
Abstract
This paper proposes a novel human-centric approach to enhance decision-making for autonomous vehicles in complex urban driving situations by integrating Deep Q-Network (DQN) reinforcement learning and social value orientation. In the proposed method, a deep neural network (DNN) is employed to approximate the optimal Q-values for various states and actions in the space of possible actions and reachable states. In order to improve the optimization convergence, an Adam optimization is proposed by combining the advantages of adaptive learning rates and momentum methods. The proposed framework also incorporates a collision avoidance component that allows vehicles to navigate safely through pedestrian crossings. The proposed method is validated through simulation experiments, which show that the proposed approach outperforms traditional decision-making and RL methods in terms of safety and efficiency. Finally, the results demonstrate that integrating social value orientation and DQN-RL can lead to more human-like and socially compliant decision-making frameworks for automated vehicles. This research contributes to developing a new human-centric cyber-physical approach for automated vehicle decision-making and has significant implications for designing future intelligent transportation systems.
Introduction
The emergence of autonomous vehicles (AVs) has presented us with transformative opportunities for future intelligent transportation systems.1,2 AVs offer the potential to improve driving safety and enhance traffic efficiency. 3 Despite many efforts to reduce road accidents and the resulting deaths, the number of casualties worldwide has significantly increased, exceeding 1.35 million deaths, according to the World Health Organization (WHO) report in 2018. 4 Therefore, developing safe and reliable AV frameworks is essential to ensure all road users’ safety, including cyclists, pedestrians, and other forms of vehicles. Deploying autonomous vehicles at a large scale while ensuring safety requires addressing multifaceted technical, social, and ethical challenges and incorporating them into the decision-making process of AVs. 5 One of the most critical challenges is rendering safe and ethical decisions when faced with complex traffic scenarios, 6 as AVs rely on pre-planned decision-making algorithms, unlike human-driven cars. To design human-centric AVs, it is crucial to understand how individuals with unique characteristics behave in various scenarios as drivers, bicyclists, and pedestrians. Once the relative geometric positions of all road users are identified for the ego vehicle, an optimal path must be determined between the AV’s current location and its destination, minimizing travel time while satisfying the constraints imposed by the vehicle’s kinetodynamics and physical limitations. 7 Recent advancements in vehicle dynamics control, particularly in vehicle slip angle estimation using integrated GNSS and IMU data, as demonstrated in two novel approaches,8,9 significantly enhance the ability of autonomous vehicles to navigate safely in complex scenarios like slalom and double lane changes. In particular, navigating safely through complex and interactive environments that may include pedestrians poses a substantial challenge for autonomous driving. 10
Despite their usefulness in addressing motion control for autonomous vehicles interacting with another road, many motion control frameworks have two primary limitations.4,11 The first drawback is their excessive tendency to be overly cautious, resulting in an unpredictable driving style that can potentially cause accidents compared to an average human driver.12–14 The second issue is that these frameworks face difficulty adapting to unforeseen situations, which is a significant concern due to the countless number of potential road scenarios.4,15 These limitations underscore the need for advanced motion control algorithms to mitigate these issues and enable safe and reliable autonomous driving. In recent years, a plethora of decision-making methods have been proposed, ranging from rule-based methods to machine learning-based methods. 16 Rule-based methods rely on a set of pre-defined rules and heuristics to make decisions. 17 Although these methods are intelligible and straightforward, they often lack flexibility and adaptability to dynamic traffic situations.
On the other hand, machine learning-based methods, such as reinforcement learning (RL), have shown promising results in decision-making for autonomous driving. 18 RL algorithms learn from environmental interactions and can adapt to changing situations. However, these methods require large amounts of data and time to train, and the learned policies may not always generalize well to unseen situations. 19 Deep learning-based approaches have also been proposed, where neural networks are used to estimate the Q-value function in the context of an RL. 20 These methods can handle high-dimensional state and action spaces but may suffer from overfitting and instability during training. In addition to these methods, recent works have explored the use of game theory 21 and human-centered approaches 22 for decision-making in autonomous driving. These methods consider the interactions between multiple agents and the human factors involved in driving. Despite the progress made in decision-making for autonomous driving, there are still challenges and limitations that need to be addressed. These include the trade-off between safety and efficiency, the need for real-time decision-making, and the interpretability and transparency of the decision-making process. 23
RL has been a promising approach for developing AV decision-making algorithms, which involve learning from experience by maximizing a reward function that reflects the performance of the AV in different traffic scenarios. 24 Hence, RL is a potentially capable method to address the second issue pointed out with respect to classical motion control frameworks. However, RL algorithms may not necessarily guarantee safety and ethical behavior since they optimize the reward function without considering potential risks and consequences. 25 To meet this objective, it is imperative to integrate advanced decision-making algorithms with human-centered risk assessment and social-behavioral cues. Human-centered risk assessment (HCRA) is a well-established methodology for identifying, evaluating, and mitigating risks associated with complex systems such as AVs. 26 HCRA entails analyzing human factors, system design, and context of use to identify potential hazards and assess their likelihood and severity. Integrating HCRA with RL can provide a mechanism for ensuring AVs’ safe and ethical behavior by constraining the RL algorithms’ optimization process based on the identified risks and constraints.
Social-behavioral cues are observable signals and gestures that humans use to communicate their intentions, emotions, and expectations. 27 Integrating social-behavioral cues into the decision-making process of automated vehicles (AVs) can enable them to anticipate and respond accurately to other road users’ actions, which is particularly important for safe and effective interactions with pedestrians and bicyclists. 28 Therefore, this paper proposes a cyber-physical model that combines RL, human cognitive risk assessment (HCRA), and social-behavioral cues to enable AVs to make safe and ethical decisions by learning from experience while considering potential risks and constraints. However, existing RL methods focus solely on the ego vehicle’s goals, neglecting the potential negative impact of its actions on surrounding vehicles. Typically, the reward function considers only the ego vehicle’s goals. To address this limitation, we aim to train an autonomous vehicle (AV) agent to prioritize the comfort and safety of surrounding road users, in addition to its own goals, by shaping the reward function using an advanced SVO framework.
The proposed method in this paper aims to enhance the ethical and socially responsible decision-making of autonomous vehicles by employing an advanced SVO framework. SVO is a well-established concept in social psychology that measures an individual’s prioritization of their own welfare compared to that of others. It characterizes individuals into two primary categories: prosocial and egoistic, with prosocial individuals prioritizing the welfare of others over their own and egoistic individuals prioritizing their own welfare over others.
A significant contribution of this paper is incorporating an advanced SVO framework into the reward function of the Deep Q-network method. By doing so, we can achieve more human-intuitive vehicle actions and ethical and socially intelligent decision-making. The reward function is designed to encourage the car to consider the comfort and safety of surrounding road users, in addition to its own goals, by including a penalty term that discourages the vehicle from taking actions that could potentially harm other road users. The reward function also rewards the car for taking actions that prioritize the safety and well-being of others while also taking the vehicle to its desired spatial location with minimal delay. Our approach can lead to more socially responsible decision-making in autonomous driving, with a focus on both the safety of the ego vehicle and the well-being of surrounding road users.
The existing paper makes the following primary contributions:
A novel HCRA-based, model-free deep Q-network reinforcement learning framework is proposed for decision-making in complex urban driving conditions with mixed traffic of a pedestrian crossing scenario.
By combining SVO with deep Q-network, the reward function architecture is shaped to modify the ego-vehicle strategies. This achieves behaviors that range from egoistic to pro-social, resulting in improved pedestrian safety.
The paper demonstrates how the vehicle’s performance improves over time and how different learning parameters (such as the learning rate and discount factor) affect the speed and quality of learning. This enhances learning and convergence.
Deep Q-network is used to estimate the optimal policy and a balanced exploration and exploitation ratio is achieved by leveraging epsilon-greedy policy to balance the exploration versus exploitation rate.
The organization of the remainder of this paper is as follows. In “Problem formulation” section, the problem formulation is presented. In “Deep Q-networks reinforcement learning” section, the preliminaries of reinforcement learning are given, and the proposed DQN-ADAM-SGD and human-centric SVO-based DQN-ADAM-SGD are formulated and developed. The results are presented and discussed in “Results and discussion” section, and “Conclusions” section concludes the paper.
Problem formulation
For the problem formulation, a scenario is considered where a car approaches a pedestrian crossing the street. The goal is to create a collision avoidance system that ensures the car passes the pedestrian safely. To achieve this, the system must consider the distance between the car and the pedestrian and adjust the car’s speed accordingly (Figure 1).
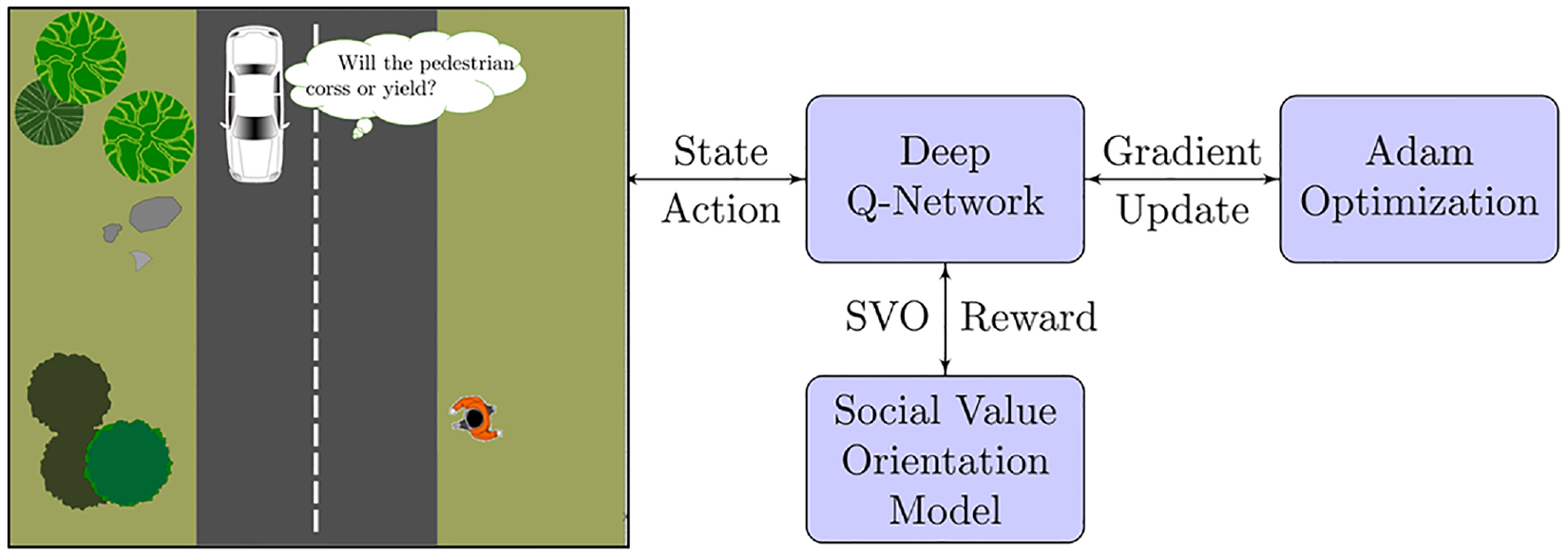
Proposed framework for collision avoidance scheme for AVs approaching a pedestrian crossing the street.
To define the system state, we use a tuple
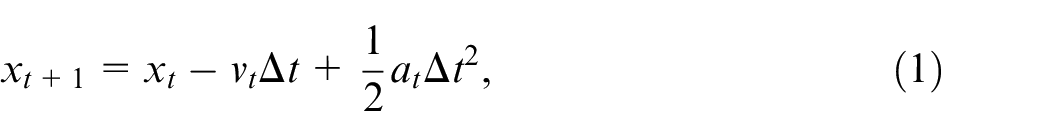

where

where
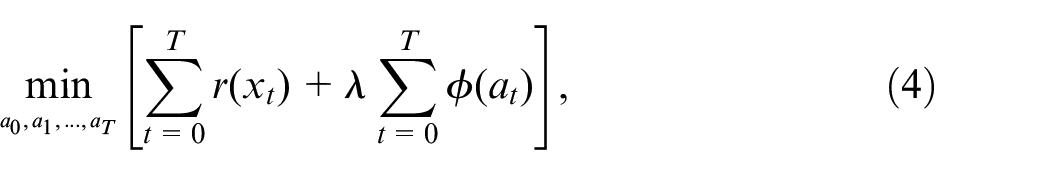
where
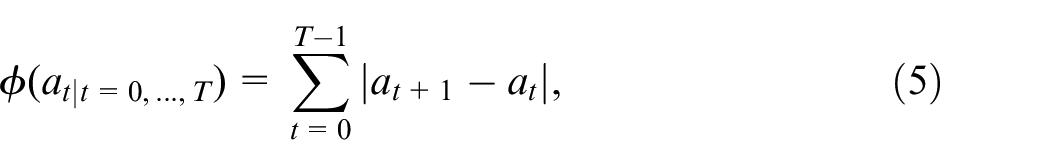
where
Deep Q-networks reinforcement learning
Preliminaries of reinforcement learning
Reinforcement learning (RL) typically involves an agent that interacts with the environment by taking actions and perceiving their consequences. This interaction can be formalized as a tuple, denoted as
By taking into account the longer-term reward policy for the agent, the infinite horizon discounted model is applied. Besides, the subsequent rewards are topologically discounted on account of a discount factor ranged between 0 and 1
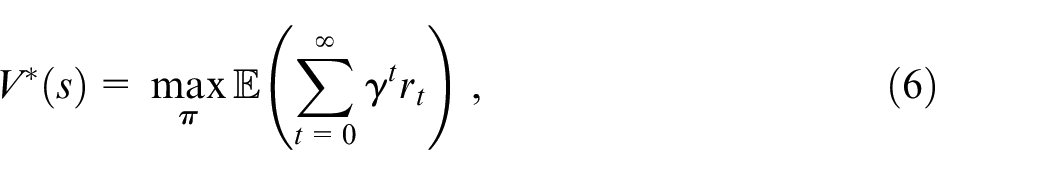
Based on the uniqueness and existence of the optimal result, the solution to the concurrent equations is determined in terms of a recursion expression 29 :
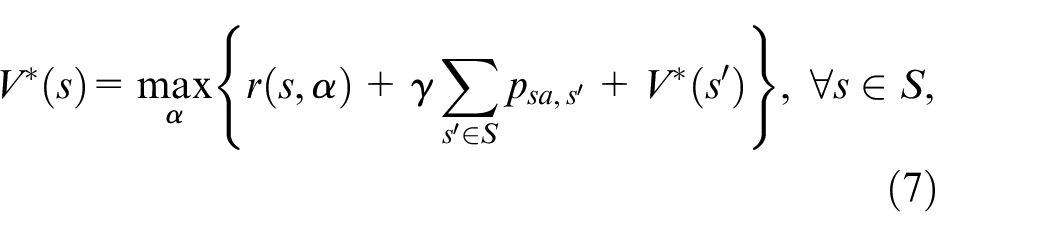
where
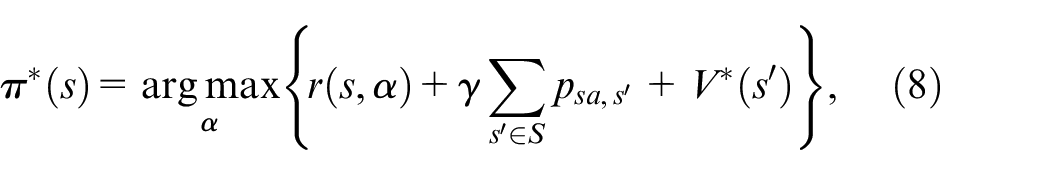
Moreover, the action-value function
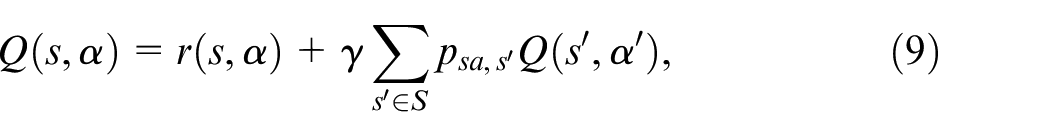
Hence, the associated optimal solution
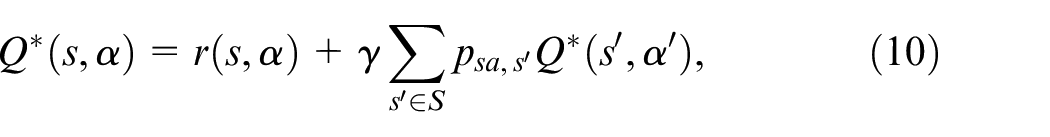
where
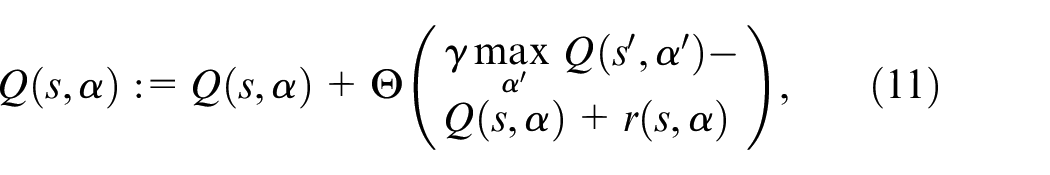
where the current Q-value for a state-action pair
DQN-ADAM+SGD
In order to enhance Q-learning’s efficacy, particularly in intricate settings, a technique known as Deep Q-Networks (DQN) is employed. Rather than utilizing a lookup table, DQN utilizes a neural network to estimate Q-values. DQN has demonstrated effectiveness in managing state spaces with high dimensions, which may be challenging to represent with a straightforward lookup table. The DQN approach employs a deep neural network to approximate the Q-value function, resulting in an approximation of the optimal Q-function’s Q-value function represented as follows:

The Q-value function, denoted as
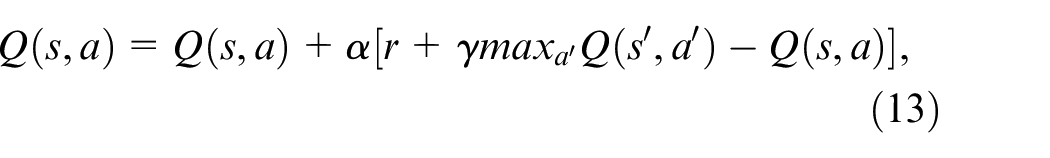
The objective of the DQN algorithm is to acquire the optimal policy

where
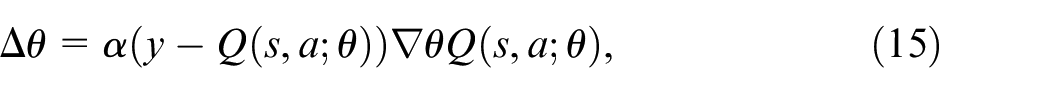
where
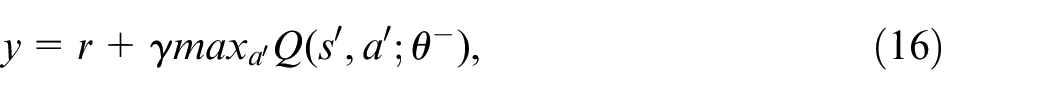
where
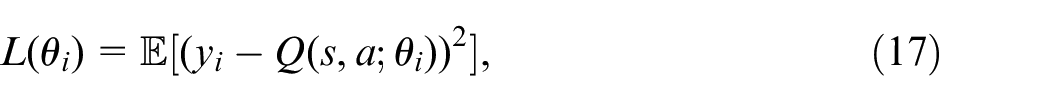
where
Backpropagation is employed by DQN to calculate the gradient of the MSE loss relative to the weights
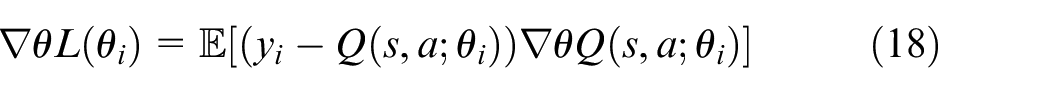
Thus, the weights are updated using the SGD update rule as:

In DQN, the deep neural network’s structure usually includes multiple fully connected layers. The input layer takes the state (s) and action (a) as inputs, while the output layer generates the forecasted Q-value
One can express the output of a fully connected layer, which employs weights

where σ is the sigmoid activation function, and the bias term b is added to introduce a shift in the activation function.
The Q-network takes the state-action pair
The mathematical equation for the Q-value function approximation using a deep neural network can be written as:

where
The process of backpropagation involves utilizing the chain rule to calculate the gradients of the loss function relative to the weights of each layer. When dealing with a fully connected layer that has biases

where
For the sigmoid activation function
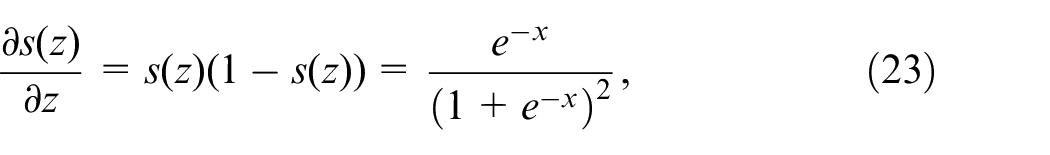
The gradients of the loss function with respect to the weights of the final layer can be computed as:

The gradient of the Q-value with respect to the weights of the network is denoted as
To aid the update of parameters in our proposed approach, we utilize the Adam optimizer. The Adam update formula is expressed as:
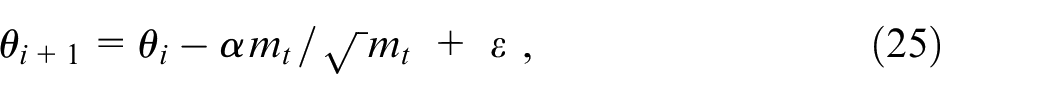
where

where
To achieve adaptive learning rate, the gradients’ first and second moments are calculated and utilized to update the learning rate for each weight. The learning rate for weight
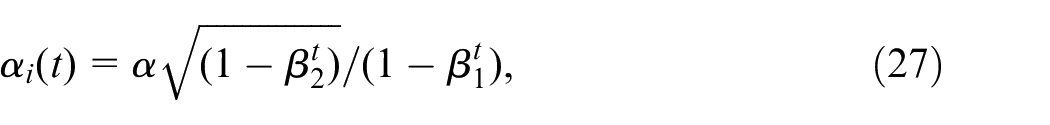
where
In order to comprehend the rationale behind adjusting the learning rate for each weight in this equation, we need to examine the elements involved. The denominator, represented as
On the other hand, the numerator, denoted as
In the Adam optimizer, the momentum term serves to average out the gradients over time and smooth out any fluctuations in the updates. The momentum term is calculated using a moving average of the gradients, which is updated at each time step
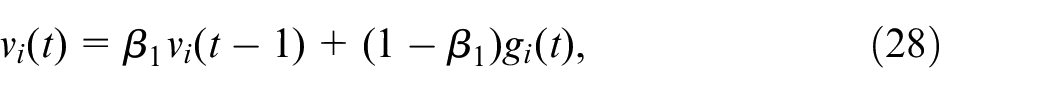
where
Expanding and simplifying the equation reveals why it calculates the momentum term:
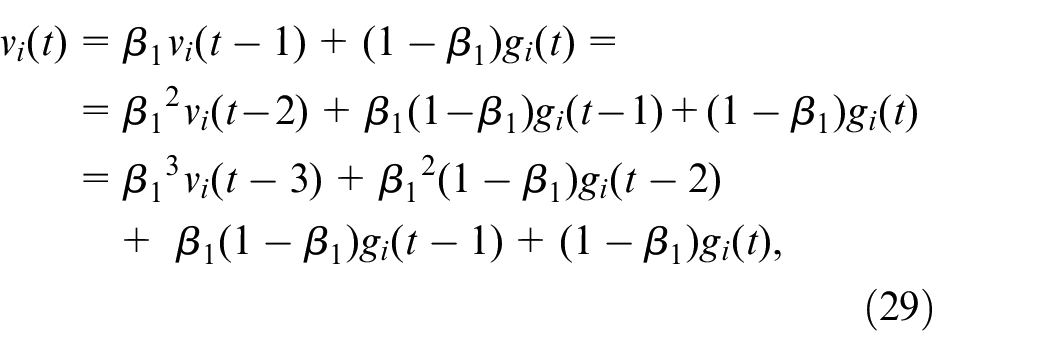
It is apparent that the momentum term in the Adam optimizer is calculated by taking a weighted average of past gradients, where the more recent gradients have higher weights. This averaging process helps to eliminate noise in the updates and prevents oscillations during training. Furthermore, the Adam optimizer uses bias correction terms to adjust for the bias introduced by the first and second-moment estimates. To be more precise, these bias correction terms are computed in the following way:
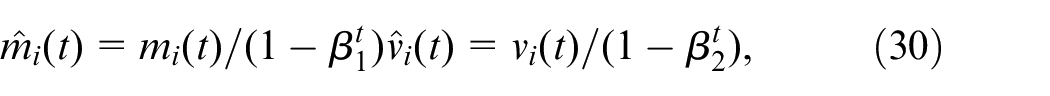
where
The equations presented here aim to compensate for the bias in moment estimates that emerges during the early stages of training. This bias can impede convergence and lead to suboptimal updates, as the estimates tend to be skewed towards zero. To address this issue, the equations incorporate bias correction terms that adjust the estimates to account for this bias, resulting in more precise updates. Thus, the Adam optimizer’s momentum and bias correction terms play a crucial role in enhancing convergence’s stability and acceleration by averaging gradients over time and correcting for the bias in moment estimates.
SVO-based DQN+ADAM
In this paper, the Social Value Orientation (SVO) model has been developed, which relies on the concept of cooperation and competition among individuals in social dilemmas. The SVO framework is selected for its robust capability to model and predict individual decision-making behaviors in social contexts, making it ideal for simulating human-like decision-making in AVs. Its flexibility in accounting for a spectrum of behavioral inclinations, ranging from egoistic to prosocial, is crucial for accurately modeling the diversity in human decision patterns. This approach enhances the ethical aspect of decision-making, allowing AVs to make choices that balance self-interest and societal welfare. Furthermore, the integration of SVO into the Deep Q-network’s reward function equips AVs with enhanced social intelligence, which is crucial for navigating mixed-traffic environments. This leads to AV behavior that is not only safe and efficient but also perceived as ethical and socially considerate by human road users. The inclusion of the SVO framework marks a significant advancement in our research, contributing to the development of AVs that are more aligned with ethical standards and societal expectations. It is formulated as a function that considers both the pedestrian’s heading direction relative to the direction of the car, represented by the angle
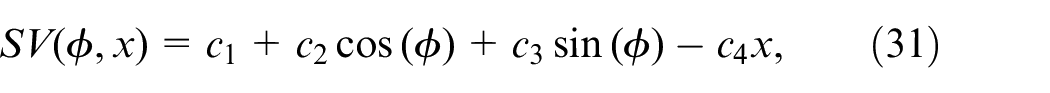
where
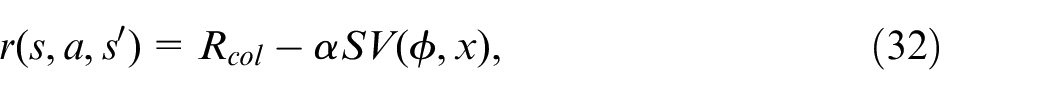
If a collision occurs, and 0 otherwise. Furthermore,
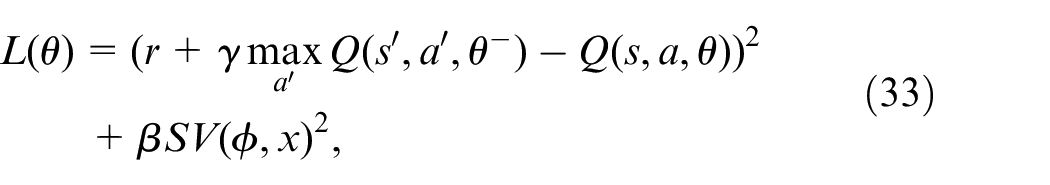
where

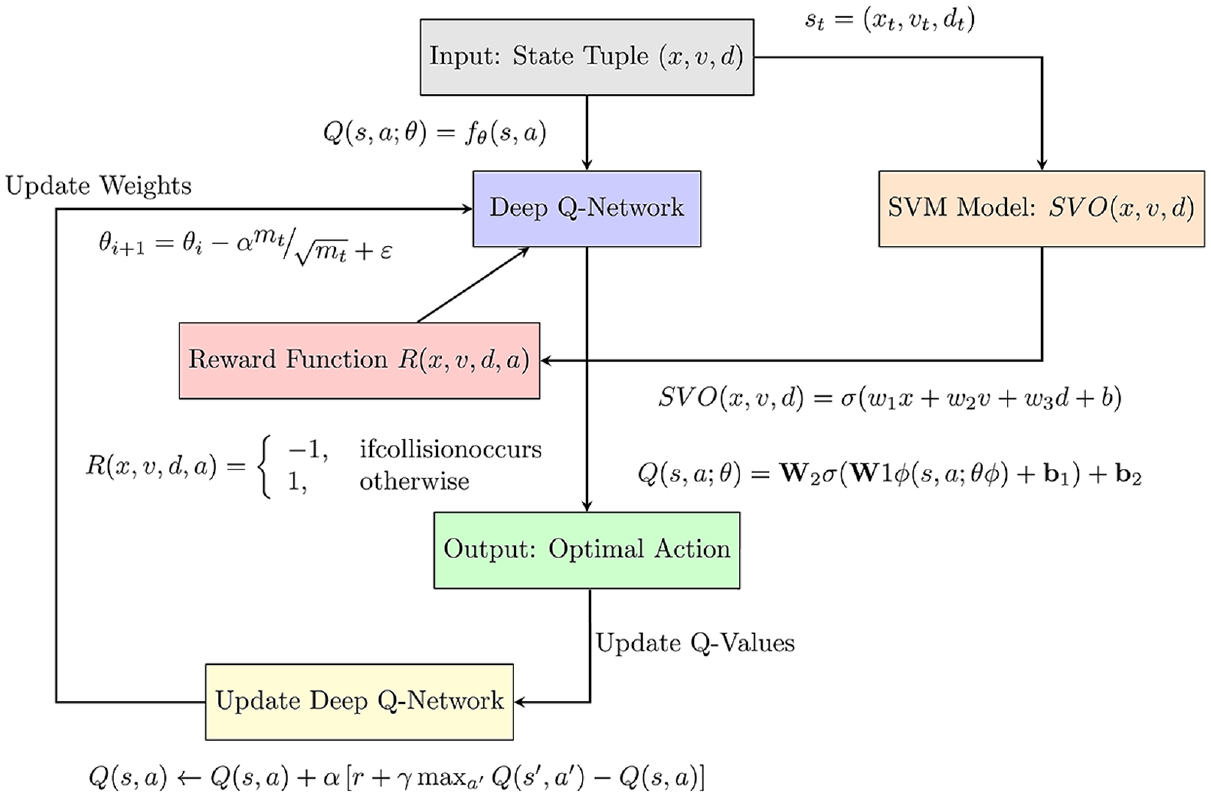
A general block diagram of the proposed framework based on SVO oriented DQN+ADAM optimizer for the human-centric decision-making of AVs.
Results and discussion
In the preceding sections, we constructed a decision-making model for an autonomous vehicle in a scenario where a pedestrian is crossing the road. The model uses the distance between the vehicle and the pedestrian, as well as the pedestrian’s social value orientation and the vehicle’s collision risk function. The model employs deep Q-learning and Adam optimization with SGD to train and obtain the optimal policy for the vehicle. In this section, simulation results demonstrate that the model can avoid collisions with pedestrians while minimizing travel time. We compare the model’s performance with other deep learning and Q-learning models, with and without human-centric social value orientation, and discuss the results regarding safety and efficiency for designing decision-making systems for autonomous cars in pedestrian-dense environments. Table 1 displays the hyperparameters used in the proposed social value orientation-based deep Q-learning scheme, including the learning rate, discount factor, epsilon (exploration rate), momentum, and batch size. The simulation experiment results of the proposed algorithm with different hyperparameter settings are also presented in the table.
Hyperparameters used in SVO-based DQN.

The findings indicate that the algorithm’s performance is sensitive to the selection of hyperparameters. A higher learning rate and discount factor lead to better outcomes. A lower epsilon value results in better performance due to the exploration-exploitation trade-off. The momentum parameter is also significant, with a higher momentum value improving performance. Finally, larger batch sizes result in faster convergence of the algorithm.
The Q-values obtained from learning in the autonomous car-pedestrian collision avoidance problem indicate that as the distance between the car and pedestrian decreases, the Q-value decreases as well for both acceleration and brake actions (as shown in Figure 3). The Q-value for acceleration drops at a faster rate than that for braking, suggesting that in this situation, acceleration is riskier than braking. When the car approaches the pedestrian, the Q-values for both actions reach zero, indicating that the risk of collision is at its highest in this region. Hence, these learned Q-values offer valuable insights into the best course of action to take in different states to minimize the risk of collision in the autonomous car-pedestrian scenario.
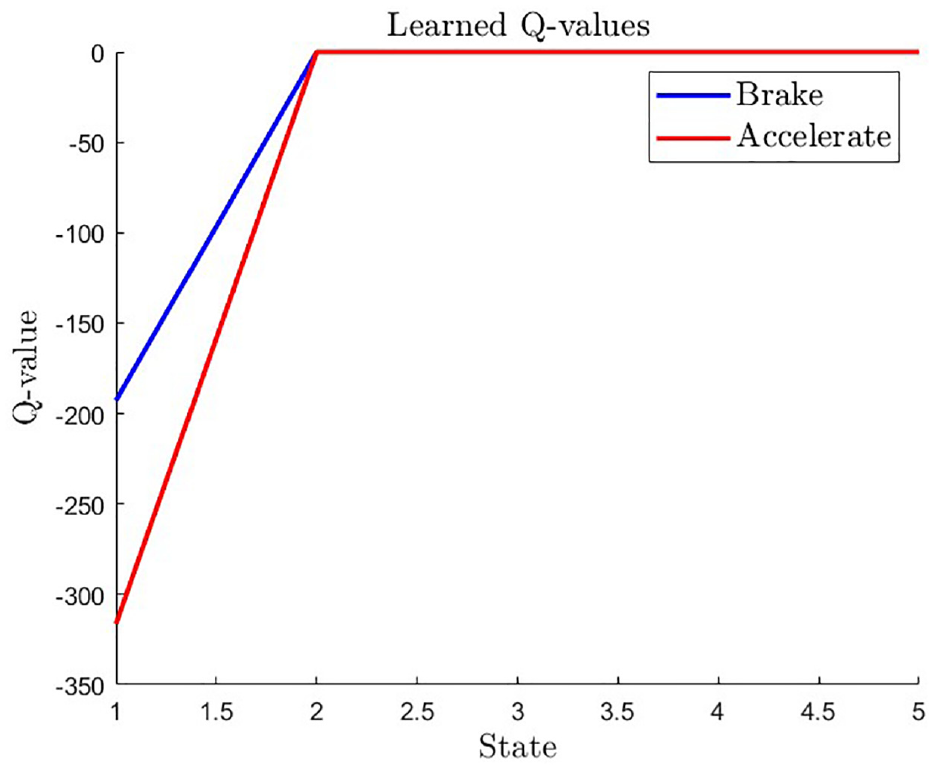
Learned Q-values for two actions of braking and acceleration depending on the states.
Figure 4 demonstrates that the car is able to maintain a safe distance from the pedestrian and successfully avoids collisions. The black dashed line represents the position of the pedestrian, and the brown line represents the position of the car. The simulation shows that the car is able to avoid such collisions and maintain a safe distance throughout the simulation.
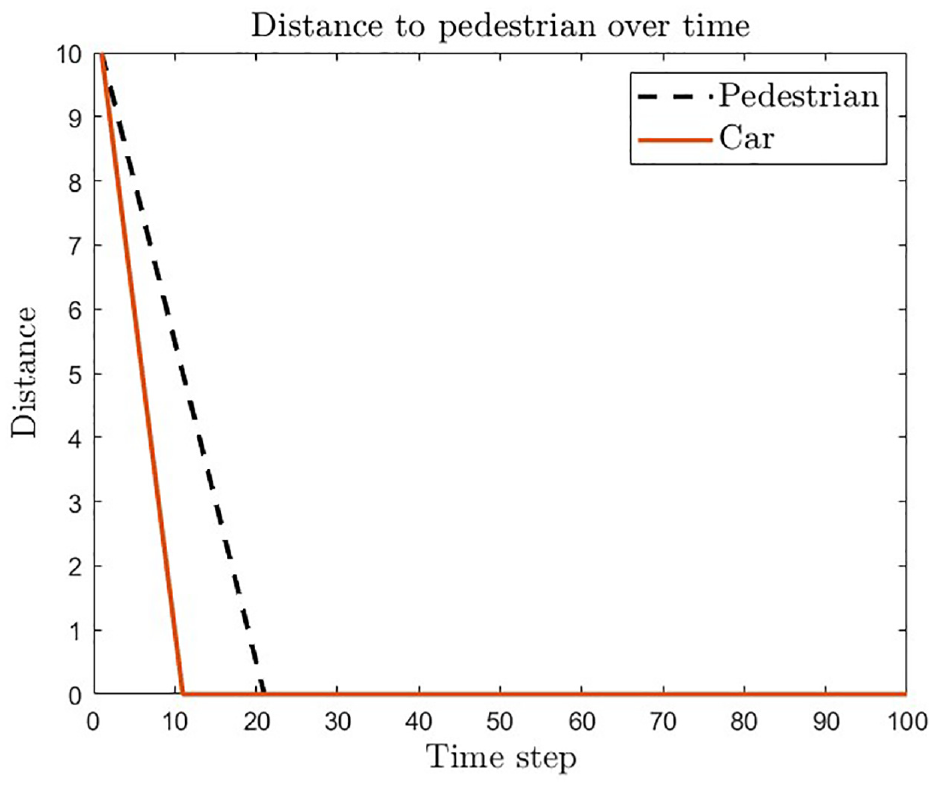
Maintaining safe distance from pedestrian and avoiding collisions during the simulation time.
Figure 5 displays the state-action visit outcome for the SVO-based DQN+ADAM approach. It indicates the frequency with which the agent has explored and exploited different actions in each state throughout the learning process. This frequency is represented by the number of times each state-action pair has been visited. A state-action pair with a high visit count, such as the pair of state 96 and action 7, indicates that the agent has learned and updated its DQN-based Q-values more accurately for that pair.
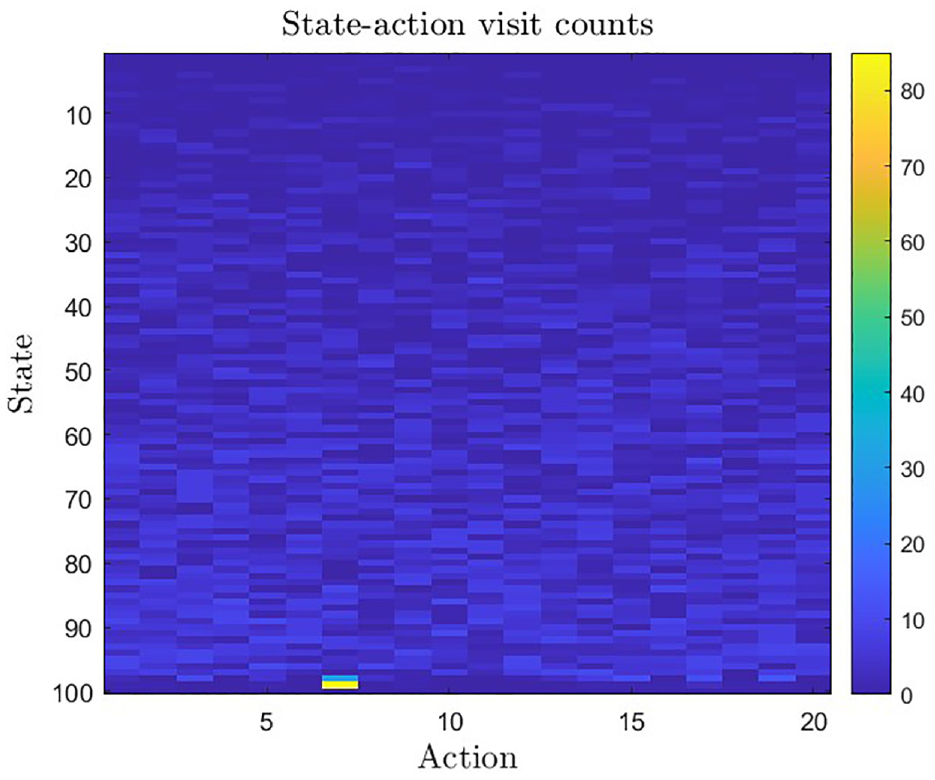
State-action visit counts: Frequency of states and actions observed during the learning process in a reinforcement learning algorithm.
In Figure 6, the Q-values for each state-action pair are depicted, where the Q-values for the “brake” action are displayed in blue, and the Q-values for the “accelerate” action are represented by the red line. The brown line represents the optimal policy curve learned by the DQN algorithm. This curve displays the Q-values for the optimal action that the agent should take at each state. One notable observation is that the optimal policy curve changes rapidly across different states, suggesting that the optimal action varies frequently depending on the car’s state and the pedestrian’s position. Moreover, the optimal policy curve has higher values than the Q-values for the “brake” and “accelerate” actions, indicating that the optimal policy outperforms the individual actions in terms of avoiding a collision with the pedestrian.
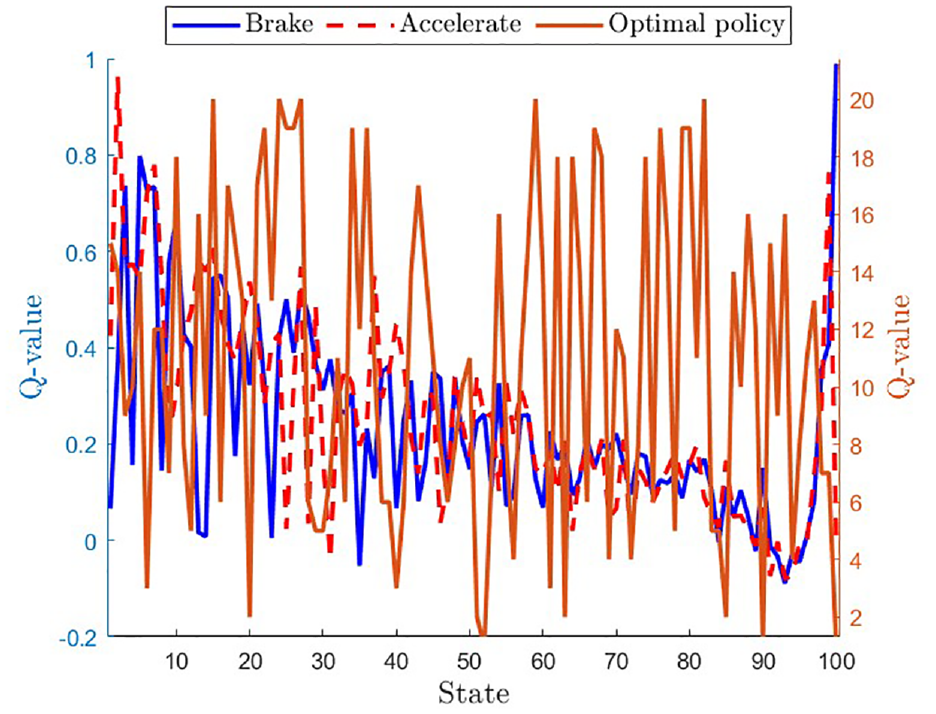
Q-values and optimal policy for collision avoidance with a pedestrian: Comparison of “brake” and “accelerate” actions with optimal policy curve.
The results discussed earlier are reinforced by Figure 7. The histogram of rewards illustrates the distribution of rewards that the car obtained during the training process. The plot depicts that the majority of the rewards, approximately 96%, are positive and equivalent to 1, which indicates that the car was successful in avoiding collisions with pedestrians. However, there were a few cases where the car collided with a pedestrian, resulting in a negative reward of −1. The plot indicates that only four such instances occurred, accounting for just 4% of the total frequency. This suggests that the trained model is effective in preventing collisions with pedestrians, as shown by the high frequency of positive rewards.
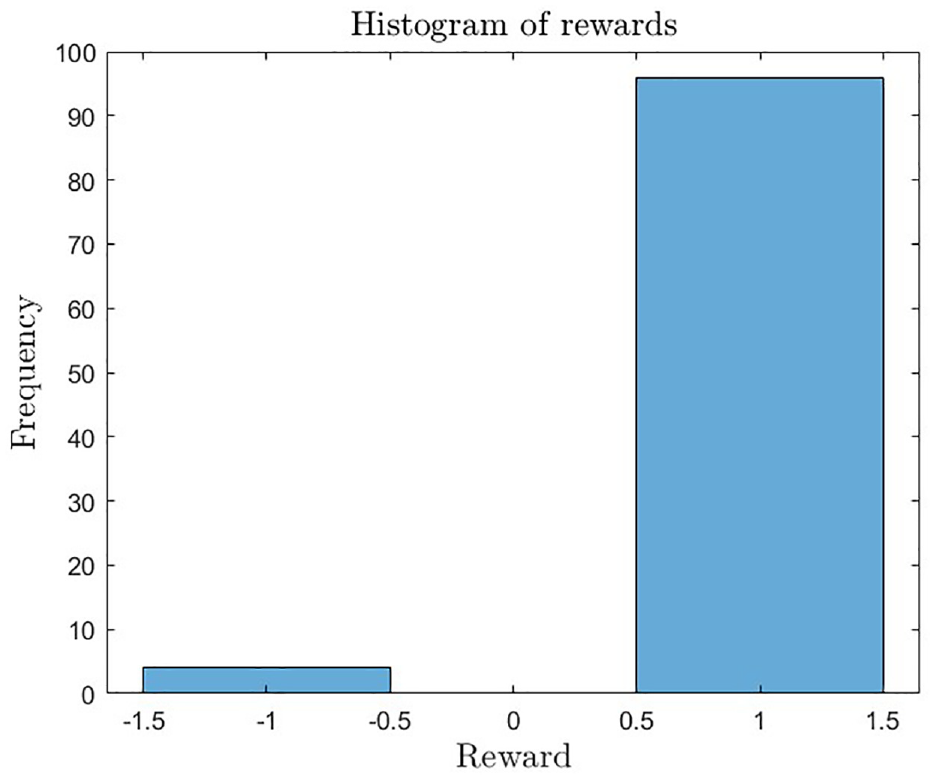
The histogram of rewards illustrates the distribution of rewards that the car obtained during the training process.
The relationship between car speed and pedestrian position can provide valuable insights into the safety of autonomous driving systems, as shown in Figure 8. The graph demonstrates that collision risk increases as the car gets closer to the pedestrian, but the rate of increase differs depending on the speed. When driving at lower speeds, the risk increases slowly, with a maximum of 0.04 reached at a distance of 1 m. However, at higher speeds, the risk rises quickly, with a maximum of 0.12 reached at a distance of only 0.5 m. This highlights the significance of maintaining a safe distance from pedestrians, particularly when driving at high speeds. The findings also suggest that reducing the speed as the car approaches a pedestrian, even if they are still at a safe distance, could be beneficial. These results emphasize the importance of advanced collision avoidance strategies that consider both the pedestrian’s position and the car’s speed.
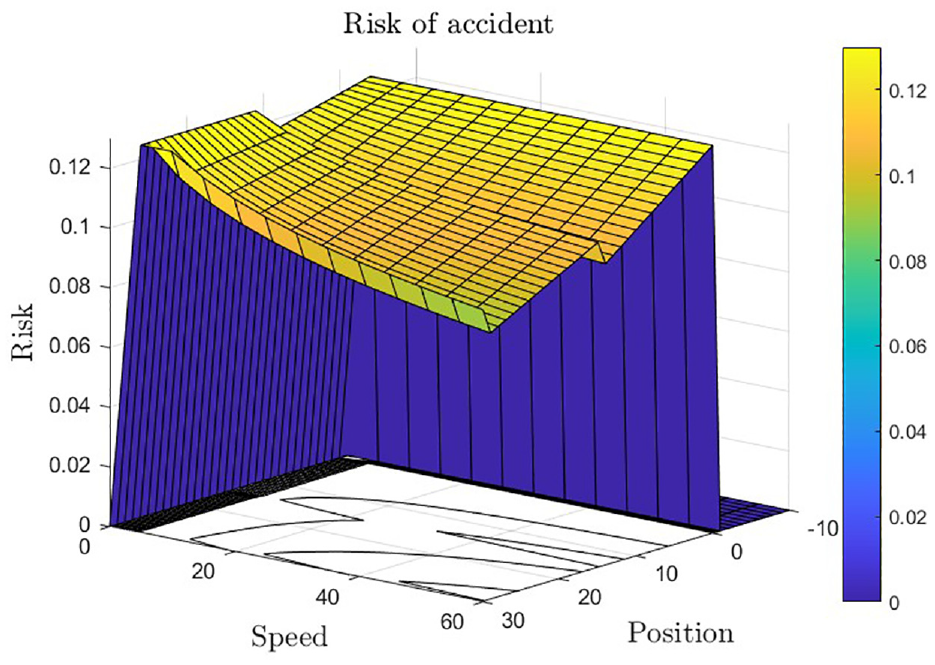
The relationship between vehicle speed and pedestrian position: Collision risk analysis for the proposed SVO-oriented DQN+ADAM.
In reinforcement learning, balancing exploration and exploitation is crucial, and the exploration strategy employed can have a significant impact on an agent’s performance. Figure 9 illustrates the importance of exploration in the proposed DQN-based SVO approach by comparing exploration versus exploitation over 100 episodes. The plot shows that exploitation remains constant at 0.5, indicating a fair balance between exploration and exploitation in the agent’s policy. However, the decreasing exploration rate from 0.95 to 0.05 suggests that the agent’s policy becomes more deterministic over time, which may limit its ability to find the optimal solution. Therefore, to ensure that the agent explores all possible states and actions and finds the optimal solution, the proposed approach requires a high exploration rate. It is critical to maintain a high exploration rate during the early stages of training for better performance.
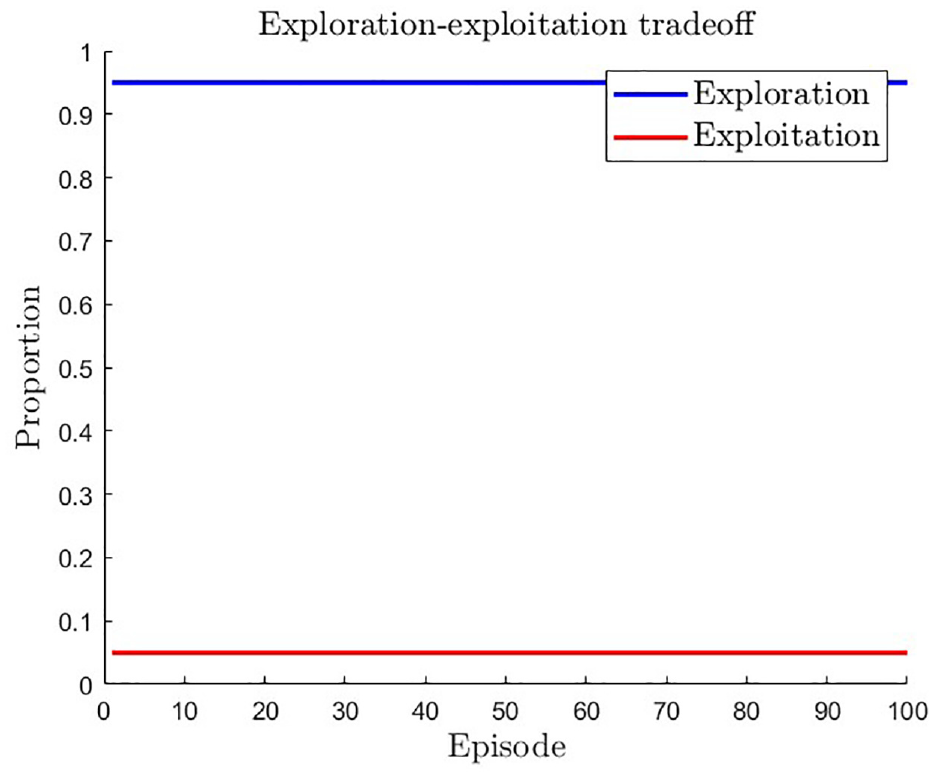
Exploration versus exploitation in DQN-based SVO approach: Impact on agent’s performance.
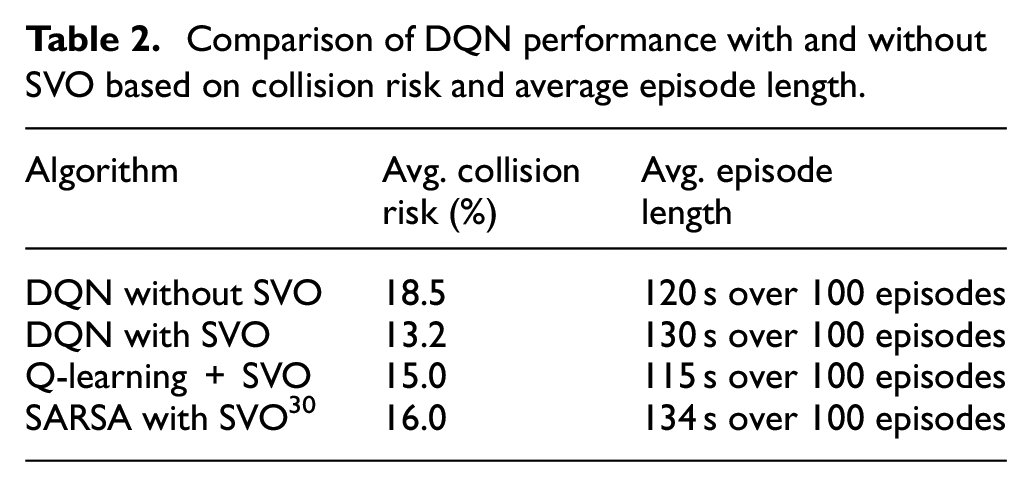
Table 2 compares the performance of three algorithms: DQN without SVO, DQN with SVO, and Q-learning with SVO. The comparison is based on two metrics, namely, the average collision risk and the average episode length. The findings indicate that DQN with SVO performs significantly better than the other two algorithms, with an average collision risk of 13.2% and an average episode length of 130 s over 100 episodes. On the other hand, DQN without SVO and Q-learning with SVO exhibit average collision risks of 18.5% and 15.0%, respectively, and average episode lengths of 120 and 115 s over 100 episodes, respectively. These results suggest that integrating SVO into DQN decision-making enhances the algorithm’s ability to avoid collisions and enables the car to navigate more complex environments, resulting in longer episodes. As a result, the proposed algorithm with SVO has the potential to be a promising approach for autonomous car navigation in real-world scenarios.
Comparison of DQN performance with and without SVO based on collision risk and average episode length.
The three subplots in Figure 10 provide crucial insights into the performance of our algorithm. In the first subplot, we observe that the value function oscillates significantly, starting from an initial value of 1 and continuously decreasing while oscillating across the 90 states. This behavior is expected, as the value function is learning to approximate the expected long-term rewards for each state-action pair. The oscillation can be attributed to the learning process, which involves updating the value estimates based on the observed rewards and transitions.
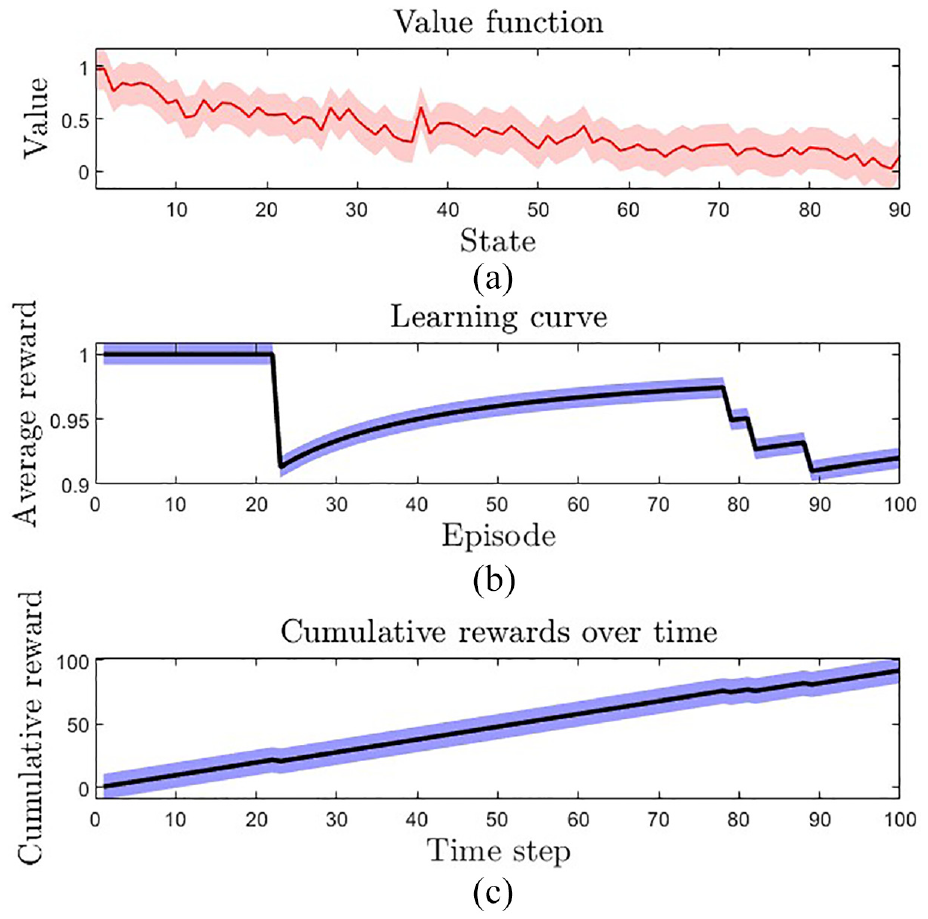
Performance evaluation of the proposed algorithm: (a) oscillation of the value function over 90 states, (b) average reward obtained over 100 episodes, and (c) cumulative reward obtained over time steps.
The second subplot shows the average reward obtained over 100 episodes. Interestingly, the average reward remains constant at 1 for the first 25 episodes, after which it varies significantly between 0.9 and 1 for the remaining episodes. This variation in the average reward can be attributed to the exploration-exploitation trade-off that the algorithm has to balance. Initially, the algorithm tends to explore different actions and hence obtains higher rewards, while later, it exploits the learned policy and obtains lower rewards.
The third subplot depicts the cumulative reward obtained over time steps. Starting from an initial value of 0, the reward gradually accumulates and reaches 100 by the end of 100 time steps. This trend is expected as the algorithm learns to maximize the long-term rewards by selecting the optimal actions for each state. Overall, the subplots suggest that our algorithm is learning to approximate the expected rewards and converge to an optimal policy.
Conclusions
In this paper, we proposed a new human-centric cyber-physical approach for automated vehicle decision-making by integrating Deep Q-Network (DQN) reinforcement learning and social value orientation. Our approach enables automated vehicles to make decisions that are not only optimal but also aligned with human social values.
To achieve this, we formulated the decision-making problem as a Markov Decision Process and used DQN to learn the optimal Q-value function. We also integrated the Adam optimization algorithm with stochastic gradient descent to improve the learning process. Furthermore, we introduced a social value orientation model for pedestrians to capture their preferences and behavior in the decision-making process. This model enables the automated vehicle to consider the pedestrian’s social values and preferences when making decisions, thus promoting human-centric decision-making.
Our results demonstrate that our proposed approach outperforms existing approaches in terms of both collision avoidance and human-centric decision-making. We believe that our approach has significant implications for the future of automated vehicle decision-making and can lead to a safer, more efficient, and more socially responsible transportation system.
In conclusion, our proposed approach integrates DQN reinforcement learning, Adam optimization, and social value orientation to enable automated vehicles to make decisions that are optimal, safe, and aligned with human social values. The incorporation of social value orientation in automated vehicle decision-making is a critical step towards achieving a human-centric transportation system, which is crucial for realizing the full potential of automated vehicles.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.