
Abstract
Aircraft health management has been researched at both component and system levels. In instances of certain aircraft faults, like the Boeing 777 fuel icing problem, there is evidence suggesting that a platform approach using an Integrated Vehicle Health Management (IVHM) system could have helped detect faults and their interaction effects earlier, before they became catastrophic. This paper reviews aircraft health management from the aircraft maintenance point of view. It emphasizes the potential of a platform solution to diagnose faults, and their interaction effects, at an early stage. The paper conducts a thorough analysis of existing literature concerning maintenance and its evolution, delves into the application of Artificial Intelligence (AI) techniques in maintenance, explains the rationale behind their employment, and illustrates how AI implementation can enhance fault detection using platform sensor data. Further, it discusses how computational severity and criticality indexes (health indexes) can potentially be complementary to the use of AI for the provision of maintenance information on aircraft components, for assisting operational decisions.
Keywords
Introduction
Aircraft component failure has the potential to cause the destruction of life and property, 1 so maintenance of these components is necessary. 2 Aircraft downtimes which result from unplanned maintenance, especially with commercial aircraft, can be costly for airlines, judging from the fact that direct maintenance costs about $234 million per airline and $3.67 million per aircraft, as reported for the thirty-seven 37 Maintenance Cost Technical Group (MCTG) airlines. 3 Aircraft maintenance is significant in ensuring the reliability of aircraft components, by identifying and mitigating potential hazards, thereby preventing accidents and enhancing overall flight operations. It contributes to increased availability, reducing unplanned downtimes and operational disruptions. Adhering to regulatory standards set by aviation authorities is contingent upon rigorous maintenance, which also extends an aircraft's lifecycle and optimizes cost-efficiency by averting major breakdowns. Furthermore, well-documented maintenance history positively influences an aircraft's resale value because it demonstrates that it has been consistently cared for and maintained in accordance with manufacturer recommendations and regulatory requirements. 4 Maintenance strategies have been applied to manage the health of aircraft components, from reactive maintenance 5 up to condition-based maintenance. 5 In that, subsequent development like approaching health management from a component level or system level has been explored. Further, justification for a vehicle-level approach has been given, particularly, with Framework For Aerospace Reasoning (FAVER), 6 which covers how beneficial it is to consider the relationship that exist between aircraft systems to enable faults and cascading effects detection. It does so by relying on the individual systems’ diagnostics. Due to this, in a scenario where a system’s diagnostic is not available, faults and cascading effects detection is impossible. This has presented an opportunity to consider a platform solution, which will not rely on systems’ diagnostics, but sensor data from the systems to monitor their health. With the help of Artificial Intelligence (AI), a platform diagnostic that can ensure a quicker fault and interaction effect can be developed. This will fill the gap of not depending on systems’ diagnostics for faults and interaction effects detection. Airlines have invested significantly in major aircraft maintenance programs to improve efficiencies. They continue to invest in emerging technologies, with Artificial Intelligence (AI) being a crucial part of it. 6 This is evidenced by an increase in investments in Data Exchange Technologies (XML) as well as AI programs. 6 There is evidence that applying AI techniques in maintenance can produce effective solutions in aircraft health management, to help airline operators avoid unexpected interruptions that occur due to aircraft component failure. 7 This paper covers the relationship between maintenance and AI in aircraft component health management at the platform level, and how AI techniques like machine learning can be applied to platform sensor data to generate insights that can support operational decisions. Tasks for replacing and repairing failing components are usually handled by Maintenance, Repair and Overhaul Organisations (MROs). 8 Maintenance has been approached in various ways, but in recent times airline MROs adopt Integrated Vehicle Health Management (IVHM) in maintaining complex aircraft components. 9 This approach gives MROs the advantage of looking at physical assets as a whole and considering their interacting components at the same time. 10 Implementing IVHM is usually supplemented with AI due to AI’s ability to create methodologies that utilize the decision-making capabilities of AI techniques, such as deep learning (DL) and machine learning (ML), to develop fault diagnostics and prognostics systems. 11 To provide decision support to both maintainers and operators, at the platform level of health management, the health of components can be ascertained and propagated through its corresponding subsystems and systems, 12 while providing health information at every level.
This paper is organized into six different sections including the present one. The sections that follow will discuss the history of maintenance until the present day, and cover the Maintenance, Repair, and Overhaul (MRO) business, the key handler of maintenance activities, as it significantly influences the delivery of aircraft maintenance solutions. The next parts covers how MRO businesses have evolved, and the synergy between MRO businesses and IVHM. IVHM and its implementation across industries is also discussed. The fifth segment discusses health management from a platform level, with AI as an enabler and some of its techniques that have been applied in maintenance. The sixth section discusses health index computation and criticality index, as a supplement to maintenance information on components, for making operational decisions. The final section provides a conclusion to this paper.
A brief history of maintenance
Maintenance has to do with basic servicing procedures on regular timescales, to preserve, as well as keep vehicles lubricated and counteractive maintenance to restore them when they have broken down. 13 In past times, maintenance was easier to perform due to the simple nature of the physical assets and how the resources for making parts that could be replaced were easily accessible. This was the case until the industrial revolution when more powerful machines were made, and manual efforts reduced. 13 The Wright Brothers were the first to fly a plane in 1903, in Kitty Hawk. 14 Maintenance was a craft learned through experience and not often examined analytically. 15 Its costs grew as designers reached for higher performance leading to increasingly complex equipment. Also, aviation maintenance was unregulated, and most maintenance activities were undocumented until the Air Commerce Act of 1925 was introduced. 16 The Act came along with licensing standards by the International Civil Aviation Organization (ICAO) in 1948. 16 By the late 1950s, the magnitude of maintenance costs in the airline industry had reached a level that demanded a new approach to maintenance. 16 Boeing adopted a bottom-up approach 17 as it looked to invent new ways to troubleshoot after it launched the first 747 aircraft in 1969. 16 Aircraft had started using built-in-test equipment (BITE) by this time. 18 The method was restricted by how the indicators that were placed in the system were because they failed to account for everything that could potentially malfunction. 18 Nowlan and Heap 15 in their revolutionary approach to maintenance, established Reliability-Centered Maintenance (RCM) to realize the equipment’s inherent reliability capability. The maintenance program for the Boeing 747 was the first effort to implement this approach. 15 After this came the Maintenance Steering Group (MSG-3) method, which took an up-bottom approach, used in the design of the B757 and B767, and is now a mainstream maintenance method for aircraft maintenance. In 1992, NASA introduced Integrated Vehicle Health Management (IVHM) to deliver an integrated platform capability that ensured the reliable capture of the health status of the overall aerospace system and helps to prevent its degradation or failure by providing reliable information about faults. 19 Approaches like the Aircraft Structural Integrity Program (ASIP) and Engine Structural Integrity Program (ENSIP) played crucial roles in the military aviation industry by ensuring the structural integrity of aircraft and engine components, respectively. Every subsequent development in aircraft maintenance thereafter can be attributed to technological innovation 20 or technology enablers. 13
Maintenance evolution timeline
Every physical asset undergoes wear and tear, and this is more noticeable when it breaks down. When this happens, it is rational to restore it to its functional state except the asset was meant to be used once and disposed of. 21 The reason for a maintenance strategy can be traced across industries to the need for increased availability and a reduced maintenance cost of physical assets.22–24 Also, as assets have evolved into modern, multi-technological systems, they should be handled with appropriate engineering methods, enhanced processes, and a set of maintenance procedures that make sure the asset can operate at full capacity. 25 The techniques used to increase availability, cut costs, and restore assets to a functional state gave rise to maintenance strategy. 26 A maintenance strategy is coined out of five major pillars – reactive maintenance, regularly scheduled preventative maintenance, inspection, backup equipment, and equipment upgrades. 22 These factors serve as a foundation for determining a maintenance mix, which depends on the facility, the equipment that must be maintained, and the maintenance aim. 22 When maintenance activities are carried out and what measures are included are influenced by the maintenance strategy. 27
Maintenance strategy evolution.

The purpose of Reactive Maintenance (RM) is to fix the asset when it is broken. 31 Machines tend to break down without warning, and it is essential to get them back working when this happens. 13 As shown in Table 1, reactive maintenance was emphasized in earlier times, 13 and with it, no prior data on the asset is required. Although the manpower and the amount of money spent on equipment maintenance are reduced, the drawbacks of this strategy include unpredictable and fluctuating production capacity and higher total maintenance costs. 32 For instance, unscheduled maintenance contributes about 15% to 60% to the production cost. 33 RM is usually characterized by a low failure severity and frequency, like repairing a fan blade of an aircraft after a bird strike. 30 When a life-critical system like an aircraft is in play, estimating its dysfunction before it happens is necessary. As a result, there is justification to turn to the Preventive Maintenance (PM) approach.
With Preventive Maintenance (PM), replacement and overhauling are done at certain stipulated time frames, irrespective of the status of the asset at that time to minimize unexpected breakdowns.
30
Wang
34
classifies preventive maintenance as a long-term maintenance policy that takes a record of breakdowns to plan preventive interventions. Maintenance times for assets in PM policy focusses on the assets’ age. The underlining idea is that for whichever comes first – the age or failure of the unit – it is then fixed or changed.35,36 This is carried out by applying techniques that extract from historical data of behaviour of assets, indices like Mean Time Between Failure (MTBF), and Mean Time To Repair (MTTR).
32
Preventive replacements can help minimize the number of random failures, but it can also waste resources. It is best to synchronize maintenance and inventory management strategies
27
because even an effective preventive maintenance plan that increases equipment availability suffers from these flaws: 1. Time-based or operation count-based PM programs lead to possible under-maintained or over-maintained equipment, especially in instances when the PM interval is predetermined without considering various operation regime shifts. For instance, it was found in the case of gearboxes for helicopters that although approximately half of the parts were in a convincingly functional condition, they were taken out for repairs.
28
2. Replacing the component before it fails limits how much information can be learned from the equipment’s lifecycle.
30
Figure 1 depicts the difference between reactive and preventive (proactive) maintenance. PM is not the most cost-effective program choice because of these challenges. Hence, more efficient maintenance methods such as predictive maintenance (PdM) are sought. Preventive (proactive) and reactive maintenance approach.
33
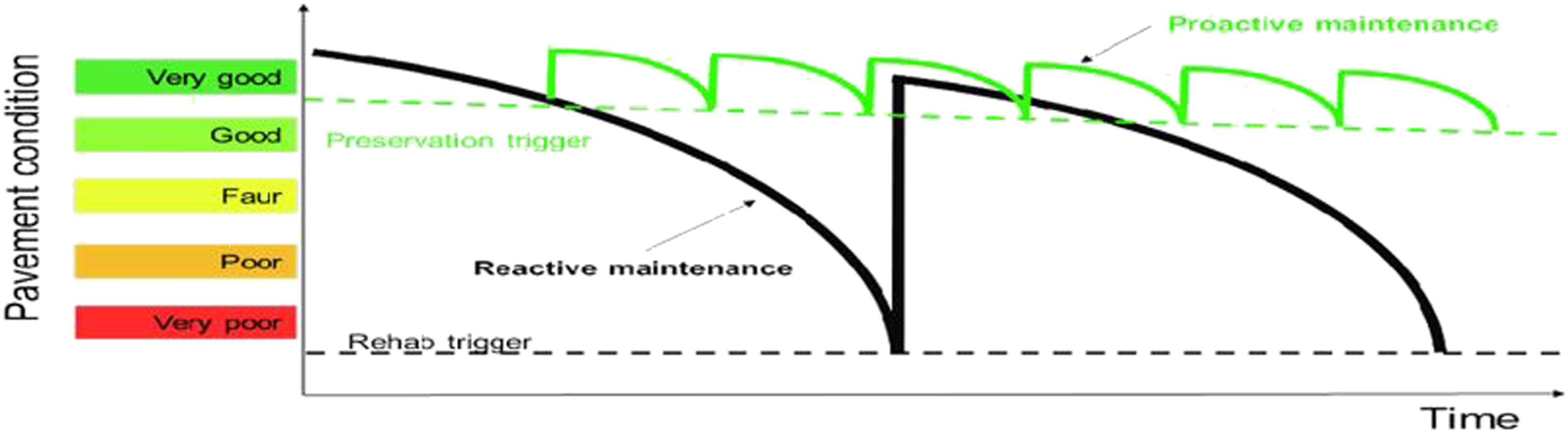
Predictive Maintenance (PdM) is the ‘right on time’ strategy. It can be grouped into reliability-centred maintenance and condition-based maintenance (CBM). In most cases, it has been implemented as CBM as its performance indicators are either measured periodically37,38 or observed continuously. 39 PdM makes pre-sets on failure rate and or any other reliability indicator of the asset so that maintenance is rolled out only when the pre-set rates or indicators are reached or triggered. Integration is the strength of PdM as it merges data with reasoning methods, and considers physical factors and known engineering constraints, so that it can diagnose a problem before it happens. 33 This approach varies from preventative maintenance such that the requirement for repair is determined by the asset’s actual state rather than a pre-determined schedule. It uses technologies to monitor the state of the asset to detect issues sooner and intervene with higher accuracy. 32 PdM has proven benefits such that Rao 40 reports that a CBM investment of $10,000 to $20,000 translates into a $500,000 yearly savings. The timeline depicted in Table 1 highlights various ways maintenance can be approached, but the question of when maintenance should take place remains. The Potential Failure – Functional Failure (P–F) curve throws light on this.
P–F interval impact on maintenance strategy
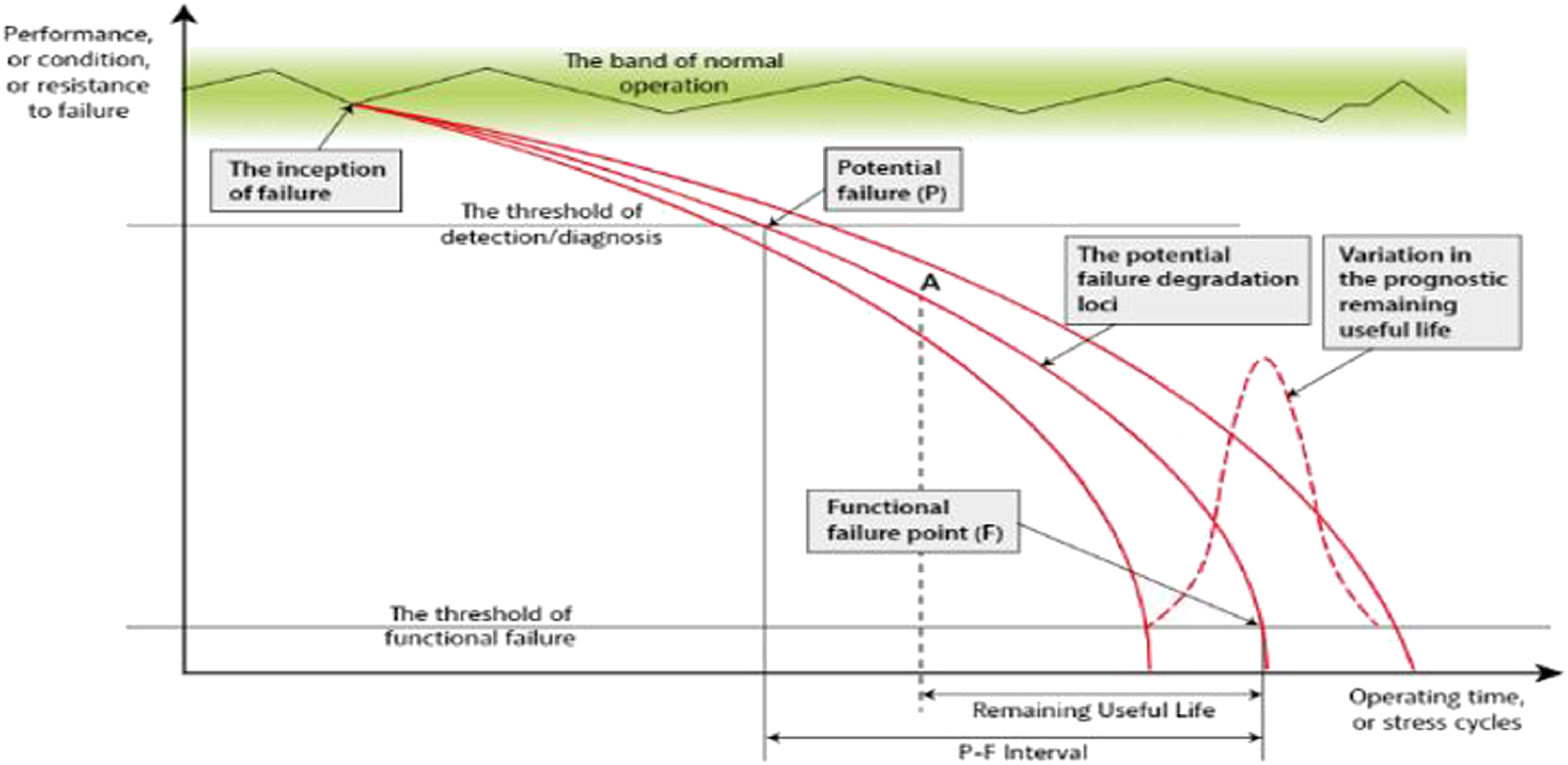
The P–F curve shows the time between an asset’s potential failure and its predicted functional failure. It informs asset owners of when it is ‘right’ to perform maintenance.
13
Initially, the state of the system or component is in good condition, but over time it begins to deteriorate. Figure 1 demonstrates the progression of failure, starting with the beginning stages and worsening until it is noticeable. This is when potential failure is detected (point P, in Figure 2). The deterioration continues until the point of functional breakdown (point F, in Figure 2). The P–F time interval provides the amount of time that a monitoring system could detect the deterioration and allow for maintenance to be performed. This interval must be long enough to make maintenance feasible and the monitoring effective. The remaining useful life (RUL) refers to the amount of time until functional failure as the deterioration moves away from point P. Figure 2 displays the RUL at any given moment, represented by point A on the curve. The P–F interval must be long enough to enable for maintenance to be performed in order for any action to be feasible and for the monitoring to have been effective. Although Jennions
13
explains how crucial this is for any organization that uses high-value assets in the P–F Curve, Figueiredo-Pinto
41
asserts that Predictive maintenance is only practicable if the deterioration pattern depicted in the P–F curve is generally constant, and a consistent gradient profile is seen for every part’s cycle of operating life. According to Refs 13,33,42 the P-F curve shown in Figure 1 aids in measuring performance per time (or usage), and not just that but it also offers the ability to monitor degradation such that action (maintenance) is taken when the depletion is more perceptible before it reaches a point of functional failure. As a result, it measures the remaining useful life (RUL) of the asset for maintenance decisions. Failures are approached differently based on the categories they fall in. Failures that are seen to impact health and safety, or that affect business operation are deemed urgent, and hence receive immediate maintenance. However, other failures that are not necessarily affecting functionality or interrupting operations, although their degradation is noticeable, are less likely to be tackled in the same swift manner.
13
The P–F interval.
14
Maintenance has evolved into Prescriptive Maintenance (PxM). It is a layer or a step above Predictive Maintenance. It draws from developing systems that can intelligently observe, predict, and augment their functional ability. 43 It leverages embedded systems that have been built into the assets, focussing on finding out the source of faults, and not just the signs. After this, it will feed the information gathered back to the system so that maintenance can be done where it is needed. Prescriptive maintenance is distinctive in the sense that not only does it forecast asset failure like Predictive Maintenance does but it also provides consequence-based suggestions for processes and maintenance from prescriptive analytics. 44 PxM is driven by the capability to have varied scenarios and simulations outside of the reality of happenings to allow maintenance teams to have a more exhaustive approach to the condition of the asset. Prescriptive maintenance heavily depends on huge data collected from sensors placed on different points of assets and manipulated or evaluated using various data analytic tools to provide information on the condition of assets. 44
In the future, maintenance strategy in aviation will gravitate towards a Conscious Aircraft 45 or self-maintenance. 21 Complex assets like aircraft will assume consciousness like a human would in observing health states and forecasting with precision, the remaining useful life of components, subsystems, and systems. At this stage, it will have the ability to monitor faults, diagnose faults, judge faults and plan repairs, as well as improve and self-learn on its own. A typical example is what is being done in F-35 airplanes, 46 where the Autonomic Logistics Information System (ALIS); a comprehensive system that serves as the central nervous system of the F-35 fleet, is used to manage and analyse vast amounts of data generated by the aircraft's various systems during operations. ALIS provides real-time health and diagnostic information to maintainers, support personnel, operators, and enables efficient maintenance. The timelines depicted in Figure 2 are like what was proposed by Ledet 29 that is, reactive maintenance, planned maintenance, predictive maintenance, reliability maintenance, and enterprise maintenance. Gallimore et al. 22 suggest that organizations, in this case MROs, should find the most appropriate maintenance strategy based on the facility, the equipment, and the maintenance aim.
MROs and their role in maintenance
MROs are the branch of the aviation business that is largely responsible for maintaining or restoring aircraft parts to a functional state. 47 This includes all technical, administrative, management, and supervisory responsibilities. 8 For instance, Hawker Pacific Aerospace (HPA) specializes in the repair and overhaul of landing gear (in airplanes and helicopters), hydromechanical components, wheels, brakes and braking systems, and the distribution and sales of new and overhauled aerospace spares.8,48–50 classify MROs by organizational structure, by placing them under independent or third-party MROs, and airline-operated-and-owned MROs. MROs have developed from when most MRO tasks were only performed by airline-operated-and-owned MROs. 47 After the deregulation of the airline industry in 1978 in the USA, 51 several new airlines did not have established MRO facilities or spare parts inventory to serve their fleet. 52 The increase in the number of low-cost carriers urged the entry of independent MRO sources that provided low-cost services ranging from line maintenance to inventory control. 8 The smaller airline carriers opted to outsource MRO activities to third parties because of the capital-intensive nature of establishing an airline MRO. 8 On the other hand, the larger airline operators were inclined to retain a presence in this line of work as it meant they could offer MRO-type services to other airlines. 53 AAR Corporation, whose operations include aircraft and engine support, engineering, and logistics is another example of an independent MRO organization. 54 In contrast, an example of an airline-operated-and-owned MRO is Lufthansa Technik, a subsidiary of Lufthansa. The joint venture between Air France Industries and KLM Engineering & Maintenance which has seen remarkable development in terms of its MRO capabilities is another example of an airline-operated-and-owned MRO organization. 8 MRO business must pay attention to the flow of value from one organization to another to decide on what brings the most benefits to it. 55 This facilitates long-lasting connections with clients, deliver more customization and superior quality, decrease inefficient use of resource and labour, and get feedback from using it, to be put back into the design and manufacturing phase. 56 In this way, whether the business is Product-oriented or Service-oriented, 55 it will be able to make a good Return on Investment (ROI). Since MRO organisations are largely responsible for maintenance, it is feasible to link it to IVHM because it helps them detect faults quicker before they happen. Maintainers want to know when a component should be replaced or if it should be replaced and an efficient way of coming to such a conclusion is implementing IVHM, which relies heavily on digitally enabled on-condition maintenance. 13
Synergy between MROs and IVHM
Definitions of IVHM.

IVHM and its implementation across industries
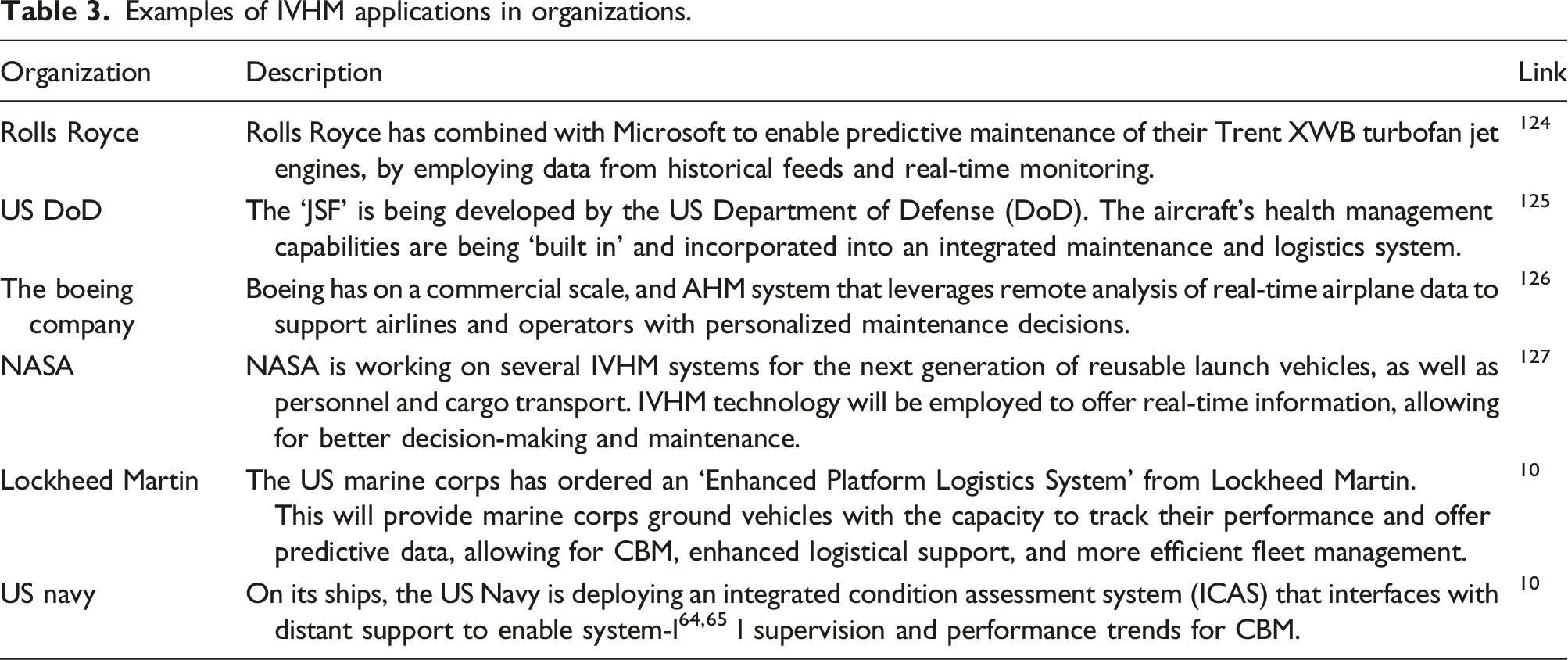
Examples of IVHM applications in organizations.
Health management from the platform view
Aircraft health management can be approached from different levels. This paper has categorised it into four levels: component, subsystem, system, and platform levels. At the component level, what is considered is the most ‘basic’ unit that faults can be traced. For example, heat exchanger, air cycle machine, and a control valve. The subsystem level consists of a combination of elements form the component level. For example, a pump, a fuel tank, or a Passenger Air Conditioner (PACK), which is made up of several parts including the above-mentioned components. In the same way, at the system level, it consists of a combination of elements from the subsystem level. For example, the aircraft fuel system, or the environmental control system, which is made of several subsystems like the PACK and the mixing manifold. At the platform level, which can also be referred to as the vehicle level, health management has to do with the entire vehicle (aircraft). The name platform is as a result of the nature in which health is managed. In this paper, platform refers to taking sensor data from the component level and propagating it through the subsystem and system levels up to the vehicle level. Figure 3 embodies the inputs needed to manage health from the platform. Health data that will be collected will help provide maintenance information to help answer the questions posed by various levels (i.e. component, subsystem, system, and platform). This information, however, will not answer operational decisions, but it will help provide inputs that can assist in making operational decisions. Operational decisions refer to the decisions that are made during the operation of an aircraft, such as decisions related to flight planning and maintenance.
75
For instance, for an operational decision like ‘can we fly,’ at the platform level, the maintenance information from the platform health management can tell the health status of the aircraft components but will not be concerned with making the decision of whether to fly or not. At the platform level of health management, the health of the asset is determined by considering the health state and the interaction effect of the components, subsystems, and systems,
76
giving it an advantage over the component or system level approaches. The Boeing 777 engine rollback at Heathrow Airport in 2008 is an example of a real-world incident.
77
The cause of the engine rollback, according to an investigation into the occurrence, was a decrease in thrust brought on by a limited fuel supply to both engines. Further inquiry into the root cause found that the fuel developed ice as a result of prolonged exposure to a temperature of less than −70°C. The fuel feed pipe was then damaged by this ice, which later burst, clogging the fuel oil heat exchanger and other fuel lines. Another example is the 2008 emergency evacuation of an Embraer 195 because of smoke in the cabin
78
where, after an inquiry into the incident, it was determined that both ACMs had suffered Stage 2 turbine blade failures. The resultant imbalance had resulted in contact between the turbine blade tips and the ACM casings, producing hot, finely divided, metallic particles that were released into the cabin air system, creating the reported symptoms of smoke and fumes inside the aircraft. Diagnosing faults in scenarios like the abovementioned incidents, where failure in one component cascades into another component, and eventually into another system, requires a system that can detect faults as well as any interaction effects between components and systems.
79
This can be achieved by adopting a platform solution. Further, to support operational decisions, faults and interaction effect detection could be supplemented with information on the health index and criticality of the components.
80
This is because not all component failures affect the functionality of the aircraft, so immediate attention should be given to ones that are crucial.
81
This presents various questions to be answered in order to provide operational decisions, as shown in Figure 3. In this vein, it is important to lay down the dependencies that exist among the components, subsystems, and systems as it was applied in damage propagation modelling for aircraft engine by Abhinav,
82
and Roemer,
83
and Roemer
12
in developing a hierarchical reasoning structure for aerospace IVHM, where distinctions between independent relationships, serial dependencies, and parallel dependencies were made uses a parent–child approach to establish this relationship for a health index framework for condition monitoring. From a platform view, answering the questions at the base of the pyramid in Figure 3 help to answer the one at the apex, when the dependencies that exist among them are established. Health management pyramid.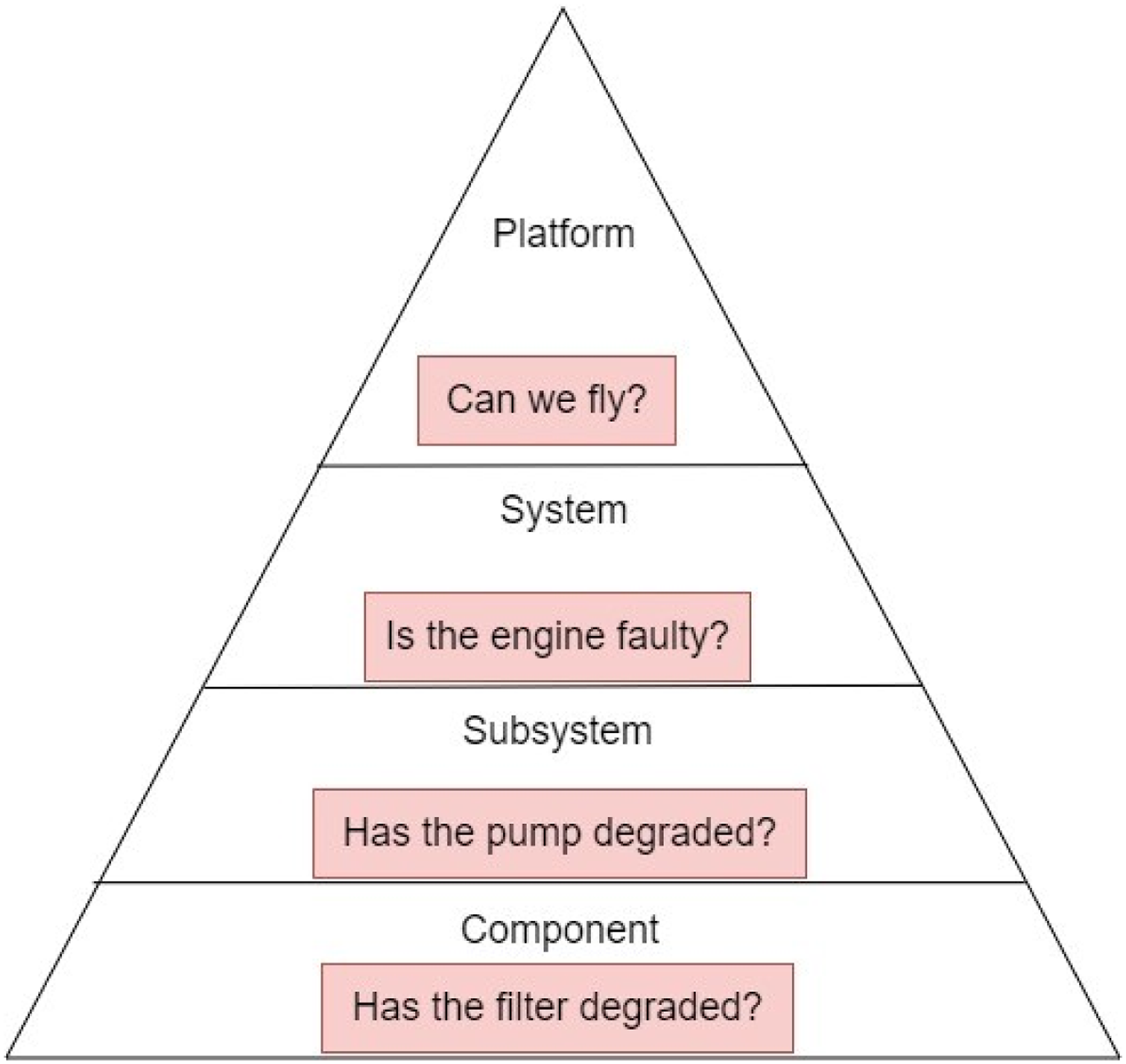
AI as an enabler for health management
The approaches that have been applied to manage the health of complex assets and fall under: Data-Driven, Model-Based and Expert Systems approaches. 93 Data-driven diagnostic methods rely on data collected from sensors that are placed at strategic areas of the system.77,94,95 For instance, Skywise, which is designed by Airbus to handle integrations of commercial and operational systems, processing large volumes of data such as time-series data coming from aircraft sensors, structured data from operational and maintenance data and unstructured data such as technical documents. 96 Model-based methods use a physics model of the system or component to conduct the analysis on its health, by developing a virtual representation of the actual asset to mimic its behaviour. Its application can be found in the use of digital twins to mimic the behaviour of systems or components to simulate what-if scenarios of actual systems. For examples, as discussed in Liu et al. 85 and applied on an automotive brake pad for predictive maintenance in Rajesh et al. 86 In an extended approach, there can be a hybrid of data-driven and model-based techniques. For instance, digital twins of systems can be developed, then used to produce data, which could be processed to derive insights into fault modes in the actual systems, as done with aircraft systems in Ezhilarasu et al. 74 An expert system is derived from two fundamental concepts. 97 First, that it contains specific knowledge about a particular field, component, or system. This knowledge is a fusion of existing facts from human experts and documentation within that field. Although the system closely models the human expert, it is not a replacement for the human expert, but an assistant. 98 Rolls Royce's KBO Environment, which allows the company to capture its knowledge base, as well as best practice and performance, manufacturing, and cost criteria into a simulated model to help engineers precisely explore and try multiple “what ifs” against all identified constraints, is an example of an expert system. Another example is RuleSentry™ which has been used by Lockheed Martin to simplify system behaviour modification and operational decision making to save time and effort (RuleSentry TM Configurable Decision Support, 2013). Platform level decisions are typically concerned with efficiency matters like prioritizing component failure modes. These health management decisions typically rely on the use of technologies like artificial intelligence. To add to that, data is increasing in relevance and size. With reference to a report by the International Data Corporation (IDC), the global data sphere was to grow from 33 zettabytes in 2018 to 175 zettabytes by 2025. These figures are noteworthy when compared to the global total of 3 exabytes in 1986. Aircrafts produce huge data. The Boeing 787 creates nearly half a terabyte on a single trip, while the Airbus A380-1000 generates approximately eight terabytes daily . A General Electric (GE) jet engine creates about 20 terabytes of information per engine data per hour. For two engines on an average six-hour cross-country flight from New York to Los Angeles, the data generated is approximately 240 terabytes. The effective utilization of the vast volume of generated data demands the integration of key technologies like AI. These synergistic technologies are instrumental in facilitating continuous communication, robust data storage, and clever data analysis, to optimize data exploitation.
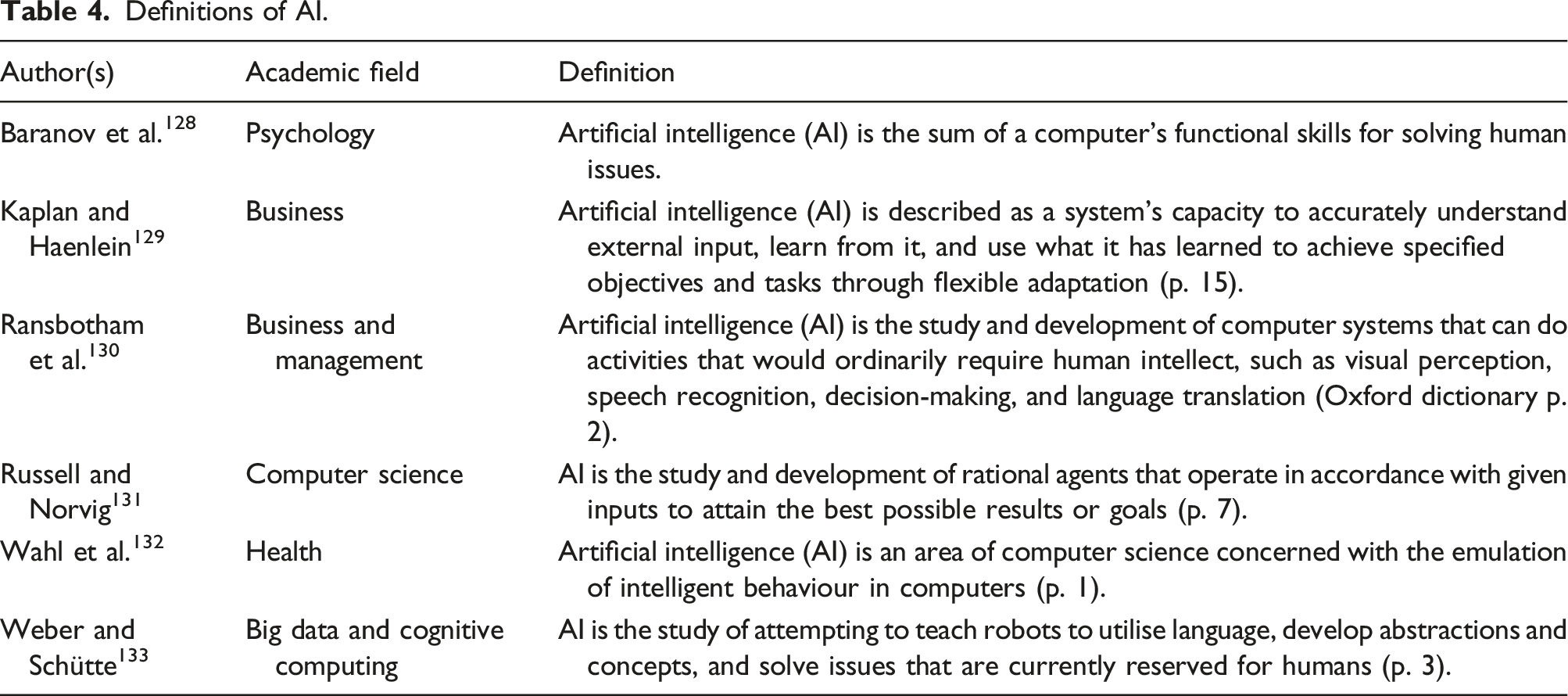
Definitions of AI.
AI techniques in maintenance
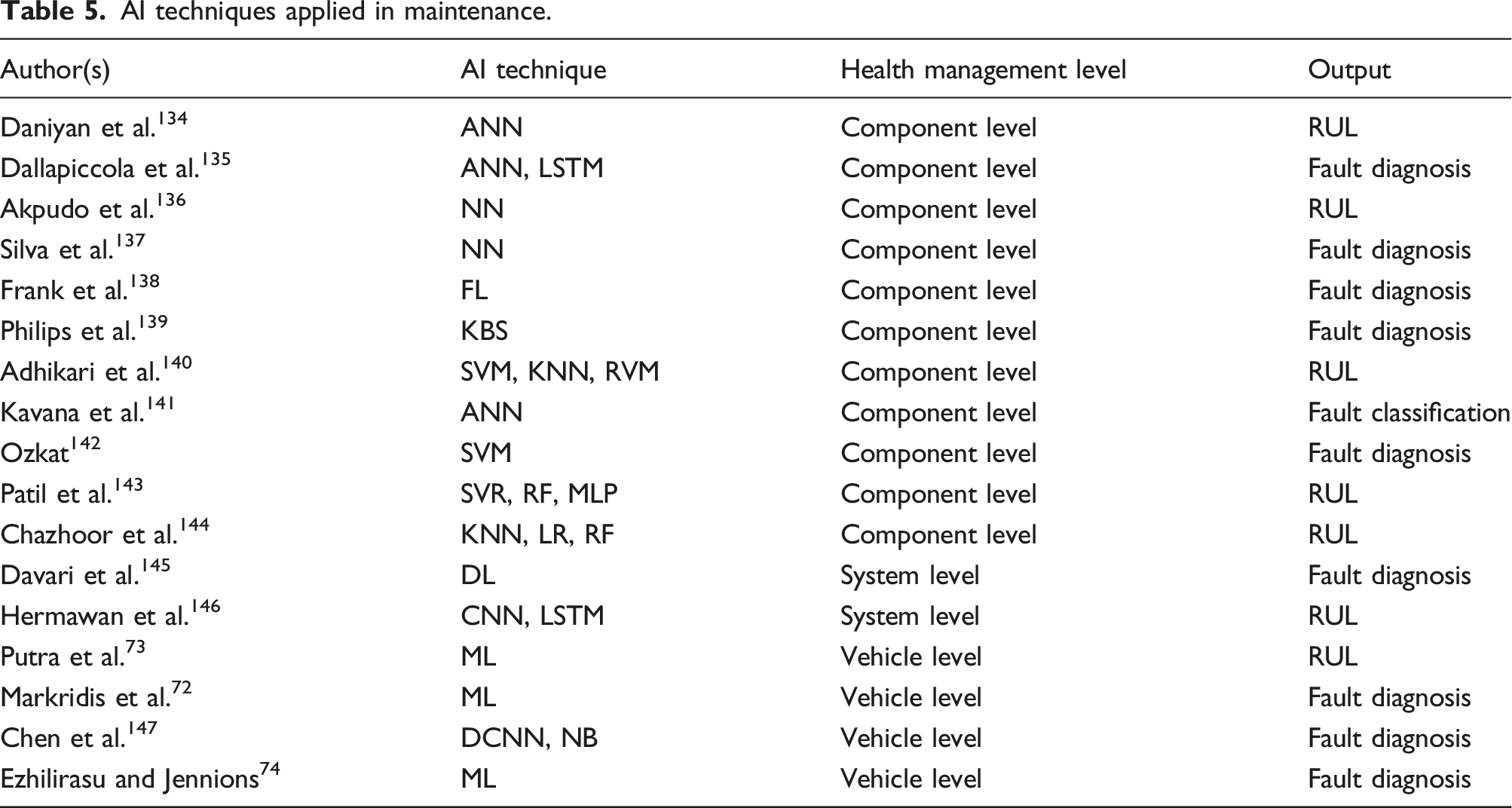
AI techniques applied in maintenance.
Health index (HI) for operational decisions
As a complementary information to the insight that will be derived from applying AI techniques to sensor data, HI can be beneficial to aircraft maintenance. It is helpful to be able to tell if a fault has been detected in a component, but it is more efficient to know the extent of that failure and its effects. 13 This paper proposes that for a platform approach to health management, computing health indexes alongside insights from applying AI could be more efficient for providing maintenance information to support operational decisions. Health index computations are rooted in finding faults and their effect on components, along with their cascading effects on other components. 80 Built-In Test Equipment (BITE) has been used as both in-field maintenance and to indicate the health state of a system. 106 In the 1950s, BITE was used to ensure uninterrupted availability and fault-free operation of critical weapons systems (Minutemen I and II missiles) and aerospace equipment (Saturn, Apollo).106,107 Similar techniques for estimating a health index have emerged after BIT. 108 For example, Automatic Test Equipment (ATE), 109 and Embedded Diagnostics/Prognostics (ED/EP). 110 While it is common to conceive of damage as an issue that increases monotonically, the domain in which damage is assessed could have non-monotonic characteristics. These may be external effects, such as partial maintenance activities, or inherent characteristics (such as recovery effects in the capacity of batteries or semiconductors). It may be required to consider specific damage propagation models for various failure types since damage propagation may display different symptoms depending on the fault mode. 111 In a bottom-up approach (components level to platform level), the health of components can be disguised by the overall health at the platform level. 83 By generating a health index to offer details on the health state of components, subsystems, and systems, a top-down (platform to components) method can effectively disclose the health of components (for maintenance decision) at the platform level. This maintenance decision can eventually be used to assist operational decisions. Managing the health of physical assets, like in the approaches mentioned Table 5, provides useful information for maintenance, but to assist an operational decision, the IVHM system might need a high-level reasoner to deduce that system’s criticality to the functioning of the entire asset. 63 Establishing the health of systems can be categorised under: (1) system health index-based, (2) integration of components’ remaining useful life (RUL), (3) influenced component-based, and (4) multiple failure modes approaches. 112 The health index (HI) of a component can be defined by the ‘functional availability’ of that component to execute the intended purpose for which it was made.83,113 Abhinav 82 proposed a component level estimation method in calculating a health index. This method determines critical parameters that point to the performance of the system from the data gathered, by computing how distant a component’s present health parameter is from certain operational boundaries. By calculating the difference between the present system state and predetermined limits, these health indexes can be estimated. Each of these health indexes is then normalised to the interval [0, 1], where one (1) indicates a healthy component and zero (0) indicates an unhealthy component. It is important to determine the critical parameters because, in specific situations, not all parameters carry the same weight of importance. For example, Abhinav 82 identified efficiency and flow as critical parameters to identify the health of an aircraft engine’s compressor and turbine. Diagle et al. 114 adopt the estimation of the end of useful life (EOL) of a system in a distributed manner by decomposing it into replaceable units, based on the concept of structural model decomposition. The distributed framework computes the health of components, which then feeds into their corresponding systems to estimate the health of these systems. One strength of this approach, which can help component health index propagation, is how it provides a tool (structural model decomposition) to merge local prognostics results into a system-level result. In the case of Chang et al., 115 a health index (Remaining useful life (RUL)) was computed based on a multi-input neural network, using long short-term memory (LSTM) for RUL prediction, and the previous monitoring data and the future operational condition settings. These two data streams are manipulated and combined to predict the RUL of the examined components. Wang et al. 116 applied a strategy in a similar manner to estimate the system health of aero engines by taking into consideration several operating conditions. At the platform level, it may be required to propagate health states from preceding levels. Roemer 113 proposes a reasoning architecture to propagate aggregated component health indexes up to the system level, in Unmanned Aerial Vehicles (UAVs). This propagation is done by quantifying the remaining functionality at every point, in three separate levels. At the lowest level, the diagnostic reasoning starts with the raw sensor data and attempts to categorise hidden failure mode symptoms. The mid-level of the reasoning architecture is used to ascertain the overall functional availability of the subsystems that make up the whole, that is, what effects do the failure modes that have been recognised have on the functional availability of the subsystem? The challenge of determining and measuring functional availability, but from a system-wide viewpoint, is present at the system-level reasoning, the highest level of onboard reasoning. At this level, the system’s capacity to carry out planned activities is determined using the functional availability evaluations, or condition indicators, from all of the underlying components. This architecture has a connection to the approach in Roemer, 83 where a hierarchical reasoning is designed to support IVHM to provide real-time health state and information on remaining available functionality from various levels of functionality; LRU, assembly, subsystem, and overall system or vehicle. After computing the health indexes at the component level, a successive process rolls up the effects to the subsystem level. The process in Roemer 83 distinguishes between independent relationships, serial dependencies, and parallel dependencies among the functional areas. This can be instrumental in making operational decisions because the nature of the relationship that exists between the components can provide information on how crucial they are to the asset’s functionality at the platform level. The methods in these approaches can be applied to Figure 3 to aggregate the health results from the component, subsystem, and system levels to the platform. Kamtsiuris et al. 12 tackle health estimation of physical assets by employing an inheritance mechanism. The authors describe a system as a set of subsystems, components, or parts that are connected structurally and functionally in a hierarchy. 117 With this hierarchy, a parent–child relationship is established between components, subsystems, and the system. Individual components that make up a subsystem are referred to as a ‘child’ of that subsystem, while that subsystem is the ‘parent.’ In the same vein, individual subsystems that make up a system are referred to as a ‘child’ of that system, while the system itself is the ‘parent.’ That is, every ‘parent’ inherits its health state from its ‘children’. The estimation of health indexes can be rolled up to the platform level by computing the health state of a ‘parent’ at every point and propagating it to the next level in the hierarchy (i.e. from component to subsystem, to system, and to the platform levels). For example, following the structure of Figure 3, a low efficiency in an Air Cycle Machine (ACM) and Heat Exchanger fouling, at the component level, can be propagated to the Passenger Air Conditioner (PACK) at the subsystem level, and then to the ECS at the system level to be seen at the platform level. Tamssaouet et al. 118 approaches health index propagation in a slightly different way. Once a fault is detected, based on the system’s functional architecture, its estimated health state is propagated into the future to determine its system remaining useful life (SRUL). The input–output model, as it is referred to, is a unified model for system degradation, which considers interdependencies between components, mission profile, and inner component degradations. The taxonomy it considers for a physical asset is a components-system classification. Each component has its own failure mode that leads to degradation and this degradation impacts other related components. A component fails when it reaches a supposed threshold and the degradation of a system is characterised by its inoperability, which includes its components’ inoperability. The input data needed to implement this approach at the system level is the failure threshold of the systems’ components, architecture, the online health indicator value of the system’s components and the degradation trends of the system’s components with their uncertainty. Shigang et al. 119 identify the task of hierarchical health assessment as being able to analyse the effect of faults at different levels of health management, given a determined health status at the lower level. This falls in line with the questions that will be faced in making operational decisions, as shown in the pyramid in Figure 3. Shigang 119 adopts a multi-layer Bayesian network for hierarchical health assessment, by assigning probabilities to fault statuses at lower levels and propagating it to higher levels. A similar application of the Bayesian networks is seen in Barua and Khorasani,120,121 where a Component Dependency Model (CDM) for hierarchical fault diagnosis is developed to facilitate a systematic diagnosis of faults at different health management levels of satellites. This can inform maintainers of the probability of a fault getting worse if that fault can potentially affect the overall functioning of the physical asset. In a nutshell, this section shows how employing a HI to supplement the application of AI to diagnose faults has the tendency to improve maintenance information to support operational decisions.
Summary and conclusions
This paper attempts to report the relationship between AI and maintenance, for tackling aircraft component health management from the platform-level. To that effect, it reviews how maintenance has evolved over time, up to where Prescriptive Maintenance (PM) is being done to support CBM, the role of MROs and why they typically adopt IVHM for maintenance. It also touches on how the level of health management has been at the component or system levels and how due to the nature of certain aircraft faults, these approaches might not be able to detect the faults in time. Hence, justifying why a platform level approach can be useful, as it will be able to detect faults and the interaction effects of components quickly. Further, it touches on what might be needed when handling aircraft component health from a platform view - providing information to answer the questions posed by Figure 3, for assisting operational decision. It reviews work on health index computation and suggests that an IVHM system might need a reasoner that can output a criticality index of the components to assist in making an operational decision.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.