
Abstract
Visual search is facilitated when the target is repeatedly encountered at a fixed position within an invariant (vs. randomly variable) distractor layout—that is, when the layout is learned and guides attention to the target, a phenomenon known as contextual cuing. Subsequently changing the target location within a learned layout abolishes contextual cuing, which is difficult to relearn. Here, we used lateralized event-related electroencephalogram (EEG) potentials to explore memory-based attentional guidance (N = 16). The results revealed reliable contextual cuing during initial learning and an associated EEG-amplitude increase for repeated layouts in attention-related components, starting with an early posterior negativity (N1pc, 80–180 ms). When the target was relocated to the opposite hemifield following learning, contextual cuing was effectively abolished, and the N1pc was reversed in polarity (indicative of persistent misguidance of attention to the original target location). Thus, once learned, repeated layouts trigger attentional-priority signals from memory that proactively interfere with contextual relearning after target relocation.
Keywords
Attentional orienting in scenes is supported by statistical learning of environmental regularities (Palmer, 1975). Thus, for example, finding a searched-for target item, such as some product on a supermarket shelf, is facilitated by having found it repeatedly at the same location within an invariant (i.e., predictable) arrangement relative to other, nontarget (distractor) items. In a comparable laboratory setting, observers are likewise faster in detecting a target letter embedded in a set of distractor letters when the spatial arrangement of the search items is repeated across trials. Such repeatedly encountered target–distractor arrangements, or contexts, come to guide visual search, cuing attention to the target location (a phenomenon known as contextual cuing; Chun & Jiang, 1998). A potential explanation for contextual cuing is that visual search is supported by learned templates that represent spatial target–distractor relations in long-term memory (LTM). If such a template matches the current search display, it becomes activated and guides scanning toward the target location by increasing its priority for the allocation of attention in a top-down fashion (Brady & Chun, 2007).
Just a few (~3) repetitions of a target presented at a fixed location relative to an invariant distractor arrangement suffice to produce a reliable contextual-cuing effect. But once a memory representation of repeated target–distractor relations has been acquired, it does not readily adapt to a change of the target location within an otherwise unchanged distractor context. In fact, such a change immediately and completely abolishes contextual cuing, and it takes an extended period of practice with the changed location (~80 repetitions of each repeated display) for a contextual-cuing effect to be newly established (Zellin, von Mühlenen, Müller, & Conci, 2014). Thus, although initial context learning occurs rapidly, incorporating a relocated target into an existing context representation takes a great many exposures to the new arrangement (Makovski & Jiang, 2010; Manginelli & Pollmann, 2009; Zellin, Conci, von Mühlenen, & Müller, 2013).
Zinchenko, Conci, Taylor, Müller, and Geyer (2019) surmised that this is so because previously acquired target–distractor associations continue to interfere with the updating of the changed contextual relations after the target relocation, because the initially acquired context cues (i.e., acquired spatial LTM templates) persist in directing attention to the original target location. This is consistent with classical notions of automatic attending acquired as a result of perceptual learning and involving the transfer of control from working memory to LTM representations (Logan, 1988; Schneider & Shiffrin, 1977; Shiffrin & Schneider, 1977; Woodman, Carlisle, & Reinhart, 2013). Alternatively, the difficulty of adapting to a changed target location within an otherwise unchanged display layout may simply be due to a general difficulty in establishing a memory representation that is highly similar to an existing one (Palmeri, 1997).
The present study was designed to test the attentional-misguidance conjecture by combining a contextual-cuing paradigm comprising an initial learning phase and a subsequent relocation phase (Manginelli & Pollmann, 2009) with the measurement of lateralized event-related potentials (ERPs), including not only the posterior contralateral negativity (PCN; also referred to as the N2pc) but also the N1pc and the contralateral delay activity (CDA; also referred to as the sustained PCN). The PCN—a negative-going ERP at posterior electrode sites contralateral to the location of an attended item—has been shown to index the allocation of focal attention to a target in visual search (Eimer, 1996; Luck & Hillyard, 1994; Töllner, Conci, & Müller, 2015). From prior electroencephalography (EEG) studies of contextual cuing, it is known that repeated contexts elicit greater PCN amplitudes than nonrepeated contexts (Johnson, Woodman, Braun, & Luck, 2007), with the amplitude of the PCN correlating positively with the size of the behavioral contextual-cuing effect (Schankin & Schubö, 2009). Accordingly, this modulation of the PCN amplitude reflects facilitated attentional guidance to the target location as a result of contextual learning.
An additional component of interest is the N1pc. This component originates earlier than the PCN, approximately 80 ms to 180 ms after stimulus onset, and is primarily considered to reflect an initial, automatic orienting response to salient items in a display array (e.g., Sänger & Wascher, 2011). Moreover, using magnetoencephalography, Chaumon, Drouet, and Tallon-Baudry (2008) already observed an increased negativity to repeated contexts 90 ms after stimulus onset, showing that contextual cuing involves rather early occipital activations. Consistent with this finding, an N1pc effect can be seen in the figures in Schankin and Schubö’s (2009) article (even though they did not explicitly analyze this component). Similarly, Summerfield, Rao, Garside, and Nobre (2011) reported LTM-driven expectation effects (of a target occurring at a certain scene location) to elicit an early P1 response (~130 ms after target onset) at electrodes contralateral to the learned target position, albeit in a nonstandard contextual-cuing paradigm.
Statement of Relevance
Human observers are surprisingly efficient at detecting and learning regularities in the placement of task-relevant target objects embedded in consistent contexts of other (distractor) objects. For example, visual search for a smartphone icon is typically easier and quicker on one’s own device, on which the icons are in a familiar arrangement, relative to someone else’s. Such learned context–target associations come to guide the allocation of attention in visual search, though how this occurs is still not completely understood. We show that even for scenes of abstract items, spatial long-term memory aids attentional processing very rapidly, with the earliest brain signatures of memory-based guidance becoming evident just 80 ms after display onset. Further, these early bias signals persist even after consistent repositioning of the target to another location within the learned scene layout. This indicates that learned scenes generate a fast and involuntary internal orienting response that supports the guidance of attention in visual search.
Finally, even though an explanation in terms of contextual misguidance would mainly relate to mechanisms of attentional orienting and selection (as reflected in the N1pc and PCN), we also examined the CDA, a sustained negativity 400 ms to 800 ms after stimulus presentation that is thought to reflect postselective (focal-attentional) processing of items held in memory (Mazza, Turatto, Umiltà, & Eimer, 2007; Töllner, Conci, Rusch, & Müller, 2013; Woodman & Vogel, 2008). We analyzed the CDA because there is evidence that postselective processing of stimuli in the focus of attention (for selecting the appropriate response) also contributes to the contextual-cuing effect (Kunar, Flusberg, Horowitz, & Wolfe, 2007; Schankin & Schubö, 2009).
Method
Participants
Sixteen participants took part in this study (12 females; age: M = 26.7 years, range = 8 years; all right-handed and all with normal or corrected-to-normal visual acuity). The sample size was determined on the basis of the effect-size measures from previous studies that examined contextual cuing in combination with EEG (e.g., Schankin & Schubö, 2009, 2010). Accordingly, our sample size was appropriate to detect an f(U) effect size of 1.0 with 85% power (η p 2 = .4, groups = 2, number of measurements = 4), given an alpha level of .05 and a nonsphericity correction of 1. The study was approved by the Ethics Committee of the Department of Psychology, Ludwig-Maximilians-Universität München. All participants provided written informed consent and received €20 for taking part in the study.
Apparatus and stimuli
The experimental routine was programmed in MATLAB (MathWorks, Natick, MA) with Psychophysics Toolbox extensions (Pelli, 1997) and run on a Windows 7 Intel PC. Participants were seated in a dimly lit room in front of a 23-in. LCD monitor (ASUS, Taipei, Taiwan; refresh rate: 60 Hz; display resolution: 1,920 × 1,080 pixels) at a viewing distance of 60 cm (participants’ heads were on a chin rest). The search displays consisted of 12 gray items (luminance: 1.0 cd/m2; one target and 11 distractors) presented against a black background (0.11 cd/m2; see Fig. 1). All stimuli subtended 0.41° of visual angle in width and height. The items were arranged on three (invisible) concentric circles around the display center (radii: 1.74°, 3.48°, and 5.22°, respectively). In repeated displays, the locations and orientations of the distractors were held constant across trials; in nonrepeated displays, all distractors (i.e., their locations and orientations) were generated anew on each trial. Note that in all presented displays, the location of the target was repeated, but its left/right orientation was determined randomly and was thus unpredictable. As a result, a repeated context could be associated only with a specific repeated-target location but not with a specific target identity. Following Chun and Jiang (1998), researchers have used this approach in most contextual-cuing studies to ensure that contextual facilitation of reaction times (RTs) is due to the repeated context guiding attention toward a given target location rather than to facilitation of the selection of the manual response invariably associated with a given repeated display.
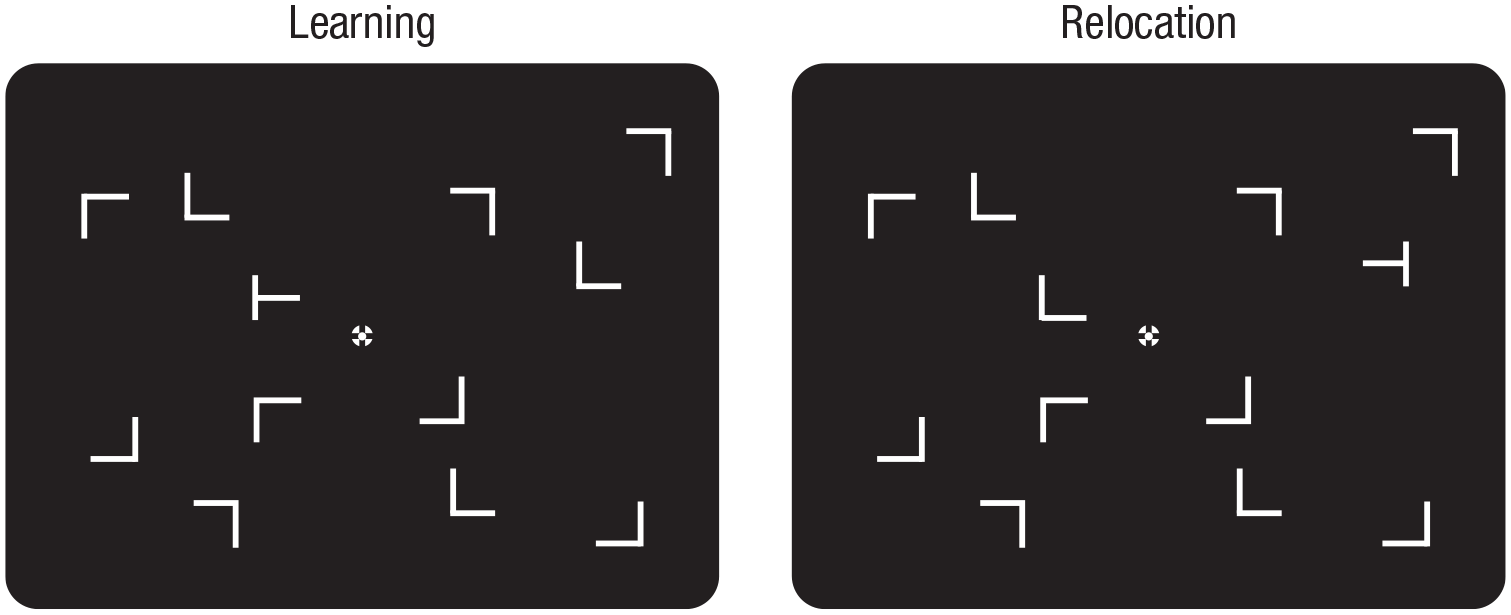
Example of repeated-context search displays in the learning and relocation phases of the experiment. During the learning phase, each display contained an initial target (a T shape rotated 90° to either the left or the right) among 11 distractors; in the subsequent relocation phase, the target was then swapped with a distractor from the opposite hemifield, but the display layout was otherwise held constant.
Targets were randomly positioned on Rings 1 to 3. There were 24 possible target locations overall, eight of which (two in each quadrant) were used for repeated displays with constant distractor layouts throughout the experiment. Another set of eight target locations (two in each quadrant) was used for nonrepeated displays with random distractor arrangements. Finally, a third set of eight target locations (two in each quadrant) was used for repeated displays in the relocation phase. For each type of display, two of the eight target locations were on Ring 1 and three each were on Rings 2 and 3, ensuring comparable variability of target eccentricity across conditions. Importantly, for a given repeated display, the target would be presented in opposite hemifields during the initial learning and the subsequent relocation phase (i.e., the relocated target swapped its position with a distractor in the opposite hemifield; see Fig. 1 for an example).
All displays were balanced—they contained 12 search items, six of which were presented on each side of the central fixation point. The target was also equally likely to appear on the left and the right side of each display type. The target was a T shape rotated randomly by 90° to either the left or the right; the 11 remaining items were L-shaped distractors rotated randomly at orthogonal orientations (0°, 90°, 180°, or 270°). That is, participants had to find a shape that differed from the distractors by a conjunction of two line elements and then discern the shape’s orientation to respond. Even though the task to search for a T among Ls affords some degree of bottom-up guidance (Moran, Zehetleitner, Müller, & Usher, 2013), this is a hard task involving serial scanning, and it leaves ample scope for contextual cues to facilitate top-down attentional target selection and, in turn, to postselectively identify the response-relevant target feature. For this reason, it is the most commonly used task in research on contextual cuing. Each phase (learning, relocation) consisted of 25 blocks × 16 trials (yielding 800 trials in total), with an equal number of repeated and nonrepeated display layouts. Before commencing the experiment proper, participants performed one practice block of 16 trials (data not recorded).
Trial sequence
A trial started with the presentation of a central fixation cross (size: 0.25°; luminance: 1.0 cd/m2) for 500 ms. Participants were instructed to fixate on the cross throughout the trial and use their peripheral vision to locate and identify the target. Each search display disappeared after 700 ms, leaving only the fixation cross, which stayed on screen until the participant responded. If the target T was tilted to the right, they had to press the right arrow button on a computer keyboard with their corresponding index finger; if the target was tilted to the left, they had to press the left arrow button. Following an erroneous response, the word “Wrong” appeared on the screen for 1,500 ms. Each trial was followed by a blank intertrial interval of 1,000 ms.
Eye tracking
To confirm that participants maintained central fixation, we performed concurrent eye tracking using an EyeLink 1000 system (SR Research, Ontario, Canada).
EEG recording
The EEG was continuously sampled at 1 kHz using Ag/AgCl active electrodes (actiCAP system; Brain Products, Munich, Germany) from 64 scalp sites in accordance with the international 10-10 system. To monitor for blinks and eye movements, we additionally recorded the electrooculogram by means of electrodes placed at the outer canthi of the eyes and, respectively, the superior and inferior orbits. All electrophysiological signals were amplified using BrainAmp amplifiers (Brain Products) with a 0.1 Hz to 250 Hz band-pass filter. During data acquisition, all electrodes were referenced to FCz and rereferenced off-line to averaged mastoids. All electrode impedances were kept below 5 kΩ.
Prior to being segmented, the raw data were visually inspected in order to manually remove nonstereotypical noise; subsequently, the data were band-pass filtered using a 0.1 Hz to 70 Hz Butterworth infinite-impulse-response filter (24 dB/octave). Next, an infomax independent-component analysis was run to identify components representing blinks and horizontal eye movements and to remove these artifacts before back projection of the residual components (1% of all trials were removed because of eye-movement artifacts). For the ERP analyses, the continuous EEG was segmented into 1,000-ms epochs relative to a 200-ms prestimulus interval used for baseline correction. Only trials with correct responses and without artifacts (any signal exceeding ±60 μV), bursts of electromyographic activity (as defined by voltage steps or sampling points larger than 50 μV), and activity lower than 0.5 μV within intervals of 500 ms (indicating dead channels) were accepted for further analysis on an individual-channel basis before averaging the ERP waves. To extract the three components of interest (N1pc, PCN, CDA) independently of the spatial location of the target in the left/right hemifield, we subtracted ERPs from parieto-occipital electrodes (PO7 and PO8) ipsilateral to the target’s location from contralateral ERPs. The latencies of the components were defined individually as the maximum negatively directed deflection in the time ranges of 80 ms to 180 ms (N1pc), 180 ms to 350 ms (PCN), and 500 ms to 800 ms (CDA) after stimulus presentation. We computed ERP amplitudes by averaging 10 (N1pc) and 20 (PCN) sample points, respectively, before and after the maximum deflection, and in the case of the CDA, by averaging activity over the time window from 500 ms to 800 ms.
Recognition test
At the end of the experiment, participants performed a yes/no recognition test intended to identify whether they had any explicit memory of the repeated configurations. To this end, eight repeated displays from the search task and eight newly composed displays were shown, and participants were asked to indicate whether or not they had seen a given display previously. The eight repeated and eight nonrepeated displays were presented in random order. Displays were presented with a target at the initial learning-phase location because explicit recognition of a given repeated context (if demonstrable at all) would be expected to manifest more clearly for the initial, more reliably learned target–distractor relations. The recognition responses were nonspeeded, and no error feedback was provided.
Results
Behavioral data
Individual mean error rates and RTs were calculated for each combination of factors (Epoch × Context × Phase). For the RT analysis, trials with errors and with RTs more than 2.5 standard deviations from the mean were excluded from analysis, leading to the removal of less than 2% of all trials. Mean values for each experimental condition were then submitted to a repeated measures analysis of variance (ANOVA) with the factors phase (learning, relocation), context (repeated, nonrepeated), and epoch (1–5; one experimental epoch combining data across five consecutive trial blocks). Greenhouse-Geisser-corrected values are reported when Mauchley’s test of sphericity was significant (p < .05). When interactions were significant, least-significant-difference post hoc tests were conducted for further comparisons.
Figure 2 depicts the mean RTs for repeated and nonrepeated displays for each epoch in the learning and relocation phases. The ANOVA revealed a significant main effect of context, F(1, 15) = 29.23, p < .001, η p 2 = .66, 95% confidence interval (CI) = [.29, .79]. Participants responded faster to repeated than to nonrepeated displays (Ms = 832 ms vs. 901 ms, respectively), which is indicative of an overall contextual-cuing effect (66 ms). The main effects of phase, F(1, 15) = 6.11, p = .026, η p 2 = .29, 95% CI = [.00, .55], and epoch, F(4, 60) = 9.71, p < .001, η p 2 = .39, 95% CI = [.03, .62], were also significant: RTs were shorter in the relocation phase than in the learning phase (Ms = 833 ms vs. 900 ms, respectively), and within each phase (most markedly during learning) they decreased across successive epochs (Epoch 1: M = 933 ms, Epoch 5: M = 818 ms), which is indicative of a general procedural task-learning effect. Most importantly, the Context × Phase interaction was significant, F(1, 15) = 22.44, p < .001, η p 2 = .6, 95% CI = [.20, .76]: There was a robust, significant contextual-cuing effect during the learning phase (119 ms), F(1, 15) = 31.22, p < .001, η p 2 = .68, 95% CI = [.31, .80], but no reliable effect during the relocation phase (17 ms), F(1, 15) = 3.1, p = .098, η p 2 = .17, 95% CI = [.00, .45].
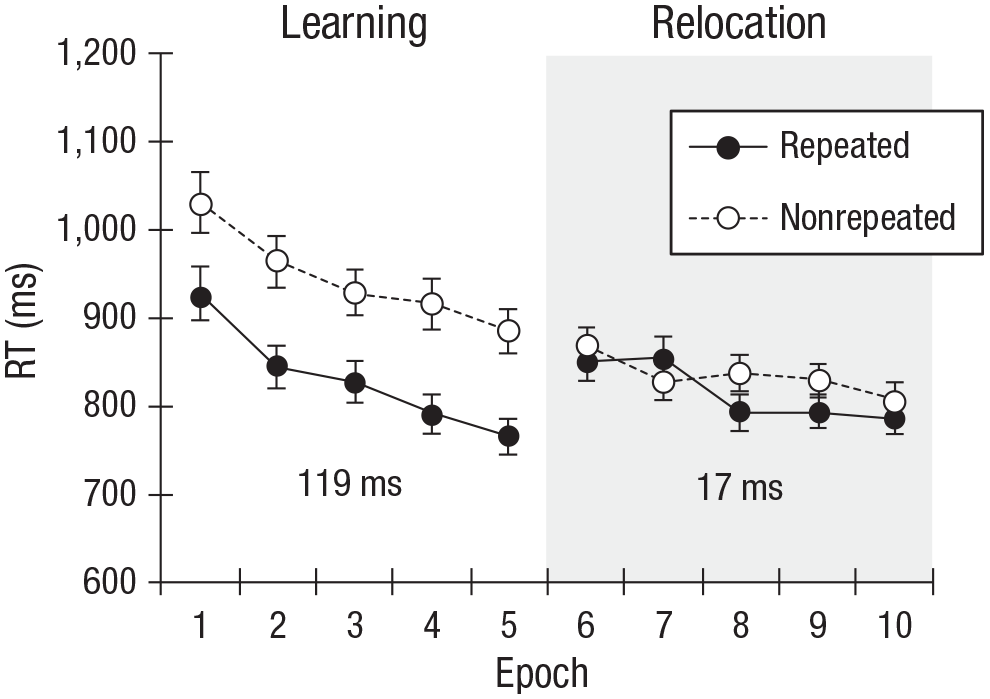
Mean reaction time (RT) for repeated and nonrepeated contexts as a function of epoch, separately for the learning and relocation phases. Error bars indicate 95% confidence intervals. In addition, the mean contextual-cuing effect (RTs to nonrepeated contexts minus RTs to repeated contexts) for each phase is given in numerical values.
Of note, the contextual-cuing effect was statistically significant already in Epoch 1 (i.e., after only five repetitions of each repeated display). This rapid acquisition of contextual cuing is in line with the findings of previous studies (e.g., Geyer, Shi, & Müller, 2010; Conci & von Mühlenen, 2009; Zellin, Conci, von Mühlenen, & Müller, 2011). To examine the evolution of contextual cuing more closely, we compared the cuing effect across the individual (five) blocks of Epoch 1. Contextual cuing was nonreliable in Block 1, F(1, 15) = 3.43, p > .05, η p 2 = .19, 95% CI = [.00, .47], and Block 2, F(1, 15) = 2.89, p > .05, η p 2 = .16, 95% CI = [.00, .44], but was significant from Block 3 onward—Block 3: F(1, 15) = 13.58, p = .002, η p 2 = .48; Block 4: F(1, 15) = 5.21, p = .037, η p 2 = .26; Block 5: F(1, 15) = 5.67, p = .031, η p 2 = .27. Thus, a contextual-cuing effect developed after only two to three encounters of the repeated contexts.
The overall rate of response errors was approximately 12%; this is relatively high by the standards of search RT experiments but modest when the limited display exposure time and the prevention of eye movements are taken into account. A repeated measures ANOVA on the mean error rates revealed a significant main effect of context, F(1, 15) = 4.6, p = .049, η p 2 = .23, 95% CI = [.00, .51]: Accuracy was higher for repeated relative to nonrepeated contexts (Ms = 11.1% vs. 12.8%, respectively). In addition, there was a significant main effect of epoch, F(4, 60) = 2.97, p = .026, η p 2 = .17, 95% CI = [.00, .45]: Participants became more accurate across epochs within a given phase (Epoch 1: M = 13.3%, Epoch 5: M = 10.7%). Finally, the Context × Phase interaction was significant, F(1, 15) = 15.98, p = .001, η p 2 = .52, 95% CI = [.12, .70]: During learning, accuracy was significantly greater for repeated than for nonrepeated displays (Ms = 9% vs. 14.2%, respectively), F(1, 15) = 14.77, p = .002, η p 2 = .5, 95% CI = [.10, .69]. This advantage vanished (turned into a numerical disadvantage) during the relocation phase (repeated contexts: M = 13.3%, nonrepeated contexts: M = 11.5%), F(1, 15) = 3.11, p = .098, η p 2 = .17, 95% CI = [.00, .45]. Thus, the pattern of RT effects is mirrored, and reinforced, by the error effects, ruling out speed/accuracy trade-offs.
Finally, as depicted in Figure 3b, both the eye-tracking data and the electrooculogram showed that participants were very accurate at maintaining central fixation, and there was no difference across the experimental conditions.
Electrophysiological data
Individual mean amplitudes were calculated for each factorial combination, separately for each of the three ERP components. Mean amplitudes for each experimental condition were then submitted to repeated measures ANOVAs with the factors phase (learning, relocation) and context (repeated, nonrepeated). Figure 3a presents the ERP waves contralateral and ipsilateral to the target for nonrepeated and repeated contexts in the learning and relocation phases. Figure 4 depicts the corresponding difference waves for the two phases, and Figures 5a, 5b, and 5c show the mean amplitudes across conditions for the N1pc, PCN, and CDA components, respectively.
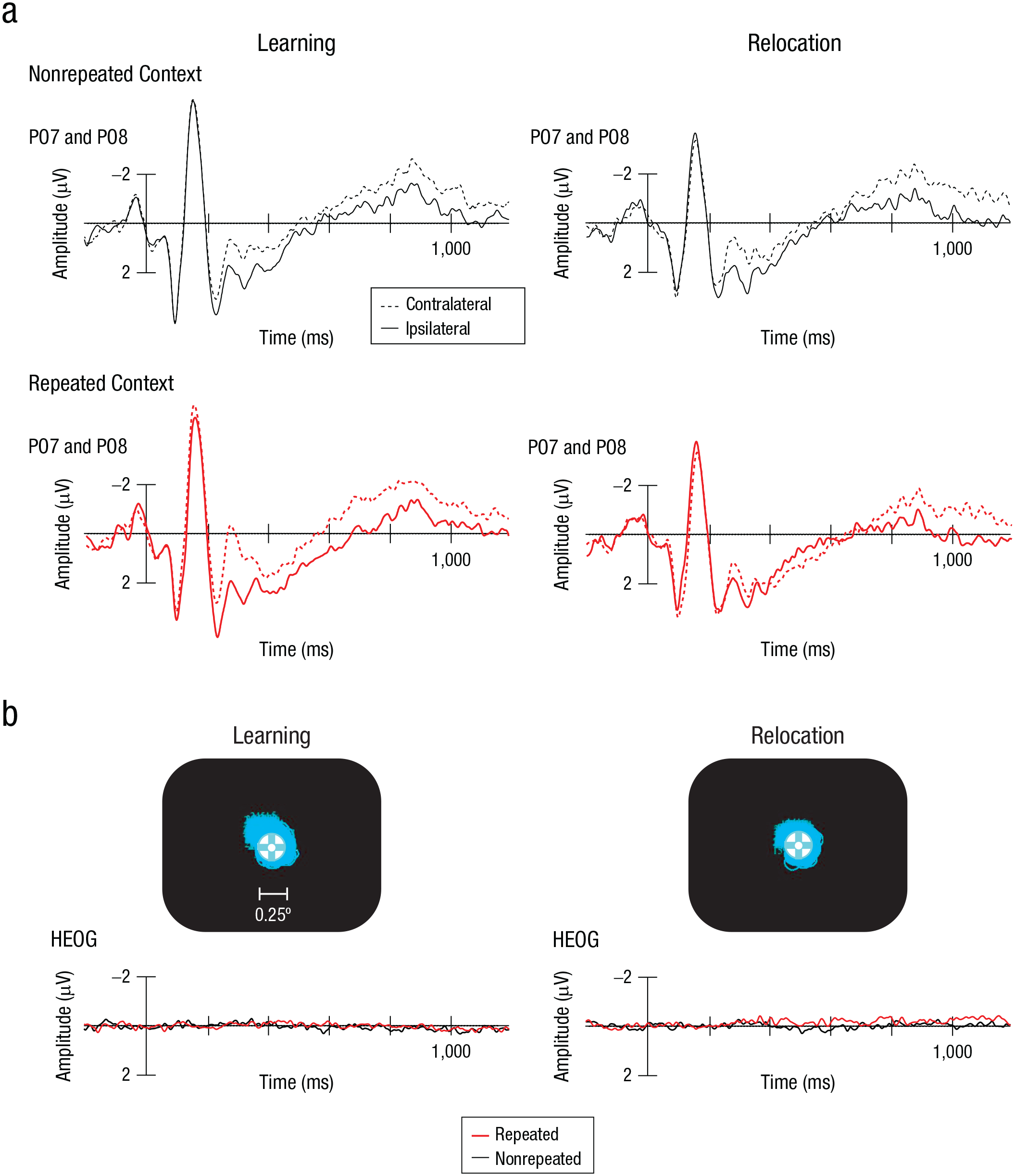
Event-related potentials (ERPs) and eye-tracking data. Grand-average ERPs (a) at electrodes contra- and ipsilateral to the target (PO7 and PO8) are shown separately for nonrepeated (black) and repeated (red) contexts, separately for the learning phase and the relocation phase. The screen captures (b) show eye-tracking data for one representative participant in the learning phase and the relocation phase. The corresponding horizontal electrooculogram (HEOG) waveforms show results for repeated- and nonrepeated-context trials, averaged across all participants.
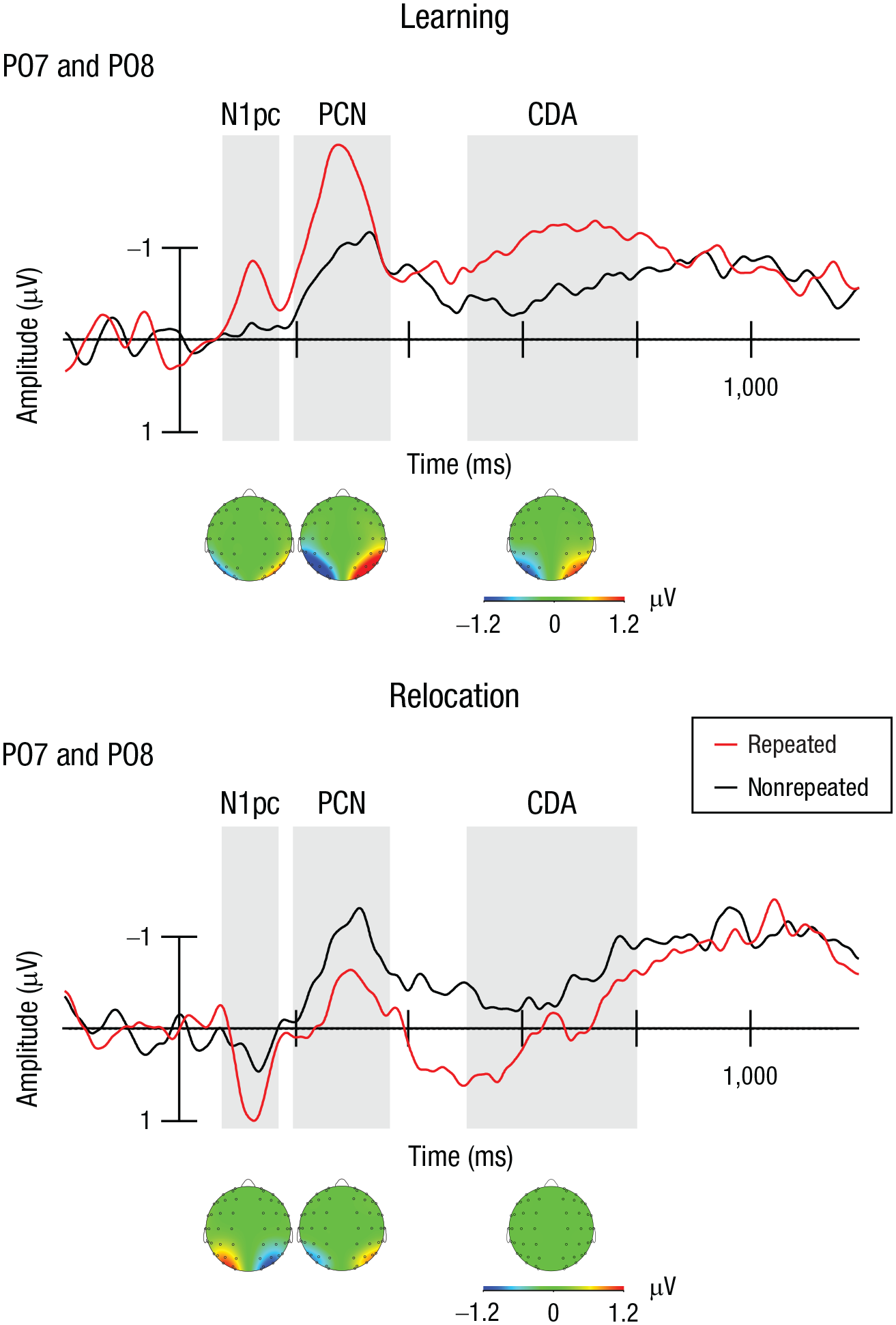
Event-related potential difference waveforms (contralateral – ipsilateral; electrodes PO7 and PO8) for repeated and nonrepeated contexts, separately for the learning phase and the relocation phase. The shaded gray areas illustrate the timing of the N1pc, posterior contralateral negativity (PCN), and contralateral delay activity (CDA) components. Each component is depicted with a corresponding scalp distribution.
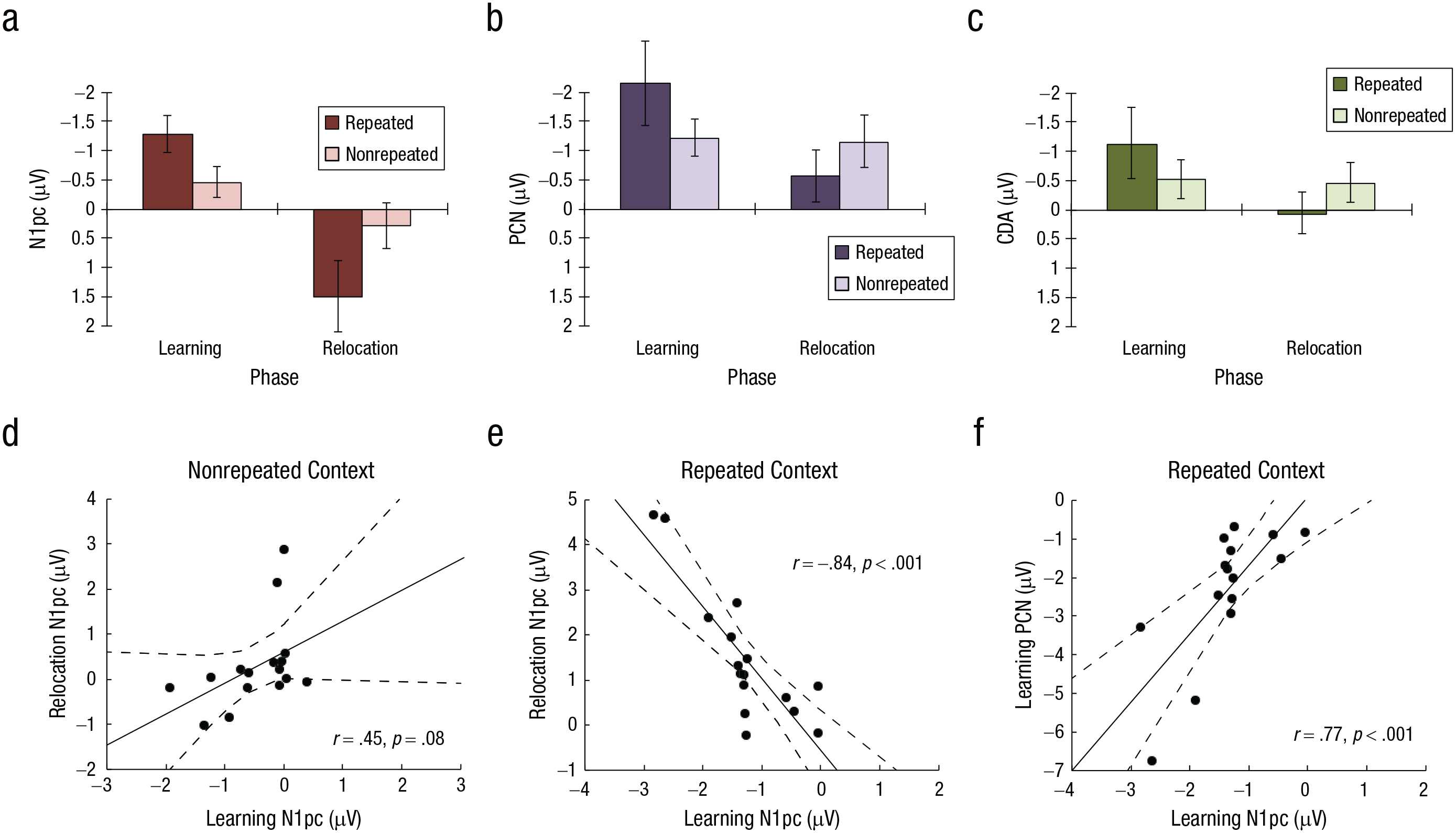
Peak amplitudes and correlations. Mean peak amplitudes in the (a) N1pc, (b) PCN (posterior contralateral negativity), and (c) contralateral delay activity (CDA) components are shown for repeated and nonrepeated contexts in the learning and relocation phases. Error bars indicate 95% confidence intervals. The scatterplots in (d) and (e) show the relation between individual N1pc amplitudes in the learning and relocation phases for nonrepeated and repeated contexts, respectively. The scatterplot in (f) shows the relation between the N1pc and PCN amplitudes in the learning phase for the repeated context. Solid lines indicate best-fitting regressions, and dashed lines denote 95% confidence intervals.
In an initial analysis, we used Welch’s two-sample t tests to compare the mean amplitudes of the difference waves at baseline (200 ms prior to stimulus onset) with the N1pc amplitude in the learning and relocation phases. These analyses confirmed that this relatively small component differed from random fluctuations in the ERP data. Compared with amplitudes in the baseline period, the N1pc exhibited a more negative deflection in the learning phase (N1pc: M = −0.87 µV, baseline: M = −0.0006 µV), t(15) = −6.89, p < .001, Cohen’s d = −3.55, whereas it actually became more positive in the relocation phase (N1pc: M = 0.88 µV, baseline: M = 0.003 µV), t(15) = 3.89, p < .01, Cohen’s d = 2.01.
Next, the N1pc amplitudes were submitted to a Phase × Context ANOVA. This analysis revealed a significant main effect of phase, F(1, 15) = 36.14, p < .001, η p 2 = .71, 95% CI = [.35, .82]; amplitudes in the learning phase were negative, compared with a positive deflection in the relocation phase (learning: M = −0.87 µV, relocation: M = 0.88 µV). Importantly, the Phase × Context interaction was also significant, F(1, 15) = 12.12, p = .003, η p 2 = .45, 95% CI = [.06, .66]: In the learning phase, repeated displays elicited an increased negative amplitude (M = −1.28 µV) relative to nonrepeated displays (M = −0.46 µV), t(15) = −3.34, p < .01, Cohen’s d = −1.72, but this difference was reversed in the relocation phase, in which repeated displays showed a reliable, more positive-going deflection (M = 1.49 µV) than nonrepeated displays (M = 0.28 µV), t(15) = 2.88, p < .02, Cohen’s d = 1.48. Thus, the N1pc exhibited a phase-specific reversal: It showed a negative deflection (and increased amplitude) contralateral to the target for repeated (vs. nonrepeated) displays during initial learning. By contrast, following the target relocation to the position of a distractor in the opposite hemifield, the N1pc exhibited a positive deflection and increased amplitude contralateral to the relocated target for repeated (vs. nonrepeated) displays (Fig. 5a). The latter finding indicates essentially that after the target-location change, the N1pc did show an increased negativity contralateral to the previous (i.e., now ipsilateral) target—as if a spatial bias persisted toward the initially learned target location. In fact, a follow-up analysis comparing the N1pc cuing effects (i.e., the difference in amplitude between nonrepeated and repeated displays) across the first half (Epochs 6 and 7) and the second half (Epoch 9 and 10) of the relocation phase showed that the spatial bias toward the initially learned target location remained undiminished throughout the entire relocation phase (cuing effects in first half: M = −1.96 µV, cuing effects in second half: M = −2.98 µV), t(15) = 1.66, p > .11.
Evidence for such a bias due to learning was also obtained in an additional correlational analysis of the N1pc amplitudes. For nonrepeated displays, the individual mean amplitude showed a positive but nonsignificant relationship between the learning and relocation phases (r = .45, p = .08; see Fig. 5d). For repeated displays, by contrast, there was a strong negative correlation between the N1pc amplitudes in the learning and relocation phases (r = −.84, p < .001; see Fig. 5e); that is, the stronger the negative amplitude deflection during learning, the stronger the positive deflection after the target relocation, which again points to the persistence, in individual participants, of the initial spatial bias toward the originally learned target location.
The analysis of the PCN again revealed a significant main effect of phase, characterized by more negative-going amplitudes in the learning phase (M = −1.68 µV) compared with the relocation phase (M = −0.85 µV), F(1, 15) = 9.92, p = .007, η p 2 = .4, 95% CI = [.04, .62]. The Phase × Context interaction was also significant, F(1, 15) = 5.84, p = .029, η p 2 = .28, 95% CI = [.00, .55]: In the learning phase, repeated displays elicited an increased PCN amplitude (M = −2.15 µV) relative to nonrepeated displays (M = −1.21 µV), t(15) = −2.52, p = .023, Cohen’s d = −1.3. In the relocation phase, by contrast, this difference was nonsignificant overall (repeated: M = −0.56 µV, nonrepeated: M = −1.15 µV), t(15) = 1.795, p = .093, Cohen’s d = 0.92 (see Fig. 5b). Numerically, though, the cuing effect was reversed (suggesting some cost for repeated displays), and if anything, this was more marked in the second half than in the first half of the relocation phase (cuing effect in first half: M = 0.07 µV, cuing effect in second half: M = −0.71 µV), t(15) = −2.12, p = .051. Accordingly, the PCN results show no evidence of adaptation to the target-location change, consistent with the pattern seen in the behavioral data.
An additional correlational analysis revealed that for repeated displays, the negative amplitude deflection during learning in the N1pc was predictive of the strength of the negativity in the subsequent PCN (r = .77, p < .001; see Fig. 5f): That is, the cuing effect in the PCN scaled with the corresponding difference in the earlier N1pc component. Thus, although the N1pc and PCN are typically considered to reflect—at least to some extent—functionally independent processes (which, for instance, reveal differential responses to target relocation), the N1pc nevertheless shows a certain carryover and thus partly determines the subsequent PCN (and possibly also the CDA).
Finally, the analysis of the CDA component yielded a significant main effect of phase, because of more negative-going amplitudes in the learning phase (M = −0.82 µV) compared with the relocation phase (M = −0.19 µV), F(1, 15) = 6.68, p = .021, η p 2 = .31, 95% CI = [.004, .57]. Moreover, the Phase × Context interaction was again significant, F(1, 15) = 7.03, p = .018, η p 2 = .32, 95% CI = [.08, .57], owing to a more negative amplitude for repeated (M = −1.12 µV) than nonrepeated (M = −0.51 µV) contexts in the learning phase, t(15) = −2.13, p = .05, Cohen’s d = −1.09; in the relocation phase, by contrast, the negative-going deflection was abolished for repeated displays (M = 0.07 µV), whereas the amplitude remained consistently negative for nonrepeated displays (M = −0.45 µV), t(15) = 2.43, p < .05, Cohen’s d = 1.25. In brief, the CDA exhibited an enhanced sustained negativity in the learning phase for repeated displays, which then vanished in the relocation phase (see Fig. 5c).
Recognition test
In the recognition test, conducted after the search task, there was no difference between the rates of hits (correct recognition of repeated displays as repeated: 46.1%) and false alarms (erroneous recognition of nonrepeated displays as repeated: 48.4%), t(15) = −0.39, p > .6, Cohen’s d = −0.2. There was, thus, no evidence of explicit context memory in the current experiment, consistent with previous findings (e.g., Chun & Jiang, 1998).
Discussion
In the present study, we examined a series of lateralized ERP components to elucidate the mechanisms involved in the initial acquisition of spatial target–distractor context memories and their adaptation to target-location changes. We observed search-guiding context–target associations to be established rapidly. However, once these associations were acquired, relocating the target to a distractor position in the opposite hemifield within an otherwise unchanged context instantly abolished the contextual-cuing effect, which did not recover within five epochs after target relocation. That is, the initially established set of contextual associations was resistant to incorporating target-location changes—which, according to Zinchenko et al.’s (2019) hypothesis, is likely due to acquired context cues producing massive proactive interference.
In terms of the ERP effects, acquisition of contextual cuing during the initial learning phase was associated with enhanced N1pc, PCN, and CDA components in response to repeated displays. Accordingly, contextual facilitation of search performance involves a whole cascade of processing stages, from early target localization through attentional engagement of the target to focal-attentional stimulus analysis (see below). After the target-location change, the increased negative amplitude for repeated relative to nonrepeated displays either flipped completely and, in turn, exhibited a positive-going deflection (N1pc) or showed no reliable difference (PCN); alternately, the amplitude deflection was significantly reduced (CDA). Thus, both the behavioral and the electrophysiological measures showed a consistent modulation of processing by the change of the target location.
The variation of the N1pc appears to play an important role in the abolishing of contextual facilitation after the target relocation. During learning, the acquisition of search-guiding context cues was associated with an increased negativity as early as 80 ms to 120 ms after stimulus onset—which is consistent, in terms of both timing and topography, with Chaumon et al.’s (2008) magnetoencephalography study. After the relocation of the target to the opposite hemifield, the N1pc reversed its polarity and exhibited a positive-going deflection that was stronger for repeated displays. That is, the N1pc still peaked contralateral to the initial target location, before the target was repositioned to the opposite hemifield. This is indicative of the persistence of the initially acquired spatial bias. This finding is consistent with Pollmann and Manginelli’s (2009) report that following target relocation, overt eye movements still tend to be directed toward the initially learned location. Further, it corroborates Zinchenko et al.’s (2019) hypothesis that the failure to update an established set of contextual associations is attributable to persistent misguidance of attention to the original target location. This misguidance effect reflects an automatized, context-triggered orienting response to a target foil, which is relatively impervious to unlearning and replacement by orienting to the new target location (cf. Schneider & Shiffrin, 1977). In mechanistic terms, repeated target–distractor arrangements may come to be stored as search-guiding templates in spatial LTM. Presentation of such an arrangement on a trial, both before and after target relocation, would rapidly activate the appropriate template, which then biases priority computations to deploy attention to the specified location in a top-down manner. We propose that the observed N1pc modulation reflects part of such an automatized template-matching and visuospatial-orienting process.
Previous studies have linked the N1pc to a reflexive orienting response, such as to perceptually salient stimuli (Sänger & Wascher, 2011; Wiegand et al., 2015). Importantly, in the current study, we observed a comparable automatic orienting response—but not to a stimulus made salient by low-level feature contrast (in fact, all display items were equally nonsalient) but rather to a stimulus cued solely by an acquired spatial LTM representation. This indicates that the N1pc is not exclusively invoked by bottom-up saliency-driven processes; rather, it may also arise when a complex pattern of display items activates an acquired memory representation that biases visuospatial orienting in a top-down manner. To what extent the N1pc in the present study reflects a full-fledged process of LTM template matching and attentional orienting may be debatable. Full orienting to, and engagement of attention at, the indicated target location may take longer than 160 ms and so may be better reflected by the subsequent PCN component (see below). Nevertheless, the strong correlation of the N1pc with the PCN amplitude points to an important, early role of the N1pc in contextual cuing. Specifically, the N1pc may reflect only the first loop in a template-matching and attentional-orienting process that takes several iterations to evolve to full strength over time.
The novelty of our N1pc results may be gleaned by comparing them with Summerfield et al.’s (2011) finding of an early P1 effect. In their paradigm, the critical target displays were realistic scenes with a target located at a scene-specific position, where the association between target location and scene had been acquired explicitly in a session prior to the EEG recording. These target displays were preceded by cue displays (the scenes without the target, previewed for 500–900 ms), allowing the learned target location to be retrieved from LTM and act as a 100% valid spatial-attention cue. This condition was compared with scenes that had also been learned before but without the scene being associated with a target location, which resulted in a neutral-cue condition. Activity specific to valid memory cues became evident only 300 ms to 600 ms after cue-display onset, in line with the time course of voluntary orienting (Müller & Rabbitt, 1989). The P1 elicited by the sudden, salient target onset within the cue display would then be consistent with reports of sensory gain for validly cued targets (Luck, Fan, & Hillyard, 1993). In our standard contextual-cuing paradigm, by contrast, the learning was implicit, the target display was not separated from the cue display, and the target itself was nonsalient, requiring search rather than simple detection. Critically, the N1pc we observed reflected an early bias toward the old location even after the target relocation to the opposite hemifield. Because the old location was now occupied by a distractor, the N1pc likely reflected early memory-cue-related activity. Also, because the acquired memory cue was now 100% invalid, the persistent N1pc toward the old location would indicate that the misorientation was triggered involuntarily, or—in terms of Shiffrin and Schneider’s (1977) “unavoidability” criterion—automatically. In this regard, our results go beyond the work of Summerfield and colleagues: Their early component was target related, and with the explicitly learned and 100% valid memory cues, orienting was likely voluntary (see also Patai, Doallo, & Nobre, 2012; Summerfield, Lepsien, Gitelman, Mesulam, & Nobre, 2006).
The subsequent PCN component, which is thought to reflect the allocation of focal attention to target items, exhibited larger amplitudes when the target was presented within a repeated context during initial learning. This replicates earlier findings (Johnson et al., 2007; Schankin & Schubö, 2009, 2010) and is consistent with the notion of contextual cuing involving facilitated shifting of attention to the target location. However, the change of the target location in the relocation phase abolished (in fact, numerically reversed) the PCN advantage for repeated displays. This suggests that the initially enhanced allocation of attention to, or the engagement of attention at, the original location diminished as a result of the target relocation, without an enhancement already being established for the changed location. In line with Zivony, Allon, Luria, and Lamy’s (2018) recent attentional-engagement (as opposed to “shifting”) account of the PCN, this is perhaps best explained in terms of a lessening of attentional engagement at the old location following the earlier orienting response.
Finally, contextual cuing was also reflected in the CDA component during initial learning. In visual search, the CDA has been linked to postselective processing of the item in the focus of attention: establishing that the selected item is a searched-for target (in the present paradigm, a T) and, if so, extracting the information required for response (the orientation of the T; e.g., Mazza et al., 2007; Töllner et al., 2013; Woodman & Vogel, 2008). In line with this, as well as with previous studies of contextual cuing (Kunar et al., 2007; Schankin & Schubö, 2009), the increased CDA to repeated displays implies that contextual learning also enhances the processing of the target item at a postselective stimulus-analysis stage, perhaps as a result of the enhanced engagement of attention also reflected in the PCN. In the relocation phase, the CDA for repeated displays was substantially reduced. This reduction may reflect less efficient target evaluation after the relocation; in other words, more evidence needs to be accumulated for deciding that the relocated target is a target rather than a distractor, and this evaluation of the target is in turn expressed in prolonged RTs as well as a “washed-out” CDA.
In summary, the present study shows that acquired, LTM-based context cues render a top-down attentional bias toward the learned location. A change of the target location within an otherwise invariant context instantly abolishes the behavioral contextual-cuing effect and interferes with relearning. We argue that this is a result of a persistent misguidance signal, which may be traced back to the medial temporal lobe (Geyer, Baumgartner, Müller, & Pollmann, 2012; Kasper, Grafton, Eckstein, & Giesbrecht, 2015). Electrophysiological markers of guidance became evident already by around 80 ms after display onset. In terms of marker timing and scalp distribution, the guidance signals are comparable with the priority signals produced by salient pop-out stimuli. Strikingly, they persisted even after target relocation, diverting attention away from the new target location—a kind of LTM-induced capture effect.
Footnotes
Transparency
Action Editor: Sachiko Kinoshita
Editor: Patricia J. Bauer
Author Contributions
T. Geyer, M. Conci, and A. Zinchenko developed the study concept. All of the authors contributed to the study design. A. Zinchenko performed testing and data collection as well as data analysis. Data were interpreted by T. Geyer, M. Conci, A. Zinchenko, T. Töllner, and H. J. Müller. A. Zinchenko drafted the manuscript, and T. Geyer, M. Conci, T. Töllner, and H. J. Müller provided critical revisions. All authors approved the final version of the manuscript for submission.