
Abstract
Research has recently shown that efficient selection relies on the implicit extraction of environmental regularities, known as statistical learning. Although this has been demonstrated for scenes, similar learning arguably also occurs for objects. To test this, we developed a paradigm that allowed us to track attentional priority at specific object locations irrespective of the object’s orientation in three experiments with young adults (all Ns = 80). Experiments 1a and 1b established within-object statistical learning by demonstrating increased attentional priority at relevant object parts (e.g., hammerhead). Experiment 2 extended this finding by demonstrating that learned priority generalized to viewpoints in which learning never took place. Together, these findings demonstrate that as a function of statistical learning, the visual system not only is able to tune attention relative to specific locations in space but also can develop preferential biases for specific parts of an object independently of the viewpoint of that object.
In everyday life, we must process complex visual input, and it has become increasingly clear that we can do this efficiently because our cognitive machinery is sensitive to regularities in the environment. Most visual input is highly repetitive and structured, which makes it possible to predict what information will appear next on the basis of the current sensory input (Friston, 2009; Kok et al., 2017). Extracting regularities from the environment is one of the most fundamental abilities of any living organism and is often referred to as visual statistical learning (VSL; Chun & Jiang, 1998; Fiser & Aslin, 2001, 2002). Numerous studies have shown that the extraction of regularities via VSL can proceed without the intention to learn, and observers often appear to be unaware of the learning (Turk-Browne et al., 2005), although the extent to which learning is truly unconscious is debated (Vicente-Conesa et al., 2022).
Recently, a surge of studies demonstrated the importance of VSL in shaping attentional selection (for recent reviews, see Theeuwes et al., 2022; van Moorselaar & Slagter, 2020). Classic work by Biederman and colleagues already demonstrated that in specific environments, we expect that particular objects will often co-occur and that certain objects are placed at specific locations (Biederman, 1972; Biederman et al., 1982). For example, a coffeemaker, a pan, and a knife are likely to be found in a kitchen scene, and within that kitchen at a particular location (on the countertop, probably not on the floor). Although this and subsequent work using real-world scenes (Võ & Wolfe, 2012, 2013) has provided much insight into how attentional selection is shaped by previous experiences, using real-world scenes also has the drawback that one cannot control how much learning occurs outside the laboratory setting (e.g., one person may have much experience with scenes, whereas another may have little experience with such scenes). Thus, to establish not only what is learned but also how and when the association is learned, it is important to study VSL with rigorous control over the experimental stimuli.
Recent lab studies have confirmed the ubiquitous role of statistical learning in the shaping of attentional priority. For example, in so-called contextual cuing tasks, participants need to detect the T-shaped target among a series of L-shaped distractors. Unbeknownst to the participants, half of the displays appear repeatedly with the target and distractors in the same configuration, whereas other displays appear only once during the experiment. Participants learn this spatial regularity as they become faster at identifying the target in the repeated search displays in comparison with the novel displays (Chun & Jiang, 1998). Similarly, when the target is more likely to appear within particular locations or quadrants within a search display, participants become faster at finding targets presented at these high-probability locations than targets presented at low-probability locations (Ferrante et al., 2018; Geng & Behrmann, 2005; Huang et al., 2022). It is argued that through statistical learning, observers are able to extract the distributional properties of objects within scenes, which in turn optimizes visual selection (Frost et al., 2015; Theeuwes et al., 2022).
Although it is firmly established that we are able to learn the distributional properties in time and space of objects within scenes, not much—if anything—is known about learning regularities regarding the locations of key parts within objects. For example, most people are able to turn on a laptop even if they have never seen that laptop before. Because of our previous encounters with laptops, we have learned which parts of the laptop are most likely to contain the power button. This raises the intriguing possibility that learned attentional biases are not restricted to a spatiotopic reference frame but that attention can also be tuned to object regularities in a way that is independent from the viewpoint of that object.
The present study was designed to test the feasibility of within-object statistical learning. Specifically, we examined whether participants could learn that specific parts within an object were more likely to contain relevant information than other parts of the same object. Figure 1 shows the basic procedure. On each trial, participants had to search for a rotated T, which was located at one of two possible locations within an object (i.e., hammers or shoes). Critically, although these objects could appear in any of four possible orientations, in biased blocks, one part of the object (e.g., head of the hammer) contained the target with higher probability (67.5%; independent of orientation). By contrast in neutral blocks, the target appeared with equal probability at both side of the object across all orientations.
Statement of Relevance
The amount of information that constantly enters our senses far surpasses our visual system’s processing capacity. Fortunately, this perceptual problem can be simplified by taking advantage of the fact that the world is highly repetitive and therefore predictable. For example, there is abundant evidence that we can learn distributional properties in time and space of objects within scenes. However, to date, it has remained unclear whether human observers can also learn to prioritize specific key parts within objects on the basis of prior experience. Here, we demonstrated not only that people have the remarkable ability to learn to prioritize relevant locations within objects but also that this learning is viewpoint independent. This shows that in addition to learning within a retinotopic reference frame, statistical learning within object-centered system is also possible, allowing us to attentionally prioritize those locations that are relevant within a particular object independently of its spatiotopic (i.e., external world) coordinates.
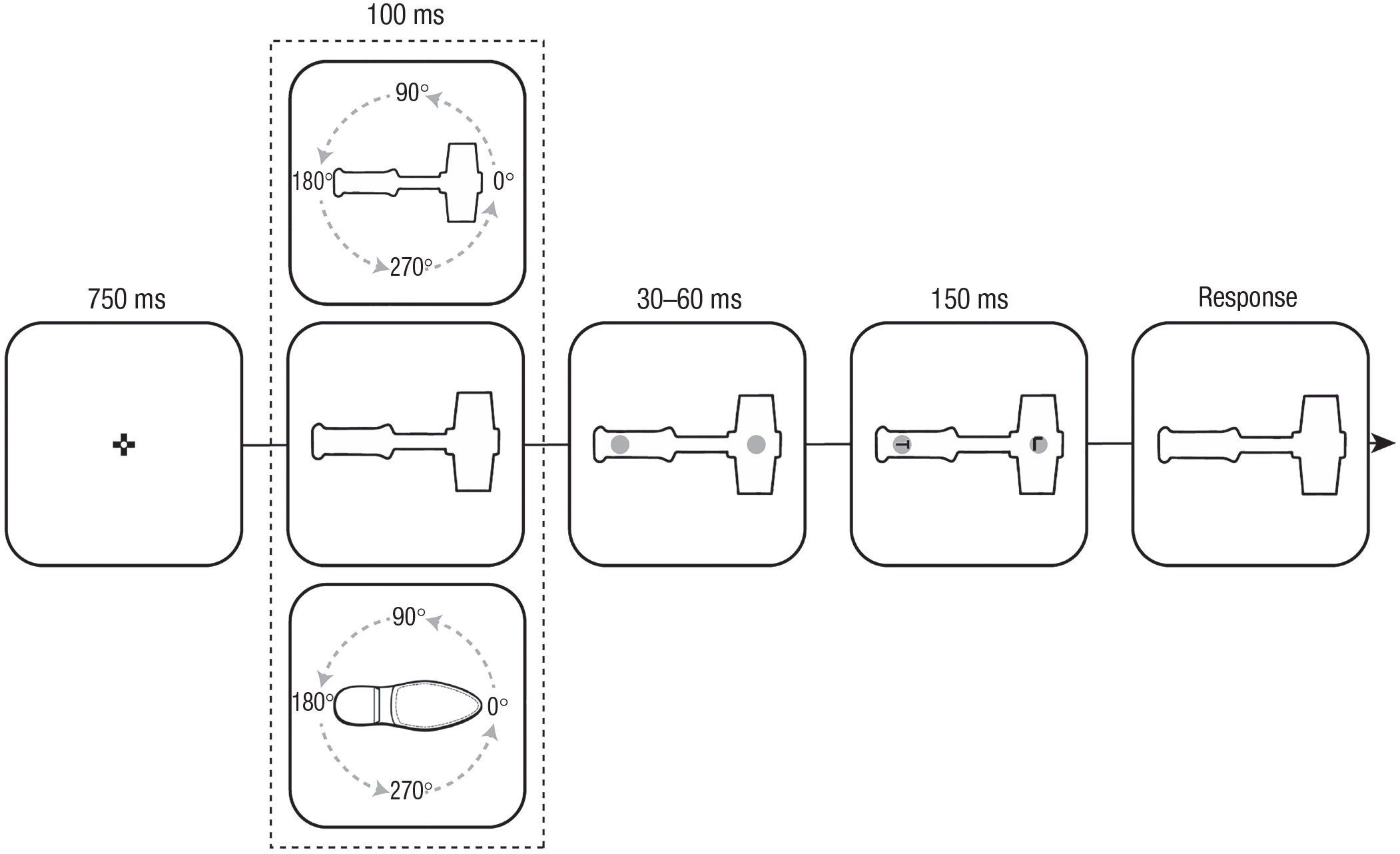
Schematic of the experimental procedure. On each trial, an object (either a hammer or a shoe, presented in separate blocks) was shown in one of four orientations. Across all three experiments (all Ns = 80), participants responded to the orientation of the target letter T (tilted left or right) while ignoring an L-shaped distractor. To induce statistical learning in biased blocks in all orientations, we made sure that the target letter appeared in one part of the object with a higher probability (67.5%). In Experiment 1a, both objects shared the same high-probability location. In Experiment 1b, only half of the experiment contained biased blocks; in the remaining neutral blocks, the object was presented without a spatial imbalance. By contrast, in Experiment 2, in neutral blocks, the axes alongside which the objects were presented changed from the cardinal axes (i.e., 0°, 90°, 180°, 270°) to the intercardinal axes (i.e., 45°, 135°, 225°, 315°) or vice versa. The design of Experiment 2 thus allowed us to test whether learned prioritization at the high-probability object locations would generalize to new viewpoints in which learning did not take place during a test phase.
This design allowed us to test whether attentional priority became biased toward the high-probability object location over time (Experiment 1). If so, then we expected that the relevant parts of the object would be prioritized in selection over less relevant parts. Critically, in the present paradigm, this prioritization is necessarily tied to a specific location within the object and thus independent from the actual retinotopic location on the screen. Indeed, for learning to be adaptive, once it is learned that, for example, the head of a hammer is more likely to contain relevant information, this location within the object should be prioritized independently of the current viewpoint of that hammer. Hence, in Experiment 2, we tested whether the learned attentional bias within a given object would generalize to other viewpoints of that object in which learning never took place (Experiment 2).
Open Practices Statement
Deidentified data for all experiments along with the data-analysis scripts (custom Python 3 scripts) and code for running the experiments have been made publicly available at OSF and can be accessed at https://osf.io/cuwxe/. None of the experiments were preregistered.
Experiments 1a and 1b: Object-Specific Attentional Prioritization
Method
Participants
Participants were recruited online via the local universities’ participant pool through Sona Systems (for research credits) and via the online platform Prolific (www.prolific.co; fixed payment, £3.34).
Participants recruited via the local participant pool were Dutch and international bachelor students enrolled in the psychology program at Vrije Universiteit Amsterdam. Prescreening criteria for Prolific participants consisted of having a minimal approval rate of 90%, being between 18 and 40 years old, and having participated in at least 10 studies. There was no restriction based on nationality, and hence the sample contained participants from across the world. For a discussion of the reliability of this participant pool, see Peer et al. (2017). Prior to the experiments, which were conducted online on a JATOS server (Lange et al., 2015), participants provided digital informed consent via Qualtrics (https://www.qualtrics.com/). Data sets were analyzed only when an experiment was completed in full. Because we developed this paradigm to study object-based statistical learning, we had no prior results to predetermine sample size. We chose to collect 80 data sets for each experiment after replacement of outliers (see below) on the basis of an a priori power analysis (α = .05, power = .85) using G*Power (Version 3.1; Faul et al., 2007), which yielded a projected sample size of 76 for the simplest within-group comparison in a study with a small to medium effect size (d = 0.35). The ethical committee of the Vrije Universiteit Faculty of Behavioral and Movement Sciences approved the study, which conformed to the Declaration of Helsinki.
The final sample in Experiment 1a (mean age = 22 years, range = 18–37; 57 female) was obtained after replacing three participants who were identified as outliers (one on the basis of overall reaction times [RTs] and two on the basis of overall accuracy; > 2.5 SD from the group mean). The final sample in Experiment 1b (mean age = 24 years, range = 18–40; 55 female) was obtained after replacing five participants who were identified as outliers (two on the basis of overall RTs and three on the basis of overall accuracy).
Task, stimuli, and procedure
Because the experiment was conducted online, and we thus had little control over the experimental setting, we will report pixel values to describe the stimuli for replication purposes. The experiment was created in OpenSesame (Version 3; Mathôt et al., 2012) using OSWEB (Version 1.4).
Each trial started with a 750-ms white fixation display, in which a black-and-white circular fixation point, as designed by Thaler et al. (2013), was shown at the center of the screen. Subsequently a placeholder screen appeared in which one of the objects (i.e., a shoe or a hammer; see Fig. 1) was presented in one of four orientations (i.e., rotated 0°, 90°, 180°, or 270°) for a randomly jittered duration (30–60 ms). Embedded within the objects were two gray placeholder circles (radius = 10 pixels) at both sides of the object (90 pixels away from fixation). Within these gray circles, two black letters, a T and an L, rotated left or right and up or down, respectively (counterbalanced across trials), appeared. To prevent eye movements during visual search, we made the target letters visible for only 150 ms (Heeman et al., 2019). During the response period, the object remained on screen until response with a time-out of 2,000 ms. Critically, targets appeared with a higher probability (62.5%) at one side of the object (counterbalanced across participants). This spatial imbalance was the same for each of the four object orientations, which were randomly intermixed across trials.
In Experiment 1a, the search object switched from a hammer to a shoe, or vice versa, halfway through the experiment (order counterbalanced across participants), whereas the high-probability location of the object did not change. By contrast in Experiment 1b, only one of the objects had a spatial imbalance, and thus half of the experimental blocks contained an object with a high-probability location (order counterbalanced across participants), whereas in the other object, the target appeared with equal probability at both sides of the object (biased object counterbalanced across participants).
Participants were instructed to keep their eyes on fixation and to indicate whether the target letter T was rotated left or right using the arrow buttons on the keyboard. The experiment consisted of six experimental blocks of 64 trials each (16 trials for each orientation), preceded by a series of 15 practice trials without a spatial imbalance. The practice block continued to repeat until average RT was below 1,100 ms and average accuracy was above 70%. Participants were encouraged to respond as fast as possible while keeping the number of errors to a minimum, and they received feedback on their performance (i.e., mean RT and accuracy) at the end of each block. After the last block, participants were asked to indicate whether they noticed the spatial imbalance, to indicate which of the two objects contained this spatial imbalance, and to indicate whether there was a higher probability that the top or the bottom of the selected object contained the target letter. 1
Data analysis
Search-time analyses were limited to data from trials with correct responses only. RTs were filtered in a two-step trimming procedure: Trials with RTs shorter than 200 ms were excluded, after which data were trimmed on the basis of a cutoff value of 2.5 standard deviations from the mean per participant. Exclusion of incorrect responses (10.9% and 9.2% in Experiments 1a and 1b, respectively) and data trimming (2.4% and 2.4% in Experiments 1a and 1b, respectively) resulted in an overall loss of 13.2% and 11.6% of trials in Experiments 1a and 1b, respectively. Remaining RTs were analyzed with repeated measures analyses of variance (ANOVAs), and reported p values are Greenhouse-Geiser corrected in case of sphericity violations. ANOVAs were followed by planned comparisons with paired-samples t tests using JASP software (JASP Team, 2018). In case of nonsignificant findings, we also report the Bayes factor (BF) in support of the null model. In case of interactions, this factor represents the model comparisons between models that contain the effect and equivalate models stripped of the effect (BFexcl).
Results
Experiment 1a: object-based statistical learning
To examine whether high-probability target locations within objects were prioritized for selection, we conducted a repeated measures ANOVA with the within-subjects factors target location (high probability, low probability) and image order (Object 1, Object 2). As visualized in Figure 2a, target letters were identified faster in high- relative to low-probability target locations within the objects, F(1, 79) = 5.5, p = .021, η p 2 = .066. Although overall responses were faster to the second object (i.e., second half of the experiment), F(1, 79) = 6.1, p = .016, η p 2 = .072, reflecting a general practice effect, there was no evidence that learned prioritization differed as a function of whether the biased object was the first or the second object that was encountered—interaction: F(1, 79) = 0.23, p = .63, η p 2 = .003, BFexcl = 5.1. A repeated measures ANOVA with the within-subjects factors target location (high probability, low probability) and object (hammer, shoe) also did not yield a reliable interaction, F(1, 79) = 0.19, p = .67, η p 2 = .002, BFexcl = 5.5, showing that the learned prioritization at high-probability target locations also did not differ between objects. Critically, whereas overall response times were faster for objects in the horizontal than the vertical plane—main effect of orientation: F(2.4) = 9.1, p < .001, η p 2 = .10—learned prioritization also did not differ between orientations—interaction: F(2, 158) = 0.26, p = .77, η p 2 = .003, BFexcl = 45.1.
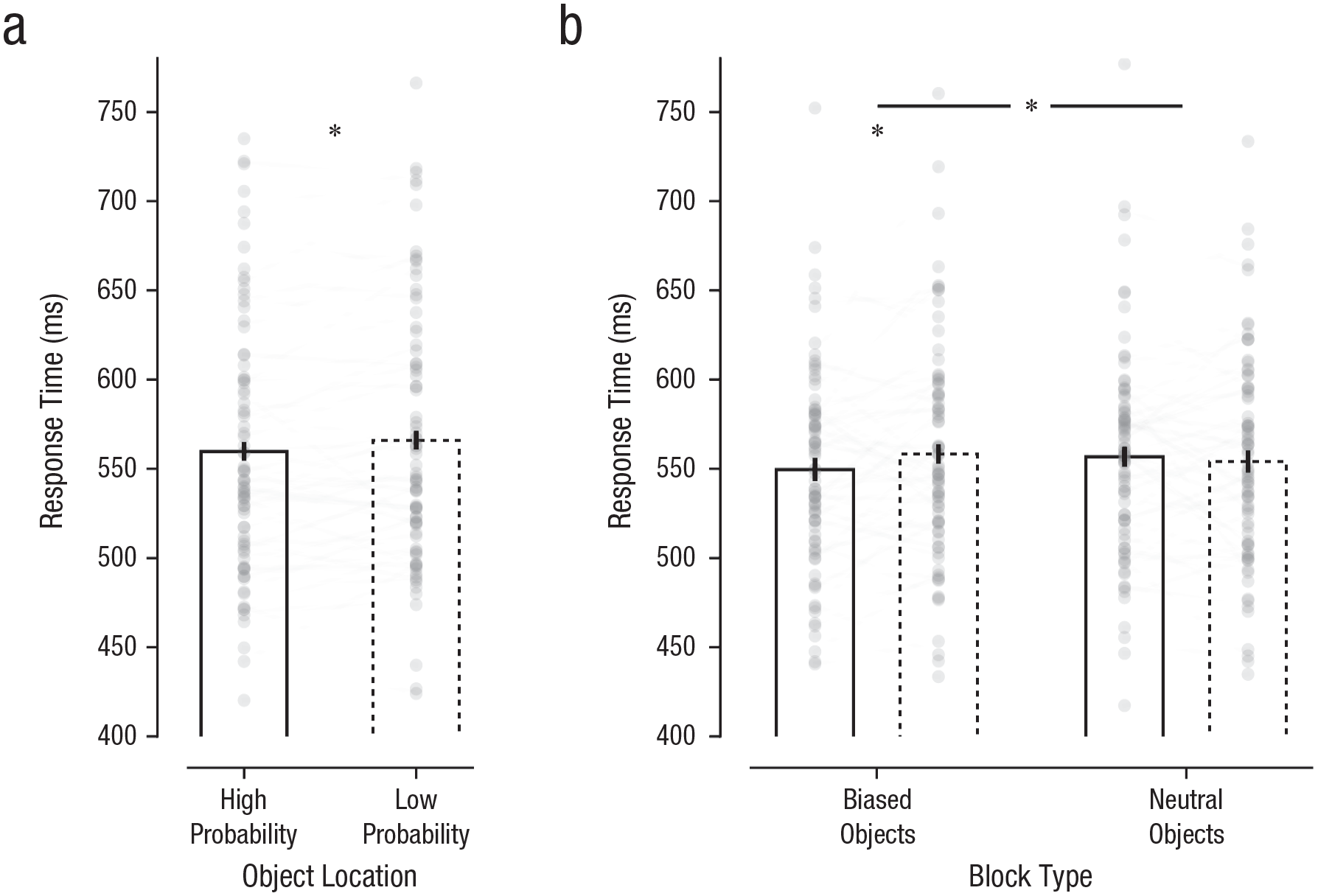
Learned attentional prioritization at high-probability object locations in Experiments 1a and 1b. Mean response time is shown for (a) each object location in Experiment 1a and (b) each block type and object location in Experiment 1b. Solid and dashed bars indicate high- and low-probability object locations, respectively. The height of each bar reflects the population average, and error bars represent 95% within-subjects confidence intervals (Morey, 2008). Data from each participant are represented as gray dots. Lines connect each individual participant’s performance. Asterisks indicate significant between-condition differences (p < .05).
Experiment 1b: object-specific prioritization
To further corroborate the object-based statistical learning observed in Experiment 1a, we constructed Experiment 1b so that only one of the objects contained a spatial imbalance, whereas in the other object, the target appeared with equal probability across locations. As visualized in Figure 2b, a repeated measures ANOVA with the within-subjects factors object (biased, neutral) and target location (high probability, low probability) yielded a reliable interaction, F(1, 79) = 5.90, p = .017, η p 2 = .069, again reflecting a difference between high- and low-probability target locations in the biased objects, t(79) = 2.5, p = .016, d = 0.28, but critically not in the neutral objects, t(79) = 0.8, p = 0.43, d = 0.088, BF01 = 6.0. Also, when the analyses were limited to biased blocks, learned prioritization again did not differ between orientations—interaction: F(2, 201) = 0.69, p = .54, η p 2 = .009, BFexcl = 23.5.
After having established that participants learned to prioritize specific parts of the biased object, we explored whether this effect generalized to neutral objects (that were clearly distinct from the biased object; e.g., hammer → shoe). For this purpose, we limited the analyses to participants who started the experiment with the biased object. In line with the main analysis, results showed no evidence that the part of the object that was prioritized in the first half of the experiment (e.g., bottom of shoe) continued to be prioritized when the object switched (e.g., bottom of hammer), not even in the first block, t(40) = 0.48, p = .64, d = 0.075. Together, these findings demonstrate that participants learned to prioritize specific parts of the objects irrespective of the specifics of the object and the viewpoint of those objects.
Experiments 1a and 1b: intertrial repetition effects
A concern in studies examining location-probability learning is that results may reflect intertrial priming instead of statistical learning across longer timescales (Maljkovic & Nakayama, 1994; van Moorselaar et al., 2021). Unlike in previous studies, however, here the high-probability location was not static because it depended on the orientation of the object. Indeed, because the object rotated across orthogonal axes, each retinotopic location contained the target with equal probability. Nevertheless, we also examined whether the observed benefit at the high-probability object location was modulated by intertrial spatial priming (by collapsing the data from biased blocks in Experiments 1a and 1b). Critically, the difference between high- and low-probability locations remained reliable when we excluded all trials in which the target appeared at the same retinotopic locations as in the preceding trial (12.2%), t(159) = 2.35, p = .02, d = 0.19. These findings demonstrate that the observed effects reflect object-based statistical learning over longer timescales rather than intertrial priming effects.
Experiments 1a and 1b: awareness of the high-probability target location
Numerous studies have shown that the extraction of regularities from the environment and the adaptations to these regularities can proceed without the intention to learn and without conscious awareness (Perruchet & Pacton, 2006; Turk-Browne, 2012). Yet in visual search experiments manipulating spatial target probabilities, awareness as probed by post hoc questionnaires is typically relatively high. To examine whether the observed speedup at high-probability object locations was modulated by explicit knowledge, we asked participants at the end of the experiment whether they noticed the spatial imbalance and to indicate which part of the object had a higher target probability. Of the 51 participants who indicated that they noticed the spatial imbalance, only 26 (16 and 10 in Experiments 1a and 1b, respectively) correctly identified the high-probability location. Excluding these participants did not change the overall effect, t(133) = 2.58, p = .011, d = 0.22. Although this does not rule out the possibility that participants had some explicit knowledge regarding the underlying manipulation (Vadillo et al., 2020; Vicente-Conesa et al., 2022), it appears that the observed prioritization did not reflect a deliberate strategy but instead suggested implicit statistical learning.
Experiment 2: Transfer of Object-Based Statistical Learning
Although the results from Experiment 1 confirmed that participants can learn to prioritize specific parts within an object, it remained unclear whether the learned prioritization was specific to display configurations in which learning took place or whether it continued to be applied when that same object was presented in a new viewpoint. That is, in the experiments thus far, all orientations contained the spatial imbalance. In Experiment 2, to test whether learned object prioritization generalizes to new viewpoints once it is in place, we presented the same object in four novel orientations that participants had never seen before after a learning phase. Critically, in this transfer phase, the spatial imbalance was removed, allowing us to test whether learned prioritization within an object remains in place when the object is presented in an orientation in which learning never took place.
Method
The methodology of Experiment 2 was identical to that of Experiment 1, except for the following changes. The final sample (mean age = 27 years, range 19–38; 30 female) was obtained after we replaced five participants who were identified as outliers (two on the basis of overall RTs and three on the basis of overall accuracy). Only a single object was presented throughout the entire experiment (counterbalanced across participants), with the spatial imbalance being present only in the first five blocks. In the final block, we not only removed the spatial imbalance but also changed the axes alongside which the objects were presented, without any explicit instructions, from the cardinal axes (i.e., 0°, 90°, 180°, 270°) to the intercardinal axes (i.e., 45°, 135°, 225°, 315°) or vice versa (counterbalanced across participants 2 ). Finally, at the end of the experiment, participants were asked to indicate whether they noticed the spatial imbalance (yes/no), to indicate whether they noticed that this spatial imbalance was removed when the axes changed (yes/no), and to indicate which part of the object had a higher probability of containing the target. Exclusion of incorrect responses (9.3%) and data trimming (2.4%) resulted in an overall loss of 11.7% of trials.
Results
To examine whether high-probability object locations continued to be prioritized after learning when seen from different viewpoints, we first entered RTs into a repeated measures ANOVA with the within-subjects factors block (biased, neutral) and target location (high probability, low probability, where locations were artificially coded in neutral blocks as high and low on the basis of their status in the biased blocks). As visualized in Figure 3a, targets were again detected faster at high- relative to low-probability object locations—main effect of target location: F(1, 79) = 5.27, p = .024, η p 2 = .063. Critically, although overall RTs were reliably slower in the neutral block—main effect of block: F(1, 79) = 18.16, p < .001, η p 2 = .19, arguably because of the surprise caused by the introduction of new object orientations, the Block × Target Location interaction failed to reach significance, F(1, 79) = 3.02, p = .086, η p 2 = .037, suggesting that the learned prioritization in the biased blocks indeed transferred to the neutral blocks.
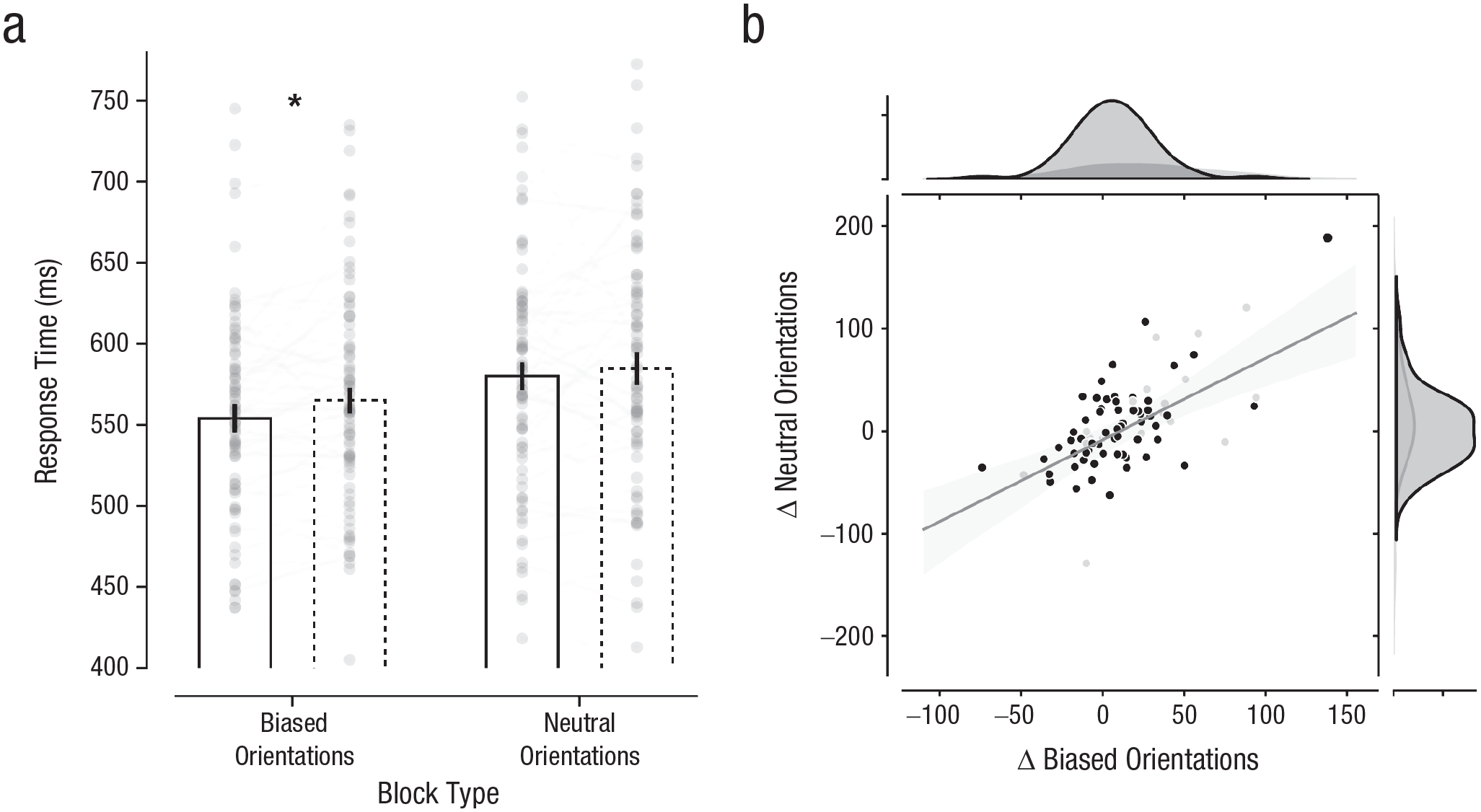
Learned attentional prioritization at high-probability object locations in Experiment 2. Mean response time (a) is shown for each block type and object location. Solid and dashed bars indicate high- and low-probability object locations, respectively. The height of each bar reflects the population average, and error bars represent 95% within-subjects confidence intervals (Morey, 2008). Data from each participant are represented as gray dots. Lines connect each individual participant’s performance. The asterisk indicate a significant between-condition difference (p < .05). The scatterplot (b) shows the relation between the change in neutral orientations as a function of the change in biased orientations. Data from participants classified as aware (i.e., who indicated that they noticed the spatial imbalance and correctly identified the high-probability object location) are shown as gray dots, and data from unaware participants are shown in black. The solid line shows the best-fitting regression and was calculated across all participants.
Although the lack of an interaction is consistent with the idea that the learned effect in the biased blocks generalized to new orientations in the neutral block, it should be noted that the interaction was trending, and a Bayesian analysis yielded only moderate evidence against a model including the interaction term outperforming a two-main-effects model (BFexcl = 4.0). Also, planned pairwise comparisons yielded a reliable difference between the high- and low-probability locations in the biased blocks, t(79) = 3.35 p = .001, d = 0.37, but not in the neutral blocks, t(79) = 1.04, p = .30, d = 0.12. Therefore, we further explored the transfer of learned prioritization across individual participants. As visualized in Figure 3b, there was a relatively strong and reliable correlation between the learned benefit in the biased blocks and the observed difference between the high- and low-probability object locations in the neutral blocks, Pearson’s r(78) = .55, p < .001. Although this correlation was slightly attenuated, it remained highly robust after we excluded seven outliers on the basis of a 1.5 interquartile rule, Pearson’s r(71) = .49, p < .001. This correlation highlights that those participants in which object-based statistical learning was most pronounced also showed the largest transfer to the neutral blocks. Indeed, a pairwise comparison between the high- and low-probability object locations in the neutral blocks limited to those participants in which learning took place in the biased blocks (i.e., RT biased high < RT biased low) showed reliably faster RTs at the high- than the low-probability location, t(48) = 3.38, p = .001, d = 0.48.
Of the 27 participants who indicated that they noticed the spatial imbalance, 20 correctly identified the high-probability location. As is clearly visible in Figure 3b, the transfer from biased to neutral blocks did not differ between participants classified as aware and those classified as unaware. Indeed, the observed speedup at high-probability object locations in the biased blocks, although only marginal, remained reliable when these aware participants were excluded, t(59) = 1.99, p = .051, d = 0.26. Together, these findings demonstrate that once a regularity is learned, the resulting attentional prioritization at high-probability locations continues to be applied without any clear intention in new locations that were not yet encountered and hence in which learning never took place.
General Discussion
The current results add to a growing body of findings demonstrating that the visual system is not only remarkably sensitive to regularities in the environment but also adjusts attentional priority in response to these regularities. Previous research has demonstrated that spatial locations can be prioritized as a function of selection history (Ferrante et al., 2018; Jiang, Swallow, & Rosenbaum, 2013; Jiang, Swallow, Rosenbaum, & Herzig, 2013; Sauter et al., 2019; Wang & Theeuwes, 2018) and that this specific priority landscape can be dynamically adjusted as a function of time (Boettcher et al., 2022; Xu et al., 2021). Recently, it was also demonstrated that statistical learning is structured by target-object category such that the targets that matched recently encountered within-category regularities (e.g., red bag packs) were located faster in a categorical search task (Bahle et al., 2021). Thus, statistical learning not only adjusts priority in time and space but also exerts strong control over the instantiation of category-based attentional templates for subsequent visual searches. The present study adds to this literature, demonstrating for the first time that within particular object representations, the visual system may develop a preferential bias for specific (relevant) parts of that object.
It is important to note that if attentional prioritization would have been in retinotopic (world-centered) coordinates only, there would be no attentional bias in the current experimental setup because the target was presented with equal likelihood at all retinotopic locations. Previous findings of attentional prioritization resulting from statistical learning were explained in terms of weight changes within the spatial priority map; specifically, that locations that were more likely to contain a target were upregulated, and locations that were likely to contain a distractor were downregulated (Theeuwes et al., 2022). The current findings demonstrate that in addition to statistical learning in a spatiotopic reference frame, object-centered attentional systems may also independently adjust attentional priority in response to object regularities. Previous studies have already demonstrated a coexistence of retinotopic and object-centered representations (Theeuwes et al., 2013; Tipper et al., 1999), which is consistent with separate attentional systems for visual object processing and spatial processing. Although spatiotopic organized priority maps are associated with the dorsal “where” pathway, object processing is linked to the ventral stream in inferior temporal cortex (Mishkin & Ungerleider, 1982; Ungerleider & Haxby, 1994). These separate pathways thus allow, at any moment, for the coexistence of separate attentional systems that, as shown by the current findings, both tune their priority to regularities in the environment.
Experiment 2 is critical in that it shows that priority biases within a particular object that were learned from one viewpoint generalize to all other viewpoints, even to those that the participant never saw before. For example, if participants learned to prioritize the head of a hammer when the hammer was presented along the vertical axis (e.g., straight up or straight down), this preference remained in place even when the hammer was presented at a 45° angle, despite participants never having learned to prioritize the head of the hammer when presented in this orientation. The observation that those participants showing the strongest object-based statistical learning also showed the largest transfer to novel orientations highlights the strength of object-based statistical learning. This experiment confirms that there is a generalization of attentional priority with objects that is independent of the viewpoint in which these biases were learned.
Even though this across-viewpoint transfer of learned regularities highlights the strength of object-based statistical learning, it should be noted that the within-object benefits were relatively small across experiments (ΔM = ~9 ms). Given that the effects of statistical learning on attentional selection are usually much larger (see Theeuwes et al., 2022, for a review), one may question the functional significance of within-object statistical learning. That being said, it should be realized that studies investigating object-based attention effects typically report smaller effects than studies investigating spatial attention. Indeed, the first study that demonstrated object-based attention effects reported an object-based effect of 13 ms (Egly et al., 1994), and other paradigms using variants of the classic paradigm reported similar effects between approximately 10 ms and 20 ms (Hecht & Vecera, 2007; Moore et al., 1998). Even though the current paradigm is clearly different from the standard object-based attention paradigms, it may therefore not be that surprising that within-object effects are smaller compared with learned spatial attentional biases. Nevertheless, the current finding is the first demonstration that in addition to space-based statistical learning, the visual system can also generate attentional biases independent of the spatial coordinates of the specific object in space.
It is important to note that most participants were not aware of the spatial imbalance that was present in the display. Even though most studies investigating statistical learning and visual search have reported little to no awareness of the regularities present in the display (see Theeuwes et al., 2022), in the current experiment, one may have expected higher awareness because each object contained only two relevant locations. It could be argued that under such conditions, participants would notice that the target is more likely to be presented at one location and therefore not at the other. At the same time, however, it should be noted that the spatial imbalance was quite subtle (62.5% at the high-probability location), and objects appeared randomly in one of four orientations, which makes the spatial imbalance less apparent. Critically, when all participants who showed some awareness of the imbalance were removed from the analysis, the results remained basically the same. This implies that awareness of the imbalance in the display plays no role in learning (see also Gao & Theeuwes, 2022), and it strengthens the notion that these object-based effects are not strategic in origin.
We claim that through statistical learning the weights within the spatial priority map are adjusted such that relevant locations are upregulated, whereas irrelevant locations are downregulated (Theeuwes et al., 2022). Critically, this spatial priority map is generally assumed to be retinotopically organized because this is an effective principle for initial visual processing allowing for a coherent spatial binding of features across various cortical areas (Itti & Koch, 2001; Zelinsky & Bisley, 2015). Yet the prioritization within objects reported here cannot rely on retinal coordinates but instead must be object-based. Consistent with this notion of an object-based priority map are findings demonstrating that some neurons in the ventral intraparietal area respond to the location of an object in space instead of to the location on the retina (e.g., Duhamel et al., 1997). We have to assume, therefore, that prioritization occurs only after the object has been identified (within the ventral stream) and priority maps associated with the object have been recruited to bias attention toward a particular location within the object.
Although our results support the idea that observers could learn to prioritize specific parts of an object, it should be noted that the viewing conditions in our experiments differed substantially from our real-world interactions with objects. Here, we changed viewpoints by rotating the object, whereas in real-life, such viewpoint changes usually result from a change of perspective initiated by the observer (e.g., as a result of movement). Such user-initiated viewpoint changes could be mimicked in future research using virtual reality (Snow & Culham, 2021). Moreover, we not only limited learning to only two objects but also used the same exemplar of each object throughout the entire experiment. By contrast, in real life, we constantly encounter different variants of specific object categories. To establish higher ecological validity, future research should both include a larger variety of objects and test whether learning is specific to the object exemplar containing the regularity or also generalizes to other object exemplars (e.g., other type of hammers).
In sum, the current findings show that participants are not limited to learning attentional biases within space-based representation (retinotopic coordinates relative to the participant) but can also learn attentional biases that are object-based, operating independently of the spatial coordinates of the specific object in space.
Footnotes
Transparency
Action Editor: Angela Lukowski
Editor: Patricia J. Bauer
Author Contributions