
Abstract
Railroads are one of society’s fundamental infrastructures, facilitating the transportation of passengers and goods over vast distances. Rail status data is immensely important for ensuring the safe and efficient operation of railroad networks. However, analyzing ultrasonic inspection data is a labor-intensive process and relies heavily on the expertise of experienced inspectors. To detect internal defects of the rail accurately and automatically, this paper proposes a customized image recognition method based on a convolutional neural network with limited B-scan rail image data collected within the industry. The proposed method uses EfficientNet-b7 as the backbone network to fully extract the B-scan rail image data features. With the help of transfer learning and data augmentation techniques, the backbone network is substantially enhanced so that it can understand high-level features of the object without being trained with large-scale B-scan image data. We establish a real-world internal rail defect dataset with 280 B-scan images and test our proposed method. The results reveal that the highest accuracy of the other mainstream CNN-based methods is 76.25% and the accuracy of the traditional method based on a support vector machine classifier trained with Tamura texture and LBP features is 60.00%. Our proposed EfficientNet-b7 model classifies rail defect B-scan images with an accuracy of 85.00%, precision of 84.71%, and recall of 85.00%. Compared to other rail internal defect detection methods, this method is more accurate. With the help of transfer learning and data augmentation, our proposed method achieves better performance and requires less data.
Introduction
Rail will gradually deteriorate due to exposure to the natural environment and the dynamic load of rolling stocks. At a certain point of deterioration, rail breaks or cracks. Broken rails is the leading cause of major derailments and hazardous material release accidents. 1 From 2011 to 2021, there were an average of 20 mainline broken-rail derailments per year on U.S. Class I railroads. 2 According to the Association of American Railroads, over $24.8 billion was spent on U.S. freight railroad maintenance and capital expenditures in 2017. 3 Between 2000 and 2017, around 6,450 freight-train derailments occurred, leading to $2.5 billion worth of rolling stock damage and infrastructure loss.4,5 Broken rails is also the leading cause of derailments for European Union (EU) countries,6,7 and the maintenance costs for the 27 EU countries for repairing broken rails are around €2 billion per year.
Train accident data from the Federal Railway Administration of the United States shows that in 2022, 359 train derailment incidents occurred due to rail defects, while track defects were the second most common cause of train derailments that year. In recent years, requirements for rail inspection have considerably increased due to the increasing mileage, traffic, and train speeds.8,9 In India, rail passenger traffic has increased by almost 200% and freight traffic has increased by 150% since 2000. 8 Moreover, fewer train operational delays related to rail defect inspection could reduce operational costs. Over $23 billion per year on average was spent on capital expenditures and maintenance expenses related to America’s freight railroads. 10 Thus, a more accurate and efficient rail inspection system is needed to meet the rising safety standards and reduce costs, leading to huge potential yearly savings for railroad inspection and operation.
In the United States, Sperry developed an automatic rail flaw detector car to inspect surfaces and internal rail defects. In internal rail defect inspection, railroad companies utilize ultrasonic sensors to generate ultrasonic echo at various angles to detect internal sections of the rail 11 and output B-scan images. B-scan image analysis is the most widely used method for rail inspection. However, such analysis is time-consuming and depends on experienced analysts, which makes large-scale rail defect inspection difficult, amongst other problems. Due to a lack of intelligence, conducting inspections and reporting together in rail defect ultrasonic detection remains challenging.
Literature review
In the past decade, deep learning-based detection and segmentation methods have been successfully applied to many fields of civil engineering.12–16 Cha12,13 designed deep learning-based crack damage detection using convolutional neural networks and constructed an autonomous structural visual inspection tool, which uses region-based deep learning to detect multiple damage types.
Researchers have also used thermography and other more sophisticated imaging tools to detect internal defects via deep learning-based detection and segmentation methods,17,18 and Rahmat used thermography to segment the internal damage of concrete based on an attention-based generative adversarial network and detected subsurface damage of a steel bridge using deep learning and an uncooled micro-bolometer. For pixel-level segmentation, Kang19,20 developed a semantic transformer representation network and a faster region proposal convolutional neural network for concrete crack segmentation. Choi 21 proposed a semantic damage detection network for the real-time segmentation of superficial cracks in structures.
In railroad engineering currently, piezoelectric ultrasonic detection is mainly used to detect internal rail defects. The detection process involves specialized equipment, including walking sticks, a dual-track rail flaw detector, and a rail flaw detection vehicle. In accordance with industry standards, the utilization of ultrasonic detection to identify internal rail defects allows for the determination of basic information such as the size and location of the damage primarily through the analysis of B-scan images. However, the B-scan images of internal rail defects are significantly different from the other internal damage. The quality of B-scan images depends on manual operation, so the methods used in other fields may not be suitable to solve the problems studied in this paper. The traditional method extracts ultrasonic image features by manually designing a rail ultrasonic image data feature extractor and then classifying rail defects using machine learning classifiers.22–24 Researchers have attempted to customize feature extraction of B-scan images and integrate them with machine learning techniques to classify rail defects. Wu 22 extracted the color, contour, and other features in the algorithm and put them into the perceptron model for rail defect classification. Huang 23 proposed a B-scan image rail defect algorithm to extract image features based on the Tamura texture feature and local binary patterns (LBP), and to classify rail defects with a support vector machine (SVM). These methods could achieve high accuracy in rail defect classification but would require experienced data scientists to design specific image feature extractors and classifiers, which might lead to low robustness and low generalizability for unseen data.
Summary of traditional methods and CNN-based methods.

Contributions
Developing and customizing a deep learning model for internal rail defect classification based on B-scan images faces several challenges. The novelty of this study is that it provides a clear, big picture of the field, and an implementable and generalized solution for these challenges. Currently, a comprehensive investigation of B-scan images for internal rail defects is missing. This study reviews current nondestructive rail diagnostics technology, common internal rail defects, and corresponding B-scan image characteristics.
The existing deep learning methodologies for internal rail defect detection can achieve acceptable performance with a large volume of high-quality data, but risk severe overfitting. Collecting high-quality rare data of negative class, such as B-scan images of internal defects in rails, is challenging and expensive. In this research, we collected four types and up to 280 rail internal defect B-scan images from the industry, which were obtained by dual-rail ultrasonic flaw detectors. To cope with this small industry dataset, we customized and modified dense layers of the EfficientNet-b7 model and then used transfer learning to optimize the model, which substantially enhanced its capacity to understand high-level image traits and fit for the downstream task of rail defect detection in B-scan images. This method allows a model trained on a customized small dataset to achieve great performance.
It is especially hard to gather enough images of all the types of internal rail defects for model training. The low number of negative samples will lead to unbalanced dataset and degrade model. Therefore, we developed a novel internal rail defect classification algorithm based on the modified EfficientNet-b7 and data augmentation, with the aim of classifying internal rail defects on the B-scan images without requiring too much training data, achieving better accuracy. The experiment’s results indicate that in rail ultrasonic data analytics, even with limited and unbalanced industry data, a promising CNN-based internal rail defect detection model can be established with the help of a transfer learning technique and data augmentation.
Material and methods
Material
The B-scan images of common internal rail defects and their characteristics
B-scan images used for training and testing.

Ultrasound detector probe color and corresponding parameters.
Rail transverse defect
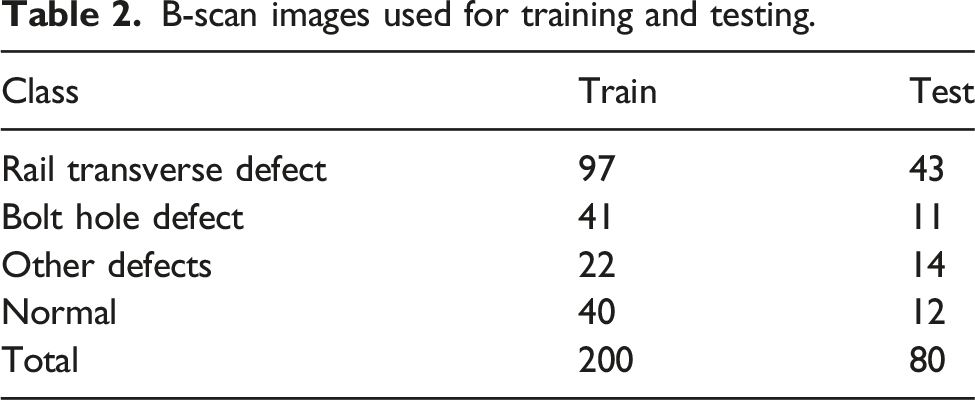
Rail transverse defect is the primary internal rail defect. The size of the rail transverse defect will directly affect the strength of the rail and pose a threat to driving safety. Therefore, it is important to identify the rail transverse defect. In the B-scan image data we collected, rail transverse defects represent the most significant proportion. B-scan images of rail transverse defects are shown in Figure 2 (a). The echo appears near the rail head line. This type of defect is detected by anteromedial and posteromedial 70° probes, with three possible situations: (1) the anteromedial and posteromedial 70° probes appear to echo at the same time; (2) only the anteromedial 70° probe appears to echo; or (3) only the posteromedial 70° probe appears to echo. In summary, the rail transverse defect is detected by 70° probes and the echoes all appear near the rail head line. B-scan images of (a) rail transverse defect and (b) bolt hole defect.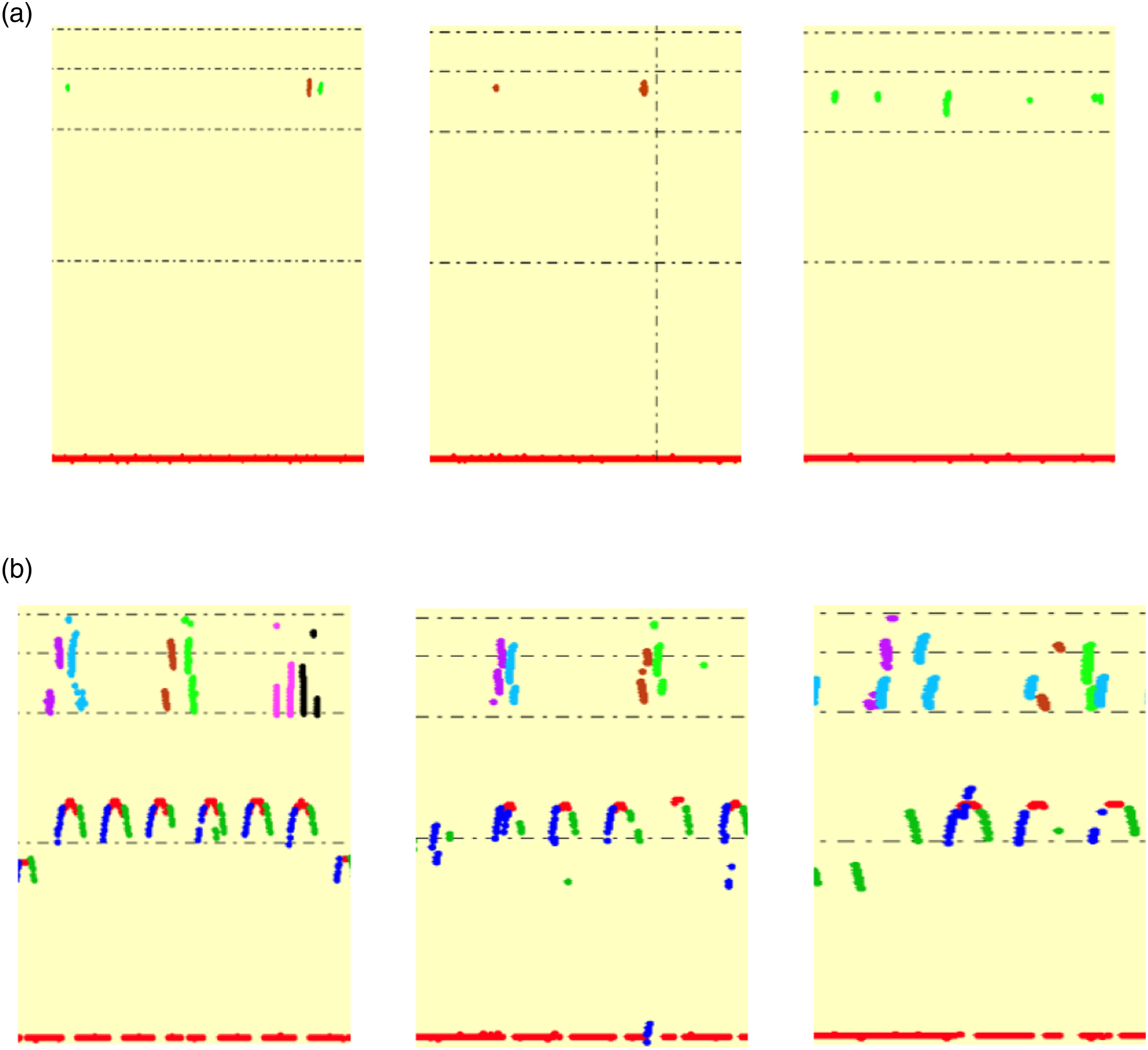
Bolt hole defect
Bolt hole defects can be detected by the forward and backward 37° straight probes and the 0° probe. The echo appears near the bolt hole line that is situated in the middle section of the B-scan image. The bolt hole defect is detected when the forward 37° or backward 37° probe echo exceeds the lower boundary of the bolt hole. If the 0° probe echo is abnormal in the upper boundary or in the lower boundary of the bolt hole line, a bolt hole defect also appears. B-scan images of bolt hole defects are depicted in Figure 2 (b).
Other internal rail defects
Beyond rail transverse defects and bolt hole defects, other main internal rail defects include rail head horizontal crack, rail end horizontal crack, rail jaw horizontal crack, and rail bottom transverse crack, as shown in Figure 3. B-scan images of other rail defects: (a) rail head horizontal crack, (b) rail end horizontal crack, (c) rail jaw horizontal crack, and (d) rail bottom transverse crack.
Most defects appear near the bolt hole position and their detailed classification depends on the 0°, the forward 37°, and backward 37° probe echo. If the abnormal echoes appear near the head line, the defects will be classified as rail head horizontal crack or rail end horizontal crack. If the abnormal echoes appear near the bolt hole line, a rail jaw horizontal crack is indicated. If the bottom of the rail oscillates and abnormal echoes appear, a rail bottom transverse crack is detected.
Methods
A general CNN includes the data input layer, followed by the convolutional layer, pooling layer, fully connected layer, and the final output layer. CNN extracts the essential features of the input image through multi-convolutional computations for the subsequent decision. However, most features observed in B-scan images of rail defects exhibit high degrees of similarity and insignificance. Consequently, traditional CNN encounters challenges when extracting meaningful features for accurate classification of rail defects in B-scan images. Additionally, a well-trained CNN relies heavily on the availability of a large dataset, which is often limited in various scenarios, including medical image analysis. To address this issue, data augmentation is proposed to augment the dataset by incorporating geometric transformations, color changes, rotations, zooming, and other similar operations. 30 In this research, we enlarge our dataset during the model training process. In the traditional CNN training process, the input dataset will go through the model, and the model will update tremendous weights of convolutional layers and others by a backpropagation algorithm for better training accuracy. However, when applied to smaller datasets, the weight number of the CNN model is far larger than the number of training data instances. Overfitting will emerge quickly during the training process and degrade the model. Such a model will not fully understand the patterns and features of a small dataset. The transfer training technique is proposed 31 to conduct domain adaptation for the CNN models and to ease the negative impacts of overfitting. With the transfer training technique, a CNN model can enhance understanding of high-level features and achieve acceptable training performance with a large dataset like ImageNet. 32 Users can customize this pre-trained model for various tasks and fine-tune it on a given small dataset.
In this research, we selected EfficientNet as our backbone network, which is widely used in computer vision. Wang et al. 33 modified EfficientNet-b3 to detect lymph node metastases in breast cancer. Zhang et al. 34 proposed LightWeightTextureNet based on EfficientNet to examine ultrasonic images for material texture classification. These studies show that the application of EfficientNet to ultrasonic rail defect data is promising. Therefore, EfficientNet-b7 was selected to build the classification model for internal rail defects in B-scan images using transfer learning and data augmentation techniques.
EfficientNet
In the deep CNN model training process, network depth, width, and resolution settings are crucial. He et al. proposed ResNet, consisting of residual blocks, pooling layers, and dense layers.
35
Residual block, which is a stack of convolutional layers with multi-scale and other layers, allows ResNet to achieve incredible accuracy. This appropriate and deeper layer combination allows the CNN model to achieve better optimization faster. However, finding such a combination requires extensive computational resources and human efforts, which are not available with limited resources. Unlike the traditional deep CNN model, EfficientNet can scale the model with three dimensions (depth, width, and resolution) using a compound coefficient.36,37 To find the compound coefficients, the general convolutional network N and the following function are defined. Additionally, the memory and flop limits are set for the convolutional network N. The typical N comprises multiple sub-networks. Here we define a sub-network as one stage of the N which is represented by X. In the function N, the stage will be repeated L
k
times, where k denotes the stage. For each stage, we represent the input of the stage with CNN depth, width, and resolution under corresponding constraints. The goal is to maximize the accuracy with limited training resources.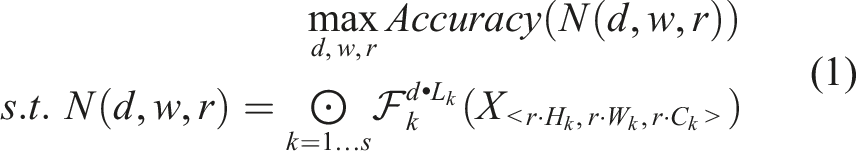
Where d,w,r are the coefficients of the scaling network: depth, width, and resolution. 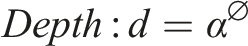
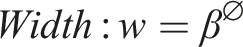
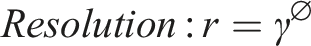
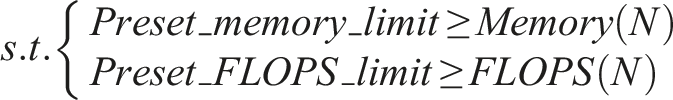
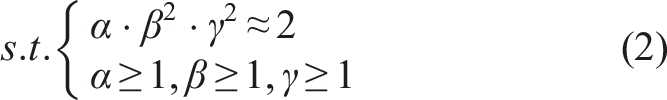
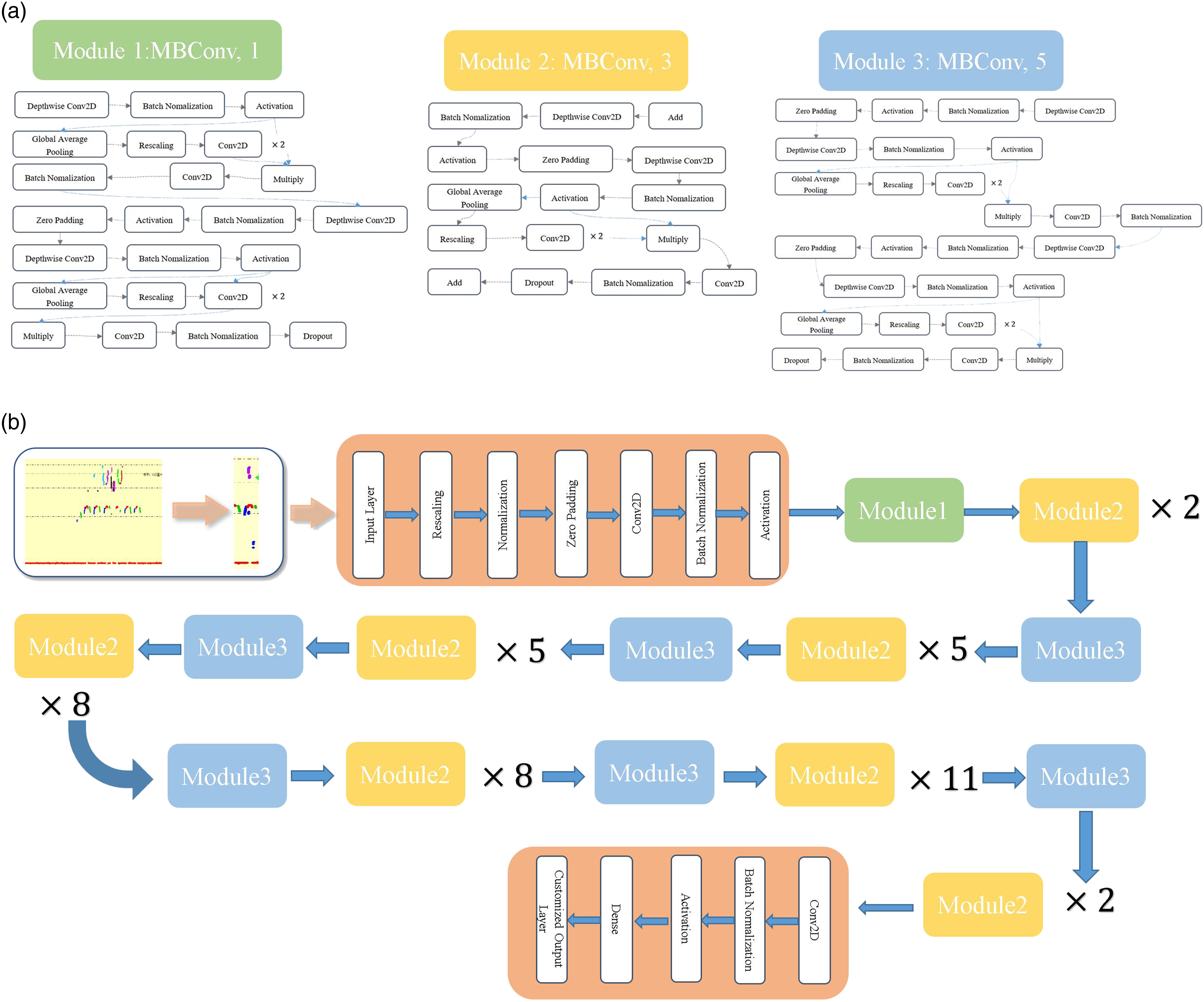
To determine the compound coefficient, EfficientNet selected the mobile inverted bottleneck convolution (MBConv) module as the backbone network, which consists of a 1 × 1 convolution layer, a convolution layer with a larger stripe, and multi-batch normalization layers, with the stripe number of the middle convolution layer inside MBConv being 3 or 5. The structure of MBConv is depicted in Figure 4(a). EfficientNet-b7 is found using grid search and includes 55 MBConv modules, two convolution layers, one global average pooling layer, a fully connected layer, and a softmax classification layer. The network architecture of EfficientNet-b7 is depicted in Figure 4(b). The structure of (a) MBConv and (b) EfficientNet-b7.
36
Transfer learning and data augmentation
Current CNN-based networks require massive high-quality data to achieve satisfactory accuracy. Lab-constructed data can partially solve this problem and meet basic training needs. However, these models are often inaccurate when used in the real-world due to data bias. Further, collecting high-quality rare data of negative class is challenging and expensive in infrastructure industries. The problem of unbalanced data will emerge. Transfer learning aims to transfer knowledge from the source domain to the target domain. 30 With the help of transfer learning technique, CNN models can improve their model capacity, and fine-tune on the small and customized. Additionally, to make our dataset more balanced, we enlarge rare data of negative class in our dataset using the data augmentation technique during the training process. Data augmentation is a commonly used method to increase the amount of data for training data, which is used to prevent overfitting and improve the performance of deep learning models. 30 Data augmentation commonly used in computer vision includes cropping, flipping, rotation, scaling, etc. In our research, we select cropping, flipping, rotation, and scaling to enlarge and balance our dataset because this could retain most of the valuable information while introducing less bias. Overall, we introduce transfer learning and data augmentation techniques in our training process to ease the impact of lacking data and unbalanced data.
Our dataset contains 280 images, which is far below the number of EfficientNet-b7 weights, which is over 66 million. The EfficientNet-b7 would overfit if only trained with our small dataset, and the accuracy and generalization ability of the model would significantly degrade. To avoid such a situation, we first pre-trained the EfficientNet-b7 with ImageNet. After training with large dataset, the pre-trained EfficientNet-b7 achieved strong generalization ability and could fully extract and understand high-level image features. We froze the weights of the input and middle layers with this network and modified the final output dense layers to fit our task. Finally, the customized pre-trained network was fine-tuned on our dataset, and the ideal network was obtained after multiple trainings.
Experiments and discussion
This section first applies our proposed customized EfficientNet-b7 network and then compares it with other methods. The computational hardware resources include an Intel(R) Xeon(R) i7-7700K@ 4.20 GHz CPU, 32 GB of 3200 MHz memory, and an NVIDIA GTX 1080Ti GPU, and the software environments of our machine include Windows 10, Python 3.5.5, Opencv 4.0.0, Cuda 9.2, Cudnn 7.2.1, Pytorch 1.4.0, and other Python packages.
Dataset
All B-scan image data was provided by a Chinese rail agency. LabelImg is a graphical image annotation tool written in Python which uses Qt for its graphical interface. Since the original length of the raw data is too long, it is not appropriate to input into the model. Images will therefore be cut to a size of 100 pixels × 400 pixels by LabelImg. A sample image is shown in Figure 5. Sample image.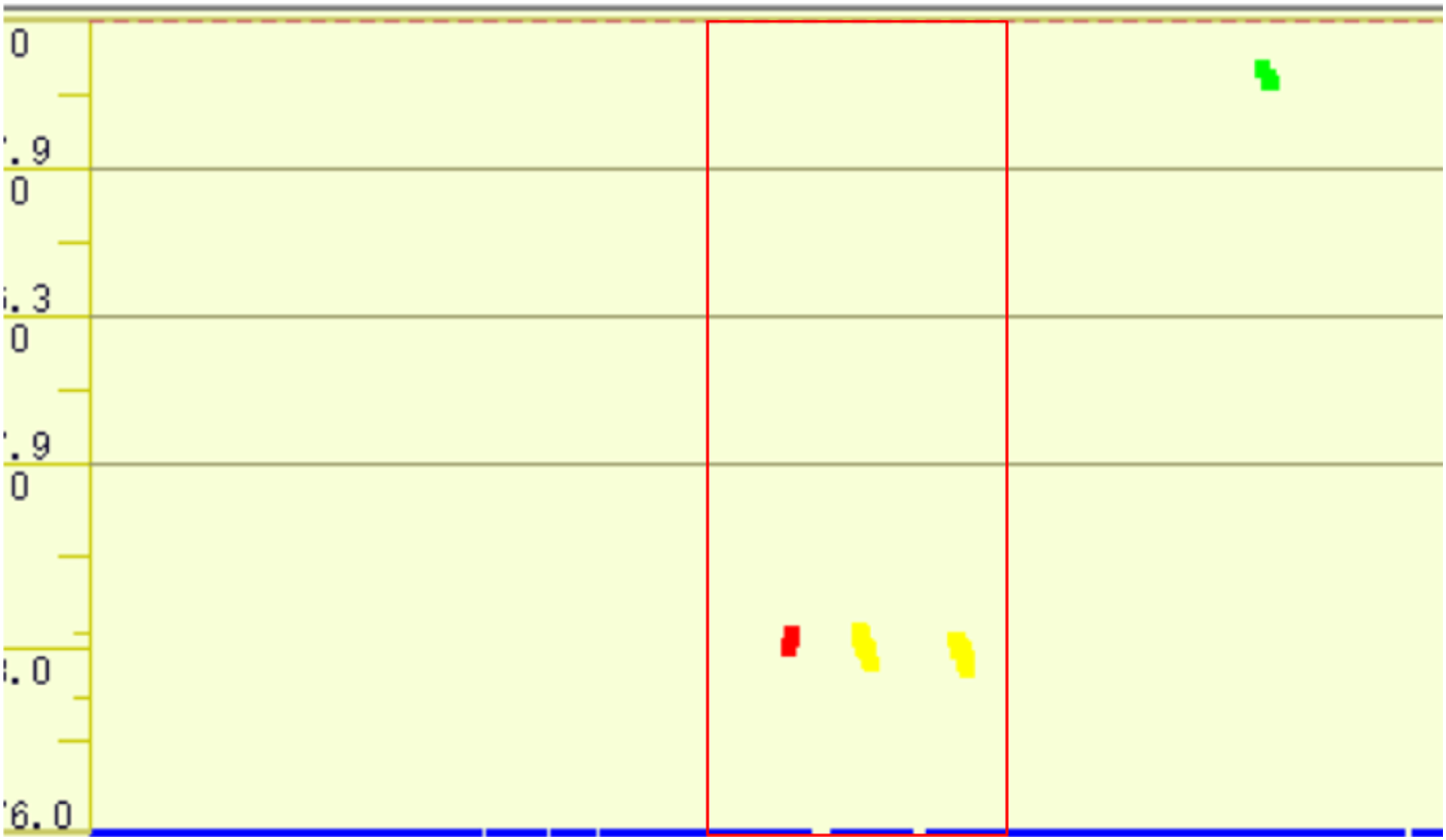
After cutting the images, three types of typical internal rail defects are selected. They are rail transverse defect, bolt hole defect, and other defects. The numbers of B-scan images used for training and testing of all classes are included in Table 2.
Evaluation metrics and definitions
The following is a list of abbreviations for model evaluation metrics and definitions used in this research. TP: True Positive TN: True Negative FP: False Positive FN: False Negative Acc: Accuracy is the ratio of true classifications among all classifications. P: Precision is the ratio of true positive classifications among true positive and false positive classifications. R: Recall is the ratio of true positive classifications among true positive classifications and false negative classifications. F1: F1-score is the harmonic mean of precision and recall. G-Mean: The Geometric Mean is square root of precision and recall.
Training hyperparameters configuration of proposed customized efficientNet-b7
In intensive fine-tuning experiments, the optimal combination of hyperparameters was obtained via 200 training images and 80 test images. The loss function we utilized is cross-entropy. The network hyperparameters include learning rate, weight decay, epoch, momentum, and batch size, and their values are 0.0001, 0.00,001, 100, 0.9, and 32, respectively.
Traditional approach example
Texture traits are crucial for recognizing objects.
38
Researchers have conducted various trials combining texture traits of B-scan images and traditional machine learning classifiers to classify internal rail defects.39,40 Based on the pattern of human visual perception, researchers designated six textural features known as Tamura texture features: coarseness, contrast, directionality, line-likeness, regularity, and roughness.
38
However, the texture features of images in the industry are not smooth enough to process. LBP is proposed to smooth the images. Huang
23
proposed an internal rail defect classification model using B-scan image data based on an image processing algorithm, which utilizes Tamura texture features and an LBP combined algorithm to extract the feature vectors of the rail defect B-scan images. Then, these feature vectors are trained with a solid SVM for classifying rail defects. The framework of this method is depicted in Figure 6. The results from Huang
23
show that such an SVM classifier can classify five classes of internal rail defects in B-scan images with high accuracy, and the algorithm is different from image matching and simple rules-based methods. It can continuously learn and train according to the different training sample sets provided, to obtain the optimal classifier suitable for the current training sample set. This mechanism of their method differs from the CNN-based method and achieves high accuracy in their dataset. The framework of Huang’s method.
23

CNN-based methods
Sun 25 proposed a novel multi-stage model based on AlexNet and the DBSCAN method to classify rail B-scan images. AlexNet is a deep convolutional neural network architecture and consists of eight layers, including five convolutional layers and three fully connected layers. 25
Chen et al. 27 proposed an improved YOLO V3 target detector algorithm to classify internal rail defects using B-scan images. DarkNet-53 is the backbone network for YOLOv3. DarkNet-53 consists of 53 convolutional layers, including shortcut connections and residual blocks.
With deeper convolutional layers, traditional CNN doesn’t achieve high accuracy. The deeper convolutional layers make it hard for the model to converge optimally and introduce the vanishing gradient problem. Hu et al.
28
modified ResNet-50, one variant of ResNet, for classifying internal rail defects in B-scan images. ResNet-50 as trained on the dataset from Hu outperforms some traditional machine learning methods.
23
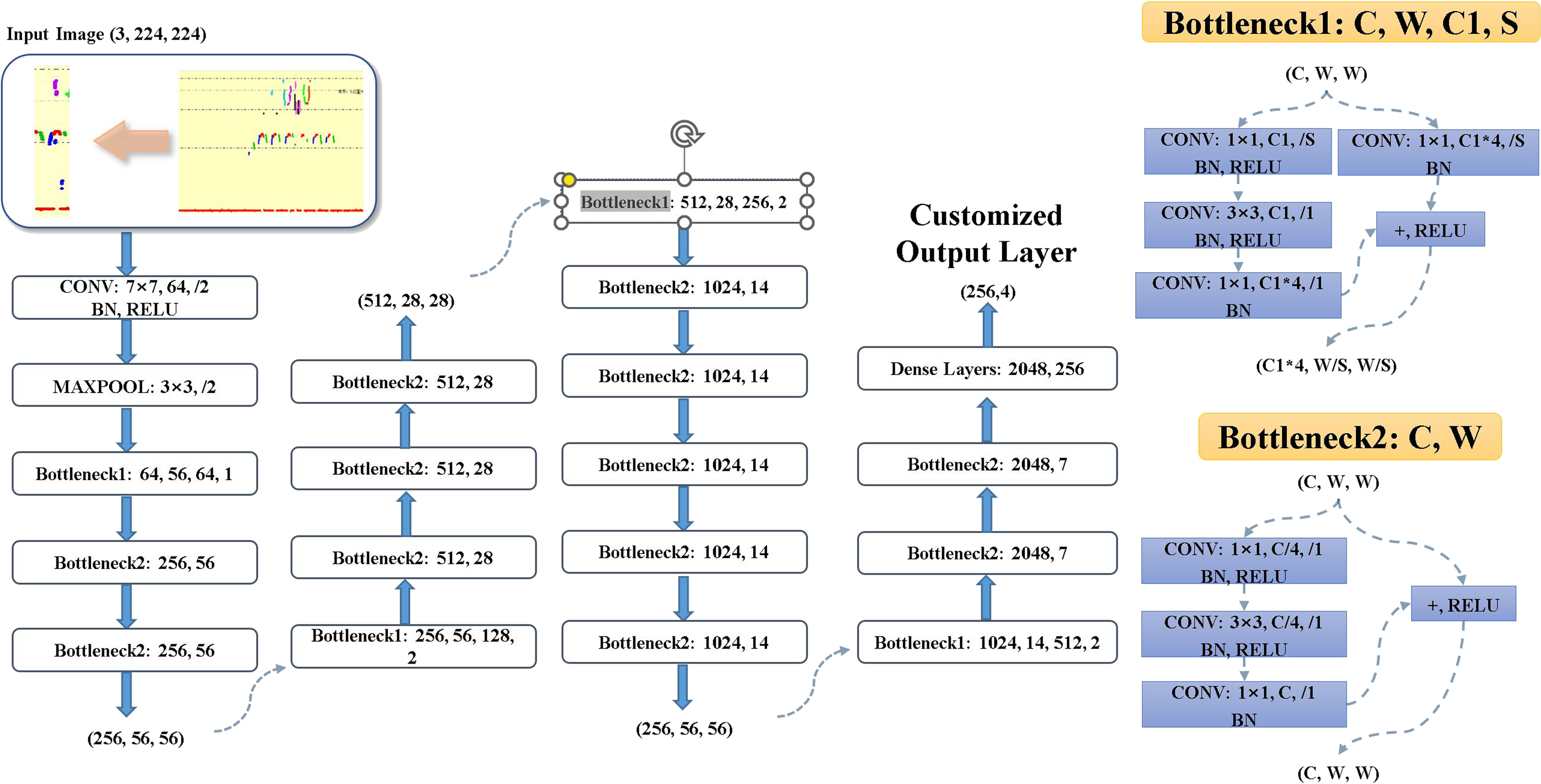
The general ResNet-50 model is comprised of 48 convolutional layers, one max pooling layer, one average pooling layer, and a fully connected output layer. The structure of the ResNet-50 model is depicted in Figure 7. ResNet-50 network architecture.
28
In this research, we selected the CNN-based model pre-trained on the ImageNet dataset and fine-tuned it on our dataset with data augmentation. With the help of transfer learning, we froze convolutional layers, max-pooling layers, and average pooling layers and customized the dense layer and the final output layer for the fine-tuning of our dataset. Extensive experiments were conducted on the fine-tuning network and initial network, and the results are analyzed in the following sections.
Comparison
Model evaluation of traditional method and CNN-based methods
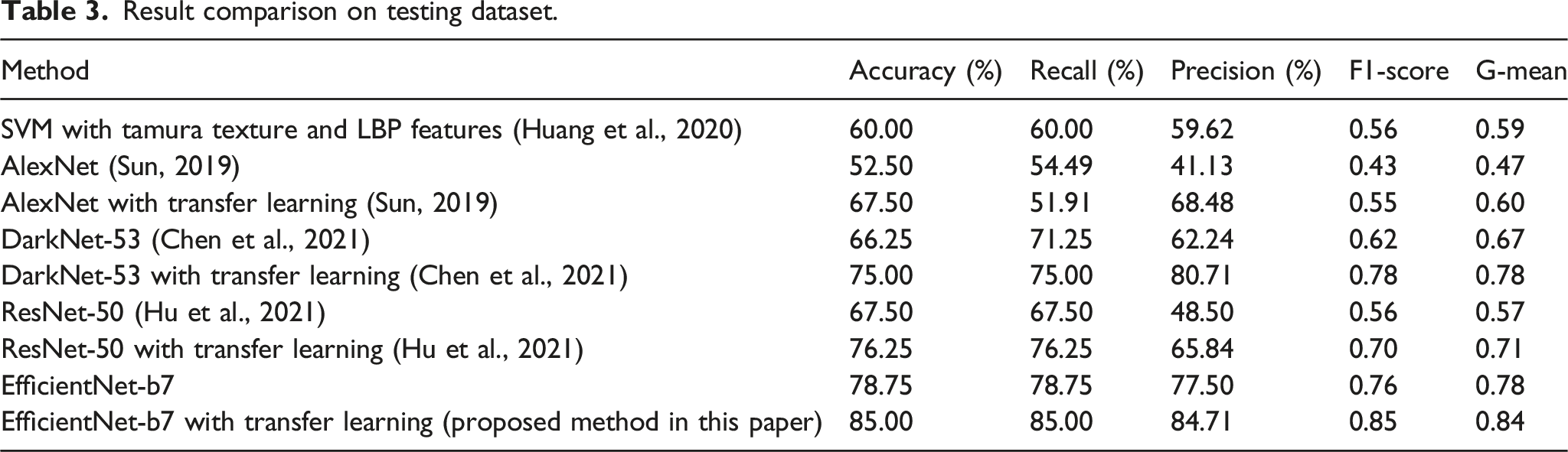
Result comparison on testing dataset.
Huang’s method relies on manually designed image features and SVM for classification. The goal of SVM is largely to separate the data points into a much higher-dimensional decision space. The dataset we utilize in our study was sourced from the industry and contains a considerable amount of noise signal. This noise signal poses a challenge for Huang's method to effectively extract the valuable and significant features from our dataset solely relying on the Tamura texture feature and LBP. The insufficient feature set doesn’t allow the following SVM classifier to obtain the optimal maximum interval hyperplane to classify the internal rail defect, which means that plenty of data points lie on the decision boundary of this SVM classifier. More feature extraction methods need to be introduced and properly designed to fit more scenarios.
Model evaluation of other CNN-based models and proposed EfficientNet-b7
The CNN-based methods in this research, except for AlexNet, achieve higher accuracy than the traditional method. However, ResNet-50 achieves 76.25% accuracy on our dataset only by deepening the network with fixed height, width and resolution, which means some crucial B-scan image feature information will be ignored, leading ultimately to wrong classifications. Trying to capture most of the significant image features, our modified EfficientNet-b7 selected a better compound coefficient combination among depth, width, and resolution. EfficientNet-b7 keeps the image information in multi-scale more reasonably and reaches the desired coverage in fewer steps. Compared to other CNN-based models, the capacity of our proposed model demonstrates an improvement, and these characteristics allow our modified EfficientNet-b7 to achieve the best accuracy. Even without the help of transfer learning, our modified EfficientNet-b7 can achieve a higher level of accuracy than other CNN-based models trained with transfer learning.
As shown in Table 3, EfficientNet-b7 with transfer learning achieves the highest accuracy, recall, and precision. In some scenarios of model evaluation, precision and recall can be contradictory. Thus, the F1-score is selected for the overall evaluation of models. Additionally, we compared the G-Mean of these models. EfficientNet-b7 with transfer learning also achieves the highest F1-score and the best G-Mean out of these models. This shows that our proposed method achieves better performance on multi-class classification and classifies the B-scan internal rail defects more accurately.
Conclusions
Traditional machine learning classifiers with manual feature extraction can achieve high accuracy on certain dataset, but struggle with general dataset compared to CNN models. The goal of manual feature extraction is to identify morphologic characteristics of rail defect B-scan data. Optimal feature selection is based on detecting differences between defects. Proper feature selection increases detection rate and speed, but designing a good extractor is time-consuming and may only work for specific data. CNN models extract features directly from data and update independently, eliminating the need for manual extraction. While tremendous and balanced datasets are necessary for training, obtaining such data is challenging in the industry.
In this paper, we collect and standardize the B-scan image dataset of internal rail defects, a specific scenario in the ultrasound field. Because of the rarity of internal rail defects compared with normal data, this dataset is unbalanced and will lead to significant bias during the training process. We conducted data augmentation during the training process and combined it with transfer learning techniques to ameliorate our dataset's lack of data and unbalanced data. Our investigation reveals that, with an unbalanced and low volume of B-scan rail data in the industry, we can develop a high-performance CNN model with the help of data augmentation and transfer learning techniques.
The results show that even with a small dataset, the rail defect classification algorithm based on EfficientNet-b7 with transfer learning and data augmentation techniques differs from simple image pattern matching and can be applied to the field of rail internal defect detection. After some trials, it appears that EfficientNet architecture with data augmentation could lead to the development of a feasible model without requiring too much training data. During the fine-tuning process of transfer learning, our model can obtain a good initial understanding of images and achieve good classification on our small dataset. The proposed EfficientNet-b7 model classifies internal rail defect on B-scan images with an accuracy of 85.00%, precision of 84.71%, recall of 85.00%, F1-score of 0.85, and G-mean of 0.84, which shows its superior performance on our small dataset and model capacity compared to traditional methods and other CNN models.
In the future, we intend to work with site engineers in railroad companies to deploy our proposed methods with ultrasonic flaw detectors and achieve real-time internal rail defect detection. Although our proposed method shows great potential in ultrasonic rail defect detection with less data needed, as compared to mainstream approaches, more real-world ultrasound rail defect data would be beneficial to improve our model’s capacity. Furthermore, our methods can be applied to other image-based industrial evaluations with rare image dataset, such as fault diagnosis in the electric sectors using thermal images.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.