
Abstract
A test scenario generation method based on combinatorial testing (CT) and Bayesian Network for autonomous vehicles is proposed in this paper. Firstly, some parameters are selected to describe the test scenarios which are classified according to road types and driving tasks. Then, the constraint sets for the scenarios with forbidden tuples are established to avoid the generated cases do not conform to the reality, in which the construct constraint set (CCS) algorithm is utilized to compute implied constraints. Furthermore, the Bayesian networks is used as the probabilistic models of the scenarios, where the traffic participants are represented as object nodes and the relative relationships between the participants are converted into the network structures. Finally, an improved automatic efficient test case generator (AETG) is developed to generate test cases. By considering both probability and frequency, the select function is designed for determining the values of scenario parameters. And the generation mode can be changed by modifying the weight and target parameters. The effectiveness of the proposed method is evaluated by generating six typical test scenarios. Compared with other algorithms, the numbers of test cases in the sets generated by this method are less and the probability deviations are smaller.
Keywords
Introduction
With the rapid development of artificial intelligence technology, more and more vehicles have automated driving functions, which have led to lots of discussions on the safety issues about it. 1 Although automated driving technology can avoid some traffic accidents, it brings new risks to driving behavior. 2 For this reason, before many autonomous vehicles are put on the market, various tests are required to verify their safety and reliability.
Based on the mortality rate of vehicle accident, at least 240 million kilometers of road test without fault is required to prove an autonomous vehicle is safe and reliable. 3 When a fault occurs during the test, the mileage will continue to increase. Therefore, it is difficult to use only road test to verify the safety of autonomous driving. The simulation scenario test method will shorten the test cycle. 4
There are many types of scenarios, including: driving test scenario, 5 illegal scenario, 6 normal scenarios, 7 and generated scenarios. 8 The driving test scenarios are derived from the driving test projects. 9 The scenarios are representative, but there are few types. It is not possible to conduct comprehensive tests on autonomous vehicles.
The illegal scenario6,10 is a special kind of scenario in which there are traffic participants violating traffic laws. Illegal scenarios can test how autonomous vehicles work when other traffic participants violate traffic laws. However, it is not convenient to use illegal scenarios to build a large-scale scenario library, because the semantic information in the documents is difficult to process in batch.
The normal scenarios are obtained by collecting the traffic environment of the real world. Some normal scenario libraries have been established.7,11–14 Using normal scenarios to test autonomous vehicles can make the test content closer to the real-world traffic environment. However, the collection of normal scenarios requires numerous drivers to drive vehicles equipped with various instruments on the real road. The cost is high and it takes a long time. Furthermore, there are a large number of repeated scenarios in the collected scenarios, which results in low efficiency.
Most scenarios are collected from real-world, except the generated scenarios which are simulated in the computer. In order to obtain a large number of scenarios quickly and conveniently, several test scenario generation methods have been proposed. A new test case can be obtained by changing the combination of parameter values in the scenarios. Therefore, a type of scenario library could have a large number of test cases, but it is impossible for an autonomous vehicle to perform all case tests. Rocklage et al. 15 used the CT method to generate test cases for scenarios, which can greatly reduce the size of the scenario libraries and improve test efficiency. However, there are some constraints between parameters in complex scenarios, and some combinations of parameter values do not meet the real situations, which need to be avoided during the generation process.
The CT method is widely used in software testing, which generates a set of test cases by choosing a smaller combinations of parameter value. And now there are many CT tools that can be directly used to generate test cases. For example, Xia et al. 16 used the PICT (pairwise independent combinatorial testing tool) to generate test cases. Khastgir et al. 17 used the Vital (constrained randomization engine) to generate test cases. With the help of these tools, test cases can be quickly generated without to write the CT program.
The above studies are all dedicated to generating a smaller test case set to achieve full coverage of parameter combinations, but the results generated are random. Researchers have found that using scenarios with a low probability of occurrence in the real world can perform intensive tests on automated driving to improve test efficiency. 18 However, there is a small proportion of scenarios with small probability in the randomly generated test case set.
In order to solve the above problem, a test scenario generation method combining the CT and the Bayesian network 19 is presented to ensure that the test case set is small in size while the average probability of generating test cases can be adjusted. The motivation of the proposed improved AETG algorithm is that the occurrence probability of the generated test cases can be controlled. Compared with other methods, this method can switch the generation mode by modifying the design parameters. The method can either generate a set of test cases by considering the probability, or only use the CT to generate test cases. The target parameter in the method determines whether the test case with the largest probability or the smallest probability is generated, that is, a probability dependent parameter. It should be pointed out that the scenarios generated by this method do not consider the interaction between objects, because all background objects in the scenarios move according to a predetermined trajectory except for the vehicle under test. The test cases set generated by the improved AETG algorithm can not only include all combinations in the uncovered combination set like the traditional combinatorial test algorithms, but also have more test cases with small occurrence probability when the value of the target parameter is small (i.e. the level of exposure to dangerous events is very high, and the evaluation of the autonomous vehicles is accelerated 20 ). In this study, the algorithm generates a few test scenarios in a short period of time, only a few seconds, which is suitable for repetitive testing of single autonomous driving function, such as automatic parking system test. It is assumed that the motion state of the objects in the test scenarios remains unchanged during testing, and the objects move according to predefined trajectories or remain stationary.
The following sections are organized as follows: Section 2 defines the data structure of the scenario. Section 3 describes how to find the constraints between the parameters of scenario. Section 4 introduces the Bayesian network used to generate the scenario. Section 5 combines the Bayesian network with the AETG to obtain a new test scenario generation method. Section 6 verifies the effectiveness of the proposed method by comparing the test case sets generated by the Combinatorial Testing Based on Complexity (CTBC) algorithm.
Parameters of test scenario
Test scenario can be described by a set of parameters, and different parameters form different scenario test cases. However, not all combinations of the values are reasonable, the unreasonable combinations constitute the constraint set of the test scenario. In order to simplify the model and reduce the calculation workload, some critical parameters are selected to describe the scenarios. The parameters can be divided into three categories: environment, road and object. The framework of the test scenario is shown in the Figure 1 below.
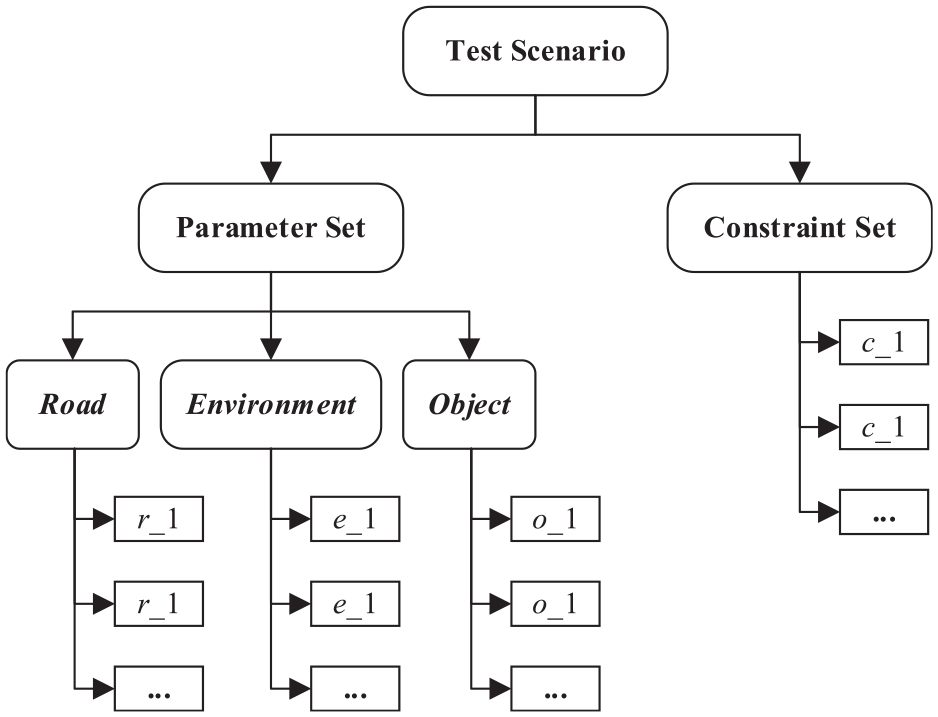
Framework of Test Scenario.
Environment
The environment describes the environmental conditions in the scenario, which include weather, intensity, and light. When using the CT to generate the scenario, the parameters are required to be discrete. Table 1 shows the value ranges of environment. In order to reduce calculation workload during test case generation, only three values for each environment parameter have been determined. The intensity is used to represent the weather intensity in the scenario. For example, when it rains, the greater the intensity, the greater the rainfall. During the simulation test, the environment will affect the sensor model of the tested vehicle. The environment in the scenarios is constant and does not change with time.
Value range of environment.

We combine sunny and cloudy into one category of weather parameters, because neither of them has particles in the air to block the detection of the sensor. And we merge rainy and snowy into another category, because the diameters of raindrops and snowflakes are both several millimeters. However, the diameter of the particles for foggy is about less than 100 microns.
Road
The road is used to describe the condition of road segment in the scenarios. A continuous road is divided into several road segments. Taking the Ramp entrance as an example, it can be divided into 4 road segments, as shown in Figure 2.
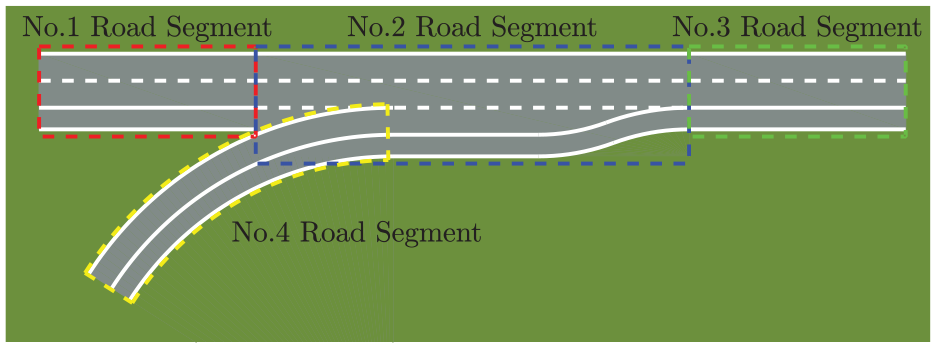
Road segments of ramp entrance.
In order to accurately describe the positions and postures of the road segments in the scenario, a coordinate system on the road segment is established, called the road segment coordinate system (RSCS), as shown in Figure 3. According to the radius, the road segments in the scenario can be divided into two categories: straight road segment and curved road segment. On the straight road segment, a rectangular coordinate system is established, called the straight road segment coordinate system (SRSCS). On the curved road segment, a polar coordinate system is established, called the curved road segment coordinate system (CRSCS). In this paper, the coordinate system of the scenario is called the scenario coordinate system (SCS).
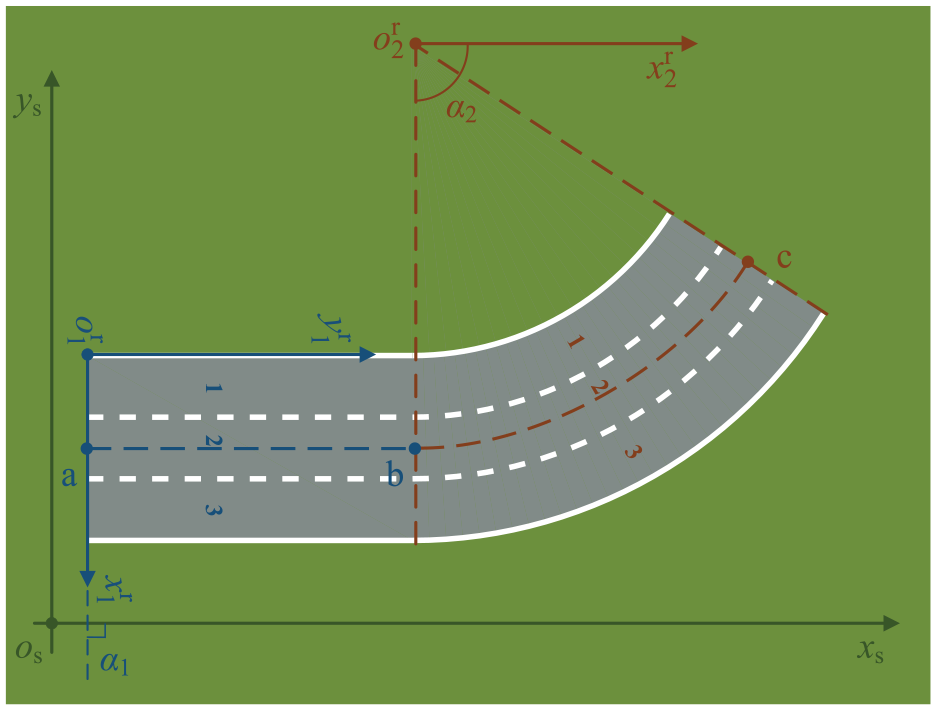
Coordinate system of road segment.
The road includes following parameters: Lr, Rr,
Value range of road.

Object
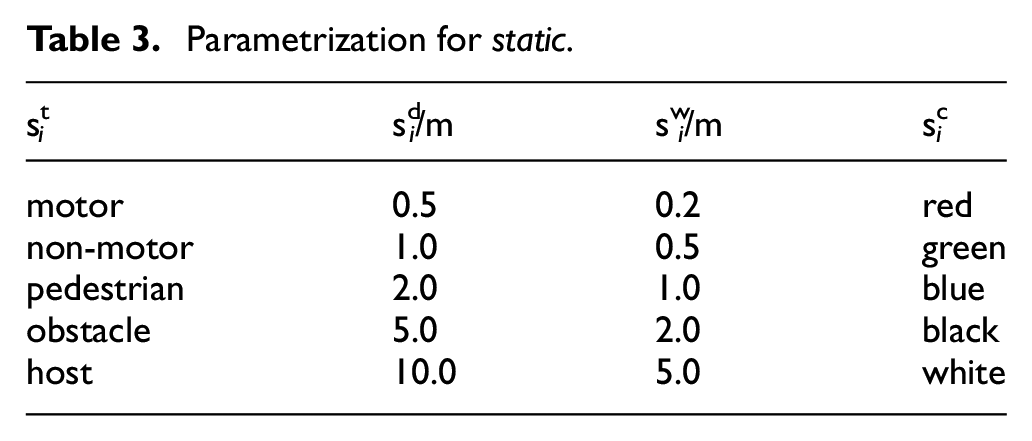
The object records the information of the traffic participant in the scenario, which have two parameters: static and dynamic. The static includes: the type of object
Parametrization for static.
Similar to the RSCS, every object in the scenario also has a coordinate system, called the object coordinate system (OCS), as shown in Figure 4.
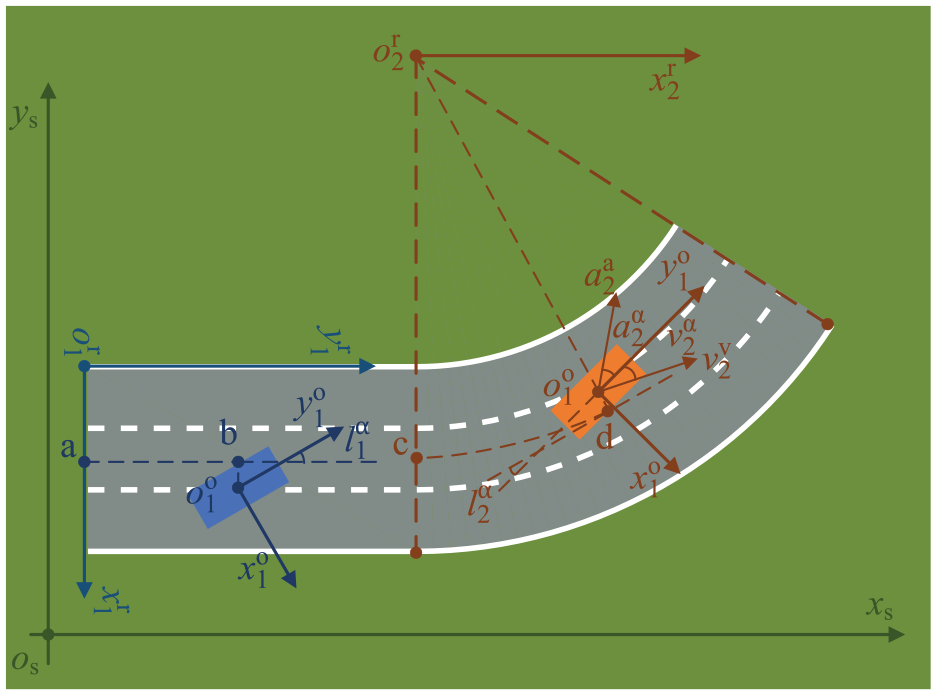
Coordinate system of object.
The dynamic describes the movement state of object at the beginning of scenario, which includes:
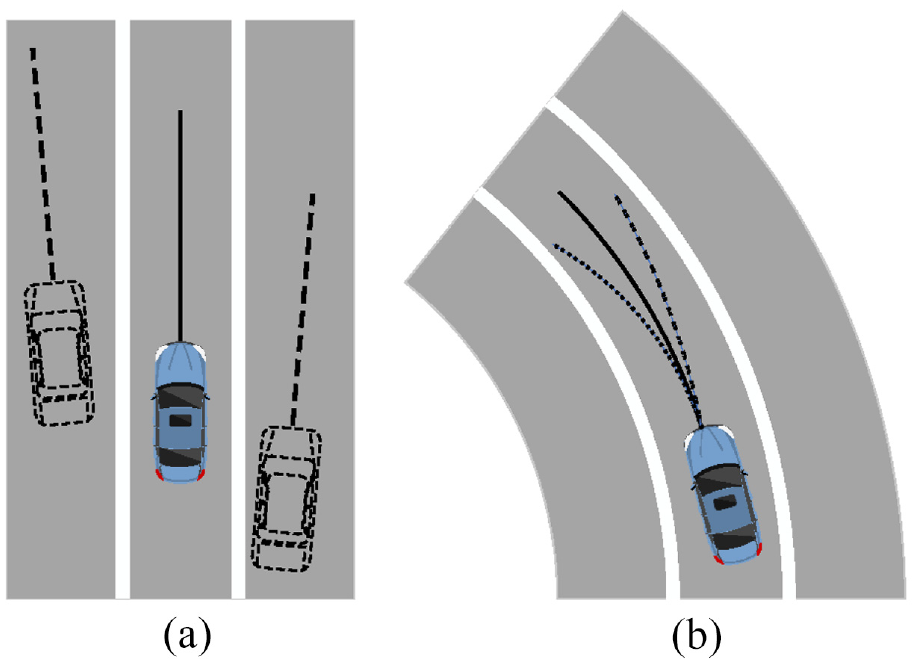
Predetermined trajectory of objects: (a) starting position and postural change and (b) radius change.
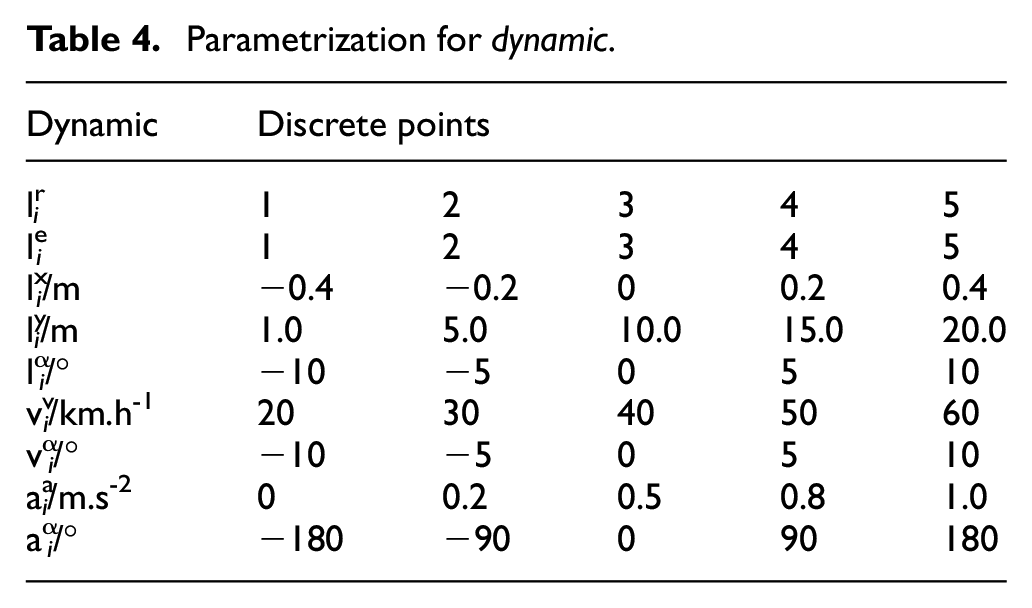
Some discrete points that the dynamic can take are shown in Table 4.
Parametrization for dynamic.
The
Type of scenario
There are many types of scenarios, it is difficult to use a unified framework to generate all types. Therefore, we classify test scenarios based on road type and driving task, and some types of scenarios are shown in Table 5.
Some types of scenarios.

In the scenarios, the host vehicle needs to complete some driving tasks. Take the Scenario 1 in Table 5 as an example, the scenario occurs at an ETC. The host vehicle needs to follow the front vehicle through ETC, which mainly to evaluate the longitudinal control capability of the host vehicle. In this paper, we set the roads of each type of the scenarios to constant values, and only use the CT on object and environment to generate the test cases.
In order to display the generated scenarios more intuitively, schematic diagrams of the scenarios are drawn, as shown in Figure 6. Various colored squares are used to represent objects in the scenarios. The white square in the figures represents the vehicle under test, and other vehicles and pedestrians in the scenarios are represented by squares of different colors and sizes.
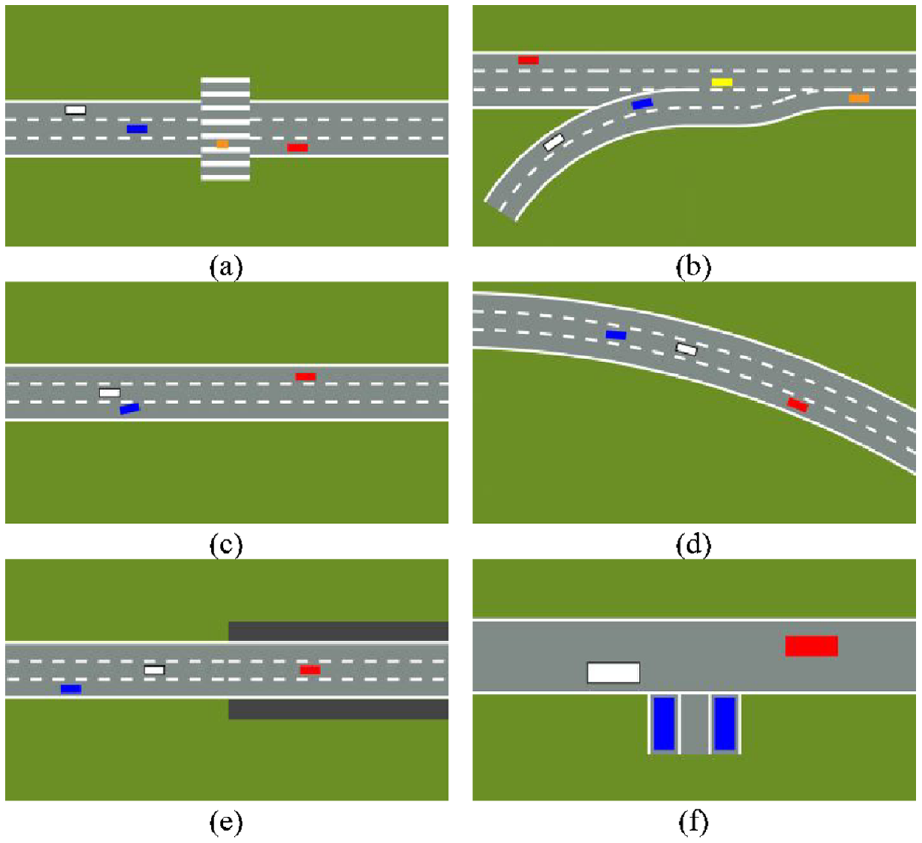
Schematic diagrams of the scenarios: (a) Scenario S_1 (b) Scenario S_2 (c) Scenario S_3 (d) Scenario S_4 (e) Scenario S_5 (f) Scenario S_6.
Constraints in test scenario
There are constraints between various parameters, and the combination of some parameters may not conform to the actual situation (i.e. do not meet the constraints), such as the interference of object position at the beginning of the scenario. To avoid generating such test cases, all constraints need to be listed. Because different types of scenarios are quite different, we establish constraint sets for each scenario one by one.
Initial constraint set
In this paper, the roads in each type of scenario are constant value, and the environment is too simple to ignore the constraints, so we only consider the constraints of objects. The sources of constraints are as follows: no object interference, obstacles keeping stationary, objects do not appear, driving task. All the constraints are represented by forbidden tuples,
21
which is a method widely used in the CT. For example, in Figure 4, the value range of
Some constraints may be difficult to convert directly into forbidden tuples. In this case, they need to be converted into other types of tuples firstly, such as must tuples, 22 and then converted into forbidden tuples. For example, in Figure 4, if the No. 1 object is an obstacle, it needs to keep stationary, and the speed and acceleration are both 0. The must tuple is as follows:
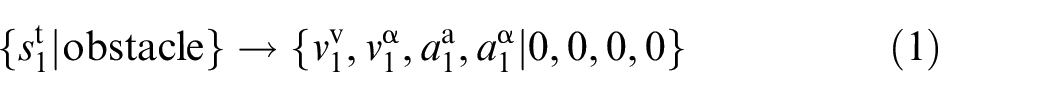
Exclude the value combinations in must tuples from all the value combinations of the

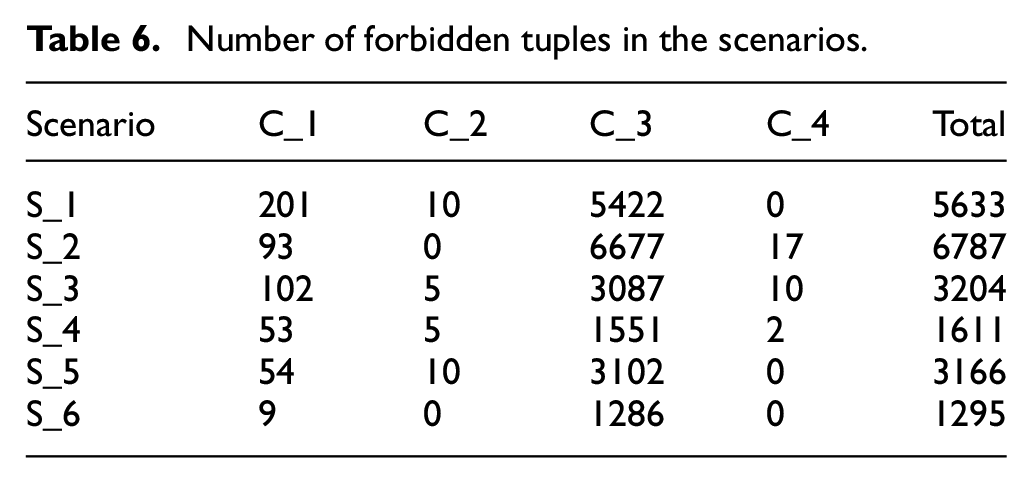
Table 6 shows the number of forbidden tuples in the scenarios of Table 5. Each column represents the number of forbidden tuples converted from a constraint. The C_1 is the constraint that no object interference, the C_2 is the constraint that obstacles keeping stationary, the C_3 is the constraint that objects do not appear, the C_4 is the constraint that driving task. The last column is the total numbers of forbidden tuples.
Number of forbidden tuples in the scenarios.
The initial constraint set is generated by converting various constraints into forbidden tuples. The road type and driving task may be different from each scenario, so the initial constraint set is not universal. In order to control the size of the initial constraint set, the number of objects in the scenario was reduced as much as possible. If the range of the parameters are expanded or the number of objects increases, the size of the initial constraint set will increase rapidly, which will lead to a long time for the generation of test cases.
Implied forbidden tuple
If a forbidden tuple c is induced by other forbidden tuples, then c is an implied forbidden tuple. Suppose there are parameters {a, b, c}; a, b, c∈{1, 2}; forbidden tuples set {∼{a,c|(2,−,2)}, ∼{b,c|(-,2,1)}}. When parameters a = 2, b = 2, it can be inferred that the value range of parameter c is empty. Therefore, the implied forbidden tuple ∼{a,b|(2,2,-)} must be added to the forbidden tuples set.
Ignoring implied forbidden tuples may lead to some invalid test cases, which further leads to inaccurate test planning and wasted effort. There are usually implied forbidden tuples in the initial constraint set, and an algorithm is needed to find them. In this paper, we use the modified construct constraint set (CCS) algorithm 23 to search for the implied forbidden tuples. The algorithm looks for the constraint parameters after each implied constraint search to avoid the implied constraints from generating new constraint parameters, not just at the beginning. The search for implied constraints will not end until there are no new constraint parameters.
Now, the modified CCS algorithm is introduced in detail as shown below. Only the constraint set that does not contain implied constraints can be used for the test case generation, otherwise it may cause the parameter range empty when the test case is generated.

Construction of Bayesian network
In this paper, the Bayesian network is used to calculate the probability of parameter values under different conditions. For different scenarios, the parameters and constraints are different, so the Bayesian network is also different. Because the road and environment are relatively simple, we assume that their parameters obey an independent and uniform distribution, and the Bayesian network is mainly used to calculate the probability of the objects.
Structure of Bayesian network
In the Bayesian network, object node represents the object in the scenario, which contains parameter nodes: type node, position node, velocity node and acceleration node. Figure 7 shows the Bayesian network of S_3, where
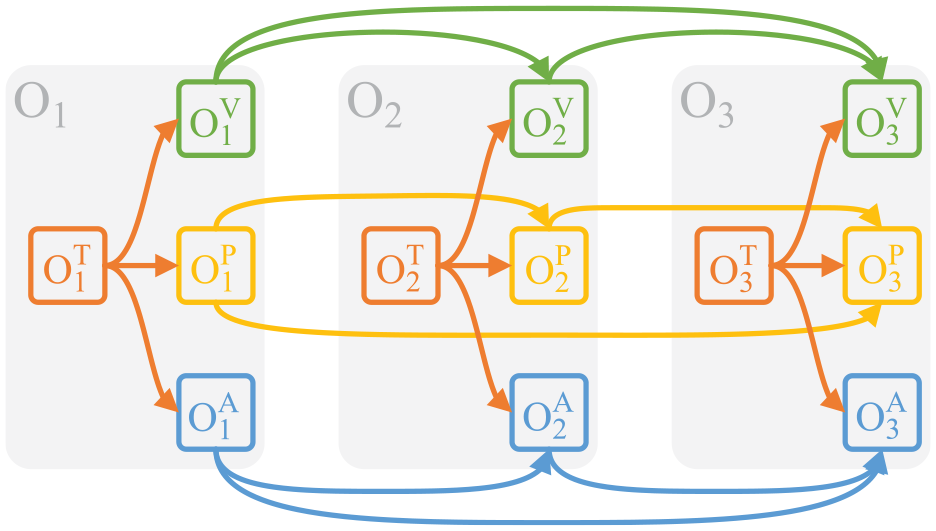
Bayesian network of S_3.
The parameter nodes contain several scenario parameters as shown in Table 7, and the value of the nodes are combinations of the parameter values.
Scenario parameters in parameter nodes.

In object nodes, due to the lack of real data of various scenarios, the probability distribution of type nodes is simplified to independent and uniform distribution, which contains object parameters: type, color, length and width, and is the parent node of other parameter nodes. We use distance interaction, velocity interaction, and acceleration interaction to represent the interaction between object nodes, and the Bayesian network shown in Figure 7 is used to represent these interactions. In order to quantify the interaction, a series of relative parameters are defined. The relative distance is the minimum distance between the bounding boxes of two objects, and the relative velocity (acceleration) is the vector sum of the velocities (acceleration) of two objects.
Conditional probability
The conditional probability of Bayesian network usually needs to be trained based on a large amount of statistical data. However, due to the lack of data, we used the method of mapping relative parameters to probability, as shown below.
There are some models that use relative distance, relative speed and relative acceleration to quantify the risk of driving environment, such as Driving Risk Field (DRF)24,25 and Enhanced Time to Collision (ETTC).26,27 Since the probability of dangerous scenarios in real driving environment is usually low, we assume that there is a correlation between the probability and the driving environmental risk, and the relative parameters can be used to map the conditional probability.
Initialize the range of unvalued parameter node node as v ={v1, v2, …, vn};
Find the valued parameter nodes of the same type as node, get Node ={node1, node2, …, nodei}, and the process of node value selecting are shown in Algorithm 3;
Calculate relative parameter (relative distance, relative velocity and relative acceleration) between node and
Calculate the mean and standard deviation of each row in the
Map
Calculate the average of
It is very difficult to obtain the marginal probability distribution and conditional probability distribution in the real world, because there are so many scenario parameters and most of them are difficult to collect.
Due to the lack of real data, we simplified the probability distribution function. And in this paper, we focus on the construction of test cases generation algorithm rather than the acquisition of probability distribution. When mapping
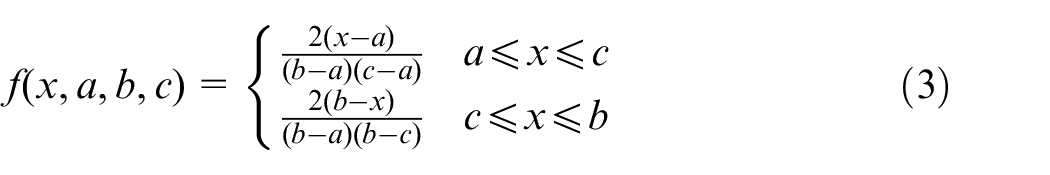
Where, a is the minimum value of x, b is the maximum value of x, and c is the value of x corresponding to the triangle vertex.
The
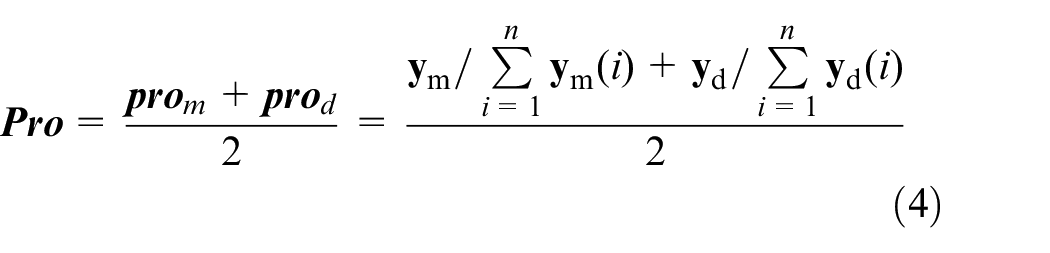
Where, n is the length of vector
Scenario generation algorithm
If all the combinations of parameters are put into a test case set, a very large test case set will be obtained because the number of parameters in the scenario is huge, it is difficult to traverse this test case set. In this paper, we use the CT to reduce the size of test case set. The CT is widely used in the software testing, aiming to select a small number of test cases from the huge combination space to improve the test efficiency. The current common test case generation algorithms include: the automatic efficient test case generator (AETG), 29 the test case generator (TCG), 30 and the in-parameter order, (IPO) 31 etc.
Uncovered combination set
Before using the test case generation algorithms to generate test cases, it is necessary to generate an uncovered combination set, and the generated test case set should include all combinations in the uncovered combination set. The uncovered combination set is any values combination of any n
Uncovered combination set.



As the n
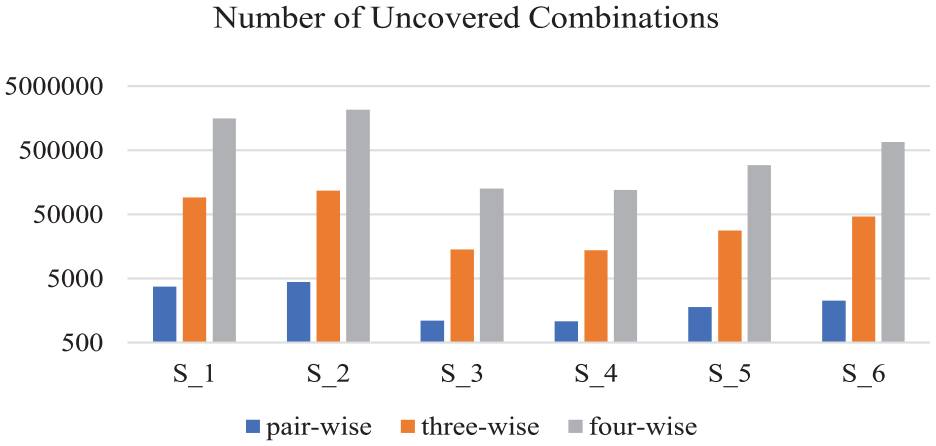
Number of uncovered combinations.
Selection function
In AETG, which value of the scenario parameter is selected to form the test case depends on the number of times that the value appears in the uncovered pair-wise combination set, 33 and the value with the highest frequency will be preferred. The frequency calculation algorithm used in this paper is as follows.
In order to make the test case generation process affected by the probability, the selection function is used as an indicator to determine the values of the scenario parameters, as shown in (5).
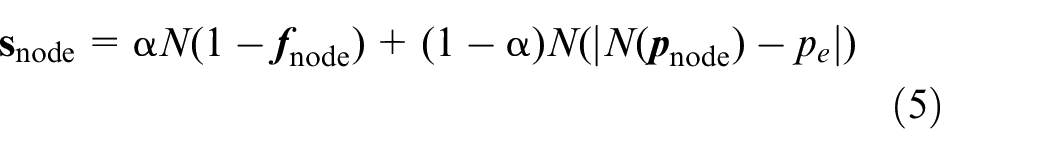
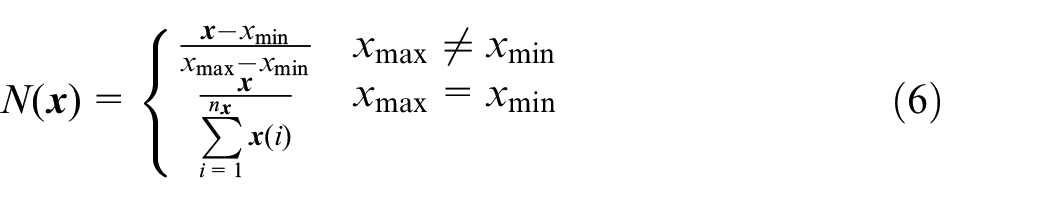
Where, the α is the weight, 0 ≤ α ≤ 1, as α increases, the test case generation process is more affected by the frequency and less affected by the probability. The pe is target parameter, 0 ≤ pe ≤ 1, it is a probability dependent parameter which represents the ratio of the expected test case probability to all test case probabilities and. N(
Test case generation
The AETG algorithm is one of the most common test case generation algorithms. When the AETG algorithm works, test cases containing uncovered combinations will be generated one by one, and the parameters in the test cases will be valued one by one. We replace the selection indicator of scenario parameters in the algorithm with selection function, and the improved AETG algorithm is shown in Algorithm 3.
In the process of generating test cases, for the node
When Algorithm 3 runs to the later stage of test case generation, if the value of α is too small, it is possible to always generate
Result of scenario generation
In order to analyze the impact of weight α and target parameter pe on the generated results, the improved AETG algorithm is used to generate test cases using different α and pe. In addition, we compared the generated results with the CTBC algorithm. 34
Probability deviation
In order to verify the improved AETG algorithm can generate test cases close to the expected probability, we designed a test scenario with a smaller parameter space based on the S_6 scenario. All test cases in the parameter space are found, and then the Bayesian network is used to calculate their respective probabilities. The expected probability is the probability that target parameter pe corresponds to the probabilities of all test cases, as shown in (7).
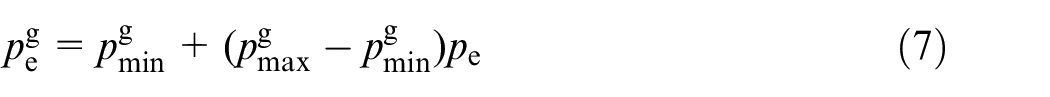
Where, the
The probability deviation is used to measure the degree of deviation of test case probability from the expected probability, as shown in (8).

Where, the
Now, an optimal test case set (OTCS) that can cover all uncovered combinations with the smallest probability deviation can be found. The probability deviations of the test case sets generated by the improved AETG algorithm and the CTBC algorithm when the target parameter pe and the weight α both change from 0 to 1 are compared with the probability deviations of OTCS, as shown in Figure 9.
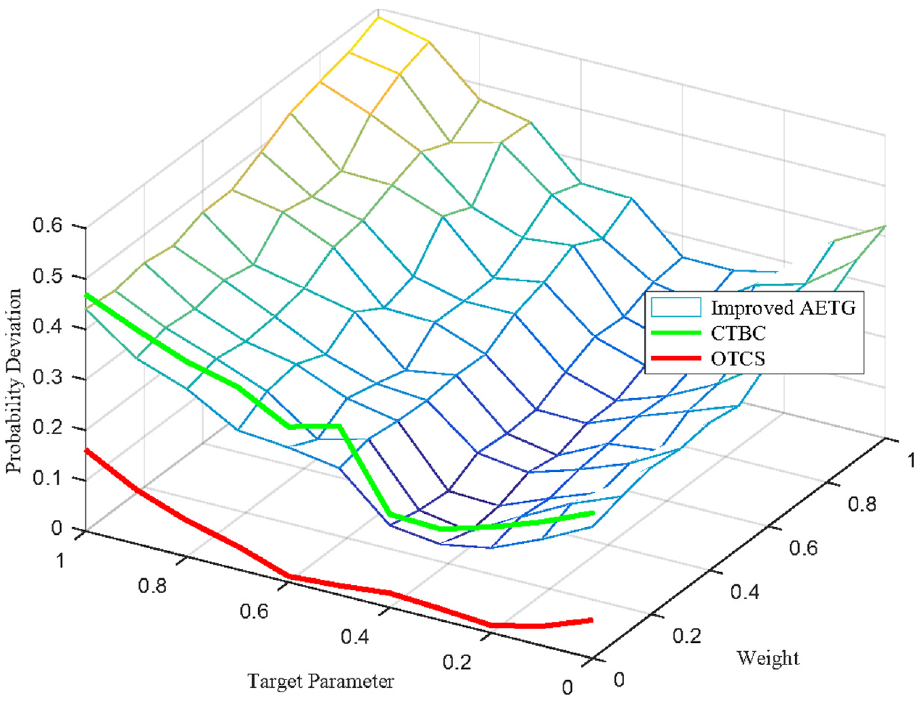
Probability deviations of the test case sets in the test scenario with a smaller parameter space.
In Figure 9, the probability deviations belonging to CTBC and OTCS are represented as curves because they are not affected by weights. It can be seen from Figure 9 that the probability deviations of OTCS are the smallest among the three algorithms, and it is always less than 0.2. However, OTCS can only be applied to the test scenario with a small parameter space, and the computation will increase sharply as the parameter space increases.
If only the influence of the target parameters is considered, it can be found that when pe is between 0.3 and 0.4, the probability deviation of the test case set generated by the three algorithms is very small. As the target parameters increase or decrease, the probability deviations will increase. The main reason for this phenomenon is the probability deviation distribution of the test cases in the parameter space. Figure 10 shows the number of test cases with different probability deviations in the parameter space when the target parameter changes from 0 to 1. In the defined small parameter space, the probability of most test cases is close to the expected probability when the target parameter is 0.3 or 0.4.
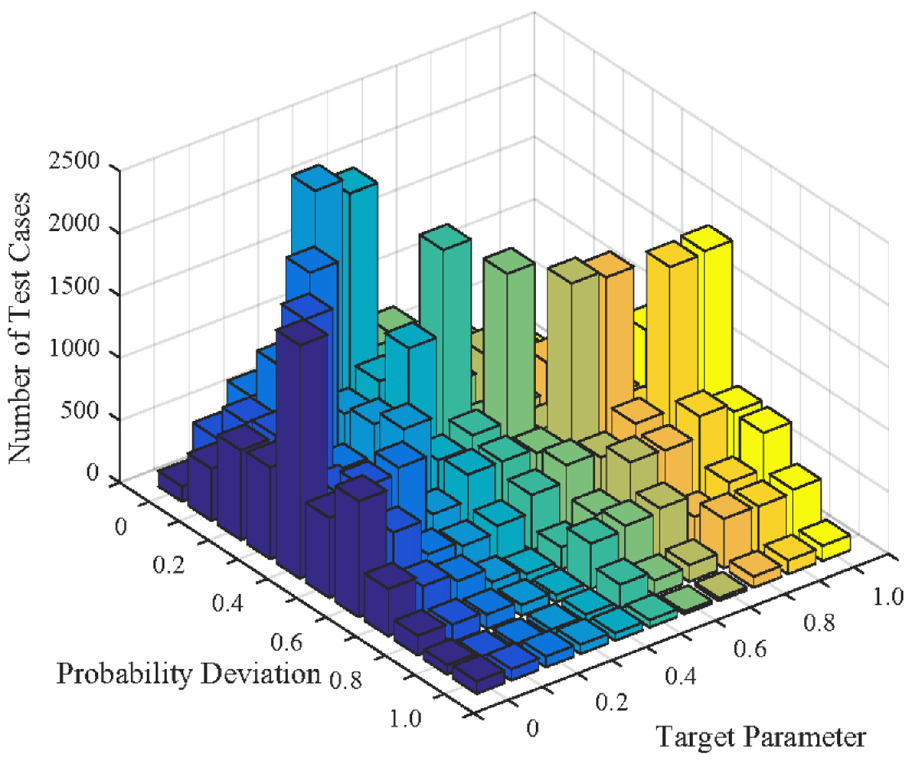
Probability deviation distribution of the test cases in the parameter space.
For the improved AETG algorithm, the probability deviations of the generated test case sets will gradually increase with the increase of weight. The weight determines the influence of probability and frequency on the test case generation, as shown in (5). If the weight is 1, the frequency has the greatest impact on the algorithm, resulting in a large probability deviation of the generated test case set.
When the target parameter pe = 0.3 and the weight α changes from 0 to 1, the probability deviations of the test case sets generated by the improved AETG algorithm and the CTBC algorithm are shown in Figure 11. In the figure, the probability deviation of the optimal test case set is about 0.02. The CTBC algorithm is not affected by the weight, and the probability deviation is always about 0.18. With the increase of the weight, the probability deviation of the test case sets generated by the improved AETG algorithm becomes larger. Compared with the CTBC algorithm, the probability deviations of test case sets generated by improved AETG algorithm is slightly smaller when the weight is less than 0.5.
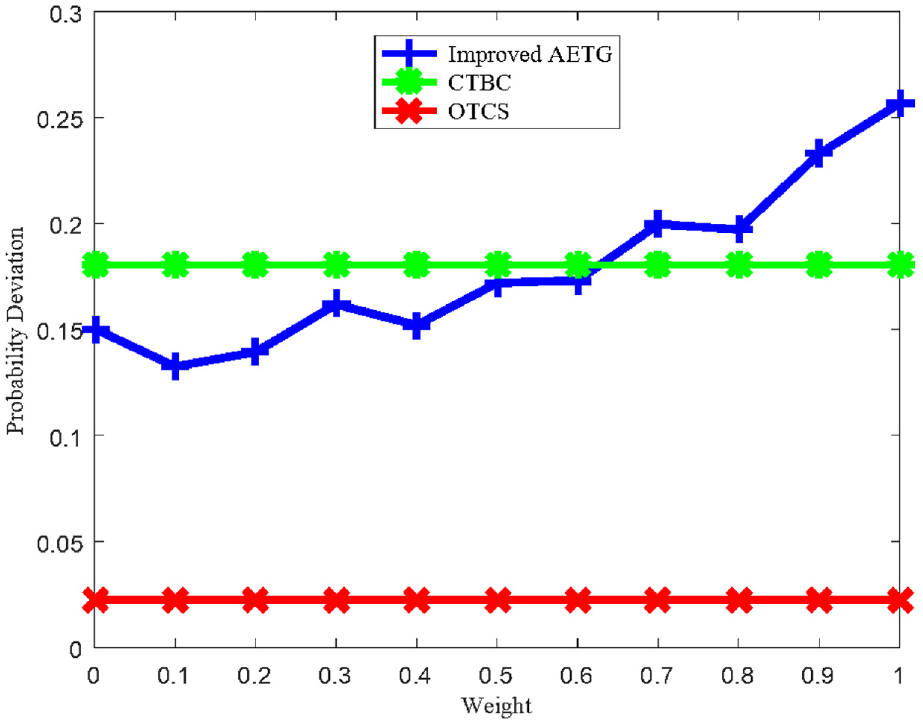
Influence of weight on probability deviation (α = 0–1, pe = 0.3).
In order to verify the accuracy of the probability deviation calculation, some test cases are selected to judge the probability subjectively based on the schematic diagrams, and the judgment results were compared with the calculated values. Four test cases are randomly selected from the test case sets where the weight α = 0.2 and the target parameter pe = 0.3, the probability deviations are shown in Table 9.
Probability deviations of test cases.
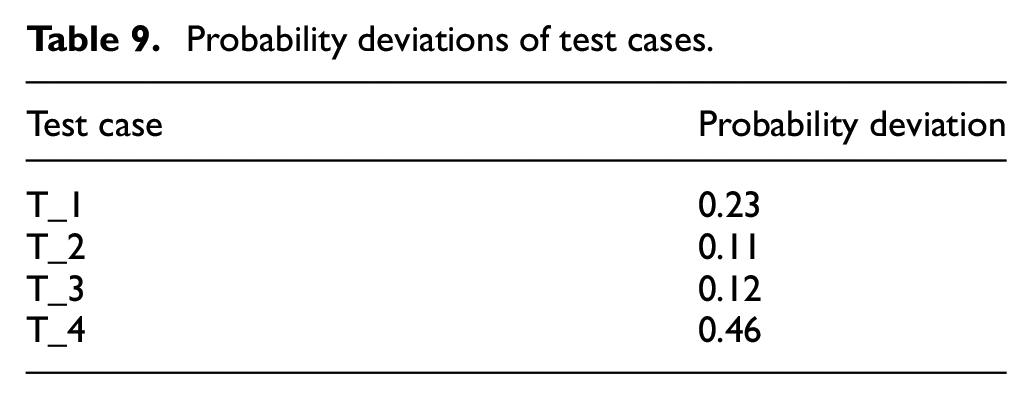
The schematic diagrams of the test cases are shown in Figure 12. In the scenario, all objects remain static at the beginning, so the probabilities of the test cases are only related to relative distances between the objects. The relative distances in Bayesian network includes: the relative distance between the vehicle under test and the object in left parking space, the relative distance between the vehicle under test and the obstacle on the road, the relative distance between the objects in the left and right parking spaces, the relative distance between the objects in the left/right parking spaces and the obstacle on the road.
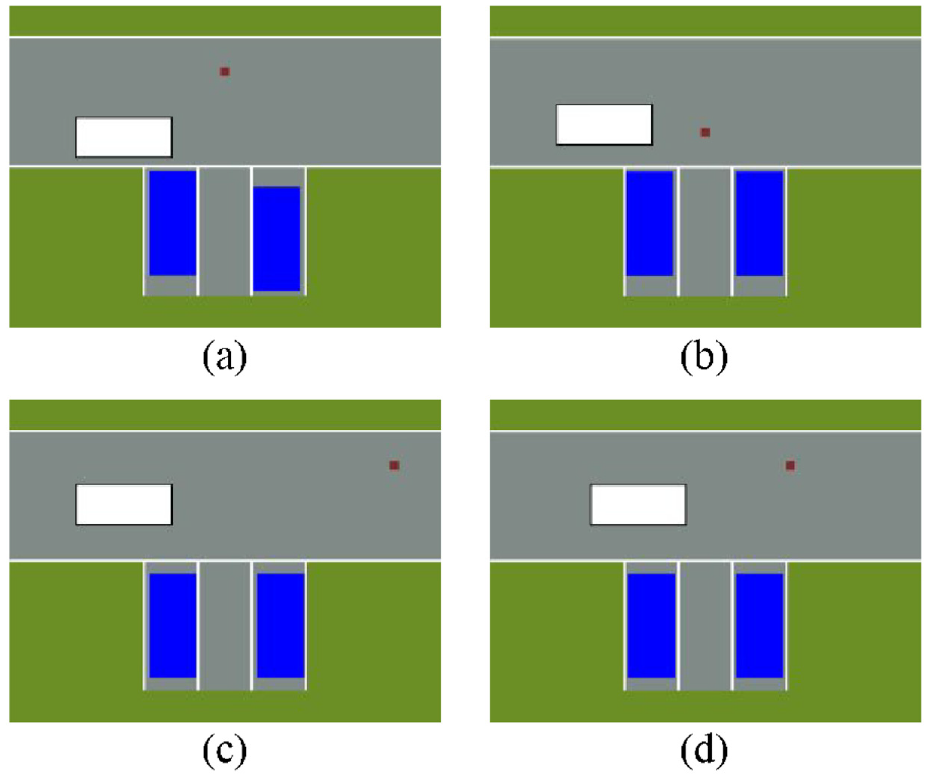
Schematic diagrams of test cases: (a) Test case T_1, (b) Test case T_2, (c) Test case T_3, and (d) Test case T_4.
It can be found from the schematic diagrams that the relative distances between objects in the T_2 is relatively small, while the relative distances between objects in the T_3 is relatively large, and their probability is small. In Table 9, the probability deviations of the two test cases are relatively small, the probabilities of the test cases are close to the expected probability
Number of test cases
As the number of test cases increases, the cost of completing the tests also increases. Therefore, the size of test case sets is also an important criterion for evaluating test case generation algorithms. When the target parameter pe and the weight α both change from 0 to 1, the improved AETG algorithm and the CTBC algorithm are used to generate test cases in the test scenario with a smaller parameter space, and the sizes of the test case sets are shown in Figure 13.
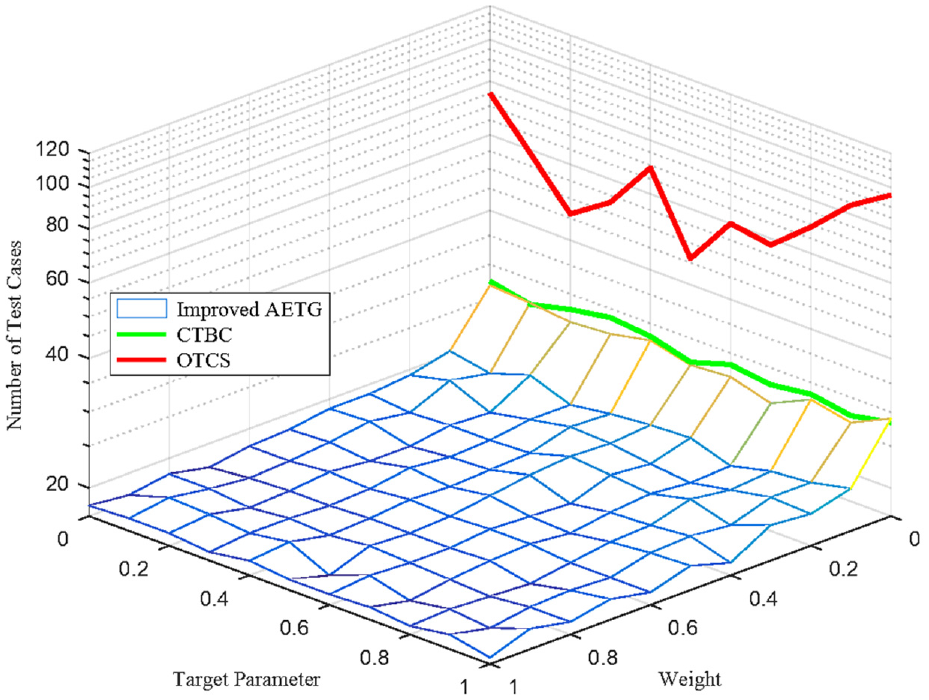
Number of the test cases in the test scenario with a smaller parameter space.
The number of optimal test cases is far exceeding the test case sets generated by the two algorithms, and the number fluctuates roughly around 60 due to the influence of target parameters. The size of the test case sets generated by the CTBC algorithm is smaller than the optimal test case sets, but slightly larger than the test case sets generated by the improved AETG algorithm. The number of the test cases fluctuates roughly around 30 affected by the target parameters. Compared with the target parameter, the sizes of the test case sets generated by the improved AETG algorithm is more sensitive to the weight.
Since the target parameter has little effect on the size of the test case set, we use the improved AETG algorithm and the CTBC algorithm to generate the test cases of the scenarios in Table 5 where pe = 0.3 and α increase from 0 to 1, the sizes of the test case sets are shown in Figure 14.
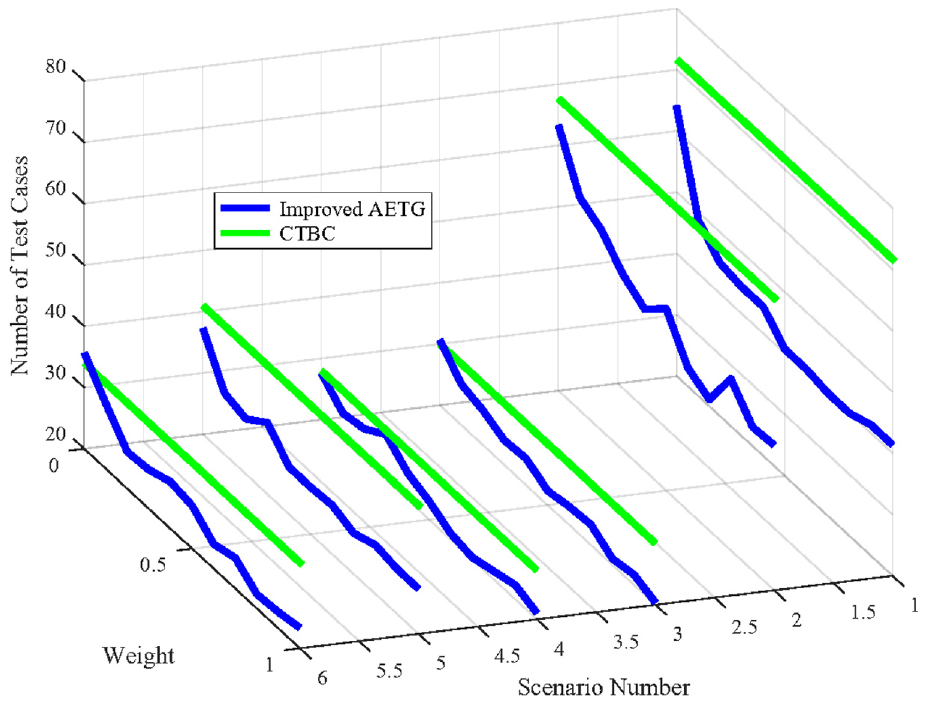
Number of the test cases in the sample scenarios (α = 0–1, pe = 0.3).
The size of the test case set generated by the improved AETG algorithm is slightly smaller than of the CTBC algorithm, and the gap between the two test case sets gradually expends with the increase of weight. The parameter space and constraint set of each scenario are different, which leads to different sizes of test case sets.
Conclusion
Test scenario generation method is one of the key research directions of automated driving vehicle. In this paper, a test case generation algorithm for specific driving scenarios based on combinatorial testing and Bayesian network is proposed. When generating test cases, a group of test cases with different probabilities can be obtained by adjusting the weights and target parameters to meet the test tasks with different requirements.
By discretizing the continuous probability distribution, the conditional probability table of the scenario can be calculated by the relative parameters between the scenario objects. A composite selection function is formulated according to the probability and frequency of scenario cases. Then, the selection function is used as indicator to select the combination of parameter values when generating test cases.
Compared with the test case set generated by CTBC algorithm, the probability deviation of the test case set generated by the proposed improved AETG algorithm is smaller when the weight is less than 0.5, and the size of the test case set is smaller. The probability distribution of test cases is affected by their parameter space. In order to generate as many test cases with specific probability as possible, it is necessary to specially construct the parameter space of the test scenario.
This study focuses on the design of the test scenario generation method, but does not apply the scenarios to test autonomous vehicle. As the future work, an autonomous vehicle scenario simulation platform will be established, and the test efficiency of using the generated scenarios will be analyzed. Furthermore, we will establish the probability distribution functions based on real scenario data, considering the dynamic trajectory generation of objects and the interaction between multiple objects.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Anhui Science and Technology Key Special Program under [Grant No. 201903a05020016, 202004b11020002], Natural Science Foundation of Anhui Province [Grant No. 2208085QE153] and National Key R&D Program of China [Grant No. 2018YFB0105102]. The authors would like to thank the reviewers for their time and suggestions.