
Abstract
An inherent feature of any choice is the set size from which that choice is made (i.e., the number of available options in a choice set). Choice set size impacts the likelihood of landing on a more preferred option: Larger sets are more likely to contain an option matching one’s preferences. Nevertheless, in six preregistered experiments with 10,092 U.S. adults, we demonstrated that people consistently underestimated the effect of set size when predicting others’ liking for a chosen option. We propose this effect arises because, although people recognize that set size predicts liking of a chosen option, they typically fail to attend to it when considering others’ choices. Accordingly, this effect was attenuated when attention was drawn to set size, specifically (a) when participants considered multiple set sizes simultaneously, (b) when the decision process was framed as ranking rather than choosing, or (c) when participants were prompted to recall set size before predicting others’ preferences.
People often try to predict others’ preferences by observing choices. Gift givers turn to recipients’ past choices as valuable clues to what they might enjoy most (Galak et al., 2016). Retailers study customers’ purchase patterns to understand consumer demand. Streaming services analyze users’ viewing and listening histories to inform recommendations.
Although past choices provide a reasonable starting point for understanding others’ preferences, research suggests relying on past choices often leads to systematic mispredictions of others’ preferences (Barasz & Kim, 2022). In particular, past findings point to a tendency to overattribute others’ choice outcomes to inherent preferences and overextrapolate from observed choices. People infer deeper motives from others’ chosen options (e.g., associating voting for Trump with heightened concerns over immigration; Barasz et al., 2019) and overestimate how much others dislike alternatives that differ from the chosen options (e.g., assuming someone who chooses a lake vacation would dislike a city vacation; Barasz et al., 2016). What is more, even experts are not immune to these misjudgments (Hoch, 1988).
The fact that people overinfer from choice outcomes suggests they might not draw appropriate inferences from the choice context. In fact, past work in social psychology provides extensive evidence that people tend to draw dispositional inferences from observed behaviors while underestimating situational factors, a fundamental tendency referred to as the “correspondence bias” (Jones & Harris, 1967; Ross, 1977). In a classic study conducted by Jones and Harris (1967), participants inferred strong pro- or anti-Castro attitudes from student essays, even when they learned the essayists were assigned those stances. In choice perception, as in attitude perception, people may focus only on what others choose rather than the context in which the choice was made. However, if people primarily attribute others’ behaviors to innate tendencies, they may believe that choosing an option reflects one’s inherent preferences without considering how the context might have shaped the choice.
Building on the idea that people draw dispositional inferences from others’ behaviors, we theorized that, in choice perception, people focus on choice outcomes rather than draw information from choice contexts. In particular, we examined a novel contextual factor that may be overlooked when predicting others’ preferences on the basis of their choices: choice set size, or the number of options available in the choice set. Logically, expanding a choice set generally increases the likelihood of selecting a more preferred option (Rieskamp et al., 2006; Savage, 1954). For instance, one’s favorite ice cream flavor is more likely to be included in a larger (vs. smaller) array of flavors. Thus, liking for a chosen option should be higher when it emerges from a larger set. 1 People need not use set size to infer anything about their own preferences; the size of the choice set is largely incidental to evaluations of one’s own preferences. Rather, people are more likely to rate their chosen option from a larger array as more well liked because a larger set increases the chances of a preference match. 2
In this research, however, we predicted that when observing others’ choices, people would overextrapolate from the observed choice and fail to incorporate set size in forecasting the other person’s liking. That is, observers may fail to recognize that a large number of alternatives should convey a stronger preference for the final selection. This failure of perception may lead observers to evaluate others’ liking for a particular chosen option as roughly similar regardless of whether the choice came from a larger or smaller set.
Although our proposal is broadly related to the correspondence bias, it is worth noting that the situational constraint examined in most social-perception contexts (e.g., being assigned to write a pro-Castro essay) is completely external to the behavior. In choice contexts, however, the number of available options is inherent to the choice itself, meaning that observers should be familiar with the predictive value of choice set size. Thus, it is even more striking when people disregard choice set size.
Research and Transparency Statement
General disclosures
Preregistration disclosures
Study 1
Study 2
Study 3
Study 4
Study 5
Study 6
All studies
The Current Research
Six preregistered experiments (N = 10,092) documented that people underestimated the influence of choice set size when predicting others’ preferences for the chosen option, even though a larger set increases the likelihood of selecting a more preferred option for themselves. We refer to this phenomenon—specifically the interaction effect between evaluation target and choice set size—as “choice set size neglect.”
Study 1
Method
Do people accurately predict the influence of the number of options on others’ liking for their choices? Study 1 provided an initial test of this question.
Participants
Two thousand and one U.S. participants recruited on Prolific completed the study. Per our preregistered exclusions, we included only the first response for duplicate responses from the same Prolific ID or same IP address (six exclusions) and excluded participants who failed the attention check (two exclusions). Our final sample included 1,993 participants with an average age of 35.69 years (SD = 12.81); 932 reported their gender as female (46.76%), 1,030 as male (51.68%), and 24 as gender not listed (1.20%). Seven participants preferred not to disclose their gender (0.35%).
Procedure
Participants were randomly assigned to one of four conditions in a 2 (target: self or other) × 2 (choice set size: six options or two options) between-subjects design. All participants read a hypothetical scenario about choosing a side dish in a restaurant.
The restaurant offered either six or two side dish options. In the six-options condition, the restaurant offered a choice among spring mix salad, fresh fruit cup, roasted snap peas, mac and cheese, seasoned fries, and onion rings (the first three were healthy options and the last three were unhealthy options). In the two-options condition, participants chose between one healthy option and one unhealthy option randomly selected from the set of six options.
In the self condition, participants imagined that they were at a restaurant and were asked to choose a side dish from the available options. On the next page, they rated their liking for the chosen option—“How much do you like [name of the chosen option]?”—on a scale from 1 (not at all) to 7 (very much). In the other condition, participants read that Person A was at a restaurant and chose an option from the (either six or two) options offered by the restaurant. In this study, the proportion of each side dish chosen by Person A was determined by the actual choice share in a pilot study. On the next page, participants predicted Person A’s liking for the chosen option—“How much do you think Person A likes [name of the chosen option]?”—on the same scale. After completing this dependent measure, participants also completed several exploratory measures (described in full in Supplement 2).
Results
We conducted an ordinary least squares (OLS) regression on target (contrast-coded), choice set size (contrast-coded), and their interaction, including fixed effects for whether a healthy or unhealthy option was chosen. Figure 1 presents the results.
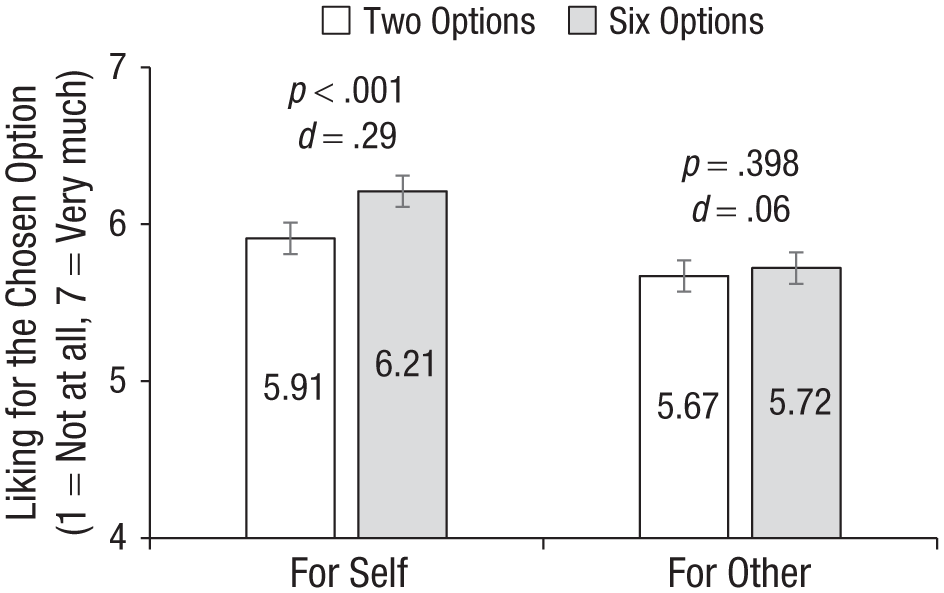
Study 1 results. Error bars represent 95% confidence intervals.
A main effect of choice set size revealed that participants reported and predicted greater liking for the chosen option when there were six side dish options rather than two options (b = 0.17, SE = 0.05, p < .001). Importantly, this was qualified by a significant interaction between target and choice set size (b = −0.24, SE = 0.09, p = .009, η2 = .003) such that choice set size influenced only participants’ own liking for the chosen option.
Specifically, participants choosing a dish for themselves reported liking the chosen option significantly more when there were six options (M = 6.21, SD = 0.93) than when there were two options (M = 5.91, SD = 1.12), b = 0.29, SE = 0.06, p < .001, d = 0.29, 95% confidence interval (CI) = [0.16, 0.41]. This difference was eliminated among participants predicting others’ liking (Msix options = 5.72, SD = 1.04; Mtwo options = 5.67, SD = 1.02), b = 0.05, SE = 0.06, p = .398, d = 0.06, 95% CI = [−0.07, 0.18].
That is, even though the availability of a more preferred side dish was more likely when the restaurant offered more options, such that participants would typically rate the chosen option more highly when more options were present (as reflected in the self condition), participants did not predict this effect for others’ choices. For robustness, we also conducted the same regression including fixed effects for the specific side dish option chosen. This analysis yielded results with the same significance level as our preregistered analysis (see Supplement 3).
Study 2
Method
Study 1 found that although a larger number of available options (six vs. two options) increased the likelihood of people finding a more preferred selection, they did not seem to intuit how choice set size predicted others’ liking. Study 2 investigated whether this phenomenon extended to a wider range of choice set sizes (two, four, six, and eight options).
Participants
Three thousand two hundred and seven U.S. participants recruited on Prolific completed the study across two waves of data collection. We initially preregistered to collect data from 1,600 participants and found the sample was underpowered for the interaction of interest. Therefore, we created a new preregistration to collect data from another 1,600 participants; we report the aggregate results below per our preregistration for the second wave. We report analyses on the initial preregistered sample size in Supplement 3. Following our preregistered exclusions, we included only the first response for duplicate responses from the same Prolific ID or same IP address (50 exclusions) and excluded participants who failed the attention check (nine exclusions). The exclusions left us with a final sample of 3,148 participants with an average age of 40.67 years (SD = 13.37); 1,534 reported their gender as female (48.73%), 1,559 as male (49.52%), and 42 as gender not listed (1.33%). Thirteen participants preferred not to disclose their gender (0.41%).
Procedure
Participants were randomly assigned to one of eight conditions in a 2 (target: self or other) × 4 (choice set size: two, four, six, or eight options) between-subjects design. Study 2 used a procedure similar to that in Study 1 with four differences. First, we introduced two new choice set size conditions in which the restaurant offered four or eight side dish options. Importantly, in all conditions with fewer than eight options (i.e., two, four, or six options), the available options were randomly selected from the available choices in the eight-options condition. Second, the eight options in Study 2 were all healthy side dishes: spring mix salad, fresh fruit cup, roasted snap peas, quinoa salad, sauteed brussels sprouts, roasted carrots and fennel, mashed cauliflower, and roasted sweet potato wedges. Third, instead of rating liking on a scale from 1 to 7, participants completed the dependent measure on a scale from 0 to 100 (0 = not at all, 100 = very much). Fourth, in the other condition, instead of referring to the evaluation target as Person A, we used a gender-neutral name Taylor. Taylor’s choice was randomly selected from the available options presented in the scenario.
Results
We conducted an OLS regression predicting liking on target (contrast-coded), choice set size (contrast-coded), and their interaction. We also included fixed effects for which side dish was chosen. Figure 2 presents the results. We found a main effect of choice set size such that, on average, both reported and predicted liking increased with a larger number of available options (b = 2.02, SE = 0.30, p < .001, η2 = .014). Importantly, the main effect was qualified by a significant interaction between target and choice set size (b = 2.27, SE = 0.60, p < .001, η2 = .005) such that choice set size influenced liking to a larger extent when participants reported their own liking (b = 3.02, SE = 0.47, p < .001, η2 = .025) than when they predicted Taylor’s liking (b = 0.85, SE = 0.37, p = .022, η2 = .003; for completeness, we examine each pairwise comparison between choice set size conditions, see Supplement 3).
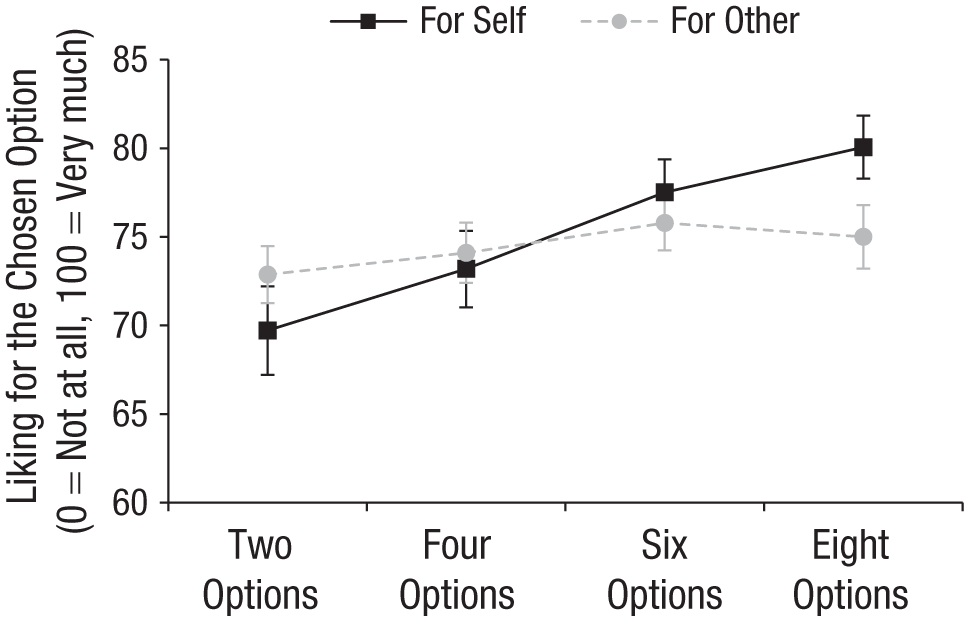
Study 2 results. Error bars represent 95% confidence intervals.
Study 2 found that although expanding the choice set increased the likelihood of having a more preferred option and thus positively predicted participants’ own liking of their chosen option, it had a much smaller impact on predictions of others’ liking. This effect was not unique to the comparison between two and six options but rather extended to set sizes of four and eight options as well. In subsequent studies, to simplify the design and to ensure sufficient statistical power for examining interaction effects, we limited our choice set size conditions to two versus six options.
Study 3
Method
We theorize that when evaluating others’ choices, people focus more on the final selection and less on contextual factors, even a factor as integral to decision-making as choice set size. The theorized process can arise in one of two possible ways. One possibility is that people do not recognize how choice set size should affect one’s choice in the first place. This account should predict that observers will still have trouble making inferences about others’ preferences from different choice sets regardless of how salient the choice set size becomes.
Another possibility is that people can intuit how choice set size influences the choice process but simply fail to consider it when observing others’ choices in isolation. This account predicts that when attention is drawn to choice set size, people become more sensitive to this information and thus are more likely to take it into account when predicting others’ preferences.
Study 3 aimed to tease apart these two possibilities by manipulating whether choice set size was presented in a within-subjects manner, which prompted a joint evaluation mode and made choice set size salient, or in a between-subjects manner, which, as in previous studies, prompted a separate evaluation mode.
Participants
Six hundred and two U.S. participants recruited on Prolific completed the study. Following our preregistered exclusions, we included only the first response for duplicate responses from the same Prolific ID or same IP address (five exclusions) and excluded participants who failed the attention check (10 exclusions). Our final sample included 587 participants with an average age of 38.24 years (SD = 11.52); 292 reported their gender as female (49.74%), 294 as male (50.09%), and one as gender not listed (0.17%).
Procedure
Participants were randomly assigned to one of three between-subjects conditions: separate evaluation (two options) versus separate evaluation (six options) versus joint evaluation (two and six options). Participants read a side dish scenario similar to that in Studies 1 and 2. The separate evaluation conditions closely mirrored the design in previous studies: participants read about a person named Avery who was dining at a restaurant. Avery ordered their main dish and was given a choice set of six side dish options (same options as in Study 2) or two side dishes (randomly selected from the six options).
In the joint evaluation condition, participants read about two people, Avery and Blake, who were dining at the same restaurant. Both of them ordered their main course and needed to choose a side dish. One of them was given a choice set of six side dishes (same options as in the separate evaluation conditions), and the other was given a choice set of two side dishes (randomly selected from the six options). We counterbalanced whether participants first read about the person having a larger or smaller choice set. Importantly, both Avery and Blake chose the same side dish.
To increase the realism of the scenario and to avoid participants making discrepant inferences based on choice set sizes, we provided a brief explanation for the choice set size in all conditions that was randomly selected from a set of three explanations for the purpose of stimulus sampling: (1) The person ordered a sandwich (vs. a lunch plate) that came with a set of two (vs. six) side dish options, (2) the person came for lunch (vs. for dinner) and the menu contained two (vs. six) side dish options, and (3) the person came on a weekday (vs. on the weekend) and was offered two (vs. six) side dish options. As described in the Results section below, we controlled for the explanation as a fixed effect in our analysis.
Participants indicated how much they thought the target person liked their chosen side dish by answering the question “How much do you think Avery likes [the chosen option]?” on a scale from 1 (not at all) to 7 (very much). For the joint evaluation condition, participants were also asked to answer the question “How much do you think Blake likes [the chosen option]?” on the same scale.
Results
Our goal was to examine whether the effect of choice set size (two vs. six options) on predicted liking differed between joint evaluation mode (i.e., between-subjects design) and separate evaluation mode (i.e., within-subjects design). Each participant in the joint evaluation condition contributed two rows to the dataset: one for each choice set size. As preregistered, we ran a mixed linear effects model on predicted liking with fixed effects for the evaluation mode, choice set size, and their interaction, including a fixed effect for the reason for choice set size and a random intercept for participant ID.
Figure 3 presents the results. We found a significant interaction between choice set size and evaluation mode (b = 0.93, SE = 0.12, p < .001) such that the difference in predicted liking between choice set sizes was significantly attenuated in separate evaluation compared to joint evaluation. In particular, when participants read about both Avery and Blake in joint evaluation, they predicted that the person choosing from a set of six options would have significantly greater liking (M = 6.03, SD = 1.17) than the person choosing the identical option from a set of two options (M = 4.81, SD = 1.39), b = 1.22, SE = 0.11, p < .001, d = 0.95, 95% CI = [0.74, 1.16]. When participants only read about Avery in separate evaluation, they also correctly intuited that Avery would have a greater liking when choosing from a set of six options (M = 5.69, SD = 1.04) than choosing from a set of two options (M = 5.42, SD = 1.09), b = 0.28, SE = 0.11, p = .010, d = 0.26, 95% CI = [0.12, 0.40], but this difference was significantly attenuated compared to the difference observed in joint evaluation. In other words, when the difference in choice set sizes was brought to the forefront in a within-subjects design (and thus in a joint evaluation mode), people more strongly intuited the influence of choice set size on others’ liking.
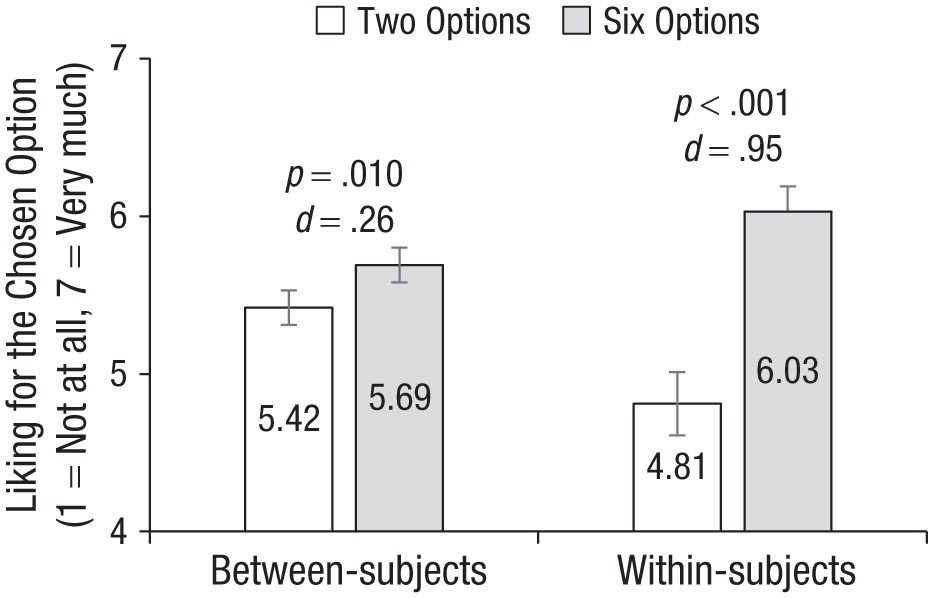
Study 3 results. Error bars represent 95% confidence intervals. P values for each pairwise comparison come from ordinary least squares (OLS) regressions, including a fixed effect for the reason for choice set size and clustering standard errors by participant.
Study 4
Method
Study 3 found that in a within-subjects design, people sensibly inferred the relationship between choice set size and choosers’ preferences. When considering others’ choices in isolation, however, we proposed that people would tend to overly focus on the chosen option and would not be sufficiently sensitive to choice set size as an important situational variable. By this account, prompting people to attend to choice set size should mitigate the tendency. We tested this prediction in two studies. Study 4 provided an initial test by reframing the decision process as ranking, thus making the number of forgone options—and subsequently, the choice set size—more salient to observers because they could see how choosers explicitly evaluated those forgone options. We predicted that ranking choices would emphasize to observers that an option chosen from a larger set should be liked more, given that there were a greater number of forgone options from these sets.
Participants
One thousand six hundred and two U.S. participants recruited on Prolific completed the study. Following our preregistered exclusions, we included only the first response for duplicate responses from the same Prolific ID or same IP address (nine exclusions) and excluded participants who failed the attention check (15 exclusions). Our final sample included 1,578 participants with an average age of 36.55 years (SD = 13.01); 772 reported their gender as female (48.92%), 774 as male (49.05%), and 26 as gender not listed (1.65%). Six participants preferred not to disclose their gender (0.38%).
Procedure
Participants were randomly assigned to one of four conditions in a 2 (choice set size: six options or two options) × 2 (decision frame: choose or rank) between-subjects design. Because this study focused on whether the process of ranking would mitigate prediction errors in others’ preferences, all participants considered another person’s preference. Participants read two scenarios about other people’s decisions in randomized order. One scenario described a person named Taylor’s choice of side dish, and the other described a person named Jordan’s choice of political candidates. Both scenarios contained a set of either two or six options. We manipulated choice set size in the same way as in previous studies.
We additionally manipulated the framing of the other person’s decision. Figure 4 presents an example in the six-options condition from the voting scenario. In the choose-frame condition (Fig. 4, left), the decision was framed in a similar way as in previous studies. Specifically, participants read that the person chooses one option, with the chosen option highlighted in a table listing all possible options. In the rank-frame condition (Fig. 4, right), participants read that the person “ranks the options and ranks [the chosen option] as #1.” They saw the same table as in the choose-frame condition, with an additional column containing the rank information for each option. The chosen option was ranked as first, and we randomized the ranks for all other available options. After reading each scenario, participants predicted how much the other person liked the chosen option on the same scale as in Study 1 (1 = not at all, 7 = very much).
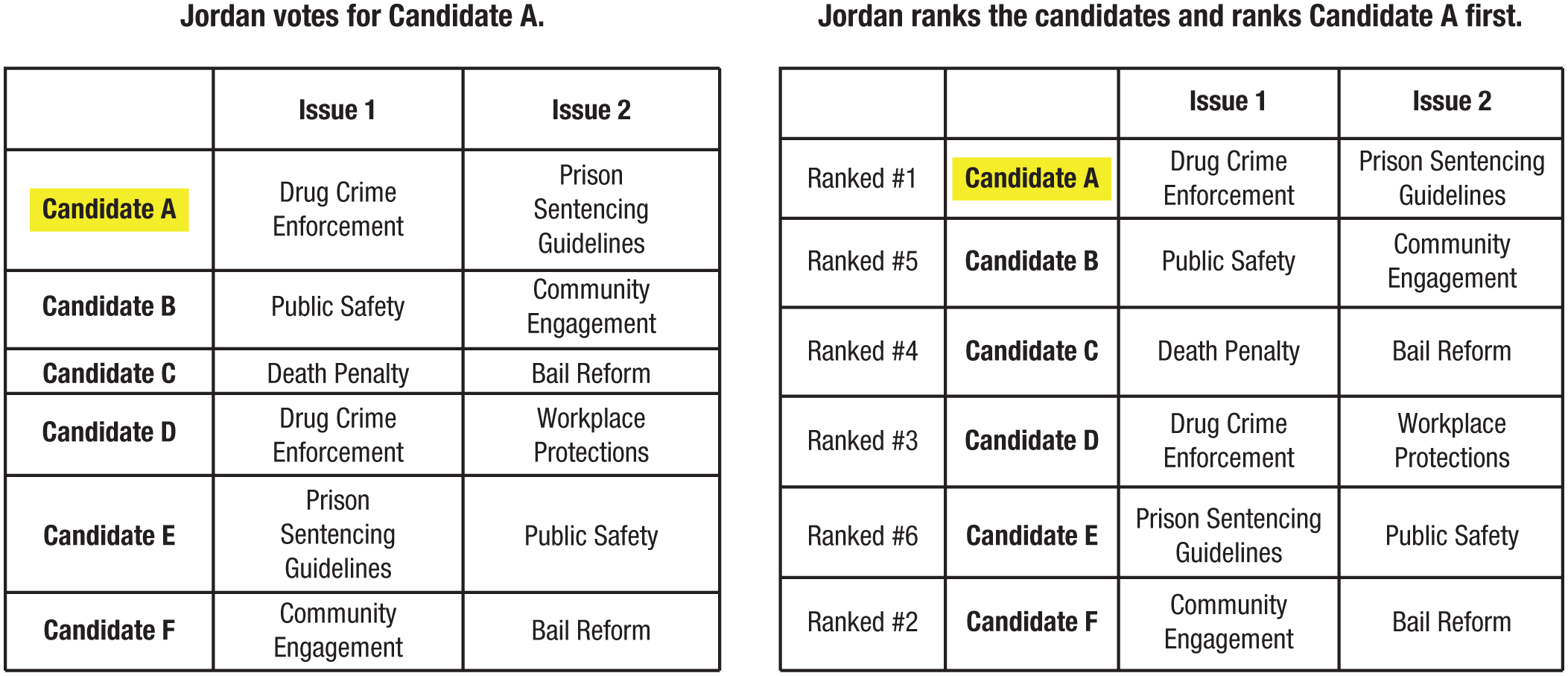
Voting-scenario stimuli in Study 4 (six-options condition). The choose-frame condition is shown on the left, and the rank-frame condition is shown on the right.
Results
As preregistered, we conducted an OLS regression on choice set size, decision frame, and their interaction, including fixed effects for scenario and clustering standard errors by participant. Figure 5 presents the results by scenario. Participants predicted greater liking for the chosen option from a choice set size of six options rather than two options (b = 0.35, SE = 0.04, p < .001). In addition, a significant main effect of the decision frame revealed that participants predicted greater liking when the decision was framed as ranking rather than (merely) choosing (b = 0.33, SE = 0.04, p < .001).
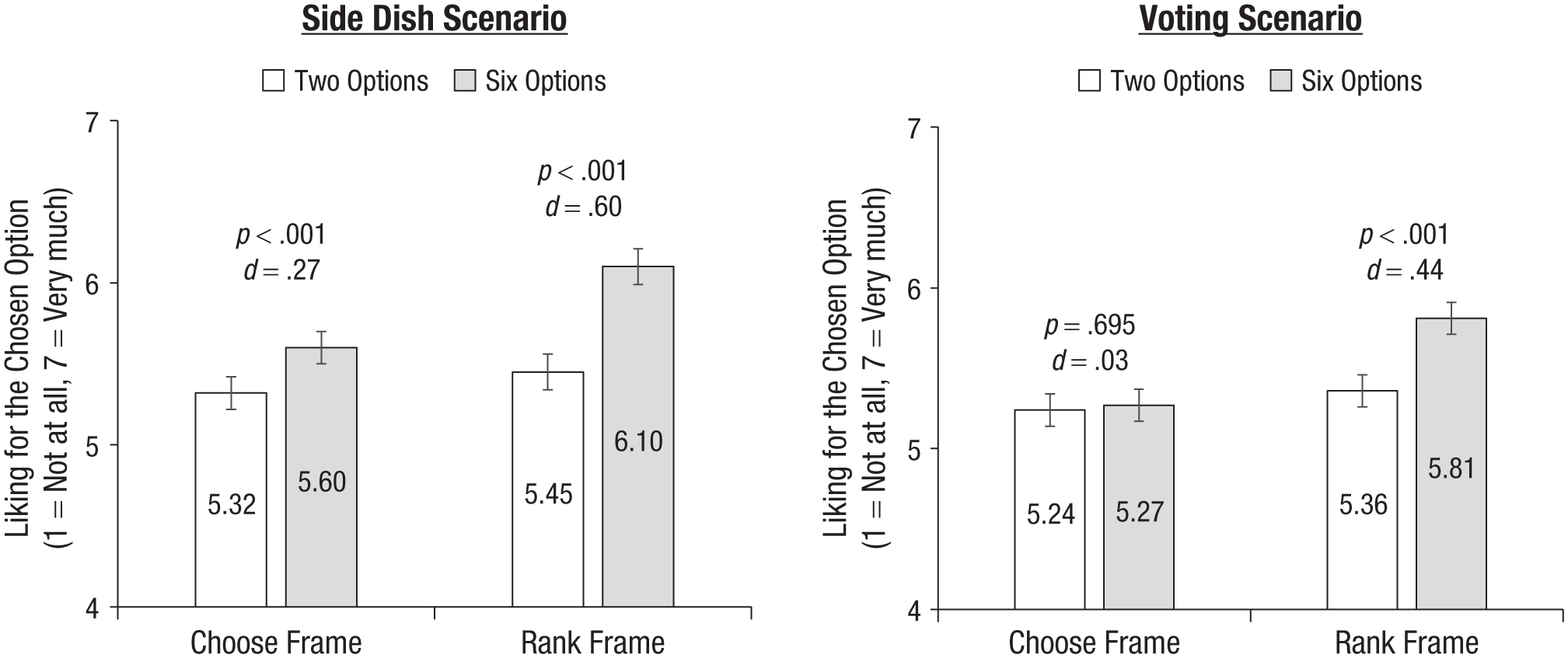
Study 4 results. Error bars represent 95% confidence intervals.
Most importantly and consistent with our prediction, these main effects were qualified by a significant interaction between choice set size and decision frame (b = 0.39, SE = 0.08, p < .001). When the other person chose their preferred option, choice set size had a small (but significant) impact on predicted liking (Msix options = 5.43, SD = 1.08; Mtwo options = 5.28, SD = 1.00), b = 0.16, SE = 0.06, p = .009, d = 0.15, 95% CI = [0.05, 0.25]. However, when the other person ranked the available options, choice set size had a greater impact on predicted liking: Participants thought this other person would like the final choice significantly more if there were six options (M = 5.96, SD = 1.08) than if there were two options (M = 5.41, SD = 1.02), b = 0.55, SE = 0.06, p < .001, d = 0.52, 95% CI = [0.42, 0.62]. As is evident from Figure 5, the differences were primarily driven by the six-options/rank-frame condition such that participants realized that the other person must like the final choice considerably more when ranked in the context of six options compared with when ranked in the context of only two options.
Study 5
Method
Study 4 found that framing the choice process as ranking increased the gap in predicted liking across choice set sizes. Although this pattern is in line with the prediction of our attention-based account, alternative explanations remain possible. For example, participants might have inferred that someone who took the time and effort to rank different options must have engaged in more deliberation and thus would like their choice more, especially when ranking from a larger choice set. To provide more definitive evidence for the attention account, Study 5 directly manipulated attention to choice set size. Specifically, we tested a set-size-salient condition in which we first reiterated the number of available options at the end of the scenario, increasing the salience of set size. We then prompted participants to recall the choice set size to ensure that they paid attention to that information. We predicted that those in this condition would be more likely to take choice set size into account when predicting others’ preferences.
Participants
One thousand two hundred and two U.S. participants recruited on Connect completed the study. Following our preregistered exclusions, we included only the first response for duplicate responses from the same Connect ID or same IP address (one exclusion) and excluded participants who failed the attention check (no exclusions). Our final sample included 1,201 participants with an average age of 41.87 years (SD = 12.74); 616 reported their gender as female (51.29%), 566 as male (47.13%), and 13 as gender not listed (1.08%). Six participants preferred not to disclose their gender (0.50%).
Procedure
Participants were randomly assigned to one of four conditions in a 2 (choice set size: six options or two options) × 2 (set size salience: yes or no) between-subjects design. Similar to Study 4, because we were chiefly interested in whether the salience of choice set size would increase sensitivity to set size in predicting others’ preferences, all participants considered another person’s preference. Participants read about Taylor’s choice of side dish as in previous studies, in which the restaurant offered a set of either two or six options. One key difference in the scenario was that, to facilitate the manipulation of set size salience (described below), we incorporated brief conversations into the scenario. For example, the waiter introduced the side dish options by stating, “We offer two [six] side dish options.” And Taylor ordered the side dish by responding, “I’d like the [name of the chosen side dish] please.” In the control (i.e., set size not salient) conditions, participants proceeded to predict Taylor’s liking for their chosen option, just like in previous studies.
In the set-size-salient conditions, we reiterated the choice set size as part of the scenario on the next page and then on the following page prompted participants to indicate the correct choice set size. In particular, at the end of the scenario, participants read the following: “After Taylor settles in with their main dish and [the chosen dish] as the side dish, a friend asks, ‘By the way, how many side dish options did they give you to choose from?’ Taylor responds, ‘There were two [six] options to choose from.’” On the next page, those in the set-size-salient conditions responded to the question “In this scenario, how many side dish options does the restaurant offer?” The choices were two, three, four, five, and six. After reading the scenario, all participants predicted how much Taylor liked the chosen option on a scale from 0 (not at all) to 100 (very much), as in Study 2.
Results
As preregistered, we conducted an OLS regression on choice set size, set size salience, and their interaction. Figure 6 presents the results. Overall, participants predicted greater liking for the chosen side dish when there were six options rather than two options available (b = 6.97, SE = 0.89, p < .001, η2 = .048). The set size salience manipulation did not significantly influence the predicted liking (b = −0.94, SE = 0.89, p = .293, η2 < .001).
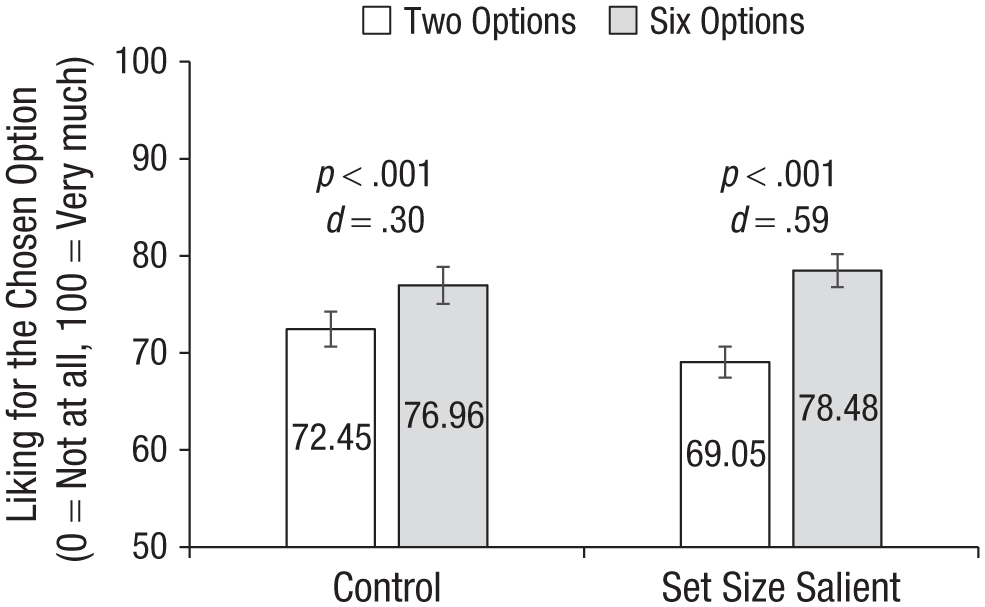
Study 5 results. Error bars represent 95% confidence intervals.
Consistent with the prediction of our attention account, we found a significant interaction between choice set size and set size salience (b = −4.92, SE = 1.79, p = .006, η2 = .006). When we brought attention to the number of available options, participants predicted significantly greater liking for the chosen option from a set of six (M = 78.48, SD = 15.03) than from a set of two (M = 69.05, SD = 16.81), b = 9.43, SE = 1.30, p < .001, d = 0.59, 95% CI = [0.43, 0.75]. This difference was significantly more muted when choice set size was not reemphasized (Msix options = 76.96, SD = 14.40; Mtwo options = 72.45, SD = 15.50), b = 4.51, SE = 1.22, p < .001, d = 0.30, 95% CI = [0.14, 0.46]. Interestingly, unlike Study 4, in which the ranking manipulation mostly increased participants’ predicted liking in the six-options condition, the set size salience manipulation moved predicted liking apart in both directions: In the two-options condition, predicted liking reduced from an average of 72.45 (SD = 15.50) at baseline to an average of 69.05 (SD = 16.81) when set size was made salient; in the six-options condition, predicted liking increased from a baseline average of 76.96 (SD = 14.40) to an average of 78.48 (SD = 15.03) when set size was made salient.
Study 6
Method
Study 6 tested whether the neglect of choice set size extended to predictions of downstream behaviors. Specifically, we examined choices to donate to charity and predictions of others’ donation behavior. We expected that individuals making their own choices would be more likely to find a more preferred charity from a larger choice set and thus donate more to the chosen charity, but those predicting others’ donations would not anticipate this difference.
Participants
One thousand five hundred and ninety-nine U.S. participants recruited on Prolific completed the study. Following our preregistered exclusions, we included only the first response for duplicate responses from the same Prolific ID or same IP address (14 exclusions). Our final sample included 1,585 participants with an average age of 38.91 years (SD = 13.37); 776 participants reported their gender as female (48.96%), 773 as male (48.77%), and 31 as gender not listed (1.96%). Five participants preferred not to disclose their gender (0.32%).
Procedure
Participants were randomly assigned to one of four conditions in a 2 (target: self or other) × 2 (choice set size: six options or two options) between-subjects design. In the self condition, participants first completed a real-effort task to earn an additional bonus of 50 cents. The task required them to alternatively press the button “a” then “b” 200 times (DellaVigna & Pope, 2018). A JavaScript interface was updated in real time to show how many “ab” combinations participants had typed so far, and participants were allowed to proceed to the next page only after they had entered 200 “ab” combinations. All participants earned a bonus of 50 cents after successfully completing the task. They then read that they could donate a portion of their bonus (0–50 cents) to a charitable organization. Depending on the choice set size condition participants were assigned to, they saw a choice from either six or two eligible charities. In the six-options condition, participants saw a list of charities, including Feeding America, Americare, Doctors Without Borders, World Wildlife, National Pediatric Cancer Foundation, and Clean Air Task Force, and indicated which charity they would want to donate to. In the two-options condition, participants chose between two charities randomly selected from the six abovementioned charities. Immediately after making the choice, participants answered the questions “How much of your 50-cent bonus would you like to donate to [name of the chosen charity]?” by entering a number from 0 to 50 into a textbox. Their donation amount to the chosen charity was our primary dependent measure.
In the other condition, participants first completed a practice typing task in which they typed “a” and “b” alternatively 50 times. After successfully completing the typing practice, they learned that other participants completed the same typing task in which they typed 200 “ab” combinations, earned a 50-cent bonus, and had the opportunity to donate part of their bonus to a chosen charity. Their task was to predict the average donation amount of participants in that previous study. Depending on the choice set size condition, participants saw either six or two eligible charities (as in the self condition) and were asked to consider those participants who chose one of the charities (randomly selected from the available charities). They predicted the donation amount by answering the question “On average, how much of their 50-cent bonus do you think these participants donated to [name of the chosen charity]?” This prediction was incentivized for accuracy such that participants could earn a bonus of 50 cents if their predictions were within 2 cents of the correct answer and a bonus of 25 cents if their predictions were within 5 cents of the correct answer.
After completing the primary measure, participants reported how much they liked the chosen charity (in the self condition) or predicted, on average, how much these other participants liked their chosen charity (in the other condition), both on the same scale as in previous studies (1 = not at all, 7 = very much).
Results
Donation amount
As preregistered, we conducted an OLS regression in which we regressed the donation amount on target, choice set size, and their interaction. Figure 7 (left) presents the results. A main effect of target revealed that the predicted donation amount (M = 18.01, SD = 12.03) was significantly greater than the actual donation amount (M = 13.64, SD = 16.95), b = 4.33, SE = 0.74, p < .001, η2 = .021. This was qualified by a significant interaction (b = 3.29, SE = 1.48, p = .026, η2 = .003) such that a larger choice set size marginally increased the actual donation amount in the self condition (Msix options = 14.82, SD = 17.67; Mtwo options = 12.60, SD = 16.24), b = 2.22, SE = 1.20, p = .064, d = 0.13, 95% CI = [−0.01, 0.27], but directionally decreased the predicted donation amount in the other condition (Msix options = 17.51, SD = 12.31; Mtwo options = 18.57, SD = 11.70), b = −1.07, SE = 0.86, p = .215, d = −0.09, 95% CI = [−0.23, 0.05]. We conducted the same analysis after log-transforming the donation amount and found consistent results (see Supplement 3). These results are in line with our previous findings on preference predictions and demonstrate that the effect also extends to people’s prediction of downstream behaviors.
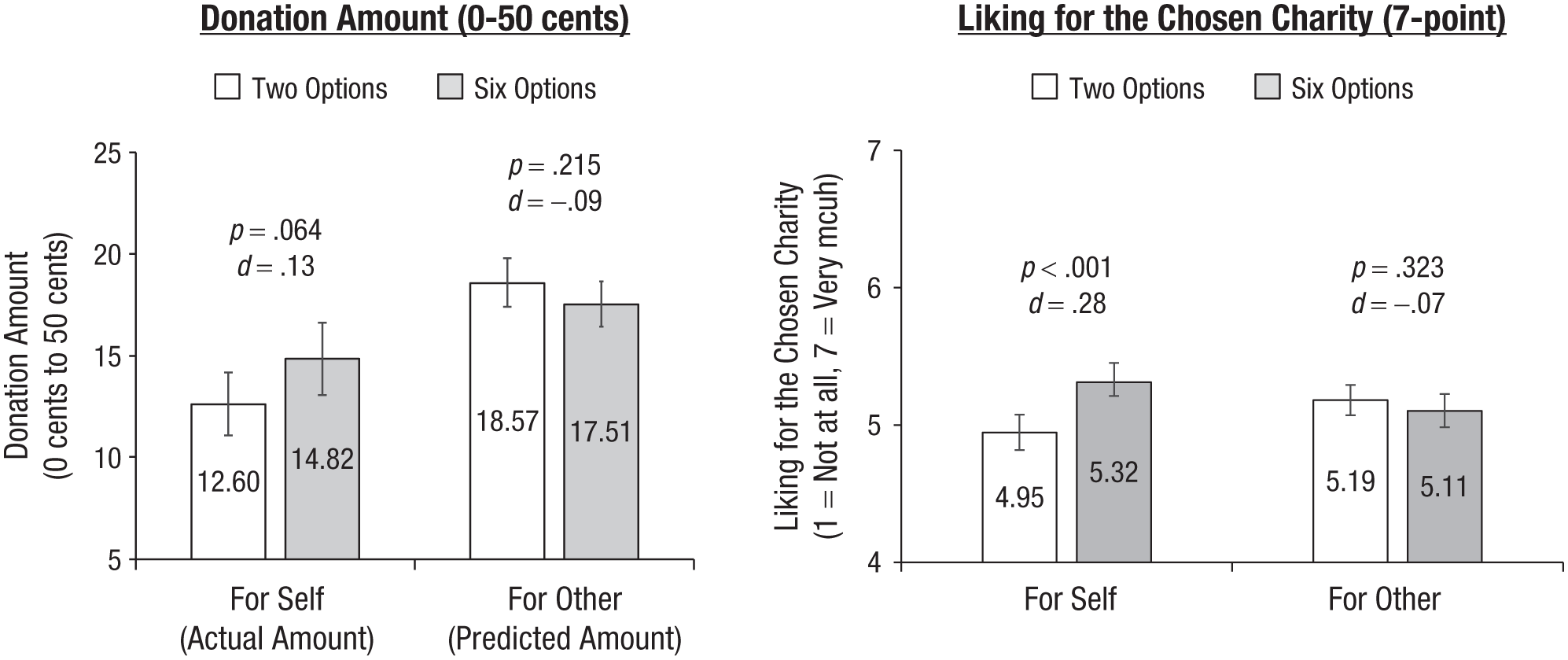
Study 6 results. The donation amount to the chosen charity is shown on the left, and the liking for the chosen charity is shown on the right. Error bars represent 95% confidence intervals.
Liking
We conducted the same OLS regression on the liking measure. Figure 7 (right) presents these results. Consistent with our prior studies, the results revealed a significant interaction between target and choice set size (b = −0.46, SE = 0.13, p < .001, η2 = .008) such that participants reported a significantly greater liking for their chosen charity from a larger choice set in the self condition (Msix options = 5.32, SD = 1.30; Mtwo options = 4.95, SD = 1.40), b = 0.38, SE = 0.10, p < .001, d = 0.28, 95% CI = [0.14, 0.42], but those in the other condition did not predict this difference (Msix options = 5.11, SD = 1.27; Mtwo options = 5.19, SD = 1.18), b = −0.09, SE = 0.09, p = .323, d = −0.07, 95% CI = [−0.21, 0.07].
Mediated moderation on donation amount
In an exploratory analysis, we examined the indirect effect from the interaction of experimental conditions to donation amount through liking. We found that liking significantly mediated the effect of the interaction between target and choice set size on donation amount—indirect effect: b = −2.22; bootstrapped 95% CI = [−3.40, −1.06]. Specifically, when participants made their own choice, having more charity options increased their liking, which in turn predicted donation amount—indirect effect through liking: b = 2.01; bootstrapped 95% CI = [0.96, 3.07]. When participants observed others’ choices, however, the number of available charities did not significantly influence predicted liking and therefore did not influence their prediction of others’ donation amount—indirect effect through liking: b = −0.36; bootstrapped 95% CI = [−1.00, 0.38].
General Discussion
Choice set size is an inherent feature of any choice. As the principle of regularity posits and as simulations (in Supplement 1) illustrate, adding available options increases the odds of selecting a well-liked option (Rieskamp et al., 2006; Savage, 1954). Although people seem aware of this when directly comparing different set sizes (Study 3), we found consistent evidence that they underestimate the influence of set size when inferring others’ liking from one-off choices. We propose this effect arises because people focus on the chosen option, infer that others largely like their choices, and do not attend sufficiently to the choice context when gauging the magnitude of others’ preference.
An important assumption of the principle of regularity and in our simulation is that individuals have largely stable preferences. However, other explanations could also account for the pattern in the self condition. For example, if choosing from a larger set is more effortful, people might rationalize that they like their chosen option more after undergoing greater effort. Although our work does not directly speak to why people report greater liking for selections from larger sets, relaxing the assumption of stable preferences does not undermine our core effect. Rather, it would change the interpretation of what people mispredict when evaluating others’ choices: Instead of (or in addition to) ignoring the statistical influence of set size, they might also overlook the psychological inferences others draw from the choice process itself. In either case, the misprediction of others’ preferences remains.
At first glance, the bias we propose may seem at odds with social projection, the tendency to expect others to make choices similar to our own (Cho & Knowles, 2013; Orhun & Urminsky, 2013; Ross et al., 1977). However, whereas social projection involves how we expect others to share our specific preferences (e.g., “I like chocolate, so I assume you will too”), we examined how people overgeneralize the robustness of others’ preferences (e.g., “I prefer chocolate from this set of flavors, but perhaps you prefer chocolate regardless of the available options”).
Our proposal that people use a simplified mental model when understanding others’ decision-making process aligns with past findings on choice perception. Just as people form impressions of others’ choices by relying on a “core representation” (Jung et al., 2020), an incorrect assumption of homogeneous preferences (Barasz et al., 2016), or a heuristic based on market prevalence (Reit & Critcher, 2020), so do they infer others’ preferences by solely focusing on the choice outcome and neglecting the choice process. Although past research and the current work highlight different factors that lead choice perception astray, they converge on the notion that people form simplified impressions of others’ choices and disregard the complexity in how choices are made.
Furthermore, our findings align with prior work regarding the correspondence bias and actor-observer asymmetry in interpersonal attributions. Observers often attribute actors’ negative behaviors to disposition while attributing their own to situational factors (Ross & Nisbett, 2011). Similarly, when making inferences about actors’ choices, observers tend to associate the choice with actors’ stable preferences, even though their own choices may be driven by the context (e.g., choice set size).
Our findings also relate to the tendency to see others’ choices as being driven by approach motivation—choosing a desired option—rather than avoidance motivation—rejecting undesired options (Miller & Nelson, 2002). If people expect others’ choices are driven more by approach motivation, they may focus excessively on the desirability of the chosen option without sufficiently considering others’ preferences for or against the rejected options. We note this account cannot fully explain our findings, such as why choice set size neglect was attenuated in a within-subjects design (Study 3). Nevertheless, the default tendency to perceive approach motivation may help to explain why people typically neglect contextual factors.
Future Directions
Although our studies asked participants to predict strangers’ preferences, people might make more accurate predictions for close friends on the basis of greater knowledge of their friends’ preferences, attenuating our effect. Similarly, future research could explore the moderating role of expertise. For example, a sommelier may be more likely to consider the wine menu’s offerings than a general manager and thus better predict customers’ wine preferences when making inventory decisions.
Our studies used relatively small sets, but in many contexts, choices can come from even larger sets. According to research on choice overload, people should be less satisfied with choices from extremely large sets (Chernev et al., 2015). Our work suggests observers might have a simplistic view of others’ decision-making process and even underestimate the burden of choice overload on others. Future research could investigate whether the current findings extend to extremely large sets (e.g., with 50 options) in which choice overload could come into play.
The effect we documented yields testable predictions across real-world contexts. For one, decision makers risk overcommitting to the observed choice, mistaking it for an innate strong preference. Over time, as decision makers repeatedly overinvest in a purportedly popular choice, the range of options offered to customers may become more entrenched and narrow than it potentially should be. As one troubling example, this effect may exacerbate polarization in a two-party electoral system: Observers perceive votes as indicating strong preference for a candidate, but with only two options, the perceived support for the chosen candidate may be overestimated. Party strategists may in turn double down on policies that would appeal to their candidates’ most ardent supporters, mistakenly assuming those policies are broadly popular, further perpetuating partisan differences.
Broadly, our findings suggest observers mistakenly believe that limited choice sets are sufficient and thus fail to appreciate the benefit of adding options. Gift givers may frequently purchase gifts similar to what recipients already own rather than exploring new options. Restaurants may stick to few offerings on the basis of positive past sales, overlooking the appeal of larger assortments. Retailers may avoid entering markets with few competitors, mistakenly assuming consumers in those markets have stable strong preferences that would be unmoved by the entry of a new competitor. When observing choices from smaller (vs. larger) sets, observers should have less confidence about the strength of others’ preferences, yet we argue the predictive power of set size will consistently be underestimated.
Conclusion
Choice set size is intrinsic to any choice and predicts how much people like their own selection. However, when observing others’ choices, people largely ignore this crucial contextual factor and make inferences as though others’ choices were mostly driven by stable preferences. These insights suggest a novel factor that can lead choice perception astray and offer a simple reminder for practitioners that what people choose from can help explain what they end up choosing.
Supplemental Material
sj-docx-1-pss-10.1177_09567976251400333 – Supplemental material for Choice Set Size Neglect in Predicting Others’ Preferences
Supplemental material, sj-docx-1-pss-10.1177_09567976251400333 for Choice Set Size Neglect in Predicting Others’ Preferences by Beidi Hu, Alice Moon and Eric VanEpps in Psychological Science
Footnotes
Acknowledgements
We thank attendees at Deborah Small’s lab meeting, Clayton Critcher, the review team for their valuable feedback, and Yvette Zaiying Yang, Ruby Chen, and Maria Rojas Londono for research assistance.
Transparency
Action Editor: Betsy Levy Paluck
Editor: Simine Vazire
Author Contributions
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.