
Abstract
Bimodal bilinguals are hearing individuals fluent in a sign and a spoken language. Can the two languages influence each other in such individuals despite differences in the visual (sign) and vocal (speech) modalities of expression? We investigated cross-linguistic influences on bimodal bilinguals’ expression of spatial relations. Unlike spoken languages, sign uses iconic linguistic forms that resemble physical features of objects in a spatial relation and thus expresses specific semantic information. Hearing bimodal bilinguals (n = 21) fluent in Dutch and Sign Language of the Netherlands and their hearing nonsigning and deaf signing peers (n = 20 each) described left/right relations between two objects. Bimodal bilinguals expressed more specific information about physical features of objects in speech than nonsigners, showing influence from sign language. They also used fewer iconic signs with specific semantic information than deaf signers, demonstrating influence from speech. Bimodal bilinguals’ speech and signs are shaped by two languages from different modalities.
In spoken language, bilinguals activate their two languages simultaneously, allowing the languages to influence each other (e.g., Costa, 2005; Indefrey, Şahin, & Gullberg, 2017). It is not known, however, whether cross-linguistic influence between speech and sign also occurs in bimodal bilinguals, 1 hearing individuals fluent in a sign (visual) and a spoken (vocal) language. Here, we investigated cross-linguistic influence in bimodal bilinguals who are fluent in Sign Language of the Netherlands (NGT) and in Dutch. We focused on the domain of spatial language in which differences in modality are mostly visible with respect to how spatial information is encoded (Emmorey, McCullough, Mehta, Ponto, & Grabowski, 2013).
In sign languages, the hands and body are used for linguistic expression. This allows for the use of visually iconic forms, in which there are varying degrees of visual resemblance between the form of the linguistic expression and its meaning. This is especially prominent in the domain of spatial language (see Fig. 1). Most expressions of spatial language are highly iconic and allow signers to express specific semantic information about the physical features of objects in a spatial relation, such as their shape or orientation. For example, to describe a picture of a pen located to the right of a glass, signers first introduce the lexical signs for the objects involved (e.g., glass and pen) and later choose iconic hand shapes that visually resemble features of each object, such as a round hand shape to depict the round shape of the glass and an index finger to depict the elongated shape of the pen (see Fig. 1a). These hand shapes are then placed into the signing space, corresponding in an iconic way to the relative relation and orientation of the objects in the picture. The iconic hand shapes, called depicting signs (Ferrara & Halvorsen, 2017; also known as classifier constructions, e.g., Emmorey & Herzig, 2003), allow signers to express specific information about the physical features of the objects in addition to the location of objects relative to each other.

Two types of iconic linguistic expressions to describe that “the pen is to the right of the glass” in Sign Language of the Netherlands (NGT). In (a), the hands represent specific information about shape and orientation of the entities located in space (right vs. left). In (b), the hands represent less specific information, forming the lexical sign for “right,” in which the hand shape for spelling the letter “R” moves to the right side in space to indicate the location of the pen in relation to the signer’s body (rightmost picture). RH = right hand; LH = left hand; HS = hand shape.
Signers may also use a less iconic linguistic strategy. They can use lexical signs, such as “left” and “right” (see Fig. 1b; Manhardt et al., 2020). These are performed toward the left or the right of the body to represent the spatial relations between objects. Lexical signs do not express any specific information about the physical features of the objects. Thus, they are more akin to categorical forms such as left and right in spoken languages.
Unlike in sign languages, the vocal modality in spoken languages does not allow visual resemblance between form and meaning. Spoken languages also show more variation among each other in the domain of spatial expressions than sign languages, which are more similar to each other because of the presence of iconicity. Even though some spoken languages can express more specific semantic information about objects’ spatial relations (e.g., Aikhenvald, 2006; Brown, 1994), most spoken languages use arbitrary and categorical speech forms, such as left and right. These forms lack specific information about physical features of objects (for differences in Dutch and NGT in depicting left/right relations, see Manhardt et al., 2020).
Focusing on such differences between sign and spoken languages, we investigated whether and how cross-linguistic influences across modalities occur between NGT and Dutch in bimodal bilinguals’ descriptions of left/right relations. Hearing native NGT and Dutch bimodal bilinguals described spatial relations in each language. These were compared with the productions of their hearing nonsigning and deaf signing peers. Previous studies have shown that bimodal bilinguals use more iconic gestures accompanying speech than their nonsigning peers, indicating an influence from sign language (e.g., Casey & Emmorey, 2009; Weisberg, Casey, Sevcikova Sehyr, & Emmorey, 2020). However, this influence is shown only within the same modality, not across modalities, that is, from sign to gesture but not between sign and speech.
In our study, we first explored cross-modal influences from sign to speech and asked whether bimodal bilinguals’ use of iconic forms can influence expressions in their speech by enhancing semantically specific information about object shape and orientation in their spoken expressions. Alternatively, such influence might not be present because of differences in modality and iconic versus categorical formats of representation in the two languages. Secondly, we examined influences within one modality. We asked whether bimodal bilinguals produce more iconic gestures as well as depict signs along with their spoken utterances (so-called code blends to refer to signs used along with speech in bimodal bilinguals; Emmorey, Borinstein, & Thompson, 2005). Thirdly, in cases in which we found cross-modal as well as within-modality influences, we checked whether these influences occur independent of each other. Finally, we explored whether cross-linguistic influences can be bidirectional, in that speech can also influence sign. Bimodal bilinguals might prefer using more lexical signs for left and right than their deaf peers. For example, their forms may be reduced in iconicity and thus be less semantically specific because of the influence of using categorical and arbitrary speech forms such as left and right in Dutch. If we found bi-directional influences, this would constitute novel evidence that bimodal bilinguals’ productions do not resemble those of two monolinguals in one, as shown for spoken-language bilinguals (see Grosjean, 1989); instead, they can be shaped by two languages from different modalities.
Statement of Relevance
Languages influence each other in bilinguals. Do we also see such cross-linguistic influences when one language is signed but the other is spoken? This was tested in bimodal bilinguals, a special population of hearing language users who acquire both languages early in development. We demonstrated for the first time that modality differences are not a constraint for cross-linguistic influence. Moreover, not only does sign influence speech but also speech influences sign. In particular, our finding that exposure to both languages enriches rather than hinders spoken language is relevant for debates on whether learning sign language is detrimental for spoken-language acquisition, such as for children with cochlear implants. Our findings are also relevant to the broader cognitive-science audience, in whom there is a growing interest in iconicity, the role of the body in language and bilingualism.
Method
The methods reported in this experiment were approved by the Humanities Ethics Assessment Committee of Radboud University.
Participants
The participants were 21 hearing native Dutch and NGT bimodal bilinguals (11 female; age: M = 34.33 years, SD = 16.62). Additionally, 20 hearing nonsigning speakers of Dutch (11 female; age: M = 33.25 years, SD = 10.95) and 20 deaf native NGT signers (16 female; age: M = 34 years, SD = 2.5) were recruited as control groups. We determined sample size on the basis of convenience and previous research (e.g., Casey & Emmorey, 2009; Pyers & Emmorey, 2008; Weisberg et al., 2020) that used bimodal-bilingual sample sizes of fewer than 15 individuals per group. However, no power analyses were conducted in this previous research.
All deaf signers were born deaf and raised by deaf parents. They all acquired NGT at an early age from their deaf signing parents and also acquired Dutch in its written form when entering school (age: M = 3.5 years, SD = 2.8). NGT was the primary language of instruction (for self-rated literacy skills in Dutch, see Table S1 in the Supplemental Material available online). Four deaf signers received a cochlear implant later in their lives (at ages 12, 30, 37, and 48 years, respectively). Hence, none of the signers had access to auditory Dutch from birth. Overall, our deaf signing participants had considerable knowledge of written Dutch. Consequently, they might have experienced some sort of influence from Dutch. However, we expected these possible influences to be less than for bimodal bilinguals, who have more exposure and access to both spoken and written Dutch in production as well as comprehension.
All hearing nonsigners acquired Dutch as their native language and learned additional languages (mostly English, German, or French) later in their lives through instructional settings (for more information on nonsigners’ language background, see Table S2 in the Supplemental Material). We selected hearing nonsigners and deaf native signers as control groups because they acquired Dutch and NGT as their first languages without formal instruction.
All bimodal bilinguals were born to at least one deaf parent, except one who grew up with a deaf sister (younger by a year; when she was born, the family began to learn NGT). Despite this delay in the NGT input, we included this bimodal bilingual participant in our study because of the participant’s very early and naturalistic exposure to NGT. Consequently, all bimodal bilinguals had access to NGT naturally at home and acquired Dutch from the surrounding community from early on (similar to language populations studied by de Quadros, 2018; de Quadros & Lillo-Martin, 2018; Pichler, Lillo-Martin, & Palmer, 2018). Eight of the 21 bimodal bilinguals were trained sign-language interpreters. On a 5-point Likert-type scale, bimodal bilinguals rated their language use (1 = never, 2 = rarely, 3 = sometimes, 4 = most of the time, 5 = all the time) and their proficiency (1 = beginner, 2 = intermediate, 3 = advanced, 4 = native-like, 5 = native) in Dutch and NGT separately, for both comprehension and production. Comprehension scores for Dutch included scores for reading and listening, whereas the scores for NGT included understanding. Production scores for Dutch included speaking and writing, whereas the scores for NGT included signing.
Bimodal bilinguals indicated that they use Dutch (M = 4.80, SD = 0.41) more often than NGT (M = 3.65, SD = 0.93), paired-samples t test: t(20) = −5.21, p < .001, Cohen’s d = −1.59 (effect sizes were calculated using the effsize package; Version 0.7.6; Torchiano, 2019). All bimodal bilinguals rated their proficiency for production in NGT and Dutch to be somewhere between advanced and native-like, although scores were significantly higher for Dutch (M = 4.55, SD = 0.51) than for NGT (M = 3.85, SD = 0.93), paired-samples t test: t(20) = −2.77, p = .012, Cohen’s d = −0.89 (for similar rating asymmetry in bimodal bilinguals, see de Quadros, 2018; de Quadros & Lillo-Martin, 2018). For comprehension, bimodal bilinguals rated themselves as almost native in both Dutch (M = 4.75, SD = 0.44) and NGT (M = 4.50, SD = 0.69), paired-samples t test: t(20) = −1.56, p = .14, Cohen’s d = −0.43. All bimodal bilinguals reported Dutch as the language they speak best and feel most comfortable with. We additionally assessed language proficiency using objective assessment tools for NGT and Dutch. To do so, we used fluency measures such as grammatical and narrative skills for NGT and speech rate in Dutch.
For NGT, we used an assessment tool for narrative production created for British Sign Language development (Herman et al., 2004). Retellings of a 3.41-min video were scored by a deaf native NGT signer on narrative structure, grammar, and in particular, the use of depicting signs. Scores indicated no differences between bimodal bilinguals and deaf native signers in narrative structure, independent-samples t test: t(38) = 0.22, p = .83, Cohen’s d = 0.07, or in the use of depicting signs and other grammatical aspects, independent-samples t test: t(38) = 1.52, p = .14, Cohen’s d = 0.05, showing high NGT proficiency and appropriate use of depicting signs in our bimodal bilingual sample.
For Dutch, we assessed speech fluency by measuring participants’ speech rate (number of syllables/time) using the speech-analysis software Praat (Boersma & Weenink, 2001). Previous research suggests that speech rate and fluency are tightly linked. In particular, higher speech rates are associated with higher language proficiency (e.g., Daller, Yıldız, de Jong, Kan, & Başbagˆi, 2011; Polinsky, 2008). To measure speech fluency, we selected a 30-s speech sample from participants’ retelling of the same narrative that was used for the NGT assessment and calculated participants’ speech rate (for the script, see de Jong & Wempe, 2009). Bimodal bilinguals’ speech rate (M = 3.56, SD = 0.46) did not significantly differ from that of Dutch nonsigners (M = 3.39, SD = 0.43), independent-samples t test: t(39) = −1.21, p = .23, Cohen’s d = −0.39, showing evidence for high Dutch proficiency in the bimodal bilingual sample.
Materials
We used the same stimuli as did Manhardt et al. (2020). These stimuli consisted of 84 displays of four pictures. Each display contained the same two objects but in different spatial relations to each other (i.e., left/right, front/behind, on/in; see Fig. 2). An arrow appeared in the center of the screen and indicated the target picture. We used 28 displays as experimental trials in which the target picture always displayed objects in a left versus right spatial relation, whereas the remaining three pictures depicted other spatial configurations (i.e., front/behind, on/in). In our analysis, we focused on left/right relations. A previous study (Manhardt et al., 2020) had shown that deaf native signers of NGT use a variety of depicting and lexical signs in describing left/right relations. Thus, we decided to focus on left/right relations because they offer variation in the type of signs that signers can choose to use. This allowed us to detect possible cross-linguistic influences in bimodal bilinguals. We included 56 fillers in which target pictures displayed other spatial relations such as front/behind and on/in in addition to left/right.

Example of an experimental display with a ground object (the glass) and a figure object (the pencil) in different spatial relations. The arrow indicates the target picture that the participant needed to describe to the addressee.
We pretested all visual displays to ensure that participants could name the presented objects. We used two sets of lists that were counterbalanced within and across participants and also across sessions. Consequently, bimodal bilinguals did not describe the same pictures across their two sessions.
All experimental displays contained a ground object in the middle and figure objects located around the ground object. Ground objects (e.g., glass in Fig. 2) did not have intrinsic directionality or orientation such as top or bottom. In this way, we made sure that participants used left/right rather than front/behind expressions. The majority of figure objects (e.g., pencil in Fig. 2) did have intrinsic directionality (48 out of 56), allowing a differentiation in object orientation. All ground and figure objects were everyday objects that were familiar to the participants and allowed the use of basic hand shapes for depicting signs (for a complete list of objects, see Table S3 in the Supplemental Material). We counterbalanced the location of each configuration across participants and trials. Furthermore, we kept the orientation of intrinsic figure objects equal across different types of displays. That is, in left/right configurations, we placed elongated objects vertically in relation to the ground object, and the top of the object was pointing upward on the screen. In front/behind/on configurations, we placed the figure object horizontally in relation to the ground object. For in configurations, we placed the figure object vertically inside the ground object. We kept the distance between the ground and figure objects equal across displays for the different spatial relations (e.g., left/right, front/behind).
Procedure
We tested bimodal bilinguals twice, once in NGT and once in Dutch. The two sessions were 3 to 5 weeks apart, and the order of sessions was counterbalanced across participants. Nonsigners and deaf signers were tested only once in their native language. In addition to including the speaker/signer participant, each session also included an addressee to elicit a natural communicative situation and informative descriptions. The addressee was not a naive subject but was employed by the experimenter to create a communicative setting for the participant.
We tested participants individually on a laptop. Three practice trials preceded the experiment. Trials started with a fixation cross shown for 2,000 ms, followed by a display introducing the four pictures for 1,000 ms to familiarize participants with the objects. After that, an arrow pointed at one of the four pictures and disappeared after 500 ms. The four pictures remained on the screen for 2,000 ms so participants had time to plan their spatial descriptions. At the end of 2,000 ms, a gray visual-noise screen was presented. Participants had to describe to the addressee the picture indicated by the arrow after the gray screen had disappeared. After a description was completed, the trained addressee pretended to choose the correct picture from the same four-picture set on a separate tablet. In each trial, participants’ and addressees’ picture displays were arranged differently from each other (e.g., the participant’s target picture was in the upper left corner, whereas the same picture was located in the lower right corner on the addressee’s tablet). This four-picture setup ensured that the participant would give a full and informative description of the target picture so that it could be identified by the addressee. Participants initiated the next trial by pressing the Enter key. We controlled the timing of each trial element (e.g., fixation cross, introduction of four-picture display) to ensure that all participants had equal viewing times of the visual displays before describing them.
Importantly, bimodal bilinguals were not tested in a bimodal bilingual context because that could have enhanced cross-linguistic influence. Thus, during the Dutch sessions, the addressee was always a hearing Dutch native nonsigner. During NGT sessions, both the addressee and the experimenter were deaf native NGT signers. Addressees gave no feedback during the sessions so they would not influence or bias the descriptions. Participants were free to choose how much information they wanted to convey in their picture descriptions to help the addressee identify the correct spatial relation.
Data coding
We coded the linguistic descriptions using ELAN, a free annotation tool (http://tla.mpi.nl/tools/tla-tools/elan/). Trained hearing native Dutch and deaf native signers of NGT annotated and coded the data. We coded Dutch data for speech and manual productions (i.e., iconic gestures and depicting signs) that occurred accompanying speech across nonsigners and bimodal bilinguals. We coded NGT data for signed productions. An additional coder checked all coding to find consensus. If no consensus could be found, we excluded the descriptions from further analyses (5.81% of all descriptions/trials).
Speech productions (Dutch spoken sessions)
For speech, we assessed whether each picture description contained semantically specific information. If descriptions contained only an introduction of the objects and type of the spatial relation (e.g., “the lollipop is to the left of the glass”), we considered them expressions that were not semantically specific. If descriptions contained additional information about the objects’ shape or orientation (e.g., “the lollipop is to the left of the glass and the sugar part of the lollipop is pointing upwards”), we considered them semantically specific expressions.
Manual productions accompanying speech (Dutch spoken sessions)
For manual productions accompanying speech, the deaf native NGT signer distinguished depicting signs from gestures to the best of his or her abilities. We then assessed whether each picture description contained manual productions with semantically specific information (through either iconic gestures or depicting signs; see Fig. 3). We considered manual pro-ductions to be semantically specific if they depicted object shape or object orientation (see Fig. 3b). We considered manual productions to be not semantically specific if they indicated only the location of the figure object in relation to the ground object without depicting shape or orientation information (e.g., with small beat-like hand movements, pointing to the left or right of the participant’s body, or using lexical signs for left and right; see Fig. 3c).

Examples of a target picture (a) and different types of manual productions by bimodal bilinguals used to describe the target picture in Dutch (b, c). In (b), the participant uses a manual production that expresses semantically specific information. While the participant utters, “The lollipop is lying left of the glass,” the participant’s left hand shows the shape and orientation of the lollipop’s stick, and the right hand shows the shape of the glass. In (c), the participant uses a manual production that conveys nonspecific semantic information. A pointing gesture to the left indicates the location of the lollipop in response to the spoken expression, “a glass with a lollipop on the left side.”
Sign productions (NGT signed sessions)
For each signed picture description in NGT, we first distinguished between two main types of descriptions: (a) using depicting signs, which are highly iconic and semantically specific (see Figs. 1a and 1b), and (b) using lexical signs for left and right (see Fig. 1b), which are more categorical than depicting signs and not semantically specific. Second, we coded for double strategies, that is, descriptions that contained lexical signs for left and right followed by depicting signs within one response (depicting signs followed by lexical signs for left and right can also occur, although less frequently; see also Manhardt et al., 2020, for NGT; Sümer, 2015, for Turkish Sign Language).
Data analysis
For Dutch (during Dutch spoken sessions), we first analyzed whether bimodal bilinguals produced more semantically specific picture descriptions than their nonsigning peers. Next, we analyzed whether bimodal bilinguals were more likely than nonsigners to produce spoken descriptions together with manual productions that express semantically specific information. Finally, we combined the two types of data and analyzed occurrences of semantically specific descriptions per modality (i.e., speech only, manual only, speech + manual) in bimodal bilinguals only. The aim of this analysis was to assess whether sign can influence speech and the expressions in manual modality accompanying speech in an independent manner. For example, if we were to find changes in speech, this could be either due to the adaptation of speech to the increased use of iconic gestures or depicting signs in the manual modality or due to direct cross-linguistic influences from sign to speech. This analysis was intended to distinguish between these two types of influences.
For NGT (during signed descriptions), to assess whether speech can influence sign, we analyzed whether bimodal bilinguals produced more descriptions with lexical signs for left and right than their deaf signing peers, reflecting the influence of using categorical expressions in Dutch.
For all analyses, we used binomial data as the dependent variable. Data were averaged over picture descriptions/trials and participants. All analyses were conducted in the R programming environment (Version 3.3.1; R Core Team, 2016). We used the package lme4 (Version 1.1-19; Bates, Mächler, Bolker, & Walker, 2015) to analyze the data in a logistic regression or in a generalized linear mixed-effects regression (Baayen, Davidson, & Bates, 2008). Categorical predictors were coded as numeric contrasts. We used a backward-selection procedure in which insignificant predictors were removed.
Results
Sign influences speech
The results of a logistic regression comparing whether bimodal bilinguals produced more picture descriptions with semantically specific information than nonsigners demonstrated a main effect of group (β = 2.75, SE = 0.31, z = 9.01, p < .001; see Fig. 4a). Bimodal bilinguals produced more speech descriptions that were semantically specific (mean proportion = .12, SD = .32) than their nonsigning peers (mean proportion = .03, SD = .11). Figure 4b illustrates the variety of semantically specific descriptions used by bimodal bilinguals (for the original Dutch version, see Fig. S1 in the Supplemental Material). Object orientation was the most commonly emphasized semantically specific feature.
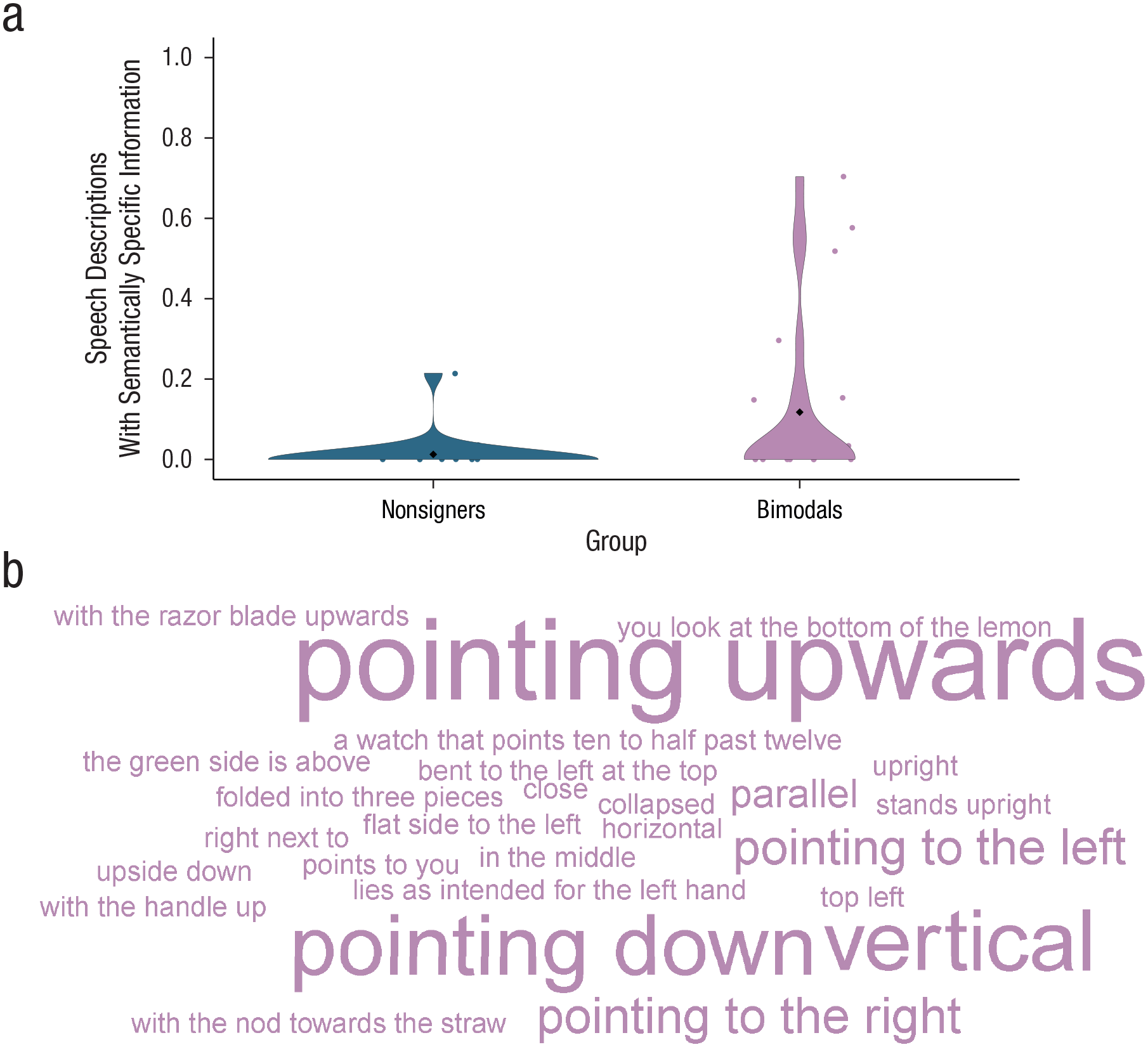
Speech descriptions with semantically specific information. The graph (a) shows the proportion of speech descriptions that contained semantically specific information, separately for nonsigners and bimodal bilinguals. Dots represent individual participant data. Diamonds represent group means. The width of the violin plots indicates the density of the data, and the length of the violins shows the range of data points. The word cloud (b) illustrates the variety of semantically specific descriptions used by bimodal bilinguals (English translations are shown here; for the original Dutch version, see Fig. S1 in the Supplemental Material). Larger font size indicates higher frequency of usage.
There was no effect of session order for bimodal bilinguals (β = 3.52, SE = 2.11, z = 1.67, p = .10), indicating that bimodal bilinguals’ semantically specific descriptions were not due to or primed by describing similar pictures in an earlier session in NGT (for information on the order analysis, see the Supplemental Material).
Sign influences manual productions accompanying speech
Bimodal bilinguals’ overall manual productions were more likely to consist of depicting signs accompanying speech (manual productions per 100 words: M = 0.69, SD = 1.13) compared with gestures (M = 0.11, SD = 0.36), whereas nonsigners rarely gestured (M = 0.05, SD = 0.26). We assessed whether picture descriptions were accompanied by manual productions that expressed semantically specific information across nonsigners and bimodal bilinguals. Note that we did not distinguish between depicting signs accompanying spoken expressions and iconic gestures because we aimed to assess the amount of semantically specific information that each manual production conveyed in general. A logistic regression analysis showed that bimodal bilinguals produced more speech descriptions that were accompanied by semantically specific manual productions (mean proportion = .31, SD = .46) than their nonsigning peers (mean proportion = .01, SD = .11; β = 3.77, SE = 0.39, z = 9.70, p < .001; see Fig. 5).
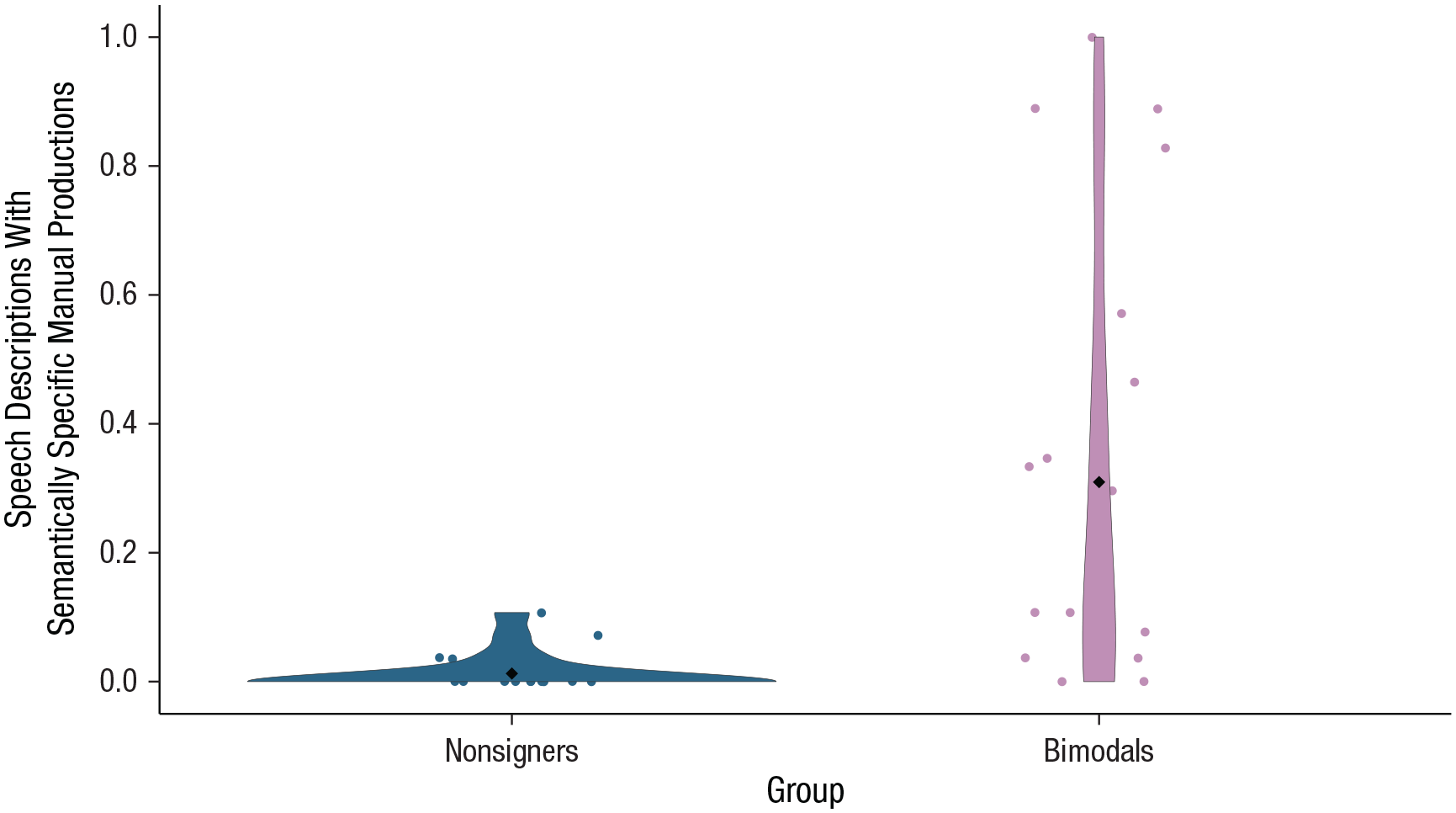
Proportion of speech descriptions that contained semantically specific manual productions, separately for nonsigners and bimodal bilinguals. Dots represent individual participant data. Diamonds represent group means. The width of the violin plots indicates the density of the data, and the length of the violins shows the range of data points.
There was no effect of session for bimodal bilinguals (β = −0.50, SE = 1.52, z = −0.33, p = .74), indicating that the increase in semantically specific manual productions in bimodal bilinguals’ descriptions was not due to or primed by describing similar pictures in an earlier session in NGT (for information on the order analysis, see the Supplemental Material).
Semantically specific information expressed in different modalities
After showing that sign influences both speech and the manual modality accompanying speech, we investigated next whether either type of influence occurs independently or whether expressions in one modality are simply adaptations to the information expressed in the other. To do so, we assessed whether semantically specific expressions occurred in speech, in the manual modality only, or in both modalities simultaneously. The former would indicate independent influences from sign, and the latter would indicate adaptation of changes in one modality to the other.
The most parsimonious generalized linear mixed-effects regression model included random intercepts for participants and items as well as uncorrelated random slopes for modality by items. We found that bimodal bilinguals produced more descriptions that are semantically specific in speech only (mean proportion = .07, SD = .26) or in the manual modality only (mean proportion = .27, SD = .44) than descriptions in both modalities simultaneously (mean proportion = .04, SD = .20; β = 1.50, SE = 0.37, z = 3.89, p < .001; see Fig. 6). Thus, an increase in semantic specificity in speech descriptions or in manual productions can occur independent of each other and show evidence of influence from sign directly. In a second analysis, we compared speech-only with manual-only productions. This analysis revealed that within-modality influence from sign to manual productions was more common than cross-modal influence from sign to speech (β = −2.17, SE = 0.34, z = −6.23, p < .001).
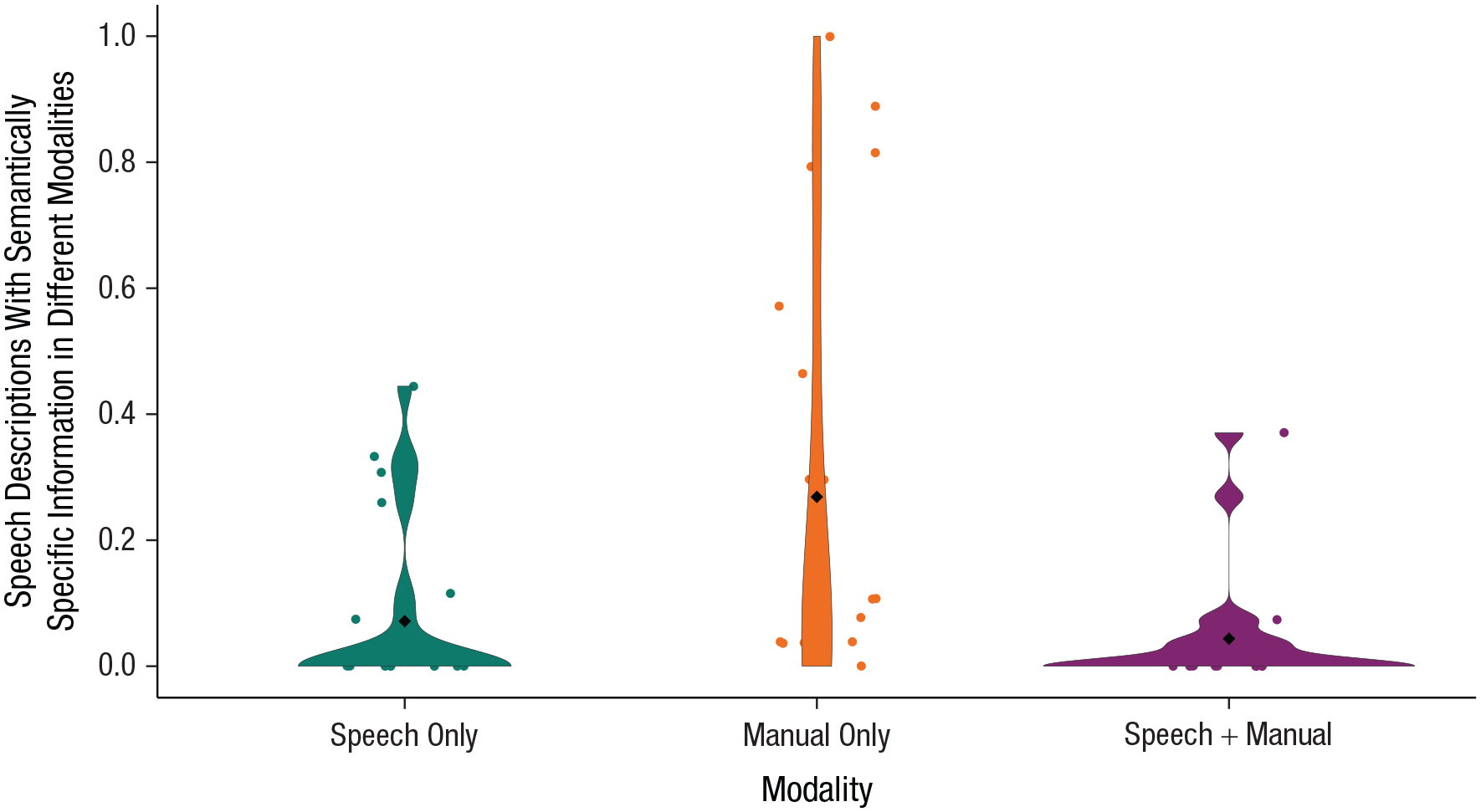
Proportion of speech descriptions that contained semantically specific information, separately for speech-only productions, manual-only productions, and both together. Dots represent individual participant data. Diamonds represent group means. The width of the violin plots indicates the density of the data, and the length of the violins shows the range of data points.
Speech influences sign
To investigate whether speech influences signed expressions, we assessed whether bimodal bilinguals expressed fewer semantically specific expressions, that is, more lexical signs of left/right and fewer depicting signs in NGT because of the influence from using categorical forms in Dutch (e.g., left/right). We therefore analyzed the different description types, such as lexical signs only versus depicting signs only versus double strategies, in deaf signers and bimodal bilinguals.
The most parsimonious generalized linear mixed-effects regression model included random intercepts for participants and items as well as random slopes for description type by items. The analysis yielded main effects of description type and group. Most importantly, the interaction between description type and group was significant when we compared bimodal bilinguals’ descriptions with lexical signs (mean proportion = .27, SD = .45) and depicting signs (mean proportion = .18, SD = .38) with descriptions by their deaf native signing peers (lexical signs: mean proportion = .18, SD = .38; depicting signs: mean proportion = .37, SD = .48; β = 1.76, SE = 0.27, z = 6.52, p < .001; see Fig. 7). The bimodal bilinguals used more descriptions with lexical signs and fewer descriptions with depicting signs, compared with their signing peers. No significant interaction was found when we compared bimodal bilinguals and deaf native signers’ descriptions containing double strategies (β = −0.25, SE = 0.25, z = −0.97, p = .33).
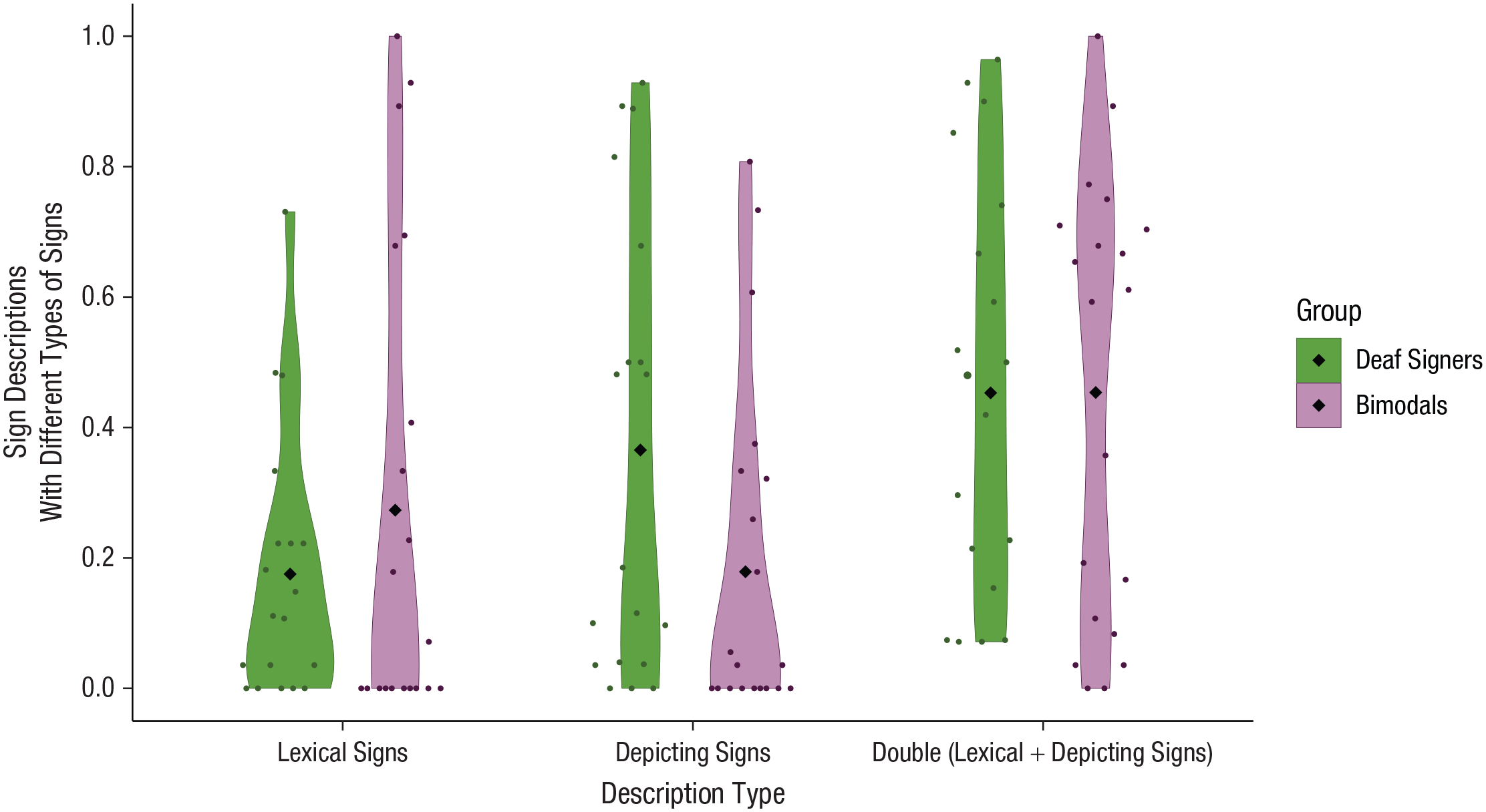
Proportion of descriptions made using lexical signs, depicting signs, and both types together, separately for deaf native signers and bimodal bilinguals. Dots represent individual participant data. Diamonds represent group means. The width of the violin plots indicates the density of the data, and the length of the violins shows the range of data points.
There was a main effect of session order for bimodal bilinguals (β = 1.75, SE = 0.26, z = 6.66, p < .001; for more details, see the Supplemental Material). This suggests that when NGT sessions followed Dutch sessions, bimodal bilinguals used fewer mixed descriptions with double strategies (mean proportion = .41, SD = .49) than descriptions with depicting or lexical signs alone, compared with when NGT sessions preceded Dutch sessions (mean proportion = .50, SD = .49). Crucially, the increased use of lexical signs in bimodal bilinguals’ signed descriptions was not related to the order of sessions. Rather, it was related to cross-linguistic influence across modalities from Dutch to NGT.
Discussion
Bimodal bilinguals expressed more specific information about the physical features of objects, such as their shape and orientation, in speech than did nonsigners, showing an influence from sign to speech. This extends findings regarding cross-linguistic influences within a single modality, specifically in the domain of spatial language in bilinguals (e.g., Indefrey et al., 2017), to cross-linguistic influences across modalities. It further shows that language distance is not an obstacle for cross-linguistic influences in bilinguals (contrary to previous suggestions; e.g., Kellerman, 1979) and can be found even between languages expressed in completely different formats.
Furthermore, in line with previous research (e.g., Casey & Emmorey, 2009; Gu, Zheng, & Swerts, 2019), our results showed that bimodal bilinguals produced more semantically specific manual productions, such as iconic gestures or depicting signs, accompanying their speech than their nonsigning peers. We also showed that both cross-modality and within-modality influences from sign to speech or to manual productions could occur independently. Interestingly, the influence from signs to manual productions accompanying speech was stronger than from depicting signs to speech. Furthermore, enhanced semantic specificity in speech was mostly limited and evident through orientation information about the objects. Semantic specificity in manual productions, however, was found through a variety of specific features, namely, size, shape, and orientation. Therefore, even though sign can influence speech, this influence is more constrained than influence from sign to the manual modality accompanying speech. This suggests that cross-linguistic influences are stronger within the same modality, that is, from sign to manual productions, than across modalities, that is, from sign to speech. This can be because of the lack of corresponding forms between sign and speech.
Lastly, we showed that cross-modal influences can occur in bimodal bilinguals not only from sign to speech but also from speech to sign. Bimodal bilinguals produced fewer descriptions with depicting signs and more descriptions with lexical signs for left and right than their deaf peers. This demonstrates that bimodal bilinguals used fewer semantically specific expressions in their signs because of influence from speech.
Overall, both the bidirectional influences between sign and speech and the influence from sign to the manual modality suggest that bimodal bilinguals activate NGT while speaking Dutch and vice versa. Moreover, these coactivations can occur across modalities. This supports previous claims about the coactivation of sign languages while using spoken languages (e.g., Emmorey, Borinstein, Thompson, & Gollan, 2008; Giezen & Emmorey, 2016), extending evidence from the lexical to the sentence level of spatial descriptions.
Taken together, these findings provide further evidence for an existing bimodal bilingual language-production model (see Emmorey et al., 2008; based on Kita & Özyürek, 2003; Levelt, 1989; also see Lillo-Martin, de Quadros, & Pichler, 2016). The model proposes a shared message generator (preverbal message) but separate and interfacing production systems (i.e., formulators) for sign and speech (see Fig. 8). Additionally, it involves an action generator (a general mechanism for creating action plans) that is responsible for the production of gestures and that interacts with the message generator.
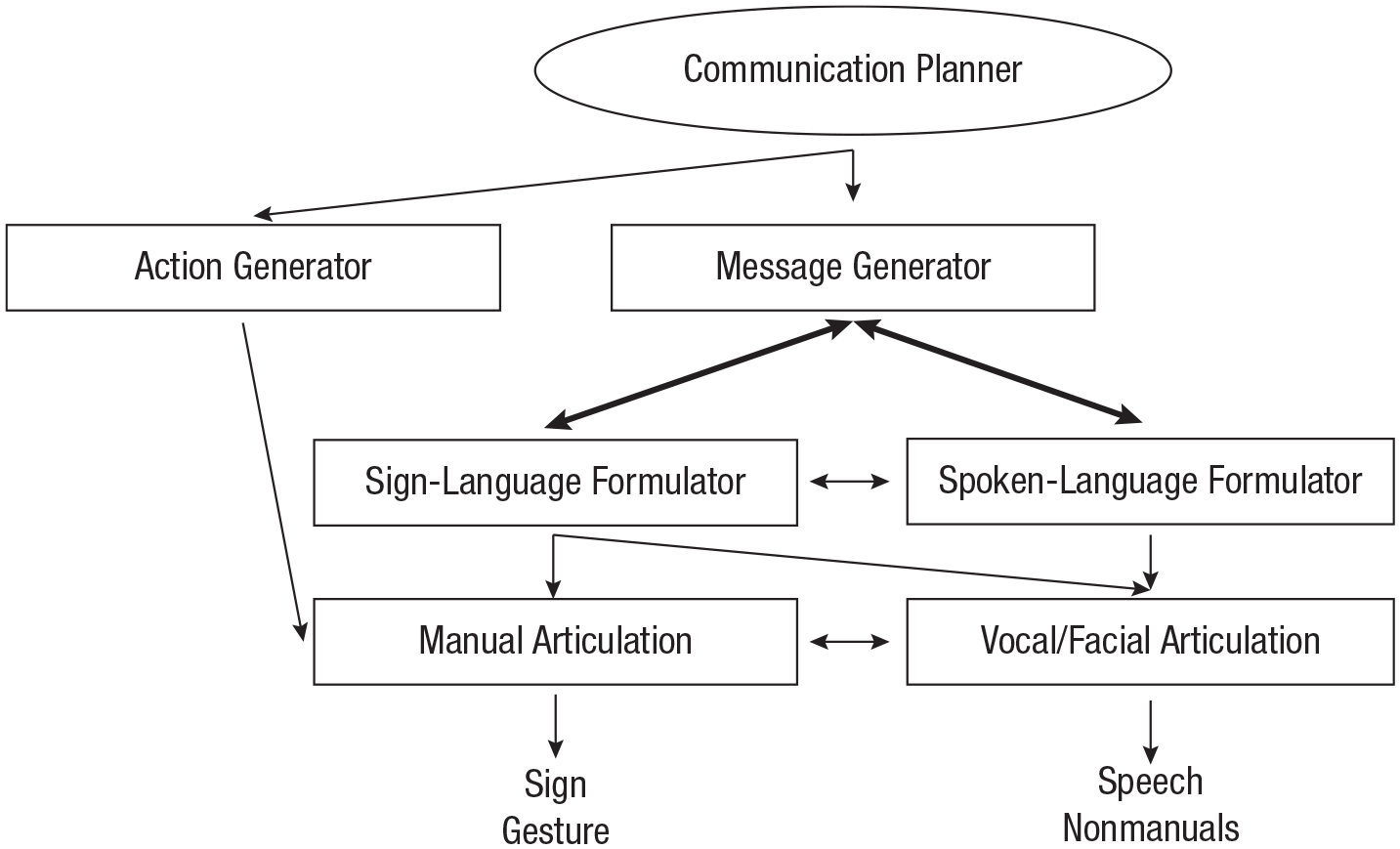
Model of bilingual language production. Bold arrows indicate where our findings provide additional evidence for the model. The model proposes a shared message generator (preverbal message) but separate and interfacing production systems (i.e., formulators) for sign and spoken language in order to produce manual activation, such as signs and gestures, or vocal/facial articulation, such as speech and facial expressions. Additionally, it involves an action generator (a general mechanism for creating action plans) that is responsible for the production of gestures and that interacts with the message generator. Figure adapted from Emmorey, Borinstein, Thompson, and Gollan (2008).
Accordingly, we propose that semantically specific information in the message generator used for iconic NGT expressions, such as depicting signs, could influence bimodal bilinguals to produce more semantically specific expressions in speech through the spoken-language formulator. This then results in cross-linguistic influence from NGT to Dutch. At the same time, manual productions accompanying Dutch could be generated through the route from the message generator influenced by NGT to the action generator, as has been proposed for American Sign Language (Casey & Emmorey, 2009). Speech can influence sign through the message generator, which is affected by categorical forms in Dutch. The message generator influenced by Dutch might then influence the sign-language formulator, resulting in more lexical and less semantically specific signs in NGT. Our study provides the first evidence for the routes between the message generator and both sign- and spoken-language formulators (see Fig. 8, bold lines). This is also in line with assumptions that commonly used expressions in a specific language would guide attention to certain aspects of states and events (Manhardt et al., 2020; Slobin, 2003) at the level of the message generator (Kita & Özyürek, 2003), extending it to the mind of bimodal bilinguals.
Finally, our findings contribute to the debate on using sign language as well as spoken language with children who are deaf or hard of hearing, such as those receiving cochlear implants. Often, speech and hearing professionals advise against using sign language after receiving cochlear implants, arguing that sign interferes in such cases with the development of speech (e.g., Humphries et al., 2012). Our findings show that being exposed to sign together with spoken language from birth does not hinder speech and communication but might make it even richer because bimodal bilinguals’ speech and sign productions are shaped by two dynamically intertwined languages from different modalities.
Supplemental Material
sj-docx-1-pss-10.1177_0956797620968789 – Supplemental material for A Tale of Two Modalities: Sign and Speech Influence Each Other in Bimodal Bilinguals
Supplemental material, sj-docx-1-pss-10.1177_0956797620968789 for A Tale of Two Modalities: Sign and Speech Influence Each Other in Bimodal Bilinguals by Francie Manhardt, Susanne Brouwer and Aslı Özyürek in Psychological Science
Footnotes
Acknowledgements
We thank our bimodal bilingual and deaf participants as well as deaf assistant Tom Uittenbogert. We thank Dilay Z. Karadöller, Beyza Sümer, and Ercenur Unal for help with designing the study.
Transparency
Action Editor: Rebecca Treiman
Editor: D. Stephen Lindsay
Author Contributions
All the authors contributed to the study concept and design. F. Manhardt collected the data. F. Manhardt analyzed and interpreted the data under the supervision of S. Brouwer and A. Özyürek. F. Manhardt drafted the manuscript, and S. Brouwer and A. Özyürek provided critical revisions. All the authors approved the final manuscript for submission.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.