com, www.searchenginejournal.com, www.gs.statcounter.com, and www.ebizmba.com that showed the statistics of usage and popularity of search engines, and hence a list of top search engines introduced by these sites was used. Some search engines that are native to a particular country (such as Baidu, which is native to China) were then removed from the list. A survey of site statistics showed that among the general search engines, the highest rate of usage belonged to Google (70.60%), Bing (13.02%), Yahoo (2.30%), and DuckDuckGo (0.44%), and therefore these four search engines were selected.
The search terms were selected through a three-step process as follows: (1) using http://Schema.org ontology, (2) using schema.org ontology and MeSH (Medical Subject Headings) and LCSH (Library of Congress Subject Headings), and (3) final selection of search terms by the expert team.
In the first step, since the search engines are among the public Internet search tools, in choosing search terms, general words and phrases were used. To this end, 10 general subject categories based on the ontology of schema.org were first considered: (1) products and things, (2) persons, (3) organizations, (4) medical entities, (5) geographical places, (6) events and incidents, (7) intangible works or things, (8) creative works, (9) action and practice (procedures and processes), and (10) other items (Schema.org Community Group, 2022).
In the second step, after determining the 10 general subject categories, using the hierarchies of these 10 categories, and the two authoritative sources of MeSH and LCSH, subcategories were determined for each category. Besides, the number of subcategories considered for the first–10th categories was 6, 5, 2, 6, 5, 2, 1, 3, 9, and 1, respectively, hence amounting to a total of 40 subcategories (appendix 1).
In the final step, for each of these 40 cases, two–three search terms with their synonyms were identified and given to a three-member team of information retrieval specialists to select the most suitable one. As a result, a search term was selected for each subcategory (Appendix 1). According to the literature review that Zeynali Zeynali-Tazehkandi and Nowkarizi (2021) have carried out on the number of queries or simulated work tasks, it seems that 40 search terms are reasonable.
In order to score the relevance of the records, the relevance judgment criterion was determined. The searches were conducted by one of the researchers and the first 20 records were saved in an Excel file by each search engine. Matching the search results with the search terms based on the determined judgment criteria was done by both researchers, and in cases of ambiguity, we received help from a subject expert related to that field.
After recording the retrieved results for each search term in each search engine, calculations were made based on the combined indicator criteria. First, the scoring methods related to relevance in previous studies such as Chu and Rosenthal (1996), Oppenheim et al. (2000), Leighton and Srivastava (1999), CheshmehSohrabi and Sadati (2022) were reviewed. Then, a four-level fuzzy spectrum from 0 to 3 was determined (a score of 3 for fully relevant records, a score of 2 for records that are somewhat relevant to the user’s needs, a score of 1 for slightly relevant records, and a score of zero for unrelated records). To calculate the criteria in each of the search engines, an Excel file was created. For each criterion, one sheet was included in that file. A file composed of 40 queries and the result of the first 20 retrieved records were thus created. Finally, the scores of some criteria and calculations of formulas such as AP, NDCG, BPREF, and ERR under the Excel software were obtained.
The new search engine performance indicator
In this study, a total of 125 documents related to the subject of search engine performance evaluation were examined. After studying these sources, 72 criteria for evaluating the performance of search engines were identified (Appendix 2). Subsequently, the existing criteria and their strengths and weaknesses were reviewed, and 22 criteria were selected from the studied criteria (Appendix 3). In order to select the criteria, we considered the important aspects of search engine performance as well as the basic needs of users in data retrieval, because suitable criteria for search engines performance evaluation are those in which user’s behavior is acceptably modeled. These 22 criteria were divided into nine general categories. Then, through a survey of subject matter experts, agreement was reached on six general categories of criteria, and sub-criteria were also determined in two general criteria of relevance and ranking. A total of 10 criteria were selected in the form of six general categories. Validation of the proposed combined indicator in this study was obtained by the Delphi method and using the opinions of experts in the field of information retrieval and information system. In the second stage of the Delphi, the criteria were agreed upon by obtaining a high Kendall score (0.882) and then prioritized. According to the Delphi survey, among the first 9 general categories (1) relevance, (2) ranking, (3) recall, (4) coverage, (5) stability, (6) ratio of unrelated documents, (7) information novelty ratio (newness and originality), (8) ratio of dead (inactive) links, and (9) proportion of duplicate hits, according to expert scores, two criteria of stability and ratio of dead links were removed, due to their low scores, from the list of general criteria. The criterion of recall in information systems based on the opinions of experts, was subsumed under the general criterion of relevance. Six general categories representing the essential needs and expectations of users of data retrieval performance in a search engine are: (1) relevance, (2) ranking, (3) information novelty ratio, (4) coverage, (5) ratio of unrelated documents, and 6) proportion of duplicate hits. The criteria of relevance and ranking include subgroups as defined in Table 2. Table 3 describes each of the combined index criteria.
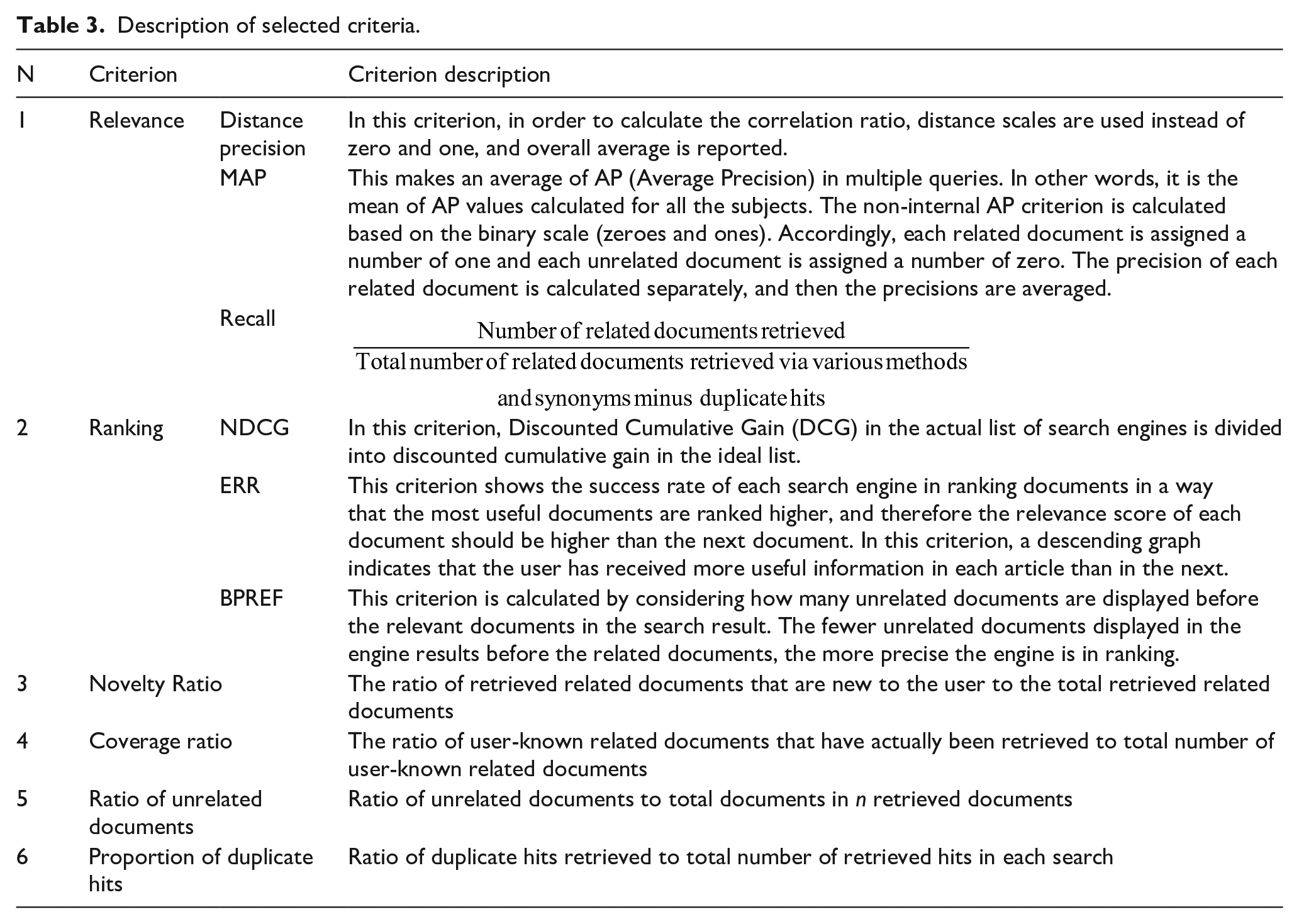
Selected criteria for search engine evaluation.

Description of selected criteria.
Using the Delphi results, weights were assigned to different criteria based on their priority, and the combined indicator was then formulated. Weighing was performed numerically and criteria with higher importance were given a higher weight. Besides, criteria that showed positive aspects of search engine performance were assigned positive scores, while criteria that showed negative aspects of search engine performance were assigned negative scores. The designed coefficients and formulas were reported to the experts and the majority of them agreed with the designed coefficients and formulas. Thus, the validation of the proposed combined index was performed through the Delphi method.
In total, the proposed combined indicator consists of 10 criteria (namely), (1) Distance precision, (2) MAP, (3) Recall, (4) NDCG, (5) ERR, (6) BPREF, (7) Novelty Ratio, (8) Coverage ratio, 9) Ratio of unrelated documents, and 10) Proportion of duplicate hits) in six categories (namely), (1) Relevance, (2) Ranking, (3) Information novelty ratio, (4) Coverage, (5) Ratio of unrelated documents, and (6) Proportion of duplicate hits). The relevance and ranking criteria are divided into various sub-criteria is because no single sub-criterion can show the difference of the two search engines as a sub-criterion indicates only some evaluation aspects. Although these 10 criteria were previously introduced by researchers and were used individually or in combination in previous studies to evaluate the effectiveness of information retrieval systems (examples of which were introduced in the introduction section), a combined indicator with these criteria and features has not been introduced so far.
The combined indicator’s criteria and sub-criteria are then given weight numerically with respect to their priority, and resultantly the combined indicator’s formula is formed. By numerical weighting, more weight is assigned to the criteria with frequent uses and higher importance, from the users’ standpoint, in retrieval efficiency evaluation. Besides, a positive score is given to the criteria that indicate the positive side of search engine efficiency, and vice versa.
The relevance and ranking criteria have been assigned a higher coefficient than novelty and coverage to avoid flaws in the evaluation results. If a search engine has a greater coverage and a lower relevance than another engine, then these two engines might be the same in terms of efficiency considering the sameness of other criteria.
After a user searches the Web, the search engine undertakes two tasks to verify relevant document in its database: (1) provision of query-related results, and (2) ranking of the results and placing of the most relevant documents at the beginning of the list. Accordingly, the relevance and ranking criteria were given a higher coefficient (a value of 2) due to their importance. If numerous relevant documents are retrieved without placing the most relevant at the top of the list, the system performance is weak. Moreover, if various unrelated documents are included but the ranking is good, the search engine performance is inappropriate. Consequently, relevance and ranking are two key parameters with quite equal importance. Besides, a coefficient of 1 is ascribed to the novelty and coverage criteria. Unrelated documents and proportion of duplicate hits were negative ratios. By using the aforementioned coefficients in the combined indicator, search engine information retrieval efficiency can be calculated as follows:

This metric integrates the following search engine evaluation criteria: “(1) Distance precision, (2) MAP, (3) Recall, (4) NDCG, (5) ERR, (6) BPREF, (7) Novelty Ratio, (8) Coverage ratio, (9) Ratio of unrelated documents, and (10) Proportion of duplicate hits.” The combined indicator can be written as follows:
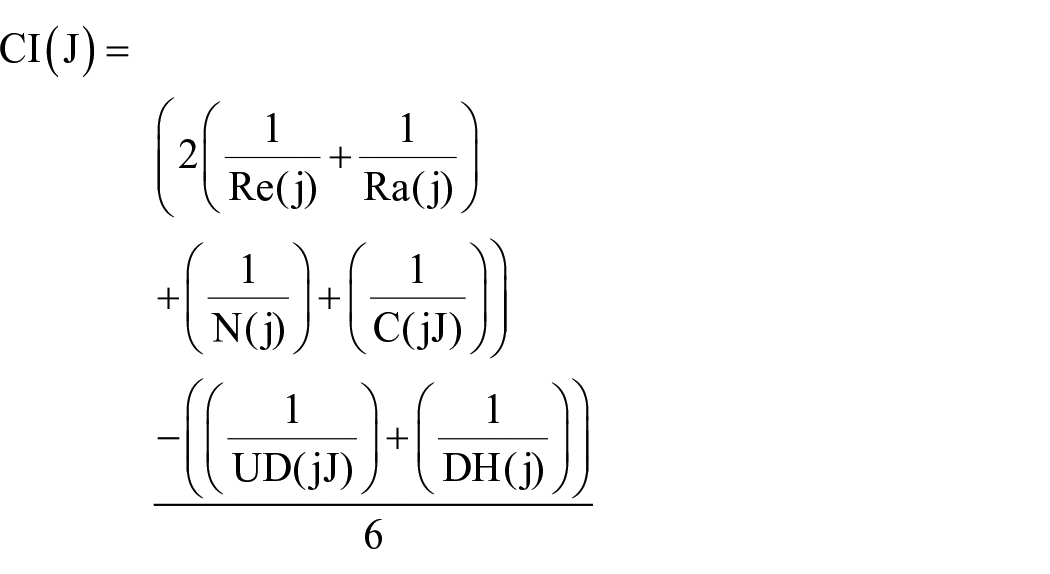
CI(j) = the average of six indicators, which is between zero and one.
Re(j) = the average of
Ra(j) = the average of
N(j) = the average of
C(j) = the average of
UD(j) = the average of
DH(j) = the average of
6 = The value 6 shows the denominator. The fraction has been divided by 6 because the coefficients of relevance, ranking, novelty, and coverage are 2, 2, 1, and 1, respectively, amounting to a total value of 6. Assume an ideal search engine in which the score of the combined indicator is 1. If the relevance score is equal to 1, the ranking score is equal to 1, and the coverage and novelty scores are each 1, then the total, taking the coefficients into account, will be 6. Since in an ideal search tool, a value of 0 is expected for the ratios of duplicate records and unrelated documents, the deduction is 6. If the combined indicator is divided by 6, the value of 1 is achieved. The obtained number from the fraction represents the combined indicator value, and the closer it is to 1, the higher the engine efficiency.
This indicator has been built upon the previous formulas and metrics such as recall and precision (Buckland and Gey, 1994; Lancaster, 1978, 1979), novelty (Bharat and Broder, 1998), coverage (Henzinger et al., 2000), and duplicate hits (Gwizdka and Chignell, 1999), and the article of Marek and Pawlak (1976).
Working method
In this section, Google, Yahoo, DuckDuckGo, and Bing search engines were evaluated based on the designed combined indicator. First, 40 terms were searched in each engine. For each search term, the status of the first 20 documents retrieved based on distance correlation scores, binary correlation scores, new information for the user, total number of related documents, total number of unrelated documents, total number of new documents, total number of retrieved documents, total number of related documents retrieved with all synonyms by removing duplicates, the number of dead (inactive) links, and the number of duplicate links was calculated and shown in tables. Then, based on the data of these tables, the formulas related to the evaluation criteria were calculated.
Results
The performance status of search engines based on the combined indicator designed
The data in Tables 4 to 7 show:
Average scores of combined indicator criteria in Google (appendix 4).
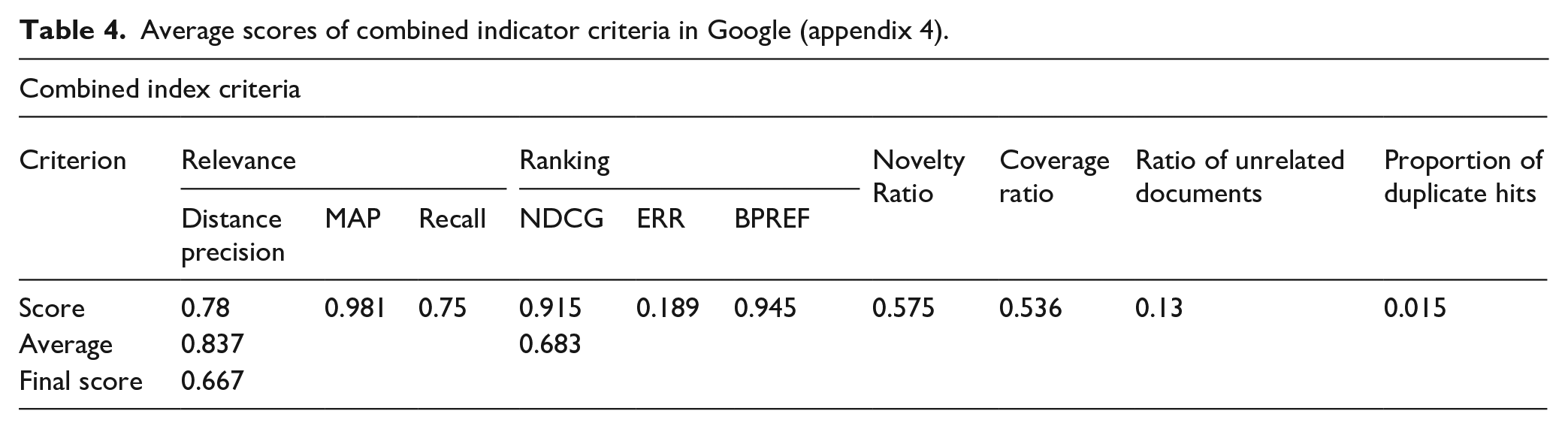
Average scores of combined indicator criteria in Yahoo.
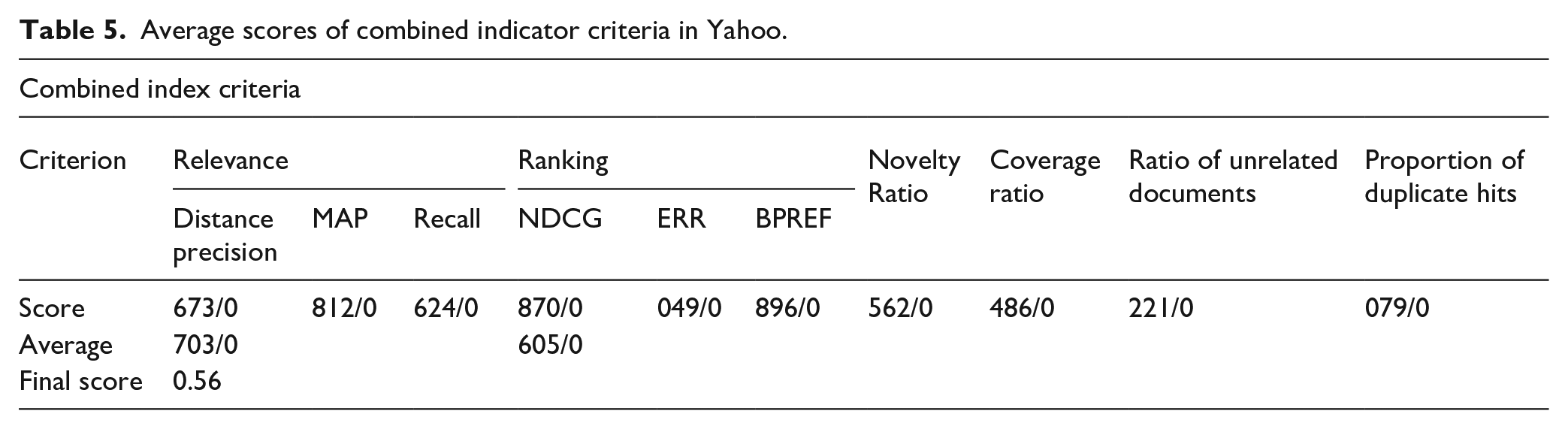
Average scores of combined index indicator in DuckDuckGo.
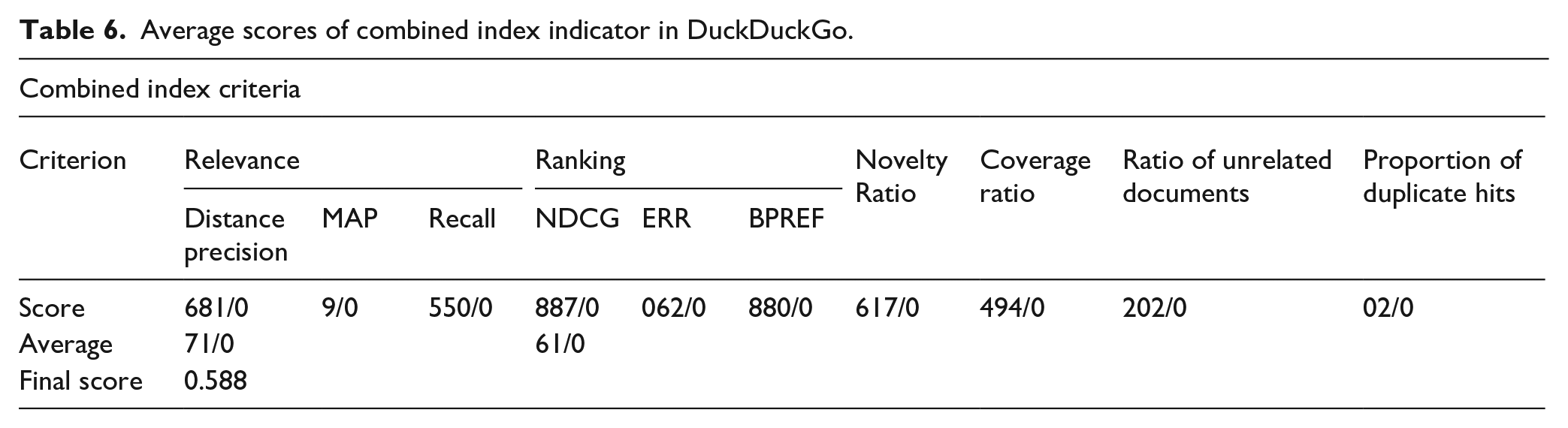
Average scores of combined indicator criteria in Bing.
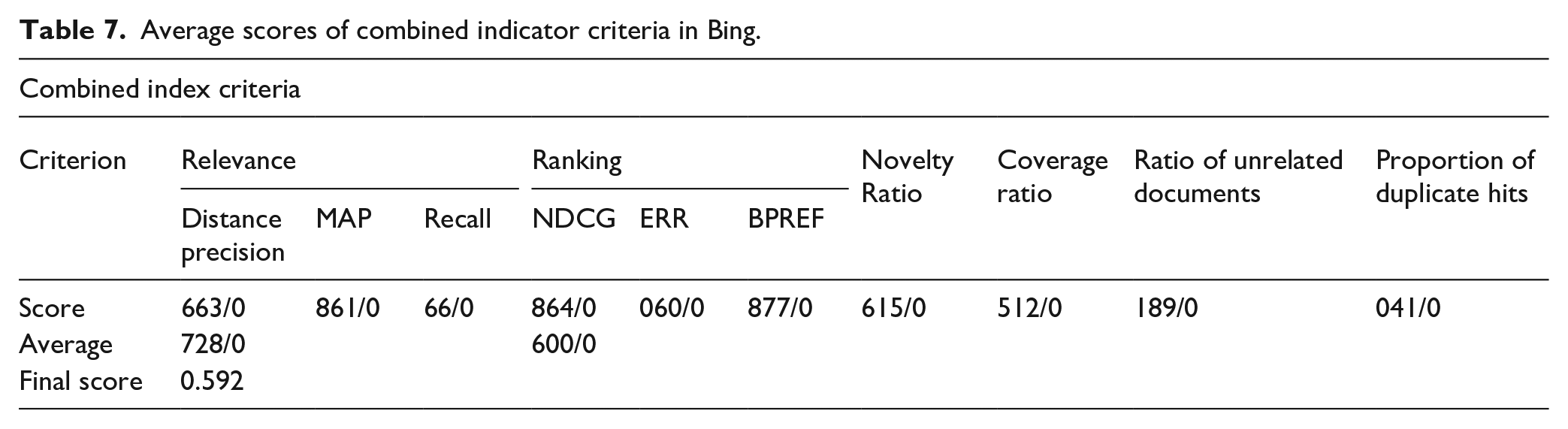
The scores of the four search engines Google, Yahoo, DuckDuckGo, and Bing are listed in Table 8 based on combined indicator:
Search engine scores by combined indicator.
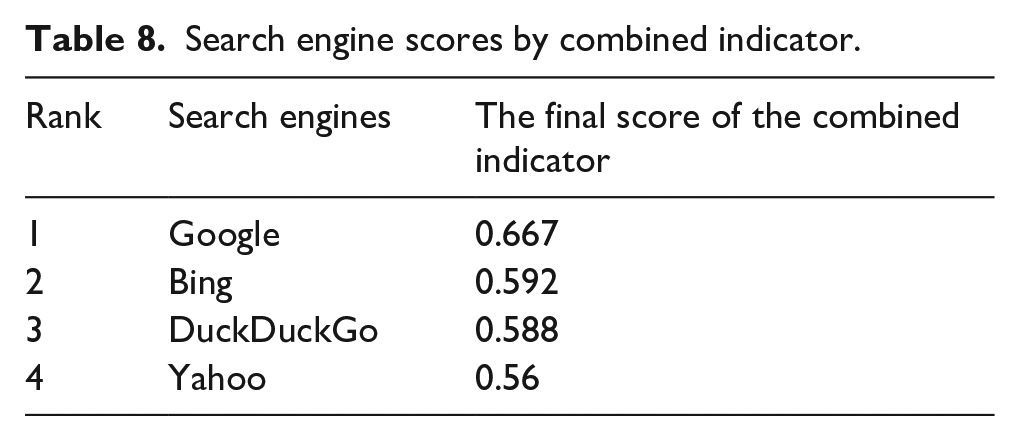
According to the data in Table 8, Google search engine has the best performance (0.667) among the surveyed engines based on the combined index, followed by Bing (0.592), DuckDuckGo (0.588), and Yahoo (0.56). Therefore, the highest rate of the combined index belongs to Google and the lowest belongs to Yahoo.
Comparison of four search engines based on combined index criteria scores
In this section, the scores of each of the combined index criteria in the four search engines are compared.
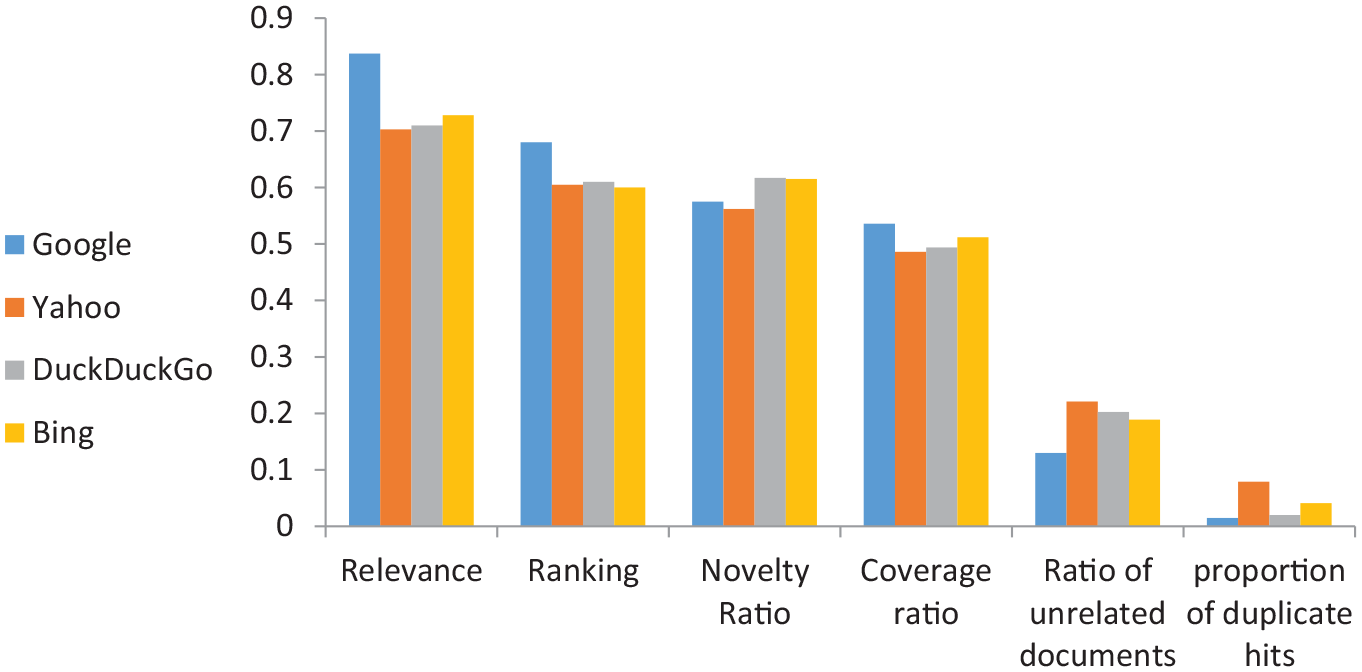
According to Figure 1, among the search engines, Google search engine has the most relevance, followed by Bing, DuckDuckGo and Yahoo, respectively, with very little difference. In terms of ranking, the highest rank belongs to Google search engine, followed by DuckDuckGo, Yahoo, and Bing with a slight difference from each other. In terms of novelty, the search engines are in the order from DuckDuckGo, Bing, Google, to Yahoo. Therefore, the highest value belongs to DuckDuckGo and the lowest belongs to Yahoo. The maximum coverage belongs to Google search engine, followed by Bing, DuckDuckGo and Yahoo. The highest ratio of unrelated documents belongs to Yahoo search engine and the lowest belongs to Google. The highest proportion of duplicate hits belongs to the Yahoo search engine and the lowest to the Google search engine. The order of search engines with respect to the proportion of duplicate hits is as follows: Yahoo, Bing, DuckDuckGo, and Google. Thus, the level of relevance, ranking and coverage in Google search engine is higher than other engines. Moreover, the Google has less unrelated and duplicate hits than the other three engines. Overall, the Google has performed well in terms of relevance, ranking, coverage, unrelated documents ratio, and proportion of duplicate hits; however, in terms of novelty, Google performance is poor, compared to the other search engines.
Comparison of the four search engines based on combined indicator scores.
In this section, in each search engine, the scores of each of the combined indicator criteria are compared. It is also specified in which criteria each search engine has obtained higher scores.
Values indicate that in the Google search engine, the order of the criteria from maximum to minimum includes relevance, ranking, novelty, coverage, unrelated document ratio and proportion of duplicate hits. Thus, relevance and ranking have the highest values of the combined indicator in Google search engine.
In the Yahoo search engine, DuckDuckGo and Bing, the highest value is related to relevance and the lowest is related to duplicate hits. The order of the criteria is similar in Google and Yahoo search engines, and the highest value is related to the relevance criterion, followed by the ranking criterion, and the lowest is related to the ratio of unrelated documents and proportion of duplicate hits. The order of the criteria in the two search engines DuckDuckGo and Bing is the same, and the highest amount is related to relevance, novelty and ranking, followed by coverage, ratio of unrelated documents and proportion of duplicate hits. This is consistent with the desired performance characteristics of a search engine, because the lower the rate of unrelated and duplicate documents in a search engine and the higher the quality of ranking and relevance of articles, the better the performance of that search engine.
Discussion and conclusion
To select a search engine with a better performance in data retrieval, it is essential to evaluate the performance of the search engines. There are many criteria for evaluating search engines, but none of these criteria alone indicates the performance of search engines. Evaluation criteria should work to optimize information retrieval systems. These criteria should reflect the essential needs of users. Search engine evaluations based solely on precision and recall will not be complete and will not cover all aspects of what a user expects from a search engine. A set of criteria must therefore be considered. Some evaluation criteria are designed for specific situations, for example, various search criteria are used in specific situations where there is ambiguity in the search term. In designing the combined indicator, an attempt has been made to select criteria that have the necessary comprehensiveness and exclusiveness in meeting the user’s needs. Accordingly, the proposed combined indicator consist of six general criteria of relevance, ranking, novelty, coverage, proportion of duplicate hits, and ratio of unrelated document. Either of the relevance and ranking criteria has 3 sub-criteria. The six general criteria show the basic expectations and needs of users of information retrieval in a search engine. Moreover, the reason for designing sub-criteria for measuring relevance and ranking is that relevance and ranking cannot be measured by the mere use of a single criterion, and each of the criteria has pros and cons, and in some cases cannot improve the performance of an engine well. The MAP criterion, considering the rankings of related documents, does not suffer from the disadvantages of the conventional precision criterion. This criterion is calculated based on a binary scale and cannot show the difference between the performance of two search engines if the number of related documents is high and cannot also separate completely related documents from slightly related documents. The distance precision does not have this problem and is calculated based on the distance scale. However, neither of these two criteria alone can be used to evaluate the performance of search engines, and neither can show the difference in retrieval performance across several engines. The combined use of both criteria can eliminate the shortcomings of the criteria. For more clarity, some explanations are provided below.
In some cases, distance precision alone cannot tell the difference between the performance of two search engines. The following example illustrates this issue (Table 9; Sirotkin, 2013).
Relevance scores of two search engines.

In this example, since in engines A and B, there are 3 documents with a relevance score of 3, 2 documents with a score of 2, 2 documents with a score of 1, and 3 documents with a score of zero, that is, the number of documents with the same relevance score in the two engines is equal, so the distance precision of engines A and B is equal (distance precision = 0.5), but the relevance performance of the two search engines is different. In engine A, the first five documents are relevant, while in engine B, the first three documents are relevant. In engine A, among the first five related documents, two have a score of 3, 2 have a score of 2 and 1 has a score of 1, while in engine B, in the first three documents, a document has a score of 3, a document has a score of 2 and a document has a score of 1. Therefore, the performance of engines A and B in terms of relevance is not the same. Therefore, if we calculate the AP of the two engines, the rate of AP in engine A is 0.9, while it is 0.7 in engine B.
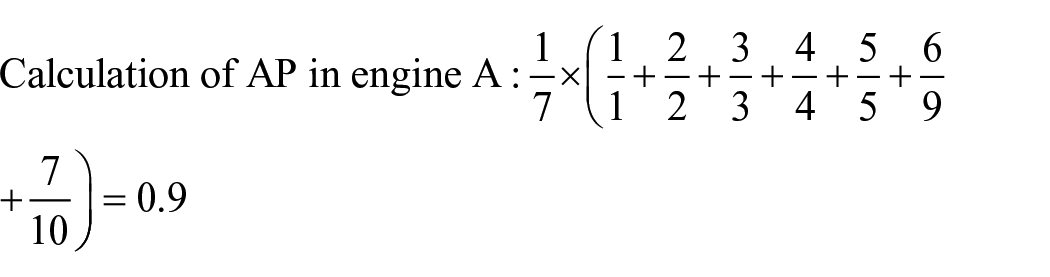
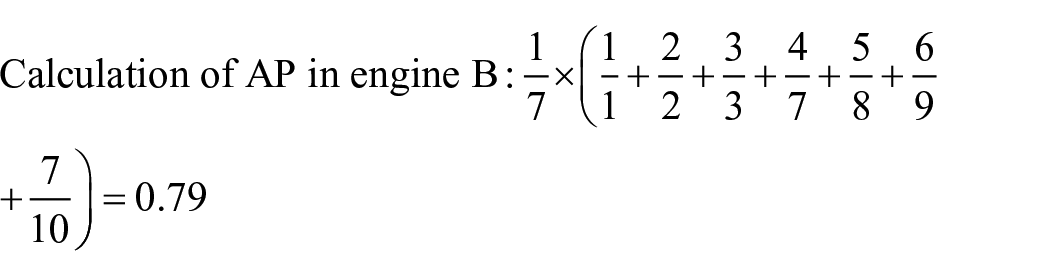
Therefore, the distance precision cannot show the difference between engines A and B (which is equal to 0.5 in the two engines), but the non-internal average precision shows the difference in the performance of the two engines.
The following example is the opposite of the previous example. Here, the AP value cannot show the performance of the two engines, and rather the distance precision shows this difference (Table 10; Sirotkin, 2013):
Relevance scores of search engines A and B.

In search engine A, the first ten documents are relevant and in this case AP = 1. Besides, in search engine B, the first three documents are related and the other seven documents are unrelated, in which case AP = 1. However, engines A and B show different performance with dissimilar distance precisions. The distance precision of engine A is 0.76, while the distance precision of engine B is 0.2.
In this study, in the evaluation of the studied engines, which was done by the sub-criteria of relevance and ranking, in addition to the points mentioned above, some other interesting points were also observed.
For example, in the DuckDuckGo search engine, in subjects 1 and 26, the number of related documents in the first 20 documents retrieved is equal (equal to 8). In subject 1, the first two documents were relevant but documents 3 and 4 were unrelated; however, in subject 26, the first five documents were relevant but documents 6 and 7 were irrelevant. The AP value was 0.72 in the former and 0.78 in the latter. Therefore, although the number of related documents in the two subjects is the same, the AP precision in the two subjects is different. The subject in which the related documents were higher had a higher AP.
From the above example, it is understood that neither distance precision nor AP is able to show the differences between the two engines through relevance criterion; therefore, it is better to combine these two indicators so that the disadvantages can be removed.
The criterion of recall in information systems is also added to the aforesaid criteria, because this criterion considers all documents related to keywords or synonymous expressions. Therefore, this criterion is used to calculate the system capability in retrieving synonyms. The higher a search engine’s ability to retrieve synonyms of a search term, the higher the recall score in its information systems.
In this study, while evaluating engines through ranking criteria, other findings were obtained as follows:
The NDCG criterion shows the difference between the actual and ideal rankings, and the smaller the difference, the closer the fraction is to 1 and the better the system performance. On the other hand, the BPREF criterion considers the number of unrelated documents before each relevant document and fines the system. This criterion indicates that the user passes several unrelated documents before reaching a related document, and hence this is a good criterion for showing the performance of a system. However, like the AP, in some cases it may have bugs. The BPREF problem is similar to the AP problem. The following example illustrates this well.
If in the n recovered documents, all unrelated documents are in the last ranks, then BPREF will be 1, no matter how many unrelated documents exist. For example, if out of 20 documents retrieved, the first 2 documents are related and the rest are unrelated, BPREF is equal to 1, and if the first 10 documents are related and the rest are unrelated, BPREF is still equal to 1, or if, out of 20 documents retrieved, the first 17 documents are related and the last 3 documents are unrelated, BPREF is equal to 1. Now if all 20 of the 20 documents retrieved are related, the BPREF is still 1. Therefore, the performance of an engine with 17 related documents and 3 unrelated documents at the end is the same as the performance of an engine with 20 related documents. Therefore, in cases where BPREF is equal to 1, this criterion alone cannot afford to evaluate the performance of two engines and the NDCG criterion should be used along with it.
In this study, concerning the combined indicator criteria in search engines, the highest value is related to relevance criteria. In Google search engine, which has a higher relevance than the other three engines, the ranking also received a higher score than the other three engines. This is consistent with the results of Al-Maskari et al. (2007) who reported a significant correlation between precision and ranking.
In the present study, Google search engine received the highest combined indicator score among the studied engines, followed by Bing, DuckDuckGo and Yahoo. Therefore, the highest combined indicator belongs to Google and the lowest belongs to Yahoo. The results of this study are in line with those of Singh and Sharan (2013) in suggesting that Google search engine performs better than Yahoo and DuckDuckGo in answering questions; however, our findings are different from theirs in suggesting that Bing search engine has a better responding performance than Yahoo and DuckDuckGo.
In the present study, among the considered engines, Google has the highest relevance. The results of this study are in line with the results of Ajayi and Elegbeleye (2014) in that Google outperforms Yahoo in terms of relevance. However, in Ajayi and Elegbeleye (2014), Yahoo has higher precision than Bing, which is inconsistent with the results of this study.
In terms of ranking, the highest ranking belongs to Google, followed by DuckDuckGo, Yahoo and Bing, with a slight difference. These results are in line with the results of Kaur et al. (2011), who found that Google outperforms Yahoo and Bing in terms of rankings. Google outperformed the other three engines in all the three sub-criteria of relevance (distance precision, average precision, and recall). Google also outperforms the other three search engines in all the three sub-criteria of ranking (descending cumulative gain, expected reciprocal rank, and binary preferences). Google’s good performance in terms of relevance and ranking, as well as their sub-criteria, is due to Google’s strong algorithms in this area.
In terms of novelty criterion, the search engines are in the order from DuckDuckGo, Bing, Google to Yahoo, and thus the highest value belongs to DuckDuckGo and the lowest to Yahoo. Therefore, Google is weaker than DuckDuckGo and Bing in terms of the novelty of documents, but has a better position than Yahoo. Accordingly, to retrieve new documents, it is better to use Google rather than Yahoo, but among the four search engines, the best choice is the DuckDuckGo search engine. The highest ratio of coverage belongs to Google search engine, followed by Bing, DuckDuckGo, and Yahoo. Therefore, Google is the best option for searching subjects such as history, in which the search engine should cover a high percentage of information on the web and retrieve the most relevant documents from the web. The highest proportion of unrelated documents belongs to Yahoo and the lowest belongs to Google. Besides, the highest proportion of duplicate hits belongs to Yahoo and the lowest to the Google search engine. The order of search engines in terms of the proportion of duplicate hits is: Yahoo, Bing, DuckDuckGo and Google. Therefore, Yahoo has more duplicate and irrelevant documents than the other three search engines and needs more powerful algorithms and methods to remove duplicate and irrelevant documents. Examining the scores of criteria in specific and general subjects in the four search engines shows that the highest and lowest criteria (except in a few cases) belong to different subjects. In other words, the highest rate of a given criterion in each search engine belongs to a different subject (for example, the highest distance precision in the four search engines belongs to different subjects) and the same is true for the lowest rate of each criterion. Therefore, search engines have different retrieval performances on the same subjects, and this is due to different retrieval algorithms and methods in search engines.
Lack of a clear standard for scoring retrieved documents and lack of a standard framework for selecting criteria were among the limitations of this study. On the other hand, some search engines provide search results based on the user’s geographical location, and thus the results of a search in several geographical locations may be different, and this problem creates a challenge in the evaluation of search engines.
Researchers are recommended to use our proposed combined indicator criteria and formula to evaluate search engines. The proposed combined indicator provides greater integration and coherence in search engine evaluations and also helps to consider important aspects of search engine performance in evaluations.
Users are also advised to choose the right search engine based on the results of the evaluation of the four search engines. According to our findings, in general, Google search engine had the best performance compared to Yahoo, Bing and DuckDuckGo; however, if a certain criterion is more important for users, they can get the best performance from the search engine in which the said criterion has the highest rate. For example, for a user who gives more weight to the novelty of documents, it is better to use DuckDuckGo or Bing as these two search engines have a better performance than Google or Yahoo in this regard.
Based on the results, search engines have different performance in different criteria and might show good performance in one criterion and poor performance in another criterion. Therefore, search engine designers are recommended to improve search engine performance by consider all the criteria in the proposed combined indicator and use the said indicator to identify the strengths and weaknesses of search engine performance.
Due to the fact that the documents retrieved in Google and Yahoo search engines are less updated, the designers of Google and Yahoo search engines are advised to improve the novelty of retrieved documents. Due to the fact that the ratio of unrelated documents and proportion of duplicate hits in Yahoo search engine are more than Google, DuckDuckGo, and Bing; Yahoo search engine designers are advised to reduce the unrelated and duplicate documents in retrieving documents.
In this work, we introduced a new combined indicator for evaluating information retrieval systems’ performance and a formula to calculate that. We applied the proposed combined indicator to evaluate Google, DuckDuckGo, Bing, and Yahoo. In the scope of this work and as future work, it would be interesting to evaluate the search engines that are less popular or known. The evaluation of other information retrieval systems, especially digital libraries, based on this indicator, can be the next task. Moreover, in our experiments, we searched and retrieved search terms and investigated the results based on the relevance judgment criterion by consulting some experts. Thus, a future task is to conduct searches by users in a normal environment. In this work, we focused on general search terms. However, we also plan to study the search terms in a specialized field. For this purpose, we will ask the experts to select search queries and evaluate the results retrieved by search engines.
Supplemental Material
sj-docx-1-lis-10.1177_09610006221138579 – Supplemental material for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator
Supplemental material, sj-docx-1-lis-10.1177_09610006221138579 for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator by Azadeh Hajian Hoseinabadi and Mehrdad CheshmehSohrabi in Journal of Librarianship and Information Science
Supplemental Material
sj-docx-2-lis-10.1177_09610006221138579 – Supplemental material for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator
Supplemental material, sj-docx-2-lis-10.1177_09610006221138579 for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator by Azadeh Hajian Hoseinabadi and Mehrdad CheshmehSohrabi in Journal of Librarianship and Information Science
Supplemental Material
sj-docx-3-lis-10.1177_09610006221138579 – Supplemental material for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator
Supplemental material, sj-docx-3-lis-10.1177_09610006221138579 for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator by Azadeh Hajian Hoseinabadi and Mehrdad CheshmehSohrabi in Journal of Librarianship and Information Science
Supplemental Material
sj-docx-4-lis-10.1177_09610006221138579 – Supplemental material for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator
Supplemental material, sj-docx-4-lis-10.1177_09610006221138579 for Proposing a New Combined Indicator for Measuring Search Engine Performance and Evaluating Google, Yahoo, DuckDuckGo, and Bing Search Engines based on Combined Indicator by Azadeh Hajian Hoseinabadi and Mehrdad CheshmehSohrabi in Journal of Librarianship and Information Science
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.