
Abstract
Visual working memory (VWM) is limited in capacity, though memorizing meaningful objects may refine this limitation. However, meaningful and meaningless stimuli typically differ perceptually, and objects’ associations with meaning are usually already established outside the laboratory, potentially confounding experimental findings. Here, in two experiments with young adults (N = 45 and N = 20), we controlled for these influences by having observers actively learn associations of (for them) initially meaningless stimuli: Chinese characters, half of which were consistently paired with pictures of animals or everyday objects in a learning phase. This phase was preceded and followed by a (pre- and postlearning) change-detection task to assess VWM performance. The results revealed that short-term retention was enhanced after learning, particularly for meaning-associated characters, although participants did not quite reach the accuracy level attained by native Chinese observers (young adults, N = 20). These results thus provide direct experimental evidence that participants’ VWM of objects is boosted by them having acquired a long-term-memory association with meaning.
Keywords
The short-term retention of objects in the absence of continuous visual input is usually associated with visual working memory (VWM): a system that supports goal-directed behavior by buffering a limited amount of visual information across short periods of time. One widely used paradigm to investigate VWM is the change-detection task (Luck & Vogel, 1997), in which observers are asked to memorize several objects in an initial memory display. After a short retention interval, observers are presented with a probe item and are asked to indicate whether the probe has changed relative to the object shown previously in the memory display at the same location. Typically, observers succeed in memorizing three to four objects from the memory display (Cowan, 2001; Luck & Vogel, 1997). But this upper limit (as an estimate of VWM capacity) may also vary. For instance, it may be three to four for relatively simple objects such as colored squares, but it may drop to just one or two items for more complex objects like Chinese characters or irregular polygons (Alvarez & Cavanagh, 2004; Eng et al., 2005). Although similarity variations across different item categories may contribute to this capacity reduction for complex versus simple objects (Awh et al., 2007), the global regularity and complexity of the to-be-memorized items play a role as well (Chen et al., 2016, 2018), as does the presence of predictable, structured item arrangements in natural environments (Chen et al., 2021; Conci & Müller, 2014; Hollingworth & Henderson, 2000; Hu & Jacobs, 2021; Nie et al., 2017).
The predictability of to-be-memorized items may also be enhanced by presenting meaningful objects, where the meaning of an object may improve short-term retention by activating preexisting links with LTM that provide semantic or conceptual associative knowledge about the object—thus facilitating its retrievability from VWM. Consistent with this, VWM capacity is higher for upright versus inverted faces (Asp et al., 2021; Curby & Gauthier, 2007; Scolari et al., 2008). Moreover, various everyday objects (e.g., doughnuts, butterflies, chairs) can be better memorized than simple colored squares (Brady et al., 2016) or scrambled and thus meaningless (but perceptually matched) versions of these objects (Stojanoski et al., 2019; Veldsman et al., 2017). Familiarity with letter fonts (Ngiam et al., 2019) and the frequency of usage of Chinese characters (Dall et al., 2021) have also been shown to modulate VWM. Together, these findings show that observers’ familiarity with a given item can improve their ability to maintain this item in VWM, enhancing the capacity to retain even relatively complex real-world objects.
Importantly, and in addition to such familiarity-related benefits, VWM may be further improved by specific knowledge associations that observers have with individual objects. For instance, expertise about specific cars (Curby et al., 2009), Pokémon characters (Xie & Zhang, 2017), or faces of celebrities (Jackson & Raymond, 2008) can improve VWM for the respective objects. In fact, the benefits of knowledge about individual objects are demonstrable even when one controls for the perceptual input and complexity of the to-be-memorized objects (e.g., the flags of European countries; Conci et al., 2021). These findings may be taken to suggest that the representation of a given object in VWM is enhanced by the activation of specific LTM knowledge associated with this object. Thus, it appears that long-term knowledge about specific objects (e.g., a picture of Brad Pitt or Jennifer Aniston vs. an unfamiliar face) engenders VWM benefits over and above those because of general familiarity with a given object category (e.g., upright, meaningful vs. inverted or scrambled faces; Jackson & Raymond, 2008). Accordingly, acquiring more detailed meaning associations with specific objects would lead to stronger improvements in the short-term retention of these objects compared with mere familiarity with the respective stimulus class.
Statement of relevance
It is intuitively plausible that meaningful objects can be remembered better than meaningless objects. For instance, people are typically better at memorizing a picture of a cookie than that of a green square. However, previous visual working memory (VWM) studies have often confounded potential benefits accruing from preexisting (long-term) object knowledge with concurrent variations in perceptual and familiarity-related properties of the to-be-memorized stimuli. Improved short-term retention could thus be owing to increased familiarity or additional perceptual details provided with these objects. To eliminate such confounds and isolate the influence of knowledge, the current study presented observers with, for them, initially meaningless stimuli (Chinese characters), a subset of which was associated with specific meanings (animal pictures or everyday objects) during the experiment. The results revealed that acquiring a meaning association of Chinese characters with real-world objects indeed improved visual working memory (VWM), thus demonstrating that short-term retention can be boosted by associative long-term memory (LTM).
With this background, the goal of the current study was to systematically look for additional VWM gains that may be derived from specific knowledge associated with a given object beyond the influence of overall item familiarity. Importantly, we presented our observers with, to them, initially meaningless stimuli and controlled the semantic meaning they came to associate with these stimuli experimentally—thus going beyond previous studies that, by using stimuli that were meaningful before the experiment, in essence provided only indirect, correlational evidence for beneficial effects of meaning on VWM capacity. In particular, we introduced Chinese characters as to-be-memorized stimuli (Fig. 1a)—symbols that had no specific meaning to participants at the start of the experiment. Then, during the experiment, a subset of these characters was associated with specific meanings, by being paired with pictures of specific animals (Fig. 1b) or other real-world objects (Fig. 4a). Another subset of characters was presented without any meaning associations, allowing participants to become familiar with these items without acquiring any representations of meaning. Thus, comparing VWM performance across both subsets effectively controlled for participants’ general familiarity with the stimulus material, permitting us to isolate any specific benefit derived from the association of the items with specific acquired meanings.

Stimulus set used in Experiment 1. In (a), Chinese four-stroke characters are presented in the change-detection and associative-learning tasks. In (b), we show pictures of animals selected from the Bank of Standardized Stimuli (BOSS; Brodeur et al., 2014). These pictures were presented in the associative-learning task to convey arbitrary selected meanings of the Chinese characters.
Note that some previous studies already used training procedures to investigate learning-induced effects on VWM (Blalock, 2015; Chen et al., 2006; Oberauer et al., 2017; Sims et al., 2022; Zimmer et al., 2012). Typically, however, the training was merely designed to increase participants’ familiarity with a certain class of stimuli (e.g., polygons, Chinese characters, colored objects), without providing specific semantic object associations. The training-induced familiarity mostly resulted in reliable, though small, improvements in VWM performance—establishing that repeated exposure to to-be-memorized stimuli facilitates VWM. Going beyond this, in the current study, we directly compared the benefits accruing from item familiarity to those arising from the acquisition of knowledge of the objects’ specific meanings.
Experiment 1
Method
Experiment 1 consisted of a main experiment plus a control experiment. The main experiment, which comprised three parts, tested a sample of observers that were unfamiliar with the Chinese language and writing system. Part 1 consisted of a change-detection task, in which observers were asked to memorize (to them, meaningless) Chinese characters and report, after a short retention interval, whether a subsequently presented probe item was the same as or different from the stimulus presented initially at the same location (Fig. 2a).
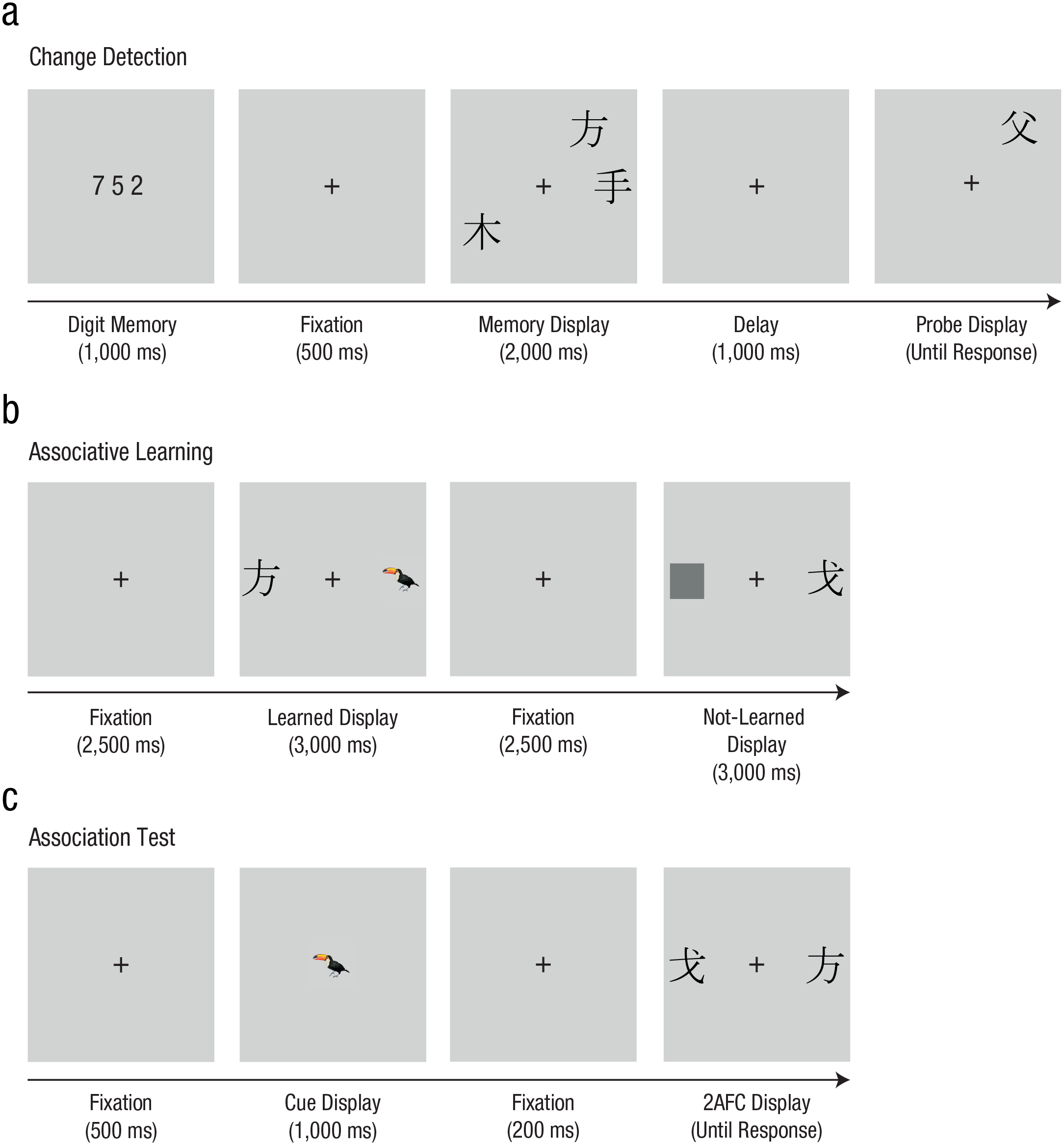
Task sequence in Experiment 1. In (a), an example of a trial in the change-detection task is illustrated. Each trial started with the presentation of three to-be-repeated digits. After a short delay, the actual memory display was presented. A short retention interval followed and then a probe item was shown, which required a change/no-change response (in the depicted example, the correct response would be “change”). Shown in (b) are example trial sequences in the associative-learning task, which presented either consistent (yet arbitrarily selected) pairings of a given Chinese character and an animal picture (learned set) or the Chinese character together with a dark-gray square (not-learned set). No overt response was required from participants during this part of the experiment, but they were simply instructed to remember the presented character–animal pairs. In (c) is shown an example trial sequence of the association test, which was administered after each learning task block. Following an initial fixation cross, a cue display with one animal picture was presented. After a short retention interval, a two-alternative forced choice (2AFC) display appeared, containing two Chinese characters. Participants were asked to indicate which of the presented stimuli (left vs. right) was paired with the cued animal (in the depicted example, the correct response would be “right”).
Part 2 then consisted of an associative-learning task, in which half of the previously shown Chinese characters were each presented together with a picture of an animal, allowing observers to associate a given character and its consistently paired, yet randomly selected, animal—thus inducing the acquisition of (arbitrary) meanings for these characters (learned set)—that is, the buildup of experimentally induced LTM knowledge structures. The other half of the previously presented characters were simply presented together with a meaningless dark-gray placeholder square, thus serving as a baseline (not-learned set).
First, all item pairs were each presented one after the other, without requiring any response. Observers were asked to either memorize the character–animal pairs or to passively view the characters presented with a placeholder (Fig. 2b). Thus, in this part of the experiment, observers were trained to learn the (fake) Chinese meaning of animals for half of the presented characters. Subsequently, a test was administered in which first an animal cue would be presented, followed by the presentation of two Chinese characters, requiring observers to make a two-alternative forced-choice (2AFC) response to indicate the character that was associated with the cued animal (Fig. 2c). Of note, the presentation of the items in the nonlearned set during training was equated in terms of overall viewing time with that in the learned set, thus providing a control for basic item familiarity.
The third part of the experiment was identical to the first: observers performed the same change-detection task as described above (Fig. 1a), except that now, after the second part, the Chinese characters on a given trial were either associated with meaning (learned set) or not (nonlearned set). This comparison allowed us to investigate whether the controlled acquisition of meaning associations would improve VWM capacity beyond the basic effect of item familiarity.
In addition to this main experiment, we performed a control experiment testing the very same change-detection task (Fig. 2a) in a second sample of observers—people who had learned Chinese as their native language. The aim was to gauge the level of performance that could be expected from observers who were highly familiar with the presented stimuli and for whom all the displayed Chinese characters would be strongly associated with meaning. After the control experiment an additional questionnaire was provided, asking the observers to provide the actual meaning of each character, in order to confirm that the Chinese observers in fact knew the meaning of the presented items.
Participants
Forty-five adults (mean age = 25.8 years; 15 male, 30 female; 41 right-handed, 4 left-handed) participated in the main experiment. None of them was able to read, write, or speak Chinese. A second sample of 20 adults whose native language was Chinese (mean age = 25.6 years; 4 male, 16 female; all right-handed) was recruited for the control experiment that consisted of only one session of the change-detection task. All participants had normal or corrected-to-normal vision and received payment of either €9/hr or course credit for their participation. Both samples, of university students, were comparable in terms of age, t(63) = 0.17, p > .80, d = 0.05, and gender distribution, t(63) = 1.08, p > .28, d = 0.29. The experimental procedure was in accordance with the Declaration of Helsinki and approved by the Ethics Committee of the Psychology Department at Ludwig-Maximilians-Universität München. All participants provided written informed consent prior to the experiment.
The sample size was determined on the basis of the effect sizes from previous comparable studies that had tested 12 to 25 participants per experiment (Brady et al., 2016; Conci et al., 2021). On this basis, our analysis revealed that a sample of 15 participants would be required to detect an effect size f of 0.35 with a power of 80% at an alpha of .05. We further increased our sample to 45 in the main experiment and 20 in the control experiment to ensure sufficient statistical power to detect a difference between meaningless and meaningful stimuli and to also be able to demonstrate an effect of the learning manipulation in the main experiment (which might be expected to particularly benefit from a larger sample; e.g., Blalock, 2015).
Apparatus and stimuli
Stimulus presentation and data collection was controlled by a Windows PC running MATLAB and Psychophysics toolbox extensions (Brainard, 1997; Pelli, 1997). All stimuli were presented on a gray background (178 cd/m2) on a 24-in. LCD monitor (1920 × 1080 pixels in screen resolution, 60-Hz refresh rate) at a viewing distance of approximately 57 cm. The experimental stimuli consisted of 16 Chinese characters of intermediate complexity, which were drawn in black ink (0.2 cd/m2) from four strokes each, thus being roughly matched in terms of their perceptual details (Fig. 1a); there were also 16 colored pictures of well-known animals (elephant, wolf, polar bear, tortoise, cow, fish, red fox, toucan, ladybird, zebra, rhinoceros, tiger, giraffe, kangaroo, sheep and scorpion; see Fig. 1b), selected from the Bank of Standardized Stimuli (BOSS; Brodeur et al., 2014). These pictures were presented in the associative-learning phase of the main experiment, in which a given Chinese character would either be consistently paired with one of the animal pictures or with a (noninformative) dark-gray square (8.3 cd/m2). The pairing of a character with an animal picture was chosen randomly per observer, in order to minimize any perceptual differences that might occur for a given item pair. We restricted the induced meaning associations to be of a single, arbitrarily chosen category (i.e., animals) to ensure that the selected sets of objects (and characters) were all roughly comparable.
Procedure
In the main experiment, participants first completed one session of the change-detection task, followed by the associative-learning task, after which they performed a second session of the change-detection task (see Fig. 2).
In the initial change-detection task, a given trial started with the presentation of a black fixation cross (500 ms), followed by a display that presented three black digits (in 24-pt. Arial font) for 1,000 ms, which participants were asked to continuously repeat aloud throughout the trial in order to prevent verbalization strategies (see Brady et al., 2016, Conci et al., 2021, and Jackson & Raymond, 2008, for a comparable procedure). Performance of this digit-repetition task was monitored by the experimenter throughout the experimental session. After another 500-ms blank display with the fixation cross, the memory display was presented for 2,000 ms. This rather long exposure duration was chosen because VWM performance for meaningful objects may be particularly enhanced by extended encoding times (Brady et al., 2016). For each memory display, either three or six distinct Chinese characters (each subtended 1.3° × 1.3° of visual angle) were presented randomly at eight possible equidistant locations on a virtual circle with a radius of 8.4° of visual angle. Before the start of the experiment, all 16 Chinese characters (see Fig. 1a) were randomly assigned to one of two stimulus sets—the learned and not-learned sets. The items in the learned set would, in the second part of the experiment, be paired with a meaningful image of an animal, whereas the items in the not-learned set would be presented together with a meaningless dark-gray square (further details follow later). A given trial in the change-detection task would always present only stimuli from one predefined set. The memory display was followed by a retention interval, showing a blank screen with a fixation cross for 1,000 ms.
Next, a probe stimulus was presented. On no-change trials, this probe would present the same item that had previously been shown at the same location in the memory display; on change trials, by contrast, the probe depicted a new, randomly selected item from the same stimulus set as in the memory display (but which had not been presented in the current trial). This probe display remained visible until a response was made. Participants responded with the left and right mouse key, respectively, to indicate whether the probe item was the same or different from the item at the same location in the previous memory display (see Fig. 2a; in the example, the correct response would be “different”). Observers were asked to respond as accurately as possible; there was no stress on response speed. Trials were separated from each other by an interval of 1,000 ms.
After completion of the first session of the change-detection task, the associative-learning task was performed. In each of the six blocks of associative learning, an initial learning part was followed by a test part. During the learning part, observers were presented with two items, each approximately 2.8° × 2.8° of visual angle in size, that were placed 4.2° to the left and right, respectively, of the central fixation cross. One item presented one of the 16 Chinese characters that had previously been used in the change-detection task. If the respective character was part of the learned set, it was presented together with a predefined, yet randomly selected, picture of an animal. If the character was part of the not-learned set, it would be presented together with a dark-gray placeholder square. Each trial first presented a central fixation cross (for 2,500 ms), followed by the display that contained the item pairs (for 3,000 ms; see Fig. 2b). The assignment of characters and animal pictures to the left and right side of the display was random, but with an equal distribution for each stimulus set. Observers were informed that the depicted Chinese character was associated with the meaning of the presented animal. They were instructed to remember the meaning of the presented characters. In case a given character was shown together with the gray square, observers were told to passively view the presented character. The mapping of characters to animals was generated randomly for each participant. The arbitrary pairing between characters and animals was implemented to rule out that any systematic perceptual variations between the item pairs could influence observers’ ability to learn the associations provided. Each character appeared only once per learning part in a given block. No responses were required.
In the subsequent test part of a given block, a recognition test was performed: After a 500-ms presentation of a blank screen with a fixation cross, a cue display was shown for 1,000 ms, depicting one of the eight animals that had been presented for associative learning. After another fixation display (200 ms), two Chinese characters were shown 4.2° to the left and right of the central fixation cross (see Fig. 2c). The cue and test items in this task again subtended approximately 2.8° × 2.8° of visual angle. One of these characters was the learned character that (in the leaning part) had been associated with the picture of the cued animal, whereas the other character was one of the eight not-learned items. Participants were asked to make a 2AFC response to indicate which of the two characters (on the left or right side of the display) corresponded to the cued animal, using the left or right mouse key. For instance, based on the example stimulus pairings presented in Figure 2b, the correct response to the cue (i.e., to the toucan) for the example test trial in Figure 2c would be a right click. The 2AFC display remained on screen until a response was made.
In the third part of the experiment, after completing the associative-learning task, observers again performed the change-detection task. The only difference relative to the first part of the experiment was that the participants had (by now) learned the meanings of half of the characters (i.e., for the learned set).
The control experiment tested an additional sample of Chinese native speakers in a single session of the change-detection task, assessing the performance level of individuals who entered the experiment with strong preestablished associations relating to the real meaning of the presented Chinese characters. To further ascertain that the presented characters were in fact known by these observers, a questionnaire was provided after the experiment. This questionnaire presented all 16 Chinese characters from the experiment and asked observers whether they knew the correct meaning of each stimulus (yes or no). If they responded with “yes,” they were also asked to provide the meaning of the character in English or German.
Design
In the change-detection task, three experimental factors were systematically varied: set size (3, 6), change (yes, no), and set type (learned, not learned). In the control experiment, the factor set type would not be relevant, as the native Chinese observers supposedly (and factually) knew the meaning of all presented characters. All factors were presented with equal probability and in randomized order across each experimental session. Each change-detection session consisted of six blocks of 60 trials, resulting in 360 experimental trials. At the beginning of the experiment, all participants additionally performed 10 randomly generated practice trials. The associative-learning task consisted of six blocks of 16 trials in the initial learning part and eight trials in the subsequent test part, yielding 96 learning and 48 test trials overall.
Results
VWM performance in the change-detection task was determined by the signal-detection sensitivity measure d-prime (d′; see Macmillan & Creelman, 2004). In the first part of the main experiment, performance did not differ between the learned and not-learned character sets: the d′ scores were 1.3 for both sets, t(44) = 0.52, p > .60, d = 0.08, indicative of essential (prelearning) comparability of the two randomly selected sets of Chinese characters. Given this, we aggregated the two sets into a single condition to reflect the overall performance before learning (i.e., before the provision of consistent object-character associations in the second part of the experiment). The aggregated d′ scores revealed a reliable difference between the two memory-set sizes, t(44) = 12.15, p < .001, d = 1.81: Performance was higher for three versus six to-be-remembered items (d′ scores of 1.8 vs. 0.8; see Fig. 3a).
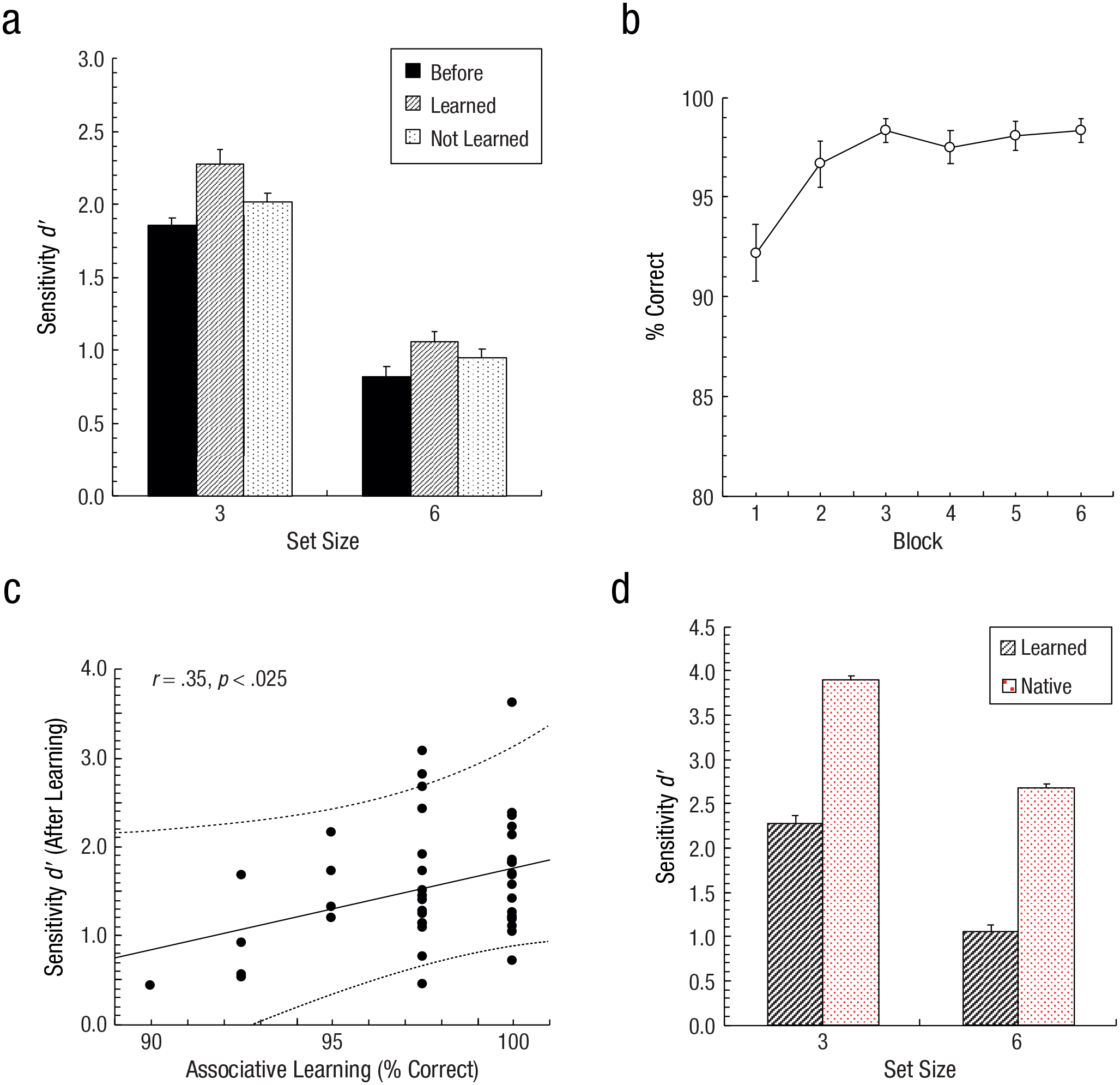
Results from Experiment 1. Shown in (a) are mean change-detection sensitivity d′ scores as a function of set size for the various stimulus sets (before learning, learned sets, and not-learned sets, depicted by solid, dashed, and dotted bars, respectively). In (b) are shown mean percentages of correct responses as a function of block in the association test. The correlation between individual change-detection d′ performance scores for the learned set and the asymptotic performance in the associative-learning task (% correct values averaged across Blocks 2–6) is illustrated in (c). The dotted lines denote 95% confidence intervals. In (d) we show mean change-detection d′ scores as a function of set size in the sample of non-Chinese-speaking participants (in the learned set) and in the sample of native Chinese observers—black/dashed, and red/dotted bars, respectively. Error bars represent the within-subjects standard errors of the mean.
It should be noted that the mean d′ score of 1.3 (and a corresponding estimated capacity K of 1.8; see Cowan, 2001) before learning indicates that the task was rather difficult for our non-Chinese-speaking observers. Nevertheless, this score is comparable to a previous study (Awh et al., 2007), which reported a K of 1.9 in a change-detection task that also presented Chinese characters (albeit for a shorter encoding time; see Experiment 2 below). Thus, notwithstanding some procedural differences, the baseline performance in the current experiment appears to be in line with previous findings.
In the subsequent associative-learning task in the second part of the experiment, observers displayed highly accurate performance in the 2AFC task (mean overall accuracy = 96.8%, range = 89.6%–100%). A repeated-measures analysis of variance (ANOVA) on the accuracies with the within-subjects factor learning block (1–6) yielded a significant effect, F(5, 44) = 5.30, p < .001, η2 = .11, and as indicated by a series of post hoc comparisons (with Bonferroni correction), performance improved after Block 1 (92.2%, ts > 3.0, ps < .04, ds > 0.45) and then rapidly reached an asymptotic, near-ceiling level from Block 2 onward (Block 2 to Block 6: 96.3% to 98.8%, respectively; ts < 1.1, ps = 1.0, ds < 0.17; Fig. 3b). This shows that observers acquired (and correctly recognized) the arbitrarily determined associations between the animal pictures and the Chinese characters after just one or two repetitions.
In order to test how the learning affected the change-detection performance in the subsequent third part of the experiment, another repeated-measures ANOVA was performed on the d′ scores, with set type (prelearning/baseline, learned, not learned) and set size (3, 6) as within-subjects factors. Both main effects turned out to be significant: set size, F(1, 44) = 200.19, p < .001, η2 = .56, and set type, F(2, 88) = 10.22, p < .001, η2 = .03. The set-size effect was due to performance being again higher overall with three versus six to-be-memorized items (d′ scores of 2.0 vs. 0.9, respectively). More interestingly, performance across the three set types revealed a graded difference, with d′ scores of 1.3 versus 1.5 versus 1.7 for the prelearning (baseline), not-learned, and learned sets, respectively. Although the sensitivity for the not-learned set was statistically comparable to the prelearning baseline, t(44) = 1.95, p = .162, d = 0.29, the learned set revealed significantly higher scores compared with both the not-learned set, t(44) = 2.56, p < .04, d = 0.38, and the prelearning set, t(44) = 4.51, p < .001, d = 0.67 (all comparisons performed with Bonferroni correction; see Fig. 3a). The interaction was not significant, p = .41. An additional correlational analysis showed that the individual asymptotic performance in the associative-learning task (i.e., the average across Blocks 2 to 6) was related to the mean d′ detection sensitivity after learning, r = .35, p < .025 (Fig. 3c). This suggests that individual success in learning the meaning of the Chinese characters indeed enhanced performance in the subsequent change-detection task. Together, this pattern shows that acquiring a meaning association between a character and a depicted object substantially improves VWM.
Finally, in the additional control experiment, which tested memory performance in a sample of native Chinese speakers, change-detection performance was quite high overall (d′ = 2.9) and again higher with three (3.8) versus six (2.7) to-be-remembered items, t(19) = 11.00, p < .001, d = 2.46.
A further analysis was performed to compare the overall change-detection performance between the nonnative observers (main experiment) and the sample of native Chinese observers (control experiment). A repeated-measures analysis with set size (3, 6) as a within-subjects factor and group (nonnative, native) as a between-subjects factor again revealed a significant main effect of set size, F(1, 63) = 282.35, p < .001, η2 = .20. Additionally, there was a significant between-group difference, F(1, 63) = 111.61, p < .001, η2 = .48, with the Chinese natives exhibiting higher d′ scores than the nonnative observers (2.9 vs. 1.5). Of note, an identical ANOVA on the d′ scores of only the learned set (in the nonnative observers) revealed an analogous outcome: main effects of set size, F(1, 63) = 126.98, p < .001, η2 = .20, and group, F(1, 63) = 59.11, p < .001, η2 = .34—the latter indicating that even after learning the meaning of the characters, the nonnative observers still performed worse than the Chinese natives (mean d′ scores across set sizes of 1.7 vs. 2.9; Fig. 3d). Neither analysis revealed a reliable interaction, ps > .3.
The questionnaire that assessed knowledge about the actual meaning of the Chinese characters in the control experiment showed that the native Chinese observers were able to report the correct meaning of the 16 Chinese characters used in the experiment with high accuracy (mean accuracy = 96.9%, range = 93.8%–100%, except for one observer who recognized only 43.8% of all characters). Together, this demonstrates that learning of meaningful (yet arbitrary) character-animal associations (in non-Chinese-speaking observers) can substantially enhance memory performance, though this benefit is still small when compared with the level of performance exhibited by native observers, who had been exposed to these meaningful characters for many years.
Experiment 2
Experiment 1 demonstrated that learning consistent associations of Chinese characters with arbitrarily assigned pictures of animals enhances the capacity of VWM. Experiment 2 was designed to directly replicate this learning-induced memory improvement, using Chinese characters that are associated with a wider range of objects and reflect their actual meanings (see examples in Fig. 4a), thus increasing the ecological validity of our findings. Moreover, Experiment 2 aimed to provide additional controls for possible influences of (a) verbal working memory and (b) a bias in attentional priority toward the learned category.
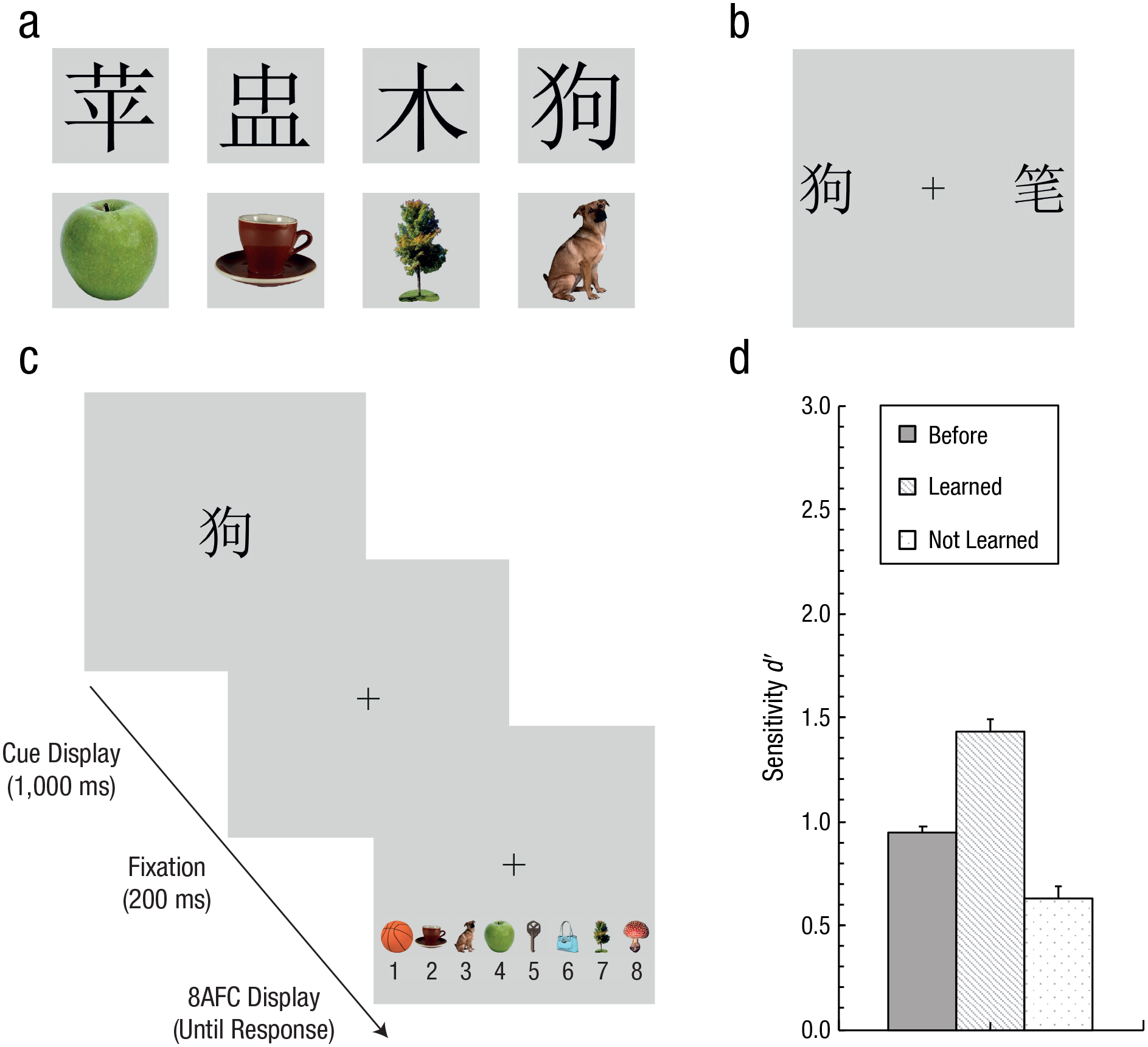
Procedure in Experiment 2. Examples of the Chinese characters and their associated pictures (which in Experiment 2 were more directly related to the actual meaning of the Chinese characters) are shown in (a). The experiment started with a change-detection task comparable to Experiment 1’s, followed by an associative-learning part, after which the change-detection task was presented again. The learned associations between the Chinese characters and pictures were then tested in two separate tasks, which were administered after the second change-detection task: First, a two-alternative forced choice (2AFC) recognition test (b) presented displays with pairs of learned and not-learned characters, from which observers were required to select the learned character. In the example, the character for “dog” (left) would be from the to-be-selected learned set, whereas the character for “pen” (right) was not learned. In a second 8AFC recall test (c), a given learned character would be preceded by a display that presented images of all eight learned objects. Observers would be required to identify the object that matched the meaning of the presented character. In the example, the displayed character would match the third option (dog). Overall mean d′ scores in the before-learning, learned, and not-learned stimulus sets (d) are depicted by solid, dashed, and dotted bars, respectively, in the change-detection task. Error bars represent within-subjects standard errors of the mean.
Method
Experiment 1 already employed a digit-memory task to prevent verbalization strategies during VWM retention in the change-detection task. It has previously been shown that digit memory (when combined with a change-detection task) is usually very accurate (Brady et al., 2016; Conci et al., 2021), without revealing any influence of the verbal memory load upon the recall of meaningless versus meaningful stimuli retained in VWM (Jackson & Raymond, 2008; see also Xie & Zhang, 2017). However, the relatively long presentation duration of the memory display in Experiment 1 (2,000 ms), which was also employed in comparable studies (e.g., Brady et al., 2016; Conci et al., 2021; Jackson & Raymond, 2008), might nevertheless have allowed observers to establish some crude verbal description, which could have facilitated the retention of the meaningful characters (after learning), despite continuous digit rehearsal. To further reduce such a potential influence, in Experiment 2 the presentation duration of the memory display was shortened by a factor of four, from 2,000 ms (in Experiment 1) to 500 ms, thus substantially curtailing the encoding time and the concurrent time available to establish a verbal memory description.
It might also be argued that the associative-learning task, rather than inducing specific LTM-knowledge representations that would link a given character to a given picture, might simply have trained observers to broadly categorize the characters from the learned versus the not-learned set (Ashby & Maddox, 2011). Such a learned categorization of the characters might not only explain the accurate performance in the association test but could also have instigated an attentional bias prioritizing the learned set, thus enhancing VWM performance after learning (see, e.g., Swan et al., 2016, for an attentional bias in VWM based on task relevance). To rule out such a potential category-specific attentional bias (instead of LTM-based learning of specific meanings), we changed the associative-learning task in Experiment 2. The basic procedure of the initial associative-learning part was essentially the same as in Experiment 1. However, the subsequent test of the acquired associations was administered only after the main experiment, that is, after the second session of the change-detection task—to further exclude any bias that might result from the testing procedure itself. Moreover, the association test now was composed of two task variants: a first 2AFC recognition test, which asked observers to select the previously learned character in a display that contained both a learned and a second, not-learned character (Fig. 4b). This test thus essentially required observers to broadly categorize the presented stimuli into learned and not-learned subsets. In contrast, correctly performing the subsequent (8AFC) recall test required observers to have acquired a specific meaning association in the learning phase. In this task, first, a probe was presented depicting a given learned character, which was followed by a display that presented all eight learned images, from which observers would have to select the appropriate object related to the meaning of the probed character (Fig. 4c). In this way, we tested the specific, previously acquired LTM association for a given Chinese character.
Participants
Twenty adults (mean age = 23.2 years; 7 male, 13 female; 19 right-handed, 1 left-handed) who were unable to read, write, or speak Chinese participated in Experiment 2. All participants had normal or corrected-to-normal vision and received either payment or course credits for their participation.
Stimuli, design, and procedure
The experiment started with an initial change-detection task that comprised eight blocks of 40 trials—identical to the procedure for Experiment 1 except that the duration of the initial memory display was reduced to only 500 ms (comparable, e.g., to Awh et al., 2007). Moreover, in Experiment 2, a different set of 16 Chinese characters was presented. These characters were chosen to match the actual meaning of the depicted objects (apple, bag, ball, bird, butterfly, cup, dog, gun, key, mushroom, pen, shoe, spoon, table, tree, and turtle), which were again selected from the BOSS database (Brodeur et al., 2014) and which would be displayed together with the characters in the subsequent associative-learning task (see example pairs in Fig. 4a). The procedure for this task was comparable to Experiment 1’s except that new sets of characters and corresponding, directly related real-world objects were used as stimuli. There were eight blocks of 16 trials during which observers passively viewed (and were instructed to memorize) pairs that either presented characters and objects (learned set) or characters and a gray placeholder square, respectively (not-learned set). After the associative-learning task, the change-detection task was administered again. Finally, two novel tasks were employed, which tested the learning of associations between characters and objects. First, there was a 2AFC recognition test consisting of four blocks of eight trials, which displayed randomly selected pairs of a given learned and a second nonlearned Chinese character. Each trial started with a blank display with a fixation cross (500 ms), followed by a display with the two Chinese characters, which were randomly presented 4.2° to the left and right of central fixation (see Fig. 4b). Participants were asked to indicate which of the two characters (on the left or right) was part of the previously learned set by responding with the left or right mouse key, respectively. Next, the 8AFC recall test was performed. This test again comprised four blocks of eight trials. A given trial would first present a fixation display (500 ms), followed by a cue display (1,000 ms) that presented at the center of the screen one randomly selected Chinese character (2.8° × 2.8°) from the learned set. After another fixation display (200 ms), all eight pictures from the learned set were presented 1.8° below the central fixation cross in random order in a row with the numbers 1 to 8, printed in black (16-pt Arial font) underneath each picture (Fig. 4c). Each picture subtended 1.8° × 1.8° and was separated from the next by 0.7°. Participants were asked to identify the single object (from the eight available options) that corresponded to the cued character by typing the corresponding number on the keyboard.
Results
In a first step, we assessed the learning of associations between characters and pictures in the recognition and recall tests that were administered toward the end of the experiment. Accuracy in the 2AFC recognition test was very high (mean overall accuracy = 99.1%, range = 93.8%–100%), which indicates that our observers were able to adequately recognize and categorize the characters from the learned set. Moreover, they were also able to identify the specific objects that were associated with a given character in the 8AFC recall test (mean accuracy = 72.8%), with performance being well above chance level (i.e., 12.5%, given eight possible responses, t(19) = 6.60, p < .001, d = 1.48). It should, however, be noted that four observers were not able to correctly identify the meanings of the probed characters in the recall task (their accuracy was 0%). Nevertheless, the remaining 16 observers achieved a rather high recall accuracy overall (91.0%; one participant only reached an accuracy of 25%, but the scores for all other 15 participants ranged from 84.4% to 100%). To ensure that variations in VWM performance in Experiment 2 reflected actual LTM learning of specific character-to-object associations, the analyses reported in the following were all based on the sample of 16 observers that were able to perform the recall task above chance level. Note, however, that the pattern of results would essentially be the same when analyzing the complete sample.
The analysis of the change-detection performance before the actual learning yielded no difference between the d’ scores for the learned (1.0) and not-learned (0.9) character sets, t(15) = 1.57, p > .13, d = 0.39. Having thus established comparability of VWM performance for the two randomly generated stimulus sets, they were therefore again aggregated into a single before learning condition. These aggregated (prelearning) scores again revealed a decrease in performance (d′ scores of 1.3 and 0.6) with an increase in the set size (from three to six items), t(15) = 10.08, p < .001, d = 2.52. The mean d′ of 0.95 (and the corresponding memory estimate K of 1.3) before learning indicates that the VWM task with the novel stimulus set (with overall more variable and complex Chinese characters) was again rather difficult for the observers.
Next, we investigated how associative learning affected the change-detection performance. To this end, the d′ scores were subjected to a repeated-measures ANOVA with the within-subjects factors of set type (prelearning, learned, not learned) and set size (3, 6). The results yielded significant main effects of set size, F(1, 15) = 20.27, p < .001, η2 = .57, and set type, F(2, 30) = 38.31, p < .001, η2 = .72. Performance decreased from three to six to-be-memorized items (d′ scores of 1.2 vs. 0.8). Importantly, across the three set types, VWM performance again showed a systematic difference (d′ scores of 0.9 vs. 0.6 vs. 1.4 for the prelearning, not-learned, and learned sets, respectively). As in Experiment 1, the sensitivity for the learned set was substantially higher compared with both the prelearning set, t(15) = 5.15, p < .001, d = 1.29, and the not-learned set, t(15) = 8.70, p < .001, d = 2.17. In addition, the sensitivity for the not-learned set was somewhat reduced compared with the prelearning set, t(15) = 3.54, p < .005, d = 0.88 (all comparisons with Bonferroni correction; Fig. 4d). Finally, the set size by set type interaction was also significant, F(2, 30) = 8.70, p = .001, η2 = .36. Performance dropped with three to-be-remembered, meaningless items as the experiment progressed (d′ scores of 1.3 and 0.7 for the prelearning and not-learned sets, respectively; p < .001), whereas memory sensitivity was low in general in six-item displays (d′ scores of 0.6 and 0.5 for the prelearning and not-learned sets, respectively, p = 1.0). However, no such performance decrease (which might have resulted from a progressive increase of fatigue) was observed for the learned characters (d′ scores of 1.5 and 1.4 for three- and six-item displays, respectively), for which sensitivity was substantially larger compared with the not-learned set (ps < .001, all comparisons with Bonferroni correction). Together, this pattern shows (in general agreement with Experiment 1) that learning a specific association between a given Chinese character and an object leads to a pronounced improvement in VWM capacity.
General Discussion
The current experiments implemented a training procedure to investigate the extent to which familiarity and meaning can improve VWM—under conditions that controlled for perceptual differences between stimuli across conditions, standardized the acquisition of LTM knowledge (in the associative-learning phase) across observers, and prevented them from using verbalization strategies to encode the stimuli (in the VWM task).
In Experiment 1, the initial change-detection performance, before actual learning, showed memory capacity to be severely limited for our non-Chinese-speaking observers (d′ = 1.3). The subsequent learning of character-to-animal associations was quite successful, already reaching a plateau (97.8% accuracy) in Block 2. Following the acquisition of these associations, the change-detection performance for the learned set of characters was significantly improved (d′ = 1.7), not only relative to the prelearning baseline but also compared with the improvement rendered by mere training-induced familiarity with the stimulus material (i.e., the not-learned set; d′ = 1.5). Moreover, individual learning success with the character-to-animal associations was correlated with the change-detection performance after the learning process. Experiment 2 then essentially replicated this meaning-dependent increase in VWM performance, even though the memory items were presented for a shorter encoding duration to further prevent verbal VWM contamination. Also, to strengthen the ecological validity of the learning manipulation, Experiment 2 introduced a categorically more varied set of to-be-acquired object-character associations—which also yielded a substantial learning-induced increase in memory capacity (from d′ = 0.9 before learning to d′ = 1.4 after learning). Moreover, the concurrent high level of performance in two novel association tests—recognition and recall—administered after the critical, second VWM test (which yielded accuracies of 99.1% for recall and 91.0% for recognition) demonstrated that the improvement in memory sensitivity is not simply attributable to some general attentional bias toward the learned set. Rather, the high recognition accuracy, in particular, strongly indicates that the observed VWM improvement after training actually derives from successful long-term learning of individual character-object associations. Thus, the two experiments consistently show that the buildup of explicit LTM knowledge representations for items that later have to be retained substantially improves the capacity to hold these items in an active, available state in VWM.
Nevertheless, an additional control experiment (performed with the characters used in Experiment 1) showed that the improved capacity for learned, meaning-associated items displayed by our non-Chinese-speaking observers (postlearning d′ of 1.7) was rather small compared with the standard VWM performance exhibited by our education-, age-, and gender-matched sample of native Chinese observers (d′ = 2.9). This suggests that the long-term (i.e., essentially lifelong) experience with the presented stimuli in the native Chinese observers had led to a more solid consolidation of the object-meaning associations in LTM compared with the rather short training procedure implemented in the present study (which, however, sufficed to significantly enhance VWM performance).
Overall, these current findings support previous reports of improved VWM performance for various meaningful (vs. meaningless) categories of stimuli (Asp et al., 2021; Brady et al., 2016; Conci et al., 2021; Curby et al., 2009; Dall et al., 2021; Hu & Jacobs, 2021; Jackson & Raymond, 2008; Ngiam et al., 2019; Shoval & Makovski, 2022; Xie & Zhang, 2017). The current study extends these findings by showing that this meaning-related improvement directly derives from the acquisition of object-meaning associations in LTM (here, experimentally controlled)—where reliable improvements in the VWM storage capacity are manifested already after just a few encounters of the to-be-associated stimuli. To further increase the ecological validity, future research could explore how the controlled acquisition of meaning generalizes across other types of objects and the amount of repetition with the to-be-learned material.
Beyond demonstrating a basic connection between LTM-based knowledge and VWM, our findings further indicate that the amount of information stored in relation to a given object in LTM directly enhances the retrievability of that item representation in VWM. We observed a graded effect of LTM knowledge upon VWM storage, which ranged from a comparably low level of performance with meaningless characters to a substantial benefit for meaningful characters that had come to have specific memory associations. Nevertheless, lifelong-trained native observers still outperformed our non-Chinese-speaking observers (see also Evans et al., 2011), indicating that the level of LTM consolidation directly impacts the capacity of VWM. This pattern of benefits deriving from longer-term learning is consistent with previous studies. For instance, Sørensen and Kyllingsbæk (2012) found that an increase in expertise with letters improved VWM capacity for these stimuli across different age groups; similarly, Dall et al. (2016) found reading ability in Japanese (for novices vs. experts) to be reflected in concurrent VWM measures.
Our findings are also broadly consistent with previous studies that used training procedures to optimize VWM retention (Blalock, 2015; Chen et al., 2006; Oberauer et al., 2017; Sims et al., 2022; Zimmer et al., 2012). Typically, comparing meaningless items before versus after a familiarization phase, these studies reported overall rather moderate improvements in performance. In the current study, the acquisition of specific (and explicit) knowledge representations was found to engender substantial VWM benefits, whereas overall familiarity with the items had little, if any, impact on performance. It thus appears that establishing specific knowledge structures is particularly effective in producing substantial gains in VWM performance, whereas familiarity-based improvements typically require a certain amount of training and depend on the overall number of the to-be-learned items (Sørensen & Kyllingsbæk, 2012).
A potential theoretical explanation of our findings would assume that the encoding of a given object into VWM leads to an automatic activation of knowledge structures related to this object in LTM. An account largely consistent with this view is the embedded-processing model (Cowan, 1999; see also Oberauer, 2002). In this view, VWM reflects an activated entity of LTM, thus readily promoting close interactions between both memory systems and their inherent representations. In agreement with this, Brady et al. (2016) showed that the contralateral delay activity, an electrophysiological marker of VWM, is increased when meaningful (as compared with meaningless) objects are presented, suggesting that LTM-based knowledge directly enhances the active retention of this object in VWM.
Similarly, a recent computational model of VWM, by Hedayati et al. (2022), assumes that increased familiarity with visual stimuli generates conceptual knowledge about these objects. In this view, LTM-based knowledge structures essentially reflect an emergent feature of visual information processing that, in turn, provides categorical codes that are available in a compressed format in some latent representation and come to benefit performance in subsequent encounters, thereby strengthening the meaning representations currently held in VWM (see also Sørensen & Kyllingsbæk, 2012). Acquired knowledge about the meaning of a Chinese character might thus activate LTM knowledge structures associated with this stimulus, with information in LTM in turn enhancing the retention of that item in VWM.
In summary, we have shown that VWM can be substantially enhanced by systematically manipulating the acquisition of long-term knowledge related to to-be-memorized objects. Rather than being just correlational in nature, this LTM-related boost of VWM reflects a causal effect that can be induced by a systematic experimental manipulation, namely, making observers learn to associate semantic meaning with specific stimuli.
Footnotes
Transparency
Action Editor: Karen Rodrigue
Editor: Patricia J. Bauer
Author Contributions