
Abstract
All alphabetic orthographies use letters in printed words to represent the phonemes in spoken words, but they differ in the consistency of the relationship between letters and phonemes. English appears to be the least consistent alphabetic orthography phonologically, and, consequently, children learn to read more slowly in English than in languages with more consistent orthographies. In this article, we report the first longitudinal evidence that the growth of reading skills is slower and follows a different trajectory in English than in two much more consistent orthographies (Spanish and Czech). Nevertheless, phoneme awareness, letter-sound knowledge, and rapid automatized naming measured at the onset of literacy instruction did not differ in importance as predictors of variations in reading development among the three languages. These findings suggest that although children may learn to read more rapidly in more consistent than in less consistent orthographies, there may nevertheless be universal cognitive prerequisites for learning to read in all alphabetic orthographies.
In alphabetic orthographies, letters represent phonemes (speech sounds). Such orthographies differ in their phonological consistency (how predictable the relationship is between letters in printed words and phonemes in spoken words). English, of all languages studied, has the least consistent alphabetic orthography in this respect, and as a result, children appear to learn to read more slowly in English than in languages with more consistent orthographies (Share, 2008; Ziegler & Goswami, 2005). Most evidence about differences in the rate of reading development among different orthographies comes from cross-sectional studies. In a study of 14 European countries, Seymour, Aro, and Erskine (2003) showed that children learning to read in languages with relatively consistent orthographies had fluent and accurate (> 80%) word reading by the end of Grade 1, whereas in English, children had much lower levels of accuracy (34%; see also Share, 2008; Ziegler & Goswami, 2005). However, no study has yet been conducted to directly compare the growth of early reading skills among different language groups in a longitudinal study using directly equivalent measures. Therefore, it is not known how patterns of growth in reading differ, nor whether the predictors of growth in reading skill differ, across languages. We addressed these questions here, in the first cross-linguistic study of the patterns of growth in reading.
Rates of Growth in Different Orthographies
Longitudinal studies focusing on the earliest phases of reading development in individual languages report patterns of growth that are nonlinear in English (Compton, 2003; Skibbe, Grimm, Bowles, & Morrison, 2012; Torgesen et al., 1999), Finnish (e.g., Leppänen, Niemi, Aunola, & Nurmi, 2004; Parrila, Aunola, Leskinen, Nurmi, & Kirby, 2005), and Dutch (Verhoeven & van Leeuwe, 2011). The study by Skibbe et al. (2012) of English-speaking U.S. children from preschool to Grade 2 found that growth in single-word reading skills accelerated at the start of schooling and decelerated in second grade. However, the duration and perhaps the acceleration of the growth spurt that accompanies the start of reading instruction may vary across different orthographies. Children learning to read English seem to undergo a longer lasting growth spurt in kindergarten and Grade 1 (Hill, Bloom, Rebeck Black, & Lipsey, 2008; Skibbe et al., 2012), whereas the growth spurt for children learning the highly consistent Finnish orthography appears limited to the first grade only (Leppänen et al., 2004; Parrila et al., 2005). However, these studies differed in many critical ways, including the reading measures used, which makes comparisons among languages difficult.
Predictors of Growth in Different Orthographies
In addition to understanding the patterns of growth in reading across languages, it is important to understand the cognitive skills influencing individual differences in rates of growth. Claims about possible differences in the predictors of reading achievement in different languages have generated controversy. There is now good evidence that word-reading ability in English is predicted by three core skills: letter knowledge, awareness of phonemes in spoken words, and rapid automatized naming (RAN) of visual stimuli. However, there has been considerable debate about the relative importance of these three abilities as predictors of reading development in other alphabetic orthographies (see Caravolas et al., 2012, and Share, 2008). Some authors have argued that in consistent orthographies, phoneme awareness is a less important, and RAN a more important, predictor of variations in reading ability than in English (e.g., de Jong & van der Leij, 1999; Wimmer, Mayringer, & Landerl, 2000). In contrast, recent large-scale cross-linguistic studies have suggested that the cognitive correlates of word-reading accuracy and speed are relatively similar across orthographies differing in consistency (Vaessen et al., 2010; Ziegler et al., 2010). These studies reported only concurrent associations, however, which makes any claims about causal processes ambiguous.
Recently, we conducted a short-term longitudinal study comparing beginning readers of English with beginning readers of three languages with highly consistent orthographies (Spanish, Slovak, and Czech; Caravolas et al., 2012). Phonemic awareness, letter knowledge, and RAN (assessed prior to or at the start of formal schooling) were longitudinal predictors of reading skill in the middle of Grade 1 and had similar relative importance in all languages. These results suggest that the cognitive skills driving reading development might be universal across alphabetic orthographies. However, we estimated predictors of reading achievement only in the earliest phase of literacy development, when children are learning the alphabetic principle—that graphemes (letters) correspond more or less systematically to phonemes (sounds). In the current study, we explored, for the first time, the patterns of growth and the predictors of all components of growth in three languages over a 28-month period from kindergarten (reception year in England) until the end of Grade 2.
Several longitudinal growth-curve studies have assessed the cognitive skills that predict initial reading levels (intercepts) and rates of growth in reading (slopes) in different individual orthographies (Compton, 2000, 2003; Leppänen et al., 2004; Lervåg & Hulme, 2009; Nakamoto, Lindsey, & Manis, 2007; Torgesen et al., 1999). However, these studies provide few insights into possible differences in the predictors of growth in different orthographies because they focused on different phases of children’s reading development using different measures of reading ability. We argue that, theoretically, if the core predictors of early reading achievement are the same across alphabetic orthographies (Caravolas et al., 2012; Melby-Lervåg, Lyster, & Hulme, 2012), then phoneme awareness, letter knowledge, and RAN should all predict early starting levels of reading (intercepts) in consistent orthographies as well as in English. Moreover, if the learning mechanisms that enable children to develop word-recognition skills are also universal, then the predictors of rates of growth and acceleration of growth should also be similar across orthographies.
The Current Study
No study has reported a direct cross-linguistic comparison of the patterns of growth during the early phases of reading development in consistent versus inconsistent orthographies. Here, we followed three language groups (English, Czech, and Spanish) from our earlier study (Caravolas et al., 2012) and assessed them six times between kindergarten and the end of second grade. All groups had comparable levels of initial reading ability (see Table 1). To ensure parity in the measures used across languages, we created a battery of parallel tests and administered an identical measure of reading at all time points. This design allowed us to ask two questions of considerable theoretical importance. First, do the rates and patterns of growth in early word reading differ as a function of orthographic consistency? Second, do the predictors of individual variations in growth rate vary as a function of orthographic consistency?
Mean Scores and Reliabilities for All Variables at All Time Points for the Three Language Groups
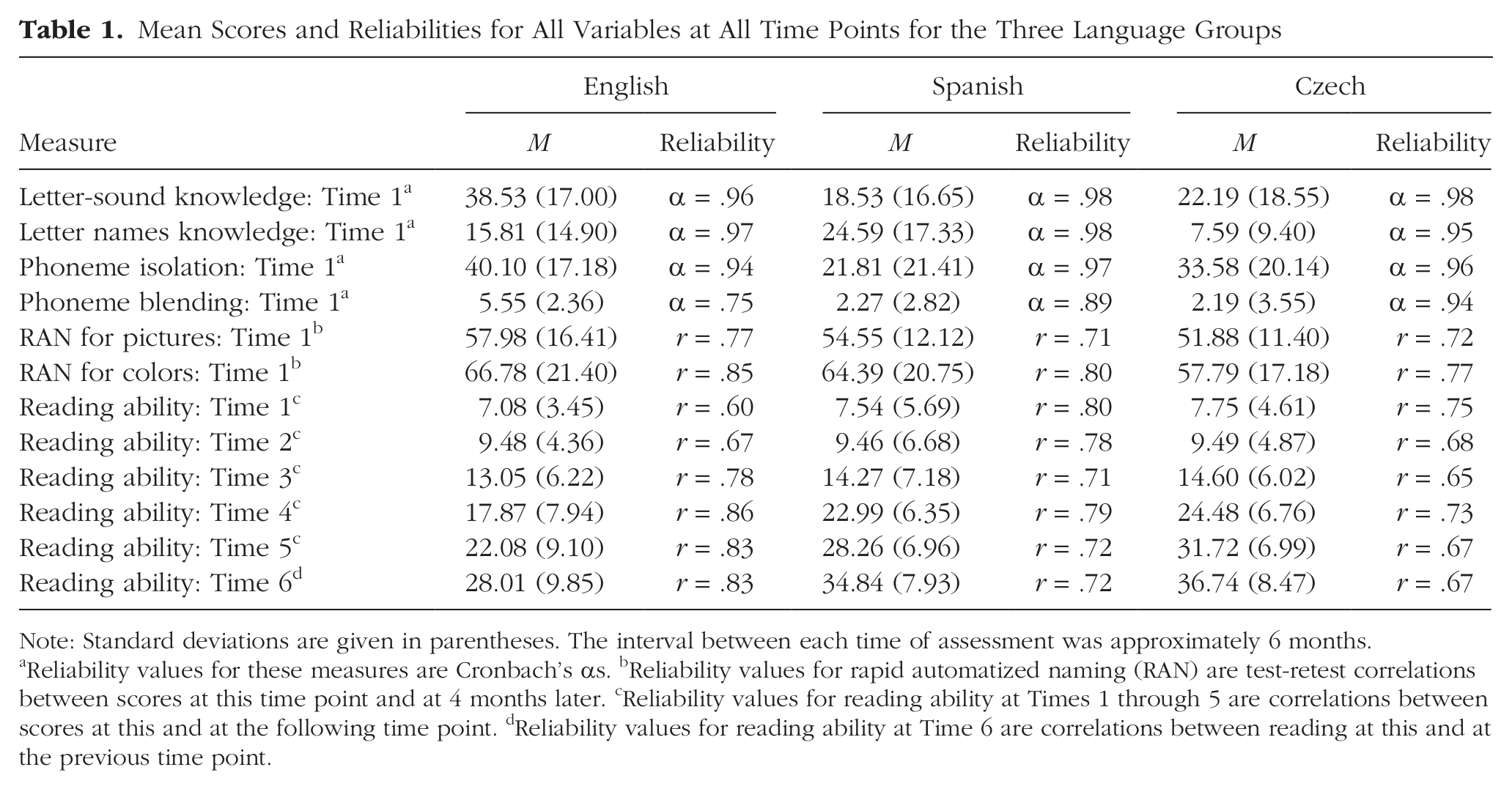
Note: Standard deviations are given in parentheses. The interval between each time of assessment was approximately 6 months.
Reliability values for these measures are Cronbach’s αs. bReliability values for rapid automatized naming (RAN) are test-retest correlations between scores at this time point and at 4 months later. cReliability values for reading ability at Times 1 through 5 are correlations between scores at this and at the following time point. dReliability values for reading ability at Time 6 are correlations between reading at this and at the previous time point.
Method
Participants
Groups of pupils were assessed six times (at intervals of roughly 6 months, at the middle and end of each school year) over 3 school years from reception year (England) and final kindergarten year (Czech Republic, Spain) until the end of second grade. The sample comprised 523 participants. The 185 English participants (97 boys, 88 girls) attended nine primary schools in cities throughout the North of England. The 150 Czech participants (74 boys, 76 girls), recruited from Prague and smaller cities in Bohemia, came from 20 kindergartens and then moved into 44 different primary schools in Grade 1. The 188 Spanish participants (103 boys, 85 girls) attended 5 kindergartens in the first year and 7 primary schools around Granada in the subsequent years of the study. For the whole sample, the percentages of missing children between Time 1 and later time points were 5.35 (Time 2), 5.16 (Time 3), 7.08 (Time 4), 10.13 (Time 5), and 13.96 (Time 6). All children were monolingual. At initial testing, English children had a mean age of 60.27 months (SD = 3.67, range = 53–67), Spanish children had a mean age of 66.72 months (SD = 3.66, range = 61–73), and Czech children had a mean age of 71.86 months (SD = 4.04, range = 64–85). The group differences in age reflect differences in the age of school entry across countries. Further details regarding these groups’ general ability scores and the schooling practices in the three countries are reported in Caravolas et al. (2012).
Measures
Parallel batteries of tests were created in each language. At each time point, children were assessed on a battery of language and literacy tests administered in the same fixed order. Here, we describe only the measures with direct relevance to the present study, namely letter knowledge, phoneme awareness, and RAN, which were measured at Time 1 as predictors of growth, and the measure of reading ability, which was administered at each of the six time points. The descriptive statistics and reliability estimates for each measure are presented in Table 1 (full details of these tasks are given in Caravolas et al., 2012).
Letter knowledge (Time 1)
To assess letter knowledge, we asked children to pronounce the sounds and names of each letter of their alphabet. Letters were presented separately in upper and lower case, and separate estimates of letter-sound and letter-name knowledge were derived by summing across both cases.
Phoneme awareness (Time 1)
We administered two different tasks to measure phoneme awareness: phoneme isolation and phoneme blending. These tasks were parallel in design and content across languages, and we administered them individually on separate days. Phoneme isolation required the child to pronounce in isolation the initial or final phoneme in 32 nonword items; phoneme blending required the child to blend aurally presented phonemic segments into high frequency, imageable words.
RAN (Time 1)
Parallel versions of an object-naming and a color-naming task were created such that, across languages, the depicted stimuli were identical and corresponded to names of one or two syllables that were comparable in familiarity and frequency. In two trials, children were asked to name sequentially and as fast as they could five items repeated eight times over five lines of an A4 (8.3 in × 11 in.) card.
Picture-Word Matching Test (Times 1 through 6)
To assess reading ability, we administered a picture-word matching test. In this test, children read silently and selected from sets of four possible printed words the one that corresponded to an accompanying picture. A graded list of 52 (63 at Time 6) target words was created, which were cognates across all three languages and were equated as closely as possible across languages for grade level, frequency band, and syllable structure. Three distractor words accompanied each target item: These consisted of one with a similar spelling, one with a similar meaning, and one unrelated word. The order of items was the same in all languages, and the order of the target and distractors was counterbalanced. The test was administered in paper-and-pencil format to groups of three to five children for 3 min. Further details are provided in the Supplemental Material available online.
Results
The mean scores, standard deviations, and reliabilities for all variables at all time points are shown for all groups in Table 1. Analyses were done with Mplus 6.1 (Muthén & Muthén, 2011) using maximum-likelihood estimation. Extreme outliers (p < .001) in the reading scores at Time 1 were deleted from the data set. Extreme outliers (p < .001) in other variables were replaced by the next highest value (Tabachnick & Fidell, 2001). Missing values were handled with full-information maximum-likelihood estimation. Correlations among all variables at all time points for the English, Spanish, and Czech samples are shown in Tables S1, S2, and S3, respectively, in the Supplemental Material.
Differences in patterns of growth in reading across orthographies
To compare the growth of reading skills in the three orthographies, we constructed a three-group, unconditional latent-growth model. For the consistent orthographies, we expected slow growth before the initiation of formal reading instruction (Time 1–Time 2), a marked acceleration immediately after formal reading instruction started (Time 2–Time 4), and a period of slower growth once basic alphabetic skills were acquired at the later time points (Time 4–Time 6). For the English group, which had just begun formal instruction at the start of our study, we expected relatively faster growth at the outset, followed by a steadier rate of growth. To model this pattern, we estimated a piecewise growth model in which the first part (Times 1–4) consisted of a quadratic model, and the second part consisted of a linear model. This model had four growth constructs; a simplified graphical description of it is shown in Figure 1. The first construct (intercept) represents the initial level of reading skills at Time 1. The second construct represents early linear growth (Slope 1: the instantaneous rate of linear growth at Time 1). The third construct (quadratic) represents the acceleration of growth between Times 1 and 4, and the fourth construct (Slope 2) represents the rate of linear growth between Times 4 through 6.
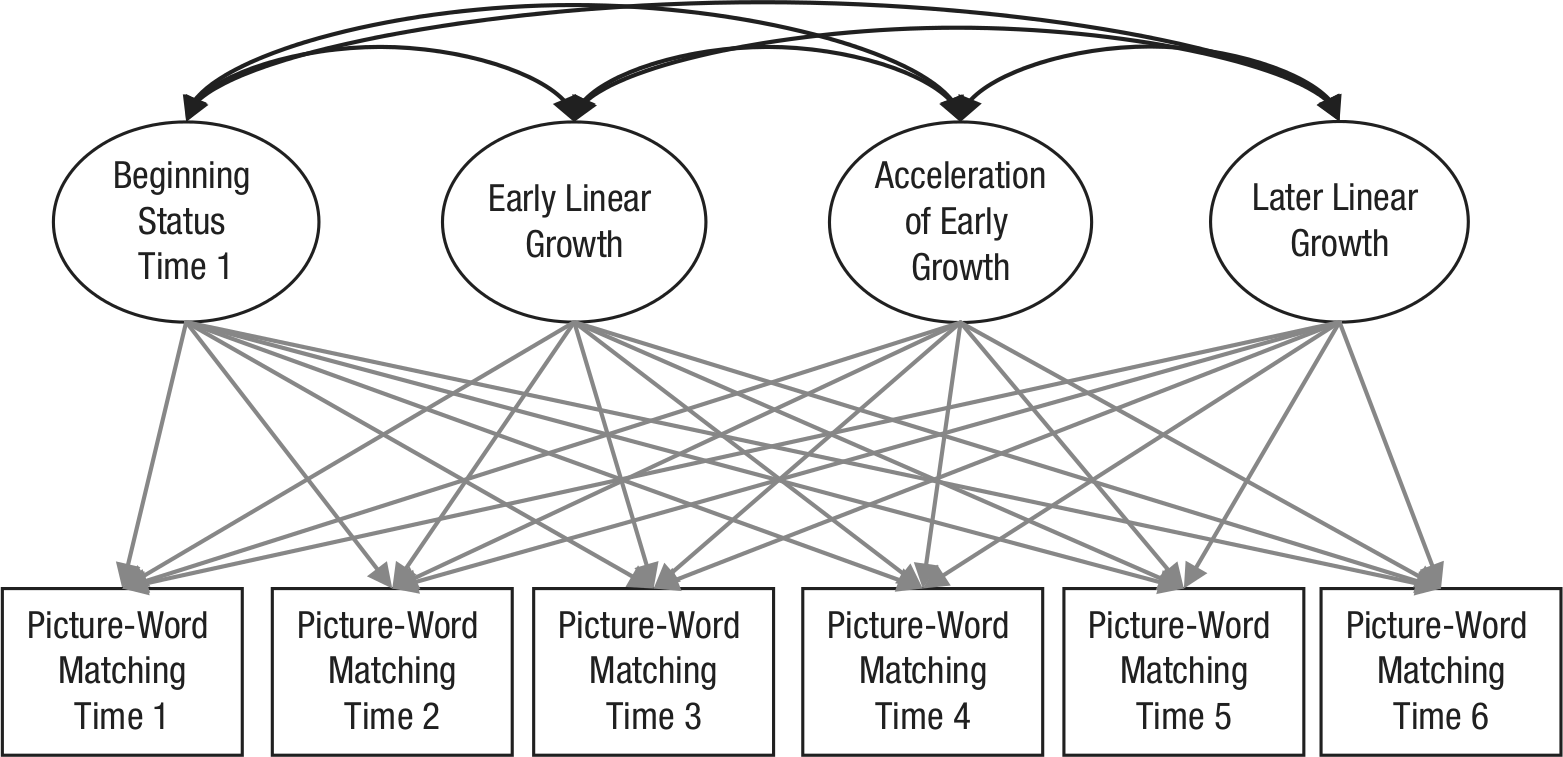
Unconditional three-group piecewise growth model of beginning reading skills. The rectangles refer to the observed reading variables at the six time points, and the ellipses refer to the latent growth constructs that underlie reading ability from Times 1 through 6. The gray arrows represent the factor loadings that are fixed in order to produce the four latent growth constructs: These constructs are initial level of reading skills (beginning status), the instantaneous rate of growth at Time 1 (early linear growth), the acceleration of growth between Times 1 and 4 (acceleration of early growth), and the linear growth between Times 4 and 6 (later linear growth). The black arrows represent the covariances (correlations) between the latent growth constructs.
This model, in which the residuals of the observed variables were fixed to be equal but the four growth constructs were freely estimated over the three groups, fitted the data very well, χ2(33, N = 523) = 45.52, p < .072; comparative fit index (CFI) = .994; Tucker-Lewis index (TLI) = .992; root mean square error of approximation (RMSEA) = .047, 90% confidence interval (CI) = [.000, .077]; standardized root mean residual (SRMR) = .053. This model was then used to test for mean differences in each of the four growth constructs over the three orthographies.
The means and standard deviations for the final model, in which means that were not significantly different were fixed to be equal, are shown in Table 2. The correlations between the different growth constructs for each language group in this unconditional-growth model are shown in Table 3. Although children in all three orthographies started out with equal reading skills, the growth patterns differed between the English group and the Spanish and Czech groups. The latter two groups showed faster growth in reading than English children did once formal reading instruction began. This final model fitted the data very well, χ2(37, N = 523) = 51.81, p < .054; CFI = .993; TLI = .991; RMSEA = .048, 90% CI = [.000, .077]; SRMR = .063; the estimated mean growth curves are plotted in Figure 2. Despite faster growth at the outset, the English group showed steadier early growth during reception year and Grade 1 than the Spanish and Czech groups did; this was indicated by a significantly slower acceleration term. For the Spanish and Czech groups, the acceleration of early growth was pronounced and strongly negatively correlated with the early linear growth. Children who started with a steep linear growth did not accelerate as quickly later on compared with those who showed slower early growth (presumably because there is a limit to the maximal rate at which reading can grow in this period). After a growth spurt in Grade 1, the children learning more consistent orthographies resumed a linear pattern of growth in reading, albeit at a faster rate than their English peers.
Means for the Unconditional-Growth Model
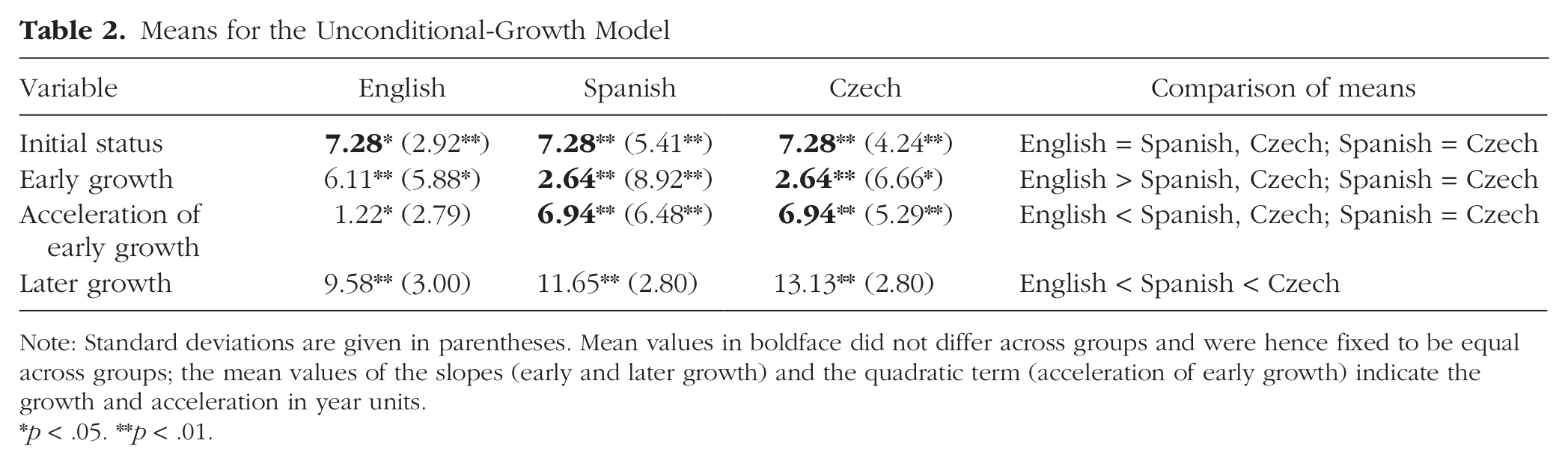
Note: Standard deviations are given in parentheses. Mean values in boldface did not differ across groups and were hence fixed to be equal across groups; the mean values of the slopes (early and later growth) and the quadratic term (acceleration of early growth) indicate the growth and acceleration in year units.
p < .05. **p < .01.
Correlations Between Growth Constructs in the Unconditional-Growth Model for the Three Language Groups

p < .05. **p < .01.
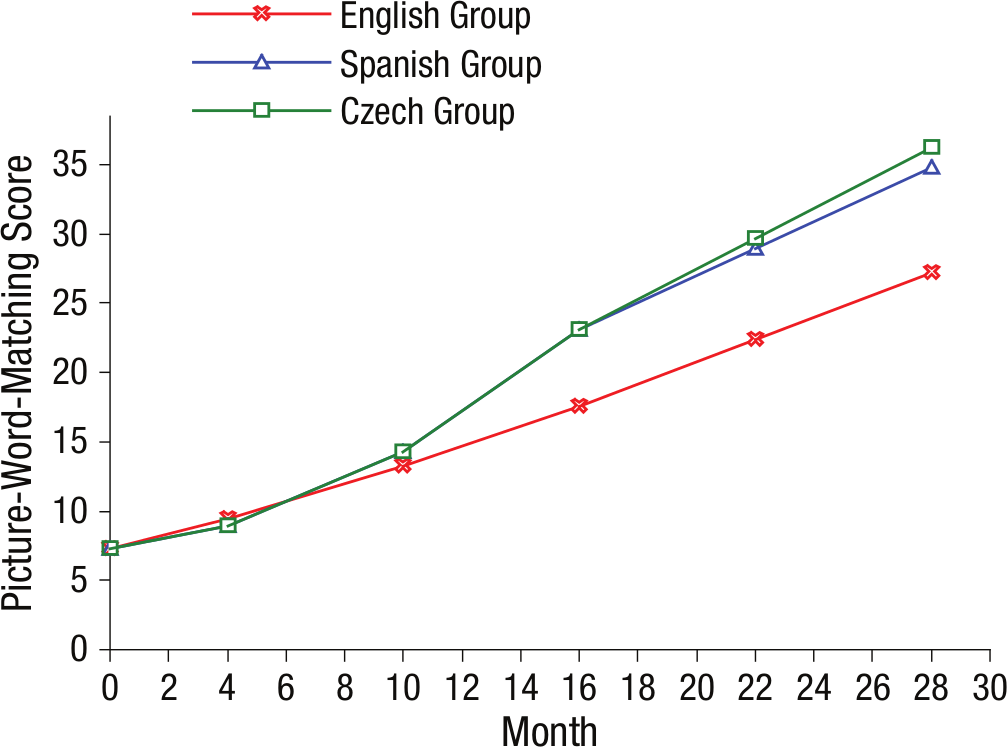
Results from the unconditional three-group piecewise growth model: estimated reading ability (measured by scores on the picture-word matching test) as a function of time.
Differences in the prediction of growth in reading across orthographies
We next examined whether letter knowledge, phoneme awareness, and RAN at Time 1 differed in influence as predictors of individual differences in the growth of reading skills across the three orthographies. To simplify the models, we constructed composite scores of the z-transformed variables (M = 0, SD = 1) of the three predictor constructs. We then constructed a three-group model in which the four growth constructs were predicted from the three predictors. In addition, we let the lower-order growth constructs predict the higher-order growth constructs. This was done so that the impact of the predictor variables on the later growth constructs would not be confounded by covariation between the predictor variables and the earlier growth constructs (see Lervåg & Hulme, 2010, for a discussion). In the current model, initial linear growth was negatively correlated with the acceleration of growth. Therefore, when we assessed whether a predictor was related to the acceleration of growth, we partialed out the effects of initial linear slope (a failure to do so would have resulted in a negative correlation between the predictor and acceleration, which would be an artifact of the negative correlation between the initial slope and the acceleration term). A path diagram summarizing the model is shown in Figure 3. This model fitted the data well, χ2(51, N = 523) = 62.55, p < .129; CFI = .995; TLI = .991; RMSEA = .036, 90% CI = [.000, .064]; SRMR = .039, and was used as a baseline model in order to test the degree to which the impact of letter knowledge, phoneme awareness, and RAN on the four growth constructs differed between the three groups.
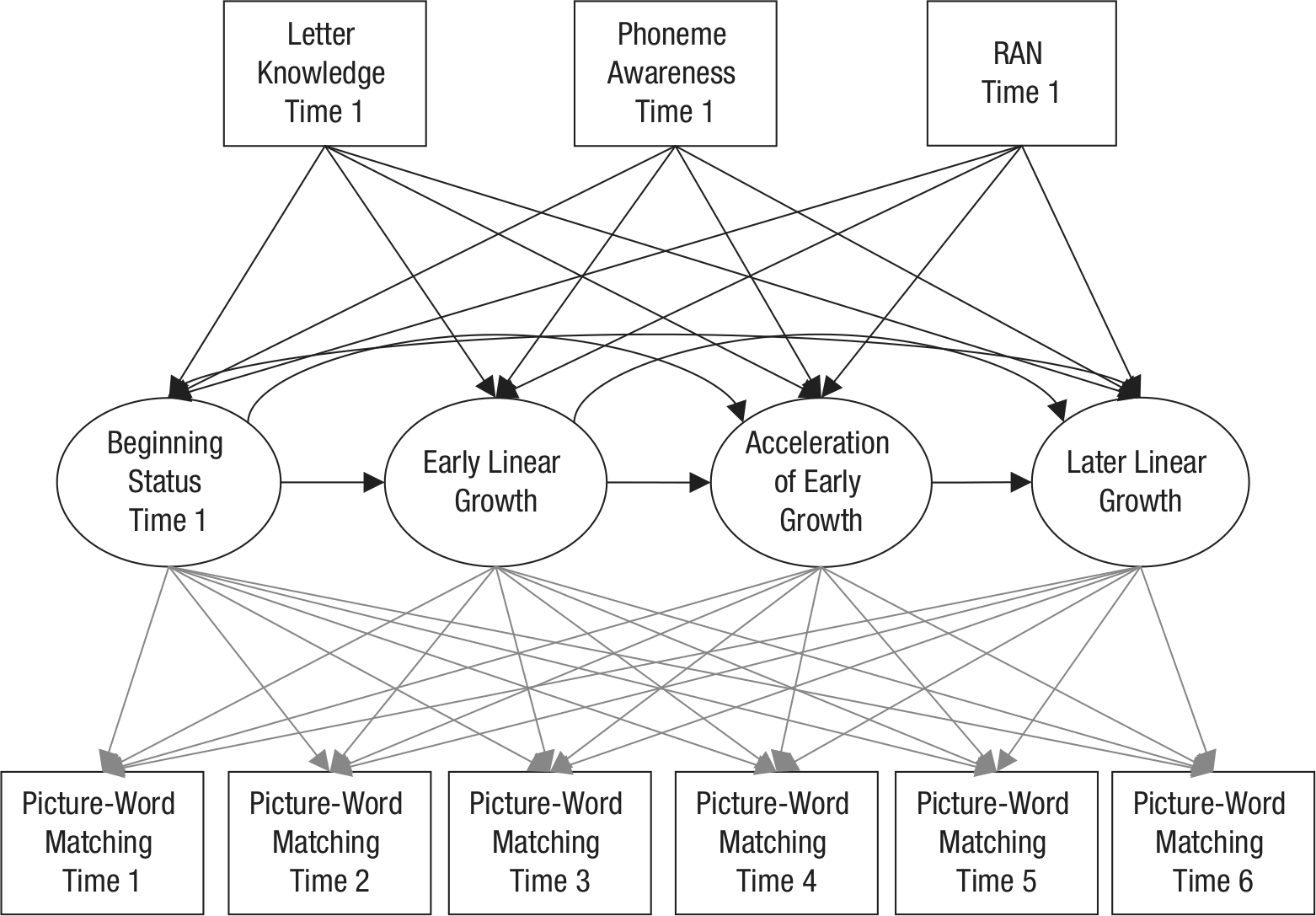
Conditional three-group piecewise growth model: the growth of beginning reading skills as predicted from letter knowledge, phoneme awareness, and rapid automatized naming (RAN). The rectangles represent observed variables, and the ellipses represent the latent growth constructs underlying development in reading between Times 1 through 6. The gray arrows from the latent growth constructs to the observed reading scores represent the factor loadings that were fixed in order to produce the four growth constructs. The black arrows from Time 1 letter knowledge, phoneme awareness, and RAN to the latent growth factors represent the fact that the growth constructs are predicted from those three variables plus earlier growth constructs.
First, we found that there was a difference in the predictive pattern among the three groups: A model in which the impact of letter knowledge, phoneme awareness, and RAN on the four growth constructs was constrained to be equal over groups fitted the data significantly less well than a comparable model in which the regressions were freely estimated over groups, Δχ2(24) = 55.56, p = .001. Second, we found that there were no differences in the predictive pattern between the Spanish and the Czech groups: A model in which the impact of letter knowledge, phoneme awareness, and RAN on the four growth constructs was constrained to be equal between the Spanish and the Czech group had a similar fit to the model in which the regressions were freely estimated over groups, Δχ2(15) = 15.71, p = .205.
Further testing of models in a hierarchical fashion showed that only one predictor differed in its influence on growth across groups: Letter knowledge was a stronger predictor of initial reading skills in English than in Spanish and Czech. A further model was tested in which all the regressions from the three predictors to the four growth constructs were constrained to be equal over the three groups, except the regression from letter knowledge to initial status in reading (which was freely estimated for the English group only). This model did not differ from the model in which all regressions were freely estimated over all groups, Δχ2(23) = 24.76, p = .363.
Thus, the role of letter knowledge, phoneme awareness, and RAN as predictors of beginning reading skills was similar in all three orthographies; the exception was letter knowledge, which was a less important concurrent predictor at the first time point in English than in Spanish and Czech. This final model fitted the data very well, χ2(74, N = 523) = 87.31, p < .138; CFI = .995; TLI = .993; RMSEA = .032, 90% CI = [.000, .057]; SRMR = .049; the unstandardized and standardized regression coefficients for this model can be found in Table 4. As can be seen, all three predictors explained variations in initial reading skills. Furthermore, letter knowledge and phoneme awareness both explained variations in the growth of reading skills, but only RAN explained variations in the acceleration of growth in reading skills. None of the predictors explained variations in the later growth in reading, which, together with the nonsignificant variance in the later growth factor, suggest that once a child’s early reading system is set up, there is a high degree of longitudinal stability in the rate of later growth. 1
Results From the Model Predicting the Growth of Reading Skills From Letter Knowledge, Phoneme Awareness, and Rapid Automatized Naming at Time 1
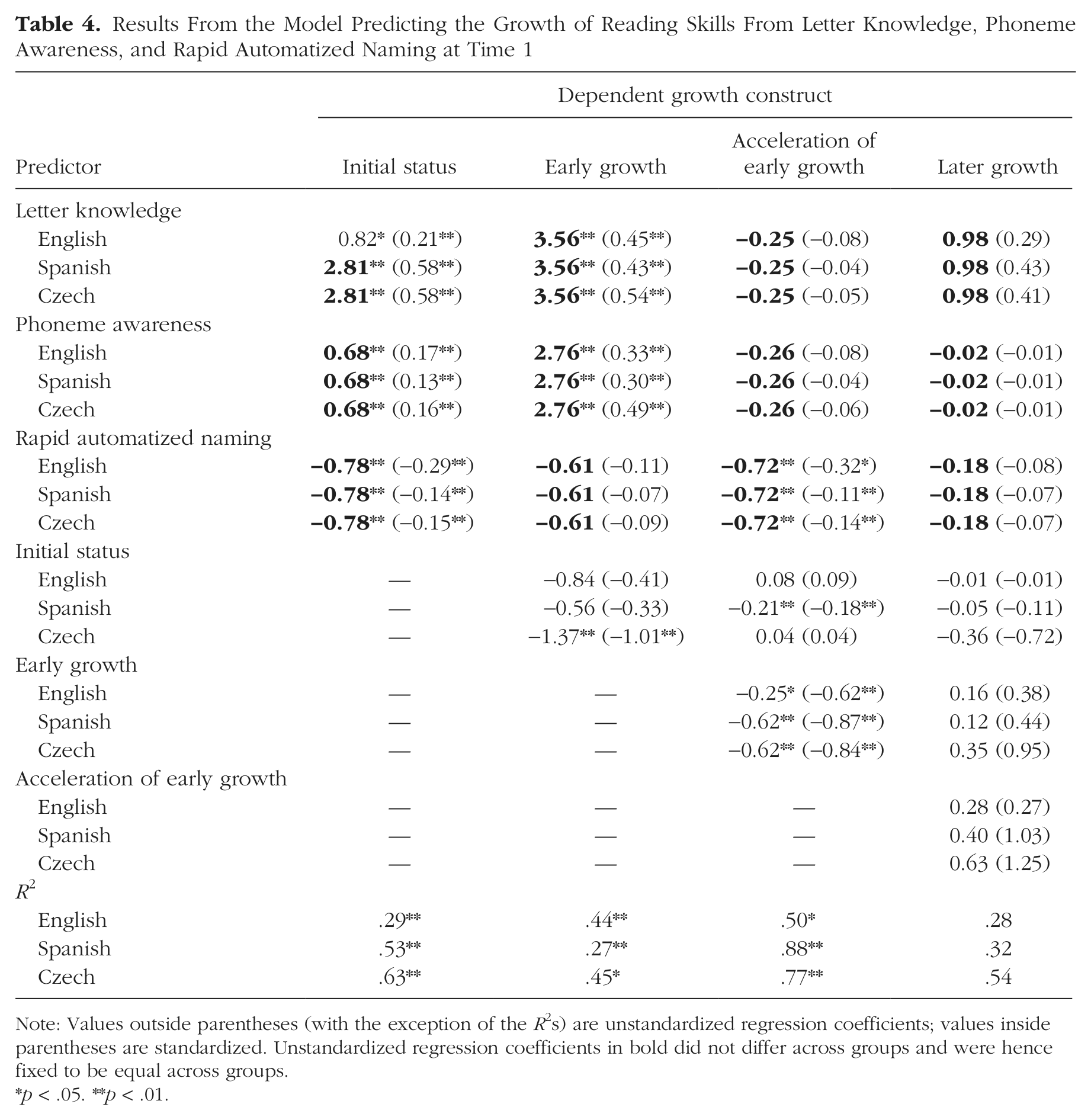
Note: Values outside parentheses (with the exception of the R2 s) are unstandardized regression coefficients; values inside parentheses are standardized. Unstandardized regression coefficients in bold did not differ across groups and were hence fixed to be equal across groups.
p < .05. **p < .01.
Discussion
This is the first cross-linguistic study to assess reading growth trajectories in children learning to read English and more consistent orthographies (Spanish and Czech). The English children began formal reading instruction around Time 1 (Month 0 in Fig. 2), whereas the Spanish and Czech children only began formal reading instruction between Time 2 and Time 3 (Month 8). Strikingly, in this first 8-month period, when only the English children were being taught to read, the rates of growth in reading were essentially identical in the three orthographies. However, once the Spanish and Czech children started formal reading instruction (around Month 8), they showed a steep increase in growth followed by a subsequent deceleration. In short, we saw clear evidence that learning to read is more difficult in English than in the two more consistent orthographies. For both consistent orthographies, as soon as reading instruction begins, there is a rapid growth spurt followed by deceleration once children have “cracked the code.” In English, children show slower rates of growth in reading during their first 8 months or so of reading instruction, and their reading skills continue to develop at a relatively slow and steady rate over an extended period of time. This pattern confirms the view (Seymour et al., 2003; Share, 2008) that learning to read in English is more difficult than in more consistent orthographies.
Despite enduring group differences in the rate of growth, a common finding in all three languages was the absence of significant variation in growth within groups between Times 2 and 3. This is consistent with the suggestion that once a child’s early reading system is set up, there is a high degree of longitudinal stability (e.g., Lervåg, Bråten, & Hulme, 2009; Parrila et al., 2005): If a child was a good reader or a poor reader by the end of Grade 1 (16 months into our study), he or she was likely to remain so.
The other critical issue addressed here was whether the same cognitive factors predict the growth of reading skills in English as in other more consistent orthographies. Until recently, a dominant claim has been that reading development in consistent orthographies depends on a rather different mix of underlying skills than it does in inconsistent orthographies, such as English. According to this argument, phoneme awareness plays only a weak role (e.g., Georgiou, Parrila, & Papadopoulos, 2008) or a transient role (e.g., de Jong & van der Leij, 1999) as a predictor of reading development in consistent orthographies, whereas it is a reliable long-term predictor in English. In contrast, RAN has been argued to be a strong predictor of reading development over a protracted developmental period in consistent orthographies (e.g., Wimmer et al., 2000).
The design of the current study allowed for a fine-grained analysis of how critical cognitive skills (phoneme awareness, letter knowledge, and RAN) relate to the different aspects of the growth of reading skills. We found that, with one exception, the patterns of prediction did not differ in strength across the three languages. Phoneme awareness, letter knowledge, and RAN all predicted individual differences in initial levels of reading ability. The impact of phoneme awareness and RAN did not differ across the three languages, but letter knowledge was a weaker predictor of initial reading levels in English than in the two consistent orthographies. This last effect may relate to the impact of orthographic consistency; whereas good letter knowledge allows for accurate decoding in phonologically consistent orthographies, in which letters correspond to sounds in highly predictable ways, this is less true in an inconsistent orthography like English.
Looking at predictors of the rate of reading growth between Time 1 and Time 4 (the first 16 months of our study), variations in early growth were predicted by phoneme awareness and letter knowledge to similar degrees across all three languages, whereas RAN predicted the rate of acceleration of growth in this period—also to a similar degree. Thus, whereas phoneme awareness and letter knowledge were associated with the very early growth of reading skills, RAN was associated with how quickly this growth rate accelerated during the first 16 months. This result aligns well with earlier studies that have found RAN to predict reading for a more protracted period than phoneme awareness and letter knowledge (e.g., Landerl & Wimmer, 2008; Lervåg et al., 2009).
Finally, none of our predictors (phoneme awareness, letter knowledge, and RAN) predicted variations in the rate of reading growth between Time 4 and Time 6 (the final 12 months of our study). This, along with the absence of significant variation in growth in later development, points to a high degree of longitudinal stability in typical reading development across languages. Further studies are needed to investigate the possibility that there may be subgroups of children with distinctive reading-growth profiles (cf. Parrila et al., 2005), which may differ between orthographies. Overall, however, our findings suggest an essentially universal pattern of prediction of growth in reading in all three languages studied (at least in the measure of silent word reading used here, which it should be noted correlates highly with reading aloud).
In summary, children learn to read in English (a phonologically inconsistent orthography) more slowly than in more consistent orthographies. However, learning to read in all alphabetic orthographies studied so far appears to depend heavily on individual differences in three core cognitive skills: phoneme awareness, letter knowledge, and RAN. The similar patterns of prediction from these three measures across languages suggest that the same mechanisms are involved in learning to read in any alphabetic orthography.
Footnotes
Acknowledgements
We are grateful to research fellows of the Enhancing Literary Development in European Languages network, Petroula Mousikou, Naymé Salas, Eduardo Onochie-Quintanilla, and Miroslav Litavský for their contributions to this study.
Declaration of Conflicting Interests
The authors declared that they had no conflicts of interest with respect to their authorship or the publication of this article.
Funding
The research leading to this study was supported by funding from the European Community’s Seventh Framework Programme (FP7/2007-2013) under Grant Agreement No. ELDEL PITN-GA-2008-215961-2 to Markéta Caravolas.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.