
Abstract
This study investigates which combination of institutional and infrastructural arrangements positively impact research data sharing and reuse in a specific case. We conducted a qualitative case study of the institutional and infrastructural arrangements implemented at Delft University of Technology in the Netherlands. In the examined case, it was fundamental to change the mindset of researchers and to make them aware of the benefits of sharing data. Therefore, arrangements should be designed bottom-up and used as a “carrot” rather than as a “stick.” Moreover, support offered to researchers should cover at least legal, financial, administrative, and practical issues of research data management and should be informal in nature. Previous research describes generic institutional and infrastructural instruments that can stimulate open research data sharing and reuse. This study is among the first to analyze what and how infrastructural and institutional arrangements work in a particular context. It provides the basis for other scholars to study such arrangements in different contexts. Open data policymakers, universities, and open data infrastructure providers can use our findings to stimulate data sharing and reuse in practice, adapted to the contextual situation. Our study focused on a single case and a particular part of the university. We recommend repeating this research in other contexts, that is, at other universities, faculties, and involving other research data infrastructure providers.
Keywords
Introduction
Open research data increasingly receives attention from research funders, governments, and academic institutions (e.g. European Commission, 2019; European Research Council Executive Agency, 2017; OECD, 2015; Patel, 2016; Saywell and Crocker, 2019; Ventura et al., 2020; Zuiderwijk and Spiers, 2019). In this paper, we define open research data as research data that is freely and publicly made available for the long term, in open, interoperable, and machine-readable formats, accompanied by sufficient metadata, and legally fit to be crawled, reused, and modified (Australian National Data Service, n.d.; Austin et al., 2017; European Commission, 2017; Kondo et al., 2018; Lindman and Tammisto, 2011; Open Knowledge Foundation, n.d.; Zuiderwijk and Spiers, 2019). Open research data includes quantitative and qualitative data in various forms and types, including observational, experimental, theoretical, and computational data.
Openly sharing research data is expected to increase the cost-effectiveness and democratization of the data (Borgerud and Borglund, 2020). Another potential benefit is that access to research data allows for the verification of results and reduces the duplication of research efforts, both inside and outside academia (Patel, 2016; Saywell and Crocker, 2019; Zuiderwijk and Spiers, 2019). Open research data can also increase researchers’ citation count and acknowledgment of their work (Bullini Orlandi et al., 2019; Fecher and Friesike, 2014; Fries, 2014; Mosconi et al., 2019; Piwowar et al., 2007; Steel et al., 2019; Yarime, 2017).
However, often for good reasons, researchers are reluctant to share their research data openly and to reuse data shared openly by other researchers. For example, researchers may be lacking the time, money, and necessary data management skills to share and reuse research data (European Commission, 2019; Gertrudis-Casado et al., 2016; OECD, 2015; Yarime, 2017; Zuiderwijk et al., 2012). Another inhibitor is a perceived sense of competition with other researchers: researchers may fear that other researchers scrutinize their data and discover something novel before they do (Borgerud and Borglund, 2020; Yarime, 2017). Moreover, researchers may be reluctant to share and reuse research data due to legal matters such as copyright, licenses, and data (privacy) sensitivity (Borgerud and Borglund, 2020; Patel, 2016; Viseur, 2015).
The majority of challenges for open research data sharing and use cannot be mitigated completely. Nevertheless, the negative impact of many challenges can be reduced with suitable infrastructural and institutional arrangements, as suggested by previous research (Altayar, 2018; Zuiderwijk, 2015). In this study, we refer to arrangements as the combination of individual instruments. We define institutional arrangements as the combination of instruments related to formal structures (e.g. university policies), informal structures (e.g. norms, culture), and operational mechanisms (e.g. existing data-sharing processes) that research institutions can employ to incentivize open research data sharing and use (derived from North, 2005; Williamson, 2009). Examples of institutional instruments include implementing data-sharing policies (Patel, 2016) and offering educational programs about research data management (Kondo et al., 2018; Steel et al., 2019).
We define infrastructural arrangements as the combination of instruments related to technical elements (e.g. open data portals, (meta)data standards and formats, and tools for processing, searching, analyzing, and visualizing data) and governance elements (e.g. mechanisms to enhance privacy, trust, and interaction with other data providers and users) to stimulate open research data sharing and use (derived from Zuiderwijk, 2015). Examples of infrastructural instruments include offering openly available infrastructures (Patel, 2016) and having data quality indicators on the platform (Charalabidis et al., 2014). The term open data infrastructure may refer to multiple data sharing and reuse environments, such as repositories, archives, portals, and platforms. These infrastructures must account for a wide range of data sources and (meta)data semantics (Abbà et al., 2015), which may vary per domain (Borgerud and Borglund, 2020; Neuroth et al., 2013).
Infrastructural and institutional arrangements can be studied in isolation, yet combining them is expected to increase their effectiveness. For example, the challenge of “lacking rewards for sharing open research data” may be addressed by a scientific output assessment system that adequately takes account of open data sharing contributions of researchers (European Members of the International Council for Science, 2018) combined with acknowledging researchers’ data sharing behavior on their institutional website (infrastructural and institutional instrument). As another example, the challenge of “lacking skills to use open research data” may be addressed by improving the ease of use of open research data portals (infrastructural instrument) in combination with researcher training for using such portals (institutional instrument).
While previous research provides an overview of possible institutional and infrastructural instruments (e.g. Fecher and Friesike, 2014; Patel, 2016), there is a lack of insight into what combinations of instruments (i.e. arrangements) positively affect research data sharing and reuse in particular contexts. Some arrangements may be more valuable in certain situations than others. For example, infrastructural and institutional arrangements need to be adjusted to the knowledge and skills of the involved researchers and support staff. Moreover, the country, organizational structure, and information needs of an institution shape its information and knowledge management systems (Deja, 2019). Due to the lack of deep, contextual insight, it is currently difficult to assess the effectiveness of various arrangements for different situations.
This research aims to investigate which combination of institutional and infrastructural arrangements have a positive impact on research data sharing and reuse in a specific situation, using a case study research approach. Our contribution to the library and information science literature is twofold. First, this study is among the first to provide a contextualized overview of institutional and infrastructural arrangements potentially useful for universities and academic libraries to stimulate open research data sharing and reuse. Second, this study discusses the potential impact of implementing certain arrangements in the particular case of a Dutch university active in open science policy implementation. Practically, at university and academic library level, the lessons learnt from this study may be useful for open research data policymakers, staff supporting research data infrastructure development and use, and individual researchers. Ultimately, our findings should allow researchers to examine the effectiveness of the identified arrangements in different contexts. Finally, implementing adequate infrastructural and institutional arrangements enables research institutions and research data infrastructure providers to better support and stimulate data sharing and reuse behavior by researchers.
This paper is structured as follows. First, we provide an overview of infrastructural and institutional instruments as identified from previous research. Next, we describe the case study research approach adopted in this study, and discuss the contextual aspects that should be kept in mind when interpreting our case study findings. Thereafter, we present the case study findings and discuss the implications of our findings for university policy makers (including research support staff), governmental policymakers, research funding agencies, and individual researchers. Finally, we present our research conclusions.
Research background
This section provides an overview of infrastructural instruments (section “Infrastructural instruments to support open research data sharing and reuse”) and institutional instruments (section “Institutional instruments to support open research data sharing and reuse”) to support research data sharing and reuse as derived from previous research. We identified these instruments through a literature review using the queries “(open research data) AND (infrastructural OR institutional) AND (arrangement*)” and “(‘open research data’) AND (infrastructure* OR institution*)” in Scopus. The systematic literature review was complemented with a snowballing technique, as recommended by Jalali and Wohlin (2012). The relevance of all results was first assessed based on the title and abstract. The remaining results were further judged on their quality, actuality, and relevance.
Infrastructural instruments to support open research data sharing and reuse
This section describes instruments that infrastructure providers can use to support data sharing and reuse. Table 1 summarizes the infrastructural instruments derived from previous research.
Infrastructural instruments to support open research data sharing and reuse, as identified in the literature.
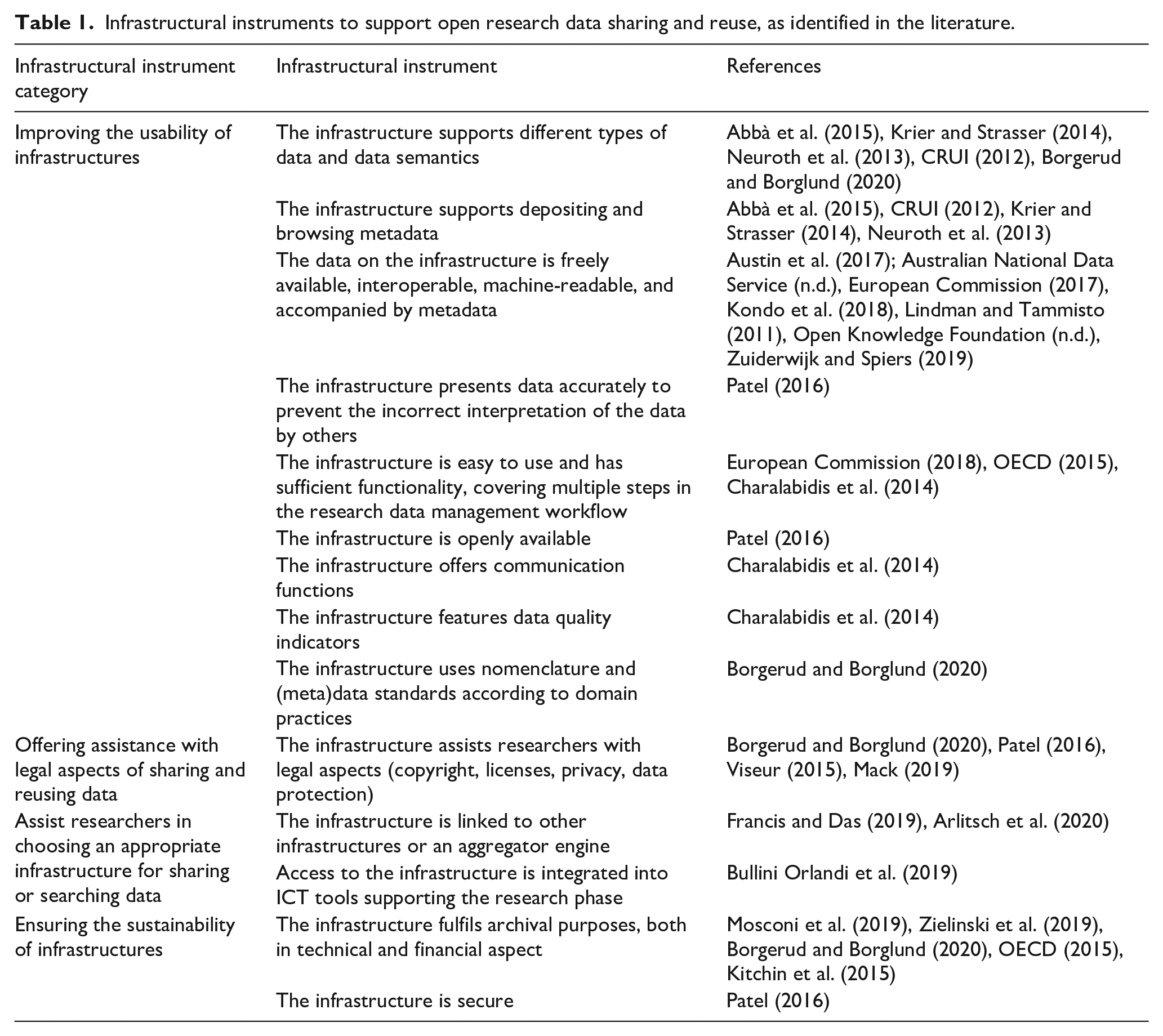
The first group of infrastructural instruments identified from the literature concerns
The second group of instruments focusses on
A third group of instruments deals with
The fourth group of instruments is about
The infrastructural instruments described above can be implemented by research institutions to support and stimulate open research data sharing and use. They can be combined with the institutional instruments as mentioned in the next section.
Institutional instruments to support open research data sharing and reuse
Table 2 provides an overview of institutional instruments available to research institutions (such as universities) to support data sharing and reuse by their researchers.
Institutional instruments to support open research data sharing and reuse, as identified in the literature.
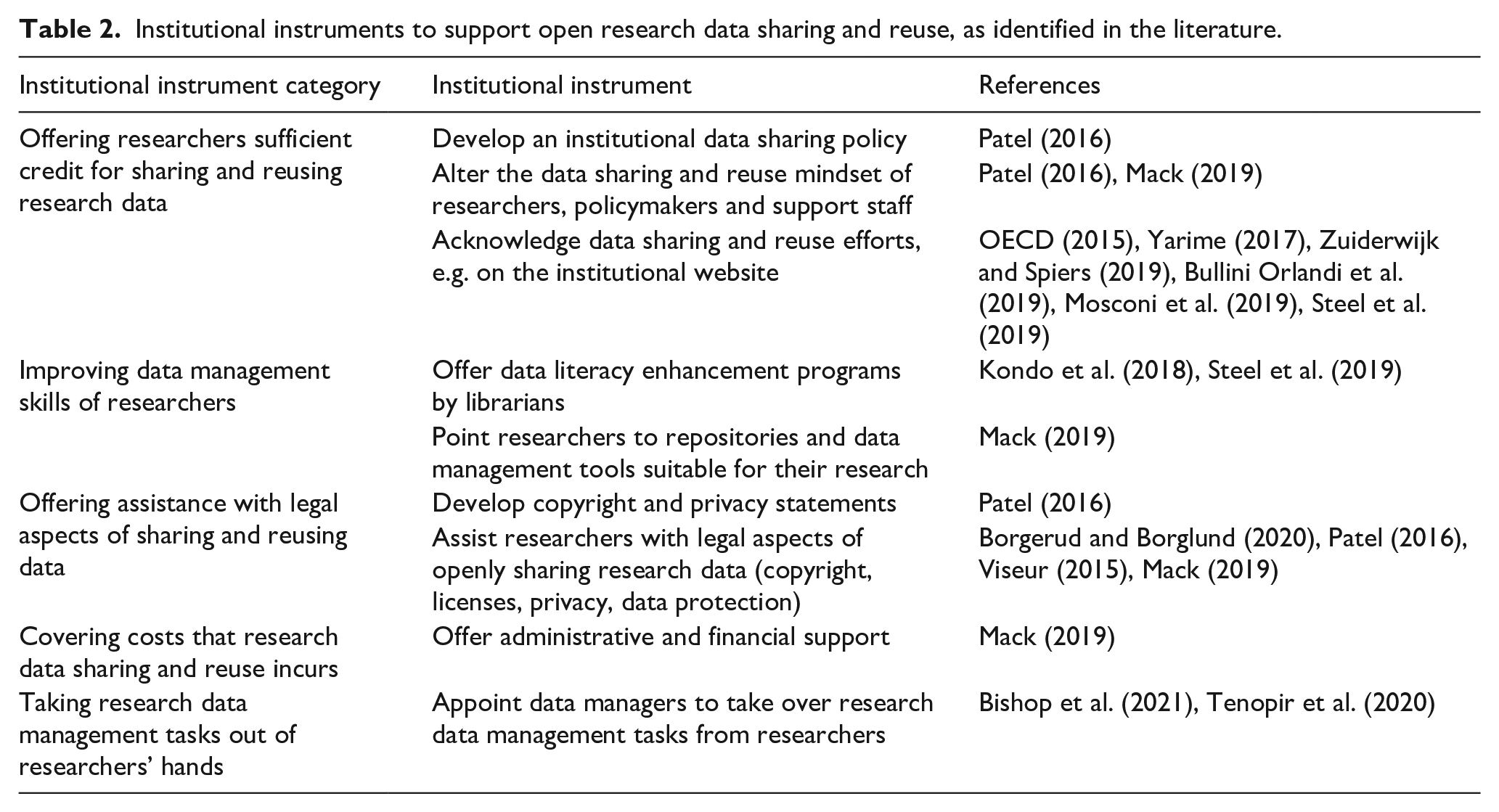
The first institutional instrument category identified in the literature concerns
Institutions should also acknowledge researchers’ data sharing efforts better at an institutional level. For example, institutions can evaluate research output in terms of shared data (Yarime, 2017; Zuiderwijk and Spiers, 2019). For this, a scientific output assessment system such as “altmetrics” can be used (European Members of the International Council for Science, 2018).
The second instrument category intends to
The third institutional instrument category concerns
The fourth institutional instrument category entails
A fifth category is
Case study research approach
In this section, we describe the motivation for taking a case study research approach (section “Motivation for case study research approach”), and explain our study selection criteria (section “Case selection criteria”) and information sources (section “Case study information sources”). We finish by describing how we analyzed the interview transcripts (section “Analysis of interview transcripts”).
Motivation for case study research approach
We adopted a case study research approach to investigate which institutional and infrastructural arrangements positively impact research data sharing and reuse. The qualitative case study method “investigates a contemporary phenomenon (the “case”) in depth and within its real-world context, especially when the boundaries between phenomenon and context may not be clearly evident” (Yin, 2018: 45). Yin (2018) recommends the case study approach for situations in which “(1) your main research questions are “how” or “why” questions, (2) you have little or no control over behavioral events, and (3) your focus of study is a contemporary (as opposed to entirely historical) phenomenon” (p. 32). Moreover, case studies are suitable when personal experiences and the context of certain behavior play a fundamental role (Benbasat et al., 1987; Bonoma and Wong, 1985).
The above-mentioned aspects characterize this research. First, this study is highly exploratory: the phenomenon under investigation has not been studied extensively yet. Previous research does not address the impact of contextual aspects on the effectiveness of institutional and infrastructural arrangements to support open research data sharing and reuse. Second, we aim to provide a deep and rich understanding of how and why specific arrangements positively impact open research data sharing and reuse in a particular context, in this way answering “how” and “why” questions. For this reason, the authors adopted an interpretative approach. It is not the goal to formulate an objective truth, but instead to represent the perspectives and interpretations given in the case study information sources (Walsham 1995). The inferences and conclusions that result from these inductive analyses can then be extrapolated to other cases (e.g. universities or academic libraries) (Walsham and Waema, 1994). Third, we, as investigators, have no control over the data sharing and reuse behavior. And fourth, this research examines current data sharing and reuse behavior, rather than historical phenomena.
Case selection criteria
In case study research, the researchers typically define case selection criteria and then select a specific case (Yin, 2018). Using theoretical sampling, our case study selection criteria were as follows:
The case concerns research data sharing and reuse in the Netherlands and enables access to relevant interviewees. Since the authors were located in the Netherlands and speak the language, a Dutch case would be most convenient.
In the case, both infrastructural and institutional arrangements are implemented.
The case concerns a Dutch public university, as we assume that non-public and commercial research institutions have less incentive to stimulate sharing research data.
The university must have extensive experience in stimulating research data sharing and reuse. As this experience is hard to measure, we defined two proxies. Out of all Dutch public universities, we selected universities that a) have a research data management policy available on the internet, and b) supplement this with publicly available faculty-specific policies for the majority of their faculties.
At the moment of our study, four Dutch public universities fulfilled these criteria: Delft University of Technology (TU Delft), University of Groningen, Utrecht University, and Free University Amsterdam. 1 For practical reasons, primarily easy access to interviewees, we selected the TU Delft as the institution to study. Our selected case thus concerns the institutional and infrastructural arrangements that the TU Delft implements to stimulate data sharing and reuse, and what experience researchers, policy makers, and support staff have with these arrangements. Section “Case description: Research data sharing and reuse at Delft University of Technology” describes the selected case in more detail.
Case study information sources
To reduce bias in case study research, Yin (2018) recommends the use of multiple information sources. Table 3 provides an overview of the information sources for our case study.
An overview of the case study’s information sources.
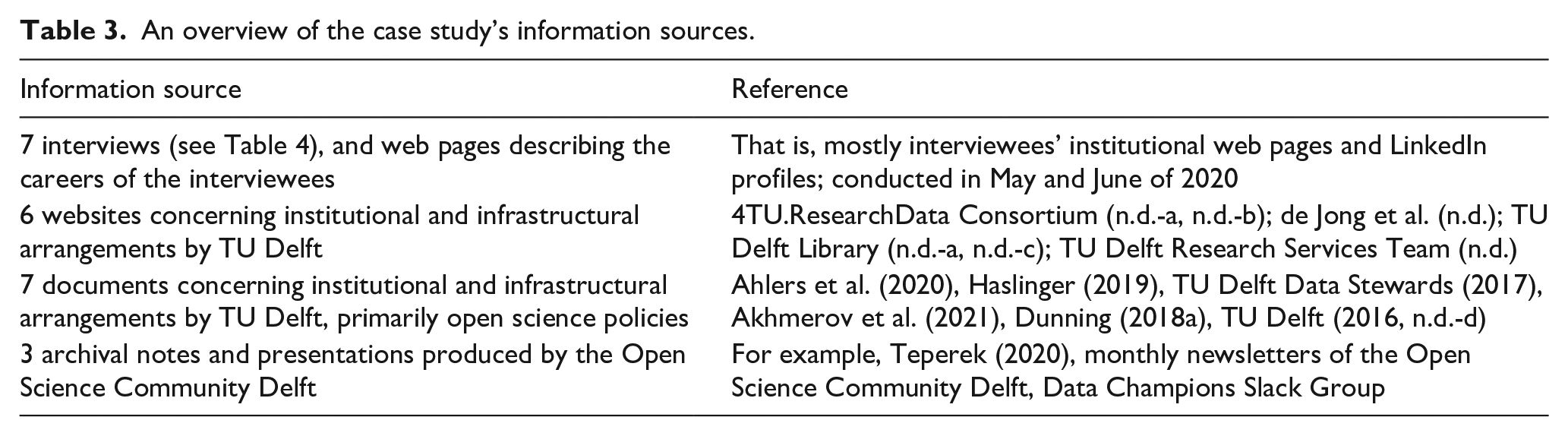
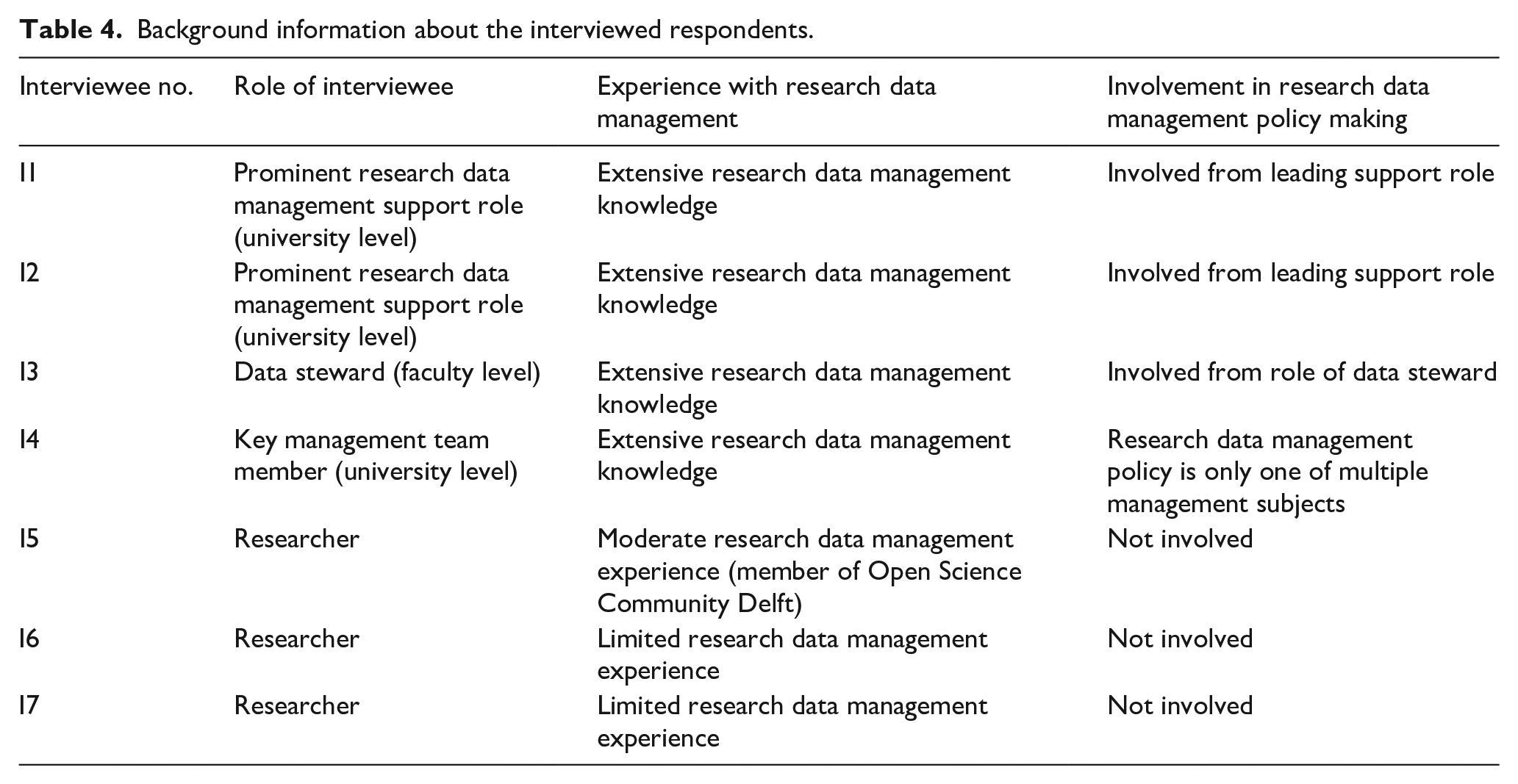
Table 4 describes the roles of the selected interviewees and their experience with research data management. The interviewed data steward and researchers (i.e. I3, I5, I6 and I7) are all employed at the same faculty (which we do not mention for confidentiality reasons). The other interviewees (i.e. I1, I2, and I4) operate on a university-wide level.
Background information about the interviewed respondents.
Analysis of interview transcripts
The interviews covered five parts: (1) the interviewees’ background, (2) the (perceived) familiarity of researchers with the support options for openly sharing and reusing research data available at the institution, and the demand for these options, (3) why they believe researchers seek support for research data sharing and reuse, (4) the (perceived) familiarity, satisfaction, level of understanding, and compliance by researchers with research data management policies and resources, and (5) how the interviewees think researchers use the available research data infrastructures to upload or find research data. We gave interviewees time to elaborate on personal experiences and their motivations or struggles when sharing or reusing research data.
We fully transcribed and anonymized the interviews. Interviewees could review the transcripts, which resulted in adding two minor clarifications. Next, we coded the transcripts using the ATLAS.ti version 9.1.7 software, a standard tool for qualitative document analysis (Alasseri et al., 2018). We applied theory-driven coding to the transcripts, meaning that we developed labels to make sense of the interview data based on theory and concepts before starting the coding process (DeCuir-Gunby et al., 2011). For this step, we used the literature described in section “Research background.” As recommended by DeCuir-Gunby et al. (2011), we then applied open, axial and focused coding.
For the open coding process, we followed the recommendations by Lindlof (1995) and started the open coding process by reading every transcript. We then marked and categorized relevant parts and built codes around the identified categories. This process resulted in a long list of codes. Next, we reviewed the codes in their context using axial coding. Axial coding let us relate (sub)categories and their properties, allowing us to make the “disassembled” pieces of the transcripts into one coherent analysis again (Charmaz, 2006; Corbin and Strauss, 1988). During this step, we put the codes into overarching categories. Finally, we tested the reliability of the resulting codes using focused coding. Focused coding entails “using the most significant and/or frequent earlier codes to sift through large amounts of data” (Charmaz, 2006: 57). We identified the most important variables, reread the transcripts, and selectively recoded the transcripts where applicable. In this coding round, we also split certain codes to apply to only researchers (indicated with the suffix [R]) or to policymakers and support staff (suffix [PM/SS]). The coded, anonymized transcripts and codebook are publicly available as supplementary data at https://doi.org/10.4121/19635147.
Case description: Research data sharing and reuse at Delft University of Technology
This section describes the case we studied, namely the infrastructural and institutional arrangements for research data sharing and reuse by Delft University of Technology. The TU Delft is a Dutch university that is the scholarly home to roughly 27,300 students, 6300 staff members, and 2900 Ph.D. candidates (TU Delft, 2022). Its road to Open Science is long: the first initiatives of the university started almost two decades ago (TU Delft, 2012). The institution signed the Berlin Declaration on Open Access in 2005 (TU Delft, 2016). The university considered open access a strategic priority in its Strategic Plan for 2012 to 2017 (TU Delft, 2012) and enacted a separate policy on Open Access Publishing in 2016 (TU Delft, 2016). In the Strategic Framework for 2018–2024, this focus was broadened to Open Science in general (TU Delft, 2018). In 2019, the university fostered a Strategic Plan Open Science for 2020–2024 (Haslinger, 2019), which included a policy on research software sharing (Akhmerov et al., 2021).
More specifically, for research data management, the university set up institutional arrangements in 2017. The university defines successful research data management in terms of three fundamental pillars: infrastructure, culture, and policy (Dunning, 2018b). Hence, the university introduced data sharing funding opportunities and educational resources, and installed data stewards and research data officers at the university library and all faculties (Dunning, 2017). The Research Data Framework Policy followed in 2018 and was updated in 2020 (Ahlers et al., 2020). This document forms an overarching framework for the entire university. The framework is supplemented by faculty-specific policies, first developed in 2018 (Dunning, 2018a). One critical instrument, that has been in place since 2010, is the 4TU.ResearchData Repository. The TU Delft manages this repository with Eindhoven University of Technology, the University of Twente, and Wageningen University & Research, all Dutch universities. Despite these institutional ties, the infrastructure offers its services to researchers worldwide (4TU.ResearchData Consortium, n.d.-c). In the year 2021, 835 datasets were published on the repository (4TU.ResearchData Consortium, n.d.-d). In the same year, all datasets uploaded amassed over one million views and 330.000 downloads (4TU.ResearchData Consortium, 2022).
Case study findings: Infrastructural and institutional instruments in practice
Our case study revealed how infrastructural and institutional arrangements for data sharing and reuse are perceived in practice. Below, we categorize the identified instruments using the categories derived in section “Infrastructural instruments to support open research data sharing and reuse.” The categories are underlined and the identified instruments are depicted in italics. When we refer to statements of the interviewees, we refer to the interviewee number between square brackets.
Infrastructural instruments
Table 5 categorizes the identified infrastructural instruments. First, we identified infrastructural instruments that influence
Infrastructural instruments to support open research data sharing and reuse, as identified through the case study.

The most important instrument related to
We derived three instruments to
Institutional instruments
The previous section discussed our case study findings regarding infrastructural instruments. This section presents the findings concerning institutional instruments for open research data sharing and reuse (see Table 6).
Institutional instruments to support open research data sharing and reuse, as identified in the case study.
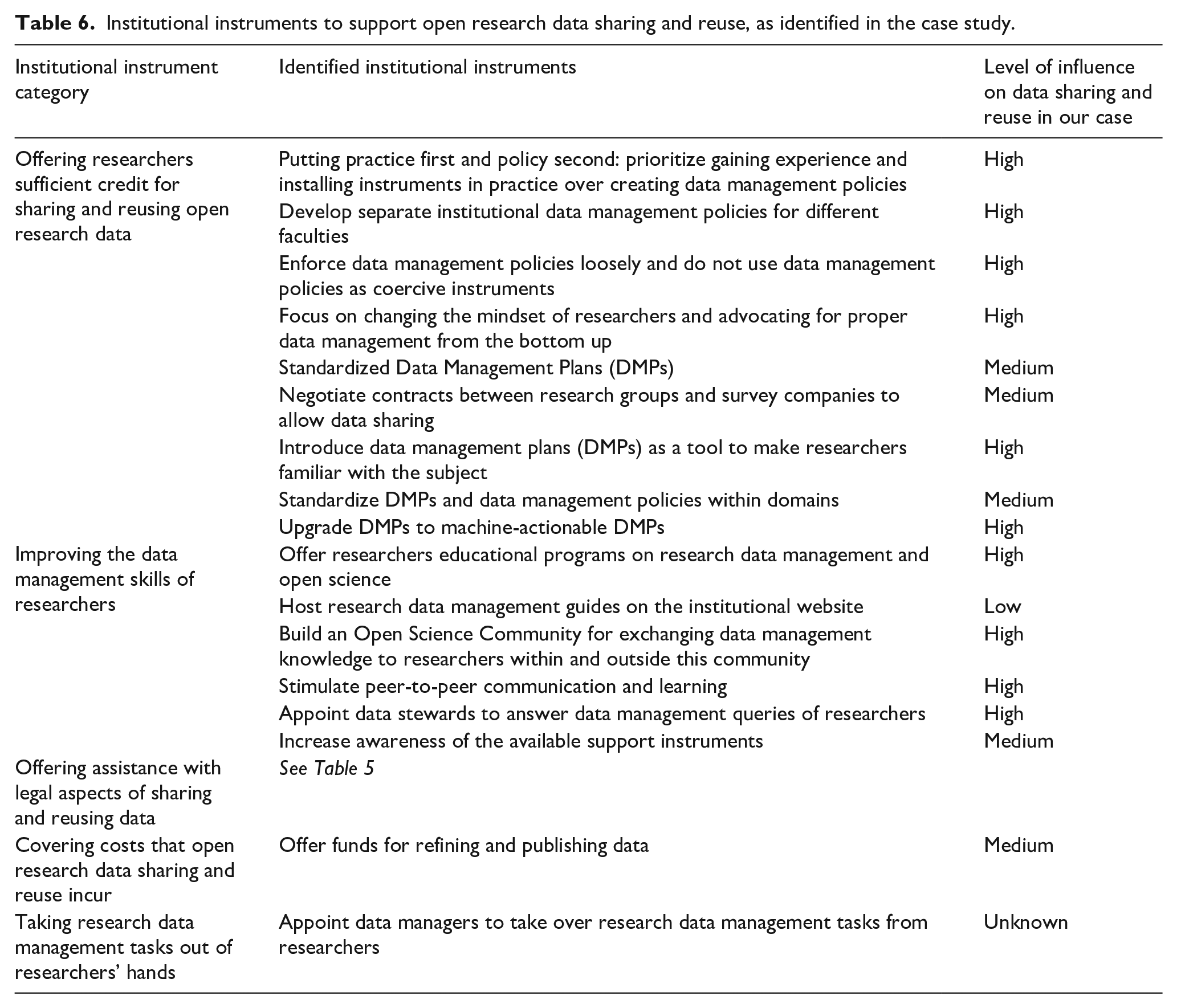
Interviewees spoke about various instruments related to
Moreover, several interviewees state that the data management policies should not be used as coercive instruments [I1, I2, I4]. They should instead serve as a measure of last resort in case of unwilling researchers, given the administrative burden that policies impose on researchers [I1, I2, I4]. All policymakers and support staff deem changing the mindset and advocating for proper data management from the bottom up more effective. [I2] even claims that “[t]he policy is the least important thing. The best way to change people’s minds is with people like the data stewards and the data managers. So the informal support, right, just there next door.”
The interviewees also referred to the institutional instrument “Data Management Plans (DMPs).” DMPs force researchers to think about how they will manage and publish their data, and may therefore be required by funders and ethics committees. This is good to get researchers involved with the subject [I2, I3, I4]. However, similar to policies, DMPs are usually perceived as an obligation and met by equivalent resistance [I1, I2]. Researchers may cut corners to just “tick the box,” as [I3] describes: “For project proposals, they don’t care so much. They just want to have the document so that their proposal is complete, [. . .] they are less worried about will the data be properly stored” [I3]. Furthermore, one policymaker aptly noted that “[f]illing a DMP does not really mean you will change your habits when you are doing research. That is much more difficult to measure” [I2]. An extra complicating matter is that institutions and funders may enforce inconsistent policies and DMP templates. These should therefore be standardized within domains, both nationally and internationally [I4]. A positive illustration is that the Dutch Research Council (NWO) has its own template, but also approves of the TU Delft DMP template, so that researchers can comply with requirements of both parties with a single DMP (Clare et al., 2021).
Currently, the university library aims to make data management plans “less of a form and more of a service” by taking steps toward machine-actionable DMPs. Particular information entered in a data management plan is then processed and linked to different services automatically [I1, I2]. For example, once a question about the size of the data to be produced in the research is answered, a message is sent to the information technology department to allocate storage to the researcher [I1]. Another example is that if the data management plan contains dates, the researcher receives an automated reminder to either take the corresponding action or update the plan when the date is nearing [I2].
In the second category of institutional instruments, all interviewed policymakers and support staff talked extensively about how they aim to
Besides educational programs, the university library maintains research data management guides on the university website. The impact of these guides is low; [I2] is not too enthusiastic about them: “I think putting lots of information on the library website doesn’t work so well, because then people have to navigate the pages, they have to understand the language, it takes time.” This is confirmed by [I7], who had consulted a guide on research data management on the institutional website and found a figure indicating what steps to take in data management, which was simply too complicated (TU Delft Library, n.d.-b).
Furthermore, in the examined case, spreading knowledge through the researcher community was deemed a powerful institutional instrument. One way to do this is through the Open Science Community Delft; a group of data management enthusiasts that researchers can approach for any data queries (Clare, 2019). Moreover, the university launched the 4TU.ResearchData Community last year, as well as working groups on FAIR code and privacy issues (Clare et al., 2021). The installation of data stewards in faculties also fits this arrangement. Likewise, the interviewed policymakers agreed that communication about research data management (developments) should happen through community and peer-to-peer contact or by educating new researchers. [I4] underlines the importance of peer behavior: “If you see that people in your research groups or research area, nationally or internationally, are doing that, then you probably will follow that behavior. So you need some good champions, people who are known in the field, for making that first move.”
Moreover, all interviewees state that appointing a Data Steward in each university faculty has proven its value extensively. The library is responsible for coordinating the network of data stewards (Ahlers et al., 2020). Data stewards are the first contact point for any data-related query for anyone in the faculty. Because of their research background, researchers perceive them more as peers than as administration [I1]. The stewards also approve of and provide feedback on data management plans, so every researcher that fills one in knows of the possibility to ask them questions [I1, I3]. The interviewed data steward [I3] indicated that more than half of the researchers approach him because they need approval on a document. He said: “The fun thing is that despite being formal things that they have to do, I get rather positive feedback after the meetings that we have once we’re done working with the DMP. Usually, people say ‘oh, well that was actually helpful.’” All interviewees highly appreciate the informal nature of the contact with data stewards. Nonetheless, senior researchers are used to the availability of formal support services and tend to go for those, as they operate more independent than, for example, PhD-students [I3].
Finally, for institutional instruments to achieve their value, researchers must be aware of their presence. Data stewards as the primary data management contact points for researchers can point researchers to other support instruments [I1, I4]. In addition, several educational instruments could be used to raise participants’ awareness about arrangements. Leaders of large research groups following data management courses can spread knowledge of arrangements and good practices among their peers. Moreover, [I4] notes that awareness of specific arrangements should be raised at tactical moments in which the researcher may need them, for example, when a new employee or research project starts [I4].
In the category of
Finally, in the category of
Discussion
Our study suggests that combining infrastructural and institutional instruments in useful, contextualized arrangements can enhance their effectiveness. The interviews with, firstly, the researchers, and secondly, the policymakers and support staff made clear that researchers encounter different challenges in different parts of the research data management process. An important notion is that mitigating only a subset of these barriers will not suffice, as each of these barriers—such as lacking financial means, lacking knowledge on how data sharing or reuse, or not knowing which infrastructure to use—have the ability to block the data sharing or reuse in its entirety. Relatedly, applying the instruments complementarily increases their effectiveness. For example, appointing faculty data stewards will help less knowledgeable researchers to comply with formal data sharing policies. Similarly, educating researchers on how to share or reuse data provides a window for informing them about other institutional and infrastructural instruments available to them, so that they know where to look in which situation. Institutions and infrastructure providers should therefore maintain a broad perspective on the entire research data management process and combine different instruments to increase their individual effectiveness. In sum, the findings emphasize that instruments should be combined to form arrangements that tackle multiple data sharing and reuse challenges, on both an institutional and infrastructural level. Studying or implementing individual instruments insufficiently stimulates data sharing and reuse, as the experienced difficulties are intertwined and span a wide spectrum. Therefore, we recommend both practitioners and scholars to maintain a broader and overarching perspective, rather than focus efforts on one or a limited number of disconnected instruments. In interpreting this study’s findings, the reader should consider various contextual aspects that influence open research data sharing and reuse in our specific case study. First, the examined university operates in certain research disciplines and one of its key objectives is to create impact for a better society (TU Delft, n.d.-c, 2018). Because research at the TU Delft focuses on technical-scientific solutions to societal problems (TU Delft, n.d.-a, n.d.-b), the scientific knowledge developed can, indeed, easily be deployed for societal gain. Publishing new-found knowledge and corresponding research data is thus part of fulfilling this mission. In other words: the research disciplines in which the TU Delft operates, could be of more open nature than other disciplines, such as genomics (Piwowar and Vision, 2013), genetics and life sciences (Campbell and Bendavid, 2003), and astronomy (Wallis et al., 2013; Zuiderwijk and Spiers, 2019). The university acknowledges that some disciplines (e.g. “microscopy data, material science, the life sciences, hydrology”) have more momentum and stronger disciplinary communities discussing data sharing than others (Teperek et al., 2019).
Another crucial contextual aspect is that the TU Delft has already made significant progress in the field of open science and open research data in the past years (see section “Case description: Research data sharing and reuse at Delft University of Technology”). Generally speaking, the research data management skills of its researchers are thus likely to be better developed than those of researchers in less experienced universities. Thus, researchers of the TU Delft need different support arrangements than researchers at institutions less familiar with open data, as changing research practices call for tailored support services (Cooper et al., 2019). For example, researchers that are only just getting into research data management are more likely to share a series of frequently occurring questions; they could be better off with generic educational arrangements to first increase their general data management skills.
Furthermore, the TU Delft is located in the Netherlands and thus affected by the Dutch culture. The Dutch culture is strongly feminine and values inclusivity, solidarity and consensus, rather than competition and success (Hofstede Insights, 2021). Researchers sharing their data to facilitate research by others might thus well be a result of Dutch culture. The Netherlands also score relatively high on the scale of long-term orientation (Hofstede Insights, 2021), which results in a willingness to invest resources for dealing with future challenges. Investing in institutional and infrastructural arrangements, and consequently the actual sharing and reuse of research data, can be considered a necessity on the long term given benefits such as reducing the duplication of research efforts, and increasing the cost-effectiveness and democratization of research. On the other hand, the Netherlands scores relatively high on the scale of individualism. Sharing data for the benefit of others seems out of line with this characteristic. However, data sharing and reuse also benefits the sharer (see section). It could be that researchers in the Netherlands are more strongly motivated by arrangements with a tangible benefit for themselves.
Finally, we note that open science has long been on the Dutch political agenda. In 2013, the Dutch government took steps to accelerate the shift to open access publishing of articles, by bringing stakeholders together in both a national and international context (Dekker, 2013). The Netherlands further pushed for open science during the Dutch presidency of the European Union in 2016 (Enserink, 2016), hosting a conference that resulted in the “Amsterdam Call for Action on Open Science” (NLU, 2016). This document contains concrete actions to stimulate open access to publications and sharing of research data. In 2017, the National Plan Open Science was presented, wherein relevant stakeholders signed a “Declaration on Open Science” and constituted the National Platform Open Science (NLU, 2016). In this same context, a report on the Dutch data landscape was published in 2020, proposing actions to optimize sharing and reusing of research data (de Vries et al., 2020). These national policies, plans, and ambitions could explain the progress that TU Delft has made in the field of open science, resulting in different institutional and infrastructural arrangements compared to universities in other countries.
Conclusion
This research aimed to investigate which combination of institutional and infrastructural arrangements positively impact research data sharing and reuse. Using a case study approach, we found that the institutional arrangements offered should at least include financial and administrative instruments (e.g. fulfilling formal requirements, such as funder or institutional policies). Moreover, institutions should strive for disciplinary standardization of policies and data management plans, to prevent hindering collaborations outside the university. Furthermore, our interviewees deemed changing the mindset of researchers fundamental: researchers should become aware of the benefits of sharing data. We found that universities recently starting with data sharing encouragement are best off installing non-policy-related infrastructural and institutional arrangements before creating a policy. Finally, implementing legal instruments (e.g. handling licenses and privacy issues) and operational instruments (e.g. increasing data management skills and helping in identifying fitting infrastructures) are considered to positively impact research data sharing and reuse; these instruments can be implemented on both an infrastructural and institutional level. The interviewees lauded that data stewards function as an approachable one-stop-shop for support in all named support areas.
This study contributes to the library, information science and open science literature by providing insight into how the instruments recommended by the literature should be adapted and applied to function properly in the context of a specific case. To the best of our knowledge, our study is the first to show how infrastructural and institutional arrangements for data sharing and reuse can be combined to increase their effectiveness. Moreover, this study revealed the importance of timing; researchers must be made aware of the existing infrastructural and institutional arrangements at the moments when they most likely need them. Using our framework of infrastructural and institutional instruments discussed in the literature and applied in our case study, other scholars can examine the effectiveness of the identified infrastructural and institutional instruments in other contexts and derive new insights on contextualization. As a societal and practical contribution, open data policymakers, universities, and open data infrastructure providers can use our findings to stimulate data sharing and reuse in practice, adapted to the contextual situation.
This study focused on a single case and, besides several other information sources, it involved seven interviews with staff, particularly from the university library and a single university faculty. The findings may thus not necessarily reflect the situation of other faculties, institutions, and infrastructures. In addition, the authors of this paper work for the same university as the interviewees. We strived to avoid bias and maintain academic objectivity and criticism in our reporting and analysis by analyzing the data with multiple persons, by involving interviewees with different roles (i.e. policy makers, data managers, and researchers), by letting research participants review our results (including transcript reviews), by verifying the interview findings with multiple other data sources (e.g. policy documents), and by checking for alternative explanations of various findings. Furthermore, one of the authors presented the study’s findings in a keynote of an academic conference (ICTeSSH 2020) and collected feedback from peers.
We recommend future research to conduct case studies at other faculties, universities, and research data infrastructure providers—thus case studies of other contexts. This would further increase knowledge of which institutional and infrastructural arrangements work best in which contexts. A valuable method for such arrangement development would be iterative prototyping and hands-on workshops with research data management policymakers, support staff, and researchers with both considerable and limited experience in research data sharing. This multi-actor approach would take all relevant perspectives into account and further stimulate open research data sharing and reuse at an institutional and infrastructural level.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.